Post Syndicated from Rita Kozlov original http://blog.cloudflare.com/workers-pricing-scale-to-zero/
Today we are announcing new pricing for Cloudflare Workers and Pages Functions, where you are billed based on CPU time, and never for the idle time that your Worker spends waiting on network requests and other I/O. Unlike other platforms, when you build applications on Workers, you only pay for the compute resources you actually use.
Why is this exciting? To date, all large serverless compute platforms have billed based on how long your function runs — its duration or “wall time”. This is a reflection of a new paradigm built on a leaky abstraction — your code may be neatly packaged up into a “function”, but under the hood there’s a virtual machine (VM). A VM can’t be paused and resumed quickly enough to execute another piece of code while it waits on I/O. So while a typical function might take 100ms to run, it might typically spend only 10ms doing CPU work, like crunching numbers or parsing JSON, with the rest of time spent waiting on I/O.
This status quo has meant that you are billed for this idle time, while nothing is happening.
With this announcement, Cloudflare is the first and only global serverless platform to offer standard pricing based on CPU time, rather than duration. We think you should only pay for the compute time you actually use, and that’s how we’re going to bill you going forward.
Old pricing — two pricing models, each with tradeoffs
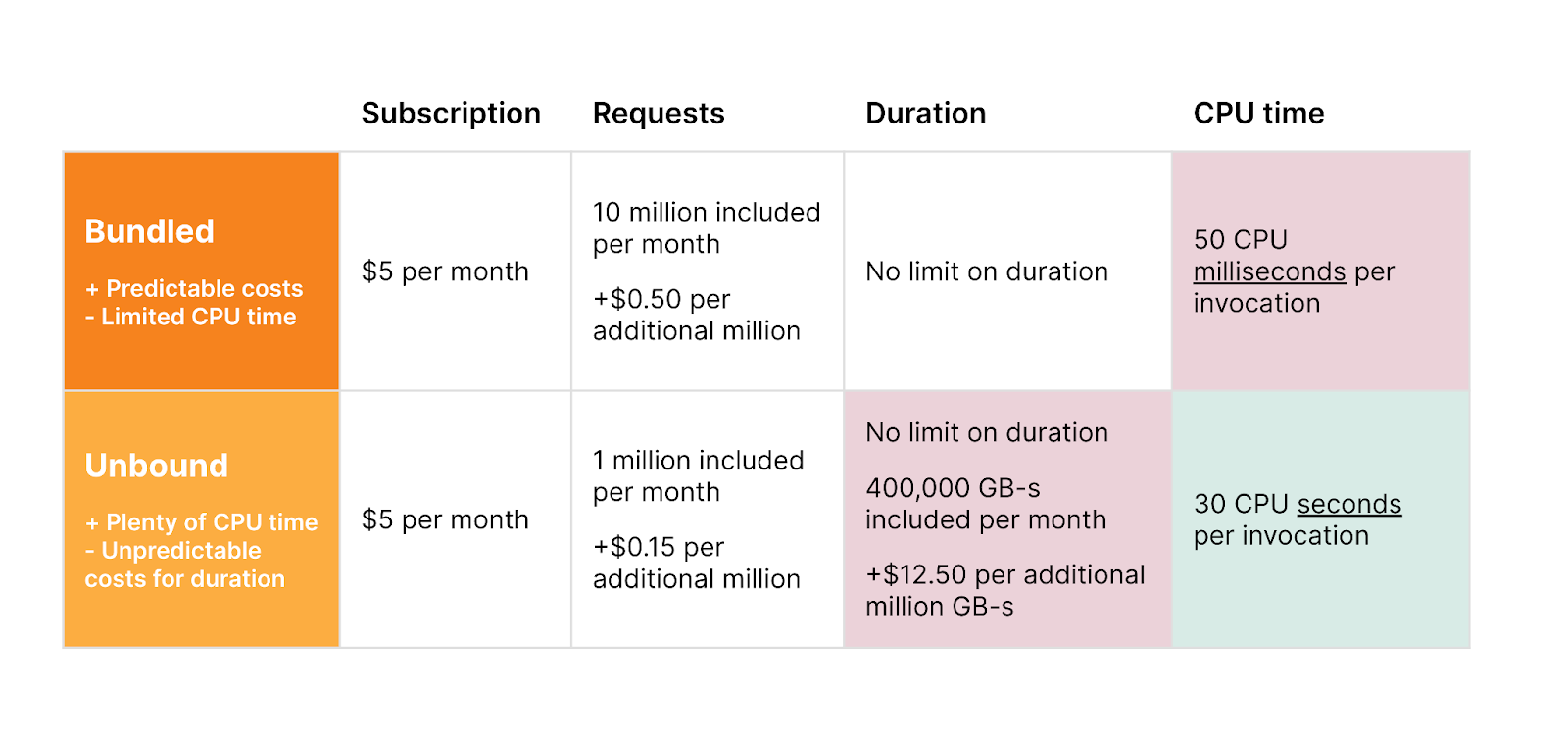
New pricing — one simple and predictable pricing model

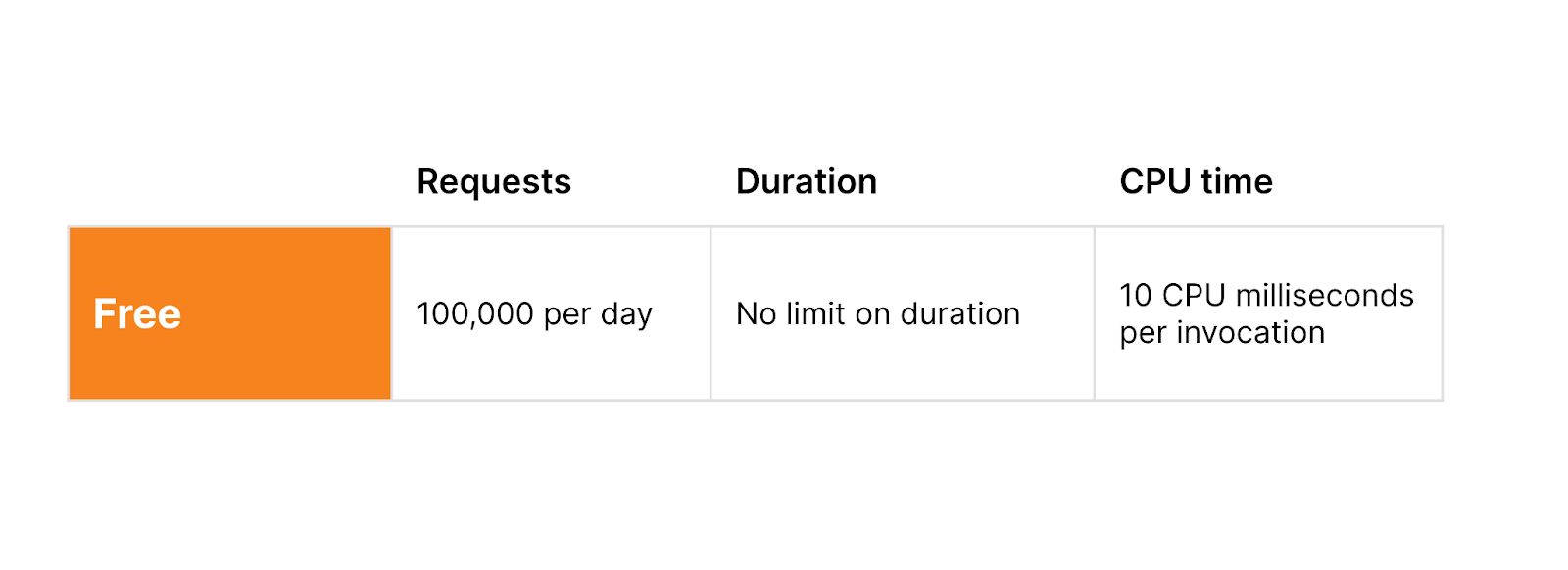
With the same generous Free plan
Unlike wall time (duration, or GB-s), CPU time is more predictable and under your control. When you make a request to a third party API, you can’t control how long that API takes to return a response. This time can be quite long, and vary dramatically — particularly when building AI applications that make inference requests to LLMs. If a request takes twice as long to complete, duration-based billing means you pay double. By contrast, CPU time is consistent and unaffected by time spent waiting on I/O — purely a function of the logic and processing of inputs on outputs to your Worker. It is entirely under your control.
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You’ll be able to estimate how much new pricing will cost in the Cloudflare dashboard. For the majority of current applications, new pricing is the same or less expensive than the previous Bundled and Unbound pricing plans.
If you’re on our Workers Paid plan, you will have until March 1, 2024 to switch to the new pricing on your own, after which all of your projects will be automatically migrated to new pricing. If you’re an Enterprise customer, any contract renewals after March 1, 2024, will use the new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect. And since CPU time is fully in your control, the more you optimize your Worker’s compute time, the less you’ll pay. Your incentives are aligned with ours, to make efficient use of compute resources on Region: Earth.
The challenge of truly scaling to zero
The beauty of serverless is that it allows teams to focus on what matters most — delivering value to their customers, rather than managing infrastructure. It saves you money by effortlessly scaling up and down all over the world based on your traffic, whether you’re an early stage startup or Shopify during Black Friday.
One of the promises of serverless is the idea of scaling to zero — once those big days subside, you no longer have to pay for virtual machines to sit idle before your autoscaling kicks in, or be charged by the hour for instances that you barely ended up using. No compute = no bills for usage. Or so, at least, is the promise of serverless.
Yet, there’s one hidden cost, where even in the serverless world you will find yourself paying for idle resources — what happens when your function is sitting around waiting on I/O? With pricing based on the duration that a function runs, you’re still billed for time that your service is doing zero work, and just waiting on network requests.
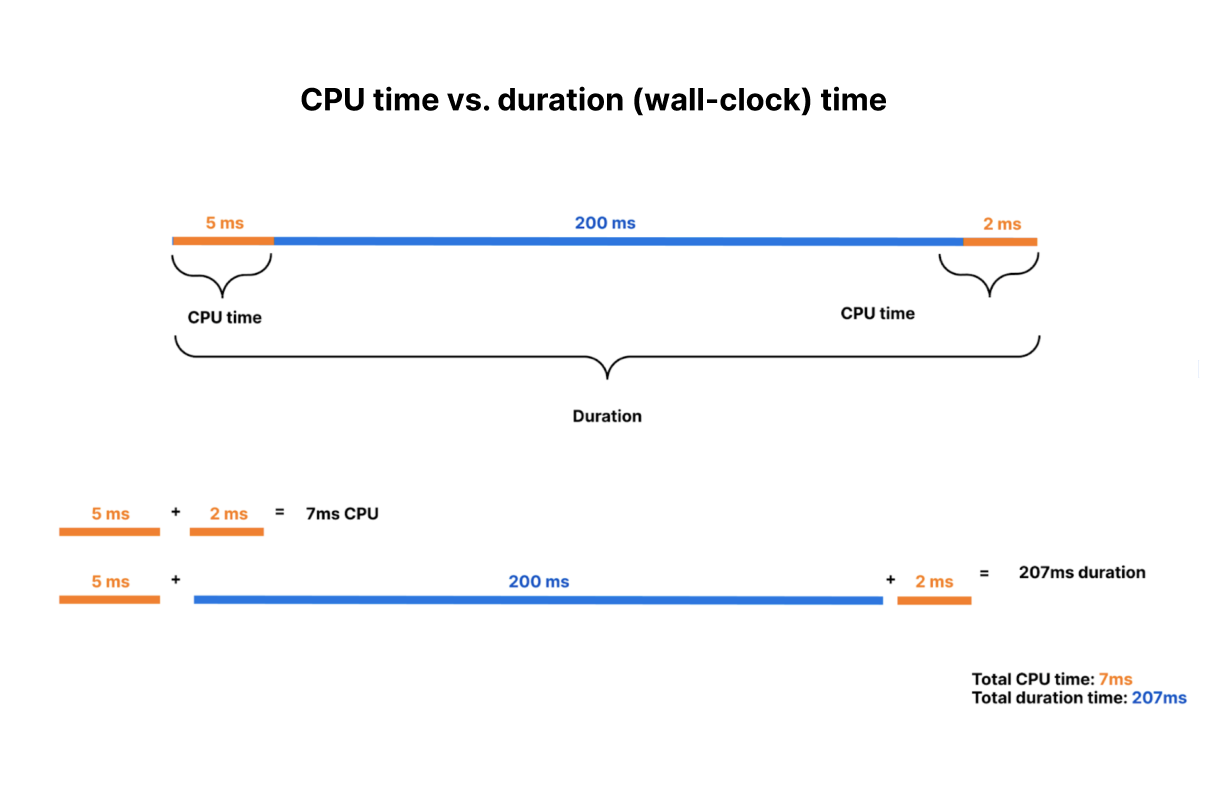
Most applications spend far more time waiting on this I/O than they do using the CPU, often ten times more.
Imagine a similar scenario in your own life — you grab a cab to go to the airport. On the way, the driver decides to stop to refuel and grab a snack, but leaves the meter running. This is not time spent bringing you closer to your destination, but it’s time that you’re paying for. Now imagine for the time the driver was refueling the car, the meter was paused. That’s the difference between CPU time and duration, or wall clock time.
But rather than waiting on the driver to refuel or grab a Snickers bar, what is it that you’re actually paying for when it comes to serverless compute?
Time spent waiting on services you don’t control
Most applications depend on one or many external service providers. Providers of hosted large language models (LLMs) like GPT-4 or Stable Diffusion. Databases as a service. Payment processors. Or simply an API request to a system outside your control. This is where software development is headed — rather than reinventing the wheel and slowly building everything themselves, both fast-moving startups and the Fortune 500 increasingly build using other services to avoid undifferentiated heavy lifting.
Every time an application interacts with one of these external services, it has to send data over the network and wait until it receives a response. And while some services are lightning fast, others can take considerable time, like waiting for a payment processor or for a large media file to be uploaded or converted. Your own application sits idle for most of the request, waiting on services outside your control.
Until today, you’ve had to pay while your application waits. You’ve had to pay more when a service you depend on has an operational issue and slows down, or times out in responding to your request. This has been a disincentive to incrementally move parts of your application to serverless.
Cloudflare’s new pricing: the first serverless platform to truly scale down to zero
The idea of “scale to zero” is that you never have to keep instances of your application sitting idle, waiting for something to happen. Serverless is more than just not having to manage servers or virtual machines — you shouldn’t have to provision and manage the number of compute resources that are available or warm.
Our new pricing takes the “scale to zero” concept even further, and extends it to whether your application is actually performing work. If you’re still paying while nothing is happening, we don’t think that’s truly scale to zero. Your application is idle. The CPU can be used for other tasks. Whether your application is “running” is an old concept lifted from an era before multi-tenant cloud platforms. What matters is if you are actually using compute resources.
Pay less, deploy everywhere, without hidden costs
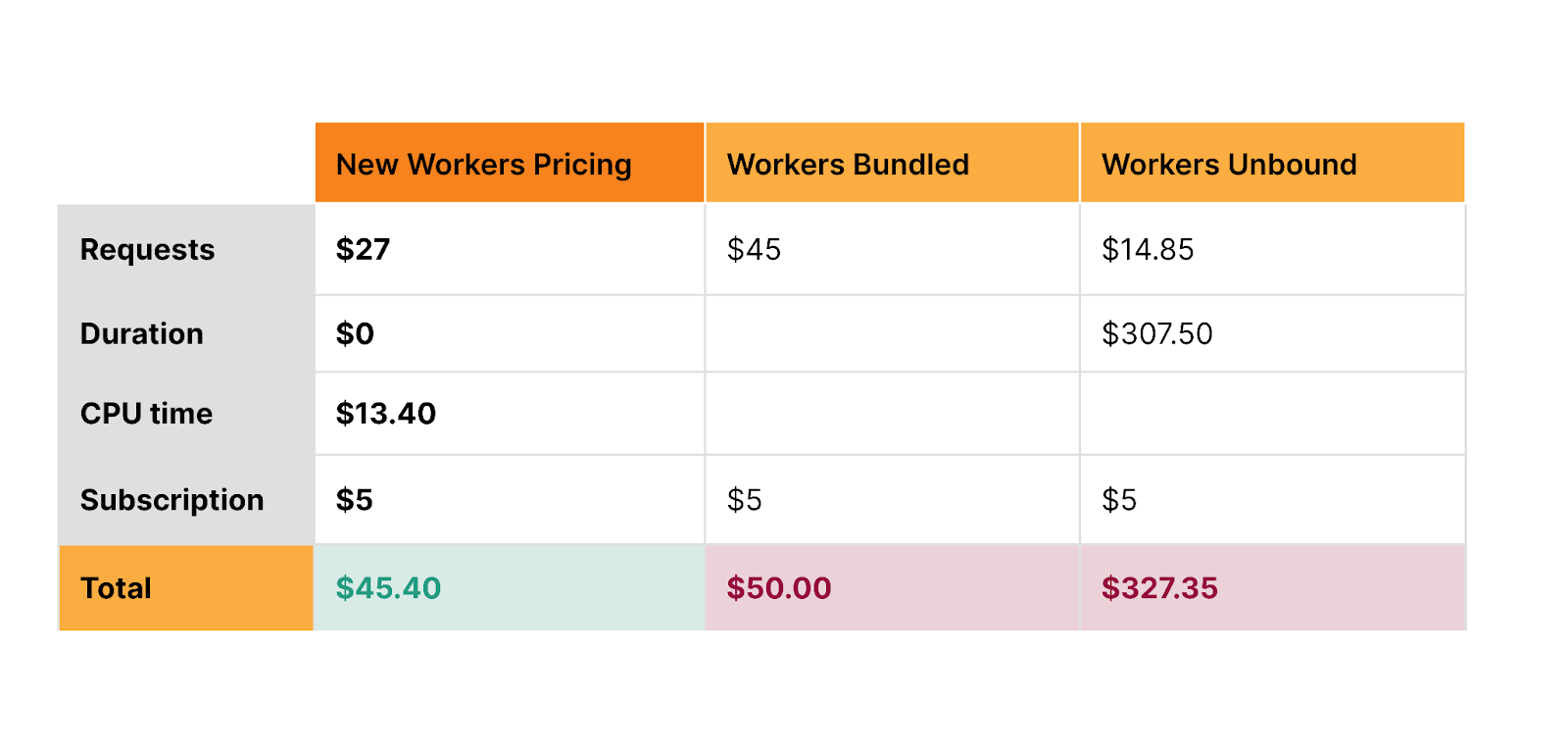
Let’s compare what you’d pay on new Workers pricing to AWS Lambda, for the following Worker:
- One billion requests per month
- Seven CPU milliseconds per request
- 200ms duration per request

The above table is for informational purposes only. Prices are limited to the public fees as of September 20, 2023, and do not include taxes and any other fees. AWS Lambda and Lambda @ Edge prices are based on publicly available pricing in US-East (Ohio) region as published on https://aws.amazon.com/lambda/pricing/
Workers are the most cost-effective option, and are globally distributed, automatically optimized with Smart Placement, and integrated with Durable Objects, R2, KV, Cache, Queues, D1 and more. And with Workers, you never have to pay extra for provisioned concurrency, pay a penalty for streaming responses, or incur egregious egress fees.
New Workers pricing makes building AI applications dramatically cheaper
Yesterday we announced a new suite of products to let you build AI applications on Cloudflare — Workers AI, AI Gateway, and our new vector database, Vectorize.
Nearly everyone is building new products and features using AI models right now. Large language models and generative AI models are incredibly powerful. But they aren’t always fast — asking a model to create an image, transcribe a segment of audio, or write a story often takes multiple seconds — far longer than a typical API response or database query that we expect to return in tens of milliseconds. There is significant compute work going on behind the scenes, and that means longer duration per request to a Worker.
New Workers pricing makes this much less expensive than it was previously on the Unbound usage model.
Let’s take the same example as above, but instead assume the duration of the request is two seconds (2000ms), because the Worker makes an inference request to a large AI model. With new Workers pricing, you pay the exact same amount, no matter how long this request takes.
No surprise bills — set a maximum limit on CPU time for each Worker
Surprise bills from cloud providers are an unfortunately common horror story. In the old way of provisioning compute resources, forgetting to shut down an instance of a database or virtual machine can cost hundreds of dollars. And accidentally autoscaling up too high can be even worse.
We’re building new safeguards to prevent these kinds of scenarios on Workers. As part of new pricing, you will be able to cap CPU usage on a per-Worker basis.
For example, if you have a Worker with a p99 CPU time of 15ms, you might use this to set a max CPU limit of 40ms — enough headroom to ensure that your worker will run successfully, while ensuring that even if you ship a bug that causes a CPU time to ratchet up dramatically, or have an edge case that causes infinite recursion, you can’t suddenly rack up a giant unexpected bill, or be vulnerable to a denial of wallet attack. This can be particularly helpful if your worker handles variable or user-generated input, to guard against edge cases that you haven’t accounted for.
Alternatively, if you’re running a production service, but want to make sure you stay on top of your costs, we will also be adding the option to configure notifications that can automatically email you, page you, or send a webhook if your worker exceeds a particular amount of CPU time per request. You will be able to choose at what threshold you want to be notified, and how.
New ways to “hibernate” Durable Objects while keeping connections alive
While Workers are stateless functions, Durable Objects are stateful and long-lived, commonly used to coordinate and persist real-time state in chat, multiplayer games, or collaborative apps. And unlike Workers, duration-based pricing fits Durable Objects well. As long as one or more clients are connected to a Durable Object, it keeps state available in memory. Durable Objects pricing will remain duration-based, and is not changing as part of this announcement.
What about when a client is connected to a Durable Object, but no work has happened for a long time? Consider a collaborative whiteboard app built using Durable Objects. A user of the app opens the app in a browser tab, but then forgets about it, and leaves it running for days, with an open WebSocket connection. Just like with Workers, we don’t think you should have to pay for this idle time. But until recently, there hasn’t been an API to signal to us that a Durable Object can be safely “hibernated”.
The recently introduced Hibernation API, currently in beta, allows you to set an automatic response to be used while hibernated and serialize state such that it survives hibernation. This gives Cloudflare the inputs we need in order to maintain open WebSocket connections from clients, while “hibernating” the Durable Object such that it is not actively running, and you are not billed for idle time. The result is that your state is always available in-memory when actually need it, but isn’t unnecessarily kept around when it’s not. As long as your Durable Object is hibernating, even if there are active clients still connected over a WebSocket, you won’t be billed for duration.
Snippets make Cloudflare’s CDN programmable — for free
What if you just want to modify a header, do a country code redirect, or cache a custom query? Developers have relied on Workers to program Cloudflare’s CDN like this for many years. With the announcement of Cloudflare Snippets last year, now in alpha, we’re making it free.
If you use Workers today for these smaller use cases, to customize any of Cloudflare’s application services, Snippets will be the optimal, zero cost option.
A serverless platform without limits
Developers are building ever larger and more complex full-stack applications on Workers each month. Our promise to you is to help you scale in any direction, without worrying about paying for idle time or having to manage and provision compute resources across regions.
This also means not having to worry about limits. Workers already serves many millions of requests per second, and scales and performs so well that we are rebuilding our own CDN on top of Workers. Individual Workers can now be up to 10MB, with a max startup time of 400ms, and can be easily composed together using Service Bindings. Entire platforms are built on top of Workers, with a growing number of companies allowing their own customers to write and deploy custom code and applications via Workers for Platforms. Some of the biggest platforms in the world rely on Cloudflare and the Workers platform during the most critical moments.
New pricing removes limits on the types of applications that could be built cost effectively with duration-based pricing. It removes the ceiling on CPU time from our original request-based pricing. We’re excited to see what you build, and are committed to being the development platform where you’re not constrained by limits on scale, regions, instances, concurrency or whatever else you need to handle to grow and operate globally.
When will new pricing be available?
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You will have until March 1, 2024, or the end of your Enterprise contract, whichever comes later, to switch to new pricing on your own, after which all of your projects will be automatically migrated to new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect.
Between now and then, we want to hear from you. We’ve based new pricing off feedback we’ve heard from developers building serverless applications, and companies estimating and projecting their costs. Tell us what you think of new pricing by sharing your feedback in this survey. We read every response.