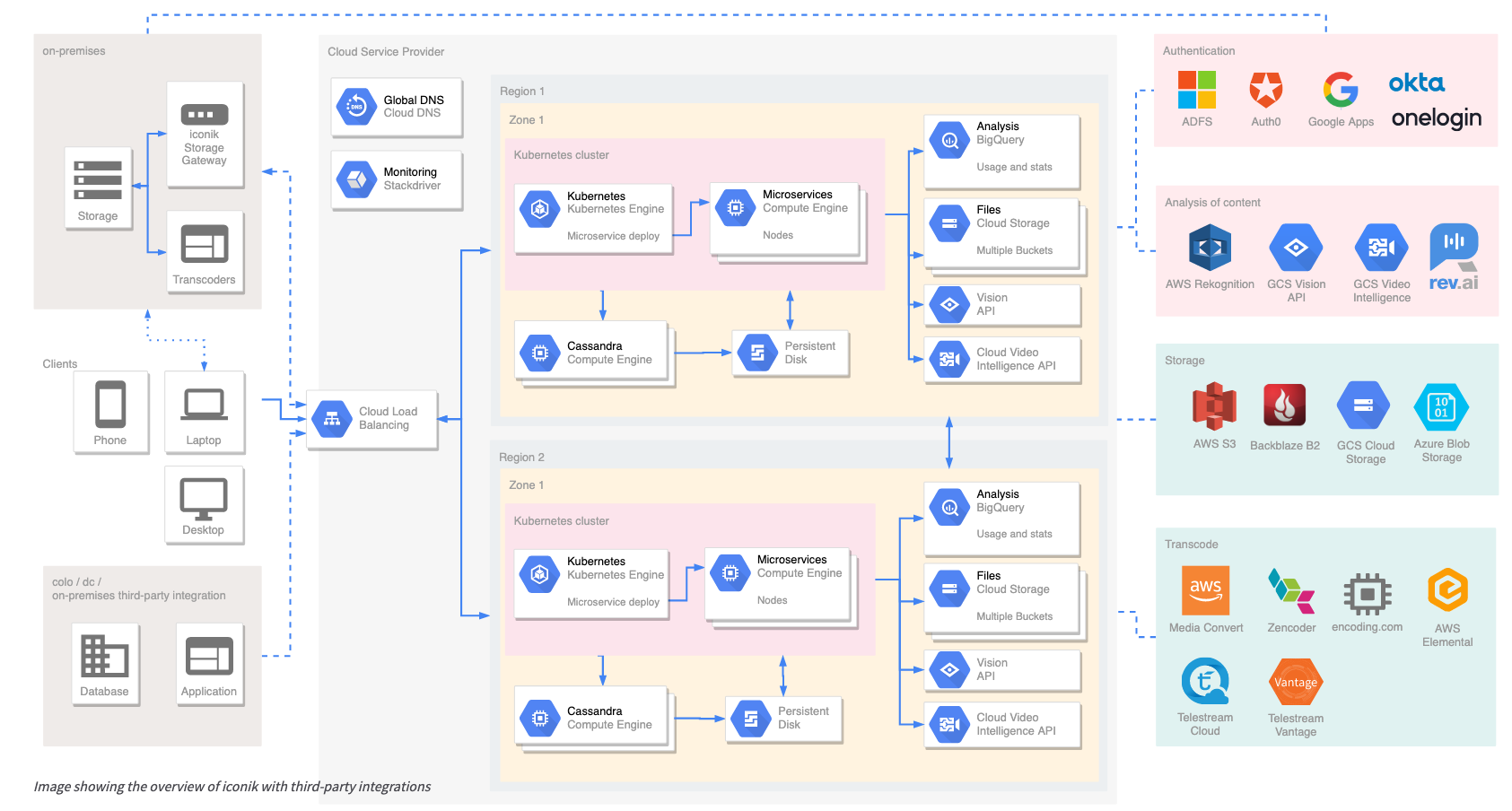
Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/free-cloud-storage-whats-the-catch/

Major cloud storage providers including Amazon and Google offer free tiers of storage or promotional credits to incentivize developers and startups to begin storing data on their clouds. While this may seem attractive to early-stage businesses looking for an affordable jumpstart, it’s important to consider the long-term realities of scaling your business once you’re beyond the threshold of these freebie offers.
As your business evolves, so does how you utilize, store, and manage your data. Aiden Korotkin, the founder of AK Productions—a full-service video production company based in Washington, D.C.—learned this the hard way. He was quick to choose Google Cloud Storage when he was getting started, only to realize it wasn’t the right fit as his business grew.
At the time, Google offered a promotional credit. “That lasted about a year,” Korotkin said, and when the credit expired, it forced him to take a closer look at the cost efficiency and security of the Google Cloud Platform. “I realized that it’s super confusing,” he explained, “you have a lot of options, but it seems like chaos unless you know exactly what you’re doing.”
Making the Cloud Storage Decision: How Much Will “Free” Cost You?
The overhead of managing your cloud platform is only one of the factors to consider when planning your cloud infrastructure rollout. Complexity, predictability, and retrieval are all things you should keep in mind when picking the right solution for your business case. Evaluating all of these factors helps you understand the true cost of ownership and the value of the platform over time.
We hope this guide to three key factors for cloud storage selection will help you decide the right, next best step for you and your growing business.
Factor 1: Complexity
The promotional offers that many cloud storage providers boast are fairly straightforward and clear: Google Cloud Free Tier offers a three month free trial with a $300 credit to use with any Google Cloud services. AWS Free Tier offers various free services including 5GB of S3 Storage for 12 months. Both providers also have incentive funds for startups which can be unlocked through incubators or VCs which grant additional credits of up to tens of thousands of dollars. For next to nothing your data is on its way and you can move on.
But while it may be tempting to jump on one of these offers, it’s worth spending some time learning the breakdown of data storage and utilization costs for each platform, as well as understanding any longer-term or service-related fees you may be on the hook for. Decoding your monthly bill or dealing with surprising service charges when you’re managing a few gigabytes or terabytes is doable, but as you grow, navigating the tiered pricing structures that many of the legacy cloud providers operate under becomes quite complicated.
That’s a bit of an understatement. The reality of the situation is that a whole industry of consultants and businesses has sprung up around this issue. These third-party vendors specialize in helping businesses understand and optimize their cloud invoices from Amazon AWS and Google Cloud Storage. When you need to hire another business just to understand what you’re paying for, it’s time to ask some questions about whether they’re right for you.
Tiered pricing may make sense for businesses who are capable of optimizing their infrastructure to a T. But how many startups does that describe? Most early-stage entrepreneurs do not have the resources to undertake this feat of planning and engineering and find themselves struggling to keep their cloud costs down when they graduate from free plans.
As if the complexity of pricing tables wasn’t bad enough, understanding what you can do with your data once it is stored can be highly confusing, too. Consider egress fees: These are the fees you’ll pay to download your data from the cloud. Most major cloud providers including Amazon and Google charge high egress fees ranging anywhere from $90 to $120+ per terabyte. Attempting to gauge just how expensive egress will be for you can feel impossible. As a result, businesses often begin storing data on these cloud platforms with ease, but as their data sets grow, they find themselves unable to leave due to the high egress costs.
With Amazon AWS, many businesses find that the complexity transcends pricing and stretches into the functionalities provided by the platform. Without the right tools and resources, you may spend hours or days configuring your environment. Tristan Pelligrino, co-founder of Motion, a B2B content marketing agency, spent significant amounts of time simply setting up and onboarding new users. “The interface is very complex. It felt like I was recreating the wheel every time I set up a new user experience,” Pelligrino said. “It was frustrating, but someone had to do it.” The problem being, every moment he spent on AWS was time he wasn’t investing in his creative work.

Not having a 360 degree awareness of your platform’s functionality and how to properly configure it may seem like a minor issue, but sometimes the complexity can obscure vital information. Like when you discover that your backup solution isn’t actually backing up your data. The team at Crisp Video Group, a creative agency serving law firms, scrambled to recover what they could when they realized that their Amazon S3 configuration had failed to back up 109 days worth of data.
At the end of the day, understanding, and oftentimes, avoiding complexity is key in the cloud storage selection process. If it’s not crystal clear what you need and what you’re going to be paying, you may want to consider how much an initial dose of “free” will cost you in the long run. Which leads to factor two.
Factor 2: Predictability
As an early-stage startup, it’s hard to predict how quickly you’re going to grow, which makes it even harder to predict your cloud costs on a monthly or annual basis. Most cloud providers will make it extremely easy to spin up new servers and store data, but as you scale, it’s important to have a clear idea of the costs involved so that you can attain predictable growth. Without this control, cloud storage costs could spiral, significantly hurting your OpEx margins and potentially making useful data inaccessible or unusable in make or break situations.
Predicting your cloud storage costs should be simple, in theory. You have three main dimensions: storage (how much data you store), download (the fee to get your data out of the cloud), and transactions (“stuff” you might do to your data inside the cloud). Yet most vendors continue to make it extremely difficult to understand your monthly bill which adds unnecessary strain when budgeting and forecasting your cloud spend. According to ZDNet, “37% of IT executives found their cloud storage costs to be unpredictable.”
This was the case for Gavin Wade, the founder & CEO of the SaaS photography platform CloudSpot, who realized that his business’s 700TB+ of data stored on Amazon S3 was eating into their OpEx margins. Even more discouraging was the realization that it would be an even bigger financial undertaking to move the data to another service.
“We had a few internal conversations where we concluded that we were stuck with Amazon. That’s never a good feeling in business,” Wade mentioned, as his team looked for other places to affect changes and cut costs.
Being able to accurately project your cash flow is essential to being able to take advantage of other opportunities as they arise. If you make the choice early on to lock into a provider that doesn’t offer predictability on a budget line, you won’t have the clarity you need when it’s most important.

Factor 3: Retrieval
Along with tiered pricing, most cloud providers offer several storage classes meant for different use cases. Again, this may be useful if you have optimized accordingly, but more often than not, these storage classes add unnecessary complexity. This is especially true when it comes to the timing and expense of getting your data back, or, retrieval.
Amazon S3 offers the following storage classes:
| S3 Standard: |
Active data that needs to be accessed frequently and quickly. |
| S3 Intelligent-Tiering: |
Moves data automatically across tiers depending on usage. |
| S3 Standard-Infrequent Access: |
Data that is accessed less frequently but requires rapid access when needed. |
| S3 Glacier: |
Long-term archive with longer retrieval times ranging from minutes to hours. |
| S3 Deep Glacier: |
Long-term archive comparable to magnetic tape libraries with the slowest retrieval times. |
You’ll typically see the terms “hot” and “cold” storage used to describe the nature in which the data is stored and accessed. Hot storage, in this case, S3 Standard, stores data that needs to be accessed right away. Most cloud providers including Amazon and Google charge a premium for hot data because it is resource-intensive.
Cold storage, such as Amazon’s S3 Glacier and Deep Glacier classes, store data that is accessed less frequently and doesn’t require the fast access of warmer or hot data. This tier is commonly used for archival purposes. Though prices for cold storage systems are lower than hot storage, they often incur high retrieval costs and access to the data in cold storage typically requires patience and planning. If you are unable to predict when data will be needed and have time-sensitive retrieval requirements, cold storage may not be suitable for your needs.
As you’re starting out, it can be easy to convince yourself that some data will be less important to you in the long run, especially when making that decision locks you into a cheaper storage tier. But it’s easy to underestimate just how valuable readily accessible data can be in the long run. And whatever decision you make in this regard will only compound over time as your data expands.
Even larger organizations with years of experience in innovation, like Complex Networks, found Amazon S3’s tiered structure problematic as they scaled their production efforts. “S3 has multiple storage classes, each with its associated costs, fees, and wait times,” said Jermaine Harrell, Manager of Media Infrastructure & Technology at Complex Networks. Working with Amazon Glacier to archive content, they found that the long retrieval times and ballooning retrieval costs made the solution untenable for their specific use case.
A realistic approach to your retrieval needs is an essential day one decision if you’re in a data intensive business.
Finding the Right Platform
It helps to read the fine print to make sure there are no hidden costs or minimum duration fees associated with the cloud platform you are considering. Find a platform that is simple when it comes to pricing and billing—this will be helpful in the long run as you scale your cloud infrastructure.
As you grow, budgeting for your cloud spend should be simple, so it’s best to avoid dealing with tiered, complicated pricing structures if you can. A cloud service with a flat pricing structure will allow you to forecast your OpEx spend, without needing to scan pages of pricing tables and charts.
Lastly, if you need to tap into your data at any given moment, make sure it’s readily available without having to pay premiums for cold storage retrieval and wait days just to access your data. Cold storage options are becoming less and less useful for most modern organizations that need to tap into their data at any given moment.
Though it may be tempting to take up Amazon or Google Cloud for their incentive programs and promotional credits, the perceived price and true value of their platforms may not be apparent upon first glance. Most early-stage startups do not have the time, resources, and money to continually upkeep and reevaluate their cloud services. So even before they begin to scale, it’s important to choose a service that is transparent, predictable, and allows you to access all of your data when you need it.
The post Free Cloud Storage: What’s the Catch? appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.