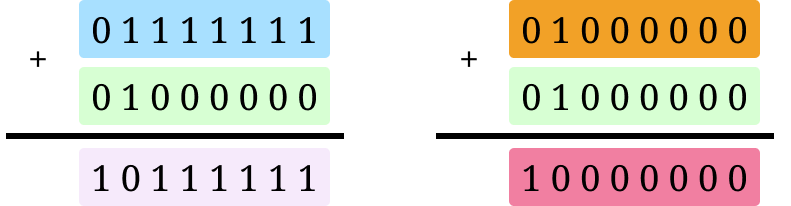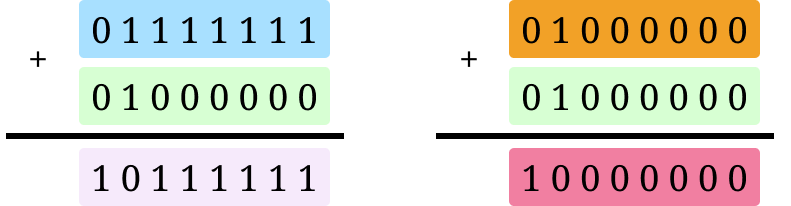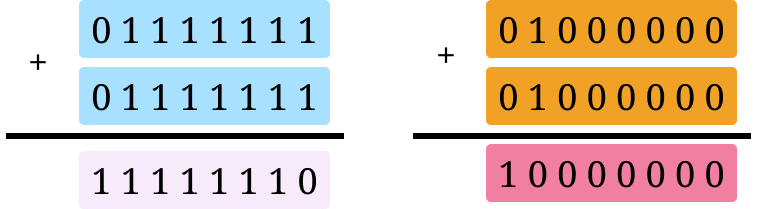Here’s a short list of recent technical blog posts to give you something to read today.
Internet Explorer, we hardly knew ye
Microsoft has announced the end-of-life for the venerable Internet Explorer browser. Here we take a look at the demise of IE and the rise of the Edge browser. And we investigate how many bots on the Internet continue to impersonate Internet Explorer versions that have long since been replaced.
Live-patching security vulnerabilities inside the Linux kernel with eBPF Linux Security Module
Looking for something with a lot of technical detail? Look no further than this blog about live-patching the Linux kernel using eBPF. Code, Makefiles and more within!
Hertzbleed explained
Feeling mathematical? Or just need a dose of CPU-level antics? Look no further than this deep explainer about how CPU frequency scaling leads to a nasty side channel affecting cryptographic algorithms.
Early Hints update: How Cloudflare, Google, and Shopify are working together to build a faster Internet for everyone
The HTTP standard for Early Hints shows a lot of promise. How much? In this blog post, we dig into data about Early Hints in the real world and show how much faster the web is with it.
Private Access Tokens: eliminating CAPTCHAs on iPhones and Macs with open standards
Dislike CAPTCHAs? Yes, us too. As part of our program to eliminate captures there’s a new standard: Private Access Tokens. This blog shows how they work and how they can be used to prove you’re human without saying who you are.
Optimizing TCP for high WAN throughput while preserving low latency
Network nerd? Yeah, me too. Here’s a very in depth look at how we tune TCP parameters for low latency and high throughput.
You may have heard a bit about the Hertzbleed attack that was recently disclosed. Fortunately, one of the student researchers who was part of the team that discovered this vulnerability and developed the attack is spending this summer with Cloudflare Research and can help us understand it better.
The first thing to note is that Hertzbleed is a new type of side-channel attack that relies on changes in CPU frequency. Hertzbleed is a real, and practical, threat to the security of cryptographic software.
“If you are an ordinary user and not a cryptography engineer, probably not: you don’t need to apply a patch or change any configurations right now. If you are a cryptography engineer, read on. Also, if you are running a SIKE decapsulation server, make sure to deploy the mitigation described below.”
Notice: As of today, there is no known attack that uses Hertzbleed to target conventional and standardized cryptography, such as the encryption used in Cloudflare products and services. Having said that, let’s get into the details of processor frequency scaling to understand the core of this vulnerability.
In short, the Hertzbleed attack shows that, under certain circumstances, dynamic voltage and frequency scaling (DVFS), a power management scheme of modern x86 processors, depends on the data being processed. This means that on modern processors, the same program can run at different CPU frequencies (and therefore take different wall-clock times). For example, we expect that a CPU takes the same amount of time to perform the following two operations because it uses the same algorithm for both. However, there is an observable time difference between them:
Trivia: Could you guess which operation runs faster?
Before giving the answer we will explain some details about how Hertzbleed works and its impact on SIKE, a new cryptographic algorithm designed to be computationally infeasible for an adversary to break, even for an attacker with a quantum computer.
Frequency Scaling
Suppose a runner is in a long distance race. To optimize the performance, the heart monitors the body all the time. Depending on the input (such as distance or oxygen absorption), it releases the appropriate hormones that will accelerate or slow down the heart rate, and as a result tells the runner to speed up or slow down a little. Just like the heart of a runner, DVFS (dynamic voltage and frequency scaling) is a monitor system for the CPU. It helps the CPU to run at its best under present conditions without being overloaded.
Just as a runner’s heart causes a runner’s pace to fluctuate throughout a race depending on the level of exertion, when a CPU is running a sustained workload, DVFS modifies the CPU’s frequency from the so-called steady-state frequency. DVFS causes it to switch among multiple performance levels (called P-states) and oscillate among them. Modern DVFS gives the hardware almost full control to adjust the P-states it wants to execute in and the duration it stays at any P-state. These modifications are totally opaque to the user, since they are controlled by hardware and the operating system provides limited visibility and control to the end-user.
The ACPI specification defines P0 state as the state the CPU runs at its maximum performance capability. Moving to higher P-states makes the CPU less performant in favor of consuming less energy and power.
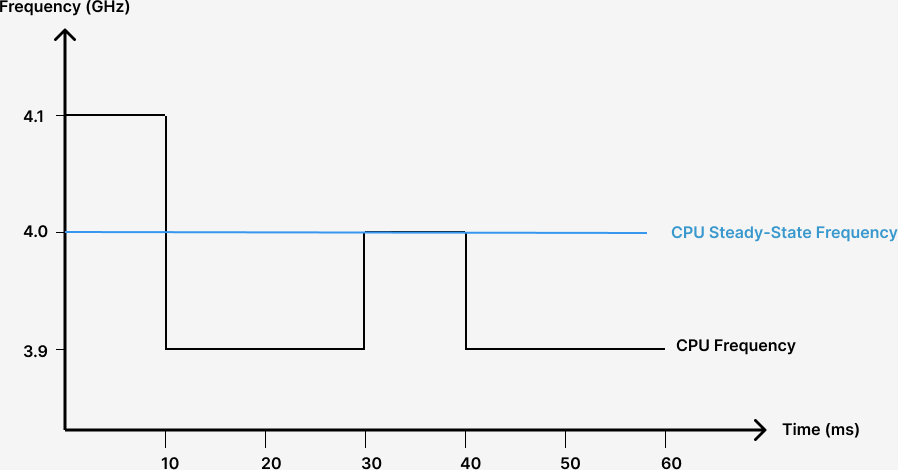
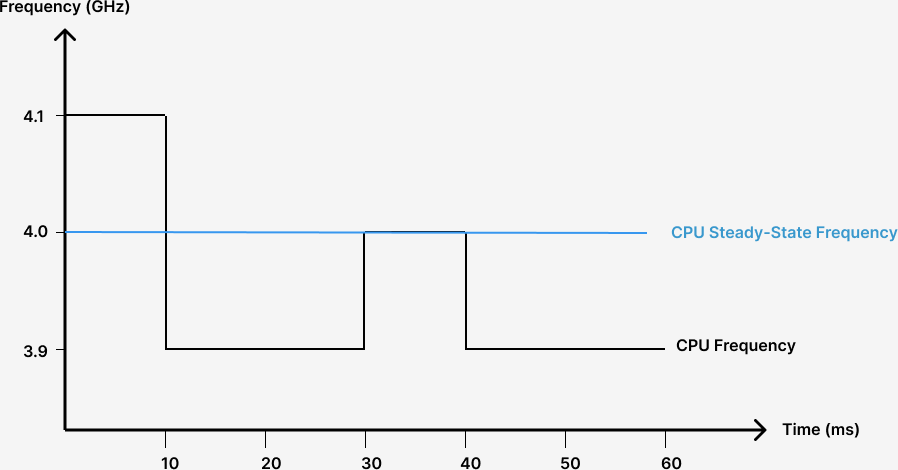
Suppose a CPU’s steady-state frequency is 4.0 GHz. Under DVFS, frequency can oscillate between 3.9-4.1 GHz.
How long does the CPU stay at each P-state? Most importantly, how can this even lead to a vulnerability? Excellent questions!
Modern DVFS is designed this way because CPUs have a Thermal Design Point (TDP), indicating the expected power consumption at steady state under a sustained workload. For a typical computer desktop processor, such as a Core i7-8700, the TDP is 65 W.
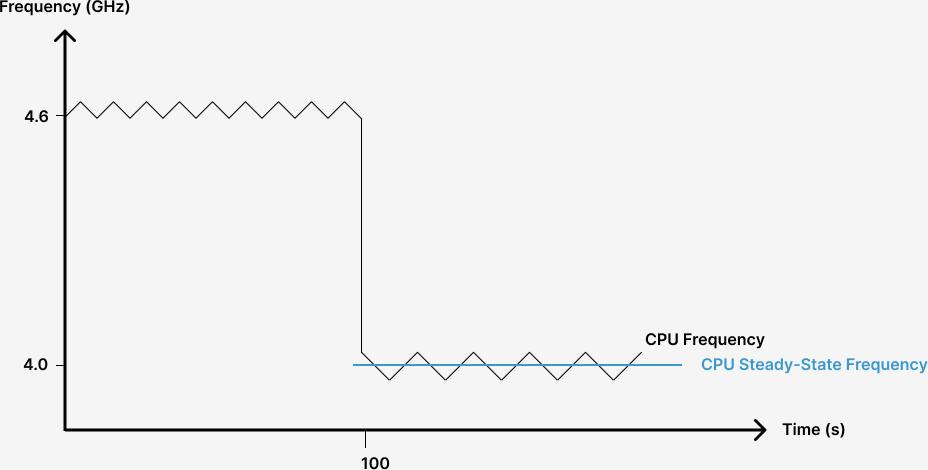
To continue our human running analogy: a typical person can sprint only short distances, and must run longer distances at a slower pace. When the workload is of short duration, DVFS allows the CPU to enter a high-performance state, called Turbo Boost on Intel processors. In this mode, the CPU can temporarily execute very quickly while consuming much more power than TDP allows. But when running a sustained workload, the CPU average power consumption should stay below TDP to prevent overheating. For example, as illustrated below, suppose the CPU has been free of any task for a while, the CPU runs extra hard (Turbo Boost on) when it just starts running the workload. After a while, it realizes that this workload is not a short one, so it slows down and enters steady-state. How much does it slow down? That depends on the TDP. When entering steady-state, the CPU runs at a certain speed such that its current power consumption is not above TDP.
CPU entering steady state after running at a higher frequency.
Beyond protecting CPUs from overheating, DVFS also wants to maximize the performance. When a runner is in a marathon, she doesn’t run at a fixed pace but rather her pace floats up and down a little. Remember the P-state we mentioned above? CPUs oscillate between P-states just like runners adjust their pace slightly over time. P-states are CPU frequency levels with discrete increments of 100 MHz.
CPU frequency levels with discrete increments
The CPU can safely run at a high P-state (low frequency) all the time to stay below TDP, but there might be room between its power consumption and the TDP. To maximize CPU performance, DVFS utilizes this gap by allowing the CPU to oscillate between multiple P-states. The CPU stays at each P-state for only dozens of milliseconds, so that its temporary power consumption might exceed or fall below TDP a little, but its average power consumption is equal to TDP.
To understand this, check out this figure again.
If the CPU only wants to protect itself from overheating, it can run at P-state 3.9 GHz safely. However, DVFS wants to maximize the CPU performance by utilizing all available power allowed by TDP. As a result, the CPU oscillates around the P-state 4.0 GHz. It is never far above or below. When at 4.1 GHz, it overloads itself a little, it then drops to a higher P-state. When at 3.9 GHz, it recovers itself, it quickly climbs to a lower P-state. It may not stay long in any P-state, which avoids overheating when at 4.1 GHz and keeps the average power consumption near the TDP.
This is exactly how modern DVFS monitors your CPU to help it optimize power consumption while working hard.
Again, how can DVFS and TDP lead to a vulnerability? We are almost there!
Frequency Scaling vulnerability
The design of DVFS and TDP can be problematic because CPU power consumption is data-dependent! The Hertzbleed paper gives an explicit leakage model of certain operations identifying two cases.
First, the larger the number of bits set (also known as the Hamming weight) in the operands, the more power an operation takes. The Hamming weight effect is widely observed with no known explanation of its root cause. For example,
The addition on the left will consume more power compared to the one on the right.
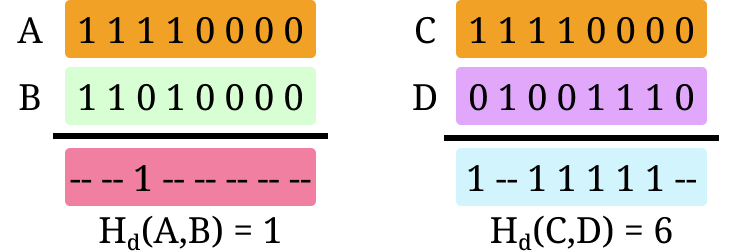
Similarly, when registers change their value there are power variations due to transistor switching. For example, a register switching its value from A to B (as shown in the left) requires flipping only one bit because the Hamming distance of A and B is 1. Meanwhile, switching from C to D will consume more energy to perform six bit transitions since the Hamming distance between C and D is 6.
Hamming distance
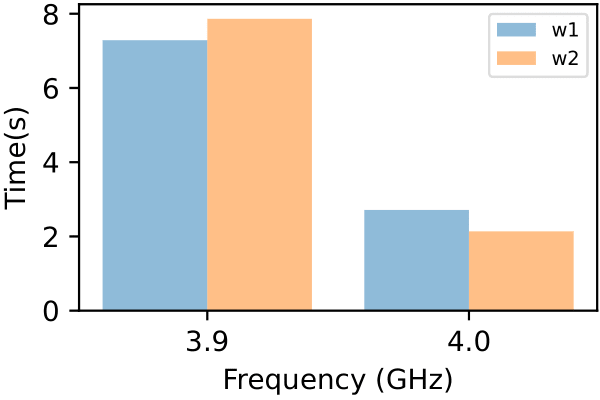
Now we see where the vulnerability is! When running sustained workloads, CPU overall performance is capped by TDP. Under modern DVFS, it maximizes its performance by oscillating between multiple P-states. At the same time, the CPU power consumption is data-dependent. Inevitably, workloads with different power consumption will lead to different CPU P-state distribution. For example, if workload w1 consumes less power than workload w2, the CPU will stay longer in lower P-state (higher frequency) when running w1.
Different power consumption leads to different P-state distribution
As a result, since the power consumption is data-dependent, it follows that CPU frequency adjustments (the distribution of P-states) and execution time (as 1 Hertz = 1 cycle per second) are data-dependent too.
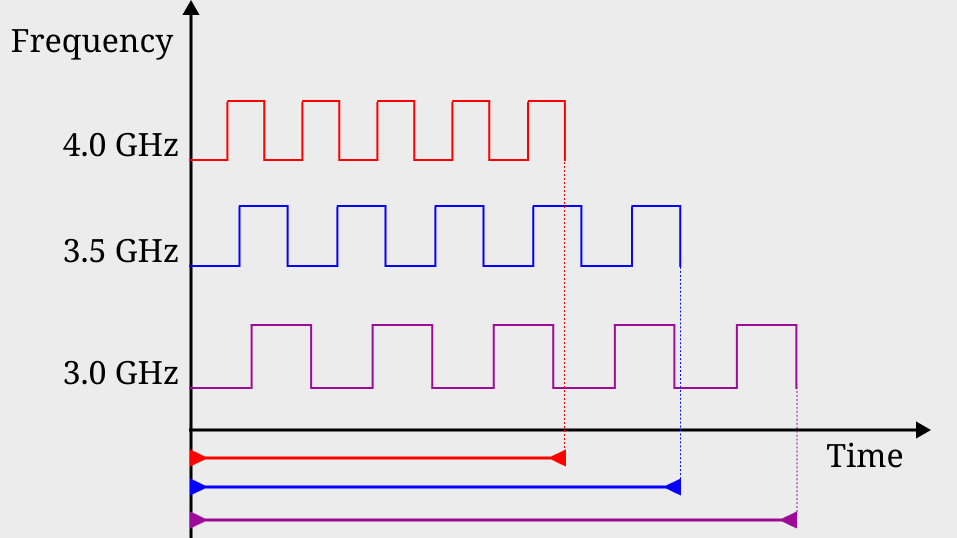
Consider a program that takes five cycles to finish as depicted in the following figure.
CPU frequency directly translate to running time
As illustrated in the table below, f the program with input 1 runs at 4.0 GHz (red) then it takes 1.25 nanoseconds to finish. If the program consumes more power with input 2, under DVFS, it will run at a lower frequency, 3.5 GHz (blue). It takes more time, 1.43 nanoseconds, to finish. If the program consumes even more power with input 3, under DVFS, it will run at an even lower frequency of 3.0 GHz (purple). Now it takes 1.67 nanoseconds to finish. This program always takes five cycles to finish, but the amount of power it consumes depends on the input. The power influences the CPU frequency, and CPU frequency directly translates to execution time. In the end, the program’s execution time becomes data-dependent.
Execution time of a five cycles program
Frequency
4.0 GHz
3.5 GHz
3.0 GHz
Execution Time
1.25 ns
1.43 ns
1.67 ns
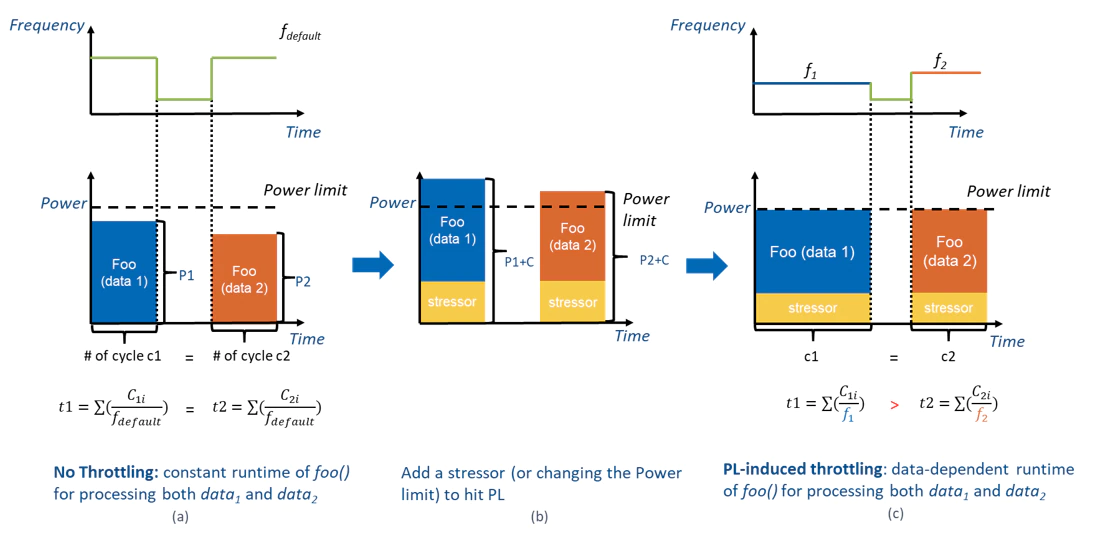
To give you another concrete example: Suppose we have a sustained workload Foo. We know that Foo consumes more power with input data 1, and less power with input data 2. As shown on the left in the figure below, if the power consumption of Foo is below the TDP, CPU frequency as well as running time stays the same regardless of the choice of input data. However, as shown in the middle, if we add a background stressor to the CPU, the combined power consumption will exceed TDP. Now we are in trouble. CPU overall performance is monitored by DVFS and capped by TDP. To prevent itself from overheating, it dynamically adjusts its P-state distribution when running workload with various power consumption. P-state distribution of Foo(data 1) will have a slight right shift compared to that of Foo(data 2). As shown on the right, CPU running Foo(data 1) results in a lower overall frequency and longer running time. The observation here is that, if datais a binary secret, an attacker can infer databy simply measuring the running time of Foo!
Complete recap of Hertzbleed. Figure taken from Intel’s documentation.
This observation is astonishing because it conflicts with our expectation of a CPU. We expect a CPU to take the same amount of time computing these two additions.
However, Hertzbleed tells us that just like a person doing math on paper, a CPU not only takes more power to compute more complicated numbers but also spends more time as well! This is not what a CPU should do while performing a secure computation! Because anyone that measures the CPU execution time should not be able to infer the data being computed on.
This takeaway of Hertzbleed creates a significant problem for cryptography implementations because an attacker shouldn’t be able to infer a secret from program’s running time. When developers implement a cryptographic protocol out of mathematical construction, a goal in common is to ensure constant-time execution. That is, code execution does not leak secret information via a timing channel. We have witnessed that timing attacks are practical: notable examples are those shown by Kocher, Brumley-Boneh, Lucky13, and many others. How to properly implement constant-time code is subject of extensive study.
Historically, our understanding of which operations contribute to time variation did not take DVFS into account. The Hertzbleed vulnerability derives from this oversight: any workload which differs by significant power consumption will also differ in timing. Hertzbleed proposes a new perspective on the development of secure programs: any program vulnerable to power analysis becomes potentially vulnerable to timing analysis!
Which cryptographic algorithms are vulnerable to Hertzbleed is unclear. According to the authors, a systematic study of Hertzbleed is left as future work. However, Hertzbleed was exemplified as a vector for attacking SIKE.
Brief description of SIKE
The Supersingular Isogeny Key Encapsulation (SIKE) protocol is a Key Encapsulation Mechanism (KEM) finalist of the NIST Post-Quantum Cryptography competition (currently at Round 3). The building block operation of SIKE is the calculation of isogenies (transformations) between elliptic curves. You can find helpful information about the calculation of isogenies in our previous blog post. In essence, calculating isogenies amounts to evaluating mathematical formulas that take as inputs points on an elliptic curve and produce other different points lying on a different elliptic curve.
SIKE bases its security on the difficulty of computing a relationship between two elliptic curves. On the one hand, it’s easy computing this relation (called an isogeny) if the points that generate such isogeny (called the kernel of the isogeny) are known in advance. On the other hand, it’s difficult to know the isogeny given only two elliptic curves, but without knowledge of the kernel points. An attacker has no advantage if the number of possible kernel points to try is large enough to make the search infeasible (computationally intractable) even with the help of a quantum computer.
Similarly to other algorithms based on elliptic curves, such as ECDSA or ECDH, the core of SIKE is calculating operations over points on elliptic curves. As usual, points are represented by a pair of coordinates (x,y) which fulfill the elliptic curve equation
$ y^2= x^3 + Ax^2 +x $
where A is a parameter identifying different elliptic curves.
For performance reasons, SIKE uses one of the fastest elliptic curve models: the Montgomery curves. The special property that makes these curves fast is that it allows working only with the x-coordinate of points. Hence, one can express the x-coordinate as a fraction x = X / Z, without using the y-coordinate at all. This representation simplifies the calculation of point additions, scalar multiplications, and isogenies between curves. Nonetheless, such simplicity does not come for free, and there is a price to be paid.
The formulas for point operations using Montgomery curves have some edge cases. More technically, a formula is said to be complete if for any valid input a valid output point is produced. Otherwise, a formula is not complete, meaning that there are some exceptional inputs for which it cannot produce a valid output point.
In practice, algorithms working with incomplete formulas must be designed in such a way that edge cases never occur. Otherwise, algorithms could trigger some undesired effects. Let’s take a closer look at what happens in this situation.
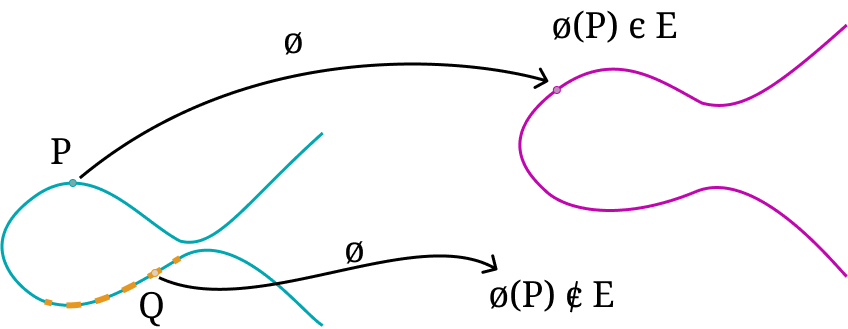
A subtle yet relevant property of some incomplete formulas is the nature of the output they produce when operating on points in the exceptional set. Operating with anomalous inputs, the output has both coordinates equal to zero, so X=0 and Z=0. If we recall our basics on fractions, we can figure out that there is something odd in a fraction X/Z = 0/0; furthermore it was always regarded as something not well-defined. This intuition is not wrong, something bad just happened. This fraction does not represent a valid point on the curve. In fact, it is not even a (projective) point.
The domino effect
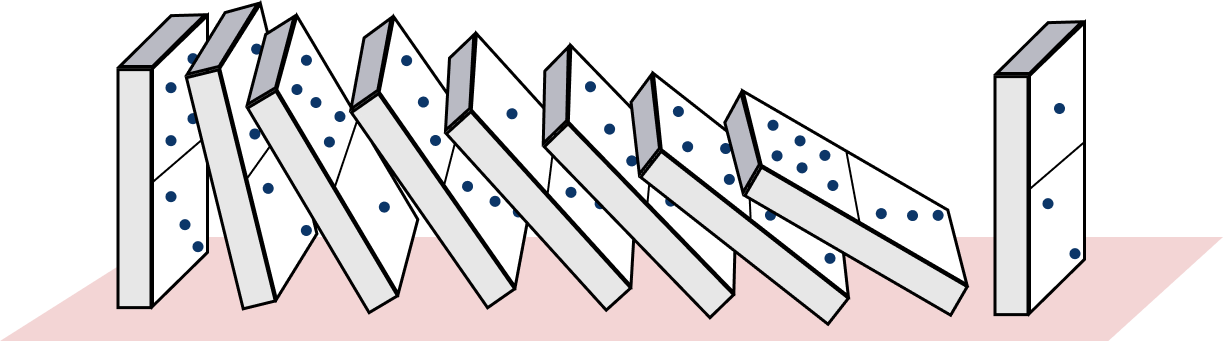
Exploiting this subtlety of mathematical formulas makes a case for the Hertzbleed side-channel attack. In SIKE, whenever an edge case occurs at some point in the middle of its execution, it produces a domino effect that propagates the zero coordinates to subsequent computations, which means the whole algorithm is stuck on 0. As a result, the computation gets corrupted obtaining a zero at the end, but what is worse is that an attacker can use this domino effect to make guesses on the bits of secret keys.
Trying to guess one bit of the key requires the attacker to be able to trigger an exceptional case exactly at the point in which the bit is used. It looks like the attacker needs to be super lucky to trigger edge cases when it only has control of the input points. Fortunately for the attacker, the internal algorithm used in SIKE has some invariants that can help to hand-craft points in such a way that triggers an exceptional case exactly at the right point. A systematic study of all exceptional points and edge cases was, independently, shown by De Feo et al. as well as in the Hertzbleed article.
With these tools at hand, and using the DVFS side channel, the attacker can now guess bit-by-bit the secret key by passing hand-crafted invalid input points. There are two cases an attacker can observe when the SIKE algorithm uses the secret key:
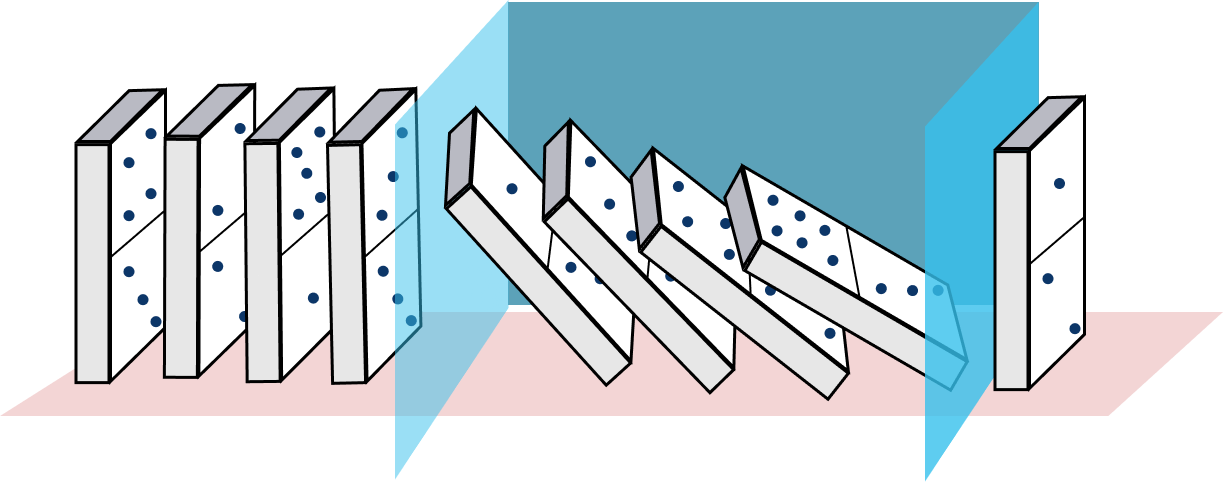
If the bit of interest is equal to the one before it, no edge cases are present and computation proceeds normally, and the program will take the expected amount of wall-time since all the calculations are performed over random-looking data.
On the other hand, if the bit of interest is different from the one before it, the algorithm will enter the exceptional case, triggering the domino effect for the rest of the computation, and the DVFS will make the program run faster as it automatically changes the CPU’s frequency.
Using this oracle, the attacker can query it, learning bit by bit the secret key used in SIKE.
Ok, let’s recap.
SIKE uses special formulas to speed up operations, but if these formulas are forced to hit certain edge cases then they will fail. Failing due to these edge cases not only corrupts the computation, but also makes the formulas output coordinates with zeros, which in machine representation amount to several registers all loaded with zeros. If the computation continues without noticing the presence of these edge cases, then the processor registers will be stuck on 0 for the rest of the computation. Finally, at the hardware level, some instructions can consume fewer resources if operands are zeroed. Because of that, the DVFS behind CPU power consumption can modify the CPU frequency, which alters the steady-state frequency. The ultimate result is a program that runs faster or slower depending on whether it operates with all zeros versus with random-looking data.
Hertzbleed’s authors contacted Cloudflare Research because they showed a successful attack on CIRCL, our optimized Go cryptographic library that includes SIKE. We worked closely with the authors to find potential mitigations in the early stages of their research. While the embargo of the disclosure was in effect, another research group including De Feo et al. independently described a systematic study of the possible failures of SIKE formulas, including the same attack found by the Hertzbleed team, and pointed to a proper countermeasure. Hertzbleed borrows such a countermeasure.
What countermeasures are available for SIKE?
The immediate action specific for SIKE is to prevent edge cases from occurring in the first place. Most SIKE implementations provide a certain amount of leeway, assuming that inputs will not trigger exceptional cases. This is not a safe assumption. Instead, implementations should be hardened and should validate that inputs and keys are well-formed.
Enforcing a strict validation of untrusted inputs is always the recommended action. For example, a common check on elliptic curve-based algorithms is to validate that inputs correspond to points on the curve and that their coordinates are in the proper range from 0 to p-1 (as described in Section 3.2.2.1 of SEC 1). These checks also apply to SIKE, but they are not sufficient.
What malformed inputs have in common in the case of SIKE is that input points could have arbitrary order—that is, in addition to checking that points must lie on the curve, they must also have a prescribed order, so they are valid. This is akin to small subgroup attacks for the Diffie-Hellman case using finite fields. In SIKE, there are several overlapping groups in the same curve, and input points having incorrect order should be detected.
The countermeasure, originally proposed by Costello, et al., consists of verifying whether the input points are of the right full-order. To do so, we check whether an input point vanishes only when multiplied by its expected order, and not before when multiplied by smaller scalars. By doing so, the hand-crafted invalid points will not pass this validation routine, which prevents edge cases from appearing during the algorithm execution. In practice, we observed around a 5-10% performance overhead on SIKE decapsulation. The ciphertext validation is already available in CIRCL as of version v1.2.0. We strongly recommend updating your projects that depend on CIRCL to this version, so you can make sure that strict validation on SIKE is in place.
Closing comments
Hertzbleed shows that certain workloads can induce changes on the frequency scaling of the processor, making programs run faster or slower. In this setting, small differences on the bit pattern of data result in observable differences on execution time. This puts a spotlight on the state-of-the-art techniques we know so far used to protect against timing attacks, and makes us rethink the measures needed to produce constant-time code and secure implementations. Defending against features like DVFS seems to be something that programmers should start to consider too.
Although SIKE was the victim this time, it is possible that other cryptographic algorithms may expose similar symptoms that can be leveraged by Hertzbleed. An investigation of other targets with this brand-new tool in the attacker’s portfolio remains an open problem.
Hertzbleed allowed us to learn more about how the machines we have in front of us work and how the processor constantly monitors itself, optimizing the performance of the system. Hardware manufacturers have focused on performance of processors by providing many optimizations, however, further study of the security of computations is also needed.
If you are excited about this project, at Cloudflare we are working on raising the bar on the production of code for cryptography. Reach out to us if you are interested in high-assurance tools for developers, and don’t forget our outreach programs whether you are a student, a faculty member, or an independent researcher.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.