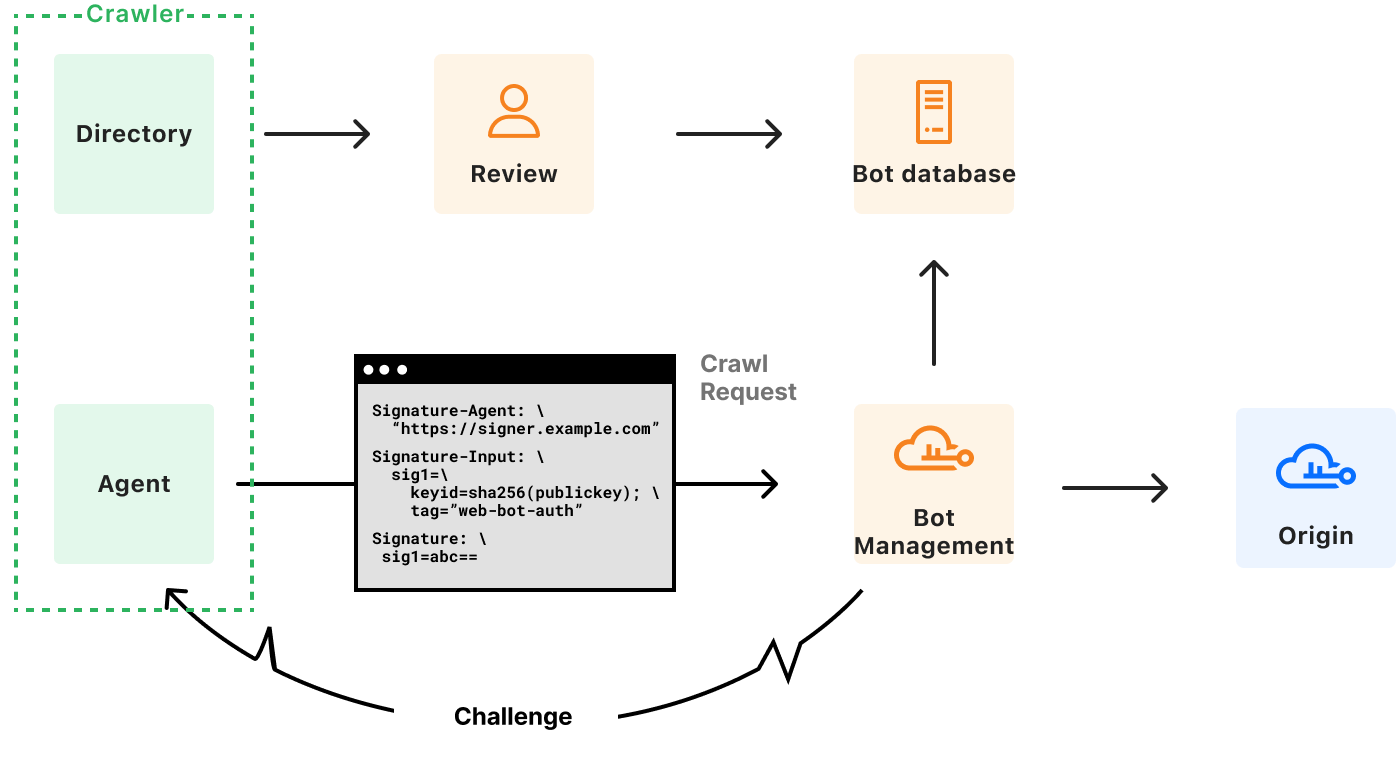
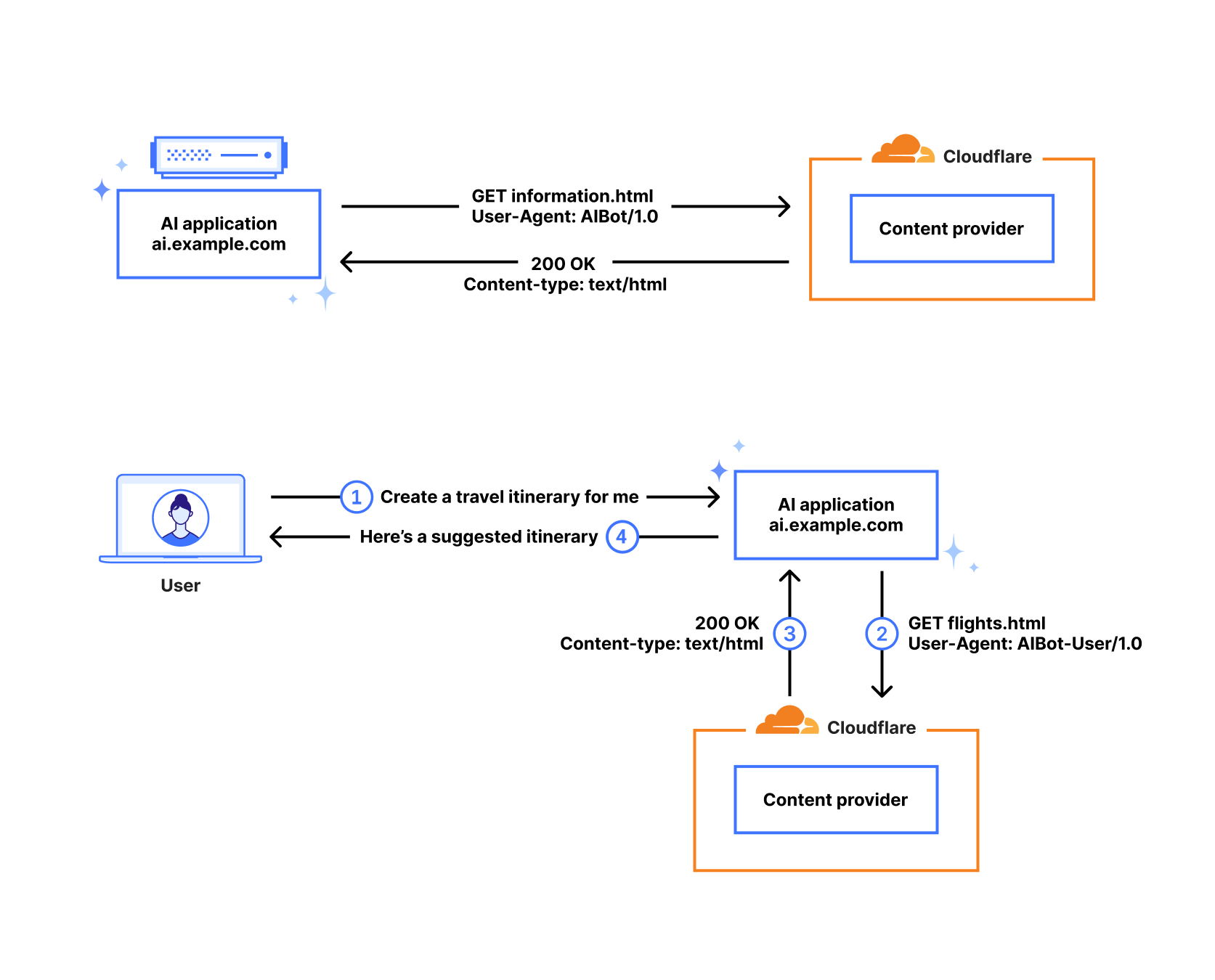
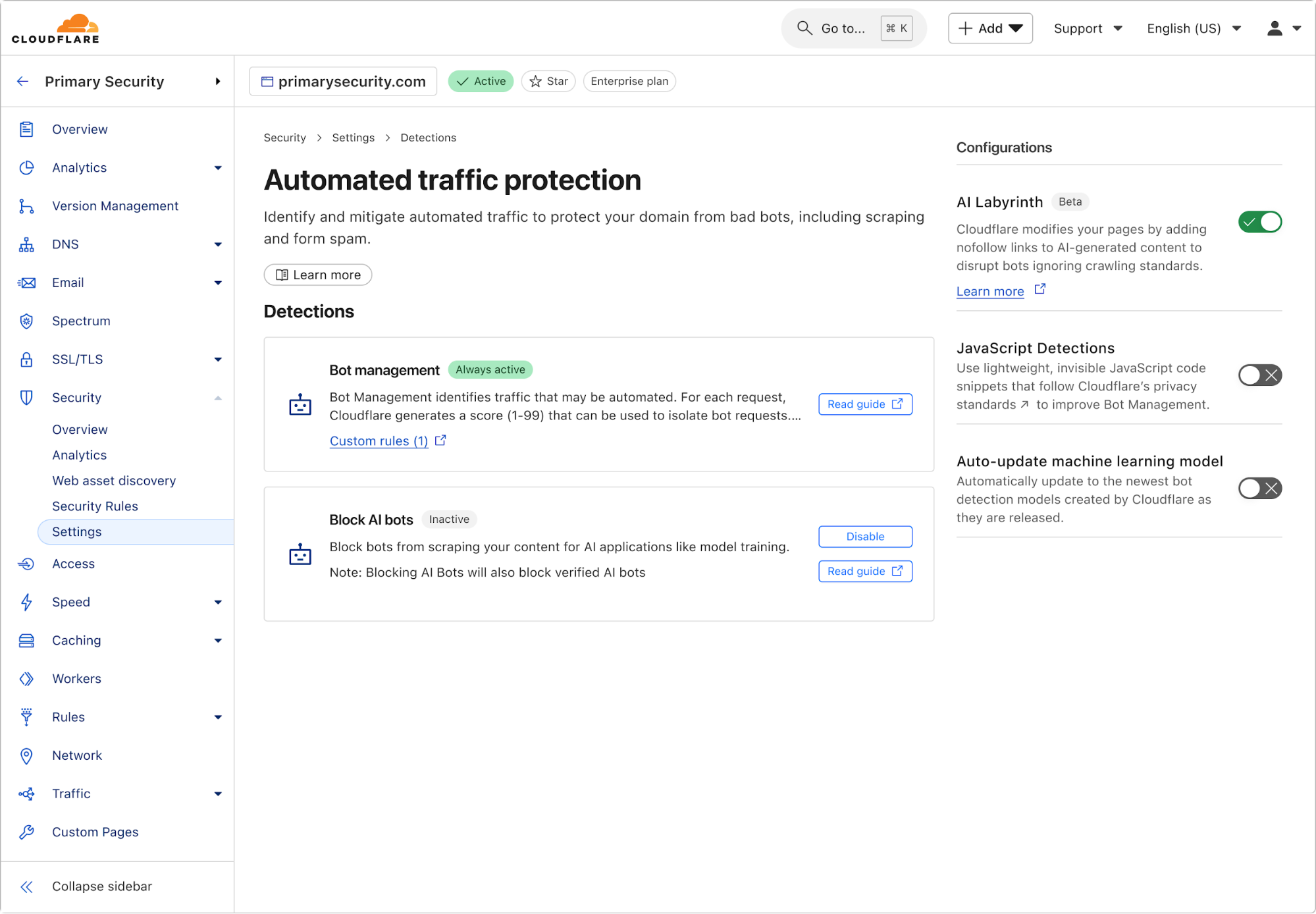
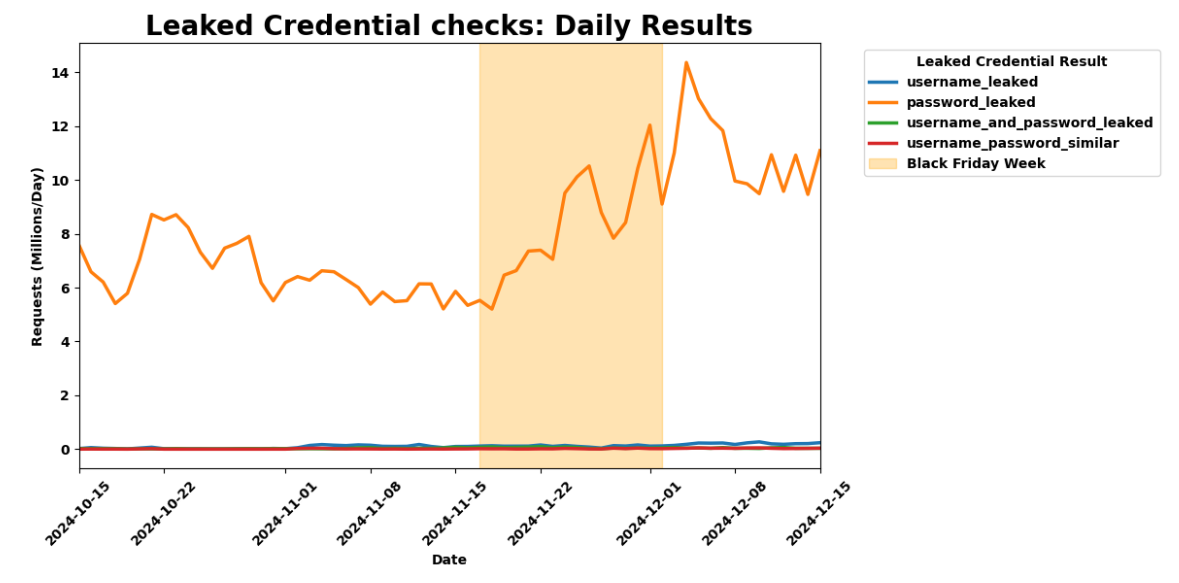
As bots and agents start cryptographically signing their requests, there is a growing need for website operators to learn public keys as they are setting up their service. I might be able to find the public key material for well-known fetchers and crawlers, but what about the next 1,000 or next 1,000,000? And how do I find their public key material in order to verify that they are who they say they are? This problem is called discovery.
We share this problem with Amazon Bedrock AgentCore, a comprehensive agentic platform to build, deploy and operate highly capable agents at scale, and their AgentCore Browser, a fast, secure, cloud-based browser runtime to enable AI agents to interact with websites at scale. The AgentCore team wants to make it easy for each of their customers to sign their own requests, so that Cloudflare and other operators of CDN infrastructure see agent signatures from individual agents rather than AgentCore as a monolith. (Note: this method does not identify individual users.) In order to do this, Cloudflare needed a way to ingest and register the public keys of AgentCore’s customers at scale.
In this blog post, we propose a registry of bots and agents as a way to easily discover them on the Internet. We also outline how Web Bot Auth can be expanded with a registry format. Similar to IP lists that can be authored by anyone and easily imported, the registry format is a list of URLs at which to retrieve agent keys and can be authored and imported easily.
We believe such registries should foster and strengthen an open ecosystem of curators that website operators can trust.
A need for more trustworthy authentication
In May, we introduced a protocol proposal called Web Bot Auth, which describes how bot and agent developers can cryptographically sign requests coming from their infrastructure.
There have now been multiple implementations of the proposed protocol, from Vercel to Shopify to Visa. It has been actively discussed and contributions have been made. Web Bot Auth marks a first step towards moving from brittle identification, like IPs and user agents, to more trustworthy cryptographic authentication. However, like IP addresses, cryptographic keys are a pseudonymous form of identity. If you operate a website without the scale and reach of large CDNs, how do you discover the public key of known crawlers?
The first protocol proposal suggested one approach: bot operators would provide a newly-defined HTTP header Signature-Agent that refers to an HTTP endpoint hosting their keys. Similar to IP addresses, the default is to allow all, but if a particular operator is making too many requests, you can start taking actions: increase their rate limit, contact the operator, etc.
With all that in mind, we come to the following problem. How can Cloudflare ensure customers have control over the traffic they want to allow, with sensible defaults, while fostering an open curation ecosystem that doesn’t lock in customers or small origins?
Such an ecosystem exists for lists of IP addresses (e.g. avestel-bots-ip-lists) and robots.txt (e.g. ai-robots-txt). For both, you can find canonical lists on the Internet to easily configure your website to allow or disallow traffic from those IPs. They provide direct configuration for your nginx or haproxy, and you can use it to configure your Cloudflare account. For instance, I could import the robots.txt below:
User-agent: MyBadBot
Disallow: /
This is where the registry format comes in, providing a list of URLs pointing to Signature Agent keys:
# AI Crawler
https://chatgpt.com/.well-known/http-message-signatures-directory
https://autorag.ai.cloudflare.com/.well-known/http-message-signatures-directory
# Test signature agent card
https://http-message-signatures-example.research.cloudflare.com/.well-known/http-message-signatures-directory
And that’s it. A registry could contain a list of all known signature agents, a curated list for academic research agents, for search agents, etc.
Anyone can maintain and host these lists. Similar to IP or robots.txt list, you can host such a registry on any public file system. This means you can have a repository on GitHub, put the file on Cloudflare R2, or send it as an email attachment. Cloudflare intends to provide one of the first instances of this registry, so that others can contribute to it or reference it when building their own.
Learn more about an incoming request
Knowing the Signature-Agent is great, but not sufficient. For instance, to be a verified bot, Cloudflare requires a contact method, in case requests from that infrastructure suddenly fail or change format in a way that causes unexpected errors upstream. In fact, there is a lot of information an origin might want to know: a name for the operator, a contact method, a logo, the expected crawl rate, etc.
Therefore, to complement the registry format, we have proposed a signature-agent card format that extends the JWKS directory (RFC 7517) with additional metadata. Similar to an old-fashioned contact card, it includes all the important information someone might want to know about your agent or crawler.
We provide an example below for illustration. Note that the fields may change: introducing jwks-uri, logo being more descriptive, etc.
Amazon Bedrock AgentCore, an agentic platform for building and deploying AI agents at scale, adopted Web Bot Auth for its AgentCore Browser service (learn more in their post). AgentCore Browser intends to transition from a service signing key that is currently available in their public preview, to customer-specific keys, once the protocol matures. Cloudflare and other operators of origin protection service will be able to see and validate signatures from individual AgentCore customers rather than AgentCore as a whole.
Cloudflare also offers a registry for bots and agents it trusts, provided through Radar. It uses the registry format to allow for the consumption of bots trusted by Cloudflare on your server.
You can use these registries today – we’ve provided a demo in Go for Caddy server that would allow us to import keys from multiple registries. It’s on cloudflare/web-bot-auth. The configuration looks like this:
:8080 {
route {
# httpsig middleware is used here
httpsig {
registry "http://localhost:8787/test-registry.txt"
# You can specify multiple registries. All tags will be checked independantly
registry "http://example.test/another-registry.txt"
}
# Responds if signature is valid
handle {
respond "Signature verification succeeded!" 200
}
}
}
There are several reasons why you might want to operate and curate a registry leveraging the Signature Agent Card format:
Monitor incoming Signature-Agents. This should allow you to collect signature-agent cards of agents reaching out to your domain.
Import them from existing registries, and categorize them yourself. There could be a general registry constructed from the monitoring step above, but registries might be more useful with more categories.
Establish direct relationships with agents. Cloudflare does this for itsbot registry for instance, or you might use a public GitHub repository where people can open issues.
Learn from your users. If you offer a security service, allowing your customers to specify the registries/signature-agents they want to let through allows you to gain valuable insight.
Moving forward
As cryptographic authentication for bots and agents grows, the need for discovery increases.
With the introduction of a lightweight format and specification to attach metadata to Signature-Agent, and curate them in the form of registries, we begin to address this need. The HTTP Message Signature directory format is being expanded to include some self-certified metadata, and the registry maintains a curation ecosystem.
Down the line, we predict that clients and origins will choose the signature-agent they trust, use a common format to migrate their configuration between CDN providers, and rely on a third-party registry for curation. We are working towards integrating these capabilities into our bot management and rule engines.
IP addresses have historically been treated as stable identifiers for non-routing purposes such as for geolocation and security operations. Many operational and security mechanisms, such as blocklists, rate-limiting, and anomaly detection, rely on the assumption that a single IP address represents a cohesive, accountableentity or even, possibly, a specific user or device.
But the structure of the Internet has changed, and those assumptions can no longer be made. Today, a single IPv4 address may represent hundreds or even thousands of users due to widespread use of Carrier-Grade Network Address Translation (CGNAT), VPNs, and proxymiddleboxes. This concentration of traffic can result in significant collateral damage – especially to users in developing regions of the world – when security mechanisms are applied without taking into account the multi-user nature of IPs.
This blog post presents our approach to detecting large-scale IP sharing globally. We describe how we build reliable training data, and how detection can help avoid unintentional bias affecting users in regions where IP sharing is most prevalent. Arguably it’s those regional variations that motivate our efforts more than any other.
Why this matters: Potential socioeconomic bias
Our work was initially motivated by a simple observation: CGNAT is a likely unseen source of bias on the Internet. Those biases would be more pronounced wherever there are more users and few addresses, such as in developing regions. And these biases can have profound implications for user experience, network operations, and digital equity.
The reasons are understandable for many reasons, not least because of necessity. Countries in the developing world often have significantly fewer available IPs, and more users. The disparity is a historical artifact of how the Internet grew: the largest blocks of IPv4 addresses were allocated decades ago, primarily to organizations in North America and Europe, leaving a much smaller pool for regions where Internet adoption expanded later.
To visualize the IPv4 allocation gap, we plot country-level ratios of users to IP addresses in the figure below. We take online user estimates from the World Bank Group and the number of IP addresses in a country from Regional Internet Registry (RIR) records. The colour-coded map that emerges shows that the usage of each IP address is more concentrated in regions that generally have poor Internet penetration. For example, large portions of Africa and South Asia appear with the highest user-to-IP ratios. Conversely, the lowest user-to-IP ratios appear in Australia, Canada, Europe, and the USA — the very countries that otherwise have the highest Internet user penetration numbers.
The scarcity of IPv4 address space means that regional differences can only worsen as Internet penetration rates increase. A natural consequence of increased demand in developing regions is that ISPs would rely even more heavily on CGNAT, and is compounded by the fact that CGNAT is common in mobile networks that users in developing regions so heavily depend on. All of this means that actions known to be based on IP reputation or behaviour would disproportionately affect developing economies.
Cloudflare is a global network in a global Internet. We are sharing our methodology so that others might benefit from our experience and help to mitigate unintended effects. First, let’s better understand CGNAT.
When one IP address serves multiple users
Large-scale IP address sharing is primarily achieved through two distinct methods. The first, and more familiar, involves services like VPNs and proxies. These tools emerge from a need to secure corporate networks or improve users’ privacy, but can be used to circumvent censorship or even improve performance. Their deployment also tends to concentrate traffic from many users onto a small set of exit IPs. Typically, individuals are aware they are using such a service, whether for personal use or as part of a corporate network.
Separately, another form of large-scale IP sharing often goes unnoticed by users: Carrier-Grade NAT (CGNAT). One way to explain CGNAT is to start with a much smaller version of network address translation (NAT) that very likely exists in your home broadband router, formally called a Customer Premises Equipment (or CPE), which translates unseen private addresses in the home to visible and routable addresses in the ISP. Once traffic leaves the home, an ISP may add an additional enterprise-level address translation that causes many households or unrelated devices to appear behind a single IP address.
The crucial difference between large-scale IP sharing is user choice: carrier-grade address sharing is not a user choice, but is configured directly by Internet Service Providers (ISPs) within their access networks. Users are not aware that CGNATs are in use.
The primary driver for this technology, understandably, is the exhaustion of the IPv4 address space. IPv4’s 32-bit architecture supports only 4.3 billion unique addresses — a capacity that, while once seemingly vast, has been completely outpaced by the Internet’s explosive growth. By the early 2010s, Regional Internet Registries (RIRs) had depleted their pools of unallocated IPv4 addresses. This left ISPs unable to easily acquire new address blocks, forcing them to maximize the use of their existing allocations.
While the long-term solution is the transition to IPv6, CGNAT emerged as the immediate, practical workaround. Instead of assigning a unique public IP address to each customer, ISPs use CGNAT to place multiple subscribers behind a single, shared IP address. This practice solves the problem of IP address scarcity. Since translated addresses are not publicly routable, CGNATs have also had the positive side effect of protecting many home devices that might be vulnerable to compromise.
CGNATs also create significant operational fallout stemming from the fact that hundreds or even thousands of clients can appear to originate from a single IP address. This means an IP-based security system may inadvertently block or throttle large groups of users as a result of a single user behind the CGNAT engaging in malicious activity.
This isn’t a new or niche issue. It has been recognized for years by the Internet Engineering Task Force (IETF), the organization that develops the core technical standards for the Internet. These standards, known as Requests for Comments (RFCs), act as the official blueprints for how the Internet should operate. RFC 6269, for example, discusses the challenges of IP address sharing, while RFC 7021 examines the impact of CGNAT on network applications. Both explain that traditional abuse-mitigation techniques, such as blocklisting or rate-limiting, assume a one-to-one relationship between IP addresses and users: when malicious activity is detected, the offending IP address can be blocked to prevent further abuse.
In shared IPv4 environments, such as those using CGNAT or other address-sharing techniques, this assumption breaks down because multiple subscribers can appear under the same public IP. Blocking the shared IP therefore penalizes many innocent users along with the abuser. In 2015 Ofcom, the UK’s telecommunications regulator, reiterated these concerns in a report on the implications of CGNAT where they noted that, “In the event that an IPv4 address is blocked or blacklisted as a source of spam, the impact on a CGNAT would be greater, potentially affecting an entire subscriber base.”
While the hope was that CGNAT was only a temporary solution until the eventual switch to IPv6, as the old proverb says, nothing is more permanent than a temporary solution. While IPv6 deployment continues to lag, CGNAT deployments have become increasingly common, and so do the related problems.
CGNAT detection at Cloudflare
To enable a fairer treatment of users behind CGNAT IPs by security techniques that rely on IP reputation, our goal is to identify large-scale IP sharing. This allows traffic filtering to be better calibrated and collateral damage minimized. Additionally, we want to distinguish CGNAT IPs from other large-scale sharing (LSS) IP technologies, such as VPNs and proxies, because we may need to take different approaches to different kinds of IP-sharing technologies.
To do this, we decided to take advantage of Cloudflare’s extensive view of the active IP clients, and build a supervised learning classifier that would distinguish CGNAT and VPN/proxy IPs from IPs that are allocated to a single subscriber (non-LSS IPs), based on behavioural characteristics. The figure below shows an overview of our supervised classifier:
While our classification approach is straightforward, a significant challenge is the lack of a reliable, comprehensive, and labeled dataset of CGNAT IPs for our training dataset.
Detecting CGNAT using public data sources
Detection begins by building an initial dataset of IPs believed to be associated with CGNAT. Cloudflare has vast HTTP and traffic logs. Unfortunately there is no signal or label in any request to indicate what is or is not a CGNAT.
To build an extensive labelled dataset to train our ML classifier, we employ a combination of network measurement techniques, as described below. We rely on public data sources to help disambiguate an initial set of large-scale shared IP addresses from others in Cloudflare’s logs.
Distributed Traceroutes
The presence of a client behind CGNAT can often be inferred through traceroute analysis. CGNAT requires ISPs to insert a NAT step that typically uses the Shared Address Space (RFC 6598) after the customer premises equipment (CPE). By running a traceroute from the client to its own public IP and examining the hop sequence, the appearance of an address within 100.64.0.0/10 between the first private hop (e.g., 192.168.1.1) and the public IP is a strong indicator of CGNAT.
Traceroute can also reveal multi-level NAT, which CGNAT requires, as shown in the diagram below. If the ISP assigns the CPE a private RFC 1918 address that appears right after the local hop, this indicates at least two NAT layers. While ISPs sometimes use private addresses internally without CGNAT, observing private or shared ranges immediately downstream combined with multiple hops before the public IP strongly suggests CGNAT or equivalent multi-layer NAT.
Although traceroute accuracy depends on router configurations, detecting private and shared IP ranges is a reliable way to identify large-scale IP sharing. We apply this method to distributed traceroutes from over 9,000 RIPE Atlas probes to classify hosts as behind CGNAT, single-layer NAT, or no NAT.
Scraping WHOIS and PTR records
Many operators encode metadata about their IPs in the corresponding reverse DNS pointer (PTR) record that can signal administrative attributes and geographic information. We first query the DNS for PTR records for the full IPv4 space and then filter for a set of known keywords from the responses that indicate a CGNAT deployment. For example, each of the following three records matches a keyword (cgnat, cgn or lsn) used to detect CGNAT address space:
WHOIS and Internet Routing Registry (IRR) records may also contain organizational names, remarks, or allocation details that reveal whether a block is used for CGNAT pools or residential assignments.
Given that both PTR and WHOIS records may be manually maintained and therefore may be stale, we try to sanitize the extracted data by validating the fact that the corresponding ISPs indeed use CGNAT based on customer and market reports.
Collecting VPN and proxy IPs
Compiling a list of VPN and proxy IPs is more straightforward, as we can directly find such IPs in public service directories for anonymizers. We also subscribe to multiple VPN providers, and we collect the IPs allocated to our clients by connecting to a unique HTTP endpoint under our control.
Modeling CGNAT with machine learning
By combining the above techniques, we accumulated a dataset of labeled IPs for more than 200K CGNAT IPs, 180K VPNs & proxies and close to 900K IPs allocated that are not LSS IPs. These were the entry points to modeling with machine learning.
Feature selection
Our hypothesis was that aggregated activity from CGNAT IPs is distinguishable from activity generated from other non-CGNAT IP addresses. Our feature extraction is an evaluation of that hypothesis — since networks do not disclose CGNAT and other uses of IPs, the quality of our inference is strictly dependent on our confidence in the training data. We claim the key discriminator is diversity, not just volume. For example, VM-hosted scanners may generate high numbers of requests, but with low information diversity. Similarly, globally routable CPEs may have individually unique characteristics, but with volumes that are less likely to be caught at lower sampling rates.
In our feature extraction, we parse a 1% sampled HTTP requests log for distinguishing features of IPs compiled in our reference set, and the same features for the corresponding /24 prefix (namely IPs with the same first 24 bits in common). We analyse the features for each of the VPNs, proxies, CGNAT, or non LSS IP. We find that features from the following broad categories are key discriminators for the different types of IPs in our training dataset:
Client-side signals: We analyze the aggregate properties of clients connecting from an IP. A large, diverse user base (like on a CGNAT) naturally presents a much wider statistical variety of client behaviors and connection parameters than a single-tenant server or a small business proxy.
Network and transport-level behaviors: We examine traffic at the network and transport layers. The way a large-scale network appliance (like a CGNAT) manages and routes connections often leaves subtle, measurable artifacts in its traffic patterns, such as in port allocation and observed network timing.
Traffic volume and destination diversity: We also model the volume and “shape” of the traffic. An IP representing thousands of independent users will, on average, generate a higher volume of requests and target a much wider, less correlated set of destinations than an IP representing a single user.
Crucially, to distinguish CGNAT from VPNs and proxies (which is absolutely necessary for calibrated security filtering), we had to aggregate these features at two different scopes: per-IP and per /24 prefixes. CGNAT IPs are typically allocated large blocks of IPs, whereas VPNs IPs are more scattered across different IP prefixes.
Classification results
We compute the above features from HTTP logs over 24-hour intervals to increase data volume and reduce noise due to DHCP IP reallocation. The dataset is split into 70% training and 30% testing sets with disjoint /24 prefixes, and VPN and proxy labels are merged due to their similarity and lower operational importance compared to CGNAT detection.
Then we train a multi-class XGBoost model with class weighting to address imbalance, assigning each IP to the class with the highest predicted probability. XGBoost is well-suited for this task because it efficiently handles large feature sets, offers strong regularization to prevent overfitting, and delivers high accuracy with limited parameter tuning. The classifier achieves 0.98 accuracy, 0.97 weighted F1, and 0.04 log loss. The figure below shows the confusion matrix of the classification.
Our model is accurate for all three labels. The errors observed are mainly misclassifications of VPN/proxy IPs as CGNATs, mostly for VPN/proxy IPs that are within a /24 prefix that is also shared by broadband users outside of the proxy service. We also evaluate the prediction accuracy using k-fold cross validation, which provides a more reliable estimate of performance by training and validating on multiple data splits, reducing variance and overfitting compared to a single train–test split. We select 10 folds and we evaluate the Area Under the ROC Curve (AUC) and the multi-class logloss. We achieve a macro-average AUC of 0.9946 (σ=0.0069) and log loss of 0.0429 (σ=0.0115). Prefix-level features are the most important contributors to classification performance.
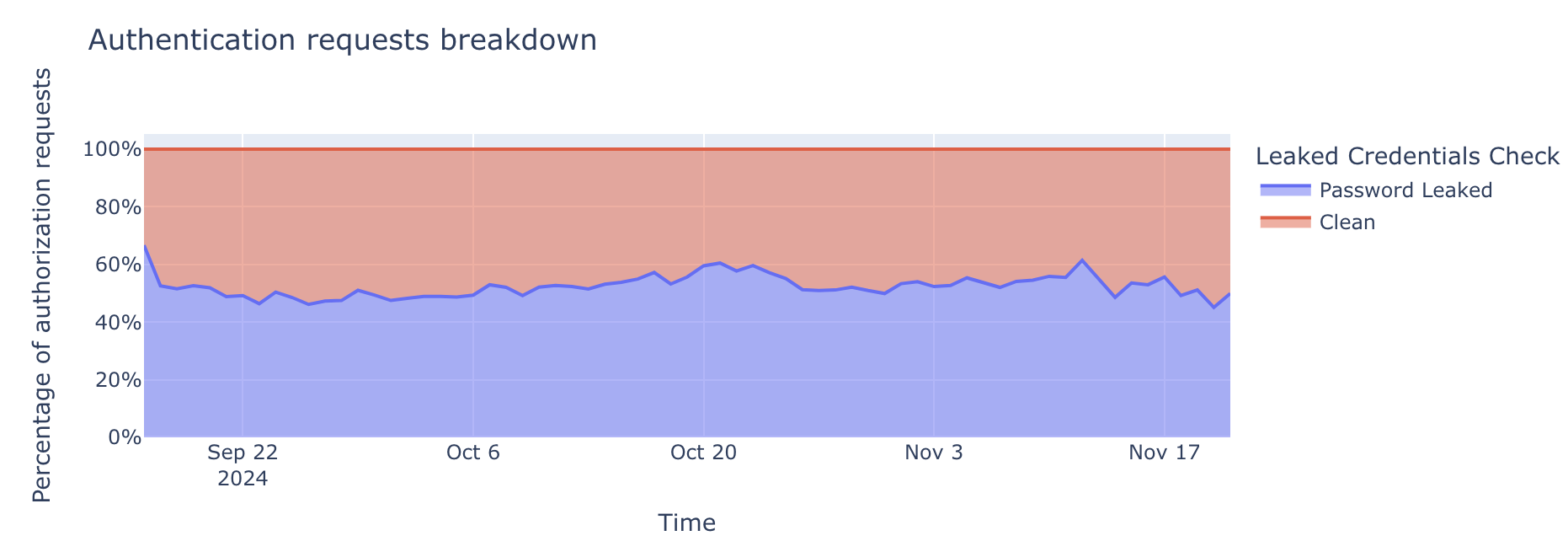
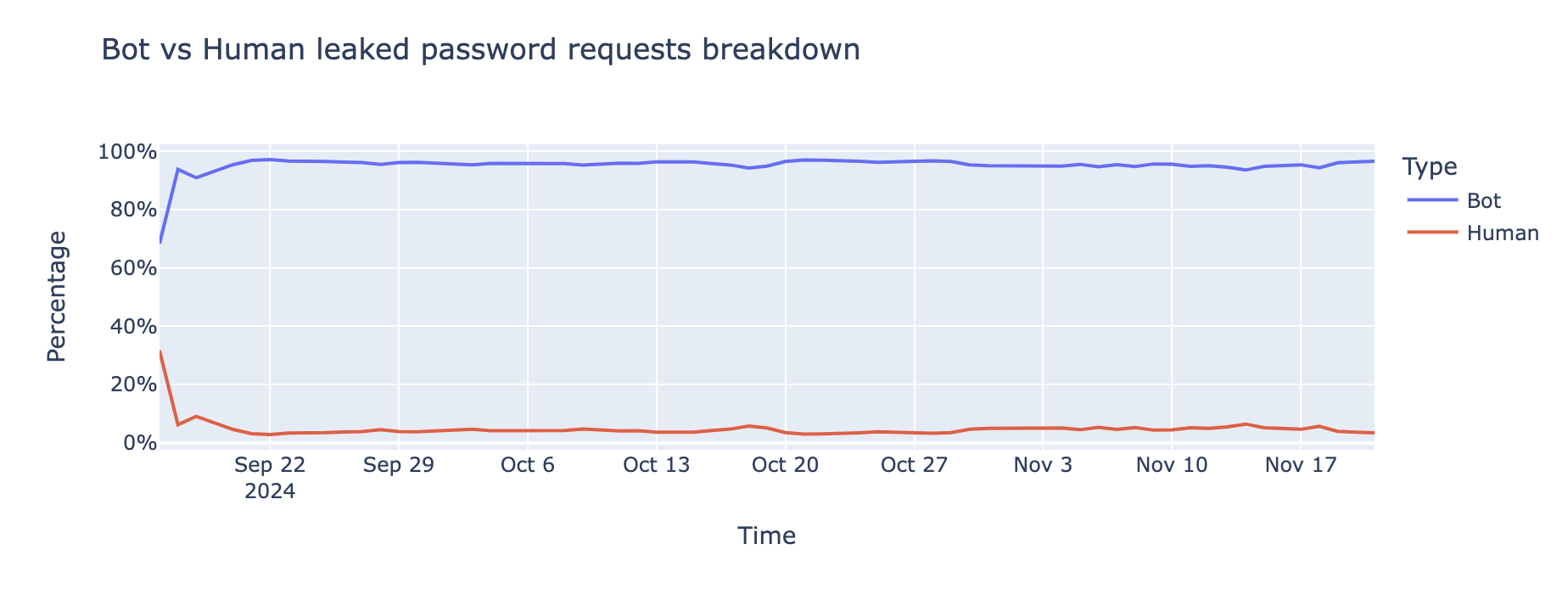
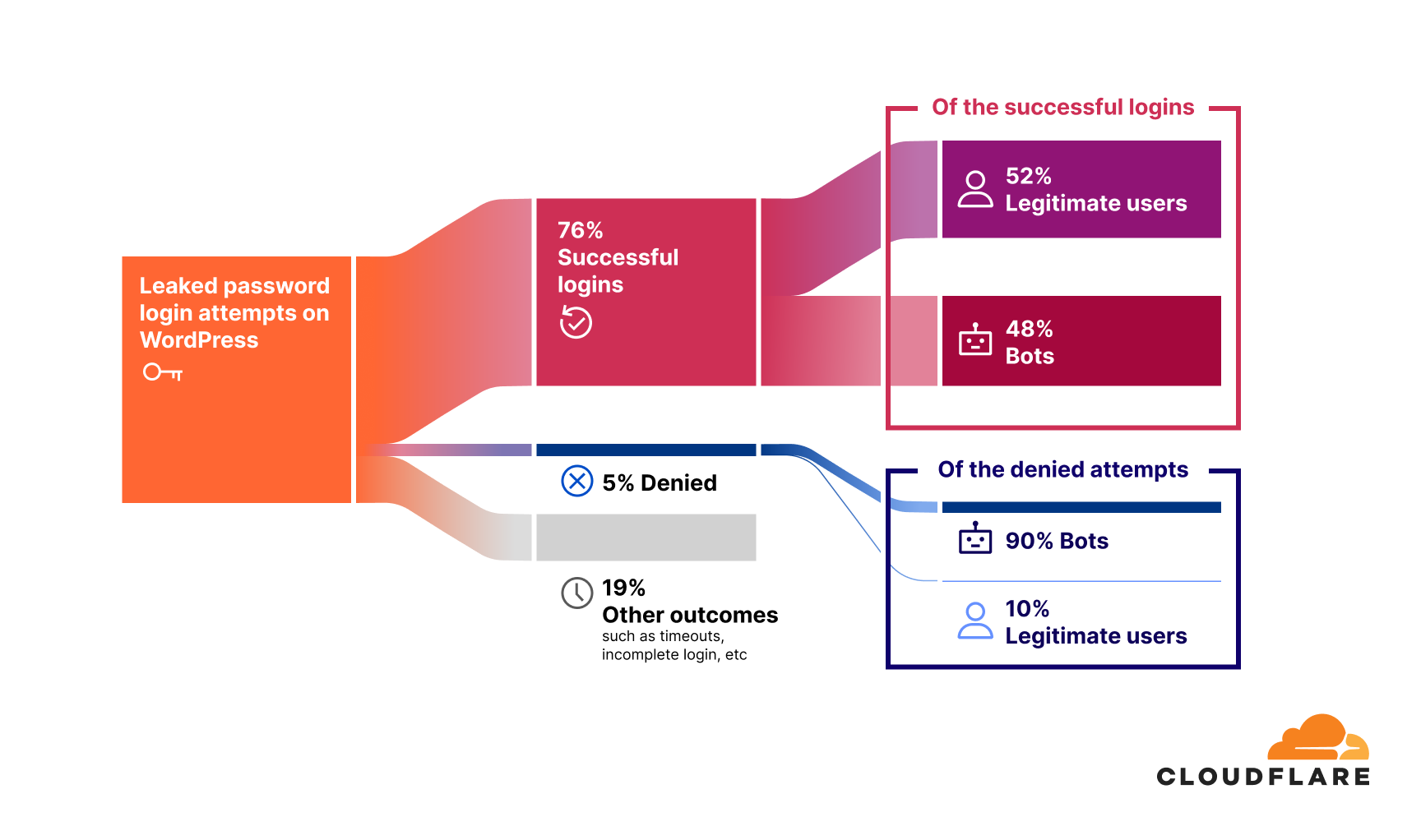
Users behind CGNAT are more likely to be rate limited
The figure below shows the daily number of CGNAT IP inferences generated by our CDN-deployed detection service between December 17, 2024 and January 9, 2025. The number of inferences remains largely stable, with noticeable dips during weekends and holidays such as Christmas and New Year’s Day. This pattern reflects expected seasonal variations, as lower traffic volumes during these periods lead to fewer active IP ranges and reduced request activity.
Next, recall that actions that rely on IP reputation or behaviour may be unduly influenced by CGNATs. One such example is bot detection. In an evaluation of our systems, we find that bot detection is resilient to those biases. However, we also learned that customers are more likely to rate limit IPs that we find are CGNATs.
We analyze bot labels by analyzing how often requests from CGNAT and non-CGNAT IPs are labeled as bots. Cloudflare assigns a bot score to each HTTP request using CatBoost models trained on various request features, and these scores are then exposed through the Web Application Firewall (WAF), allowing customers to apply filtering rules. The median bot rate is nearly identical for CGNAT (4.8%) and non-CGNAT (4.7%) IPs. However, the mean bot rate is notably lower for CGNATs (7%) than for non-CGNATs (13.1%), indicating different underlying distributions. Non-CGNAT IPs show a much wider spread, with some reaching 100% bot rates, while CGNAT IPs cluster mostly below 15%. This suggests that non-CGNAT IPs tend to be dominated by either human or bot activity, whereas CGNAT IPs reflect mixed behavior from many end users, with human traffic prevailing.
Interestingly, despite bot scores that indicate traffic is more likely to be from human users, CGNAT IPs are subject to rate limiting three times more often than non-CGNAT IPs. This is likely because multiple users share the same public IP, increasing the chances that legitimate traffic gets caught by customers’ bot mitigation and firewall rules.
This tells us that users behind CGNAT IPs are indeed susceptible to collateral effects, and identifying those IPs allows us to tune mitigation strategies to disrupt malicious traffic quickly while reducing collateral impact on benign users behind the same address.
A global view of the CGNAT ecosystem
One of the early motivations of this work was to understand if our knowledge about IP addresses might hide a bias along socio-economic boundaries—and in particular if an action on an IP address may disproportionately affect populations in developing nations, often referred to as the Global South. Identifying where different IPs exist is a necessary first step.
The map below shows the fraction of a country’s inferred CGNAT IPs over all IPs observed in the country. Regions with a greater reliance on CGNAT appear darker on the map. This view highlights the geodiversity of CGNATs in terms of importance; for example, much of Africa and Central and Southeast Asia rely on CGNATs.
As further evidence of continental differences, the boxplot below shows the distribution of distinct user agents per IP across /24 prefixes inferred to be part of a CGNAT deployment in each continent.
Notably, Africa has a much higher ratio of user agents to IP addresses than other regions, suggesting more clients share the same IP in African ASNs. So, not only do African ISPs rely more extensively on CGNAT, but the number of clients behind each CGNAT IP is higher.
While the deployment rate of CGNAT per country is consistent with the users-per-IP ratio per country, it is not sufficient by itself to confirm deployment. The scatterplot below shows the number of users (according to APNIC user estimates) and the number of IPs per ASN for ASNs where we detect CGNAT. ASNs that have fewer available IP addresses than their user base appear below the diagonal. Interestingly the scatterplot indicates that many ASNs with more addresses than users still choose to deploy CGNAT. Presumably, these ASNs provide additional services beyond broadband, preventing them from dedicating their entire address pool to subscribers.
What this means for everyday Internet users
Accurate detection of CGNAT IPs is crucial for minimizing collateral effects in network operations and for ensuring fair and effective application of security measures. Our findings underscore the potential socio-economic and geographical variations in the use of CGNATs, revealing significant disparities in how IP addresses are shared across different regions.
At Cloudflare we are going beyond just using these insights to evaluate policies and practices. We are using the detection systems to improve our systems across our application security suite of features, and working with customers to understand how they might use these insights to improve the protections they configure.
Our work is ongoing and we’ll share details as we go. In the meantime, if you’re an ISP or network operator that operates CGNAT and want to help, get in touch at [email protected]. Sharing knowledge and working together helps make better and equitable user experience for subscribers, while preserving web service safety and security.
Cloudflare launched fifteen years ago with a mission to help build a better Internet. Over that time the Internet has changed and so has what it needs from teams like ours. In this year’s Founder’s Letter, Matthew and Michelle discussed the role we have played in the evolution of the Internet, from helping encryption grow from 10% to 95% of Internet traffic to more recent challenges like how people consume content.
This year’s themes focused on helping prepare the Internet for a new model of monetization that encourages great content to be published, fostering more opportunities to build community both inside and outside of Cloudflare, and evergreen missions like making more features available to everyone and constantly improving the speed and security of what we offer.
We shipped a lot of new things this year. In case you missed the dozens of blog posts, here is a breakdown of everything we announced during Birthday Week 2025.
To support a diverse and open Internet, we are now sponsoring Ladybird (an independent browser) and Omarchy (an open-source Linux distribution and developer environment).
We are opening our office doors in four major cities (San Francisco, Austin, London, and Lisbon) as free hubs for startups to collaborate and connect with the builder community.
We are removing cost as a barrier for the next generation by giving students with .edu emails 12 months of free access to our paid developer platform features.
We are partnering with Coinbase to create the x402 Foundation, encouraging the adoption of the x402 protocol to allow clients and services to exchange value on the web using a common language
Our Automatic SSL/TLS system has upgraded over 6 million domains to more secure encryption modes by default and will soon automatically enable post-quantum connections.
We made our CSAM Scanning Tool easier to adopt by removing the need to create and provide unique credentials, helping more site owners protect their platforms.
Updates across Workers and beyond for a more powerful developer platform – such as support for larger and more concurrent Container images, support for external models from OpenAI and Anthropic in AI Search (previously AutoRAG), and more.
A deep-dive into how we’ve hardened the Workers runtime with new defense-in-depth security measures, including V8 sandboxes and hardware-assisted memory protection keys.
We announced the Cloudflare Email Service private beta, allowing developers to reliably send and receive transactional emails directly from Cloudflare Workers.
The TCP Connection Time (Trimean) graph shows that we are the fastest TCP connection time in 40% of measured ISPs – and the fastest across the top networks.
We are using our network’s vast performance data to tune congestion control algorithms, improving speeds by an average of 10% for QUIC traffic.
Come build with us!
Helping build a better Internet has always been about more than just technology. Like the announcements about interns or working together in our offices, the community of people behind helping build a better Internet matters to its future. This week, we rolled out our most ambitious set of initiatives ever to support the builders, founders, and students who are creating the future.
For founders and startups, we are thrilled to welcome Cohort #6 to the Workers Launchpad, our accelerator program that gives early-stage companies the resources they need to scale. But we’re not stopping there. We’re opening our doors, literally, by launching new physical hubs for startups in our San Francisco, Austin, London, and Lisbon offices. These spaces will provide access to mentorship, resources, and a community of fellow builders.
We’re also investing in the next generation of talent. We announced free access to the Cloudflare developer platform for all students, giving them the tools to learn and experiment without limits. To provide a path from the classroom to the industry, we also announced our goal to hire 1,111 interns in 2026 — our biggest commitment yet to fostering future tech leaders.
And because a better Internet is for everyone, we’re extending our support to non-profits and public-interest organizations, offering them free access to our production-grade developer tools, so they can focus on their missions.
Whether you’re a founder with a big idea, a student just getting started, or a team working for a cause you believe in, we want to help you succeed.
Until next year
Thank you to our customers, our community, and the millions of developers who trust us to help them build, secure, and accelerate the Internet. Your curiosity and feedback drive our innovation.
It’s been an incredible 15 years. And as always, we’re just getting started!
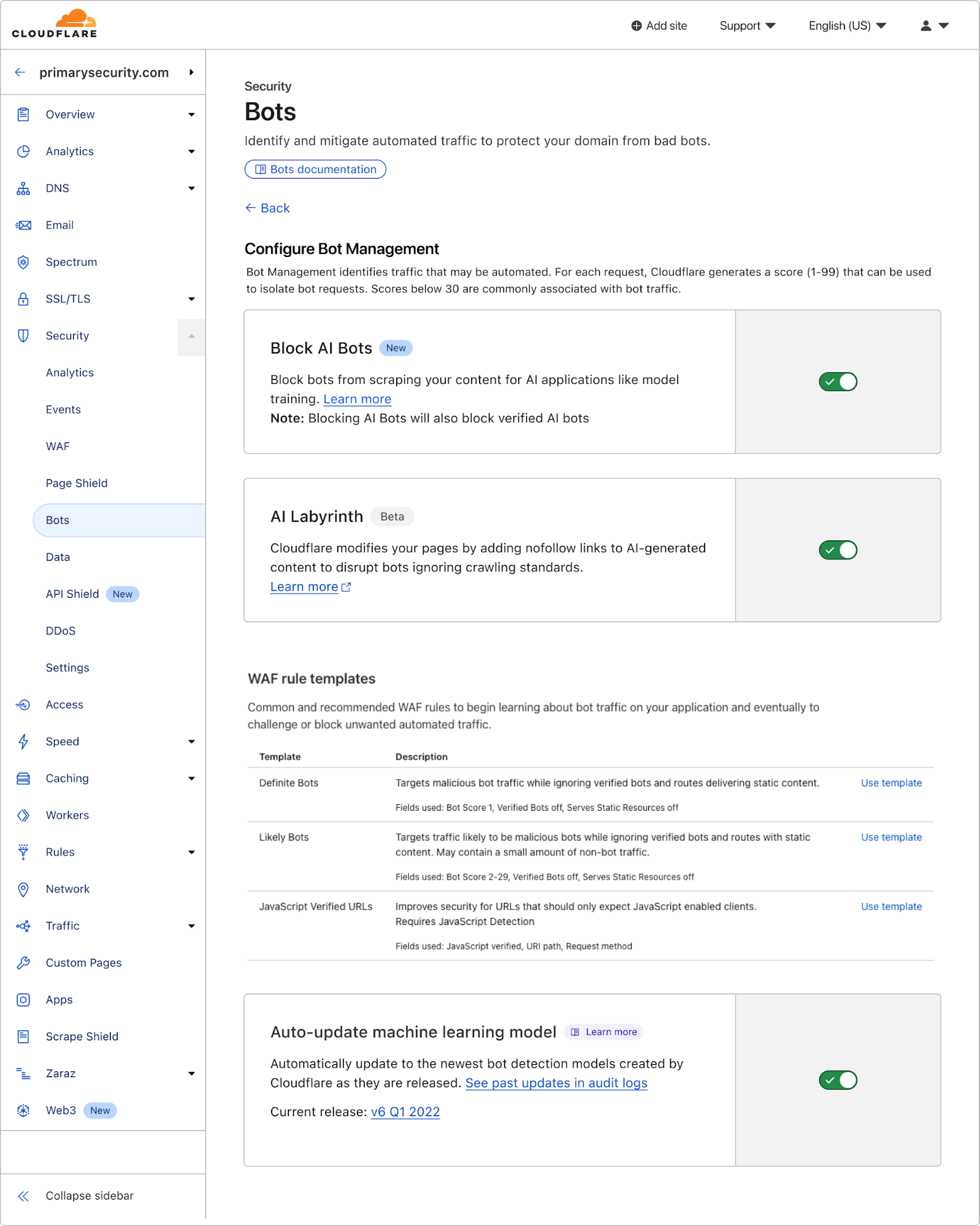
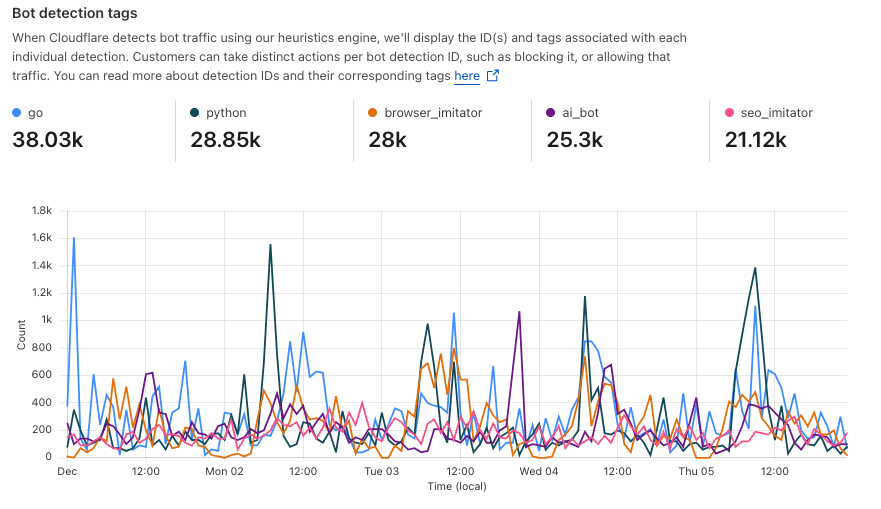
Today, we are announcing a new approach to catching bots: using models to provide behavioral anomaly detection unique to each bot management customer and stop sophisticated bot attacks.
With this per-customer approach, we’re giving every bot management customer hyper-personalized security capabilities to stop even the sneakiest bots. We’re doing this by not only making a first-request judgement call, but also by tracking behavior of bots who play the long-game and continuously execute unwanted behavior on our customers’ websites. We want to share how this service works, and where we’re focused. Our new platform has the power to fuel hundreds of thousands of unique detection suites, and we’ve heard our first target loud and clear from site owners: protect websites from the explosion of sophisticated, AI-driven web scraping.
The new arms race: the rise of AI-driven scraping
The battle against malicious bots used to be a simpler affair. Attackers used scripts that were fairly easy to identify through static, predictable signals: a request with a missing User-Agent header, a malformed method name, or traffic from a non-standard port was a clear indicator of malicious intent. However, the Internet is always evolving. As websites became more dynamic to create rich user experiences, attackers evolved their tools in response. The simple scripts of yesterday were replaced by headless browsers and automation frameworks, capable of rendering pages and mimicking human interaction with far greater fidelity.
AI has made this even trickier. The rise of Generative AI has fundamentally changed the capabilities and the motivations of attackers. The web scraping of today isn’t limited to competitive price intelligence or content aggregation, but driven by the voracious appetite of Large Language Models (LLMs) for training data.
Cloudflare’s data shows this shift in stark terms. In mid-2025, crawling for the purpose of AI model training accounted for nearly 80% of all AI bot activity on our network, a significant increase from the year prior. Modern scraping tools are now AI-powered themselves. They leverage LLMs for semantic understanding of page content, use computer vision to solve visual challenges, and employ reinforcement learning to navigate complex websites they’ve never seen before. The evolution of these bots exposes critical vulnerability in the traditional, one-size-fits-all approach to security. While global threat intelligence is immensely powerful for stopping widespread attacks, these new AI-powered scrapers are designed to blend in. They can rotate IP addresses through residential proxies, generate human-like user agents, and mimic plausible browsing patterns. A request from one of these bots might not look anomalous when compared to the trillions of requests we see across the Cloudflare network, but would appear anomalous when compared to the established patterns of legitimate users on a specific website. This means we need to build defenses against these bots from every angle we have — from the global view to specific behavior on a single application.
Globally scalable bot fingerprinting
To target specific well-known bots or bot actors, we leverage the Cloudflare network to fingerprint bots that we see behave similarly across millions of websites. Since June, Cloudflare’s bot detection security analysts have written 50 heuristics to catch bots using a variety of signals, including but not limited to HTTP/2 fingerprints and Client Hello extensions. By observing traffic on millions of websites, we establish a baseline of legitimate fingerprints of common browsers and benign devices. When a new, unique fingerprint suddenly appears across many different sites, it’s a tell-tale sign of a distributed botnet or a new automation tool, allowing our analysts to block the bot’s signature itself and neutralize the entire campaign, regardless of the thousands of different IP addresses it might use.
Recently, we also introduced detection improvements to tackle residential proxy networks and similar commercial proxies, which are used by attackers to make their bots appear as thousands of distinct real visitors, allowing them to bypass traditional security measures. The superpower of this detection improvement? Combining the vast amount of network data we see with particular client-side fingerprints obtained through the millions of challenge solves that happen across the Internet daily. Challenges have always served as an ideal mitigation action for customers who want to protect their applications without compromising real-user experience, but now they also serve as a gift that keeps on giving: in this case, feeding the Cloudflare threat detection teams a constant stream of client-side information that allows us to pattern match to determine IP addresses that are used by residential proxy networks.
This detection improvement is already ingesting data from the entire Cloudflare network, automatically catching more malicious traffic for all customers using Super Bot Fight Mode (bot protection included for Pro, Business, and all Enterprise customers) and Enterprise Bot Management. Examining 7 days of data from the time of authoring this post, we’ve observed 11 billion requests from millions of unique IP addresses that we’ve identified as connected to residential or commercial proxy networks. This is just one piece of the global detection puzzle; the existing residential proxy detection features in our MLalready catch tens of millions of requests every hour.
Hyper-personalized security: learning what’s normal for you
The new arms race against AI-powered bots necessitates a closer look — something more precise. For instance, a script that systematically scrapes every user profile on a social media site, or every product listing on an e-commerce platform, is exhibiting behavior that is fundamentally abnormal for that application, even if a standalone request appears benign. This realization is at the heart of our new strategy: to win this new arms race, defenses must become as bespoke and adaptive as the attacks they face.
To meet this challenge, we built a new, foundational platform engineered to deploy custom machine learning models for every bot management customer. We’re creating a unique defense for every application. Because each website has different traffic, the traffic that we flag as anomalous will, of course, be different for each zone — for this system, we want to be clear that data from one customer’s zone won’t be used to train the model for another customer’s use.
Announcing this as a new platform capability, rather than a single feature, is a deliberate choice. It aligns with how we’ve approached our most significant innovations, from Cloudflare Workers changing how developers build applications, to AI Gateway creating a single control plane for AI observability and security. By focusing on the platform, we tackle the scraping problems our customers are seeing today and power future detections as bot attacks become increasingly sophisticated.
Our new generation of per-customer anomaly detection is a three-step process, designed to identify malicious behavior by first understanding what constitutes legitimate traffic for each individual website and API.
Step 1: Establishing a dynamic baseline
For each customer zone, our behavioral detections ingest traffic data to build a baseline of normal activity. Rather than taking a static snapshot, our new platform ingests data to make living, continuously updated calculations of what “normal” looks like on a specific website. This approach understands seasonality, recognizes traffic spikes from legitimate marketing campaigns, and maps the typical pathways users take through a site. This approach evolves the concept of Anomaly Detection already present in our Enterprise Bot Management suite, but applies it at a far more granular and dynamic per-customer level.
Step 2: Identifying the anomalies
Once the baseline of “normal” is established, we begin the true work — identifying deviations. Because the baseline is specific to each website, the anomalies detected are highly contextual, perhaps even invisible to a global system. We can examine a few different types of websites to unpack this:
For a gaming company: A normal traffic baseline might show millions of users making frequent, rapid API calls to a matchmaking service or an in-game inventory system. A behavioral detection model trained on this baseline would immediately flag a single user making slow, methodical, sequential API calls to scrape the entire player leaderboard. This behavior, while low in volume, is a clear anomaly against the backdrop of normal gameplay patterns.
For a retail website: The normal baseline is a complex funnel of users browsing categories, viewing products, adding items to a cart, and proceeding to checkout. These detections would identify an actor that systematically visits every single product page in alphabetical order at a machine-like pace, without ever interacting with the cart or session cookies, as a significant anomaly indicative of content scraping.
For a media publisher: Normal user behavior involves reading a few articles, following internal links, and spending a measurable amount of time on each page. An anomaly would be a script that hits thousands of article URLs per minute, spending less than a second on each, purely to extract the text content for AI model training.
In each case, the malicious activity is defined not by a universal signature, but by its deviation from the application’s unique, established norm.
Step 3: Generating actionable findings
Detecting an anomaly is only half the battle. The power of bot management comes from its seamless integration into the Cloudflare security ecosystem you already use, turning detection into immediate, actionable findings. Customers can benefit from these behavioral detection improvements in two ways:
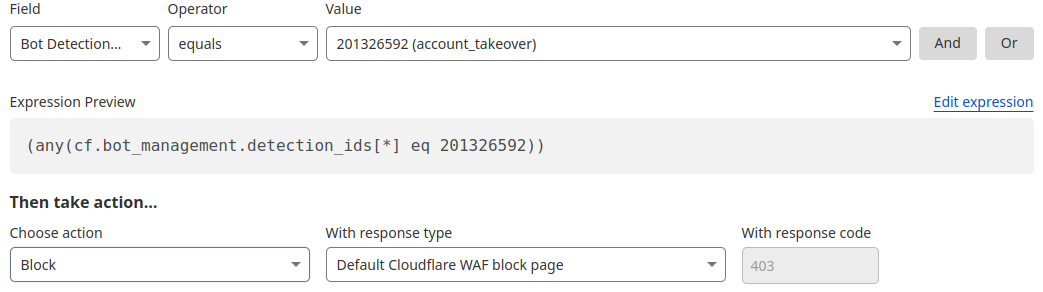
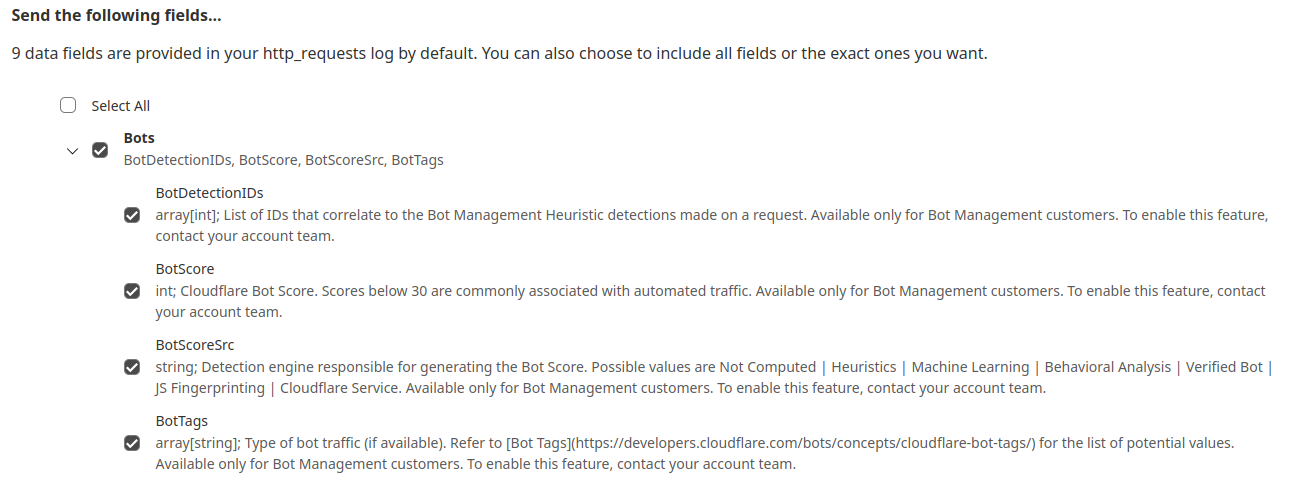
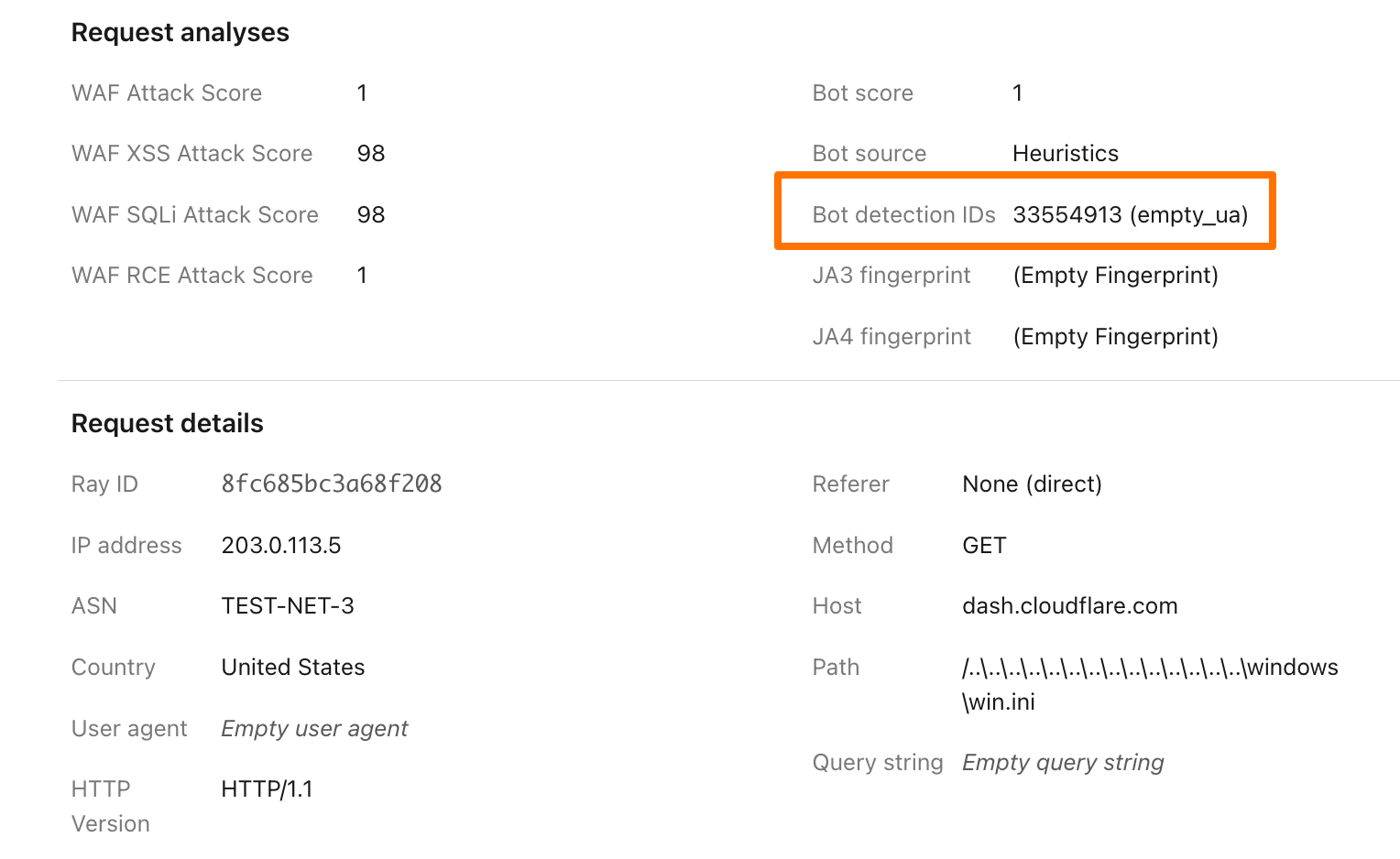
New Bot Detection IDs: For our Enterprise customers, we’re introducing a new set of Bot Detection IDs. Website owners and security teams can write WAF security rules to challenge, rate-limit, or block traffic based on the specific anomalies flagged by these detections. Since each detection type is tied to a unique ID, customers can see exactly what kind of behavior caused a request to be flagged as anomalous, offering a detailed, per-request view into stealthy malicious traffic. And for a wider view, customers can filter by Detection ID from their Security Analytics, to see the bigger picture of all traffic captured by that detection type.
Improving Bot Score: Another key output from these new, per-customer models will be to directly influence the Bot Score of a request. A request flagged as anomalous will have its score lowered, moving it into the “Likely Automated” (scores 2-29) or “Automated” (score 1) categories. This means that existing WAF custom rules based on Bot Score will automatically see impact and become more effective against bespoke attacks, with no changes required. This functionality update is available today for our latest account takeover detection, residential proxy detections and our recent enhancements, and will be implemented in the future for our behavioral scraping detection.
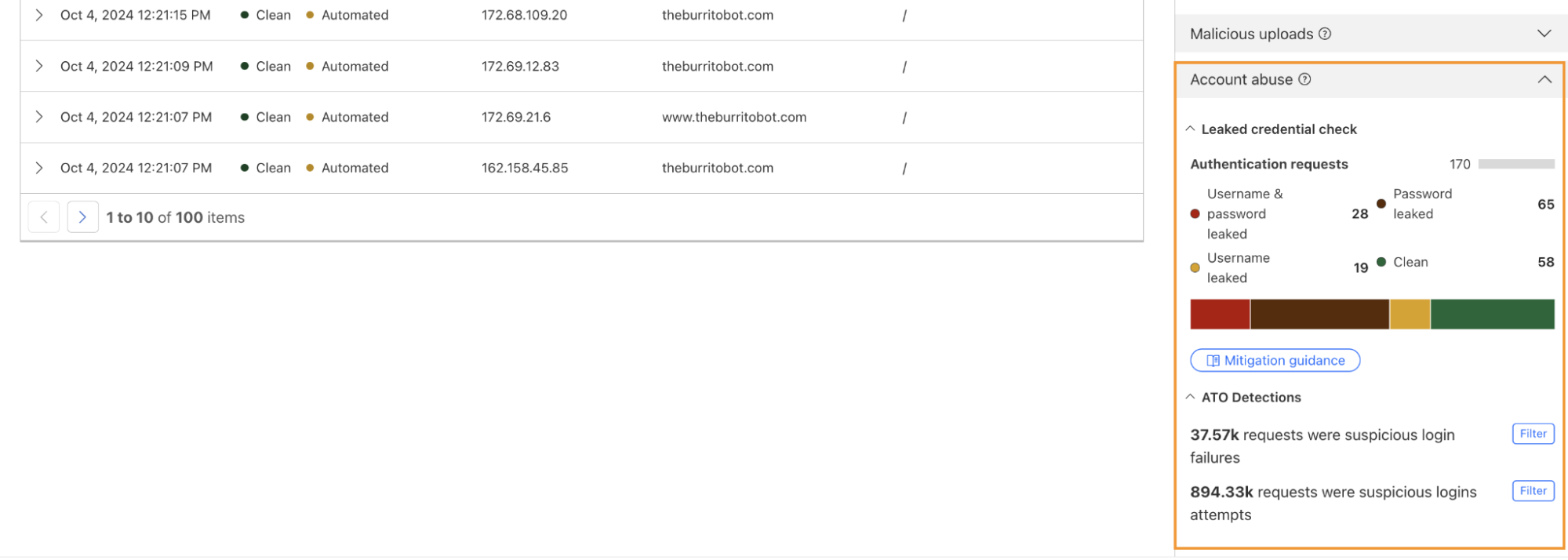
This three-step process is already in action with our behavioral detections to catch account takeover attacks. Taking bot detection ID 201326598 as an example: it (1) establishes a zone-level baseline that understands what normal traffic patterns look like for a specific website, (2) examines anomalous login failures to identify brute force and credential stuffing attacks, then (3) allows customers to mitigate these attacks by automatically influencing bot score and offering more visibility with the detection ID’s analytics.
This integration strategy creates a flywheel effect: the new intelligence from these improved detections immediately enhances the value of existing products like Super Bot Fight Mode, Bot Management, and the WAF, making the entire Cloudflare platform stronger for you.
Taking on sophisticated scrapers
The first challenge we’re tackling is sophisticated scraping. AI-driven scraping is one of the most pressing and rapidly evolving threats facing website owners today, and its adaptive nature makes it an ideal adversary for a system designed to fight an enemy that constantly changes its tactics.
The first generation of our improved behavioral detections are tuned specifically to detect scraping by analyzing signals that go beyond simple request headers. These include:
Behavioral Analysis: Looking at session traversal paths, the sequence of requests, and interaction (or lack thereof) with dynamic page elements.
Client Fingerprinting: Analyzing subtle signals from the client to identify signs of automation such as JA4 fingerprints in the context of the customer’s specific traffic baseline.
Content-Agnostic Detection: These models do not need to understand the content of a page, only the patterns of how it is being accessed. This makes them highly scalable and efficient, without actually using the unique content on a website to make judgement calls.
How do these scraping detections look, in practice? We validated our logic for detecting scraping with early adopters in a closed beta, in order to receive ground-truth feedback and tune our detections. As with any ideal detection, our goal is to capture as much malicious traffic as possible, without compromising the experience of legitimate website visitors. Looking at just a 24-hour period, our new scraping detections have caught hundreds of millions of requests, flagging 138 million scraping requests on just 5 of our early beta zones.
Naturally, we see an overlap with our existing system of bot scoring, but the numbers here show us concretely that our new method of behavioral detections have a completely new value add: 34% of the requests flagged by our new scraping detections would not have been detected by our existing bot score system, making us all the more eager to use these novel detections to inform the way we score automation.
A birthday gift for the Internet
Our mission to help build a better Internet means that when we develop powerful new defenses, we believe in democratizing access to them. Protecting the entire Internet from new and evolving threats requires raising the baseline of security for everyone.
In that spirit, we’re excited to announce that our enhanced behavioral detections will not only roll out to bot management customers, but will also benefit Cloudflare customers using our global Super Bot Fight Modesystem. For our Enterprise Bot Management customers, we automatically tune our detections based on the exact traffic for each zone. Because these advanced models are trained on your zone’s specific traffic, they detect even the most evasive attacks: from account takeovers to web scraping to other attacks executed through residential proxy networks — and we consider this only the tip of the iceberg of behavioral bot profiling.
The road ahead
Our initial focus on scraping is just the beginning of a new wave of behavioral bot detections. The infrastructure we’ve built is a flexible, powerful foundation for tackling a wide range of malicious behavior on your websites; the same principles of establishing a per-customer baseline and detecting anomalies can be applied to other critical threats that are unique to an application’s logic, such as credential stuffing, inventory hoarding, carding attacks, and API abuse.
We are moving into an era where generic defenses are no longer enough. As threats become more personal, so must the defenses against them, and paving this path of behavioral detections is our latest gift to the Internet. Our first offering of scraping behavioral detections is just around the corner: customers will be able to turn on this new detection from the Security Overview page in their dashboard.
(We’re always looking for enthusiastic humans to help us in our mission against bots! If you’re interested in helping us build a better Internet, check out our open positions.)
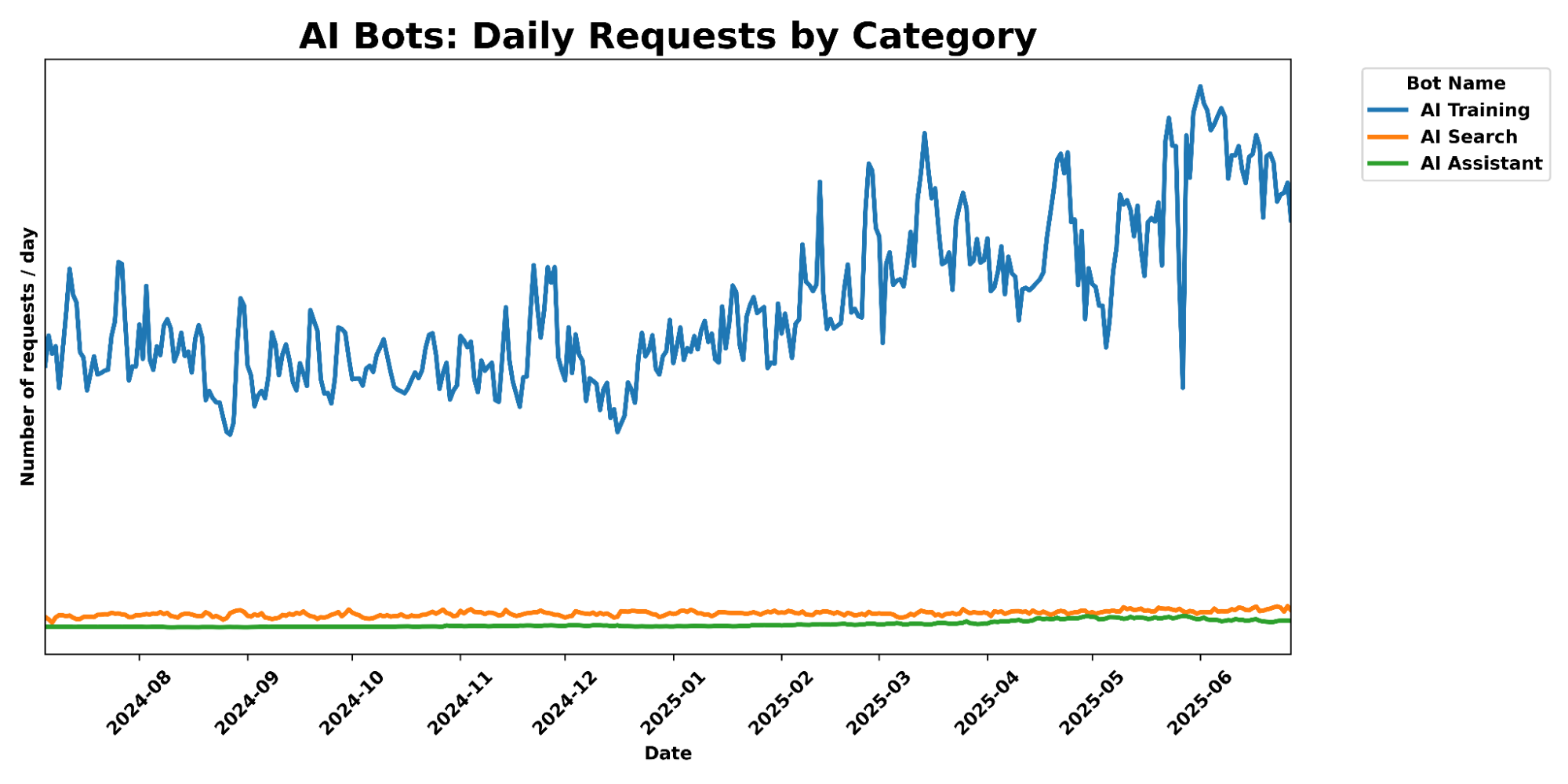
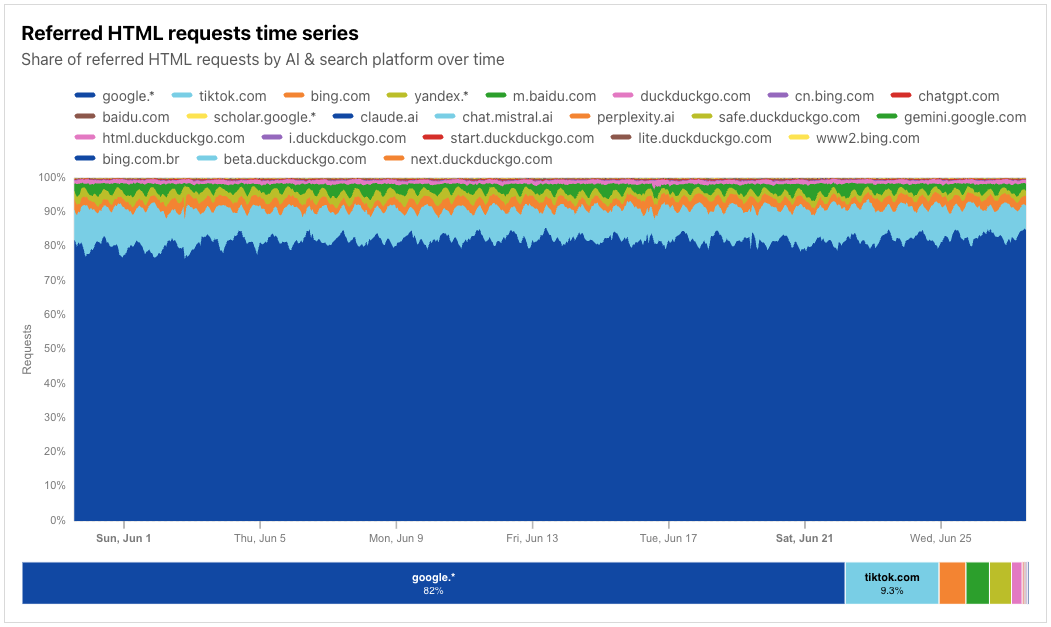
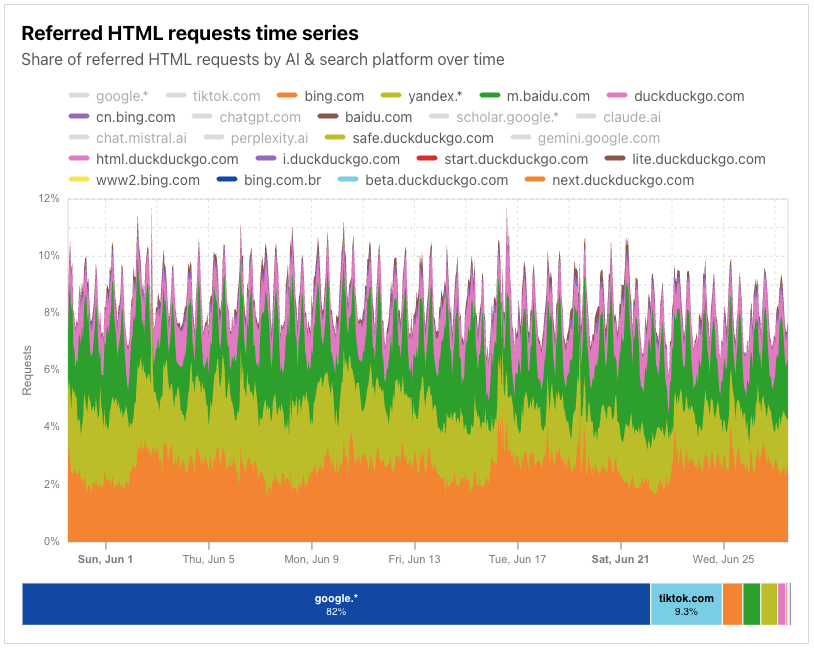
In 2025, Generative AI is reshaping how people and companies use the Internet. Search engines once drove traffic to content creators through links. Now, AI training crawlers — the engines behind commonly-used LLMs — are consuming vast amounts of web data, while sending far fewer users back. We covered this shift, along with related trends and Cloudflare features (like pay per crawl) in early July. Studies from Pew Research Center (1, 2) and Authoritas already point to AI overviews — Google’s new AI-generated summaries shown at the top of search results — contributing to sharp declines in news website traffic. For a news site, this means lots of bot hits, but far fewer real readers clicking through — which in turn means fewer people clicking on ads or chances to convert to subscriptions.
Cloudflare’s data shows the same pattern. Crawling by search engines and AI services surged in the first half of 2025 — up 24% year-over-year in June — before slowing to just 4% year-over-year growth in July. How is the space evolving? Which crawling purposes are most common, and how is that changing? Spoiler: training-related crawling is leading the way. In this post, we track AI and search bot crawl activity, what purposes dominate, and which platforms contribute the least referral traffic back to creators.
Key takeaways
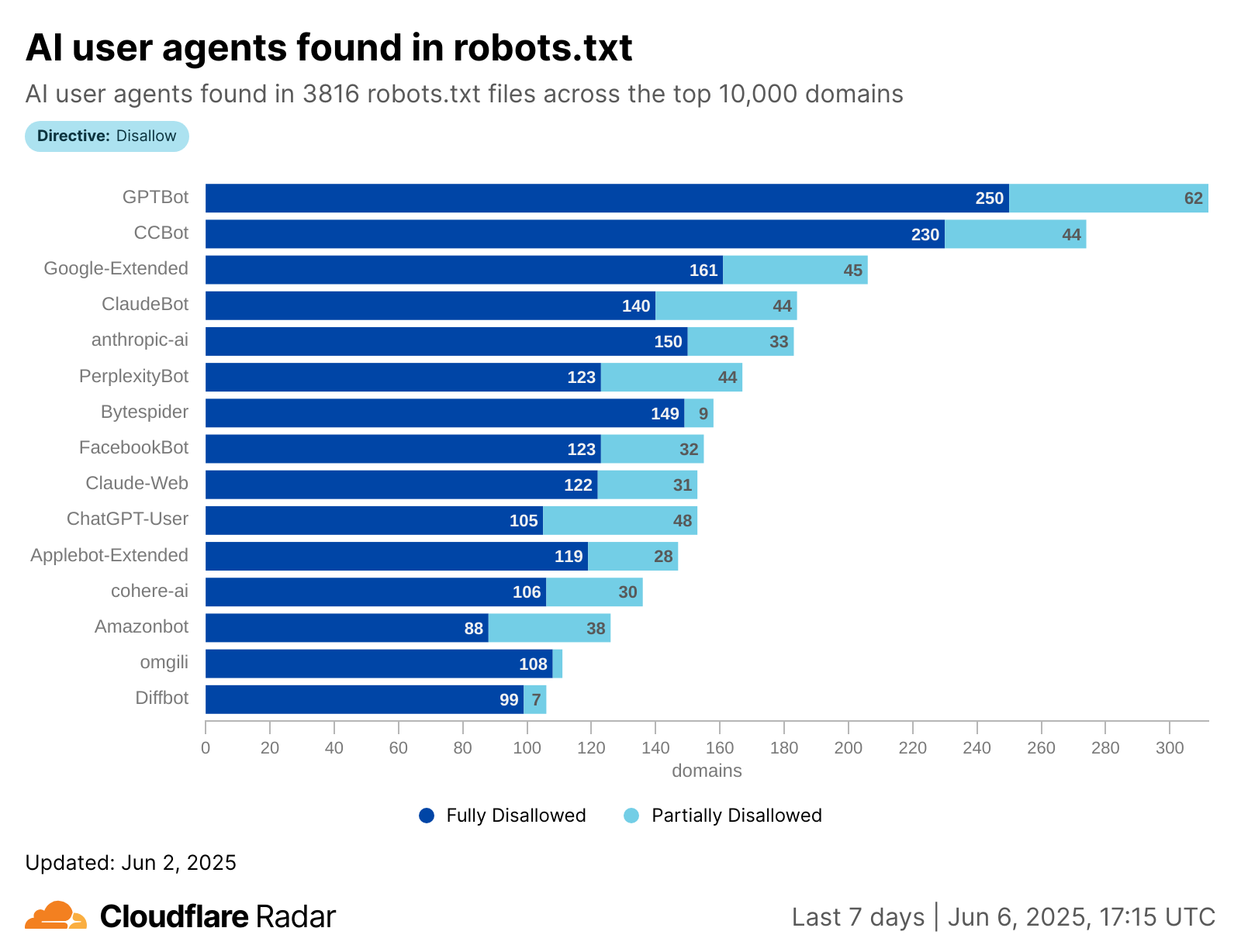
Training crawling grows: Training now drives nearly 80% of AI bot activity, up from 72% a year ago.
Publisher referrals drop: Google referrals to news sites fell, with March 2025 down ~9% compared to January.
AI & search crawling increase: Crawling rose 32% year-over-year in April 2025, before slowing to 4% year-over-year growth in July.
AI-only crawler shifts: OpenAI’s GPTBot more than doubled in share of AI crawling traffic (4.7% to 11.7%), Anthropic’s ClaudeBot rose (6% to ~10%), while ByteDance’s Bytespider fell from 14.1% to 2.4%.
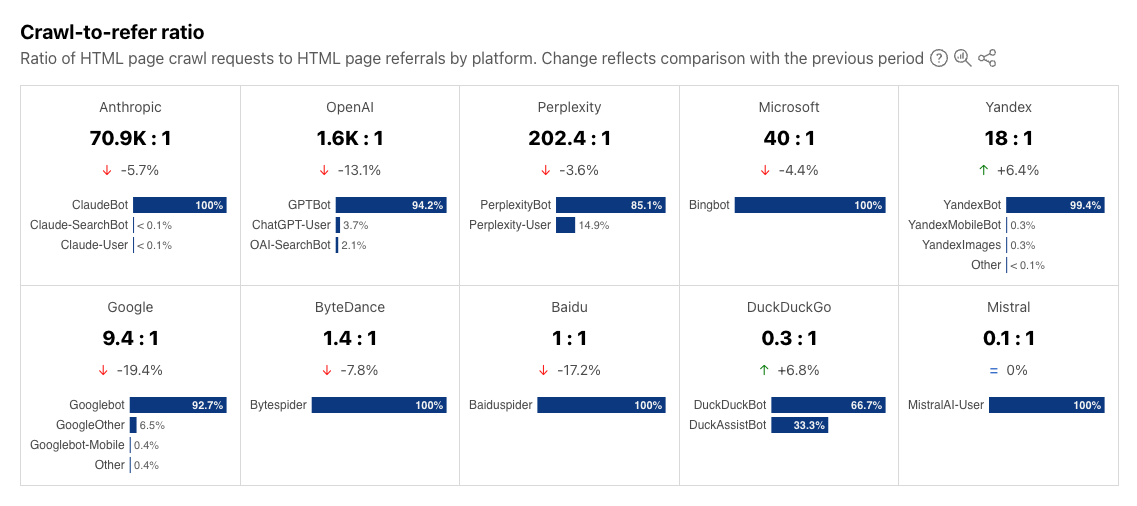
Crawl-to-refer imbalance (how many pages a bot crawls per page that a user clicks back to): Anthropic increased referrals but still leads with 38,000 crawls per visitor in July (down from 286,000:1 in January). Perplexity decreased referrals in 2025 — with more crawling but fewer referrals at 194 crawls per visitor in July.
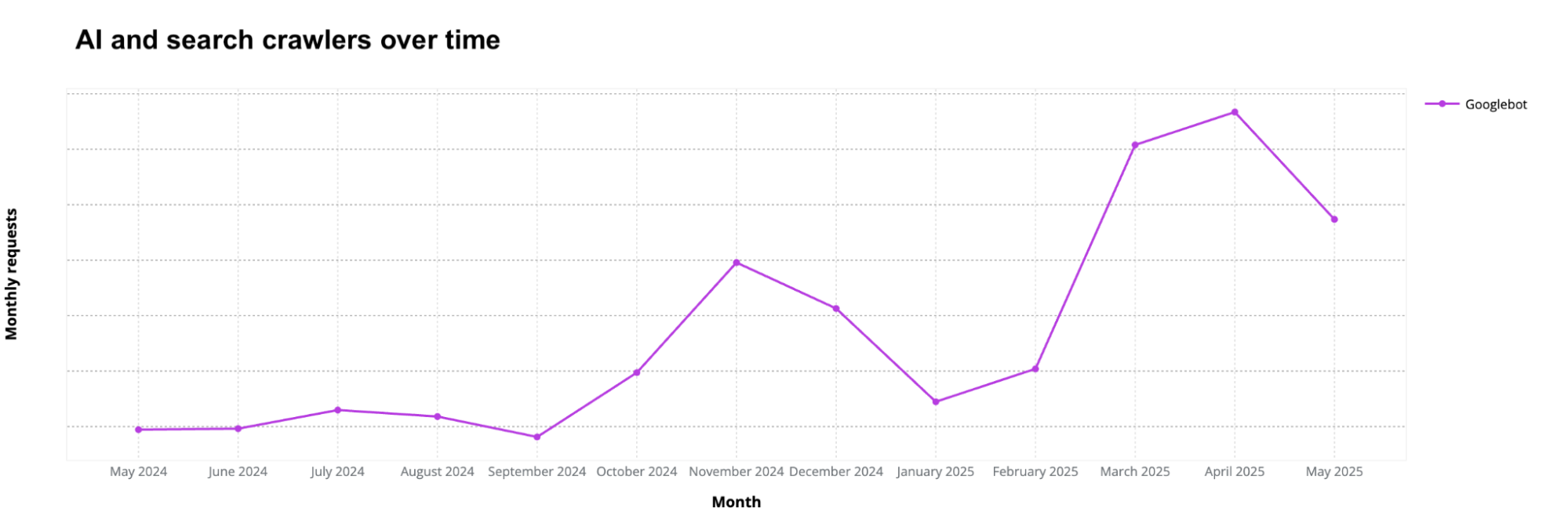
Referral traffic from search is already shifting, as we noted above and as studies have shown. In our dataset of news-related customers (spanning the Americas, Europe, and Asia), Google’s referrals have been clearly declining since February 2025. This drop is unusual, since overall Internet traffic (and referrals as well) historically has only dipped during July and August — the summer months when the Northern Hemisphere is largely on break from school or work. The sharpest and least seasonal decline came in March. Despite being a 31-day month, March had almost the same referral volume as the shorter, 28-day February.
Looking at longer comparisons: March 2025 referral traffic from Google was 9% lower than January, the same drop seen in June. April was worse, down 15% compared with January.
This drop seems to coincide with some of Google’s changes. AI Overviews launched in the U.S. in May 2024, but in March 2025, Google upgraded AI Overviews with Gemini 2.0, introduced AI Mode in Labs, and expanded Overviews to more European countries. By May 2025, AI Mode rolled out broadly in the U.S. with Gemini 2.5, adding conversational search, Deep Search, and personalized recommendations.
The search-to-news site pipeline seems to be weakening, replaced in part by AI-driven results.
Looking at a daily perspective, we can also spot a clear U.S.-election-related peak in referrals from Google to the cohort of known news sites on November 5–6, 2024.
AI and search crawling: spring surge (+24%), summer slowdown
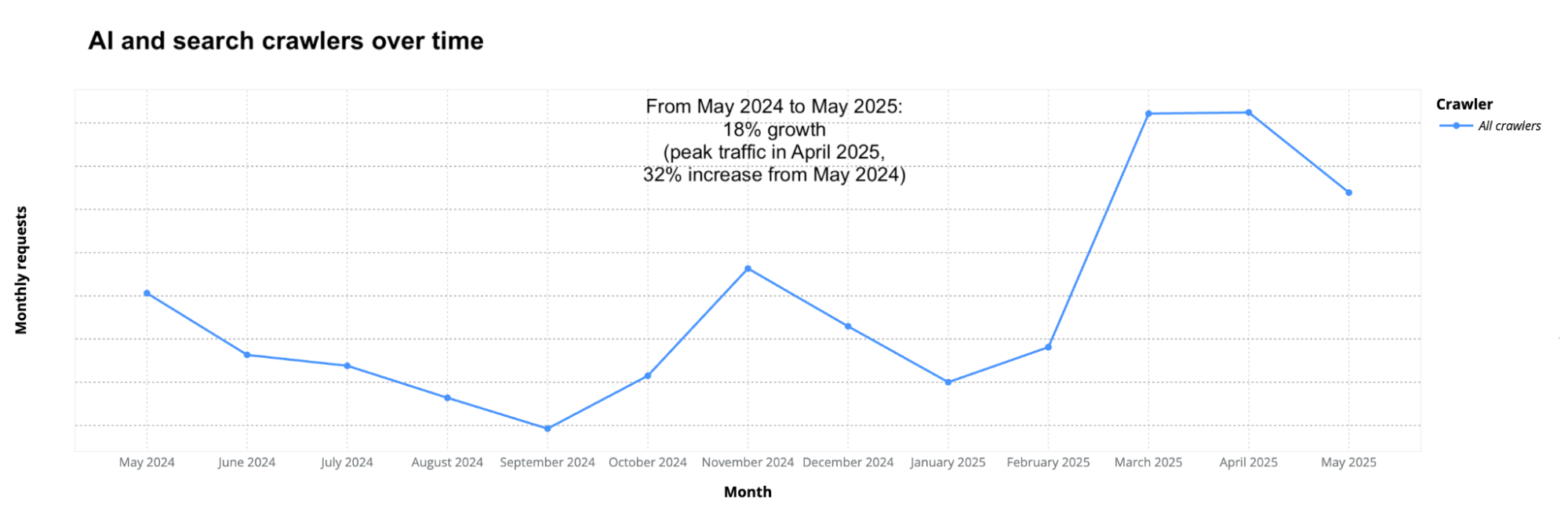
In June, we talked about search and AI crawler growth, and our picture of the trend is now more complete with more data. To focus only on AI and search crawlers, and to remove the bias of customer growth, we analyzed a fixed set of customers from specific weeks, a method we’ve also used in the Cloudflare Radar Year in Review.
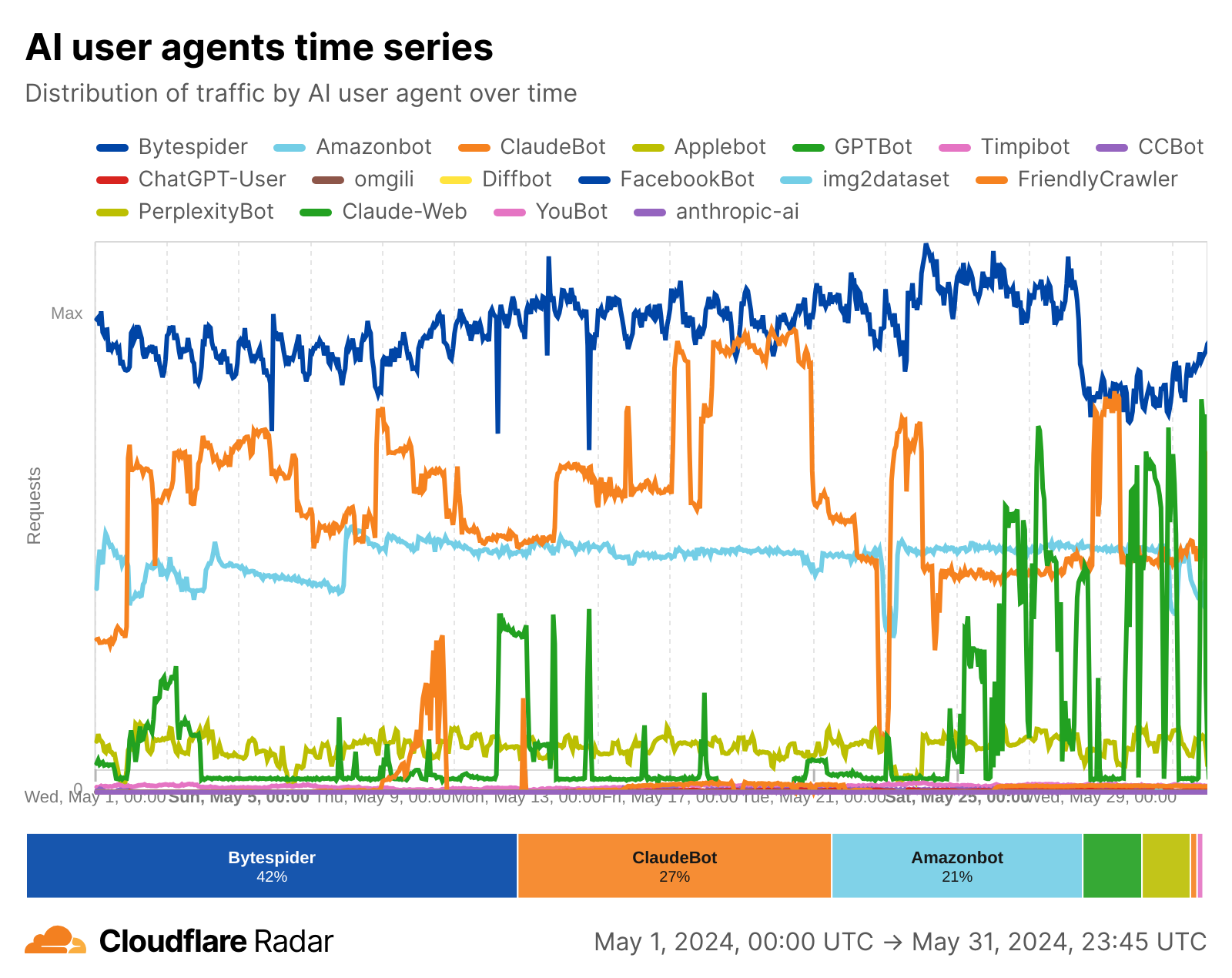
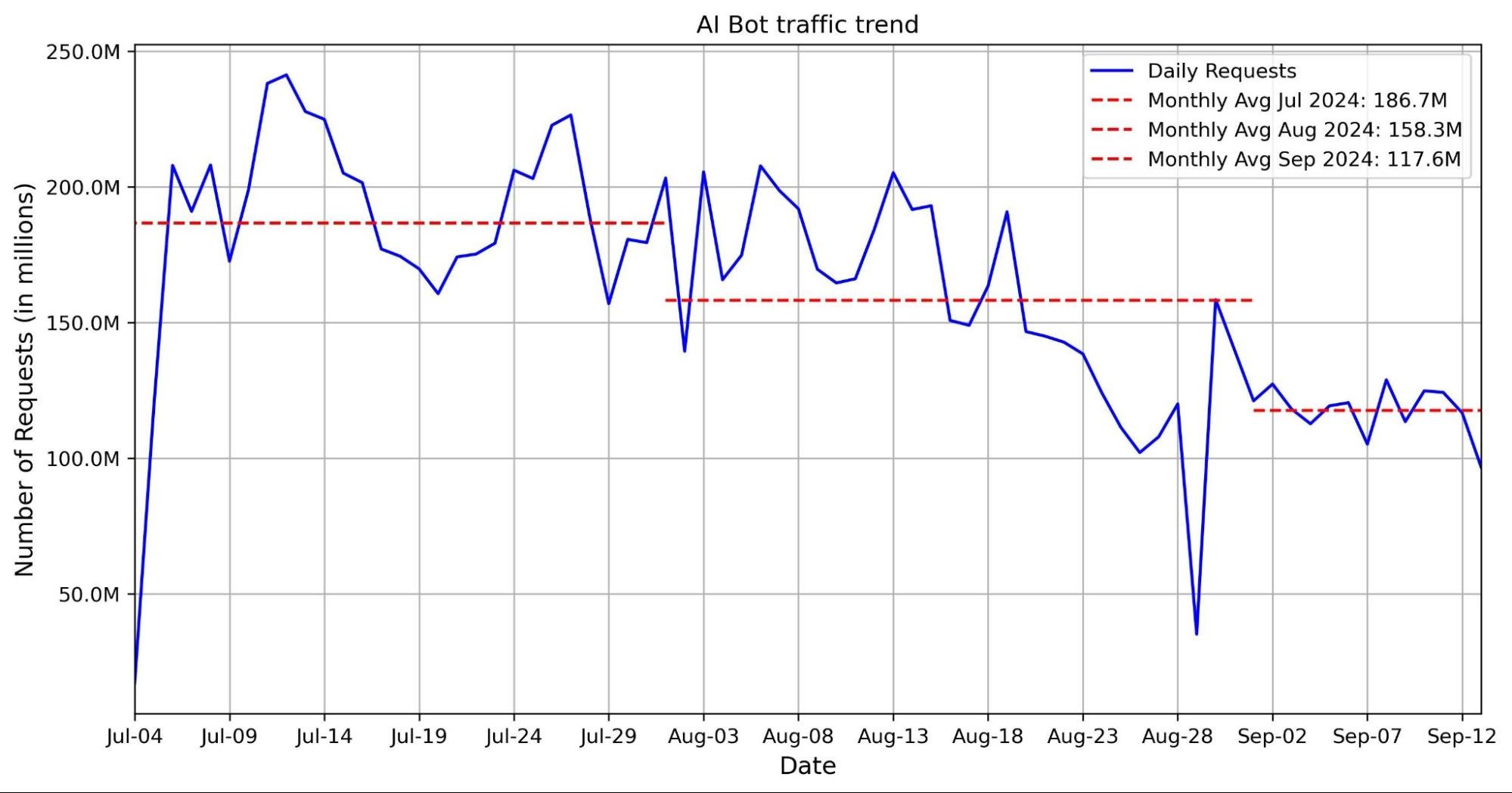
What the data shows: crawling spiked twice: first in November 2024, then again between March and April 2025. April 2025 alone was up 32% compared with May 2024, the first full month where we have comparable data. After that surge, growth stabilized. In June 2025, crawling traffic was still 24% higher year-over-year, but by July the increase was down to just 4%. That shift highlights how quickly crawler activity can accelerate and then cool down.
As the chart below shows, crawling traffic rose sharply in March and April. It remained high but slightly lower in May, before starting to drop in June. The seasonal dip is similar to what we see in overall Internet traffic during the Northern Hemisphere’s summer months (August and September are often the quietest), though in the case of crawlers, this is likely due to reduced overall web activity rather than bots themselves taking a “break.” Historically, activity tends to rise again in November — as it did in 2024 for AI and search bot traffic — when people spend more time online for shopping and seasonal habits (a pattern we’ve seen in past years).
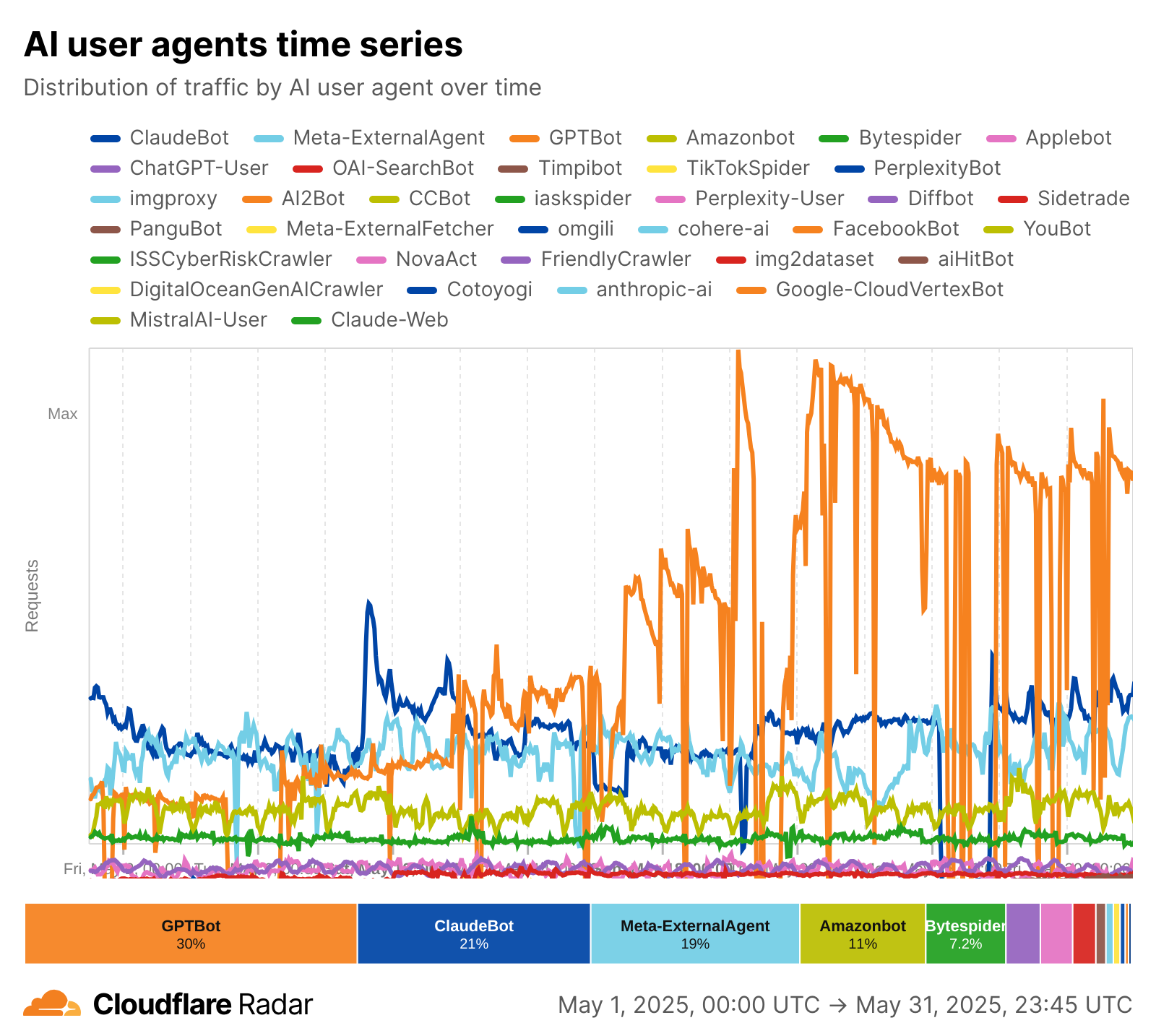
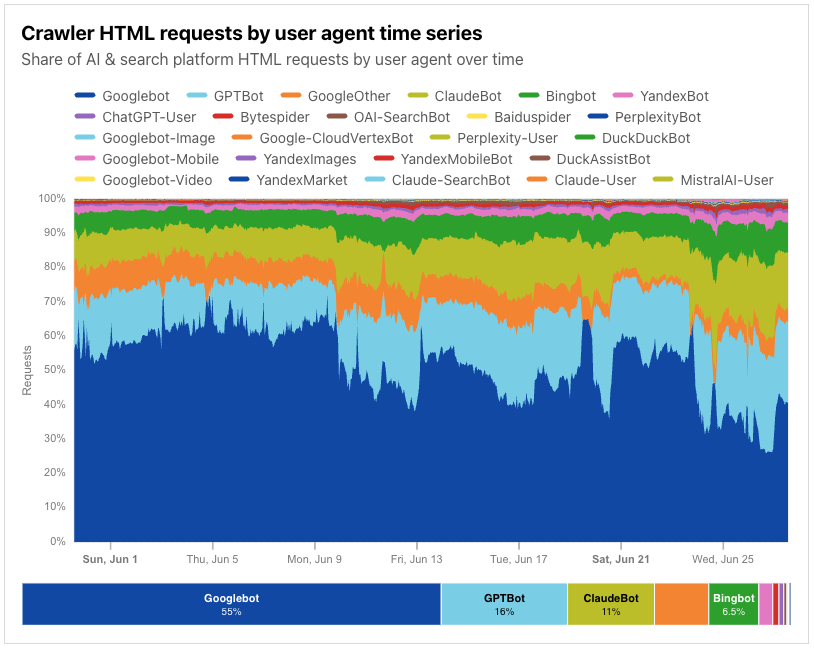
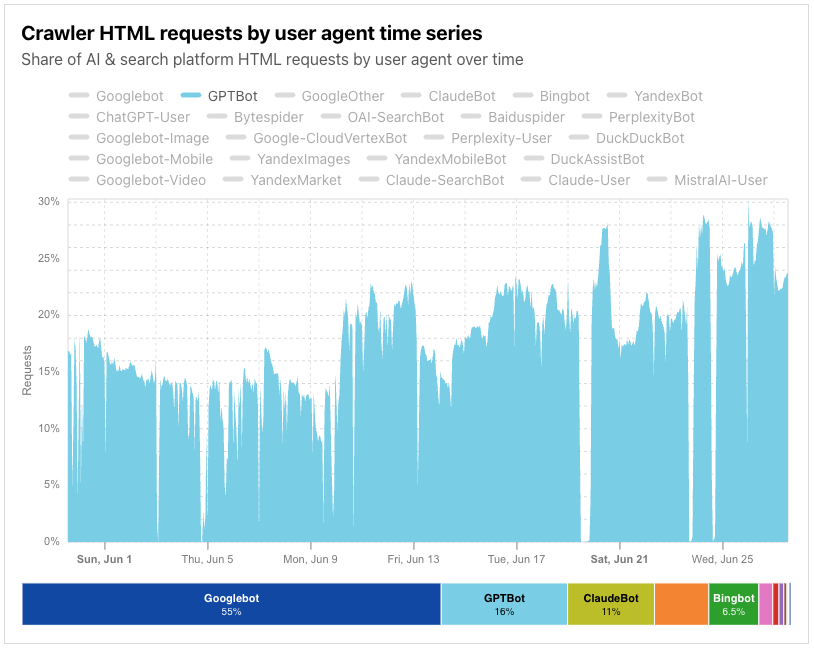
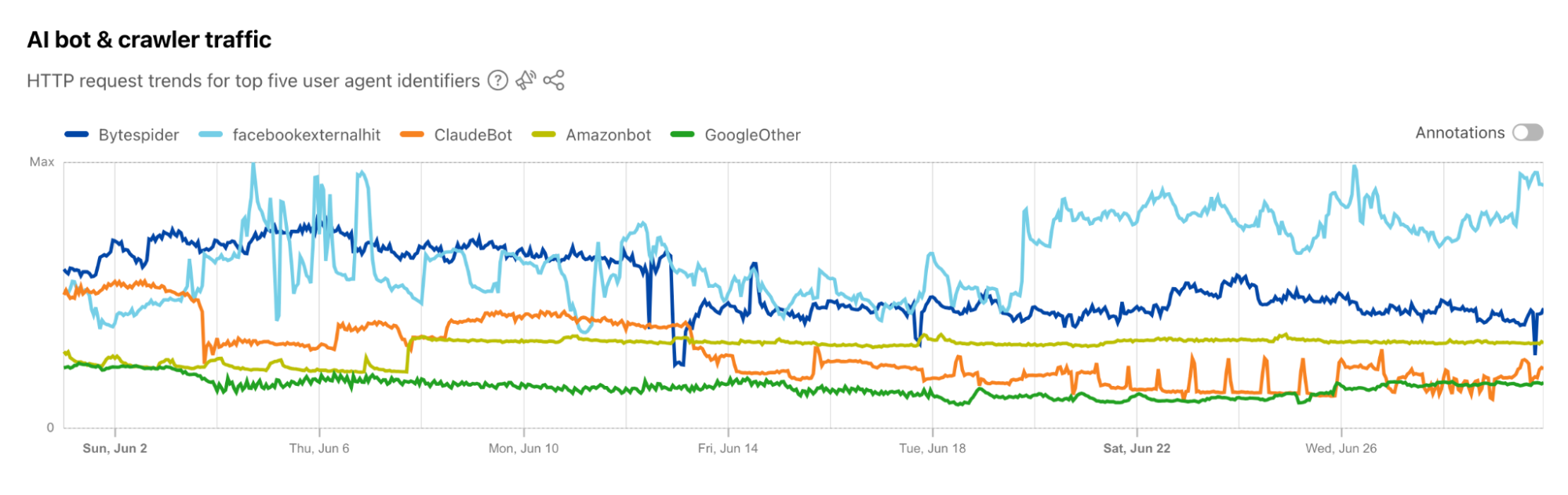
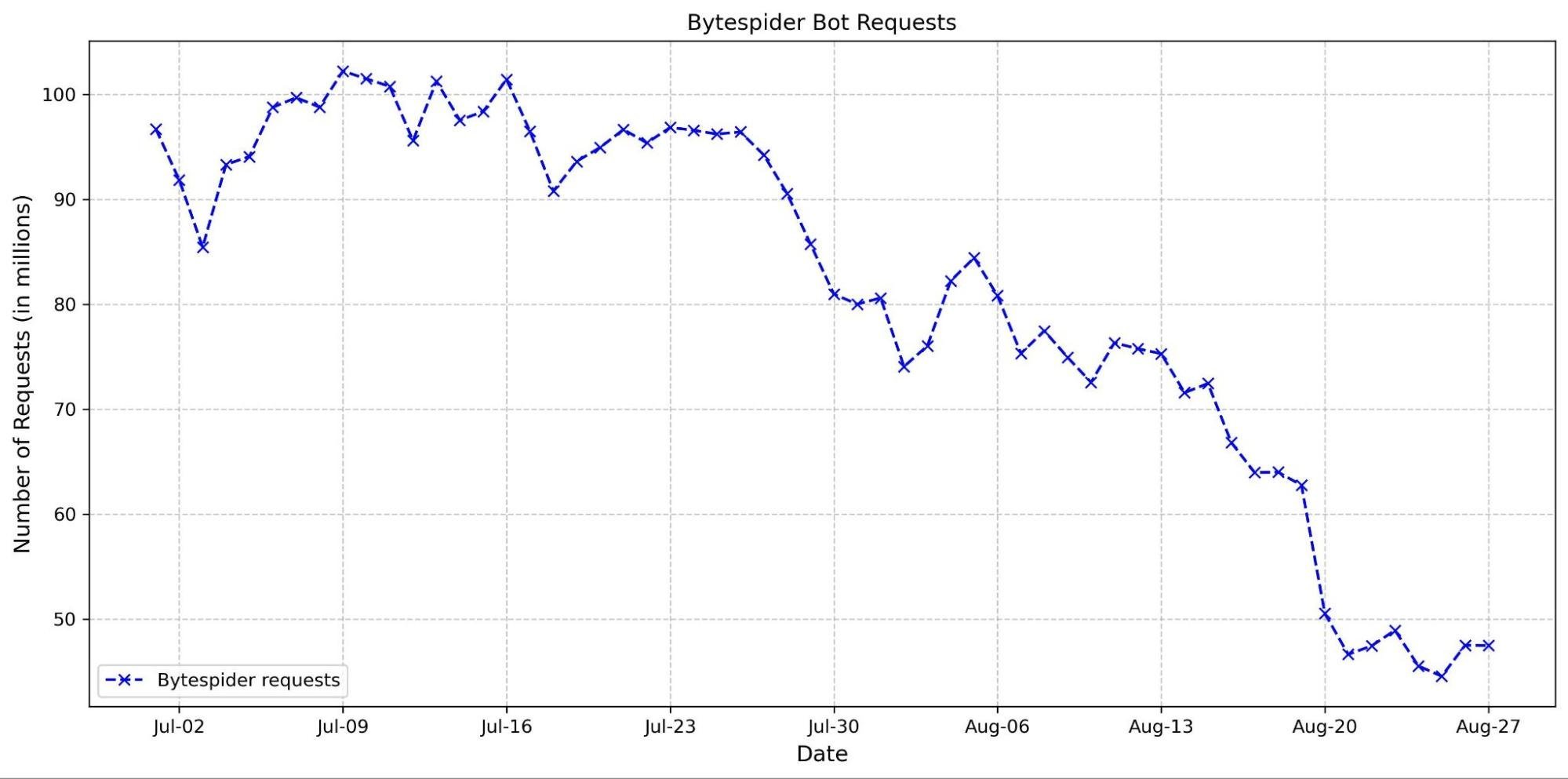
Googlebot is still the anchor, accounting for 39% of all AI and search crawler traffic, but the fastest growth now comes from AI-specific crawlers, though bots related to Amazon and ByteDance (Bytespider) have lost significant ground. GPTBot’s share grew from 4.7% in July 2024 to 11.7% in July 2025. ClaudeBot also increased, from 6% to nearly 10%, while Meta’s crawler jumped from 0.9% to 7.5%. By contrast, Amazonbot dropped from 10.2% to 5.9%, and ByteDance’s Bytespider dropped from 14.1% to just 2.4%.
The table below shows how market shares have shifted between July 2024 and July 2025:
Bot name
% share July 2024
% share July 2025
Δ percentage-point change
1
Googlebot
37.5
39
1.5
2
GPTBot
4.7
11.7
7
3
ClaudeBot
6
9.9
3.9
4
Bingbot
8.7
9.3
0.6
5
Meta-ExternalAgent
0.9
7.5
6.5
6
Amazonbot
10.2
5.9
-4.3
7
Googlebot-Image
4.1
3.3
-0.8
8
Yandex
5
2.9
-2.1
9
GoogleOther
4.6
2.7
-1.8
10
Bytespider
14.1
2.4
-11.6
11
Applebot
1.8
1.5
-0.3
12
ChatGPT-User
0.1
0.9
0.9
13
OAI-SearchBot
0
0.9
0.9
14
Baiduspider
0.5
0.5
0
15
Googlebot-Mobile
0.2
0.4
0.2
AI-only crawlers: OpenAI rises, ByteDance falls
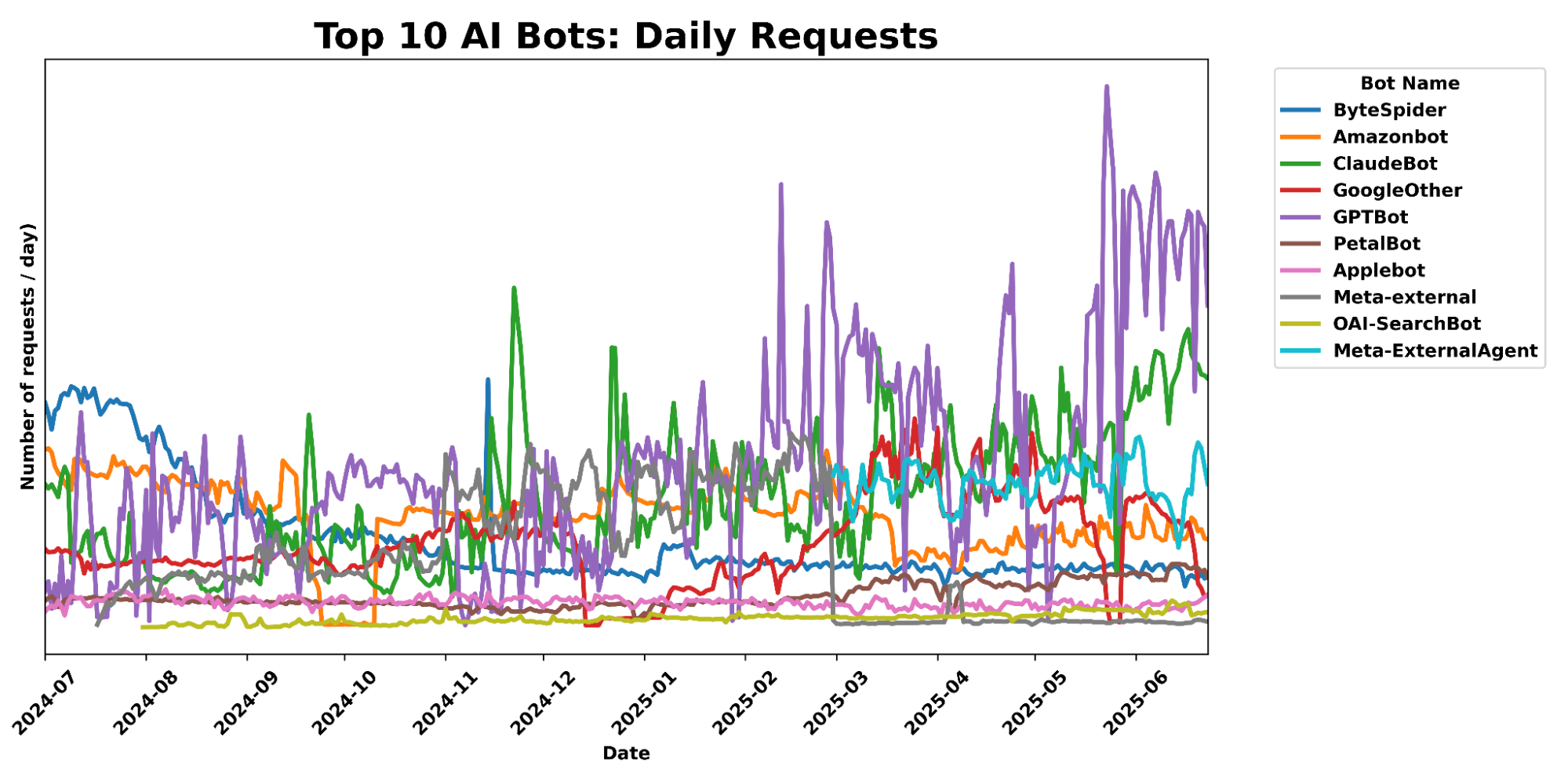
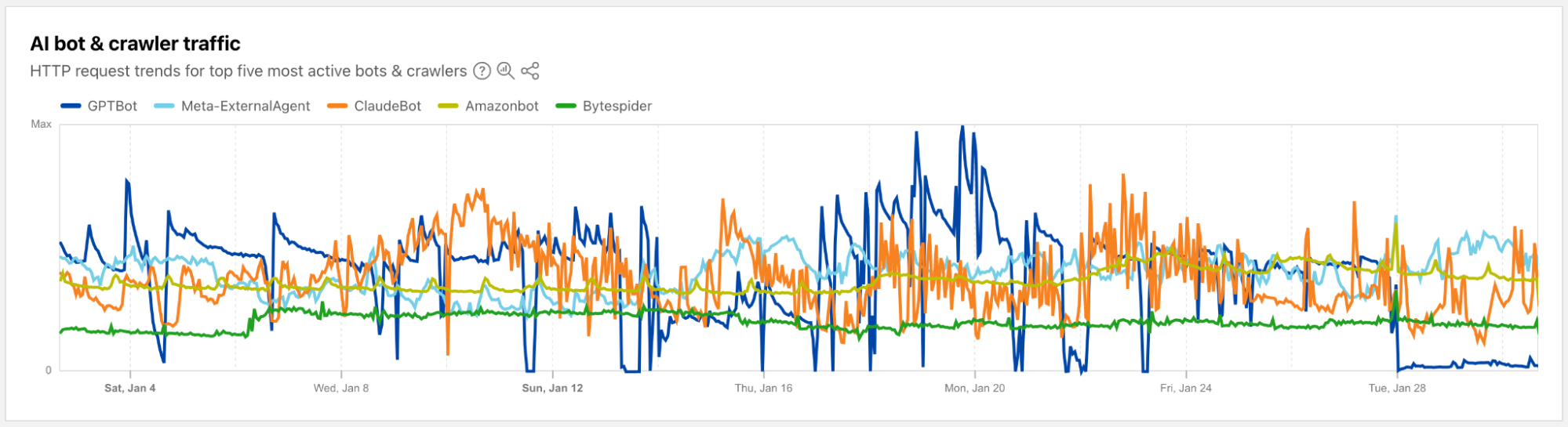
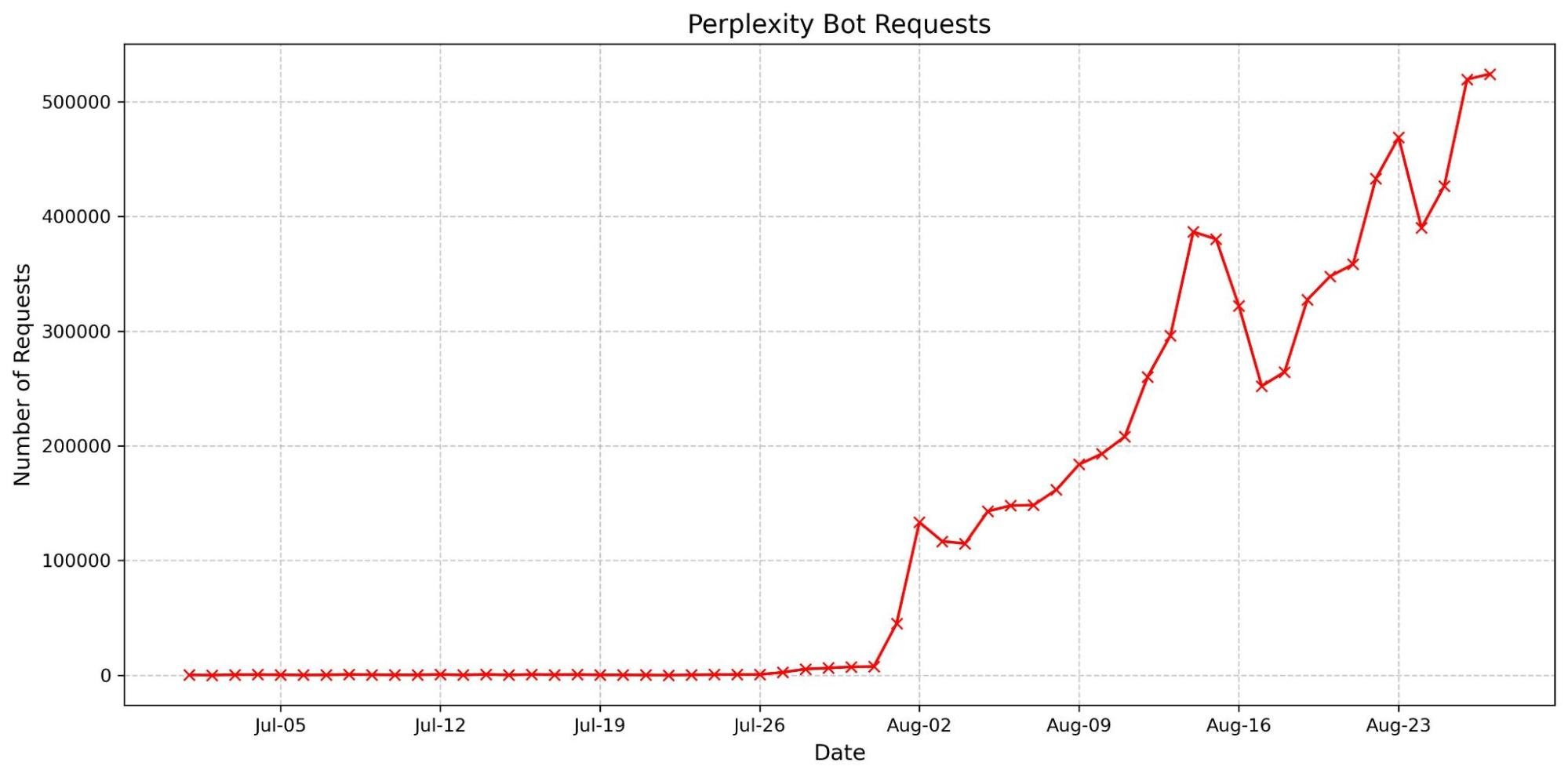
Looking only at AI bot traffic (as tracked on our Radar AI page), the trend is clear. Since January 2025, GPTBot has steadily increased its crawling volume, driven mainly by training-related activity. ClaudeBot crawling accelerated in June, while Amazonbot and Bytespider activity slowed.
The chart below shows how GPTBot surged over the past 12 months, overtaking Amazonbot and Bytespider, which both fell sharply:
A comparison between July 2024 and July 2025 makes the shift even more obvious. GPTBot gained 16 percentage points, Meta’s crawler rose by more than 15, and ClaudeBot grew by 8. On the shrinking side, Amazonbot dropped 12 percentage points and Bytespider dropped over 31 percentage points.
AI-only bots
July 2024 %
July 2025 %
Δ percentage-point change
1
GPTBot
11.9
28.1
16.1
2
ClaudeBot
15
23.3
8.3
3
Meta-ExternalAgent
2.4
17.7
15.3
4
Amazonbot
26.4
14.1
-12.3
5
Bytespider
37.3
5.8
-31.5
6
Applebot
4.9
3.7
-1.2
7
ChatGPT-User
0.2
2.4
2.2
8
OAI-SearchBot
0
2.2
2.2
9
TikTokSpider
0
0.7
0.7
10
imgproxy
0
0.7
0.7
11
PerplexityBot
0
0.4
0.4
12
Google-CloudVertexBot
0
0.3
0.3
13
AI2Bot
0
0.2
0.2
14
Timpibot
0.6
0.1
-0.5
15
CCBot
0.1
0.1
0
We covered the functionality of these bots in our June blog post.
Crawling by purpose: training dominates
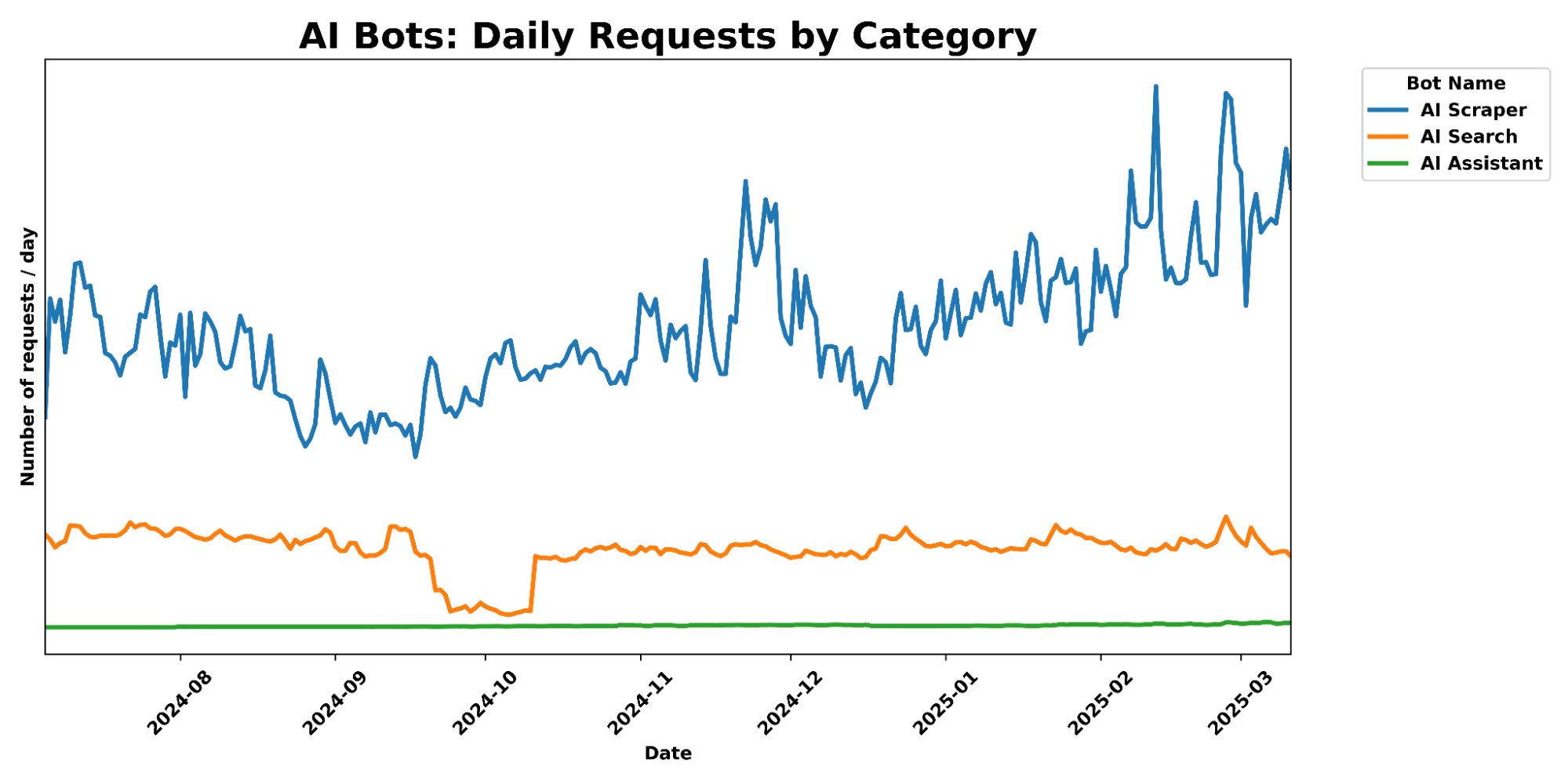
Training is the clear leader. (We classify purpose based on operator disclosures and industry sources, a method we explained in this AI Week blog.) Over the past 12 months, 80% of AI crawling was for training, compared with 18% for search and just 2% for user actions. In the last six months, the share for training rose further to 82%, while search dropped to 15% and user actions increased slightly to 3%.
The chart below shows how training-related crawling steadily grew over the past year, far outpacing other purposes:
The year-over-year comparison reinforces this trend. In July 2024, training accounted for 72% of AI crawling. By July 2025, it had risen to 79%. Over the same period, search fell from 26% to 17%, while user actions grew modestly from 2% to 3.2%.
Crawl-to-refer ratios shifts: tens of thousands of bot crawls per human click
The crawl-to-refer ratio measures how many pages a platform crawls compared with how often it drives users to a website. In practice, a high ratio means heavy crawling but little referral traffic. For example, for every visitor Anthropic refers back to a website, its crawlers have already visited tens of thousands of pages.
Why does this metric matter? It highlights the imbalance between how much content AI systems consume and how little traffic they return. For publishers, it can feel like giving away the raw material for free. With that in mind, here’s how different platforms compare from January to July 2025.
Anthropic remains the most crawl-heavy platform. Even after an 87% decline this year, it still crawled 38,000 pages for every referred page visit in July 2025 — the highest imbalance among major AI players. Referrals may be improving, though, after Anthropic added web search to Claude in March 2025 (initially for U.S. paid users) and expanded it globally by May to all users, including the free tier. The feature introduced direct citations with clickable URLs, creating new referral pathways.
The full dataset is below, showing January–July 2025 ratios by platform ordered by the highest ratio average:
(Note: a rising ratio means more bot crawling per human click sent back, while a falling ratio means less bot crawling per human click sent back)
Anthropic recorded the steepest decrease in bot to human traffic, down 86.7%. From 286,930 bots per human in January, to 38,065 bots per human in July, the change shows a dramatic increase in referrals. Despite the change, it remains by far the most crawl-heavy platform, with tens of thousands of pages still crawled for every referral.
Perplexity moved in the opposite direction, with bot crawling increasing +256.7% relative to human visitors; climbing from 54 bots per human in January to 195 bots per human in July. While the ratio is still far below Anthropic, the increase shows it is crawling more heavily, relative to the traffic it refers, than it did earlier.
OpenAI ratio dropped slightly, from 1,217 bots per human in January to 1,091 in July (-10%). The shift is smaller than Anthropic’s but suggests OpenAI is sending a bit more referral traffic relative to its crawling.
Microsoft stayed steady, with its ratio moving only slightly, from 38.5 bots per human in January to 40.7 in July (+6%). This consistency suggests stable behavior from Bing-linked services.
Yandex increased from 15.5 bots per human in January to 21.4 in July (+38%). The overall ratio is far smaller than Anthropic’s or Perplexity’s, but it shows Yandex is crawling more heavily relative to the traffic it sends back.
Alongside measuring crawling volumes and referral traffic (now also visible on the AI Insights page of Cloudflare Radar), it’s worth looking at whether AI operators follow good practices when deploying their bots. Cloudflare data shows that most leading AI crawlers are on our verified bots list, meaning their IP addresses match published ranges and they respect robots.txt. But adoption of newer standards like WebBotAuth — which uses cryptographic signatures in HTTP messages to confirm a request comes from a specific bot, and is especially relevant today — is still missing.
Google, Meta, and OpenAI run distinct bots for different purposes, while Anthropic lags in verification. That makes it easier for bad actors to spoof its crawler and ignore robots.txt, since without verification, it’s hard to distinguish real from fake traffic — leaving its compliance effectively unclear. (A longer list of AI bots is available here).
Conclusion and what’s next
If training-related crawling continues to dominate while referrals stay flat, creators face a paradox: feeding AI systems without gaining traffic in return. Many want their content to appear in chatbot answers, but without monetization or cooperation, the incentive to produce quality work declines.
The Web now stands at a fork in the road. Either a new balance emerges — one where the new AI era helps sustain publishers and creators — or AI turns the open web into a one-way training set, extracting value with little flowing back.
You can learn more about some of these data trends on Cloudflare Radar’s updated AI Insights page.
Today, we are announcing Cloudflare’s Browser Developer Program, a collaborative initiative to strengthen partnership between Cloudflare and browser development teams.
At Cloudflare, we aim to help build a better Internet. One way we achieve this is by providing website owners with the tools to detect and block unwanted traffic from bots through Cloudflare Challenges or Turnstile. As both bots and our detection systems become more sophisticated, the security checks required to validate human traffic become more complicated. While we aim to strike the right balance, we recognize these security measures can sometimes cause issues for legitimate browsers and their users.
Building a better web together
A core objective of the program is to provide a space for intentional collaboration where we can work directly with browser developers to ensure that both accessibility and security can co-exist. We aim to support the evolving browser landscape, while upholding our responsibility to our customers to deliver the best security products. This program provides a dedicated channel for browser teams to share feedback, report issues, and help ensure that Cloudflare’s Challenges and Turnstile work seamlessly with all browsers.
What the program includes
Browser developers in the program will benefit from:
A two-way communication channel to Cloudflare’s team dedicated to addressing browser-specific concerns, feedback, and issues.
Best practices for building and testing against Cloudflare Challenges and Turnstile.
A private community forum for updates, questions, and discussion between browser developers and Cloudflare engineers.
Early visibility into updates or changes to that may impact how your browser handles Cloudflare Challenges.
(If applicable) Testing integration where we will incorporate your browser into our testing pipeline and monitor its performance with our releases.
This program is designed as a partnership where Cloudflare will, with our best effort, ensure our security products work properly with all browsers, while giving browser developers a voice in how these systems evolve. As an output of this program, we expect to publish clear browser requirements to run Cloudflare Challenges while striking the balance between openness and security.
For end users browsing the web, we continue to support a wide range of browsers. We will continue to update this list based on the insights and collaborations from the Browser Developer Program. We are also committed to ensuring our Challenge interstitial pages and Turnstile provide clear, actionable UI/UX for any error or failed states, making it easier for you to understand and resolve issues you may encounter.
How to apply
If you are working on a browser and want to ensure your users have a seamless experience with Cloudflare-protected websites, we encourage you to apply here.
We’ll ask for basic information about your project and ask you to sign our Browser Developer Program Agreement. In addition, we expect participants to adhere to our Community Code of Conduct and commit to constructive engagement.
Once you’re accepted, you’ll be invited to a private space in the Cloudflare Community where you can engage directly with our team.
Why is this important?
Cloudflare Challenges, a security mechanism to verify whether a visitor is a human or a bot, serve a wide variety of browsers in the world today. Chrome leads with 68.0%, Safari at 8.7%, Firefox at 6.3%, Edge at 4.8%, and Opera at 6.2%. However, the very long tail of browsers that collectively make up the remaining traffic, each representing less than 1% individually but together painting a picture of an incredibly diverse web ecosystem.
Browser traffic distribution, with 100+ browsers comprising the ‘Other’ category
This diversity spans a wide range of environments, each with unique constraints and capabilities:
Emerging and experimental browsers pushing the boundaries of web technology
Privacy-focused browsers such as DuckDuckGo that prioritize user data protection
Embedded browsers inside social media apps like Facebook, Instagram, and TikTok
WebViews used by mobile applications
Gaming and VR browsers such as Oculus for headsets and gaming consoles
Smart device browsers built into classroom displays and home appliances
Supporting this level of diversity poses real engineering challenges. Many of these browsers deviate from standard assumptions. Some lack full support for modern Web APIs, others operate under more stringent data privacy policies, and some are optimized for environments where our script to verify visitors may be hindered or blocked from running properly. These browsers are not bad or malicious. But their behavior may fall outside the typical patterns observed in mainstream browsers, which can lead to problematic or failed Challenge flows which we would like to avoid.
From an engineering perspective, our job is to strike a difficult balance. If our logic is too rigid that it expects only the behaviors of the majority, we risk excluding legitimate users on less conventional platforms. But if we relax our standards too much, we increase the attack surface for abuse. We cannot overfit to the top 5 browsers, nor can we afford to treat all clients as equal in capability or trustworthiness.
The Browser Developer Program is one way to close this gap. By working directly with browser teams, especially those building for niche or emerging environments, we can better understand the constraints they operate under and collaborate to make each of our systems more compatible and resilient.
Join us!
This program is free to join, and is open to any browser developer, no matter the size or the lifecycle stage. Our goal is to listen, learn, and collaborate with browser developers to create a better experience for everyone.
We believe this program will ultimately benefit end users the most. By joining this program, you will help us build solutions that prioritize both the security needs of businesses as well as the diverse ways people access the Internet.
We are observing stealth crawling behavior from Perplexity, an AI-powered answer engine. Although Perplexity initially crawls from their declared user agent, when they are presented with a network block, they appear to obscure their crawling identity in an attempt to circumvent the website’s preferences. We see continued evidence that Perplexity is repeatedly modifying their user agent and changing their source ASNs to hide their crawling activity, as well as ignoring — or sometimes failing to even fetch — robots.txtfiles.
The Internet as we have known it for the past three decades is rapidly changing, but one thing remains constant: it is built on trust. There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences. Based on Perplexity’s observed behavior, which is incompatible with those preferences, we have de-listed them as a verified bot and added heuristics to our managed rules that block this stealth crawling.
How we tested
We received complaints from customers who had both disallowed Perplexity crawling activity in their robots.txt files and also created WAF rules to specifically block both of Perplexity’s declared crawlers: PerplexityBot and Perplexity-User. These customers told us that Perplexity was still able to access their content even when they saw its bots successfully blocked. We confirmed that Perplexity’s crawlers were in fact being blocked on the specific pages in question, and then performed several targeted tests to confirm what exact behavior we could observe.
We created multiple brand-new domains, similar to testexample.com and secretexample.com. These domains were newly purchased and had not yet been indexed by any search engine nor made publicly accessible in any discoverable way. We implemented a robots.txt file with directives to stop any respectful bots from accessing any part of a website:
We conducted an experiment by querying Perplexity AI with questions about these domains, and discovered Perplexity was still providing detailed information regarding the exact content hosted on each of these restricted domains. This response was unexpected, as we had taken all necessary precautions to prevent this data from being retrievable by their crawlers.
Obfuscating behavior observed
Bypassing Robots.txt and undisclosed IPs/User Agents
Our multiple test domains explicitly prohibited all automated access by specifying in robots.txt and had specific WAF rules that blocked crawling from Perplexity’s public crawlers. We observed that Perplexity uses not only their declared user-agent, but also a generic browser intended to impersonate Google Chrome on macOS when their declared crawler was blocked.
Declared
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0; +https://perplexity.ai/perplexity-user)
20-25m daily requests
Stealth
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36
3-6m daily requests
Both their declared and undeclared crawlers were attempting to access the content for scraping contrary to the web crawling norms as outlined in RFC 9309.
This undeclared crawler utilized multiple IPs not listed in Perplexity’s official IP range, and would rotate through these IPs in response to the restrictive robots.txt policy and block from Cloudflare. In addition to rotating IPs, we observed requests coming from different ASNs in attempts to further evade website blocks. This activity was observed across tens of thousands of domains and millions of requests per day. We were able to fingerprint this crawler using a combination of machine learning and network signals.
An example:
Of note: when the stealth crawler was successfully blocked, we observed that Perplexity uses other data sources — including other websites — to try to create an answer. However, these answers were less specific and lacked details from the original content, reflecting the fact that the block had been successful.
How well-meaning bot operators respect website preferences
In contrast to the behavior described above, the Internet has expressed clear preferences on how good crawlers should behave. All well-intentioned crawlers acting in good faith should:
Be transparent. Identify themselves honestly, using a unique user-agent, a declared list of IP ranges or Web Bot Auth integration, and provide contact information if something goes wrong.
Be well-behaved netizens. Don’t flood sites with excessive traffic, scrape sensitive data, or use stealth tactics to try and dodge detection.
Serve a clear purpose. Whether it’s powering a voice assistant, checking product prices, or making a website more accessible, every bot has a reason to be there. The purpose should be clearly and precisely defined and easy for site owners to look up publicly.
Separate bots for separate activities. Perform each activity from a unique bot. This makes it easy for site owners to decide which activities they want to allow. Don’t force site owners to make an all-or-nothing decision.
Follow the rules. That means checking for and respecting website signals like robots.txt, staying within rate limits, and never bypassing security protections.
OpenAI is an example of a leading AI company that follows these best practices. They clearly outline their crawlers and give detailed explanations for each crawler’s purpose. They respect robots.txt and do not try to evade either a robots.txt directive or a network level block. And ChatGPT Agent is signing http requests using the newly proposed open standard Web Bot Auth.
When we ran the same test as outlined above with ChatGPT, we found that ChatGPT-User fetched the robots file and stopped crawling when it was disallowed. We did not observe follow-up crawls from any other user agents or third party bots. When we removed the disallow directive from the robots entry, but presented ChatGPT with a block page, they again stopped crawling, and we saw no additional crawl attempts from other user agents. Both of these demonstrate the appropriate response to website owner preferences.
How can you protect yourself?
All the undeclared crawling activity that we observed from Perplexity’s hidden User Agent was scored by our bot management system as a bot and was unable to pass managed challenges. Any bot management customer who has an existing block rule in place is already protected. Customers who don’t want to block traffic can set up rules to challenge requests, giving real humans an opportunity to proceed. Customers with existing challenge rules are already protected. Lastly, we added signature matches for the stealth crawler into our managed rule that blocks AI crawling activity. This rule is available to all customers, including our free customers.
What’s next?
We announced Content Independence Day almost one month ago, giving content creators and publishers more control over how their content is accessed. Today, over two and a half million websites have chosen to completely disallow AI training through our managed robots.txt feature or our managed rule blocking AI Crawlers. Every Cloudflare customer is now able to selectively decide which declared AI crawlers are able to access their content in accordance with their business objectives.
We expected a change in bot and crawler behavior based on these new features, and we expect that the techniques bot operators use to evade detection will continue to evolve. Once this post is live the behavior we saw will almost certainly change, and the methods we use to stop them will keep evolving as well.
Cloudflare is actively working with technical and policy experts around the world, like the IETF efforts to standardize extensions to robots.txt, to establish clear and measurable principles that well-meaning bot operators should abide by. We think this is an important next step in this quickly evolving space.
As a site owner, how do you know which bots to allow on your site, and which you’d like to block? Existing identification methods rely on a combination of IP address range (which may be shared by other services, or change over time) and user-agent header (easily spoofable). These have limitations and deficiencies. In our last blog post, we proposed using HTTP Message Signatures: a way for developers of bots, agents, and crawlers to clearly identify themselves by cryptographically signing requests originating from their service.
Since we published the blog post on Message Signatures and the IETF draft for Web Bot Auth in May 2025, we’ve seen significant interest around implementing and deploying Message Signatures at scale. It’s clear that well-intentioned bot owners want a clear way to identify their bots to site owners, and site owners want a clear way to identify and manage bot traffic. Both parties seem to agree that deploying cryptography for the purposes of authentication is the right solution.
Today, we’re announcing that we’re integrating HTTP Message Signatures directly into our Verified Bots Program. This announcement has two main parts: (1) for bots, crawlers, and agents, we’re simplifying enrollment into the Verified Bots program for those who sign requests using Message Signatures, and (2) we’re encouraging all bot operators moving forward to use Message Signatures over existing verification mechanisms. Because Verified Bots are considered authenticated, they do not face challenges from our Bot Management to identify as bots, given they’re already identified as such.
For site owners, no additional action is required – Cloudflare will automatically validate signatures on our edge, and if that validation is a success, that traffic will be marked as verified so that site owners can use the verified bot fields to create Bot Management and WAF rules based on it.
This isn’t just about simplifying things for bot operators — it’s about giving website owners unparalleled accuracy in identifying trusted bot traffic, cutting down on the overhead for cryptographic verification, and fundamentally transforming how we manage authentication across the Cloudflare network.
Become a Verified Bot with Message Signatures
Cloudflare’s existing Verified Bots program is for bots that are transparent about who they are and what they do, like indexing sites for search or scanning for security vulnerabilities. You can see a list of these verified bots in Cloudflare Radar:
A preview of the Verified Bots page on Cloudflare Radar.
In the past, in order to apply to be a verified bot, we used to ask for IP address ranges or reverse DNS names so that we could verify your identity. This required some manual steps like checking that the IP address range is valid and is associated with the appropriate ASN.
With the integration of Message Signatures, we’re aiming to streamline applications into our Verified Bot program. Bots applying with well-formed Message Signatures will be prioritized, and approved more quickly!
At a high level, signing your requests with web bot auth consists of the following steps:
Generate a valid signing key. See Signing Key section for step-by-step instructions.
Host a JSON web key set containing your public key under /.well-known/http-message-signature-directory of your website.
Sign responses for that URL using a Web Bot Auth library, one signature for each key contained in it, to prove you own it. See the Hosting section for step-by-step instructions.
Register that URL with us, using our Verified Bots form. This can be done directly in your Cloudflare account. See our documentation.
Sign requests using a Web Bot Auth library.
As an example, Cloudflare Radar’s URL Scanner lets you scan any URL and get a publicly shareable report with security, performance, technology, and network information. Here’s an example of what a well-formed signature looks like for requests coming from URL Scanner:
GET /path/to/resource HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
Signature-Agent: "https://web-bot-auth-directory.radar-cfdata-org.workers.dev"
Signature-Input: sig=("@authority" "signature-agent");\
created=1700000000;\
expires=1700011111;\
keyid="poqkLGiymh_W0uP6PZFw-dvez3QJT5SolqXBCW38r0U";\
tag="web-bot-auth"
Signature:sig=jdq0SqOwHdyHr9+r5jw3iYZH6aNGKijYp/EstF4RQTQdi5N5YYKrD+mCT1HA1nZDsi6nJKuHxUi/5Syp3rLWBA==:
Since we’ve already registered URLScanner as a Verified Bot, Cloudflare will now automatically verify that the signature in the Signature header matches the request — more on that later.
Register your bot
Access the Verified Bots submission form on your account. If that link does not immediately take you there, go to your Cloudflare account → Account Home → the three dots next to your account name → Configurations → Verified Bots.
For the verification method, select “Request Signature”, then enter the URL of your key directory in Validation Instructions. Specifying the User-Agent values is optional if you’re submitting a Request Signature bot.
Once your application has gone through our (now shortened) review process, you don’t need to take any further action.
Message Signature verification for origins
Starting today, Cloudflare is ramping up verification of cryptographic signatures provided by automated crawlers and bots. This is currently available for all Free and Pro plans, and as we continue to test and validate at scale, will be released to all Business and Enterprise plans. This means that as time passes, the number of unauthenticated web crawlers should diminish, ensuring most bot traffic is authenticated before it reaches your website’s servers, helping to prevent spoofing attacks.
At a high level, signature verification works like this:
A bot or agent sends a request to a website behind Cloudflare.
Cloudflare’s Message Signature verification service checks for the Signature, Signature-Input, and Signature-Agent headers.
It checks that the incoming request presents a keyid parameter in your Signature-Input that points to a key we already know.
It looks at the expires parameter in the incoming bot request. If the current time is after expiration, verification fails. This guards against replay attacks, preventing malicious agents from trying to pass as a bot by retrying messages they captured in the past.
It checks that you’ve specified a tag parameter indicating web-bot-auth, to indicate your intent that the message be handled using web bot authentication specifically
It looks at all the components chosen in your Signature-Input header, and constructs a signature base from it.
If all pre-flight checks pass, Cloudflare attempts to verify the signature base against the value in Signature field using an ed25519 verification algorithm and the key supplied in keyid.
Verified Bots and other systems at Cloudflare use a successful verification as proof of your identity, and apply rules corresponding to that identity.
If any of the above steps fail, Cloudflare falls back to existing bot identification and mitigation mechanisms. As the system matures, we would strengthen these requirements, and limit the possibilities of a soft downgrade.
As a site owner, you can segment your Verified Bot traffic by its type and purpose by adding the Verified Bot Categories field cf.verified_bot_category as a filter criterion in WAF Custom rules, Advanced Rate Limiting, and Late Transform rules. For instance, to allow the Bibliothèque nationale de France and the Library of Congress, and institutions dedicated to academic research, you can add a rule that allows bots in the Academic Research category.
Where we’re going next
HTTP Message Signatures is a primitive that is useful beyond Cloudflare – the IETF standardized it as part of RFC 9421.
As discussed in our previous blog post, Cloudflare believes that making Message Signatures a core component of bot authentication on the web should follow the same path. The specifications for the protocol are being built in the open, and they have already evolved following feedback.
Moreover, due to widespread interest, the IETF is considering forming a working group around Web Bot Auth. Should you be a crawler, an origin, or even a CDN, we invite you to provide feedback to ensure the solution gets stronger, and suits your needs.
A better, more trusted Internet
For bot, agent, and crawler operators that act transparently and provide vital services for the Internet, we’re providing a faster and more automated path to being recognized as a Verified Bot, reducing manual processes. We trust that this approach improves bot authentication from what were formerly brittle and unreliable authentication methods, to a secure and reliable alternative. It should reduce the overall volume of friction and hurdles genuinely useful bots face.
For site owners, Message Signatures provides better assurance that the bot traffic is legitimate — automatically recognized and allowed, minimizing disruption to essential services (e.g., search engine indexing, monitoring). In line with our commitments to making TLS/SSL and Post-Quantum certificates available for everyone, we’ll always offer the cryptographic verification of Message Signatures for all sites because we believe in a safer and more efficient Internet by fostering a trusted environment for both human and automated traffic.
If you have a feature request, feedback, or are interested in partnering with us, please reach out.
Web crawlers are not new. The World Wide Web Wanderer debuted in 1993, though the first web search engines to truly use crawlers and indexers were JumpStation and WebCrawler. Crawlers are part of one of the backbones of the Internet’s success: search. Their main purpose has been to index the content of websites across the Internet so that those websites can appear in search engine results and direct users appropriately. In this blog post, we’re analyzing recent trends in web crawling, which now has a crucial and complex new role with the rise of AI.
Not all crawlers are the same. Bots, automated scripts that perform tasks across the Internet, come in many forms: those considered non-threatening or “good” (such as API clients, search indexing bots like Googlebot, or health checkers) and those considered malicious or “bad” (like those used for credential stuffing, spam, or scraping content without permission). In fact, around 30% of global web traffic today, according to Cloudflare Radar data, comes from bots, and even exceeds human Internet traffic in some locations.
A new category, AI crawlers, has emerged in recent years. These bots collect data from across the web to train AI models, improving tools and experiences, but also raising issues around content rights, unauthorized use, and infrastructure overload. We aimed to confirm the growth of both search and AI crawlers, examine specific AI crawlers, and understand broader crawler usage.
This is increasingly relevant with the rapid adoption of AI, growing content rights concerns, and data privacy discussions. Some sites and creators are looking to limit or block AI crawlers using tools like robots.txt or firewall rules. Others, like Dutch indie maker and entrepreneur Pieter Levels, have embraced them: “I’m 100% fine with AI crawlers… very important to rank in LLMs [large language models]”.
It’s important to note that crawlers serve different purposes. For example, the facebookexternalhit bot is not included in this analysis, as it is used by Facebook to fetch page content when generating previews for shared links. However, within this post, we are only focusing on AI and search crawlers that are indexing or scraping website content.
AI-only crawlers perspective
Let’s start with an AI-only crawler perspective that we currently have on Cloudflare Radar, focused only on crawlers advertised as AI-related. To identify them, we’re using here a list derived from an open-source project that helps website owners manage and control access to AI crawlers — especially those used to train large language models (LLMs). It also provides guidance on what to include in robots.txtfiles (more on that below). The data shown below is based on matching those crawler names with user-agent strings in HTTP requests. (Further details, including one exception, about this method can be found at the end of the blog post.)
The AI crawler landscape saw a significant shift between May 2024 and May 2025, with GPTBot (from OpenAI) emerging as the dominant force, surging from 5% to 30% share, and Meta-ExternalAgent (from Meta) making a strong new entry at 19%. This growth came at the expense of former leader Bytespider, which plummeted from 42% to 7%, as well as other AI crawlers like ClaudeBot and Amazonbot, which also saw declines. Our data clearly indicates a reordering of top AI crawlers, highlighting the increasing prominence of OpenAI and Meta in this category.
May 2024
May 2025
Rank
Bot Name
Share (May 2024)
Rank
Bot Name
Share (May 2025)
1
Bytespider
42%
1
GPTBot
30%
2
ClaudeBot
27%
2
ClaudeBot
21%
3
Amazonbot
21%
3
Meta-ExternalAgent
19%
4
GPTBot
5%
4
Amazonbot
11%
5
Applebot
4.1%
5
Bytespider
7.2%
Rank
Bot Name
Share (May 2024)
Rank
Bot Name
Share (May 2025)
1
Bytespider
42%
1
GPTBot
30%
2
ClaudeBot
27%
2
ClaudeBot
21%
3
Amazonbot
21%
3
Meta-ExternalAgent
19%
4
GPTBot
5%
4
Amazonbot
11%
5
Applebot
4.1%
5
Bytespider
7.2%
For additional context, the list below includes further information about the bots with higher crawling shares seen above. This information comes from the same open-source list mentioned above and from publications by companies like OpenAI, which explain how their crawlers are used.
GPTBot – OpenAI’s crawler used to improve and train large language models like ChatGPT.
ClaudeBot – Anthropic’s crawler for training and updating the Claude AI assistant.
Meta-ExternalAgent – Meta’s bot likely used for collecting data to train or fine-tune LLMs.
Amazonbot – Amazon’s crawler that gathers data for its search and AI applications.
Bytespider – ByteDance’s AI data collector, often linked to training models like Ernie or TikTok-related AI.
Applebot – Apple’s web crawler primarily for Siri and Spotlight search, possibly used in AI development.
OAI-SearchBot – OpenAI’s search-focused crawler, likely used for retrieving real-time web info for models.
ChatGPT-User – Represents API-based or browser usage of ChatGPT in connection with user interactions.
PerplexityBot – Crawler from Perplexity.ai, which powers their AI answer engine using real-time web data.
Webmasters can inform crawler operators of whether they want these bots and crawlers to access their content by setting out rules in a file called robots.txt, which tells crawlers what pages they should or shouldn’t access. As we’ve seen recently, crawlers honoring your robots.txt policies is voluntary, but Cloudflare announced tools like AI Audit to help content creators to enforce it.
Now, as we’ve seen, the landscape of web crawling is evolving rapidly, driven by the merging roles of search engines and AI. AI is now deeply integrated into search, seen in Google’s AI Overviews and AI Mode, but also in social media platforms, like Meta AI on Instagram. So, let’s broaden our analysis to include these wider AI-driven crawling activities.
General AI and search crawling growth: +18%
A broader view reveals the growth of crawling traffic from both search and AI crawlers over the first few months of 2025. To remove customer growth bias, we’ll analyze trends using a fixed set of customers from specific weeks (a method we’ve used in our Cloudflare Radar Year in Review): the first week of May 2024, a week in November 2024, and the first week of April 2025.
Using that method, we found that AI and search crawler traffic grew by 18% from May 2024 to May 2025 (comparing full-month periods). The increase was even higher, at 48%, when including new Cloudflare customers added during that time. Peak AI and search crawling traffic occurred in April 2025, with a 32% increase compared to May 2024. This confirms that crawling traffic has clearly risen over the past year, but also that growth is not always constant. Google remains the dominant player, and its share is growing too, as we’ll see in the next section.
As the next chart shows, crawling traffic increased sharply in March and April 2025 and remained high, though slightly lower, in May.
The patterns on the above crawling chart also seem to reflect broader seasonal patterns and general human Internet traffic patterns. In 2024, traffic dropped during the summer in the Northern Hemisphere, with August and September being the least active months. And like overall Internet traffic, it then rose in November, when people are typically more online due to shopping and seasonal habits, as we’ve seen in past analyses.
Googlebot crawling grew 96% in one year
Googlebot, which indexes content for Google Search, was clearly the top crawler throughout the period and showed strong growth, up 96% from May 2024 to May 2025, reflecting increased crawling by Google. Crawling traffic peaked in April 2025, reaching 145% higher than in May 2024. It’s also important to mention that Google made changes to its search and launched AI Overviews in its search engine during this time — first in the US in May 2024, then in more countries later.
Two trends stand out when looking at daily data for Google-related crawlers, as shown in the graph below. First, Googlebot and the more recent GoogleOther (a web crawler from 2023 for “research and development”) account for most of Google’s crawling activity. Second, there were two visible drops in crawling traffic: one on December 14, 2024 (around a Google Search update), and another from May 20 to May 28, 2025. That May 20 drop occurred around the same time as the rollout of AI Mode on Google Search in the US, although the timing may be coincidental.
Breakdown of top 20 AI and search web crawlers
Ranking crawlers by their share of total requests gives a clearer picture of which bots are gaining or losing ground, especially among those focused on search and AI. The table below shows a clear trend: some AI bots have grown rapidly since last year (with growth beginning even earlier), while many traditional search crawlers have remained flat or lost share (as in the case of Bing and its Bingbot crawler). The main exception is Googlebot.
The next table shows the percentage share of each crawler out of all crawling traffic generated by this specific cohort of over 30 AI & search crawlers observed by Cloudflare in May 2024 and May 2025. The table below also includes the change in percentage points and the growth or decline in raw request volume. Crawlers are ranked by their share in May 2025. Key crawler shifts include GPTBot rising sharply (+305%), while Bytespider dropped dramatically (-85%).
Rank
Bot name
Share
May 2024
Share
May 2025
Δ percentage-point change
Raw requests growth (May 2024 to May 2025)
1
Googlebot
30%
50%
+20 pp
96%
2
Bingbot
10%
8.7%
-1.3 pp
2%
3
GPTBot
2.2%
7.7%
+5.5 pp
305%
4
ClaudeBot
11.7%
5.4%
-6.3 pp
-46%
5
GoogleOther
4.4%
4.3%
-0.1 pp
14%
6
Amazonbot
7.6%
4.2%
-3.4 pp
-35%
7
Googlebot-Image
4.5%
3.3%
-1.2 pp
-13%
8
Bytespider
22.8%
2.9%
-19.8 pp
-85%
9
Yandex
2.8%
2.2%
-0.7 pp
-10%
10
ChatGPT-User
0.1%
1.3%
+1.2 pp
2,825%
11
Applebot
1.9%
1.2%
-0.7 pp
-26%
12
Timpibot
0.3%
0.6%
+0.3 pp
133%
13
Baiduspider
0.5%
0.4%
-0.1 pp
7%
14
PerplexityBot
<0.01%
0.2%
+0.2 pp
157,490%
15
DuckDuckBot
0.2%
0.1%
-0.1 pp
-16%
16
SeznamBot
0.1%
0.1%
2%
17
Yeti
0.1%
0.1%
47%
18
coccocbot
0.1%
0.1%
-3%
19
Sogou
0.1%
0.1%
-22%
20
Yahoo! Slurp
0.1%
0.0%
-0.1 pp
-8%
Rank
Bot name
Share May 2024
Share May 2025
Δ percentage-point change
Raw requests growth (May 2024 to May 2025)
1
Googlebot
30%
50%
+20 pp
96%
2
Bingbot
10%
8.7%
-1.3 pp
2%
3
GPTBot
2.2%
7.7%
+5.5 pp
305%
4
ClaudeBot
11.7%
5.4%
-6.3 pp
-46%
5
GoogleOther
4.4%
4.3%
-0.1 pp
14%
6
Amazonbot
7.6%
4.2%
-3.4 pp
-35%
7
Googlebot-Image
4.5%
3.3%
-1.2 pp
-13%
8
Bytespider
22.8%
2.9%
-19.8 pp
-85%
9
Yandex
2.8%
2.2%
-0.7 pp
-10%
10
ChatGPT-User
0.1%
1.3%
+1.2 pp
2,825%
11
Applebot
1.9%
1.2%
-0.7 pp
-26%
12
Timpibot
0.3%
0.6%
+0.3 pp
133%
13
Baiduspider
0.5%
0.4%
-0.1 pp
7%
14
PerplexityBot
<0.01%
0.2%
+0.2 pp
157,490%
15
DuckDuckBot
0.2%
0.1%
-0.1 pp
-16%
16
SeznamBot
0.1%
0.1%
2%
17
Yeti
0.1%
0.1%
47%
18
coccocbot
0.1%
0.1%
-3%
19
Sogou
0.1%
0.1%
-22%
20
Yahoo! Slurp
0.1%
0.0%
-0.1 pp
-8%
Based on this data, two major shifts in web crawling occurred between May 2024 and May 2025:
1. Some AI crawlers rose sharply. GPTBot (from OpenAI) increased its share from 2.2% to 7.7% (+5.5 pp), with a 305% rise in requests. This underscores the data demand for training large language models like ChatGPT. GPTBot jumped from #9 in May 2024 to #3 in May 2025.
Another OpenAI crawler, ChatGPT-User, saw requests surge by 2,825%, reaching a 1.3% share. This reflects a large rise in ChatGPT user activity or API-based interactions that involve accessing web content. PerplexityBot (from Perplexity.ai), despite a small 0.2% share, recorded the highest growth rate: a staggering 157,490% increase in raw requests.
Meanwhile, some AI crawlers saw steep declines. ClaudeBot (Anthropic) fell from 11.7% to 5.4% of total traffic and dropped 46% in requests. Bytespider plummeted 85% in request volume, falling from #2 to #8 in crawler share (now at just 2.9%).
Both Amazonbot and Applebot, also considered AI crawlers, saw decreases in share and in raw requests (–35% and –26%, respectively).
2. Google’s dominance expanded. Googlebot’s share rose from 30% to 50%, supporting search indexing, but potentially also having AI-related purposes (such as new AI Overviews in Google Search). And GoogleOther (the crawler introduced in 2023) also increased in crawling traffic, 14%. Other Google crawlers not in the top 20, like Googlebot-News, also grew significantly (+71% in requests). There’s a clear trend of growth in these Google-related web crawlers at a time when the company is investing heavily in combining AI with search.
Also in the search category, Bingbot’s share (from Microsoft) declined slightly from 10% to 8.7% (-1.3 pp), though its raw requests still grew modestly by 2%.
These trends show that web crawling is increasingly dominated by bots from Google and OpenAI, reflecting clear shifts over the course of a year. Google also appears to be adapting how it collects data to support both traditional search and AI-driven features.
Also worth noting is FriendlyCrawler, which no longer appears in the top 20 list as of May 2025 (now ranked #35). It was #14 in May 2024 with a 0.2% share, but saw a 100% drop in requests by May 2025. This bot is known to index and analyze website content, although its owner and purpose remain unclear. Typically, crawlers like this are used for improving search results, market research, or analytics.
robots.txt & AI bots: GPTBot leads twice
Recent data from June 6, 2025, from Cloudflare Radar shows that out of 3,816 domains (from the top 10,000) where we were able to find a robots.txt file, 546 (about 14%) had “allow” or “disallow” (fully or partially) directives targeting AI bots in particular.
This leaves many site owners in a gray area because it’s not always clear how effective robots.txt is in managing AI crawlers. Some site owners may not think to use it specifically for AI bots, while others might be unsure whether these bots even respect robots.txt rules, especially newer or less transparent crawlers. In other cases, sites use partial rules to fine-tune access, trying to balance visibility and protection without fully opting in or out.
The “disallow” rules appear far more often than “allow” rules. The most frequently blocked bot was GPTBot, disallowed by 312 domains (250 fully, 62 partially), followed by CCBot and Google-Extended, as shown in the following graph.
Although GPTBot was the most blocked, it was also the most explicitly allowed, with 61 domains granting access (18 fully, 43 partially). Still, very few sites openly and explicitly allow AI bots, and when they do, it’s usually for limited sections. Note that bots not listed in a site’s robots.txt are effectively allowed by default.
As AI crawling increases, more websites are moving from passive signals like robots.txt to active protections like Web Application Firewalls. The ecosystem is shifting, with a growing focus on enforceable controls.
Note: When we analyze crawler traffic, we compare user-agent tokens found in robots.txt files (like those for AI crawlers) with the actual user-agent strings in HTTP requests. It’s important to note that some robots.txt tokens, such as Google-Extended, aren’t user-agent substrings. As described in RFC 9309, one goal of these token may be to signal the purpose of the crawler. For instance, Google uses Google-Extended in robots.txt to see if your content can be used for AI training, but the traffic itself still comes from standard Google user-agents like Googlebot. Because of this, not every robots.txt entry will have a direct match in HTTP request logs.
Conclusion
As AI crawlers reshape the Internet, websites face both new challenges and new opportunities in managing their online presence.
This analysis highlights the growing impact of AI on web crawling, showing a clear shift from traditional search indexing to data collection for training AI models. The detailed statistics, such as Googlebot’s continued growth and the rapid rise of AI-specific crawlers, offer context for understanding how this space is evolving and what it means for the future of web content access.
The trend toward stronger, enforceable blocking methods, something Cloudflare has also been invested, signals a key shift in how websites may control their interactions with AI systems going forward.
Many publishers, content creators and website owners currently feel like they have a binary choice — either leave the front door wide open for AI to consume everything they create, or create their own walled garden. But what if there was another way?
At Cloudflare, we started from a simple principle: we wanted content creators to have control over who accesses their work. If a creator wants to block all AI crawlers from their content, they should be able to do so. If a creator wants to allow some or all AI crawlers full access to their content for free, they should be able to do that, too. Creators should be in the driver’s seat.
After hundreds of conversations with news organizations, publishers, and large-scale social media platforms, we heard a consistent desire for a third path: They’d like to allow AI crawlers to access their content, but they’d like to get compensated. Currently, that requires knowing the right individual and striking a one-off deal, which is an insurmountable challenge if you don’t have scale and leverage.
What if I could charge a crawler?
We believe your choice need not be binary — there should be a third, more nuanced option: You can charge for access. Instead of a blanket block or uncompensated open access, we want to empower content owners to monetize their content at Internet scale.
We’re excited to help dust off a mostly forgotten piece of the web: HTTP response code 402.
Introducing pay per crawl
Pay per crawl, in private beta, is our first experiment in this area.
Pay per crawl integrates with existing web infrastructure, leveraging HTTP status codes and established authentication mechanisms to create a framework for paid content access.
Each time an AI crawler requests content, they either present payment intent via request headers for successful access (HTTP response code 200), or receive a 402 Payment Required response with pricing. Cloudflare acts as the Merchant of Record for pay per crawl and also provides the underlying technical infrastructure.
Publisher controls and pricing
Pay per crawl grants domain owners full control over their monetization strategy. They can define a flat, per-request price across their entire site. Publishers will then have three distinct options for a crawler:
Allow: Grant the crawler free access to content.
Charge: Require payment at the configured, domain-wide price.
Block: Deny access entirely, with no option to pay.
An important mechanism here is that even if a crawler doesn’t have a billing relationship with Cloudflare, and thus couldn’t be charged for access, a publisher can still choose to ‘charge’ them. This is the functional equivalent of a network level block (an HTTP 403 Forbidden response where no content is returned) — but with the added benefit of telling the crawler there could be a relationship in the future.
While publishers currently can define a flat price across their entire site, they retain the flexibility to bypass charges for specific crawlers as needed. This is particularly helpful if you want to allow a certain crawler through for free, or if you want to negotiate and execute a content partnership outside the pay per crawl feature.
To ensure integration with each publisher’s existing security posture, Cloudflare enforces Allow or Charge decisions via a rules engine that operates only after existing WAF policies and bot management or bot blocking features have been applied.
Payment headers and access
As we were building the system, we knew we had to solve an incredibly important technical challenge: ensuring we could charge a specific crawler, but prevent anyone from spoofing that crawler. Thankfully, there’s a way to do this using Web Bot Auth proposals.
Once registration is accepted, crawler requests should always include signature-agent, signature-input, and signature headers to identify your crawler and discover paid resources.
Once a crawler is set up, determination of whether content requires payment can happen via two flows:
Reactive (discovery-first)
Should a crawler request a paid URL, Cloudflare returns an HTTP 402 Payment Required response, accompanied by a crawler-price header. This signals that payment is required for the requested resource.
The crawler can then decide to retry the request, this time including a crawler-exact-price header to indicate agreement to pay the configured price.
GET /example.html
crawler-exact-price: USD XX.XX
Proactive (intent-first)
Alternatively, a crawler can preemptively include a crawler-max-price header in its initial request.
GET /example.html
crawler-max-price: USD XX.XX
If the price configured for a resource is equal to or below this specified limit, the request proceeds, and the content is served with a successful HTTP 200 OK response, confirming the charge:
HTTP 200 OK
crawler-charged: USD XX.XX
server: cloudflare
If the amount in a crawler-max-price request is greater than the content owner’s configured price, only the configured price is charged. However, if the resource’s configured price exceeds the maximum price offered by the crawler, an HTTP402 Payment Required response is returned, indicating the specified cost. Only a single price declaration header, crawler-exact-price or crawler-max-price, may be used per request.
The crawler-exact-price or crawler-max-price headers explicitly declare the crawler’s willingness to pay. If all checks pass, the content is served, and the crawl event is logged. If any aspect of the request is invalid, the edge returns an HTTP 402 Payment Required response.
Financial settlement
Crawler operators and content owners must configure pay per crawl payment details in their Cloudflare account. Billing events are recorded each time a crawler makes an authenticated request with payment intent and receives an HTTP 200-level response with a crawler-charged header. Cloudflare then aggregates all the events, charges the crawler, and distributes the earnings to the publisher.
Content for crawlers today, agents tomorrow
At its core, pay per crawl begins a technical shift in how content is controlled online. By providing creators with a robust, programmatic mechanism for valuing and controlling their digital assets, we empower them to continue creating the rich, diverse content that makes the Internet invaluable.
We expect pay per crawl to evolve significantly. It’s very early: we believe many different types of interactions and marketplaces can and should develop simultaneously. We are excited to support these various efforts and open standards.
For example, a publisher or new organization might want to charge different rates for different paths or content types. How do you introduce dynamic pricing based not only upon demand, but also how many users your AI application has? How do you introduce granular licenses at internet scale, whether for training, inference, search, or something entirely new?
The true potential of pay per crawl may emerge in an agentic world. What if an agentic paywall could operate entirely programmatically? Imagine asking your favorite deep research program to help you synthesize the latest cancer research or a legal brief, or just help you find the best restaurant in Soho — and then giving that agent a budget to spend to acquire the best and most relevant content. By anchoring our first solution on HTTP response code 402, we enable a future where intelligent agents can programmatically negotiate access to digital resources.
Getting started
Pay per crawl is currently in private beta. We’d love to hear from you if you’re either a crawler interested in paying to access content or a content creator interested in charging for access. You can reach out to us at http://www.cloudflare.com/paypercrawl-signup/ or contact your Account Executive if you’re an existing Enterprise customer.
Cloudflare is giving all website owners two new tools to easily control whether AI bots are allowed to access their content for model training. First, customers can let Cloudflare create and manage a robots.txt file, creating the appropriate entries to let crawlers know not to access their site for AI training. Second, all customers can choose a new option to block AI bots only on portions of their site that are monetized through ads.
The new generation of AI crawlers
Creators that monetize their content by showing ads depend on traffic volume. Their livelihood is directly linked to the number of views their content receives. These creators have allowed crawlers on their sites for decades, for a simple reason: search crawlers such as Googlebot made their sites more discoverable, and drove more traffic to their content. Google benefitted from delivering better search results to their customers, and the site owners also benefitted through increased views, and therefore increased revenues.
But recently, a new generation of crawlers has appeared: bots that crawl sites to gather data for training AI models. While these crawlers operate in the same technical way as search crawlers, the relationship is no longer symbiotic. AI training crawlers use the data they ingest from content sites to answer questions for their own customers directly, within their own apps. They typically send much less traffic back to the site they crawled. Our Radar team did an analysis of crawls and referrals for sites behind Cloudflare. As HTML pages are arguably the most valuable content for these crawlers, we calculated crawl ratios by dividing the total number of requests from relevant user agents associated with a given search or AI platform where the response was of Content-type: text/html by the total number of requests for HTML content where the Referer: header contained a hostname associated with a given search or AI platform. As of June 2025, we find that Google crawls websites about 14 times for every referral. But for AI companies, the crawl-to-refer ratio is orders of magnitude greater. In June 2025, OpenAI’s crawl-to-referral ratio was 1,700:1, Anthropic’s 73,000:1. This clearly breaks the “crawl in exchange for traffic” relationship that previously existed between search crawlers and publishers. (Please note that this calculation reflects our best estimate, recognizing that traffic referred by native apps may not always be attributed to a provider due to a lack of a Referer: header, which may affect the ratio.)
And while sites can use robots.txt to tell these bots not to crawl their site, most don’t take this first step. We found that only about 37% of the top 10,000 domains currently have a robots.txt file, showing that robots.txt is underutilized in this age of evolving crawlers.
That’s where Cloudflare comes in. Our mission is to help build a better Internet, and a better Internet is one with a huge thriving ecosystem of independent publishers. So, we’re taking action to keep that ecosystem alive.
Giving ALL customers full control
Protecting content creators isn’t new for Cloudflare. In July 2024, we gave everyone on the Cloudflare network a simple way to block all AI scrapers with a single click for free. We’ve already seen more than 1 million customers enable this feature, which has given us some interesting data.
Since our last update, we can see that Bytespider, our previous top bot, has seen traffic volume decline 71.45% since the first week of July 2024. During the same time, we saw an increased number of Bytespider requests that customers chose to specifically block. In contrast, GPTBot traffic volume has grown significantly as it has become more popular, now even surpassing traffic we see from big traditional tech players like Amazon and ByteDance.
The share of sites accessed by particular crawlers has gone down across the board since our last update. Previously, Bytespider accessed >40% of websites protected by Cloudflare, but that number has dropped to only 9.37%. GPTBot has taken the top spot for most sites accessed, but while its request volume has grown significantly (noted above), the share of sites it crawls has actually decreased since last year from 35.46% to 28.97%, with an increase in customers blocking.
AI Bot
Share of Websites Accessed
GPTBot
28.97%
Meta-ExternalAgent
22.16%
ClaudeBot
18.80%
Amazonbot
14.56%
Bytespider
9.37%
GoogleOther
9.31%
ImageSiftBot
4.45%
Applebot
3.77%
OAI-SearchBot
1.66%
ChatGPT-User
1.06%
And while AI Search and AI Assistant crawling related activity has exploded in popularity in the last 6 months, we still see their total traffic pale in comparison to AI training crawl activity, which has seen a 65% increase in traffic over the past 6 months.
To this end, we launched free granular auditing in September 2024 to help customers understand which crawlers were accessing their content most often, and created simple templates to block all or specific crawlers. And in December 2024, we made it easy for publishers to automatically block crawlers that weren’t respecting robots.txt. But we realized many sites didn’t have the time to create or manage their own robots.txt file. Today, we’re going two steps further.
Step 1: fully managed robots.txt
When it comes to managing your website’s visibility to search engine crawlers and other bots, the robots.txt file is a key player. This simple text file acts like a traffic controller, signaling to bots which parts of the website they should or should not access. We can think of robots.txt as a “Code of Conduct” sign posted at a community pool, listing general dos and don’ts, according to the pool owner’s wishes. While the sign itself does not enforce the listed directives, well-behaved visitors will still read the sign and follow the instructions they see. On the other hand, poorly-behaved visitors who break the rules risk getting themselves banned.
What do these files actually look like? Take Google’s as an example, visible to anyone at https://www.google.com/robots.txt. Parsing its contents, you’ll notice four directives in the set of instructions: User-agent, Disallow, Allow, and Sitemap. In a robots.txt file, the User-agent directive specifies which bots the rules apply to. The Disallow directive tells those bots which parts of the website they should avoid. In contrast, the Allow directive grants specific bots permission to access certain areas. Finally, theSitemap directive shows a bot which pages it can reach, so that it won’t miss any important pages. The Internet Engineering Task Force (IETF) formalized the definition and language for the Robots Exclusion Protocol in RFC 9309, specifying the exact syntax and precedence of these directives. It also outlines how crawlers should handle errors or redirects while stressing that compliance is voluntary and does not constitute access control.
Website owners should have agency over AI bot activity on their websites. We mentioned that only 37% of the top 10,000 domains on Cloudflare even have a robots.txt file. Of those robots files that do exist, few include Disallow directives for the top AI Bots that we see on a daily basis. For instance, as of publication, GPTBot is only disallowed in 7.8% of the robots.txt files found for the top domains; Google-Extended only shows up in 5.6%; anthropic-ai, PerplexityBot, ClaudeBot, and Bytespider each show up in under 5%. Furthermore, the difference between the 7.8% of Disallow directives for GPTBot and the ~5% of Disallow directives for other major AI crawlers suggests a gap between the desire to prevent your content from being used for AI model training and the proper configuration that accomplishes this by calling out bots like Google-Extended. (After all, there’s more to stopping AI crawlers than disallowing GPTBot.)
Along with viewing the most active bots and crawlers, Cloudflare Radar also shares weekly updates on how websites are handling AI bots in their robots.txt files. We can examine two snapshots below, one from June 2025 and the other from January 2025:
Radar snapshot from the week of June 23, 2025, showing the top AI user agents mentioned in the Disallow directive in robots.txt files across the top 10,000 domains. The 3 bots with the highest number of Disallows are GPTBot, CCBot, and facebookexternalhit.
Radar snapshot from the week of January 26, 2025, showing the top AI user agents mentioned in the Disallow directive in robots.txt files across the top 10,000 domains. The 3 bots with the highest number of Disallows are GPTBot, CCBot, and anthropic-ai.
From the above data, we also observe that fewer than 100 new robots.txt files have been added among the top domains between January and June. One visually striking change is the ratio of dark blue to light blue: compared to January, there is a steep decrease in “Partially Disallowed” permissions; websites are now flat-out choosing “Fully Disallowed” for the top AI crawlers, including GPTBot, CCBot, and Google-Extended. This underscores the changing landscape of web crawling, particularly the relationship of trust between website owners and AI crawlers.
Putting up a guardrail with Cloudflare’s managed robots.txt
Many website owners have told us they’re in a tricky spot in this new era of AI crawlers. They’ve poured time and effort into creating original content, have published it on their own sites, and naturally want it to reach as many people as possible. To do that, website owners make their sites accessible to search engine crawlers, which index the content and make it discoverable in search results. But with the rise of AI-powered crawlers, that same content is now being scraped not just for indexing, but also to train AI models, often without the creator’s explicit consent. Take Googlebot, for example: it’s an absolute requirement for most website owners to allow for SEO. But Google crawls with user agent Googlebot for both SEO and AI training purposes. Specifically disallowing Google-Extended (but not Googlebot) in your robots.txt file is what communicates to Google that you do not want your content to be crawled to feed AI training.
So, what if you don’t want your content to serve as training data for the next AI model, but don’t have the time to manually maintain an up-to-date robots.txt file? Enter Cloudflare’s new managed robots.txt offering. Once enabled, Cloudflare will automatically update your existing robots.txt or create a robots.txt file on your site that includes directives asking popular AI bot operators to not use your content for AI model training. For instance, Cloudflare’s managed robots.txt signals your preference to Google-Extended and Applebot-Extended, amongst others, that they should not crawl your site for AI training, while keeping your domain(s) SEO-friendly.
Cloudflare dashboard snapshot of the new managed robots.txt activation toggle
This feature is available to all customers, meaning anyone can enable this today from the Cloudflare dashboard. Once enabled, website owners who previously had no robots.txt file will now have Cloudflare’s managed bot directives live on their website. What about website owners who already have a robots.txt file? The contents of Cloudflare’s managed robots.txt will be prepended to site owners’ existing file. This way, their existing Block directives – and the time and rationale put into customizing this file – are honored, while still ensuring the website has AI crawler guardrails managed by Cloudflare.
As the AI bot landscape changes with new bots on the rise, Cloudflare will keep our customers a step ahead by updating the directives on our managed robots.txt, so they don’t have to worry about maintaining things on their own. Once enabled, customers won’t need to take any action in order for any updates of the managed robots.txt content to go live on their site.
We believe that managing crawling is key to protecting the open Internet, so we’ll also be encouraging every new site that onboards to Cloudflare to enable our managed robots.txt. When you onboard a new site, you’ll see the following options for managing AI crawlers:
This makes it effortless to ensure that every new customer or domain onboarded to Cloudflare gives clear directives to how they want their content used.
Under the hood: technical implementation
To implement this feature, we developed a new module that intercepts all inbound HTTP requests for /robots.txt. For all such requests, we’ll check whether the zone has opted in to use Cloudflare’s managed robots.txt by reading a value from our distributed key-value store. If they have, the module then responds with the Cloudflare’s managed robots.txt directives, prepended to the origin’s robot.txt if there is an existing file. We prepend so we can add a generalized header that instructs all bots on the customers preferences for data use, as defined in the IETF AI preferences proposal. Note that in robots.txt, the most specific matchmust always be used, and since our disallow expressions are scoped to cover everything, we can ensure a directive we prepend will never conflict with a more targeted customer directive. If the customer has not enabled this feature, the request is forwarded to the origin server as usual, using whatever the customer has written in their own robots.txt file. (While caching origin’s robots.txt could reduce latency by eliminating a round trip to the origin, the impact on overall page load times would be minimal, as robots.txt requests comprise a small fraction of total traffic. Adding cache update/invalidation would introduce complexity with limited benefit, so we prioritized functionality and reliability in our implementation.)
Step 2: block, but only where you show ads
Adding an entry to your robots.txt file is the first step to telling AI bots not to crawl you. But robots.txt is an honor system. Nothing forces bots to follow it. That’s why we introduced our one-click managed rule to block all AI bots across your zone. However, some customers want AI bots to visit certain pages, like developer or support documentation. For customers who are hesitant to block everywhere, we have a brand-new option: let us detect when ads are shown on a hostname, and we will block AI bots ONLY on that hostname. Here’s how we do it.
First, we use multiple techniques to identify if a request is coming from an AI bot. The easiest technique is to identify well-behaved crawlers that publicly declare their user agent, and use dedicated IP ranges. Often we work directly with these bot makers to add them to our Verified Bot list.
Many bot operators act in good faith by publicly publishing their user agents, or even cryptographically verifying their bot requests directly with Cloudflare. Unfortunately, some attempt to appear like a real browser by using a spoofed user agent. It’s not new for our global machine learning models to recognize this activity as a bot, even when operators lie about their user agent. When bad actors attempt to crawl websites at scale, they generally use tools and frameworks that we’re able to fingerprint, and we use Cloudflare’s network of over 57 million requests per second on average, to understand how much we should trust the fingerprint. We compute global aggregates across many signals, and based on these signals, our models are able to consistently and appropriately flag traffic from evasive AI bots.
When we see a request from an AI bot, our system checks if we have previously identified ads in the response served by the target page. To do this, we inspect the “response body” — the raw HTML code of the web page being sent back. After parsing the HTML document, we perform a comprehensive scan for code patterns commonly found in ad units, which signals to us that the page is serving an ad. Examples of such code would be:
Here, the div-container has the ui-advert class commonly used for advertising. Similarly, links to commonly used ad servers like Google Syndication are a good signal as well, such as the following:
By streaming and directly parsing small chunks of the response using our ultra-fast LOL HTML parser, we can perform scans without adding any latency to the inspected response.
So as not to reinvent the wheel, we are adopting techniques similar to those that ad blockers have been using for years. Ad blockers fundamentally perform two separate tasks to block advertisements in a browser. The first is to block the browser from fetching resources from ad servers, and the second is to suppress displaying HTML elements that contain ads. For this, ad blockers rely on large filter lists such as EasyList that contain both so-called URL block filters that match outgoing request URLs against a set of patterns, and block them if they match one of the filters, and CSS selectors that are designed to match HTML ad elements.
We can use both of these techniques to detect if an HTML response contains ads by checking external resources (e.g. content referenced by HREF or SCRIPT tags) against URL block filters, and the HTML elements themselves against CSS selectors. Because we do not actually need to block every single advertisement on a site, but rather detect the overall presence of ads on a site, we can achieve the same detection efficacy when shrinking the number of CSS and URL filters down from more than 40,000 in EasyList to the 400 most commonly seen ones to increase our computational efficiency.
Because some sites load ads dynamically rather than directly in the returned HTML (partially to avoid ad blocking), we enrich this first information source with data from Content Security Policy (CSP) reports. The Content Security Policy standard is a security mechanism that helps web developers control the resources (like scripts, stylesheets, and images) a browser is allowed to load for a specific web page, and browsers send reports about loaded resources to a CSP management system, which for many sites is Cloudflare’s Page Shield product. These reports allow us to relate scripts loaded from ad servers directly with page URLs. Both of these information sources are consumed by our endpoint management service, which then matches incoming requests against hostnames that we already know are serving ads.
We do all of this on every request for any customer who opts in, even free customers.
To enable this feature, simply navigate to the Security > Settings > Bots section of the Cloudflare dashboard, and choose either Block on pages with Ads or Block Everywhere.
The AI bot hunt: finding and identifying bots
The AI bot landscape has exploded and continues to grow with an exponential trajectory as more and more operators come online. At Cloudflare, our team of security researchers are constantly identifying and classifying different AI-related crawlers and scrapers across our network.
There are two major ways in which we track AI bots and identify those that are poorly behaved:
1. Our customers play a crucial role by directly submitting reports of misbehaved AI bots that may not yet be classified by Cloudflare. (If you have an AI bot that comes to mind here, we’d love for you to let us know through our bots submission form today.) Once such a bot comes to our attention, our security analysts investigate to determine how it should be categorized.
2. We’re able to derive insights through analysis of the massive scale of our customers’ traffic that we observe. Specifically, we can see which AI agents visit which websites and when, drawing out trends or patterns that might make a website owner want to disallow a given AI bot. This bird’s-eye view on abusive AI bot behavior was paramount as we started to determine the content of a managed robots.txt.
What’s next?
Our new managed robots.txt and blocking AI bots on pages with ads features are available to all Cloudflare customers, including everyone on a Free plan. We encourage customers to start using them today – to take control over how the content on your website gets used. Looking ahead, Cloudflare will monitor the IETF’s pending proposal allowing website publishers to control how automated systems use their content and update our managed robots.txt accordingly. We will also continue to provide more granular control around AI bot management and investigate new distinguishing signals as AI bots become more and more precise. And if you’ve seen suspicious behavior from an AI scraper, contribute to the Internet ecosystem by letting us know!
Content publishers welcomed crawlers and bots from search engines because they helped drive traffic to their sites. The crawlers would see what was published on the site and surface that material to users searching for it. Site owners could monetize their material because those users still needed to click through to the page to access anything beyond a short title.
Artificial Intelligence (AI) bots also crawl the content of a site, but with an entirely different delivery model. These Large Language Models (LLMs) do their best to read the web to train a system that can repackage that content for the user, without the user ever needing to visit the original publication.
The AI applications might still try to cite the content, but we’ve found that very few users actually click through relative to how often the AI bot scrapes a given website. We have discussed this challenge in smaller settings, and today we are excited to publish our findings as a new metric shown on the AI Insights page on Cloudflare Radar.
Visitors to Cloudflare Radar can now review how often a given AI model sends traffic to a site relative to how often it crawls that site. We are sharing this analysis with a broad audience so that site owners can have better information to help them make decisions about which AI bots to allow or block and so that users can understand how AI usage in aggregate impacts Internet traffic.
How does this measurement work?
As HTML pages are arguably the most valuable content for these crawlers, the ratios displayed are calculated by dividing the total number of requests from relevant user agents associated with a given search or AI platform where the response was of Content-type: text/html by the total number of requests for HTML content where the Referer header contained a hostname associated with a given search or AI platform.
The diagrams below illustrate two common crawling scenarios, and show that companies may use different user agents depending on the purpose of the crawler. The top one represents a simple transaction where the example AI platform is requesting content for the purposes of training an LLM, representing itself as AIBot. The bottom one represents a scenario where the example AI platform is requesting content to service a user request — looking for flight information, for example. In this case, it is representing itself as AIBot-User. Request traffic from both of these user agents would be aggregated under a single platform name for the purposes of our analysis.
When a user clicks on a link on a website or application, the client will often send a Referer: header as part of the request to the target site. In the diagram below, the example AI platform has returned content that contains links to external sites in response to a user interaction. When the user clicks on a link, a request is made to the content provider that includes ai.example.com in the Referer: header, letting them know where that request traffic came from. Hostnames are associated with their respective platforms for the purpose of our analysis.
Observations
Reviewing the ratios
The new metric is presented as a simple table, comparing the number of aggregate HTML page requests from crawlers (user agents) associated with a given platform to the number of HTML page requests from clients referred by a hostname associated with a given platform. The calculated ratio is always normalized to a single referral request.
The table below shows that for the period June 19-26, 2025, as an example, the ratios range from Anthropic’s 70,900:1 down to Mistral’s 0.1:1. This means that Anthropic’s AI platform Claude made nearly 71,000 HTML page requests for every HTML page referral, while Mistral sent 10x as many referrals as crawl requests. (However, traffic referred by Claude’s native app does not include a Referer: header, and we believe that the same holds true for traffic generated from other native apps as well. As such, because the referral counts only include traffic from the Web-based tools from these providers, these calculations may overstate the respective ratios, but it is unclear by how much.)
Of course, due in part to changes in crawling patterns, these ratios will change over time. The table above also displays the ratio changes as compared to the previous period, with changes ranging from increases of over 6% for DuckDuckGo and Yandex to Google’s 19.4% decrease. The week-over-week drop in Google’s ratio is related to an observed drop in crawling traffic from GoogleBot starting on June 24, while Yandex’s week-over-week growth is related to an observed increase in YandexBot crawling activity that started on June 21, as seen in the graphs below.
Changes and trends in the underlying activity can be seen in the associated Data Explorer view, as well as in the raw data available via API endpoints (timeseries, summary). Note that the shares of both referral and crawl traffic are relative to the sets of referrers and crawlers included in the graphs, and not Cloudflare traffic overall.
For example, in the referrer-centric view below, covering nearly the first four weeks of June 2025, we can see that referral traffic is dominated by search platform Google, with a fairly consistent diurnal pattern visible in the data. (The google.* entry covers referral traffic from the main google.com site, as well as local sites, such as google.es or google.com.tw.) Because of prefetching driven by the use of speculation rules, referral traffic coming from Google’s ASN (AS15169) is specifically excluded from analysis here, as it doesn’t represent active user consumption of content.
Clear diurnal patterns are also visible in the referral request shares of other search platforms, although the request shares are a fraction of what is seen from Google.
Throughout June, the share of traffic referred by AI platforms was significantly lower, even in aggregate, than the share of traffic referred by search platforms.
Changes in crawling traffic
As noted above, the change in ratio values over time can be driven by shifts in crawling activity. These shifts are visible in the crawling traffic shares available in Data Explorer, as well as in the raw data available via API endpoints (timeseries, summary). In the crawler-centric view below, covering nearly the first four weeks of June 2025, we can see that the share of requests related to Google’s crawling activity for both their Googlebot and GoogleOther identifiers falls over the course of the month, with several peak/valley periods. A similar pattern observed in HTTP request traffic from Google’s AS15169 during that same time period loosely matches this observed drop in share.
In addition, it appears that OpenAI’s GPTBot saw multiple periods where little-to-no crawling activity was observed throughout the month.
What this means for content providers
These ratios directly impact the viability of content publication on the Internet. While they will vary over time, the trend continues to be more crawls and fewer referrals when compared in relation to each other. Legacy search index crawlers would scan your content a couple of times, or less, for each visitor sent. A site’s availability to crawlers made their revenue model more viable, not less.
The new data we are observing suggests that is no longer the case. These models continue to consume more content, more frequently, despite sending the same or less traffic to the source of its content.
We have released new tools over the last year to help site owners take control back. With a single click, publishers can block the kinds of AI crawlers that train against their content. And today, we announced new ways to make the exchange of value fair for both sides of the equation. However, we continue to recommend that content creators audit and then enforce their preferred policies for AI crawlers.
One more thing…
In addition to providing these new insights around crawling and referral traffic and associated trends, we’ve also taken the opportunity to launch expanded Verified Bots content. The Bots page on Cloudflare Radar includes a paginated list of Verified Bots, displaying the bot name, owner, category, and rank (based on request volume). This list has now been expanded into a standalone directory in a new Bots section. The directory, shown below, displays a card for each Verified Bot, showing the bot name, a description, the bot owner and category, and verification status. Users can search the directory by bot name, owner, or description, and can also filter by category (selecting just Monitoring & Analytics bots, for example).
Clicking on a bot name within a card brings up a bot-specific page that includes metadata about the bot, information on how the bot’s user agent is represented in HTTP request headers and how it should be specified in robots.txt directives, and a traffic graph that shows associated HTTP request volume trends for the selected time period (with a default comparison to the previous period). Associated data is also available via the API. As we add additional information to these bot-specific pages in the future, we will document the updates in Changelog entries.
With the rise of traffic from AI agents, what’s considered a bot is no longer clear-cut. There are some clearly malicious bots, like ones that DoS your site or do credential stuffing, and ones that most site owners do want to interact with their site, like the bot that indexes your site for a search engine, or ones that fetch RSS feeds.
Historically, Cloudflare has relied on two main signals to verify legitimate web crawlers from other types of automated traffic: user agent headers and IP addresses. The User-Agent header allows bot developers to identify themselves, i.e. MyBotCrawler/1.1. However, user agent headers alone are easily spoofed and are therefore insufficient for reliable identification. To address this, user agent checks are often supplemented with IP address validation, the inspection of published IP address ranges to confirm a crawler’s authenticity. However, the logic around IP address ranges representing a product or group of users is brittle – connections from the crawling service might be shared by multiple users, such as in the case of privacy proxies and VPNs, and these ranges, often maintained by cloud providers, change over time.
Cloudflare will always try to block malicious bots, but we think our role here is to also provide an affirmative mechanism to authenticate desirable bot traffic. By using well-established cryptography techniques, we’re proposing a better mechanism for legitimate agents and bots to declare who they are, and provide a clearer signal for site owners to decide what traffic to permit.
Today, we’re introducing two proposals – HTTP message signatures and request mTLS – for friendly bots to authenticate themselves, and for customer origins to identify them. In this blog post, we’ll share how these authentication mechanisms work, how we implemented them, and how you can participate in our closed beta.
Existing bot verification mechanisms are broken
Historically, if you’ve worked on ChatGPT, Claude, Gemini, or any other agent, you’ve had several options to identify your HTTP traffic to other services:
You define a user agent, an HTTP header described in RFC 9110. The problem here is that this header is easily spoofable and there’s not a clear way for agents to identify themselves as semi-automated browsers — agents often use the Chrome user agent for this very reason, which is discouraged. The RFC states: “If a user agent masquerades as a different user agent, recipients can assume that the user intentionally desires to see responses tailored for that identified user agent, even if they might not work as well for the actual user agent being used.”
You publish your IP address range(s). This has limitations because the same IP address might be shared by multiple users or multiple services within the same company, or even by multiple companies when hosting infrastructure is shared (like Cloudflare Workers, for example). In addition, IP addresses are prone to change as underlying infrastructure changes, leading services to use ad-hoc sharing mechanisms like CIDR lists.
You go to every website and share a secret, like a Bearer token. This is impractical at scale because it requires developers to maintain separate tokens for each website their bot will visit.
We can do better! Instead of these arduous methods, we’re proposing that developers of bots and agents cryptographically sign requests originating from their service. When protecting origins, reverse proxies such as Cloudflare can then validate those signatures to confidently identify the request source on behalf of site owners, allowing them to take action as they see fit.
A typical system has three actors:
User: the entity that wants to perform some actions on the web. This may be a human, an automated program, or anything taking action to retrieve information from the web.
Agent: an orchestrated browser or software program. For example, Chrome on your computer, or OpenAI’s Operator with ChatGPT. Agents can interact with the web according to web standards (HTML rendering, JavaScript, subrequests, etc.).
Origin: the website hosting a resource. The user wants to access it through the browser. This is Cloudflare when your website is using our services, and it’s your own server(s) when exposed directly to the Internet.
In the next section, we’ll dive into HTTP Message Signatures and request mTLS, two mechanisms a browser agent may implement to sign outgoing requests, with different levels of ease for an origin to adopt.
Introducing HTTP Message Signatures
HTTP Message Signatures is a standard that defines the cryptographic authentication of a request sender. It’s essentially a cryptographically sound way to say, “hey, it’s me!”. It’s not the only way that developers can sign requests from their infrastructure — for example, AWS has used Signature v4, and Stripe has a framework for authenticating webhooks — but Message Signatures is a published standard, and the cleanest, most developer-friendly way to sign requests.
We’re working closely with the wider industry to support these standards-based approaches. For example, OpenAI has started to sign their requests. In their own words:
“Ensuring the authenticity of Operator traffic is paramount. With HTTP Message Signatures (RFC 9421), OpenAI signs all Operator requests so site owners can verify they genuinely originate from Operator and haven’t been tampered with” – Eugenio, Engineer, OpenAI
Without further delay, let’s dive in how HTTP Messages Signatures work to identify bot traffic.
Scoping standards to bot authentication
Generating a message signature works like this: before sending a request, the agent signs the target origin with a public key. When fetching https://example.com/path/to/resource, it signs example.com. This public key is known to the origin, either because the agent is well known, because it has previously registered, or any other method. Then, the agent writes a Signature-Input header with the following parameters:
A validity window (created and expires timestamps)
A Key ID that uniquely identifies the key used in the signature. This is a JSON Web Key Thumbprint.
A tag that shows websites the signature’s purpose and validation method, i.e. web-bot-auth for bot authentication.
In addition, the Signature-Agent header indicates where the origin can find the public keys the agent used when signing the request, such as in a directory hosted by signer.example.com. This header is part of the signed content as well.
For those building bots, we propose signing the authority of the target URI, i.e. crawler.search.google.com for Google Search, operator.openai.com for OpenAI Operator, workers.dev for Cloudflare Workers, and a way to retrieve the bot public key in the form of signature-agent, if present.
The User-Agent from the example above indicates that the software making the request is Chrome, because it is an agent that uses an orchestrated Chrome to browse the web. You should note that MyBotCrawler/1.1 is still present. The User-Agent header can actually contain multiple products, in decreasing order of importance. If our agent is making requests via Chrome, that’s the most important product and therefore comes first.
At Internet-level scale, these signatures may add a notable amount of overhead to request processing. However, with the right cryptographic suite, and compared to the cost of existing bot mitigation, both technical and social, this seems to be a straightforward tradeoff. This is a metric we will monitor closely, and report on as adoption grows.
Generating request signatures
We’re making several examples for generating Message Signatures for bots and agents available on Github (though we encourage other implementations!), all of which are standards-compliant, to maximize interoperability.
Imagine you’re building an agent using a managed Chromium browser, and want to sign all outgoing requests. To achieve this, the webextensions standard provides chrome.webRequest.onBeforeSendHeaders, where you can modify HTTP headers before they are sent by the browser. The event is triggered before sending any HTTP data, and when headers are available.
Here’s what that code would look like:
chrome.webRequest.onBeforeSendHeaders.addListener(
function (details) {
// Signature and header assignment logic goes here
// <CODE>
},
{ urls: ["<all_urls>"] },
["blocking", "requestHeaders"] // requires "installation_mode": "force_installed"
);
Cloudflare provides a web-bot-auth helper package on npm that helps you generate request signatures with the correct parameters. onBeforeSendHeaders is a Chrome extension hook that needs to be implemented synchronously. To do so, we import {signatureHeadersSync} from “web-bot-auth”. Once the signature completes, both Signature and Signature-Input headers are assigned. The request flow can then continue.
const request = new URL(details.url);
const created = new Date();
const expired = new Date(created.getTime() + 300_000)
// Perform request signature
const headers = signatureHeadersSync(
request,
new Ed25519Signer(jwk),
{ created, expires }
);
// `headers` object now contains `Signature` and `Signature-Input` headers that can be used
Using our debug server, we can now inspect and validate our request signatures from the perspective of the website we’d be visiting. We should now see the Signature and Signature-Input headers:
In this example, the homepage of the debugging server validates the signature from the RFC 9421 Ed25519 verifying key, which the extension uses for signing.
The above demo and code walkthrough has been fully written in TypeScript: the verification website is on Cloudflare Workers, and the client is a Chrome browser extension. We are cognisant that this does not suit all clients and servers on the web. To demonstrate the proposal works in more environments, we have also implemented bot signature validation in Go with a plugin for Caddy server.
Experimentation with request mTLS
HTTP is not the only way to convey signatures. For instance, one mechanism that has been used in the past to authenticate automated traffic against secured endpoints is mTLS, the “mutual” presentation of TLS certificates. As described in our knowledge base:
Mutual TLS, or mTLS for short, is a method formutual authentication. mTLS ensures that the parties at each end of a network connection are who they claim to be by verifying that they both have the correct privatekey. The information within their respectiveTLS certificates provides additional verification.
While mTLS seems like a good fit for bot authentication on the web, it has limitations. If a user is asked for authentication via the mTLS protocol but does not have a certificate to provide, they would get an inscrutable and unskippable error. Origin sites need a way to conditionally signal to clients that they accept or require mTLS authentication, so that only mTLS-enabled clients use it.
A TLS flag for bot authentication
TLS flags are an efficient way to describe whether a feature, like mTLS, is supported by origin sites. Within the IETF, we have proposed a new TLS flag called req mTLS to be sent by the client during the establishment of a connection that signals support for authentication via a client certificate.
This proposal leverages the tls-flags proposal under discussion in the IETF. The TLS Flags draft allows clients and servers to send an array of one bit flags to each other, rather than creating a new extension (with its associated overhead) for each piece of information they want to share. This is one of the first uses of this extension, and we hope that by using it here we can help drive adoption.
When a client sends the req mTLS flag to the server, they signal to the server that they are able to respond with a certificate if requested. The server can then safely request a certificate without risk of blocking ordinary user traffic, because ordinary users will never set this flag.
Let’s take a look at what an example of such a req mTLS would look like in Wireshark, a network protocol analyser. You can follow along in the packet capture here.
The extension number is 65025, or 0xfe01. This corresponds to an unassigned block of TLS extensions that can be used to experiment with TLS Flags. Once the standard is adopted and published by the IETF, the number would be fixed. To use the req mTLS flag the client needs to set the 80th bit to true, so with our block length of 12 bytes, it should contain the data 0b0000000000000000000001, which is the case here. The server then responds with a certificate request, and the request follows its course.
This example library allows you to configure Go to send req mTLS 0xfe01 bytes in the TLS Flags extension. If you’d like to test your implementation out, you can prompt your client for certificates against req-mtls.research.cloudflare.com using the Cloudflare Research client cloudflareresearch/req-mtls. For clients, once they set the TLS Flags associated with req mTLS, they are done. The code section taking care of normal mTLS will take over at that point, with no need to implement something new.
Two approaches, one goal
We believe that developers of agents and bots should have a public, standard way to authenticate themselves to CDNs and website hosting platforms, regardless of the technology they use or provider they choose. At a high level, both HTTP Message Signatures and request mTLS achieve a similar goal: they allow the owner of a service to authentically identify themselves to a website. That’s why we’re participating in the standardizing effort for both of these protocols at the IETF, where many other authentication mechanisms we’ve discussed here — from TLS to OAuth Bearer tokens –— been developed by diverse sets of stakeholders and standardized as RFCs.
Evaluating both proposals against each other, we’re prioritizing HTTP Message Signatures for Bots because it relies on the previously adopted RFC 9421 with several reference implementations, and works at the HTTP layer, making adoption simpler. request mTLS may be a better fit for site owners with concerns about the additional bandwidth, but TLS Flags has fewer implementations, is still waiting for IETF adoption, and upgrading the TLS stack has proven to be more challenging than with HTTP. Both approaches share similar discovery and key management concerns, as highlighted in a glossary draft at the IETF. We’re actively exploring both options, and would love to hear from both site owners and bot developers about how you’re evaluating their respective tradeoffs.
The bigger picture
In conclusion, we think request signatures and mTLS are promising mechanisms for bot owners and developers of AI agents to authenticate themselves in a tamper-proof manner, forging a path forward that doesn’t rely on ever-changing IP address ranges or spoofable headers such as User-Agent. This authentication can be consumed by Cloudflare when acting as a reverse proxy, or directly by site owners on their own infrastructure. This means that as a bot owner, you can now go to content creators and discuss crawling agreements, with as much granularity as the number of bots you have. You can start implementing these solutions today and test them against the research websites we’ve provided in this post.
Bot authentication also empowers site owners small and large to have more control over the traffic they allow, empowering them to continue to serve content on the public Internet while monitoring automated requests. Longer term, we will integrate these authentication mechanisms into our AI Audit and Bot Management products, to provide better visibility into the bots and agents that are willing to identify themselves.
Being able to solve problems for both origins and clients is key to helping build a better Internet, and we think identification of automated traffic is a step towards that. If you want us to start verifying your message signatures or client certificates, have a compelling use case you’d like us to consider, or any questions, please reach out.
Today, we’re excited to announce AI Labyrinth, a new mitigation approach that uses AI-generated content to slow down, confuse, and waste the resources of AI Crawlers and other bots that don’t respect “no crawl” directives. When you opt in, Cloudflare will automatically deploy an AI-generated set of linked pages when we detect inappropriate bot activity, without the need for customers to create any custom rules.
AI Labyrinth is available on an opt-in basis to all customers, including the Free plan.
Using Generative AI as a defensive weapon
AI-generated content has exploded, reportedly accounting for four of the top 20 Facebook posts last fall. Additionally, Medium estimates that 47% of all content on their platform is AI-generated. Like any newer tool it has both wonderful and malicious uses.
At the same time, we’ve also seen an explosion of new crawlers used by AI companies to scrape data for model training. AI Crawlers generate more than 50 billion requests to the Cloudflare network every day, or just under 1% of all web requests we see. While Cloudflare has several tools for identifying and blocking unauthorized AI crawling, we have found that blocking malicious bots can alert the attacker that you are on to them, leading to a shift in approach, and a never-ending arms race. So, we wanted to create a new way to thwart these unwanted bots, without letting them know they’ve been thwarted.
To do this, we decided to use a new offensive tool in the bot creator’s toolset that we haven’t really seen used defensively: AI-generated content. When we detect unauthorized crawling, rather than blocking the request, we will link to a series of AI-generated pages that are convincing enough to entice a crawler to traverse them. But while real looking, this content is not actually the content of the site we are protecting, so the crawler wastes time and resources.
As an added benefit, AI Labyrinth also acts as a next-generation honeypot. No real human would go four links deep into a maze of AI-generated nonsense. Any visitor that does is very likely to be a bot, so this gives us a brand-new tool to identify and fingerprint bad bots, which we add to our list of known bad actors. Here’s how we do it…
How we built the labyrinth
When AI crawlers follow these links, they waste valuable computational resources processing irrelevant content rather than extracting your legitimate website data. This significantly reduces their ability to gather enough useful information to train their models effectively.
To generate convincing human-like content, we used Workers AI with an open source model to create unique HTML pages on diverse topics. Rather than creating this content on-demand (which could impact performance), we implemented a pre-generation pipeline that sanitizes the content to prevent any XSS vulnerabilities, and stores it in R2 for faster retrieval. We found that generating a diverse set of topics first, then creating content for each topic, produced more varied and convincing results. It is important to us that we don’t generate inaccurate content that contributes to the spread of misinformation on the Internet, so the content we generate is real and related to scientific facts, just not relevant or proprietary to the site being crawled.
This pre-generated content is seamlessly integrated as hidden links on existing pages via our custom HTML transformation process, without disrupting the original structure or content of the page. Each generated page includes appropriate meta directives to protect SEO by preventing search engine indexing. We also ensured that these links remain invisible to human visitors through carefully implemented attributes and styling. To further minimize the impact to regular visitors, we ensured that these links are presented only to suspected AI scrapers, while allowing legitimate users and verified crawlers to browse normally.
A graph of daily requests over time, comparing different categories of AI Crawlers.
What makes this approach particularly effective is its role in our continuously evolving bot detection system. When these links are followed, we know with high confidence that it’s automated crawler activity, as human visitors and legitimate browsers would never see or click them. This provides us with a powerful identification mechanism, generating valuable data that feeds into our machine learning models. By analyzing which crawlers are following these hidden pathways, we can identify new bot patterns and signatures that might otherwise go undetected. This proactive approach helps us stay ahead of AI scrapers, continuously improving our detection capabilities without disrupting the normal browsing experience.
By building this solution on our developer platform, we’ve created a system that serves convincing decoy content instantly while maintaining consistent quality – all without impacting your site’s performance or user experience.
How to use AI Labyrinth to stop AI crawlers
Enabling AI Labyrinth is simple and requires just a single toggle in your Cloudflare dashboard. Navigate to the bot management section within your zone, and toggle the new AI Labyrinth setting to on:
Once enabled, the AI Labyrinth begins working immediately with no additional configuration needed.
AI honeypots, created by AI
The core benefit of AI Labyrinth is to confuse and distract bots. However, a secondary benefit is to serve as a next-generation honeypot. In this context, a honeypot is just an invisible link that a website visitor can’t see, but a bot parsing HTML would see and click on, therefore revealing itself to be a bot. Honeypots have been used to catch hackers as early as the late 1986 Cuckoo’s Egg incident. And in 2004, Project Honeypot was created by Cloudflare founders (prior to founding Cloudflare) to let everyone easily deploy free email honeypots, and receive lists of crawler IPs in exchange for contributing to the database. But as bots have evolved, they now proactively look for honeypot techniques like hidden links, making this approach less effective.
AI Labyrinth won’t simply add invisible links, but will eventually create whole networks of linked URLs that are much more realistic, and not trivial for automated programs to spot. The content on the pages is obviously content no human would spend time-consuming, but AI bots are programmed to crawl rather deeply to harvest as much data as possible. When bots hit these URLs, we can be confident they aren’t actual humans, and this information is recorded and automatically fed to our machine learning models to help improve our bot identification. This creates a beneficial feedback loop where each scraping attempt helps protect all Cloudflare customers.
What’s next
This is only the first iteration of using generative AI to thwart bots for us. Currently, while the content we generate is convincingly human, it won’t conform to the existing structure of every website. In the future, we’ll continue to work to make these links harder to spot and make them fit seamlessly into the existing structure of the website they’re embedded in. You can help us by opting in now.
Within the Cloudflare Application Security team, every machine learning model we use is underpinned by a rich set of static rules that serve as a ground truth and a baseline comparison for how our models are performing. These are called heuristics. Our Bot Management heuristics engine has served as an important part of eight global machine learning (ML) models, but we needed a more expressive engine to increase our accuracy. In this post, we’ll review how we solved this by moving our heuristics to the Cloudflare Ruleset Engine. Not only did this provide the platform we needed to write more nuanced rules, it made our platform simpler and safer, and provided Bot Management customers more flexibility and visibility into their bot traffic.
Bot detection via simple heuristics
In Cloudflare’s bot detection, we build heuristics from attributes like software library fingerprints, HTTP request characteristics, and internal threat intelligence. Heuristics serve three separate purposes for bot detection:
Bot identification: If traffic matches a heuristic, we can identify the traffic as definitely automated traffic (with a bot score of 1) without the need of a machine learning model.
Train ML models: When traffic matches our heuristics, we create labelled datasets of bot traffic to train new models. We’ll use many different sources of labelled bot traffic to train a new model, but our heuristics datasets are one of the highest confidence datasets available to us.
Validate models: We benchmark any new model candidate’s performance against our heuristic detections (among many other checks) to make sure it meets a required level of accuracy.
While the existing heuristics engine has worked very well for us, as bots evolved we needed the flexibility to write increasingly complex rules. Unfortunately, such rules were not easily supported in the old engine. Customers have also been asking for more details about which specific heuristic caught a request, and for the flexibility to enforce different policies per heuristic ID. We found that by building a new heuristics framework integrated into the Cloudflare Ruleset Engine, we could build a more flexible system to write rules and give Bot Management customers the granular explainability and control they were asking for.
The need for more efficient, precise rules
In our previous heuristics engine, we wrote rules in Lua as part of our openresty-based reverse proxy. The Lua-based engine was limited to a very small number of characteristics in a rule because of the high engineering cost we observed with adding more complexity.
With Lua, we would write fairly simple logic to match on specific characteristics of a request (i.e. user agent). Creating new heuristics of an existing class was fairly straight forward. All we’d need to do is define another instance of the existing class in our database. However, if we observed malicious traffic that required more than two characteristics (as a simple example, user-agent and ASN) to identify, we’d need to create bespoke logic for detections. Because our Lua heuristics engine was bundled with the code that ran ML models and other important logic, all changes had to go through the same review and release process. If we identified malicious traffic that needed a new heuristic class, and we were also blocked by pending changes in the codebase, we’d be forced to either wait or rollback the changes. If we’re writing a new rule for an “under attack” scenario, every extra minute it takes to deploy a new rule can mean an unacceptable impact to our customer’s business.
More critical than time to deploy is the complexity that the heuristics engine supports. The old heuristics engine only supported using specific request attributes when creating a new rule. As bots became more sophisticated, we found we had to reject an increasing number of new heuristic candidates because we weren’t able to write precise enough rules. For example, we found a Golang TLS fingerprint frequently used by bots and by a small number of corporate VPNs. We couldn’t block the bots without also stopping the legitimate VPN usage as well, because the old heuristics platform lacked the flexibility to quickly compile sufficiently nuanced rules. Luckily, we already had the perfect solution with Cloudflare Ruleset Engine.
Our new heuristics engine
The Ruleset Engine is familiar to anyone who has written a WAF rule, Load Balancing rule, or Transform rule, just to name a few. For Bot Management, the Wireshark-inspired syntax allows us to quickly write heuristics with much greater flexibility to vastly improve accuracy. We can write a rule in YAML that includes arbitrary sub-conditions and inherit the same framework the WAF team uses to both ensure any new rule undergoes a rigorous testing process with the ability to rapidly release new rules to stop attacks in real-time.
Writing heuristics on the Cloudflare Ruleset Engine allows our engineers and analysts to write new rules in an easy to understand YAML syntax. This is critical to supporting a rapid response in under attack scenarios, especially as we support greater rule complexity. Here’s a simple rule using the new engine, to detect empty user-agents restricted to a specific JA4 fingerprint (right), compared to the empty user-agent detection in the old Lua based system (left):
--- Adds heuristic to be used for inference in `detect` method
-- @param heuristic schema.Heuristic table
function EmptyUserAgentHeuristic:add(heuristic)
self.heuristic = heuristic
end
--- Detect runs empty user agent heuristic detection
-- @param ctx context of request
-- @return schema.Heuristic table on successful detection or nil otherwise
function EmptyUserAgentHeuristic:detect(ctx)
local ua = ctx.user_agent
if not ua or ua == '' then
return self.heuristic
end
end
return _M
ref: empty-user-agent
description: Empty or missing
User-Agent header
action: add_bot_detection
action_parameters:
active_mode: false
expression: http.user_agent eq
"" and cf.bot_management.ja4 = "t13d1516h2_8daaf6152771_b186095e22b6"
The Golang heuristic that captured corporate proxy traffic as well (mentioned above) was one of the first to migrate to the new Ruleset engine. Before the migration, traffic matching on this heuristic had a false positive rate of 0.01%. While that sounds like a very small number, this means for every million bots we block, 100 real users saw a Cloudflare challenge page unnecessarily. At Cloudflare scale, even small issues can have real, negative impact.
When we analyzed the traffic caught by this heuristic rule in depth, we saw the vast majority of attack traffic came from a small number of abusive networks. After narrowing the definition of the heuristic to flag the Golang fingerprint only when it’s sourced by the abusive networks, the rule now has a false positive rate of 0.0001% (One out of 1 million). Updating the heuristic to include the network context improved our accuracy, while still blocking millions of bots every week and giving us plenty of training data for our bot detection models. Because this heuristic is now more accurate, newer ML models make more accurate decisions on what’s a bot and what isn’t.
New visibility and flexibility for Bot Management customers
While the new heuristics engine provides more accurate detections for all customers and a better experience for our analysts, moving to the Cloudflare Ruleset Engine also allows us to deliver new functionality for Enterprise Bot Management customers, specifically by offering more visibility. This new visibility is via a new field for Bot Management customers called Bot Detection IDs. Every heuristic we use includes a unique Bot Detection ID. These are visible to Bot Management customers in analytics, logs, and firewall events, and they can be used in the firewall to write precise rules for individual bots.
Detections also include a specific tag describing the class of heuristic. Customers see these plotted over time in their analytics.
To illustrate how this data can help give customers visibility into why we blocked a request, here’s an example request flagged by Bot Management (with the IP address, ASN, and country changed):
Before, just seeing that our heuristics gave the request a score of 1 was not very helpful in understanding why it was flagged as a bot. Adding our Detection IDs to Firewall Events helps to paint a better picture for customers that we’ve identified this request as a bot because that traffic used an empty user-agent.
In addition to Analytics and Firewall Events, Bot Detection IDs are now available for Bot Management customers to use in Custom Rules, Rate Limiting Rules, Transform Rules, and Workers.
Account takeover detection IDs
One way we’re focused on improving Bot Management for our customers is by surfacing more attack-specific detections. During Birthday Week, we launched Leaked Credentials Check for all customers so that security teams could help prevent account takeover (ATO) attacks by identifying accounts at risk due to leaked credentials. We’ve now added two more detections that can help Bot Management enterprise customers identify suspicious login activity via specific detection IDs that monitor login attempts and failures on the zone. These detection IDs are not currently affecting the bot score, but will begin to later in 2025. Already, they can help many customers detect more account takeover events now.
Detection ID 201326592 monitors traffic on a customer website and looks for an anomalous rise in login failures (usually associated with brute force attacks), and ID 201326593 looks for an anomalous rise in login attempts (usually associated with credential stuffing).
Protect your applications
If you are a Bot Management customer, log in and head over to the Cloudflare dashboard and take a look in Security Analytics for bot detection IDs 201326592 and 201326593.
These will highlight ATO attempts targeting your site. If you spot anything suspicious, or would like to be protected against future attacks, create a rule that uses these detections to keep your application safe.
Security and attacks continues to be a very active environment, and the visibility that Cloudflare Radar provides on this dynamic landscape has evolved and expanded over time. To that end, during 2023’s Security Week, we launched our URL Scanner, which enables users to safely scan any URL to determine if it is safe to view or interact with. During 2024’s Security Week, we launched an Email Security page, which provides a unique perspective on the threats posed by malicious emails, spam volume, the adoption of email authentication methods like SPF, DMARC, and DKIM, and the use of IPv4/IPv6 and TLS by email servers. For Security Week 2025, we are adding several new DDoS-focused graphs, new insights into leaked credential trends, and a new Bots page to Cloudflare Radar. We are also taking this opportunity to refactor Radar’s Security & Attacks page, breaking it out into Application Layer and Network Layer sections.
Below, we review all of these changes and additions to Radar.
Layered security
Since Cloudflare Radar launched in 2020, it has included both network layer (Layers 3 & 4) and application layer (Layer 7) attack traffic insights on a single Security & Attacks page. Over the last four-plus years, we have evolved some of the existing data sets on the page, as well as adding new ones. As the page has grown and improved over time, it risked becoming unwieldy to navigate, making it hard to find the graphs and data of interest. To help address that, the Security section on Radar now features separate Application Layer and Network Layer pages. The Application Layer page is the default, and includes insights from analysis of HTTP-based malicious and attack traffic. The Network Layer page includes insights from analysis of network and transport layer attacks, as well as observed TCP resets and timeouts. Future security and attack-related data sets will be added to the relevant page. Email Security remains on its own dedicated page.
A geographic and network view of application layer DDoS attacks
Radar’s quarterly DDoS threat reports have historically provided insights, aggregated on a quarterly basis, into the top source and target locations of application layer DDoS attacks. A new map and table on Radar’s Application Layer Security page now provide more timely insights, with a global choropleth map showing a geographical distribution of source and target locations, and an accompanying list of the top 20 locations by share of all DDoS requests. Source location attribution continues to rely on the geolocation of the IP address originating the blocked request, while target location remains the billing location of the account that owns the site being attacked.
Over the first week of March 2025, the United States, Indonesia, and Germany were the top sources of application layer DDoS attacks, together accounting for over 30% of such attacks as shown below. The concentration across the top targeted locations was quite different, with customers from Canada, the United States, and Singapore attracting 56% of application layer DDoS attacks.
In addition to extended visibility into the geographic source of application layer DDoS attacks, we have also added autonomous system (AS)-level visibility. A new treemap view shows the distribution of these attacks by source AS. At a global level, the largest sources include cloud/hosting providers in Germany, the United States, China, and Vietnam.
For a selected country/region, the treemap displays a source AS distribution for attacks observed to be originating from that location. In some, the sources of attack traffic are heavily concentrated in consumer/business network providers, such as in Portugal, shown below. However, in other countries/regions that have a large cloud provider presence, such as Ireland, Singapore, and the United States, ASNs associated with these types of providers are the dominant sources. To that end, Singapore was listed as being among the top sources of application layer DDoS attacks in each of the quarterly DDoS threat reports in 2024.
Have you been pwned?
Every week, it seems like there’s another headline about a data breach, talking about thousands or millions of usernames and passwords being stolen. Or maybe you get an email from an identity monitoring service that your username and password were found on the “dark web”. (Of course, you’re getting those alerts thanks to a complementary subscription to the service offered as penance from another data breach…)
This credential theft is especially problematic because people often reuse passwords, despite best practices advising the use of strong, unique passwords for each site or application. To help mitigate this risk, starting in 2024, Cloudflare began enabling customers to scan authentication requests for their websites and applications using a privacy-preserving compromised credential checker implementation to detect known-leaked usernames and passwords. Today, we’re using aggregated data to display trends in how often these leaked and stolen credentials are observed across Cloudflare’s network. (Here, we are defining “leaked credentials” as usernames or passwords being found in a public dataset, or the username and password detected as being similar.)
Leaked credentials detection scans incoming HTTP requests for known authentication patterns from common web apps and any custom detection locations that were configured. The service uses a privacy-preserving compromised credential checking protocol to compare a hash of the detected passwords to hashes of compromised passwords found in databases of leaked credentials. A new Radar graph on the worldwide Application Layer Security page provides visibility into aggregate trends around the detection of leaked credentials in authentication requests. Filterable by authentication requests from human users, bots, or all (human + bot), the graph shows the distribution requests classified as “clean” (no leaked credentials detected) and “compromised” (leaked credentials, as defined above, were used). At a worldwide level, we found that for the first week of March 2025, leaked credentials were used in 64% of all, over 65% of bot, and over 44% of human authorization requests.
This suggests that from a human perspective, password reuse is still a problem, as is users not taking immediate actions to change passwords when notified of a breach. And from a bot perspective, this suggests that attackers know that there is a good chance that leaked credentials for one website or application will enable them to access that same user’s account elsewhere.
As a complement to the leaked credentials data, Radar is also now providing a worldwide view into the share of authentication requests originating from bots. Note that not all of these requests are necessarily malicious — while some may be associated with credential stuffing-style attacks, others may be from automated scripts or other benign applications accessing an authentication endpoint. (Having said that, automated malicious attack request volume far exceeds legitimate automated login attempts.) During the first week of March 2025, we found that over 94% of authentication requests came from bots (were automated), with the balance coming from humans. Over that same period, bot traffic only accounted for 30% of overall requests. So although bots don’t represent a majority of request traffic, authentication requests appear to comprise a significant portion of their activity.
Bots get a dedicated page
As a reminder, bot traffic describes any non-human Internet traffic, and monitoring bot levels can help spot potential malicious activities. Of course, bots can be helpful too, and Cloudflare maintains a list of verified bots to help keep the Internet healthy. Given the importance of monitoring bot activity, we have launched a new dedicated Bots page in the Traffic section of Cloudflare Radar to support these efforts. For both worldwide and location views over the selected time period, the page shows the distribution of bot (automated) vs. human HTTP requests, as well as a graph showing bot traffic trends. (Our bot score, combining machine learning, heuristics, and other techniques, is used to identify automated requests likely to be coming from bots.)
Both the 2023 and 2024 Cloudflare Radar Year in Review microsites included a “Bot Traffic Sources” section, showing the locations and networks that Cloudflare determined that the largest shares of automated/likely automated traffic was originating from. However, these traffic shares were published just once a year, aggregating traffic from January through the end of November.
In order to provide a more timely perspective, these insights are now available on the new Radar Bots page. Similar to the new DDoS attacks content discussed above, the worldwide view includes a choropleth map and table illustrating the locations originating the largest shares of all bot traffic. (Note that a similar Traffic Characteristics map and table on the Traffic Overview page ranks locations by the bot traffic share of the location’s total traffic.) Similar to Year in Review data linked above, the United States continues to originate the largest share of bot traffic.
In addition, the worldwide view also breaks out bot traffic share by AS, mirroring the treemap shown in the Year in Review. As we have noted previously, cloud platform providers account for a significant amount of bot traffic.
At a location level, depending on the country/region selected, the top sources of bot traffic may be cloud/hosting providers, consumer/business network providers, or a mix. For instance, France’s distribution is shown below, and four ASNs account for just over half of the country’s bot traffic. Of these ASNs, two (AS16276 and AS12876) belong to cloud/hosting providers, and two (AS3215 and AS12322) belong to network providers.
In addition, the Verified Bots list has been moved to the new Bots page on Radar. The data shown and functionality remains unchanged, and links to the old location will automatically be redirected to the new one.
Summary
The Cloudflare dashboard provides customers with specific views of security trends, application and network layer attacks, and bot activity across their sites and applications. While these views are useful at an individual customer level, aggregated views at a worldwide, location, and network level provide a macro-level perspective on trends and activity. These aggregated views available on Cloudflare Radar not only help customers understand how their observations compare to the larger whole, but they also help the industry understand emerging threats that may require action.
The underlying data for the graphs and data discussed above is available via the Radar API (Application Layer, Network Layer, Bots, Leaked Credentials). The data can also be interactively explored in more detail across locations, networks, and time periods using Radar’s Data Explorer and AI Assistant. And as always, Radar and Data Explorer charts and graphs are downloadable for sharing, and embeddable for use in your own blog posts, websites, or dashboards.
Accessing private content online, whether it’s checking email or streaming your favorite show, almost always starts with a “login” step. Beneath this everyday task lies a widespread human mistake we still have not resolved: password reuse. Many users recycle passwords across multiple services, creating a ripple effect of risk when their credentials are leaked.
Based on Cloudflare’s observed traffic between September – November 2024, 41% of successful logins across websites protected by Cloudflare involve compromised passwords. In this post, we’ll explore the widespread impact of password reuse, focusing on how it affects popular Content Management Systems (CMS), the behavior of bots versus humans in login attempts, and how attackers exploit stolen credentials to take over accounts at scale.
Scope of the analysis
Our data analysis focuses on traffic from Internet properties on Cloudflare’s free plan, which includes leaked credentials detection as a built-in feature. Leaked credentials refer to usernames and passwords exposed in known data breaches or credential dumps — for this analysis, our focus is specifically on leaked passwords. With 30 million Internet properties, comprising some 20% of the web, behind Cloudflare, this analysis provides significant insights. The data primarily reflects trends observed after the detection system was launched during Birthday Week in September 2024.
Nearly 41% of logins are at risk
One of the biggest challenges in authentication is distinguishing between legitimate human users and malicious actors. To understand human behavior, we focus on successful login attempts (those returning a 200 OK status code), as this provides the clearest indication of user activity and real account risk. Our data reveals that approximately 41% of successful human authentication attempts involve leaked credentials.
Despite growing awareness about online security, a significant portion of users continue to reuse passwords across multiple accounts. And according to a recent study by Forbes, users will, on average, reuse their password across four different accounts. Even after major breaches, many individuals don’t change their compromised passwords, or still use variations of them across different services. For these users, it’s not a matter of “if” attackers will use their compromised passwords, it’s a matter of “when”.
When we expand to include bot-driven traffic in this analysis, the problem of leaked credentials becomes even more noticeable. Our data reveals that 52% of all detected authentication requests contain leaked passwords found in our database of over 15 billion records, including the Have I Been Pwned (HIBP) leaked password dataset.
This percentage represents hundreds of millions of daily authentication requests, originating from both bots and humans. While not every attempt succeeds, the sheer volume of leaked credentials in real-world traffic illustrates how common password reuse is. Many of these leaked credentials still grant valid access, amplifying the risk of account takeovers.
Attackers heavily use leaked password datasets
Bots are the driving force behind credential-stuffing attacks, the data indicates that95% of login attempts involving leaked passwords are coming from bots,indicating that they are part of credential stuffing attacks.
Equipped with credentials stolen from breaches, bots systematically target websites at scale, testing thousands of login combinations in seconds.
Data from the Cloudflare network exposes this trend, showing that bot-driven attacks remain alarmingly high over time. Popular platforms like WordPress, Joomla, and Drupal are frequent targets, due to their widespread use and exploitable vulnerabilities, as we will explore in the upcoming section.
Once bots successfully breach one account, attackers reuse the same credentials across other services to amplify their reach. They even sometimes try to evade detection by using sophisticated evasion tactics, such as spreading login attempts across different source IP addresses or mimicking human behavior, attempting to blend into legitimate traffic.
The result is a constant, automated threat vector that challenges traditional security measures and exploits the weakest link: password reuse.
Brute force attacks against WordPress
Content Management Systems (CMS) are used to build websites, and often rely on simple authentication and login plugins. This is convenient, but also makes them frequent targets of credential stuffing attacks due to their widespread adoption. WordPress is a very popular content management system with a well known user login page format. Because of this, websites built on WordPress often become common targets for attackers.
Across our network, WordPress accounts for a significant portion of authentication requests. This is unsurprising given its market share. However, what stands out is the alarming number of successful logins using leaked passwords, especially by bots.
76% of leaked password login attempts for websites built on WordPress are successful.
Of these, 48% of successful logins are bot-driven.This is a shocking figure that indicates nearly half of all successful logins are executed by unauthorized systems designed to exploit stolen credentials. Successful unauthorized access is often the first step in account takeover (ATO) attacks.
The remaining 52% of successful logins originate from legitimate, non-bot users. This figure, higher than the average of 41% across all platforms, highlights how pervasive password reuse is among real users, putting their accounts at significant risk.
Only 5% of leaked password login attempts result in access being denied.
This is a low number compared to the successful bot-driven login attempts, and could be tied to a lack of security measures like rate-limiting or multi-factor authentication (MFA). If such measures were in place, we would expect the share of denied attempts to be higher. Notably, 90% of these denied requests are bot-driven, reinforcing the idea that while some security measures are blocking automated logins, many still slip through.
The overwhelming presence of bot traffic in this category points to ongoing automated attempts to brute-force access.
The remaining 19% of login attempts fall under other outcomes, such as timeouts, incomplete logins, or users who changed their passwords, so they neither count as direct “successes” nor do they register as “denials”.
Keeping user accounts safe with Cloudflare
If you’re a user, start with changing reused or weak passwords and use unique, strong ones for each website or application. Enable multi-factor authentication (MFA) on all of your accounts that support it, and start exploring passkeys as a more secure, phishing-resistant alternative to traditional passwords.
For website owners, activate leaked credentials detection to monitor and address these threats in real time and issue password reset flows on leaked credential matches.
Additionally, enable features like Rate Limiting and Bot Management tools to minimize the impact of automated attacks. Audit password reuse patterns, identify leaked credentials within your systems, and enforce robust password hygiene policies to strengthen overall security.
By adopting these measures, both individuals and organizations can stay ahead of attackers and build stronger defenses.
During 2024’s Birthday Week, we launched an AI bot & crawler traffic graph on Cloudflare Radar that provides visibility into which bots and crawlers are the most aggressive and have the highest volume of requests, which crawl on a regular basis, and more. Today, we are launching a new dedicated “AI Insights” page on Cloudflare Radar that incorporates this graph and builds on it with additional metrics that you can use to understand AI-related trends from multiple perspectives. In addition to the traffic trends, the new section includes a view into the relative popularity of publicly available Generative AI services based on 1.1.1.1 DNS resolver traffic, the usage of robots.txt directives to restrict AI bot access to content, and open source model usage as seen by Cloudflare Workers AI.
Below, we’ll review each section of the new AI Insights page in more detail.
AI bots and crawlers traffic trends
Tracking traffic trends for AI bots can help us better understand their activity over time. Initially launched in September 2024 on Radar’s Traffic page, the AI bot & crawler traffic graph has moved to the AI Insights page and provides visibility into traffic trends gathered globally over the selected time period for the top five most active AI bots & crawlers. The associated list of user agents tracked here is based on the ai.robots.txt list, and will be updated with new entries as they are identified. The time series and summary data for this graph is available from the Radar API, and traffic trends for the full set of AI bots & crawlers we see traffic from can be viewed in the Data Explorer.
Popularity of Generative AI services
Over the last several years, the Cloudflare Radar Year in Review has analyzed request traffic data from our 1.1.1.1 DNS resolver to present rankings of the most popular Internet services, both generally and across several categories. In both 2023 and 2024, this section included rankings for publicly-available Generative AI services, with ChatGPT topping the list both years. While an accompanying blog post provides a more detailed look at how the rankings shifted over the course of the year, it too is looking through the rearview mirror. That is, it doesn’t provide visibility into the changes as they are occurring. The new Generative AI services popularity graph shows the relative rankings of these services and platforms based on DNS request traffic for domains associated with these services aggregated at a daily level. The underlying time series data is available through the Radar API, using the serviceCategory=Generative%20AI parameter.
The graph below shows that as of the end of January 2025, the top five services were fairly stable over the preceding four weeks, but there was regular movement among those ranked #6-10. We expect that the rankings will continue to change over time. DeepSeek, a Generative AI service that took the industry by storm at the end of January, can be seen making its initial appearance at #9 on January 26, rising rapidly to #3 on January 29, just three days later.
Analysis of robots.txt files
Content providers can attempt to control access to their full site, or specific portions of it, through the use of Allow or Disallow directives in a robots.txt file. However, successful access control is dependent on the bots respecting the listed directives. Cloudflare’s AI Audit gives you visibility and control into how AI bots are interacting with your website, and now Cloudflare Radar gives you insights into how other sites are handling them.
On a weekly basis, we analyze Radar’s top 10,000 domains to determine which associated sites publish robots.txt files, as well as aggregating the AI-specific directives within those files. In our new AI user agents found in robots.txt graph, seen below, we are now providing insights into actions that these top sites are taking with respect to AI bots. These actions are specified by directives that allow or disallow access by a given user agent (bot identifier) for either all content on the site (Fully Allowed/Disallowed) or certain sections (Partially Allowed/Disallowed).
In addition, we have also organized these domains by category (for example, Ecommerce or News & Media), highlighting the specific bots that the sites within those categories have listed in their directives. For example, the News & Media domain category graph shown below illustrates that these types of sites almost universally fully disallow access to their sites by AI user agents.
Changing the directive to “Allow” shows a much smaller set of user agents, with a drastically smaller set of sites explicitly allowing full or partial access. (Note that if a user agent is not listed in a robots.txt file, and a wildcard “*” user agent is not specified, then access is fully allowed by default.)
In addition to appearing on the AI Insights page, the underlying data is available for further exploration and analysis through the Radar API and the Data Explorer.
Popularity of models and tasks on Workers AI
The AI model landscape is rapidly evolving, with providers regularly releasing more powerful models, capable of tasks like text and image generation, speech recognition, and image classification. Cloudflare works closely with AI model providers to ensure that Workers AI supports these models as soon as possible following their release. On the new AI Insights page, Radar now provides visibility into the popularity of publicly available supported models (Workers AI model popularity) as well as the types of tasks (Workers AI task popularity) that these models perform, based on customer account share. Extended insights, including share trends and summary shares for the full list of models and tasks, as well as the ability to compare model and task shares across time periods, are available through the Data Explorer. The underlying model popularity and task popularity data is also available through API endpoints.
Conclusion
The AI space is extremely dynamic, with new platforms, services, and models regularly appearing. In some cases, these new entrants even have the power to upset the market as they see rapid growth in interest and usage. And over two years since ChatGPT was announced, there continues to be tension between content providers and AI platforms about scraping content for model training. The new “AI Insights” page on Cloudflare Radar provides timely trends and information about this dynamic space, enabling industry observers and participants to better understand how it is changing and evolving over time.
If you share AI Insights graphs on social media, be sure to tag us: @CloudflareRadar (X), noc.social/@cloudflareradar (Mastodon), and radar.cloudflare.com (Bluesky). You can also reach out on social media, or contact us via email, with suggestions for AI metrics that we can explore adding to the page in the future.
Back in 2021, we covered the antics of Grinch Bots and how the combination of proposed regulation and technology could prevent these malicious programs from stealing holiday cheer.
Fast-forward to 2024 — the Stop Grinch Bots Act of 2021 has not passed, and bots are more active and powerful than ever, leaving businesses to fend off increasingly sophisticated attacks on their own. During Black Friday 2024, Cloudflare observed:
29% of all traffic on Black Friday was Grinch Bots. Humans still accounted for the majority of all traffic, but bot traffic was up 4x from three years ago in absolute terms.
1% of traffic on Black Friday came from AI bots. The majority of it came from Claude, Meta, and Amazon. 71% of this traffic was given the green light to access the content requested.
63% of login attempts across our network on Black Friday were from bots. While this number is high, it was down a few percentage points compared to a month prior, indicating that more humans accessed their accounts and holiday deals.
Human logins on e-commerce sites increased 7-8% compared to the previous month.
These days, holiday shopping doesn’t start on Black Friday and stop on Cyber Monday. Instead, it stretches through Cyber Week and beyond, including flash sales, pre-orders, and various other promotions. While this provides consumers more opportunities to shop, it also creates more openings for Grinch Bots to wreak havoc.
Black Friday – Cyber Monday by the numbers
Black Friday and Cyber Monday in 2024 brought record-breaking shopping — and grinching. In addition to looking across our entire network, we also analyzed traffic patterns specifically on a cohort of e-commerce sites.
Legitimate shoppers flocked to e-commerce sites, with requests reaching an astounding 405 billion on Black Friday, accounting for 81% of the day’s total traffic to e-commerce sites. Retailers reaped the rewards of their deals and advertising, seeing a 50% surge in shoppers week-over-week and a 61% increase compared to the previous month.
Unfortunately, Grinch Bots were equally active. Total e-commerce bot activity surged to 103 billion requests, representing up to 19% of all traffic to e-commerce sites. Nearly one in every five requests to an online store was not a real customer. That’s a lot of resources to waste on bogus traffic. Cyber Week was a battleground, with bots hoarding inventory, exploiting deals, and disrupting genuine shopping experiences.
The upside, if there is one, is that there was more human activity on e-commerce sites (81%) than observed on our network more broadly (71%).
The Grinch Bot’s Modus Operandi
Cloudflare saw 4x more bot requests than what we observed in 2021. Being able to observe and score all this traffic at scale means we can help customers keep the grinches away. We also got to see patterns that help us better identify the concentration of these attacks:
19% of traffic on e-commerce sites was Grinch Bots
1% of traffic to e-commerce sites was from AI Bots.
63% of login attempt requests across our network were from bots
22% of bot activity originated from residential proxy networks
What are all of these bots up to?
AI bots
This year marked a breakthrough for AI-driven bots, agents, and models, with their impact spilling into Black Friday. AI bots went from zero to one, now making up 1% of all bot traffic on e-commerce sites.
AI-driven bots generated 29 billion requests on Black Friday alone, with Meta-external, Claudebot, and Amazonbot leading the pack. Based on their owners, these bots are meant to crawl to augment training data sets for Llama, Claude, and Alexa respectively.
We looked at e-commerce sites specifically to find out if these bots were treating all content equally. While Meta-External and Amazonbot were still in the Top 3 of AI bots reaching e-commerce sites, Bytedance’s Bytespider crawled the most shopping sites.
Account Takeover (ATO) bots
In addition to scraping, crawling, and shopping, bots also targeted customer accounts on Black Friday. We saw 14.1 billion requests from bots to /login endpoints, accounting for 63% of that day’s login attempts.
While this number seems high, intuitively it makes sense, given that humans don’t log in to accounts every day, but bots definitely try to crack accounts every day. Interestingly, while humans only accounted for 36% of traffic to login pages on Black Friday, this number was up 7-8% compared to the prior month. This suggests that more shoppers logged in to capitalize on deals and discounts on Black Friday than in preceding weeks. Human logins peaked at around 40% of all traffic to login sites on the Monday before Thanksgiving, and again on Cyber Monday.
Separately, we also saw a 37% increase in leaked passwords used in login requests compared to the prior month. During Birthday Week, we shared how 65% of internet users are at risk of ATO due to re-use of leaked passwords. This surge, coinciding with heightened human and bot traffic, underscores a troubling pattern: both humans and bots continue to depend on common and compromised passwords, amplifying security risks.
Proxy bots: Regardless of whether they’re crawling your content or hoarding your wares, 22% of bot traffic originated from residential proxy networks. This obfuscation makes these requests look like legitimate customers browsing from their homes rather than large cloud networks. The large pool of IP addresses and the diversity of networks poses a challenge to traditional bot defense mechanisms that rely on IP reputation and rate limiting.
Moreover, the diversity of IP addresses enables the attackers to rotate through them indefinitely. This shrinks the window of opportunity for bot detection systems to effectively detect and stop the attacks. The use of residential proxies is a trend we have been tracking for months now and Black Friday traffic was within the range we’ve seen throughout this year.
If you’re using Cloudflare’s Bot Management, your site is already protected from these bots since we update our bot score based on these types of network fingerprints. In May 2024, we introduced our latest model optimized for detecting residential proxies. Early results show promising declines in this type of activity, indicating that bot operators may be reducing their reliance on residential proxies.
The Christmas “Yule” log: how customers can protect themselves
35% of all traffic on Black Friday was Grinch Bots. To keep Grinch Bots at bay, businesses need year-round bot protection and proactive strategies tailored to the unique challenges of holiday shopping.
(2) Monitor potential Account Takeover (ATO) attacks: Bots often test stolen credentials in the months leading up to Cyber Week to refine their strategies. Re-use of stolen credentials makes businesses even more vulnerable. Our account abuse detections help customers monitor login paths for leaked credentials and traffic anomalies.
Check out more examples of related rules you can create.
(3) Rate limit account and purchase paths: Apply rate-limiting best practices on critical application paths. These include limiting new account access/creation from previously seen IP addresses, and leveraging other network fingerprints, to help prevent promo code abuse and inventory hoarding, as well as identifying account takeover attempts through the application of detection IDs and leaked credential checks.
(4) Block AI bots abusing shopping features to maintain fair access for human users. If you’re using Cloudflare, you can quickly block all AI bots by enabling our automatic AI bot blocking feature.
What to expect in 2025?
Over the next year, e-commerce sites should expect to see more humans shopping for longer periods. As sale periods lengthen (like they did in 2024) we expect more peaks in human activity on e-commerce sites across November and December. This is great for consumers and great for merchants.
More AI bots and agents will be integrated into e-commerce journeys in 2025. AI bots will not only be crawling sites for training data, but will also integrate into the shopping experience. AI bots did not exist in 2021, but now make up 1% of all bot traffic. This is only the tip of the iceberg and their growth will explode in the next year. We expect this to pose new risks as bots mimic and act on behalf of humans.
More sophisticated automation through network, device, and cookie cycling will also become a bigger threat. Bot operators will continue to employ advanced evasion tactics like rotating devices, IP addresses, and cookies to bypass detection.
Grinch Bots are evolving, and regulation may be slowing, but businesses don’t have to face them alone. We remain resolute in our mission to help build a better Internet … and holiday shopping experience.
Even though the holiday season is closing out soon, bots are never on vacation. It’s never too late or too early to start protecting your customers and your business from grinches that work all year round.
Wishing you all happy holidays and a bot-free new year!
The continued growth of AI has fundamentally changed the Internet over the past 24 months. AI is increasingly ubiquitous, and Cloudflare is leaning into the new opportunities and challenges it presents in a big way. This year for Cloudflare’s birthday, we’ve extended our AI Assistant capabilities to help you build new WAF rules, added AI bot traffic insights on Cloudflare Radar, and given customers new AI bot blocking capabilities.
AI Assistant for WAF Rule Builder
At Cloudflare, we’re always listening to your feedback and striving to make our products as user-friendly and powerful as possible. One area where we’ve heard your feedback loud and clear is in the complexity of creating custom and rate-limiting rules for our Web Application Firewall (WAF). With this in mind, we’re excited to introduce a new feature that will make rule creation easier and more intuitive: the AI Assistant for WAF Rule Builder.
By simply entering a natural language prompt, you can generate a custom or rate-limiting rule tailored to your needs. For example, instead of manually configuring a complex rule matching criteria, you can now type something like, “Match requests with low bot score,” and the assistant will generate the rule for you. It’s not about creating the perfect rule in one step, but giving you a strong foundation that you can build on.
The assistant will be available in the Custom and Rate Limit Rule Builder for all WAF users. We’re launching this feature in Beta for all customers, and we encourage you to give it a try. We’re looking forward to hearing your feedback (via the UI itself) as we continue to refine and enhance this tool to meet your needs.
AI bot traffic insights on Cloudflare Radar
AI platform providers use bots to crawl and scrape websites, vacuuming up data to use for model training. This is frequently done without the permission of, or a business relationship with, the content owners and providers. In July, Cloudflare urged content owners and providers to “declare their AIndependence”, providing them with a way to block AI bots, scrapers, and crawlers with a single click. In addition to this so-called “easy button” approach, sites can provide more specific guidance to these bots about what they are and are not allowed to access through directives in a robots.txt file. Regardless of whether a customer chooses to block or allow requests from AI-related bots, Cloudflare has insight into request activity from these bots, and associated traffic trends over time.
Tracking traffic trends for AI bots can help us better understand their activity over time — which are the most aggressive and have the highest volume of requests, which launch crawls on a regular basis, etc. The new AI bot & crawler traffic graph on Radar’s Traffic page provides insight into these traffic trends gathered over the selected time period for the top known AI bots. The associated list of bots tracked here is based on the ai.robots.txt list, and will be updated with new bots as they are identified. Time series and summary data is available from the Radar API as well. (Traffic trends for the full set of AI bots & crawlers can be viewed in the new Data Explorer.)
Blocking more AI bots
For Cloudflare’s birthday, we’re following up on our previous blog post, Declaring Your AIndependence, with an update on the new detections we’ve added to stop AI bots. Customers who haven’t already done so can simply click the button to block AI bots to gain more protection for their website.
Enabling dynamic updates for the AI bot rule
The old button allowed customers to block verified AI crawlers, those that respect robots.txt and crawl rate, and don’t try to hide their behavior. We’ve added new crawlers to that list, but we’ve also expanded the previous rule to include 27 signatures (and counting) of AI bots that don’t follow the rules. We want to take time to say “thank you” to everyone who took the time to use our “tip line” to point us towards new AI bots. These tips have been extremely helpful in finding some bots that would not have been on our radar so quickly.
For each bot we’ve added, we’re also adding them to our “Definitely automated” definition as well. So, if you’re a self-service plan customer using Super Bot Fight Mode, you’re already protected. Enterprise Bot Management customers will see more requests shift from the “Likely Bot” range to the “Definitely automated” range, which we’ll discuss more below.
Under the hood, we’ve converted this rule logic to a Cloudflare managed rule (the same framework that powers our WAF). This enables our security analysts and engineers to safely push updates to the rule in real-time, similar to how new WAF rule changes are rapidly delivered to ensure our customers are protected against the latest CVEs. If you haven’t logged back into the Bots dashboard since the previous version of our AI bot protection was announced, click the button again to update to the latest protection.
The impact of new fingerprints on the model
One hidden beneficiary of fingerprinting new AI bots is our ML model. As we’ve discussed before, our global ML model uses supervised machine learning and greatly benefits from more sources of labeled bot data. Below, you can see how well our ML model recognized these requests as automated, before and after we updated the button, adding new rules. To keep things simple, we have shown only the top 5 bots by the volume of requests on the chart. With the introduction of our new managed rule, we have observed an improvement in our detection capabilities for the majority of these AI bots. Button v1 represents the old option that let customers block only verified AI crawlers, while Button v2 is the newly introduced feature that includes managed rule detections.
So how did we make our detections more robust? As we have mentioned before, sometimes a single attribute can give a bot away. We developed a sophisticated set of heuristics tailored to these AI bots, enabling us to effortlessly and accurately classify them as such. Although our ML model was already detecting the vast majority of these requests, the integration of additional heuristics has resulted in a noticeable increase in detection rates for each bot, and ensuring we score every request correctly 100% of the time. Transitioning from a purely machine learning approach to incorporating heuristics offers several advantages, including faster detection times and greater certainty in classification. While deploying a machine learning model is complex and time-consuming, new heuristics can be created in minutes.
The initial launch of the AI bots block button was well-received and is now used by over 133,000 websites, with significant adoption even among our Free tier customers. The newly updated button, launched on August 20, 2024, is rapidly gaining traction. Over 90,000 zones have already adopted the new rule, with approximately 240 new sites integrating it every hour. Overall, we are now helping to protect the intellectual property of more than 146,000 sites from AI bots, and we are currently blocking 66 million requests daily with this new rule. Additionally, we’re excited to announce that support for configuring AI bots protection via Terraform will be available by the end of this year, providing even more flexibility and control for managing your bot protection settings.
Bot behavior
With the enhancements to our detection capabilities, it is essential to assess the impact of these changes to bot activity on the Internet. Since the launch of the updated AI bots block button, we have been closely monitoring for any shifts in bot activity and adaptation strategies. The most basic fingerprinting technique we use to identify AI bot looking for simple user-agent matches. User-agent matches are important to monitor because they indicate the bot is transparently announcing who they are when they’re crawling a website.
The graph below shows a volume of traffic we label as AI bot over the past two months. The blue line indicates the daily request count, while the red line represents the monthly average number of requests. In the past two months, we have seen an average reduction of nearly 30 million requests, with a decrease of 40 million in the most recent month.This decline coincides with the release of Button v1 and Button v2. Our hypothesis is that with the new AI bots blocking feature, Cloudflare is blocking a majority of these bots, which is discouraging them from crawling.
This hypothesis is supported by the observed decline in requests from several top AI crawlers. Specifically, the Bytespider bot reduced its daily requests from approximately 100 million to just 50 million between the end of June and the end of August (see graph below). This reduction could be attributed to several factors, including our new AI bots block button and changes in the crawler’s strategy.
We have also observed an increase in the accountability of some AI crawlers. The most basic fingerprinting technique we use to identify AI bot looking for simple user-agent matches. User-agent matches are important to monitor because they indicate the bot is transparently announcing who they are when they’re crawling a website. These crawlers are now more frequently using their agents, reflecting a shift towards more transparent and responsible behavior. Notably, there has been a dramatic surge in the number of requests from the Perplexity user agent. This increase might be linked to previous accusationsthat Perplexity did not properly present its user agent, which could have prompted a shift in their approach to ensure better identification and compliance.
These trends suggest that our updates are likely affecting how AI crawlers interact with content. We will continue to monitor AI bot activity to help users control who accesses their content and how. By keeping a close watch on emerging patterns, we aim to provide users with the tools and insights needed to make informed decisions about managing their traffic.
Wrap up
We’re excited to continue to explore the AI landscape, whether we’re finding more ways to make the Cloudflare dashboard usable or new threats to guard against. Our AI insights on Radar update in near real-time, so please join us in watching as new trends emerge and discussing them in the Cloudflare Community.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.