Post Syndicated from Tahir Aziz original https://aws.amazon.com/blogs/big-data/enhance-your-security-posture-by-storing-amazon-redshift-admin-credentials-without-human-intervention-using-aws-secrets-manager-integration/
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Today, tens of thousands of AWS customers—from Fortune 500 companies, startups, and everything in between—use Amazon Redshift to run mission-critical business intelligence (BI) dashboards, analyze real-time streaming data, and run predictive analytics. With the constant increase in generated data, Amazon Redshift customers continue to achieve success in delivering better service to their end-users, improving their products, and running an efficient and effective business.
AWS Secrets Manager helps you manage, retrieve, and rotate database credentials, and natively supports storing database secrets for Amazon Relational Database Service (Amazon RDS), Amazon Aurora, Amazon Redshift, and Amazon DocumentDB (with MongoDB compatibility). We recommend you use Secrets Manager for storing Amazon Redshift user credentials because it allows you to configure safer secret rotation, customize fine-grained access control, and audit and monitor secrets centrally. You can natively use existing Secrets Manager secrets to access Amazon Redshift using the Amazon Redshift API and query editor.
Until now, you would have needed to configure your Amazon Redshift admin credentials in plaintext, or let Amazon Redshift generate credential for you. To store these credentials in Secrets Manager, you either needed to manually create a secret, or configure scripts with the credentials hardcoded or generated. Both options required a human to retrieve them. Amazon Redshift now allows you to create and store admin credentials automatically without a human needing to see the credentials. As part of this workflow, the admin credentials are configured to rotate every 30 days automatically. By reducing the need for humans to see the secret during configuration, you can increase the security posture of your Amazon Redshift data warehouse and improve the accuracy of your audit trails.
In this post, we show how to integrate Amazon Redshift admin credentials with Secrets Manager for both new and previously provisioned Redshift clusters and Amazon Redshift Serverless namespaces.
Prerequisites
Complete the following prerequisites before starting:
- Have admin privileges to create and manage Redshift Serverless namespaces or Redshift clusters.
- Have admin privileges to create and manage secrets in Secrets Manager.
- Optionally, have a Redshift Serverless namespace or a Redshift cluster to enable Secrets Manager integration.
- Optionally, have different AWS Key Management Service (AWS KMS) keys for credentials encryption with Secrets Manager.
- Have access to Amazon Redshift Query Editor v2.
Set up a new cluster using Secrets Manager
In this section, we provide steps to configure either a Redshift provisioned cluster or a Redshift Serverless workgroup with Secrets Manager.
Create a Redshift provisioned cluster
To get started using Secrets Manager with a new Redshift provisioned cluster, complete the following steps:
- On the Amazon Redshift console, choose Create cluster.
- Define the Cluster configuration and Sample data sections as needed.
- In the Database configurations section, specify your desired admin user name.
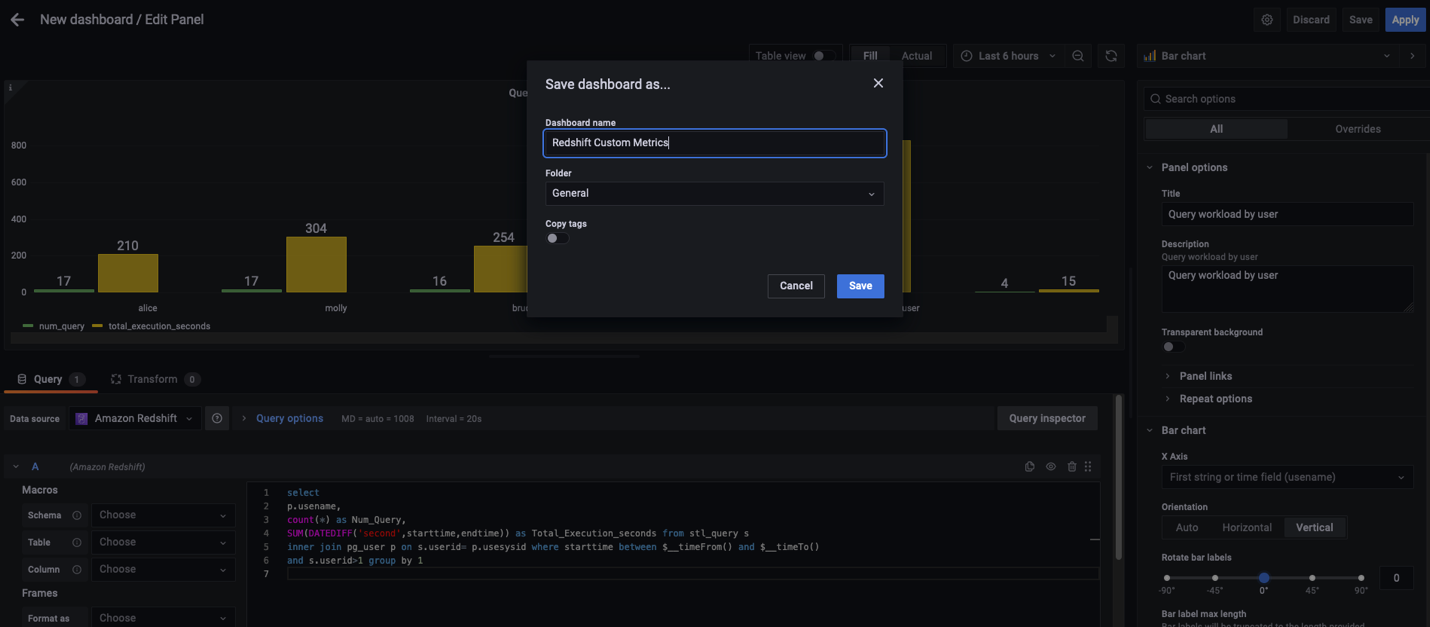
- To use Secrets Manager to automatically create and store your password, select Manage admin credentials in AWS Secrets Manager.
- You can also customize the encryption settings with your own AWS customer managed KMS key by creating a key or choosing an existing one. This is the key that is used to encrypt the secret in Secrets Manager. If you don’t select Customize encryption settings, an AWS managed key will be used as default.

- Provide the information in Cluster permissions and Additional configurations as appropriate and choose Create cluster.
- When the cluster is available, you can check the ARN of the secret containing the admin password on the Properties tab of the cluster in the Database configurations section.



Create a Redshift Serverless workgroup
To get started using Secrets Manager with Redshift Serverless, create a Redshift Serverless workgroup with the following steps:
- On the Amazon Redshift Serverless dashboard, choose Create workgroup.
- Define the Workgroup name, Capacity, and Network and security sections as appropriate and choose Next.
- Select Create a new namespace and provide a suitable name
- In the Database name and password section, select Customize admin user and credentials.
- Provide an admin user name.
- In the Admin password section, select Manage admin credentials in AWS Secrets Manager.
- You can also customize the encryption settings with your own AWS customer managed KMS key by creating a key or choosing an existing one. This is the key that is used to encrypt the secret in Secrets Manager. If you don’t select Customize encryption settings, an AWS managed key will be used as default.

- Provide the information in the Permissions and Encryption and security sections as appropriate and choose Next.
- Review the selected options and choose Create.
- When the status of the newly created workgroup and namespace is Available, choose the namespace.

- You can find the Secrets Manager ARN with admin credentials under General information.




Enable Secrets Manager for an existing Redshift cluster
In this section, we provide steps to enable Secrets Manager for an existing Redshift provisioned cluster or a Redshift Serverless namespace.
Configure an existing Redshift provisioned cluster
To enable Secrets Manager for an existing Redshift cluster, follow these steps:
- On the Amazon Redshift console, choose the cluster that you want to modify.

- On the Properties tab, choose Edit admin credentials.

- Select Manage admin credentials in AWS Secrets Manager.
- To use AWS KMS to encrypt the data, select Customize encryption options and either choose an existing KMS key or choose Create an AWS KMS key.
- Choose Save changes.

- When the cluster is available, you can check the ARN of the secret containing the admin password on the Properties tab of the cluster in the Database configurations section.





Configure an existing Redshift Serverless namespace
To enable Secrets Manager on an existing Amazon Redshift Serverless namespace, follow these steps:
- On the Amazon Redshift Serverless Dashboard, choose the namespace that you want to modify.
- On the Actions menu, choose Edit admin credentials.

- Select Customize admin user credentials.
- Select Manage admin credentials in AWS Secrets Manager.
- To use AWS KMS to encrypt the data, select Customize encryption settings and either choose an existing AWS KMS key or choose Create an AWS KMS key.
- Choose Save changes.
- When the namespace status is Available, you can see the Secrets Manager ARN under Admin password ARN in the General information section.



Manage secrets in Secrets Manager
To manage the admin credentials in Secrets Manager, follow these steps:
- On the Secrets Manager console, choose the secret that you want to modify.
Amazon Redshift creates the secret with rotation enabled by default and a rotation schedule of every 30 days.
- To view the admin credentials, choose Retrieve secret value.
- To change the secret rotation, choose Edit rotation.

- Define the new rotation frequency and choose Save.

- To rotate the secret immediately, choose Rotate secret immediately and choose Rotate.




Secrets Manager can be integrated with your application via the AWS SDK, which is available in Java, JavaScript, C#, Python3, Ruby, and Go. The supported language code snippet is available in the Sample code section.
- Choose the tab for your preferred language and use the code snippet provided in your application.


Restore a snapshot
New warehouses can be launched from both serverless and provisioned snapshots. You have the choice to configure the restored cluster to use Secrets Manager credentials, even if the source cluster didn’t use Secrets Manager, by following these steps:
- Navigate to either the Redshift snapshot dashboard for snapshots of provisioned clusters or the Redshift data backup dashboard for snapshots of serverless workgroups and choose the snapshot you’d like to restore from.
On the provisioned snapshot dashboard, on the Restore snapshot menu, choose Restore to provisioned cluster or Restore to serverless namespace.

On the serverless snapshot dashboard, on the Actions menu, under Restore serverless snapshot, choose Restore to provisioned cluster or Restore to serverless namespace.

If you’re restoring to a serverless endpoint from either option, you will need to have the target serverless namespace configured in advance.


- If you’re restoring to a warehouse using a snapshot that doesn’t have Secrets Manager credentials configured, you can enable it in the Database configuration section of the snapshot restoration page by selecting Manage admin credentials in AWS Secrets Manager.
- You can also customize the encryption settings with your own AWS customer managed KMS key by creating a key or choosing an existing one. If you don’t select Customize encryption settings, an AWS managed key will be used as default.
- If the snapshot was taken from a cluster that was using Secrets Manager to manage its admin credentials and you’re restoring to a provisioned cluster, you can optionally choose to update the key used to encrypt credentials in Secrets Manager. Otherwise, if you’d like to use the same configuration as the source snapshot, you can choose the same key as before.

- After you configure all the necessary details, choose Restore cluster from snapshot/Save changes to launch your provisioned cluster, or choose Restore to write the snapshot data to the namespace.

Connect to Amazon Redshift via Query Editor v2 using Secrets Manager
To connect to Amazon Redshift using Query Editor v2, complete the following steps:
- On the Amazon Redshift console, choose the cluster that you want to connect to.
- On the Properties tab, locate the admin user and admin password ARN.
- Make a note of the ARN to be used in the later steps.

- At the top of the cluster details page, on the Query data menu, choose Query in query editor v2.

- Locate the Redshift cluster or Redshift Serverless workgroup you want to connect to and choose the options menu (three dots) next to its name, then choose Create connection.

- In the connection window, select AWS Secrets Manager.
- For Secret, choose the appropriate secret for your cluster.
- Choose Create connection.



Note that access to the secrets can be controlled by AWS Identity and Access Management (IAM) permissions.

The connection should be established to your cluster now and you will be able to see the database objects in your cluster as well as run queries against your cluster

Conclusion
In this post, we demonstrated how the Secrets Manager integration with Amazon Redshift has simplified storing admin credentials. It’s a simple-to-use feature that is available immediately and automates the important task of maintaining admin credentials and rotating them for your Redshift data warehouse. Try it out today and leave a comment if you have any questions or suggestions.
About the Authors
 Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
 Julia Beck is an Analytics Specialist Solutions Architect at AWS. She supports customers in validating analytics solutions by architecting proof of concept workloads designed to meet their specific needs.
Julia Beck is an Analytics Specialist Solutions Architect at AWS. She supports customers in validating analytics solutions by architecting proof of concept workloads designed to meet their specific needs.
 Ekta Ahuja is a Senior Analytics Specialist Solutions Architect at AWS. She is passionate about helping customers build scalable and robust data and analytics solutions. Before AWS, she worked in several different data engineering and analytics roles. Outside of work, she enjoys baking, traveling, and board games.
Ekta Ahuja is a Senior Analytics Specialist Solutions Architect at AWS. She is passionate about helping customers build scalable and robust data and analytics solutions. Before AWS, she worked in several different data engineering and analytics roles. Outside of work, she enjoys baking, traveling, and board games.










 Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.
Nikos Koulouris is a Software Development Engineer at AWS. He received his PhD from University of California, San Diego and he has been working in the areas of databases and analytics.



 Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga. Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada.
Fabrizio Napolitano is a Principal Specialist Solutions Architect for DB and Analytics. He has worked in the analytics space for the last 20 years, and has recently and quite by surprise become a Hockey Dad after moving to Canada. Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom.
Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom. Sohaib Katariwala is an Analytics Specialist Solutions Architect at AWS. He has over 12 years of experience helping organizations derive insights from their data.
Sohaib Katariwala is an Analytics Specialist Solutions Architect at AWS. He has over 12 years of experience helping organizations derive insights from their data.