Post Syndicated from Ziad Wali original https://aws.amazon.com/blogs/big-data/best-practices-for-upgrading-from-amazon-redshift-dc2-to-ra3-and-amazon-redshift-serverless/
Amazon Redshift is a fast, petabyte-scale cloud data warehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, delivering the best price-performance.
With a fully managed, AI-powered, massively parallel processing (MPP) architecture, Amazon Redshift drives business decision-making quickly and cost-effectively. Previously, Amazon Redshift offered DC2 (Dense Compute) node types optimized for compute-intensive workloads. However, they lacked the flexibility to scale compute and storage independently and didn’t support many of the modern features now available. As analytical demands grow, many customers are upgrading from DC2 to RA3 or Amazon Redshift Serverless, which offer independent compute and storage scaling, along with advanced capabilities such as data sharing, zero-ETL integration, and built-in artificial intelligence and machine learning (AI/ML) support with Amazon Redshift ML.
This post provides a practical guide to plan your target architecture and migration strategy, covering upgrade options, key considerations, and best practices to facilitate a successful and seamless transition.
Upgrade process from DC2 nodes to RA3 and Redshift Serverless
The first step towards upgrade is to understand how the new architecture should be sized; for this, AWS provides a recommendation table for provisioned clusters. When determining the configuration for Redshift Serverless endpoints, you can assess compute capacity details by examining the relationship between RPUs and memory. Each RPU allocates 16 GiB of RAM. To estimate the base RPU requirement, divide your DC2 nodes cluster’s total RAM by 16. These recommendations provide guidance in sizing the initial target architecture but depend on the computing requirements of your workload. To better estimate your requirements, consider conducting a proof of concept that uses Redshift Test Drive to run potential configurations. To learn more, see Find the best Amazon Redshift configuration for your workload using Redshift Test Drive and Successfully conduct a proof of concept in Amazon Redshift. After you decide on the target configuration and architecture, you can build the strategy for upgrading.

Architecture patterns
The first step is to define the target architecture for your solution. You can choose the main architecture pattern that best aligns with your use case from the options presented in Architecture patterns to optimize Amazon Redshift performance at scale. There are two main scenarios, as illustrated in the following diagram.
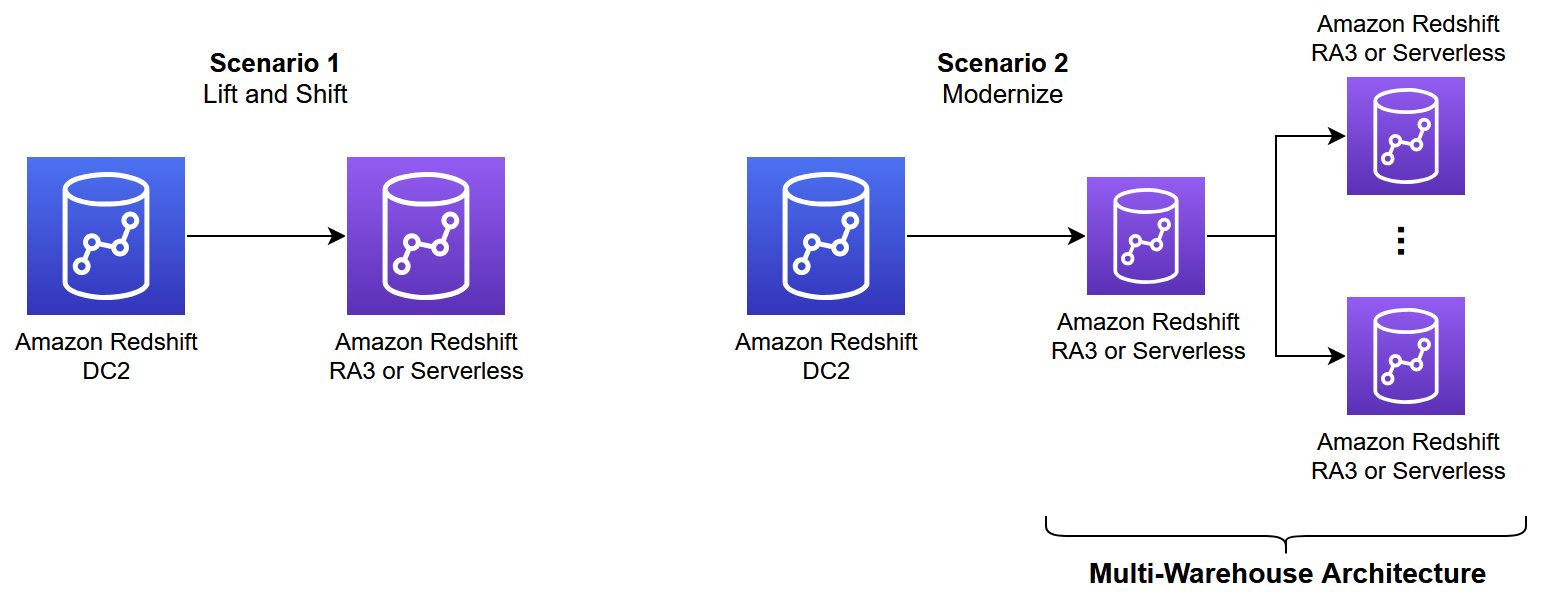
At the time of writing, Redshift Serverless doesn’t have manual workload management; everything runs with automatic workload management. Consider isolating your workload into multiple endpoints based on use case to enable independent scaling and better performance. For more information, refer to Architecture patterns to optimize Amazon Redshift performance at scale.
Upgrade strategies
You can choose from two possible upgrade options when upgrading from DC2 nodes to RA3 nodes or Redshift Serverless:
- Full re-architecture – The first step is to evaluate and assess the workloads to determine whether you could benefit from a modern data architecture, then re-architect the existing platform during the upgrade process from DC2 nodes.
- Phased approach– This is a two-stage strategy. The first stage involves a straightforward migration to the target RA3 or Serverless configuration. In the second stage, you can modernize the target architecture by taking advantage of cutting-edge Redshift features.
We usually recommend a phased approach, which allows for a smoother transition while enabling future optimization. The first stage of a phased approach consists of the following steps:
- Evaluate an equivalent RA3 nodes or Redshift Serverless configuration for your existing DC2 cluster, using the sizing guidelines for provisioned clusters or the compute capacity options for serverless endpoints.
- Thoroughly validate the chosen target configuration in a non-production environment using Redshift Test Drive. This automated tool simplifies the process of simulating your production workloads on various potential target configurations, enabling a comprehensive what-if analysis. This step is strongly recommended.
- Proceed to the upgrade process when you are satisfied with the price-performance ratio of a particular target configuration, using one of the methods detailed in the following section.
Redshift RA3 instances and Redshift Serverless provide access to powerful new capabilities, including zero-ETL, Amazon Redshift Streaming Ingestion, data sharing writes, and independent compute and storage scaling. To maximize these benefits, we recommend conducting a comprehensive review of your current architecture (the second stage of a phased approach) to identify opportunities for modernization using Amazon Redshift’s latest features. For example:
- Implement a multi-warehouse architecture using data sharing to separate your workloads and enhance performance.
- Implement zero-ETL to streamline operations and reduce maintenance overhead if you currently rely on AWS Database Migration Service (AWS DMS) for transferring data from transactional sources to Amazon Redshift
Upgrade options
You can choose from three ways to resize or upgrade a Redshift cluster from DC2 to RA3 or Redshift Serverless: snapshot restore, classic resize, and elastic resize.
Snapshot restore
The snapshot restore method follows a sequential process that begins with capturing a snapshot of your existing (source) cluster. This snapshot is then used to create a new target cluster with your desired specifications. After creation, it’s essential to verify data integrity by confirming that data has been correctly transferred to the target cluster. An important consideration is that any data written to the source cluster after the initial snapshot must be manually transferred to maintain synchronization.
This method offers the following advantages:
- Allows for the validation of the new RA3 or Serverless setup without affecting the existing DC2 cluster
- Provides the flexibility to restore to different AWS Regions or Availability Zones
- Minimizes cluster downtime for write operations during the transition
Keep in mind the following considerations:
- Setup and data restore might take longer than elastic resize.
- You might encounter data synchronization challenges. Any new data written to the source cluster after snapshot creation requires manual copying to the target. This process might need multiple iterations to achieve full synchronization and require downtime before cutoff.
- A new Redshift endpoint is generated, necessitating connection updates. Consider renaming both clusters in order to maintain the original endpoint (make sure the new target cluster adopts the original source cluster’s name)
Classic resize
Amazon Redshift creates a target cluster and migrates your data and metadata to it from the source cluster using a backup and restore operation. All your data, including database schemas and user configurations, is accurately transferred to the new cluster. The source cluster restarts initially and is unavailable for a few minutes, causing minimal downtime. It quickly resumes, allowing both read and write operations as the resize continues in the background.
Classic resize is a two-stage process:
- Stage 1 (critical path) – During this stage, metadata migration occurs between the source and target configurations, temporarily placing the source cluster in read-only mode. This initial phase is typically brief. When this phase is complete, the cluster is made available for read and write queries. Although tables originally configured with
KEYdistribution style are temporarily stored usingEVENdistribution, they will be redistributed to their originalKEYdistribution during Stage 2 of the process. - Stage 2 (background operations) – This stage focuses on restoring data to its original distribution patterns. This operation runs in the background with low priority without interfering with the primary migration process. The duration of this stage varies based on multiple factors, including the volume of data being redistributed, ongoing cluster workload, and the target configuration being used.
The overall resize duration is primarily determined by the data volume being processed. You can monitor progress on the Amazon Redshift console or by using the SYS_RESTORE_STATE system view, which displays the percentage completed for the table being converted (accessing this view requires superuser privileges).
The classic resize approach offers the following advantages:
- All possible target node configurations are supported
- A comprehensive reconfiguration of the source cluster rebalances the data slices to default per node, leading to even data distribution across the nodes
However, keep in mind the following:
- Stage 2 redistributes the data for optimal performance. However, Stage 2 runs at a lower priority, and in busy clusters, it can take a long time to complete. To speed up the process, you can manually run the
ALTER TABLE DISTSTYLEcommand on your tables havingKEY DISTSTYLE. By executing this command, you can prioritize the data redistribution to happen faster, mitigating any potential performance degradation due to the ongoing Stage 2 process. - Due to the Stage 2 background redistribution process, queries can take longer to complete during the resize operation. Consider enabling concurrency scaling as a mitigation strategy.
- Drop unnecessary and unused tables before initiating a resize to speed up data distribution.
- The snapshot used for the resize operation becomes dedicated to this operation only. Therefore, it can’t be used for a table restore or other purpose.
- The cluster must operate within a virtual private cloud (VPC).
- This approach requires a new or a recent manual snapshot taken before initiating a classic resize.
- We recommend scheduling the operation during off-peak hours or maintenance windows for minimal business impact.
Elastic resize
When using elastic resize to change the node type, Amazon Redshift follows a sequential process. It begins by creating a snapshot of your existing cluster, then provisions a new target cluster using the most recent data from that snapshot. While data transfers to the new cluster in the background, the system remains in read-only mode. As the resize operation approaches completion, Amazon Redshift automatically redirects the endpoint to the new cluster and stops all connections to the original one. If any issues arise during this process, the system typically performs an automatic rollback without requiring manual intervention, though such failures are rare.
Elastic resize offers several advantages:
- It’s a quick process that takes 10–15 minutes on average
- Users maintain read access to their data during the process, experiencing only minimal interruption
- The cluster endpoint remains unchanged throughout and after the operation
When considering this approach, keep in mind the following:
- Elastic resize operations can only be performed on clusters using the EC2-VPC platform. Therefore, it’s not available for Redshift Serverless.
- The target node configuration must provide sufficient storage capacity for existing data.
- Not all target cluster configurations support elastic resize. In such cases, consider using classic resize or snapshot restore.
- After the process is started, elastic resize can’t be stopped.
- Data slices remain unchanged; this can potentially cause some data or CPU skew.
Upgrade recommendations
The following flowchart visually guides the decision-making process for choosing the appropriate Amazon Redshift upgrade method.
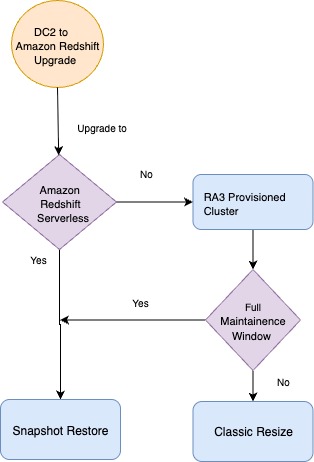
When upgrading Amazon Redshift, the method depends on the target configuration and operational constraints. For Redshift Serverless, always use the snapshot restore method. If upgrading to an RA3 provisioned cluster, you can choose from two options: use snapshot restore if a full maintenance window with downtime is acceptable, or choose classic resize for minimal downtime, because it rebalances the data slices to default per node, leading to even data distribution across the nodes. Although you can use elastic resize for certain node type changes (for example, DC2 to RA3) within specific ranges, it’s not recommended because elastic resize doesn’t change the number of slices, potentially leading to data or CPU skew, which can later impact the performance of the Redshift cluster. However, elastic resize remains the primary recommendation when you need to add or reduce nodes in an existing cluster.
Best practices for migration
When planning your migration, consider the following best practices:
- Conduct a pre-migration assessment using Amazon Redshift Advisor or Amazon CloudWatch.
- Choose the right target architecture based on your use cases and workloads. You can use Redshift Test Drive to determine the right target architecture.
- Backup using manual snapshots, and enable automated rollback.
- Communicate timelines, downtime, and changes to stakeholders.
- Update runbooks with new architecture details and endpoints.
- Validate workloads using benchmarks and data checksum.
- Use maintenance windows for final syncs and cutovers.
By following these practices, you can achieve a controlled, low-risk migration that balances performance, cost, and operational continuity.
Conclusion
Migrating from Redshift DC2 nodes to RA3 nodes or Redshift Serverless requires a structured approach to support performance, cost-efficiency, and minimal disruption. By selecting the right architecture for your workload, and validating data and workloads post-migration, organizations can seamlessly modernize their data platforms. This upgrade facilitates long-term success, helping teams fully harness RA3’s scalable storage or Redshift Serverless auto scaling capabilities while optimizing costs and performance.







 Ziad WALI is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys sports and spending time in nature.
Ziad WALI is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing, where he enjoys building reliable, scalable, and efficient solutions. Outside of work, he enjoys sports and spending time in nature. Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies.
Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies. Srikant Das is an Acceleration Lab Solutions Architect at Amazon Web Services. His expertise lies in constructing robust, scalable, and efficient solutions. Beyond the professional sphere, he finds joy in travel and shares his experiences through insightful blogging on social media platforms.
Srikant Das is an Acceleration Lab Solutions Architect at Amazon Web Services. His expertise lies in constructing robust, scalable, and efficient solutions. Beyond the professional sphere, he finds joy in travel and shares his experiences through insightful blogging on social media platforms.





