Post Syndicated from Junho Choi original https://blog.cloudflare.com/road-to-grpc/
Cloudflare launched support for gRPC® during our 2020 Birthday Week. We’ve been humbled by the immense interest in the beta, and we’d like to thank everyone that has applied and tried out gRPC! In this post we’ll do a deep-dive into the technical details on how we implemented support.
What is gRPC?
gRPC is an open source RPC framework running over HTTP/2. RPC (remote procedure call) is a way for one machine to tell another machine to do something, rather than calling a local function in a library. RPC has been around in the history of distributed computing, with different implementations focusing on different areas, for a long time. What makes gRPC unique are the following characteristics:
- It requires the modern HTTP/2 protocol for transport, which is now widely available.
- A full client/server reference implementation, demo, and test suites are available as open source.
- It does not specify a message format, although Protocol Buffers are the preferred serialization mechanism.
- Both clients and servers can stream data, which avoids having to poll for new data or create new connections.
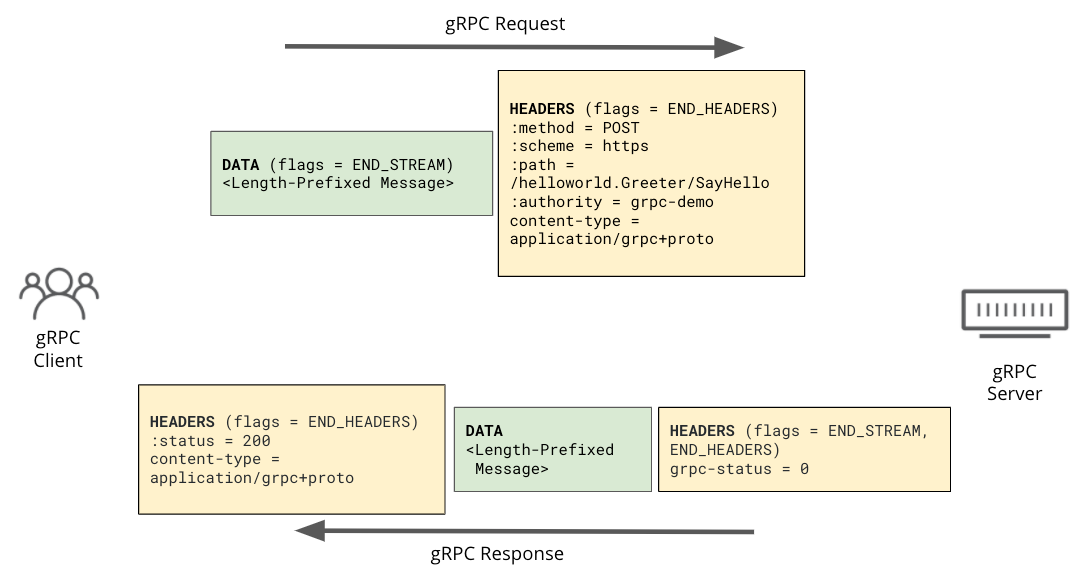
In terms of the protocol, gRPC uses HTTP/2 frames extensively: requests and responses look very similar to a normal HTTP/2 request.
What’s unusual, however, is gRPC’s usage of the HTTP trailer. While it’s not widely used in the wild, HTTP trailers have been around since 1999, as defined in original HTTP/1.1 RFC2616. HTTP message headers are defined to come before the HTTP message body, but HTTP trailer is a set of HTTP headers that can be appended after the message body. However, because there are not many use cases for trailers, many server and client implementations don’t fully support them. While HTTP/1.1 needs to use chunked transfer encoding for its body to send an HTTP trailer, in the case of HTTP/2 the trailer is in HEADER frame after the DATA frame of the body.
There are some cases where an HTTP trailer is useful. For example, we use an HTTP response code to indicate the status of request, but the response code is the very first line of the HTTP response, so we need to decide on the response code very early. A trailer makes it possible to send some metadata after the body. For example, let’s say your web server sends a stream of large data (which is not a fixed size), and in the end you want to send a SHA1 checksum of the data you sent so that the client can verify the contents. Normally, this is not possible with an HTTP status code or the response header which should be sent at the beginning of the response. Using a HTTP trailer header, you can send another header (e.g. Checksum: XXX) after having sent all the data.
gRPC uses HTTP trailers for two purposes. To begin with, it sends its final status (grpc-status) as a trailer header after the content has been sent. The second reason is to support streaming use cases. These use cases last much longer than normal HTTP requests. The HTTP trailer is used to give the post processing result of the request or the response. For example if there is an error during streaming data processing, you can send an error code using the trailer, which is not possible with the header before the message body.
Here is a simple example of a gRPC request and response in HTTP/2 frames:
Adding gRPC support to the Cloudflare Edge
Since gRPC uses HTTP/2, it may sound easy to natively support gRPC, because Cloudflare already supports HTTP/2. However, we had a couple of issues:
- The HTTP request/response trailer headers were not fully supported by our edge proxy: Cloudflare uses NGINX to accept traffic from eyeballs, and it has limited support for trailers. Further complicating things, requests and responses flowing through Cloudflare go through a set of other proxies.
- HTTP/2 to origin: our edge proxy uses HTTP/1.1 to fetch objects (whether dynamic or static) from origin. To proxy gRPC traffic, we need support connections to customer gRPC origins using HTTP/2.
- gRPC streaming needs to allow bidirectional request/response flow: gRPC has two types of protocol flow; one is unary, which is a simple request and response, and another is streaming, which allows non-stop data flow in each direction. To fully support the streaming, the HTTP message body needs to be sent after receiving the response header on the other end. For example, client streaming will keep sending a request body after receiving a response header.
Due to these reasons, gRPC requests would break when proxied through our network. To overcome these limitations, we looked at various solutions. For example, NGINX has a gRPC upstream module to support HTTP/2 gRPC origin, but it’s a separate module, and it also requires HTTP/2 downstream, which cannot be used for our service, as requests cascade through multiple HTTP proxies in some cases. Using HTTP/2 everywhere in the pipeline is not realistic, because of the characteristics of our internal load balancing architecture, and because it would have taken too much effort to make sure all internal traffic uses HTTP/2.
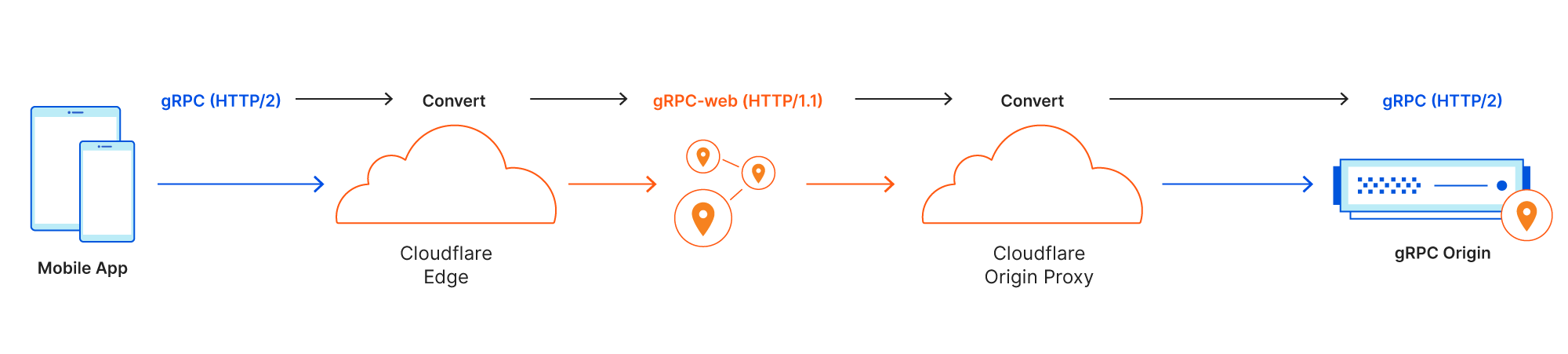
Converting to HTTP/1.1?
Ultimately, we discovered a better way: convert gRPC messages to HTTP/1.1 messages without a trailer inside our network, and then convert them back to HTTP/2 before sending the request off to origin. This would work with most HTTP proxies inside Cloudflare that don’t support HTTP trailers, and we would need minimal changes.
Rather than inventing our own format, the gRPC community has already come up with an HTTP/1.1-compatible version: gRPC-web. gRPC-web is a modification of the original HTTP/2 based gRPC specification. The original purpose was to be used with the web browsers, which lack direct access HTTP/2 frames. With gRPC-web, the HTTP trailer is moved to the body, so we don’t need to worry about HTTP trailer support inside the proxy. It also comes with streaming support. The resulting HTTP/1.1 message can be still inspected by our security products, such as WAF and Bot Management, to provide the same level of security that Cloudflare brings to other HTTP traffic.
When an HTTP/2 gRPC message is received at Cloudflare’s edge proxy, the message is “converted” to HTTP/1.1 gRPC-web format. Once the gRPC message is converted, it goes through our pipeline, applying services such as WAF, Cache and Argo services the same way any normal HTTP request would.
Right before a gRPC-web message leaves the Cloudflare network, it needs to be “converted back” to HTTP/2 gRPC again. Requests that are converted by our system are marked so that our system won’t accidentally convert gRPC-web traffic originated from clients.
HTTP/2 Origin Support
One of the engineering challenges was to support using HTTP/2 to connect to origins. Before this project, Cloudflare didn’t have the ability to connect to origins via HTTP/2.
Therefore, we decided to build support for HTTP/2 origin support in-house. We built a standalone origin proxy that is able to connect to origins via HTTP/2. On top of this new platform, we implemented the conversion logic for gRPC. gRPC support is the first feature that takes advantage of this new platform. Broader support for HTTP/2 connections to origin servers is on the roadmap.
gRPC Streaming Support
As explained above, gRPC has a streaming mode that request body or response body can be sent in stream; in the lifetime of gRPC requests, gRPC message blocks can be sent at any time. At the end of the stream, there will be a HEADER frame indicating the end of the stream. When it’s converted to gRPC-web, we will send the body using chunked encoding and keep the connection open, accepting both sides of the body until we get a gRPC message block, which indicates the end of the stream. This requires our proxy to support bidirectional transfer.
For example, client streaming is an interesting mode where the server already responds with a response code and its header, but the client is still able to send the request body.
Interoperability Testing
Every new feature at Cloudflare needs proper testing before release. During initial development, we used the envoy proxy with its gRPC-web filter feature and official examples of gRPC. We prepared a test environment with envoy and a gRPC test origin to make sure that the edge proxy worked properly with gRPC requests. Requests from the gRPC test client are sent to the edge proxy and converted to gRPC-web, and forwarded to the envoy proxy. After that, envoy converts back to gRPC request and sends to gRPC test origin. We were able to verify the basic behavior in this way.
Once we had basic functionality ready, we also needed to make sure both ends’ conversion functionality worked properly. To do that, we built deeper interoperability testing.
We referenced the existing gRPC interoperability test cases for our test suite and ran the first iteration of tests between the edge proxy and the new origin proxy locally.
For the second iteration of tests we used different gRPC implementations. For example, some servers sent their final status (grpc-status) in a trailers-only response when there was an immediate error. This response would contain the HTTP/2 response headers and trailer in a single HEADERS frame block with both the END_STREAM and END_HEADERS flags set. Other implementations sent the final status as trailer in a separate HEADERS frame.
After verifying interoperability locally we ran the test harness against a development environment that supports all the services we have in production. We were then able to ensure no unintended side effects were impacting gRPC requests.
We love dogfooding! One of the first services we successfully deployed edge gRPC support to is the Cloudflare drand randomness beacon. Onboarding was easy and we’ve been running the beacon in production for the last few weeks without a hitch.
Conclusion
Supporting a new protocol is exciting work! Implementing support for new technologies in existing systems is exciting and intricate, often involving tradeoffs between speed of implementation and overall system complexity. In the case of gRPC, we were able to build support quickly and in a way that did not require significant changes to the Cloudflare edge. This was accomplished by carefully considering implementation options before settling on the idea of converting between HTTP/2 gRPC and HTTP/1.1 gRPC-web format. This design choice made service integration quicker and easier while still satisfying our user’s expectations and constraints.
If you are interested in using Cloudflare to secure and accelerate your gRPC service, you can read more here. And if you want to work on interesting engineering challenges like the one described in this post, apply!
gRPC® is a registered trademark of The Linux Foundation.