With millions of developers around the world building on Cloudflare, we are constantly inspired by what you all are building with us. Every Developer Week, we’re excited to get your hands on new products and features that can help you be more productive, and creative, with what you’re building. But we know our job doesn’t end when we put new products and features in your hands during Developer Week. We also need to cultivate welcoming community spaces where you can come get help, share what you’re building, and meet other developers building with Cloudflare.
We’re excited to close out Developer Week by sharing updates on our Workers Launchpad program, our latest Developer Challenge, and the work we’re doing to ensure our community spaces – like our Discord and Community forums – are safe and inclusive for all developers.
Helping startups go further with Workers Launchpad
In late 2022, we initiated the $2 billion Workers Launchpad Funding Program aimed at aiding the more than one million developers who use Cloudflare’s Developer Platform. This initiative particularly benefits startups that are investing in building on Cloudflare to propel their business growth.
The Workers Launchpad Program offers a variety of resources to help builders scale faster and reach more customers. The program includes, but is not limited to:
Fostering a community of like-minded founders
Facilitating introductions to the Launchpad’s VC partner network of 40+ leading investors
Company-building support and mentorship through virtual Founders Bootcamp sessions
Organizing technical office hours with our engineers
Access to preview upcoming Cloudflare products and Product Managers
Culminating in a Demo Day, for participants to share their stories globally with investors and prospective customers.
So far, 50 amazing startups from 13 countries have successfully graduated from the Workers Launchpad program. We finished up Cohort #1 in March 2023, and Cohort #2 wrapped up August 2023.
Meet Cohort #3 of the Workers Launchpad!
Since the end of Cohort #2, we have received hundreds of new applications from startups across the globe. Startup applicants showcased incredible tools and software across a variety of industries, including AI, SaaS, Supply Chain, Media, Gaming, Hospitality, and Developer Productivity. While we were encouraged by this wave of applicants’ ability to build amazing technology, there were a few that stood out that are leveraging Cloudflare’s Developer Suite to scale their business.
With that being said, we would like to introduce you to the 29 startups that have been chosen to participate in Cohort #3 of Workers Launchpad:
Below, you will find a brief summary of what problems these startups are looking to solve:
AI-powered marketing agent that leverages Gen AI to optimize businesses’ online presence and drive more traffic.
The Cloudflare team is looking forward to working with Cohort #3 participants and sharing what they are building on Cloudflare. To follow along with Cohort #3 of Workers Launchpad, follow @CloudflareDev and join our Developer Discord server.
Are you a startup and interested in joining Cohort #4? Apply here!
AI developer challenge
Now that Workers AI is GA, we’re excited to see what our community can build. We’ve teamed up with our friends at DEV who will be running an AI Developer challenge, which officially launched on Wednesday, April 3, and runs until Sunday, April 14, 2024, when submissions close.
For this challenge, you will build a Workers AI application that makes use of AI task types from Cloudflare’s growing catalog of Open Models. Apps will be evaluated on innovation, creativity, and demonstration of underlying technology with prizes awarded by DEV for the best overall app, as well as projects leveraging multiple models and tasks. For more information and details on how to participate, including DEV’s rules and requirements, head over to the official challenge page.
Creating an inclusive community
Our community has been growing really fast over the past year, so fast that it’s becoming more difficult to welcome each new member that joins our Discord server every day, and Developer Week has always been one of the main drivers of this growth.
When you come into the Cloudflare developer community, it’s important to us that you’re entering a space that is safe and welcoming. Even though we already have rules for the server and community forums, we needed guidelines for our community programs, so that’s why we’ve created a new Code of Conduct that promotes inclusivity, respect, and will help us create a better community for everyone.
Do you want to be part of this and help us create a more inclusive and helpful community? Then please share your feedback and tell us what you would like to see improved in our community and our Discord server in this thread.
Transferring your domains to a new registrar isn’t something you do every day, and getting any step of the process wrong could mean downtime and disruption. That’s why this Speed Week we’ve prepared a domain transfer checklist. We want to empower anyone to quickly transfer their domains to Cloudflare Registrar, without worrying about missing any steps along the way or being left with any unanswered questions.
Domain Transfer Checklist
Confirm eligibility
Confirm you want to use Cloudflare’s nameservers: We built our registrar specifically for customers who want to use other Cloudflare products. This means domains registered with Cloudflare can only use our nameservers. If your domain requires non-Cloudflare nameservers then we’re not the right registrar for you.
Confirm your domain is not a premium domain or internationalized domain name (IDNs):Cloudflare currently does not support premium domains or internationalized domain names (Unicode).
Confirm your domain hasn’t been registered or transferred in the past 60 days:ICANN rules prohibit a domain from being transferred if it has been registered or previously transferred within the last 60 days.
Confirm your WHOIS Registrant contact information hasn’t been updated in the past 60 days: ICANN rules also prohibit a domain from being transferred if the WHOIS Registrant contact information was modified in the past 60 days.
Before you transfer
Gather your credentials for your current registrar:Make sure you have your credentials for your current registrar. It’s possible you haven’t logged in for many years and you may have to reset your password.
Make note of your current DNS settings:When transferring your domain, Cloudflare will automatically scan your DNS records, but you’ll want to capture your current settings in case there are any issues.
Remove WHOIS privacy (if necessary):In most cases, domains may be transferred even if WHOIS privacy services have been enabled. However, some registrars may prohibit the transfer if the WHOIS privacy service has been enabled.
Renew your domain if up for renewal in the next 15 days:If your domain is up for renewal, you’ll need to renew it with your current registrar before initiating a transfer to Cloudflare.
Unlock the domain: Registrars include a lightweight safeguard to prevent unauthorized users from starting domain transfers – often called a registrar or domain lock. This lock prevents any other registrar from attempting to initiate a transfer. Only the registrant can enable or disable this lock, typically through the administration interface of the registrar.
Sign up for Cloudflare:If you don’t already have a Cloudflare account, you can sign up here.
Add your domain to Cloudflare:You can add a new domain to your Cloudflare account by following these instructions.
Add a valid credit card to your Cloudflare account:If you haven’t already added a payment method into your Cloudflare dashboard billing profile, you’ll be prompted to add one when you add your domain.
Wait for your DNS changes to propagate: Registrars can take up to 24 hours to process nameserver updates. You will receive an email when Cloudflare has confirmed that these changes are in place. You can’t proceed with transferring your domain until this process is complete.
Initiating and confirming transfer process
Request an authorization code:Cloudflare needs to confirm with your old registrar that the transfer flow is authorized. To do that, your old registrar will provide an authorization code to you. This code is often referred to as an authorization code, auth code, authinfo code, or transfer code. You will need to input that code to complete your transfer to Cloudflare. We will use it to confirm the transfer is authentic.
Initiate your transfer to Cloudflare: Visit the Transfer Domains section of your Cloudflare dashboard. Here you’ll be presented with any domains available for transfer. If your domain isn’t showing, ensure you completed all the proceeding steps. If you have, review the list on this page to see if any apply to your domain.
Review the transfer price: When you transfer a domain, you are required by ICANN to pay to extend its registration by one year from the expiration date. You will not be billed at this step. Cloudflare will only bill your card when you input the auth code and confirm the contact information at the conclusion of your transfer request.
Input your authorization code:In the next page, input the authorization code for each domain you are transferring.
Confirm or input your contact information:In the final stage of the transfer process, input the contact information for your registration. Cloudflare Registrar redacts this information by default but is required to collect the authentic contact information for this registration.
Approve the transfer with Cloudflare: Once you have requested your transfer, Cloudflare will begin processing it, and send a Form of Authorization (FOA) email to the registrant, if the information is available in the public WHOIS database. The FOA is what authorizes the domain transfer.
Approve the transfer with your previous registrar: After this step, your previous registrar will also email you to confirm your request to transfer. Most registrars will include a link to confirm the transfer request. If you follow that link, you can accelerate the transfer operation. If you do not act on the email, the registrar can wait up to five days to process the transfer to Cloudflare. You may also be able to approve the transfer from within your current registrar dashboard.
Follow your transfer status in your Cloudflare dashboard: Your domain transfer status will be viewable under Account Home > Overview > Domain Registration for your domain.
After you transfer
Test your site and email:After the transfer is complete, you’ll want to test your site to ensure everything is working properly. If you encounter any issues or have any questions you can always talk with us on our community forums or Discord server.
Developer Week 2023 is officially a wrap. Last week, we shipped 34 posts highlighting what has been going on with our developer platform and where we’re headed in the future – including new products & features, in-depth tutorials to help you get started, and customer stories to inspire you.
We’ve loved already hearing feedback from you all about what we’ve shipped:
🤯 Serverless machine learning deployments – OMG! We used to need a team of devops to deploy a todo list MVP, it’s now 3 clicks with workers. They’re gonna do the same with ML workloads. Just like that. Boom. https://t.co/AcKUQ79fv0
Love this direction, for open source, for demos and running things on edge.
It's still in development, but as someone who've built an AI product on top of Cloudflare and has been asking for something like this, I'm really excited! https://t.co/AnywRDqecb
Yes! Loving this! I definitely this is the right direction and will help the general DevX and onboarding to the platform a lot ❤️! https://t.co/rEQWreeS96
We hope you’re able to spend the coming weeks slinging some code and experimenting with some of the new tools we shipped last week. As you’re building, join us in our developers discord and let us know what you think.
In case you missed any of our announcements here’s a handy recap:
The emergence of large language models (LLMs) is going to change the way developers write, debug, and modify code. Developer Platforms need to evolve to integrate AI capabilities to assist developers in their journeys.
Run pre-trained machine learning models and inference tasks on Cloudflare’s global network with Constellation AI. We’ll maintain a catalog of verified and ready-to-use models, or you can upload and train your own.
When getting started with a new technology comes a lot of questions on how to get started. Finding answers quickly is a time-saver. To help developers build in the fastest way possible we’ve introduced Cursor, an experimental AI assistant, to answer questions you may have about the Developer Platform. The assistant responds with both text and relevant links to our documentation to help you go further.
ChatGPT, recently allowed the ability for developers to create custom extensions to make ChatGPT even more powerful. It’s now possible to provide guidance to the conversational workflows within ChatGPT such as up-to-date statistics and product information. We’ve published plugins for Radar and our Developer Documentation and a tutorial showing how you can build your own plugin using Workers.
With any new technology comes concerns about risk and AI is no different. If you want to build with AI and maintain a Zero Trust security posture, Cloudflare One offers a collection of features to build with AI without increased risk. We’ve also compiled some best practices around securing your LLM.
Training large language models requires massive amount of compute which has led AI companies to look at multi-cloud architectures, with R2 and MosaicML companies can build these infrastructures at a fraction of the cost.
AI startups no longer need affiliation with an accelerator or an employee referral to gain access to the Startup Program. Bootstrapped AI startups can apply today to get free access to Cloudflare services including R2, Workers, Pages, and a host of other security and developer services.
A tutorial on building your first LangChainJS and Workers application to build more sophisticated applications by switching between LLMs or chaining prompts together.
We’ve partnered with other database providers, including Neon, PlanetScale, and Supabase, to make authenticating and connecting back to your databases there just work, without having to copy-paste credentials and connection strings back and forth.
Connect back to existing PostgreSQL and MySQL databases directly from Workers with outbound TCP sockets allowing you to connect to any database when building with Workers.
D1 is now not only significantly faster, but has a raft of new features, including the ability to time travel: restore your database to any minute within the last 30 days, without having to make a manual backup.
Bringing compute closer to the end user isn’t always the right answer to improve performance. Smart Placement for Workers and Pages Functions moves compute to the optimal location whether that is closer to the end user or closer to backend services and data.
Get valuable insights from your data when you use Snowflake to query data stored in your R2 data lake and load data from R2 into Snowflake’s Data Cloud.
Create Cloudflare CLI (C3) is a companion CLI to Wrangler giving you a single entry-point to configure Cloudflare via CLI. Pick your framework, all npm dependencies are installed, and you’ll receive a URL for where your application was deployed.
Manage all your Workers scripts and Pages projects from a single place in the Cloudflare dashboard. Over the next year we’ll be working to converge these two separate experiences into one eliminating friction when building.
Now in beta, the build system for Pages includes the latest versions of Node.js, Python, Hugo, and more. You can opt in to use this for existing projects or stay on the existing system, so your builds won’t break.
Having a local development environment that mimics production as closely as possible helps to ensure everything runs as expected in production. You can test every aspect prior to deployment. Wrangler 3 now leverages Miniflare3 based on workerd with local-by-default development.
Our terms of service were not clear about serving content hosted on the Developer Platform via our CDN. We’ve made it clearer that customers can use the CDN to serve video and other large files stored on the Developer Platform including Images, Pages, R2, and Stream.
A retrospective on the first year of Workers for Platform, what’s coming next, and featuring how customers like Shopify and Grafbase are building with it.
Deploy a Worker script that requires Browser Rendering capabilities through Wrangler.
Watch on Cloudflare TV
If you missed any of the announcements or want to also view the associated Cloudflare TV segments, where blog authors went through each announcement, you can now watch all the Developer Week videos on Cloudflare TV.
“Our goal for LangChain is to empower developers around the world to build with AI. We want LangChain to work wherever developers are building, and to spark their creativity to build new and innovative applications. With this new launch, we can't wait to see what developers build with LangChainJS and Cloudflare Workers. And we're excited to put more of Cloudflare's developer tools in the hands of our community in the coming months.” – Harrison Chase, Co-Founder and CEO, LangChain
In this post, we’ll share why we’re so excited about LangChain and walk you through how to build your first LangChainJS + Cloudflare Workers application.
For the uninitiated, LangChain is a framework for building applications powered by large language models (LLMs). It not only lets you fairly seamlessly switch between different LLMs, but also gives you the ability to chain prompts together. This allows you to build more sophisticated applications across multiple LLMs, something that would be way more complicated without the help of LangChain.
Building your first LangChainJS + Cloudflare Workers application
There are a few prerequisites you have to set up in order to build this application:
An OpenAI account: If you don’t already have one, you can sign up for free.
A paid Cloudflare Workers account: If you don’t already have an account, you can sign up here and upgrade your Workers for $5 per month.
Node & npm: If this is your first time working with node, you can get it here.
Next create a new folder called langchain-workers, navigate into that folder and then within that folder run wrangler init.
When you run wrangler init you’ll select the following options:
✔Would you like to use git to manage this Worker? … yes
✔ No package.json found. Would you like to create one? … yes
✔ Would you like to use TypeScript? … no
✔ Would you like to create a Worker at src/index.js? › Fetch handler
✔ Would you like us to write your first test? … no
With our Worker created, we’ll need to set up the environment variable for our OpenAI API Key. You can create an API key in your OpenAI dashboard. Save your new API key someplace safe, then open your wrangler.toml file and add the following lines at the bottom (making sure to insert you actual API key):
[vars]
OPENAI_API_KEY = "sk…"
Then we’ll install LangChainjs using npm:
npm install langchain
Before we start writing code we can make sure everything is working properly by running wrangler dev. With wrangler dev running you can press b to open a browser. When you do, you'll see “Hello World!” in your browser.
A sample application
One common way you may want to use a language model is to combine it with your own text. LangChain is a great tool to accomplish this goal and that’s what we’ll be doing today in our sample application. We’re going to build an application that lets us use the OpenAI language model to ask a question about an article on Wikipedia. Because I live in (and love) Brooklyn, we’ll be using the Wikipedia article about Brooklyn. But you can use this code for any Wikipedia article, or website, you’d like.
Because language models only know about the data that they were trained on, if we want to use a language model with new or specific information we need a way to pass a model that information. In LangChain we can accomplish this using a ”document”. If you’re like me, when you hear “document” you often think of a specific file format but in LangChain a document is an object that consists of some text and optionally some metadata. The text in a document object is what will be used when interacting with a language model and the metadata is a way that you can track information about your document.
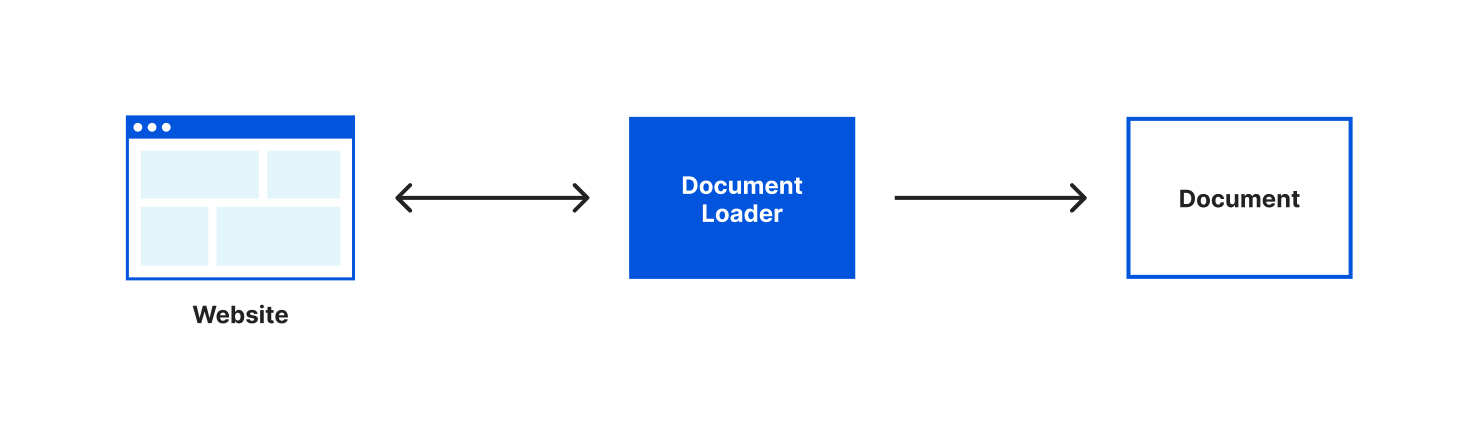
Most often you’ll want to create documents from a source of pre-existing text. LangChain helpfully provides us with different document loaders to make loading text from many different sources easy. There are document loaders for different types of text formats (for example: CSV, PDFs, HTML, unstructured text) and that content can be loaded locally or from the web. A document loader will both retrieve the text for you and load that text into a document object. For our application, we’ll be using the webpages with Cheerio document loader. Cheerio is a lightweight library that will let us read the content of a webpage. We can install it using npm install cheerio.
After we’ve installed cheerio we’ll import the CheerioWebBaseLoader at the top of our src/index.js file:
import { CheerioWebBaseLoader } from "langchain/document_loaders/web/cheerio";
With CheerioWebBaseLoader imported, we can start using it within our fetch function:.
In this code, we’re configuring our loader with the Wikipedia URL for the article about Brooklyn, run the load() function and log the result to the console. Like I mentioned earlier, if you want to try this with a different Wikipedia article or website, LangChain makes it very easy. All we have to do is change the URL we’re passing to our CheerioWebBaseLoader.
Let’s run wrangler dev, load up our page locally and watch the output in our console. You should see:
Loaded page
Array(1) [ Document ]
Our document loader retrieved the content of the webpage, put that content in a document object and loaded it into an array.
This is great, but there’s one more improvement we can make to this code before we move on – splitting our text into multiple documents.
Many language models have limits on the amount of text you can pass to them. As well, some LLM APIs charge based on the amount of text you send in your request. For both of these reasons, it’s helpful to only pass the text you need in a request to a language model.
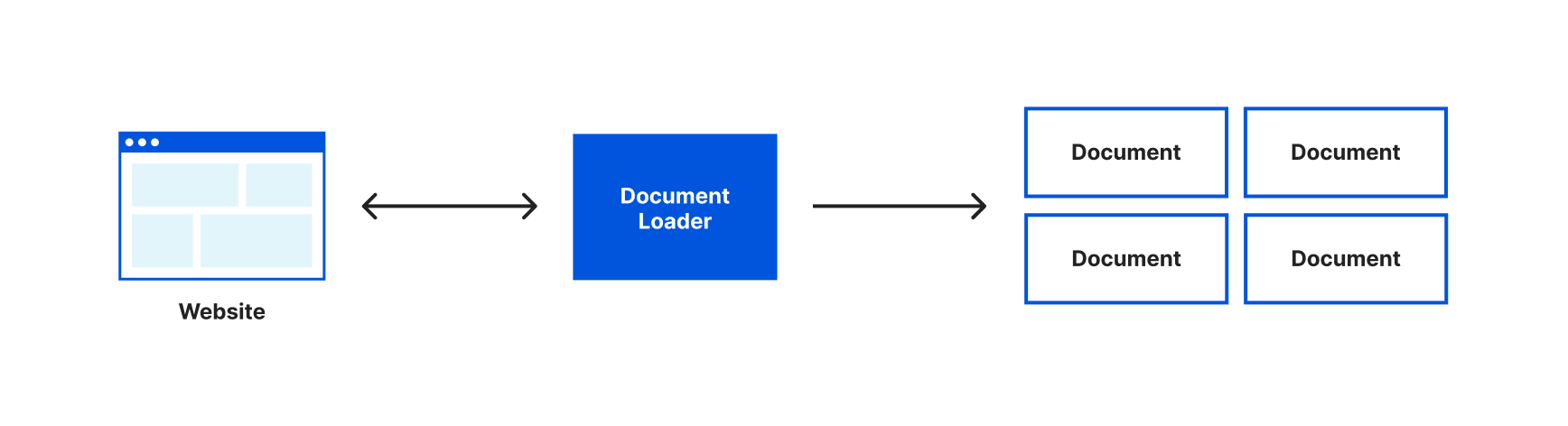
Currently, we’ve loaded the entire content of the Wikipedia page about Brooklyn into one document object and would send the entirety of that text with every request to our language model. It would be more efficient if we could only send the relevant text to our language model when we have a question. The first step in doing this is to split our text into smaller chunks that are stored in multiple document objects. To assist with this LangChain gives us the very aptly named Text Splitters.
We can use a text splitter by updating our loader to use the loadAndSplit() function instead of load(). Update the line where we assign docs to this:
const docs = await loader.loadAndSplit();
Now start the application again with wrangler dev and load our page. This time in our console you’ll see something like this:
Instead of an array with one document object, our document loader has now split the text it retrieved into multiple document objects. It’s still a single Wikipedia article, LangChain just split that text into chunks that would be more appropriately sized for working with a language model.
Even though our text is split into multiple documents, we still need to be able to understand what text is relevant to our question and should be sent to our language model. To do this, we’re going to introduce two new concepts – embeddings and vector stores.
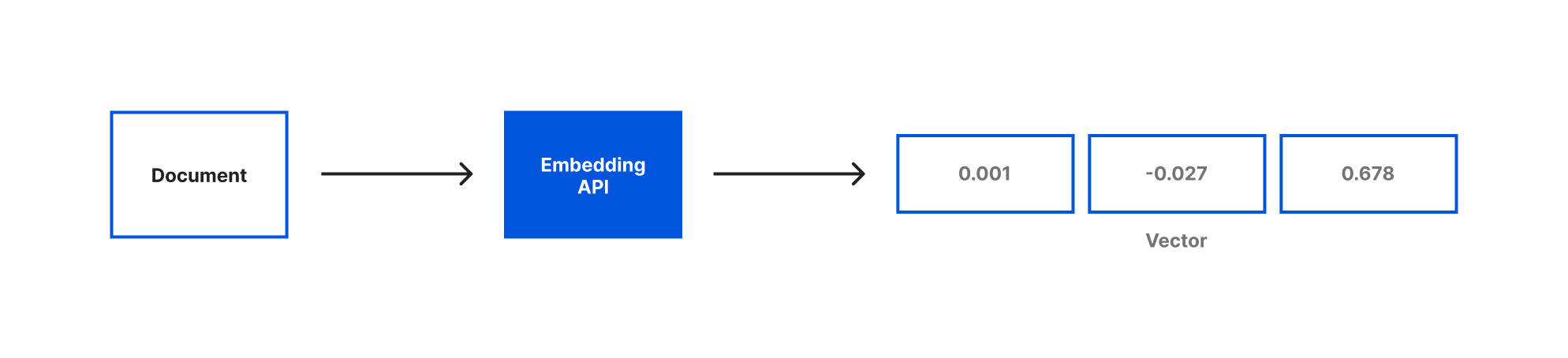
Embeddings are a way of representing text with numerical data. For our application we’ll be using OpenAI Embeddings to generate our embeddings based on the document objects we just created. When you generate embeddings the result is a vector of floating point numbers. This makes it easier for computers to understand the relatedness of the strings of text to each other. For each document object we pass the embedding API, a vector will be created.
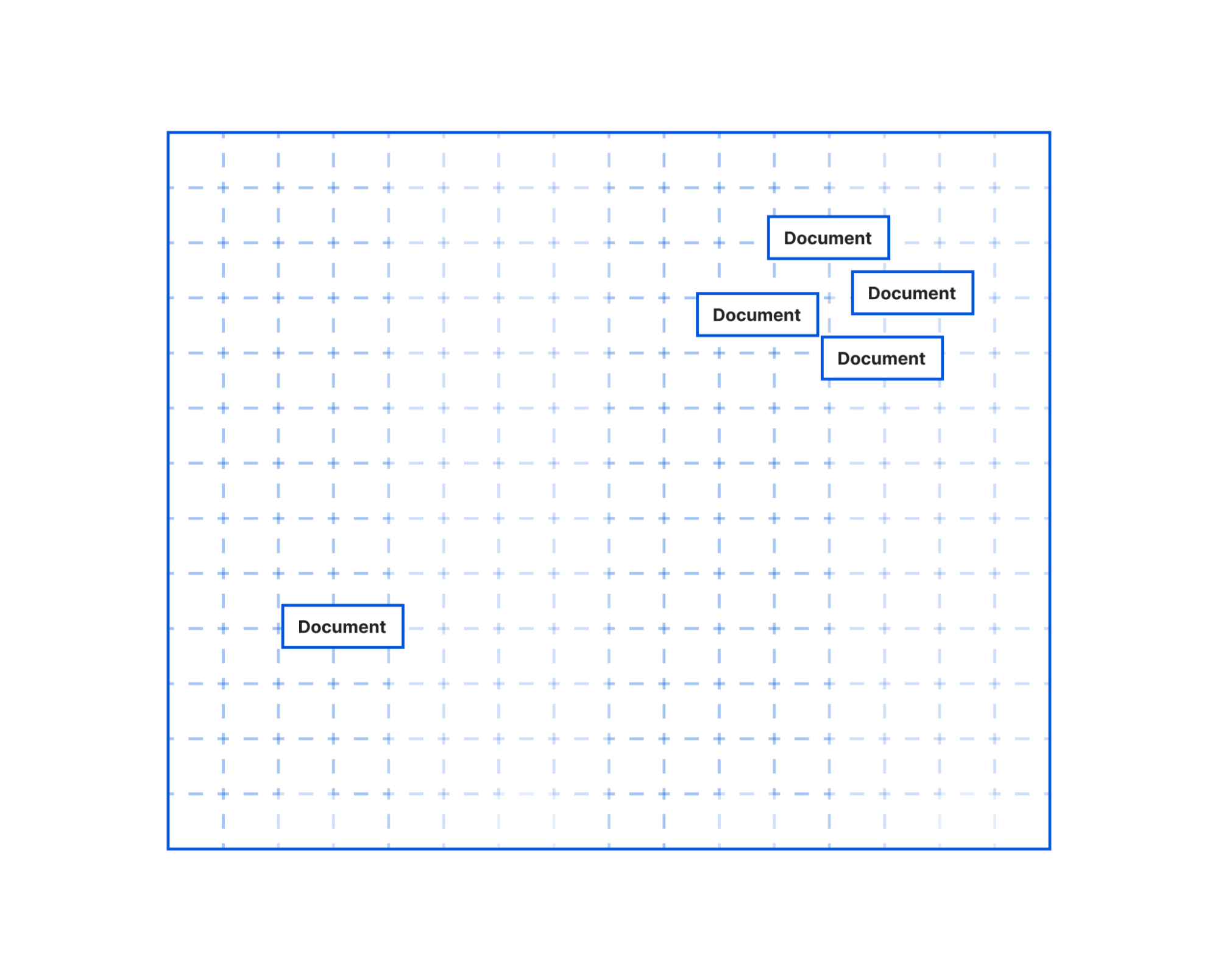
When we compare vectors, the closer numbers are to each other the more related the strings are. Inversely, the further apart the numbers are then the less related the strings are. It can be helpful to visualize how these numbers would allow us to place each document in a virtual space:
In this illustration, you could imagine how the text in the document objects that are bunched together would be more similar than the document object further off. The grouped documents could be text pulled from the article’s section on the history of Brooklyn. It’s a longer section that would have been split into multiple documents by our text splitter. But even though the text was split the embeddings would allow us to know this content is closely related to each other. Meanwhile, the document further away could be the text on the climate of Brooklyn. This section was smaller, not split into multiple documents, and the current climate is not as related to the history of Brooklyn, so it’s placed further away.
Embeddings are a pretty fascinating and complicated topic. If you’re interested in understanding more, here's a great explainer video that takes an in-depth look at the embeddings.
Once you’ve generated your documents and embeddings, you need to store them someplace for future querying. Vector stores are a kind of database optimized for storing & querying documents and their embeddings. For our vector store, we’ll be using MemoryVectorStore which is an ephemeral in-memory vector store. LangChain also has support for many of your favorite vector databases like Chroma and Pinecone.
We’ll start by adding imports for OpenAIEmbeddings and MemoryVectorStore at the top of our file:
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
Then we can remove the console.log() function we had in place to show how our loader worked and replace them with the code to create our Embeddings and Vector store:
const store = await MemoryVectorStore.fromDocuments(docs, new OpenAIEmbeddings({ openAIApiKey: env.OPENAI_API_KEY}));
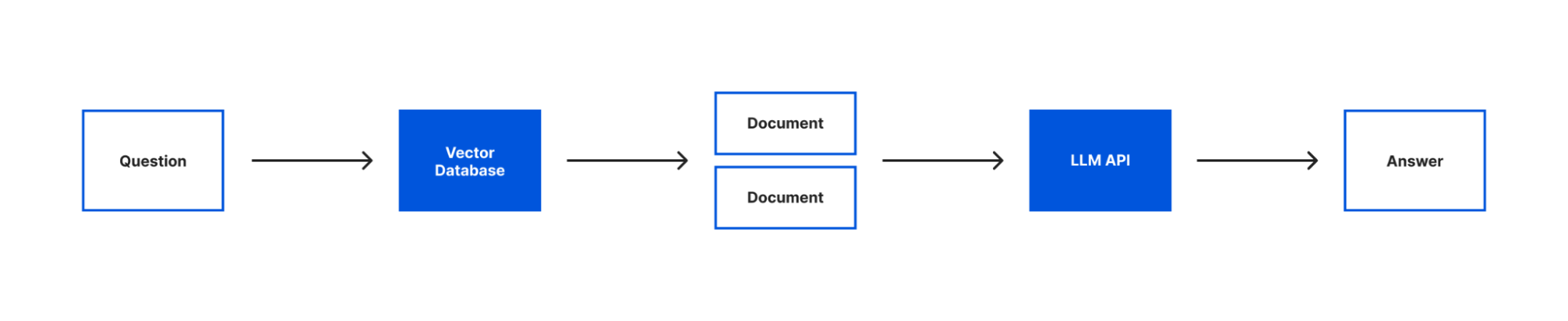
With our text loaded into documents, our embeddings created and both stored in a vector store we can now query our text with our language model. To do that we’re going to introduce the last two concepts that are core to building this application – models and chains.
When you see models in LangChain, it’s not about generating or creating models. Instead, LangChain provides a standard interface that lets you access many different language models. In this app, we’ll be using the OpenAI model.
Chains enable you to combine a language model with other sources of information, APIs, or even other language models. In our case, we’ll be using the RetreivalQAChain. This chain retrieves the documents from our vector store related to a question and then uses our model to answer the question using that information.
To start, we’ll add these two imports to the top of our file:
import { OpenAI } from "langchain/llms/openai";
import { RetrievalQAChain } from "langchain/chains";
Then we can put this all into action by adding the following code after we create our vector store:
const model = new OpenAI({ openAIApiKey: env.OPENAI_API_KEY});
const chain = RetrievalQAChain.fromLLM(model, store.asRetriever());
const question = "What is this article about? Can you give me 3 facts about it?";
const res = await chain.call({
query: question,
});
return new Response(res.text);
In this code the first line is where we instantiate our model interface and pass it our API key. Next we create a chain passing it our model and our vector store. As mentioned earlier, we’re using a RetrievalQAChain which will look in our vector store for documents related to our query and then use those documents to get an answer for our query from our model.
With our chain created, we can call the chain by passing in the query we want to ask. Finally, we send the response text we got from our chain as the response to the request our Worker received. This will allow us to see the response in our browser.
With all our code in place, let’s test it again by running wrangler dev. This time when you open your browser you will see a few facts about Brooklyn:
Right now, the question we’re asking is hard coded. Our goal was to be able to use LangChain to ask any question we want about this article. Let’s update our code to allow us to pass the question we want to ask in our request. In this case, we’ll pass a question as an argument in the query string (e.g. ?question=When was Brooklyn founded). To do this we’ll replace the line we’re currently assigning our question with the code needed to pull a question from our query string:
const { searchParams } = new URL(request.url);
const question = searchParams.get('question') ?? "What is this article about? Can you give me 3 facts about it?";
This code pulls all the query parameters from our URL using a JavaScript URL’s native searchParams property, and gets the value passed in for the “question” parameter. If a value isn’t present for the “question” parameter, we’ll use the default question text we were using previously thanks to JavaScripts’s nullish coalescing operator.
With this update, run wrangler dev and this time visit your local url with a question query string added. Now instead of giving us a few fun facts about Brooklyn, we get the answer of when Brooklyn was founded. You can try this with any question you may have about Brooklyn. Or you can switch out the URL in our document loader and try asking similar questions about different Wikipedia articles.
With our code working locally, we can deploy it with wrangler publish. After this command completes you’ll receive a Workers URL that runs your code.
You + LangChain + Cloudflare Workers
You can find our full LangChain example application on GitHub. We can’t wait to see what you all build with LangChain and Cloudflare Workers. Join us on Discord or tag us on Twitter as you’re building. And if you’re ever having any trouble or questions, you can ask on community.cloudflare.com.
Today we’re excited to be launching Cursor – our experimental AI assistant, trained to answer questions about Cloudflare’s Developer Platform. This is just the first step in our journey to help developers build in the fastest way possible using AI, so we wanted to take the opportunity to share our vision for a generative developer experience.
Whenever a new, disruptive technology comes along, it’s not instantly clear what the native way to interact with that technology will be.
However, if you’ve played around with Large Language Models (LLMs) such as ChatGPT, it’s easy to get the feeling that this is something that’s going to change the way we work. The question is: how? While this technology already feels super powerful, today, we’re still in the relatively early days of it.
While Developer Week is all about meeting developers where they are, this is one of the things that’s going to change just that — where developers are, and how they build code. We’re already seeing the beginnings of how the way developers write code is changing, and adapting to them. We wanted to share with you how we’re thinking about it, what’s on the horizon, and some of the large bets to come.
How is AI changing developer experience?
If there’s one big thing we can learn from the exploding success of ChatGPT, it’s the importance of pairing technology with the right interface. GPT-3 — the technology powering ChatGPT has been around for some years now, but the masses didn’t come until ChatGPT made it accessible to the masses.
Since the primary customers of our platform are developers, it’s on us to find the right interfaces to help developers move fast on our platform, and we believe AI can unlock unprecedented developer productivity. And we’re still in the beginning of that journey.
Wave 1: AI generated content
One of the things ChatGPT is exceptionally good at is generating new content and articles. If you’re a bootstrapped developer relations team, the first day playing around with ChatGPT may have felt like you struck the jackpot of productivity. With a simple inquiry, ChatGPT can generate in a few seconds a tutorial that would have otherwise taken hours if not days to write out.
This content still needs to be tested — do the code examples work? Does the order make sense? While it might not get everything right, it’s a massive productivity boost, allowing a small team to multiply their content output.
In terms of developer experience, examples and tutorials are crucial for developers, especially as they start out with a new technology, or seek validation on a path they’re exploring.
However, with AI generated content, it’s always going to be limited to well, how much of it you generated. To compare it to the newspaper, this content is still one size fits all. If as a developer you stray ever so slightly off the beaten path (choose a different framework than the one tutorial suggests, or a different database), you’re still left to put the pieces together, navigating tens of open tabs in order to stitch together your application.
If this content is already being generated by AI, however, why not just go straight to the source, and allow developers to generate their own, personal guides?
Wave 2: Q&A assistants
Since developers love to try out new technologies, it’s no surprise that developers are going to be some of the early adopters for technology such as ChatGPT. Many developers are already starting to build applications alongside their trusted bard, ChatGPT.
Rather than using generated content, why not just go straight to the source, and ask ChatGPT to generate something that’s tailored specifically for you?
There’s one tiny problem: the information is not always up to date. Which is why plugins are going to become a super important way to interact.
But what about someone who’s already on Cloudflare’s docs? Here, you want a native experience where someone can ask questions and receive answers. Similarly, if you have a question, why spend time searching the docs, if you can just ask and receive an answer?
Wave 3: generative experiences
In the examples above, you were still relying on switching back and forth between a dedicated AI interface and the problem at hand. In one tab you’re asking questions, while in another, you’re implementing the answers.
But taking things another step further, what if AI just met you where you were? In terms of developer experience, we’re already starting to see this in the authoring phase. Tools like GitHub Copilot help developers generate boilerplate code and tests, allowing developers to focus on more complex tasks like designing architecture and algorithms.
Sometimes, however, the first iteration AI comes up with might not match what you, the developer had in mind, which is why we’re starting to experiment with a flow-based generative approach, where you can ask AI to generate several versions, and build out your design with the one that matches your expectations the most.
The possibilities are endless, enabling developers to start applications from prompts rather than pre-generated templates.
We’re excited for all the possibilities AI will unlock to make developers more productive than ever, and we’d love to hear from you how AI is changing the way you change applications.
We’re also excited to share our first steps into the realm of AI driven developer experience with the release of our first two ChatGPT plugins, and by welcoming a new member of our team —Cursor, our docs AI assistant.
Our first milestone to AI driven UX: AI Assisted Docs
As the first step towards using AI to streamline our developer experience, we’re excited to introduce a new addition to our documentation to help you get answers as quickly as possible.
How to use Cursor
Here’s a sample exchange with Cursor:
You’ll notice that when you ask a question, it will respond with two pieces of information: a text based response answering your questions, and links to relevant pages in our documentation that can help you go further.
Here’s what happens when we ask “What video formats does Stream support?”.
If you were looking through our examples you may not immediately realize that this specific example uses both Workers and R2.
In its current state, you can think of it as your assistant to help you learn about our products and navigate our documentation in a conversational way. We’re labeling Cursor as experimental because this is the very beginning stages of what we feel like a Cloudflare AI assistant could do to help developers. It is helpful, but not perfect. To deal with its lack of perfection, we took an approach of having it do fewer things better. You’ll find there are many things it isn’t good at today.
How we built Cursor
Under the hood, Cursor is powered by Workers, Durable Objects, OpenAI, and the Cloudflare developer docs. It uses the same backend that we’re using to power our ChatGPT Docs plugin, and you can read about that here.
It uses the “Search-Ask” method, stay tuned for more details on how you can build your own.
A sneak peek into the future
We’re already thinking about the future, we wanted to give you a small preview of what we think this might look like here:
With this type of interface, developers could use a UI to have an AI generate code and developers then link that code together visually. Whether that’s with other code generated by the AI or code they’ve written themselves. We’ll be continuing to explore interfaces that we hope to help you all build more efficiently and can’t wait to get these new interfaces in your hands.
We need your help
Our hope is to quickly update and iterate on how Cursor works as developers around the world use it. As you’re using it to explore our documentation, join us on Discord to let us know your experience.
When OpenAI launched ChatGPT plugins in alpha we knew that it opened the door for new possibilities for both Cloudflare users and developers building on Cloudflare. After the launch, our team quickly went to work seeing what we could build, and today we’re very excited to share with you two new Cloudflare ChatGPT plugins – the Cloudflare Radar plugin and the Cloudflare Docs plugin.
The Cloudflare Radar plugin allows you to talk to ChatGPT about real-time Internet patterns powered by Cloudflare Radar.
The Cloudflare Docs plugin allows developers to use ChatGPT to help them write and build Cloudflare applications with the most up-to-date information from our documentation. It also serves as an open source example of how to build a ChatGPT plugin with Cloudflare Workers.
Let’s do a deeper dive into how each of these plugins work and how we built them.
Cloudflare Radar ChatGPT plugin
When ChatGPT introduced plugins, one of their use cases was retrieving real-time data from third-party applications and their APIs and letting users ask relevant questions using natural language.
Cloudflare Radar has lots of data about how people use the Internet, a well-documented public API, an OpenAPI specification, and it’s entirely built on top of Workers, which gives us lots of flexibility for improvements and extensibility. We had all the building blocks to create a ChatGPT plugin quickly. So, that's what we did.
We added an OpenAI manifest endpoint which describes what the plugin does, some branding assets, and an enriched OpenAPI schema to tell ChatGPT how to use our data APIs. The longest part of our work was fine-tuning the schema with good descriptions (written in natural language, obviously) and examples of how to query our endpoints.
Amusingly, the descriptions ended up much improved by the need to explain the API endpoints to ChatGPT. An interesting side effect is that this benefits us humans also.
{
"/api/v1/http/summary/ip_version": {
"get": {
"operationId": "get_SummaryIPVersion",
"parameters": [
{
"description": "Date range from today minus the number of days or weeks specified in this parameter, if not provided always send 14d in this parameter.",
"required": true,
"schema": {
"type": "string",
"example": "14d",
"enum": ["14d","1d","2d","7d","28d","12w","24w","52w"]
},
"name": "dateRange",
"in": "query"
}
]
}
}
Luckily, itty-router-openapi, an easy and compact OpenAPI 3 schema generator and validator for Cloudflare Workers that we built and open-sourced when we launched Radar 2.0, made it really easy for us to add the missing parts.
import { OpenAPIRouter } from '@cloudflare/itty-router-openapi'
const router = OpenAPIRouter({
aiPlugin: {
name_for_human: 'Cloudflare Radar API',
name_for_model: 'cloudflare_radar',
description_for_human: "Get data insights from Cloudflare's point of view.",
description_for_model:
"Plugin for retrieving the data based on Cloudflare Radar's data. Use it whenever a user asks something that might be related to Internet usage, eg. outages, Internet traffic, or Cloudflare Radar's data in particular.",
contact_email: '[email protected]',
legal_info_url: 'https://www.cloudflare.com/website-terms/',
logo_url: 'https://cdn-icons-png.flaticon.com/512/5969/5969044.png',
},
})
We incorporated our changes into itty-router-openapi, and now it supports the OpenAI manifest and route, and a few other options that make it possible for anyone to build their own ChatGPT plugin on top of Workers too.
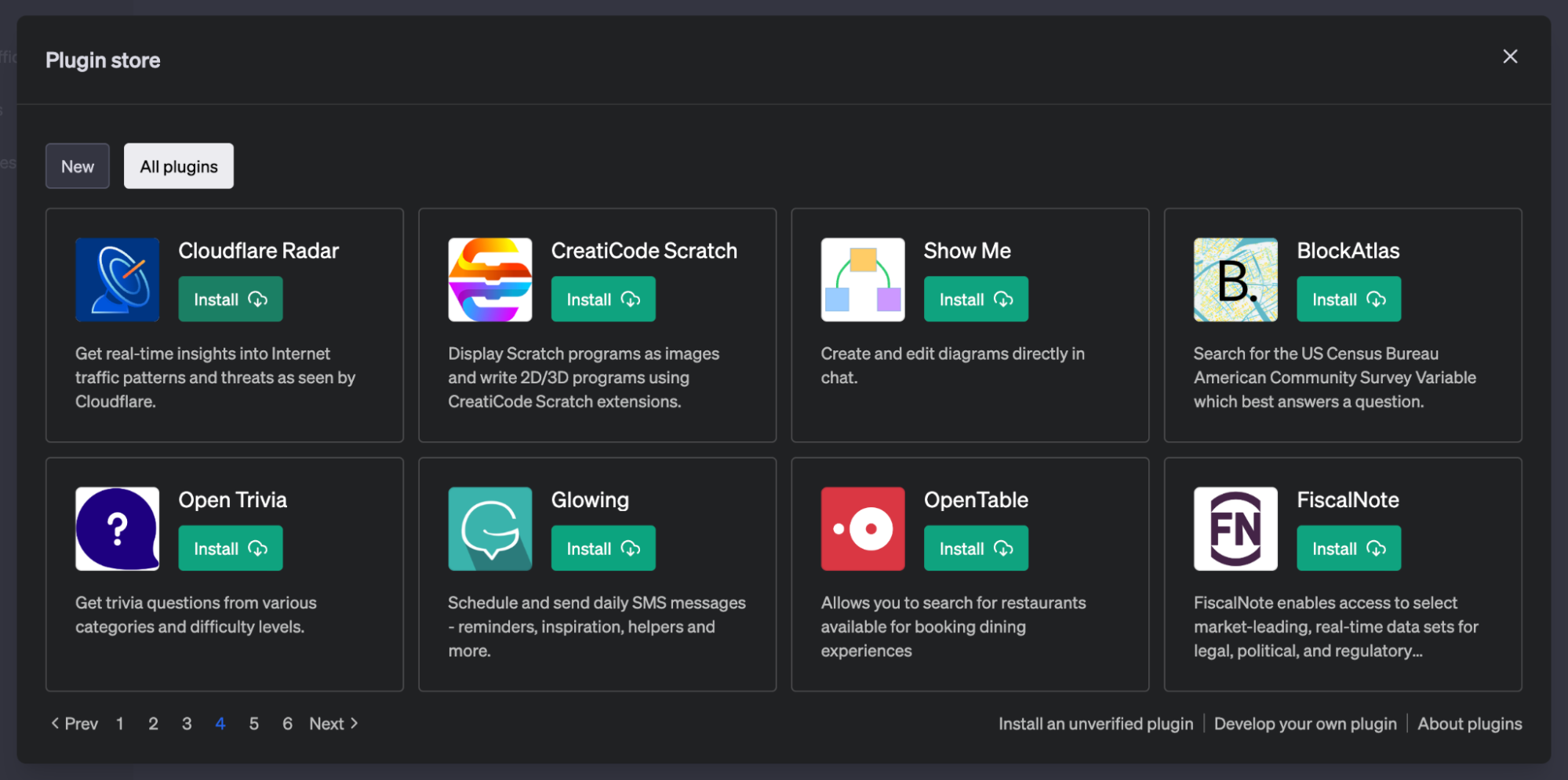
The Cloudflare Radar ChatGPT is available to non-free ChatGPT users or anyone on OpenAI’s plugin's waitlist. To use it, simply open ChatGPT, go to the Plugin store and install Cloudflare Radar.
Once installed, you can talk to it and ask questions about our data using natural language.
When you add plugins to your account, ChatGPT will prioritize using their data based on what the language model understands from the human-readable descriptions found in the manifest and Open API schema. If ChatGPT doesn't think your prompt can benefit from what the plugin provides, then it falls back to its standard capabilities.
Another interesting thing about plugins is that they extend ChatGPT's limited knowledge of the world and events after 2021 and can provide fresh insights based on recent data.
Here are a few examples to get you started:
"What is the percentage distribution of traffic per TLS protocol version?"
"What's the HTTP protocol version distribution in Portugal?"
Now that ChatGPT has context, you can add some variants, like switching the country and the date range.
“How about the US in the last six months?”
You can also combine multiple topics (ChatGPT will make multiple API calls behind the scenes and combine the results in the best possible way).
“How do HTTP protocol versions compare with TLS protocol versions?”
Out of ideas? Ask it “What can I ask the Radar plugin?”, or “Give me a random insight”.
Be creative, too; it understands a lot about our data, and we keep improving it. You can also add date or country filters using natural language in your prompts.
Cloudflare Docs ChatGPT plugin
The Cloudflare Docs plugin is a ChatGPT Retrieval Plugin that lets you access the most up-to-date knowledge from our developer documentation using ChatGPT. This means if you’re using ChatGPT to assist you with building on Cloudflare that the answers you’re getting or code that’s being generated will be informed by current best practices and information located within our docs. You can set up and run the Cloudflare Docs ChatGPT Plugin by following the read me in the example repo.
The plugin was built entirely on Workers and uses KV as a vector store. It can also keep its index up-to-date using Cron Triggers, Queues and Durable Objects.
The plugin is a Worker that responds to POST requests from ChatGPT to a /query endpoint. When a query comes in, the Worker converts the query text into an embedding vector via the OpenAI embeddings API and uses this to find, and return, the most relevant document snippets from Cloudflare’s developer documentation.
The way this is achieved is by first converting every document in Cloudflare’s developer documentation on GitHub into embedding vectors (again using OpenAI’s API) and storing them in KV. This storage format allows you to find semantically similar content by doing a similarity search (we use cosine similarity), where two pieces of text that are similar in meaning will result in the two embedding vectors having a high similarity score. Cloudflare’s entire developer documentation compresses to under 5MB when converted to embedding vectors, so fetching these from KV is very quick. We’ve also explored building larger vector stores on Workers, as can be seen in this demo of 1 million vectors stored on Durable Object storage. We’ll be releasing more open source libraries to support these vector store use cases in the near future.
So ChatGPT will query the plugin when it believes the user’s question is related to Cloudflare’s developer tools, and the plugin will return a list of up-to-date information snippets directly from our documentation. ChatGPT can then decide how to use these snippets to best answer the user’s question.
The plugin also includes a “Scheduler” Worker that can periodically refresh the documentation embedding vectors, so that the information is always up-to-date. This is advantageous because ChatGPT’s own knowledge has a cutoff of September 2021 – so it’s not aware of changes in documentation, or new Cloudflare products.
The Scheduler Worker is triggered by a Cron Trigger, on a schedule you can set (eg, hourly), where it will check which content has changed since it last ran via GitHub’s API. It then sends these document paths in messages to a Queue to be processed. Workers will batch process these messages – for each message, the content is fetched from GitHub, and then turned into embedding vectors via OpenAI’s API. A Durable Object is used to coordinate all the Queue processing so that when all the batches have finished processing, the resulting embedding vectors can be combined and stored in KV, ready for querying by the plugin.
This is a great example of how Workers can be used not only for front-facing HTTP APIs, but also for scheduled batch-processing use cases.
Let us know what you think
We are in a time when technology is constantly changing and evolving, so as you experiment with these new plugins please let us know what you think. What do you like? What could be better? Since ChatGPT plugins are in alpha, changes to the plugins user interface or performance (i.e. latency) may occur. If you build your own plugin, we’d love to see it and if it’s open source you can submit a pull request on our example repo. You can always find us hanging out in our developer discord.
It is an incredibly exciting time to be a developer.
The frameworks, libraries and developer tools we depend on keep leveling up in ways that allow us to build more efficiently. On top of that, we’re using AI-powered tools like ChatGPT and GitHub Copilot to ship code quicker than many of us ever could have imagined. This all means we’re spending less time on boilerplate code and setup, and more time writing the code that makes our applications unique.
It’s not only a time when we’re equipped with the tools to be successful in new ways, but we're also finding inspiration in what’s happening around us. It feels like every day there’s an advancement with AI that changes the boundaries of what we can build. Across meetups, conferences, chat rooms, and every other place we gather as developers, we’re pushing each other to expand our ideas of what is possible.
With so much excitement permeating through the global developer community, we couldn’t imagine a better time to be kicking off Developer Week here at Cloudflare.
A focus on developer experience
A big part of any Innovation Week at Cloudflare is bringing you all new products to play with. And this year will be no different, there will be plenty of new products coming your way over the next seven days, and we can’t wait for you to get your hands on them. But we know that for developers it can sometimes be more exciting to see a tool you already use upgrade its developer experience than to get something new. That’s why as we’ve planned for this Developer Week we have been particularly focused on how we can make our developer experience more seamless by addressing many of your most requested features & fixes.
Part of making our developer experience more seamless is ensuring you all can bring the technologies you already know and love to Cloudflare. We’ve especially heard this from you all when it comes to deploying JAMstack applications on Cloudflare. Without spoiling too much, if you’re using a frontend framework and building JAMstack applications we’re excited about what we’re shipping for you this week.
A platform born in the Age of AI
We want developers to be able to build anything they’re excited about on Cloudflare. And one thing a lot of us are excited about right now are AI applications. AI is something that’s been part of Cloudflare’s foundation since the beginning. We are a company that was born in the age of AI. A core part of how we work towards our mission to help build a better Internet is by using machine learning to help protect your applications.
Through this week, we want to empower you with the tools and wisdom we’ve gathered around AI and machine learning. As well as showing you how to use Cloudflare with some of your new favorite AI developer tools. We’ll be shipping sample code, tutorials, tips and best practices. And that wisdom won’t only be coming from us, we’ll be sharing the stories of customers who have built on us and give you all an opportunity to learn from the companies that inspire us.
Why I joined Cloudflare
This is special Developer Week for me because it’s my first Developer Week at Cloudflare. I joined a little over a month ago to lead our Developer Relations & Community team.
When I found out I was joining Cloudflare I called up one of my closest friends, and mentors, to share the news. He immediately said “What are you going to do? Developers are all already using Cloudflare. No matter how big or small of a project I build, I always use Cloudflare. It’s the last thing I set up before I deploy.” He couldn’t have set the stage better for me to share why I’m excited to join and a theme you’ll see throughout this week.
For many developers, you know us for our CDN, and we are one of the last pieces of infrastructure you set up for your project. Since we launched Cloudflare Workers in 2017, we’ve been shipping tools intended to help empower you not only at the end of your journey, but from the moment you start building a new project. Myself, and my team, are here to help you discover and be successful with all of our developers tools. We’ll be here from the moment you start building, when you go into production and all the way through when you’re scaling your application to millions of users around the world.
Whether you are one of the over one million developers already building on Cloudflare or you’re starting to use us for the first time during this Developer Week, I can’t wait to meet you.
Welcome to Developer Week 2023
We’re excited to kick off another Developer Week. Through this week we’ll tell you about the new tools we’re shipping and share how many of them were built. We’ll show you how you can use them, and share stories from customers who are using our developer platform today. We hope you’ll be part of the conversation, whether that’s on discord, Cloudflare TV, community.cloudflare.com, or social media.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.