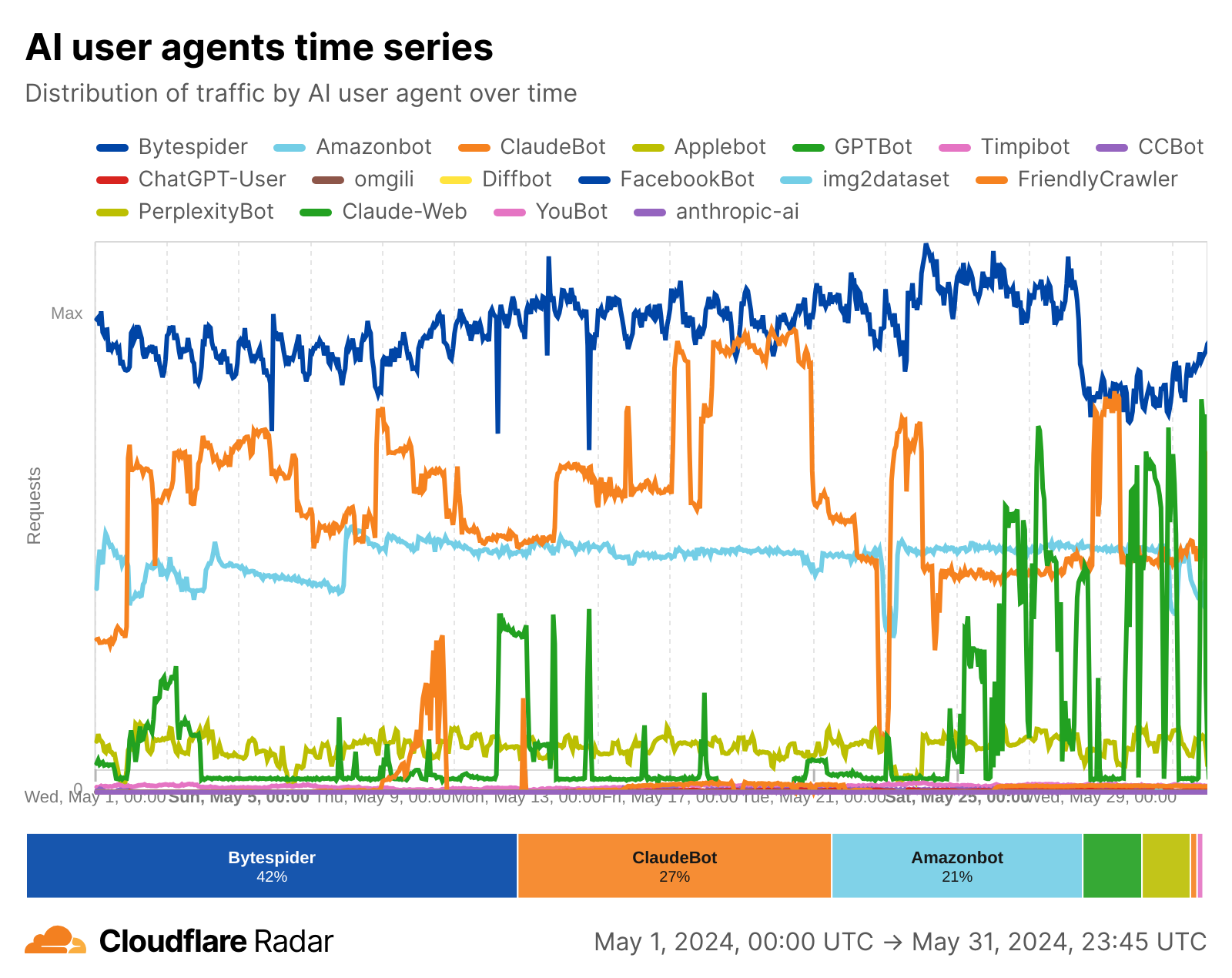
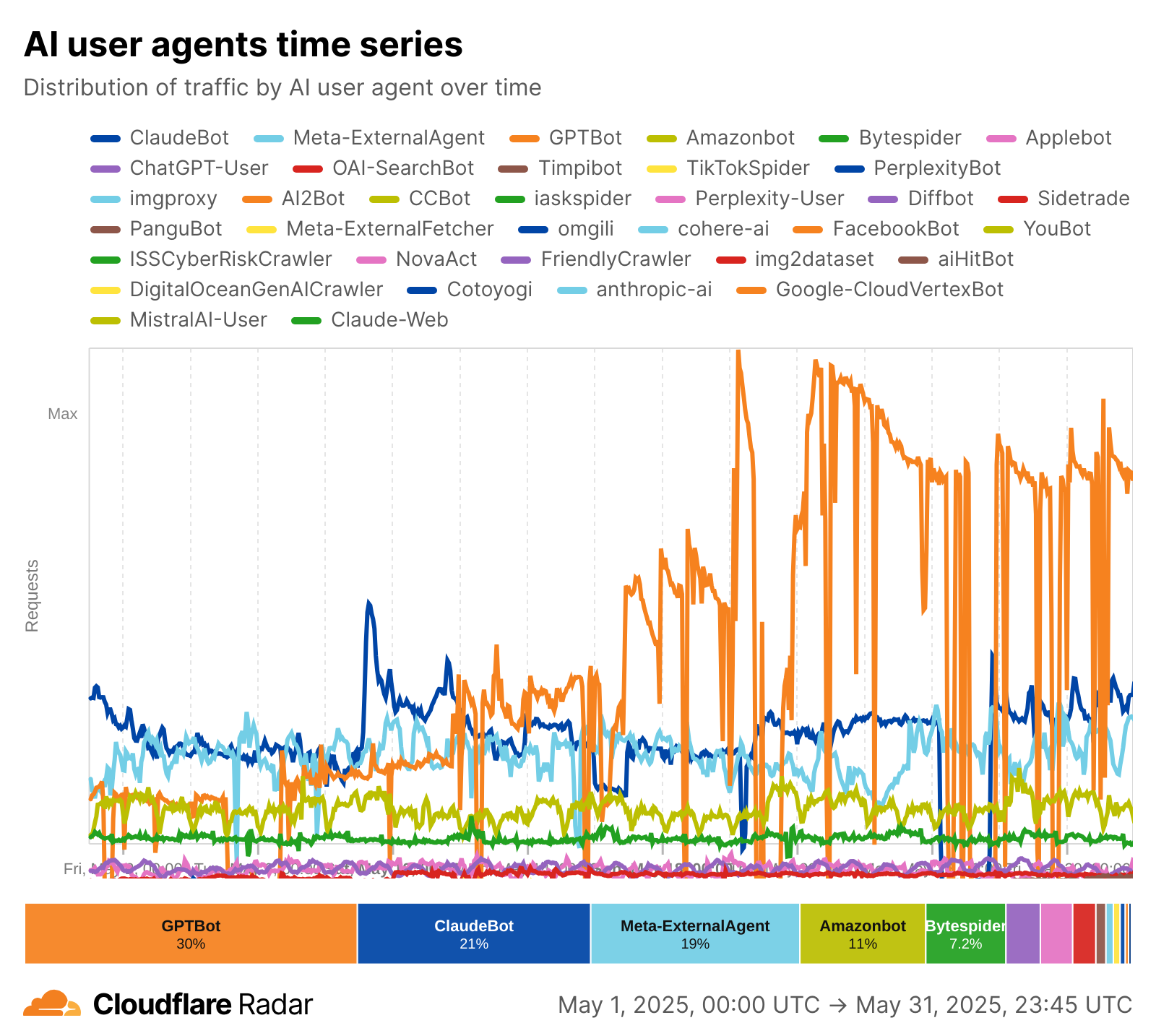
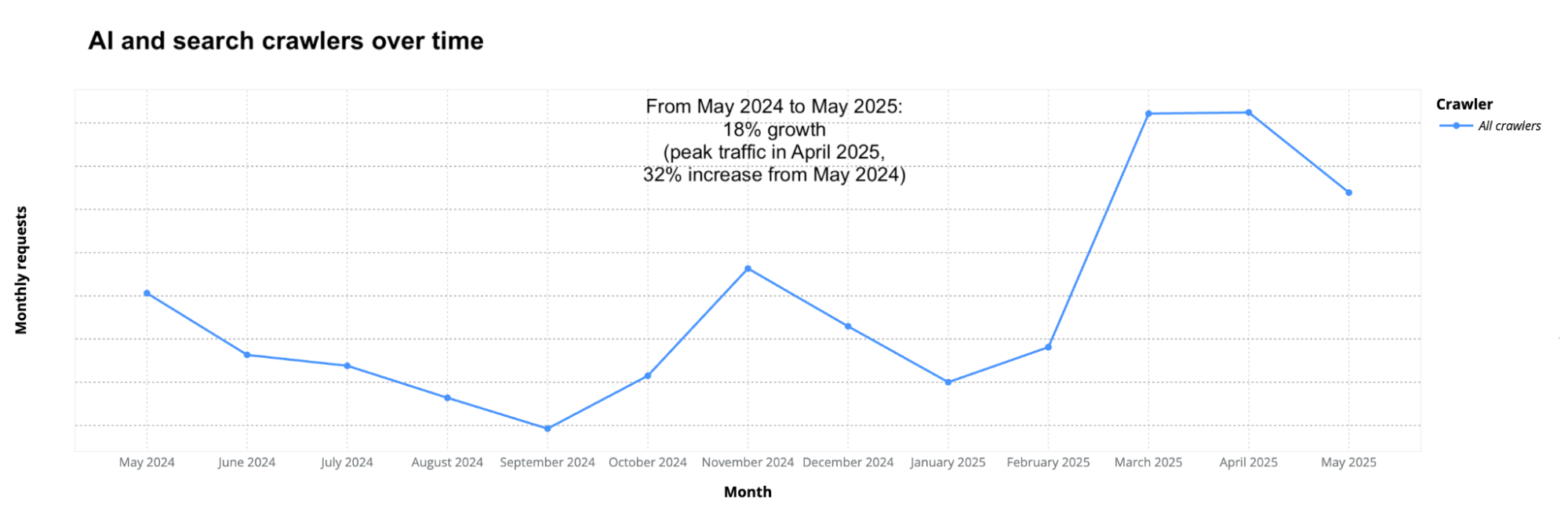
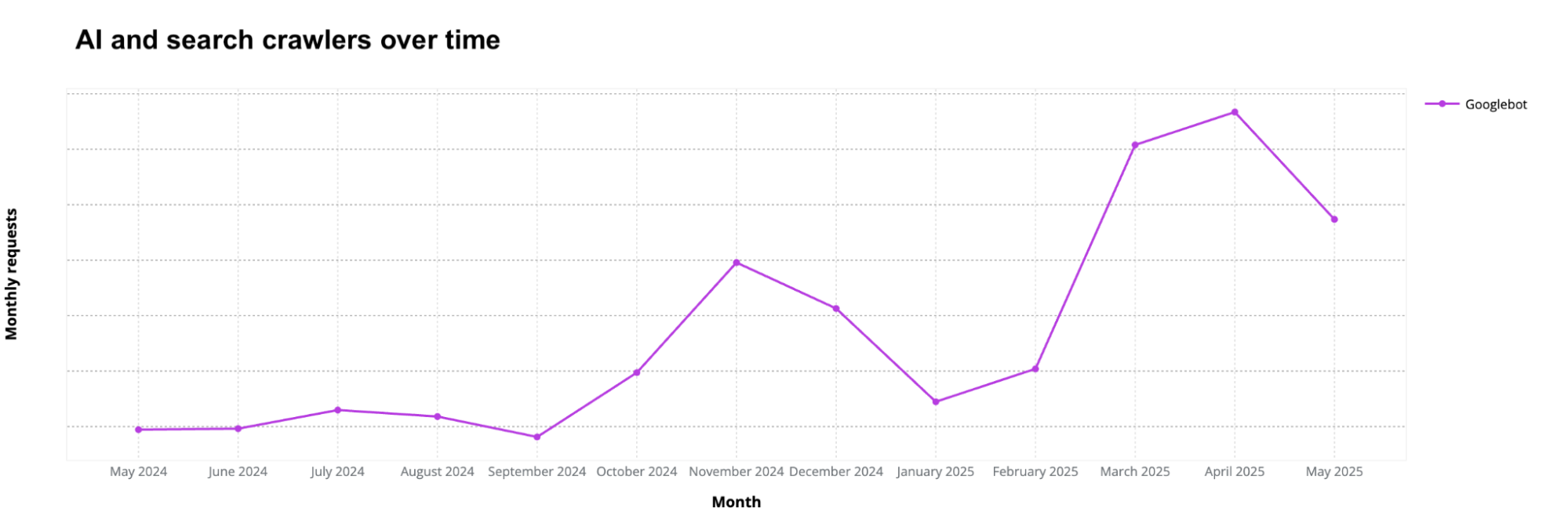
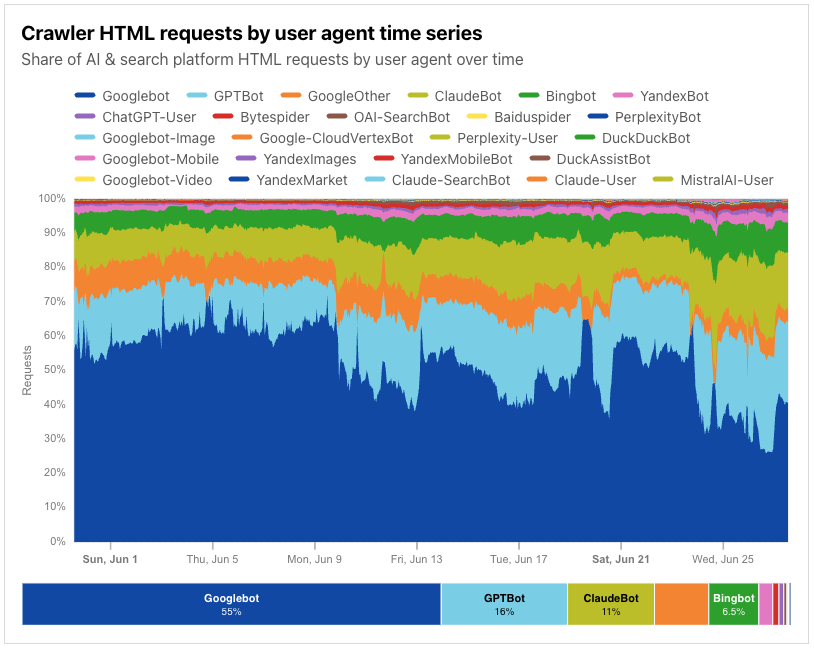
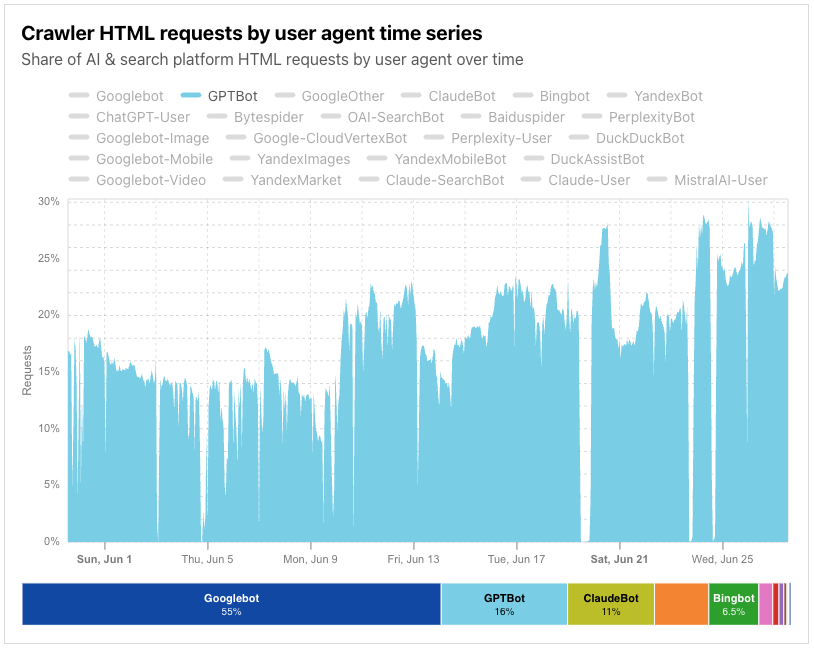
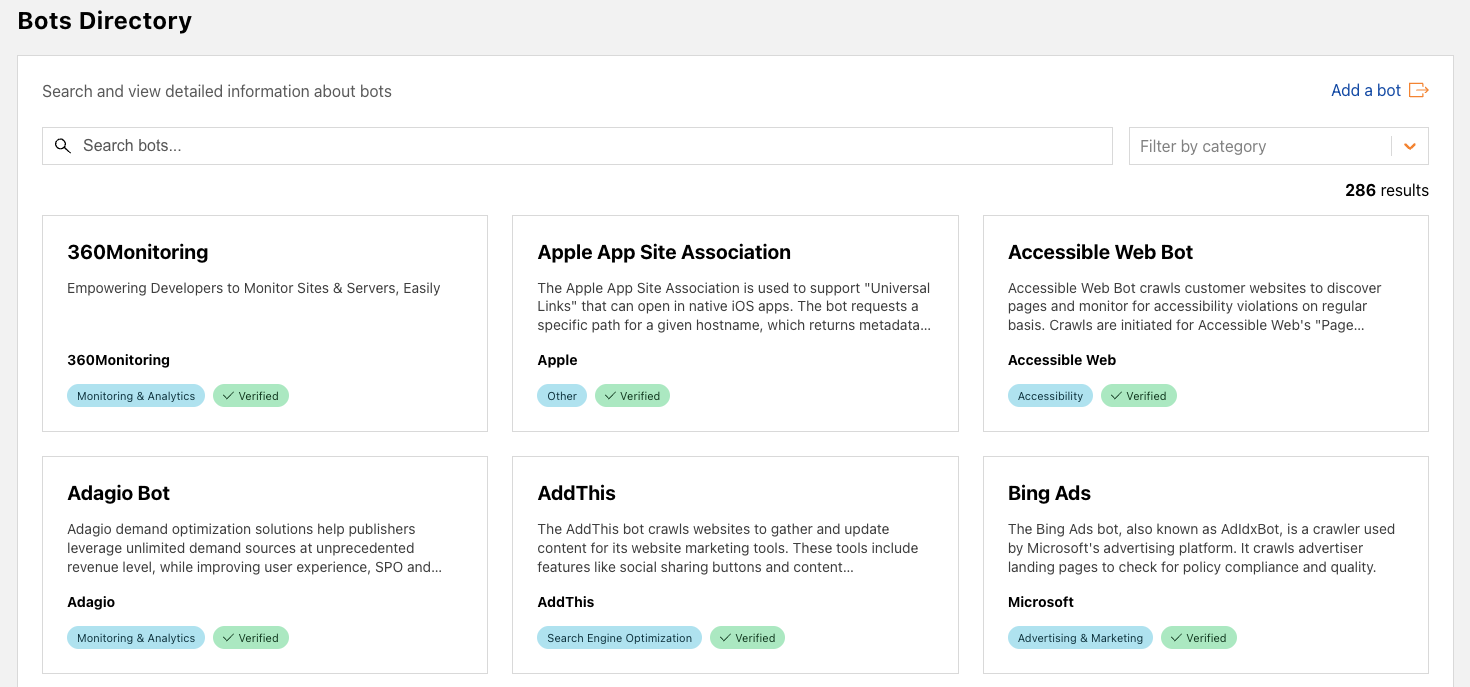
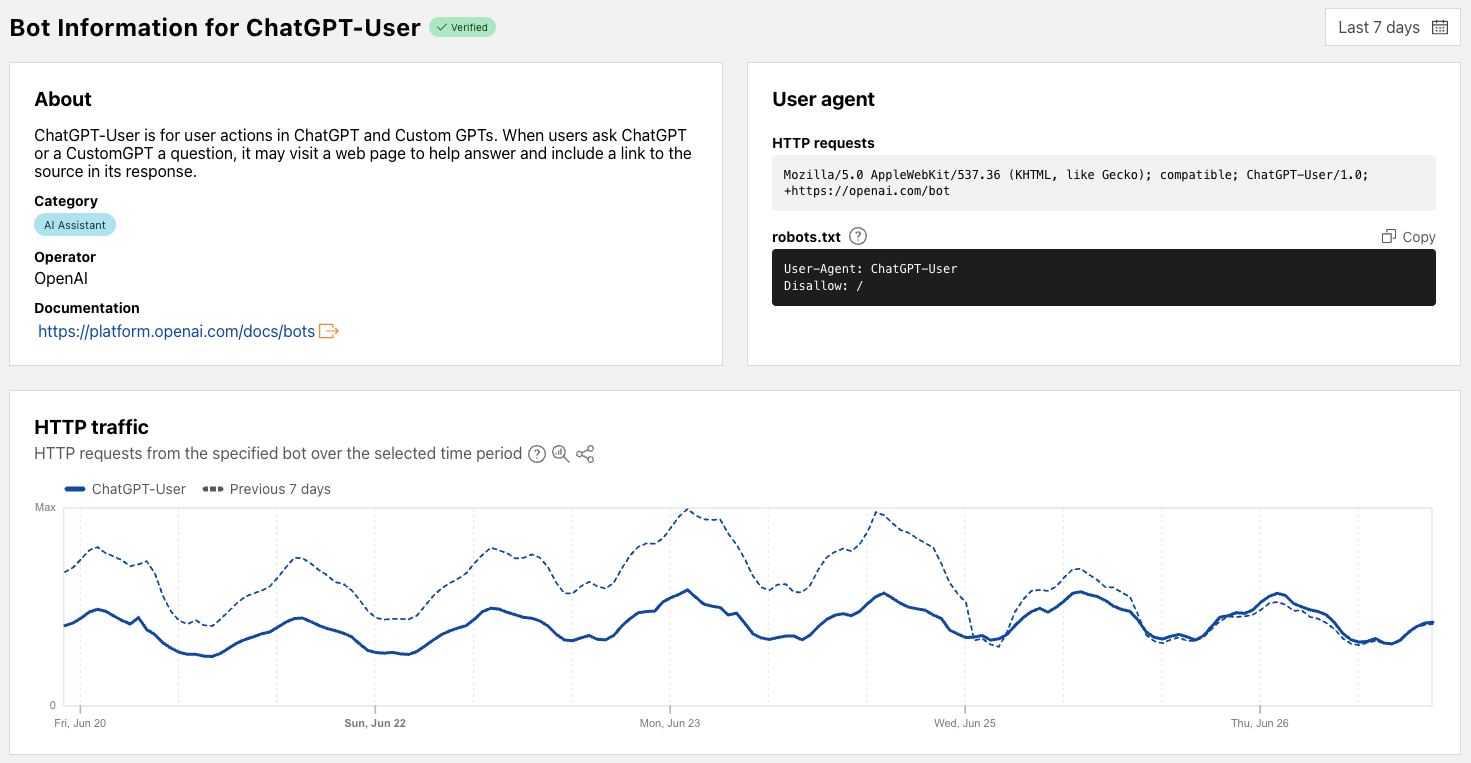
Post Syndicated from Zaid Zaid original https://blog.cloudflare.com/the-white-house-ai-action-plan-a-new-chapter-in-u-s-ai-policy/
On July 23, 2025, the White House unveiled its AI Action Plan (Plan), a significant policy document outlining the current administration’s priorities and deliverables in Artificial Intelligence. This plan emerged after the White House received over 10,000 public comments in response to a February 2025 Request for Information (RFI). Cloudflare’s comments urged the White House to foster conditions for U.S. leadership in AI and support open-source AI, among other recommendations.
There is a lot packed into the three pillar, 28-page Plan.
-
Pillar I: Accelerate AI Innovation. Focuses on removing regulations, enabling AI adoption and developing, and ensuring the availability of open-source and open-weight AI models.
-
Pillar II: Build American AI Infrastructure. Prioritizes the construction of high-security data centers, bolstering critical infrastructure cybersecurity, and promoting Secure-by-Design AI technologies.
-
Pillar III: Lead in International AI Diplomacy and Security. Centers on providing America’s allies and partners with access to AI, as well as strengthening AI compute export control enforcement.
Each of these pillars outlines policy recommendations for various federal agencies to advance the plan’s overarching goals. There’s much that the Plan gets right. Below we cover a few parts of the Plan that we think are particularly important.
The Plan takes the position that the U.S. is in a global race to achieve AI dominance, and that it is a national priority for U.S. technology companies to be the gold standard for AI globally. Through the Plan, President Trump commits his Administration to support American workers, technology, and energy to achieve that objective.
We share the view that governments have a helpful role to play in shaping rules and regulations that will enable private-sector innovation to flourish. For Cloudflare’s network to continue to operate globally, we need the U.S. government to shape and influence the right regulatory conditions. They should balance national and economic security concerns, promote consensus industry-led international standards, and support interoperable regulatory regimes.
Far too often in recent years, we’ve observed policy developments that have unnecessarily increased restrictions on U.S. technology providers and have made it challenging to operate. Protectionist mandates, including data sovereignty requirements, customer data retention policies, various supervisory and government access requirements, do little to improve security or innovation and have unintended consequences. Protectionism increases costs for businesses, limits access to world-class technologies, and increases cybersecurity risk.
Implementing policies that guarantee access to global, distributed edge-compute networks and the freedom to choose the best technology for users’ needs will help ensure the right conditions to enable AI to flourish.
The Plan endorses open-source and open-weight AI models to spur innovation and to benefit commercial and government adoption. The plan recommends ensuring access to computing resources to increase capability in the start up and academic worlds.
Cloudflare shares the view that open-source AI models play a crucial role in driving innovation. As recognized in the Plan, these models offer companies flexibility, freeing them from dependence on closed providers and enabling the use of AI with sensitive data where exporting to closed models might not be possible. That’s why Cloudflare includes access to more than fifty open-source models as part of our Workers AI model catalog.
However, access to open-source models alone is not enough to harness AI’s potential. A complete ecosystem is needed to build and deploy the AI applications and tools that will usher in the new age imagined by the Plan. Cloudflare’s global network, with our GPU-powered inference, can play an essential role. Having a distributed network like ours which allows AI inference at the edge is critical for fast, efficient AI development and for building the next generation of AI applications.
Open ecosystems are deeply embedded in Cloudflare’s DNA. Our developer platform democratizes access, providing powerful tools for anyone to build and deploy applications. We offer global network infrastructure that removes complexities and reduces barriers. This lets AI developers innovate freely, using many different AI models, without relying on gatekeepers. Our commitment to making these tools easy to use mirrors the Plan’s call to foster innovation and support U.S. AI leadership by enabling developers to use open-source AI models to build, deploy, and scale new AI applications globally.
The Plan stresses the importance of cybersecurity for AI in several ways. There are two we want to highlight.
First, it endorses the use of AI technologies for the cybersecurity of critical infrastructure. The use of AI-assisted cyber-defense tools are force multipliers for network defenders, and will be absolutely necessary for all organizations — but particularly critical infrastructure — to protect against cyber threats.
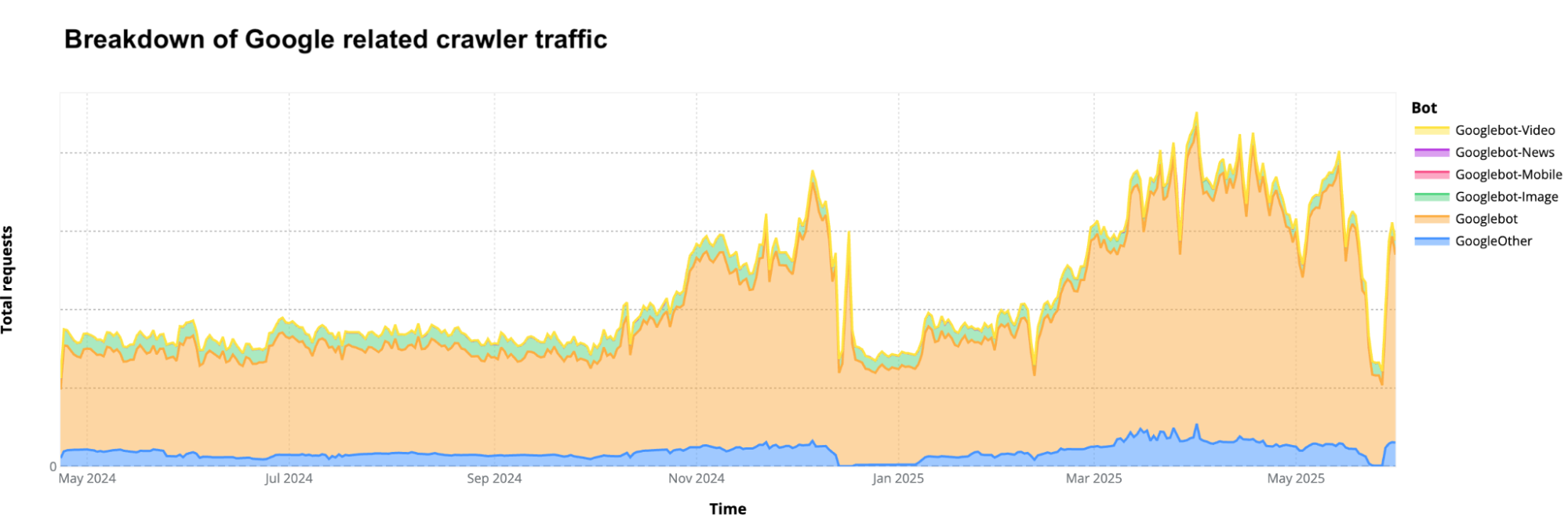
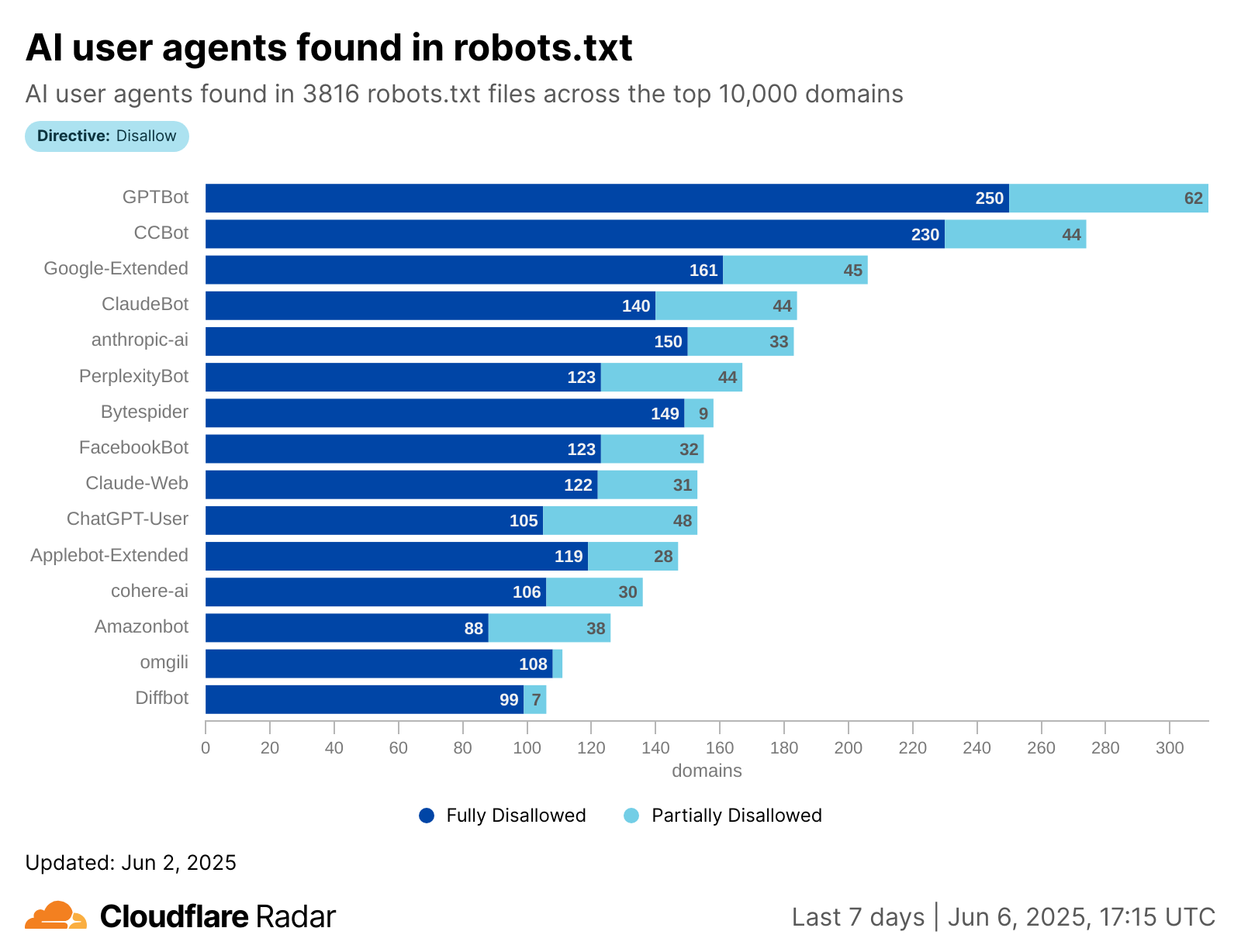
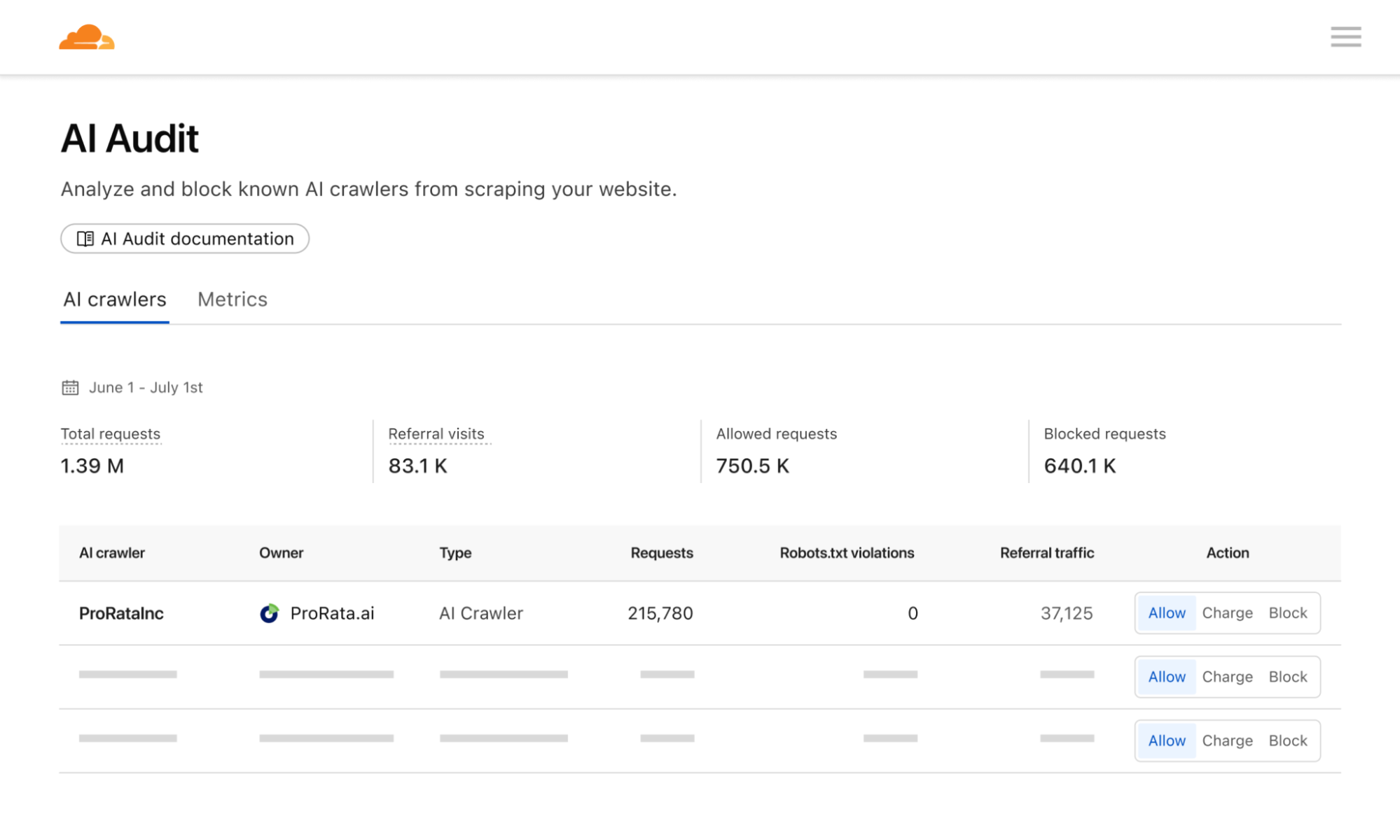
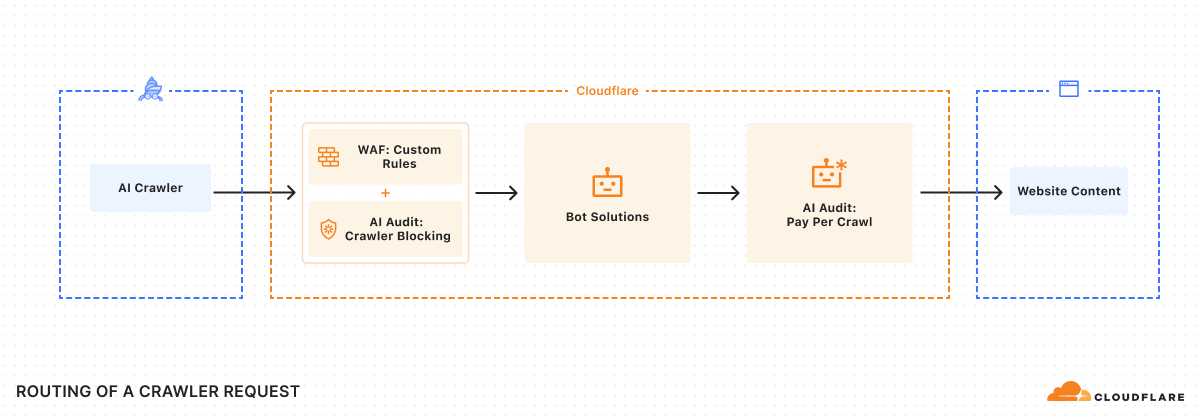
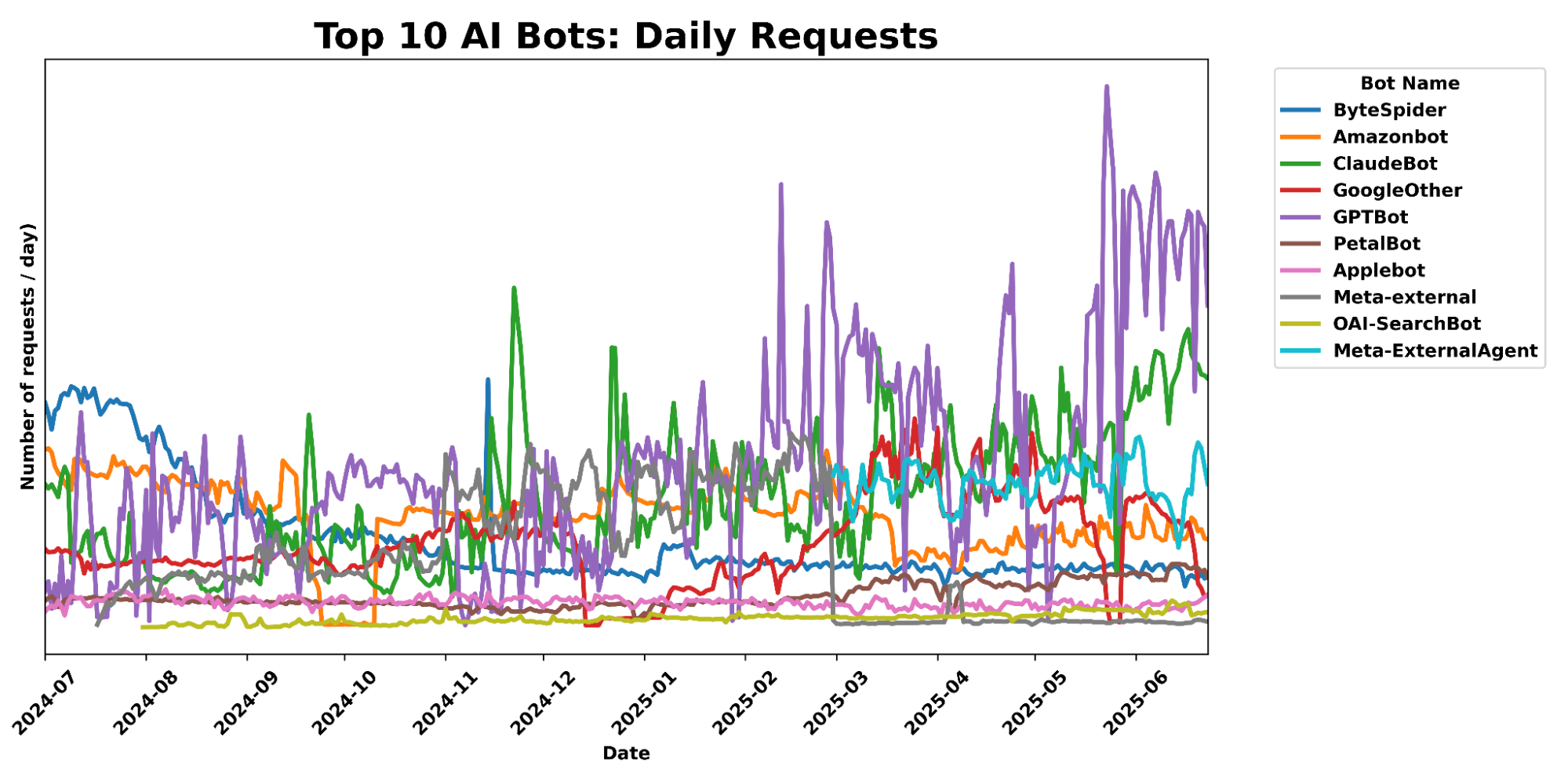
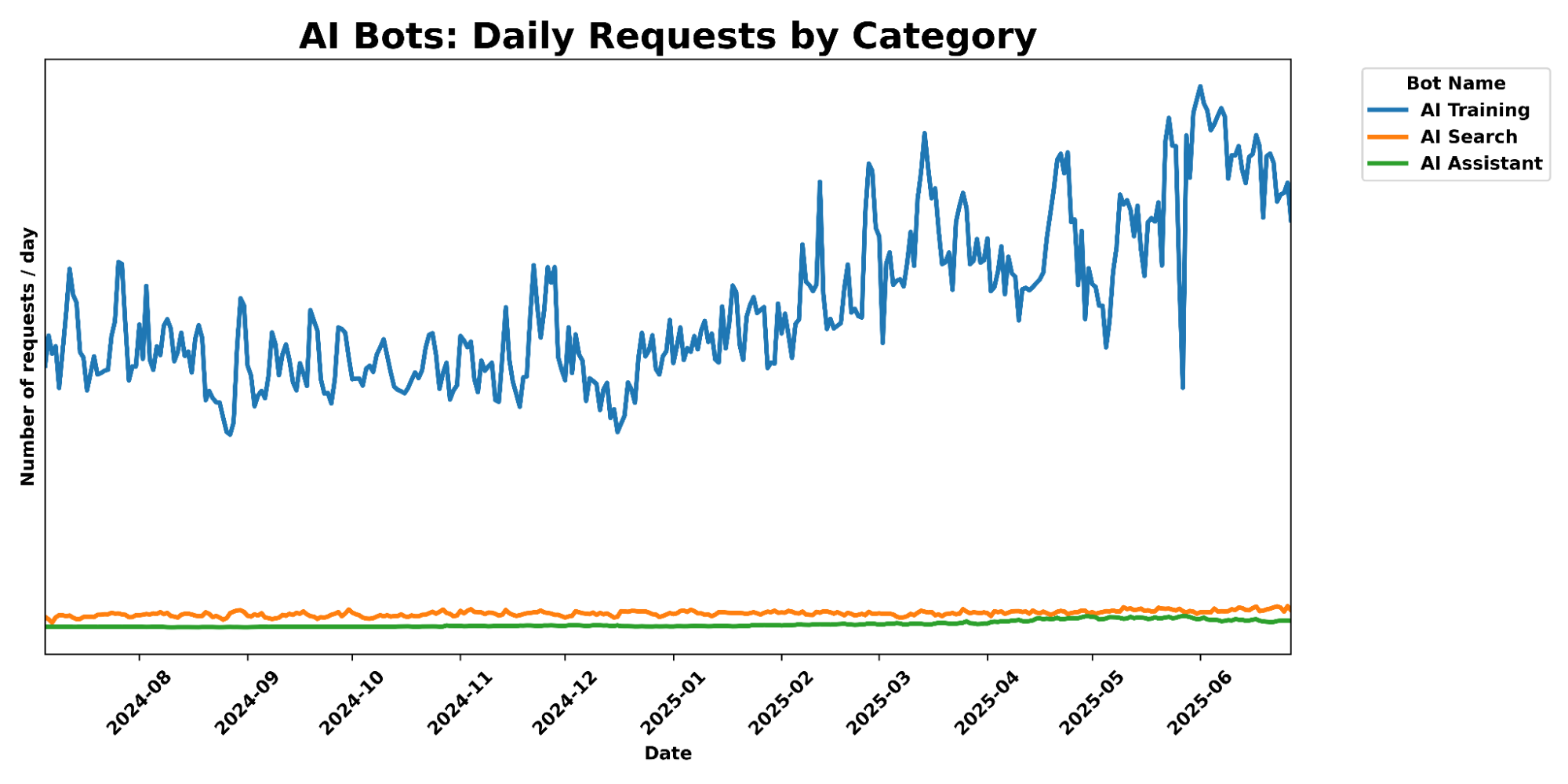
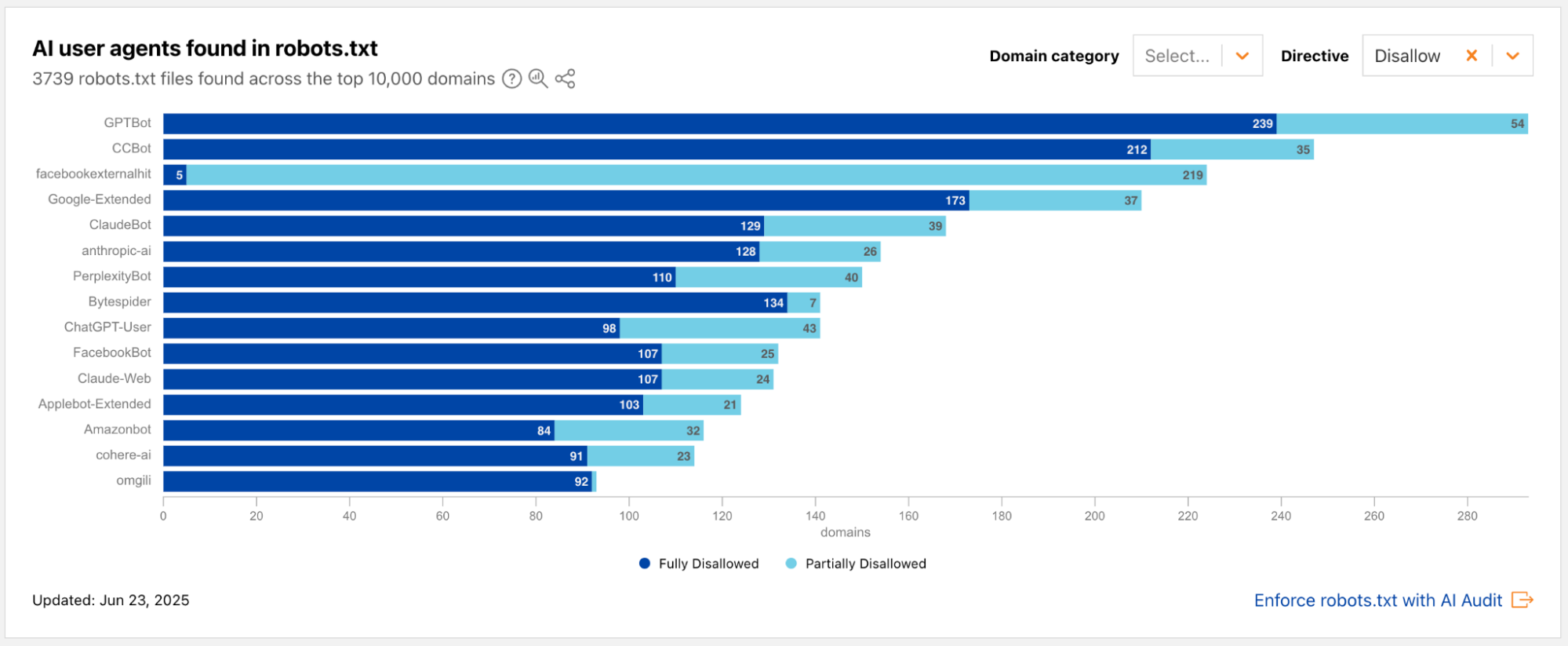
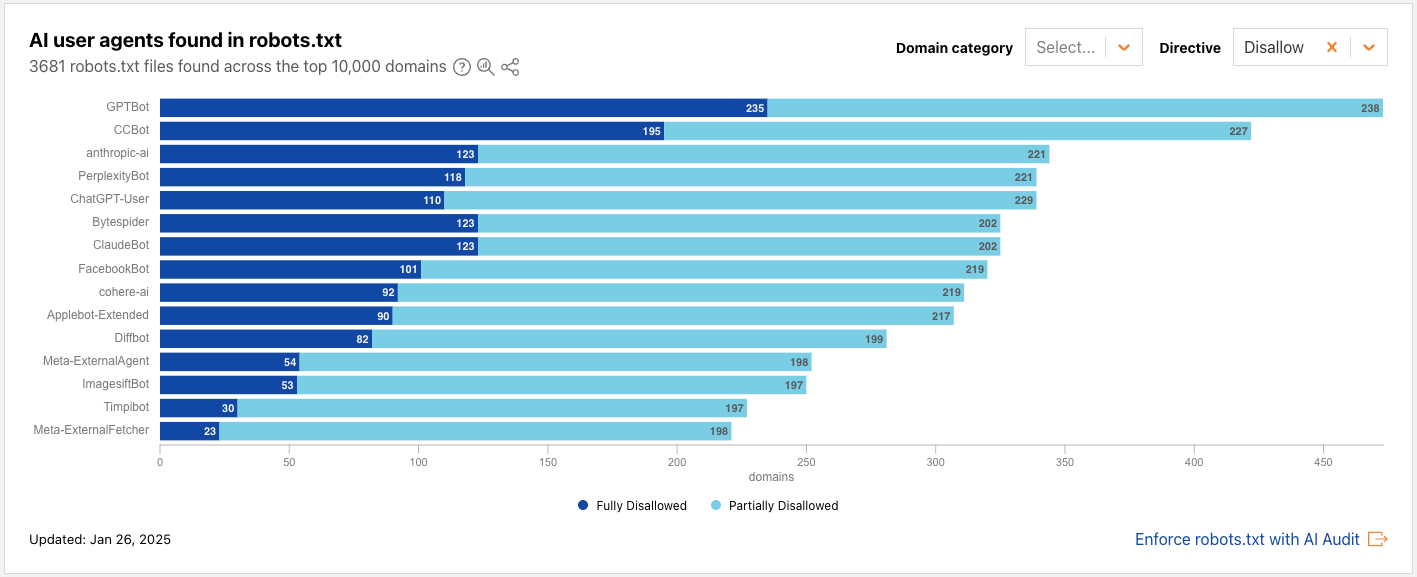
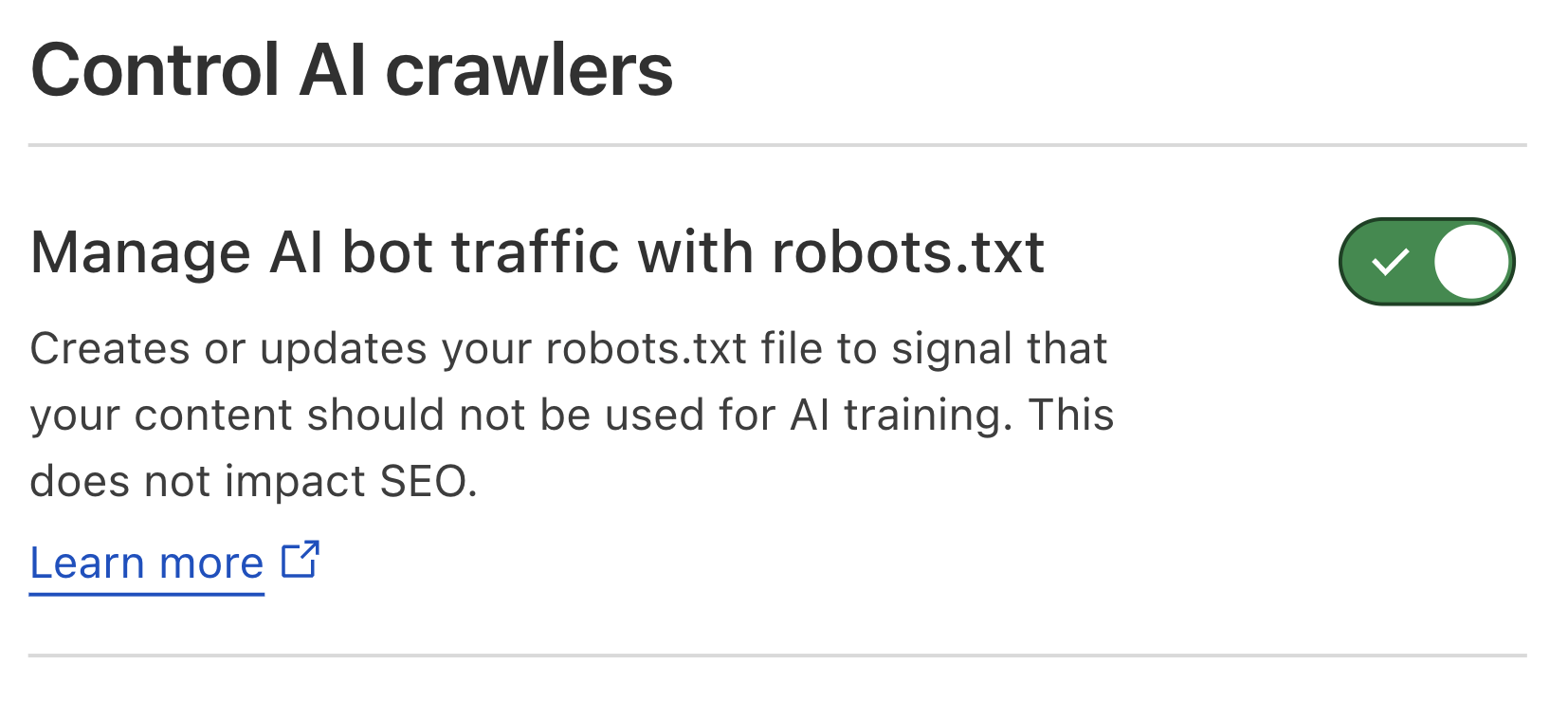
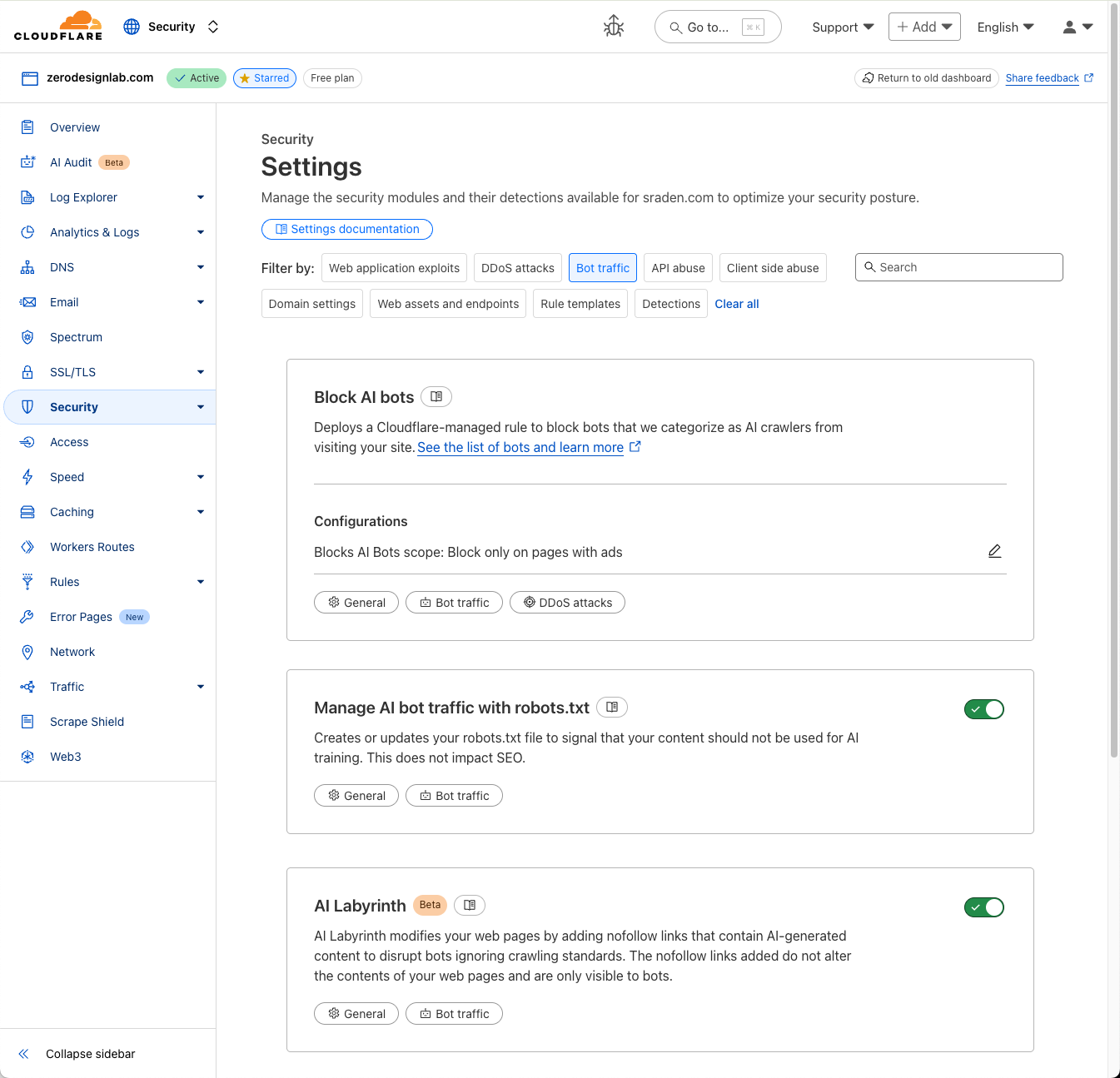
Cloudflare’s network uses predictive AI and machine learning to block 247 billion cyberattacks daily. Under the theory of Defensive AI, Cloudflare uses information to constantly improve the effectiveness of our security solutions. With AI Labyrinth, we’ve even created a new tool that uses AI to trap AI. It is a new, next generation honeypot and cybersecurity defensive tool that leverages AI to confuse crawlers and bots that ignore “no crawl” directives. Instead of blocking these bots, AI Labyrinth directs bots into an endless maze of convincing, AI-generated pages.
Second, to address potential vulnerabilities in AI technologies, the Plan tasks the U.S. government with ensuring that they are secure-by-design.
To secure AI, Cloudflare has been active in shaping the cybersecurity and risk management of AI technologies. We have supported and provided feedback to the U.S. National Institute of Standards and Technology’s efforts to develop a Cybersecurity Profile for Artificial Intelligence. This is critically important and builds on our Secure-by-Design commitment.
We look forward to working with the Administration on the proposed AI information sharing and analysis center and the proposed vulnerability information exchange.
The Plan envisions the federal government playing a key role in accelerating AI adoption. Cloudflare can help. As the Plan notes, integrating AI can significantly enhance public service, making government more efficient and effective. Most, if not all, federal agencies now have Chief AI Officers, indicating a clear commitment to this technological shift. The government can further its efforts by fostering information sharing between government agencies, promoting best practices, and training its workforce to maximize AI’s efficiency gains.
Cloudflare can be a key partner in this journey. Our platform provides the secure, reliable, and scalable infrastructure necessary for federal agencies to deploy AI applications with full-stack AI building blocks. Cloudflare is FedRAMP Moderate authorized, and we are committed to FedRAMP High. By leveraging Cloudflare’s global network, federal agencies can ensure their AI initiatives are resilient and accessible, driving greater public benefit.
To lead on AI internationally, the Plan outlines a dual strategy, presenting two approaches in tension with each other: aggressive AI export to allies and partners, and stringent restrictions on exporting AI compute and semiconductors. On one hand, the Plan emphasizes that providing the full U.S. AI technology stack is crucial to prevent allies from turning to rivals. This aims to solidify a global AI alliance and ensure the enduring diffusion of American technology.
Conversely, the plan calls for strengthening export control enforcement and plugging loopholes to prevent export of sensitive technologies. The administration seeks to use export controls — restrictions on what goods a company can export — to deny foreign adversaries access to certain resources for both geostrategic competition and national security concerns. The challenge arises because overly stringent export controls, while aiming to deny access to adversaries, may inadvertently make it harder to export AI even to allies.
This dual approach highlights a critical tightrope walk. Cloudflare, along with many other industry players, will be watching closely to see how the administration balances these competing goals. Providing individuals across the world with access to resources that enable them to innovate and build applications close to their end users aligns with our mission to help build a better, more connected Internet. Having a globally distributed network like ours also enables U.S. AI companies to deploy their services globally. Although we appreciate the need for restricting access to sensitive compute resources, overly broad or imprecise controls could inadvertently stifle innovation and impede the open exchange of ideas crucial for AI development. The implementation of export controls must be meticulously balanced to target adversaries effectively without unwittingly hindering the very innovation and secure global digital ecosystem it seeks to protect.
A reassuring aspect of the Plan is its clear recognition of the private sector’s indispensable role. The document repeatedly emphasizes the need for collaboration with industry and consultation with leading technology companies across various recommended policy actions. For instance, it specifically calls for establishing programs within the Department of Commerce to gather proposals from industry consortia for AI export packages. Furthermore, for strengthening AI compute export control enforcement, it advises exploring new measures “in collaboration with industry.” This commitment to partnership is essential to navigate the complexities of AI development and deployment. This collaboration with industry will ensure that policies are technically feasible, globally effective, and avoid unforeseen negative impacts on the digital economy and cybersecurity.
The Plan represents a critical moment for U.S. AI leadership, and Cloudflare stands ready to partner in shaping the future of this critical technology. We applaud the Plan’s focus on accelerating AI development, building robust infrastructure, and leading global diplomacy. The Internet’s global nature means that achieving these goals requires a delicate balance, particularly as the business model for the AI-powered web rapidly evolves. Cloudflare champions an approach that fosters innovation while upholding an open, secure, and interoperable Internet. By prioritizing consensus-driven standards and ensuring that regulations do not inadvertently create barriers to a globally distributed AI infrastructure, we help ensure continued U.S. technological leadership and a sustainable, beneficial AI ecosystem.