Post Syndicated from Sivaprasad Mahamkali original https://aws.amazon.com/blogs/big-data/modernize-your-etl-platform-with-aws-glue-studio-a-case-study-from-bms/
This post is co-written with Ramesh Daddala, Jitendra Kumar Dash and Pavan Kumar Bijja from Bristol Myers Squibb.
Bristol Myers Squibb (BMS) is a global biopharmaceutical company whose mission is to discover, develop, and deliver innovative medicines that help patients prevail over serious diseases. BMS is consistently innovating, achieving significant clinical and regulatory successes. In collaboration with AWS, BMS identified a business need to migrate and modernize their custom extract, transform, and load (ETL) platform to a native AWS solution to reduce complexities, resources, and investment to upgrade when new Spark, Python, or AWS Glue versions are released. In addition to using native managed AWS services that BMS didn’t need to worry about upgrading, BMS was looking to offer an ETL service to non-technical business users that could visually compose data transformation workflows and seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine. AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor ETL jobs in AWS Glue. Offering this service reduced BMS’s operational maintenance and cost, and offered flexibility to business users to perform ETL jobs with ease.
For the past 5 years, BMS has used a custom framework called Enterprise Data Lake Services (EDLS) to create ETL jobs for business users. Although this framework met their ETL objectives, it was difficult to maintain and upgrade. BMS’s EDLS platform hosts over 5,000 jobs and is growing at 15% YoY (year over year). Each time the newer version of Apache Spark (and corresponding AWS Glue version) was released, it required significant operational support and time-consuming manual changes to upgrade existing ETL jobs. Manually upgrading, testing, and deploying over 5,000 jobs every few quarters was time consuming, error prone, costly, and not sustainable. Because another release for the EDLS framework was pending, BMS decided to assess alternate managed solutions to reduce their operational and upgrade challenges.
In this post, we share how BMS will modernize leveraging the success of the proof of concept targeting BMS’s ETL platform using AWS Glue Studio.
Solution overview
This solution addresses BMS’s EDLS requirements to overcome challenges using a custom-built ETL framework that required frequent maintenance and component upgrades (requiring extensive testing cycles), avoid complexity, and reduce the overall cost of the underlying infrastructure derived from the proof of concept. BMS had the following goals:
- Develop ETL jobs using visual workflows provided by the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a low-code environment that allows you to compose data transformation workflows, seamlessly run them on the AWS Glue Apache Spark-based serverless data integration engine, and inspect the schema and data results in each step of the job.
- Migrate over 5,000 existing ETL jobs using native AWS Glue Studio in an automated and scalable manner.
EDLS job steps and metadata
Every EDLS job comprises one or more job steps chained together and run in a predefined order orchestrated by the custom ETL framework. Each job step incorporates the following ETL functions:
- File ingest – File ingestion enables you to ingest or list files from multiple file sources, like Amazon Simple Storage Service (Amazon S3), SFTP, and more. The metadata holds configurations for the file ingestion step to connect to Amazon S3 or SFTP endpoints and ingest files to target location. It retrieves the specified files and available metadata to show on the UI.
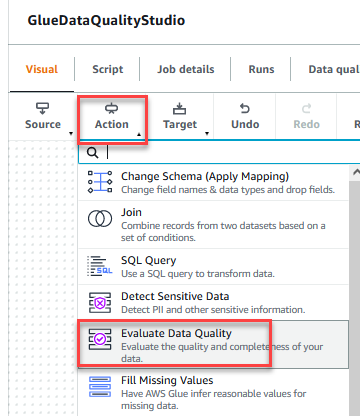
- Data quality check – The data quality module enables you to perform quality checks on a huge amount of data and generate reports that describe and validate the data quality. The data quality step uses an EDLS ingested source object from Amazon S3 and runs one to many data conformance checks that are configured by the tenant.
- Data transform join – This is one of the submodules of the data transform module that can perform joins between the datasets using a custom SQL based on the metadata configuration.
- Database ingest – The database ingestion step is one of the important service components in EDLS, which facilitates you to obtain and import the desired data from the database and export it to a specific file in the location of your choice.
- Data transform – The data transform module performs various data transformations against the source data using JSON-driven rules. Each data transform capability has its own JSON rule and, based on the specific JSON rule you provide, EDLS performs the data transformation on the files available in the Amazon S3 location.
- Data persistence – The data persistence module is one of the important service components in EDLS, which enables you to obtain the desired data from the source and persist it to an Amazon Relational Database Service (Amazon RDS) database.
The metadata corresponding to each job step includes ingest sources, transformation rules, data quality checks, and data destinations stored in an RDS instance.
Migration utility
The solution involves building a Python utility that reads EDLS metadata from the RDS database and translating each of the job steps into an equivalent AWS Glue Studio visual editor JSON node representation.
AWS Glue Studio provides two types of transforms:
- AWS Glue-native transforms – These are available to all users and are managed by AWS Glue.
- Custom visual transforms – This new functionality allows you to upload custom-built transforms used in AWS Glue Studio. Custom visual transforms expand the managed transforms, enabling you to search and use transforms from the AWS Glue Studio interface.
The following is a high-level diagram depicting the sequence flow of migrating a BMS EDLS job to an AWS Glue Studio visual editor job.

Migrating BMS EDLS jobs to AWS Glue Studio includes the following steps:
- The Python utility reads existing metadata from the EDLS metadata database.
- For each job step type, based on the job metadata, the Python utility selects either the native AWS Glue transform, if available, or a custom-built visual transform (when the native functionality is missing).
- The Python utility parses the dependency information from metadata and builds a JSON object representing a visual workflow represented as a Directed Acyclic Graph (DAG).
- The JSON object is sent to the AWS Glue API, creating the AWS Glue ETL job. These jobs are visually represented in the AWS Glue Studio visual editor using a series of sources, transforms (native and custom), and targets.
Sample ETL job generation using AWS Glue Studio
The following flow diagram depicts a sample ETL job that incrementally ingests the source RDBMS data in AWS Glue based on modified timestamps using a custom SQL and merges it into the target data on Amazon S3.

The preceding ETL flow can be represented using the AWS Glue Studio visual editor through a combination of native and custom visual transforms.
Custom visual transform for incremental ingestion
Post POC, BMS and AWS identified there will be a need to leverage custom transforms to execute a subset of jobs leveraging their current EDLS Service where Glue Studio functionality will not be a natural fit. The BMS team’s requirement was to ingest data from various databases without depending on the existence of transaction logs or specific schema, so AWS Database Migration Service (AWS DMS) wasn’t an option for them. AWS Glue Studio provides the native SQL query visual transform, where a custom SQL query can be used to transform the source data. However, in order to query the source database table based on a modified timestamp column to retrieve new and modified records since the last ETL run, the previous timestamp column state needs to be persisted so it can be used in the current ETL run. This needs to be a recurring process and can also be abstracted across various RDBMS sources, including Oracle, MySQL, Microsoft SQL Server, SAP Hana, and more.
AWS Glue provides a job bookmark feature to track the data that has already been processed during a previous ETL run. An AWS Glue job bookmark supports one or more columns as the bookmark keys to determine new and processed data, and it requires that the keys are sequentially increasing or decreasing without gaps. Although this works for many incremental load use cases, the requirement is to ingest data from different sources without depending on any specific schema, so we didn’t use an AWS Glue job bookmark in this use case.
The SQL-based incremental ingestion pull can be developed in a generic way using a custom visual transform using a sample incremental ingestion job from a MySQL database. The incremental data is merged into the target Amazon S3 location in Apache Hudi format using an upsert write operation.
In the following example, we’re using the MySQL data source node to define the connection but the DynamicFrame of the data source itself is not used. The custom transform node (DB incremental ingestion) will act as the source for reading the data incrementally using the custom SQL query and the previously persisted timestamp from the last ingestion.

The transform accepts as input parameters the preconfigured AWS Glue connection name, database type, table name, and custom SQL (parameterized timestamp field).
The following is the sample visual transform Python code:
To merge the source data into the Amazon S3 target, a data lake framework like Apache Hudi or Apache Iceberg can be used, which is natively supported in AWS Glue 3.0 and later.

You can also use Amazon EventBridge to detect the final AWS Glue job state change and update the Amazon DynamoDB table’s last ingested timestamp accordingly.
Build the AWS Glue Studio job using the AWS SDK for Python (Boto3) and AWS Glue API
For the sample ETL flow and the corresponding AWS Glue Studio ETL job we showed earlier, the underlying CodeGenConfigurationNode struct (an AWS Glue job definition pulled using the AWS Command Line Interface (AWS CLI) command aws glue get-job –job-name <jobname>) is represented as a JSON object, shown in the following code:
The JSON object (ETL job DAG) represented in the CodeGenConfigurationNode is generated through a series of native and custom transforms with the respective input parameter arrays. This can be accomplished using Python JSON encoders that serialize the class objects to JSON and subsequently create the AWS Glue Studio visual editor job using the Boto3 library and AWS Glue API.
Inputs required to configure the AWS Glue transforms are sourced from the EDLS jobs metadata database. The Python utility reads the metadata information, parses it, and configures the nodes automatically.
The order and sequencing of the nodes is sourced from the EDLS jobs metadata, with one node becoming the input to one or more downstream nodes building the DAG flow.
Benefits of the solution
The migration path will help BMS achieve their core objectives of decomposing their existing custom ETL framework to modular, visually configurable, less complex, and easily manageable pipelines using visual ETL components. The utility aids the migration of the legacy ETL pipelines to native AWS Glue Studio jobs in an automated and scalable manner.
With consistent out-of-the box visual ETL transforms in the AWS Glue Studio interface, BMS will be able to build sophisticated data pipelines without having to write code.
The custom visual transforms will extend AWS Glue Studio capabilities and fulfill some of the BMS ETL requirements where the native transforms are missing that functionality. Custom transforms will help define, reuse, and share business-specific ETL logic among all the teams. The solution increases the consistency between teams and keeps the ETL pipelines up to date by minimizing duplicate effort and code.
With minor modifications, the migration utility can be reused to automate migration of pipelines during future AWS Glue version upgrades.
Conclusion
The successful outcome of this proof of concept has shown that migrating over 5,000 jobs from BMS’s custom application to native AWS services can deliver significant productivity gains and cost savings. By moving to AWS, BMS will be able to reduce the effort required to support AWS Glue, improve DevOps delivery, and save an estimated 58% on AWS Glue spend.
These results are very promising, and BMS is excited to embark on the next phase of the migration. We believe that this project will have a positive impact on BMS’s business and help us achieve our strategic goals.
About the authors
 Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services. Siva leads customer engagements related to real-time streaming solutions, data lakes, analytics using opensource and AWS services. Siva enjoys listening to music and loves to spend time with his family.
Sivaprasad Mahamkali is a Senior Streaming Data Engineer at AWS Professional Services. Siva leads customer engagements related to real-time streaming solutions, data lakes, analytics using opensource and AWS services. Siva enjoys listening to music and loves to spend time with his family.
 Dan Gibbar is a Senior Engagement Manager at AWS Professional Services. Dan leads healthcare and life science engagements collaborating with customers and partners to deliver outcomes. Dan enjoys the outdoors, attempting triathlons, music and spending time with family.
Dan Gibbar is a Senior Engagement Manager at AWS Professional Services. Dan leads healthcare and life science engagements collaborating with customers and partners to deliver outcomes. Dan enjoys the outdoors, attempting triathlons, music and spending time with family.
 Shrinath Parikh as a Senior Cloud Data Architect with AWS. He works with customers around the globe to assist them with their data analytics, data lake, data lake house, serverless, governance and NoSQL use cases. In Shrinath’s off time, he enjoys traveling, spending time with family and learning/building new tools using cutting edge technologies.
Shrinath Parikh as a Senior Cloud Data Architect with AWS. He works with customers around the globe to assist them with their data analytics, data lake, data lake house, serverless, governance and NoSQL use cases. In Shrinath’s off time, he enjoys traveling, spending time with family and learning/building new tools using cutting edge technologies.
 Ramesh Daddala is a Associate Director at BMS. Ramesh leads enterprise data engineering engagements related to enterprise data lake services (EDLs) and collaborating with Data partners to deliver and support enterprise data engineering and ML capabilities. Ramesh enjoys the outdoors, traveling and loves to spend time with family.
Ramesh Daddala is a Associate Director at BMS. Ramesh leads enterprise data engineering engagements related to enterprise data lake services (EDLs) and collaborating with Data partners to deliver and support enterprise data engineering and ML capabilities. Ramesh enjoys the outdoors, traveling and loves to spend time with family.
 Jitendra Kumar Dash is a Senior Cloud Architect at BMS with expertise in hybrid cloud services, Infrastructure Engineering, DevOps, Data Engineering, and Data Analytics solutions. He is passionate about food, sports, and adventure.
Jitendra Kumar Dash is a Senior Cloud Architect at BMS with expertise in hybrid cloud services, Infrastructure Engineering, DevOps, Data Engineering, and Data Analytics solutions. He is passionate about food, sports, and adventure.
 Pavan Kumar Bijja is a Senior Data Engineer at BMS. Pavan enables data engineering and analytical services to BMS Commercial domain using enterprise capabilities. Pavan leads enterprise metadata capabilities at BMS. Pavan loves to spend time with his family, playing Badminton and Cricket.
Pavan Kumar Bijja is a Senior Data Engineer at BMS. Pavan enables data engineering and analytical services to BMS Commercial domain using enterprise capabilities. Pavan leads enterprise metadata capabilities at BMS. Pavan loves to spend time with his family, playing Badminton and Cricket.
 Shovan Kanjilal is a Senior Data Lake Architect working with strategic accounts in AWS Professional Services. Shovan works with customers to design data and machine learning solutions on AWS.
Shovan Kanjilal is a Senior Data Lake Architect working with strategic accounts in AWS Professional Services. Shovan works with customers to design data and machine learning solutions on AWS.







 Ziad WALI is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing where he enjoys building reliable, scalable and efficient solutions. Outside of work, he enjoys sports and spending time in nature.
Ziad WALI is an Acceleration Lab Solutions Architect at Amazon Web Services. He has over 10 years of experience in databases and data warehousing where he enjoys building reliable, scalable and efficient solutions. Outside of work, he enjoys sports and spending time in nature.