Post Syndicated from Raj Ramasubbu original https://aws.amazon.com/blogs/big-data/deploy-real-time-analytics-with-startree-for-managed-apache-pinot-on-aws/
This post is cowritten with Mayank Shrivastava and Barkha Herman from StarTree.
Building a low-latency, high-concurrency, real-time online analytical processing (OLAP) solution has been previously explored on the AWS Big Data Blog, where we walked through how to build a real-time analytics solution with Apache Pinot on AWS, in which streaming sources, such as Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Kinesis Data Streams, produce events that are ingested and processed in real time within Apache Pinot.
However, this approach requires self-management of the infrastructure required to run Pinot, as well as a number of manual processes to run in production. StarTree is a managed alternative that offers similar benefits for real-time analytics use cases.
In this post, we introduce StarTree as a managed solution on AWS for teams seeking the advantages of Pinot. We highlight the key distinctions between open-source Pinot and StarTree, and provide valuable insights for organizations considering a more streamlined approach to their real-time analytics infrastructure.
By examining these aspects, you can make an informed decision between open source Pinot and StarTree for your specific real-time analytics needs.
StarTree overview
One of the founders of Apache Pinot, Kishore Gopalakrishna, launched StarTree to equip organizations globally with the power of real-time data and build a fully managed platform for real-time analytics. Handling over 1 billion queries per week and ingesting over 1 million events per second, StarTree Cloud removes the burden of infrastructure management so companies can focus on delivering real-time insights to end-users.
Open source Pinot requires in-house expertise that can challenge well-established technical teams to provision hardware, configure environments, tune performance, maintain security, adhere to data governance requirements, manage software updates, and constantly monitor for system issues. Organizations interested in decreasing their time to value with a managed Pinot solution can take advantage of the expertise of StarTree’s team to accelerate setup, deploy an architecture ready for scale, and offload infrastructure maintenance.
Improving security with SOC 2, SSO, and RBAC
Critical enterprise security features can be challenging to implement in open source Pinot environments. With StarTree’s managed Pinot, role-based access control (RBAC) simplifies administration for Pinot and allows organizations to assign and monitor user access based on roles to enforce secure and efficient access to sensitive data. StarTree Cloud provides enterprise-grade security with SOC 2 compliance, enhanced encryption, and single sign-on (SSO) capabilities.
Using automated data ingestion at scale
The minion task framework is a native component of Pinot to offload computationally intensive tasks away from the other Pinot components to conserve resources for low-latency queries and support real-time stream ingestion. StarTree can handle larger volumes of data efficiently with highly scalable implementations of minion tasks and a minion auto scaling feature that eliminates unnecessary infrastructure costs during idle times, as seen in the below figure.
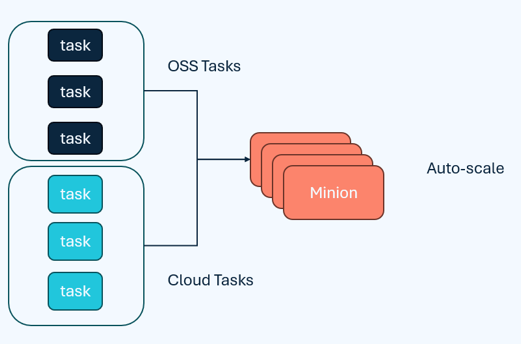
StarTree’s automatic data ingestion framework is ideal for enterprise workloads because it improves scalability and reduces the data maintenance complexity often found in open source Pinot deployments. StarTree supports a large number of managed connectors, which are used to maintain metadata about the source and ingest data seamlessly into the platform. The data is then modelled to help you organize and structure the data fetched from the selected data source into Pinot tables. Indexes are then configured to optimize query performance, as per the flow in the diagram below.

Tiered storage for real-time query processing
With open source Pinot, tiered storage can be used for deep storage like Amazon Simple Storage Service (Amazon S3) for backup but not query processing, because storage is tightly coupled with compute and requires manual configuration of tenants with different storage speeds and server specifications. In the following diagram, an Amazon S3 tier is defined for the data to be moved from tightly coupled SSD to cloud storage when the data is 30 days old.

On the other hand, StarTree transitions less-frequently accessed data to cost-effective storage like Amazon S3, while maintaining quick access to frequently accessed data. StarTree’s tiered storage enables automation for real-time query processing with index pinning, prefetching, and intelligent data movement between hot and cold storage, optimizing both performance and cost. StarTree’s sophisticated approach to tiered storage is highly flexible and reduces replication overhead by keeping a single copy in cloud storage, which prevents the limitations of compressed deep store copies, as you can see in the below diagram

Improving scalability with off-heap upserts
Companies like Amberdata benefit from StarTree’s upsert support to routinely upsert 350,000 events per second, with peak workloads reaching 1 million upserts per second. StarTree Cloud enhanced upsert functionality boosts efficiency, usability, and scalability through the implementation of off-heap upserts. Behind the scenes, Pinot servers manage specific upsert metadata to determine if a newly inserted record’s primary key was previously encountered and identifies the current segment holding it. As shown below, StarTree Cloud moves this off-heap, enabling a scalable cache of metadata as the on-heap memory restrictions are removed

Customer success stories using Pinot with StarTree for real-time analytics
The following customers highlight their success using Pinot for StarTree:
- Sovrn provides down-to-the-second, real-time data for their customers with StarTree’s managed Pinot as an adtech solution provider for web publishers, down from what was previously a 24- to 48-hour turnaround time for producing reports.
- Amberdata, a blockchain and crypto market intelligence company, uses StarTree for real-time analytics to improve query performance, reduce SLA times, and lower infrastructure costs. Joanes Espanol, CTO and Co-Founder of Amberdata, shared about their experience with StarTree’s managed Pinot, “We are now in the subseconds to milliseconds range, and the higher query concurrency means we can serve more customers faster. We’ve been able to reduce our infrastructure costs and reduce our dependencies on older technologies.”
- Nubank identifies anomalies across massive datasets instantly with StarTree to power observability and anomaly detection in their customer-facing applications, enabling real-time monitoring and customer insights at scale.
Flexible deployment options for StarTree Cloud
StarTree offers multiple deployment options, including a StarTree hosted software as a service (SaaS) or customer hosted SaaS. StarTree hosted SaaS is ideal for organizations interested in fully offloading the operational burden of infrastructure management, scaling, performance tuning, and security from their team so they can focus on analytics. StarTree’s customer hosted SaaS provides flexibility for customers interested in deploying the solution within their AWS environment or other platform of choice. This is suitable for organizations who require higher infrastructure management controls in their perimeter but still want the operational ease of a managed service.
Self-managed Pinot or StarTree
Pinot can deliver value for real-time analytics scenarios with different deployment methods. The choice of deployment method will come down to organizational priorities and trade-offs. Teams with the capability and willingness to manage open source software on a commodity infrastructure at scale might opt to deploy self-managed Pinot on AWS. Teams interested in reducing time troubleshooting performance bottlenecks, optimizing resource usage, and minimizing downtime can use StarTree’s managed service.
Conclusion
In this post, we presented StarTree as a managed solution on AWS for teams seeking the advantages of Apache Pinot. Like Pinot, StarTree addresses the need for a low-latency, high-concurrency, real-time online analytical processing (OLAP) solution. In addition, StarTree offers a managed experience for real-time and batch Pinot workloads, offering enhanced security, automated data ingestion, tiered storage, and off-heap upserts. These features improve security, scalability, and manageablity for organizations looking to run Pinot in production.
Developers interested in learning more about managed Pinot can deploy real-time analytics with StarTree to test it out or join a session with StarTree’s head of product. StarTree is an AWS ISVA partner and is available on AWS Marketplace.
About the Authors
 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
 Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
 Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.
Ismail Makhlouf is a Senior Specialist Solutions Architect for Data Analytics at AWS. Ismail focuses on architecting solutions for organizations across their end-to-end data analytics estate, including batch and real-time streaming, big data, data warehousing, and data lake workloads. He primarily partners with airlines, manufacturers, and retail organizations to support them to achieve their business objectives with well-architected data platforms.
 Renee Berry is a Senior Partner Development Manager with the AWS Global Startup Program, working with venture backed startups partnering with AWS to scale their growth.
Renee Berry is a Senior Partner Development Manager with the AWS Global Startup Program, working with venture backed startups partnering with AWS to scale their growth.
 Mayank Shrivastava is a founding engineer of Apache Pinot and a PMC member for the project. He is currently a Fellow at StarTree Inc., where he also heads their Center of Excellence.
Mayank Shrivastava is a founding engineer of Apache Pinot and a PMC member for the project. He is currently a Fellow at StarTree Inc., where he also heads their Center of Excellence.
 Barkha Herman is a technologist and developer advocate who founded WiTVoices and South Florida Women in Tech. She fosters inclusive tech communities.
Barkha Herman is a technologist and developer advocate who founded WiTVoices and South Florida Women in Tech. She fosters inclusive tech communities.







 Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 20 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Sr. Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 20 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with product team and customer to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Pratik Das is a Senior Product Manager with AWS Lake Formation. He is passionate about all things data and works with customers to understand their requirements and build delightful experiences. He has a background in building data-driven solutions and machine learning systems in production.
Pratik Das is a Senior Product Manager with AWS Lake Formation. He is passionate about all things data and works with customers to understand their requirements and build delightful experiences. He has a background in building data-driven solutions and machine learning systems in production.





 Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.










 Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.
Raj Ramasubbu is a Senior Analytics Specialist Solutions Architect focused on big data and analytics and AI/ML with Amazon Web Services. He helps customers architect and build highly scalable, performant, and secure cloud-based solutions on AWS. Raj provided technical expertise and leadership in building data engineering, big data analytics, business intelligence, and data science solutions for over 18 years prior to joining AWS. He helped customers in various industry verticals like healthcare, medical devices, life science, retail, asset management, car insurance, residential REIT, agriculture, title insurance, supply chain, document management, and real estate.






















 Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty.
Rahul Sonawane is a Principal Analytics Solutions Architect at AWS with AI/ML and Analytics as his area of specialty. Sundeep Kumar is a Sr. Data Architect, Data Lake at AWS, helping customers build data lake and analytics platform and solutions. When not building and designing data lakes, Sundeep enjoys listening music and playing guitar.
Sundeep Kumar is a Sr. Data Architect, Data Lake at AWS, helping customers build data lake and analytics platform and solutions. When not building and designing data lakes, Sundeep enjoys listening music and playing guitar.








 Vivek Kansal works with the Amazon OpenSearch team. In his role as Principal Software Engineer, he uses his experience in the areas of security, policy engines, cloud-native solutions, and networking to help secure customer data in OpenSearch Service and OpenSearch Serverless in an evolving threat landscape.
Vivek Kansal works with the Amazon OpenSearch team. In his role as Principal Software Engineer, he uses his experience in the areas of security, policy engines, cloud-native solutions, and networking to help secure customer data in OpenSearch Service and OpenSearch Serverless in an evolving threat landscape.