Post Syndicated from Alexandra Moraru http://blog.cloudflare.com/author/alexandra/ original https://blog.cloudflare.com/safeguarding-your-brand-identity-logo-matching-for-brand-protection
In an era dominated by digital landscapes, protecting your brand’s identity has become more challenging than ever. Malicious actors regularly build lookalike websites, complete with official logos and spoofed domains, to try to dupe customers and employees. These kinds of phishing attacks can damage your reputation, erode customer trust, or even result in data breaches.
In March 2023 we introduced Cloudflare’s Brand and Phishing Protection suite, beginning with Brand Domain Name Alerts. This tool recognizes so-called “confusable” domains (which can be nearly indistinguishable from their authentic counterparts) by sifting through the trillions of DNS requests passing through Cloudflare’s DNS resolver, 1.1.1.1. This helps brands and organizations stay ahead of malicious actors by spotting suspicious domains as soon as they appear in the wild.
Today we are excited to expand our Brand Protection toolkit with the addition of Logo Matching. Logo Matching is a powerful tool that allows brands to detect unauthorized logo usage: if Cloudflare detects your logo on an unauthorized site, you receive an immediate notification.
The new Logo Matching feature is a direct result of a frequent request from our users. Phishing websites often use official brand logos as part of their facade. In fact, the appearance of unauthorized logos is a strong signal that a hitherto dormant suspicious domain is being weaponized. Being able to identify these sites before they are widely distributed is a powerful tool in defending against phishing attacks. Organizations can use Cloudflare Gateway to block employees from connecting to sites with a suspicious domain and unauthorized logo use.
Imagine having the power to fortify your brand’s presence and reputation. By detecting instances where your logo is being exploited, you gain the upper hand in protecting your brand from potential fraud and phishing attacks.
Getting started with Logo Matching
For most brands, the first step to leveraging Logo Matching will be to configure Domain Name Alerts. For example, we might decide to set up an alert for example.com, which will use fuzzy matching to detect lookalike, high-risk domain names. All sites that trigger an alert are automatically analyzed by Cloudflare’s phishing scanner, which gathers technical information about each site, including SSL certificate data, HTTP request and response data, page performance data, DNS records, and more — all of which inform a machine-learning based phishing risk analysis.
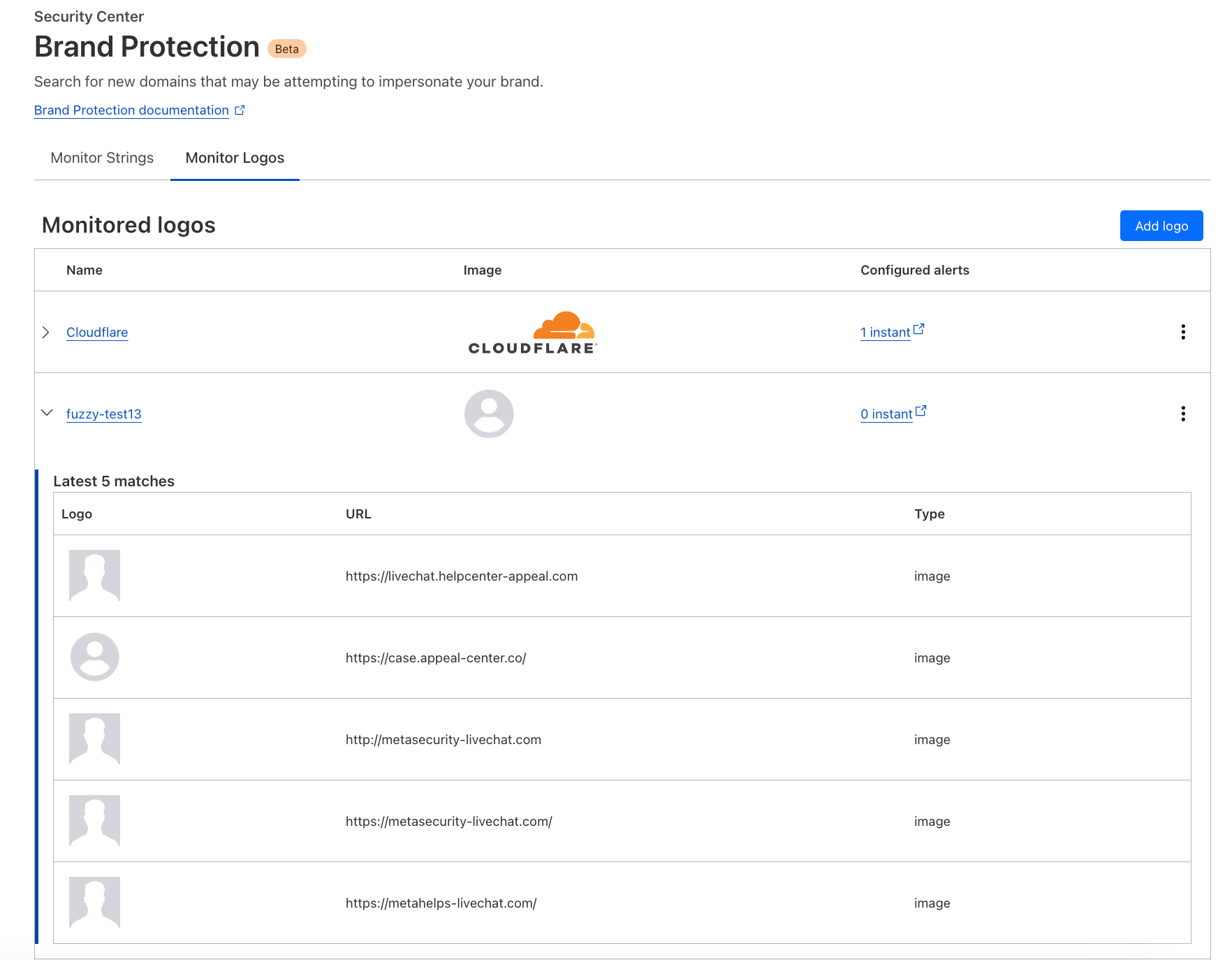
Logo Matching further extends this scan by looking for matching images. The system leverages image recognition algorithms to crawl through scanned domains, identifying matches even when images have undergone slight modifications or alterations.
Once configured, Domain Name Alerts and the scans they trigger will continue on an ongoing basis. In addition, Logo Matching monitors for images across all domains scanned by Cloudflare’s phishing scanner, including those scanned by other Brand Protection users, as well as scans initiated via the Cloudflare Radar URL scanner, and the Investigate Portal within Cloudflare’s Security Center dashboard.
How we built Logo Matching for Brand Protection
Under the hood of our API Insights
Now, let’s dive deeper into the engine powering this feature – our Brand Protection API. This API serves as the backbone of the entire process. Not only does it enable users to submit logos and brand images for scanning, but it also orchestrates the complex matching process.
When a logo is submitted through the API, the Logo Matching feature not only identifies potential matches but also allows customers to save a query, providing an easy way to refer back to their queries and see the most recent results. If a customer chooses to save a query, the logo is swiftly added to our data storage in R2, Cloudflare’s zero egress fee object storage. This foundational feature enables us to continuously provide updated results without the customer having to create a new query for the same logo.
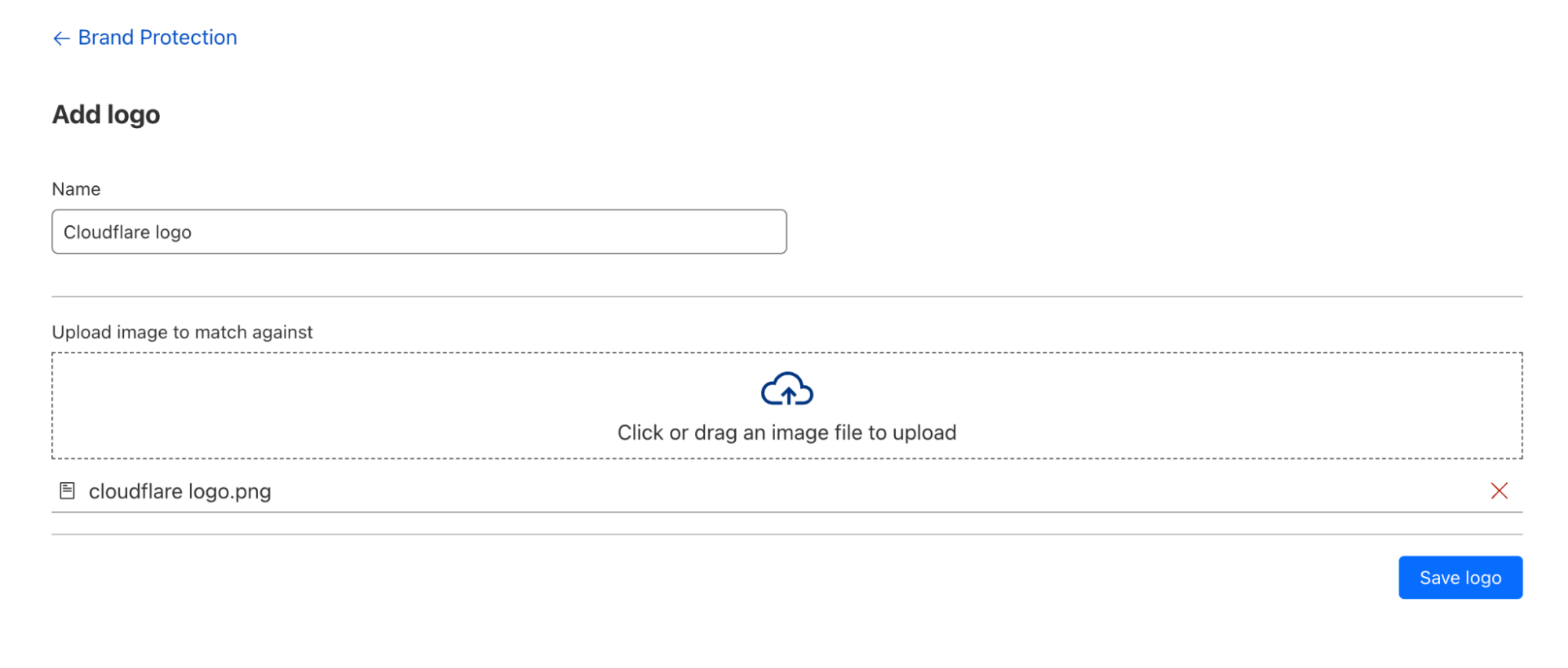
The API ensures real-time responses for logo submissions, simultaneously kick-starting our internal scanning pipelines. An image look-back ID is generated to facilitate seamless tracking and processing of logo submissions. This identifier allows us to keep a record of the submitted images, ensuring that we can efficiently manage and process them through our system.
Scan result retrieval
As images undergo scanning, the API remains the conduit for result retrieval. Its role here is to constantly monitor and provide the results in real time. During scanning, the API ensures users receive timely updates. If scanning is still in progress, a “still scanning” status is communicated. Upon completion, the API is designed to relay crucial information — details on matches if found, or a simple “no matches” declaration.
Storing and maintaining logo data
In the background, we maintain a vectorized version of all user-uploaded logos when the user query is saved. This system, acting as a logo matching subscriber, is entrusted with the responsibility of ensuring accurate and up-to-date logo matching.
To accomplish this, two strategies come into play. Firstly, the subscriber stays attuned to revisions in the logo set. It saves vectorized logo sets with every revision and regular checks are conducted by the subscriber to ensure alignment between the vectorized logos and those saved in the database.
While monitoring the query, the subscriber employs a diff-based strategy. This recalibrates the vectorized logo set against the current logos stored in the database, ensuring a seamless transition into processing.
Shaping the future of brand protection: our roadmap ahead
With the introduction of the Logo Matching feature, Cloudflare’s Brand Protection suite advances to the next level of brand integrity management. By enabling you to detect and analyze, and act on unauthorized logo usage, we’re helping businesses to take better care of their brand identity.
At Cloudflare, we’re committed to shaping a comprehensive brand protection solution that anticipates and mitigates risks proactively. In the future, we plan to add enhancements to our brand protection solution with features like automated cease and desist letters for swift legal action against unauthorized logo use, proactive domain monitoring upon onboarding, simplified reporting of brand impersonations and more.
Getting started
If you’re an Enterprise customer, sign up for Beta Access for Brand protection now to gain access to private scanning for your domains, logo matching, save queries and set up alerts on matched domains. Learn more about Brand Protection here.