Post Syndicated from Kris Severijns original https://aws.amazon.com/blogs/architecture/how-commbank-made-their-commsec-trading-platform-highly-available-and-operationally-resilient/
CommSec, Australia’s leading online broker and a subsidiary of the Commonwealth Bank of Australia (CommBank), helps millions of customers grow their wealth by making it easy, accessible and affordable to invest in both Australian and international markets.
CommSec plays an essential role in customers’ financial journeys, providing essential services such as market research, portfolio management, and trade execution. With customers expecting round-the-clock availability, the platform must maintain exceptional reliability. Additionally, as a regulated entity under the Australian Securities & Investments Commission (ASIC), CommSec must preserve high platform resilience and maintain data sovereignty within Australia to protect the integrity of Australia’s financial markets. In this post, we explore how CommSec used AWS services to build a resilient, high-performing trading platform while meeting strict regulatory requirements and delivering an exceptional customer experience.
Challenges of operating a multicloud environment
In a pioneering move within CommBank, CommSec became the first critical workload to transition from on-premises data centers to the public cloud. In 2015, CommBank migrated CommSec’s web and mobile tier, and then migrated their application tier in 2019. As a leader and early cloud adopter, CommSec began with an active-active multicloud architecture to build confidence in the resilience of the public cloud, using the AWS Asia Pacific (Sydney) Region as one of its fault domains. Operating a multicloud environment presented several challenges. The complexity of maintaining two deployment pipelines, an operating model spanning two public cloud platforms, and a custom failover process requiring external witness capabilities created operational overhead. This reduced development velocity and engineering proficiency while maintaining a dependency on on-premises data centers. At the same time, the limited opportunity to use cloud-based services to keep parity and compatibility with both public clouds stifled innovation.
Solution overview
As AWS became CommBank’s preferred cloud provider, the CommSec team rearchitected its app, web, and mobile tiers in early 2025 to run entirely on AWS. With the move to AWS as their sole cloud provider, they took advantage of a new fault isolation boundary to establish a resilience posture similar to what they had with their multicloud solution, but with a simplified architecture.
In the previous design, if an issue or outage occurred in a cloud provider or physical data center, traffic was routed and served through the alternate cloud. With the consolidation of the platform on AWS, the CommSec team decided on an Availability Zone as the new fault isolation boundary. Using Amazon Application Recovery Controller (ARC) zonal shift, they can perform a failover to minimize impact to the customer in case of infrastructure or application gray failures while satisfying the requirement to have a physical and logical isolation using multiple Availability Zones in a Region. ARC zonal shift was enabled on their load balancers, so the CommSec team could divert traffic away from an impaired Availability Zone without relying on control plane actions. The same ARC zonal shift capability is being used to help the CommSec team manage application gray failures by reducing customer impact when they occur.
Consolidating on AWS and using ARC zonal shift to manage failures helped the CommSec team realize several important benefits:
- Out-of-the-box failover capabilities with ARC zonal shift enabled the team to implement comprehensive and automated procedures to move traffic away from an Availability Zone.
- Comprehensive playbooks that undergo regular validation exercises to verify the effectiveness of the failover procedures and operational readiness.
- Standardized deployment pipelines and simplified configuration made operating system patching and code deployments two times faster.
- They saw a 25% base capacity reduction by running the CommSec platform across three AWS Availability Zones compared to two stacks on each public cloud (four stacks) in the past, bringing down operational costs.
The following diagram illustrates the solution architecture.
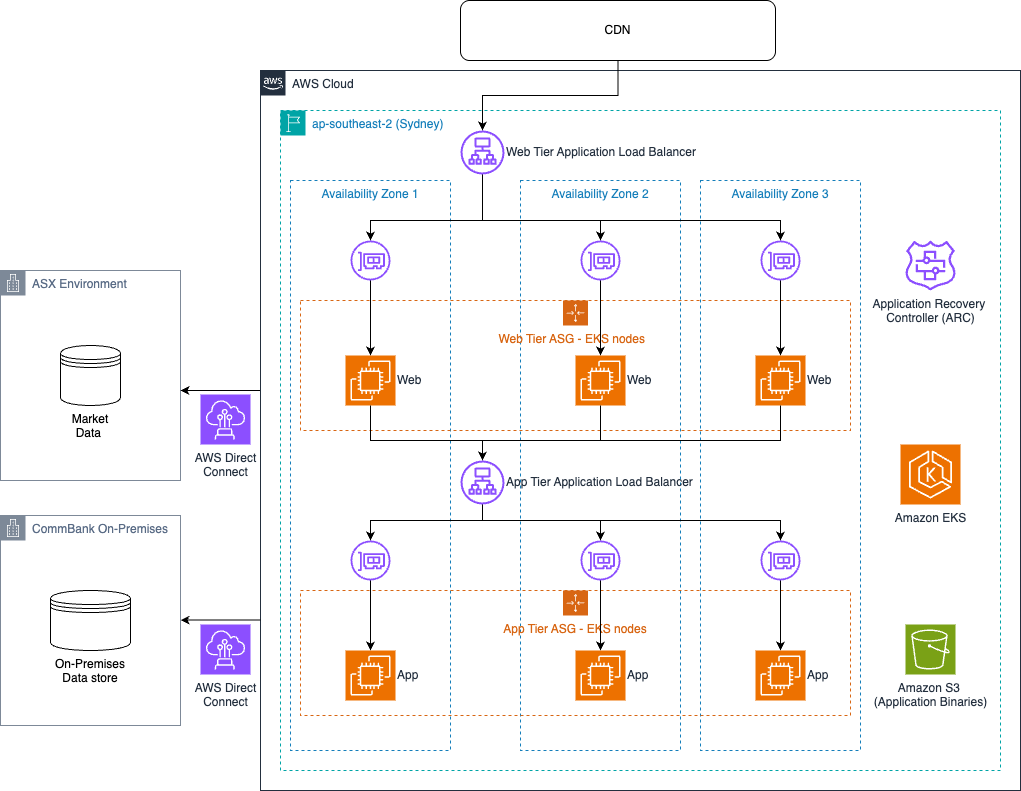
The CommSec team introduced several resilience improvements:
- With scale-in and scale-out happening multiple times a day, the process of scaling needed to be as resilient as possible. The CommSec team made sure the entire scale-out bootstrap process had no dependencies on external resources by storing and retrieving application binaries from Amazon Simple Storage Service (Amazon S3) buckets within the same AWS account.
- Because traffic patterns are incredibly spiky, especially during market open (CommSec traffic often increases threefold between 9:59-10:02 AM on market open), the team implemented Load balancer Capacity Unit (LCU) reservations on the web tier load balancers. This provided sufficient Application Load Balancer (ALB) capacity at the start of the trading day without having to rely on reactive scaling for this predictable spike.
- They implemented ALB health checks for hard failures to automatically remove instances from target groups. Traffic will shift away from the targets when health checks fail, with alerts signaling the operational team to investigate and remediate.
- New AWS Direct Connect connections from AWS to the Australian Liquidity Centre (which hosts the Australian Stock Exchange (ASX)’s primary trading, clearing, and settlement systems) were established to improve the reliability of the connectivity to financial markets, including ASX and CBOE exchanges.
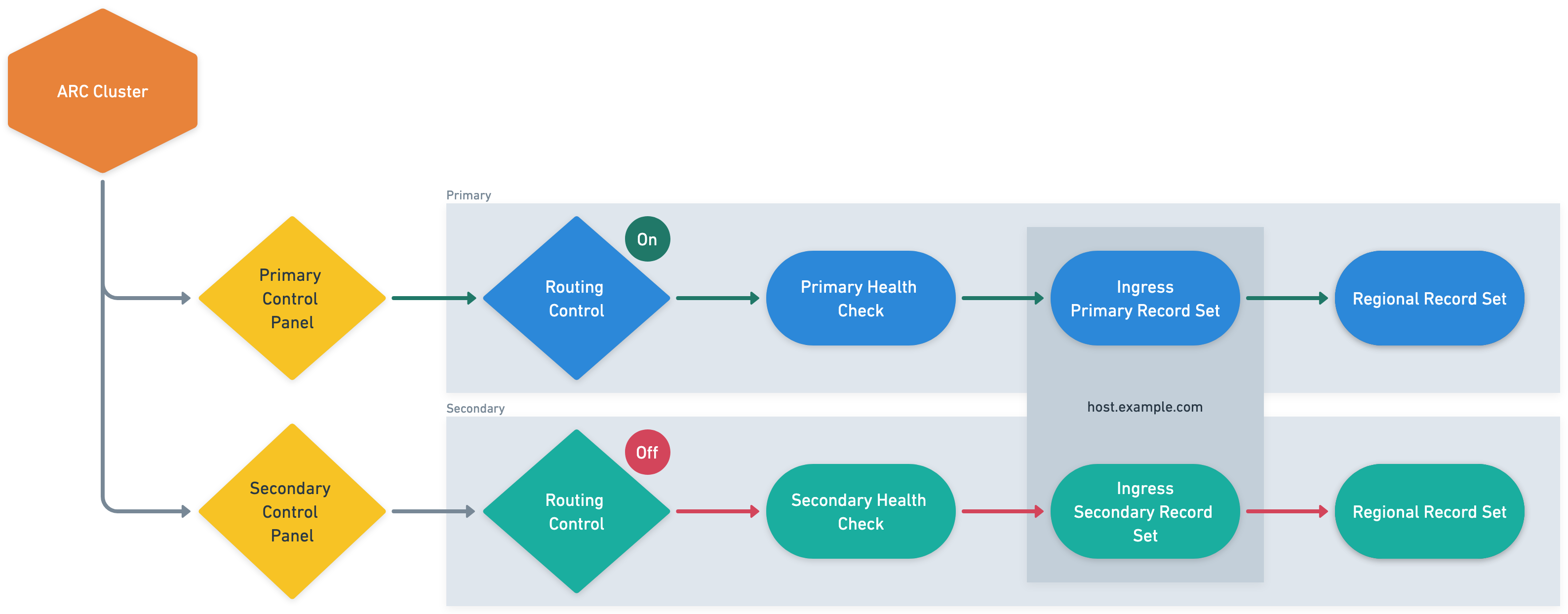
ARC zonal shift to help mitigate impairments
In 2023, AWS launched zonal shift, part of Amazon Application Recovery Controller. With zonal shift, you can shift application traffic away from an Availability Zone in a highly available manner for supported resources. This action helps quickly recover an application when an Availability Zone experiences an impairment, reducing the duration and severity of impact to the application due to events such as power outages and hardware or software failures. Zonal shift supports Application and Network Load Balancers, Amazon EC2 Auto Scaling Groups, and Amazon Elastic Kubernetes Service (Amazon EKS).
The CommSec team enabled ARC zonal shift on their ALBs for their web and application tier with cross-zone load balancing enabled. When started, zonal shift takes two actions. First, it removes the IP address of the load balancer node in the specified Availability Zone from DNS, so new queries won’t resolve to that endpoint. This stops future client requests from being sent to that node. Second, it instructs the load balancer nodes in the other Availability Zones not to route requests to targets in the impaired Availability Zone. Cross-zone load balancing is still used in the remaining Availability Zones during the zonal shift, as shown in the following figure.
After the issue is resolved and the application is available again in all Availability Zones, the CommSec team cancels the zonal shift, and traffic is redistributed across all three Availability Zones.
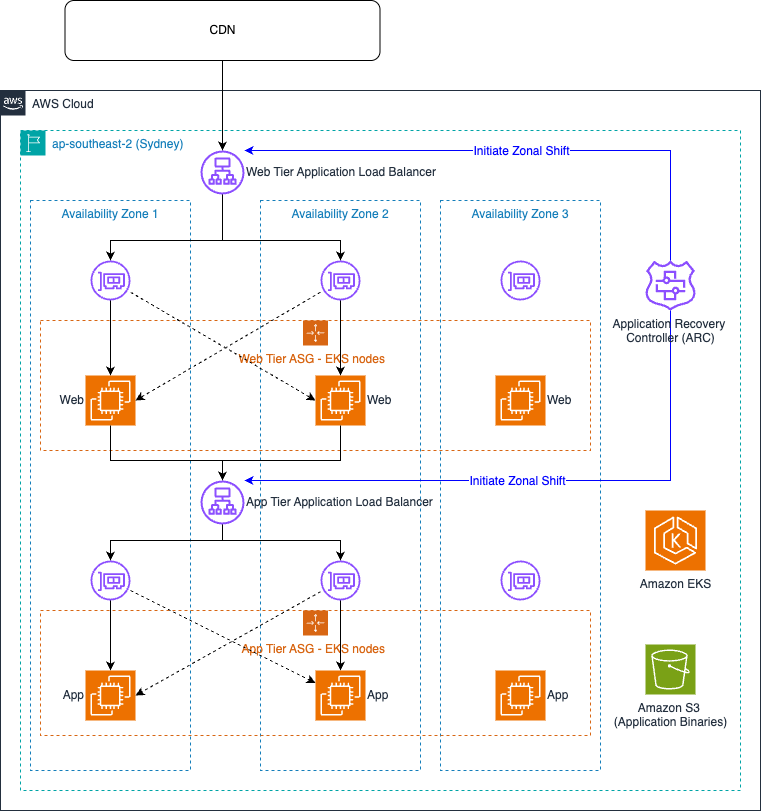
Benefits of ARC zonal shift
ARC zonal shift helps organizations maintain higher availability SLAs, reduce operational costs associated with multi-step manual failover procedures, and minimize revenue loss from service disruptions. The straightforward nature of ARC zonal shift helps teams conduct frequent, on-demand, low-risk testing of their Availability Zone evacuation procedures. The ability to perform regular validation makes sure failover processes remain reliable and builds organizational confidence in disaster recovery capabilities.
“ARC zonal shift is the most efficient way for CommSec to use AWS services whilst meeting our resilience requirements. It provided an out-of-the-box solution that was easier than trying to implement an Availability Zone recovery solution ourselves. Hopefully it’s something we will never need, but our regular resilience testing ensures it’s there and will work if we ever need it.”
– Henry Zhao, CommBank Staff Software Engineer.
Conclusion
By using AWS services and implementing a robust Multi-AZ architecture, the CommSec trading platform continues to meet the demanding needs of Australia’s leading online broker. The combination of ARC zonal shift capabilities, optimized load balancer configurations, and comprehensive runbooks and operational procedures has enabled CommSec to maintain exceptional reliability while serving over millions of customers. CommSec’s journey showcases how careful architectural decisions and AWS managed services can help organizations achieve both operational excellence and superior customer experience for mission-critical financial applications.
To learn more, refer to AWS Fault Isolation Boundaries and Amazon Application Recovery Controller.