Post Syndicated from Chandan Rupakheti original https://aws.amazon.com/blogs/big-data/introducing-simplified-interaction-with-the-airflow-rest-api-in-amazon-mwaa/
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that builds upon Apache Airflow, offering its benefits while eliminating the need for you to set up, operate, and maintain the underlying infrastructure, reducing operational overhead while increasing security and resilience.
Today, we are excited to announce an enhancement to the Amazon MWAA integration with the Airflow REST API. This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically. The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines.
In this post, we discuss the enhancement and present several use cases that the enhancement unlocks for your Amazon MWAA environment.
Airflow REST API
The Airflow REST API is a programmatic interface that allows you to interact with Airflow’s core functionalities. It’s a set of HTTP endpoints to perform operations such as invoking Directed Acyclic Graphs (DAGs), checking task statuses, retrieving metadata about workflows, managing connections and variables, and even initiating dataset-related events, without directly accessing the Airflow web interface or command line tools.
Before today, Amazon MWAA provided the foundation for interacting with the Airflow REST API. Though functional, the process of obtaining and managing access tokens and session cookies added complexity to the workflow. Amazon MWAA now supports a simplified mechanism for interacting with the Airflow REST API using AWS credentials, significantly reducing complexity and improving overall usability.
Enhancement overview
The new InvokeRestApi capability allows you to run Airflow REST API requests with a valid SigV4 signature using your existing AWS credentials. This feature is now available to all Amazon MWAA environments (2.4.3+) in supported Amazon MWAA AWS Regions. By acting as an intermediary, this REST API processes requests on behalf of users, requiring only the environment name and API request payload as inputs.
Integrating with the Airflow REST API through the enhanced Amazon MWAA API provides several key benefits:
- Simplified integration – The new
InvokeRestApi capability in Amazon MWAA removes the complexity of managing access tokens and session cookies, making it straightforward to interact with the Airflow REST API.
- Improved usability – By acting as an intermediary, the enhanced API delivers Airflow REST API execution results directly to the client, reducing complexity and improving overall usability.
- Automated administration – The simplified REST API access enables automating various administrative and management tasks, such as managing Airflow variables, connections, slot pools, and more.
- Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events. This supports the growing emphasis on event-driven data pipelines.
- Data-aware scheduling – Using the dataset-based scheduling feature in Airflow, the enhanced API enables the Amazon MWAA environment to manage the incoming workload and scale resources accordingly, improving the overall reliability and efficiency of event-driven pipelines.
In the following sections, we demonstrate how to use the enhanced API in various use cases.
How to use the enhanced Amazon MWAA API
The following code snippet shows the general request format for the enhanced REST API:
POST /restapi/Name HTTP/1.1
Content-type: application/json
{
Name: String,
Method: String,
Path: String,
QueryParameters: Json,
Body: Json
}
The Name of the Amazon MWAA environment, the Path of the Airflow REST API endpoint to be called, and the HTTP Method to use are the required parameters, whereas QueryParameters and Body are optional and can be used as needed in the API calls.
The following code snippet shows the general response format:
{
RestApiStatusCode: Number,
RestApiResponse: Json
}
The RestApiStatusCode represents the HTTP status code returned by the Airflow REST API call, and the RestApiResponse contains the response payload from the Airflow REST API.
The following sample code snippet showcases how to update the description field of an Airflow variable using the enhanced integration. The call uses the AWS Python SDK to invoke the Airflow REST API for the task.
import boto3
# Create a boto3 client
mwaa_client = boto3.client("mwaa")
# Call the enhanced REST API using boto3 client
# Using QueryParameters, you can selectively specify the field to be updated
# Without QueryParameters, all fields will be updated
response = mwaa_client.invoke_rest_api(
Name="<your-environment-name>",
Method="PATCH",
Path=f"/variables/<your-variable-key>",
Body={
"key": "<key>",
"value": "<value>",
"description": "<description>"
},
QueryParameters={
"update_mask": ["description"]
}
)
# Access the outputs of the REST call
status_code = response["RestApiStatusCode"]
result = response['RestApiResponse']
To make the invoke_rest_api SDK call, the calling client should have an AWS Identity and Access Management (IAM) principal of airflow:InvokeRestAPI attached to call the requisite environment. The permission can be scoped to specific Airflow roles (Admin, Op, User, Viewer, or Public) to control access levels.
This simple yet powerful REST API supports various use cases for your Amazon MWAA environments. Let’s review some important ones in the subsequent sections.
Automate administration and management tasks
Prior to this launch, to automate configurations and setup of resources such as variables, connections, slot pools, and more, you had to develop a lengthy boilerplate code to make API requests to the Amazon MWAA web servers. You had to handle the cookie and session management in the process. You can simplify this automation with the new enhanced REST API support.
For this example, let’s assume you want to automate maintaining your Amazon MWAA environment variables. You need to perform API operations such as create, read, update, and delete on Airflow variables to achieve this task. The following is a simple Python client to do so (mwaa_variables_client.py):
import boto3
# Client for managing MWAA environment variables
class MWAAVariablesClient:
# Initialize the client with environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# List all variables in the MWAA environment
def list(self):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="GET",
Path="/variables"
)
output = response['RestApiResponse']['variables']
return output
# Get a specific variable by key
def get(self, key):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="GET",
Path=f"/variables/{key}"
)
return response['RestApiResponse']
# Create a new variable with key, value, and optional description
def create(self, key, value, description=None):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path="/variables",
Body={
"key": key,
"value": value,
"description": description
}
)
return response['RestApiResponse']
# Update an existing variable's value and description
def update(self, key, value, description, query_parameters=None):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="PATCH",
Path=f"/variables/{key}",
Body={
"key": key,
"value": value,
"description": description
},
QueryParameters=query_parameters
)
return response['RestApiResponse']
# Delete a variable by key
def delete(self, key):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="DELETE",
Path=f"/variables/{key}"
)
return response['RestApiStatusCode']
if __name__ == "__main__":
client = MWAAVariablesClient("<your-mwaa-environment-name>")
print("\nCreating a test variable ...")
response = client.create(
key="test",
value="Test value",
description="Test description"
)
print(response)
print("\nListing all variables ...")
variables = client.list()
print(variables)
print("\nGetting the test variable ...")
response = client.get("test")
print(response)
print("\nUpdating the value and description of test variable ...")
response = client.update(
key="test",
value="Updated Value",
description="Updated description"
)
print(response)
print("\nUpdating only description of test variable ...")
response = client.update(
key="test",
value="Updated Value",
description="Yet another updated description",
query_parameters={ "update_mask": ["description"] }
)
print(response)
print("\nDeleting the test variable ...")
response_code = client.delete("test")
print(f"Response code: {response_code}")
print("\nFinally, getting the deleted test variable ...")
try:
response = client.get("test")
print(response)
except Exception as e:
print(e.response["RestApiResponse"])
Assuming that you have configured your terminal with appropriate AWS credentials, you can run the preceding Python script to achieve the following results:
$python mwaa_variables_client.py
Creating a test variable ...
{'description': 'Test description', 'key': 'test', 'value': 'Test value'}
Listing all variables ...
[{'key': 'test', 'value': 'Test value'}]
Getting the test variable ...
{'key': 'test', 'value': 'Test value'}
Updating the value and description of test variable ...
{'description': 'Updated description', 'key': 'test', 'value': 'Updated Value'}
Updating only description of test variable ...
{'description': 'Yet another updated description', 'key': 'test', 'value': 'Updated Value'}
Deleting the test variable ...
Response code: 204
Finally, getting the deleted test variable ...
{'detail': 'Variable does not exist', 'status': 404, 'title': 'Variable not found', 'type': 'https://airflow.apache.org/docs/apache-airflow/2.8.1/stable-rest-api-ref.html#section/Errors/NotFound'}
Let’s further explore other useful use cases.
Build event-driven data pipelines
The Airflow community has been actively innovating to enhance the platform’s data awareness, enabling you to build more dynamic and responsive workflows. When we announced support for version 2.9.2 in Amazon MWAA, we introduced capabilities that allow pipelines to react to changes in datasets, both within Airflow environments and in external systems. The new simplified integration with the Airflow REST API makes the implementation of data-driven pipelines more straightforward.
Consider a use case where you need to run a pipeline that uses input from an external event. The following sample DAG runs a bash command supplied as a parameter (any_bash_command.py):
"""
This DAG allows you to execute a bash command supplied as a parameter to the DAG.
The command is passed as a parameter called `command` in the DAG configuration.
"""
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.models.param import Param
from datetime import datetime
with DAG(
dag_id="any_bash_command",
schedule=None,
start_date=datetime(2022, 1, 1),
catchup=False,
params={
"command": Param("env", type="string")
},
) as dag:
cli_command = BashOperator(
task_id="triggered_bash_command",
bash_command="{{ dag_run.conf['command'] }}"
)
With the help of the enhanced REST API, you can create a client that can invoke this DAG, supplying the bash command of your choice as follows (mwaa_dag_run_client.py):
import boto3
# Client for triggering DAG runs in Amazon MWAA
class MWAADagRunClient:
# Initialize the client with MWAA environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# Trigger a DAG run with specified parameters
def trigger_run(self,
dag_id,
dag_run_id=None,
logical_date=None,
data_interval_start=None,
data_interval_end=None,
note=None,
conf=None,
):
body = {}
if dag_run_id:
body["dag_run_id"] = dag_run_id
if logical_date:
body["logical_date"] = logical_date
if data_interval_start:
body["data_interval_start"] = data_interval_start
if data_interval_end:
body["data_interval_end"] = data_interval_end
if note:
body["note"] = note
body["conf"] = conf or {}
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path=f"/dags/{dag_id}/dagRuns",
Body=body
)
return response['RestApiResponse']
if __name__ == "__main__":
client = MWAADagRunClient("<your-mwaa-environment-name>")
print("\nTriggering a dag run ...")
result = client.trigger_run(
dag_id="any_bash_command",
conf={
"command": "echo 'Hello from external trigger!'"
}
)
print(result)
The following snippet shows a sample run of the script:
$python mwaa_dag_run_client.py
Triggering a dag run ...
{'conf': {'command': "echo 'Hello from external trigger!'"}, 'dag_id': 'any_bash_command', 'dag_run_id': 'manual__2024-10-21T16:56:09.852908+00:00', 'data_interval_end': '2024-10-21T16:56:09.852908+00:00', 'data_interval_start': '2024-10-21T16:56:09.852908+00:00', 'execution_date': '2024-10-21T16:56:09.852908+00:00', 'external_trigger': True, 'logical_date': '2024-10-21T16:56:09.852908+00:00', 'run_type': 'manual', 'state': 'queued'}
On the Airflow UI, the trigger_bash_command task shows the following execution log:
[2024-10-21, 16:56:12 UTC] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2024-10-21, 16:56:12 UTC] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-10-21, 16:56:12 UTC] {subprocess.py:75} INFO - Running command: ['/usr/bin/bash', '-c', "echo 'Hello from external trigger!'"]
[2024-10-21, 16:56:12 UTC] {subprocess.py:86} INFO - Output:
[2024-10-21, 16:56:12 UTC] {subprocess.py:93} INFO - Hello from external trigger!
[2024-10-21, 16:56:12 UTC] {subprocess.py:97} INFO - Command exited with return code 0
[2024-10-21, 16:56:12 UTC] {taskinstance.py:340} ▶ Post task execution logs
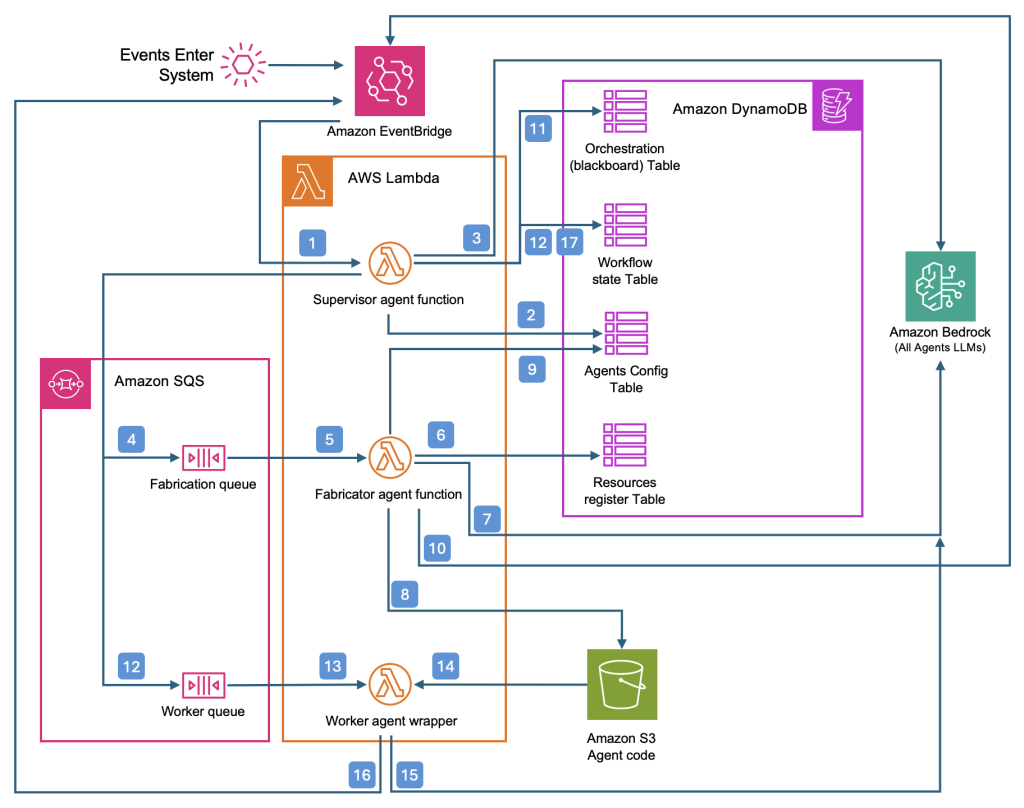
You can further expand this example to more useful event-driven architectures. Let’s expand the use case to run your data pipeline and perform extract, transform, and load (ETL) jobs when a new file lands in an Amazon Simple Storage Service (Amazon S3) bucket in your data lake. The following diagram illustrates one architectural approach.

In the context of invoking a DAG through an external input, the AWS Lambda function would have no knowledge of how busy the Amazon MWAA web server is, potentially leading to the function overwhelming the Amazon MWAA web server by processing a large number of files in a short timeframe.
One way to regulate the file processing throughput would be to introduce an Amazon Simple Queue Service (Amazon SQS) queue between the S3 bucket and the Lambda function, which can help with rate limiting the API requests to the web server. You can achieve this by configuring maximum concurrency for Lambda for the SQS event source. However, the Lambda function would still be unaware of the processing capacity available in the Amazon MWAA environment to run the DAGs.
In addition to the SQS queue, to help afford the Amazon MWAA environment manage the load natively, you can use the Airflow’s data-aware scheduling feature using datasets. This approach involves using the enhanced Amazon MWAA REST API to create dataset events, which are then used by the Airflow scheduler to schedule the DAG natively. This way, the Amazon MWAA environment can effectively batch the dataset events and scale resources based on the load. Let’s explore this approach in more detail.
Configure data-aware scheduling
Consider the following DAG that showcases a framework for an ETL pipeline (data_aware_pipeline.py). It uses a dataset for scheduling.
"""
DAG to run the given ETL pipeline based on the datalake dataset event.
"""
from airflow import DAG, Dataset
from airflow.decorators import task
from datetime import datetime
# Create a dataset
datalake = Dataset("datalake")
# Return a list of S3 file URIs from the supplied dataset events
def get_resources(dataset_uri, triggering_dataset_events=None):
events = triggering_dataset_events[dataset_uri] if triggering_dataset_events else []
s3_uris = list(map(lambda e: e.extra["uri"], events))
return s3_uris
with DAG(
dag_id="data_aware_pipeline",
schedule=[datalake],
start_date=datetime(2022, 1, 1),
catchup=False
):
@task
def extract(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Running data extraction for {resource} ...")
@task
def transform(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Running data transformation for {resource} ...")
@task()
def load(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Loading finalized data for {resource} ...")
extract() >> transform() >> load()
In the preceding code snippet, a Dataset object called datalake is used to schedule the DAG. The get_resources function extracts the extra information that contains the locations of the newly added files in the S3 data lake. Upon receiving dataset events, the Amazon MWAA environment batches the dataset events based on the load and schedules the DAG to handle them appropriately. The modified architecture to support the data-aware scheduling is presented below.

The following is a simplified client that can create a dataset event through the enhanced REST API (mwaa_dataset_client.py):
import boto3
# Client for interacting with MWAA datasets
class MWAADatasetClient:
# Initialize the client with environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# Create a dataset event in the MWAA environment
def create_event(self, dataset_uri, extra=None):
body = {
"dataset_uri": dataset_uri
}
if extra:
body["extra"] = extra
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path="/datasets/events",
Body=body
)
return response['RestApiResponse']
The following is a code snippet for the Lambda function in the preceding architecture to generate the dataset event, assuming the function is configured to handle one S3 PUT event at a time (dataset_event_lambda.py):
import os
import json
from mwaa_dataset_client import MWAADatasetClient
environment = os.environ["MWAA_ENV_NAME"]
client = MWAADatasetClient(environment)
def handler(event, context):
# Extract S3 file URI from SQS record
record = event["Records"][0]
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
s3_file_uri = f"s3://{bucket}/{key}"
# Create a dataset event
result = client.create_event(
dataset_uri="datalake",
extra={"uri": s3_file_uri}
)
return {
"statusCode": 200,
"body": json.dumps(result)
}
As new files get dropped into the S3 bucket, the Lambda function will generate a dataset event per file, passing in the Amazon S3 location of the newly added files. The Amazon MWAA environment will schedule the ETL pipeline upon receiving the dataset events. The following diagram illustrates a sample run of the ETL pipeline on the Airflow UI.

The following snippet shows the execution log of the extract task from the pipeline. The log shows how the Airflow scheduler batched three dataset events together to handle the load.
[2024-10-21, 16:47:15 UTC] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file1.csv ...
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file2.csv ...
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file3.csv ...
[2024-10-21, 16:47:15 UTC] {python.py:240} INFO - Done. Returned value was: None
[2024-10-21, 16:47:16 UTC] {taskinstance.py:340} ▶ Post task execution logs
In this way, you can use the enhanced REST API to create data-aware, event-driven pipelines.
Considerations
When implementing solutions using the enhanced Amazon MWAA REST API, it’s important to consider the following:
- IAM permissions – Make sure the IAM principal making the
invoke_rest_api SDK call has the airflow:InvokeRestAPI permission on the Amazon MWAA resource. To control access levels, the permission can be scoped to specific Airflow roles (Admin, Op, User, Viewer, or Public).
- Error handling – Implement robust error handling mechanisms to handle various HTTP status codes and error responses from the Airflow REST API.
- Monitoring and logging – Set up appropriate monitoring and logging to track the performance and reliability of your API-based integrations and data pipelines.
- Versioning and compatibility – Monitor the versioning of the Airflow REST API and the Amazon MWAA service to make sure your integrations remain compatible with any future changes.
- Security and compliance – Adhere to your organization’s security and compliance requirements when integrating external systems with Amazon MWAA and handling sensitive data.
You can start using the simplified integration with the Airflow REST API in your Amazon MWAA environments with Airflow version 2.4.3 or greater, in all currently supported Regions.
Conclusion
The enhanced integration between Amazon MWAA and the Airflow REST API represents a significant improvement in the ease of interacting with Airflow’s core functionalities. This new capability opens up a wide range of use cases, from centralizing and automating administrative tasks, improving overall usability, to building event-driven, data-aware data pipelines.
As you explore this new feature, consider the various use cases and best practices outlined in this post. By using the new InvokeRestApi, you can streamline your data management processes, enhance operational efficiency, and drive greater value from your data-driven systems.
About the Authors
 Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
 Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.
Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.
 Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation.
Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation. Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.
Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.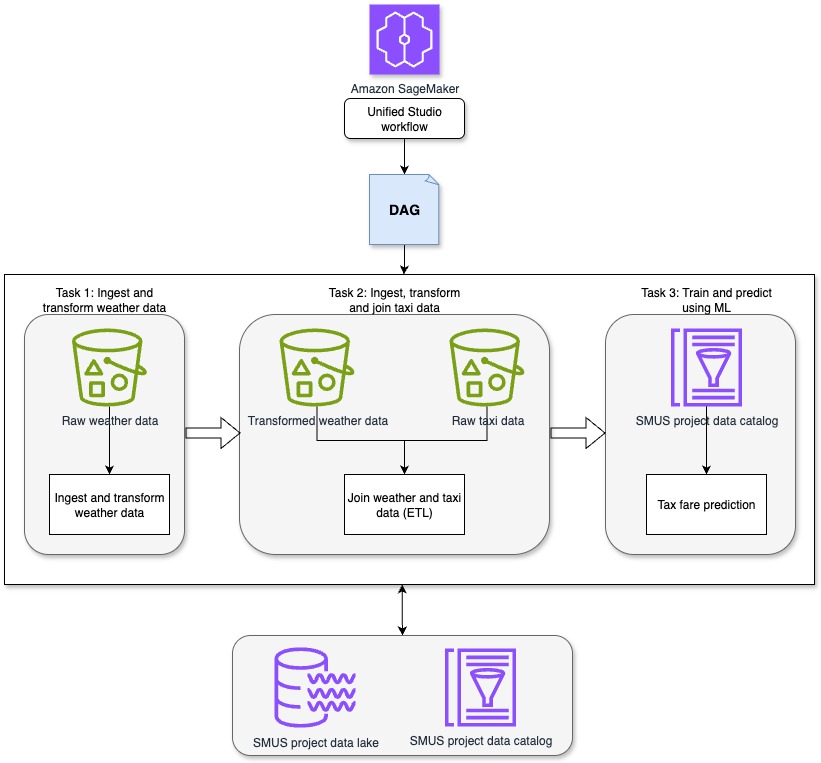
















 Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music. Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.
Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.













 Dave Horne is a Sr. Solutions Architect supporting Federal System Integrators at AWS. He is based in Washington, DC, and has 15 years of experience building, modernizing, and integrating systems for public sector customers. Outside of work, Dave enjoys playing with his kids, hiking, and watching Penn State football!
Dave Horne is a Sr. Solutions Architect supporting Federal System Integrators at AWS. He is based in Washington, DC, and has 15 years of experience building, modernizing, and integrating systems for public sector customers. Outside of work, Dave enjoys playing with his kids, hiking, and watching Penn State football! Robert Kessler is a Solutions Architect at AWS supporting Federal Partners, with a recent focus on generative AI technologies. Previously, he worked in the satellite communications segment supporting operational infrastructure globally. Robert is an enthusiast of boats and sailing (despite not owning a vessel), and enjoys tackling house projects, playing with his kids, and spending time in the great outdoors.
Robert Kessler is a Solutions Architect at AWS supporting Federal Partners, with a recent focus on generative AI technologies. Previously, he worked in the satellite communications segment supporting operational infrastructure globally. Robert is an enthusiast of boats and sailing (despite not owning a vessel), and enjoys tackling house projects, playing with his kids, and spending time in the great outdoors.














 Florian Mair is a Senior Solutions Architect and data streaming expert at AWS. He is a technologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe.
Florian Mair is a Senior Solutions Architect and data streaming expert at AWS. He is a technologist that helps customers in Germany succeed and innovate by solving business challenges using AWS Cloud services. Besides working as a Solutions Architect, Florian is a passionate mountaineer, and has climbed some of the highest mountains across Europe. Benjamin Meyer is a Senior Solutions Architect at AWS, focused on Games businesses in Germany to solve business challenges by using AWS Cloud services. Benjamin has been an avid technologist for 7 years, and when he’s not helping customers, he can be found developing mobile apps, building electronics, or tending to his cacti.
Benjamin Meyer is a Senior Solutions Architect at AWS, focused on Games businesses in Germany to solve business challenges by using AWS Cloud services. Benjamin has been an avid technologist for 7 years, and when he’s not helping customers, he can be found developing mobile apps, building electronics, or tending to his cacti.



















 Amazon EventBridge Scheduler | Schedule tasks over +200 targets!
Amazon EventBridge Scheduler | Schedule tasks over +200 targets!