Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/opening-the-aws-european-sovereign-cloud/
Deutsch | English | Español | Français | Italiano
As a European citizen, I understand first-hand the importance of digital sovereignty, especially for our public sector organisations and highly regulated industries. Today, I’m delighted to share that the AWS European Sovereign Cloud is now generally available to all customers. We first announced our plans to build this new independent cloud infrastructure in 2023, and today it’s ready to meet the most stringent sovereignty requirements of European customers with a comprehensive set of AWS services.

Berlin, Brandenburg Gate at sunset
Meeting European sovereignty requirements
Organizations across Europe face increasingly complex regulatory requirements around data residency, operational control, and governance independence. Too often today, European organisations with the highest sovereignty requirements are stuck in legacy on-premises environments or offerings with reduced services and functionality. In response to this critical need, the AWS European Sovereign Cloud is the only fully featured and independently operated sovereign cloud backed by strong technical controls, sovereign assurances, and legal protections. Public sector entities and businesses in highly regulated industries need cloud infrastructure that provides enhanced sovereignty controls that maintain the innovation, security, and reliability they expect from modern cloud services. These organisations require assurance that their data and operations remain under European jurisdiction, with clear governance structures and operational autonomy within the European Union (EU).
A new independent cloud infrastructure for Europe
The AWS European Sovereign Cloud represents a physically and logically separate cloud infrastructure, with all components located entirely within the EU. The first AWS Region in the AWS European Sovereign Cloud is located in the state of Brandenburg, Germany, and is generally available today. This Region operates independently from existing AWS Regions. The infrastructure features multiple Availability Zones with redundant power and networking, designed to operate continuously even if connectivity with the rest of the world is interrupted.
We plan to extend the AWS European Sovereign Cloud footprint from Germany across the EU to support stringent isolation, in-country data residency, and low latency requirements. This will start with new sovereign Local Zones located in Belgium, the Netherlands, and Portugal. In addition, you will be able to extend the AWS European Sovereign Cloud infrastructure with AWS Dedicated Local Zones, AWS AI Factories, or AWS Outposts in locations you select, including your own on-premises data centres.
The AWS European Sovereign Cloud and its Local Zones provide enhanced sovereign controls through its unique operational model. The AWS European Sovereign Cloud will be operated exclusively by EU residents located in the EU. This covers activities such as day-to-day operations, technical support, and customer service. We’re gradually transitioning the AWS European Sovereign Cloud to be operated exclusively by EU citizens located in the EU. During this transition period, we will continue to work with a blended team of EU residents and EU citizens located in the EU.
The infrastructure is managed through dedicated European legal entities established under German law. In October 2025, AWS appointed Stéphane Israël, an EU citizen residing in the EU, as managing director. Stéphane will be responsible for the management and operations of the AWS European Sovereign Cloud, including infrastructure, technology, and services, as well as leading AWS broader digital sovereignty efforts. In January 2026, AWS also appointed Stefan Hoechbauer (Vice President, Germany and Central Europe, AWS) as a managing director of the AWS European Sovereign Cloud. He will work alongside Stéphane Israel to lead the AWS European Sovereign Cloud.
An advisory board comprised exclusively of EU citizens, and including two independent third-party representatives, provides additional oversight and expertise on sovereignty matters.
Enhanced data residency and control
The AWS European Sovereign Cloud provides comprehensive data residency assurances so you can meet the most stringent data residency requirements. As with our existing AWS Regions around the world, all your content remains within the Region you select unless you choose otherwise. Beyond content, customer-created metadata including roles, permissions, resource labels, and configurations also stays within the EU. The infrastructure features its own dedicated AWS Identity and Access Management (IAM) and billing system, all operating independently within European borders.
Technical controls built into the infrastructure prevent access to the AWS European Sovereign Cloud from outside the EU. The infrastructure includes a dedicated European trust service provider for certificate authority operations and uses dedicated Amazon Route 53 name servers. These servers will only use European Top-Level Domains (TLDs) for their own names. The AWS European Sovereign Cloud has no critical dependencies on non-EU personnel or infrastructure.
Security and compliance framework
The AWS European Sovereign Cloud maintains the same core security capabilities you expect from AWS, including encryption, key management, access governance, and the AWS Nitro System for compute isolation. This means your EC2 instances benefit from cryptographically verified platform integrity and hardware-enforced boundaries that prevent unauthorized access to your data without compromising on performance, giving you both the sovereignty controls and the computational power your workloads require. The infrastructure undergoes independent third-party audits, with compliance programs including ISO/IEC 27001:2013, SOC 1/2/3 reports, and Federal Office for Information Security (BSI) C5 attestation.
The AWS European Sovereign Cloud: Sovereign Reference Framework defines the specific sovereignty controls across governance independence, operational control, data residency, and technical isolation. This framework is available in AWS Artifact and provides end-to-end visibility through SOC 2 attestation.
Comprehensive service availability
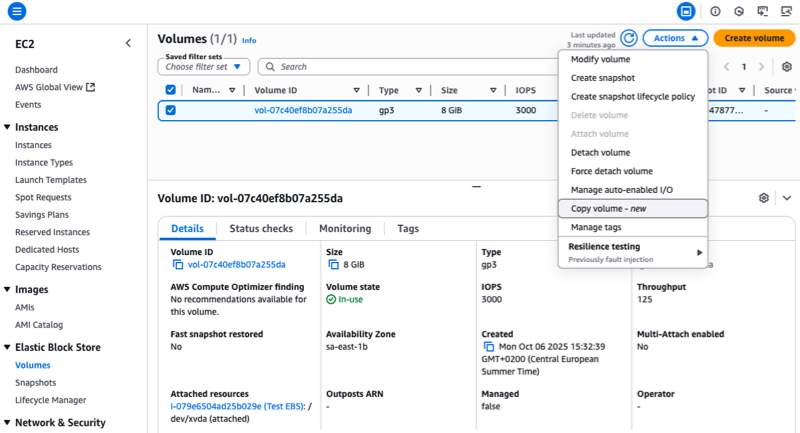
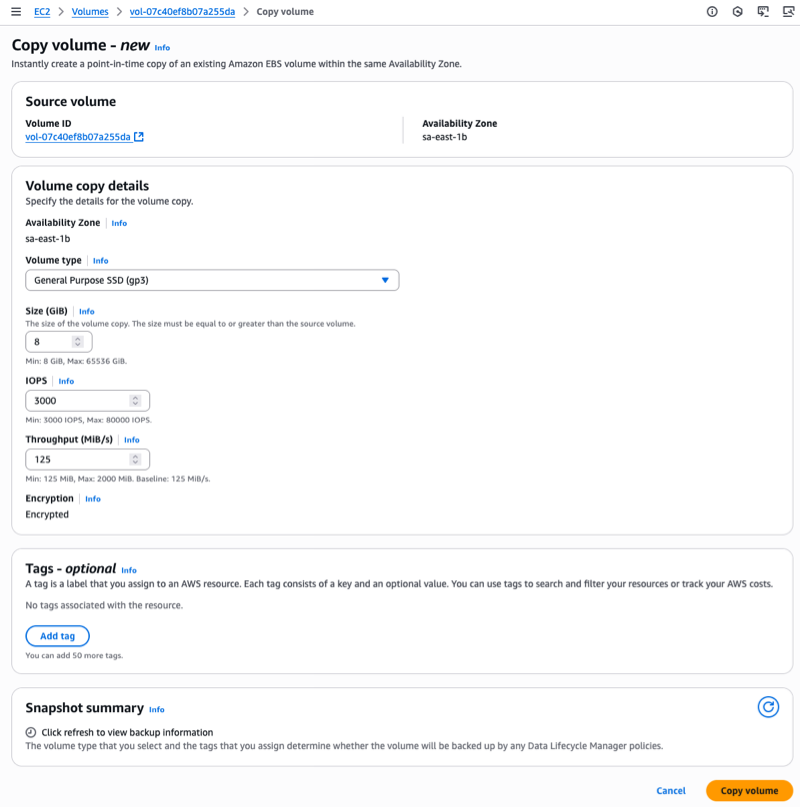
You can access a broad range of AWS services in the AWS European Sovereign Cloud from launch, including Amazon SageMaker and Amazon Bedrock for artificial intelligence and machine learning (AI/ML) workloads. For compute, you can use Amazon Elastic Compute Cloud (Amazon EC2) and AWS Lambda. Container orchestration is available through Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Elastic Container Service (Amazon ECS). Database services include Amazon Aurora, Amazon DynamoDB, and Amazon Relational Database Service (Amazon RDS). Storage options include Amazon Simple Storage Service (Amazon S3) and Amazon Elastic Block Store (Amazon EBS), with networking through Amazon Virtual Private Cloud (Amazon VPC) and security services including AWS Key Management Service (AWS KMS) and AWS Private Certificate Authority. For an up-to-date list of services, refer to the AWS Capabilities matrix recently published on the AWS Builder Center.
The AWS European Sovereign Cloud is supported by AWS Partners who are committed to helping you meet your sovereignty requirements. Partners including Adobe, Cisco, Cloudera, Dedalus, Esri, Genesys, GitLab, Mendix, Pega, SAP, SnowFlake, Trend Micro, and Wiz are making their solutions available in the AWS European Sovereign Cloud, providing you with the tools and services you need across security, data analytics, application development, and industry-specific workloads. This broad partner support helps you build sovereign solutions that combine AWS services with trusted partner technologies.
Significant investment in European infrastructure
The AWS European Sovereign Cloud is backed by a €7.8 billion investment in infrastructure, jobs creation, and skills development. This investment is expected to contribute €17.2 billion to the European economy through 2040 and support roughly 2,800 full-time equivalent jobs annually in local businesses.
Some technical details
The AWS European Sovereign Cloud is available to all customers, regardless of where they are located. You can access the infrastructure using the partition name aws-eusc and the Region name eusc-de-east-1. A partition is a group of AWS Regions. Each AWS account is scoped to one partition.
The infrastructure supports all standard AWS access methods including the AWS Management Console, AWS SDKs, and the AWS Command Line Interface (AWS CLI), making it straightforward to integrate into your existing workflows and automation. After having created a new root account for the AWS European Sovereign Cloud partition, you start by creating new IAM identities and roles specific to this infrastructure, giving you complete control over access management within the European sovereign environment.
Getting started
The AWS European Sovereign Cloud provides European organisations with enhanced sovereignty controls whilst maintaining access to AWS innovation and capabilities. You can contract for services through Amazon Web Services EMEA SARL, with pricing in EUR and billing in any of the eight currencies we support today. The infrastructure uses familiar AWS architecture, service portfolio, and APIs, making it straightforward to build and migrate applications.
The AWS European Sovereign Cloud addendum contains the additional contractual commitments for the AWS European Sovereign Cloud.
For me as a European, this launch represents the AWS commitment to meeting the specific needs of our continent and providing the cloud capabilities that drive innovation across industries. I invite you to find out more about the AWS European Sovereign Cloud and how it can help your organisation meet its sovereignty requirements. Read Overview of the AWS European Sovereign Cloud to learn more about the design goals and approach, sign up for a new account, and plan for the deployment of your first workload today.
German version
Start der AWS European Sovereign Cloud
Als Bürger Europas weiß ich aus eigener Erfahrung, wie wichtig digitale Souveränität ist, insbesondere für unsere öffentlichen Einrichtungen und stark regulierten Branchen. Ich freue mich, Ihnen heute mitteilen zu können, dass die AWS European Sovereign Cloud nun für alle Kunden allgemein verfügbar ist. Wir haben unsere Pläne zum Aufbau dieser neuen unabhängigen Cloud-Infrastruktur erstmals im Jahr 2023 vorgestellt. Heute ist diese Infrastruktur bereit, mit einem umfassenden Angebot an AWS-Services die strengsten Souveränitätsanforderungen europäischer Kunden zu erfüllen.
Berlin, Brandenburger Tor bei Sonnenuntergang
Erfüllung europäischer Souveränitätsanforderungen
Organisationen in ganz Europa sehen sich mit zunehmend komplexen regulatorischen Anforderungen in Bezug auf Datenresidenz, operative Kontrolle und Unabhängigkeit der Governance konfrontiert. Europäische Organisationen mit höchsten Souveränitätsanforderungen sind heutzutage allzu oft in veralteten lokalen Umgebungen oder Angeboten mit eingeschränkten Services und Funktionen gefangen. Die AWS European Sovereign Cloud ist die Antwort auf diesen dringenden Bedarf. Sie ist die einzige unabhängig betriebene souveräne Cloud mit vollem Funktionsumfang, die durch strenge technische Kontrollen, Souveränitätszusicherungen und rechtlichen Schutz abgesichert ist. Einrichtungen des öffentlichen Sektors und Unternehmen in stark regulierten Branchen benötigen eine Cloud-Infrastruktur, die erweiterte Souveränitätskontrollen bietet und gleichzeitig die von modernen Cloud-Services erwartete Innovation, Sicherheit und Zuverlässigkeit gewährleistet. Diese Organisationen benötigen die Zusicherung, dass ihre Daten und Aktivitäten unter europäischer Zuständigkeit bleiben, mit klaren Governance-Strukturen und operativer Autonomie innerhalb der Europäischen Union (EU).
Eine neue unabhängige Cloud-Infrastruktur für Europa
Die AWS European Sovereign Cloud ist eine physisch und logisch getrennte Cloud-Infrastruktur, deren Komponenten sich vollständig innerhalb der EU befinden. Die erste AWS-Region in der AWS European Sovereign Cloud befindet sich im deutschen Bundesland Brandenburg und ist ab heute allgemein verfügbar. Diese Region arbeitet unabhängig von bestehenden AWS-Regionen. Die Infrastruktur umfasst mehrere Availability Zones mit redundanter Stromversorgung und Netzwerkverbindung, die auch bei einer Unterbrechung der Verbindung zum Rest der Welt einen kontinuierlichen Betrieb gewährleisten.
Wir beabsichtigen, die Präsenz der AWS European Sovereign Cloud von Deutschland aus EU-weit auszuweiten, um strenge Anforderungen hinsichtlich Isolierung, Datenresidenz innerhalb einzelner Länder und geringer Latenz zu erfüllen. Dies beginnt mit neuen souveränen Local Zones in Belgien, den Niederlanden und Portugal. Darüber hinaus können Sie die Infrastruktur der AWS European Sovereign Cloud mit dedizierten AWS Local Zones, AWS AI Factories oder AWS Outposts an Standorten Ihrer Wahl, einschließlich Ihrer eigenen lokalen Rechenzentren, erweitern.
Dank ihres einzigartigen Betriebsmodells bieten die AWS European Sovereign Cloud und ihre Local Zones erweiterte Souveränitätskontrollen. Der Betrieb der AWS European Sovereign Cloud wird ausschließlich von EU-Bürgern mit Wohnsitz in der EU sichergestellt. Dies umfasst Aktivitäten wie den täglichen Betrieb, den technischen Support und den Kundenservice. Wir stellen die AWS European Sovereign Cloud schrittweise so um, dass als Betriebspersonal ausschließlich EU-Bürger mit Wohnsitz in der EU zum Einsatz kommen. Während dieser Übergangsphase werden wir weiterhin mit einem gemischten Team aus in der EU ansässigen Personen und in der EU lebenden EU-Bürgern arbeiten.
Die Infrastruktur wird durch spezielle europäische juristische Personen nach deutschem Recht verwaltet. Im Oktober 2025 berief AWS Stéphane Israël, einen in der EU ansässigen EU-Bürger, zum Geschäftsführer. Stéphane wird für das Management und den Betrieb der AWS European Sovereign Cloud verantwortlich zeichnen. Dies umfasst die Bereiche Infrastruktur, Technologie und Services sowie die Federführung bei den breit angelegten Initiativen von AWS auf dem Gebiet der digitalen Souveränität. Im Januar 2026 ernannte AWS zudem Stefan Hoechbauer (Vice President, Germany and Central Europe, AWS) zum Geschäftsführer der AWS European Sovereign Cloud. Er wird gemeinsam mit Stéphane Israel die Leitung der AWS European Sovereign Cloud innehaben.
Ein Beirat, dem ausschließlich EU-Bürger, einschließlich zwei unabhängigen externen Vertretern, angehören, fungiert als zusätzliche Kontrollinstanz und bringt Fachwissen in Fragen der Souveränität ein.
Verbesserte Datenresidenz und -kontrolle
Die AWS European Sovereign Cloud bietet umfassende Garantien hinsichtlich der Datenresidenz, sodass Sie selbst die strengsten Anforderungen in diesem Bereich erfüllen können. Wie auch bei unseren bestehenden AWS-Regionen weltweit verbleiben alle Ihre Inhalte in der von Ihnen ausgewählten Region, sofern Sie keine anderen Einstellungen vornehmen. Neben den Inhalten verbleiben auch die vom Kunden erstellten Metadaten, einschließlich Rollen, Berechtigungen, Ressourcenbezeichnungen und Konfigurationen, innerhalb der EU. Die Infrastruktur verfügt über ein eigenes AWS Identity and Access Management (IAM) und ein eigenes Abrechnungssystem – beides wird innerhalb der europäischen Grenzen unabhängig betrieben.
In die Infrastruktur integrierte technische Kontrollen verhindern den Zugriff auf die AWS European Sovereign Cloud von außerhalb der EU. Die Infrastruktur umfasst einen dedizierten europäischen Trust Service Provider für Zertifizierungsstellen und nutzt dedizierte Amazon-Route-53-Namenserver. Diese Server verwenden ausschließlich europäische Top-Level-Domains (TLDs) für ihre eigenen Namen. Die AWS European Sovereign Cloud unterliegt keinen kritischen Abhängigkeiten hinsichtlich Personal oder Infrastruktur außerhalb der EU.
Sicherheits- und Compliance-Framework
Die AWS European Sovereign Cloud bietet dieselben zentralen Sicherheitsfunktionen, die Sie von AWS erwarten. Dazu gehören Verschlüsselung, Schlüsselverwaltung, Zugriffskontrolle und das AWS Nitro System für die Isolierung von Rechenressourcen. Dies bedeutet, dass Ihre EC2-Instanzen von einer kryptografisch verifizierten Plattformintegrität und hardwaregestützten Grenzen profitieren, die unbefugten Zugriff auf Ihre Daten verhindern, ohne die Leistung zu beeinträchtigen. So erhalten Sie sowohl die Souveränitätskontrollen als auch die Rechenleistung, die Ihre Workloads erfordern. Die Infrastruktur wird unabhängigen Audits durch Dritte unterzogen. Die Compliance-Programme umfassen ISO/IEC 27001:2013, SOC-1/2/3-Berichte und das C5-Zertifikat des Bundesamtes für Sicherheit in der Informationstechnik (BSI).
Das AWS European Sovereign Cloud: Sovereign Reference Framework definiert spezifische Souveränitätskontrollen in den Bereichen Governance-Unabhängigkeit, operative Kontrolle, Datenresidenz und technische Isolierung. Dieses Framework ist in AWS Artifact verfügbar und bietet durch SOC-2-Zertifizierung durchgängige Transparenz.
Umfassende Serviceverfügbarkeit
Von Beginn an steht Ihnen in der AWS European Sovereign Cloud eine breite Palette von AWS-Services zur Verfügung – darunter Amazon SageMaker und Amazon Bedrock für Workloads im Bereich Künstliche Intelligenz und Machine Learning (KI/ML). Für die Rechenleistung stehen Ihnen Amazon Elastic Compute Cloud (Amazon EC2) und AWS Lambda zur Verfügung. Die Container-Orchestrierung ist über den Amazon Elastic Kubernetes Service (Amazon EKS) und den Amazon Elastic Container Service (Amazon ECS) verfügbar. Zu den Datenbank-Services gehören Amazon Aurora, Amazon DynamoDB und Amazon Relational Database Service (Amazon RDS). Die Speicheroptionen umfassen Amazon Simple Storage Service (Amazon S3) und Amazon Elastic Block Store (Amazon EBS) mit Vernetzung über Amazon Virtual Private Cloud (Amazon VPC) und Sicherheits-Services wie AWS Key Management Service (AWS KMS) und AWS Private Certificate Authority. Eine aktuelle Liste der Services finden Sie in der AWS-Funktionsmatrix, die kürzlich im AWS Builder Center veröffentlicht wurde.
Die AWS European Sovereign Cloud wird von AWS-Partnern unterstützt, die es sich zur Aufgabe gemacht haben, Ihnen bei der Erfüllung Ihrer Souveränitätsanforderungen zur Seite zu stehen. Partner wie Adobe, Cisco, Cloudera, Dedalus, Esri, Genesys, GitLab, Mendix, Pega, SAP, SnowFlake, Trend Micro und Wiz stellen ihre Lösungen in der AWS European Sovereign Cloud zur Verfügung und bieten Ihnen die Tools und Services, die Sie in den Bereichen Sicherheit, Datenanalyse, Entwicklung von Anwendungen und branchenspezifische Workloads benötigen. Dank dieser umfassenden Unterstützung durch Partner können Sie eigenständige Lösungen, die AWS-Services mit bewährten Partnertechnologien kombinieren, entwickeln.
Erhebliche Investitionen in die europäische Infrastruktur
Hinter der AWS European Sovereign Cloud steht eine Investition in Höhe von 7,8 Milliarden Euro in Infrastruktur, die Schaffung von Arbeitsplätzen und die Entwicklung von Kompetenzen. Diese Investition wird bis 2040 voraussichtlich 17,2 Milliarden Euro zur europäischen Wirtschaftsleistung beitragen und jährlich rund 2 800 Vollzeitstellen in lokalen Unternehmen sichern.
Einige technische Details
Die AWS European Sovereign Cloud steht allen Kunden zur Verfügung, unabhängig davon, wo sie sich befinden. Sie können mit dem Partitionsnamen aws-eusc und dem Regionsnamen eusc-de-east-1 auf die Infrastruktur zugreifen. Eine Partition ist eine Gruppe von AWS-Regionen. Jedes AWS-Konto ist auf eine Partition beschränkt.
Die Infrastruktur unterstützt alle gängigen AWS-Zugriffsmethoden, einschließlich der AWS Management Console, AWS SDKs und der AWS Command Line Interface (AWS CLI), sodass sie sich problemlos in Ihre bestehenden Workflows und Automatisierungsprozesse integrieren lässt. Nachdem Sie ein neues Root-Konto für die Partition der AWS European Sovereign Cloud erstellt haben, beginnen Sie mit der Erstellung neuer IAM-Identitäten und -Rollen, die speziell für diese Infrastruktur vorgesehen sind. Dadurch erhalten Sie die vollständige Kontrolle über die Zugriffsverwaltung innerhalb der europäischen souveränen Umgebung.
Erste Schritte
Die AWS European Sovereign Cloud bietet europäischen Organisationen erweiterte Souveränitätskontrollen und gewährleistet gleichzeitig den Zugriff auf die Innovationen und Funktionen von AWS. Sie können Services über Amazon Web Services EMEA SARL in Auftrag geben. Die Preise werden in Euro angegeben und die Abrechnung erfolgt in einer der acht Währungen, die wir derzeit unterstützen. Die Infrastruktur basiert auf der bekannten AWS-Architektur, dem AWS-Serviceportfolio und den AWS-APIs, wodurch die Entwicklung und Migration von Anwendungen vereinfacht wird.
Der AWS European Sovereign Cloud Addendum enthält die zusätzlichen vertraglichen Verpflichtungen für die AWS European Sovereign Cloud.
Für mich als Europäer symbolisiert dieser Launch das Engagement von AWS, den spezifischen Anforderungen unseres Kontinents gerecht zu werden und Cloud-Funktionen bereitzustellen, die Innovationen in allen Branchen vorantreiben. Ich lade Sie ein, mehr über die AWS European Sovereign Cloud zu erfahren und zu entdecken, wie sie Ihrer Organisation dabei helfen kann, ihre Souveränitätsanforderungen zu erfüllen. Lesen Sie die Übersicht über die AWS European Sovereign Cloud und erfahren Sie mehr über die Designziele und den Ansatz. Registrieren Sie sich für ein neues Konto und planen Sie noch heute die Bereitstellung Ihrer ersten Workload.
French version
Ouverture de l’AWS European Souvereign Cloud
En tant que citoyen européen, je mesure personnellement l’importance de la souveraineté numérique, en particulier pour nos organisations du secteur public et les industries fortement réglementées. Aujourd’hui, j’ai le plaisir d’annoncer que l’AWS European Sovereign Cloud est désormais disponible pour l’ensemble de nos clients. Nous avions annoncé pour la première fois notre projet de construction de cette nouvelle infrastructure cloud indépendante en 2023, et elle est aujourd’hui prête à répondre aux exigences de souveraineté les plus strictes des clients européens, avec un large ensemble de services AWS.
Berlin, porte de Brandebourg au coucher du soleil
Répondre aux exigences européennes en matière de souveraineté
Partout en Europe, les organisations sont confrontées à des exigences réglementaires de plus en plus complexes en matière de résidence des données, de contrôle opérationnel et d’indépendance de la gouvernance. Trop souvent aujourd’hui, les organisations européennes ayant les besoins de souveraineté les plus élevés se retrouvent contraintes de rester sur des environnements sur site, ou de recourir à des offres cloud aux services et fonctionnalités limités. Pour répondre à cet enjeu critique, l’AWS European Sovereign Cloud est le seul cloud souverain entièrement fonctionnel, exploité de manière indépendante, et reposant sur des contrôles techniques robustes, des garanties de souveraineté et des protections juridiques solides. Les acteurs du secteur public et les entreprises des secteurs fortement réglementés ont besoin d’une infrastructure cloud offrant des contrôles de souveraineté renforcés, sans renoncer à l’innovation, à la sécurité et à la fiabilité attendues des services cloud modernes. Ces organisations doivent avoir l’assurance que leurs données et leurs opérations restent sous juridiction européenne, avec des structures de gouvernance claires et une autonomie opérationnelle au sein de l’Union européenne (UE).
Une nouvelle infrastructure cloud indépendante pour l’Europe
L’AWS European Sovereign Cloud repose sur une infrastructure cloud physiquement et logiquement distincte, dont l’ensemble des composants est situé exclusivement au sein de l’UE. La première région AWS de l’AWS European Sovereign Cloud est implantée dans le Land de Brandebourg, en Allemagne, et est disponible dès aujourd’hui. Cette région fonctionne de façon indépendante par rapport aux autres régions AWS existantes. L’infrastructure comprend plusieurs zones de disponibilité, avec des systèmes redondants d’alimentation et de réseau, conçus pour fonctionner en continu même en cas d’interruption de la connectivité avec le reste du monde.
Nous prévoyons d’étendre l’empreinte de l’AWS European Sovereign Cloud depuis l’Allemagne à l’ensemble de l’UE, afin de répondre aux exigences strictes d’isolation, de résidence des données dans certains pays et de faible latence. Cette extension débutera avec de nouvelles Local Zones souveraines situées en Belgique, aux Pays-Bas et au Portugal. En complément, vous pourrez étendre l’infrastructure de l’AWS European Sovereign Cloud à l’aide des AWS Dedicated Local Zones, des AWS AI Factories ou d’AWS Outposts, dans les sites de votre choix, y compris au sein de vos propres centres de données sur site.
L’AWS European Sovereign Cloud et ses Local Zones offrent des contrôles de souveraineté renforcés grâce à un modèle opérationnel unique. L’AWS European Sovereign Cloud est exploité exclusivement par des résidents de l’UE basés dans l’UE. Cela couvre notamment les opérations quotidiennes, le support technique et le service client. Nous sommes en train d’opérer une transition progressive afin que l’AWS European Sovereign Cloud soit exploité exclusivement par des citoyens de l’UE résidant dans l’UE. Durant cette période de transition, nous continuons de travailler avec une équipe mixte composée de résidents de l’UE et de citoyens de l’UE basés dans l’UE.
L’infrastructure est gérée par des entités juridiques européennes dédiées, établies conformément au droit allemand. En octobre 2025, AWS a nommé Stéphane Israël, citoyen de l’UE résidant dans l’UE, au poste de directeur général. Stéphane est responsable de la gestion et de l’exploitation de l’AWS European Sovereign Cloud, couvrant l’infrastructure, la technologie et les services, ainsi que de la direction des initiatives plus larges d’AWS en matière de souveraineté numérique. En janvier 2026, AWS a également nommé Stefan Hoechbauer (Vice-président, Allemagne et Europe centrale, AWS) comme directeur général de l’AWS European Sovereign Cloud. Il travaillera aux côtés de Stéphane Israël pour piloter l’AWS European Sovereign Cloud.
Un conseil consultatif, composé exclusivement de citoyens de l’UE et incluant deux représentants indépendants, apporte un niveau supplémentaire de supervision et d’expertise sur les questions de souveraineté.
Résidence des données et contrôle renforcés
L’AWS European Sovereign Cloud fournit des garanties complètes en matière de résidence des données afin de répondre aux exigences les plus strictes. Comme dans les régions AWS existantes à travers le monde, l’ensemble de vos contenus reste dans la région que vous sélectionnez, sauf indication contraire de votre part. Au-delà des contenus, les métadonnées créées par les clients — telles que les rôles, les autorisations, les étiquettes de ressources et les configurations — restent également au sein de l’UE. L’infrastructure dispose de son propre système dédié de AWS Identity and Access Management (IAM) et de facturation, opérant de manière totalement indépendante à l’intérieur des frontières européennes.
Des contrôles techniques intégrés à l’infrastructure empêchent tout accès à l’AWS European Sovereign Cloud depuis l’extérieur de l’UE. L’infrastructure comprend un prestataire européen de services de confiance dédié pour les opérations d’autorité de certification et utilise des serveurs de noms Amazon Route 53 dédiés. Ces serveurs n’utilisent que des domaines de premier niveau (TLD) européens pour leurs propres noms. L’AWS European Sovereign Cloud ne présente aucune dépendance critique vis-à-vis de personnels ou d’infrastructures situés en dehors de l’UE.
Cadre de sécurité et de conformité
L’AWS European Sovereign Cloud conserve les capacités de sécurité fondamentales attendues d’AWS, notamment le chiffrement, la gestion des clés, la gouvernance des accès et le système AWS Nitro pour l’isolation des charges de calcul. Concrètement, vos instances EC2 bénéficient d’une intégrité de plateforme vérifiée cryptographiquement et de frontières matérielles, empêchant tout accès non autorisé à vos données sans compromis sur les performances. Vous bénéficiez ainsi à la fois des contrôles de souveraineté et de la puissance de calcul nécessaires à vos charges de travail. L’infrastructure fait l’objet d’audits indépendants réalisés par des tiers, et s’inscrit dans des programmes de conformité incluant ISO/IEC 27001:2013, les rapports SOC 1/2/3, ainsi que l’attestation C5 de l’Office fédéral allemand pour la sécurité de l’information (BSI).
Le AWS European Sovereign Cloud: Sovereign Reference Framework définit précisément les contrôles de souveraineté couvrant l’indépendance de la gouvernance, le contrôle opérationnel, la résidence des données et l’isolation technique. Ce cadre est disponible dans AWS Artifact et offre une visibilité de bout en bout via une attestation SOC 2.
Disponibilité étendue des services
Dès son lancement, l’AWS European Sovereign Cloud donne accès à un large éventail de services AWS, notamment Amazon SageMaker et Amazon Bedrock pour les charges de travail d’intelligence artificielle et de machine learning (IA/ML). Pour le calcul, vous pouvez utiliser Amazon Elastic Compute Cloud (Amazon EC2) et AWS Lambda. L’orchestration de conteneurs est disponible via Amazon Elastic Kubernetes Service (Amazon EKS) et Amazon Elastic Container Service (Amazon ECS). Les services de bases de données incluent Amazon Aurora, Amazon DynamoDB et Amazon Relational Database Service (Amazon RDS). Les options de stockage comprennent Amazon Simple Storage Service (Amazon S3) et Amazon Elastic Block Store (Amazon EBS), avec des capacités réseau via Amazon Virtual Private Cloud (Amazon VPC) et des services de sécurité tels que AWS Key Management Service (AWS KMS) et AWS Private Certificate Authority. Pour obtenir la liste la plus à jour des services disponibles, consultez la matrice des capacités AWS récemment publiée sur l’AWS Builder Center.
L’AWS European Sovereign Cloud est supporté par de nombreux partenaires AWS engagés à vous aider à répondre à vos exigences de souveraineté. Des partenaires tels qu’Adobe, Cisco, Cloudera, Dedalus, Esri, Genesys, GitLab, Mendix, Pega, SAP, SnowFlake, Trend Micro et Wiz rendent leurs solutions disponibles sur l’AWS European Sovereign Cloud, vous offrant ainsi les outils et services nécessaires dans les domaines de la sécurité, de l’analyse de données, du développement applicatif et des charges de travail spécifiques à certains secteurs industriels. Cet ensemble de partenaires vous permet de construire des solutions souveraines combinant les services AWS et des technologies de partenaires de confiance.
Un investissement majeur dans l’infrastructure européenne
L’AWS European Sovereign Cloud s’appuie sur un investissement de 7,8 milliards d’euros dans l’infrastructure, la création d’emplois et le développement des compétences. Cet investissement devrait contribuer à hauteur de 17,2 milliards d’euros à l’économie européenne d’ici 2040 et soutenir environ 2.800 emplois équivalent temps plein par an au sein des entreprises locales.
Quelques détails techniques
L’AWS European Sovereign Cloud est accessible à tous les clients, quel que soit leur lieu d’implantation. Vous pouvez accéder à l’infrastructure en utilisant le nom de partition aws-eusc et le nom de région eusc-de-east-1. Une partition correspond à un ensemble de régions AWS. Chaque compte AWS est rattaché à une seule partition.
L’infrastructure prend en charge toutes les méthodes d’accès AWS standards, y compris la console de gestion AWS, les AWS SDKs et la AWS Command Line Interface (AWS CLI), ce qui facilite son intégration dans vos flux de travail et vos automatisations existants. Après avoir créé un nouveau compte racine pour la partition AWS European Sovereign Cloud, vous commencez par définir de nouvelles identités et rôles IAM spécifiques à cette infrastructure, vous donnant un contrôle total sur la gestion des accès au sein de l’environnement souverain européen.
Pour commencer
L’AWS European Sovereign Cloud offre aux organisations européennes des contrôles de souveraineté renforcés tout en leur permettant de continuer à bénéficier de l’innovation et des capacités d’AWS. Vous pouvez contractualiser les services via Amazon Web Services EMEA SARL, avec une tarification en euros et une facturation possible dans l’une des huit devises que nous prenons en charge aujourd’hui. L’infrastructure repose sur une architecture, un portefeuille de services et des API AWS familiers, ce qui simplifie le développement et la migration des applications.
L’avenant AWS European Sovereign Cloud précise les engagements contractuels supplémentaires propres à l’AWS European Sovereign Cloud.
En tant qu’Européen, ce lancement illustre l’engagement d’AWS à répondre aux besoins spécifiques de notre continent et à fournir les capacités cloud qui stimulent l’innovation dans tous les secteurs. Je vous invite à découvrir l’AWS European Sovereign Cloud et à comprendre comment il peut aider votre organisation à satisfaire ses exigences de souveraineté. Consultez Overview of the AWS European Sovereign Cloud (en anglais) pour en savoir plus sur les objectifs de conception et l’approche retenue, créez un nouveau compte et planifiez dès aujourd’hui le déploiement de votre première charge de travail.
Italian version
Lancio di AWS European Sovereign Cloud
Come cittadino europeo, conosco benissimo l’importanza della sovranità digitale, in particolare per le nostre organizzazioni del settore pubblico e dei settori altamente regolamentati. Oggi sono lieto di annunciare che AWS European Sovereign Cloud è ora generalmente disponibile per tutti i clienti. Abbiamo annunciato per la prima volta i nostri piani per la creazione di questa nuova infrastruttura cloud indipendente nel 2023. Finalmente oggi è pronta a soddisfare i più rigorosi requisiti di sovranità dei clienti europei con un set completo di servizi AWS.
Berlino, Porta di Brandeburgo al tramonto
Soddisfare i requisiti di sovranità europea
Le organizzazioni di tutta Europa devono far fronte a requisiti normativi sempre più complessi in materia di residenza dei dati, controllo operativo e indipendenza della governance. Troppo spesso, le organizzazioni europee con i più elevati requisiti di sovranità sono bloccate a causa di offerte o ambienti on-premises legacy con funzionalità e servizi ridotti. In risposta a questa esigenza fondamentale, l’AWS European Sovereign Cloud rappresenta l’unico cloud sovrano con funzionalità complete e a gestione autonoma. supportato da solidi controlli tecnici, garanzie di sovranità e protezioni legali. Gli enti pubblici e le aziende di settori altamente regolamentati necessitano di un’infrastruttura cloud che fornisca controlli di sovranità avanzati che garantiscano l’innovazione, la sicurezza e l’affidabilità che si aspettano dai moderni servizi cloud. Queste organizzazioni devono essere certe che i propri dati e le proprie operazioni restino sotto la giurisdizione europea, con chiare strutture di governance e autonomia operativa nell’ambito dell’Unione europea (UE).
Una nuova infrastruttura cloud indipendente per l’Europa
L’AWS European Sovereign Cloud rappresenta un’infrastruttura cloud separata fisicamente e logicamente, con tutti i componenti situati interamente all’interno dell’UE. La prima Regione AWS nell’AWS European Sovereign Cloud, situata nello stato di Brandeburgo (Germania) e ora disponibile a livello generale, opera indipendentemente dalle Regioni AWS esistenti. L’infrastruttura presenta diverse zone di disponibilità con risorse di alimentazione e rete ridondanti, progettate per funzionare continuamente anche in caso di interruzione della connettività con il resto del mondo.
Abbiamo intenzione di estendere la presenza dell’AWS European Sovereign Cloud dalla Germania all’intera UE per supportare i rigorosi requisiti di isolamento, residenza dei dati all’interno di un determinato Paese e bassa latenza. Inizieremo con nuove zone locali sovrane situate in Belgio, nei Paesi Bassi e in Portogallo. Inoltre, sarà possibile estendere l’infrastruttura AWS European Sovereign Cloud con Zone locali AWS dedicate, AWS AI Factories o AWS Outposts in posizioni selezionate, inclusi i data center on-premises.
L’AWS European Sovereign Cloud e le relative zone locali forniscono controlli sovrani avanzati tramite un modello operativo esclusivo. L’AWS European Sovereign Cloud sarà gestito esclusivamente da residenti UE che si trovano nell’UE. Ciò copre attività come operazioni quotidiane, supporto tecnico e servizio clienti. Stiamo gradualmente trasformando l’AWS European Sovereign Cloud in modo che sia gestito esclusivamente da cittadini UE che si trovano nell’UE. Durante questo periodo di transizione, continueremo a lavorare con un team misto di residenti e cittadini comunitari che si trovano nell’UE.
L’infrastruttura è gestita da entità giuridiche europee dedicate, costituite secondo il diritto tedesco. Nell’ottobre 2025, AWS ha assegnato l’incarico di managing director a Stéphane Israël, cittadino comunitario residente nell’UE. Sarà responsabile della gestione e delle operazioni dell’AWS European Sovereign Cloud, inclusi infrastruttura, tecnologia e servizi, oltre a guidare le più ampie iniziative di sovranità digitale di AWS. Nel gennaio 2026, AWS ha inoltre nominato managing director dell’AWS European Sovereign Cloud Stefan Höchbauer (vicepresidente, Germania ed Europa centrale, AWS). Collaborerà con Stéphane Israël per guidare l’AWS European Sovereign Cloud.
Un comitato consultivo composto esclusivamente da cittadini comunitari, inclusi due rappresentanti terzi indipendenti, fornirà ulteriore supervisione e competenza in materia di sovranità.
Ottimizzazione del controllo e della residenza dei dati
L’AWS European Sovereign Cloud offre garanzie complete sulla residenza dei dati in modo da poter soddisfare i requisiti più rigorosi in materia. Come per le nostre Regioni AWS esistenti a livello mondiale, tutti i contenuti restano all’interno della Regione selezionata, a meno che non si scelga diversamente. Oltre ai contenuti, anche i metadati creati dai clienti, tra cui ruoli, autorizzazioni, etichette delle risorse e configurazioni, restano nell’ambito dell’UE. L’infrastruttura è dotata di un proprio sistema AWS Identity and Access Management (AWS IAM) e di fatturazione dedicato, completamente gestito in modo indipendente all’interno dei confini europei.
I controlli tecnici integrati nell’infrastruttura impediscono l’accesso all’AWS European Sovereign Cloud dall’esterno dell’UE. L’infrastruttura include un provider di servizi fiduciari europeo dedicato per le operazioni delle autorità di certificazione e utilizza nameserver Amazon Route 53 dedicati. Questi server utilizzeranno solo domini di primo livello (TLD) europei per i propri nomi. L’AWS European Sovereign Cloud non ha dipendenze fondamentali da personale o infrastrutture non UE.
Framework di sicurezza e conformità
L’AWS European Sovereign Cloud mantiene le stesse funzionalità di sicurezza di base di AWS, tra cui crittografia, gestione delle chiavi, governance degli accessi e AWS Nitro System per l’isolamento computazionale. Ciò significa che le istanze EC2 beneficiano dell’integrità della piattaforma verificata a livello di crittografia e dei limiti imposti dall’hardware che impediscono l’accesso non autorizzato ai dati senza compromettere le prestazioni, offrendo i controlli di sovranità e la potenza di calcolo richiesti dai carichi di lavoro. L’infrastruttura è sottoposta ad audit di terze parti indipendenti, con programmi di conformità che includono ISO/IEC 27001:2013, report SOC 1/2/3 e attestazione C5 dell’Ufficio Federale per la Sicurezza Informatica (BSI).
L’AWS European Sovereign Cloud: Sovereign Reference Framework definisce i controlli di sovranità specifici in termini di indipendenza della governance, controllo operativo, residenza dei dati e isolamento tecnico. Questo framework è disponibile in AWS Artifact e fornisce visibilità end-to-end tramite l’attestazione SOC 2.
Disponibilità completa del servizio
Dal momento del lancio, sarà possibile accedere a un’ampia gamma di servizi AWS nell’AWS European Sovereign Cloud, tra cui Amazon SageMaker e Amazon Bedrock per carichi di lavoro di intelligenza artificiale e machine learning (IA/ML). Per i calcoli, è possibile utilizzare Amazon Elastic Compute Cloud (Amazon EC2) e AWS Lambda. L’orchestrazione di container è disponibile tramite Amazon Elastic Kubernetes Service (Amazon EKS) e Amazon Elastic Container Service (Amazon ECS). I servizi di database includono Amazon Aurora, Amazon DynamoDB e Amazon Relational Database Service (Amazon RDS). Le opzioni di storage includono Amazon Simple Storage Service (Amazon S3) e Amazon Elastic Block Store (Amazon EBS), con connessione in rete tramite Amazon Virtual Private Cloud (Amazon VPC) e servizi di sicurezza tra cui Servizio AWS di gestione delle chiavi (AWS KMS) e Autorità di certificazione privata AWS (AWS Private CA). Per un elenco aggiornato dei servizi, è possibile consultare l’elenco delle funzionalità AWS pubblicato di recente su AWS Builder Center.
L’AWS European Sovereign Cloud è supportato dai partner AWS, che aiutano a soddisfare i propri requisiti di sovranità. Partner come Adobe, Cisco, Cloudera, Dedalus, Esri, Genesys, GitLab, Mendix, Pega, SAP, SnowFlake, Trend Micro e Wiz stanno rendendo disponibili le loro soluzioni nell’AWS European Sovereign Cloud, fornendo gli strumenti e i servizi necessari per la sicurezza, l’analisi dei dati, lo sviluppo di applicazioni e i carichi di lavoro specifici del settore. Questo ampio supporto dei partner aiuta a creare soluzioni sovrane che combinano i servizi AWS con tecnologie di partner affidabili.
Investimenti significativi nelle infrastrutture europee
L’AWS European Sovereign Cloud è sostenuto da un investimento di 7,8 miliardi di euro destinati a infrastrutture, creazione di posti di lavoro e sviluppo delle competenze. Si prevede che questo investimento contribuirà con 17,2 miliardi di euro all’economia europea fino al 2040 e sosterrà circa 2.800 posti di lavoro equivalenti a tempo pieno all’anno nelle aziende locali.
Alcuni dettagli tecnici
L’AWS European Sovereign Cloud è disponibile per tutti i clienti, indipendentemente da dove si trovino. È possibile accedere all’infrastruttura utilizzando il nome della partizione aws-eusc e il nome della Regione eusc-de-east-1. Una partizione è un gruppo di Regioni AWS. Ogni account AWS è associato a una partizione.
L’infrastruttura supporta tutti i metodi di accesso AWS standard, tra cui la Console di gestione AWS, gli SDK AWS e l’interfaccia della linea di comando AWS (AWS CLI), semplificando l’integrazione nell’automazione e nei flussi di lavoro esistenti. Dopo aver creato un nuovo account root per la partizione Di AWS European Sovereign Cloud, si inizia creando nuove identità e ruoli IAM specifici per questa infrastruttura, che consentiranno di avere il controllo completo sulla gestione degli accessi all’interno dell’ambiente sovrano europeo.
Nozioni di base
L’AWS European Sovereign Cloud fornisce alle organizzazioni europee controlli di sovranità avanzati pur mantenendo l’accesso all’innovazione e alle funzionalità di AWS. È possibile contrattare servizi tramite Amazon Web Services EMEA SARL, con prezzi in EUR e fatturazione in una delle otto valute supportate oggi. L’infrastruttura utilizza l’architettura AWS, il portafoglio di servizi e le API tradizionali, semplificando la creazione e la migrazione delle applicazioni.
L’addendum di AWS European Sovereign Cloud include gli impegni contrattuali aggiuntivi per l’AWS European Sovereign Cloud.
Per me come europeo, questo lancio rappresenta l’impegno di AWS per soddisfare le esigenze specifiche del nostro continente e fornire le funzionalità cloud che guidano l’innovazione in tutti i settori. Invito tutti a scoprire di più sull’AWS European Sovereign Cloud e su come può aiutare le organizzazioni a soddisfare i requisiti di sovranità. Nella Panoramica di AWS European Sovereign Cloud sono disponibili maggiori informazioni sugli obiettivi e sull’approccio di progettazione, creare un nuovo account e pianificare l’implementazione del primo carico di lavoro oggi stesso.
Spanish version
Apertura de AWS European Sovereign Cloud
Como ciudadano europeo, comprendo de primera mano la importancia de la soberanía digital, especialmente para las organizaciones de nuestro sector público y las industrias altamente reguladas. Hoy me complace anunciar que la AWS European Sovereign Cloud ya está disponible de forma generalizada para todos los clientes. Anunciamos por primera vez nuestros planes de crear esta nueva infraestructura de nube independiente en 2023, y hoy está lista para cumplir los requisitos de soberanía más estrictos de los clientes europeos con un exhaustivo conjunto de servicios de AWS.
Berlín, Puerta de Brandeburgo al atardecer
Cumplimiento de los requisitos de soberanía europeos
Las organizaciones de toda Europa se enfrentan a unos requisitos normativos cada vez más complejos en relación con la residencia de los datos, el control operativo y la independencia de la gobernanza. Hoy en día, con demasiada frecuencia, las organizaciones europeas con los requisitos de soberanía más estrictos se ven atrapadas en entornos locales heredados u ofertas con servicios y funcionalidades reducidos. En respuesta a esta necesidad crítica, la AWS European Sovereign Cloud es la única nube soberana independiente con todas las características que está respaldada por sólidos controles técnicos, garantías de soberanía y protecciones legales. Las entidades del sector público y las empresas de industrias altamente reguladas necesitan una infraestructura en la nube que proporcione controles de soberanía mejorados que mantengan la innovación, la seguridad y la fiabilidad que se esperan de los servicios modernos en la nube. Estas organizaciones necesitan la garantía de que sus datos y operaciones permanecen bajo la jurisdicción europea, con estructuras de gobernanza claras y autonomía operativa dentro de la Unión Europea (UE).
Una nueva infraestructura de nube independiente para Europa
La AWS European Sovereign Cloud es una infraestructura de nube separada de manera física y lógica, en la que todos los componentes están ubicados íntegramente dentro de la UE. La primera región de AWS de la AWS European Sovereign Cloud se encuentra en el estado de Brandeburgo (Alemania) y ya está disponible para el público en general. Esta región opera de forma independiente de las regiones de AWS existentes. La infraestructura cuenta con varias zonas de disponibilidad con fuentes de alimenacion y redes redundantes, diseñadas para funcionar de forma continua incluso si se interrumpe la conectividad con el resto del mundo.
Tenemos previsto ampliar la presencia de la AWS European Sovereign Cloud de Alemania a toda la UE para cumplir los requisitos de aismlamiento estrictos, residencia de los datos dentro del país y baja latencia. Esto comenzará con nuevas zonas locales soberanas ubicadas en Bélgica, los Países Bajos y Portugal. Además, podrá ampliar la infraestructura de la AWS European Sovereign Cloud con zonas locales dedicadas de AWS, AWS AI Factories o AWS Outposts en las ubicaciones que elija, incluidos sus propios centros de datos locales.
La AWS European Sovereign Cloud y sus zonas locales proporcionan controles soberanos mejorados a través de su modelo operativo único. La AWS European Sovereign Cloud será operada exclusivamente por residentes de la UE ubicados en la UE. Abarca actividades como las operaciones diarias, la asistencia técnica y el servicio de atención al cliente. Estamos realizando una transición gradual de la AWS European Sovereign Cloud para que se opere exclusivamente por ciudadanos de la UE ubicados en la UE. Durante este período de transición, seguiremos trabajando con un equipo mixto de residentes de la UE y ciudadanos de la UE ubicados en la UE.
La infraestructura se administra a través de entidades jurídicas europeas especializadas constituidas en el marco de la legislación alemana. En octubre de 2025, AWS nombró director general a Stéphane Israël, ciudadano de la UE que reside en la UE. Stéphane será responsable de la administración y las operaciones de la AWS European Sovereign Cloud, lo que incluye la infraestructura, la tecnología y los servicios, además de liderar los esfuerzos más amplios de AWS en materia de soberanía digital. En enero de 2026, AWS también nombró a Stefan Hoechbauer (vicepresidente de AWS para Alemania y Europa Central) director general de la AWS European Sovereign Cloud. Stefan dirigirá la AWS European Sovereign Cloud junto con Stéphane Israël.
Un consejo consultivo compuesto exclusivamente por ciudadanos de la UE, que incluye a dos representantes independientes externos, proporciona supervisión y experiencia adicional en materia de soberanía.
Mejor control y residencia de datos
La AWS European Sovereign Cloud ofrece amplias garantías de residencia de datos para que pueda cumplir los requisitos más estrictos en materia de residencia de datos. Al igual que ocurre con nuestras regiones de AWS existentes en todo el mundo, todo el contenido permanece dentro la región que elija, a menos que decida lo contrario. Además del contenido, los metadatos creados por los clientes, incluidos los roles, los permisos, las etiquetas de recursos y las configuraciones, también permanecen dentro de la UE. La infraestructura cuenta con su propio sistema dedicado de AWS Identity and Access Management (AWS IAM) y facturación, que funciona de forma independiente dentro de las fronteras europeas.
Los controles técnicos integrados en la infraestructura impiden el acceso a la AWS European Sovereign Cloud desde fuera de la UE. La infraestructura incluye un proveedor de servicios de confianza europeo dedicado para las operaciones de las autoridades de certificación y utiliza servidores de nombres de Amazon Route 53 dedicados. Estos servidores solo usarán dominios de nivel superior europeos para sus propios nombres. La AWS European Sovereign Cloud no tiene dependencias críticas de personal o infraestructura fuera de la UE.
Marco de seguridad y cumplimiento
La AWS European Sovereign Cloud mantiene las mismas capacidades de seguridad básicas que cabe esperar de AWS, como el cifrado, la administración de claves, la gobernanza del acceso y AWS Nitro System para el aislamiento de la computación. Esto significa que sus instancias de EC2 se benefician de la integridad de la plataforma verificada criptográficamente y de los límites impuestos por el hardware que impiden el acceso no autorizado a sus datos sin comprometer el rendimiento, lo que le proporciona tanto los controles de soberanía como la potencia computacional que requieren sus cargas de trabajo. La infraestructura se somete a auditorías independientes externas, con programas de cumplimiento que incluyen la norma ISO/IEC 27001:2013, informes SOC 1/2/3 y la certificación C5 de la Oficina Federal de Seguridad de la Información.
El marco de referencia de soberanía de la AWS European Sovereign Cloud define los controles de soberanía específicos en relación con la independencia de la gobernanza, el control operativo, la residencia de datos y el aislamiento técnico. Este marco está disponible en AWS Artifact y proporciona visibilidad total a través de la certificación SOC 2.
Disponibilidad total del servicio
Puede acceder a una amplia variedad de servicios de AWS en la AWS European Sovereign Cloud desde su lanzamiento, incluidos Amazon SageMaker y Amazon Bedrock para cargas de trabajo de inteligencia artificial y machine learning. Para el procesamiento, puede usar Amazon Elastic Compute Cloud (Amazon EC2) y AWS Lambda. La orquestación de contenedores está disponible a través de Amazon Elastic Kubernetes Service (Amazon EKS) y Amazon Elastic Container Service (Amazon ECS). Los servicios de bases de datos incluyen Amazon Aurora, Amazon DynamoDB y Amazon Relational Database Service (Amazon RDS). Dispone de opciones de almacenamiento como Amazon Simple Storage Service (Amazon S3) y Amazon Elastic Block Store (Amazon EBS), con redes a través de Amazon Virtual Private Cloud (Amazon VPC) y servicios de seguridad como AWS Key Management Service (AWS KMS) y AWS Private Certificate Authority. Para obtener una lista actualizada de los servicios, consulte la matriz de capacidades de AWS que se ha publicado recientemente en AWS Builder Center.
La AWS European Sovereign Cloud cuenta con el respaldo de los socios de AWS, que se comprometen a ayudarle a cumplir sus requisitos de soberanía. Socios como Adobe, Cisco, Cloudera, Dedalus, Esri, Genesys, GitLab, Mendix, Pega, SAP, SnowFlake, Trend Micro y Wiz ofrecen sus soluciones en la AWS European Sovereign Cloud, lo que le proporciona las herramientas y los servicios que necesita en materia de seguridad, análisis de datos, desarrollo de aplicaciones y cargas de trabajo específicas del sector. Este amplio apoyo de los socios le ayuda a crear soluciones soberanas que combinan los servicios de AWS con tecnologías de socios de confianza.
Inversión importante. en la infraestructura europea
La AWS European Sovereign Cloud está respaldada por una inversión de 7.800 millones de EUR en infraestructura, creación de empleo y desarrollo de habilidades. Se espera que esta inversión aporte 17.200 millones de EUR a la economía europea para 2040 y ayude a crear el equivalente a aproximadamente 2.800 puestos de trabajo a tiempo completo por año en empresas locales.
Algunos detalles técnicos
La AWS European Sovereign Cloud está disponible para todos los clientes, independientemente de dónde se encuentren. Puede acceder a la infraestructura utilizando el nombre de partición aws-eusc y el nombre de región eusc-de-east-1. Una partición es un grupo de regiones de AWS. Cada cuenta de AWS tiene limitado su alcance a una sola partición.
La infraestructura admite todos los métodos de acceso estándar de AWS, como la Consola de administración de AWS, los AWS SDK y la Interfaz de la línea de comandos de AWS (AWS CLI), lo que facilita la integración en sus flujos de trabajo y automatización existentes. Tras crear una nueva cuenta raíz para la partición de la AWS European Sovereign Cloud, primero deberá crear nuevas identidades y roles de IAM específicos para esta infraestructura, lo que le permitirá tener un control total sobre la administración del acceso en el entorno soberano europeo.
Cómo empezar
La AWS European Sovereign Cloud proporciona a las organizaciones europeas controles de soberanía mejorados, al tiempo que mantiene el acceso a la innovación y las capacidades de AWS. Puede contratar los servicios a través de Amazon Web Services EMEA SARL, con precios en EUR y facturación en cualquiera de las ocho divisas que admitimos actualmente. La infraestructura utiliza la arquitectura, la cartera de servicios y las API habituales de AWS, lo que facilita la creación y la migración de aplicaciones.
La adenda de la AWS European Sovereign Cloud contiene los compromisos contractuales adicionales para la AWS European Sovereign Cloud.
Para mí, como europeo, este lanzamiento representa el compromiso de AWS de satisfacer las necesidades específicas de nuestro continente y proporcionar las capacidades en la nube que impulsan la innovación en todos los sectores. Le invito a descubrir más sobre la AWS European Sovereign Cloud y cómo puede ayudar a su organización a cumplir sus requisitos de soberanía. Lea la descripción general de la AWS European Sovereign Cloud para obtener más información sobre los objetivos y el enfoque del diseño, regístrese para obtener una nueva cuenta y planifique hoy mismo el despliegue de su primera carga de trabajo.

 .
.