Although Grab is a tech company, not everyone is an engineer. Many team members don’t use GitLab daily, and Markdown’s quirks can be challenging for them. This made adopting the Docs-as-Code culture a hurdle, particularly for non-engineering teams responsible for key engineering-facing documents. In this article, we’ll discuss how we’ve streamlined the Docs-as-Code process for technical contributors, specifically non-engineers, who are not very familiar with GitLab and might face challenges with Markdown. For more on the benefits of the Docs-as-Code approach, check out this blog on the subject.
As part of our ongoing efforts to enhance the TechDocs experience, we’ve introduced a rich text editor for those who prefer a WYSIWYG (What You See Is What You Get) interface on top of a Git workflow, helping to simplify authoring. We’ll also cover how we plan to improve the workflow for non-engineering teams contributing to service and standalone documentation.
The need for a rich text editor
Ask any developer today, and they’ll likely tell you that Markdown is the go-to format for documentation. Due to its simplicity, whether it’s GitHub, GitLab, Bitbucket, or other platforms, Markdown has become the default choice, even for issue tracking. It’s also integrated into most text editors, like IntelliJ, VS Code, Vim, and Emacs, with handy plugins for syntax highlighting and previewing.
Engineers are gradually embracing the Docs-as-Code approach and enjoying the benefits of writing the documentation in Markdown format directly in their IDEs and pushing them out as merge requests (MR). However, non-engineers face the nuance of writing in Markdown and going through the Git workflow. This is when the call for a WYSIWYG (What You See Is What You Get) editor aka TechDocs editor came about. This solution brought about several benefits to non-engineers. It provides a familiar, UI-based experience for editing, but it still aligns with the Docs-as-Code model. This tool allows users to edit documentation via a simple UI in the Backstage portal without having to deal with the complexities of MkDocs, entity catalogs, or Markdown syntax. In the context Backstage, “entities” refer to services, platforms, tools, or libraries, and documentation is often tied to these entities to provide context sensitivity. The goal was to make it easy for people to focus on content, not the tools, and enable quick updates without the technical overhead.
We’ve kept GitLab as the central storage system, but now, with the TechDocs editor, non-engineers can contribute with ease. Figure 1 highlights our editor’s features:
Reordering
Renaming
Deleting pages
Switching between normal and Markdown views
Formatting text with titles, bullets, numbering
Figure 1: TechDocs editor in Helix TechDocs portal
Our goal for our editor is to make it more flexible, performant, and user-friendly. Based on user feedback, key priorities include customisation, extensibility for non-standard Markdown elements, and long-term maintainability.
To achieve this, we selected the Lexical framework. Compared to other Markdown-based tools like Toast UI, Lexical offers greater extensibility, allowing us to implement advanced features such as autocomplete and support for non-standard Markdown elements like Kroki diagrams.
The following flowchart illustrates how Markdown content is imported and exported within the Lexical editor, ensuring seamless integration with TechDocs.
Figure 2: Lexical Markdown transformer flow chart
By continuously iterating based on user needs, we aim to make Docs-as-Code accessible not just for engineers but for anyone contributing to documentation at Grab.
User journeys
We explored various workflows to streamline the documentation lifecycle, focusing on both creation and editing processes. By integrating these workflows into the developer portal, we ensured that users can easily create and edit documentation, enhancing overall efficiency and collaboration.
Here are the three key user journeys we focused on addressing:
Journey 1: Edit existing TechDocs
High level workflow definition:
Toggle to ‘edit’ mode: The user switches to the edit mode to start making changes to the TechDocs.
User starts editing TechDocs: The user begins the process of editing the documentation and clicks save.
User gets redirected to GitLab: If not authenticated, they are redirected to GitLab for authentication. Once authenticated, a merge request is created to update the entity YAML file and add the new TechDocs.
Access check: The system checks if the user has access to the TechDocs file repository. If not, they are prompted to request access.
Figure 3: User journey 1
Journey 2: Create stand-alone TechDocs from “Documentation” page
High level workflow definition:
User authentication:
If the user is not authenticated, they are redirected to GitLab for authentication.
If the user is already authenticated, the process skips to the next step.
Registering merge requests:
The MR is registered to a scheduler job to automatically register a new entity catalog when it detects that the MR has been merged.
This workflow ensures that users are authenticated via GitLab before proceeding and that new entity catalogs are automatically registered upon the merging of MRs.
Figure 4: User journey 2
Journey 3: Create TechDocs from “Docs” tab on entity page
High level workflow definition:
Start creating TechDocs:
User selects ‘create TechDocs’ on the ‘Docs’ tab in the Helix TechDocs portal UI.
Save and redirect:
User clicks ‘save’ and is redirected to GitLab with a merge request (MR) created to update the entity YAML file and add new TechDocs.
Access check and MR registration:
If the user has access to the entity YAML file repository, proceed with the MR. If not, prompt the user to get access.
Register the MR to a scheduler job to automatically refresh the entity catalog when it detects the MR as merged.
Figure 5: User journey 3
Phased rollout
We phased the rollout of our Markdown editor to ensure a smooth transition, allowing users to gradually adapt while we gathered feedback and iterated on features. This approach helped us address challenges early, refine usability, and deliver meaningful improvements with each phase.
Phase 1: Initial Markdown editor for developer portal
In Phase 1, we built a basic editor aligned with our documentation standards. Users can create and edit TechDocs for different entity catalogs, with support for basic Markdown and image previews for both absolute and relative paths. The editor tracks concurrent editing sessions and shows pending merge requests. It also includes Markdown configuration options to add, rename, reorganise, or delete pages. Additionally, our GitLab integration consolidates changes into a single commit and opens a merge request.
Phase 2: Independent documentation creation
Phase 2 includes expanded functionality to support independent documentation creation and related features, such as:
HTML preview and image uploads (relative paths).
Save drafts locally in the browser.
Pending MRs listed in the editor.
Draw.io and Excalidraw integration for diagrams.
MkDocs updates: change site name.
Auto-registeration of new entity catalogs when MRs are merged.
Phase 3: Advanced editor capabilities
Phase 3 introduced additional features, such as:
Support for Kroki / Mermaid diagrams.
Display concurrent edit sessions for better collaboration.
Each phase improved the editor, enhancing TechDocs at Grab with seamless GitLab integration and user-friendly features.
Integrating the ability to do a live preview
While syntax highlighting in the TechDocs editor is helpful, it can’t fully predict how the final Markdown document will appear once rendered due to Markdown flavour inconsistencies. This is especially true for elements like images, tables, and diagrams, where visual verification is crucial. To minimise these risks, the TechDocs editor includes a live preview feature, allowing users to see the fully rendered document alongside the editor in a split-screen view. This lets users verify their work as they go, preventing the need to switch back and forth between the editor and the final document, saving time and reducing potential formatting errors.
However, like most live preview features, performance challenges can arise. For larger documents, the process of continuously converting Markdown to HTML can slow down editing. External resources such as images that need to be re-rendered, can cause visual glitches or delays in the preview. Running scripts or using plugins with extended grammar also adds to the performance load, requiring frequent re-execution and potentially slowing down the experience.
To mitigate these issues, the TechDocs editor uses an inbuilt preview feature that shows users exactly how their changes are going to appear on the portal once their changes are merged. This ensures that users can confidently make adjustments and understand the final presentation before committing their updates. Additionally, the live preview feature enables more efficient collaboration by providing real-time feedback on content and formatting, further enhancing the overall documentation workflow.
GitLab integration strategy
The TechDocs editor integrates seamlessly with GitLab, allowing users to make changes effortlessly through OAuth2 authentication. When users log into the editor, they simply click the “Connect with GitLab” button, which provides access via the OAuth 2.0 protocol. Once connected, all modifications made within the editor are executed using the user’s GitLab credentials, streamlining the documentation process and ensuring a smooth experience for users as they update their documentation directly within the TechDocs framework.
To minimise Git conflicts, we considered and implemented some of these approaches:
Display pending merge requests at the top of the editor to alert users of existing changes.
Show who else is editing the same TechDocs to help users coordinate and avoid conflicts.
Include tools to automatically or semi-automatically resolve Git conflicts.
Conclusion
Bringing Docs-as-Code to a broader audience at Grab meant addressing the challenges faced by non-engineering contributors. With the introduction of a WYSIWYG editor, seamless GitLab integration, and a live preview feature, we’ve made it easier for everyone to contribute without needing deep Markdown expertise.
As we continue to improve the TechDocs editor, our focus remains on removing barriers to documentation, enhancing collaboration, and ensuring that our docs evolve alongside our fast-moving engineering teams.
Docs-as-Code isn’t just about engineers writing documentation—it’s about making documentation a natural and frictionless part of the development process for everyone.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Changing how a company approaches writing and documentation is a complex task. It’s not just about the tools and processes—it’s about shifting the mindset of the people who create and use documentation. Building a strong documentation culture means ensuring everyone takes ownership of producing high-quality content, while making the tools easy to use for everyone involved.
At Grab, our first significant step was adopting the Docs-as-Code approach, which we’ve covered in the blog Embracing a Docs-as-Code approach. This method integrated documentation into the engineering workflow, allowing teams to create and update content effortlessly.
Since then, the TechDocs working group — a collaboration between Tech Learning and the internal development team — has focused not just on improving tools, but on fostering a mindset where documentation is an essential part of everyday work. In this post, let us dive into how we’ve continued to embed high-quality documentation into the core of Grab’s engineering culture.
What is TechDocs?
Helix is Grab’s engineering platform designed to unify infrastructure, tooling, services, and documentation into a single, consistent user interface. It serves as a central hub for managing various engineering tasks and resources within Grab. Helix provides a comprehensive set of guides and tools for users.
TechDocs is an internal documentation platform built on Helix and integrates with our Docs-as-Code approach. It allows engineering teams to create, manage, and access technical content seamlessly within their workflows. TechDocs makes it easier for teams to maintain up-to-date, high-quality documentation with customised features for notification and editing.
How to create a healthy documentation culture
Over a span of 2 to 3 years, the TechDocs team executed these key steps in quarterly chunks to influence Grab’s documentation culture as seen in figure 1.
Figure 1: Key steps in influencing documentation culture in Grab
Take inventory: Assess current internal processes, tools, and user behaviour.
Finalise policy: Establish a clear policy, enforce it, and iterate based on feedback.
Empower teams: Equip creators and maintainers with tools to manage their documentation.
Take inventory: Assess existing internal processes and tools/portals and understand user behaviour
Understanding the current culture
To shift the documentation culture at a company, you need to first understand what that culture is. At Grab, with its diverse business units, tech teams, and varied documentation practices, just grasping this was a big step. We needed to look at it from two angles: how teams and business units approach documentation, and what portals hold what kinds of resources.
Here are a few observations that apply not just to Grab but to most tech companies:
People default to the easiest way to get information, either by asking someone or searching familiar places. If they can’t find a document quickly, they assume it doesn’t exist.
Different teams use different documentation tools, leading to scattered, hard-to-maintain content. Without a unified search, finding the right document is a challenge.
Documentation is often created during development but rarely maintained, resulting in outdated or duplicate content over time.
Lack of clear ownership and governance causes inconsistencies, making it harder to trust or rely on documentation.
Conducting extensive user research
The insights on understanding the culture of documentation were obtained from conducting extensive feedback-gathering activities. We adopted two separate strategies for user research:
The first focused on gathering feedback from as many people as possible. We scaled this approach to reach a wide audience across multiple teams and departments. To manage this volume, we used closed-ended questions with multiple-choice options, allowing us to collect broad, organisation-wide insights on user needs and preferences.
The second approach was more in-depth and personal. We conducted 1:1 sessions where we observed how users interacted with tools, asked open-ended questions, and dug into the reasons behind their behaviors. This helped us understand not just what users did, but why and how they did it.
From the first approach, we were able to gather that users frequently browse for Runbooks, how-to’s, and FAQs when it comes to technical documentation. They emphasise structure, ease of navigation, and up-to-date content when it comes to quality.
Based on the feedback, only 2% of engineers (1 out of 56) reported that 80-100% of on-call engineering questions were resolved using technical documentation. In contrast, 29% of engineers indicated that 40-60% of their questions were addressed through documentation, while 25% stated that 20-40% were resolved in this manner.
To improve the documentation and Docs-as-Code workflows for seamless integration of documentation into the engineering process, we built the TechDocs Editor on the Helix platform. This rich text editor allowed teams to write and maintain their documents more effectively. However, while many engineers appreciated the new features, they highlighted areas for improvement for a smoother experience. Key suggestions included enhancing the creation of merge requests (MRs), resolving conflicts more efficiently, and offering an auto-approval process. They also wanted a way to preview content before MR approval, capabilities like bulk migration, and integration options such as plugins for Jira and *Confluence wiki. Additionally, there was a call to increase clarity on what content should belong in TechDocs versus the Wiki.
Rooting TechDocs tool’s improvements in the user’s feedback
Based on the feedback received from the extensive user research, the TechDocs tool’s new features were planned and lined up based on a priority mapping that was entirely rooted in the feedback from user research and interviews. While not all feedback was directly implementable in terms of tool improvements, a significant amount was. For issues that couldn’t be resolved through tools, cultural changes and learning best practices became key to addressing the challenges.
Here are insights from the 1-1 user research that helped us enhance the TechDocs tools and processes:
Search experience is average. The search experience on the TechDocs portal has room for improvement, with a CSAT score of 58.57%. Some users prefer using a more centralised search option, as it searches across multiple platforms and offers more relevant results, especially considering gaps in documentation on the internal TechDocs portal.
Documentation landing page needs improvement. The Documentation landing page scored 10.71% CSAT, highlighting its need for better design and categorisation. Users found the page cluttered, and the categorisation was seen as random and confusing.
Reading experience is positive. Overall, users are satisfied with reading documentation on Helix, with an 88.31% CSAT for reading experience. Users appreciated the navigation’s organisation and structure. Suggestions for further improvement include:
Better table content display
Maximising content space
Enhancing color contrast
TechDocs adoption still faces challenges. Although TechDocs adoption has grown, several challenges remain:
Migration efforts: The migration process requires significant effort, and without support or a clear push, some employees do not see the need to migrate.
Cultural factors: Users continue using familiar platforms and are looking for incentives, such as unique Helix features, to consider making the move.
Accessibility: VPN access is required for some features.
Awareness: Many users are unaware of Helix TechDocs’ full range of features, such as the different search options, available search filters, and commenting capabilities.
Cross-team collaboration challenges: Users reported difficulties in collaborating with non-engineering roles. While engineers are comfortable with the Docs-as-Code approach, which allows for more flexibility and simplicity, some find the TechDocs editor useful for initial document creation or small edits.
Using this feedback, the product roadmap was set for the year to focus on addressing the top user complaints and improving the TechDocs tools accordingly.
Finalise a suitable policy and begin enforcing it. Collect feedback and reiterate
To improve discoverability and maintain consistency, we established a structured policy for organising documents. This policy ensures that documentation is stored in the right place based on its purpose and usage, making it easier for Grabbers to find what they need. The key guidelines are as follows:
Markdown for ‘create and publish’ type content: Documentation related to platforms, products, or services that don’t require frequent updates should be in markdown format and stored in GitLab. These documents were rendered in Helix.
Collaborative portals for collaborative docs: Time-sensitive and collaborative documents—such as postmortems, RFCs, design docs, and project plans— are not compatible with docs-as-code and hence should reside in portals that offer collaboration features, like easy commenting and multi-user editing. Dedicated spaces within Confluence Wiki are ideal for this purpose.
Separation of internal data: Internal documents meant only for specific teams should not mix with general engineering resources for end users. These can be stored in portals with less stringent review processes, as they don’t require the same level of quality or accuracy checks. Team-specific spaces on Confluence Wiki can serve this need effectively.
Empower creators and maintainers to self-serve documentation upkeep
More documentation doesn’t mean good documentation
Getting people to create documentation is one thing, but getting them to maintain and update it is a whole different challenge. One major issue is the lack of accountability. Without a clear owning team or point of contact (PIC) for a document, everyone assumes someone else will handle updates. This leads to stale, outdated information because no one takes responsibility. To address this, the TechDocs team introduced features like showing the “last updated” date on each page and flagging documents that hadn’t been updated in over three months. This approach helped in two ways:
Readers could quickly gauge how up-to-date the information was.
Content owners were reminded when their documents needed attention.
Another key strategy was requiring every document to have a dedicated PIC at the time of creation. This ensured:
Clear accountability for maintaining the document.
The PIC would receive notifications about outdated documents and any comments from readers, making it easier to address issues.
What about docs that are not really meant to be updated that frequently?
When building any feature, it’s important to consider different use cases. While flagging outdated documents helped maintainers keep track of their content, it could also frustrate those responsible for more static documents that don’t require frequent updates.
To make the “last updated” feature more relevant, we introduced an option for users to mark documents as “verified.” This allowed maintainers to turn off the “your doc is outdated” flag if they felt the information was still accurate. While this feature could be misused in an extremely large organisation, it worked well at Grab where internal products and employees generally rely on mutual trust and respect for maintaining simple systems and policies.
Training and info-typing workshops
The TechDocs team had a unique advantage in influencing the quality of internal product and platform documentation. Many of the creators and maintainers of these documents belonged to the same organisation, which allowed for smoother collaboration.
To elevate the quality of TechDocs, we recognised that improving the drafts produced by platform engineers was essential. This realisation led us to create self-paced training materials focused on information typing guidelines and writing best practices specifically designed for these engineers, which included:
Info-typing guidelines: Helping engineers categorise information for better clarity.
Writing best practices: Teaching techniques to enhance readability and engagement.
Building on the positive feedback from the training course, we launched interactive workshops. In these sessions, participants brought their own team’s user-facing documentation, and with the guidance of expert Tech Content Developers (TCDs), they made significant, live updates to their documents using the info-typing principles they had learned. This process enabled participants to:
Revise their documents: Make real-time improvements during the workshop.
Receive expert feedback: Gain insights from TCDs on enhancing document quality.
The workshops received outstanding feedback and were further refined to cater to the specific needs of each team, ensuring that the training remained relevant and effective for the different documentation sets they managed. By focusing on collaboration and practical learning, we were able to foster a culture of continuous improvement in our documentation practices.
Track metrics, celebrate wins. Recognise and repeat.
Recognising teams and individuals who follow best practices is key to sustaining momentum. We celebrated these wins by publicly acknowledging contributions in newsletters and internal communications, along with offering swag and rewards. Additionally, we tracked the accuracy of responses from oncall-bots, which use documentation to auto-respond to user queries on our internal communicator. By analysing whether these automated responses were accurate, we could assess the quality of the docs being referenced. Teams that kept their documentation up-to-date and adhered to our internal TechDocs policy were rewarded, further reinforcing these good practices.
Celebrating wins wasn’t a one-off—it became a regular practice, helping to solidify desired behaviors and create a cycle of continuous improvement.
What’s next
Looking ahead, we have some exciting goals to push the documentation culture even further:
Boost documentation quality: We’re aiming to improve the quality of platform docs by a significant percentage, which will help reduce support tickets and inquiries to the automated tech support bot.
Expand training: We’re ramping up training for more engineers, helping them sharpen their tech writing skills and aiming for top CSAT ratings.
Launch improved TechDocs portal: Our goal is to build better and more intuitive navigation and categorisation of content for an improved user experience.
User interviews and engagement: We’ll be working closely with champions and users across tech families to create an open feedback loop.
Enhance doc creation and editing workflows: We’ll streamline the process of creating and editing content using templates and native tools with consistent Markdown flavour usage.
Join us
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
Welcome to Monday Night Itch, a harebrained scheme to encourage folks to play more non-AAA games by adding a touch of social gamification. I thought I would be tweeting my adventures here, but I just had an experience so profound it can only be captured within a blog post.
Every Monday, find a game on itch.io, and pay at least $2 for it.
You can buy a game with a price tag, or download a free game and leave a tip, but the point of this endeavor is to put money into more places in the ecosystem. (Note that it is possible, though uncommon, for a developer to disable payments altogether.)
Play it.
Leave a nice comment.
Tell at least one person what you played, and what you thought about it.
That’s it. Buy a game, play it, tell someone about it. You can stream it, tweet it, screenshot it, or just tell your boyfriend about it. You don’t have to like it
Your score is how many times you’ve done this, and your streak is how many weeks you’ve done it in a row.
The itch app is cool. It’s a pretty thin wrapper around the website, but it adds automatic updating and big red “Launch” buttons and other stuff to make it feel a bit more like a Steam-ish thing. Do keep in mind that devs can upload whatever they want, and sometimes the itch app gets confused.
If you’re not a fan of running mystery software you downloaded from the Internet, you can just play web games and leave tips on those.
There are a lot of NSFW games on itch, but they’re hidden from the main browse pages by default. You can enable them site-wide in your user settings, or add /nsfw to the end of a browse page URL (for example, https://itch.io/games → https://itch.io/games/nsfw) to force a list of onlyNSFW games.
I decided I wanted to reward Linux releases, and also chip a few bucks towards games with a price tag that aren’t necessarily getting much exposure, so I went to the full list of recent paid Linux games. This is how I discovered Mystery Trap Adventure.
I found myself very much wanting to play this, but I also found myself wondering what sort of impact I should be trying for as the very first iteration of this project. Would I torpedo it if I played a game made by a less experienced dev? Are people looking to this expecting me to uncover unknown indie gems, like I’m wandering a beach with a metal detector?
I checked the dev’s itch profile and this is their ninth project. Every single previous work of their has only a single comment: from them, announcing that comments can be left below. That’s heartbreaking to me, and what made me absolutely sure I wanted to play this. I want to make their day.
And then, dear reader, I felt ashamed. Because who the fuck cares. The world already has enough people who believe that indie games are only valuable if they create the illusion of an eight-digit budget, and I am not here to enable them. Creative work does not need to be polished, mass-appeal, least common denominator stuff handed down from heaven by a billion-dollar international corporation in order to be interesting or worthwhile.
But more importantly, it’s my thing and I’m gonna do whatever the hell I want.
And so, Mystery Trap Adventure.
The first thing to note is that the game does not, in fact, have a Linux release. I did strongly suspect this, since a single download is flagged as all of Windows, Mac, and Linux, but the only way to be sure was to buy it. (They’re asking $4; I paid them $10.) Even Wine had trouble with it, for some reason, so I had to play it on our Windows media center.
It’s a sidescrolling platformer where you play as a dragon; you can jump about one tile high (roughly your own height) and shoot fireballs (useful for destroying bricks and defeating the boss). The main obstacle is spikes, which kill you instantly.
Right at the beginning, there’s a block you have to jump on top of, and it was very obvious that I sort of “stuck” to the side of it if I touched it. I thought at first that this was the result of a common platforming gotcha: if you model the player as a dynamic body and implement movement (including air control) as a force on them, then they will stick to walls as long as the corresponding direction is held. This happens because forces on dynamic bodies are external, as though a giant ghost hand were pushing them — so if a player is trying to air control into a wall, the friction against the wall will hold them in place, just as if you were holding a book against a wall with your hand.
(Solving that problem is beyond the scope of this post, sorry.)
Okay, common pitfall, no big deal. I wander ahead a bit. I encounter a slice of watermelon, which allows me to teleport a short distance once. I screw this up the first time while messing with the controls — there’s a wall directly in front of it, so the teleport must be used to skip past that wall — and have to restart.
Now something interesting happens. I’m in a pit with walls on both sides. I can’t teleport again, and even if I could, there are spikes beyond the next wall, so that would kill me immediately.
It dawns on me that this microscopic game has walljumping.
I’m still fairly certain that the player character is a dynamic body, but now I wonder: is the wall stickiness actually due to the friction interaction, or is it a deliberate feature to enable walljumping?
Or, perhaps more likely, is it both? Did the developer trip over this pitfall, and decide to make a gameplay feature out of it? It almost seems unbelievable. I wouldn’t consider walljumping a basic platforming ability, and it’s not obvious how to solve the friction problem, but it seems that this relatively new developer may have solved both problems by simply smashing them together.
And if that’s the case, dearest reader: I fucking love it. That is the true spirit of game development, I think — you have a big complicated simulation you want to make, and you have a big complicated engine that you want to make do it, and you have to kinda mold both of them into fitting better with the other.
I don’t know. I could be completely wrong about this came to be. Or they could have copy/pasted from someone else who had this idea. Either way, it made me smile to see.
The walljumping controls are, ahem, not exactly intuitive, which is why it took me nonzero time to realize it was an ability at all. But honestly, I liked that too. Nowadays, everyone knows exactly how every platforming ability is “supposed” to work, because devs are all copying the same ideas from each other that have been refined over a thousand different iterations. This reminded me of playing games in the early and mid 90s, before everything had standardized as much, when part of the game itself was just working out the right muscle memory to make the right things happen. It’s surprising to find nostalgia in a game because it’s not like others I’ve played before, but there it was. Working out the right timing without any visual cues felt like a puzzle in itself, and getting out of the pit without landing in the spikes was remarkably satisfying. (If it helps: I used different hands for movement and jumping, and I landed on top of the right wall before trying to jump over the spikes.)
Beyond this, the tone changes somewhat to IWBTG-esque traps with no telegraphing. Walking directly to the right will cause spikes to appear from the ground, killing you instantly. Thankfully there aren’t too many of these, and the game is very short, so simply memorizing the handful of places they appear is easy enough.
I have less to say about the rest of the game; you get another quirky powerup you only use once, dodge another couple surprise traps, and face a single boss. The boss is a very large human warrior dude who walks straight at you and swings his sword, which kills you. There’s another fruit above you, but it seems out of reach. He is definitely too tall to jump over. The only solution I found is to simply spam fireballs at him before he can reach you, but I don’t know if this is intended. It seems like it can’t be, since his “health bar” takes the form of a grid of his face behind him, and from where you enter the area, you can’t actually see the whole grid? So surely I’m supposed to be able to get further to the right? But I don’t know.
I finished the game and came back to the following reply to my original thread about this whole concept:
most, i.e. all, small Indy games are terrible.
What a snotty, entitled, mean-spirited sentiment. As if the very existence of a game with lower production values than Resident Evil 8 were a personal offense. It seems to be fairly common, too, and I just do not understand it. Small indie games aren’t trying to squeeze you for more money, lure you in with gambling, exploit your friendships, make your entire life revolve around them. They’re just there.
This attitude is like showing up to everyone who mentions YouTube just to proclaim that everything on it sucks, because Paramount movies are better. That’s great, no one asked! Sometimes I just want to see a seven-second clip of a kitten filmed in a dark room by a $20 phone, because dammit, kittens are still fun to watch. No one makes a point of dunking on videos like that, so I don’t know why anyone is so harsh on amateur games either. Especially when making games is so much more difficult!
Mystery Trap Adventure is that video. Someone had an idea, worked out how to express it, and put it out into the world just because they wanted to. I don’t expect anyone else to buy it or play it; I just want you to know that I did, and it made me smile for a few minutes.
A Chronicling of the Lyfe and Times of one Miss Pearl Twig Woods, who has Passed at a Young Age from Troubles of the Heart. She is survived by Anise, her Arch Nemesis; Cheeseball, her Adoptive Ruffian; and Napoleon, her Star-Crossed Suitor for Whom she Longed from Afar.
Pearl is… difficult to describe. She had such a strong, vibrant personality.
She was lovely, that’s for certain. She loved everyone she met. And while various people — friends, vets, etc. — have met our cats and always liked them, I don’t believe anyone has met Pearl and not adored her. Anise will check out your stuff and perhaps jump on you; Cheeseball will do antics for you and rub on your leg; but Pearl would accept you into her life and be very directly, personally affectionate with you specifically. She made you feel special.
At the same time, she was very fussy, very particular, and had a very strong sense of… her place in the world, I suppose. If she liked something, she would be having it. If she didn’t like something, she would make that exceptionally clear. She was never mean, but she would be very vocal about her boundaries.
It wasn’t uncommon to wake up to Pearl repeatedly headbutting me right in the face, pressing her head up under my chin, or giving me a nuzzle with the entire length of her body, purring all the while. If she was happy to see you, she made an entire production out of it. It wasn’t just us; guests who slept on the couch also got the Pearl wake-up call.
It was also not uncommon to wake up because Pearl had decided that she needed my pillow, and somehow this very small cat took up the entire thing. I couldn’t move her; trying to displace her from a comfortable spot would generally earn you a sad, offended meow, after which you felt guilty for even having entertained the notion in the first place.
One of her particular quirks was to often “bury” her food when she was done with it, or at least paw fruitlessly at nearby carpet. On its own, this is endearing but not unusual — burying leftovers is a common cat instinct, even if we’ve not seen it in our other cats. What made it a uniquely Pearl trait was that she would also perform this ritual if offered something she didn’t want at all. I laughed every time; it was such an audacious way to indicate utter disinterest. Take it away, please. Put it in a hole, if you would.
She got, more or less, everything she wanted. If she claimed a spot, everything about her expression and body language indicated it was clearly hers, even if that spot was your body. (Naturally, if you moved too much or even sneezed suddenly, she would tell you off for that too.) If she wanted to ride on your shoulders, that’s what would be happening. If it was time to feed her and she was too comfortable in her cat tree, well, we’d just have to hold the food up for her. She had a way of looking very pleased with herself that was impossible to argue with.
I first met Pearl in 2014, shortly after we moved to Las Vegas. She was tiny, even for a kitten, and apparently the runt of her litter. I don’t remember what specifically compelled Ash to adopt another cat, except that they love cats, but what a selection.
I cannot stress enough how small she was. You know those solid wood desks that have a column of drawers built into them on one side? You know how they often have a little decorative shape carved out at the bottom with molded edges? Pearl could crawl into that space. I couldn’t believe it the first time I saw it; the gap is so short that I’d never even thought to categorize it as a space, let alone one a cat might enter, but she slunk into it like it was nothing. I was so worried we’d have to move the desk somehow to get her out, but she usually turned around and came right out again. I still remember the very last time she did it — I could tell she was having to shimmy a bit to fit in there, and she must have noticed too, because I never saw her even try it again.
The other cats had somewhat mixed feelings. Napoleon didn’t like her at all and hissed directly in her face, but… after that, I don’t remember any bad reactions from him at all, so I guess he warmed up quick. Anise did not seem to understand what a kitten was, tried to play with her, and then acted very confused when that didn’t seem to work. And Twigs…
Oh, Twigs. Twigs was jealous. He had always been Ash’s cat, he had made himself Ash’s cat, and he very quickly inferred that Pearl was a threat to his position. Another cat! In Ash’s lap! Unthinkable!
On one particular night Ash had barred Twigs from the bedroom to sleep with just Pearl, but came downstairs to visit the kitchen. Twigs ran up to them, looked them dead in the eye, and let out a huge sad wail to convey his feelings about the depths of this betrayal.
They let him into the bedroom after that, but he opted to sit across the room and stare daggers at Pearl, moving a little closer every half hour until he was on the far corner of the bed. Just staring.
Ash eventually had to bribe him by putting some cottage cheese on Pearl’s head, after which he decided Pearl was okay. Also he found out that he could fit himself in Ash’s lap alongside Pearl, so that probably helped.
Oh, and she loved to be cozy. She loved to be cozy. Sphynxes are naturally drawn to warmth, of course, but Pearl elevated it to an artform. If I’m propped up in bed, Anise might stand next to me to look at the covers expectantly, or he might just lay down nearby. Pearl would stand right on top of me and pull at the covers with impressive force until I lifted them for her, let her lay on my chest, and tucked her in.
We’d often find Pearl very awkwardly tucked under the edge of a blanket somewhere, having attempted to insert herself beneath it with mixed success. We described this as Pearl doing it all by herself, and complimented her on how talented she was, and then fixed the blanket for her.
We have heater vents in the floor, and one of her favorite pastimes was to sit on one of those, often covering the entire thing, and be gently toasted from below. Sometimes Anise would see what a great idea that was and try to share it and they would end up squabbling.
If there was a sunbeam to be found, Pearl would find it. Much like with vents, she didn’t like to share sunbeams, even if they were half the width of the room. She found it first, you see.
Other places she discovered that were lovely and toasty included: in front of the fridge where the warm air vented out from the bottom; straddling the PS4 so the fan blew onto her tummy; next to or underneath my laptop; on top of my computer case which has a fan vent on top; in front of the heat dish we got while our furnace wasn’t working; and in a laundry hamper full of freshly-dried laundry.
She liked to go outside, too, during the summer. All of our cats are indoor-only, but once in a while we’ll take the more well-behaved ones (not Cheeseball) into the backyard to wander around on the porch and sniff things and enjoy the sun and look at a bird.
And I have never known a cat to be quite so comfortable. Perhaps Anise, on occasion, but he doesn’t have the raw talent Pearl was born with.
You could tell she was settling in if she tucked her paws in against her chest, something she always did quite deliberately and distinctly. But that was only the first stage of comfort. If you were lucky, she would stretch out one arm really far, perhaps to place her paw on you. As she dozed off she might lay flat on her side with her limbs outstretched, which meant we always had to check blankets carefully for a flattened Pearl before sitting down. And if you were really lucky, you might witness Pearl in a chaos configuration, upside-down with her paws wherever.
But even just sitting up with her eyes closed, she looked so content. Looking at photos makes me want to take a nap with her.
Sadly, Pearl had some health troubles from the start. She had a kink right at the base of her tail from the day we got her, suggesting it had been injured while at the breeder and not healed right, so she was never able to raise her tail all the way. She also came home with some sort of intestinal parasite that gave her a lot of… um, gastric distress, and while we were able to clear that up quickly, it seemed to recur soon afterwards.
We took her to the vet again, suspecting more parasites, but multiple tests turned up nothing. We tried a number of things — different food, sensitive-stomach food, wet food, more water, different treats — but could not seem to figure it out, and so Pearl just had stomachaches on and off for a while. Sometimes she would sit by the litterbox and grumble, and all I could do was try to reassure her.
It wasn’t until a few years later that Ash’s then-husband, with no explanation whatsoever, spontaneously decided to just feed her some plain chicken mixed with pumpkin purée. Just like that, she was fine. I felt like kind of an idiot for not trying that earlier, but after giving her veterinary sensitive-stomach food and seeing no change, I thought we’d ruled out food sensitivity.
We swiftly outlined a general idea of what Pearl could or could not tolerate. Chicken, pork, pumpkin: OK. Beef or any kind of organs: she immediately threw up. Fish: no good. And yet manufactured food containing only very simple things still gave her stomachaches, so our best guess was that she also couldn’t tolerate fucking xantham gum or something, which is in pretty much all pet food, including the sensitive stuff.
Regardless, we had a diet she could stomach, so for the rest of her life we made her a custom diet of ground chicken, ground pork belly, pumpkin, and some nutrient powder that didn’t bother her (which took several attempts to find). That meant no more free-feeding the other cats, so we got a big dog cage to keep the kibble in, and we’d let the other cats in there while Pearl was eating her special princess food. Thus began a multi-year saga during which, every four hours, like clockwork, Anise would start bothering me to feed him.
Please do not tell me what I could have done to dissuade Anise or space out the schedule. I guarantee, he is vastly more dastardly and annoying than you are giving him credit for. The cats run this household, and I have long since made peace with that.
The closest to any real insight we got about Pearl was that perhaps her kitten parasites had left her with IBS — a very vague diagnosis of exclusion, and the best anyone could come up with. But Pearl was happy, so that was good enough. We eventually found new treats she could stomach, too.
Pearl had relatively intense relationships with the other cats, much like she did with people.
She adored Napoleon, our furred and largest cat, for some reason. She often trotted up to him, very eager to sniff him; or when he trotted towards the kibble cage in recent years, she would run alongside him, staring sideways at him. I don’t really understand what her feelings were, and Napoleon didn’t really return them, but he at least tolerated them. Curiously, I can’t remember many attempts on Pearl’s part to snuggle up to Napoleon; she mostly snuggled with the other sphynxes.
She and Twigs (her uncle, incidentally) spent a ton of time together, and Anise was often in the mix as well. They’d often end up in a pile under or within a blanket, or all wedged into the same cat bed, or piled on a chair that had a towel on it. Sometimes she’d grumble at Anise for being too much in her personal space, but somehow Twigs’s presence seemed to defuse everything. I can’t remember her ever grumbling at Twigs, in fact.
Cheeseball is the only cat we have who’s younger than Pearl. When he was a kitten, she kind of doted on him like a mom, frequently trying to groom his head. She kept doing this into his adolescence, even as he was swiftly growing bigger than her, which was endearing and also very funny.
We moved in 2018, and spent the summer with a former acquaintance’s parents, as they had a finished and furnished basement that was practically an apartment all on its own. Unfortunately, they had four cats of their own, for a total of nine crammed into a relatively small space. (One of the parents couldn’t be around cat hair in the medium term, due to reasons.)
One of the cats, Seamus, was a maine coon, and by all accounts kind of an asshole. He made a habit out of chasing Napoleon around, which Napoleon did not like at all, and which would result in Pearl chasing him to defend Napoleon, and then Anise chasing after Pearl because everyone is running around and he doesn’t quite understand why but he doesn’t want to be left out. We kept the cats separated as best we could, but we didn’t have much space to work with, and we were already trying to sequester Cheeseball, who we’d just adopted as a kitten. Everything was just kind of a mess.
Anyway this kinda stressed everyone out.
I bring it up because of one particular event. The only segregated parts of the basement were the bathroom and a somewhat awkwardly-shaped bedroom. The bedroom was exclusively for our cats. I don’t remember exactly what led up to this, but at some point Seamus made a beeline for the bedroom while Pearl was just inside the open door. I’m guessing Napoleon was in there too.
Pearl was absolutely not having this. She stood her ground and hissed hard enough to stop this absolutely massive cat in his tracks. She was so mad that she peed on the floor (which was, thankfully, vinyl). We got there to intervene about half a second later, but wow! She drew a line in the sand and under no circumstances was this bully going to cross it. We have always looked back fondly upon this “rage piss” incident.
I think Pearl was left a little rattled, though. Even at the time, she growled at the other maine coon there, who was an absolute sweetheart and rarely did more than sit nicely and ask to be pet. Once we were out of there, she seemed a little distrusting of Anise, often growling at him or biting his haunch merely for sitting nearby (which would entice a bewildered Anise into smacking her, justifying her reaction). I wish we hadn’t stayed there.
Cheeseball was also growing up and wanted to play with Pearl, because playing is how he engages with pretty much everything; alas, he was a bit too rowdy for Pearl. Twigs, infinitely patient, was there to absorb a lot of this.
But then Twigs died, and the cats’ relationships seemed to deteriorate. Cheeseball liked Pearl, but he always wanted to fight with her, which she didn’t like. Anise liked Pearl, but she seemed to resent him a lot of the time, and there was no Twigs to separate them. Pearl liked Napoleon, but Napoleon liked to be by himself.
It was okay, but tense.
Maybe I’m overstating this. Going back through photos of Pearl, I’ve found plenty from the post-Twigs era where she’s still hanging out with Anise peacefully. A number of their conflicts even started because she would approach Anise to sit by him, then growl at him. No wonder he was confused. Sometimes she would groom him and start growling, while licking his ear. Hello? What are you doing?? What do you want from him here.
Still, that must mean she still liked him. She just had some complicated feelings. It always made me a little sad when they couldn’t get along, though. I’d gotten Anise in the first place in part to give Twigs a friend, and Pearl and Twigs had always gotten along well, and now… well.
Having said all this about how great and lovely Pearl is, her presumptuousness also made her a huge pest in some very specific ways. For example, once we’d settled into the food routine that saved her from constant stomachaces, one of her favorite things to do was to go over to the kibble cage and try to find kibble that had escaped from it. If she could get away with it, she would stick her paw between the bars and pull kibble (or the entire bowl) out to eat.
It was slightly annoying, and also very funny. We called this pulling a heist. And then she’d have awful gas some hours later.
I also very distinctly remembering getting takeout one time, which happened to include a breaded and fried slab of fish. I had the little takeout container on the table in front of me, and I think I was fiddling with the wrapper on their plastic fork or something, when Pearl came along, sniffed it… and then bit the fish and pulled the whole filet out of the container. Right in front of me! Points for boldness, I guess. She wasn’t quite so audacious any other time, but she must’ve really liked the smell of that fish.
And while she was generally pretty picky about what she would consider a toy, she did, on occasion, like to bite the arms of my glasses. Once I was laying next to her and petting her while she purred, and she stuck a paw in between my glasses and my face, pulled them off, and tried to bite them — purring all the while.
My favorite Pearl trick was what we dubbed “mouse alert”. If Pearl was looking for someone — often anyone at all, but sometimes a particular person who was absent or in a room with a closed door — she would find one of her toy mice and carry it around doing a very loud, muffled meow. If she saw you she would then drop the mouse and trot over, making happy high-pitched meows instead.
Sometimes she’d start out with regular meows, which we could hear from the other side of the house, but then they’d abruptly turn deeper and longer, and we knew she’d picked a mouse up. It was so charming and so funny. Every so often we’d find a pile of mice outside a door and we knew that Pearl had been trying to open it. She later expanded her roster to include Big Mouse — a plush almost half her size who became her favorite — and a plush of a single HIV virus that she must’ve stolen from my desk.
She didn’t play with the mice, either. I have video of her playing with a mouse when she was fairly young, but it’s not one of the mice we have now. She seemed to regard them as precious, her comforting belongings that she could almost always lure us out of hiding with. “Come look at my mouse!” Sometimes she’d carry them around quietly, just to have one or two nearby in a comfortable spot.
I tried for her whole life to get a recording of this, which proved nearly impossible, because she’d stop if she knew anyone was nearby! I got a clear recording only once, a week before she died; I was in our dark bedroom, filming into Ash’s office, and I don’t think she realized I was there. There’s a link at the bottom.
Her other favorite possession was string. Pearl loved to play string. She would ask for it by name. No, really. If she wanted to play string, she would find (or bring) a string and sit on it hoping someone noticed, and if that didn’t work, I’m pretty sure she had a specific meow for asking you to please follow her to string and then play with it.
Playing string with her was a slightly frustrating affair, but perhaps I just didn’t understand the rules. They seemed to be: I should wiggle the string; then Pearl grabs the string; then Pearl keeps the string. That doesn’t end the game, though. I should keep trying, in vain, to get the string back, while Pearl simply keeps winning.
A great thing to do was dangle it above her, at which point she’d stand up to try to get it and chomp at it, audibly. I loved her little chomp sound. I can’t even do it myself; I feel like I’d hurt my teeth.
After she was through adolescence, string was the only thing she really wanted to play with. She might’ve chased a laser pointer a couple of times, but string was the one thing she would ask for. Occasionally I’d try to play with Anise with a string, but Pearl had a fucking sixth sense for when string was happening, and she would appear from nowhere and go absolutely nuts over it while Anise sat back and watched.
In March 2021, I took Pearl to an ER vet over very rapid breathing. They told me she’d had fluid in her lungs and diagnosed her with congestive heart failure. That’s when your heart can’t pump hard enough; part of Pearl’s heart wall had thinned and weakened, and one chamber was enlarged. She had to be hospitalized overnight. I drove home thinking I’d never see her again.
They couldn’t identify a cause. She was given a prognosis of “not fantastic” and prescribed a growing mountain of medication, which Ash dutifully gave to her every twelve hours for months on end, even when Pearl refused it. Sometimes Pearl had to be bribed with treats in order to eat at all, though I later traced that to a batch of food with insufficient pumpkin for her liking.
We had to keep her stress level low, which meant keeping her completely separated from the other cats (or at the very least Cheeseball) as much as possible. That meant Ash vanished into a closed room for most of every day to work while keeping an eye on Pearl — who was, after all, Ash’s cat. That also left me with three other cats constantly vying for my attention.
For several months we often couldn’t even sleep in the same room — Pearl and Anise couldn’t be left together, and Anise makes a racket all night if he’s shut out. Early on, our roommate would often take Pearl overnight (even despite being allergic to cats), but as time went on, Ash felt a stronger impulse to be around her as much as possible. Eventually we found we could have both Anise and Pearl overnight as long as we put a sweater on Anise and had sufficient extra blankets on the bed, but honestly it felt like a constant logistical nightmare.
Even with all this, we still had several more ER visits, several more hospitalizations.
Still, Pearl seemed to be doing okay. She was happy, she engaged with us, she purred, she snuggled, she nuzzled, she played. She was fine, and stable, until she wasn’t.
It was January 11, and it was the first ER visit for rapid breathing in a while. We handed her over, they hospitalized her, and we left, assuming we’d pick her up in the morning and she’d be fine, as had always happened.
We weren’t home for long before they called us. Pearl wasn’t recovering this time, and wouldn’t make it through the night.
We raced back. We saw Pearl, struggling to breathe, even on oxygen. We pet her and told her it would be okay. She cried out for help. Ash held her.
And then we let her go.
I love and miss so many little things. She had such beautiful eyes, like Twigs did, though she squinted a lot so it always felt like a special treat when I could see them clearly. Her whole face scrunched when she meowed. She had a marble pattern, so I guess she would’ve been a calico. I didn’t even notice it when we first got her, and then one day it jumped right out at me and I felt briefly like our kitten had been replaced with a different one. She had a funny little clump of four hairs that stuck out from her hip. She had marbling on her pawpads, too.
I love her wide vocabulary of very cute little meows, in contrast with Twigs’s more raucous ones. She reserved them for special occasions, opting to chirr most of the time.
I love how, when she was surprised by something, she would simply jump straight up in the air an inch, then come down. No other movement. It was like she was tweened. I never tried to spook her on purpose to see this, but she was a little prone to being spooked.
I love how, when she’d knead at a soft blanket, she did just a few quick little motions and then she was done. It was so dainty. I always called it kitty paws, to distinguish from cat paws.
I love how she’d do a straight upwards stretch that somehow made her ears flick inside out briefly.
I love the very deliberate way she tucked her paws, and how she would gently hold onto someone’s shoulders while getting a taxi ride. Everything she did came across as so purposeful.
I love how Ash had found that rubbing their face on Pearl’s side as a kitten would get her to purr, and that kept working for her whole life, and it’s basically what she ended up doing to people in return.
I love how she had a funny obsession with water. I can’t really explain it, and I don’t know what she found so interesting. If I took a swig from my water bottle with Pearl nearby, she would climb on whatever was necessary to sniff at the nozzle. If I opened a soda with Pearl nearby, she’d stick her nose right in the opening, then recoil when the bubbles fizzed her. She didn’t enjoy baths or anything, she just liked… water. From afar. Like with Napoleon, perhaps.
I love how she nuzzled so hard that she hit maximum nuzzle, and so she would also sort of gently swipe the air with her paw as well, for extra nuzzling power.
I love her funny “bug off” sweater, illustrated with a ladybug, which seemed to capture her personality well: don’t be rude to me, but expressed in a very cute manner.
I love how she adopted the sort of extended windowsill in our bathroom as her own, and would lay there on sunny days and roll around on a towel.
I love that she was pampered right to the end. Over the course of recent weeks, Ash would keep giving me updates on Pearl’s development of a new routine, where she would sit in a Treat Spot she had designated, possibly meow once or twice, and wait very nicely until Ash gave her a treat. And then Ash would eventually capitulate, helpful before the polite ministrations of this very tiny cat, and give her a treat. It seemed that the number of treats Pearl was managing to get per day was gradually increasing, and so I asked every time: why not simply not give her a treat? But I knew the answer.
If you cried, there were decent odds that Pearl would come and comfort you, come chirp at you and nuzzle until you felt better.
When we first moved here, Ash’s ex-husband had driven the truck containing all our stuff, and he slept here one night before leaving for good. The day after he’d left, we heard Pearl doing mouse alert in the room he’d slept in, and I just broke down sobbing at the kitchen table, thinking about how Pearl liked him despite everything and was just trying to find him, and we had no way to tell her he wasn’t coming back or explain any of it to her. To her, one of her favorite people had just disappeared, and that was so sad.
But Pearl heard me, came over, jumped on the kitchen table, and purred and headbutted me like crazy. The idea that I was sad for her and she still wanted to comfort me made me cry harder.
She would also headbutt and nuzzle Ash specifically on the mouth when they sang, or do the same to me if I whistled competently. I suppose she liked music, but only from us.
Most of all, I love… how much she doted on Ash. She slept alongside them (me only a few times), she followed them around, she waited outside doors for them. They were her favorite person. I feel so bad for them, to have lost both Twigs and Pearl back to back.
It’s been… two weeks now. Just over, because it took me another day to finish this post.
I don’t know if it’s fully clicked yet. I didn’t see Pearl much during the day, since she’d be tucked away in Ash’s office slash our bedroom. I saw her mostly at night and first thing in the morning. So while I’m out here, at my desk, it’s like nothing has changed. It only sinks in when I go upstairs and see the door left open, see a bed with no Pearl tucked in it somewhere.
It’s kind of dumbfounding just how much of this house and our lives had warped around Pearl, around this one tiny cat who loved everyone. So many things have disappeared or seem superfluous now. I was already free-feeding the other cats again since Pearl wasn’t allowed to roam the house unsupervised, but now we don’t need the kibble cage at all. Half our doors had been kept closed to make a few different places for Pearl to stay, but now none of that is necessary. Litterboxes had ended up scattered throughout the house so Pearl would always have access to one; now they’re back to being in a few central locations.
Ash doesn’t have to wake up at a specific time every day to give Pearl medicine. Pearl won’t wake us up to feed her. We don’t have to make her food, ever again.
And there are so many things that were only for Pearl. This wasn’t the case for anyone else. Styx only had communal cat sweaters; his favorite toy was loose change on my desk. Twigs, too, only had sweaters that Anise and Pearl inherited; his one dedicated toy was a single very tiny mouse he sometimes played with.
But Pearl? Half the sweaters we have only fit Pearl. Her mice were very much hers. Even her string was very much hers. We have a mortar and pestle that were specifically for grinding up her medication, oral syringes only Pearl used. She had possessions of her very own, things she’s left behind.
We knew this was coming, of course. Without the intervention of modern medicine, she would have died last March, and the outlook for heart failure in a cat isn’t great. I’ve already grieved for her several times over the past year. I didn’t see her much during the summer, but I’d been trying to spend more deliberate time with her in recent months, and I’m glad I did. I regret nothing. I earned her purrs, I played string with her exactly the right amount, I woke up to her stealing my pillow. I got the full Pearl experience.
And so did she. Ash took her outside extra over the summer, let her see a bit of the outside world (even if it was only our yard). We let her roam the house when we could, banishing Cheeseball to a room by himself if necessary, though she usually ended up sitting on a vent or my lap (or trying to heist some kibble). She got lots of treats, lots of love, lots of blankets, and even a vent all to herself. What more could she ask for?
She was living on borrowed time, but we borrowed every second we could. I don’t know what else we could’ve done. And we were there for her right up until the end. We didn’t have that opportunity with Twigs; he died in the back room, surrounded by strangers.
In the end, her heart was literally too big.
This sucks.
Pearl deserved better. She was dealt a bad hand from the beginning, but she was still friendly and kind, and then this happened. She was so young, too — her eighth birthday would’ve been next month. She, like Twigs, should’ve had twice as long.
Things won’t be difficult for her any more, I guess. I don’t know how much that comforts me.
Everything else moves on. Pearl continued until the night of January 11, 2022, but can go no further. We’re forced to leave her there, retaining only memories, while time carries us gently forward, ever further away.
So here is my landmark, my stake in the ground. Pearl was here. May this mark out the shape of who she was and leave that impression upon the world for much longer.
The finality of death resolves so many questions. I often wished I could improve Pearl’s tense relationships with Anise and Cheeseball, but now there’s no problem to solve. The interactions they had are all the interactions they will ever have. The tension is gone, now. The worries about how long Pearl’s heart will last are gone too.
The cat dynamic has shifted, again. Cheeseball and Napoleon have been much more affectionate towards Ash, and Napoleon has suddenly become a lap cat. I suppose the rest of the cats missed Ash while they were siloed away with Pearl for so long. Maybe they’re grieving? Cats are so open with their emotions, but sometimes they’re still inscrutable.
Pearl’s urn is on the dresser in our bedroom, right next to Twigs. Hers is bigger than his, somehow. But that’s Pearl for you — she always knew how to take up space.
…
No, this is too dire an ending. Pearl was dealt a bad hand, but she always tried to be nice despite that. She got to see a lot of places and make a lot of friends, both people and cats and even one dog. Even when she had complex and skeptical feelings about Anise, she kept trying to be friends with him. She faltered at times, but she always did her best to uphold her principles of loveliness, strong boundaries, and please give me a treat.
That’s a lot for a tiny cat. I admire her for it, and I will not forget it.
Thank you for reading about Pearl. I hope you’ll remember her too. We loved her very much, and she put a lot of love back into the world. If you would like to experience more Pearl, here are some videos of her. I have some more to sift through, so this list may grow in the coming days.
GZDoom is the fanciest way to play Doom. Unfortunately, it has also historically been difficult to recommend to newcomers, because its default settings are… questionable.
Conspicuously, for over a decade, it defaulted to traditional Doom movement keys (no WASD) and no mouselook. I am overjoyed to discover that this is no longer the case, and it plays like a god damn FPS out of the box, but there are still a few twiddles that need twiddling. Mostly the texture filtering. Christ, the texture filtering.
Anyway GZDoom has a lot of options, so here is a handy list of the important ones. There are fewer than I expected, which is good.
Note that the routes given to the various settings are for the full options menu. Out of the box, GZDoom shows a reduced options menu, because it has a lot of options. You can get to the full menu from Full options menu near the bottom, and from there turn off the simple menu (if you want). If you get lost, you can also use the option search.
Also, virtually every setting in GZDoom takes effect instantly, even while the menu is still visible. (That’s why there are no screenshots here! Just try stuff out yourself.) It remembers where your cursor was, too, so you can exit the menu to try stuff out, then bring it back up and mash Enter a few times to get back to where you were.
By default, GZDoom uses linear upscaling on all sprites and textures, turning them into a blurry mess. This is objectively ludicrous, since the sprites and textures are pixel art.
None restores the crispy aesthetic that God intended — and when I say God, I of course mean John Carmack. No, wait, maybe I mean Adrian Carmack?
The “linear mipmap” bit means that GZDoom will still use linear downscaling, so that distant textures still somewhat resemble the actual texture and do not simply collapse into a pixel of arbitrary color. If you find this objectionable, you may of course simply set it to None.
GZDoom defaults to rendering spectres (the harder-to-see variants of the pink demons) with a sort of translucent effect, which is easier to see, which sort of defeats the purpose of making them harder to see.
This will emulate the appearance of the original game, scaled up to big chunky pixels. I actually prefer Smooth fuzz, which fits better at high resolutions and still looks like a rendering error, but pretty much anything is better than the Shadow default.
For testing purposes, it may help to pop open the console with the backtick key (top left) and type summon spectre to… well, summon a spectre.
And if all you want is something that looks kinda like Doom, you’re done! Feel free to stop reading here.
I just feel better with a little symbol in the middle of the screen. I’m holding all my guns at chest height, for some reason, so the sights on those are useless.
By default the crosshair is humongous, though, hence the scaling.
Speaking of which, fix the HUD scale.
HUD options > Scaling options > User interface scale: 3
The automatic setting is okay (and better than it used to be), but still leaves some things like pickup messages and the console as microscopic. I play in a 1080p window on a 1440p monitor, and this seems nice for me. Adjust as desired.
Use the alternative HUD.
HUD options > Alternative HUD > Enable alternative HUD: On
You’ll need to press + until the status bar disappears to actually see it.
The alternative HUD shows you everything you need to know about the state of the game, while consuming minimal space and still letting you see the weapon sprites in their full glory. It also shows you a count of kills and secrets, so you have some idea of the progress you’ve made. And it tells you a few things that you had to keep track of yourself in vanilla Doom, like what color of armor you have and whether you have the berserk fist.
(This replaces a stock fullscreen-with-info HUD that didn’t exist in vanilla Doom, but which only shows you health, armor, keys, and ammo for your current weapon. Note that if you play a WAD that heavily alters the game, there’s a chance it will add custom stuff to the stock HUD, and that stuff will not appear on the alternative HUD. It’s explicitly not moddable.)
Doom has static lighting that affects the walls and floor equally, so the transition from wall to floor/ceiling is pretty flat. A little AO helps that stand out, even if ambient occlusion is a fake idea.
Fix fake contrast.
Display options > Use fake contrast: Smooth
“Fake contrast” refers to a clever trick in the Doom engine wherein horizontal (as seen on the automap) walls draw darker than the room, and vertical walls draw lighter. In rectangular rooms, this helps avoid the “flat” feeling mentioned previously.
Unfortunately, with complex geometry — as you see frequently in modern maps, but also occasionally in the original ones — this can backfire. I’ve been fooled into thinking one particular wall in a curved hallway is a secret, just because it happened to be vertical and appeared lighter than its neighbors. Meanwhile, rooms at a slant don’t benefit at all.
Smooth preserves the effect, but gradually transitions between the original effect for orthogonal walls and normal lighting for walls at a 45° angle. (That is, a wall at a 22.5° angle will have half the fake contrast effect.)
The default particles are linear filtered, which looks awful, but I don’t think anything uses particles by default so you’d never notice. You can also set them to Square, but I think having a single pixel floating in the air looks a bit silly.
Adding particles to blood splatters and bullet puffs just looks nice. I replace the rocket trails entirely because the original Doom rocket cloud is just kinda big and clumsy and ugly.
Enable dynamic lighting.
This is on by default… sort of. GZDoom needs to be able to find the lights.pk3 and brightmaps.pk3 files bundled with it, but if it runs at all, it probably knows where they are.
So all you have to do is check Load lights and Load brightmaps in the little dialog you get when launching the game.
Probably. See, for some reason, those checkboxes are only there on Windows — in fact, I didn’t know they existed at all until two minutes ago. Even though they set a config setting, they aren’t accessible via the options menu. So if that doesn’t work for you for whatever reason, try popping open the console and doing:
autoloadlights true
autoloadbrightmaps true
Then restart the game. Glowing objects should now cast (fairly subtle!) light on nearby walls. You can see this immediately in Doom II’s first map — there should be a green glow on the floor underneath the armor bonus in the far right corner of the room. Or for a more dramatic demonstration, IDKFA and fire a rocket.
It’s just a nice touch. And unlike many attempts to add dynamic lighting to Doom, it’s not so over-the-top as to be distracting.
At the other end of the scale, there are those who want an experience as close as possible to vanilla Doom. Those people might just want to use a port closer to vanilla, like a PRBoom variant or even Chocolate Doom, but GZDoom is willing to do its best:
Quantize light levels.
Display options > Hardware renderer > Banded SW lightmode: On
Doom maps support light levels from 0 to 255, but in practice, Doom only understood… 16, I think? That’s because it was a paletted game, and it needed a colormap telling it how to darken each color while still sticking to the palette. The game only shipped with 15 such mappings, probably because 255 of them would have been ludicrous, and thus there are only 16 light levels in practice.
GZDoom’s hardware renderer isn’t bound by a palette, so it happily supports all 256 light levels. If you can’t stand this, well, it can simulate 16 for you.
Disable the hardware renderer altogether.
Set video mode > Render mode: True color SW renderer
If the very notion of accelerated rendering offends you, the original core of Doom’s renderer is still in there, just waiting for you. All you need do is turn it on. Note that this will severely restrict your ability to mouselook and will draw without vertical perspective, as the Doom renderer was designed around drawing vertical lines.
What’s that? Even true color is too much? You need the paletted glory that was the best a 386 could do? Well, Doom software renderer is also an option.
Disable mouselook.
Mouse options > Always mouselook: Off
Doom didn’t support looking up and down. Why should you?
Despite the name, this still allows you to look around horizontally. I guess technically that’s turning, not looking. Also, moving the mouse up and down will now move you (slowly) forwards or backwards.
Disable WASD.
Customize controls > Preferred keyboard layout: Classic ZDoom, then Reset to defaults
Okay now you have gone too far. This restores the very keyboard bindings I wanted to rally against — arrow keys to move, turning by default, Alt to strafe…
Disable teleporter zoom.
Display options > Teleporter zoom: Off
GZDoom does a brief zoom-in effect on your field of view after (non-silent) teleporting. Looks sick. If you hate it, here’s how to turn it off.
Restore the vanilla lite-amp goggles.
Display options > Hardware renderer > Enhanced night vision mode: Off
In vanilla Doom, the lite-amp goggles simply make the entire world render as fullbright, which looks fucking terrible. GZDoom defaults to a “night vision goggles” sort of effect that also highlights objects, but if you really can’t stand that, this twiddle is here for you.
Enable randomized pitch on sound effects.
Sound options > Randomize pitches: On
For the very ornery, I believe this behavior was in the original release of Doom but (accidentally?) broken in Doom 1.2 and all later versions. It’s really weird, but it’s the intended behavior, I guess!
Restore Doom’s automap colors.
Automap options > Map color set: Traditional Doom
This will change the automap back to its red-and-yellow-on-black glory.
It will also remove the colors that tell you where locked doors and the exit are. You might argue that those are cheating. I argue that they are the entire point of a map.
You can also turn off the automap’s monster and secret counts here if you truly wish to be as lost as possible.
Twiddle with compatibility settings.
Compatibility options > Compatibility mode: ?
You might want Doom (strict) for the closest vanilla experience that GZDoom can provide. Might. The most notable effects are:
Monsters will wake up when seeing a player with a blur sphere. By default, they usually won’t, a behavior inherited from Hexen.
Arch-viles can resurrect crushed corpses as “ghosts” that cannot be shot, only harmed by splash damage from rockets.
Pain elementals will be unable to spawn new lost souls if there are at least 21 already present in the level.
Monsters can’t be knocked off of high ledges.
You will be unable to crowdsurf, meaning you will be blocked both by imps at the foot of a cliff below you, and by cacodemons flying above you.
You can also toggle these on or off individually at your leisure.
Welcome to part 1 of this narrative series about writing a complete video game from scratch, using the PICO-8. This is actually the second part, because in this house (unlike Lua) we index from 0, so if you’re new here you may want to consult the introductory stuff and table of contents in part zero.
If you’ve been following along, welcome back, and let’s dive right in!
So far, I have… this. Which is something, and certainly much more than nothing, but all told not a lot.
Most conspicuously, this is going to be a platformer, so I need gravity. The problem with gravity is that it means things are always moving downwards, and if there’s nothing to stop them, they will continue off indefinitely into the void.
What I am trying to say here is that I feel the looming spectre of collision detection hanging over me. I’m going to need it, and I’m going to need it real soon.
And, hey, that sucks. Collision detection is a real big pain in the ass to write, so needing it this early is a hell of a big spike in the learning curve. Luckily for you, someone else has already written it: me!
Before I can get to that, though, I need to add some structure to the code I have so far. Everything I’ve written is designed to work for Star Anise and only Star Anise. That’s perfectly fine when he’s the only thing in the game, but I don’t expect he’ll stay alone for long! Collision detection in particular is a pretty major component of a platformer, so I definitely want to be able to reuse it for other things in the game. Also, collision detection is a big fucking hairy mess, so I definitely want to be able to shove it in a corner somewhere I’ll never have to look at it again.
A good start would be to build towards having a corner to shove it into.
As of where I left off last time, my special _update() and _draw() functions are mostly full of code for updating and drawing Star Anise. That doesn’t really sit right with me; as the main entry points, they should be about updating and drawing the game itself. Star Anise is part of the game, but he isn’t the whole game. All that code that’s specific to him should be put off in a little box somewhere. Cats love to be in little boxes, you see.
This raises the question of how I want to structure this project in general. And, I note: structuring a software project is hard, and you only really get a good sense of how to do it from experience. I’m still not sure I have a good sense of how to do it. Hell, I’m not convinced anyone has a good sense of how to do it.
Thankfully, this is a game, so it’s pretty obvious how to break it into pieces. (The tradeoff is that everything in a game ends up entangled with everything else no matter how you structure it, alas.) Star Anise is a separate thing in the game, so he might as well be a separate thing in the code. Later on I’ll need some more abstract structuring, but as an extremely rough guideline: if I can give it a name, it’s a good candidate to be made into a thing.
But what, exactly, is a thing in code? Most commonly (but not always), a thing is implemented with what’s called an object — a little bundle of data (what it is) with code (what it can do). I already have both of these parts for Star Anise: he has data like his position and which way he’s facing, and he has code for doing things like updating or drawing himself. A great first step would be to extract that stuff into an object, after which some other structure might reveal itself.
I do need to do one thing before I can turn get to that, though. You see, Lua is one of the few languages in common use today that doesn’t quite have built-in support for objects. Instead, it has all the building blocks you need to craft your own system for making objects. On the one hand, the way it does that is very slick and clever. On the other hand, it means you can’t write much Lua without cobbling together some arcane nonsense first, and also no one’s code quite works the same way.
Which brings me to the following magnificent monstrosity:
functionnop(...)return...end---------------------------------- simple object typelocalobj={init=nop}obj.__index=objfunctionobj:__call(...)localo=setmetatable({},self)returno,o:init(...)end-- subclassingfunctionobj:extend(proto)proto=protoor{}-- copy meta values, since lua doesn't walk the prototype chain to find themfork,vinpairs(self)doifsub(k,1,2)=="__"thenproto[k]=vendendproto.__index=protoproto.__super=selfreturnsetmetatable(proto,self)end
How does this work? What does this mean? What is a prototype chain, anyway? Dearest reader: it extremely does not matter. No one cares. I would have to stare at this for ten minutes to even begin to explain it. Every line is oozing with subtlety. To be honest, even though I describe this series as “from scratch”, this is one of the very few things that I copy/pasted wholesale from an earlier game. I know this does the bare minimum I need and I absolutely do not want to waste time reinventing it incorrectly. To drive that point home: I wrote collision detection from scratch, but I copy/pasted this. (But if you really want to know, I’ll explain it in an appendix.)
Feel free to copy/paste mine, if you like. You can also find a number of tiny Lua object systems floating around online, but with tokens at a premium, I wanted something microscopic. This basically does constructors, inheritance, and nothing else.
(Oh, I don’t think I mentioned, but the -- prefix indicates a Lua comment. Comments are ignored by the computer and tend to contain notes that are helpful for humans to follow. They don’t count against the PICO-8 token limit, but they do count against the total size limit, alas.)
The upshot is that I can now write stuff like this:
This creates a… well, terminology is tricky, but I’ll call it a type while doing air-quotes and glancing behind me to see if any Haskell programmers are listening. (It’s not much like the notion of a type in many other languages, but it’s the closest I’m going to get.) Now I can combine an x- and y-coordinate together as a single object, a single thing, without having to juggle them separately. I’m calling that kind of thing a vec, short for vector, the name mathematicians give to a set of coordinates. (More or less. That’s not quite right, but don’t worry about it yet.)
After the above incantation, I can create avec by calling it like a function. Note that the arguments ultimately arrive in vec:init, loosely called a constructor, which stores them in self.x and self.y — where self is the vec being created.
1
2
3
-- this is example code, not part of the gamelocala=vec(1,2)print("x = ",a.x," y = ",a.y)-- x = 1 y = 2
That iadd thing is a method, a special function that I can call on a vec. It’s like every vec carries around its own little bag of functions anywhere it appears — and since they’re specific to vec, I don’t have to worry about reusing names. (In fact, reusing names can be very helpful, as we’ll see later!)
The name iadd is (very!) short for “in-place add”, suggesting that the first vector adds the second vector to itself rather than creating a new third vector. That’s something I expect to be doing a lot, and making a method for it saves me some precious tokens.
1
2
3
4
5
-- example codelocalv=vec(1,2)localw=vec(3,4)v:iadd(w)print("x = ",v.x," y = ",v.y)-- x = 4 y = 6
Finally, those funny __add and __sub methods are special to Lua (if enchanted correctly, which is part of what the obj gobbledygook does) — they let me use + and - on my vecs just like they were numbers.
1
2
3
4
5
-- example codelocalq=vec(1,2)localr=vec(3,4)locals=q+rprint("x = ",s.x," y = ",s.y)-- x = 4 y = 6
This is the core idea of objects. A vec has some data — x and y — and some code — for adding another vec to itself. If I later discover some new thing I want a vec to be able to do, I can add another method here, and it’ll be available on every vec throughout my game. I can repeat myself a little bit less, and I can keep these related ideas together, separate from everything else.
Get the basic jist? I hope so, because I’ve really gotta get a move on here.
What a mouthful! But for the most part, this is the same code as before, just rearranged. For example, the new anise:draw() method has basically been cut and pasted from my old _draw() — all except the cls() call, since that has nothing to do with drawing Star Anise.
I’ve combined the px and py variables into a single vector, pos (short for “position”), which I now have to refer to as self.pos — that’s so PICO-8 knows whose pos I’m talking about. After all, it’s theoretically possible for me to create more than one Star Anise now. I won’t, but PICO-8 doesn’t know that!
A Star Anise object is created and assigned to player when the game starts, and then _update() calls player:update() and _draw() calls player:draw() to get the same effects as before.
I did make one moderately dramatic change in this code. The wordy code I had for reading buttons has become much more compact and inscrutable, and the moving variable is gone. A big part of the reason for this is that I consider Star Anise’s movement to be part of himself, but reading input to be part of the game, so I wanted to split them up. That means moving is a bit awkward, since I previously updated it as part of reading input. Instead, I’ve turned Star Anise’s movement into another vector, which I set in _update() using this mouthful:
1
2
3
4
5
6
7
8
9
-- top-levelfunctionb2n(b)returnband1or0end-- in _update()player.move=vec(b2n(btn(➡️))-b2n(btn(⬅️)),b2n(btn(⬇️))-b2n(btn(⬆️)))
The b2n() function turns a button into a number, and I only use it here. It turns true into 1 and false into 0. Think of it as measuring “how much” the button is held down, from 0 to 1, except of course there can’t be any answer in the middle.
Unpacking that a bit further, b2n(btn(➡️)) - b2n(btn(⬅️)) means “how much we’re holding right, minus how much we’re holding left”. If the player is only holding the right button, that’s 1 – 0 = 1. If they’re only holding the left button, that’s 0 – 1 = -1. If they’re holding both or neither, that’s 0. The results are the same as before, but the code is smaller.
Once Star Anise’s move is set, the rest works similarly to before: I update left based on horizontal movement (but leave it alone when there isn’t anyway), I alter his position (now using :iadd()), and I use the walk animation when he’s moving at all. And that’s it!
I like to use the term “actor” to refer to a distinct thing in the game world; it conjures a charming and concrete image of various characters performing on a stage. I think I picked it up from the Doom source code. “Entity” is more common and is used heavily in Unity, but can be confused with an “entity–component–system” setup, which Unity also supports. And then there are heretics who refer to game things as “objects” even though that’s also a programming term.
This code is a fine start, but it’s not quite what I want. There’s nothing here actually called an actor, for starters. My setup still only works for Star Anise!
I’d better fix that. The notion of an “actor” is pretty vague, so a generic actor won’t do much by itself, but it’s nice to define one as a template for how I expect real actors to work.
How does a blank actor update or draw itself? By doing nothing.
(I do assume that every actor has a position; this may not necessarily be the case in games with very broad ideas about what an “actor” is, but it’s reasonable enough for my purposes.)
Now, to link this with Star Anise, I’ll have aniseinherit from actor. That means he’ll become a specialized kind of actor, and in particular, all the methods on actor will also appear on anise. You may notice that anise was previously a specialized kind of obj (like actor and vec) — in fact, the only reason I can call vec(x, y) like a function is that it inherits some magic stuff from obj. Surprise!
1
localanise=actor:extend{
I can now delete anise:init(), since it’s identical to actor:init(). I still have anise:update() and anise:draw(), which override the methods on actor, so those don’t need changing.
Everything still only works for Star Anise, but I’m getting closer! I only need one more change. Instead of having only player, I will make a list of actors.
-- at the toplocalactors={}function_init()player=anise(vec(64,64))add(actors,player)endfunction_update()-- ...mostly same as before...foractorinall(actors)doactor:update()endendfunction_draw()cls()foractorinall(actors)doactor:draw()endend
This does pretty much what it reads like. The add() function, specific to PICO-8, adds an item to the end of a list. The all() function, also specific to PICO-8, helps go through a list. And the for blocks mean, for each thing in this list, run this code.
Now, at last, I have something that could work for actors other than Star Anise. All I need to do is define them and add them to the actors list, and they’ll automatically be updated and drawn, just like him!
Admittedly, this hasn’t gotten me anywhere concrete. The game still plays exactly the same as it did when I started. I’m betting that I’ll eventually have more than one actor, though, so I might as well lay the groundwork for that now while it’s easy. It doesn’t take much effort, and I find that if I give myself little early inroads like this, it feels like less of a slog to later come back and expand on the ideas. This is the sort of thing I meant by more structure revealing itself — once I have one actor, a natural next step is to allow for several actors.
I’ve put it off long enough. I can’t avoid it any longer. But it’s complicated enough to deserve its own post, so I don’t quite want to do it yet.
Instead, I’ll write as much code as possible except for the actual collision detection. There’s a bit more work to do to plug it in.
For example: what am I going to collide with? The only thing in the universe, currently, is Star Anise himself. It would be nice to have, say, some ground. And that’s a great excuse to toodle around a bit in the sprite editor.
I went through several iterations before landing on this. Star Anise lives on a moon, so that was my guiding principle. The moon is gray and dusty and pitted, so at first I tried drawing a tile with tiny craters in it. Unfortunately, that was a busy mess to look at when tiled, and I didn’t think I’d have enough tile space for having different variants of tiles. I’m already using 9 tiles here just to have neat edges.
And so I landed on this simple pattern with just enough texture to be reminiscent of something, which is all you really need with low-res sprite art. It worked out well enough to survive, nearly unchanged, all the way to the final game. It was inspired by a vague memory of Starbound’s moondust tiles, which I was pretty sure had diagonal striping, though I didn’t actually look at them to be sure.
You may notice I drew these on the second tab of sprites. I want to be able to find tiles quickly when drawing maps, so I thought I’d put “terrain” on a dedicated tab and reserve the first one for Star Anise, other actors, special effects, and other less-common tiles. That turned out to be a good idea.
You may also notice that one of those dots on the middle right is lit up. How mysterious! We’ll get to that next time.
With a few simple tiles drawn, I can sprinkle a couple in the map tab. I know I want Metroid-style discrete screens, so I’m not worried about camera scrolling yet; the top-left corner (16×16 tiles) is enough to play with for now.
I draw two rows of tiles at the bottom of that screen. It’s a little hard to gauge since the toolbar and status bar get in the way, but the bottom row of the screen will be at y = 15. You can also hold Spacebar to get a grid, with squares indicating every half-screen.
Finally, to make this appear in the game, I need only ask PICO-8 to draw the map before I draw actors on top of it.
The PICO-8 map() function takes (at least) six arguments: the top-left corner of the map to start drawing from, measured in tiles; the top-left corner on the screen to draw to, measured in pixels; and the width/height of the rectangle to draw from the map, measured in tiles. This will draw a 32×32 block of tiles from the top-left corner of the map to the top-left corner of the screen.
Of course, with no collision detection, those tiles are nothing more than background pixels, and the game treats them as such.
I’m not going into collision detection yet, but I can give you a taste, to give you an idea of the goals.
The core of it comes down to this line, from the end of anise:update().
1
self.pos:iadd(self.move)
That moves Star Anise by one pixel in each direction the player is holding. What I want to do is stop him when he hits something solid.
Hm, sounds hard. Let’s think for a moment about a simpler problem: how can I stop him falling through the ground, in the dumbest way possible?
The ground is flat, and it takes up the bottow two rows of tiles. That means its top edge is 14 tiles, or 112 pixels, below the top of the screen. Thus, Star Anise should not be able to move below that line.
But wait! Star Anise’s position is a single point at his top left, not even inside his helmet. What I really want is for his feet to not pass below that line, and the bottom of his feet is three tiles (24 pixels) below his position. Thus, his position should not pass below y = 112 – 24 = 88.
This isn’t going to get us very far, of course. He still walks through the air, he can still walk off the screen, and if I change the terrain then the code won’t be right any more. I’m also pretty sure I didn’t actually write this in practice. But hopefully it gives you the teeniest idea of the problem we’re going to solve next time.
Really, really, really quickly, here’s how that obj snippet works.
Lua’s primary data structure is the table. It can be used to make ordered lists of things, as I did above with actors, but it can also be used for arbitrary mappings. I can assign some value to a particular key, then quickly look that key up again later. Kind of like a Rolodex.
1
2
3
4
5
locallunekos={anise="star anise is the best",purrl="purrl is very lovely",}print(lunekos['anise'])
Note that the values (and keys!) don’t have to be strings; they can be anything you like, even other tables. But for string keys, you can do something special:
1
print(lunekos.anise)-- same as above
Everywhere you see a dot (or colon) used in Lua, that’s actually looking up a string in a table.
With me so far? Hope so.
Any Lua table can also be assigned a metatable, which is another table full of various magic stuff that affects the first table’s behavior. Most of the magic stuff takes the form of a special key, starting with two underscores, whose value is a function that will be called in particular circumstances. That function is then called a metamethod. (There’s a whole section on this in the Lua book, and a summary of metamethods on the Lua wiki.)
One common use for metamethods is to make normal Lua operators work on tables. For example, you can make a table that can be called like a function by providing the __call metamethod.
1
2
3
4
5
6
7
8
9
10
11
12
13
localt={stuff=5678,}localmeta={-- this is just a regular table key with a function for its value__call=function(tbl)print("my stuff is",tbl['stuff'])end,}setmetatable(t,meta)t()-- my stuff is 5678t['stuff']="yoinky"t()-- my stuff is yoinky
One especially useful metamethod is __index, which is called when you try to read a key from the table, but the key doesn’t exist.
Instead of a function, __index can also be another (third!) table, in which case the key will be looked up in that table instead. And if that table has a metatable with an __index, Lua will follow that too, and keep on going until it gets an answer.
This is essentially what’s called prototypical inheritance, as seen in JavaScript (and more subtly in Python): an object consists of its own values plus a prototype, and if code tries to fetch something from the object that doesn’t exist, the prototype is checked instead. Since the prototype might have its own prototype, the whole sequence is called the prototype chain.
That’s all you need to know to follow the obj snippet, so here it is again.
functionnop(...)return...endlocalobj={init=nop}obj.__index=objfunctionobj:__call(...)localo=setmetatable({},self)returno,o:init(...)end-- subclassingfunctionobj:extend(proto)proto=protoor{}-- copy meta values, since lua doesn't walk the prototype chain to find themfork,vinpairs(self)doifsub(k,1,2)=="__"thenproto[k]=vendendproto.__index=protoproto.__super=selfreturnsetmetatable(proto,self)end
The idea is that types are used both as metatables and prototypes — they are always their own __index. At first, we have only obj, which looks like this:
Now we use obj:extend{} to create a new type. Follow along and see what happens. Lua only looks for metamethods like __call directly in the metatable and ignores __index, so I copy them into the new prototype. Then I make the prototype its own __index, as with obj, and also remember the “superclass” as __super (though I never end up using it). Finally I set the “superclass” as the prototype’s metatable.
(Oh, by the way: in Lua, if you call a function with only a single table or string literal as its argument, you can leave off the parentheses. So foo{} just means foo({}).)
That produces something like the following, noting that this is not quite real Lua syntax:
Now for the magic part. When I call vec(), Lua checks the metatable. (The __call in the main table does nothing!) The metatable is obj, which does have a __call, so Lua calls that function and inserts vec as the first argument. Then obj.__call creates an empty table, assigns self (which is the first argument, so vec) as the empty table’s metatable, and calls the new table’s init method.
Ah, but the new table is empty, so it doesn’t have an init method. No problem: it has a metatable with an __index, so Lua consults that instead. The metatable’s __index is vec, and vecdoes contain an init, so that’s what gets called. (If there were no vec.init, then Lua would see that vec also has a metatable with an __index, and continued along. That’s why I didn’t need an anise.init.)
That’s also why defining vec:__add works — it puts the __add metamethod into vec, which becomes the metatable for all vector objects, thus automatically making + work on them.
That’s all there is to it. It’s possible to get much more elaborate with this in a number of ways, but this is the bare minimum — and it could still be trimmed down further.
Note that you can’t actually call obj itself. Pop quiz: why not?
What a very, very long year. I went back through my dev journal to see what I’d done and could not believe most of this happened in the past year. Even stuff from August feels like it must have been at least a year ago.
I made our first Steam release: Cherry Kisses, a polished version of a jam game we made (though didn’t finish in time to get in the jam, oops) the year before. It’s sold pretty decently, especially considering the reduced audience (adult games are hidden on Steam unless you opt into them), so that’s been nice.
I started HRT! Then I stopped HRT. Alas.
I dipped my toes into Godot for real this time with Rogue Ike, a Strawberry Jam game that was perhaps much too ambitious for a first (and time-limited) attempt but worked out as a proof of concept. I don’t think I’ll pick this back up until I’ve made something a bit more substantial, though; I’ve got a lot of bits and pieces of Godot code now but still don’t feel like I have a solid grasp of how I’d approach architecture for a new game.
I poured some feelings into a little PICO-8 game: Star Anise Chronicles: Oh No Wheres Twig??, a charming little platformer about my cat’s fursona. It’s probably my favorite thing I’ve ever released.
I did actually an incredible lot of work on fox flux over the summer and made massive strides with it in a relatively short span of time? It was a broken hopeless mess at the start of the year, and now it’s… well, not. Better art, better physics, more plot ideas, a lot more little bits and pieces implemented, a whole minigame conceived and mostly implemented, a level tally… it feels like a real game, even!
I also took a crack at a possible port of fox flux to Godot, which was informative both about Godot itself and about designing complex actors in general, but I don’t think I’m going to continue with it. Godot does make some stuff easier, but at the cost of a lot of rough edges that will seriously slow me down — a lot of basic functionality I’ve been taking for granted in my current setup of LÖVE-duct-taped-to-Tiled just does not exist in Godot, and some of the 2D tooling has major oversights that I’d have to work around. Some of this will be fixed in Godot 4, but I don’t want to wait for that just to continue on this game that I’ve already poured a lot of work into. I’ll probably do something simpler in Godot 4 when it comes out.
I poured most of the last four months of the year into a surprise project, by which I mean, I surprised myself by doing it: Lexy’s Labyrinth, a web-based and unencumbered Chip’s Challenge 2 emulator — the first of its kind! It still has some teeny compatibility issues, but for the most part it faithfully plays both the original Chip’s Challenge 1 and 2 as well as tons of community levels created over the years. It needs a bit more polish, and then I’m gonna call it “basically finished” and make a bigger effort to drum up interest in it.
I think I worked on baz, the game engine I wanted to make that was intended as a bridge between MegaZeux and PuzzleScript and bitsy? But I haven’t touched it in a while now. I also started a web-based Sudoku player and then lost interest in Sudoku again. And then there was the AC:NH companion, which I kept up with until I lost interest in Animal Crossing. Hmmm.
I did dip my toe back into blogging with the well-received CSS post, and then not so much for a while. I started the “gamedev from scratch” series to replace the ill-fated book I toyed with writing, but it has yet to see a second installment.
I feel like I miss making video games, even though I did rather a lot of it this year. I guess I don’t feel like I released any; Cherry Kisses was an existing game, Rogue Ike didn’t get further than a handful of rooms, fox flux is still quite a ways off from being done, and Lexy’s Labyrinth is really a game engine. That leaves the Star Anise game as the only “““real””” one I released, but that may not be an entirely fair way to gauge how much work I’ve done.
I do miss writing more often. I guess after everything that happened three years ago, I never quite figured out how to reconnect with the universe. Sometimes I go on a tweeting spree for a couple days, and that feels nostalgic, but in general I’ve gotten more withdrawn and don’t quite know how to shake it. I’m still trying.
I like how well Cherry Kisses did, and I’d kinda like to do small adult game releases more regularly — they’re fun to design and write, they make folks happy, and they bring in a steady trickle of sales. I have a concept for one I’m going to start on during Strawberry Jam 5 next month, but it’s a bit more ambitious, so I might have to do something smaller for Steam purposes this year. Maybe I should take this as an opportunity to get a real foothold in Godot? Cherry Kisses wasn’t terribly complicated; I could recreate something like that without much trouble, and spend some time ironing out wrinkles.
I do want to keep working on fox flux — it’s been just about four years since the jam version now, and I still love the idea and would like to get it seriously going. I’ve spent so much time on engine and design stuff that I still barely have any areas to show!
And of course I would very much love to get that gamedev from scratch series going. I promised one installment per month, and I already missed December because I was neck-deep in Lexy’s Labyrinth, so I really ought to write two in the next week. We’ll see how that goes.
I don’t know how I feel about being 34. Solidly in my mid-30s. I still remember the days, twenty years ago now, when I was the youngest person I knew in almost any circles: online, at school, whatever. Now I’m usually one of the oldest, as most folks my age are off with children and careers; whereas I’ve made a life out of making weird stuff on the internet, just like I did as a teenager.
Still, I guess that means I’m exactly where I always wanted to be.
Browsers all have autoplay restrictions now, so you’ll have to hit play on this yourself.
You may recall that I once had the ambitious idea to write a book on game development, walking the reader through making simple games from scratch in a variety of different environments, starting from simple level editors and culminating in some “real” engine.
That never quite materialized. As it turns out, writing a book is a huge slog, publishers want almost all of the proceeds, and LaTeX is an endless rabbit hole of distractions that probably consumed more time than actually writing. Also, a book about programming with no copy/paste or animations or hyperlinks kind of sucks.
I thus present to you Plan B: a series of blog posts. This is a narrative reconstruction of a small game I made recently, Star Anise Chronicles: Oh No Wheres Twig??. It took me less than two weeks and I kept quite a few snapshots of the game’s progress, so you’ll get to see a somewhat realistic jaunt through the process of creating a small game from very nearly nothing.
And unlike your typical programming tutorial, I can guarantee that this won’t get you as far as a half-assed Mario clone and then abruptly end. The game has original art and sound, a title screen, an ending, cutscenes, dialogue, UI, and more — so this series will necessarily cover how all of that came about. I will tell you why I made particular decisions, mention planned features I cut, show you the tradeoffs I made, and confess when I made life harder for myself. You know, all the stuff you actually go through when doing game development (or, frankly, any kind of software development).
The target audience is (ideally) anyone who knows what a computer is, so hopefully you can follow along no matter what your experience level. Enjoy!
This is part zero, and it’s mostly introductory stuff. Please don’t skip it! I promise there’s some meat in the latter half.
Here’s what you have to look forward to (though it is of course a WIP until the series is done). Occasionally there’ll be a snapshot of the game, but these were made on a whim during development and aren’t particularly meaningful as milestones.
For reference, I started working on the game the morning of April 29, and I released it the night of May 10, for a total of twelve days.
Part 0 (you are here): introduction, tour of PICO-8, putting something on the screen, moving around, measuring time, simple sprite animation
This is not a tutorial. Please set your expectations accordingly. Honestly, I don’t even like tutorials — too many of them are framed as something that will teach you a skill, but then only tell you what buttons to press to recreate what the author already made, with no insight as to why they made their decisions or even why they pressed those particular buttons. They often leave you hanging, with no clear next steps, no explanation of what to adjust to get different results.
I’ve never seen a platformer tutorial that actually produced a finished game. Most of them give you just enough to have a stock sprite (poorly) jump around on the screen, perhaps collect some coins, and that’s it. How do you fix the controls, add cutscenes, even make a damn title screen? That’s all left up to you.
This is something much better than a tutorial: a story. I made a video game — a real, complete video game — and I will tell you everything I can remember doing and thinking along the way. Every careful decision, every rushed tradeoff, every boneheaded mistake, every weird diversion. I don’t guarantee that anything I did is necessarily a good idea, but everything I did is an idea, and sometimes that’s all you need to get the gears turning.
If you’re interested in making a video games, I don’t promise that this series will teach you anything. But with a little effort, you can probably learn something. And to be frank, if you’re starting with zero knowledge but still manage to muddle through the whole series, you’ve got more than enough curiosity and determination to succeed at whatever you feel like doing.
The game in question is Star Anise Chronicles: Oh No Wheres Twig??, which I made with the PICO-8. (If you are from the future, I specifically used version 0.2.0i; later versions may have added conveniences I’m not using.) This is not a whizbang fully-featured game engine like Godot or Unity. If I want to draw something, I have to draw it myself. If I want physics, I have to write them myself. If I want shaders… well, that’s not going to happen, but a little ingenuity can still go a long way.
And that kind of ingenuity is what makes game development appealing to me in the first place. It’s one big puzzle: given the tools I have, what’s the most interesting thing I can make with the least amount of hapless flailing? That question will come up a number of times in this series.
If any of this sounds appealing to you, keep reading! Follow along if you can. You can get the PICO-8 (tragically not open source) for $15, and chances are you already own it — it was in the itch.io BLM bundle, so if you bought that, you’re free to download it whenever you want.
In order to replicate the experience of reading the book, I’m porting these little “admonition” boxes from what I’d started. I have a somewhat meandering writing style, and hopefully these will help get tangents out of the main text, while also better highlighting warnings and gotchas.
Here they are, in no particular order:
I reserve the right to invent more, if they’re needed and/or funny.
Game development is about a lot more than programming, but this will contain an awful lot of programming. The PICO-8 in particular tends to blur the lines between code and assets if you want to do anything fancy.
That puts me in a tricky position as an author. I want this to be accessible to people with little or no programming experience, but I can’t realistically explain every single line of code I write, or this series will never end (and will be more noise than signal for intermediate programmers).
Thus, I’m trusting you to look up basic concepts on your own if you need to. I’m writing this to fill a perceived gap, so I’ll try to focus on the gaps — finding resources on from-scratch collision detection is a crapshoot, but the web is awash in explanations of what a “variable” is. PICO-8 uses a programming language called Lua which is pretty simple and easy to pick up, so if you’re having trouble, maybe thumb through the Programming in Lua book a bit too.
Of course, if you’re just here for the ride and not too worried about writing your own game, you can skip ahead whenever you like. I’m not your mom.
(Oh, and if you’ve used Lua before, you should know that PICO-8’s Lua has been modified from stock Lua. The precise list of changes would be a big block of stuff in the middle of this already too long intro, so I’ve put it at the bottom. The upshot is: numbers are fixed-point instead of floating-point, you can use compound assignment, and the standard library is almost completely different.)
That’s probably enough words with no pictures. Time to get started.
As mentioned, this is a game built with the PICO-8. I promised I’d tell you a story, but I can’t even explain why I chose PICO-8 if you don’t know what the thing is.
PICO-8 is a “fantasy console” — a genre that it pioneered. It has a fixed screen size, its own palette, its own font, a little chiptune synthesizer, its own idea of what buttons the player can press, and so on. It’s like an emulator for an 8-bit handheld that doesn’t actually exist, plus a bunch of relatively friendly tools for making cartridges for that handheld. It even has some arbitrary limitations to preserve that aesthetic. (I carefully avoid calling them artificial limitations, because there are some technical reasons for them, and a lot of programmers do a thing with their face if you say “artificial” to them. Like you’ve just spat in their lunch.)
If you’ve got PICO-8 open, you can type splore at this little command prompt to open the cartridge explorer, which lets you download and play cartridges that have been posted to the PICO-8 BBS (forum). You might want to try a few to get a sense of what the PICO-8 can do, though bear in mind that some of the best games are incredible feats of ingenuity and not representative. A good place to start is the “featured” tab, which lists games that… I believe have been hand-picked as high-quality? Some suggestions:
Star Anise Chronicles: Oh No Wheres Twig is in there, as is our older (and first!) game Under Construction.
The original PICO-8 version of Celeste, if you weren’t aware of its origins.
Dusk Child, one of the earliest games I played and a big inspiration — it’s pretty and expansive, but doesn’t do anything I couldn’t figure out.
Just One Boss, which is just so damn crisp.
Dank Tomb, a dungeon crawler with absolutely beautiful lighting effects.
PicoHot, which is absolute fucking nonsense how dare you.
Note that when playing most games, the PICO-8 functions as though it only had six buttons: a directional pad bound to the arrow keys, and “O” and “X” buttons bound to the Z and X keys. Most games refer to those buttons by name (the PICO-8 font has built-in symbols for them) rather than keyboard key, since you might be playing on a controller or with some other bindings. You can always press Esc for the built-in menu.
…
Had fun? Great! Pressing Esc takes you back to the prompt. From there, you can press Esc again to switch to the editor (and vice versa).
Now, this is not a PICO-8 tutorial. But the PICO-8’s design and constraints immensely impact how much I could do and how I planned to do it, so I can’t very well explain my thought process without that context. Luckily, all the code and assets for the last game you played stay loaded, so I might as well give you the whirlwind tour. Even if you’re not following along with an actual copy of PICO-8, you should keep reading so you understand what I’ve got to work with.
This is the code editor, a very tiny text editor. If you’ve loaded Under Construction, feel free to page through and see what I did. (Keyboard shortcuts help a lot; see the manual for a full list of them. There are also some cheat sheets floating around, though they focus more on programming capabilities.)
You may have noticed the ominous 7695/8192 in the bottom right. That’s hinting at one of the PICO-8’s limitations: the token count. A cartridge’s source code cannot exceed 8192 tokens, or it will not run at all. A “token” is, in general terms, a single “word” of code — a number like 133, a name like animframedelay, an operator like +, a keyword like function, and so on. The term “token” is borrowed from the field of parsing, which is an entire tangent you are free to look up yourself.
The PICO-8’s definition of “token” is slightly different from its typical usage and includes a few exceptions. The common Lua keywords local and end don’t count at all; nor do commas, periods, semicolons, or comments. A string of any length is one token. A pair of parentheses, brackets, or braces only counts as one token. Negative literal numbers (e.g., -25) are one token.
The token limit is the most oppressive of the limits on your code, but there are two others. The full size of your code cannot exceed 64KiB, though in practice I’ve never come anywhere near that size and I think you’d only approach it if you were committing some serious shenanigans. More of concern, the compressed size of your code cannot exceed 15,616 bytes. I do wind up battling that one near the end of this project (as I did with Under Construction), and it can be extra frustrating since it’s hard to gauge exactly what impact any particular change will have on compression. Thankfully, and unlike with the token limit, the PICO-8 will still run a game that’s over the compressed size; it just physically cannot export it to a cartridge.
Incidentally, you can use Alt and an arrow key to move between the editors.
Here we have a tiny pixel art editor. As you might have guessed, the “native” size for a tile is 8 × 8 pixels, though you can use the bottom of the two sliders to edit bigger blocks of tiles at a time. (The screen is 128 × 128 pixels, or 16 × 16 tiles.) You have at your disposal a spritesheet of 256 such tiles, which are arranged at the bottom of the screen in four tabs of 64 tiles each. 001 here is the tile number. Each tile has its own set of 8 flags you can toggle on and off, which are represented by the eight circles just above the tabs; here, all the flags are off. The flags do nothing by themselves, but you can use them for whatever you like, and they turn out to be pretty handy.
The palette is 16 colors, as shown. There are 16 more colors on the “secret palette” which I’ll be dipping into later, but you can only swap them in; you can never have more than 16 distinct colors on screen at the same time. This is reminiscent of how some early systems actually worked.
The map editor edits the map. You only get one; if you want to carve it up somehow, that’s up to you. It’s extremely simple: you have a grid of 128 × 64 tiles (that’s 8 × 4 screenfuls), and you can pick which tile goes in each cell. No layers, no stacking, no two things in the same cell. You can pan around with the middle mouse button and zoom with the mouse wheel (or check the manual for the keyboard equivalents).
The especially nice thing about the map is that you can draw entire blocks of it with the built-in map function, which saves a whole lot of tokens over drawing a bunch of tiles by hand. Even if you’re making a game that doesn’t have a literal map, it’s a convenient way to define and draw blocks of multiple tiles.
The catch is that the bottom half of the spritesheet and the bottom half of the map are shared, so you can’t actually have a full map and a full set of tiles in the same cartridge. You could have a full 8 × 4 map and 128 tiles, or you could have a full set of 256 tiles but only an 8 × 2 map, or you can split the space up somehow, but you can’t have the maximum of both. Drawing in the bottom half of one will immediately update the other with garbage. It’s beautiful, actually, if you’re into the aesthetic of arbitrary memory being drawn as tiles.
If you have a cartridge open, you can see this yourself: check out the bottom half of the map (it helps to use Tab or the buttons in the upper left to hide the tile palette) and tabs 2 and 3 of the sprite editor. If they’re not both completely empty, something will be full of garbage. Try drawing in one or the other, if you like, and you’ll see the other update with junk. That’s the memory layout of pixel data being interpreted as map data, or vice versa. Cool, right?
The sound editor (or SFX editor) does a lot, despite being very simple conceptually, and it can be a little intimidating if you’ve never worked with sound or music before. These screenshots are the two display modes, “pitch mode” and “tracker mode” — allegedly pitch mode is more suitable for sound effects and tracker mode is more suitable for music, but I honestly have no idea how anyone does anything in pitch mode, and I use tracker mode for both. Your mileage may vary. As with the map editor, use Tab or the buttons in the top-left to switch views.
There are 64 sound effects to work with, each consisting of 32 notes played by a little chiptune synth. Notes consist of a pitch (i.e., the actual note being played), an instrument, the volume, and an optional effect.
I could say an awful lot about sound and chiptunes and what any of this means, but this is not a chiptuning tutorial, so I’ll save that for when I actually made some sounds for the game. Do feel free to mess around here, though.
There’s also a music editor, but all it does is arrange several sound effects to play at the same time, so it’s not especially interesting.
And that’s everything at my disposal! I guess that means it’s time to get started, for real. Go back to the command prompt and use reboot to get a fresh blank cartridge, if you’re planning on following along.
The first step to making a game is having a game you want to make.
I started on this at the end of April, after a very rushed month spent preparing the Steam release of Cherry Kisses. I was pretty pumped about having just published something in a very visible place for the first time, and I wanted to keep that energy going, but I didn’t want to immediately jump into an even larger thing. I wanted to make something small, something self-contained, something I could do entirely on my own. (My spouse is the better artist by far, and they did all the art for Cherry Kisses.)
The PICO-8 came to mind as the obvious platform to use. For one, the limitations make it very difficult for a game’s scope to balloon very far; you will simply run out of space and have to cut some ideas. For two, the art and audio are fairly low-resolution, so I wouldn’t have much opportunity to endlessly fuss over trying to make them perfect. For three, it runs in a browser, even on phones, so the resulting game would be easy for anyone to play. (Having to download a thing will discourage a surprising amount of casual passersby, especially if the thing is fairly small and thus low-reward.)
I also just find the PICO-8 endlessly charming, and I hadn’t touched it in a couple years and was curious how it had improved in the interim. It’s great for a game started on a whim, too, since I can jump in and start slapping stuff on the screen without worrying that my ADHD brain will start fretting over how everything should be organized.
That only left the question of what to make.
Two and a half years prior — almost three, now — I’d started on a platformer where you played as Star Anise, my cat’s fursona. It was intended to be a goofy Metroidvania where you collected cat-themed powers, ran around defeating little monsters, collected useless garbage, and generally left a trail of minor mayhem in your wake. Sadly, it was interrupted by real-life events and we haven’t touched it since.
I loved how this game was shaping up! It was so goofy, but its goofiness really opened up the design. Star Anise is great to build a game around. I can give him all manner of strong yet absurd motivations, and as long as I tie them to something vaguely cat-themed, they’ll be memorable and feel sensible. I can load him up with goofy cat-themed powers without needing any kind of justification, because he’s a cat, and everyone knows cats are basically magic anyway. He has a group of friends already built in: other cats. And most importantly, he’s just fun to play as, because everything he does is ridiculous and overboard, but you never have to feel guilty about his mischief because he’s a cat.
It’s such a good hook. I’ve wanted to make a whole series of little Star Anise games, but the furthest I’d gotten so far was Star Anise Chronicles: Escape from the Chamber of Despair — which is good, but is also a text adventure, one of the most impenetrable genres imaginable.
So why not take another crack at it? I couldn’t fit the entire original vision into a PICO-8 game, but surely I’d have enough room for Star Anise, a few of the abilities we’d come up with, and some things to interact with. At long last, a Star Anise platformer.
You could say the stars aligned. The stars. Get it? Like Star Anise. Okay.
Before I could do anything, I needed some art. Okay, that’s not true; I could have boxes moving around on the screen, but I’ve done this enough that I am beyond tired of boxes. If I’m gonna make a Star Anise game then I want to have Star Anise on the damn screen right from the start.
And right away I had to make some decisions. I wanted this to be a little bit Metroidvania style, where Star Anise gained his handful of powers throughout the game and could then explore new areas.
That meant I wanted as much map space as humanly possible, so from the very beginning I knew the sprite/map split I wanted: all map. 32 screens, but only 128 sprites.
And that made several other decisions, automatically. I probably wouldn’t have enough sprite space to include a gun and enemies and whatnot, but a puzzler would let me skip all of that.
This is why I chose PICO-8! The game basically decided its own design with only minimal input from me. Puzzle platformer with some powerups.
Now, to draw Star Anise, which meant deciding how big he should be. A very conspicuous part of his design is his huge helmet, which wouldn’t fit especially well in a single 8×8 tile, or even in two of them stacked. I decided to go one bigger and make a 2×3 block.
This wasn’t especially complicated to draw. At this size, it feels like a lot of the sprites draw themselves, too. It did help that I’d already seen my spouse’s interpretation of Star Anise from the prototype game above, but I think the general lesson there is to look at existing art that’s similar to what you want to draw and reverse-engineer the bits that make it work. Here, I made a big circle, squeezed in the narrowest possible face — a pixel each for the eyes, then three pixels for spacing — and gave him a rectangle for his body. Toss a couple stars into the inside of the helmet and, presto, that’s Star Anise.
You might be wondering about those weird extra tiles on the side! I’ll get to those in a moment.
With Star Anise drawn, the obvious first thing is to put him on the dang screen.
Some explanation may be in order. For starters, a “function” is a block of code that can be used repeatedly. (But then, this is not a programming tutorial.) These particular functions are special to the PICO-8: _init runs when the cartridge starts, _update runs every frame, and _draw also runs every frame.
What’s a frame, you ask? Well, you know how movies aren’t really showing movement, but are more like a very fast slideshow? Real life is “continuous” — that is, events occur smoothly over time, so when an object moves, it goes through every point between where it started and where it ends up. But we have no way to record that motion in full, becuase that would be an infinite amount of information! The best we can do is take a lot of snapshots very close together. And it turns out our eyes also work with snapshots (more or less), so it works well enough.
Likewise, simulating continuous behavior is extremely difficult, so video games tend to cheat the same way. We slice time into thin chunks — also called frames — and during each one, we move everything in the world ahead by that amount of time. If frames are short enough, you get the illusion that the world is behaving smoothly. Surprise! It’s all fake.
Modern games can (or should) deal with a varying frame rate, where each frame is a slightly (or greatly) different duration for any of myriad reasons. Since the PICO-8 is a faux-retro console, I’ll be using the retro term tic. It means the same thing, but it’s sometimes used for older systems where the framerate is reliably fixed, usually because it’s tied to (or even enforced by) hardware somewhere. Here it’s just emulated, but, you know, close enough.
Right, so, back to the PICO-8 itself. Every tic (of which there are 30 per second), the PICO-8 does two things: it calls _update to advance the game, then it calls _draw to draw the new state of the game to the screen. You might immediately wonder: why have these be separate if they happen one after the other anyway? Great question! The answer is that the PICO-8 does something clever — if it notices that the _update + _draw combination is taking longer than one tic (and the game is thus starting to lag), it will automatically drop down to 15 FPS. In this mode, it will call _updatetwice and then call _draw. Here is a terrible ASCII diagram.
As you can see, the game still updates twice in the same amount of time, so it still runs at the same speed, but it only draws half as often. With any luck, that saves enough effort that the game can keep running at the intended speed.
All of that is to say: the _draw function draws to the screen.
The first thing you (usually) want to do in _draw is clear the screen, which is accomplished by the charmingly terse cls(). If you don’t do this, your game will merrily draw right on top of whatever was on the screen previously: the prompt, a previous game, even the code editor.
After that, I called spr() to draw Star Anise. The usual arguments are spr(n, x, y), where n is the sprite number (visible near the middle of the screen in the sprite editor) and x, y say where to place him. He’s made up of six tiles, and you might think that drawing six tiles would thus require calling spr() six times, but it helpfully takes two more optional arguments: how many tiles to draw, as a single rectangle taken from the spritesheet. The above code thus draws a 2-by-3 block of tiles, starting from tile 1, at the coordinates (64, 64) — the center of the screen.
As is programming tradition, sprites are drawn from their top-left corner, so the initial tile is the top-left of the rectangle that gets drawn, and the coordinates are where the top-left of the drawn rectangle appears on screen. Thus, Star Anise appears with his top left “corner” in the middle of the screen.
There he is! How immensely satisfying. I always try to get something “real” drawing as early as humanly possible. It helps me feel like I’ve made some progress, like I’m working on a specific game and have made steps towards making it exist. This is already, quite clearly, a Star Anise game, but that wouldn’t be obvious if I’d started out with rectangles.
Now what? A good start would be to have him move around a bit. That’s easy enough if I introduce some state.
I do need to check what buttons the player is pressing, which I can do with btn(b), where b is the button… number. Left is button 0, right is button 1, up is button 2… but that makes for some unreadable garbage, so instead, let’s use a recently-introduced shortcut. If you hold Shift and press U, D, L, R, O, or X, the PICO-8 will insert a symbol representing that button. (I will be representing those symbols as ⬆️⬇️⬅️➡️🅾️❎, which is how the PICO-8 stores them on disk.)
Here I’ve put his position (still anchored at his top-left) into some variables, and during _update() I update them. (If you’re familiar with Lua, you may balk at += and -= — these are extensions added by PICO-8, and they save enough space that they’re definitely worth it.)
This is already halfway to being a game — it does something when I press buttons! Excellent. But also weird. This doesn’t look like Star Anise is walking around; it looks like he’s a static image being dragged by an invisible cursor or something. A very easy aesthetic improvement would be to make him not moonwalk when moving left.
That’s easy enough; the spr() function takes two more optional arguments, indicating whether to flip the sprite horizontally and/or vertically. I can just slap those in when he’s moving left. Or, well, not quite — I want to flip him when the last direction he moved was left. If he moves left and then stops, or moves left and then up and down, he should still be facing left.
Making progress, but obviously he’d look a lot better if he were animated, right?
Which, finally, brings us back to those extra tiles I drew. They’re copies of Star Anise’s legs and antenna, lightly edited to look like he’s in mid-step. The legs are sticking out all the way, and the antenna is adjusted to be… positioned slightly differently, since it’s bouncy. It’s a bit rough, but I can touch it up later.
Note that I’ve crammed as much movement into as little space as possible here. This is only a two-frame animation, so the leg movement is exaggerated to get the most bang for my buck. I don’t even duplicate the entirety of Star Anise for the other frame; instead, I only copied the tiles that change. That’ll make him more complicated to draw, but it does save me sprite space — remember, I only have 127 tiles available, and 9 of them is already 7% gone. (Writing more code to save on limited asset space is, in my experience, a pretty common PICO-8 tactic.)
Unfortunately, this makes flipping his sprite somewhat more complicated. I can’t just use that argument to spr(), because— well, I’ll get to that in a second. Here’s the updated code.
That sure got longer in a hurry! A quick overview:
I’ve introduced a global called t to act as a clock. I intend to use this for animation and other global cycles, so I don’t care about the actual time — that’s why I take it mod 120.
If you’re not familiar, the % (or “modulus”) operator gives you the remainder after division. It’s super duper useful and I wish we taught it as a primitive math operation! You can think of it like “clock arithmetic” — if it’s 9 o’clock and you wait 4 hours, it becomes 1 o’clock, which is the remainder when you divide 9 + 4 by 12. Or you can think of it as removing all chunks of something — to convert the 24-hour “13 o’clock” to 12-hour, you remove all the 12s, leaving just 1 behind. Or you can think of it as coiling the entire number line into a circle, so after 11 you wrap around to 0 and start over. (That’s not quite how clocks work, but using 0–11 turns out to be much simpler than using 1–12.)
The upshot here is that t will hit 119 and then wrap back around to zero, which is important because PICO-8 numbers can’t go any higher than 32767. If I left it to its own devices, it would still wrap around, but to the more cumbersome -32768. I don’t want a negative clock!
But why 120? Because I want to be able to divide the clock cycle into smaller animation cycles, and I can only do that evenly if the whole clock’s length is a multiple of the smaller cycle’s length. (On a more powerful system, I’d have a more elaborate animation setup, but that would cost more space and code than I’m willing to spend here.) Consider if I had a clock that wrapped around at 10, and I wanted an animation 3 tics long. I would use modulo 3 to shrink the clock, resulting in:
Whoops! Frame 0 will show twice in a row, intermittently, even seemingly at random. That’s not great. For the best chance of avoiding that problem without having to think too hard about it, I want a clock whose length is divisible by as much stuff as possible — a highly composite number. And, of course, 120 is one such number.
Next, I track whether Star Anise is moving at all, so I know whether to play the walk animation. Note that I always assume he isn’t moving, and then correct myself if it turns out he is; otherwise, the new value of moving would persist into future tics and he’d never stop.
That brings me to the new drawing code, which is a little tricky, so here it is a bit at a time:
1
2
3
4
5
6
7
8
9
-- top of the filelocalanise_stand={1,2,17,18,33,34}localanise_jump={3,2,17,18,19,35}-- in _draw()localpose=anise_standifmovingandt%8<4thenpose=anise_jumpend
This decides which tiles I’m going to draw. I can’t draw the walking part (which I’ve called “jump” because it does look like a jump in isolation, and I’ll be reusing them for that later) as a single block with spr() like before, and I’d like to share the code, so both frames are now assembled from individual tiles.
Note that tiles 1, 2, 17, 18, 33, and 34 are exactly the ones I was drawing in a single spr() call before. (The numbers increase by 16 when jumping to the next row, which makes sense, because each row has 16 tiles in it.) The other set is similar, but it has the alternate tiles substituted in.
I only want to use the jump tiles if Star Anise is moving, and if t % 8 < 4. That % turns my 120-tic clock into an 8-tic clock, then checks if we’re in the first half of it. Essentially: if it’s before noon, show the alternate frame; otherwise, show the normal standing frame.
The use of a global timer does have some subtle drawbacks here. If I tap an arrow key to move Star Anise only very briefly, then he may or may not animate, depending on whether the tap happens to be during the “stand” or “jump” intervals. A more powerful system, where every animation kept track of its own time, would always briefly show him moving. (On the other hand, this is an interesting aesthetic in its own right that kinda complements the very low-res and exaggerated animation.)
Next I need to draw the tiles, but we’ve come to the catch I mentioned before. When I draw Star Anise flipped, I’m now drawing him as a bunch of separate tiles. If I drew them in the same left-to-right order, then his left side would be flipped, and his right side would be flipped, but the whole image wouldn’t be. Er, just look at this picture.
See? The tiles are arranged the same way, but each one is individually flipped, and the result is… not what I want. I’ll need to also draw the columns in reverse order. And that’s exactly what I do:
Here I’m determining the start point and how far apart the tiles are. The variable names are fairly terse, for a couple of reasons: one, the PICO-8 screen is not very wide, so long variable names make code much harder to read; but also, math code tends to be easier to follow with shorter names anyway. I’ve even taken the naming conventions from math — the initial state of a variable is often written with a subscript zero (\(x_0\)) and a change is written with the Greek letter delta (\(\Delta x\)), so I’ve used the ASCII equivalents of those, x0 and dx.
I’m starting from Star Anise’s position, of course, and then each tile is 8 pixels right of the previous one… if he’s not flipped. If he is flipped, I want to move left, which will draw the tiles in reverse order. But that would change where he draws from, so to compensate, I also start drawing 8 pixels right of where I usually would. (Try to convince yourself that this is correct; on a flipped Star Anise, tile number 1 should draw 8 pixels left from his upper-left corner.)
All that’s left to do is the drawing itself. For each tile in the pose list, I draw that tile. Each row is two tiles wide, so after every second tile, I reset the horizontal “cursor” (x) back to where it started and move down by one row’s worth of pixels. For any other tile, I just move horizontally by dx.
The results are basically magic.
And that’s a good place to pause for now. Yes, I know, we didn’t get very far, but this is part zero! It’s mostly a test of this series and its tone for me, and a test of fortitude for you. I hope you could follow along with the minor mathematical hijinks above, because next time it gets much worse — before I can do anything else at all, I have to write collision detection. Oh boy! Stay tuned! And always feel free to ask questions, of me or anyone else!
Here are all the modifications PICO-8 has made to the language (based on Lua 5.2). If you’ve never used Lua, keep in mind that these won’t carry over if you try to write Lua anywhere else. Some of these are advanced features, so if you have no idea what something means, that’s probably fine.
Spoilers: it’s mostly that the standard library has changed.
Numbers are signed 15.16 fixed-point, rather than stock Lua’s 64-bit floating point. That means fractions can only be represented in increments of 0.0000152587890625 (= \(2^{-16}\), a cumbersome number I refer to as the “Planck size”), and numbers can’t exceed ±32768.
Compound assignment is supported: a += b works as in a = a + b in stock Lua, where + can be replaced with any binary operator.
!= is allowed as an alias for ~=.
if (foo) bar = 1 is shorthand for if foo then bar = 1 end. The parentheses are required, and the condition ends at the end of the line. (I strongly advise against using this unless you’re very desperate for space; it scans poorly and doesn’t even save tokens.)
The new @, %, and $ unary prefix operators read 1, 2, or 4 bytes from a memory address. (PICO-8’s memory, not system RAM!)
The ? unary prefix operator is equivalent to print. (I’ve never used it, and it’s not even directly documented.)
The built-in functions collectgarbage, dofile, error, pcall, require, select, and xpcall are not available (though the lack of select might be a bug).
The built-in variables _G and _VERSION are not available.
load has been replaced with a function that loads PICO-8 carts from files.
print has been replaced with a drawing function, which prints a single string at a position on screen.
tonumber and tostring have been replaced with tonum and tostr, which behave slightly differently (but tostr does still respect the __tostring metatable field).
(assert, getmetatable, ipairs, next, pairs, rawequal, rawget, rawlen, rawset, setmetatable, and type still exist and work as in stock Lua.)
The coroutine library is not available, but most of its contents are exposed directly as cocreate, coresume, costatus, and yield. There is no equivalent for coroutine.running or coroutine.wrap.
The require function and package library are not available, though the #include syntax can be used to textually substitute the contents of a Lua file.
The string library is not available. Replacement string functions are: chr, ord, split, and sub.
The table library is not available. Replacement table functions are: add, del, deli, count, all, foreach. There is no built-in way to concatenate or sort a list.
The math library is not available. Replacement math functions are: max, min, mid, flr, ceil, sin, cos, atan2, sqrt, abs, rnd, srand. There is also an integer division operator, \.
The bit32 library is not available, but bitwise operations are available as both functions — band, bor, bxor, bnot, shl, shr, lshr, rotl, rotr — and operators — &, |, ^^, ~, <<, >>, >>>, <<>, >><.
The io library is not available. Running PICO-8 cartridges have no notion of a filesystem.
The os library is not available. Running PICO-8 cartridges have no direct access to the underlying operating system. (Some facilities are exposed through the “syscall” function stat, such as accessing the current UTC or local time.)
The debug library is not available.
A number of other new functions were added, though I won’t list them all here; they’re generally for drawing, working with assets, or interacting with the PICO-8’s faux hardware.
This isn’t an easy piece to write, for reasons that will shortly become clear, but I know it’s time to explain myself on an issue surrounded by toxicity. I write this without any desire to add to that toxicity.
I admire that. I, too, would prefer not to add to the toxicity.
For people who don’t know: last December I tweeted my support for Maya Forstater, a tax specialist who’d lost her job for what were deemed ‘transphobic’ tweets. She took her case to an employment tribunal, asking the judge to rule on whether a philosophical belief that sex is determined by biology is protected in law. Judge Tayler ruled that it wasn’t.
We are off to a poor start. Framing an unrenewed contract as “losing her job” is dubious. And specifically, Judge Tayler ruled that “she will refer to a person by the sex she considered appropriate even if it violates their dignity and/or creates an intimidating, hostile, degrading, humiliating or offensive environment” — that is, she would be actively and knowingly rude towards people in the workplace, and that is not protected.
(Forstater later disingenuously claimed to have lost her job for “speaking up about women’s rights”. And I’m just now learning that she compared the use of correct pronouns to the use of rohypnol — the date rape drug — while this court case was pending. Charming.)
All the time I’ve been researching and learning, accusations and threats from trans activists have been bubbling in my Twitter timeline. This was initially triggered by a ‘like’. When I started taking an interest in gender identity and transgender matters, I began screenshotting comments that interested me, as a way of reminding myself what I might want to research later. On one occasion, I absent-mindedly ‘liked’ instead of screenshotting. That single ‘like’ was deemed evidence of wrongthink, and a persistent low level of harassment began.
This sounds like a simple misunderstanding which could have been resolved with a single explanatory tweet. Instead, your spokesperson referred to it as a “clumsy and middle-aged moment”. And now you categorize the tweet vaguely as something to research — suggesting to a casual reader that you had merely liked a link to a scholarly article, perhaps — when it was a mundane personal rant which referred to trans women as “men in dresses”.
I have a hypothesis about where the toxicity began — right there, when you clicked the heart underneath it. It’s something you know is mean and hurtful to the people it describes, and is intended to be so, and you not only defend it but cloak it in an obligatory 1984 reference. This is deceptive, mean-spirited, and shameful.
We are only on paragraph four.
Months later, I compounded my accidental ‘like’ crime by following Magdalen Burns on Twitter. Magdalen was an immensely brave young feminist and lesbian who was dying of an aggressive brain tumour. I followed her because I wanted to contact her directly, which I succeeded in doing. However, as Magdalen was a great believer in the importance of biological sex, and didn’t believe lesbians should be called bigots for not dating trans women with penises, dots were joined in the heads of twitter trans activists, and the level of social media abuse increased.
“You are fucking blackface actors. You aren’t women. You’re men who get sexual kicks from being treated like women. fuck you and your dirty fucking perversions. our oppression isn’t a fetish you pathetic, sick, fuck.”
That’s what Magdalen Berns, whose name you misspelled, had to say about trans women. (Ironically, it’s not too far off from what folks used to say — and occasionally still do — about gay folks.) I’m going to hazard a guess that this was more of a concern than any discourse about who lesbians choose to date.
The funny thing is, while I’ve seen the “gender critical” crowd complain numerous times that trans women are somehow trying to force cis lesbians to have sex with them (by tweeting about it?), I’ve virtually never witnessed the phenomenon directly — and I am neck-deep in trans Twitter. Perhaps two or three times over the years, I’ve seen some discourse about “genital attraction” and whether it’s socially influenced, which I suppose is an interesting question. On one singular occasion, such a tweet came uncomfortably close to suggesting that people were obligated to correct for what’s presumed to be social influence in who they’re attracted to, and I swiftly pushed back against it.
But the way “gender critical” folks talk about this, you’d think it was the only topic trans women ever discuss! Meanwhile, do you know who most trans women I know are dating? Each other!
I mention all this only to explain that I knew perfectly well what was going to happen when I supported Maya. I must have been on my fourth or fifth cancellation by then.
I expected the threats of violence, to be told I was literally killing trans people with my hate, to be called cunt and bitch and, of course, for my books to be burned, although one particularly abusive man told me he’d composted them.
I am genuinely sorry that people are abusive on Twitter, but I don’t know how to avoid it when you have more followers than the populations of NYC and LA combined. It’s a much broader problem, though definitely exacerbated when you support someone who has been fighting for the right to be deliberately hostile.
I’m not sure what to make of the last part. Is composting a book worse than burning it? And are you hinting a comparison between burning one’s own personal property and the actions of Nazi Germany, or am I reading too much into this conspicuous phrasing? I hope the latter, because the former would be extremely tasteless, considering that part of what was burned was the research and library of a sex research institute which was founded by the man who coined the term “transsexualism” and had trans people as both staff and clients.
What I didn’t expect in the aftermath of my cancellation was the avalanche of emails and letters that came showering down upon me, the overwhelming majority of which were positive, grateful and supportive. They came from a cross-section of kind, empathetic and intelligent people, some of them working in fields dealing with gender dysphoria and trans people, who’re all deeply concerned about the way a socio-political concept is influencing politics, medical practice and safeguarding. They’re worried about the dangers to young people, gay people and about the erosion of women’s and girl’s [sic] rights. Above all, they’re worried about a climate of fear that serves nobody – least of all trans youth – well.
I note, conspicuously, that zero of them were from trans people, or you surely would’ve mentioned as much. You give trans youth a token mention at the end, but only as an object of external concern, not as people to be listened to and trusted about their own experiences. This is a theme that I see we’ll be revisiting.
I’d stepped back from Twitter for many months both before and after tweeting support for Maya, because I knew it was doing nothing good for my mental health. I only returned because I wanted to share a free children’s book during the pandemic. Immediately, activists who clearly believe themselves to be good, kind and progressive people swarmed back into my timeline, assuming a right to police my speech, accuse me of hatred, call me misogynistic slurs and, above all – as every woman involved in this debate will know – TERF.
I note for the audience that the “gender critical” crowd — you know, TERFs — love to use the term TRA (trans rights activist) to refer to pretty much any trans person who doesn’t buy what they’re selling. I don’t know if this is meant to be a dogwhistle, but it at least quacks like one.
More generally, “activists” is a favored scare word across the political spectrum, much like “ideology” — it conjures the image of someone who is angrily trying to push Politics on you, while neatly obscuring that the political view they’re trying to push is “please don’t be cruel to me or people like me”. Are you, Rowling, not an activist? What about the people you support, like Berns? You use “activist” ten times in this essay, and every single time to describe trans people.
It’s rhetorical sleight of hand. Trans people who want to live their lives without being called blackface actors are “activists”, while the people making those comments are merely expressing concerns. Telling people what they should be able to wear earns no mention in this essay at all, but replying on a public platform to tell you that you are being hurtful is “policing your speech”.
Do you know where I first learned about this trick? From people who opposed the gay rights movement. “Gay rights activist” was a phrase I saw bandied about a lot while I was growing up, as though wanting to be able to marry one’s partner instantly transformed a person into some sort of unreasonable lobbyist, while opposing it was just the normal and natural thing to do. Frequently they’d have one gay person who agreed with them to put on a pedestal, the proof that they didn’t actually hate gay people — at least not the ones who’d sit down and shut up and accept whatever scraps they were given.
If you didn’t already know – and why should you? – ‘TERF’ is an acronym coined by trans activists, which stands for Trans-Exclusionary Radical Feminist. In practice, a huge and diverse cross-section of women are currently being called TERFs and the vast majority have never been radical feminists. Examples of so-called TERFs range from the mother of a gay child who was afraid their child wanted to transition to escape homophobic bullying, to a hitherto totally unfeminist older lady who’s vowed never to visit Marks & Spencer again because they’re allowing any man who says they identify as a woman into the women’s changing rooms.
As any best-selling author would know, if a word is used incorrectly at least two times on Twitter, it loses all meaning.
From what I’ve observed, the vast majority of people referred to as TERFs are people who claim an interest in the well-being of women and lesbians, but exclude trans women from that (or outright classify them all as predators), treat trans men as confused women, speak over or outright ignore the people they claim to be defending, and spend an awful lot of time inventing or vastly exacerbating “concerns” about trans people so as to excuse spending an awful lot of the rest of their time saying incredibly nasty things.
Ironically, radical feminists aren’t even trans-exclusionary – they include trans men in their feminism, because they were born women.
This is trans-exclusionary. It’s feminism that ignores and talks over trans men, which is a strange thing for feminists to do to people they consider to be women.
But accusations of TERFery have been sufficient to intimidate many people, institutions and organisations I once admired, who’re cowering before the tactics of the playground. ‘They’ll call us transphobic!’ ‘They’ll say I hate trans people!’ What next, they’ll say you’ve got fleas?
Not wanting to come across as hating a group of people is generally considered polite. Imagine saying this about, I don’t know, lesbians.
Speaking as a biological woman, a lot of people in positions of power really need to grow a pair (which is doubtless literally possible, according to the kind of people who argue that clownfish prove humans aren’t a dimorphic species).
Is “courage is stored in the balls” feminist now?
But since you bring up dimorphism, here’s a fun anecdote that’s relevant to my field. It seems that one of the biggest factors a neural network (“AI”) uses to determine a person’s gender is… hair length! Which isn’t a dimorphic trait, at least not how you’d think. The sexes are not really all that distinct; much of it is decoration we put on ourselves to exacerbate the differences, for some reason.
For some more anecdotes, feel free to look for reports of cis lesbians being kicked out of public women’s restrooms for looking too masculine. Like this one, or this one, or this one, or this one. Whose activism do you suppose would exacerbate this?
Firstly, I have a charitable trust that focuses on alleviating social deprivation in Scotland, with a particular emphasis on women and children. Among other things, my trust supports projects for female prisoners and for survivors of domestic and sexual abuse. I also fund medical research into MS, a disease that behaves very differently in men and women. It’s been clear to me for a while that the new trans activism is having (or is likely to have, if all its demands are met) a significant impact on many of the causes I support, because it’s pushing to erode the legal definition of sex and replace it with gender.
What a perfect example. What does it mean for MS to behave very differently in men and women? “Man” versus “woman” isn’t a switch you flip; it’s a combination of dozens of factors. If the difference is caused by hormone levels — which looks plausible — then trans women on HRT will be affected similarly to cis women, because they have the same levels of estrogen! And by excluding them — by insisting we talk only about “biological” “men” and “women” rather than specific biological factors — you are miscategorizing them for no reason.
The second reason is that I’m an ex-teacher and the founder of a children’s charity, which gives me an interest in both education and safeguarding. Like many others, I have deep concerns about the effect the trans rights movement is having on both.
Ah, you mean Lumos, the charity you cofounded with Baroness Emma Nicholson, who just yesterdaysaid that gay marriage is degrading women’s rights after attempting to repeal it in 2013? I have some deep concerns about the effect this person will have on the well-being of gay teens — and she’s not a mere “activist” or “movement”, but a lawmaker! Strange company you keep. And that’s not even getting into how she called it pedophilia for a trans charity’s website to have an escape button on it in case of abusive parents, a mere week and a half ago.
The third is that, as a much-banned author, I’m interested in freedom of speech and have publicly defended it, even unto Donald Trump.
“Much-banned”? You wrote one of the best-selling books of all time and the best-selling series of all time. You have sold at least one book for every fourteen humans alive and made almost a dozen movie deals. When you tweet, it trends for days and makes national headlines. Your freedom of speech is not at risk here — and if it were, you could probably afford to inscribe whatever you wanted to say on the face of the moon.
The fourth is where things start to get truly personal. I’m concerned about the huge explosion in young women [sic] wishing to transition and also about the increasing numbers who seem to be detransitioning (returning to their original sex), because they regret taking steps that have, in some cases, altered their bodies irrevocably, and taken away their fertility. Some say they decided to transition after realising they were same-sex attracted, and that transitioning was partly driven by homophobia, either in society or in their families.
Yes, it’s truly tragic that homophobia is still rampant, such as in the baroness you cofounded a charity with. Especially in parents. Incidentally, the most common reason given for detransitioning — which is pressure from a parent (36%, see page 108); the next is harassment/discrimination (31%), followed by having trouble getting a job (29%). Most of the other reasons given were pressure from some other external source. Only 0.4% of the people in that survey reported detransitioning because they simply did not like transition. And, by the way, detransition (even temporarily) is several times more common in trans women than trans men.
If you really want to fight detransition, the most effective action you could take would be to delete this post. But you’re approaching this from the perspective that trans men are confused, just like swaths of homophobic parents have said of their gay children.
Most people probably aren’t aware – I certainly wasn’t, until I started researching this issue properly – that ten years ago, the majority of people wanting to transition to the opposite sex were male. That ratio has now reversed. The UK has experienced a 4400% increase in girls [sic] being referred for transitioning treatment. Autistic girls [sic] are hugely overrepresented in their numbers.
Of course they are. Trans people are disproportionately autistic, so this is to be expected. I’d think this would be cause for celebration — people are being treated who previously wouldn’t have been! That’s excellent progress.
But instead of celebrating it, you suggest here that autistic trans boys are being taken advantage of. No, worse; you suggest that autistic trans boys are incapable of making decisions about their own lives, and don’t even respect them enough to refer to them as they wish to be referred to. You speak over them, dismiss them as obviously wrong out of hand, and ignore how they wish to be referred to while pretending to care about their well-being. This is deeply condescending and appalling.
As an aside, it’s quite frustrating that you so frequently refuse to connect the dots — instead you leave a trail of breadcrumbs and let some haunting conclusion form in the reader’s head, while retaining plausible deniability for yourself because you never actually said the things you’re trying to imply. That leaves you free to claim that a response like this one, which spells out the winks and nods, is yet more dismissable harassment.
The same phenomenon has been seen in the US. In 2018, American physician and researcher Lisa Littman set out to explore it. In an interview, she said:
‘Parents online were describing a very unusual pattern of transgender-identification where multiple friends and even entire friend groups became transgender-identified at the same time. I would have been remiss had I not considered social contagion and peer influences as potential factors.’
Littman mentioned Tumblr, Reddit, Instagram and YouTube as contributing factors to Rapid Onset Gender Dysphoria, where she believes that in the realm of transgender identification ‘youth have created particularly insular echo chambers.’
Her paper caused a furore. She was accused of bias and of spreading misinformation about transgender people, subjected to a tsunami of abuse and a concerted campaign to discredit both her and her work. The journal took the paper offline and re-reviewed it before republishing it.
This is probably because “rapid-onset gender dysphoria” is not a real phenomenon. The critical flaw in the idea is so blatantly obvious that you’ve very nearly spelled it out yourself: parents described an “unusual” pattern of behavior. Not the children themselves, not psychologists, not therapists. Parents. Parents who are upset that their children are coming out as trans, who are searching for some external factor to blame so they can rest assured that their children have simply been taken advantage of by some nefarious force.
I remember this all quite well from the 90s, except then it was about homosexuality. (A pattern begins to emerge.) There were no signs!, cry parents who punished their children for ever showing any signs, thus swiftly teaching them to put on a good act. It must be the media. It must be the evil other gays somehow influencing my poor child, who otherwise would be straight, like I want them to be.
The only difference is that this time it’s been given an acronym to lend it some veneer of credibility. But it’s not a clinical diagnosis; it’s a study of the feelings of parents who were caught off guard and are searching for an explanation other than “my child is trans”. Even the paper itself has a preface saying the term “should not be used in a way to imply that it explains the experiences of all gender dysphoric youth”.
There’s no mystery to be solved here, anyway. Talk to a single queer person (who isn’t isolated due to factors beyond their control) and I’ll bet you they have disproportionately many queer friends. People who are alike tend to clump together, especially if they sense that society at large is uncomfortable with them. All that’s been observed here is that trans teenagers form friend groups, and when one of them comes out, the others feel confident enough to come out as well. And their parents don’t like it, because of a culture that includes essays like this from household names with massive platforms.
However, her career took a similar hit to that suffered by Maya Forstater. Lisa Littman had dared challenge one of the central tenets of trans activism, which is that a person’s gender identity is innate, like sexual orientation. Nobody, the activists insisted, could ever be persuaded into being trans.
I remember this from the 90s, too. I remember the argument having to be made that sexual orientation is fixed and absolute and predetermined — because, regardless of how true or universal that may or may not be, the alternative is to leave the door open for parents and communities to try to “fix” gay children and ostracize the gay adults who had “persuaded” them into being gay.
Here we go again, except the “fix” for trans youth is to merely tell them to knock it off because they’re mistaken and leave it at that.
The argument of many current trans activists is that if you don’t let a gender dysphoric teenager transition, they will kill themselves. In an article explaining why he resigned from the Tavistock (an NHS gender clinic in England) psychiatrist Marcus Evans stated that claims that children will kill themselves if not permitted to transition do not ‘align substantially with any robust data or studies in this area. Nor do they align with the cases I have encountered over decades as a psychotherapist.’
They won’t necessarily kill themselves, but you could throw a rock and hit a study telling you that trans folks have a shockingly high rate of suicide attempts, and the absolute number one factor that drops that rate precipitously is transition. Or you could talk to a trans person and see if they have a friend who attempted/committed suicide because they were unable to transition (yes). Or at the very least, maybe cite someone who didn’t resign.
What a shockingly insensitive thing to say.
The writings of young trans men reveal a group of notably sensitive and clever people. The more of their accounts of gender dysphoria I’ve read, with their insightful descriptions of anxiety, dissociation, eating disorders, self-harm and self-hatred, the more I’ve wondered whether, if I’d been born 30 years later, I too might have tried to transition. The allure of escaping womanhood would have been huge. I struggled with severe OCD as a teenager. If I’d found community and sympathy online that I couldn’t find in my immediate environment, I believe I could have been persuaded to turn myself into the son my father had openly said he’d have preferred.
You call them clever, but immediately turn around and suggest that they are somehow artificially trans, that they have been “persuaded” into it. Again, you express ostensible care but use it as a springboard to dismiss them and talk over them. And what of trans women, who are well aware of what womanhood entails but still prefer it? This is precisely what I mentioned as the common TERF rhetoric, and is why people are calling you one: you speak piteously of trans men while suggesting with every word that you know better than they do what’s good for them, while trans women are… well, who knows what that omission might imply?
When I read about the theory of gender identity, I remember how mentally sexless I felt in youth. I remember Colette’s description of herself as a ‘mental hermaphrodite’ and Simone de Beauvoir’s words: ‘It is perfectly natural for the future woman to feel indignant at the limitations posed upon her by her sex. The real question is not why she should reject them: the problem is rather to understand why she accepts them.’
As I didn’t have a realistic possibility of becoming a man back in the 1980s, it had to be books and music that got me through both my mental health issues and the sexualised scrutiny and judgement that sets so many girls to war against their bodies in their teens. Fortunately for me, I found my own sense of otherness, and my ambivalence about being a woman, reflected in the work of female writers and musicians who reassured me that, in spite of everything a sexist world tries to throw at the female-bodied, it’s fine not to feel pink, frilly and compliant inside your own head; it’s OK to feel confused, dark, both sexual and non-sexual, unsure of what or who you are.
At last, you spell it out. But trans men are not confused and don’t need you to save them.
I want to be very clear here: I know transition will be a solution for some gender dysphoric people, although I’m also aware through extensive research that studies have consistently shown that between 60-90% of gender dysphoric teens will grow out of their dysphoria.
Flat-out incorrect. I assume you’re referring to research that the bulk (“65 to 94 percent”) of dysphoric prepubescent children will “grow out of it” — but if it persists beyond puberty (i.e., into their teens), it’s most likely permanent.
Again and again I’ve been told to ‘just meet some trans people.’ I have: in addition to a few younger people, who were all adorable, I happen to know a self-described transsexual woman who’s older than I am and wonderful. Although she’s open about her past as a gay man, I’ve always found it hard to think of her as anything other than a woman, and I believe (and certainly hope) she’s completely happy to have transitioned.
Describing them as “adorable” does not fill me with confidence that you listened to anything they had to say, especially in light of your repeated attempts to cast trans boys as confused or misled.
I’m glad you have 1 trans friend, whose viewpoint or input you manage to not actually mention whatsoever before using her as a foothold to make another “concerned” point:
Being older, though, she went through a long and rigorous process of evaluation, psychotherapy and staged transformation. The current explosion of trans activism is urging a removal of almost all the robust systems through which candidates for sex reassignment were once required to pass.
If you would “just meet some trans people”, you would know that the long and rigorous process is torture. Quite regularly I see tweets — from folks in the UK especially — about having to wait for up to a year or more just to see a gender therapist once, after which they have to wait even longer to even begin hormones. In the US, I’ve read no end of anecdotes from people who have to perform the right “kind” of transness to convince a therapist to write them a referral letter, after who knows how many sessions. And this is, quite often, after years of internal debate and questioning. Years and years of their lives lost forever.
All of this is predicated, once again, on the idea that trans people just don’t know what’s good for themselves.
A man [sic] who intends to have no surgery and take no hormones may now secure himself [sic] a Gender Recognition Certificate and be a woman in the sight of the law. Many people aren’t aware of this.
She would need a formal diagnosis and to have lived as a woman for at least two years. At least as written, a cis man cannot simply show up and get an F stamped on his passport. I don’t even know what possible purpose that would serve.
We’re living through the most misogynistic period I’ve experienced. Back in the 80s, I imagined that my future daughters, should I have any, would have it far better than I ever did, but between the backlash against feminism and a porn-saturated online culture, I believe things have got significantly worse for girls. Never have I seen women denigrated and dehumanised to the extent they are now. From the leader of the free world’s long history of sexual assault accusations and his proud boast of ‘grabbing them by the pussy’, to the incel (‘involuntarily celibate’) movement that rages against women who won’t give them sex, to the trans activists who declare that TERFs need punching and re-educating, men across the political spectrum seem to agree: women are asking for trouble. Everywhere, women are being told to shut up and sit down, or else.
I cannot believe you are comparing sexual assault and incels — who have committed mass shootings! — to angry trans people tweeting anime screenshots captioned “shut up” at you. “TERF” doesn’t even imply a woman — the most infamous one by far is a man, Graham Lineham!
Meanwhile, you have — multiple times in this essay — suggested that trans boys are misled and the choices they’ve made for themselves are somehow mistakes. I know you consider them women, because your exact phrasing was to call them “girls [sic] being referred for transitioning treatment” and then reframe their choices as actually being about misogyny. What kind of feminism is it to decide you know better than people you think are women? Not even decide, but take for granted, speak about as though their agency never existed to be dismissed in the first place?
I’ve read all the arguments about femaleness not residing in the sexed body, and the assertions that biological women don’t have common experiences, and I find them, too, deeply misogynistic and regressive. It’s also clear that one of the objectives of denying the importance of sex is to erode what some seem to see as the cruelly segregationist idea of women having their own biological realities or – just as threatening – unifying realities that make them a cohesive political class. The hundreds of emails I’ve received in the last few days prove this erosion concerns many others just as much. It isn’t enough for women to be trans allies. Women must accept and admit that there is no material difference between trans women and themselves.
Who has said that cis women don’t have common biological experiences? The issue is that most trans men and some nonbinary folks also have those experiences (and some cis women don’t), so if you’re going to talk about them, why not talk about the experience instead of saying “women” and presuming that everyone will intuit which of a dozen possible facets of womanhood you’re referring to?
And if the experience in question is a social one, based on other people’s perception of you as a woman, then guess what: loads of trans women will also have had those experiences.
But, as many women have said before me, ‘woman’ is not a costume. ‘Woman’ is not an idea in a man’s head. ‘Woman’ is not a pink brain, a liking for Jimmy Choos or any of the other sexist ideas now somehow touted as progressive.
The women saying those things, anecdotally, appear to have significant overlap with women who criticize trans women for not “looking” female enough. Or who, sadly, misidentify cis women as trans women for not “looking” female enough. You know, that refined classical sexism.
If trans women wear dresses, they’re treating womanhood as a costume; if they don’t, they’re faking it.
Moreover, the ‘inclusive’ language that calls female people ‘menstruators’ and ‘people with vulvas’ strikes many women as dehumanising and demeaning. I understand why trans activists consider this language to be appropriate and kind, but for those of us who’ve had degrading slurs spat at us by violent men, it’s not neutral, it’s hostile and alienating.
Clearly you don’t understand, as no one is blanket referring to “female people” as “menstruators”. The current kerfuffle started because you commented on an article titled “Creating a more equal post-COVID-19 world for people who menstruate”. It used that phrasing because it was about menstruation (and was written by three women). The only person in this whole mess who has tried to reduce women to their body parts is you, in your initial tweet, insisting that menstruation is a uniquely defining feature of womanhood.
Moreover, the article is about addressing a women’s health and women’s rights issue, and it mentions women frequently, but your only response was to criticize the title for trying to include the very people — trans men — that you keep trampling in this essay. I find your choice of priorities increasingly alarming.
If you could come inside my head and understand what I feel when I read about a trans woman dying at the hands of a violent man, you’d find solidarity and kinship. I have a visceral sense of the terror in which those trans women will have spent their last seconds on earth, because I too have known moments of blind fear when I realised that the only thing keeping me alive was the shaky self-restraint of my attacker.
I believe the majority of trans-identified people not only pose zero threat to others, but are vulnerable for all the reasons I’ve outlined. Trans people need and deserve protection. Like women, they’re most likely to be killed by sexual partners. Trans women who work in the sex industry, particularly trans women of colour, are at particular risk. Like every other domestic abuse and sexual assault survivor I know, I feel nothing but empathy and solidarity with trans women who’ve been abused by men.
So I want trans women to be safe. At the same time, I do not want to make natal girls and women less safe. When you throw open the doors of bathrooms and changing rooms to any man who believes or feels he’s a woman – and, as I’ve said, gender confirmation certificates may now be granted without any need for surgery or hormones – then you open the door to any and all men who wish to come inside. That is the simple truth.
I’m sorry for what you went through, but these few paragraphs horrify me. You understand and describe in vivid detail what some of these women go through, how their lives end, how at risk they are, and then immediately segue into how those women should not be given shelter — hell, not even just shelter, but a place to pee — because someone else might hypothetically abuse it.
I must be missing something, because this has never made sense to me. People who commit sexual assault are not especially interested in following the rules, so how is adding another rule meant to dissuade them from this contrived scheme? If someone is around to police who goes into the bathroom, why could that same person not instead intervene if someone tries to cause harm?
Anyway, what do you propose instead? You never say, which seems deeply at odds with your desire for trans women to be safe. The only alternative I ever hear involves checking identification and chromosomal analysis and all kinds of other absurdity — which is clearly aimed at trans folks and not nefarious men. Are you fine with the status quo, which is that trans people already use whatever bathroom they find most appropriate? Or do you think your trans woman friend should be forced into the men’s room, surrounded by men? Without saying one way or the other, you’re actively encouraging fear and hostility towards people who just want to pee — and not just towards trans people, but towards anyone who doesn’t “look female enough”.
On Saturday morning, I read that the Scottish government is proceeding with its controversial gender recognition plans, which will in effect mean that all a man needs to ‘become a woman’ is to say he’s one. To use a very contemporary word, I was ‘triggered’. Ground down by the relentless attacks from trans activists on social media, when I was only there to give children feedback about pictures they’d drawn for my book under lockdown, I spent much of Saturday in a very dark place inside my head, as memories of a serious sexual assault I suffered in my twenties recurred on a loop. That assault happened at a time and in a space where I was vulnerable, and a man capitalised on an opportunity. I couldn’t shut out those memories and I was finding it hard to contain my anger and disappointment about the way I believe my government is playing fast and loose with womens and girls’ safety.
Why did you take it out on the very people you just said you also want to be safe? Why did you take it out on an article that had little to do with safety and was pushing for better health and privacy? You’ve already said you know exactly how your actions will be perceived, so the backlash this time cannot have come as a surprise.
There was so much opportunity here for talking about cultural expectations and gender roles, how those foster and overlook violence and aggression from boys from a young age, how a lot of societal structures still suggest that men are “owed” something by women, or how violence is more broadly glorified in Western culture. As a world-renowned author who’s done extensive feminist research, you could surely make an impact.
Instead, you decided to hurt people.
Late on Saturday evening, scrolling through children’s pictures before I went to bed, I forgot the first rule of Twitter – never, ever expect a nuanced conversation – and reacted to what I felt was degrading language about women. I spoke up about the importance of sex and have been paying the price ever since. I was transphobic, I was a cunt, a bitch, a TERF, I deserved cancelling, punching and death. You are Voldemort said one person, clearly feeling this was the only language I’d understand.
You offered absolutely no nuance yourself, and this essay has carefully weaved around it the whole time as well. You, a straight person, co-opted the gay community’s struggle so you could wield it as a club against trans people — after tossing them Dumbledore as a token afterthought — despite having ties yourself to an MP who has actively tried to erode gay rights.
But yes, let us talk about Harry Potter and how it reflects your values. Zero non-heterosexual characters mentioned within the canon. But more of interest: where are the women? The main character, a boy; his mentor and the primary authority figure, a man; the teacher he’s at odds with, a man; the rival and entourage, all boys; his best friend, a boy; the awkward coward who gets a late redemption arc, a boy; the primary antagonist, a man; the sympathetic adult confidant, a man; the rediscovered long-lost family member, a man; the endlessly regenerating Defense Against the Dark Arts teachers, all men except for the cartoon villain Umbridge. The Weasleys have seven children; six are boys. Two of the Hogwarts founders are men, and two women… ah, but the men are the founders of the two plot-important houses. Vernon is clearly the head of the Dursley family, and their only child is a boy. On it goes.
Girls can aspire to be the nerd no one likes (hey, that’s me!), the insane woman no one believes, the abusive monster, the nurse with no personality, or one of a handful of love interests. McGonagall is extremely cool and can turn into a cat, I grant you. And I think there was someone named Bellatrix? But wasn’t she a Death Eater?
I don’t claim to be an expert on your series; on the contrary, I read them casually when they came out and haven’t revisited them since. This is the cast that left an impression on me. I have published half-hour video games with more female characters than I can name off the top of my head from the entire Harry Potter canon. Where was your concern for uplifting girls throughout the decade you spent writing the most popular book series in the history of the human race? Where was your interest in the well-being of gay teens as you dedicated untold pages to descriptions of wizard football?
I hope that’s enough nuance.
It would be so much easier to tweet the approved hashtags – because of course trans rights are human rights and of course trans lives matter – scoop up the woke cookies and bask in a virtue-signalling afterglow. There’s joy, relief and safety in conformity. As Simone de Beauvoir also wrote, “… without a doubt it is more comfortable to endure blind bondage than to work for one’s liberation; the dead, too, are better suited to the earth than the living.”
“Virtue signalling” is not in itself a bad thing; it is literally the indication to others of what our values are, so others know what we believe and how we are likely to treat them. Your essay still signals your virtues, as does mine.
“Of course” trans rights are human rights? I cannot even tell if this is meant to be serious or sarcastic, with how much seething resentment you’ve wrapped it in. Do you also consider your supposed support of lesbians to be “conformity”, since that’s no longer an especially controversial stance?
This is all outright reactionary rhetoric and you know it. You are using the very same catchphrases that the incels you so revile use when justifying their hatred for women.
Huge numbers of women are justifiably terrified by the trans activists; I know this because so many have got in touch with me to tell their stories. They’re afraid of doxxing, of losing their jobs or their livelihoods, and of violence.
Who is doxxing people? I tried to look into this and instead found a list of TERF websites with a prominent warning that they track and doxx and harass trans people; the Rational Wiki asserting that TERFs engage in doxxing; and this second-hand account that an ex-TERF was “threatened with doxing” by her own allies and “kept in a perpetual state of fear”.
And who on earth is sinking to violence over this? I find e.g. the “photo with a gun pointed at the viewer” phenomenon pretty distasteful, but it doesn’t seem to be unique to this issue, it’s not an especially credible threat of violence, and it’s the closest to actual violence I’ve ever heard of here. Surely, if anyone had come to blows, we’d never hear the end of it?
I note that Forstater’s contract wasn’t renewed because, as best as we can tell, she made her coworkers uncomfortable and the work environment hostile. Meanwhile, trans people can be (and are) fired for simply existing. Citing this as a fear people have of trans people, as though they were some large shadowy conspiracy, feels fairly tasteless.
But endlessly unpleasant as its constant targeting of me has been, I refuse to bow down to a movement that I believe is doing demonstrable harm in seeking to erode ‘woman’ as a political and biological class and offering cover to predators like few before it. I stand alongside the brave women and men, gay, straight and trans, who’re standing up for freedom of speech and thought, and for the rights and safety of some of the most vulnerable in our society: young gay kids, fragile teenagers, and women who’re reliant on and wish to retain their single sex spaces. Polls show those women are in the vast majority, and exclude only those privileged or lucky enough never to have come up against male violence or sexual assault, and who’ve never troubled to educate themselves on how prevalent it is.
By “young gay kids” and “fragile teenagers”, are you once again obliquely referring to young trans people who you take to be merely confused? What of their freedom of thought, of their right to decide who they are for themselves without seeing you use them as ammunition against other people like them? What impact do you think that will have on them, exactly?
Falling back on “freedom of speech” to defend one’s own hurtful speech is another reactionary talking point; when you cannot defend your speech on its own merits, you can only defend that it is not literally illegal to say.
What polls are you finding? 26% is not a vast majority, and it’s troubling that you proactively dismiss the women who disagree with you as aloof and uninformed. What kind of feminism is that?
The one thing that gives me hope is that the women who can protest and organise, are doing so, and they have some truly decent men and trans people alongside them. Political parties seeking to appease the loudest voices in this debate are ignoring women’s concerns at their peril. In the UK, women are reaching out to each other across party lines, concerned about the erosion of their hard-won rights and widespread intimidation. None of the gender critical women I’ve talked to hates trans people; on the contrary. Many of them became interested in this issue in the first place out of concern for trans youth, and they’re hugely sympathetic towards trans adults who simply want to live their lives, but who’re facing a backlash for a brand of activism they don’t endorse. The supreme irony is that the attempt to silence women with the word ‘TERF’ may have pushed more young women towards radical feminism than the movement’s seen in decades.
Absolute bullshit. You’ve consistently brushed off or spoken for women and trans men who disagree with you in this post alone, but frame your own stance as though it were shared by all women. Two women you’ve mentioned by name and made a point of supporting — Maya Forstater and Magdalen Berns — have said some astonishingly cruel things about trans people as blanket remarks, so I can only interpret their “non-hate” in the same way as people repeatedly told my younger self that they loved me but I would burn for all eternity if I kissed both boys and girls. If their “concern” for trans youth is anything like yours, then they’re only interested in trying to berate trans youth into not wanting to be trans any more — yet again, no different from how homophobia played out.
And, hang on, they’re hugely sympathetic towards trans adults who’re facing backlash? You must be joking. They — and you — ARE the backlash! What good is sympathy from the very people who are deliberately hurting you?
The last thing I want to say is this. I haven’t written this essay in the hope that anybody will get out a violin for me, not even a teeny-weeny one. I’m extraordinarily fortunate; I’m a survivor, certainly not a victim. I’ve only mentioned my past because, like every other human being on this planet, I have a complex backstory, which shapes my fears, my interests and my opinions. I never forget that inner complexity when I’m creating a fictional character and I certainly never forget it when it comes to trans people.
You’ve done so multiple times in this essay alone, and your heroes do it on a pretty consistent basis. What an insult to everyone who read this.
All I’m asking – all I want – is for similar empathy, similar understanding, to be extended to the many millions of women whose sole crime is wanting their concerns to be heard without receiving threats and abuse.
In the entirety of this essay, you didn’t even mention a single concrete concern. You did some vague fearmongering about how a cis man could get a piece of paper saying he’s a woman, and that’s all. Meanwhile, you managed to repeatedly misgender and patronize trans boys; paint trans adults as a nefarious political movement trying to “persuade” children; cite multiple people who’ve been fiercely nasty towards trans people as a whole, while avoiding mentioning what they actually did so you could frame them as innocent victims; invoke multiple homophobic and reactionary tropes with a quick coat of paint slapped on top; present “parents who wish their children were cis” as though it were a diagnosed phenomenon; and generally checked off every possible TERF talking point while smiling kindly the whole time.
You’re saying things you know are actively hurtful in the name of preventing a hypothetical harm that is so nebulous you can’t even describe it.
I first got into web design/development in the late 90s, and only as I type this sentence do I realize how long ago that was.
And boy, it was horrendous. I mean, being able to make stuff and put it online where other people could see it was pretty slick, but we did not have very much to work with.
I’ve been taking for granted that most folks doing web stuff still remember those days, or at least the decade that followed, but I think that assumption might be a wee bit out of date. Some time ago I encountered a tweet marvelling at what we had to do without border-radius. I still remember waiting with bated breath for it to be unprefixed!
But then, I suspect I also know a number of folks who only tried web design in the old days, and assume nothing about it has changed since.
I’m here to tell all of you to get off my lawn. Here’s a history of CSS and web design, as I remember it.
(Please bear in mind that this post is a fine blend of memory and research, so I can’t guarantee any of it is actually correct, especially the bits about causality. You may want to try the W3C’s history of CSS, which is considerably shorter, has a better chance of matching reality, and contains significantly less swearing.)
(Also, this would benefit greatly from more diagrams, but it took long enough just to write.)
My favorite artifact of this era is the book that taught me HTML: O’Reilly’s HTML: The Definitive Guide, published in several editions in the mid to late 90s. The book was indeed about HTML, with no mention of CSS at all. I don’t have it any more and can’t readily find screenshots online, but here’s a page from HTML&XHTML: The Definitive Guide, which seems to be a revision (I’ll get to XHTML later) with much the same style. Here, then, is the cutting-edge web design advice of 199X:
“Clearly delineate headers and footers with horizontal rules.”
No, that’s not a border-top. That’s an <hr>. The page title is almost certainly centered with, well, <center>.
The page uses the default text color, background, and font. Partly because this is a guidebook introducing concepts one at a time; partly because the book was printed in black and white; and partly, I’m sure, because it reflected the reality that coloring anything was a huge pain in the ass.
Let’s say you wanted all your <h1>s to be red, across your entire site. You had to do this:
1
<H1><FONTCOLOR=red>...</FONT></H1>
…every single goddamn time. Hope you never decide to switch to blue!
Oh, and everyone wrote HTML tags in all caps. I don’t remember why we all thought that was a good idea. Maybe this was before syntax highlighting in text editors was very common (read: I was 12 and using Notepad), and uppercase tags were easier to distinguish from body text.
Keeping your site consistent was thus something of a nightmare. One solution was to simply not style anything, which a lot of folks did. This was nice, in some ways, since browsers let you change those defaults, so you could read the Web how you wanted.
A clever alternate solution, which I remember showing up in a lot of Geocities sites, was to simply give every page a completely different visual style. Fuck it, right? Just do whatever you want on each new page.
That trend was quite possibly the height of web design.
Damn, I miss those days. There were no big walled gardens, no Twitter or Facebook. If you had anything to say to anyone, you had to put together your own website. It was amazing. No one knew what they were doing; I’d wager that the vast majority of web designers at the time were clueless hobbyist tweens (like me) all copying from other clueless hobbyist tweens. Half the Web was fan portals about Animorphs, with inexplicable splash pages warning you that their site worked best if you had a 640×480 screen. (Any 12-year-old with insufficient resolution should, presumably, buy a new monitor with their allowance.) Everyone who was cool and in the know used Internet Explorer 3, the most advanced browser, but some losers still used Netscape Navigator so you had to put a “Best in IE” animated GIF on your splash page too.
This was also the era of “web-safe colors” — a palette of 216 colors, where every channel was one of 00, 33, 66, 99, cc, or ff — which existed because some people still had 256-color monitors! The things we take for granted now, like 24-bit color.
In fact, a lot of stuff we take for granted now was still a strange and untamed problem space. You want to have the same navigation on every page on your website? Okay, no problem: copy/paste it onto each page. When you update it, be sure to update every page — but most likely you’ll forget some, and your whole site will become an archaeological dig into itself, with strata of increasingly bitrotted pages.
Much easier was to use frames, meaning the browser window is split into a grid and a different page loads in each section… but then people would get confused if they landed on an individual page without the frames, as was common when coming from a search engine like AltaVista. (I can’t believe I’m explaining frames, but no one has used them since like 2001. You know iframes? The “i” is for inline, to distinguish them from regular frames, which take up the entire viewport.)
PHP wasn’t even called that yet, and nobody had heard of it. This weird “Perl” and “CGI” thing was really strange and hard to understand, and it didn’t work on your own computer, and the errors were hard to find and diagnose, and anyway Geocities didn’t support it. If you were really lucky and smart, your web host used Apache, and you could use its “server side include” syntax to do something like this:
Mwah. Beautiful. Apache would see the special comments, paste in the contents of the referenced files, and you’re off to the races. The downside was that when you wanted to work on your site, all the navigation was missing, because you were doing it on your regular computer without Apache, and your web browser thought those were just regular HTML comments. It was impossible to install Apache, of course, because you had a computer, not a server.
Sadly, that’s all gone now — paved over by homogenous timelines where anything that wasn’t made this week is old news and long forgotten. The web was supposed to make information eternal, but instead, so much of it became ephemeral. I miss when virtually everyone I knew had their own website. Having a Twitter and an Instagram as your entire online presence is a poor substitute.
Space Jam, if you’re not aware, is the greatest movie of all time. It documents Bugs Bunny’s extremely short-lived basketball career, playing alongside a live action Michael Jordan to save the planet from aliens for some reason. It was followed by a series of very successful and critically acclaimed RPG spinoffs, which describe the fallout of the Space Jam and are extremely canon.
And we are truly blessed, for 24 years after it came out, its website is STILLUP. We can explore the pinnacle of 1996 web design, right here, right now.
First, notice that every page of this site is a static page. Not only that, but it’s a static page ending in .htm rather than .html, because people on Windows versions before 95 were still beholden to 8.3 filenames. Not sure why that mattered in a URL, as if you were going to run Windows 3.11 on a Web server, but there you go.
Haha, just kidding! What the fuck is CSS? Space Jam predates it by a month. (I do see a single line in the page source, but I’m pretty sure that was added much later to style some legally obligatory policy links.)
Notice the extremely precise positioning of these navigation links. This feat was accomplished the same way everyone did everything in 1996: with tables.
In fact, tables have one functional advantage over CSS for layout, which was very important in those days, and not only because CSS didn’t exist yet. You see, you can ctrl-click to select a table cell and even drag around to select all of them, which shows you how the cells are arranged and functions as a super retro layout debugger. This was great because the first meaningful web debug tool, Firebug, wasn’t released until 2006 — a whole decade later!
The markup for this table is overflowing with inexplicable blank lines, but with those removed, it looks like this:
That’s the first two rows, including the logo. You get the idea. Everything is laid out with align and valign on table cells; rowspans and colspans are used frequently; and there are some <br>s thrown in for good measure, to adjust vertical positioning by one line-height at a time.
Other fantastic artifacts to be found on this page include this header, which contains Apache SSI syntax! This must’ve quietly broken when the site was moved over the years; it’s currently hosted on Amazon S3. You know, Amazon? The bookstore?
Okay, let’s check out jam central. I’ve used my browser dev tools to reduce the viewport to 640×480 for the authentic experience (although I’d also have lost some vertical space to the title bar, taskbar, and five or six IE toolbars).
Note the frames: the logo in the top left leads back to the landing page, cleverly saving screen space on repeating all that navigation, and the top right is a fucking ad banner which has been blocked like seven different ways. All three parts are separate pages.
Note also the utterly unreadable red text on a textured background, one of the truest hallmarks of 90s web design. “Why not put that block of text on an easier-to-read background?” you might ask. You imbecile. How would I possibly do that? Only the <body> has a background attribute! I could use a table, but tables only support solid background colors, and that would look so boring!
But wait, what is this new navigation widget? How are the links all misaligned like that? Is this yet another table? Well, no, although filling a table with chunks of a sliced-up image wasn’t uncommon. But this is an imagemap, a long-forgotten HTML feature. I’ll just show you the source:
I assume this is more or less self-explanatory. The usemap attribute attaches an image map, which is defined as a bunch of clickable areas, beautifully encoded as inscrutable lists of coordinates or something.
And this stuff still works! This is in HTML! You could use it right now! Probably don’t though!
They did an important thing here: since they specified a background image (which is opaque), they also specified a background color. Without it, if the background image failed to load, the page would be white text on the default white background, which would be unreadable.
(That’s still an important thing to keep in mind. I feel like modern web development tends to assume everything will load, or sees loading as some sort of inconvenience to be worked around, but not everyone is working on a wired connection in a San Francisco office twenty feet away from a backbone.)
But about the page itself. Thumbnail grids are a classic problem of web design, dating all the way back to… er… well, at least as far back as Space Jam. The main issue is that you want to put things next to each other, whereas HTML defaults to stacking everything in one big column. You could put all the thumbnails inline, in a single row of (wrapping) text, but that wouldn’t be much of a grid — and you usually want each one to have some sort of caption.
Space Jam’s approach was to use the only real tool anyone had in their toolbox at the time: a table. It’s structured like this:
A 3×3 grid of thumbnails, left to the browser to arrange. (The last image, on a row of its own, isn’t actually part of the table.) This can’t scale to fit your screen, but everyone’s screen was pretty tiny back then, so that was slightly less of a concern. They didn’t add captions here, but since every thumbnail is wrapped in a table cell, they easily could have.
This was the state of the art in thumbnail grids in 1996. We’ll be revisiting this little UI puzzle a few times; you can see live examples (and view source for sample markup) on a separate page.
But let’s take a moment to appreciate the size of the “full-size, full-color, internet-quality” movie screenshots on my current monitor.
Hey, though, they’re less than 16 KB! That’ll only take nine seconds to download.
(I’m reminded of the problem of embedded video, which wasn’t solved until HTML5’s <video> tag some years later. Until then, you had to use a binary plugin, and all of them were terrible.)
(Oh, by the way: images within links, by default, have a link-colored border around them. Image links are usually self-evident, so this was largely annoying, and until CSS you had to disable them for every single image with <img border=0>.)
So that’s where we started, and it sucked. If you wanted any kind of consistency on more than a handful of pages, your options were very limited, and they were pretty much limited to a whole lot of copying and pasting. The Space Jam website opted to, for the most part, not bother at all — as did many others.
Then CSS came along, it was a fucking miracle. All that inline repetition went away. You want all your top-level headings to be a particular color? No problem:
123
H1{color:#FF0000;}
Bam! You’re done. No matter how many <h1>s you have in your document, every single one of them will be eye-searing red, and you never have to think about it again. Even better, you can put that snippet in its own file and have that questionable aesthetic choice applied to every page of your whole site with almost no effort! The same applied to your gorgeous tiling background image, the colors of your links, and the size of the font in your tables.
(Just remember to wrap the contents of your <style> tags in HTML comments, or old browsers without CSS support will display them as text.)
You weren’t limited to styling tags en masse, either. CSS introduced “classes” and “IDs” to target only specifically flagged elements. A selector like P.important would only affect <P CLASS="important">, and #header would only affect <H1 ID="header">. (The difference is that IDs are intended to be unique in a document, whereas classes can be used any number of times.) With these tools, you could effectively invent your own tags, giving you a customized version of HTML specific to your website!
This was a huge leap forward, but at the time, no one (probably?) was thinking of using CSS to actually arrange the page. When CSS 1 was made a recommendation in December ‘96, it barely addressed layout at all. All it did was divorce HTML’s existing abilities from the tags they were attached to. We had font colors and backgrounds because<FONT COLOR> and <BODY BACKGROUND> existed. The only feature that even remotely affected where things were positioned was the float property, the equivalent to <IMG ALIGN>, which pulled an image to the side and let text flow around it, like in a magazine article. Hardly whelming.
This wasn’t too surprising. HTML hadn’t had any real answers for layout besides tables, and the table properties were too complicated to generalize in CSS and too entangled with the tag structure, so there was nothing for CSS 1 to inherit. It merely reduced the repetition in what we were already doing with e.g. <FONT> tags — making Web design less tedious, less error-prone, less full of noise, and much more maintainable. A pretty good step forward, and everyone happily adopted it for that, but tables remained king for arranging your page.
That was okay, though; all your blog really needed was a header and a sidebar, which tables could do just fine, and it wasn’t like you were going to overhaul that basic structure very often. Copy/pasting a few lines of <TABLE BORDER=0> and <TD WIDTH=20%> wasn’t nearly as big a deal.
For some span of time — I want to say a couple years, but time passes more slowly when you’re a kid — this was the state of the Web. Tables for layout, CSS for… well, style. Colors, sizes, bold, underline. There was even this sick trick you could do with links where they’d only be underlined when the mouse was pointing at them. Tubular!
(Fun fact: HTMLemail is still basically trapped in this era.)
(And here’s about where I come in, at the ripe old age of 11, with no clue what I was doing and mostly learning from other 11-year-olds who also had no clue what they were doing. But that was fine; a huge chunk of the Web was 11-year-olds making their own websites, and it was beautiful. Why would you go to a business website when you can take a peek into the very specific hobbies of someone on the other side of the planet?)
A year and a half later, in mid ‘98, we were gifted CSS 2. (I love the background on this page, by the way.) This was a modest upgrade that addressed a few deficiencies in various areas, but most interesting was the addition of a couple positioning primitives: the position property, which let you place elements at precise coordinates, and the inline-block display mode, which let you stick an element in a line of text like you could do with images.
Such tantalizing fruit, just out of reach! Using position seemed nice, but pixel-perfect positioning was at serious odds with the fluid design of HTML, and it was difficult to make much of anything that didn’t fall apart on other screen sizes or have other serious drawbacks. This humble inline-block thing seemed interesting enough; after all, it solved the core problem of HTML layout, which is putting things next to each other. But at least for the moment, no browser implemented it, and it was largely ignored.
I can’t say for sure if it was the introduction of positioning or some other factor, but something around this time inspired folks to try doing layout in CSS. Ideally, you would completely divorce the structure of your page from its appearance. A website even came along to take this principle to the extreme — CSS Zen Garden is still around, and showcases the same HTML being radically transformed into completely different designs by applying different stylesheets.
Trouble was, early CSS support was buggy as hell. In retrospect, I suspect browser vendors merely plucked the behavior off of HTML tags and called it a day. I’m delighted to say that RichInStyle still has an extensive list of early browser CSS bugs up; here are some of my favorites:
IE 3 would ignore all but the last <style> tag in a document.
IE 3 ignored pseudo-classes, so a:hover would be treated as a.
IE 3 and IE 4 treated auto margins as zero. Actually, I think this one might’ve persisted all the way to IE 6. But that was okay, because IE 6 also incorrectly applied text-align: center to block elements.
If you set a background image to an absolute URL, IE 3 would try to open the image in a local program, as though you’d downloaded it.
Netscape 4 understood an ID selector like #id, but ignored h1#id as invalid.
Netscape 4 didn’t inherit properties — including font and text color! — into table cells.
Netscape 4 applied properties on <li> to the list marker, rather than the contents.
If the same element has both float and clear (not unreasonable), Netscape 4 for Mac crashes.
This is what we had to work with. And folks wanted to use CSS to lay out an entire page? Ha.
Yet the idea grew in popularity. It even became a sort of elitist rallying cry, a best practice used to beat other folks over the head. Tables for layout are just plain bad, you’d hear! They confuse screenreaders, they’re semantically incorrect, they interact poorly with CSS positioning! All of which is true, but it was a much tougher pill to swallow when the alternative was—
Well, we’ll get to that in a moment. First, some background on the Web landscape circa 2000.
The short version is: this company Netscape had been selling its Navigator browser (to businesses; it was free for personal use), and then Microsoft entered the market with its completely free Internet Explorer browser, and then Microsoft had the audacity to bundle IE with Windows. Can you imagine? An operating system that comes with a browser? This was a whole big thing, Microsoft was sued over it, and they lost, and the consequence was basically nothing.
But it wouldn’t have mattered either way, because they’d still done it, and it had worked. IE pretty much annihilated Netscape’s market share. Both browsers were buggy as hell, and differently buggy as hell, so a site built exclusively against one was likely to be a big mess when viewed in the other — this meant that when Netscape’s market share dropped, web designers paid less and less attention to it, and less of the Web worked in it, and its market share dropped further.
Sucks for you if you don’t use Windows, I guess. Which is funny, because there was an IE for Mac 5.5, and it was generally less buggy than IE 6. (Incidentally, Bill Gates wasn’t so much a brilliant nerd as an aggressive and ruthless businessman who made his fortune by deliberately striving to annihilate any competition standing in his way and making computing worse overall as a result, just saying.)
By the time Windows XP shipped in mid 2001, with Internet Explorer 6 built in, Netscape had gone from a juggernaut to a tiny niche player.
And then, having completely and utterly dominated, Microsoft stopped. Internet Explorer had seen a release every year or so since its inception, but IE 6 was the last release for more than five years. It was still buggy, but that was less noticeable when there was no competition, and it was good enough. Windows XP, likewise, was good enough to take over the desktop, and there wouldn’t be another Windows for just as long.
The W3C, the group who write the standards (not to be confused with W3Schools, who are shady SEO leeches), also stopped. HTML had seen several revisions throughout the mid 90s, and then froze as HTML 4. CSS had gotten an update in only a year and a half, and then no more; the minor update CSS 2.1 wouldn’t hit Candidate Recommendation status until early 2004, and took another seven years to be finalized.
With IE 6’s dominance, it was as if the entire Web was frozen in time. Standards didn’t matter, because there was effectively only one browser, and whatever it did became the de facto standard. As the Web grew in popularity, IE’s stranglehold also made it difficult to use any platform other than Windows, since IE was Windows-only and it was a coin flip whether a website would actually work with any other browser.
(One begins to suspect that monopolies are bad. There oughta be a law!)
In the meantime, Netscape had put themselves in an even worse position by deciding to do a massive rewrite of their browser engine, culminating in the vastly more standards-compliant Netscape 6 — at the cost of several years away from the market while IE was kicking their ass. It never broke 10% market share, while IE’s would peak at 96%. On the other hand, the new engine was open sourced as the Mozilla Application Suite, which would be important in a few years.
Before we get to that, some other things were also happening.
All early CSS implementations were riddled with bugs, but one in particular is perhaps the most infamous CSS bug of all time: the box model bug.
You see, a box (the rectangular space taken up by an element) has several measurements: its own width and height, then surrounding whitespace called padding, then an optional border, then a margin separating it from neighboring boxes. CSS specifies that these properties are all additive. A box with these styles:
123
width:100px;padding:10px;border:2pxsolidblack;
…would thus be 124 pixels wide, from border to border.
IE 4 and Netscape 4, on the other hand, took a different approach: they treated width and height as measuring from border to border, and they subtracted the border and padding to get the width of the element itself. The same box in those browsers would be 100 pixels wide from border to border, with 76 pixels remaining for the content.
This conflict with the spec was not ideal, and IE 6 set out to fix it. Unfortunately, simply making the change would mean completely breaking the design of a whole lot of websites that had previously worked in bothIE and Netscape.
So the IE team came up with a very strange compromise: they declared the old behavior (along with several other major bugs) as “quirks mode” and made it the default. The new “strict mode” or “standards mode” had to be opted into, by placing a “doctype” at the beginning of your document, before the <html> tag. It would look something like this:
1
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
Everyone had to paste this damn mess of a line at the top of every single HTML document for years. (HTML5 would later simplify it to <!DOCTYPE html>.) In retrospect, it’s a really strange way to opt into correct CSS behavior; doctypes had been part of the HTML spec since way back when it was an RFC. I’m guessing the idea was that, since nobody bothered actually including one, it was a convenient way to allow opting in without requiring proprietary extensions just to avoid behavior that had been wrong in the first place. Good for the IE team!
The funny thing is, quirks mode still exists and is still the default in all browsers, twenty years later! The exact quirks have varied over time, and in particular neither Chrome nor Firefox use the IE box model even in quirks mode, but there are still quite a few other emulated bugs.
Modern browsers also have “almost standards” mode, which emulates only a single quirk, perhaps the second most infamous one: if a table cell contains only a single image, the space under the baseline is removed. Under normal CSS rules, the image is sitting within a line of (otherwise empty) text, which requires some space reserved underneath for descenders — the tails on letters like y. Early browsers didn’t handle this correctly, and some otherwise strict-mode websites from circa 2000 rely on it — e.g., by cutting up a large image and arranging the chunks in table cells, expecting them to display flush against each other — hence the intermediate mode to keep them limping along.
But getting back to the past: while this was certainly a win for standards (and thus interop), it created a new problem. Since IE 6 dominated, and doctypes were optional, there was little compelling reason to bother with strict mode. Other browsers ended up emulating it, and the non-standard behavior became its own de facto standard. Web designers who cared about this sort of thing (and to our credit, there were a lot of us) made a rallying cry out of enabling strict mode, since it was the absolute barest minimum step towards ensuring compatibility with other browsers.
Meanwhile, the W3C had lost interest in HTML in favor of developing XHTML, an attempt to redesign HTML with the syntax of XML rather than SGML.
(What on Earth is SGML, you ask? I don’t know. Nobody knows. It’s the grammar HTML was built on, and that’s the only reason anyone has heard of it.)
To their credit, there were some good reasons to do this at the time. HTML was generally hand-written (as it still is now), and anything hand-written is likely to have the occasional bugs. Browsers weren’t in the habit of rejecting buggy HTML outright, so they had various error-correction techniques — and, as with everything else, different browsers handled errors differently. Slightly malformed HTML might appear to work fine in IE 6 (where “work fine” means “does what you hoped for”), but turn into a horrible mess in anything else.
The W3C’s solution was XML, because their solution to fucking everything in the early 2000s was XML. If you’re not aware, XML takes a much more explicit and aggressive approach to error handling — if your document contains a parse error, the entire document is invalid. That means if you bank on XHTML and make a single typo somewhere, nothing at all renders. Just an error.
This sucked. It sounds okay on the face of things, but consider: generic XML is usually assembled dynamically with libraries that treat a document as a tree you manipulate, then turn it all into text when you’re done. That’s great for the common use of XML as data serialization, where your data is already a tree and much of the XML structure is simple and repetitive and easy to squirrel away in functions.
HTML is not like that. An HTML document has little reliable repeating structure; even this blog post, constructed mostly from <p> tags, also contains surprise <em>s within body text and the occasional <h2> between paragraphs. That’s not fun to express as a tree. And this is a big deal, because server-side rendering was becoming popular around the same time, and generated HTML was — still is! — put together with templates that treat it as a text stream.
If HTML were only written as complete static documents, then XHTML might have worked out — you write a document, you see it in your browser, you know it works, no problem. But generating it dynamically and risking that particular edge cases might replace your entire site with an unintelligible browser error? That sucks.
It certainly didn’t help that we were just starting to hear about this newfangled Unicode thing around this time, and it was still not always clear how exactly to make that work, and one bad UTF-8 sequence is enough for an entire XML document to be considered malformed!
And so, after some dabbling, XHTML was largely forgotten. Its legacy lives on in two ways:
It got us all to stop using uppercase tag names! So long <BODY>, hello <body>. XML is case-sensitive, you see, and all the XHTML tags were defined in lowercase, so uppercase tags simply would not work. (Fun fact: to this day, JavaScript APIs report HTML tag names in uppercase.) The increased popularity of syntax highlighting probably also had something to do with this; we weren’t all still using Notepad as we had been in 1997.
A bunch of folks still think self-closing tags are necessary. You see, HTML has two kinds of tags: containers like <p>...</p> and markers like <br>. Since a <br> can’t possibly contain anything, there’s no such thing as </br>. XML, as a generic grammar, doesn’t have this distinction; every tag must be closed, but as a shortcut, you can write <br/> to mean <br></br>.
XHTML has been dead for years, but for some reason, I still see folks write <br/> in regular HTML documents. Outside of XML, that slash doesn’t do anything; HTML5 has defined it for compatibility reasons, but it’s silently ignored. It’s even actively harmful, since it might lead you to believe that <script/> is an empty <script> tag — but in HTML, it definitely is not!
I do miss one thing about XHTML. You could combine it with XSLT, the XML templating meta-language, to do in-browser templating (i.e., slot page-specific contents into your overall site layout) with no scripting required. It’s the only way that’s ever been possible, and it was cool as all hell when it worked, but the drawbacks were too severe when it didn’t. Also, XSLT is totally fucking incomprehensible.
You’re an aspiring web designer. For whatever reason, you want to try using this CSS thing to lay out your whole page, even though it was clearly intended just for colors and stuff. What do you do?
As I mentioned before, your core problem is putting things next to each other. Putting things on top of each other is a non-problem — that’s the normal behavior of HTML. The whole reason everyone uses tables is that you can slop stuff into table cells and have it laid out side-by-side, in columns.
Well, tables seem to be out. CSS 2 had added some element display modes that corresponded to the parts of a table, but to use them, you’d have to have the same three levels of nesting as real tables: the table itself, then a row, then a cell. That doesn’t seem like a huge step up, and anyway, IE won’t support them until the distant future.
There’s that position thing, but it seems to make things overlap more often than not. Hmm.
What does that leave?
Only one tool, really: float.
I said that float was intended for magazine-style “pull” images, which is true, but CSS had defined it fairly generically. In principle, it could be applied to any element. If you wanted a sidebar, you could tell it to float to the left and be 20% the width of the page, and you’d get something like this:
1234
+---------+
| sidebar | Hello, and welcome to my website!
| |
+---------+
Alas! Floating has the secondary behavior that text wraps around it. If your page text was ever longer than your sidebar, it would wrap around underneath the sidebar, and the illusion would shatter. But hey, no problem. CSS specified that floats don’t wrap around each other, so all you needed to do was float the body as well!
1234567
+---------++-----------------------------------+| sidebar | | Hello, and welcome to my website! || | | |+---------+ | Here's a longer paragraph to show | | that my galaxy brain CSS float | | nonsense prevents text wrap. |+-----------------------------------+
This approach worked, but its limitations were much more obvious than those of tables. If you added a footer, for example, then it would try to fit to the right of the body text — remember, all of that is “pull” floats, so as far as the browser is concerned, the “cursor” is still at the top. So now you need to use clear, which bumps an element down below all floats, to fix that. And if you made the sidebar 20% wide and the body 80% wide, then any margin between them would add to that 100%, making the page wider than the viewport, so now you have an ugly horizontal scrollbar, so you have to do some goofy math to fix that as well. If you have borders or backgrounds on either part, then it was a little conspicuous that they were different heights, so now you have to do some truly grotesque stuff to fix that. And the more conscientious authors noticed that screenreaders would read the entire sidebar before getting to the body text, which is a pretty rude thing to subject blind visitors to, so they came up with yet more elaborate setups to have a three-column layout with the middle column appearing first in the HTML.
The result was a design that looked nice and worked well and scaled correctly, but backed by a weird mess of CSS. None of what you were writing actually corresponded to what you wanted — these are major parts of your design, not one-off pull quotes! It was difficult to understand the relationship between the layout-related CSS and what appeared on the screen, and that would get much worse before it got better.
Armed with a new toy, we can improve that thumbnail grid. The original table-based layout was, even if you don’t care about tag semantics, incredibly tedious. Now we can do better!
This is the dream of CSS: your HTML contains the page data in some sensible form, and then CSS describes how it actually looks.
Unfortunately, with float as the only tool available to us, the results are a bit rough. This new version does adapt better to various screen sizes, but it requires some hacks: the cells have to be a fixed height, centering the whole grid is fairly complicated, and the grid effect falls apart entirely with wider elements. It’s becoming clear that what we wanted is something more like a table, but with a flexible number of columns. This is just faking it.
You also need this weird “clearfix” thing, an incantation that would become infamous during this era. Remember that a float doesn’t move the “cursor” — a fake idea I’m using, but close enough. That means that this <ul>, which is full only of floated elements, has no height at all. It ends exactly where it begins, with all the floated thumbnails spilling out below it. Worse, because any subsequent elements don’t have any floated siblings, they’ll ignore the thumbnails entirely and render normally from just below the empty “grid” — producing an overlapping mess!
The solution is to add a dummy element at the end of the list which takes up no space, but has the CSSclear: both — bumping it down below all floats. That effectively pushes the bottom of the <ul> under all the individual thumbnails, so it fits snugly around them.
Browsers would later support the ::before and ::after“generated content” pseudo-elements, which let us avoid the dummy element entirely. Stylesheets from the mid-00s were often littered with stuff like this:
As a quick aside into the world of JavaScript, the newfangled position property did give us the ability to do some layout things dynamically. I heartily oppose such heresy, not least because no one has ever actually done it right, but it was nice for some toys.
Thus began the era of “dynamic HTML” — i.e., HTML affected by JavaScript, a term that has fallen entirely out of favor because we can’t even make a fucking static blog without JavaScript any more. In the early days it was much more innocuous, with teenagers putting sparkles that trailed behind your mouse cursor or little analog clocks that ticked by in real time.
The most popular source of these things was Dynamic Drive, a site that miraculously still exists and probably has a bunch of toys not updated since the early 00s.
But if you don’t like digging, here’s an example: every year (except this year when I forgot oops), I like to add confetti and other nonsense to my blog on my birthday. I’m very lazy so I started this tradition by using this script I found somewhere, originally intended for snowflakes. It works by placing a bunch of images on the page, giving them position: absolute, and meticulously altering their coordinates over and over.
Contrast this with the version I wrote from scratch a couple years ago, which has only a tiny bit of JS to set up the images, then lets the browser animate them with CSS. It’s slightly less featureful, but lets the browser do all the work, possibly even with hardware acceleration. How far we’ve come.
Dark times can’t last forever. A combination of factors dragged us towards the light.
One of the biggest was Firefox — or, if you were cool, originally Phoenix and then Firebird — which hit 1.0 in Nov ‘04 and went on to take a serious bite out of IE. That rewritten Netscape 6 browser core, the heart of the Mozilla Suite, had been extracted into a standalone browser. It was quick, it was simple, it was much more standard-compliant, and absolutely none of that mattered.
No, Firefox really got a foothold because it had tabs. IE 6 did not have tabs; if you wanted to open a second webpage, you opened another window. It fucking sucked, man. Firefox was a miracle.
Firefox wasn’t the first tabbed browser, of course; the full Mozilla Suite’s browser had them, and the obscure (but scrappy!) Opera had had them for ages. But it was Firefox that took off, for various reasons, not least of which was that it didn’t have a giant fucking ad bar at the top like Opera did.
Designers did push for Firefox on standards grounds, of course; it’s just that that angle primarily appealed to other designers, not so much to their parents. One of the most popular and spectacular demonstrations was the Acid2 test, intended to test a variety of features of then-modern Web standards. It had the advantage of producing a cute smiley face when rendered correctly, and a fucking nightmare hellscape in IE 6. Early Firefox wasn’t perfect, but it was certainly much closer, and you could see it make progress until it fully passed with the release of Firefox 3.
It also helped that Firefox had a faster JavaScript engine, even before JIT caught on. Much, much faster. Like, as I recall, IE 6 implemented getElementById by iterating over the entire document, even though IDs are unique. Glance at some old jQuery release announcements; they usually have some performance charts, and everything else absolutely dwarfsIE 6 through 8.
Oh, and there was that whole thing where IE 6 was a giant walking security hole, especially with its native support for arbitrary binary components that only needed a “yes” click on an arcane dialog to get full and unrestricted access to your system. Probably didn’t help its reputation.
Anyway, with something other than IE taking over serious market share, even the most ornery designers couldn’t just target IE 6 and call it a day any more. Now there was a reason to use strict mode, a reason to care about compatibility and standards — which Firefox was making a constant effort to follow better, while IE 6 remained stagnant.
(I’d argue that this effect opened the door for OS X to make some inroads, and also for the iPhone to exist at all. I’m not kidding! Think about it; if the iPhone browser hadn’t actually worked with anything because everyone was still targeting IE 6, it’d basically have been a more expensive Palm. Remember, at first Apple didn’t even want native apps; it bet on the Web.)
(Speaking of which, Safari was released in Jan ‘03, based on a fork of the KHTML engine used in KDE’s Konqueror browser. I think I was using KDE at the time, so this was very exciting, but no one else really cared about OS X and its 2% market share.)
Another major factor appeared on April Fools’ Day, 2004, when Google announced Gmail. Ha, ha! A funny joke. Webmail that isn’t terrible? That’s a good one, Google.
Oh. Oh, fuck. Oh they’re not kidding. How the fuck does this even work
The answer, as every web dev now knows, is XMLHttpRequest — named for the fact that nobody has ever once used it to request XML. Apparently it was invented by Microsoft for use with Exchange, then cloned early on by Mozilla, but I’m just reading this from Wikipedia and you can do that yourself.
The important thing is, it lets you make an HTTP request from JavaScript. You could now update only part a page with new data, completely in the background, without reloading. Nobody had heard of this thing before, so when Google dropped an entire email client based on it, it was like fucking magic.
Arguably the whole thing was a mistake and has led to a hell future where static pages load three paragraphs of text in the background using XHR for no goddamn reason, but that’s a different post.
Along similar lines, August 2006 saw the release of jQuery, a similar miracle. Not only did it paper over the differences between IE’s “JScript” APIs and the standard approaches taken by everyone else (which had been done before by other libraries), but it made it very easy to work with whole groups of elements at a time, something that had historically been a huge pain in the ass. Now you could fairly easily apply CSS all over the place from JavaScript! Which is a bad idea! But everything was so bad that we did it anyway!
Hold on, I hear you cry. These things are about JavaScript! Isn’t this a post about CSS?
You’re absolutely right! I mention the rise of JavaScript because I think it led directly to the modern state of CSS, thanks to an increase in one big factor:
Firefox showed us that we could have browsers that actually, like, improve — every new improvement on Acid2 was exciting. Gmail showed us that the Web could do more than show plain text with snowflakes in front.
And folks started itching to get fancy.
The problem was, browsers hadn’t really gotten any better yet. Firefox was faster in some respects, and it adhered more closely to the CSS spec, but it didn’t fundamentally do anything that browsers weren’t supposed to be able to do already. Only the tooling had improved, and that mostly affected JavaScript. CSS was a static language, so you couldn’t write a library to make it better. Generating CSS with JavaScript was a possibility, but boy oh boy is that ever a bad idea.
Another problem was that CSS 2 was only really good at styling rectangles. That was fine in the 90s, when every OS had the aesthetic of rectangles containing more rectangles. But now we were in the days of Windows XP and OS X, where everything was shiny and glossy and made of curvy plastic. It was a little embarrassing to have rounded corners and neatly shaded swooshes in your file browser and nowhere on the Web.
Designers wanted a lot of things that CSS just could not offer.
Round corners were a big one. Square corners had fallen out of vogue, and now everyone wanted buttons with round corners, since they were The Future. (Native buttons also went out of vogue, for some reason.) Alas, CSS had no way to do this. Your options were:
Make a fixed-size background image of a rounded rectangle and put it on a fixed-size button. Maybe drop the text altogether and just make the whole thing an image. Eugh.
Make a generic background image and scale it to fit. More clever, but the corners might end up not round.
Make the rounded rectangle, cut out the corner and edges, and put them in a 3×3 table with the button label in the middle. Even better, use JavaScript to do this on the fly.
Fuck it, make your entire website one big Flash app lol
Another problem was that IE 6 didn’t understand PNGs with 8-bit alpha; it could only correctly display PNGs with 1-bit alpha, i.e. every pixel is either fully opaque or fully transparent, like GIFs. You had to settle for jagged edges, bake a solid background color into the image, or apply various fixes that centered around this fucking garbage nonsense:
Along similar lines: gradients and drop shadows! You can’t have fancy plastic buttons without those. But here you were basically stuck with making images again.
Translucency was a bit of a mess. Most browsers supported the CSS 3 opacity property since very early on… except IE, which needed another wacky Microsoft-specific filter thing. And if you wanted only the background translucent, you’d need a translucent PNG, which… well, you know.
Since the beginning, jQuery shipped with built-in animated effects like fadeIn, and they started popping up all over the place. It was kind of like the Web equivalent of how every Linux user in the mid-00s (and I include myself in this) used that fucking Compiz cube effect.
Obviously you need JavaScript to trigger an element’s disappearance in most interesting cases, but using it to control the actual animation was a bit heavy-handed and put a strain on browsers. Tabbed browsing compounded this, since browsers were largely single-threaded, and for various reasons, every open page ran in the same thread.
Oh! Alternating background colors on table rows. This has since gone out of style, but I think that’s a shame, because man did it make tables easier to read. But CSS had no answer for this, so you had to either give every other row a class like <tr class="odd"> (hope the table’s generated with code!) or do some jQuery nonsense.
CSS 2 introduced the > child selector, so you could write stuff like ul.foo > li to style special lists without messing up nested lists, and IE 6! Didn’t! Fucking! Support! It!
All those are merely aesthetic concerns, though. If you were interested in layout, well, the rise of Firefox had made your life at once much easier and much harder.
Remember inline-block? Firefox 2 actually supported it! It was buggy and hidden behind a vendor prefix, but it more or less worked, which let designers start playing with it. And then Firefox 3 supported it more or less fully, which felt miraculous. Version 3 of our thumbnail grid is as simple as a width and inline-block:
The general idea of inline-block is that the inside acts like a block, but the block itself is placed in regular flowing text, like an image. Each thumbnail is thus contained in a box, but the boxes all lie next to each other, and because of their equal widths, they flow into a grid. And since it’s functionally a line of text, you don’t have to work around any weird impact on the rest of the page like you had to do with floats.
Sure, this had some drawbacks. You couldn’t do anything with the leftover space, for example, so there was a risk of a big empty void on the right with pathological screen sizes. You still had the problem of breaking the grid with a wide cell. But at least it’s not floats.
One teeny problem: IE 6. It did technically support inline-block, but only on elements that were naturally inline — ones like <b> and <i>, not <li>. So, not ones you’d actually want (or think) to use inline-block on. Sigh.
Lucky for us, at some point an absolute genius discovered hasLayout, an internal optimization in IE that marks whether an element… uh… has… layout. Look, I don’t know. Basically it changes the rendering path for an element — making it differently buggy, like quirks mode on a per-element basis! The upshot is that the above works in IE 6 if you add a couple lines:
The leading asterisks make the property invalid, so browsers should ignore the whole line… but for some reason I cannot begin to fathom, IE 6 ignores the asterisks and accepts the rest of the rule. (Almost any punctuation worked, including a hyphen or — my personal favorite — an underscore.) The zoom property is a Microsoft extension that scales stuff, with the side effect that it grants the mystical property of “layout” to the element as well. And display: inlineshould make each element spill its contents into one big line of text, but IE treats an inline element that has “layout” roughly like an inline-block.
And here we saw the true potential of CSS messes. Browser-specific rules, with deliberate bad syntax that one browser would ignore, to replicate an effect that still isn’t clearly described by what you’re writing. Entire tutorials written to explain how to accomplish something simple, like a grid, but have it actually work on most people’s browsers. You’d also see * html, html > /**/ body, and all kinds of other nonsense. Here’s a full list! And remember that “clearfix” hack from before? The full version, compatible with every browser, is a bit worse:
Is it any wonder folks started groaning about CSS?
This was an era of blind copy/pasting in the frustrated hopes of making the damn thing work. Case in point: someone (I dug the original source up once but can’t find it now) had the bone-headed idea of always setting body { font-size: 62.5% } due to a combination of “relative units are good” and wanting to override the seemingly massive default browser font size of 16px (which, it turns out, is correct) and dealing with IE bugs. He walked it back a short time later, but the damage had been done, and now thousands of websites start off that way as a “best practice”. Which means if you want to change your browser’s default font size in either direction, you’re screwed — scale it down and a bunch of the Web becomes microscopic, scale it up and everything will still be much smaller than you’ve asked for, scale it up more to compensate and everything that actually respects your decision will be ginormous. At least we have better page zoom now, I guess.
Oh, and do remember: Stack Overflow didn’t exist yet. This stuff was passed around purely by word of mouth. If you were lucky, you knew about some of the websites about websites, like quirks mode and Eric Meyer’s website.
In fact, check out Meyer’s css/edge site for some wild examples of stuff folks were doing, even with just CSS 1, as far back as 2002. I still think complexspiral is pure genius, even though you could do it nowadays with opacity and just one image. The approach in raggedfloat wouldn’t get native support in CSS until a few years ago, with shape-outside! He also brought us CSS reset, eliminating differences between browsers’ default styles.
(I cannot understate how much of a CSSpioneer Eric Meyer is. When his young daughter Rebecca died six years ago, she was uniquely immortalized with her own CSS color name, rebeccapurple. That’s how highly the Web community thinks of him. Also I have to go cry a bit over that story now.)
Designers and developers were pushing the bounds of what browsers were capable of. Browsers were handling it all somewhat poorly. All the fixes and workarounds and libraries were arcane, brittle, error-prone, and/or heavy.
Clearly, browsers needed some new functionality. But just slopping something in wouldn’t help; Microsoft had done plenty of that, and it had mostly made a mess.
Several struggling attempts began. With the W3C’s head still squarely up its own ass — even explicitly rejecting proposed enhancements to HTML, in favor of snorting XML — some folks from (active) browser vendors Apple, Mozilla, and Opera decided to make their own clubhouse. WHATWG came into existence in June 2004, and they began work on HTML5. (It would end up defining error-handling very explicitly, which completely obviated the need for XHTML and eliminated a number of security concerns when working with arbitrary HTML. Also it gave us some new goodies, like native audio, video, and form controls for dates and colors and other stuff that had been clumsily handled by JavaScript-powered custom controls. And, um, still often are.)
Then there was CSS 3. I’m not sure when it started to exist. It emerged slowly, struggling, like a chick hatching from an egg and taking its damn sweet fucking time to actually get implemented anywhere.
I’m having to do a lot of educated guessing here, but I think it began with border-radius. Specifically, with -moz-border-radius. I don’t know when it was first introduced, but the Mozilla bug tracker has mentions of it as far back as 1999.
See, Firefox’s own UI is rendered with CSS. If Mozilla wanted to do something that couldn’t be done with CSS, they added a property of their own, prefixed with -moz- to indicate it was their own invention. And when there’s no real harm in doing so, they leave the property accessible to websites as well.
My guess, then, is that the push for CSS 3 really began when Firefox took off and designers discovered -moz-border-radius. Suddenly, built-in rounded corners were available! No more fucking around in Photoshop; you only needed to write a single line! Practically overnight, everything everywhere had its corners filed down.
And from there, things snowballed. Common problems were addressed one at a time by new CSS features, which were clustered together into a new CSS version: CSS 3. The big ones were solutions to the design problems mentioned before:
Rounded corners, provided by border-radius.
Gradients, provided by linear-gradient() and friends.
Multiple backgrounds, which weren’t exactly a pressing concern, but which turned out to make some other stuff easier.
Translucency, provided by opacity and colors with an alpha channel.
Box shadows.
Text shadows, which had been in CSS 2 but dropped in 2.1 and never implemented anyway.
Border images, so you could do even fancier things than mere rounded borders.
Transitions and animations, now doable with ease without needing jQuery (or any JS at all).
:nth-child(), which solved the alternating rows problem with pure CSS.
Transformations. Wait, what? This kinda leaked in from SVG, which browsers were also being expected to implement, and which is built heavily around transforms. The code was already there, so, hey, now we can rotate stuff with CSS! Couldn’t do that before. Cool.
Web fonts, which had been in CSS for some time but only ever implemented in IE and only with some goofy DRM-laden font format. Now we weren’t limited to the four bad fonts that ship with Windows and that no one else has!
These were pretty great! They didn’t solve any layout problems, but they did address aesthetic issues that designers had been clumsily working around by using loads of images and/or JavaScript. That meant less stuff to download and more text used instead of images, both of which were pretty good for the Web.
The grand irony is that all the stuff you could do with these features went out of style almost immediately, and now we’re back to flat rectangles again.
Several of these new gizmos were, I believe, initially developed by browser vendors and prefixed. Some later ones were designed by the CSS committee but implemented by browsers while the design was still in flux, and thus also prefixed.
So began prefix hell, which continues to this day.
Mozilla had -moz-border-radius, so when Safari implemented it, it was named -webkit-border-radius (“WebKit” being the name of Apple’s KHTML fork). Then the CSS 3 spec standardized it and called it just border-radius. That meant that if you wanted to use rounded borders, you actually needed to give three rules:
The first two made the effect actually work in current browsers, and the last one was future-proofing: when browsers implemented the real rule and dropped the prefixed ones, it would take over.
You had to do this every fucking time, since CSS isn’t a programming language and has no macros or functions or the like. Sometimes Opera and IE would have their own implementations with -o- and -ms- prefixes, bringing the total to five copies. It got much worse with gradients; the syntax went through a number of major incompatible revisions, so you couldn’t even rely on copy/pasting and changing the property name!
And plenty of folks, well, fucked it up. I can’t blame them too much; I mean, this sucks. But enough pages used only the prefixed forms, and not the final form, that browsers had to keep supporting the prefixed form for longer than they would’ve liked to avoid breaking stuff. And if the prefixed form still works and it’s what you’re used to writing, then maybe you still won’t bother with the unprefixed one.
Worse, some people would only use the form that worked in their pet choice of browser. This got especially bad with the rise of mobile web browsers. The built-in browsers on iOS and Android are Safari (WebKit) and Chrome (originally WebKit, now a fork), so you only “needed” to use the -webkit- properties. Which made things difficult for Mozilla when it released Firefox for Android.
Hey, remember that whole debacle with IE 6? Here we are again! It was bad enough that Mozilla eventually decided to implement a number of -webkit- properties, which remain supported even in desktop Firefox to this day. The situation is goofy enough that Firefox now supports some effects only via these properties, like -webkit-text-stroke, which isn’t being standardized.
Even better, Chrome’s current forked engine is called Blink, so technically it shouldn’t be using -webkit- properties either. And yet, here we are. At least it’s not as bad as the user agent string mess.
Browser vendors have pretty much abandoned prefixing, now; instead they hide experimental features behind flags (so they’ll only work on the developer’s machine), and new features are theoretically designed to be smaller and easier to stabilize.
This mess was probably a huge motivating factor for the development of Sass and LESS, two languages that produce CSS. Or… two CSS preprocessors, maybe. They have very similar goals: both add variables, functions, and some form of macros to CSS, allowing you to eliminate a lot of the repetition and browser hacks and other nonsense from your stylesheets. Hell, this blog still uses SCSS, though its use has gradually decreased over time.
But then, like an angel descending from heaven… flexbox.
Flexbox has been around for a long time — allegedly it had partial support in Firefox 2, back in 2006! It went through several incompatible revisions and took ages to stabilize. Then IE took ages to implement it, and you don’t really want to rely on layout tools that only work for half your audience. It’s only relatively recently (2015? Later?) that flexbox has had sufficiently broad support to use safely. And I could swear I still run into folks whose current Safari doesn’t recognize it at all without prefixing, even though Safari supposedly dropped the prefixes five years ago…
Anyway, flexbox is a CSS implementation of a pretty common GUI layout tool: you have a parent with some children, and the parent has some amount of space available, and it gets divided automatically between the children. You know, it puts things next to each other.
The general idea is that the browser computes how much space the parent has available and the “initial size” of each child, figures out how much extra space there is, and distributes it according to the flexibleness of each child. Think of a toolbar: you might want each button to have a fixed size (a flex of 0), but want to add spacers that share any leftover space equally, so you’d give them a flex of 1.
Once that’s done, you have a number of quality-of-life options at your disposal, too: you can distribute the extra space between the children instead, you can tell the children to stretch to the same height or align them in various ways, and you can even have them wrap into multiple rows if they won’t all fit!
With this, we can take yet another crack at that thumbnail grid:
This is miraculous. I forgot all about inline-block overnight and mostly salivated over this until it was universally supported. It even expresses very clearly what I want.
…almost. It still has the problem that too-wide cells will break the grid, since it’s still a horizontal row wrapped onto several independent lines. It’s pretty damn cool, though, and solves a number of other layout problems. Surely this is good enough. Unless…?
I’d say mass adoption of flexbox marked the beginning of the modern era of CSS. But there was one lingering problem…
IE 6 took a long, long, long time to go away. It didn’t drop below 10% market share (still a huge chunk) until early 2010 or so.
Firefox hit 1.0 at the end of 2004. IE 7 wasn’t released until two years later, it offered only modest improvements, it suffered from compatibility problems with stuff built for IE 6, and the IE 6 holdouts (many of whom were not Computer People) generally saw no reason to upgrade. Vista shipped with IE 7, but Vista was kind of a flop — I don’t believe it ever came close to overtaking XP, not in its entire lifetime.
Other factors included corporate IT policies, which often take the form of “never upgrade anything ever” — and often for good reason, as I heard endless tales of internal apps that only worked in IE 6 for all manner of horrifying reasons. Then there was the entirety of South Korea, which was legally required to use IE 6 because they’d enshrined in law some security requirements that could only be implemented with an IE 6 ActiveX control.
So if you maintained a website that was used — or worse, required — by people who worked for businesses or lived in other countries, you were pretty much stuck supporting IE 6. Folks making little personal tools and websites abandoned IE 6 compatibility early on and plastered their sites with increasingly obnoxious banners taunting anyone who dared show up using it… but if you were someone’s boss, why would you tell them it’s okay to drop 20% of your potential audience? Just work harder!
The tension grew over the years, as CSS became more capable and IE 6 remained an anchor. It still didn’t even understand PNG alpha without workarounds, and meanwhile we were starting to get more critical features like native video in HTML5. The workarounds grew messier, and the list of features you basically just couldn’t use grew longer. (I’d show you what my blog looks like in IE 6, but I don’t think it can even connect — the TLS stuff it supports is so ancient and broken that it’s been disabled on most servers!)
Shoutouts, by the way, to some folks on the YouTube team, who in July 2009 added a warning banner imploring IE 6 users to switch to anything else — without asking anyone for approval. “Within one month… over 10 percent of global IE6 traffic had dropped off.” Not all heroes wear capes.
I’d mark the beginning of the end as the day YouTube actually dropped IE 6 support — March 13, 2010, almost nine years after its release. I don’t know how much of a direct impact YouTube has on corporate users or the South Korean government, but a massive web company dropping an entire browser sends a pretty strong message.
There were other versions of IE, of course, and many of them were messy headaches in their own right. But each subsequent one became less of a pain, and nowadays you don’t even have to think too much about testing in IE (now Edge). Just in time for Microsoft to scrap their own rendering engine and turn their browser into a Chrome clone.
CSS is pretty great now. You don’t need weird fucking hacks just to put things next to each other. Browser dev tools are built in, now, and are fucking amazing — Firefox has started specifically warning you when some CSS properties won’t take effect because of the values of others! Obscure implicit side effects like “stacking contexts” (whatever those are) can now be set explicitly, with properties like isolation: isolate.
In fact, let me just list everything that I can think of that you can do in CSS now. This isn’t a guide to all possible uses of styling, but if your CSS knowledge hasn’t been updated since 2008, I hope this whets your appetite. And this stuff is just CSS! So many things that used to be impossible or painful or require clumsy plugins are now natively supported — audio, video, custom drawing, 3D rendering… not to mention the vast ergonomic improvements to JavaScript.
A grid container can do pretty much anything tables can do, and more, including automatically determining how many columns will fit. It’s fucking amazing. More on that below.
A flexbox container lays out its children in a row or column, allowing each child to declare its “default” size and what proportion of leftover space it wants to consume. Flexboxes can wrap, rearrange children without changing source order, and align children in a number of ways.
Columns will pour text into, well, multiple columns.
The box-sizing property lets you opt into the IE box model on a per-element basis, for when you need an entire element to take up a fixed amount of space and need padding/borders to subtract from that.
display: contents dumps an element’s contents out into its parent, as if it weren’t there at all. display: flow-root is basically an automatic clearfix, only a decade too late.
width can now be set to min-content, max-content, or the fit-content() function for more flexible behavior.
white-space: pre-wrap preserves whitespace, but breaks lines where necessary to avoid overflow. Also useful is pre-line, which collapses sequences of spaces down to a single space, but preserves literal newlines.
text-overflow cuts off overflowing text with an ellipsis (or custom character) when it would overflow, rather than simply truncating it. Also specced is the ability to fade out the text, but this is as yet unimplemented.
shape-outside alters the shape used when wrapping text around a float. It can even use the alpha channel of an image as the shape.
resize gives an arbitrary element a resize handle (as long as it has overflow).
writing-mode sets the direction that text flows. If your design needs to work for multiple writing modes, a number of CSS properties that mention left/right/top/bottom have alternatives that describe directions in terms of the writing mode: inset-block and inset-inline for position, block-size and inline-size for width/height, border-block and border-inline for borders, and similar for padding and margins.
Transitions smoothly interpolate a value whenever it changes, whether due to an effect like :hover or e.g. a class being added from JavaScript. Animations are similar, but play a predefined animation automatically. Both can use a number of different easing functions.
border-radius rounds off the corners of a box. The corners can all be different sizes, and can be circular or elliptical. The curve also applies to the border, background, and any box shadows.
Box shadows can be used for the obvious effect of casting a drop shadow. You can also use multiple shadows and inset shadows for a variety of clever effects.
text-shadow does what it says on the tin, though you can also stack several of them for a rough approximation of a text outline.
transform lets you apply an arbitrary matrix transformation to an element — that is, you can scale, rotate, skew, translate, and/or do perspective transform, all without affecting layout.
filter (distinct from the IE 6 one) offers a handful of specific visual filters you can apply to an element. Most of them affect color, but there’s also a blur() and a drop-shadow() (which, unlike box-shadow, applies to an element’s appearance rather than its containing box).
linear-gradient(), radial-gradient(), the new and less-supported conic-gradient(), and their repeating-* variants all produce gradient images and can be used anywhere in CSS that an image is expected, most commonly as a background-image.
scrollbar-color changes the scrollbar color, with the downside of reducing the scrollbar to a very simple thumb-and-track in current browsers.
background-size: cover and contain will scale a background image proportionally, either big enough to completely cover the element (even if cropped) or small enough to exactly fit inside it (even if it doesn’t cover the entire background).
object-fit is a similar idea but for non-background media, like <img>s. The related object-position is like background-position.
Multiple backgrounds are possible, which is especially useful with gradients — you can stack multiple gradients, other background images, and a solid color on the bottom.
text-decoration is fancier than it used to be; you can now set the color of the line and use several different kinds of lines, including dashed, dotted, and wavy.
CSS counters can be used to number arbitrary elements in an arbitrary way, exposing the counting ability of <ol> to any set of elements you want.
The ::marker pseudo-element allows you to style a list item’s marker box, or even replace it outright with a custom counter. Browser support is spotty, but improving. Similarly, the @counter-style at-rule implements an entirely new counter style (like 1 2 3, i ii iii, A B C, etc.) which you can then use anywhere, though only Firefox supports it so far.
image-set() provides a list of candidate images and lets the browser choose the most appropriate one based on the pixel density of the user’s screen.
@font-face defines a font that can be downloaded, though you can avoid figuring out how to use it correctly by using Google Fonts.
pointer-events: none makes an element ignore the mouse entirely; it can’t be hovered, and clicks will go straight through it to the element below.
image-rendering can force an image to be resized nearest-neighbor rather than interpolated, though browser support is still spotty and you may need to also include some vendor-specific properties.
clip-path crops an element to an arbitrary shape. There’s also mask for arbitrary alpha masking, but browser support is spotty and hoo boy is this one complicated.
@supports lets you explicitly write different CSS depending on what the browser supports, though it’s nowhere near as useful nowadays as it would’ve been in 2004.
A > B selects immediate children. A ~ B selects siblings. A + B selects immediate (element) siblings. Square brackets can do a bunch of stuff to select based on attributes; most obvious is input[type=checkbox], though you can also do interesting things with matching parts of <a href>.
:not() inverts a selector. :empty selects elements with no children and no text. :target selects the element jumped to with a URL fragment (e.g. if the address bar shows index.html#foo, this selects the element whose ID is foo).
::before and ::after should have two colons now, to indicate that they create pseudo-elements rather than merely scoping the selector they’re attached to. ::selection customizes how selected text appears; ::placeholder customizes how placeholder text (in text fields) appears.
Media queries do just a whole bunch of stuff so your page can adapt based on how it’s being viewed. The prefers-color-scheme media query tells you if the user’s system is set to a light or dark theme, so you can adjust accordingly without having to ask.
You can write translucent colors as #rrggbbaa or #rgba, as well as using the rgba() and hsla() functions.
Angles can be described as fractions of a full circle with the turn unit. Of course, deg and rad (and grad) are also available.
CSS variables (officially, “custom properties”) let you specify arbitrary named values that can be used anywhere a value would appear. You can use this to reduce the amount of CSS fiddling needs doing in JavaScript (e.g., recolor a complex part of a page by setting a CSS variable instead of manually adjusting a number of properties), or have a generic component that reacts to variables set by an ancestor.
calc() computes an arbitrary expression and updates automatically (though it’s somewhat obviated by box-sizing).
The vw, vh, vmin, and vmax units let you specify lengths as a fraction of the viewport’s width or height, or whichever of the two is bigger/smaller.
Phew! I’m sure I’m forgetting plenty and folks will have even longer lists of interesting tidbits in the comments. Thanks for saving me some effort! Now I can stop browsing MDN and do this final fun part.
At long last, we arrive at the final and objectively correct way to construct a thumbnail grid: using CSS grid. You can tell this is the right thing to use because it has “grid” in the name. Modern CSS features are pretty great about letting you say the thing you want and having it happen, rather than trying to coax it into happening implicitly via voodoo.
Done! That gives you a grid. You have myriad other twiddles to play with, just as with flexbox, but that’s the basic idea. You don’t even need to style the elements themselves; most of the layout work is done in the container.
The grid shorthand property looks a little intimidating, but only because it’s so flexible. It’s saying: fill the grid one row at a time, generating as many rows as necessary; make as many 250px columns as will fit, and share any leftover space between them equally.
CSS grids are also handy for laying out <dl>s, something that’s historically been a massive pain to make work — a <dl> contains any number of <dt>s followed by any number of <dd>s (including zero), and the only way to style this until grid was to float the <dt>s, which meant they had to have a fixed width. Now you can just tell the <dt>s to go in the first column and <dd>s to go in the second, and grid will take care of the rest.
And laying out your page? That whole sidebar thing? Check out how easy that is:
The web is still a little bit of a disaster. A lot of folks don’t even know that flexbox and grid are supported almost universally now; but given how long it took to get from early spec work to broad implementation, I can’t really blame them. I saw a brand new little site just yesterday that consisted mostly of a huge list of “thumbnails” of various widths, and it used floats! Not even inline-block! I don’t know how we managed to teach everyone about all the hacks required to make that work, but somehow haven’t gotten the word out about flexbox.
But far worse than that: I still regularly encounter sites that do their entire page layout with JavaScript. If you use uMatrix, your first experience is with a pile of text overlapping a pile of other text. Surely this is a step backwards? What are you possibly doing that your header and sidebar can only be laid out correctly by executing code? It’s not like the page loads with noCSS — nothing in plain HTML will overlap by default! You have to tell it to do that!
And then there’s the mobile web, which despite everyone’s good intentions, has kind of turned out to be a failure. The idea was that you could use CSS media queries to fit your normal site on a phone screen, but instead, most major sites have entirely separate mobile versions. Which means that either the mobile site is missing a bunch of important features and I’ll have to awkwardly navigate that on my phone anyway, or the desktop site is full of crap that nobody actually needs.
(Meanwhile, Google’s own Android versions of Docs/Sheets/etc. have, like, 5% of the features of the Web versions? Not sure what to make of that.)
Hmm. Strongly considering writing something that goes more into detail about improvements to CSS since the Firefox 3 era, similar to the one I wrote for JavaScript. But this post is long enough.
I don’t know what’s coming next in CSS, especially now that flexbox and grid have solved all our problems. I’m vaguely aware of some work being done on more extensive math support, and possibly some functions for altering colors like in Sass. There’s a painting API that lets you generate backgrounds on the fly with JavaScript using the canvas API, which is… quite something. Apparently it’s now in spec that you can use attr() (which evaluates to the value of an HTML attribute) as the value for any property, which seems cool and might even let you implement HTML tables entirely in CSS, but you could do the same thing with variables. I mean, um, custom properties. I’m more excited about :is(), which matches any of a list of selectors, and subgrid, which lets you add some nesting to a grid but keep grandchildren still aligned to it.
Much easier is to list some things that were the future, but fizzled out.
display: run-in has been part of CSS since version 2 (way back in ‘98), but it’s basically unsupported. The idea is that a “run-in” box is inserted, inline, into the next block, so this:
And, ah, hm, I’m starting to see why it’s unsupported. It used to exist in WebKit, but was apparently so unworkable as to be removed six years ago.
“Alternate stylesheets” were popular in the early 00s, at least on a few of my friends’ websites. The idea was that you could list more than one stylesheet for your site (presumably for different themes), and the browser would give the user a list of them. Alas, that list was always squirrelled away in a menu with no obvious indication of when it was actually populated, so in the end, everyone who wanted multiple themes just implemented an in-page theme switcher themselves.
This feature is still supported, but apparently Chrome never bothered implementing it, so it’s effectively dead.
More generally, the original CSS spec clearly expects users to be able to write their own CSS for a website — right in paragraph 2 it says
…the reader may have a personal style sheet to adjust for human or technological handicaps.
Hey, that sounds cool. But it never materialized as a browser feature. Firefox has userContent.css and some URL selectors for writing per-site rules, but that’s relatively obscure.
A common problem (well, for me) is that of styling the label for a checkbox, depending on its state. Styling the checkbox itself is easy enough with the :checked pseudo-selector. But if you arrange a checkbox and its label in the obvious way:
1
<label><inputtype="checkbox"> Description of what this does</label>
…then CSS has no way to target either the <label> element or the text node. jQuery’s (originally custom) selector engine offered a custom :has() pseudo-class, which could be used to express this:
1234
/* checkbox label turns bold when checked */label:has(input:checked){font-weight:bold;}
Early CSS 3 selector discussions seemingly wanted to avoid this, I guess for performance reasons? The somewhat novel alternative was to write out the entire selector, but be able to alter which part of it the rules affected with a “subject” indicator. At first this was a pseudo-class:
123
label:subjectinput:checked{font-weight:bold;}
Then later, they introduced a ! prefix instead:
123
!labelinput:checked{font-weight:bold;}
Thankfully, this was decided to be a bad idea, so the current specced way to do this is… :has()! Unfortunately, it’s only allowed when querying from JavaScript, not in a live stylesheet, and nothing implements it anyway. 20 years and I’m still waiting for a way to style checkbox labels.
<style scoped> was an attribute that would’ve made a <style> element’s CSS rules only apply to other elements within its immediate parent, meaning you could drop in arbitrary (possibly user-written) CSS without any risk of affecting the rest of the page. Alas, this was quietly dropped some time ago, with shadow DOM suggested as a wildly inappropriate replacement.
I seem to recall that when I first heard about Web components, they were templates you could use to reduce duplication in pure HTML? But I can’t find any trace of that concept now, and the current implementations require JavaScript to define them, so there’s nothing declarative linking a new tag to its implementation. Which makes them completely unusable for anything that doesn’t have a compelling reason to rely on JS. Alas.
<blink> and <marquee>. RIP. Though both can be easily replicated with CSS animations.
And maybe push back against Blink monoculture and use Firefox, including on your phone, unless for some reason you use an iPhone, which forbids other browser engines, which is far worse than anything Microsoft ever did, but we just kinda accept it for some reason.
I had kind of a rough year. Between medication issues, a lot of interpersonal tangles, and discovering ancient trauma, it feels like my head is full of static a lot of the time, and I don’t know how to create when I’m in that state. I might be able to function, even do rote programming work, but I just can’t synthesize.
And that sucks. I miss it. I miss writing! I barely wrote anything here all year. I’ve had a half-finished post open for months and just haven’t been able to wrap it up and get it out.
I’m working on it. It’s just hard.
Ash and I made Cherry Kisses (nsfw), probably the best puzzle game I’ve designed and the most polished game we’ve released, so that was nice. I also made a particle wipe generator out of the screen wipe effect I used in the game.
I started on baz, a game creator meant to kinda blend the styles of MegaZeux and PuzzleScript and bitsy, but it’s yet to see the light of day.
I worked a lot on fox flux — adding water physics, redesigning the player sprite, inventing some new mechanics, adding a menu, refactoring to use an ECS-like approach, massively cleaning up my collision code, and whatnot. I also got stuck in a quagmire of trying to make push physics work how I want, but never actually got it working despite pouring weeks and weeks into it, and now the whole codebase is in a broken shambles. Kind of a mixed bag there.
I finally started on GLEAM, an editor for the VN engine I’ve used for Floraverse for many years now. It’s not quite ready for public use, but it’s far enough along that I can make VNs with it and only a little manual adjusting, which is cool.
I did not expect my return to writing to be like this.
Twigs, our nine-year-old sphynx cat, has died.
He is survived by Pearl, his lovely niece; Anise, his best friend and sparring partner; Cheeseball, his wrestling protégé; and Napoleon, his oldest and dearest friend.
Twigs was Ash’s¹ cat, more than I have ever known anyone to be anyone’s cat. He loved them so much. No matter where in the house they went to sit or lie down, Twigs was practically guaranteed to appear a short time later to insert himself into their lap.
¹ For those who’ve been following along for some time, Ash used to go by Mel.
If there was no room for him, or Ash rebuffed him for whatever reason, or if he was just in the mood, his backup plan was to sit somewhere else and keep an eye on them. Sometimes I’d be talking to Ash and catch sight of Twigs behind them, staring at them. Just watching. I’d tell Ash, and they’d turn around and giggle at him, and he’d keep on staring. Sometimes they played hide-and-seek with him, ducking out of sight and then peeking back out at him; he might still be staring, or he might have trotted over to see where they went. Or they could call out to him, just say his name, and he’d acknowledge them with a little meow and come over. They could summon him silently, too, with nothing more than eye contact and a particular nod.
Sometimes we’d be sitting apart and Twigs would sit on me instead, laying chest-to-chest against me. He’d play this ridiculous game where he’d nuzzle my chin a few times, then look at Ash for a moment before doing it again. As if to say, hey, look what you’re missing out on. Or maybe just to say he hadn’t forgotten about them.
Twigs liked to sit at the top of the cat tree in our dining room, right in the path of a huge sunbeam for much of the day, where he could watch Ash at their desk and also see most of the house. We got a huge beanbag over the summer and put it behind Ash’s desk, and Twigs spent a lot of time there as well. He did his own thing at times, certainly, but it was rare for a day to go by without Twigs trying to be close to Ash.
If Ash was inaccessible — in someone else’s bedroom with the door closed, or in the backyard, or even in the bathroom for too long — Twigs would sit at the objectionable door and yell for them. I can’t think of many other cat meow I’d describe as a yell, but that’s definitively what Twigs did. MYAOOOW?MYEHHHH! When Ash was out of town, I’d often hear him trotting up and down the upstairs hallway, yelling for them — until he gave up looking for the moment and came to snuggle with me, just as intensely, like I were the one he’d been looking for all along.
His favorite thing in the world was bedtime, when Ash would finally not be distracted by anything else, and he could lay with them all night. All the cats sleep with us to varying degrees, but Twigs was usually the first to show up. His arrival was so distinct: the quiet footsteps, the weight on the bed, and then the purr would start up before we could even see him. He’d spend all night with us most nights, laying on Ash’s chest in the classic Sphinx pose or curled up behind their knees under the blanket.
I loved how frequently he showed up already purring, apparently anticipating how good of a time he was about to have. It came across as this comical overconfidence, like he took for granted that of course he would be involved in whatever Ash was doing. But his purr, as common and subdued as it was, was such a deep and full and genuine rumble. He made me feel like I’d earned it, like I must’ve done something truly admirable to earn this level of praise. I always called it regal. The purr of a king.
In the early morning hours of October 13, early enough that it was still the previous night, Twigs came downstairs and yelled. That wasn’t unusual; he’d yell for Ash’s attention all the time. But then he lay on his stomach, angled straight up like the actual Sphinx, a pose he exclusively reserved for comfy places like laps and cat beds.
Ash and I went over to check him out, but we couldn’t find any tender spots, injuries, or other obvious problems. My best guess was a stomachache, which wasn’t unheard of for Twigs; perhaps laying on his stomach helped settle it? The room was a little chilly and he wasn’t wearing a sweater, so Ash wrapped him in a blanket and set him on the beanbag he liked, in the path of a heat lamp.
We went to bed only an hour or so later, and Ash carried Twigs with them. Without the heat lamp on him, he was noticeably cold to the touch now, and starting to stumble. I didn’t think of it until later, but as cold as he was, he never shivered once.
We rushed him to a 24/7 emergency vet.
His temperature was 92 when we arrived. Normal body temperature for cats is around 100.
They set about warming him up, rushed through some authorizations, drew some blood, told us results would come in about thirty minutes.
Twigs didn’t make it that long. At 4:26 in the morning, cold and confused, somewhere in a sterile room apart from everyone he’d ever known and loved, his heart stopped.
Only three or four hours had passed since he first showed any signs of distress whatsoever, and Twigs was gone.
Twigs was so expressive! He had so much personality, and he showed all of it. Sphynxes seem a little easier to read than furred cats, but… well, Pearl is a little reserved, and Anise is downright incomprehensible. Twigs was an open book.
Photos don’t quite do him justice, since cats are easiest to photograph when they’re relaxing. All of his body language and facial expressions felt really crisp and distinct, like he wanted you to know what he was thinking, but didn’t want to ham it up. How do I even explain this? How would I explain the faces a human makes, even?
His “I love sitting on you” face, his “I want to eat that” face, his “this is a bit annoying but I’ll put up with it” face… they were all so clear and distinct, moreso than any of our other cats, moreso than any cat I’ve met. He’d even turn up the corners of his mouth when he was really happy, making a little cat smile.
His eyes were huge and beautiful, and we got to see them a lot while he played sentinel, perched somewhere with a good field of view. They were different colors, too! Only slightly, but in the right light, one was distinctly greener and the other distinctly bluer. It was obvious from a glance at his eyes whether he was staring into space, watching you, wanting something from you, or wanting to come over to you.
He was always, always delighted when someone would pet him. I don’t think Twigs ever acted solitary; he stands out as the most readily and consistently affectionate cat we’ve had. He even had a specific expression for when he was in a good mood and wanted someone to pet him, which I called “bedroom eyes” — both because he lidded his eyes a bit, and because he mostly did it when laying in bed with us. If he was especially happy, he’d come lie on your chest, scoot forwards as far as he possibly could, and give you super nuzzles all over your chin.
Twigs had a very pettable head, too. Broad, with his ears more to the sides. I always said he had a cheese head, because it reminded me of a cheese wedge? For some reason? He had a good cheese head, perfect for kissing (“kitten kisses”), which he seemed to understand was a sign of affection. He loved having his head pet so much that he’d keep tilting his head further and further back, ostensibly to press harder against your hand — but if he was perched on the top level of a cat tree, that made it harder to reach the top of his head, so you’d have to do this silly little negotiation with him. It made his smile all the easier to see, though.
He had some other quirky little “tells” that seemed subtle, but that gave away what he’d almost certainly do next: hesitating in a particular way before inexplicably dashing away, or looking up and around at the ceiling before doing a big meow.
His meows! Twigs had a huge vocabulary, and so much of it was for asking politely for things. His “yell” for when he wanted Ash was big and boisterous, with a little characteristic warble to it, and he opened his mouth comically wide when he did it. If he wanted Ash’s steak scraps (which he loved), he had a very reserved meow for asking for them. If he couldn’t get under a blanket, he had a different reserved meow for asking for help. He was the only cat who regularly did that funny chirpy meow at bugs on the wall, though we hadn’t heard that one since we left the Seattle area — Vegas didn’t have nearly as many bugs.
When Anise would roughhouse a bit too hard, Twigs had a distinct pained meow for “this is too much” that would bring one of us running. I didn’t hear it much after we got Cheeseball, who acts as a more eager sparring partner for Anise, until one day I heard a distorted version of it — and I found Twigs and Cheeseball happily wrestling! Twigs came up with a new meow, ending on a happy note rather than a painful one, just for when he was playing with this new giant kitten friend.
One of the most frustrating parts of this is that it’s so hard to capture a cat’s meows, or a lot of other subtleties. As vocal as Twigs was, he still only spoke when he had something to say, and that was rarely when he was in front of a camera. I remember them so clearly now, but how can I convey them in text? Myehhh doesn’t really cut it. (I’ve been sorting through old cat videos, but it’s slow going; I’ll throw some of them up somewhere in the near future.)
I don’t understand what happened.
The test results only showed that he was severely anemic — he had far too few red blood cells, so he couldn’t warm himself or get enough oxygen. They didn’t explain how he’d reached that point in a matter of hours without showing milder symptoms first.
The day had been entirely normal. Twigs had been happy and active earlier in the afternoon. He wasn’t in the habit of chewing or eating strange things. We keep all our cats indoors, and the others are still fine, so he couldn’t have picked up a communicable illness. If he’d ever shown any sign that anything was wrong, I know with absolute certainty that Ash would’ve noticed, just as I immediately noticed when my cat Styx had lost weight. But there was nothing.
What, then, actually happened to him? I don’t know. I’ll never know. I briefly thought to ask for an autopsy, but at the time, I couldn’t bear the thought of what that would… mean.
No explanation, no reason, nothing to blame. Twigs was his healthy happy self all day, all week, all month, all year. Right up until he wasn’t. And then he died.
Twigs was so friendly. Kind, even. He never hurt anyone; he rarely did anything unexpected or rambunctious. He rarely even messed with things he shouldn’t, in sharp contrast to Anise, who tries to push my phone off my desk anytime he wants my attention; the most Twigs would do was gingerly tap something with a paw to see if it would react, then move on.
(Well, with one exception. If he found an unguarded glass of water, but the water level was too low for him to reach it, he was smart enough to tip the whole glass over and douse everything on your desk. We switched to reusable water bottles years ago.)
I can’t think of a single time Twigs was mean or angry or even wanted to be alone. All the cats have times they’re comfortable and don’t want to be disturbed, or just aren’t in the mood, or whatever — except Twigs.
If Ash scolded him (“Twigs!”), he’d dash off to a cat tree and scrabble at it briefly, taking his frustrations out with a few quick scratches and this funny little shimmy of his hips, then forget all about it. In extreme cases, he might run upstairs to our empty bedroom, yell once or twice, then come back down. Or in milder cases, when he couldn’t get something he wanted, he’d snort audibly and that was that. It was so, so charming — if he was upset, all he needed to do was go somewhere to yell about it for a moment, and then he was fine.
He was so patient, too. Ash put little costumes on him a few times, which he took in stride — well, for a cat, at least. He was always happy to be picked up, wrapped in clothing or a blanket, and/or held in all manner of silly positions. You could check his teeth and he’d hardly mind at all. Play with his ears, shake his paw, squish his lip, whatever; he was content just to be interacted with. (I suspect there was some mutual reinforcement between Ash doing goofy things to Twigs, and Twigs laying in increasingly obnoxious ways on Ash.)
He didn’t much like having his claws trimmed, and when Ash would do it, he used to bite the squishy part of their thumb — but not bite down, only put his teeth around their hand. Enough to communicate “I don’t like this” without trying to hurt them. Ash eventually started bribing him with cat treats every few claws, and then he disliked the process a bit less.
His good nature extended to the other cats, as well. He befriended every cat we’ve ever had! I didn’t really think about it until after he died, but if I ever saw two or more cats hanging out together, Twigs was almost guaranteed to be one of them. He was the binding force of our little cat sitcom.
There was one brief exception, when Ash first adopted Pearl — the first new cat since Twigs that was 100% Ash’s. They kept Pearl with them all the time at first, and Twigs got so jealous. Very early on he made his feelings very clear: he stood on the other side of the room, stared right at Ash (and Pearl), and made a huge meow at them. Then after like three days he found out that he and Pearl could both fit in Ash’s lap and everything was fine.
He’d cozy up with Anise or Pearl for warmth, and we’d often see all three of them nestled together, as though Twigs’s soothing presence deterred Anise and Pearl from their usual squabbling. He had an awkward but friendly relationship with Napoleon, the most aloof of the cats by far, who doesn’t show much affection towards any of the others except Pearl. I remember Napoleon used to refuse to groom Twigs anywhere but on the backs of his ears (the only place he had fur!), but after some years together, we started to see Napoleon grooming Twigs’s face and neck as well. For Napoleon, that was a really close friendship.
Twigs was even friends with Apollo, the German shepherd we used to have, who was much bigger than this tiny bald cat. I have a video of Twigs and Apollo playing, where Apollo is gently nudging Twigs around with his nose and Twigs alternates between nuzzling and lightly smacking Apollo. What a sweetheart. I don’t think any other cat interacted with Apollo quite like that.
He had a somewhat more complicated dynamic with Anise, who’s a good bit rowdier and more… destructive. Anise liked to start little brawls a lot, which wasn’t quite Twigs’s usual style, but he’d play along until Anise got too rough. (It probably didn’t help that Twigs would often respond by grabbing Anise by the sweater, which allowed Anise to wriggle backwards out of it and unleash his full powers.)
It’s been funny looking at older photos; when we first got Anise, Twigs was pristine, with maybe a scar or two on his haunch somewhere. (And all down the top of his tail, which he liked to nibble with some intensity.) At the end of his life, Twigs was riddled with little round scars from where Anise had bitten his back, and even a conspicuous dark spot right on top of his head. Who bites someone’s head?
I don’t remember his relationship with Styx as clearly, but I have enough photo evidence of it. The two of them were very close and spent a lot of time snuggled together, whether sleeping or just hanging out. We even got them matching pink sweaters! I’d forgotten that was deliberate. They played together, too, though much less seriously than Anise and on more “even” terms.
Six and a half years ago, my own cat Styx died. He’d been my cat, the way Twigs was Ash’s cat, sticking to me like glue the whole time I had him. But then Styx contracted a cruel and incurable illness, one that can strike even indoor cats and prefers to take the young. He wasted away over the course of a month.
I’d like to think that, whatever it was that took Twigs from us, maybe this swift departure saved him from the kind of long and excruciating ordeal that Styx went through.
I wrote his eulogy the day after he died. I avoided looking at it for years, but finally went back and read it a few days ago. It seemed so short! Was that really all I had to say about him? I knew him for over a year, yet I feel like I barely got to know him — I think Cheeseball is already older than Styx was when he died, and Cheeseball’s personality is still rapidly developing.
I was more shocked to find my own tweets from soon after Styx’s death, saying I couldn’t even look at photos of him. How long did that last? I don’t remember.
It hurt too much, so I avoided his memory, and now so much of it is a fragmented blur. Watching him deterioriate was gut-wrenching, and the worst part of his life — but it’s what I spilled the most ink on, and the part I need the least help remembering. Why did I write so much about that month? None of it was important in the end, yet I liveblogged every gratuitous medical detail. I guess I didn’t know what else to do, watching Styx wither away in my arms, while I couldn’t do anything about it.
I still cry for him, sometimes. I get a little sad over something else, and I remember Styx, and I cry. No matter how many of the details fade, I know I had a little cat named Styx who I loved dearly, and he loved me back.
This feels like a second chance, though. I won’t make the same mistake again.
It was hard to grieve with Ash all those years ago, back when things were so awkward. Now we can mourn together, and thinking about Twigs doesn’t sting the way thinking about Styx used to. It finally feels okay to remember Styx, too, and I’ve been rediscovering some old moments as I’ve sorted through photos in search of Twigs.
We’ve been celebrating and filling our space with both of them — we printed out physical copies of our favorite photo of each and put them in little thematic frames. Their pawprint casts are together on a shelf behind Ash’s desk. Nearby is Twigs’s urn, and I’d like to put Styx’s humble grave marker next to it, once I figure out where I packed it. Ash is painting portraits of them.
At my suggestion, we threw Twigs a little goodbye party — I baked a pumpkin cake (in honor of his homemade pumpkin cat food and the one fall he loved a tiny pumpkin), Ash decorated it, and we talked about Twigs and all the things about him that we miss. I insisted we wear party hats.
I’ve been taking notes on his life ever since he died, all so I could write this eulogy for him. It’s intimidating and even more difficult than I expected, trying to capture a life that meant so much to us in only a few thousand words. I hope I’m doing him justice. I want everyone to know how good Twigs was, and how much we’ve lost.
Twigs had his sassy side, but it was always sweet and harmless. Less like typical cat aloofness, more like that charming confidence of showing up to cuddle with his purr already in full swing, completely taking for granted that he was welcome and was about to enjoy himself. Or the similar energy he put on display when you were on a couch and he wanted to sit on you: he’d identify the most Twigs-shaped nook on your body and wedge his butt backwards into it, sometimes even hoisting himself with his front legs a bit, like a human settling into a recliner.
For example: if Twigs tried to approach Ash but Ash pushed him away — e.g., because they were eating or painting or their lap was occupied — then Twigs would often do a complete circle around the table or part of the room, only to approach Ash again from the other direction. It was so comical! So gentle and friendly, but cheerfully defiant about being near Ash. As if he couldn’t even imagine that he was disallowed for the moment. The problem must have been with his approach. There’s just no other rational explanation.
Since living in Colorado, we’ve occasionally come home and opened the front door only for Twigs to immediately dart outside… just so he could cross the front porch, stop at the nearest blade of grass, and bite it. None of the other cats have ever shown any interest in grass, but every once in a great while, Twigs would just get a hankering, and it’s the only reason he’s ever so much as attempted to leave the house. (Thank goodness.)
The thing that hit hardest right after he died was the feeding routine. Several of the cats eat storebought food, kept out of reach in a big dog cage we bought for this purpose, while Pearl and Twigs share homemade food. For the last couple months, whenever I went to go open the cage to let the other cats in, Twigs would trot along with them! He wouldn’t actually go in the cage, and he’d even slow down before getting to it (so the others would get ahead and it’d be easy to keep him out), but he acted like he belonged inside. It was such a perfect reflection of his personality: he went after something he wanted, yet he stopped short of breaking the rules.
Twigs knew how to have a good time, too. He loved rollin’ around on carpet. He’d wriggle on his back, grab the carpet with his claws and pull himself along it, and clearly be having the time of his life. Our Vegas home didn’t have any carpeted floors, but we added a little carpeted platform to the stairs (so the cats wouldn’t fall off!) and he had just as good a time on that. Later we got some small cat trees with singular round platforms, and those had a carpet texture he loved as well.
Rollin’ around would put Twigs in a feisty mood, and he’d reach out to smack anyone — cat, dog, or human — who came nearby. Ash would make a game out of this: they’d tap the floor nearby or the edge of the platform, then try to pull their hand away before Twigs “got” them. Sometimes Twigs would make a very riled-up face but not try to get you, and you could wind him up a little more by performing the “cat pat” — lightly and repeatedly tapping his haunch with your fingertips. You could watch him get more rowdy in real time, and then the game was to stop before he suddenly rolled over and tried to grab your hand.
Our home near Seattle was just up the street from a big park, and on a couple occasions, Ash took Twigs out for a walk on a little leash. On one such walk, while I was holding Twigs’s leash, he suddenly darted straight away from me and towards some underbrush! The leash caught him, of course, but he was running so fast that it actually yanked him right off the ground and flipped him over. (He was fine, albeit just as surprised as we were!)
(On another walk, Twigs stood right in front of Ash and made a huge myeehhhh up at them, clearly indicating that he was Done With Outside For Now. Poor baby. Ash picked him up, wrapped him in their sweatshirt, and held him until we got home. He really knew how to say exactly what he was thinking.)
Twigs played the typical cat games as well, when he felt like it — he might join in when we were playing string with Pearl, or teleport into the room when the laser pointer came out. One of the last things Twigs played with was a tiny mouse toy, ripped and with its stuffing pouring out. He sometimes liked to carry them around, roll around on the floor fighting them, then carry them somewhere else and do it again. He had a surprising ferocity with toys at times: wild eyes and incredibly quick pounces! It made me appreciate all the more how gentle he was with cats and people.
Once in a great while he’d play fetch, repeatedly bringing the same toy (or twist-tie or something) back to Ash’s feet so they could toss it and he could pounce it again. I even have an old video of Twigs playing chase: Ash would dash down the hallway, Twigs would dart after them with an intensely serious expression, Ash would yelp that Twigs “caught” them, and then they’d run down the hallway the other way. I don’t think any other cat we’ve had has really done that! They’ll run away from us, but not try to chase us around.
(Ash put fantasy “Luneko” versions of all our cats in NEONPHASE, a little game we made a few years ago, and I was struck by how Branch Commander Twig’s personality was so serious, when Twigs struck me as mostly lighthearted and friendly. But then, I suppose Twigs was very serious — about being lighthearted and friendly.)
I can’t tell what effect this has had on the other cats. They were all friendly with Twigs. Do they wonder where he is? Do they, too, assume he’s out of sight somewhere? Are they grieving? Will they grieve later?
The other cats got to saw Styx’s body, but Twigs died elsewhere. We have no way to tell them what happened to him. They just have to… guess? After living their whole lives with him? That sucks.
I think they’ve been more affectionate over the past week or so. Or they might be cuddling more because it’s getting colder. Or I might be paying more attention to them. Hard to say.
They do seem to be expanding their roles to fill Twigs’s niche. Napoleon, best known for spending almost all his time alone, has come and hung out on the couch — virtually unheard of. Anise and Cheeseball are, well, fighting each other instead of both fighting Twigs — but they’re starting fewer fights with Pearl. Pearl, who has had absolutely no tolerance for Anise since we left Vegas, has spent whole nights asleep next to him without making a fuss.
I guess they learned a lot from him.
Twigs was also fiercely loyal, but thankfully only had to show it a couple times.
We spent last summer in Marl’s parents’ unused (finished) basement, where they kept four cats of their own. (For a total of nine. We had quite a time.) One of them, Seamus, kept antagonizing our only furry cat, Napoleon.
We aren’t really sure how or why this started, but every so often, Seamus would start chasing Napoleon around, and Napoleon would scream. I don’t know why Napoleon was so scared of him, or what Seamus thought he was doing, or why he couldn’t understand that Napoleon didn’t like it. It was a constant source of stress for everyone; Seamus did it infrequently but seemingly on a whim, and we didn’t have many options for segregating the cats outright.
The incredible thing was, every time Seamus would start chasing Napoleon… Twigs would start chasing Seamus. And then Pearl would chase along with Twigs. And this would often end with Twigs and Pearl facing Seamus down, with Twigs saying some very nasty things that I will not repeat here.
(Anise would often show up and also run around, but he didn’t seem to understand why everyone was making such a fuss. While Twigs and Pearl were cornering Seamus, Anise would be standing next to them while mostly looking confused. Hey guys I see we’re playing chase!! I love chase too!! Oh why’d we all stop?)
I wouldn’t say it helped matters much, but it was strangely heartwarming. Twigs considered Napoleon his friend and had no problem telling this strange bully cat, a Maine Coon twice his size, to fuck right off.
Oh, but that’s nothing.
Apollo, that German shepherd we used to have, once somehow managed to knock down a whole set of shelves in Ash’s room. Ash, of course, yelled his name in response. They must’ve sounded really mad, because Twigs appeared instantly. He stood right in front of Apollo (separating him from Ash), in a very aggressive stance, making some very threatening growls and meows.
And he chased Apollo out of the room and right down the hallway.
All Twigs knew was that Apollo had seriously upset Ash, and that was that. No questions asked. This tiny little cat stood up to a giant wolf, because he thought Ash needed defending. Twigs was never aggressive or mean towards Apollo any other time, before or since. This only happened once, once ever, when Twigs thought Ash was in danger.
What a brave cat! If Apollo had wished Ash (or Twigs) harm, well, I don’t like those odds. But Twigs didn’t even think twice. We’ve never stopped marvelling over it.
I say “brave” very deliberately, because Twigs while was not fearless, he stood up to his fears. The only one we really saw was a fear of, ah, foam strips. See, we used to have a tiny “gym” in the corner of the kitchen, and the equipment sat on a foam mat made out of tiles with jigsaw edges that could fit together. To give the assembled mat a smooth perimeter, the tiles also came with thin edge pieces.
Foot traffic (or cats) could knock one of the edge pieces loose, leaving a strip of black foam alone on the floor. Twigs found this highly alarming. He would crouch down and eye it very suspiciously, creep up to give it a light smack and then back off, and generally treat it like a live wire. We assume it looked like a snake to him, though no other cat took interest in the edge pieces except to play with them, and Twigs never reacted the same way to anything else snake-shaped.
But he didn’t run away. He investigated, to see if it was dangerous, see if there was a predator in his home. Even after we’d find him doing this and put the foam piece back, Twigs would creep around for a while, looking for possible snakes until he was convinced it was gone. He was clearly very wary, yet he never ran, never hid.
The only other times I recall seeing Twigs anything close to scared were when he encountered a couple of accessories that resembled large animals: a Lucario hat Ash bought many years ago, and one of those goofy horse masks. I’m not even sure if “scared” is even the right word; he looked more annoyed? He neither backed down nor tried to attack them. I only remember him standing his ground and hissing, warning them to leave him alone.
I never heard him hiss any other time.
(Ash did, though. Once as a tiny kitten, our late cat Granite sat on him. A big furry cat just sat his ass right down on this little kitten. Kitten Twigs hissed about this, but kittens aren’t very ferocious hissers, so it came out khh! khh!, which Granite ignored.Funnily enough, once Twigs grew up, he developed his own habit of sitting on furred cats!)
We haven’t had a death since Styx. Twigs’s best friend! I never once expected Twigs would be the next to go. Now Napoleon is the only one left of the original crew.
Ash moved in with me not long after adopting Twigs. I don’t think he was even a year old. I knew him his entire adult life! I lived with him longer than I’ve lived with anyone, save my parents as a kid.
For so many years, it’s been Ash and Twigs. The inseparable duo, joined at the hip. I knew it would end someday, but I was so sure that day was much further off. I thought he’d be around for another five years at least, and secretly hoped he’d make it another ten. But we only got half of that. He loved twice as hard, and his heart burned out far too early.
He had so much life left in him. He played, he ran around, he wrestled (or, at least, was wrestled upon). He was still growing, inventing new antics and new ways to interact with us.
It’s been a strange experience. I couldn’t even absorb the factual knowledge of his death at first, even as I spent much of the first few days crying. How could Twigs die? That doesn’t make any sense; I haven’t seen him yet today, but he’ll show up soon. But I feel really sad. Oh, right, that’s because Twigs died. Rinse, repeat, over and over.
We picked his ashes a few days later. It’s been nice to have him home again, and it helps to have something physical to look at, rather than just the lack of his presence. Ash intends to paint his urn.
It got easier much more quickly than I expected, and that’s been weird as well. I wanted to hold onto his memory and be happy for the time I got to spend with him, and then that actually happened. I think about him a lot (especially over the multiple days it’s taken to write this), and a lot of little things remind me of him, but they don’t make me break down in tears. Usually.
That feels a little bad. But I know that hurting less doesn’t mean I loved him any less. And I know the last thing Twigs would want is for us to be sad.
Twigs was the best. I miss so much about him. I miss the way his whole nose scrunched up when he did a big meow. I miss his distinct little trot as he came down the hallway to see you. I miss watching him do eager little circles on the floor as I got the food out. I miss how he’d smack his lips as he showed up, a distinct and inexplicable quirk I’ve never seen in any other cat, a good compliment to how long he’d spend licking his chops after eating. I miss his huge ears! I miss “savannah cat” — when he’d hook his paws over the edge of something he was lying on, like an arm or the edge of a cat bed or the corner of my computer tower. I miss what a serene and calming presence he was.
It’s funny how some of the most memorable moments are things he only did one time. He joined Ash in the bathtub once — they were reading a book and Twigs came in, hopped in the bath, and sat in water up to his neck, just to be with them. He often announced his presence with a questioning meow when coming into Ash’s Vegas room at night, and once he did this really funny “meow-ow!” kind of double meow, and we’ve repeated it to each other as a nod to Twigs ever since, even though he never did it again.
One fall, we got a tiny pumpkin — the size of a slightly disappointing donut — and Twigs was enamored with it. We’d roll it along its edge and he’d chase after it and keep biting it, and it was so cute. Another fall, we bought another one, and Twigs wasn’t interested in it at all. Very cutting-edge of him. Tiny pumpkin is so last year.
He used to be really interested in eggs, too. For a while, we couldn’t turn our backs on an egg on the counter, because Twigs would materialize and start gently batting it around. Then he lost interest.
I miss how he slept with me. He’d always slept either behind my knees or on top of the covers, but right towards the end of his life, he invented a new trick, just for me. I sleep on my side, so he couldn’t lay on my chest; instead, he went under the covers, poked his head out, and lay against my chest with his head on my pillow. Like a little person! It was so sweet. He’d then keep nuzzling my face with his cold wet nose, which was kind of annoying. I miss that, too.
Even the annoying things are conspicuously absent. He frequently stepped on my hair while I was in bed, trying to get around me to get to Ash, and wow that is painful. Twigs groomed his cat sweaters more intensely than any other cat, biting the fabric and pulling so hard that it stretched and made this horrible high-pitched squeak, like nails on a chalkboard. He loved to groom people, too — usually on the chin or upper chest, since that’s what was accessible when he lay on you. Somehow Ash got used to it (and learned to redirect him to their palm, which he’d lick for ages), but I could never bear more than a few seconds of his cheese grater tongue.
What a good cat.
I felt like I’d been waiting for this all year. I don’t want to go much into it, but death has felt like a looming spectre almost since we moved in. The pointlessness of doing things, the feeling that I’m just passing time waiting to die, the occasional intrusive thought about a tragic accident befalling one of us or one of the cats. Never Twigs, though.
Last year was harder on me than I thought. I fired on all cylinders, trying to get Ash back on their feet, and once that happened… I deflated and never quite recovered. I lost a lot of my drive, my spark, my voice. I got frustrated with difficult work much more easily. I stopped writing. I stopped interacting. I stopped trying.
I didn’t even realize. Even as I felt increasingly distant and detached from the universe, I still thought I’d been pretty normal all year with only a few rough patches. It’s been hard to compare the past to the present, separated as they are by a strange and tumultuous six months that changed almost everything. Then Ash commented that I’d seemed kind of down all year. What a jolt that was, and only a few days before Twigs died.
Twigs’s death feels like a kick in the ass. I’ve felt a lot of despair over the past year, but all of it has been tied to anxieties and what-ifs — imaginary things. But this is sad, which is very different. This carries a pain for something tangible, something real, something important, something I want to hold onto. How can any of my little fantasy fears matter, when the loss of a cat outweighs all of them combined?
I don’t want to waste any more time. I want to reflect what I admired about Twigs: kind, patient, confident, and loving. I want to make this mean something.
Twigs had a good life. He spent it around people and cats he loved dearly, and who loved him right back. He had friends when he was lonely and blankets when he was chilly.
Oh, did he ever love blankets. Sphynxes are naked and tend to seek out warmth, of course, but of the four we’ve had, Twigs was by far the one who treated heat sources like a passion rather than mere physical comfort. His ability to identify the most snuggly spot to back his ass into was nothing short of superfeline. Sometimes he’d toast himself so well that he turned a little pink! And he used to do this incredible display of cat paws, with all four paws, accompanied by the occasional meow — but only on a specific blanket that we’ve long since lost.
He was also the one who tolerated cat sweaters the best (despite inflicting the most destruction on them). Anise’s powers of antagonism are greatly reduced in a sweater, and he will run away if he sees you approaching him with one; Pearl still does a funny awkward walk with her back half lower to the ground, even after wearing them through half a dozen winters. But Twigs in a sweater just acted like Twigs.
And what a well-travelled cat! He lived in four states and drove through half a dozen others. That’s more of the world than a decent number of humans see. He got to meet and snuggle with all kinds of other cats, and even some sort of giant wolf-cat who tried to herd him occasionally. He got to see the great outdoors, then decided he didn’t like it and returned to the great indoors.
Twigs did spend a couple of his later years afflicted with “pillow paw” — his pawpads swelled up one day, for seemingly no reason. Our vet couldn’t find an underlying cause, and meanwhile it was uncomfortable for him to land on his feet from a height. Poor guy. I’m eternally grateful to the vet we found last summer, who finally solved the mystery and cured him. He got to spend his final year active and unhindered again.
Ash spent much of our last couple Vegas years secluded in their office, too, so Twigs didn’t get as much face time as I’m sure he would’ve liked. But in our new place, both of our desks are out in the open and right next to each other, so Twigs could see them whenever he wanted. Sometimes he lay on a cat bed on my desk watching them, or strolled back and forth between us both, purring up a storm.
It’s been a bit of a rollercoaster for all of us, but I think the last year was the best year of his life.
I miss Twigs, but I smile when I think about him. He made us so happy while he was here.
Twigs came into Ash’s life while they were somewhat adrift — no clear goals, no home of their own, resigned to an unhappy marriage. He stuck with them for nine whole years, unwavering in his affection. He followed them down into the darkness, down where they couldn’t feel love from anyone — anyone except Twigs.
Now Ash has work and a community they love. We have a home together, and it finally feels like one. And by sheer coincidence, Ash’s divorce was finalized mere days after Twigs died. His entire life was contained within that marriage, from birth to death.
(Oh, we’re married now. Hurrah.)
Ash adopted Twigs almost on a whim, and he left us just as abruptly. As though he’d only shown up in the first place to help Ash when they needed it, and with Marl finally out of our lives, his work here was done.
The last thing Twigs did, the night that he died, was tell us he loved us. Ash put him under the blanket to try warming him up, and at first he was by our feet… but then he crawled up to slump against me, similar to how he did when I was alone in bed, and then he climbed on Ash’s chest and lay on them for a moment. Right at the end, as cold and confused as he must’ve felt, all he wanted was to be with Ash, to be with both of us.
I don’t know where Twigs is, now. He might be nowhere. But the universe has consistently proven itself to be more baffling and beautiful than I expect, so I’ll hold out hope that he’s somewhere — somewhere he can once again see Styx, his (other) best friend in the whole wide world. Somewhere that we can see them both again, one day.
Goodbye, Twigs! We’ll always love you, and we’ll always miss you.
Thank you, so much, for everything.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
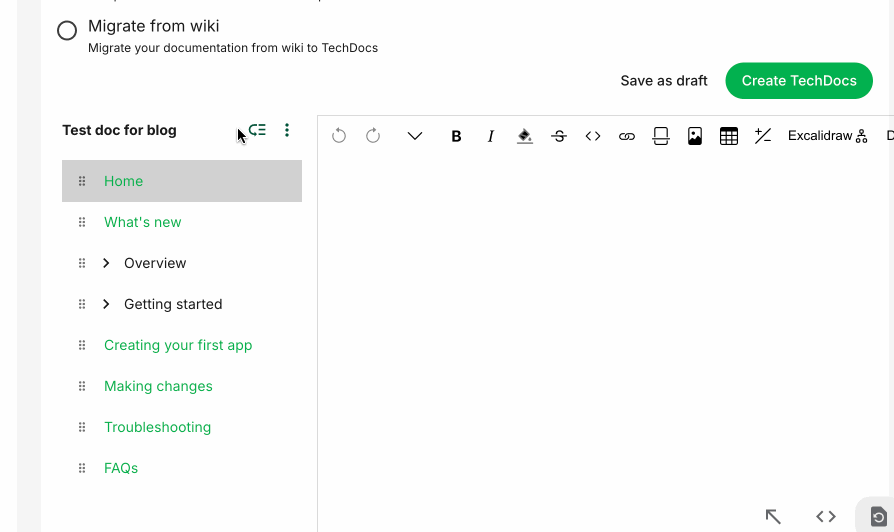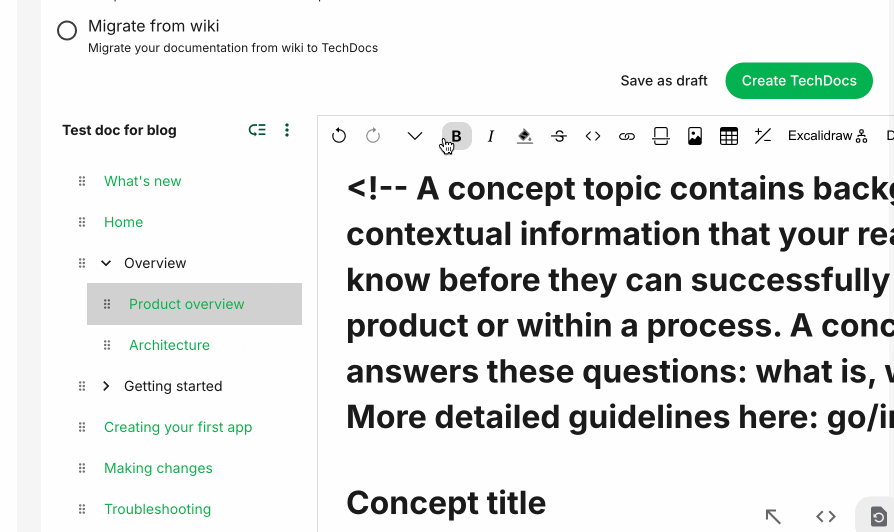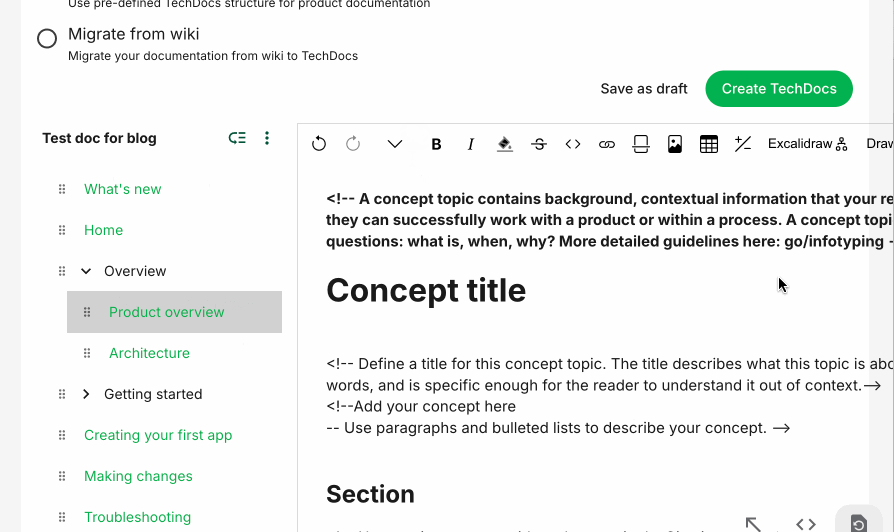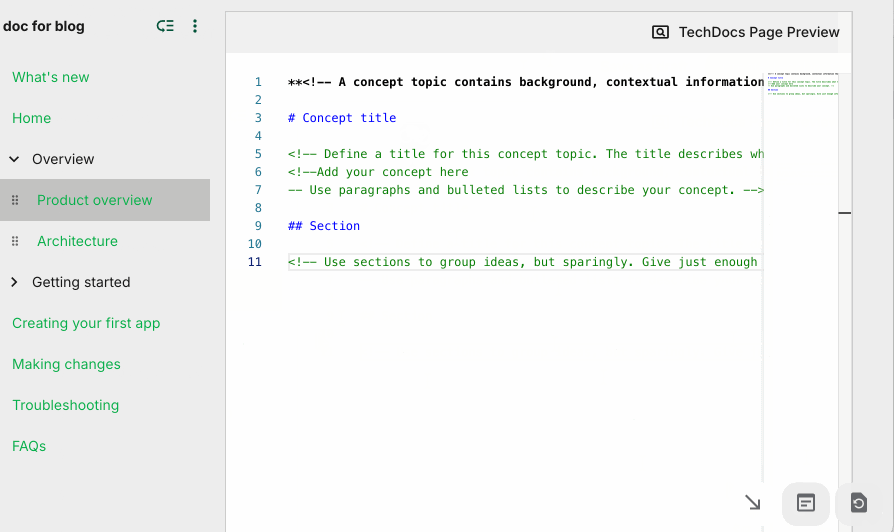
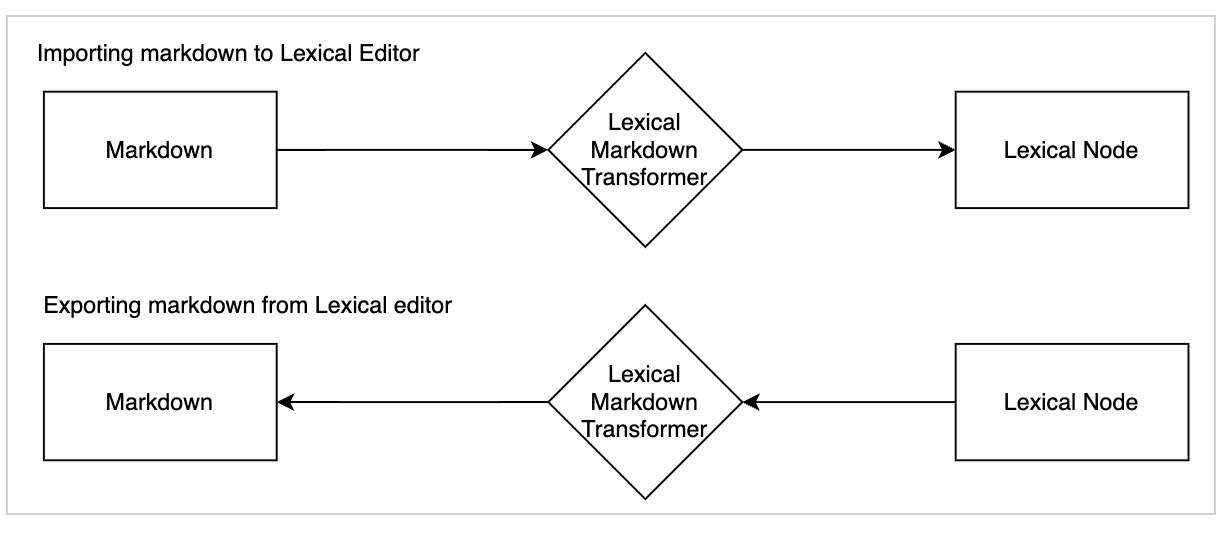
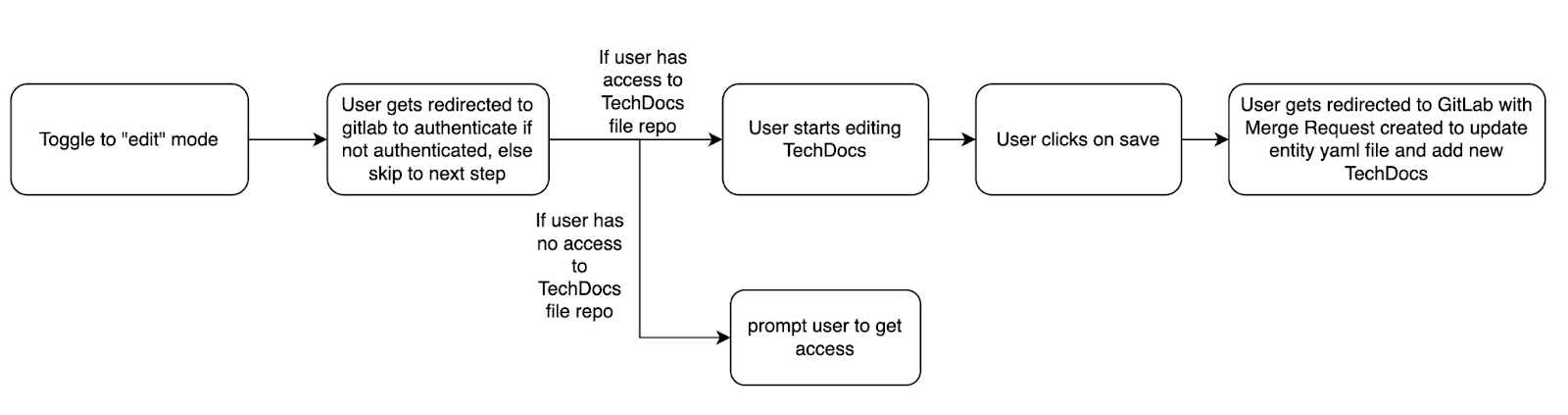

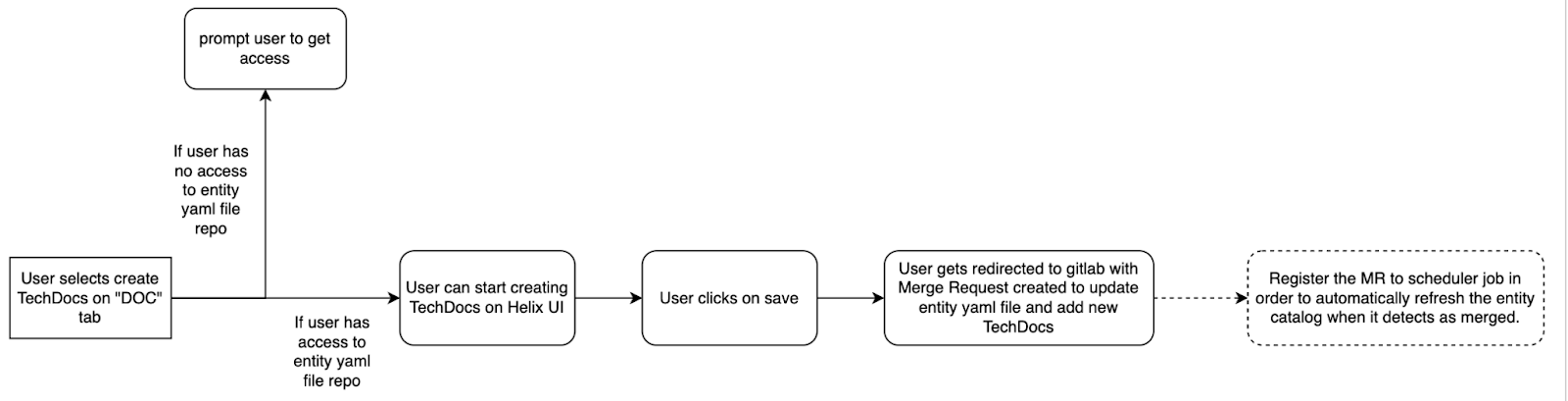
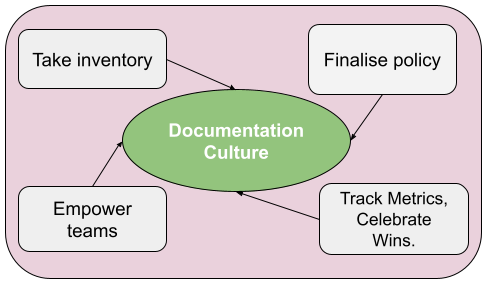
























































































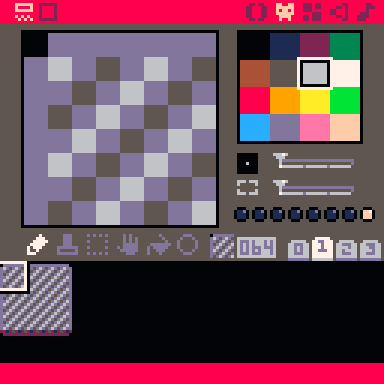







































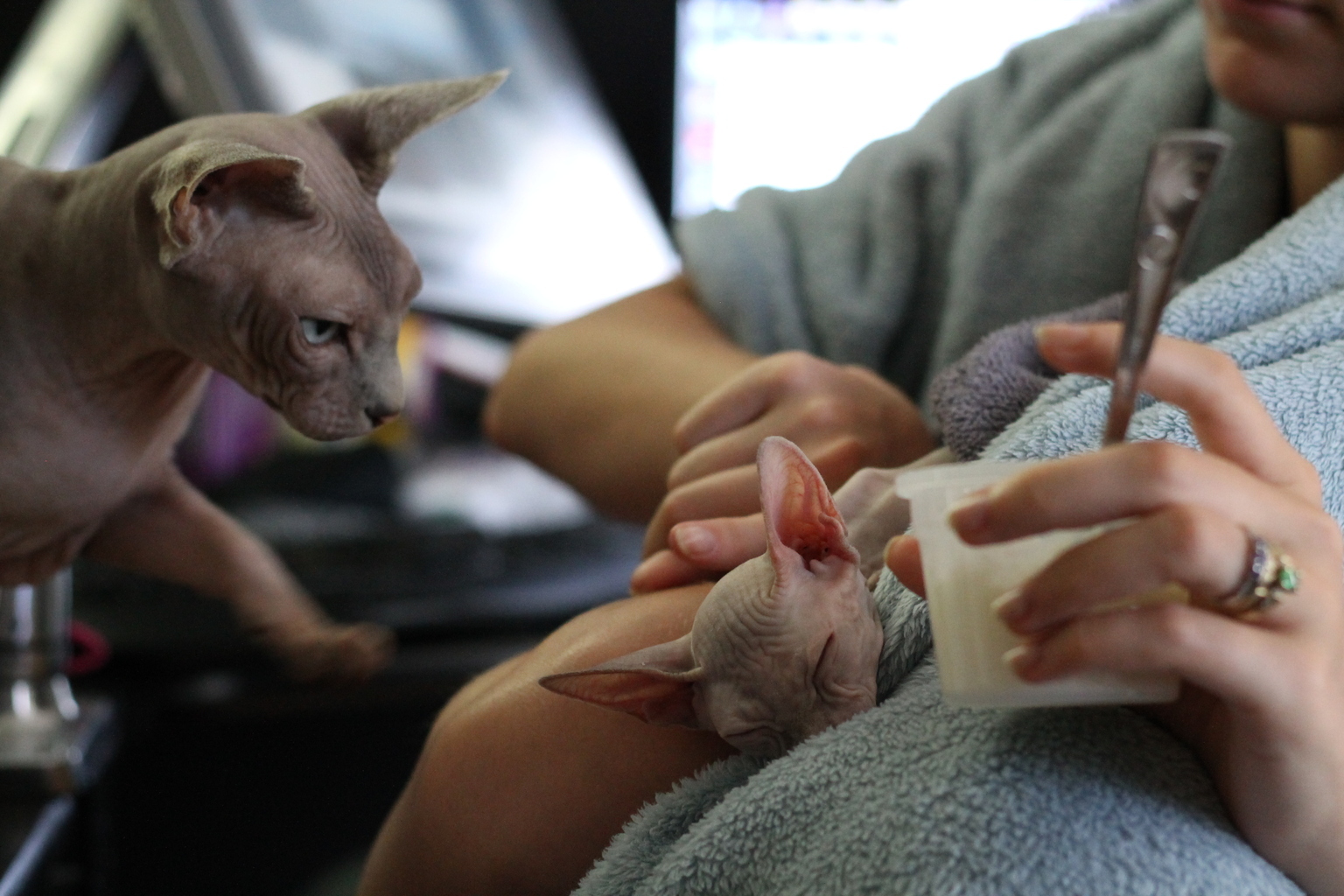






































{kind=link}