Post Syndicated from Lucas Pardue original https://blog.cloudflare.com/go-and-enhance-your-calm/
In September 2025, a thread popped up in our internal engineering chat room asking, “Which part of our stack would be responsible for sending ErrCode=ENHANCE_YOUR_CALM to an HTTP/2 client?” Two internal microservices were experiencing a critical error preventing their communication and the team needed a timely answer.
In this blog post, we describe the background to well-known HTTP/2 attacks that trigger Cloudflare defences, which close connections. We then document an easy-to-make mistake using Go’s standard library that can cause clients to send PING flood attacks and how you can avoid it.

HTTP/2 defines a binary wire format for encoding HTTP semantics. Request and response messages are encoded as a series of HEADERS and DATA frames, each associated with a logical stream, sent over a TCP connection using TLS. There are also control frames that relate to the management of streams or the connection as a whole. For example, SETTINGS frames advertise properties of an endpoint, WINDOW_UPDATE frames provide flow control credit to a peer so that it can send data, RST_STREAM can be used to cancel or reject a request or response, while GOAWAY can be used to signal graceful or immediate connection closure.
HTTP/2 provides many powerful features that have legitimate uses. However, with great power comes responsibility and opportunity for accidental or intentional misuse. The specification details a number of denial-of-service considerations. Implementations are advised to harden themselves: “An endpoint that doesn’t monitor use of these features exposes itself to a risk of denial of service. Implementations SHOULD track the use of these features and set limits on their use.”

Cloudflare implements many different HTTP/2 defenses, developed over years in order to protect our systems and our customers. Some notable examples include mitigations added in 2019 to address “Netflix vulnerabilities” and in 2023 to mitigate Rapid Reset and similar style attacks.
When Cloudflare detects that HTTP/2 client behaviour is likely malicious, we close the connection using the GOAWAY frame and include the error code ENHANCE_YOUR_CALM.
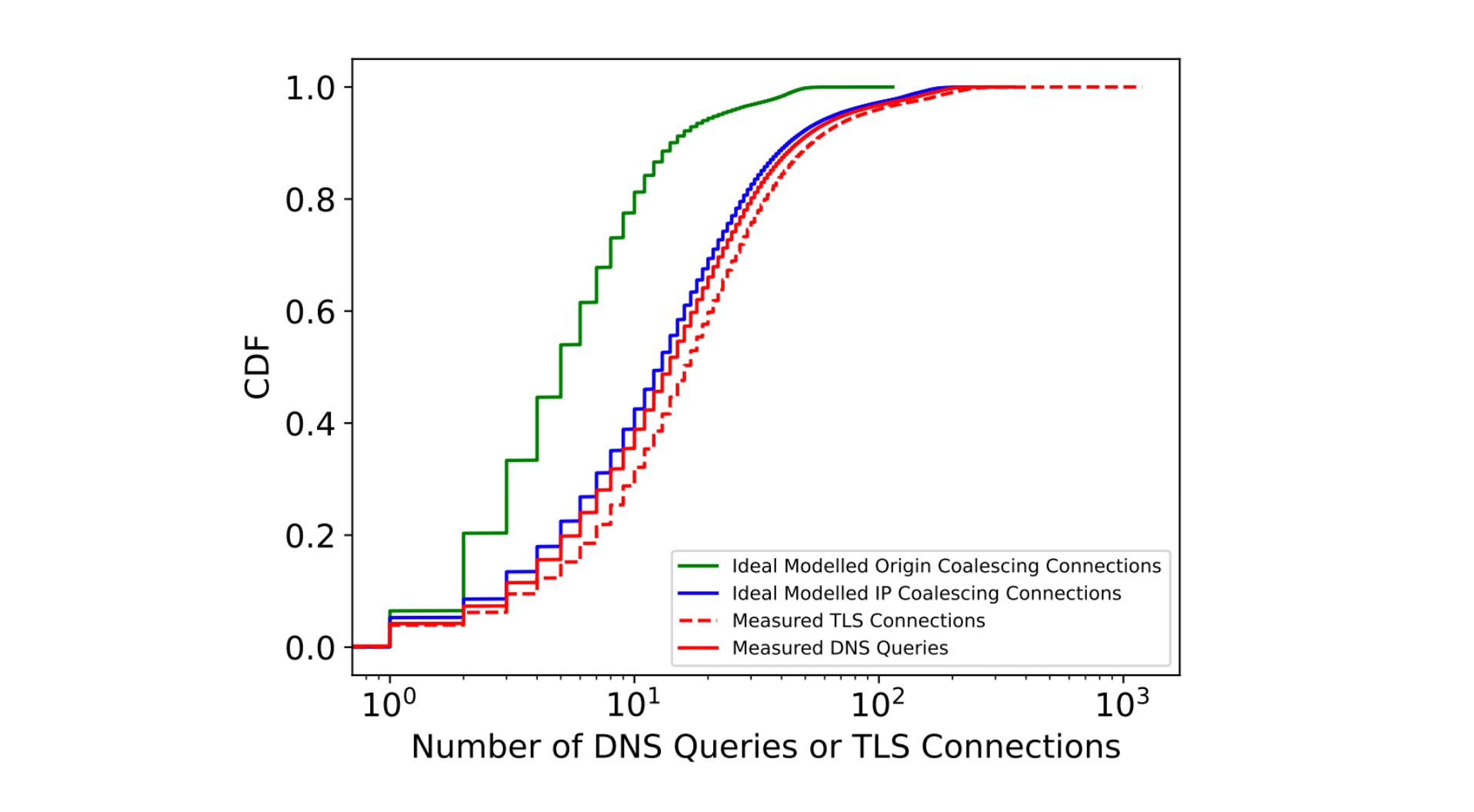
One of the well-known and common attacks is CVE-2019-9512, aka PING flood: “The attacker sends continual pings to an HTTP/2 peer, causing the peer to build an internal queue of responses. Depending on how efficiently this data is queued, this can consume excess CPU, memory, or both.” Sending a PING frame causes the peer to respond with a PING acknowledgement (indicated by an ACK flag). This allows for checking the liveness of the HTTP connection, along with measuring the layer 7 round-trip time – both useful things. The requirement to acknowledge a PING, however, provides the potential attack vector since it generates work for the peer.
A client that PINGs the Cloudflare edge too frequently will trigger our CVE-2019-9512 mitigations, causing us to close the connection. Shortly after we launched support for gRPC in 2020, we encountered interoperability issues with some gRPC clients that sent many PINGs as part of a performance optimization for window tuning. We also discovered that the Rust Hyper crate had a feature called Adaptive Window that emulated the design and triggered a similar problem until Hyper made a fix.
When that thread popped up asking which part of our stack was responsible for sending the ENHANCE_YOUR_CALM error code, it was regarding a client communicating over HTTP/2 between two internal microservices.
We suspected that this was an HTTP/2 mitigation issue and confirmed it was a PING flood mitigation in our logs. But taking a step back, you may wonder why two internal microservices are communicating over the Cloudflare edge at all, and therefore hitting our mitigations. In this case, communicating over the edge provides us with several advantages:
-
We get to dogfood our edge infrastructure and discover issues like this!
-
We can use Cloudflare Access for authentication. This allows our microservices to be accessed securely by both other services (using service tokens) and engineers (which is invaluable for debugging).
-
Internal services that are written with Cloudflare Workers can easily communicate with services that are accessible at the edge.

The question remained: Why was this client behaving this way? We traded some ideas as we attempted to get to the bottom of the issue.
The client had a configuration that would indicate that it didn’t need to PING very frequently:
t2.PingTimeout = 2 * time.Second
t2.ReadIdleTimeout = 5 * time.SecondHowever, in situations like this it is generally a good idea to establish ground truth about what is really happening “on the wire.” For instance, grabbing a packet capture that can be dissected and explored in Wireshark can provide unequivocal evidence of precisely what was sent over the network. The next best option is detailed/trace logging at the sender or receiver, although sometimes logging can be misleading, so caveat emptor.
In our particular case, it was simpler to use logging with GODEBUG=http2debug=2. We built a simplified minimal reproduction of the client that triggered the error, helping to eliminate other potential variables. We did some group log analysis, combined with diving into some of the Go standard library code to understand what it was really doing. Issac Asimov is commonly credited with the quote “The most exciting phrase to hear in science, the one that heralds new discoveries, is not ‘Eureka!’ but ‘That’s funny…'” and sure enough, within the hour someone declared–
the funny part I see is this:
2025/09/02 17:33:18 http2: Framer 0x14000624540: wrote RST_STREAM stream=9 len=4 ErrCode=CANCEL
2025/09/02 17:33:18 http2: Framer 0x14000624540: wrote PING len=8 ping="j\xe7\xd6R\xdaw\xf8+"every ping seems to be preceded by a RST_STREAM
Observant readers will recall the earlier mention of Rapid Reset. However, our logs clearly indicated ENHANCE_YOUR_CALM being triggered due to the PING flood. A bit of searching landed us on this mailing list thread and the comment “Sending a PING frame along with an RST_STREAM allows a client to distinguish between an unresponsive server and a slow response.” That seemed quite relevant. We also found a change that was committed related to this topic. This partly answered why there were so many PINGs, but it also raised a new question: Why so many stream resets?
So we went back to the logs and built up a little more context about the interaction:
2025/09/02 17:33:18 http2: Transport received DATA flags=END_STREAM stream=47 len=0 data=""
2025/09/02 17:33:18 http2: Framer 0x14000624540: wrote RST_STREAM stream=47 len=4 ErrCode=CANCEL
2025/09/02 17:33:18 http2: Framer 0x14000624540: wrote PING len=8 ping="\x97W\x02\xfa>\xa8\xabi"The interesting thing here is that the server had sent a DATA frame with the END_STREAM flag set. Per the HTTP/2 stream state machine, the stream should have transitioned to closed when a frame with END_STREAM was processed. The client doesn’t need to do anything in this state – sending a RST_STREAM is entirely unnecessary.

A little more digging and noodling and an engineer proclaimed:
I noticed that the reset+ping only happens when you call resp.Body.Close()
I believe Go’s HTTP library doesn’t actually read the response body automatically, but keeps the stream open for you to use until you call resp.Body.Close(), which you can do at any point you like.
The hilarious thing in our example was that there wasn’t actually any HTTP body to read. From the earlier example: received DATA flags=END_STREAM stream=47 len=0 data="".
Science and engineering are at times weird and counterintuitive. We decided to tweak our client to read the (absent) body via io.Copy(io.Discard, resp.Body) before closing it.
Sure enough, this immediately stopped the client sending both a useless RST_STREAM and, by association, a PING frame.
Mystery solved?
To prove we had fixed the root cause, the production client was updated with a similar fix. A few hours later, all the ENHANCE_YOUR_CALM closures were eliminated.
It’s worth noting that in some situations, ensuring the response body is always read can sometimes be unintuitive in Go. For example, at first glance it appears that the response body will always be read in the following example:
resp, err := http.DefaultClient.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
if err := json.NewDecoder(resp.Body).Decode(&respBody); err != nil {
return err
}However, json.Decoder stops reading as soon as it finds a complete JSON document or errors. If the response body contains multiple JSON documents or invalid JSON, then the entire response body may still not be read.
Therefore, in our clients, we’ve started replacing defer response.Body.Close() with the following pattern to ensure that response bodies are always fully read:
resp, err := http.DefaultClient.Do(req)
if err != nil {
return err
}
defer func() {
io.Copy(io.Discard, resp.Body)
resp.Body.Close()
}()
if err := json.NewDecoder(resp.Body).Decode(&respBody); err != nil {
return err
}HTTP/2 is a protocol with several features. Many implementations have implemented hardening to protect themselves from misuse of features, which can trigger a connection to be closed. The recommended error code for closing connections in such conditions is ENHANCE_YOUR_CALM. There are numerous HTTP/2 implementations and APIs, which may drive the use of HTTP/2 features in unexpected ways that could appear like attacks.
If you have an HTTP/2 client that encounters closures with ENHANCE_YOUR_CALM, we recommend that you try to establish ground truth with packet captures (including TLS decryption keys via mechanisms like SSLKEYLOGFILE) and/or detailed trace logging. Look for patterns of frequent or repeated frames that might be similar to malicious traffic. Adjusting your client may help avoid it getting misclassified as an attacker.
If you use Go, we recommend always reading HTTP/2 response bodies (even if empty) in order to avoid sending unnecessary RST_STREAM and PING frames. This is especially important if you use a single connection for multiple requests, which can cause a high frequency of these frames.
This was also a great reminder of the advantages of dogfooding our own products within our internal services. When we run into issues like this one, our learnings can benefit our customers with similar setups.