Post Syndicated from Jason Dalba original https://aws.amazon.com/blogs/big-data/reference-guide-to-analyze-transactional-data-in-near-real-time-on-aws/
Business leaders and data analysts use near-real-time transaction data to understand buyer behavior to help evolve products. The primary challenge businesses face with near-real-time analytics is getting the data prepared for analytics in a timely manner, which can often take days. Companies commonly maintain entire teams to facilitate the flow of data from ingestion to analysis.
The consequence of delays in your organization’s analytics workflow can be costly. As online transactions have gained popularity with consumers, the volume and velocity of data ingestion has led to challenges in data processing. Consumers expect more fluid changes to service and products. Organizations that can’t quickly adapt their business strategy to align with consumer behavior may experience loss of opportunity and revenue in competitive markets.
To overcome these challenges, businesses need a solution that can provide near-real-time analytics on transactional data with services that don’t lead to latent processing and bloat from managing the pipeline. With a properly deployed architecture using the latest technologies in artificial intelligence (AI), data storage, streaming ingestions, and cloud computing, data will become more accurate, timely, and actionable. With such a solution, businesses can make actionable decisions in near-real time, allowing leaders to change strategic direction as soon as the market changes.
In this post, we discuss how to architect a near-real-time analytics solution with AWS managed analytics, AI and machine learning (ML), and database services.
Solution overview
The most common workloads, agnostic of industry, involve transactional data. Transactional data volumes and velocity have continued to rapidly expand as workloads have been pushed online. Near-real-time data is data stored, processed, and analyzed on a continual basis. It generates information that is available for use almost immediately after being generated. With the power of near-real-time analytics, business units across an organization, including sales, marketing, and operations, can make agile, strategic decisions. Without the proper architecture to support near real-time analytics, organizations will be dependent on delayed data and will not be able to capitalize on emerging opportunities. Missed opportunities could impact operational efficiency, customer satisfaction, or product innovation.
Managed AWS Analytics and Database services allow for each component of the solution, from ingestion to analysis, to be optimized for speed, with little management overhead. It is crucial for critical business solutions to follow the six pillars of the AWS Well-Architected Framework. The framework helps cloud architects build the most secure, high performing, resilient, and efficient infrastructure for critical workloads.
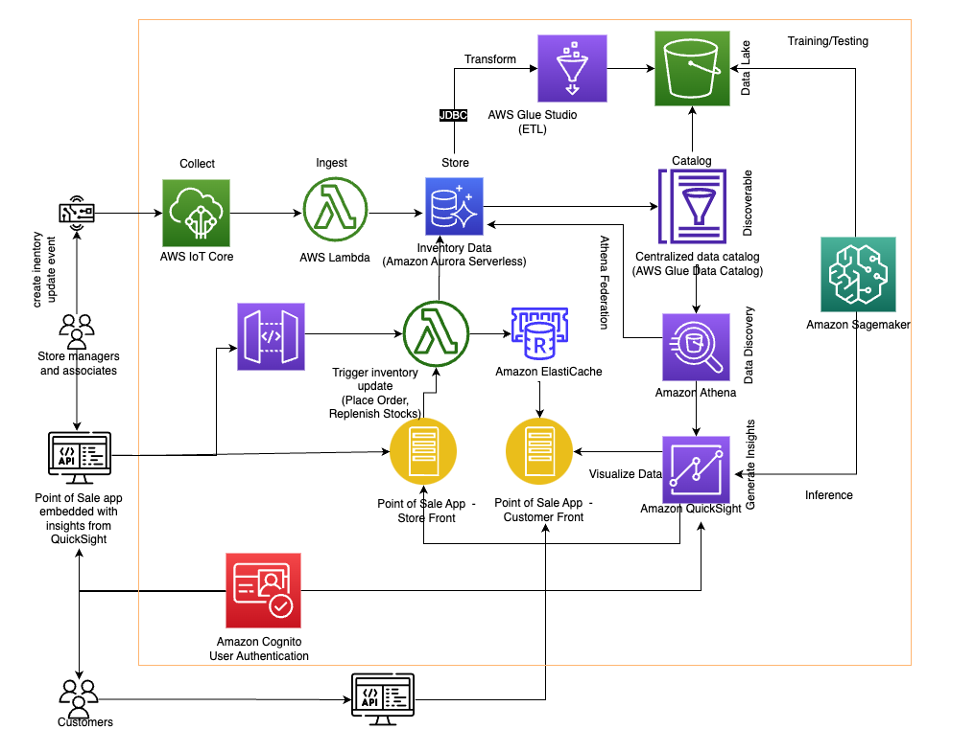
The following diagram illustrates the solution architecture.

By combining the appropriate AWS services, your organization can run near-real-time analytics off a transactional data store. In the following sections, we discuss the key components of the solution.
Transactional data storage
In this solution, we use Amazon DynamoDB as our transactional data store. DynamoDB is a managed NoSQL database solution that acts as a key-value store for transactional data. As a NoSQL solution, DynamoDB is optimized for compute (as opposed to storage) and therefore the data needs to be modeled and served up to the application based on how the application needs it. This makes DynamoDB good for applications with known access patterns, which is a property of many transactional workloads.
In DynamoDB, you can create, read, update, or delete items in a table through a partition key. For example, if you want to keep track of how many fitness quests a user has completed in your application, you can query the partition key of the user ID to find the item with an attribute that holds data related to completed quests, then update the relevant attribute to reflect a specific quests completion. There are also some added benefits of DynamoDB by design, such as the ability to scale to support massive global internet-scale applications while maintaining consistent single-digit millisecond latency performance, because the date will be horizontally partitioned across the underlying storage nodes by the service itself through the partition keys. Modeling your data here is very important so DynamoDB can horizontally scale based on a partition key, which is again why it’s a good fit for a transactional store. In transactional workloads, when you know what the access patterns are, it will be easier to optimize a data model around those patterns as opposed to creating a data model to accept ad hoc requests. All that being said, DynamoDB doesn’t perform scans across many items as efficiently, so for this solution, we integrate DynamoDB with other services to help meet the data analysis requirements.
Data streaming
Now that we have stored our workload’s transactional data in DynamoDB, we need to move that data to another service that will be better suited for analysis of said data. The time to insights on this data matters, so rather than send data off in batches, we stream the data into an analytics service, which helps us get the near-real time aspect of this solution.
We use Amazon Kinesis Data Streams to stream the data from DynamoDB to Amazon Redshift for this specific solution. Kinesis Data Streams captures item-level modifications in DynamoDB tables and replicates them to a Kinesis data stream. Your applications can access this stream and view item-level changes in near-real time. You can continuously capture and store terabytes of data per hour. Additionally, with the enhanced fan-out capability, you can simultaneously reach two or more downstream applications. Kinesis Data Streams also provides durability and elasticity. The delay between the time a record is put into the stream and the time it can be retrieved (put-to-get delay) is typically less than 1 second. In other words, a Kinesis Data Streams application can start consuming the data from the stream almost immediately after the data is added. The managed service aspect of Kinesis Data Streams relieves you of the operational burden of creating and running a data intake pipeline. The elasticity of Kinesis Data Streams enables you to scale the stream up or down, so you never lose data records before they expire.
Analytical data storage
The next service in this solution is Amazon Redshift, a fully managed, petabyte-scale data warehouse service in the cloud. As opposed to DynamoDB, which is meant to update, delete, or read more specific pieces of data, Amazon Redshift is better suited for analytic queries where you are retrieving, comparing, and evaluating large amounts of data in multi-stage operations to produce a final result. Amazon Redshift achieves efficient storage and optimum query performance through a combination of massively parallel processing, columnar data storage, and very efficient, targeted data compression encoding schemes.
Beyond just the fact that Amazon Redshift is built for analytical queries, it can natively integrate with Amazon streaming engines. Amazon Redshift Streaming Ingestion ingests hundreds of megabytes of data per second, so you can query data in near-real time and drive your business forward with analytics. With this zero-ETL approach, Amazon Redshift Streaming Ingestion enables you to connect to multiple Kinesis data streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK) data streams and pull data directly to Amazon Redshift without staging data in Amazon Simple Storage Service (Amazon S3). You can define a schema or choose to ingest semi-structured data with the SUPER data type. With streaming ingestion, a materialized view is the landing area for the data read from the Kinesis data stream, and the data is processed as it arrives. When the view is refreshed, Redshift compute nodes allocate each data shard to a compute slice. We recommend you enable auto refresh for this materialized view so that your data is continuously updated.
Data analysis and visualization
After the data pipeline is set up, the last piece is data analysis with Amazon QuickSight to visualize the changes in consumer behavior. QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people who you work with, wherever they are.
QuickSight connects to your data in the cloud and combines data from many different sources. In a single data dashboard, QuickSight can include AWS data, third-party data, big data, spreadsheet data, SaaS data, B2B data, and more. As a fully managed cloud-based service, QuickSight provides enterprise-grade security, global availability, and built-in redundancy. It also provides the user-management tools that you need to scale from 10 users to 10,000, all with no infrastructure to deploy or manage.
QuickSight gives decision-makers the opportunity to explore and interpret information in an interactive visual environment. They have secure access to dashboards from any device on your network and from mobile devices. Connecting QuickSight to the rest of our solution will complete the flow of data from being initially ingested into DynamoDB to being streamed into Amazon Redshift. QuickSight can create a visual analysis of the data in near-real time because that data is relatively up to date, so this solution can support use cases for making quick decisions on transactional data.
Using AWS for data services allows for each component of the solution, from ingestion to storage to analysis, to be optimized for speed and with little management overhead. With these AWS services, business leaders and analysts can get near-real-time insights to drive immediate change based on customer behavior, enabling organizational agility and ultimately leading to customer satisfaction.
Next steps
The next step to building a solution to analyze transactional data in near-real time on AWS would be to go through the workshop Enable near real-time analytics on data stored in Amazon DynamoDB using Amazon Redshift. In the workshop, you will get hands-on with AWS managed analytics, AI/ML, and database services to dive deep into an end-to-end solution delivering near-real-time analytics on transactional data. By the end of the workshop, you will have gone through the configuration and deployment of the critical pieces that will enable users to perform analytics on transactional workloads.
Conclusion
Developing an architecture that can serve transactional data to near-real-time analytics on AWS can help business become more agile in critical decisions. By ingesting and processing transactional data delivered directly from the application on AWS, businesses can optimize their inventory levels, reduce holding costs, increase revenue, and enhance customer satisfaction.
The end-to-end solution is designed for individuals in various roles, such as business users, data engineers, data scientists, and data analysts, who are responsible for comprehending, creating, and overseeing processes related to retail inventory forecasting. Overall, being able to analyze near-real time transactional data on AWS can provide businesses timely insight, allowing for quicker decision making in fast paced industries.
About the Authors
 Jason D’Alba is an AWS Solutions Architect leader focused on database and enterprise applications, helping customers architect highly available and scalable database solutions.
Jason D’Alba is an AWS Solutions Architect leader focused on database and enterprise applications, helping customers architect highly available and scalable database solutions.
 Veerendra Nayak is a Principal Database Solutions Architect based in the Bay Area, California. He works with customers to share best practices on database migrations, resiliency, and integrating operational data with analytics and AI services.
Veerendra Nayak is a Principal Database Solutions Architect based in the Bay Area, California. He works with customers to share best practices on database migrations, resiliency, and integrating operational data with analytics and AI services.
 Evan Day is a Database Solutions Architect at AWS, where he helps customers define technical solutions for business problems using the breadth of managed database services on AWS. He also focuses on building solutions that are reliable, performant, and cost efficient.
Evan Day is a Database Solutions Architect at AWS, where he helps customers define technical solutions for business problems using the breadth of managed database services on AWS. He also focuses on building solutions that are reliable, performant, and cost efficient.
 Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions.
Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions. Navnit Shukla is an AWS Specialist Solution Architect, Analytics, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions.
Navnit Shukla is an AWS Specialist Solution Architect, Analytics, and is passionate about helping customers uncover insights from their data. He has been building solutions to help organizations make data-driven decisions. Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions.
Vetri Natarajan is a Specialist Solutions Architect for Amazon QuickSight. Vetri has 15 years of experience implementing enterprise business intelligence (BI) solutions and greenfield data products. Vetri specializes in integration of BI solutions with business applications and enable data-driven decisions. Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in Data Analytics domain.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in Data Analytics domain.