Post Syndicated from Noritaka Sekiyama original https://aws.amazon.com/blogs/big-data/end-to-end-development-lifecycle-for-data-engineers-to-build-a-data-integration-pipeline-using-aws-glue/
Data is a key enabler for your business. Many AWS customers have integrated their data across multiple data sources using AWS Glue, a serverless data integration service, in order to make data-driven business decisions. To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle for your data integration pipelines. The following are common asks from our customers:
- Is it possible to develop and test AWS Glue data integration jobs on my local laptop?
- Are there recommended approaches to provisioning components for data integration?
- How can we build a continuous integration and continuous delivery (CI/CD) pipeline for our data integration pipeline?
- What is the best practice to move from a pre-production environment to production?
To tackle these asks, this post defines the development lifecycle for data integration and demonstrates how software engineers and data engineers can design an end-to-end development lifecycle using AWS Glue, including development, testing, and CI/CD, using a sample baseline template.
End-to-end development lifecycle for a data integration pipeline
Today, it’s common to define not only data integration jobs but also all the data components in code. This means that you can rely on standard software best practices to build your data integration pipeline. The software development lifecycle on AWS defines the following six phases: Plan, Design, Implement, Test, Deploy, and Maintain.

In this section, we discuss each phase in the context of data integration pipeline.
Plan
In the planning phase, developers collect requirements from stakeholders such as end-users to define a data requirement. This could be what the use cases are (for example, ad hoc queries, dashboard, or troubleshooting), how much data to process (for example, 1 TB per day), what kinds of data, how many different data sources to pull from, how much data latency to accept to make it queryable (for example, 15 minutes), and so on.
Design
In the design phase, you analyze requirements and identify the best solution to build the data integration pipeline. In AWS, you need to choose the right services to achieve the goal and come up with the architecture by integrating those services and defining dependencies between components. For example, you may choose AWS Glue jobs as a core component for loading data from different sources, including Amazon Simple Storage Service (Amazon S3), then integrating them and preprocessing and enriching data. Then you may want to chain multiple AWS Glue jobs and orchestrate them. Finally, you may want to use Amazon Athena and Amazon QuickSight to present the enriched data to end-users.
Implement
In the implementation phase, data engineers code the data integration pipeline. They analyze the requirements to identify coding tasks to achieve the final result. The code includes the following:
- AWS resource definition
- Data integration logic
When using AWS Glue, you can define the data integration logic in a job script, which can be written in Python or Scala. You can use your preferred IDE to implement AWS resource definition using the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation, and also the business logic of AWS Glue job scripts for data integration. To learn more about how to implement your AWS Glue job scripts locally, refer to Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container.
Test
In the testing phase, you check the implementation for bugs. Quality analysis includes testing the code for errors and checking if it meets the requirements. Because many teams immediately test the code you write, the testing phase often runs parallel to the development phase. There are different types of testing:
- Unit testing
- Integration testing
- Performance testing
For unit testing, even for data integration, you can rely on a standard testing framework such as pytest and ScalaTest. To learn more about how to achieve unit testing locally, refer to Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container.
Deploy
When data engineers develop a data integration pipeline, you code and test on a different copy of the product than the one that the end-users have access to. The environment that end-users use is called production, whereas other copies are said to be in the development or the pre-production environment.
Having separate build and production environments ensures that you can continue to use the data integration pipeline even while it’s being changed or upgraded. The deployment phase includes several tasks to move the latest build copy to the production environment, such as packaging, environment configuration, and installation.
The following components are deployed through the AWS CDK or AWS CloudFormation:
- AWS resources
- Data integration job scripts for AWS Glue
AWS CodePipeline helps you to build a mechanism to automate deployments among different environments, including development, pre-production, and production. When you commit your code to AWS CodeCommit, CodePipeline automatically provisions AWS resources based on the CloudFormation templates included in the commit and uploads script files included in the commit to Amazon S3.
Maintain
Even after you deploy your solution to a production environment, it’s not the end of your project. You need to monitor the data integration pipeline continuously and keep maintaining and improving it. More specifically, you also need to fix bugs, resolve customer issues, and manage software changes. In addition, you need to monitor the overall system performance, security, and user experience to identify new ways to improve the existing data integration pipeline.
Solution overview
Typically, you have multiple accounts to manage and provision resources for your data pipeline. In this post, we assume the following three accounts:
- Pipeline account – This hosts the end-to-end pipeline
- Dev account – This hosts the integration pipeline in the development environment
- Prod account – This hosts the data integration pipeline in the production environment
If you want, you can use the same account and the same Region for all three.
To start applying this end-to-end development lifecycle model to your data platform easily and quickly, we prepared the baseline template aws-glue-cdk-baseline using the AWS CDK. The template is built on top of AWS CDK v2 and CDK Pipelines. It provisions two kinds of stacks:
- AWS Glue app stack – This provisions the data integration pipeline: one in the dev account and one in the prod account
- Pipeline stack – This provisions the Git repository and CI/CD pipeline in the pipeline account
The AWS Glue app stack provisions the data integration pipeline, including the following resources:
- AWS Glue jobs
- AWS Glue job scripts
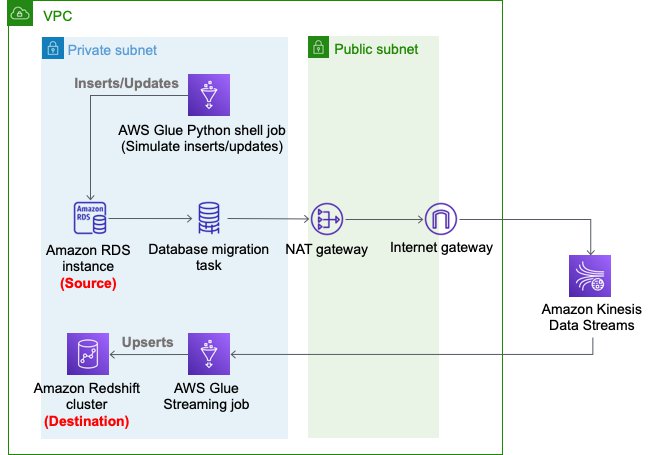
The following diagram illustrates this architecture.

At the time of publishing of this post, the AWS CDK has two versions of the AWS Glue module: @aws-cdk/aws-glue and @aws-cdk/aws-glue-alpha, containing L1 constructs and L2 constructs, respectively. The sample AWS Glue app stack is defined using aws-glue-alpha, the L2 construct for AWS Glue, because it’s straightforward to define and manage AWS Glue resources. If you want to use the L1 construct, refer to Build, Test and Deploy ETL solutions using AWS Glue and AWS CDK based CI/CD pipelines.
The pipeline stack provisions the entire CI/CD pipeline, including the following resources:
- AWS Identity and Access Management (IAM) roles
- S3 bucket
- CodeCommit
- CodePipeline
- AWS CodeBuild
The following diagram illustrates the pipeline workflow.

Every time the business requirement changes (such as adding data sources or changing data transformation logic), you make changes on the AWS Glue app stack and re-provision the stack to reflect your changes. This is done by committing your changes in the AWS CDK template to the CodeCommit repository, then CodePipeline reflects the changes on AWS resources using CloudFormation change sets.
In the following sections, we present the steps to set up the required environment and demonstrate the end-to-end development lifecycle.
Prerequisites
You need the following resources:
- Python 3.9 or later
- AWS accounts for the pipeline account, dev account, and prod account
- An AWS named profile for the pipeline account, dev account, and prod account
- The AWS CDK Toolkit (cdk command) 2.87.0 or later
- Docker
- Visual Studio Code
- Visual Studio Code Dev Containers
Initialize the project
To initialize the project, complete the following steps:
- Clone the baseline template to your workplace:
- Create a Python virtual environment specific to the project on the client machine:
We use a virtual environment in order to isolate the Python environment for this project and not install software globally.
- Activate the virtual environment according to your OS:
- On MacOS and Linux, use the following command:
- On a Windows platform, use the following command:
After this step, the subsequent steps run within the bounds of the virtual environment on the client machine and interact with the AWS account as needed.
- Install the required dependencies described in requirements.txt to the virtual environment:
- Edit the configuration file
default-config.yamlbased on your environments (replace each account ID with your own): - Run
pytestto initialize the snapshot test files by running the following command:
Bootstrap your AWS environments
Run the following commands to bootstrap your AWS environments:
- In the pipeline account, replace PIPELINE-ACCOUNT-NUMBER, REGION, and PIPELINE-PROFILE with your own values:
- In the dev account, replace PIPELINE-ACCOUNT-NUMBER, DEV-ACCOUNT-NUMBER, REGION, and DEV-PROFILE with your own values:
- In the prod account, replace PIPELINE-ACCOUNT-NUMBER, PROD-ACCOUNT-NUMBER, REGION, and PROD-PROFILE with your own values:
When you use only one account for all environments, you can just run the cdk bootstrap command one time.
Deploy your AWS resources
Run the command using the pipeline account to deploy the resources defined in the AWS CDK baseline template:
This creates the pipeline stack in the pipeline account and the AWS Glue app stack in the development account.
When the cdk deploy command is completed, let’s verify the pipeline using the pipeline account.
On the CodePipeline console, navigate to GluePipeline. Then verify that GluePipeline has the following stages: Source, Build, UpdatePipeline, Assets, DeployDev, and DeployProd. Also verify that the stages Source, Build, UpdatePipeline, Assets, DeployDev have succeeded, and DeployProd is pending. It can take about 15 minutes.

Now that the pipeline has been created successfully, you can also verify the AWS Glue app stack resource on the AWS CloudFormation console in the dev account.

At this step, the AWS Glue app stack is deployed only in the dev account. You can try to run the AWS Glue job ProcessLegislators to see how it works.
Configure your Git repository with CodeCommit
In an earlier step, you cloned the Git repository from GitHub. Although it’s possible to configure the AWS CDK template to work with GitHub, GitHub Enterprise, or Bitbucket, for this post, we use CodeCommit. If you prefer those third-party Git providers, configure the connections and edit pipeline_stack.py to define the variable source to use the target Git provider using CodePipelineSource.
Because you already ran the cdk deploy command, the CodeCommit repository has already been created with all the required code and related files. The first step is to set up access to CodeCommit. The next step is to clone the repository from the CodeCommit repository to your local. Run the following commands:
In the next step, we make changes in this local copy of the CodeCommit repository.
End-to-end development lifecycle
Now that the environment has been successfully created, you’re ready to start developing a data integration pipeline using this baseline template. Let’s walk through end-to-end development lifecycle.
When you want to define your own data integration pipeline, you need to add more AWS Glue jobs and implement job scripts. For this post, let’s assume the use case to add a new AWS Glue job with a new job script to read multiple S3 locations and join them.
Implement and test in your local environment
First, implement and test the AWS Glue job and its job script in your local environment using Visual Studio Code.
Set up your development environment by following the steps in Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container. The following steps are required in the context of this post:
- Start Docker.
- Pull the Docker image that has the local development environment using the AWS Glue ETL library:
- Run the following command to define the AWS named profile name:
- Run the following command to make it available with the baseline template:
- Run the Docker container:
- Start Visual Studio Code.
- Choose Remote Explorer in the navigation pane, then choose the arrow icon of the workspace folder in the container
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01.


If the workspace folder is not shown, choose Open folder and select /home/glue_user/workspace.
Then you will see a view similar to the following screenshot.

Optionally, you can install AWS Tool Kit for Visual Studio Code, and start Amazon CodeWhisperer to enable code recommendations powered by machine learning model. For example, in aws_glue_cdk_baseline/job_scripts/process_legislators.py, you can put comments like “# Write a DataFrame in Parquet format to S3”, press Enter key, then CodeWhisperer will recommend a code snippet similar to the following:

Now you install the required dependencies described in requirements.txt to the container environment.
- Run the following commands in the terminal in Visual Studio Code:
- Implement the code.
Now let’s make the required changes for a new AWS Glue job here.
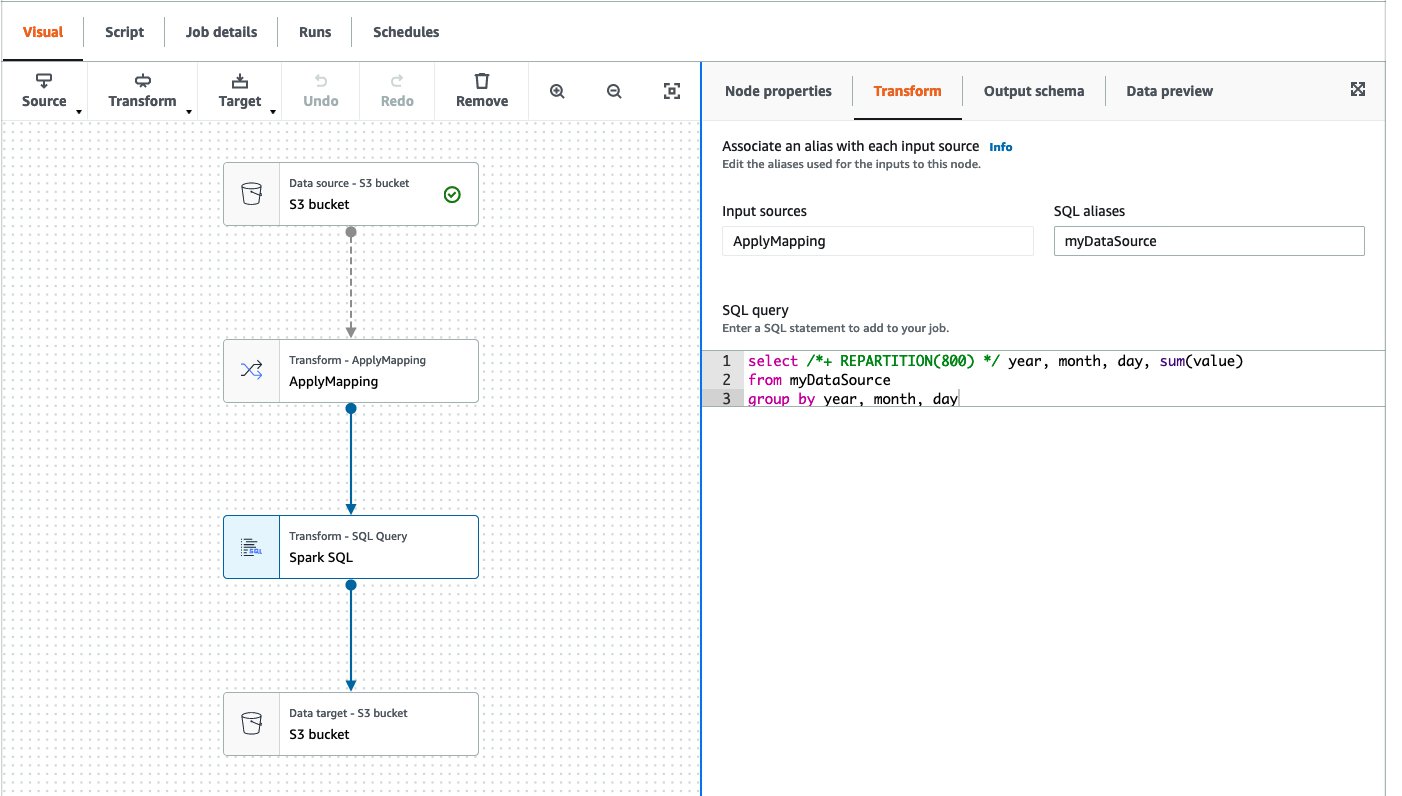
- Edit the file aws_glue_cdk_baseline/glue_app_stack.py. Let’s add the following new code block after the existing job definition of
ProcessLegislatorsin order to add the new AWS Glue jobJoinLegislators:
Here, you added three job parameters for different S3 locations using the variable config. It is the dictionary generated from default-config.yaml. In this baseline template, we use this central config file for managing parameters for all the Glue jobs in the structure <stage name>/jobs/<job name>/<parameter name>. In the proceeding steps, you provide those locations through the AWS Glue job parameters.
- Create a new job script called
aws_glue_cdk_baseline/job_scripts/join_legislators.py: - Create a new unit test script for the new AWS Glue job called
aws_glue_cdk_baseline/job_scripts/tests/test_join_legislators.py: - In default-config.yaml, add the following under
prodanddev: - Add the following under
"jobs"in the variableconfigin tests/unit/test_glue_app_stack.py, tests/unit/test_pipeline_stack.py, and tests/snapshot/test_snapshot_glue_app_stack.py (no need to replace S3 locations): - Choose Run at the top right to run the individual job scripts.


If the Run button is not shown, install Python into the container through Extensions in the navigation pane.
- For local unit testing, run the following command in the terminal in Visual Studio Code:
Then you can verify that the newly added unit test passed successfully.
- Run
pytestto initialize the snapshot test files by running following command:
Deploy to the development environment
Complete following steps to deploy the AWS Glue app stack to the development environment and run integration tests there:
- Set up access to CodeCommit.
- Commit and push your changes to the CodeCommit repo:
You can see that the pipeline is successfully triggered.

Integration test
There is nothing required for running the integration test for the newly added AWS Glue job. The integration test script integ_test_glue_app_stack.py runs all the jobs including a specific tag, then verifies the state and its duration. If you want to change the condition or the threshold, you can edit assertions at the end of the integ_test_glue_job method.
Deploy to the production environment
Complete the following steps to deploy the AWS Glue app stack to the production environment:
- On the CodePipeline console, navigate to
GluePipeline. - Choose Review under the
DeployProdstage. - Choose Approve.


Wait for the DeployProd stage to complete, then you can verify the AWS Glue app stack resource in the dev account.
Clean up
To clean up your resources, complete following steps:
- Run the following command using the pipeline account:
- Delete the AWS Glue app stack in the dev account and prod account.
Conclusion
In this post, you learned how to define the development lifecycle for data integration and how software engineers and data engineers can design an end-to-end development lifecycle using AWS Glue, including development, testing, and CI/CD, through a sample AWS CDK template. You can get started building your own end-to-end development lifecycle for your workload using AWS Glue.
About the author
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.



 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering, and BI, and is based in California. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design easy-to-use data products. In her spare time, she enjoys playing card games.
Gal Heyne is a Product Manager for AWS Glue with a strong focus on AI/ML, data engineering, and BI, and is based in California. She is passionate about developing a deep understanding of customers’ business needs and collaborating with engineers to design easy-to-use data products. In her spare time, she enjoys playing card games.







 Tomohiro Tanaka is a Senior Cloud Support Engineer on the AWS Support team. He’s passionate about helping customers build data lakes using ETL workloads. In his free time, he enjoys coffee breaks with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer on the AWS Support team. He’s passionate about helping customers build data lakes using ETL workloads. In his free time, he enjoys coffee breaks with his colleagues and making coffee at home. Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis.
Chuhan Liu is a Software Development Engineer on the AWS Glue team. He is passionate about building scalable distributed systems for big data processing, analytics, and management. In his spare time, he enjoys playing tennis. Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.
Matt Su is a Senior Product Manager on the AWS Glue team. He enjoys helping customers uncover insights and make better decisions using their data with AWS Analytic services. In his spare time, he enjoys skiing and gardening.






 Scott Long is a Front End Engineer on the AWS Glue team. He is responsible for implementing new features in AWS Glue Studio. In his spare time, he enjoys socializing with friends and participating in various outdoor activities.
Scott Long is a Front End Engineer on the AWS Glue team. He is responsible for implementing new features in AWS Glue Studio. In his spare time, he enjoys socializing with friends and participating in various outdoor activities. Sean Ma is a Principal Product Manager on the AWS Glue team. He has an 18+ year track record of innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football.
Sean Ma is a Principal Product Manager on the AWS Glue team. He has an 18+ year track record of innovating and delivering enterprise products that unlock the power of data for users. Outside of work, Sean enjoys scuba diving and college football.








































































 Sanjay Srivastava is a Principal Product Manager for AWS Lake Formation. He is passionate about building products, in particular products that help customers get more out of their data. During his spare time, he loves to spend time with his family and engage in outdoor activities including hiking, running, and gardening.
Sanjay Srivastava is a Principal Product Manager for AWS Lake Formation. He is passionate about building products, in particular products that help customers get more out of their data. During his spare time, he loves to spend time with his family and engage in outdoor activities including hiking, running, and gardening.










 Sachet Saurabh is a Senior Software Development Engineer at AWS Glue and AWS Lake Formation. He is passionate about building fault tolerant and reliable distributed systems at scale.
Sachet Saurabh is a Senior Software Development Engineer at AWS Glue and AWS Lake Formation. He is passionate about building fault tolerant and reliable distributed systems at scale. Vikas Malik is a Software Development Manager at AWS Glue. He enjoys building solutions that solve business problems at scale. In his free time, he likes playing and gardening with his kids and exploring local areas with family.
Vikas Malik is a Software Development Manager at AWS Glue. He enjoys building solutions that solve business problems at scale. In his free time, he likes playing and gardening with his kids and exploring local areas with family.






