Post Syndicated from Monika Singh original https://blog.cloudflare.com/log-analytics-using-clickhouse/

This is an adapted transcript of a talk we gave at Monitorama 2022. You can find the slides with presenter’s notes here and video here.

When a request at Cloudflare throws an error, information gets logged in our requests_error pipeline. The error logs are used to help troubleshoot customer-specific or network-wide issues.
We, Site Reliability Engineers (SREs), manage the logging platform. We have been running Elasticsearch clusters for many years and during these years, the log volume has increased drastically. With the log volume increase, we started facing a few issues. Slow query performance and high resource consumption to list a few. We aimed to improve the log consumer’s experience by improving query performance and providing cost-effective solutions for storing logs. This blog post discusses challenges with logging pipelines and how we designed the new architecture to make it faster and cost-efficient.
Before we dive into challenges in maintaining the logging pipelines, let us look at the characteristics of logs.
Characteristics of logs

Unpredictable – In today’s world, where there are tons of microservices, the amount of logs a centralized logging system will receive is very unpredictable. There are various reasons why capacity estimation of log volume is so difficult. Primarily because new applications get deployed to production continuously, existing applications are automatically scaled up or down to handle business demands or sometimes application owners enable debug log levels and forget to turn it off.
Semi-structured – Every application adopts a different logging format. Some are represented in plain-text and others use JSON. The timestamp field within these log lines also varies. Multi-line exceptions and stack traces make them even more unstructured. Such logs add extra resource overhead, requiring additional data parsing and mangling.
Contextual – For debugging issues, often contextual information is required, that is, logs before and after an event happened. A single logline hardly helps, generally, it’s the group of loglines that helps in building the context. Also, we often need to correlate the logs from multiple applications to draw the full picture. Hence it’s essential to preserve the order in which logs get populated at the source.
Write-heavy – Any centralized logging system is write-intensive. More than 99% of logs that are written, are never read. They occupy space for some time and eventually get purged by the retention policies. The remaining less than 1% of the logs that are read are very important and we can’t afford to miss them.
Logging pipeline
Like most other companies, our logging pipeline consists of a producer, shipper, a queue, a consumer and a datastore.

Applications (Producers) running on the Cloudflare global network generate the logs. These logs are written locally in Cap’n Proto serialized format. The Shipper (in-house solution) pushes the Cap’n Proto serialized logs through streams for processing to Kafka (queue). We run Logstash (consumer), which consumes from Kafka and writes the logs into ElasticSearch (datastore).The data is then visualized by using Kibana or Grafana. We have multiple dashboards built in both Kibana and Grafana to visualize the data.
Elasticsearch bottlenecks at Cloudflare
At Cloudflare, we have been running Elasticsearch clusters for many years. Over the years, log volume increased dramatically and while optimizing our Elasticsearch clusters to handle such volume, we found a few limitations.
Mapping Explosion

Mapping Explosion is one of the very well-known limitations of Elasticsearch. Elasticsearch maintains a mapping that decides how a new document and its fields are stored and indexed. When there are too many keys in this mapping, it can take a significant amount of memory resulting in frequent garbage collection. One way to prevent this is to make the schema strict, which means any log line not following this strict schema will end up getting dropped. Another way is to make it semi-strict, which means any field not part of this mapping will not be searchable.
Multi-tenancy support

Elasticsearch doesn’t have very good multi-tenancy support. One bad user can easily impact cluster performance. There is no way to limit the maximum number of documents or indexes a query can read or the amount of memory an Elasticsearch query can take. A bad query can easily degrade cluster performance and even after the query finishes, it can still leave its impact.
Cluster operational tasks
It is not easy to manage Elasticsearch clusters, especially multi-tenant ones. Once a cluster degrades, it takes significant time to get the cluster back to a fully healthy state. In Elasticsearch, updating the index template means reindexing the data, which is quite an overhead. We use hot and cold tiered storage, i.e., recent data in SSD and older data in magnetic drives. While Elasticsearch moves the data from hot to cold storage every day, it affects the read and write performance of the cluster.
Garbage collection

Elasticsearch is developed in Java and runs on a Java Virtual Machine (JVM). It performs garbage collection to reclaim memory that was allocated by the program but is no longer referenced. Elasticsearch requires garbage collection tuning. The default garbage collection in the latest JVM is G1GC. We tried other GC like ZGC, which helped in lowering the GC pause but didn’t give us much performance benefit in terms of read and write throughput.

Elasticsearch is a good tool for full-text search and these limitations are not significant with small clusters, but in Cloudflare, we handle over 35 to 45 million HTTP requests per second, out of which over 500K-800K requests fail per second. These failures can be due to an improper request, origin server errors, misconfigurations by users, network issues and various other reasons.
Our customer support team uses these error logs as the starting point to triage customer issues. The error logs have a number of fields metadata about various Cloudflare products that HTTP requests have been through. We were storing these error logs in Elasticsearch. We were heavily sampling them since storing everything was taking a few hundreds of terabytes crossing our resource allocation budget. Also, dashboards built over it were quite slow since they required heavy aggregation over various fields. We need to retain these logs for a few weeks per the debugging requirements.
Proposed solution
We wanted to remove sampling completely, that is, store every log line for the retention period, to provide fast query support over this huge amount of data and to achieve all this without increasing the cost.
To solve all these problems, we decided to do a proof of concept and see if we could accomplish our requirements using ClickHouse.
Cloudflare was an early adopter of ClickHouse and we have been managing ClickHouse clusters for years. We already had a lot of in-house tooling and libraries for inserting data into ClickHouse, which made it easy for us to do the proof of concept. Let us look at some of the ClickHouse features that make it the perfect fit for storing logs and which enabled us to build our new logging pipeline.

ClickHouse is a column-oriented database which means all data related to a particular column is physically stored next to each other. Such data layout helps in fast sequential scan even on commodity hardware. This enabled us to extract maximum performance out of older generation hardware.

ClickHouse is designed for analytical workloads where the data has a large number of fields that get represented as ClickHouse columns. We were able to design our new ClickHouse tables with a large number of columns without sacrificing performance.

ClickHouse indexes work differently than those in relational databases. In relational databases, the primary indexes are dense and contain one entry per table row. So if you have 1 million rows in the table, the primary index will also have 1 million entries. While In ClickHouse, indexes are sparse, which means there will be only one index entry per a few thousand table rows. ClickHouse indexes enabled us to add new indexes on the fly.
ClickHouse compresses everything with LZ4 by default. An efficient compression not only helps in minimizing the storage needs but also lets ClickHouse use page cache efficiently.
One of the cool features of ClickHouse is that the compression codecs can be configured on a per-column basis. We decided to keep default LZ4 compression for all columns. We used special encodings like Double-Delta for the DateTime columns, Gorilla for Float columns and LowCardinality for fixed-size String columns.
ClickHouse is linearly scalable; that is, the writes can be scaled by adding new shards and the reads can be scaled by adding new replicas. Every node in a ClickHouse cluster is identical. Not having any special nodes helps in scaling the cluster easily.
Let’s look at some optimizations we leveraged to provide faster read/write throughput and better compression on log data.
Inserter
Having an efficient inserter is as important as having an efficient data store. At Cloudflare, we have been operating quite a few analytics pipelines from where we borrowed most of the concepts while writing our new inserter. We use Cap’n Proto messages as the transport data format since it provides fast data encoding and decoding. Scaling inserters is easy and can be done by adding more Kafka partitions and spawning new inserter pods.

Batch Size
One of the key performance factors while inserting data into ClickHouse is the batch size. When batches are small, ClickHouse creates many small partitions, which it then merges into bigger ones. Thus smaller batch size creates extra work for ClickHouse to do in the background, thereby reducing ClickHouse’s performance. Hence it is crucial to set it big enough that ClickHouse can accept the data batch happily without hitting memory limits.

Data modeling in ClickHouse.
ClickHouse provides in-built sharding and replication without any external dependency. Earlier versions of ClickHouse depended on ZooKeeper for storing replication information, but the recent version removed the ZooKeeper dependency by adding clickhouse-keeper.
To read data across multiple shards, we use distributed tables, a special kind of table. These tables don’t store any data themselves but act as a proxy over multiple underlying tables storing the actual data.

Like any other database, choosing the right table schema is very important since it will directly impact the performance and storage utilization. We would like to discuss three ways you can store log data into ClickHouse.

The first is the simplest and the most strict table schema where you specify every column name and data type. Any logline having a field outside this predefined schema will get dropped. From our experience, this schema will give you the fastest query capabilities. If you already know the list of all possible fields ahead, we would recommend using it. You can always add or remove columns by running ALTER TABLE queries.
The second schema uses a very new feature of ClickHouse, where it does most of the heavy lifting. You can insert logs as JSON objects and behind the scenes, ClickHouse will understand your log schema and dynamically add new columns with appropriate data type and compression. This schema should only be used if you have good control over the log schema and the number of total fields is less than 1,000. On the one hand it provides flexibility to add new columns as new log fields automatically, but at the same time, one lousy application can easily bring down the ClickHouse cluster.
The third schema stores all fields of the same data type in one array and then uses ClickHouse inbuilt array functions to query those fields. This schema scales pretty well even when there are more than 1,000 fields, as the number of columns depends on the data types used in the logs. If an array element is accessed frequently, it can be taken out as a dedicated column using the materialized column feature of ClickHouse. We recommend adopting this schema since it provides safeguards against applications logging too many fields.
Data partitioning

A partition is a unit of ClickHouse data. One common mistake ClickHouse users make is overly granular partitioning keys, resulting in too many partitions. Since our logging pipeline generates TBs of data daily, we created the table partitioned with `toStartOfHour(dateTime).` With this partitioning logic, when a query comes with the timestamp in the WHERE clause, ClickHouse knows the partition and retrieves it quickly. It also helps design efficient data purging rules according to the data retention policies.
Primary key selection

ClickHouse stores the data on disk sorted by primary key. Thus, selecting the primary key impacts the query performance and helps in better data compression. Unlike relational databases, ClickHouse doesn’t require a unique primary key per row and we can insert multiple rows with identical primary keys. Having multiple primary keys will negatively impact the insertion performance. One of the significant ClickHouse limitations is that once a table is created the primary key can not be updated.
Data skipping indexes

ClickHouse query performance is directly proportional to whether it can use the primary key when evaluating the WHERE clause. We have many columns and all these columns can not be part of the primary key. Thus queries on these columns will have to do a full scan resulting in slower queries. In traditional databases, secondary indexes can be added to handle such situations. In ClickHouse, we can add another class of indexes called data skipping indexes, which uses bloom filters and skip reading significant chunks of data that are guaranteed to have no match.
ABR
We have multiple dashboards built over the requests_error logs. Loading these dashboards were often hitting the memory limits set for the individual query/user in ClickHouse.
The dashboards built over these logs were mainly used to identify anomalies. To visually identify an anomaly in a metric, the exact numbers are not required, but an approximate number would do. For instance, to understand that errors have increased in a data center, we don’t need the exact number of errors. So we decided to use an in-house library and tool built around a concept called ABR.

ABR stands for “Adaptive Bit Rate” – the term ABR is mainly used in video streaming services where servers select the best resolution for a video stream to match the client and network connection. It is described in great detail in the blog post – Explaining Cloudflare’s ABR Analytics
In other words, the data is stored at multiple resolutions or sample intervals and the best solution is picked for each query.
The way ABR works is at the time of writing requests to ClickHouse, it writes the data in a number of tables with different sample intervals. For instance table_1 stores 100% of data, table_10 stores 10% of data, table_100 stores 1% of data and table_1000 stores 0.1% data so on and so forth. The data is duplicated between the tables. Table_10 would be a subset of table_1.
Demo
In Cloudflare, we use in-house libraries and tools to insert data into ClickHouse, but this can be achieved by using an open source tool – vector.dev
If you would like to test how log ingestion into ClickHouse works, you can refer or use the demo here.
Make sure you have docker installed and run `docker compose up` to get started.
This would bring up three containers, Vector.dev for generating vector demo logs, writing it into ClickHouse, ClickHouse container to store the logs and Grafana instance to visualize the logs.
When the containers are up, visit http://localhost:3000/dashboards to play with the prebuilt demo dashboard.
Conclusion

Logs are supposed to be immutable by nature and ClickHouse works best with immutable data. We were able to migrate one of the critical and significant log-producing applications from Elasticsearch to a much smaller ClickHouse cluster.
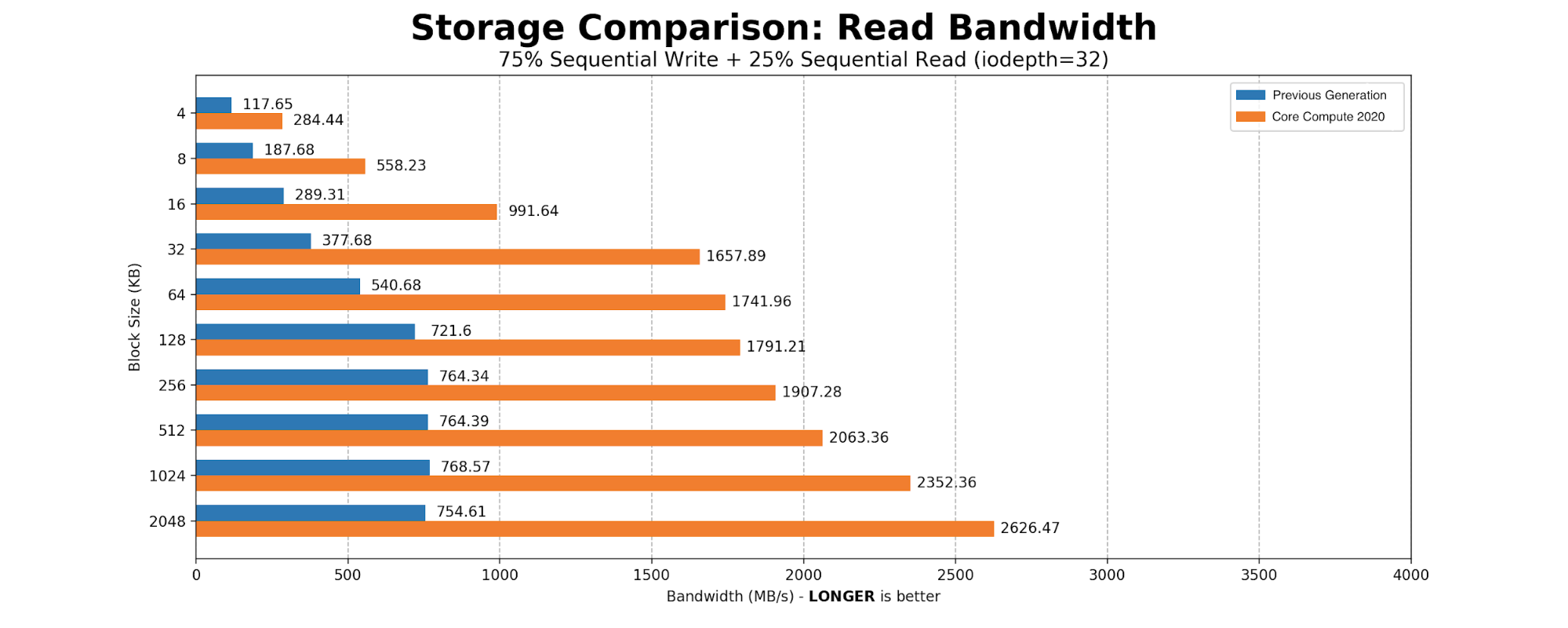
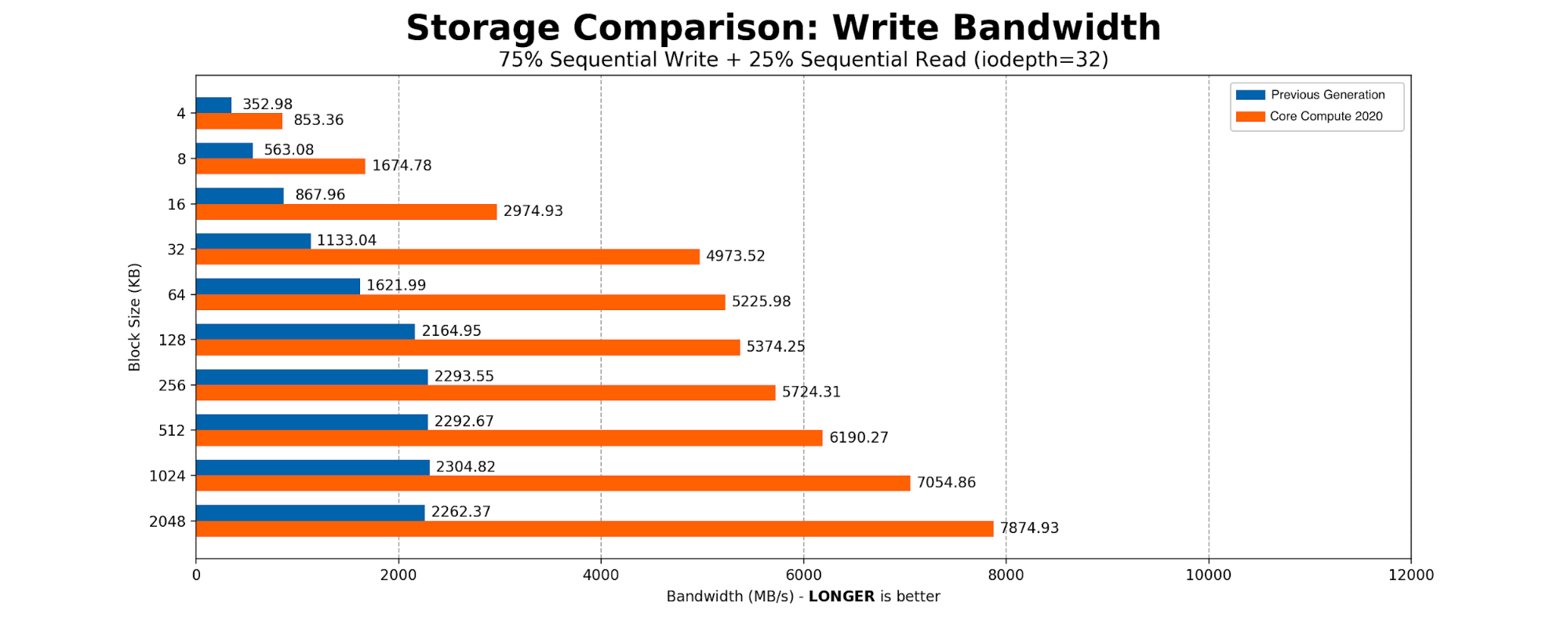
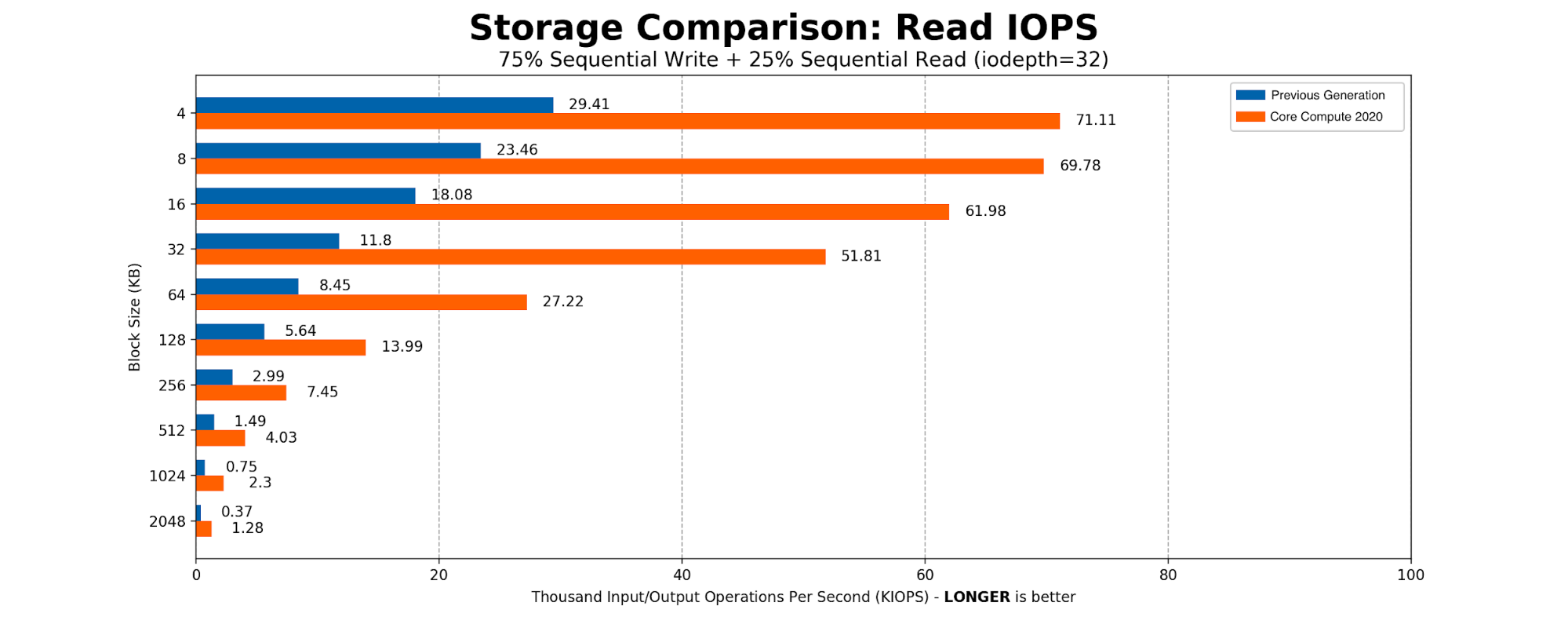
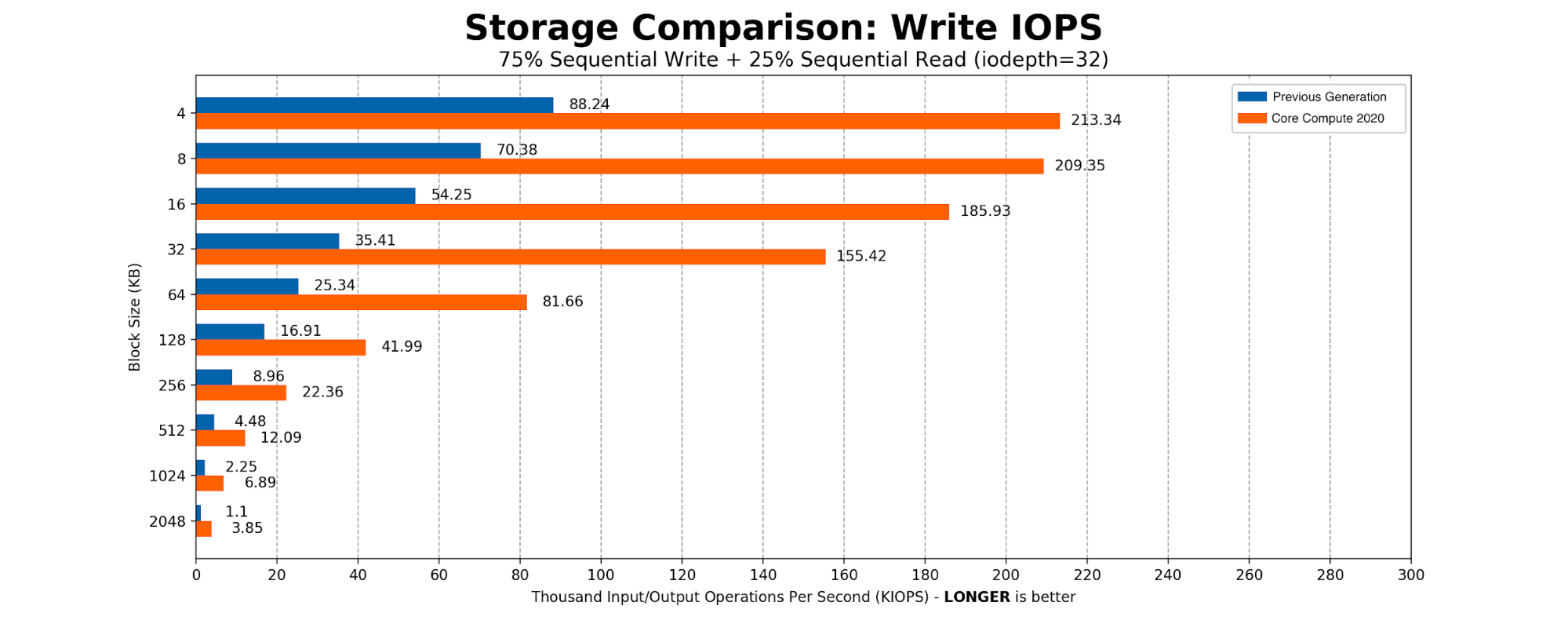
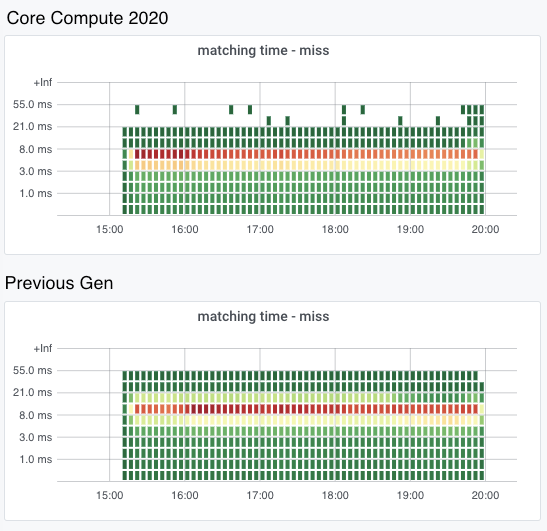
CPU and memory consumption on the inserter side were reduced by eight times. Each Elasticsearch document which used 600 bytes, came down to 60 bytes per row in ClickHouse. This storage gain allowed us to store 100% of the events in a newer setup. On the query side, the 99th percentile of the query latency also improved drastically.
Elasticsearch is great for full-text search and ClickHouse is great for analytics.