Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/leveraging-aws-nitro-enclaves-to-perform-computation-of-multiple-sensitive-datasets/
This blog post is written by, Jeff Wisman, Principal Solutions Architect and Andrew Lee, Solutions Architect.
Introduction
Many organizations have sensitive datasets that they do not want to share with others because of stringent security and compliance requirements. However, they would still like to use each other’s data to perform processing and aggregation. For example, B2B (business to business) companies often want to augment their customer information dataset with additional demographic or psychographic signals. This enrichment of data is often done by one party sending customer information to be matched against another party’s data universe. Naturally, privacy and the revealing of business-critical customer information to an external entity is a major concern here. In this blog, we present a solution where multiple parties can choose to give an isolated compute environment access to their encrypted data to be decrypted and processed in a secure way using AWS Nitro Enclaves.
Designing and building your own secure private computing solution can be challenging, with few out-of-the-box solutions. Our sample application uses Nitro Enclaves, which support the creation of an isolated execution environment called an enclave and a cryptographic attestation process for generating and validating the enclave’s identity. The attestation process makes it possible to ensure only authorized code is running, as well as integration with the AWS Key Management Service (AWS KMS), so that only enclaves that you choose can access sensitive data. Nitro Enlaves enables customers to focus more on their application instead of worrying about integration with external services. While many enterprise use cases involve complex datasets, we’ll use a hypothetical scenario to learn the fundamentals of how this works. The example proof of concept (POC) application will be centered around a third-party bidding service for real estate transactions. Buyers will submit encrypted bids to the application. Once all the bids have been entered, the application will decrypt the bids, determine the highest bidder, and return a result without disclosing the actual bid amounts to any party.
How it works
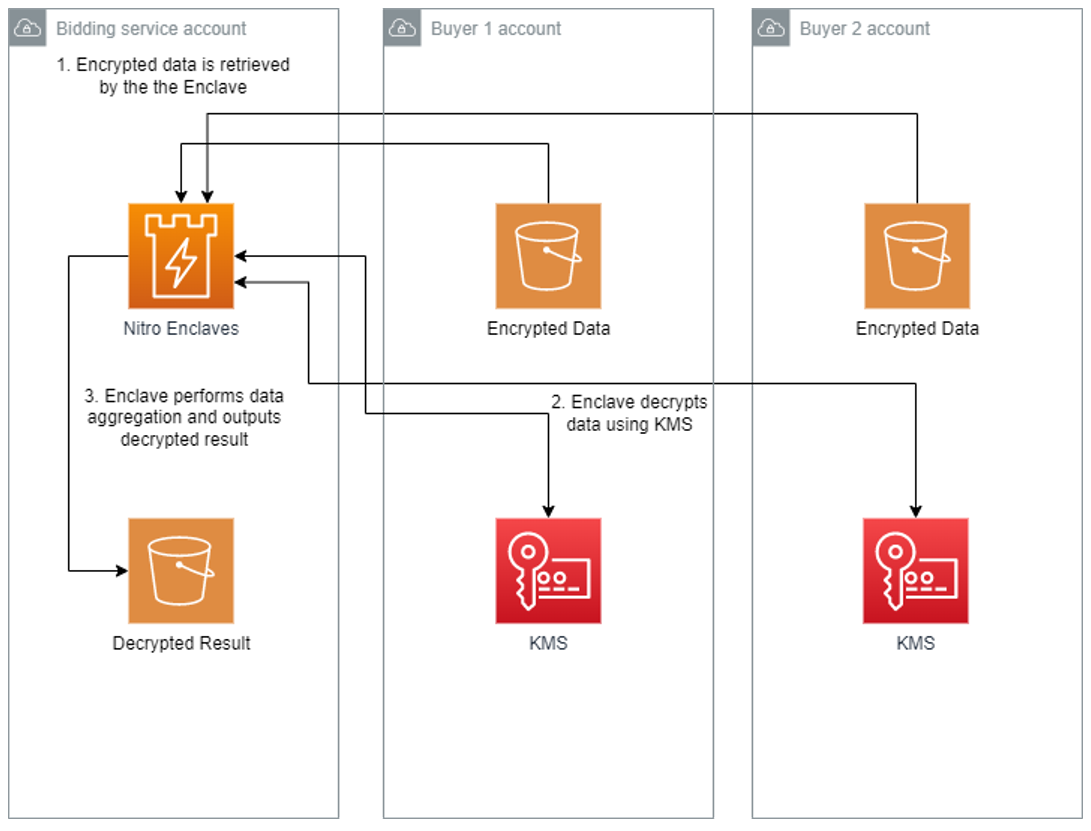
The POC will be deployed across three AWS accounts, one each for buyer-1, buyer-2, and the bidding service. The bidding service will be run in an enclave on the bidding service’s account.
- The bidding service will generate a set of measurements called platform configuration registers (PCRs) from the application code that uses the attestation process. PCRs are cryptographic measurements that are unique to an enclave. An attestation document can be used to verify the identity of the enclave and establish trust.
- The buyers will each generate their own AWS KMS key and use AWS KMS to authorize cryptographic requests from the bidding service enclave based on PCR values in the attestation document.
- The buyers will place their bids into a file, encrypt the file using AWS KMS, and store them in their own Amazon Simple Storage Service (Amazon S3)
- The bidding service will run the application, which will retrieve the encrypted bids from each buyer’s S3 bucket, decrypt the bids, calculate the highest bidder, and store the result in an S3 bucket.
Implementation
Let’s take a deeper dive into the steps involved in implementing this POC. To deploy the POC to your environment, follow the instructions in the AWS Nitro Enclaves Bidding Service GitHub project.
Enclave image generation
The first step is for the bidding service to launch the parent instance that will host the enclave. Refer to Launch the parent instance for more information about this process. The two real estate buyers, which we will call buyer-1 and buyer-2, will need to review the application code of the enclave application and agree that their data will not be exposed outside the enclave. Once they agree on the code, the bidding service generates the enclave image and a set of measurements as part of the attestation process. The buyers should also perform this process to ensure that the enclave image was generated and its measurements are from the agreed-upon application code. During the generation process, a unique set of measurements is taken of the application, which will make up its identity. When the enclave makes a request to decrypt data with AWS KMS, those measurements will be included in an attestation document to prove the enclave’s identity. Access policies in AWS KMS can then grant access to that identity. An example of a set of measurements is shown here:
Enclave Image successfully created.
{ "Measurements": { "HashAlgorithm": "Sha384 { ... }",
"PCR0":"287b24930a9f0fe14b01a71ecdc00d8be8fad90f9834d547158854b8279c74095c43f8d7f047714e98deb7903f20e3dd",
"PCR1":"aca6e62ffbf5f7deccac452d7f8cee1b94048faf62afc16c8ab68c9fed8c38010c73a669f9a36e596032f0b973d21895",
"PCR2":"0315f483ae1220b5e023d8c80ff1e135edcca277e70860c31f3003b36e3b2aaec5d043c9ce3a679e3bbd5b3b93b61d6f"
} }Preparing encrypted data
Each buyer will create an AWS KMS key and use that key to encrypt their bids. The encrypted bids will be stored in their respective S3 buckets. Because AWS KMS integrates with Nitro Enclaves to provide built-in attestation support, each buyer can add the PCR values generated earlier as a condition to their respective AWS KMS key policies. This will ensure that only the enclave application code agreed upon by both buyers will have access to utilize the keys for decryption. The following is an example of a KMS key policy with PCR values as a condition:
{
"Version": "2012-10-17",
"Id": "key-default-1",
"Statement": [{
"Sid": "Enable decrypt from enclave",
"Effect": "Allow",
"Principal": < PARENT INSTANCE ROLE ARN > ,
"Action": "kms:Decrypt",
"Resource": "",
"Condition": {
"StringEqualsIgnoreCase": {
"kms:RecipientAttestation:ImageSha384": "<PCR0 VALUE FROM BUILDING ENCLAVE IMAGE>",
"kms:RecipientAttestation:PCR1":"<PCR1 VALUE FROM BUILDING ENCLAVE IMAGE>",
"kms:RecipientAttestation:PCR2":"<PCR2 VALUE FROM BUILDING ENCLAVE IMAGE>"
}
}
}]
}The previous example only shows a key policy that uses PCR0, PCR1, and PCR2. You can further scope down the permissions by adding additional PCR values, for instance, role, parent instance ID, and a signing certificate for the enclave image. Refer to the AWS Nitro Enclaves User Guide for more details about PCR values.
Running the POC
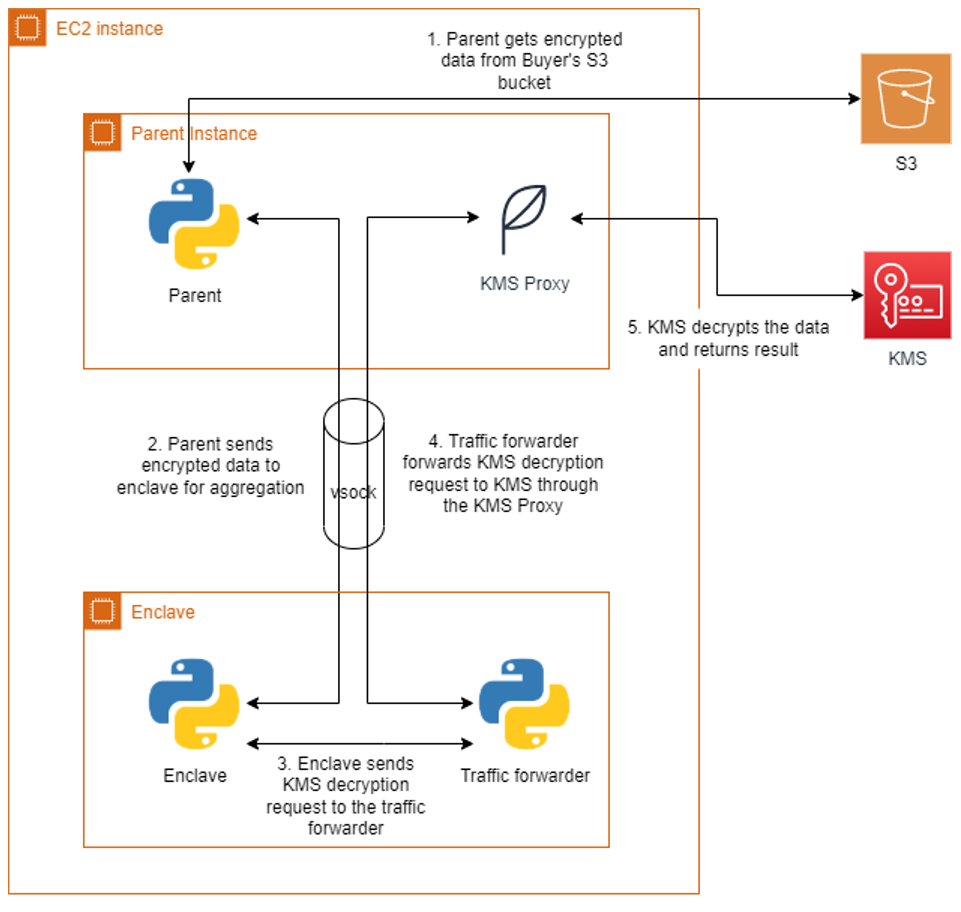
The bidding service will run the enclave image generated earlier on the parent instance. The application runs as two parts, one part on the parent instance and another in the enclave. Communication between the parent and the enclave is done through a vsock connection. An AWS KMS proxy is also used on the parent to allow communication between the enclave and AWS KMS for decrypting data. The parent application will retrieve the encrypted bids from each buyer’s S3 bucket and send them to the enclave. The enclave will decrypt the data using both buyers’ AWS KMS keys and present attestation documents signed by the Nitro Hypervisor. AWS KMS will validate that the PCR values in the attestation documents match the key policy before performing the decryption. The decryption event will be logged in AWS CloudTrail for auditing purposes. Once the encrypted bids are decrypted, the values are compared, and the winning buyer is recorded in the result. The unencrypted result is then returned to the parent and written to an S3 bucket in the bidding service’s account. A diagram of this process is shown in Figure 2.
Cleanup
Be sure you delete all the resources that were created when following the included Github project:
- Bidding service EC2 instance EC2 instance IAM role and policy
- AWS KMS Customer managed keys
- S3 Buckets for storing encrypted files
Conclusion
In this blog post, we introduced a sample POC utilizing Nitro Enclaves to allow a bidding service to process two parties’ encrypted data without revealing their data to any party. We did this by ensuring access to sensitive data is only allowed from an application running within an enclave. With the straightforward integration of AWS KMS and the attestation process, customers can quickly develop applications on Nitro Enclaves that can enable computing on encrypted datasets from multiple accounts. For more information on AWS Nitro Enclaves, see the official product documentation or the introductory videos on YouTube.