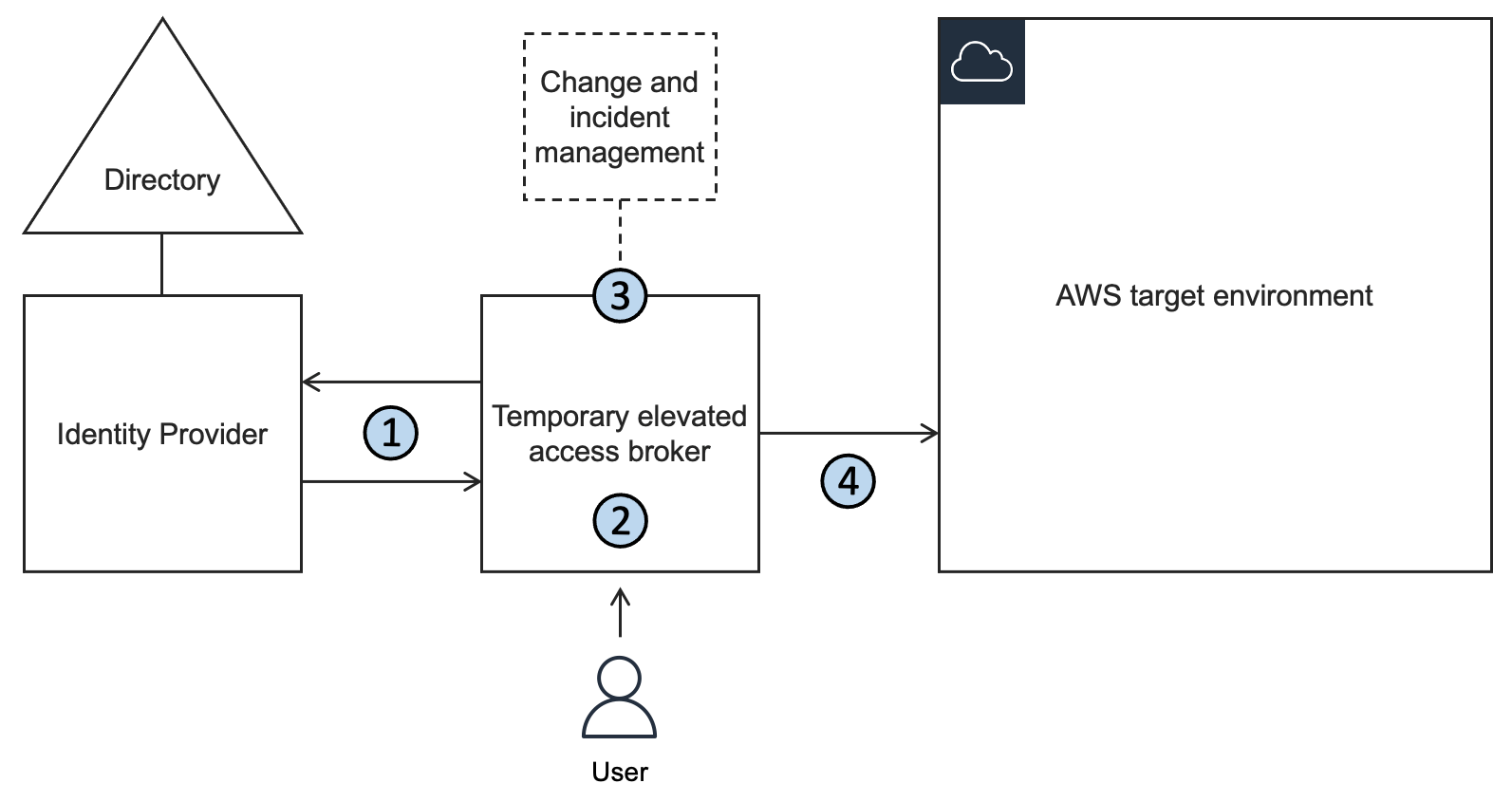
Post Syndicated from James Greenwood original https://aws.amazon.com/blogs/security/use-scalable-controls-for-aws-services-accessing-your-resources/
Sometimes you want to configure an AWS service to access your resource in another service. For example, you can configure AWS CloudTrail, a service that monitors account activity across your AWS infrastructure, to write log data to your bucket in Amazon Simple Storage Service (Amazon S3). When you do this, you want assurance that the service will only access your resource on your behalf—you don’t want an untrusted entity to be able to use the service to access your resource. Before today, you could achieve this by using the two AWS Identity and Access Management (IAM) condition keys, aws:SourceAccount and aws:SourceArn. You can use these condition keys to help make sure that a service accesses your resource only on behalf of specific accounts or resources that you trust. However, because these condition keys require you to specify individual accounts and resources, they can be difficult to manage at scale, especially in larger organizations.
Recently, IAM launched two new condition keys that can help you achieve this in a more scalable way that is simpler to manage within your organization:
aws:SourceOrgID— use this condition key to make sure that an AWS service can access your resources only when the request originates from a particular organization ID in AWS Organizations.aws:SourceOrgPaths— use this condition key to make sure that an AWS service can access your resources only when the request originates from one or more organizational units (OUs) in your organization.
In this blog post, we describe how you can use the four available condition keys, including the two new ones, to help you control how AWS services access your resources.
Background
Imagine a scenario where you configure an AWS service to access your resource in another service. Let’s say you’re using Amazon CloudWatch to observe resources in your AWS environment, and you create an alarm that activates when certain conditions occur. When the alarm activates, you want it to publish messages to a topic that you create in Amazon Simple Notification Service (Amazon SNS) to generate notifications.
Figure 1 depicts this process.

Figure 1: Amazon CloudWatch publishing messages to an SNS topic
In this scenario, there’s a resource-based policy controlling access to your SNS topic. For CloudWatch to publish messages to it, you must configure the policy to allow access by CloudWatch. When you do this, you identify CloudWatch using an AWS service principal, in this case cloudwatch.amazonaws.com.
Cross-service access
This is an example of a common pattern known as cross-service access. With cross-service access, a calling service accesses your resource in a called service, and a resource-based policy attached to your resource grants access to the calling service. The calling service is identified using an AWS service principal in the form <SERVICE-NAME>.amazonaws.com, and it accesses your resource on behalf of an originating resource, such as a CloudWatch alarm.
Figure 2 shows cross-service access.

Figure 2: Cross-service access
When you configure cross-service access, you want to make sure that the calling service will access your resource only on your behalf. That means you want the originating resource to be controlled by someone whom you trust. If an untrusted entity creates their own CloudWatch alarm in their AWS environment, for example, then their alarm should not be able to publish messages to your SNS topic.
If an untrusted entity could use a calling service to access your resource on their behalf, it would be an example of what’s known as the confused deputy problem. The confused deputy problem is a security issue in which an entity that doesn’t have permission to perform an action coerces a more privileged entity (in this case, a calling service) to perform the action instead.
Use condition keys to help prevent cross-service confused deputy issues
AWS provides global condition keys to help you prevent cross-service confused deputy issues. You can use these condition keys to control how AWS services access your resources.
Before today, you could use the aws:SourceAccount or aws:SourceArn condition keys to make sure that a calling service accesses your resource only when the request originates from a specific account (with aws:SourceAccount) or a specific originating resource (with aws:SourceArn). However, there are situations where you might want to allow multiple resources or accounts to use a calling service to access your resource. For example, you might want to create many VPC flow logs in an organization that publish to a central S3 bucket. To achieve this using the aws:SourceAccount or aws:SourceArn condition keys, you must enumerate all the originating accounts or resources individually in your resource-based policies. This can be difficult to manage, especially in large organizations, and can potentially cause your resource-based policy documents to reach size limits.
Now, you can use the new aws:SourceOrgID or aws:SourceOrgPaths condition keys to make sure that a calling service accesses your resource only when the request originates from a specific organization (with aws:SourceOrgID) or a specific organizational unit (with aws:SourceOrgPaths). This helps avoid the need to update policies when accounts are added or removed, reduces the size of policy documents, and makes it simpler to create and review policy statements.
The following table summarizes the four condition keys that you can use to help prevent cross-service confused deputy issues. These keys work in a similar way, but with different levels of granularity.
| Use case | Condition key | Value | Allowed operators | Single/multi valued | Example value |
| Allow a calling service to access your resource only on behalf of an organization that you trust. | aws:SourceOrgID |
AWS organization ID of the resource making a cross-service access request | String operators | Single-valued key | o-a1b2c3d4e5 |
| Allow a calling service to access your resource only on behalf of an organizational unit (OU) that you trust. | aws:SourceOrgPaths |
Organization entity paths of the resource making a cross-service access request | Set operators and string operators | Multivalued key | o-a1b2c3d4e5/r-ab12/ou-ab12-11111111/ou-ab12-22222222/ |
| Allow a calling service to access your resource only on behalf of an account that you trust. | aws:SourceAccount |
AWS account ID of the resource making a cross-service access request | String operators | Single-valued key | 111122223333 |
| Allow a calling service to access your resource only on behalf of a resource that you trust. | aws:SourceArn |
Amazon Resource Name (ARN) of the resource making a cross- service access request | ARN operators (recommended) or string operators | Single-valued key | arn:aws:cloudwatch:eu-west-1:111122223333:alarm:myalarm |
When to use the condition keys
AWS recommends that you use these condition keys in any resource-based policy statements that allow access by an AWS service, except where the relevant condition key is not yet supported by the service. To find out whether a condition key is supported by a particular service, see AWS global condition context keys in the AWS Identity and Access Management User Guide.
Note: Only use these condition keys in resource-based policies that allow access by an AWS service. Don’t use them in other use cases, including identity-based policies and service control policies (SCPs), where these condition keys won’t be populated.
Use condition keys for defense in depth
AWS services use a variety of mechanisms to help prevent cross-service confused deputy issues, and the details vary by service. For example, where a calling service accesses an S3 bucket, some services use S3 prefixes to help prevent confused deputy issues. For more information, see the relevant service documentation.
Where supported by the service, AWS recommends that you use the condition keys we describe in this post regardless of whether the service has another mechanism in place to help prevent cross-service confused deputy issues. This helps to make your intentions explicit, provide defense in depth, and guard against misconfigurations.
Example use cases
Let’s walk through some example use cases to learn how to use these condition keys in practice.
First, imagine you’re using Amazon Virtual Private Cloud (Amazon VPC) to manage logically isolated virtual networks. In Amazon VPC, you can configure flow logs, which capture information about your network traffic. Let’s say you want a flow log to write data into an S3 bucket for later analysis. This process is depicted in Figure 3.

Figure 3: Amazon VPC writing flow logs to an S3 bucket
This constitutes another cross-service access scenario. In this case, Amazon VPC is the calling service, Amazon S3 is the called service, the VPC flow log is the originating resource, and the S3 bucket is your resource in the called service.
To allow access, the resource-based policy for your S3 bucket (known as a bucket policy) must allow Amazon VPC to put objects there. The Principal element in this policy specifies the AWS service principal of the service that will access the resource, which for VPC flow logs is delivery.logs.amazonaws.com.
Initial policy without confused deputy prevention
The following is an initial version of the bucket policy that allows Amazon VPC to put objects in the bucket but doesn’t yet provide confused deputy prevention. We’re showing this policy for illustration purposes; don’t use it in its current form.
Note: For simplicity, we only show one of the policy statements that you need to allow VPC flow logs to write to a bucket. In a real-life bucket policy for flow logs, you need two policy statements: one allowing actions on the bucket, and one allowing actions on the bucket contents. These are described in Publish flow logs to Amazon S3. Both policy statements work in the same way with respect to confused deputy prevention.
This policy statement allows Amazon VPC to put objects in the bucket. However, it allows Amazon VPC to do that on behalf of any flow log in any account. There’s nothing in the policy to tell Amazon VPC that it should access this bucket only if the flow log belongs to a specific organization, OU, account, or resource that you trust.
Let’s now update the policy to help prevent cross-service confused deputy issues. For the rest of this post, the remaining policy samples provide confused deputy protection, but at different levels of granularity.
Specify a trusted organization
Continuing with the previous example, imagine that you now have an organization in AWS Organizations, and you want to create VPC flow logs in various accounts within your organization that publish to a central S3 bucket. You want Amazon VPC to put objects in the bucket only if the request originates from a flow log that resides in your organization.
You can achieve this by using the new aws:SourceOrgID condition key. In a cross-service access scenario, this condition key evaluates to the ID of the organization that the request came from. You can use this condition key in the Condition element of a resource-based policy to allow actions only if aws:SourceOrgID matches the ID of a specific organization, as shown in the following example. In your own policy, make sure to replace <DOC-EXAMPLE-BUCKET> and <MY-ORGANIZATION-ID> with your own information.
The revised policy states that Amazon VPC can put objects in the bucket only if the request originates from a flow log in your organization. Now, if someone creates a flow log outside your organization and configures it to access your bucket, they will get an access denied error.
You can use aws:SourceOrgID in this way to allow a calling service to access your resource only if the request originates from a specific organization, as shown in Figure 4.

Figure 4: Specify a trusted organization using aws:SourceOrgID
Specify a trusted OU
What if you don’t want to trust your entire organization, but only part of it? Let’s consider a different scenario. Imagine that you want to send messages from Amazon SNS into a queue in Amazon Simple Queue Service (Amazon SQS) so they can be processed by consumers. This is depicted in Figure 5.

Figure 5: Amazon SNS sending messages to an SQS queue
Now imagine that you want your SQS queue to receive messages only if they originate from an SNS topic that resides in a specific organizational unit (OU) in your organization. For example, you might want to allow messages only if they originate from a production OU that is subject to change control.
You can achieve this by using the new aws:SourceOrgPaths condition key. As before, you use this condition key in a resource-based policy attached to your resource. In a cross-service access scenario, this condition key evaluates to the AWS Organizations entity path that the request came from. An entity path is a text representation of an entity within an organization.
You build an entity path for an OU by using the IDs of the organization, root, and all OUs in the path down to and including the OU. For example, consider the organizational structure shown in Figure 6.

Figure 6: Example organization structure
In this example, you can specify the Prod OU by using the following entity path:
For more information about how to construct an entity path, see Understand the AWS Organizations entity path.
Let’s now match the aws:SourceOrgPaths condition key against a specific entity path in the Condition element of a resource-based policy for an SQS queue. In your own policy, make sure to replace <MY-QUEUE-ARN> and <MY-ENTITY-PATH> with your own information.
Note:
aws:SourceOrgPathsis a multivalued condition key, which means it’s capable of having multiple values in the request context. At the time of writing, it contains a single entity path if the request originates from an account in an organization, and a null value if the request originates from an account that’s not in an organization. Because this key is multivalued, you need to use both a set operator and a string operator to compare values.
In this policy, there are two conditions in the Condition block. The first uses the Null condition operator and compares with a false value to confirm that the condition key’s value is not null. The second uses set operator ForAllValues, which returns true if every condition key value in the request matches at least one value in your policy condition, and string operator StringEquals, which requires an exact match with a value specified in your policy condition.
Note: The reason for the null check is that set operator
ForAllValuesreturns true when a condition key resolves to null. With anAlloweffect and the null check in place, access is denied if the request originates from an account that’s not in an organization.
With this policy applied to your SQS queue, Amazon SNS can send messages to your queue only if the message came from an SNS topic in a specific OU.
You can use aws:SourceOrgPaths in this way to allow a calling service to access your resource only if the request originates from a specific organizational unit, as shown in Figure 7.

Figure 7: Specify a trusted OU using aws:SourceOrgPaths
Specify a trusted OU and its children
In the previous example, we specified a trusted OU, but that didn’t include its child OUs. What if you want to include its children as well?
You can achieve this by replacing the string operator StringEquals with StringLike. This allows you to use wildcards in the entity path. Using the organization structure from the previous example, the following Condition evaluates to true only if the condition key value is not null and the request originates from the Prod OU or any of its child OUs.
Specify a trusted account
If you want to be more granular, you can allow a service to access your resource only if the request originates from a specific account. You can achieve this by using the aws:SourceAccount condition key. In a cross-service access scenario, this condition key evaluates to the ID of the account that the request came from.
The following Condition evaluates to true only if the request originates from the account that you specify in the policy. In your own policy, make sure to replace <MY-ACCOUNT-ID> with your own information.
You can use this condition element within a resource-based policy to allow a calling service to access your resource only if the request originates from a specific account, as shown in Figure 8.

Figure 8: Specify a trusted account using aws:SourceAccount
Specify a trusted resource
If you want to be even more granular, you can allow a service to access your resource only if the request originates from a specific resource. For example, you can allow Amazon SNS to send messages to your SQS queue only if the request originates from a specific topic within Amazon SNS.
You can achieve this by using the aws:SourceArn condition key. In a cross-service access scenario, this condition key evaluates to the Amazon Resource Name (ARN) of the originating resource. This provides the most granular form of cross-service confused deputy prevention.
The following Condition evaluates to true only if the request originates from the resource that you specify in the policy. In your own policy, make sure to replace <MY-RESOURCE-ARN> with your own information.
Note: AWS recommends that you use an ARN operator rather than a string operator when comparing ARNs. This example uses
ArnEqualsto match the condition key value against the ARN specified in the policy.
You can use this condition element within a resource-based policy to allow a calling service to access your resource only if the request comes from a specific originating resource, as shown in Figure 9.

Figure 9: Specify a trusted resource using aws:SourceArn
Specify multiple trusted resources, accounts, OUs, or organizations
The four condition keys allow you to specify multiple trusted entities by matching against an array of values. This allows you to specify multiple trusted resources, accounts, OUs, or organizations in your policies.
Conclusion
In this post, you learned about cross-service access, in which an AWS service communicates with another AWS service to access your resource. You saw that it’s important to make sure that such services access your resources only on your behalf in order to help avoid cross-service confused deputy issues.
We showed you how to help prevent cross-service confused deputy issues by using two new condition keys aws:SourceOrgID and aws:SourceOrgPaths, as well as the other available condition keys aws:SourceAccount and aws:SourceArn. You learned that you should use these condition keys in any resource-based policy statements that allow access by an AWS service, if the condition key is supported by the service. This helps make sure that a calling service can access your resource only when the request originates from a specific organization, OU, account, or resource that you trust.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on AWS IAM re:Post or contact AWS Support.
Want more AWS Security news? Follow us on Twitter.