Post Syndicated from Alex Krivit original https://blog.cloudflare.com/instant-purge-for-all/
There’s a tradition at Cloudflare of launching real products on April 1, instead of the usual joke product announcements circulating online today. In previous years, we’ve introduced impactful products like 1.1.1.1 and 1.1.1.1 for Families. Today, we’re excited to continue this tradition by making every purge method available to all customers, regardless of plan type.
During Birthday Week 2024, we announced our intention to bring the full suite of purge methods — including purge by URL, purge by hostname, purge by tag, purge by prefix, and purge everything — to all Cloudflare plans. Historically, methods other than “purge by URL” and “purge everything” were exclusive to Enterprise customers. However, we’ve been openly rebuilding our purge pipeline over the past few years (hopefully you’ve read some of our blog series), and we’re thrilled to share the results more broadly. We’ve spent recent months ensuring the new Instant Purge pipeline performs consistently under 150 ms, even during increased load scenarios, making it ready for every customer.
But that’s not all — we’re also significantly raising the default purge rate limits for Enterprise customers, allowing even greater purge throughput thanks to the efficiency of our newly developed Instant Purge system.
Stepping back, today’s announcement represents roughly two years of focused engineering. Near the end of 2022, our team went heads down rebuilding Cloudflare’s purge pipeline with a clear yet challenging goal: dramatically increase our throughput while maintaining near-instant invalidation across our global network.
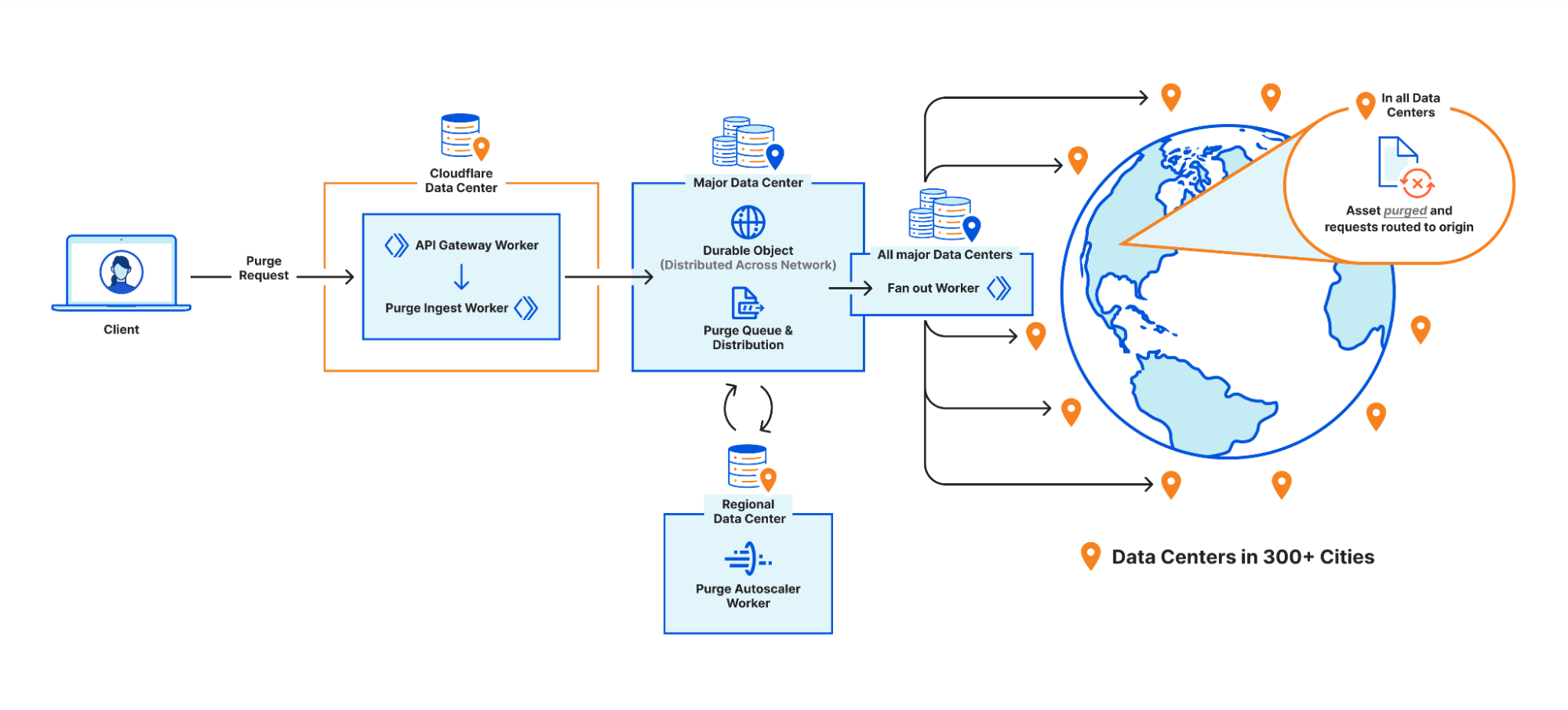
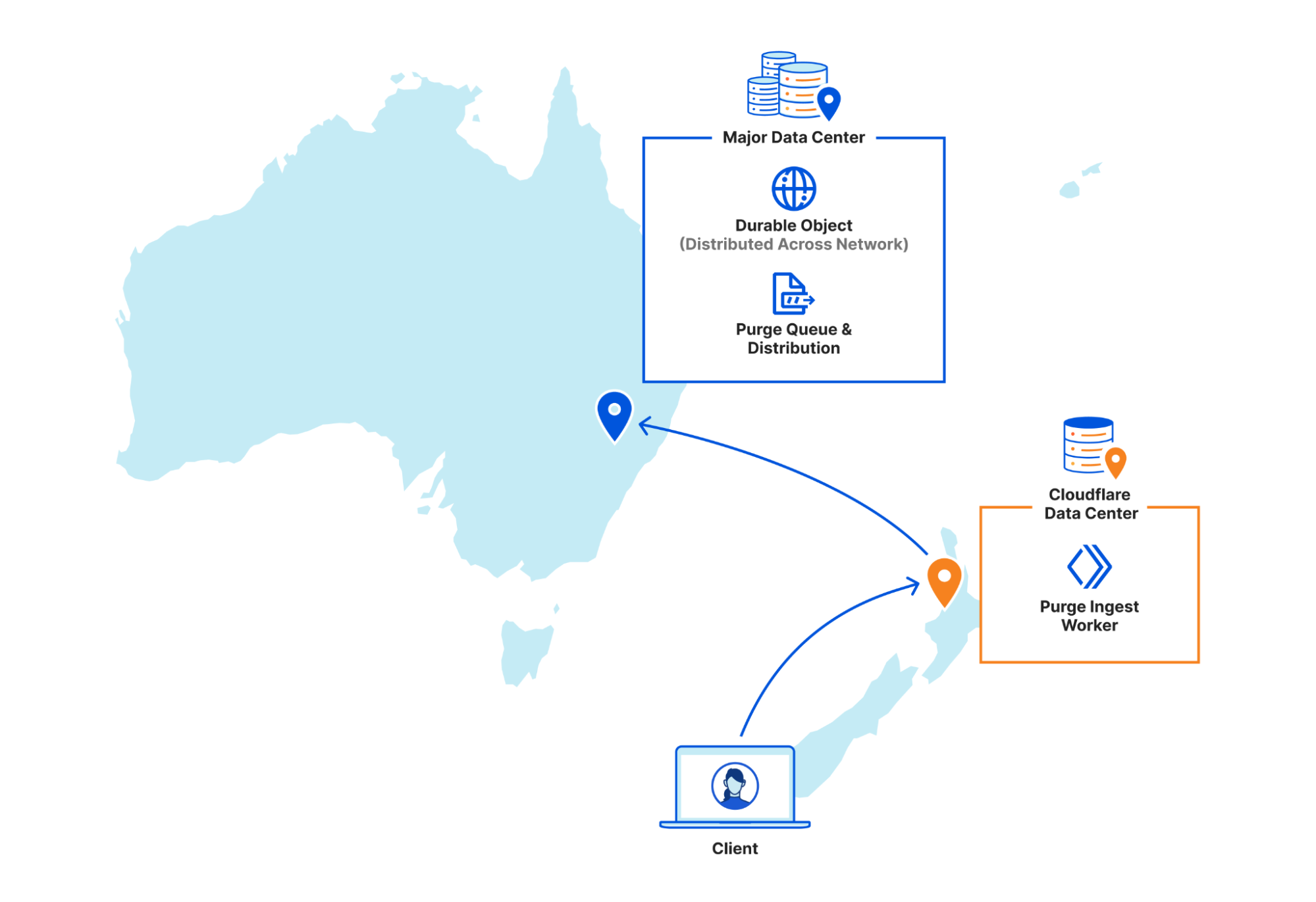
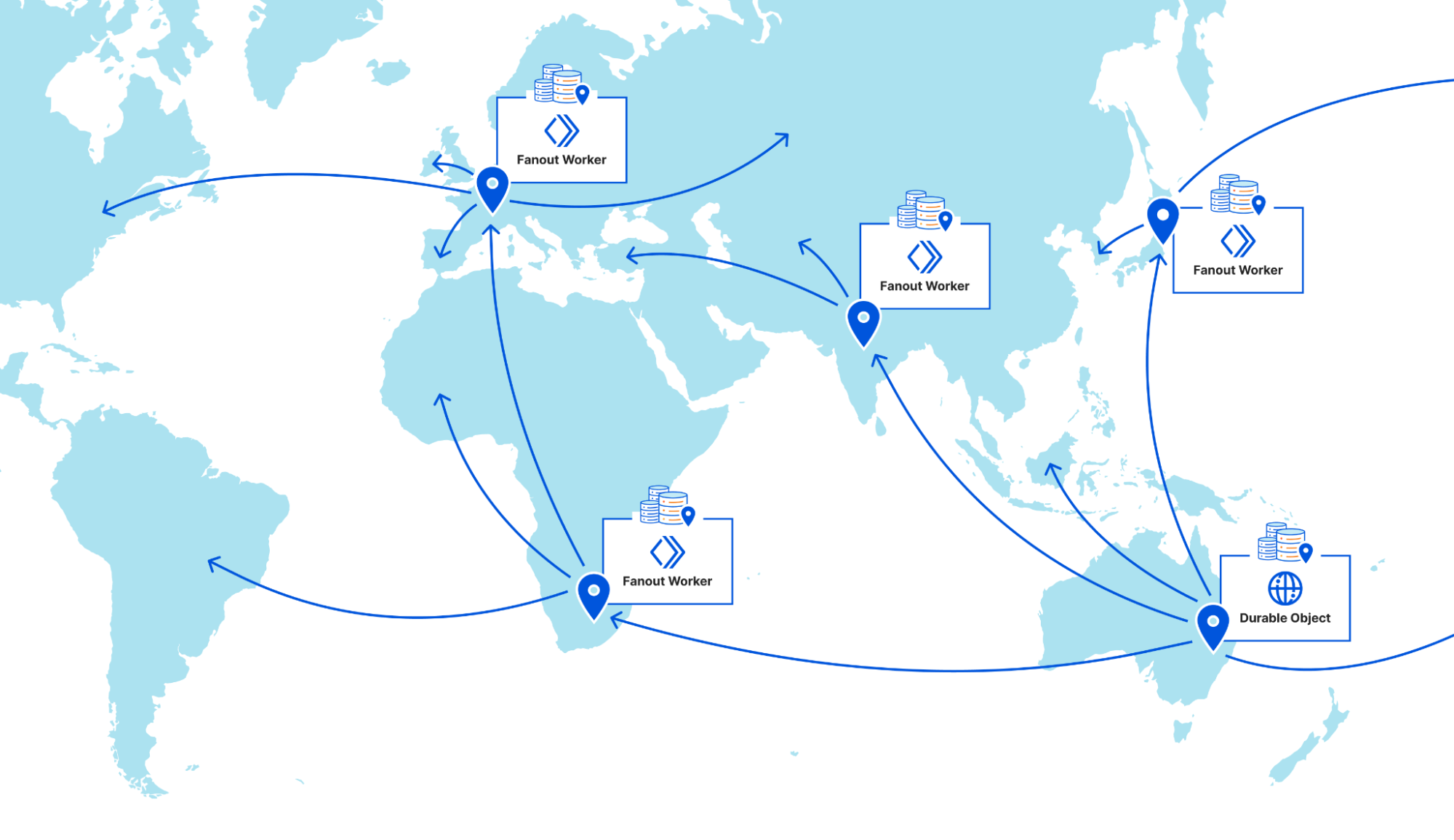
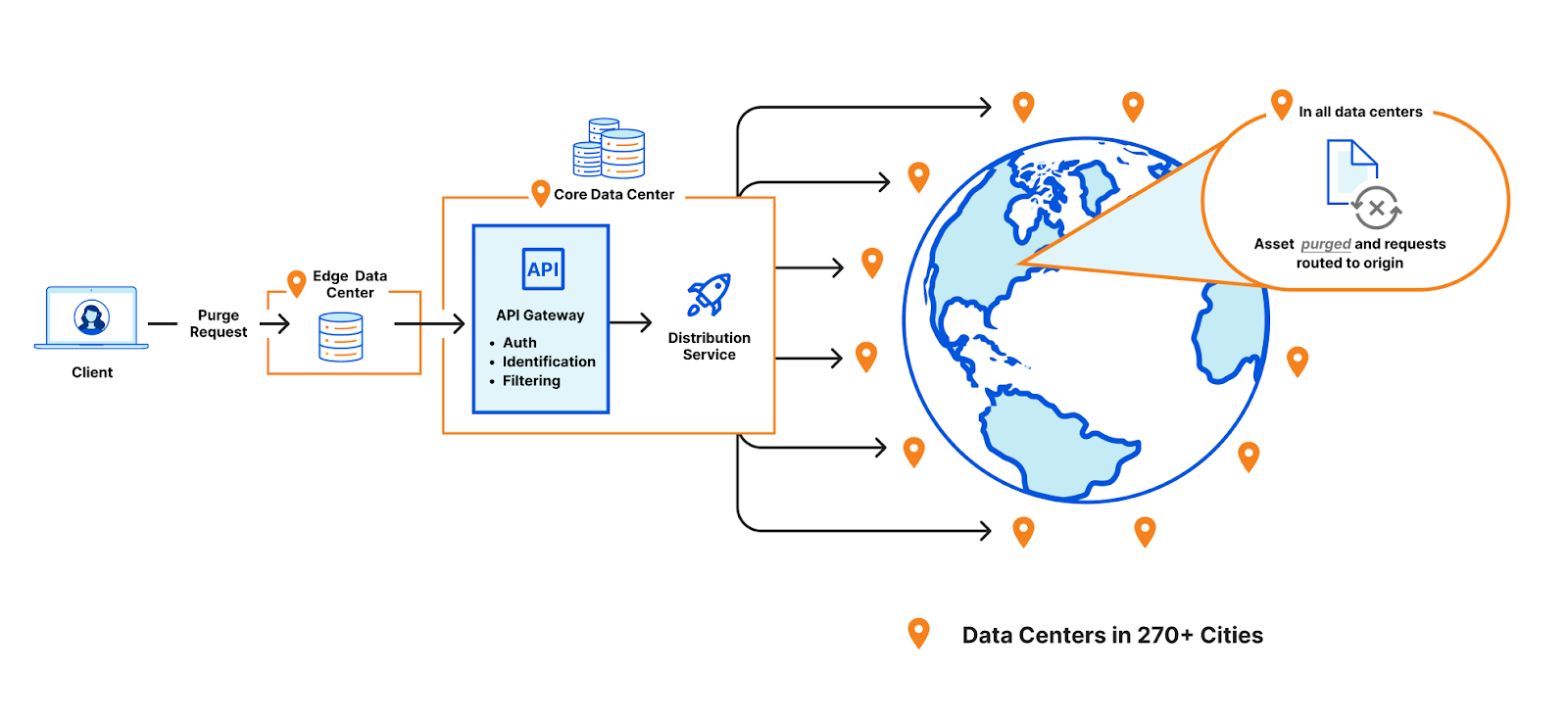
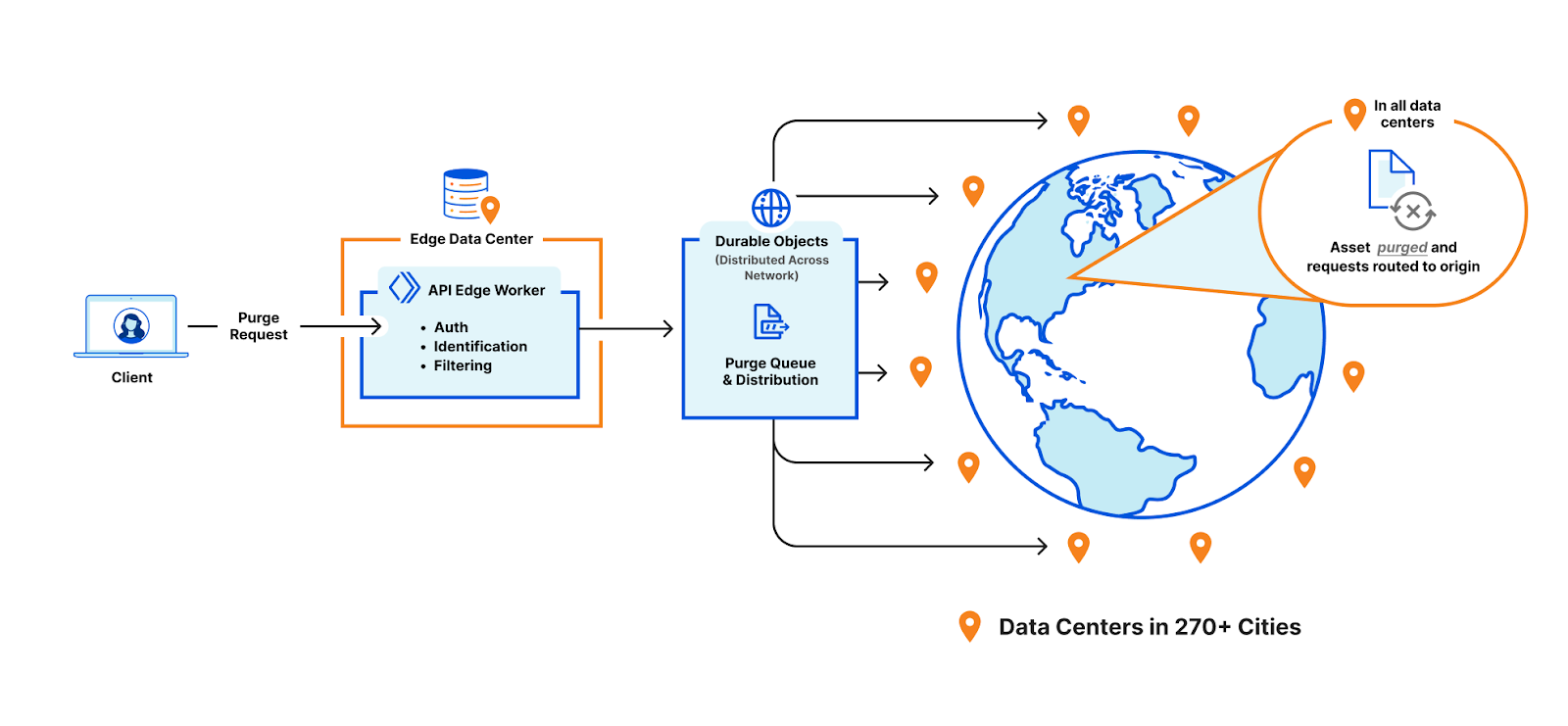
Cloudflare operates data centers in over 335 cities worldwide. Popular cached assets can reside across all of our data centers, meaning each purge request must quickly propagate to every location caching that content. Upon receiving a purge command, each data center must efficiently locate and invalidate cached content, preventing stale responses from being served. The amount of content that must be invalidated can vary drastically, from a single file, to all cached assets associated with a particular hostname. After the content has been purged, any subsequent requests will trigger retrieval of a fresh copy from the origin server, which will be stored in Cloudflare’s cache during the response.
Ensuring consistent, rapid propagation of purge requests across a vast network introduces substantial technical challenges, especially when accounting for occasional data center outages, maintenance, or network interruptions. Maintaining consistency under these conditions requires robust distributed systems engineering.
We’ve previously discussed how our new Instant Purge system was architected to achieve sub-150 ms purge times. It’s worth noting that the performance improvements were only part of what our new architecture achieved, as it also helped us solve significant scaling challenges around storage and throughput that allowed us to bring Instant Purge to all users.
Initially, our purge system scaled well, but with rapid customer growth, the storage consumption from millions of daily purge keys that needed to be stored reduced available caching space. Early attempts to manage this storage and throughput demand involved queues and batching for smoothing traffic spikes, but this introduced latency and underscored the tight coupling between increased usage and rising storage costs.
We needed to revisit our thinking on how to better store purge keys and when to remove purged content so we could reclaim space. Historically, when a customer would purge by tag, prefix or hostname, Cloudflare would mark the content as expired and allow it to be evicted later. This is known as lazy-purge because nothing is actively removed from disk. Lazy-purge is fast, but not necessarily efficient, because it consumes storage for expired but not-yet-evicted content. After examining global or data center-level indexing for purge keys, we decided that wasn’t viable due to increases in system complexity and the latency those indices could bring due to our network size. So instead, we opted for per-machine indexing, integrating indices directly alongside our cache proxies. This minimized network complexity, simplified reliability, and provided predictable scaling.
After careful analysis and benchmarking, we selected RocksDB, an embedded key-value store that we could optimize for our needs, which formed the basis of CacheDB, our Rust-based service running alongside each cache proxy. CacheDB manages indexing and immediate purge execution (active purge), significantly reducing storage needs and freeing space for caching.
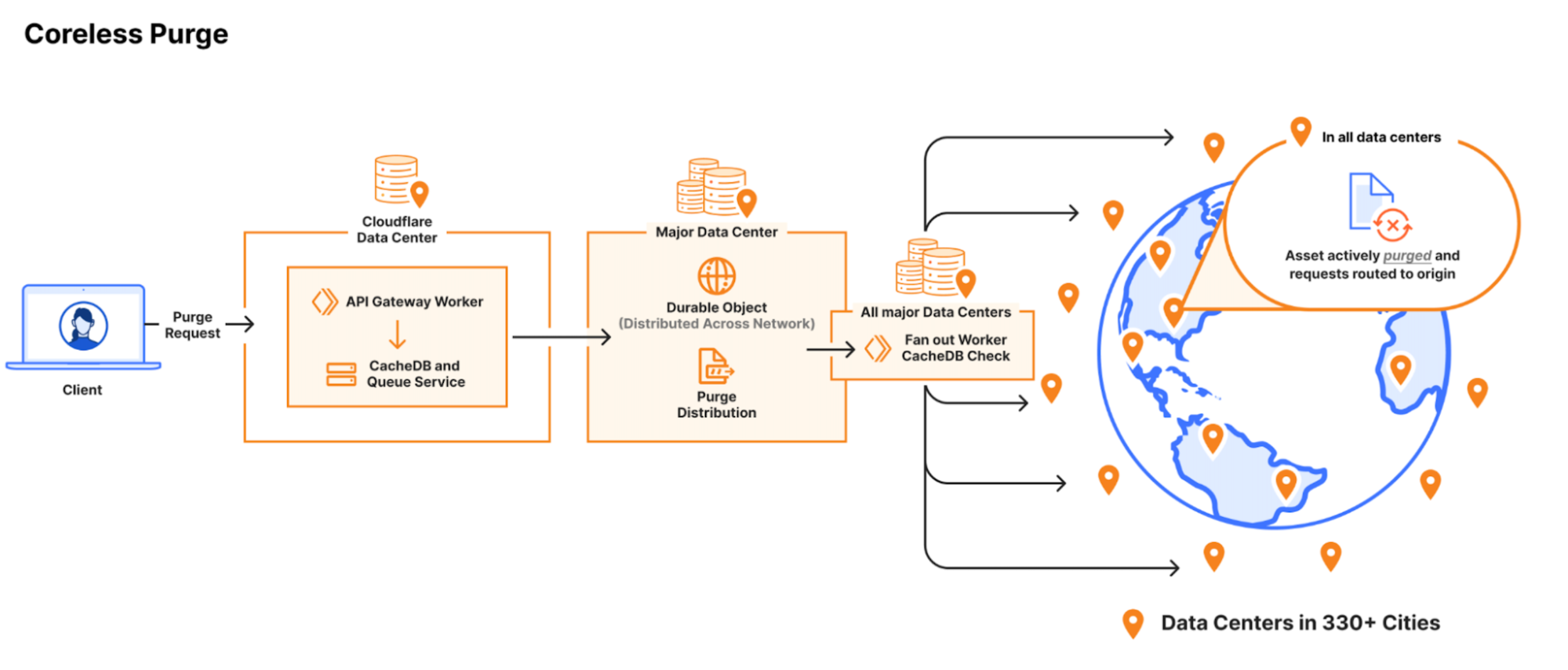
Local queues within CacheDB buffer purge operations to ensure consistent throughput without latency spikes, while the cache proxies consult CacheDB to guarantee rapid, active purges. Our updated distribution pipeline broadcasts purges directly to CacheDB instances across machines, dramatically improving throughput and purge speed.
Using CacheDB, we’ve reduced storage requirements 10x by eliminating lazy purge storage accumulation, instantly freeing valuable disk space. The freed storage enhances cache retention, boosting cache HIT ratios and minimizing origin egress. These savings in storage and increased throughput allowed us to scale to the point where we can offer Instant Purge to more customers.
For more information on how we designed the new Instant Purge system, please see the previous installment of our Purge series blog posts.
Moving on to practical considerations of using these new purge methods, it’s important to use the right method for what you want to invalidate. Purging too aggressively can overwhelm origin servers with unnecessary requests, driving up egress costs and potentially causing downtime. Conversely, insufficient purging leaves visitors with outdated content. Balancing precision and speed is vital.
Cloudflare supports multiple targeted purge methods to help customers achieve this balance.
-
Purge Everything: Clears all cached content associated with a website.
-
Purge by Prefix: Targets URLs sharing a common prefix.
-
Purge by Hostname: Invalidates content by specific hostnames.
-
Purge by URL (single-file purge): Precisely targets individual URLs.
-
Purge by Tag: Uses Cache-Tag headers to invalidate grouped assets, offering flexibility for complex cache management scenarios.
Starting today, all of these methods are available to every Cloudflare customer.
Users can select their purge method directly in the Cloudflare dashboard, located under the Cache tab in the configurations section, or via the Cloudflare API. Each purge request should clearly specify the targeted URLs, hostnames, prefixes, or cache tags relevant to the selected purge type (known as purge keys). For instance, a prefix purge request might specify a directory such as example.com/foo/bar. To maximize efficiency and throughput, batching multiple purge keys in a single request is recommended over sending individual purge requests each with a single key.
The new rate limits for Cloudflare’s purge by tag, prefix, hostname, and purge everything are different for each plan type. We use a token bucket rate limit system, so each account has a token bucket with a maximum size based on plan type. When we receive a purge request we first add tokens to the account’s bucket based on the time passed since the account’s last purge request divided by the refill rate for its plan type (which can be a fraction of a token). Then we check if there’s at least one whole token in the bucket, and if so we remove it and process the purge request. If not, the purge request will be rate limited. An easy way to think about this rate limit is that the refill rate represents the consistent rate of requests a user can send in a given period while the bucket size represents the maximum burst of requests available.
For example, a free user starts with a bucket size of 25 requests and a refill rate of 5 requests per minute (one request per 12 seconds). If the user were to send 26 requests all at once, the first 25 would be processed, but the last request would be rate limited. They would need to wait 12 seconds and retry their last request for it to succeed.
The current limits are applied per account:
|
Plan |
Bucket size |
Request refill rate |
Max keys per request |
Total keys |
|
Free |
25 requests |
5 per minute |
100 |
500 per minute |
|
Pro |
25 requests |
5 per second |
100 |
500 per second |
|
Biz |
50 requests |
10 per second |
100 |
1,000 per second |
|
Enterprise |
500 requests |
50 per second |
100 |
5,000 per second |
More detailed documentation on all purge rate limits can be found in our documentation.
We’ve spent a lot of time optimizing our purge platform. But we’re not done yet. Looking forward, we will continue to enhance the performance of Cloudflare’s single-file purge. The current P50 performance is around 250 ms, and we suspect that we can optimize it further to bring it under 200 ms. We will also build out our ability to allow for greater purge throughput for all of our systems, and will continue to find ways to implement filtering techniques to ensure we can continue to scale effectively and allow customers to purge whatever and whenever they choose.
We invite you to try out our new purge system today and deliver an instant, seamless experience to your visitors.