Post Syndicated from Pierre-Antoine Mills (Guest Author) original http://blog.cloudflare.com/how-prisma-saved-98-percent-on-distribution-costs-with-cloudflare-r2/


The following is a guest post written by Pierre-Antoine Mills, Miguel Fernández, and Petra Donka of Prisma. Prisma provides a server-side library that helps developers read and write data to the database in an intuitive, efficient and safe way.
Prisma’s mission is to redefine how developers build data-driven applications. At its core, Prisma provides an open-source, next-generation TypeScript Object-Relational Mapping (ORM) library that unlocks a new level of developer experience thanks to its intuitive data model, migrations, type-safety, and auto-completion.
Prisma ORM has experienced remarkable growth, engaging a vibrant community of developers. And while it was a great problem to have, this growth was causing an explosion in our AWS infrastructure costs. After investigating a wide range of alternatives, we went with Cloudflare’s R2 storage — and as a result are thrilled that our engine distribution costs have decreased by 98%, while delivering top-notch performance.
It was a natural fit: Prisma is already a proud technology partner of Cloudflare’s, offering deep database integration with Cloudflare Workers. And Cloudflare products provide much of the underlying infrastructure for Prisma Accelerate and Prisma Pulse, empowering user-focused product development. In this post, we’ll dig into how we decided to extend our ongoing collaboration with Cloudflare to the Prisma ORM, and how we migrated from AWS S3 + CloudFront to Cloudflare R2, with zero downtime.
Distributing the Prisma ORM and its engines
Prisma ORM simplifies data access thanks to its type-safe Prisma Client, and enables efficient database management via the Prisma CLI, so that developers can focus on product development.
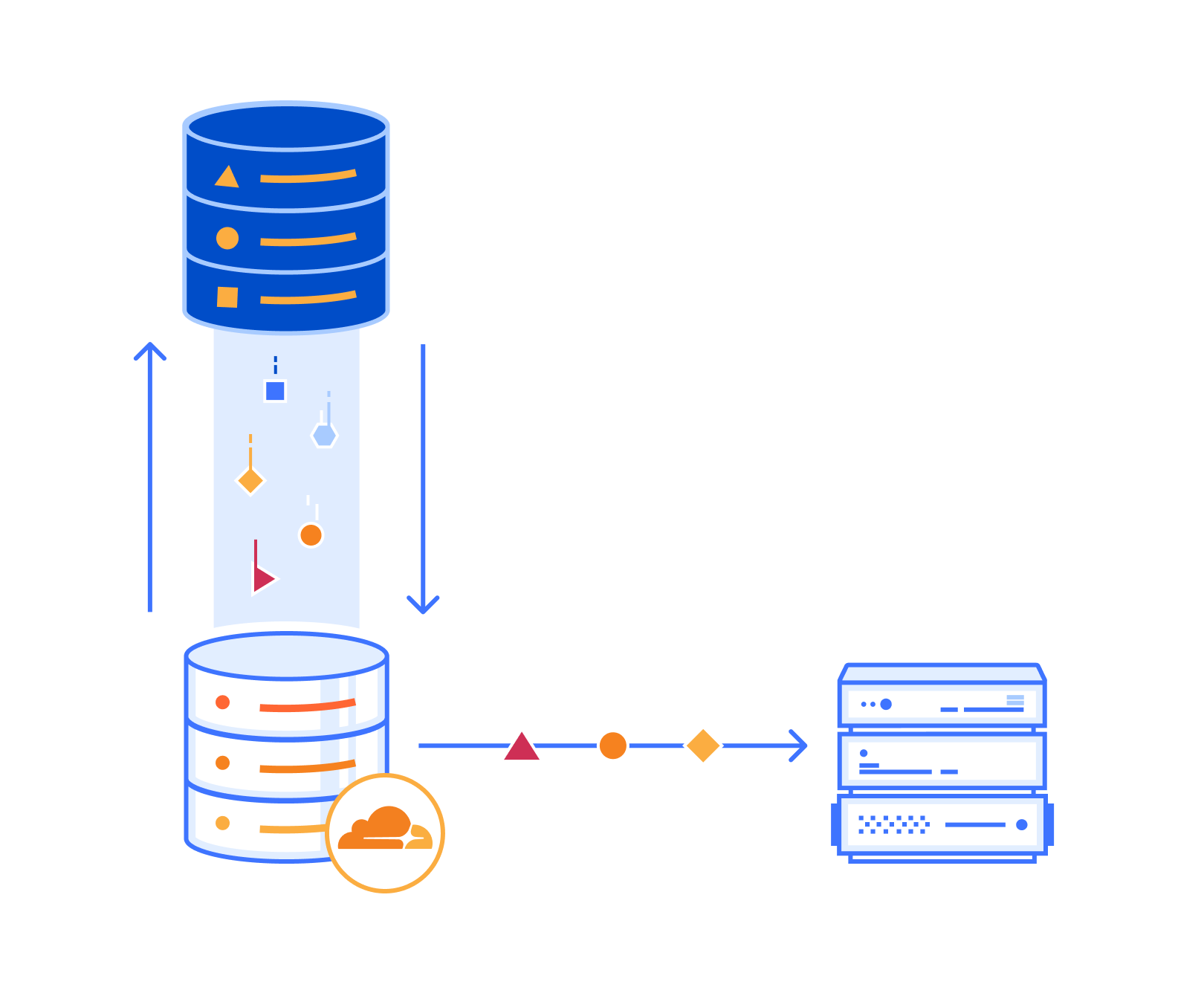
Both the Prisma Client and the Prisma CLI rely on the Prisma Engines, which are implemented in Rust and distributed as platform-specific compiled binaries. The Prisma Engines perform a variety of tasks ranging from providing information about the schema for type generation, or migrating the database, to transforming Prisma queries into SQL, and executing those queries against the database. Think of the engines as the layer in the Prisma ORM that talks to the database.

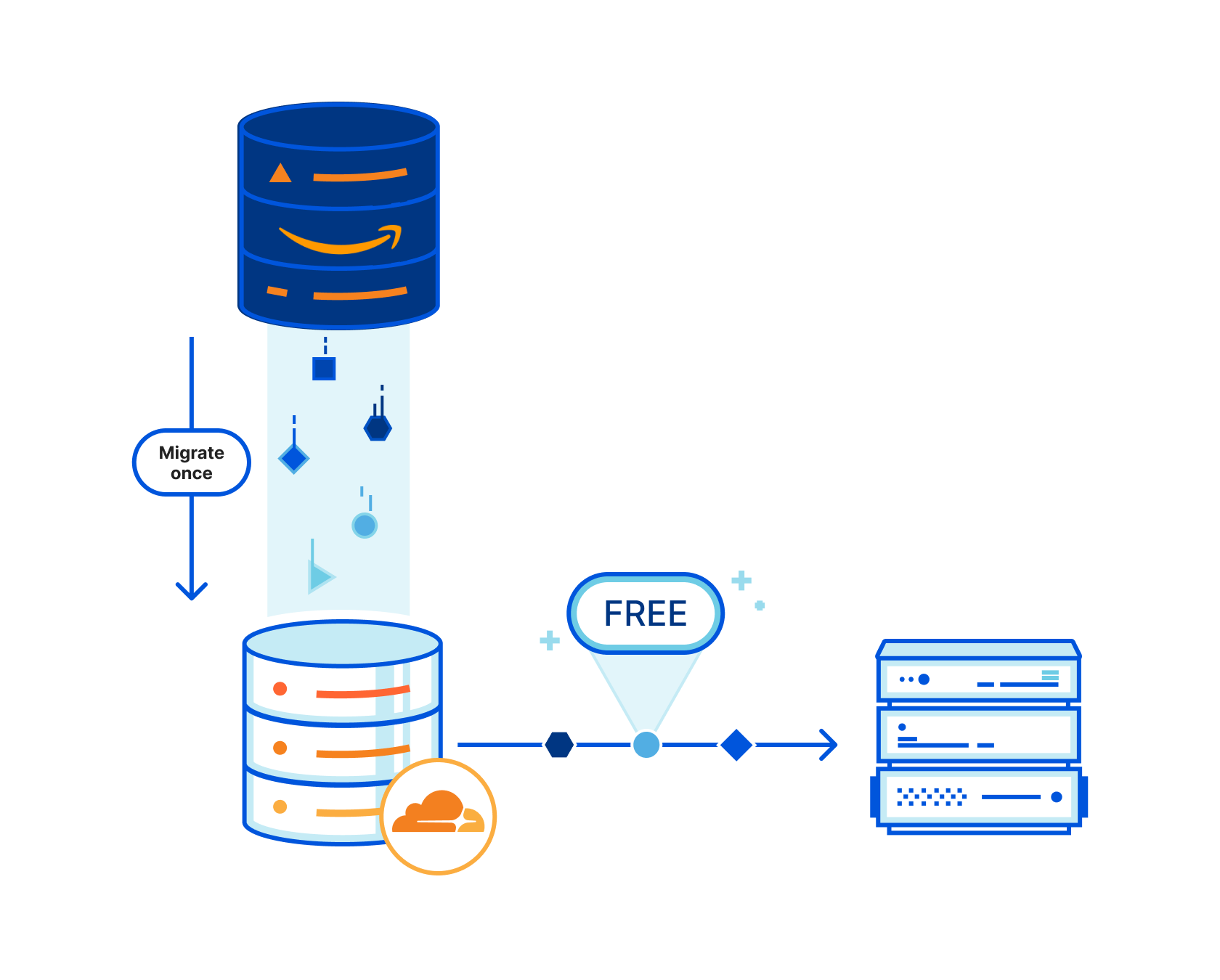
As a developer, one of the first steps to get started with Prisma is to install Prisma Client and the Prisma CLI from npm. Once installed, these packages need the Prisma Engines to be able to function. These engines have complex target-platform rules and were originally envisioned to be distributed separately from the npm package, so they can be used outside of the Node.js ecosystem. As a result, they are downloaded on demand by the Prisma CLI, only downloading what is strictly required for a given project.
As of mid-2023, the engines account for 100 million downloads a month and 250 terabytes of egress data transfer, with a continuous month-over-month increase as our user base grows. This highlights the importance of a highly available, global, and scalable infrastructure that provides low latency engine downloads to Prisma users all around the world.
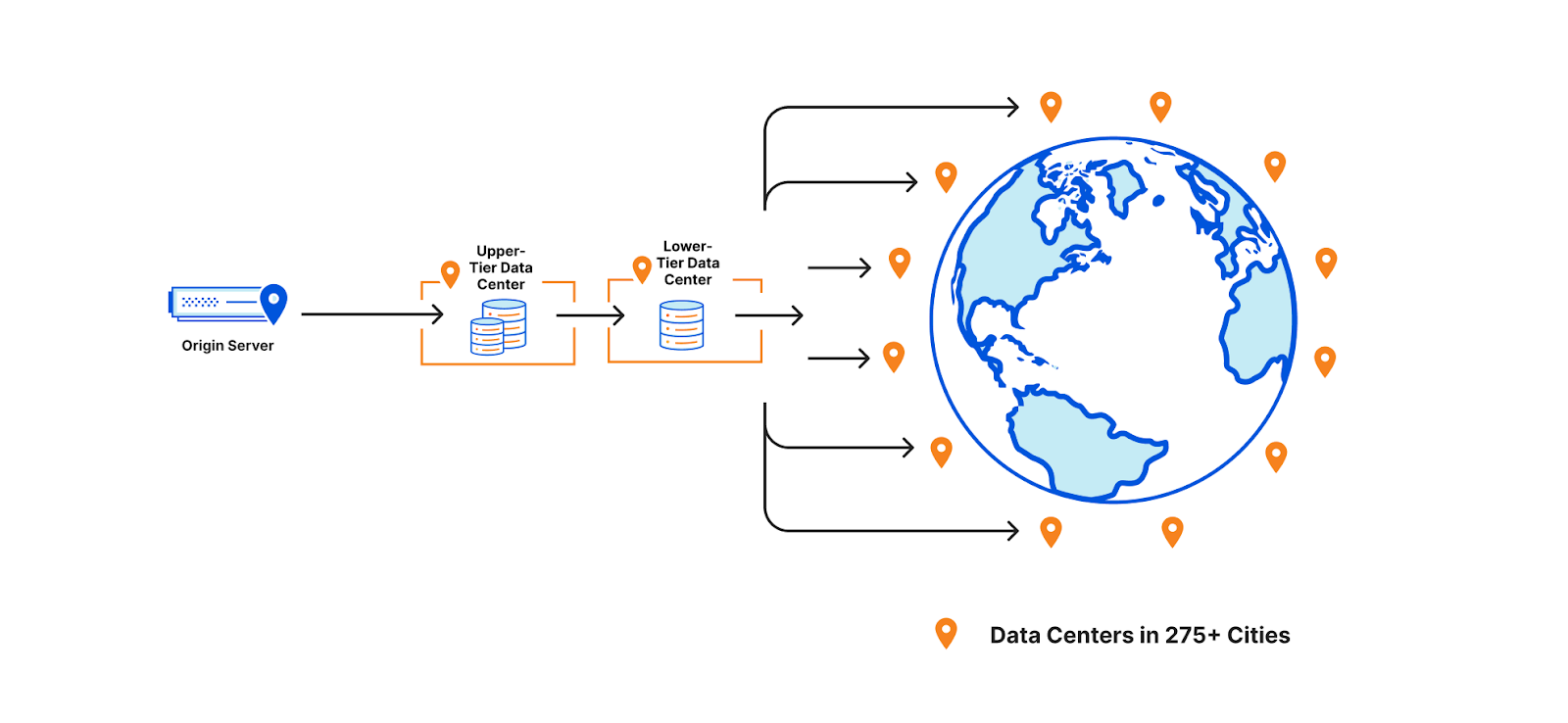
Our original solution: AWS S3 & CloudFront
During the early development of the Prisma ORM, our engineering team looked for tools to build the CDN for engine distribution. With extensive AWS experience, we went with the obvious: S3 blob storage for the engine files and CloudFront to cache contents closer to the user.

We were happy with AWS for the most part, and it was able to scale with our demands. However, as our user base continued to grow, so did the costs. At our scale of traffic, data transfer became a considerable cost item that we knew would only continue to grow.
The continuously increasing cost of these services prompted us to explore alternative options that could better accommodate our needs while at least maintaining the same level of performance and reliability. Prisma is committed to providing the best products and solutions to our users, and an essential part of that commitment is being intentional about the allocation of our resources, including sensible spending to enable us to serve our growing user base in the best way possible.
Exploring distribution options
We extensively explored different technologies and services that provided both reliable and fast engine distribution, while being cost-effective.
Free solutions: GitHub & npm
Because Prisma ORM is an open-source solution, we have explored various ways to distribute the engines through our existing distribution channels, at no cost. In this area, we had both GitHub Releases and npm as candidates to host and distribute our engine files. We dismissed GitHub Releases early on as the quality of service was not guaranteed, which was a requirement for us towards our users, so we can be sure to provide a good developer experience under all circumstances.
We also looked at npm, and confirmed that hosting the engine files would be in agreement with their Terms of Service. This made npm a viable option, but also meant we would have to change our engine download and upload logic to accommodate a different system. Additionally, this implied that we would have to update many past Prisma CLI versions, requiring our users to upgrade to take advantage of the new solution.
Paid solutions: CDNs & Cloudflare
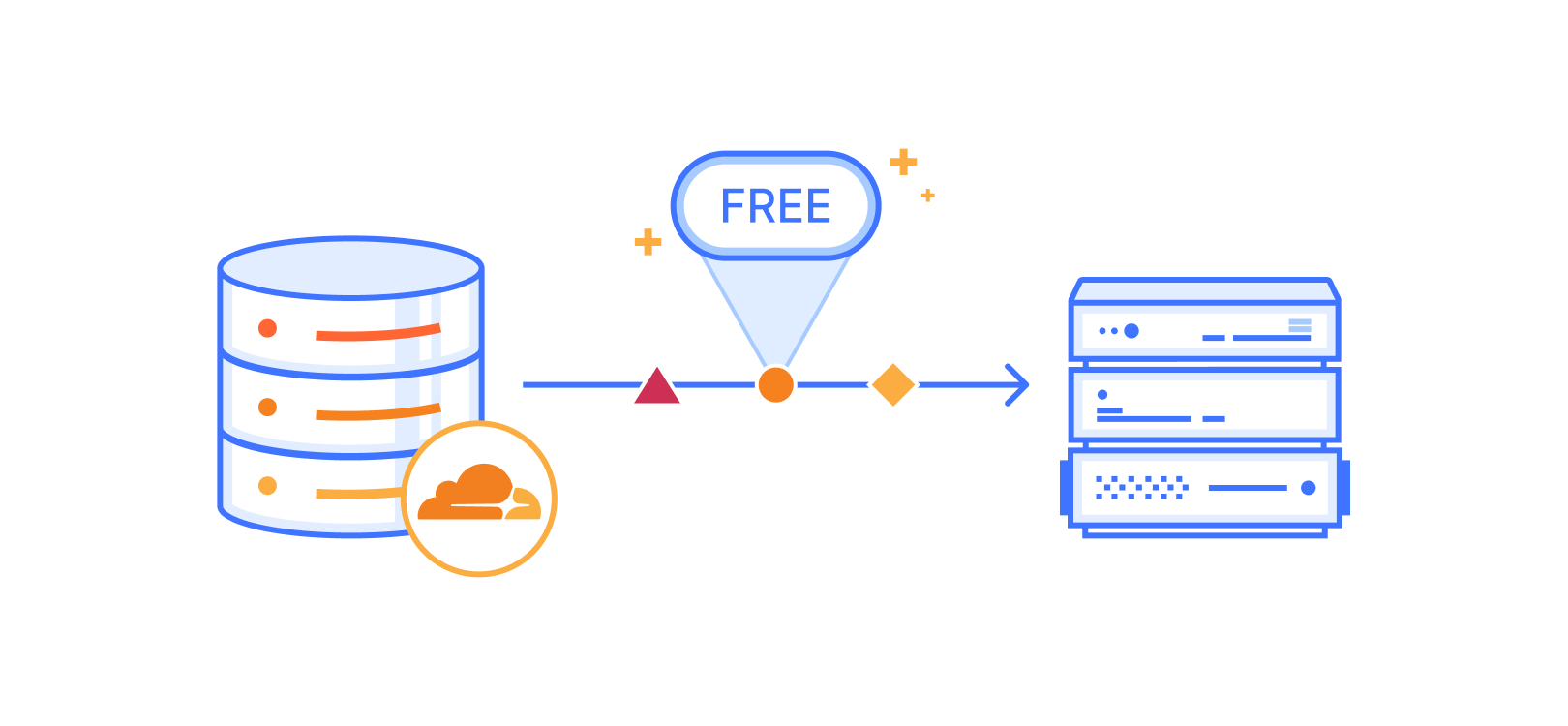
We then considered only replacing CloudFront, which accounted for 97% of our distribution costs, while retaining S3 as the origin. When we evaluated different CDNs, we found that alternatives could lead to an estimated 70% cost reduction.
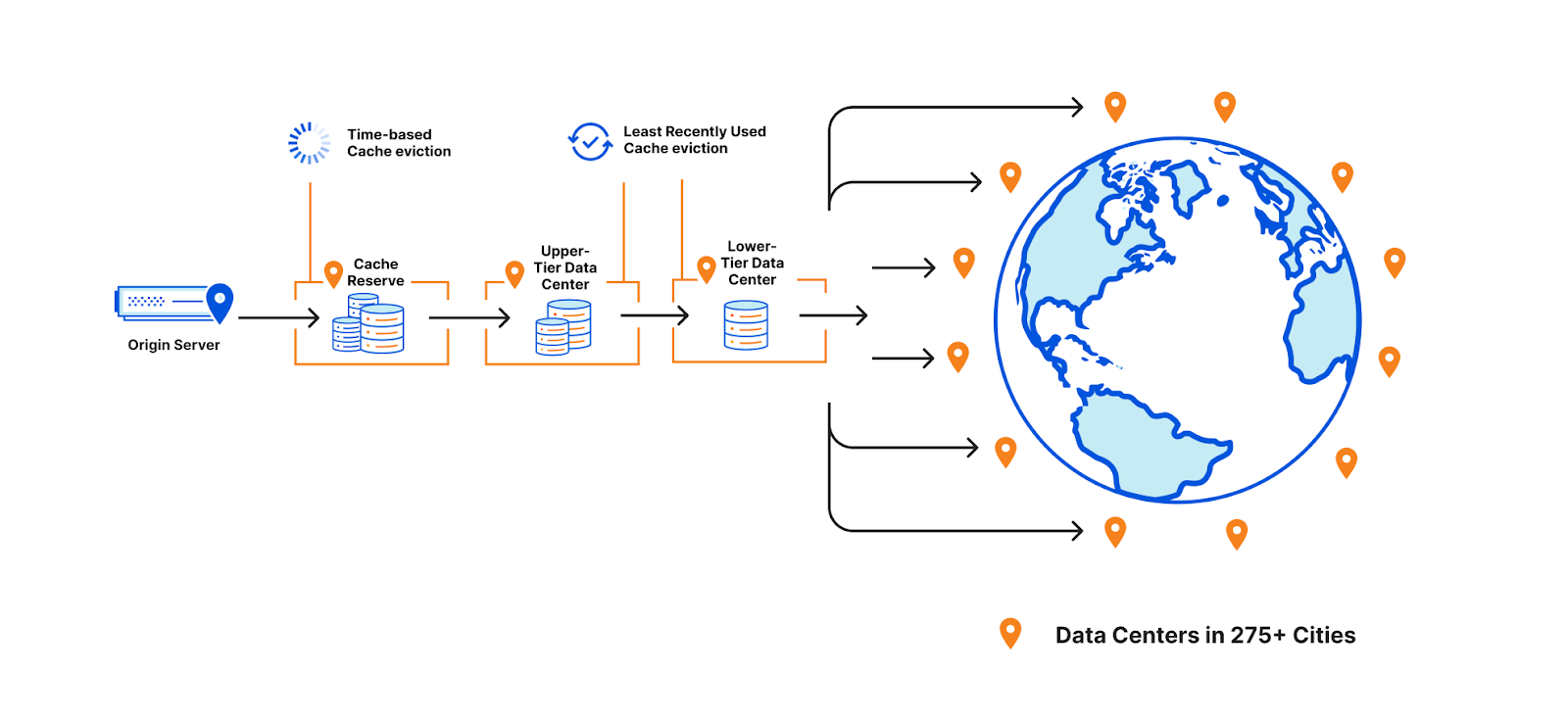
We also explored Cloudflare’s offerings and were impressed by Cloudflare R2, an alternative to AWS S3 + CloudFront. It offers robust blob storage compatible with S3 and leverages Cloudflare’s network for global low-latency distribution. Additionally, it has no egress costs, and is solely priced based on the total volume of data stored and operations on that data. Given our reliance on Cloudflare’s product portfolio for our Data Platform, and extensive experience with their Workers platform, we already had high trust in the quality of Cloudflare’s products.
To finalize our decision, we implemented a test to confirm our intuitions about Cloudflare’s quality of service. We deployed a script to 50 cities across the globe, representative of our incoming traffic, to measure download latencies for our engine files (~15MB). The test was run multiple times, with latencies for the different cache statuses recorded and compared against our previous AWS-based solution. The results confirmed that Cloudflare R2's reliability and performance were at least on par with AWS S3 + CloudFront. And because R2 is compatible with S3, we wouldn’t need to make substantial changes to our software in order to move over to Cloudflare. These were great results, and we couldn’t wait to switch!
Our solution: moving to Cloudflare’s R2
In order to move our engine file distribution to Cloudflare, we needed to ensure we could make the switch without any disruption or impact to our users.
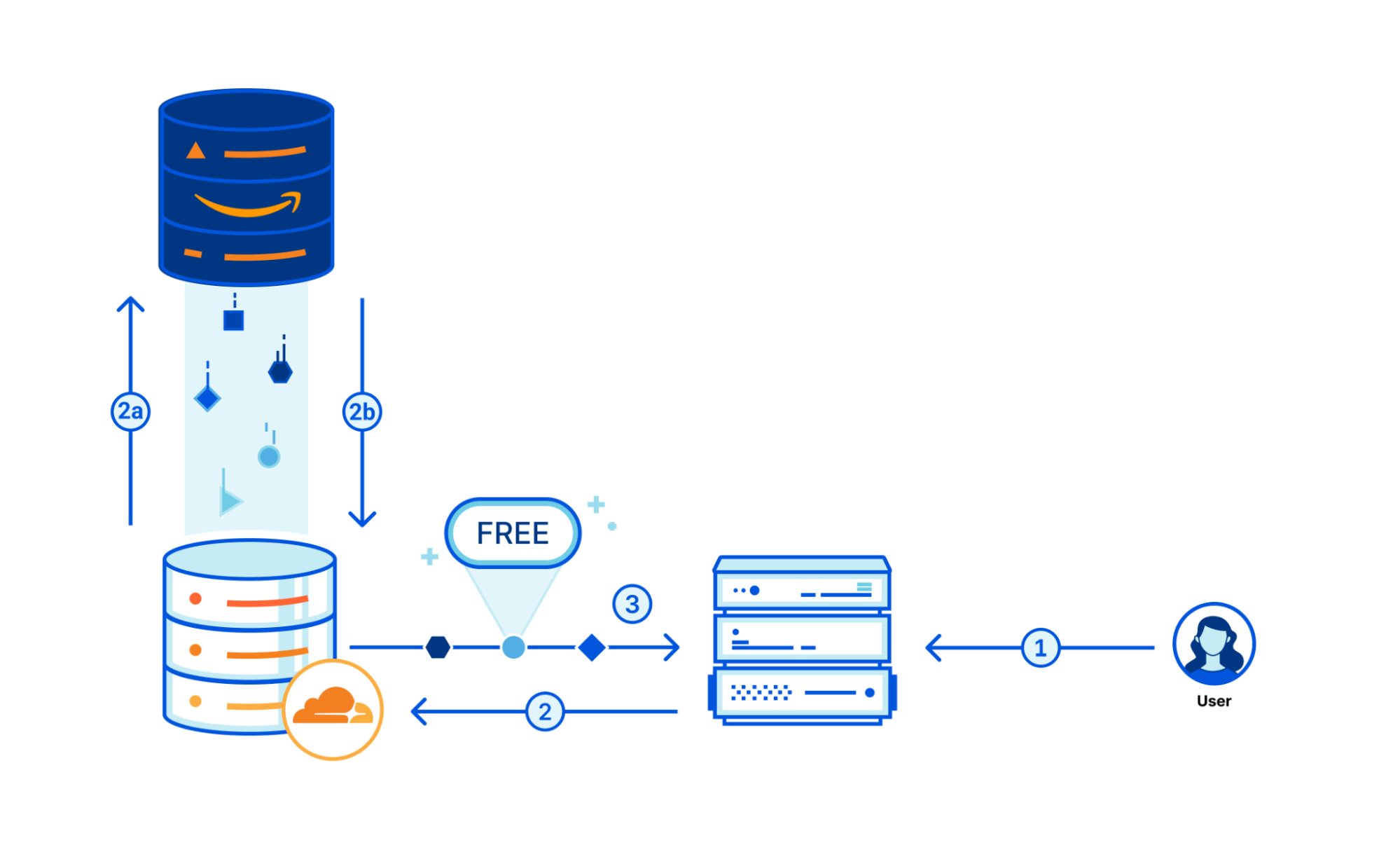
While R2 URLs match S3's format, Prisma CLI uses a fixed domain to point to the engine file distribution. This fixed domain enabled us to transition without making any changes to the code of older Prisma versions, and simply point the existing URLs to R2. However, to make the transition, we needed to change our DNS configuration to point to Cloudflare. While this seems trivial, potential issues like unexpected DNS propagation challenges, or certificate validation problems when connecting via TLS, required us to plan ahead in order to proceed confidently and safely.
We modified the Prisma ORM release pipeline to upload assets to both S3 and R2, and used the R2 Super Slurper for migrating past engine versions to R2. This ensured all Prisma releases, past and future, existed in both places. We also established Grafana monitoring checks to pull engine files from R2, using a DNS and TLS configuration similar to our desired production setup, but via an experimental domain. Those monitoring checks were later reused during the final traffic cutover to ensure that there was no service disruption.
As ensuring no impact or disruption to our users was of utmost importance, we proceeded with a gradual rollout of the DNS changes using DNS load balancing, a method where a group of alias records assigned to a domain are weighted differently. This meant that the DNS resolver directed more traffic to heavier-weighted records. We began with a load balancing configuration simulating our old setup, with one record (the control) pointing to AWS CloudFront, and the other (the candidate) pointing to R2. Initially, all weight was on the control, effectively preserving the old routing to CloudFront. We also set the lowest TTL possible, so changes in the record weights took effect as soon as possible, creating more control over DNS propagation. Additionally, we implemented a health check that would redirect all traffic to the control if download latencies were significantly higher, or if errors were detected, ensuring a stable fallback.
At this point, everything was in place and we could start the rollout.

The rollout began with a gradual increase in R2's DNS weight, and our monitoring dashboards showed that Cloudflare downloads were proportional to the weight assigned to R2. With as little as 5% traffic routed to Cloudflare, cache hit ratios neared 100%, as expected. Latencies matched the control, so the health checks were all good, and our fallback never activated. Over the duration of an hour, we gradually increased R2's DNS weight to manage 25%, 50%, and finally 100% of traffic, without any issues. The cutover could not have gone any smoother.
After monitoring for an additional two days, we simplified the DNS topology and routed to Cloudflare exclusively. We were extremely satisfied with the change, and started seeing our infrastructure costs drop considerably, as expected, not to mention the zero downtime and zero reported issues from users.
A success
Transitioning to Cloudflare R2 was easy thanks to their great product and tooling, intuitive platform and supportive team. We've had an excellent experience with their service, with consistently great uptime, performance and latency. Cloudflare proved once again to be a valuable partner to help us scale.
We are thrilled that our engine distribution costs have decreased by 98%. Cloudflare's cost-effective solution has not only delivered top-notch performance but has also brought significant savings to our operations. An all around success!
To learn more about how Prisma is building Data DX solutions with Cloudflare, take a look at Developer Experience Redefined: Prisma & Cloudflare Lead the Way to Data DX.
And if you want to see Prisma in action, get started with the Quickstart guide.