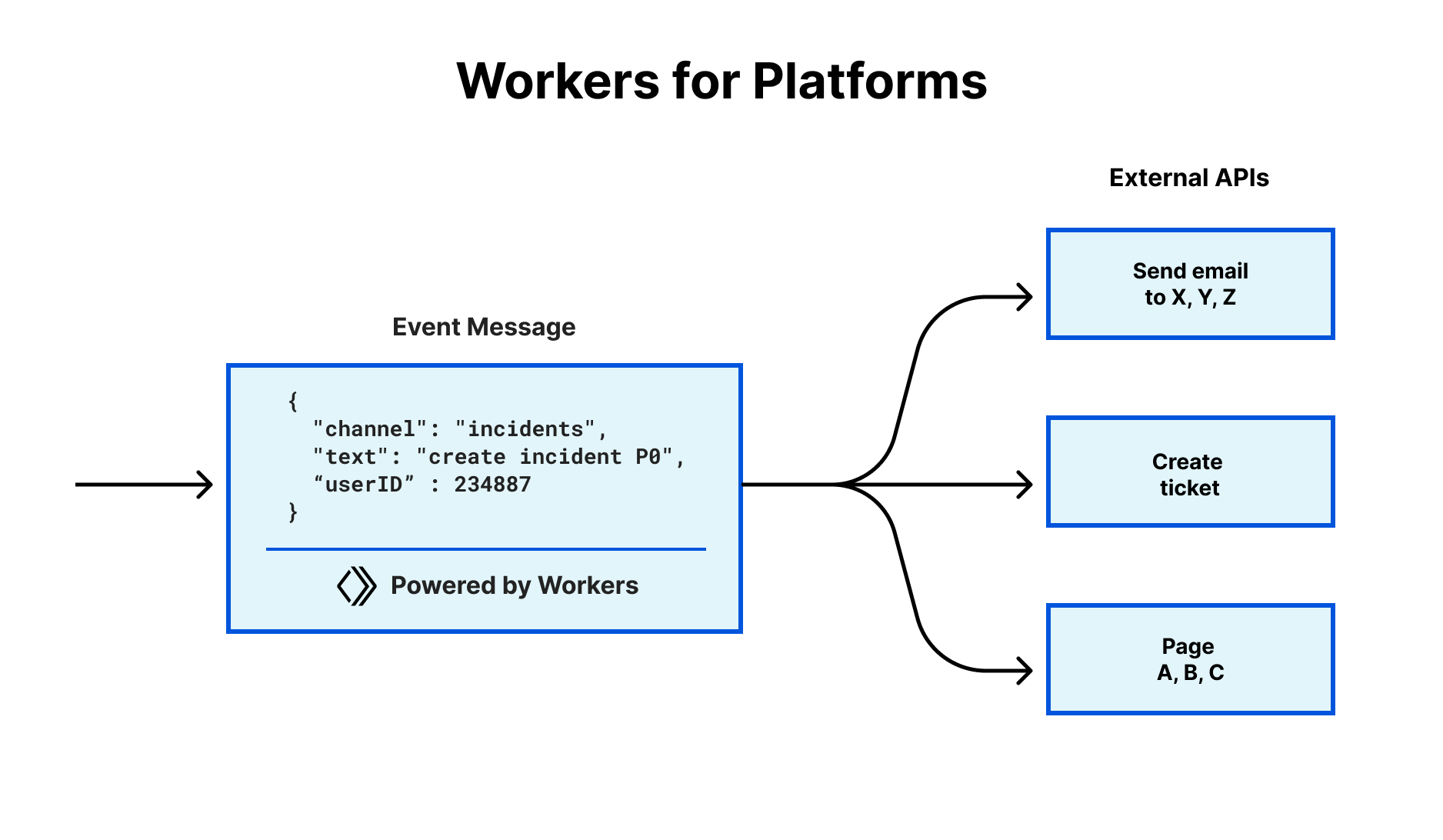
We have some big news to share today: Replicate, the leading platform for running AI models, is joining Cloudflare.
We first started talking to Replicate because we shared a lot in common beyond just a passion for bright color palettes. Our mission for Cloudflare’s Workers developer platform has been to make building and deploying full-stack applications as easy as possible. Meanwhile, Replicate has been on a similar mission to make deploying AI models as easy as writing a single line of code. And we realized we could build something even better together by integrating the Replicate platform into Cloudflare directly.
We are excited to share this news and even more excited for what it will mean for customers. Bringing Replicate’s tools into Cloudflare will continue to make our Developer Platform the best place on the Internet to build and deploy any AI or agentic workflow.
What does this mean for you?
Before we spend more time talking about the future of AI, we want to answer the questions that are top of mind for Replicate and Cloudflare users. In short:
For existing Replicate users: Your APIs and workflows will continue to work without interruption. You will soon benefit from the added performance and reliability of Cloudflare’s global network.
For existing Workers AI users: Get ready for a massive expansion of the model catalog and the new ability to run fine-tunes and custom models directly on Workers AI.
Now – let’s get back into why we’re so excited about our joint future.
The AI Revolution was not televised, but it started with open source
Before AI was AI, and the subject of every conversation, it was known for decades as “machine learning”. It was a specialized, almost academic field. Progress was steady but siloed, with breakthroughs happening inside a few large, well-funded research labs. The models were monolithic, the data was proprietary, and the tools were inaccessible to most developers. Everything changed when the culture of open-source collaboration — the same force that built the modern Internet — collided with machine learning, as researchers and companies began publishing not just their papers, but their model weights and code.
This ignited an incredible explosion of innovation. The pace of change in just the past few years has been staggering; what was state-of-the-art 18 months ago (or sometimes it feels like just days ago) is now the baseline. This acceleration is most visible in generative AI.
We went from uncanny, blurry curiosities to photorealistic image generation in what felt like the blink of an eye. Open source models like Stable Diffusion unlocked immediate creativity for developers, and that was just the beginning. If you take a look at Replicate’s model catalog today, you’ll see thousands of image models of almost every flavor, each iterating on the previous.
This happened not just with image models, but video, audio, language models and more….
But this incredible, community-driven progress creates a massive practical challenge: How do you actually run these models? Every new model has different dependencies, requires specific GPU hardware (and enough of it), and needs a complex serving infrastructure to scale. Developers found themselves spending more time fighting with CUDA drivers and requirements.txt files than actually building their applications.
This is exactly the problem Replicate solved. They built a platform that abstracts away all that complexity (using their open-source tool Cog to package models into standard, reproducible containers), letting any developer or data scientist run even the most complex open-source models with a simple API call.
Today, Replicate’s catalog spans more than 50,000 open-source models and fine-tuned models. While open source unlocked so many possibilities, Replicate’s toolset goes beyond that to make it possible for developers to access any models they need in one place. Period. With their marketplace, they also offer seamless access to leading proprietary models like GPT-5 and Claude Sonnet, all through the same unified API.
What’s worth noting is that Replicate didn’t just build an inference service; they built a community. So much innovation happens through being inspired by what others are doing, iterating on it, and making it better. Replicate has become the definitive hub for developers to discover, share, fine-tune, and experiment with the latest models in a public playground.
Stronger together: the AI catalog meets the AI cloud
Coming back to the Workers Platform mission: Our goal all along has been to enable developers to build full-stack applications without having to burden themselves with infrastructure. And while that hasn’t changed, AI has changed the requirements of applications.
The types of applications developers are building are changing — three years ago, no one was building agents or creating AI-generated launch videos. Today they are. As a result, what they need and expect from the cloud, or the AI cloud, has changed too.
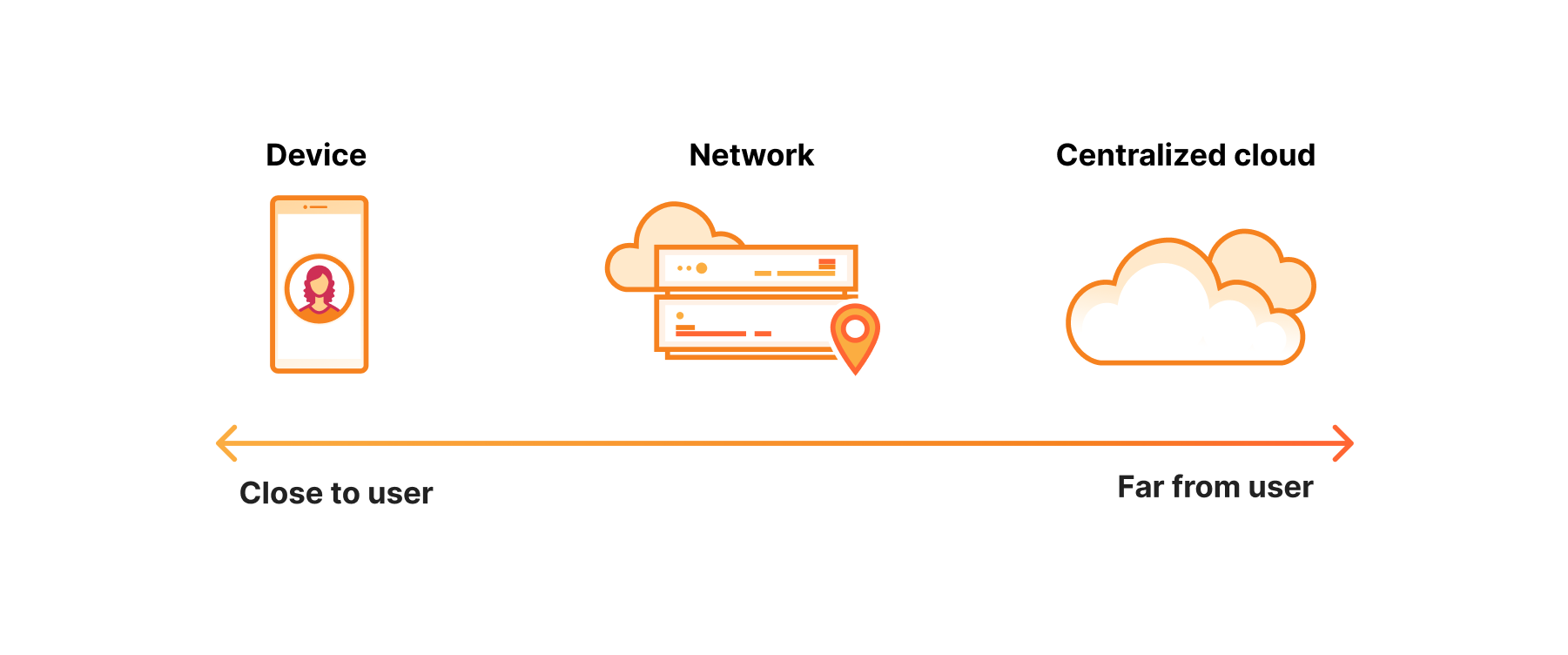
To meet the needs of developers, Cloudflare has been building the foundational pillars of the AI Cloud, designed to run inference at the edge, close to users. This isn’t just one product, but an entire stack:
Workers AI: Serverless GPU inference on our global network.
AI Gateway: A control plane for caching, rate-limiting, and observing any AI API.
Data Stack: Including Vectorize (our vector database) and R2 (for model and data storage).
Orchestration: Tools like AI Search (formerly Autorag), Agents, and Workflows to build complex, multi-step applications.
Foundation: All built on our core developer platform of Workers, Durable Objects, and the rest of our stack.
As we’ve been helping developers scale up their applications, Replicate has been on a similar mission — to make deploying AI models as easy as deploying code. This is where it all comes together. Replicate brings one of the industry’s largest and most vibrant model catalog and developer community. Cloudflare brings an incredibly performant global network and serverless inference platform. Together, we can deliver the best of both worlds: the most comprehensive selection of models, runnable on a fast, reliable, and affordable inference platform.
Our shared vision
For the community: the hub for AI exploration
The ability to share models, publish fine-tunes, collect stars, and experiment in the playground is the heart of the Replicate community. We will continue to invest in and grow this as the premier destination for AI discovery and experimentation, now supercharged by Cloudflare’s global network for an even faster, more responsive experience for everyone.
The future of inference: one platform, all models
Our vision is to bring the best of both platforms together. We will bring the entire Replicate catalog — all 50,000+ models and fine-tunes — to Workers AI. This gives you the ultimate choice: run models in Replicate’s flexible environment or on Cloudflare’s serverless platform, all from one place.
But we’re not just expanding the catalog. We are thrilled to announce that we will be bringing fine-tuning capabilities to Workers AI, powered by Replicate’s deep expertise. We are also making Workers AI more flexible than ever. Soon, you’ll be able to bring your own custom models to our network. We’ll leverage Replicate’s expertise with Cog to make this process seamless, reproducible, and easy.
The AI Cloud: more than just inference
Running a model is just one piece of the puzzle. The real magic happens when you connect AI to your entire application. Imagine what you can build when Replicate’s massive catalog is deeply integrated with the entire Cloudflare developer platform: run a model and store the results directly in R2 or Vectorize; trigger inference from a Worker or Queue; use Durable Objects to manage state for an AI agent; or build real-time generative UI with WebRTC and WebSockets.
To manage all this, we will integrate our unified inference platform deeply with the AI Gateway, giving you a single control plane for observability, prompt management, A/B testing, and cost analytics across all your models, whether they’re running on Cloudflare, Replicate, or any other provider.
Welcome to the team!
We are incredibly excited to welcome the Replicate team to Cloudflare. Their passion for the developer community and their expertise in the AI ecosystem are unmatched. We can’t wait to build the future of AI together.
Open source is the core fabric of the web, and the open source tools that power the modern web depend on the stability and support of the community.
To ensure two major open source projects have the resources they need, we are proud to announce our financial sponsorship to two cornerstone frameworks in the modern web ecosystem: Astro and TanStack.
Critically, we think it’s important we don’t do this alone — for the open web to continue to thrive, we must bet on and support technologies and frameworks that are open and accessible to all, and not beholden to any one company.
Which is why we are also excited to announce that for these sponsorships we are joining forces with our peers at Netlify to sponsor TanStack and Webflow to sponsor Astro.
Why Astro and TanStack? Investing in the Future of the Frontend
Our decision to support Astro and TanStack was deliberate. These two projects represent distinct but complementary visions for the future of web development. One is redefining the architecture for high-performance, content-driven websites, while the other provides a full-stack toolkit for building the most ambitious web applications.
Astro: the framework for the high-performance sites
When it comes to endorsing a technology, we believe actions speak louder than words.
That’s why our support for Astro isn’t just financial—it’s foundational. We run our developer documentation site, developers.cloudflare.com, entirely on Astro. This isn’t a small side project — it’s a critical resource visited by hundreds of thousands of developers every day, with dozens of contributors constantly keeping it updated. For a site like this, performance isn’t a feature; it’s a requirement.
We chose Astro because its core principles mirror our own. Its “zero JS by default” architecture delivers the raw performance and stellar SEO that a content-heavy site demands, ensuring our docs are fast and discoverable. Just as importantly, Astro is framework-agnostic, letting teams use components from React, Vue, or Svelte without vendor lock-in.
Astro makes it easy for our global team to keep content up-to-date and, most importantly, keep our docs blazing fast. Our sponsorship is a direct result of the immense value we’ve experienced firsthand.
Cloudflare’s partnership and support affirms our shared mission: to make the web faster, more open, and better for everyone who builds on it. – Fred K. Schott, Astro Co-creator, Project Steward
Webflow gives marketers, designers, and developers the freedom to build without compromise. Astro shares that same spirit by removing barriers, speeding up workflows, and opening new creative possibilities. Together with Cloudflare and Netlify, we’re helping ensure the tools our community relies on stay open, sustainable, and ready for the future. – Allan Leinwand, Webflow CTO
TanStack Start: the full-stack framework for ambitious applications
If Astro provides the ideal foundation for content-heavy sites, TanStack provides the ideal engine for complex web applications. TanStack is not a single framework but a suite of powerful, headless, and type-safe libraries that solve the hardest problems in modern application development.
Libraries like TanStack Query have become the de facto industry standard for managing asynchronous server state, elegantly solving complex challenges like caching, background refetching, and optimistic updates that once required thousands of lines of fragile, bespoke code. Similarly, TanStack Router brings full type-safety to routing, eliminating an entire class of common bugs, while TanStack Table and TanStack Form provide the robust, headless primitives needed to build sophisticated, data-intensive user interfaces.
And today, TanStack announced its official release of the release candidate for TanStack Start 1.0, taking a big stride towards production-readiness.
TanStack Start is a new full-stack framework that composes these powerful libraries into a cohesive, enterprise-grade development experience. With features like full-document Server-Side Rendering (SSR), streaming, and a “deploy anywhere” architecture, TanStack Start is designed for the modern, serverless edge. It provides the power and type-safety needed for ambitious applications and is a perfect match for deployment environments like Cloudflare Workers.
With Cloudflare alongside us, TanStack can keep raising the bar for fast, scalable, and type-safe tools for powering the next generation of web apps while protecting the openness and freedom developers depend on. – Tanner Linsley, TanStack creator
Supporting an open web is not a nice-to-have for us, but a requirement for us to fulfill our mission to build a better web. Collaborating with Cloudflare on making sure these top projects are funded is the easiest decision we can make! –Mat B, CEO
Joining forces builds a stronger open web
It is not lost on us that this coalition includes companies that compete in the market. We believe this is a feature, not a bug. It demonstrates a shared understanding that we are all building on the same open-source foundations. A healthy, innovative, and sustainable open-source ecosystem is the rising tide that lifts all of our boats.
This joint sponsorship model means Astro and TanStack are more resilient. For you, that means you can build on them with confidence, knowing they aren’t dependent on a single company’s shifting priorities.
With that, show us what you build!
The best way to support open source is to use it, build with it, and contribute back to it. See how easy it is to get started with Astro and TanStack and deploy an application to Cloudflare in minutes with the following framework guides:
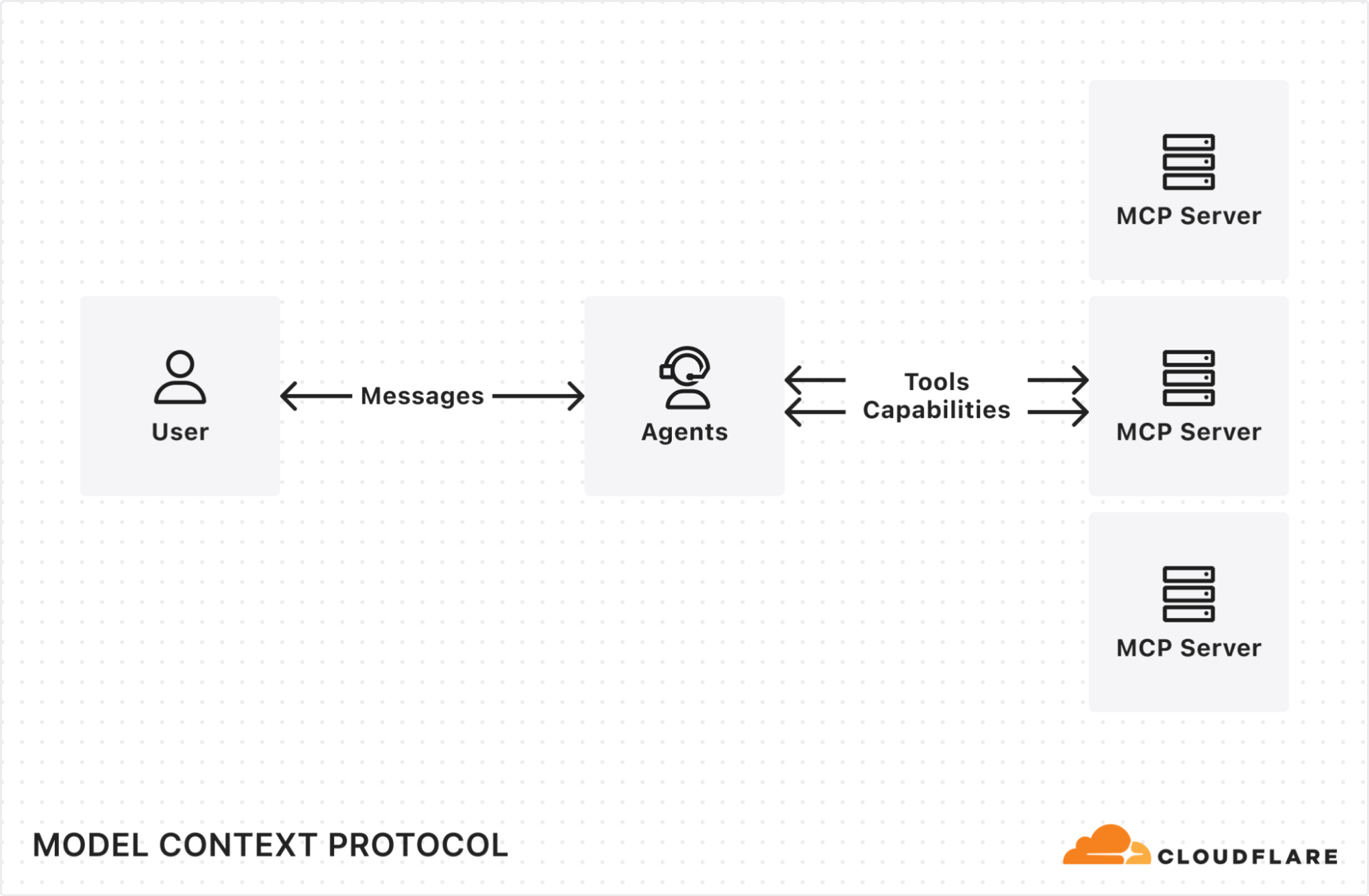
It’s not a secret that at Cloudflare we are bullish on the future of agents. We’re excited about a future where AI can not only co-pilot alongside us, but where we can actually start to delegate entire tasks to AI.
While it hasn’t been too long since we first announced our Agents SDK to make it easier for developers to build agents, building towards an agentic future requires continuous delivery towards this goal. Today, we’re making several announcements to help accelerate agentic development, including:
New Agents SDK capabilities: Build remote MCP clients, with transport and authentication built-in, to allow AI agents to connect to external services.
Hibernation for McpAgent: Automatically sleep stateful, remote MCP servers when inactive and wake them when needed. This allows you to maintain connections for long-running sessions while ensuring you’re not paying for idle time.
Durable Objects free tier: We view Durable Objects as a key component for building agents, and if you’re using our Agents SDK, you need access to it. Until today, Durable Objects was only accessible as part of our paid plans, and today we’re excited to include it in our free tier.
Workflows GA: Enables you to ship production-ready, long-running, multi-step actions in agents.
AutoRAG: Helps you integrate context-aware AI into your applications, in just a few clicks
AI agents can now connect to and interact with external services through MCP (Model Context Protocol). We’ve updated the Agents SDK to allow you to build a remote MCP client into your AI agent, with all the components — authentication flows, tool discovery, and connection management — built-in for you.
This allows you to build agents that can:
Prompt the end user to grant access to a 3rd party service (MCP server).
Use tools from these external services, acting on behalf of the end user.
Call MCP servers from Workflows, scheduled tasks, or any part of your agent.
Connect to multiple MCP servers and automatically discover new tools or capabilities presented by the 3rd party service.
MCP (Model Context Protocol) — first introduced by Anthropic — is quickly becoming the standard way for AI agents to interact with external services, with providers like OpenAI, Cursor, and Copilot adopting the protocol.
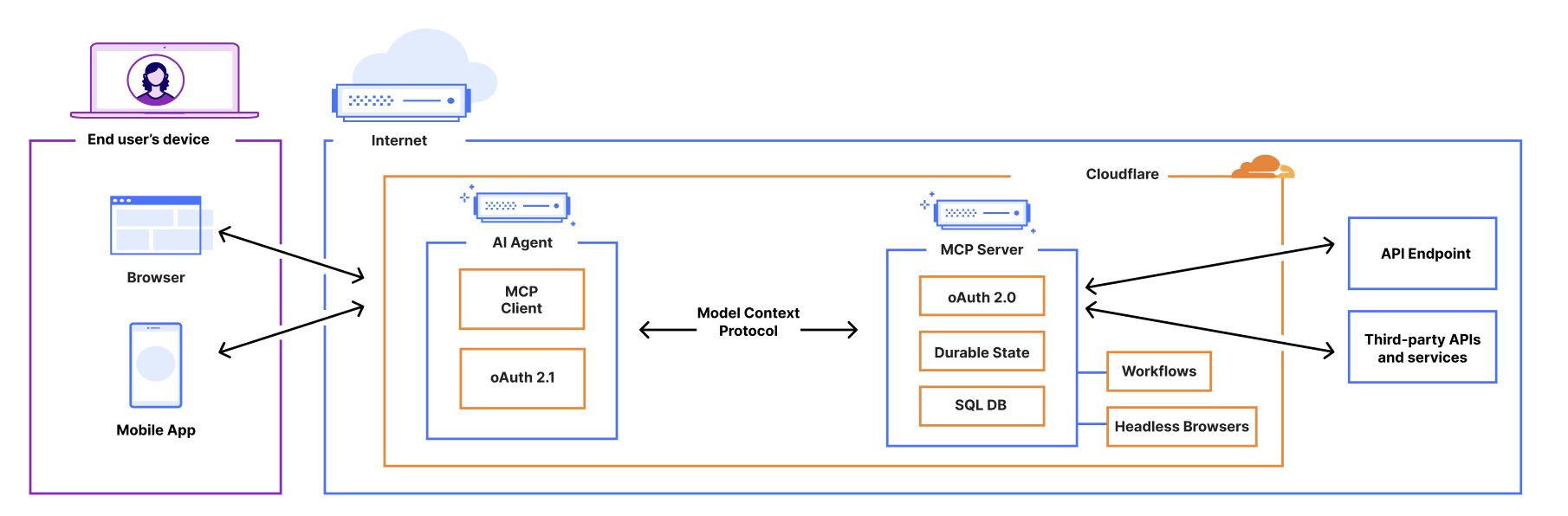
We recently announced support for building remote MCP servers on Cloudflare, and added an McpAgent class to our Agents SDK that automatically handles the remote aspects of MCP: transport and authentication/authorization. Now, we’re excited to extend the same capabilities to agents acting as MCP clients.
Want to see it in action? Use the button below to deploy a fully remote MCP client that can be used to connect to remote MCP servers.
AI Agents can now act as remote MCP clients, with transport and auth included
AI agents need to connect to external services to access tools, data, and capabilities beyond their built-in knowledge. That means AI agents need to be able to act as remote MCP clients, so they can connect to remote MCP servers that are hosting these tools and capabilities.
We’ve added a new class, MCPClientManager, into the Agents SDK to give you all the tooling you need to allow your AI agent to make calls to external services via MCP. The MCPClientManager class automatically handles:
Transport: Connect to remote MCP servers over SSE and HTTP, with support for Streamable HTTP coming soon.
Connection management: The client tracks the state of all connections and automatically reconnects if a connection is lost.
Capability discovery: Automatically discovers all capabilities, tools, resources, and prompts presented by the MCP server.
Real-time updates: When a server’s tools, resources, or prompts change, the client automatically receives notifications and updates its internal state.
Namespacing: When connecting to multiple MCP servers, all tools and resources are automatically namespaced to avoid conflicts.
Granting agents access to tools with built-in auth check for MCP Clients
We’ve integrated the complete OAuth authentication flow directly into the Agents SDK, so your AI agents can securely connect and authenticate to any remote MCP server without you having to build authentication flow from scratch.
This allows you to give users a secure way to log in and explicitly grant access to allow the agent to act on their behalf by automatically:
Supporting the OAuth 2.1 protocol.
Redirecting users to the service’s login page.
Generating the code challenge and exchanging an authorization code for an access token.
Using the access token to make authenticated requests to the MCP server.
Here is an example of an agent that can securely connect to MCP servers by initializing the client manager, adding the server, and handling the authentication callbacks:
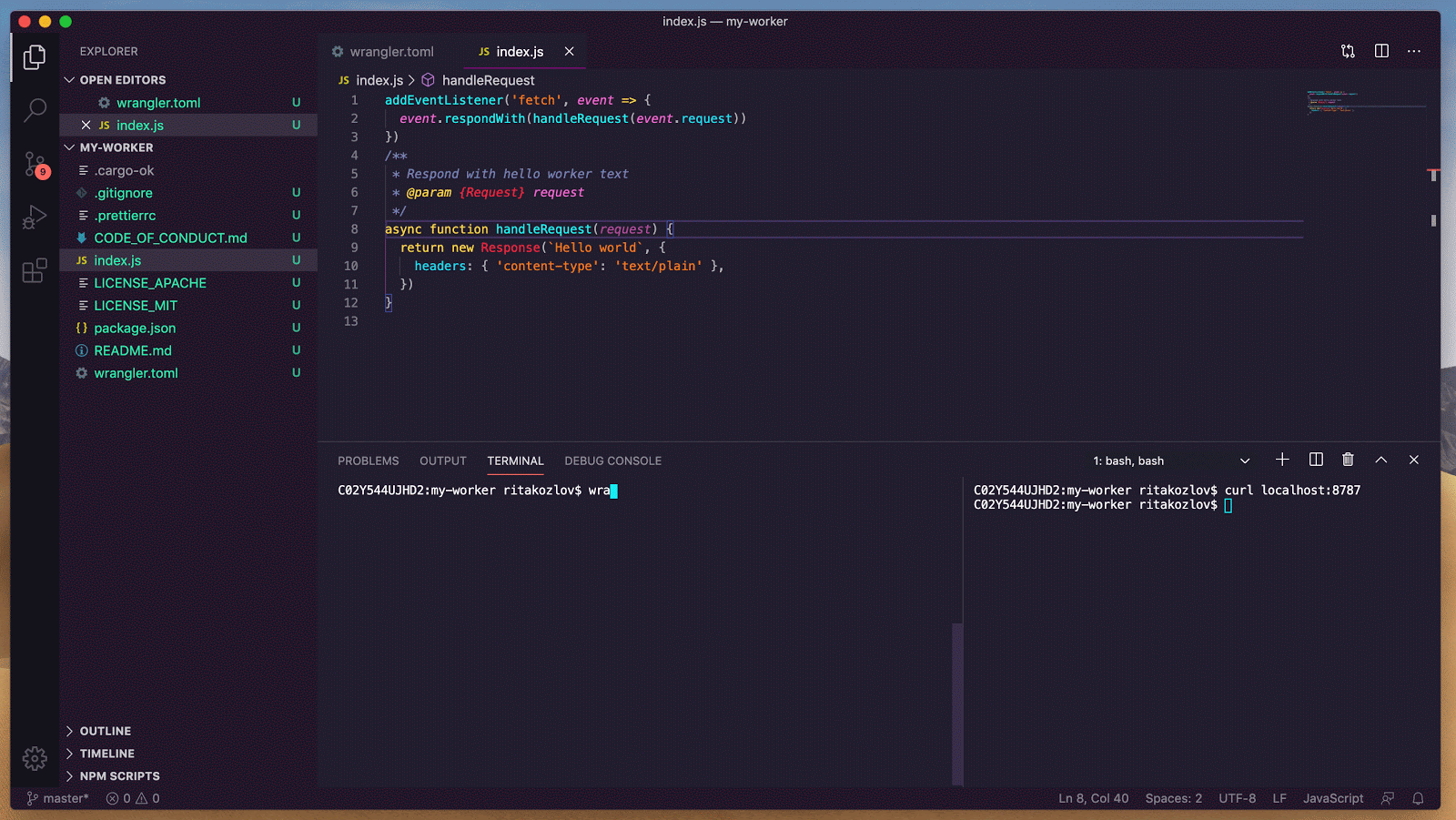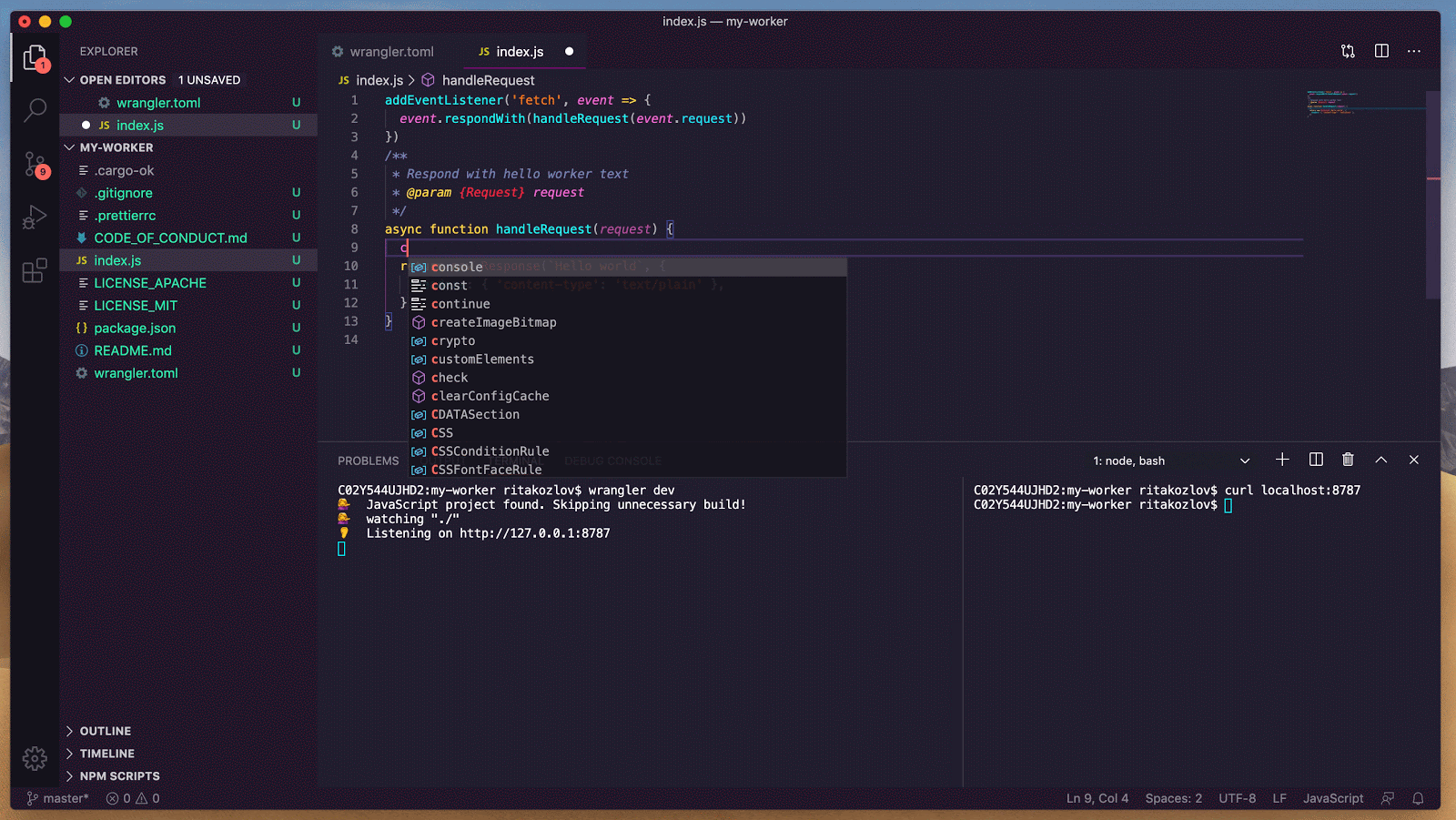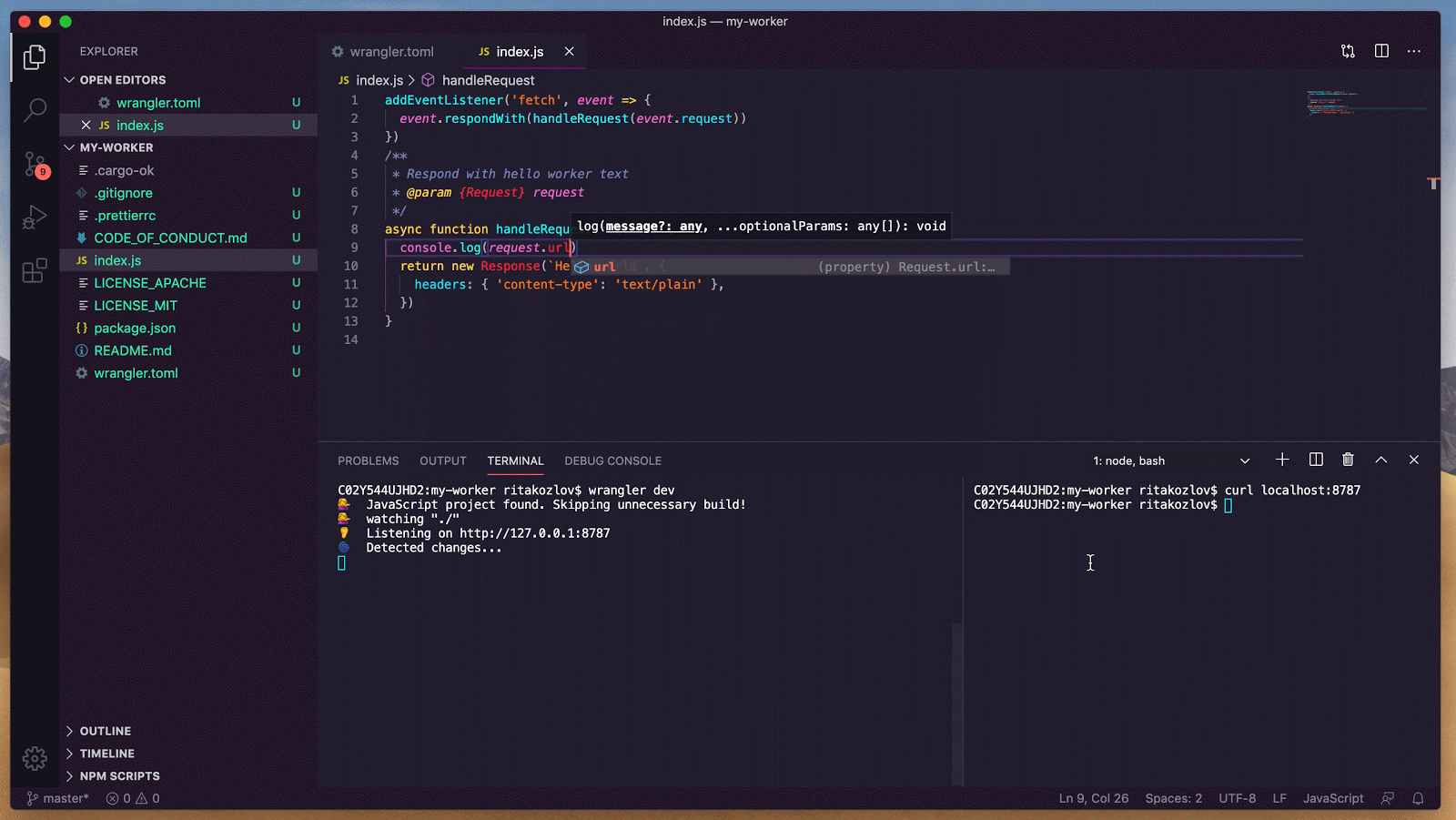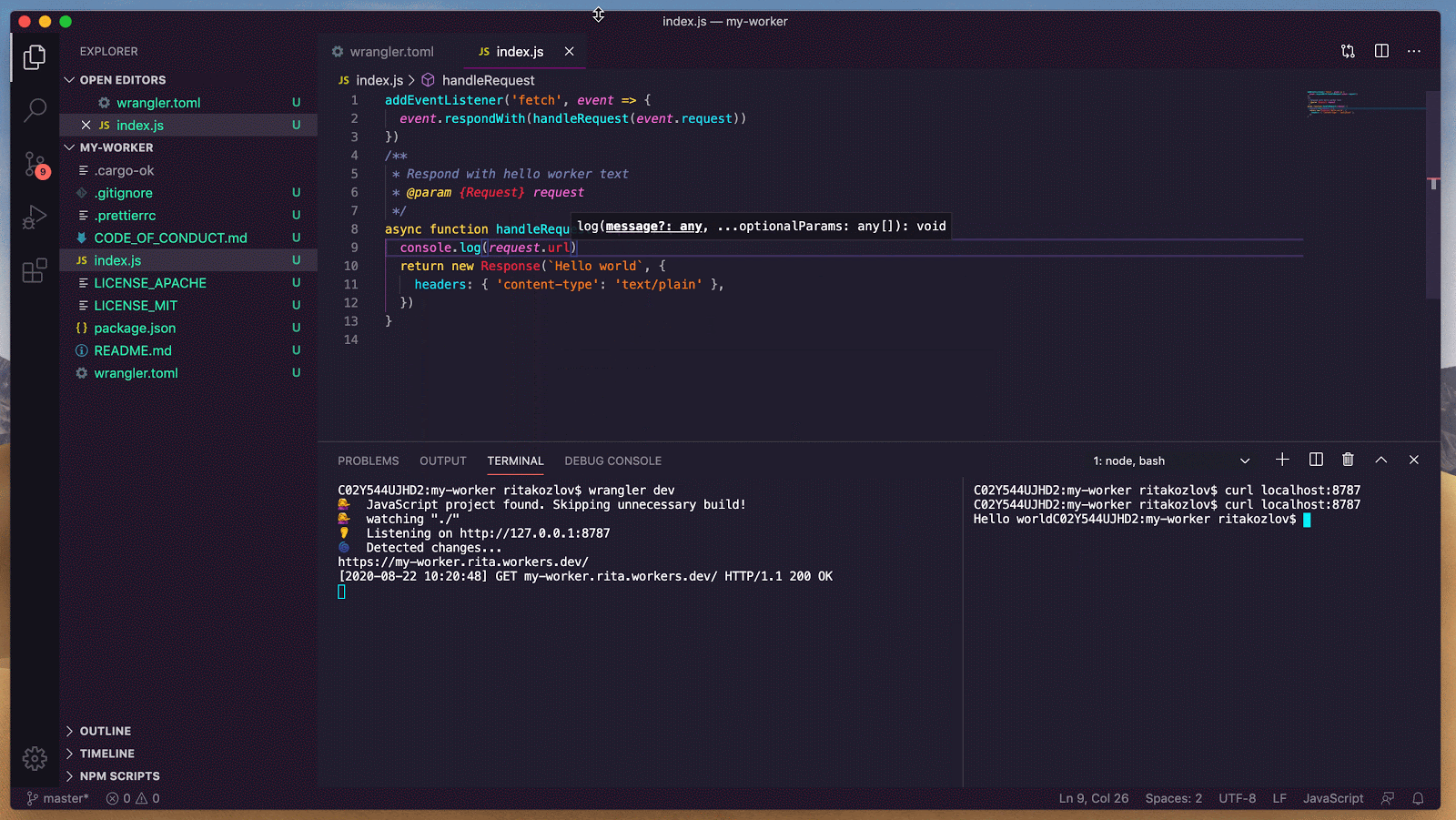
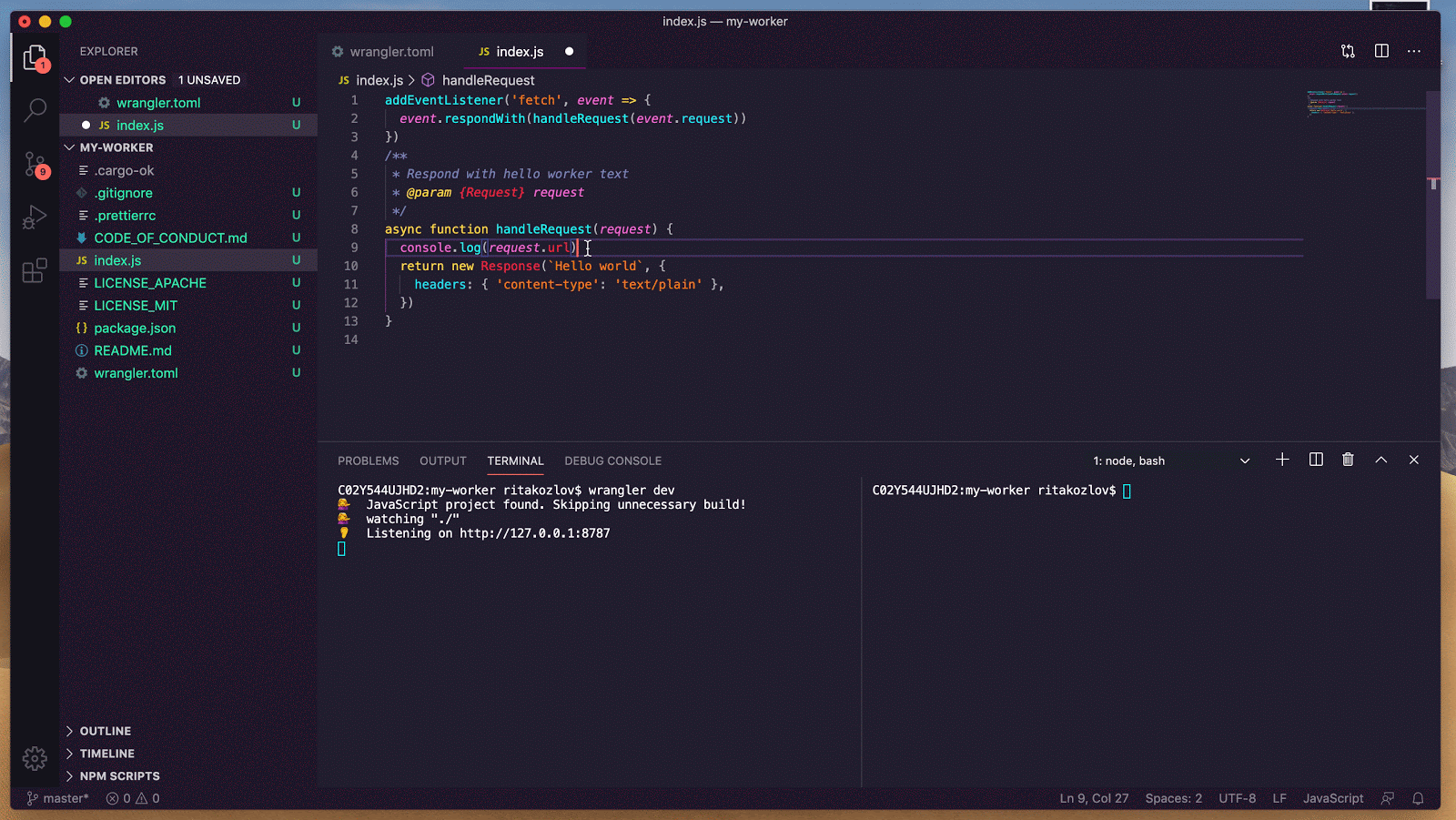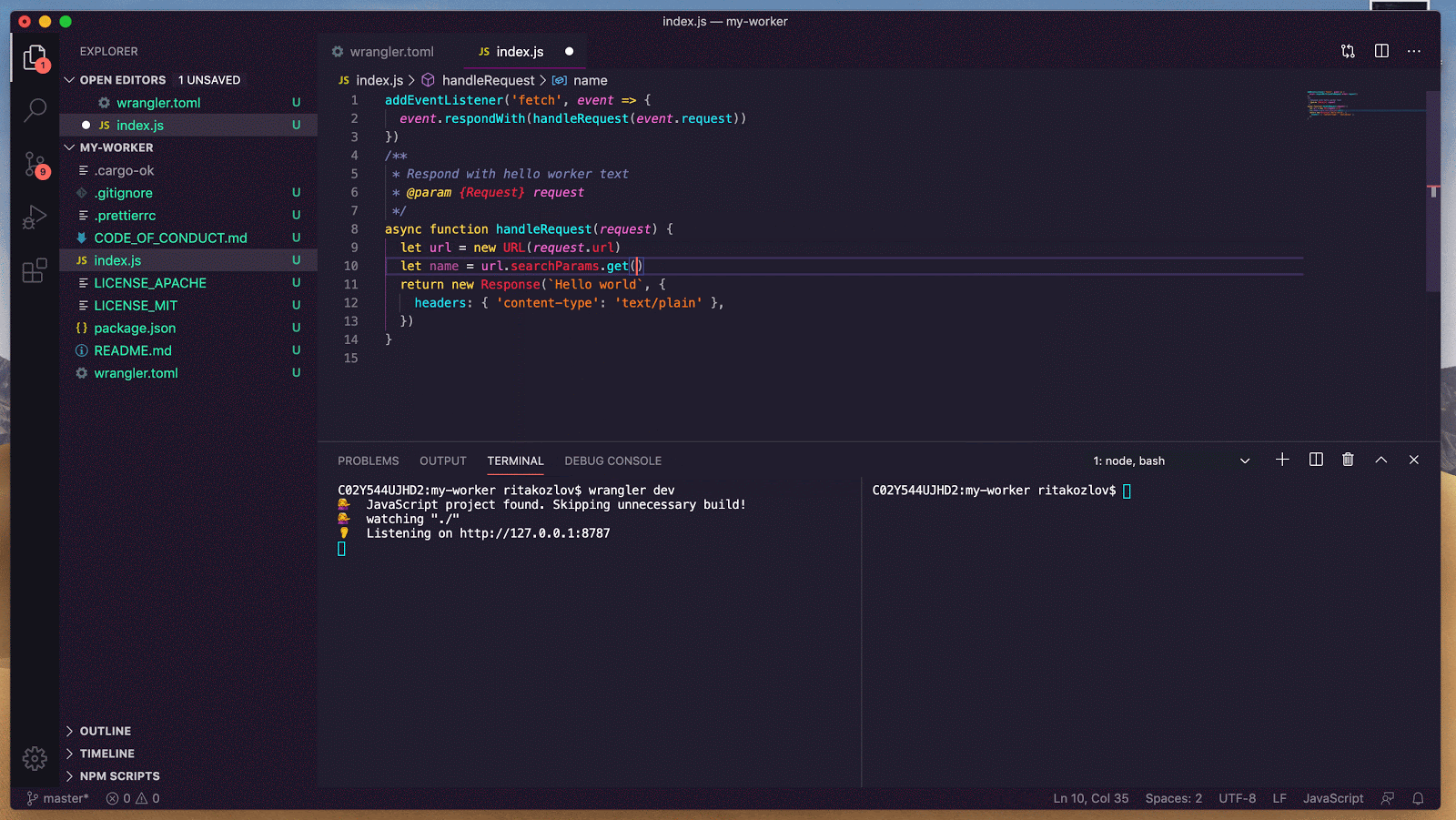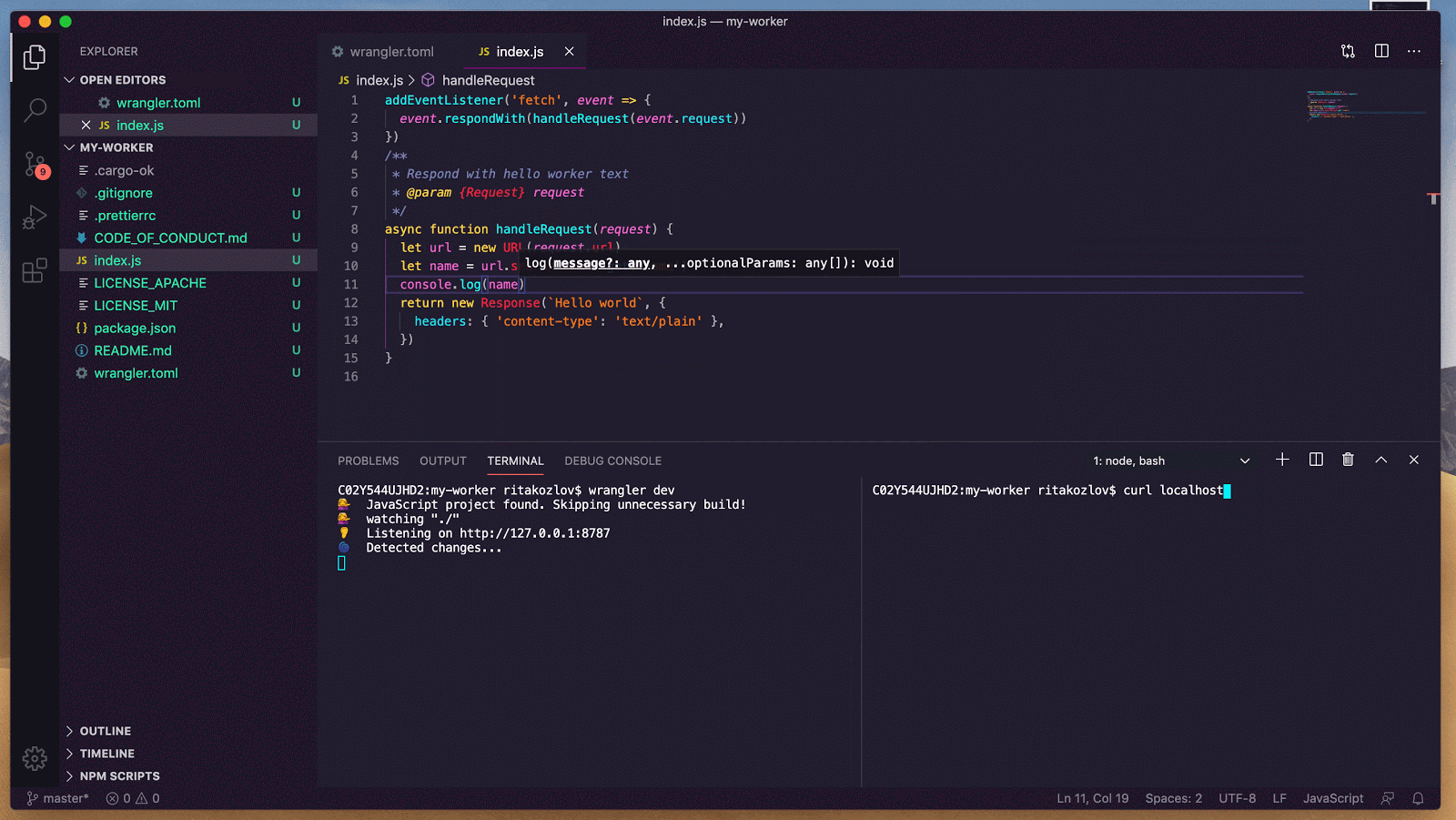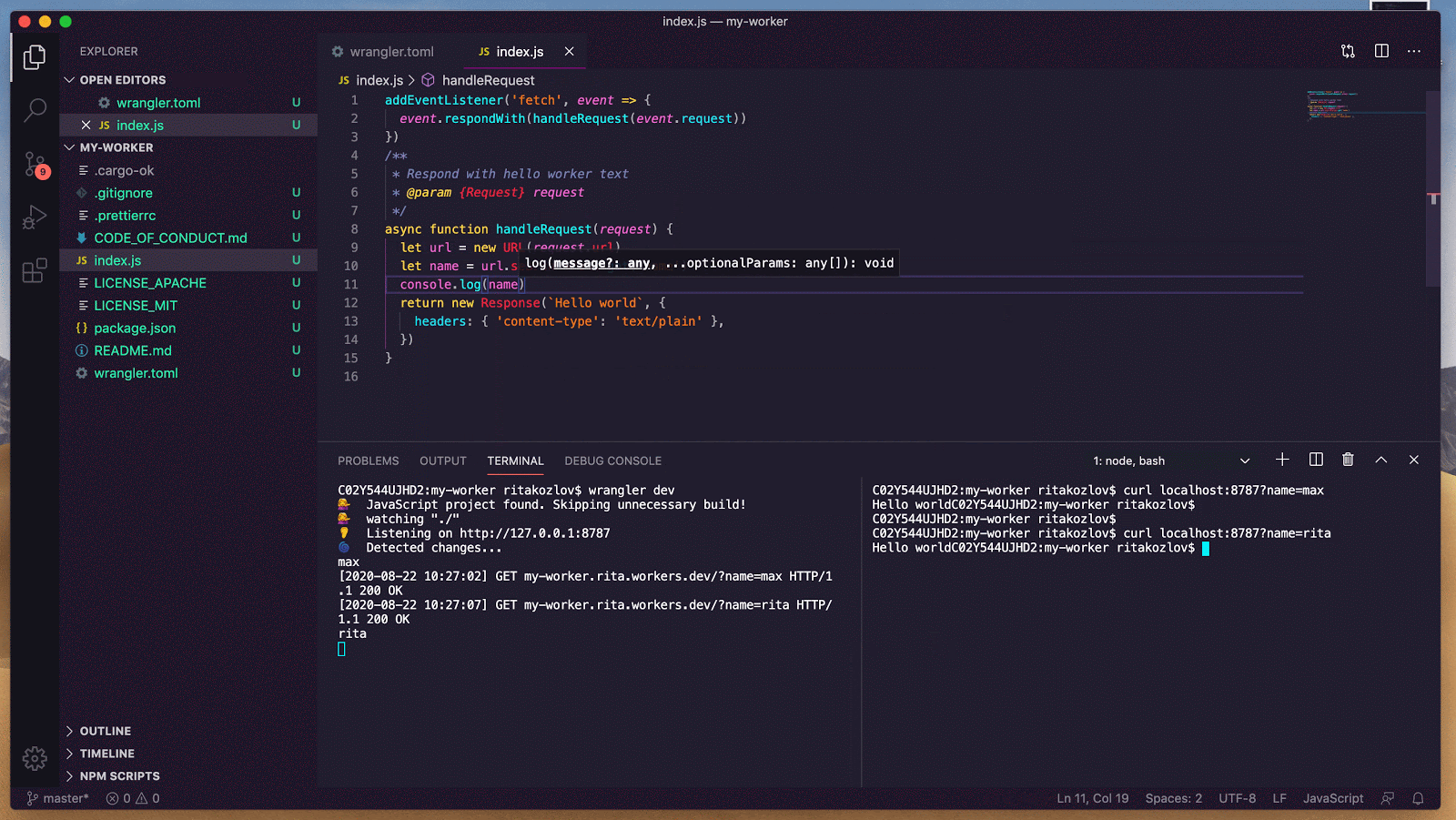
async onStart(): Promise<void> {
// initialize MCPClientManager which manages multiple MCP clients with optional auth
this.mcp = new MCPClientManager("my-agent", "1.0.0", {
baseCallbackUri: `${serverHost}/agents/${agentNamespace}/${this.name}/callback`,
storage: this.ctx.storage,
});
}
async addMcpServer(url: string): Promise<string> {
// Add one MCP client to our MCPClientManager
const { id, authUrl } = await this.mcp.connect(url);
// Return authUrl to redirect the user to if the user is unauthorized
return authUrl
}
async onRequest(req: Request): Promise<void> {
// handle the auth callback after being finishing the MCP server auth flow
if (this.mcp.isCallbackRequest(req)) {
await this.mcp.handleCallbackRequest(req);
return new Response("Authorized")
}
// ...
}
Connecting to multiple MCP servers and discovering what capabilities they offer
You can use the Agents SDK to connect an MCP client to multiple MCP servers simultaneously. This is particularly useful when you want your agent to access and interact with tools and resources served by different service providers.
The MCPClientManager class maintains connections to multiple MCP servers through the mcpConnections object, a dictionary that maps unique server names to their respective MCPClientConnection instances.
When you register a new server connection using connect(), the manager:
Creates a new connection instance with server-specific authentication.
Initializes the connections and registers for server capability notifications.
async onStart(): Promise<void> {
// Connect to an image generation MCP server
await this.mcp.connect("https://image-gen.example.com/mcp/sse");
// Connect to a code analysis MCP server
await this.mcp.connect("https://code-analysis.example.org/sse");
// Now we can access tools with proper namespacing
const allTools = this.mcp.listTools();
console.log(`Total tools available: ${allTools.length}`);
}
Each connection manages its own authentication context, allowing one AI agent to authenticate to multiple servers simultaneously. In addition, MCPClientManager automatically handles namespacing to prevent collisions between tools with identical names from different servers.
For example, if both an “Image MCP Server” and “Code MCP Server” have a tool named “analyze”, they will both be independently callable without any naming conflicts.
Use Stytch, Auth0, and WorkOS to bring authentication & authorization to your MCP server
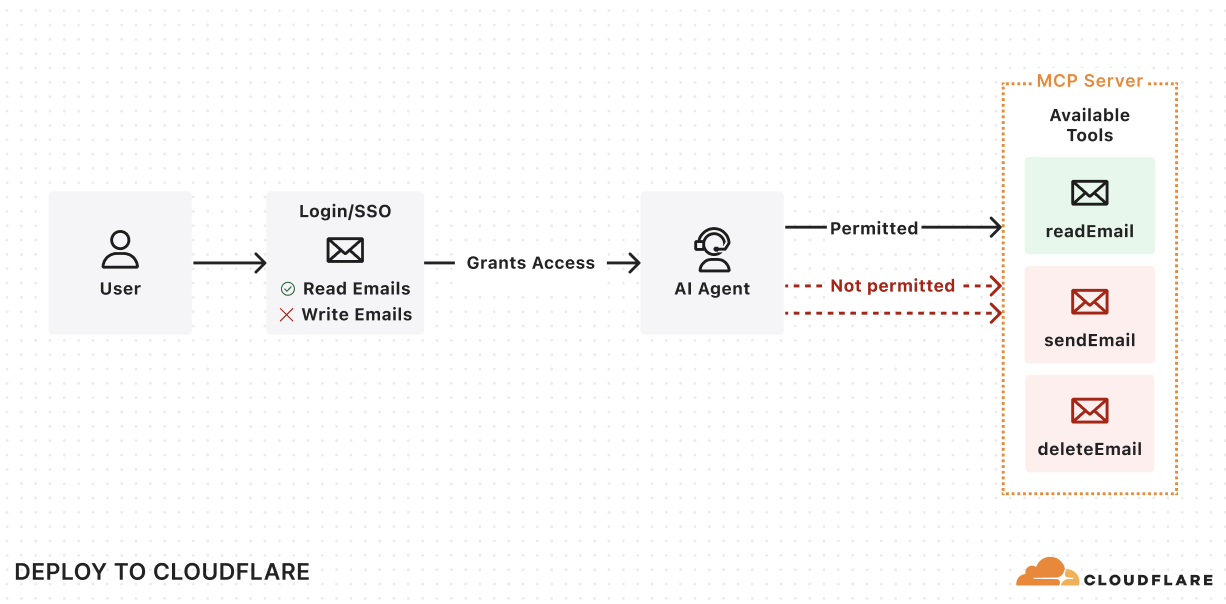
With MCP, users will have a new way of interacting with your application, no longer relying on the dashboard or API as the entrypoint. Instead, the service will now be accessed by AI agents that are acting on a user’s behalf. To ensure users and agents can connect to your service securely, you’ll need to extend your existing authentication and authorization system to support these agentic interactions, implementing login flows, permissions scopes, consent forms, and access enforcement for your MCP server.
We’re adding integrations with Stytch, Auth0, and WorkOS to make it easier for anyone building an MCP server to configure authentication & authorization for their MCP server.
You can leverage our MCP server integration with Stytch, Auth0, and WorkOS to:
Allow users to authenticate to your MCP server through email, social logins, SSO (single sign-on), and MFA (multi-factor authentication).
Define scopes and permissions that directly map to your MCP tools.
Present users with a consent page corresponding with the requested permissions.
Enforce the permissions so that agents can only invoke permitted tools.
Get started with the examples below by using the “Deploy to Cloudflare” button to deploy the demo MCP servers in your Cloudflare account. These demos include pre-configured authentication endpoints, consent flows, and permission models that you can tailor to fit your needs. Once you deploy the demo MCP servers, you can use the Workers AI playground, a browser-based remote MCP client, to test out the end-to-end user flow.
Stytch
Get started with a remote MCP server that uses Stytch to allow users to sign in with email, Google login or enterprise SSO and authorize their AI agent to view and manage their company’s OKRs on their behalf. Stytch will handle restricting the scopes granted to the AI agent based on the user’s role and permissions within their organization. When authorizing the MCP Client, each user will see a consent page that outlines the permissions that the agent is requesting that they are able to grant based on their role.
For more consumer use cases, deploy a remote MCP server for a To Do app that uses Stytch for authentication and MCP client authorization. Users can sign in with email and immediately access the To Do lists associated with their account, and grant access to any AI assistant to help them manage their tasks.
Regardless of use case, Stytch allows you to easily turn your application into an OAuth 2.0 identity provider and make your remote MCP server into a Relying Party so that it can easily inherit identity and permissions from your app. To learn more about how Stytch is enabling secure authentication to remote MCP servers, read their blog post.
“One of the challenges of realizing the promise of AI agents is enabling those agents to securely and reliably access data from other platforms. Stytch Connected Apps is purpose-built for these agentic use cases, making it simple to turn your app into an OAuth 2.0 identity provider to enable secure access to remote MCP servers. By combining Cloudflare Workers with Stytch Connected Apps, we’re removing the barriers for developers, enabling them to rapidly transition from AI proofs-of-concept to secure, deployed implementations.” — Julianna Lamb, Co-Founder & CTO, Stytch.
Auth0
Get started with a remote MCP server that uses Auth0 to authenticate users through email, social logins, or enterprise SSO to interact with their todos and personal data through AI agents. The MCP server securely connects to API endpoints on behalf of users, showing exactly which resources the agent will be able to access once it gets consent from the user. In this implementation, access tokens are automatically refreshed during long running interactions.
To set it up, first deploy the protected API endpoint:
Then, deploy the MCP server that handles authentication through Auth0 and securely connects AI agents to your API endpoint.
“Cloudflare continues to empower developers building AI products with tools like AI Gateway, Vectorize, and Workers AI. The recent addition of Remote MCP servers further demonstrates that Cloudflare Workers and Durable Objects are a leading platform for deploying serverless AI. We’re very proud that Auth0 can help solve the authentication and authorization needs for these cutting-edge workloads.” — Sandrino Di Mattia, Auth0 Sr. Director, Product Architecture.
WorkOS
Get started with a remote MCP server that uses WorkOS’s AuthKit to authenticate users and manage the permissions granted to AI agents. In this example, the MCP server dynamically exposes tools based on the user’s role and access rights. All authenticated users get access to the add tool, but only users who have been assigned the image_generation permission in WorkOS can grant the AI agent access to the image generation tool. This showcases how MCP servers can conditionally expose capabilities to AI agents based on the authenticated user’s role and permission.
“MCP is becoming the standard for AI agent integration, but authentication and authorization are still major gaps for enterprise adoption. WorkOS Connect enables any application to become an OAuth 2.0 authorization server, allowing agents and MCP clients to securely obtain tokens for fine-grained permission authorization and resource access. With Cloudflare Workers, developers can rapidly deploy remote MCP servers with built-in OAuth and enterprise-grade access control. Together, WorkOS and Cloudflare make it easy to ship secure, enterprise-ready agent infrastructure.” — Michael Grinich, CEO of WorkOS.
Hibernate-able WebSockets: put AI agents to sleep when they’re not in use
Starting today, a new improvement is landing in the McpAgent class: support for the WebSockets Hibernation API that allows your MCP server to go to sleep when it’s not receiving requests and instantly wake up when it’s needed. That means that you now only pay for compute when your agent is actually working.
We recently introduced the McpAgent class, which allows developers to build remote MCP servers on Cloudflare by using Durable Objects to maintain stateful connections for every client session. We decided to build McpAgent to be stateful from the start, allowing developers to build servers that can remember context, user preferences, and conversation history. But maintaining client connections means that the session can remain active for a long time, even when it’s not being used.
MCP Agents are hibernate-able by default
You don’t need to change your code to take advantage of hibernation. With our latest SDK update, all McpAgent instances automatically include hibernation support, allowing your stateful MCP servers to sleep during inactive periods and wake up with their state preserved when needed.
How it works
When a request comes in on the Server-Sent Events endpoint, /sse, the Worker initializes a WebSocket connection to the appropriate Durable Object for the session and returns an SSE stream back to the client. All responses flow over this stream.
The implementation leverages the WebSocket Hibernation API within Durable Objects. When periods of inactivity occur, the Durable Object can be evicted from memory while keeping the WebSocket connection open. If the WebSocket later receives a message, the runtime recreates the Durable Object and delivers the message to the appropriate handler.
Durable Objects on free tier
To help you build AI agents on Cloudflare, we’re making Durable Objects available on the free tier, so you can start with zero commitment. With Agents SDK, your AI agents deploy to Cloudflare running on Durable Objects.
Durable Objects offer compute alongside durable storage, that when combined with Workers, unlock stateful, serverless applications. Each Durable Object is a stateful coordinator for handling client real-time interactions, making requests to external services like LLMs, and creating agentic “memory” through state persistence in zero-latency SQLite storage — all tasks required in an AI agent. Durable Objects scale out to millions of agents effortlessly, with each agent created near the user interacting with their agent for fast performance, all managed by Cloudflare.
Zero-latency SQLite storage in Durable Objects was introduced in public beta September 2024 for Birthday Week. Since then, we’ve focused on missing features and robustness compared to pre-existing key-value storage in Durable Objects. We are excited to make SQLite storage generally available, with a 10 GB SQLite database per Durable Object, and recommend SQLite storage for all new Durable Object classes. Durable Objects free tier can only access SQLite storage.
Cloudflare’s free tier allows you to build real-world applications. On the free plan, every Worker request can call a Durable Object. For usage-based pricing, Durable Objects incur compute and storage usage with the following free tier limits.
Workers Free
Workers Paid
Compute: Requests
100,000 / day
1 million / month included
+ $0.15 / million
Compute: Duration
13,000 GB-s / day
400,000 GB-s / month included
+ $12.50 / million GB-s
Storage: Rows read
5 million / day
25 billion / month included
+ $0.001 / million
Storage: Rows written
100,000 / day
50 million / month included
+ $1.00 / million
Storage: SQL stored data
5 GB (total)
5 GB-month included
+ $0.20 / GB-month
Find us at agents.cloudflare.com
We realize this is a lot of information to take in, but don’t worry. Whether you’re new to agents as a whole, or looking to learn more about how Cloudflare can help you build agents, today we launched a new site to help get you started — agents.cloudflare.com.
We’re kicking off Cloudflare’s 2025 Developer Week — our innovation week dedicated to announcements for developers.
It’s an exciting time to be a developer. In fact, as a developer, the past two years might have felt a bit like every week is Developer Week. Starting with the release of ChatGPT, it has felt like each day has brought a new, disruptive announcement, whether it’s new models, hardware, agents, or other tools. From late 2024 and in just the first few months of 2025, we’ve seen the DeepSeek model challenge assumptions about what it takes to train a new state-of-the-art model, MCP introduce a new standard for how LLMs interface with the world, and OpenAI’s o4 model Ghiblify the world.
And while it’s exciting to witness a technological revolution unfold in front of your eyes, it’s even more exciting to partake in it.
A new era of innovation
One of the marvels of the recent AI revolution is the extent to which the cost of experimentation has gone down. Ideas that would have taken whole weekends, weeks, or months to build can now be turned into working code in a day. You can vibe-code your way through things you might have never even tried before, or the parts of application that just don’t excite you. Whether you’ve spent your career working on frontend, backend, mobile, distributed systems or databases — with AI, you can truly be a full-stack engineer.
AI making it faster to ship more code and expanding the audience of who can write code (anyone!) — in the next 5 years we believe more code will be written than has been in the history of software.
However, for all these seedlings of opportunity to flourish, a platform needs to exist to make it just as easy to deploy and scale the code as it was to write it.
As Andrej Karpathy said in his recent post, on building a web application: “It’s not even code, it’s… configurations, plumbing, orchestration, workflows, best practices.”
The platform for the AI era
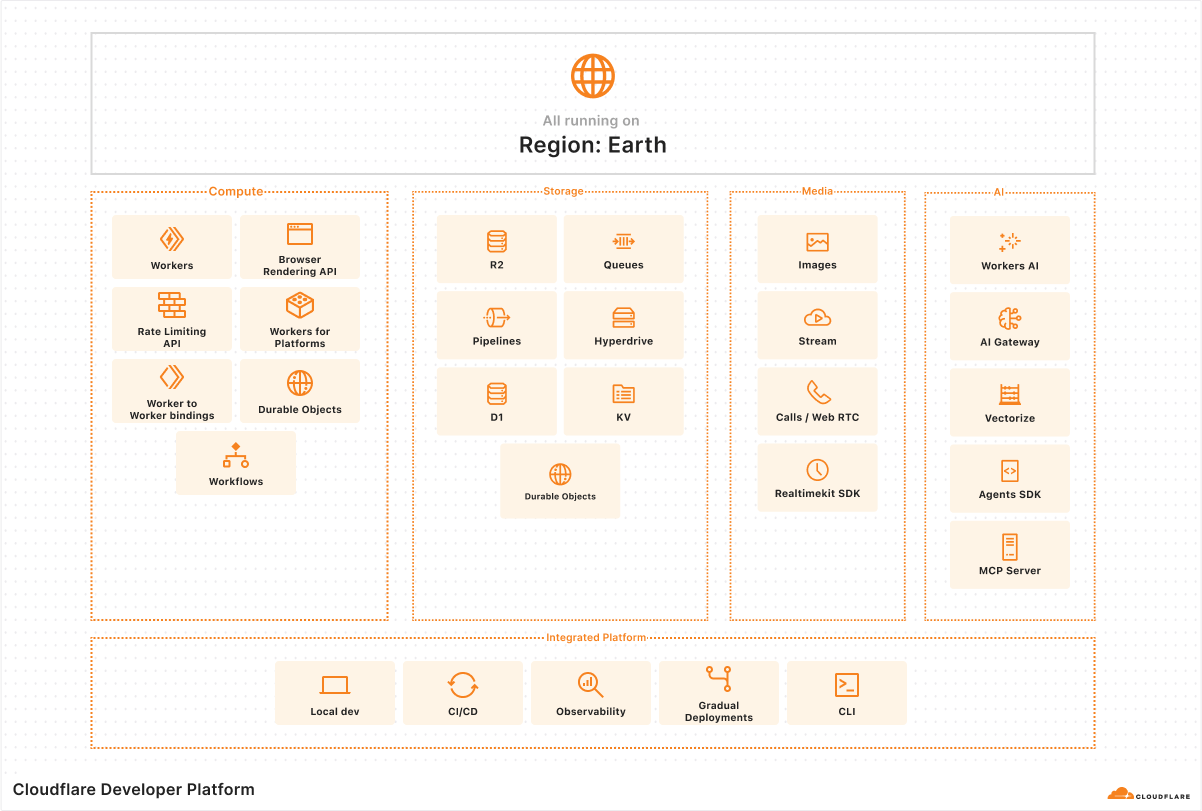
That’s Cloudflare’s vision for developers — to provide a comprehensive platform that just works. From experiment, to MVP, to scaling to millions of users.
We started on that vision almost 8 years ago now, with the launch of Cloudflare Workers, and kept chipping away at adding more and more primitives to allow developers to deploy their full-stack in one place.
Today, Cloudflare’s platform offers many of the building blocks you need: from compute, to storage, databases, and AI. With the tools you need to build along every step of the way: from local development to gradually rolling out to production, CI/CD, and observability.
And, everything you build is deployed to Region: Earth, which means you never have to think about servers, scaling, or infrastructure. This is especially important today — when the industry is moving at an unprecedented pace, the opportunity cost of slowing down is the difference between success and failure.
Developer Week 2025
We’re incredibly proud of what we’ve built over the past 8 years, yet our work is nowhere near done. As our co-founder Michelle likes to say, we’re just getting started.
And this Developer Week we’re excited to take another step forward towards our mission. So what can you expect this Developer Week?
We’ll be releasing more tools and products to continue to ensure you have everything you need when building an application, whether it’s a web app, an agent, an MCP server, or anything else you dream up.
As I previously mentioned, though, primitives are just part of the equation. Building a developer platform also means investing in the developer experience. Many of you have been building on our platform for some time, and it’s an honor we don’t take lightly. We’re constantly listening to your feedback and improving the platform based on it. So this week, some of the announcements will be a direct reflection of that.
See you around!
One of the best, most rewarding parts of getting to work on this platform over the past 8 years has been seeing all that developers built on it. We want to hear your thoughts, feedback and what you’re building, and hope you share it with us whether on X, Discord, or in person at one of our meetups in San Francisco, Austin, and London this week.
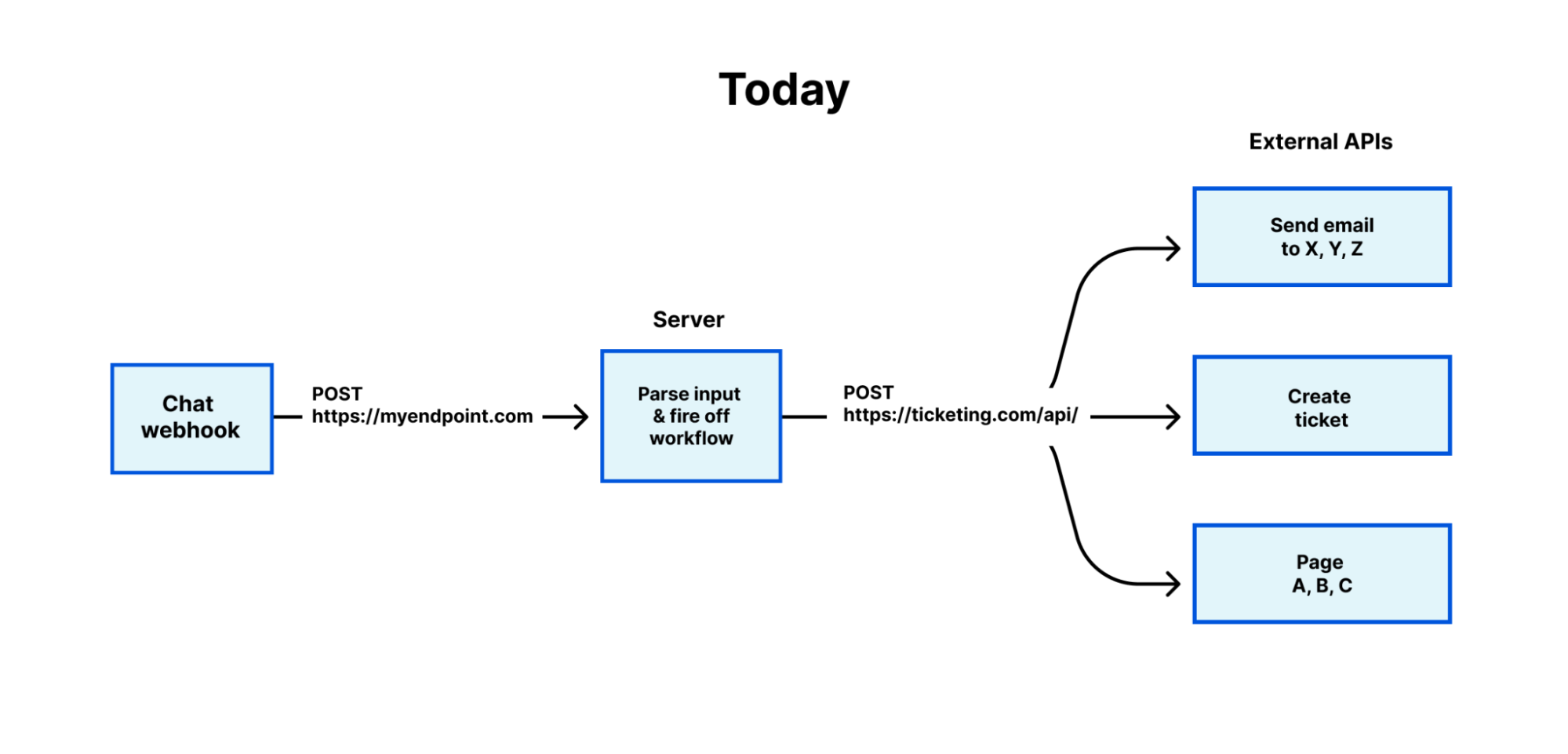
As engineers, we’re obsessed with efficiency and automating anything we find ourselves doing more than twice. If you’ve ever done this, you know that the happy path is always easy, but the second the inputs get complex, automation becomes really hard. This is because computers have traditionally required extremely specific instructions in order to execute.
The state of AI models available to us today has changed that. We now have access to computers that can reason, and make judgement calls in lieu of specifying every edge case under the sun.
That’s what AI agents are all about.
Today we’re excited to share a few announcements on how we’re making it eveneasier to build AI agents on Cloudflare, including:
agents-sdk — a new JavaScript framework for building AI agents
Updates to Workers AI: structured outputs, tool calling, and longer context windows for Workers AI, Cloudflare’s serverless inference engine
We truly believe that Cloudflare is the ideal platform for building Agents and AI applications (more on why below), and we’re constantly working to make it better — you can expect to see more announcements from us in this space in the future.
Before we dive deep into the announcements, we wanted to give you a quick primer on agents. If you are familiar with agents, feel free to skip ahead.
What are agents?
Agents are AI systems that can autonomously execute tasks by making decisions about tool usage and process flow. Unlike traditional automation that follows predefined paths, agents can dynamically adapt their approach based on context and intermediate results. Agents are also distinct from co-pilots (e.g. traditional chat applications) in that they can fully automate a task, as opposed to simply augmenting and extending human input.
Agents → non-linear, non-deterministic (can change from run to run)
Workflows → linear, deterministic execution paths
Co-pilots → augmentative AI assistance requiring human intervention
Example: booking vacations
If this is your first time working with, or interacting with agents, this example will illustrate how an agent works within a context like booking a vacation.
Imagine you’re trying to book a vacation. You need to research flights, find hotels, check restaurant reviews, and keep track of your budget.
Traditional workflow automation
A traditional automation system follows a predetermined sequence: it can take inputs such as dates, location, and budget, and make calls to predefined APIs in a fixed order. However, if any unexpected situations arise, such as flights being sold out, or the specified hotels being unavailable, it cannot adapt.
AI co-pilot
A co-pilot acts as an intelligent assistant that can provide hotel and itinerary recommendations based on your preferences. If you have questions, it can understand and respond to natural language queries and offer guidance and suggestions. However, it is unable to take the next steps to execute the end-to-end action on its own.
Agent
An agent combines AI’s ability to make judgements and call the relevant tools to execute the task. An agent’s output will be nondeterministic given: real-time availability and pricing changes, dynamic prioritization of constraints, ability to recover from failures, and adaptive decision-making based on intermediate results. In other words, if flights or hotels are unavailable, an agent can reassess and suggest a new itinerary with altered dates or locations, and continue executing your travel booking.
agents-sdk — the framework for building agents
You can now add agent powers to any existing Workers project with just one command:
$ npm i agents-sdk
… or if you want to build something from scratch, you can bootstrap your project with the agents-starter template:
$ npm create cloudflare@latest agents-starter --template=cloudflare/agents-starter
// ... and then deploy it
$ npm run deploy
agents-sdk is a framework that allows you to build agents — software that can autonomously execute tasks — and deploy them directly into production on Cloudflare Workers.
Your agent can start with the basics and act on HTTP requests…
import { Agent } from "agents-sdk";
export class IntelligentAgent extends Agent {
async onRequest(request) {
// Transform intention into response
return new Response("Ready to assist.");
}
}
Although this is just the initial release of agents-sdk, we wanted to ship more than just a thin wrapper over an existing library. Agents can communicate with clients in real time, persist state, execute long-running tasks on a schedule, send emails, run asynchronous workflows, browse the web, query data from your Postgres database, call AI models, and support human-in-the-loop use-cases. All of this works today, out of the box.
For example, you can build a powerful chat agent with the AIChatAgent class:
// src/index.ts
export class Chat extends AIChatAgent<Env> {
/**
* Handles incoming chat messages and manages the response stream
* @param onFinish - Callback function executed when streaming completes
*/
async onChatMessage(onFinish: StreamTextOnFinishCallback<any>) {
// Create a streaming response that handles both text and tool outputs
return agentContext.run(this, async () => {
const dataStreamResponse = createDataStreamResponse({
execute: async (dataStream) => {
// Process any pending tool calls from previous messages
// This handles human-in-the-loop confirmations for tools
const processedMessages = await processToolCalls({
messages: this.messages,
dataStream,
tools,
executions,
});
// Initialize OpenAI client with API key from environment
const openai = createOpenAI({
apiKey: this.env.OPENAI_API_KEY,
});
// Cloudflare AI Gateway
// const openai = createOpenAI({
// apiKey: this.env.OPENAI_API_KEY,
// baseURL: this.env.GATEWAY_BASE_URL,
// });
// Stream the AI response using GPT-4
const result = streamText({
model: openai("gpt-4o-2024-11-20"),
system: `
You are a helpful assistant that can do various tasks. If the user asks, then you can also schedule tasks to be executed later. The input may have a date/time/cron pattern to be input as an object into a scheduler The time is now: ${new Date().toISOString()}.
`,
messages: processedMessages,
tools,
onFinish,
maxSteps: 10,
});
// Merge the AI response stream with tool execution outputs
result.mergeIntoDataStream(dataStream);
},
});
return dataStreamResponse;
});
}
async executeTask(description: string, task: Schedule<string>) {
await this.saveMessages([
...this.messages,
{
id: generateId(),
role: "user",
content: `scheduled message: ${description}`,
},
]);
}
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
if (!env.OPENAI_API_KEY) {
console.error(
"OPENAI_API_KEY is not set, don't forget to set it locally in .dev.vars, and use `wrangler secret bulk .dev.vars` to upload it to production"
);
return new Response("OPENAI_API_KEY is not set", { status: 500 });
}
return (
// Route the request to our agent or return 404 if not found
(await routeAgentRequest(request, env)) ||
new Response("Not found", { status: 404 })
);
},
} satisfies ExportedHandler<Env>;
… and connect to your Agent with any React-based front-end with the useAgent hook that can automatically establish a bidirectional WebSocket, sync client state, and allow you to build Agent-based applications without a mountain of bespoke code:
We spent some time thinking about the production story here too: an agent framework that absolves itself of the hard parts — durably persisting state, handling long-running tasks & loops, and horizontal scale — is only going to get you so far. Agents built with agents-sdk can be deployed directly to Cloudflare and run on top of Durable Objects — which you can think of as stateful micro-servers that can scale to tens of millions — and are able to run wherever they need to. Close to a user for low-latency, close to your data, and/or anywhere in between.
agents-sdk also exposes:
Integration with React applications via a useAgent hook that can automatically set up a WebSocket connection between your app and an agent
An AIChatAgent extension that makes it easier to build intelligent chat agents
State management APIs via this.setState as well as a native sql API for writing and querying data within each Agent
State synchronization between frontend applications and the agent state
Agent routing, enabling agent-per-user or agent-per-workflow use-cases. Spawn millions (or tens of millions) of agents without having to think about how to make the infrastructure work, provision CPU, or scale out storage.
Over the coming weeks, expect to see even more here: tighter integration with email APIs to enable more human-in-the-loop use-cases, hooks into WebRTC for voice & video interactivity, a built-in evaluation (evals) framework, and the ability to self-host agents on your own infrastructure.
We’re aiming high here: we think this is just the beginning of what agents are capable of, and we think we can make Workers the best place (but not the only place) to build & run them.
JSON mode, longer context windows, and improved tool calling in Workers AI
When users express needs conversationally, tool calling converts these requests into structured formats like JSON that APIs can understand and process, allowing the AI to interact with databases, services, and external systems. This is essential for building agents, as it allows users to express complex intentions in natural language, and AI to decompose these requests, call appropriate tools, evaluate responses and deliver meaningful outcomes.
When using tool calling or building AI agents, the text generation model must respond with valid JSON objects rather than natural language. Today, we’re adding JSON mode support to Workers AI, enabling applications to request a structured output response when interacting with AI models. Here’s a request to @cf/meta/llama-3.1-8b-instruct-fp8-fast using JSON mode:
As you can see, the model is complying with the JSON schema definition in the request and responding with a validated JSON object. JSON mode is compatible with OpenAI’s response_format implementation:
We will continue extending this list to keep up with new, and requested models.
Lastly, we are changing how we restrict the size of AI requests to text generation models, moving from byte-counts to token-counts, introducing the concept of context window and raising the limits of the models in our catalog.
In generative AI, the context window is the sum of the number of input, reasoning, and completion or response tokens a model supports. You can now find the context window limit on each model page in our developer documentation and decide which suits your requirements and use case.
JSON mode is also the perfect companion when using function calling. You can use structured JSON outputs with traditional function calling or the Vercel AI SDK via the workers-ai-provider.
workers-ai-provider 0.1.1
One of the most common ways to build with AI tooling today is by using the popular AI SDK. Cloudflare’s provider for the AI SDK makes it easy to use Workers AI the same way you would call any other LLM, directly from your code.
A key part of building agents is using LLMs for routing, and making decisions on which tools to call next, and summarizing structured and unstructured data. All of these things need to happen quickly, as they are on the critical path of the user-facing experience.
Workers AI, with its globally distributed fleet of GPUs, is a perfect fit for smaller, low-latency LLMs, so we’re excited to make it easy to use with tools developers are already familiar with.
Why build agents on Cloudflare?
Since launching Workers in 2017, we’ve been building a platform to allow developers to build applications that are fast, scalable, and cost-efficient from day one. We took a fundamentally different approach from the way code was previously run on servers, making a bet about what the future of applications was going to look like — isolates running on a global network, in a way that was truly serverless. No regions, no concurrency management, no managing or scaling infrastructure.
The release of Workers was just the beginning, and we continued shipping primitives to extend what developers could build. Some more familiar, like a key-value store (Workers KV), and some that we thought would play a role in enabling net new use cases like Durable Objects. While we didn’t quite predict AI agents (though “Agents” was one of the proposed names for Durable Objects), we inadvertently created the perfect platform for building them.
What do we mean by that?
A platform that only charges you for what you use (regardless of how long it takes)
To be able to run agents efficiently, you need a system that can seamlessly scale up and down to support the constant stop, go, wait patterns. Agents are basically long-running tasks, sometimes waiting on slow reasoning LLMs and external tools to execute. With Cloudflare, you don’t have to pay for long-running processes when your code is not executing. Cloudflare Workers is designed to scale down and only charge you for CPU time, as opposed to wall-clock time.
In many cases, especially when calling LLMs, the difference can be in orders of magnitude — e.g. 2–3 milliseconds of CPU vs. 10 seconds of wall-clock time. When building on Workers, we pass that difference on to you as cost savings.
Serverless AI Inference
We took a similar serverless approach when it comes to inference itself. When you need to call an AI model, you need it to be instantaneously available. While the foundation model providers offer APIs that make it possible to just call the LLM, if you’re running open-source models, LoRAs, or self-trained models, most cloud providers today require you to pre-provision resources for what your peak traffic will look like. This means that the rest of the time, you’re still paying for GPUs to sit there idle. With Workers AI, you can pay only when you’re calling our inference APIs, as opposed to unused infrastructure. In fact, you don’t have to think about infrastructure at all, which is the principle at the core of everything we do.
A platform designed for durable execution
Durable Objects and Workflows provide a robust programming model that ensures guaranteed execution for asynchronous tasks that require persistence and reliability. This makes them ideal for handling complex operations like long-running deep thinking LLM calls, human-in-the-loop approval processes, or interactions with unreliable third-party APIs. By maintaining state across requests and automatically handling retries, these tools create a resilient foundation for building sophisticated AI agents that can perform complex, multistep tasks without losing context or progress, even when operations take significant time to complete.
Lastly, new and updated agents documentation
Did you catch all of that?
No worries if not: we’ve updated our agents documentation to include everything we talked about above, from breaking down the basics of agents, to showing you how to tackle foundational examples of building with agents.
We’ve also updated our Workers prompt with knowledge of the agents-sdk library, so you can use Cursor, Windsurf, Zed, ChatGPT or Claude to help you build AI Agents and deploy them to Cloudflare.
Can’t wait to see what you build!
We’re just getting started, and we love to see all that you build. Please join our Discord, ask questions, and tell us what you’re building.
Today might be April Fools, and while we like to have fun as much as anyone else, we like to use this day for serious announcements. In fact, as of today, there are over 2 million developers building on top of Cloudflare’s platform — that’s no joke!
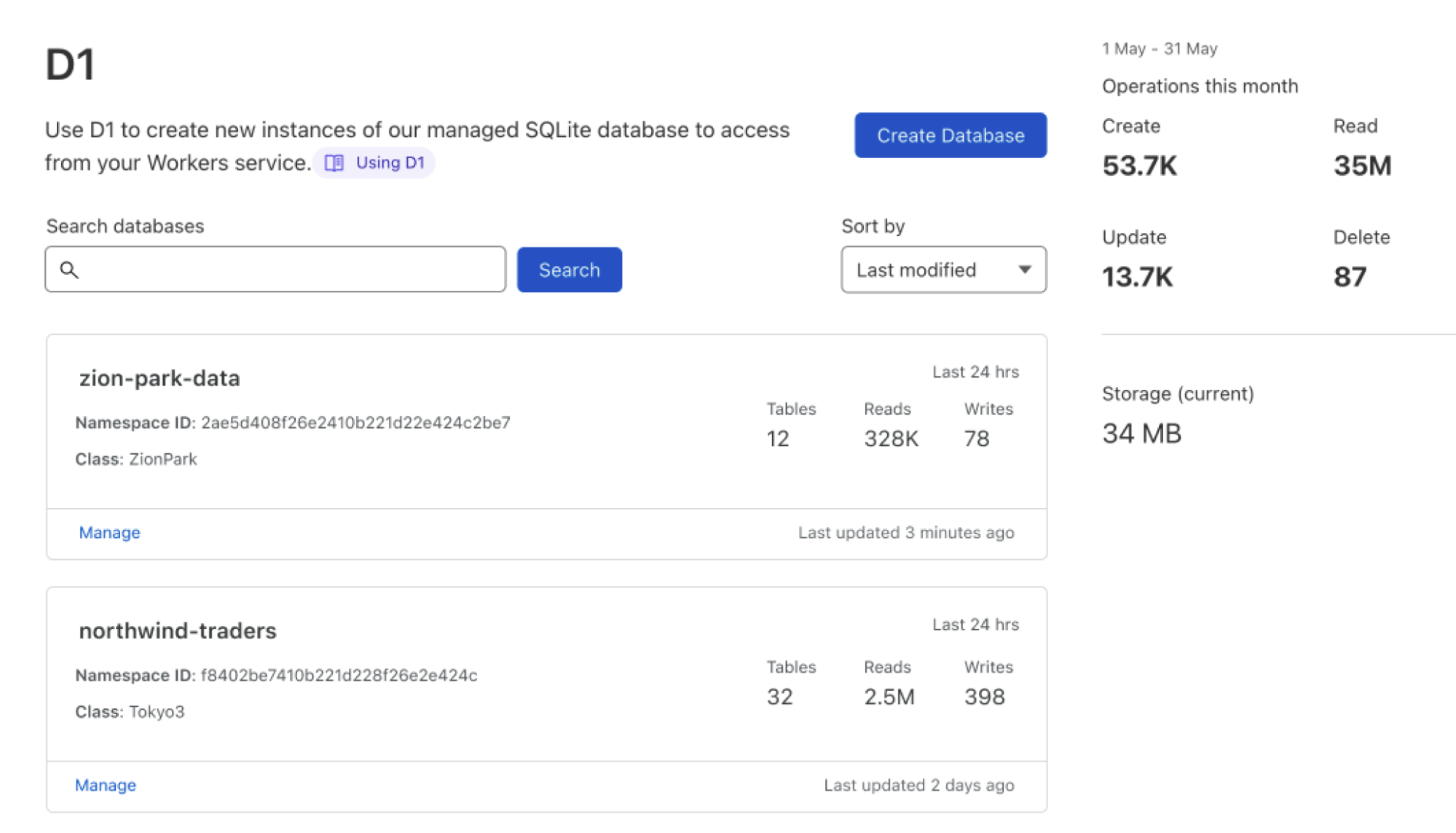
To kick off this Developer Week, we’re flipping the big “production ready” switch on three products: D1, our serverless SQL database; Hyperdrive, which makes your existing databases feel like they’re distributed (and faster!); and Workers Analytics Engine, our time-series database.
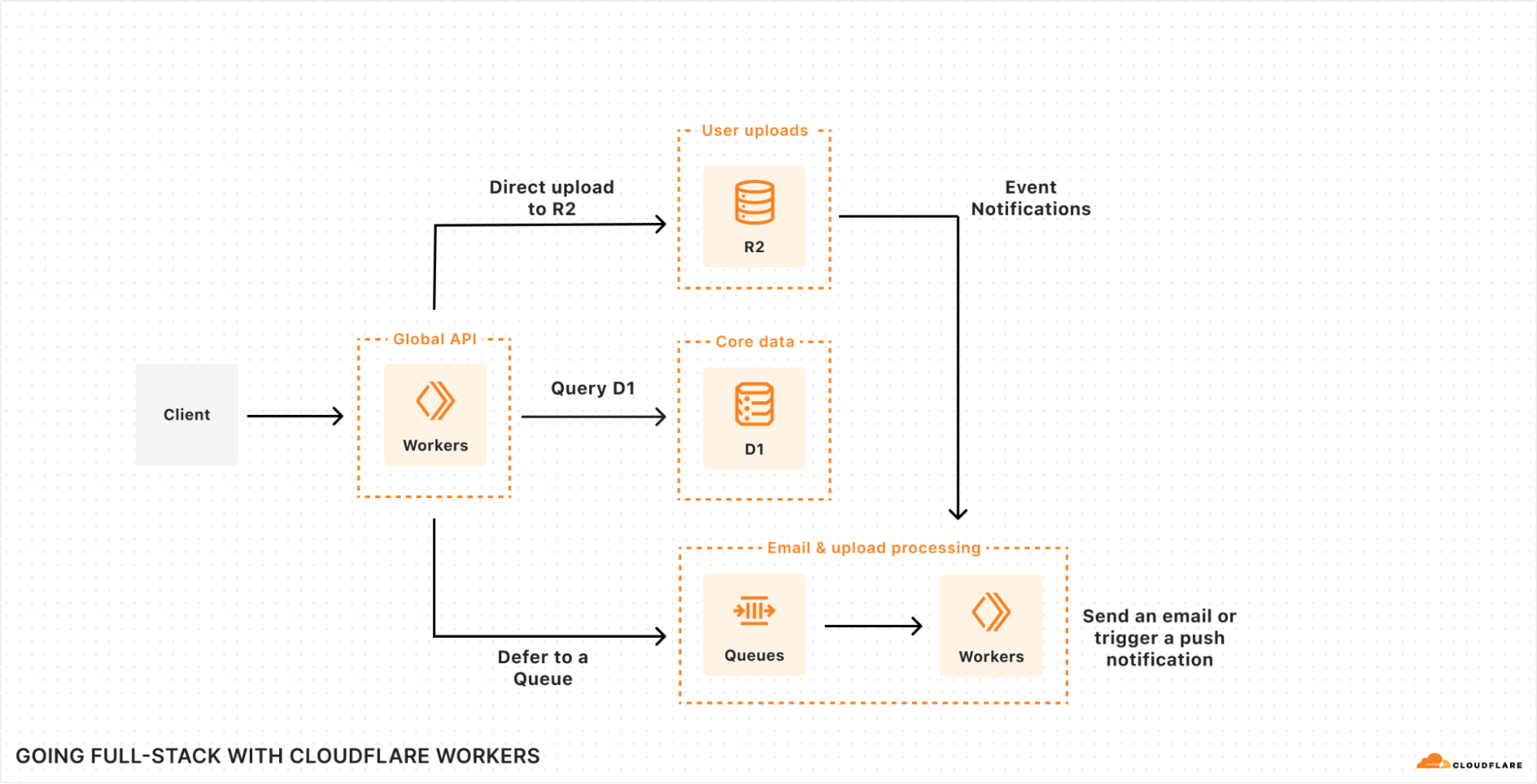
We’ve been on a mission to allow developers to bring their entire stack to Cloudflare for some time, but what might an application built on Cloudflare look like?
The diagram itself shouldn’t look too different from the tools you’re already familiar with: you want a database for your core user data. Object storage for assets and user content. Maybe a queue for background tasks, like email or upload processing. A fast key-value store for runtime configuration. Maybe even a time-series database for aggregating user events and/or performance data. And that’s before we get to AI, which is increasingly becoming a core part of many applications in search, recommendation and/or image analysis tasks (at the very least!).
Yet, without having to think about it, this architecture runs on Region: Earth, which means it’s scalable, reliable and fast — all out of the box.
D1: Production Ready
Your core database is one of the most critical pieces of your infrastructure. It needs to be ultra-reliable. It can’t lose data. It needs to scale. And so we’ve been heads down over the last year getting the pieces into place to make sure D1 is production-ready, and we’re extremely excited to say that D1 — our global, serverless SQL database — is now Generally Available.
The GA for D1 lands some of the most asked-for features, including:
Support for 10GB databases — and 50,000 databases per account;
New data export capabilities; and
Enhanced query debugging (we call it “D1 Insights”) — that allows you to understand what queries are consuming the most time, cost, or that are just plain inefficient…
… to empower developers to build production-ready applications with D1 to meet all their relational SQL needs. And importantly, in an era where the concept of a “free plan” or “hobby plan” is seemingly at risk, we have no intention of removing the free tier for D1 or reducing the 25 billion row reads included in the $5/mo Workers Paid plan:
Plan
Rows Read
Rows Written
Storage
WorkersPaid
First 25 billion / month included + $0.001 / million rows
First 50 million / month included + $1.00 / million rows
First 5 GB included
+ $0.75 / GB-mo
Workers Free
5 million / day
100,000 / day
5 GB (total)
For those who’ve been following D1 since the start: this is the same pricing we announced at open beta
But things don’t just stop at GA: we have some major new features lined up for D1, including global read replication, even larger databases, more Time Travel capabilities that will allow you to branch your database, and new APIs for dynamically querying and/or creating new databases-on-the-fly from within a Worker.
D1’s read replication will automatically deploy read replicas as needed to get data closer to your users: and without you having to spin up, manage scaling, or run into consistency (replication lag) issues. Here’s a sneak preview of what D1’s upcoming Replication API looks like:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Importantly, we will give developers the ability to maintain session-based consistency, so that users still see their own changes reflected, whilst still benefiting from the performance and latency gains that replication can bring.
You can learn more about how D1’s read replication works under the hood in our deep-dive post, and if you want to start building on D1 today, head to our developer docs to create your first database.
Hyperdrive: GA
We launched Hyperdrive into open beta last September during Birthday Week, and it’s now Generally Available — or in other words, battle-tested and production-ready.
If you’re not caught up on what Hyperdrive is, it’s designed to make the centralized databases you already have feel like they’re global. We use our global network to get faster routes to your database, keep connection pools primed, and cache your most frequently run queries as close to users as possible.
Importantly, Hyperdrive supports the most popular drivers and ORM (Object Relational Mapper) libraries out of the box, so you don’t have to re-learn or re-write your queries:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
But the work on Hyperdrive doesn’t stop just because it’s now “GA”. Over the next few months, we’ll be bringing support for the other most widely deployed database engine there is: MySQL. We’ll also be bringing support for connecting to databases inside private networks (including cloud VPC networks) via Cloudflare Tunnel and Magic WAN On top of that, we plan to bring more configurability around invalidation and caching strategies, so that you can make more fine-grained decisions around performance vs. data freshness.
As we thought about how we wanted to price Hyperdrive, we realized that it just didn’t seem right to charge for it. After all, the performance benefits from Hyperdrive are not only significant, but essential to connecting to traditional database engines. Without Hyperdrive, paying the latency overhead of 6+ round-trips to connect & query your database per request just isn’t right.
And so we’re happy to announce that for any developer on a Workers Paid plan, Hyperdrive is free. That includes both query caching and connection pooling, as well as the ability to create multiple Hyperdrives — to separate different applications, prod vs. staging, or to provide different configurations (cached vs. uncached, for example).
Plan
Price per query
Connection Pooling
WorkersPaid
$0
$0
To get started with Hyperdrive, head over to the docs to learn how to connect your existing database and start querying it from your Workers.
Queues: Pull From Anywhere
The task queue is an increasingly critical part of building a modern, full-stack application, and this is what we had in mind when we originally announced the open beta of Queues. We’ve since been working on several major Queues features, and we’re launching two of them this week: pull-based consumers and new message delivery controls.
Any HTTP-speaking client can now pull messages from a queue: call the new /pull endpoint on a queue to request a batch of messages, and call the /ack endpoint to acknowledge each message (or batch of messages) as you successfully process them:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
A pull-based consumer can run anywhere, allowing you to run queue consumers alongside your existing legacy cloud infrastructure. Teams inside Cloudflare adopted this early on, with one use-case focused on writing device telemetry to a queue from our 310+ data centers and consuming within some of our back-of-house infrastructure running on Kubernetes. Importantly, our globally distributed queue infrastructure means that messages are retained within the queue until the consumer is ready to process them.
Queues also now supports delaying messages, both when sending to a queue, as well as when marking a message for retry. This can be useful to queue (pun intended) tasks for the future, as well apply a backoff mechanism if an upstream API or infrastructure has rate limits that require you to pace how quickly you are processing messages.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
We’ll also be bringing substantially increased per-queue throughput over the coming months on the path to getting Queues to GA. It’s important to us that Queues is extremely reliable: lost or dropped messages means that a user doesn’t get their order confirmation email, that password reset notification, and/or their uploads processed — each of those are user-impacting and hard to recover from.
Workers Analytics Engine
Workers Analytics Engine provides unlimited-cardinality analytics at scale, via a built-in API to write data points from Workers, and a SQL API to query that data.
Workers Analytics Engine is backed by the same ClickHouse-based system we have depended on for years at Cloudflare. We use it ourselves to observe the health of our own services, to capture product usage data for billing, and to answer questions about specific customers’ usage patterns. At least one data point is written to this system on nearly every request to Cloudflare’s network. Workers Analytics Engine lets you build your own custom analytics using this same infrastructure, while we manage the hard parts for you.
Since launching in beta, developers have started depending on Workers Analytics Engine for these same use cases and more, from large enterprises to open-source projects like Counterscale. Workers Analytics Engine has been operating at production scale with mission-critical workloads for years — but we hadn’t shared anything about pricing, until today.
We are keeping Workers Analytics Engine pricing simple, and based on two metrics:
Data points written — every time you call writeDataPoint() in a Worker, this counts as one data point written. Every data point costs the same amount — unlike other platforms, there is no penalty for adding dimensions or cardinality, and no need to predict what the size and cost of a compressed data point might be.
Read queries — every time you post to the Workers Analytics Engine SQL API, this counts as one read query. Every query costs the same amount — unlike other platforms, there is no penalty for query complexity, and no need to reason about the number of rows of data that will be read by each query.
Both the Workers Free and Workers Paid plans will include an allocation of data points written and read queries, with pricing for additional usage as follows:
Plan
Data points written
Read queries
WorkersPaid
10 million included per month
+$0.25 per additional million
1 million included per month
+$1.00 per additional million
Workers Free
100,000 included per day
10,000 included per day
With this pricing, you can answer, “how much will Workers Analytics Engine cost me?” by counting the number of times you call a function in your Worker, and how many times you make a request to a HTTP API endpoint. Napkin math, rather than spreadsheet math.
This pricing will be made available to everyone in coming months. Between now and then, Workers Analytics Engine continues to be available at no cost. You can start writing data points from your Worker today — it takes just a few minutes and less than 10 lines of code to start capturing data. We’d love to hear what you think.
The week is just getting started
Tune in to what we have in store for you tomorrow on our second day of Developer Week. If you have questions or want to show off something cool you already built, please join our developer Discord.
It’s time to ship. For us (that’s what Innovation Weeks are all about!), and also for our developers.
Shipping itself is always fun, but getting there is not always easy. Bringing something from idea to life requires many stars to align. That’s what this week is all about — helping developers, including the two million developers already building on our platform, bring their ideas to life.
The full-stack cloud
Building applications requires assembling many different components.
The frontend, the face of the application, must be intuitive, responsive, and visually appealing to engage users effectively. Behind the scenes, you need a backend to handle data processing, storage, and retrieval, ensuring smooth functionality and performance. On top of all that, in the past year AI has entered the chat, so to speak, and increasingly every application requires an element of AI, making it a crucial part of the stack.
The job of a good platform is to provide all these components, and any others you will need, to you, the developer.
Just as there’s nothing more frustrating than coming home from the grocery store and realizing you left out an ingredient, realizing a platform is missing a major component or piece of functionality is no different.
We view providing the tooling that developers need as a critical part of our job as a platform, which is why with every Developer Week, we make it our mission to provide you with more and more pieces you may need. This week is no different — you can expect us to announce more tools and primitives from the frontend to backend to AI.
However, our job doesn’t stop there. If a good platform provides the components, a great platform goes a step further than that.
The job of a great platform is not only to provide the components, but make sure they play well with each other in a way that makes your job as a developer easier. Our vision for the developer platform is exactly that: to anticipate not just the tools you need but also think about how they work with each other, and how they integrate into your development flow.
This week, you will see announcements and deep dives that expound on our vision for an integrated platform: pulling back the curtain on the way we expose services in Workers through bindings for an integrated developer experience, talking about our vision for a unified data platform, updating you on framework support, and more.
The connectivity cloud
While we’re excited for you to build on us as much as possible, we also realize that development projects are rarely greenfield. If you’ve been at this for a long time, chances are a large portion of your application already lives somewhere, whether on another cloud, or on-prem.
That’s why we’re constantly making it easier for you to connect to existing infrastructure or other providers, and working hard to make sure you can still reap the benefits of building on Cloudflare by making your application feel fast and global, regardless of where your backend is.
And vice versa, if your data is on us, but you need to access it from other providers, it’s not our job to keep it hostage in a captivity cloud by charging a tariff for egress.
The experimentation cloud
Before you start assembling components, or even coming up with a plan or a spec for it, there’s an important but overlooked step to the development process — experimentation.
Experimentation can take many forms. Experimentation can be in the form of prototyping an MVP before you spend months developing a product or a feature. If you’ve found yourself rewriting your entire personal website just to try out a new tool or framework, that’s also experimentation.
It’s easy to overlook experimentation as a part of the process, but innovation doesn’t happen without it, which is why it’s something we always want to encourage and support as a part of our platform.
That’s why offering a generous free tier is something that’s been a part of our DNA since the very beginning, and something you can expect to forever be a staple of our platform.
The demo to production cloud
Alright, you’ve got all the tools you need, you’ve had a chance to experiment, and at some point… it’s time to ship.
Shipping is exciting, but shipping is also vulnerable and scary. You’re exposing the thing you’ve been working hard on to the world to criticize. You’re exposing your code to a world of untested edge cases and abuse. You’re exposing your colleagues who are on call to the possibility of getting paged at 1 AM due to the code you released.
Of course, the wrong answer is not shipping.
The right answer is having a platform that supports you and holds your hand through the scary parts. This means a platform that can seamlessly scale from zero to sixty. A platform gives you the tools to test your code, and release it gradually to the world to help you gain confidence. Or a platform provides the observability you need when you are trying to figure out what’s gone wrong at 1 AM.
That’s why this week, you can look forward to some announcements from us that we hope will help you sleep better.
The demo to production cloud — for inference
We talked about some of the scary parts of deploying to production, and while all these apply to AI as well, building AI applications today, especially in production, presents its own unique set of challenges.
Almost every day you see a new AI demo go viral — from Sora to Devin, it’s easy and inspiring to imagine our world completely changed by AI. But if you’ve started actually playing with and implementing AI use cases, you know the harsh reality of making AI truly work. It requires a lot of trial and error to get the results you want — choosing a model, RAG, fine-tuning…
And that’s before you even go to production.
That’s when you encounter the real challenge — provisioning enough capacity to stay up, without over-provisioning and overpaying. This is the exact challenge we set out to solve from the early days of Workers — helping developers not worry about infrastructure, just the application they want to build.
With the recent rise of AI, we’ve noticed many of these challenges return. Thankfully, managing loads and infrastructure is what we’re good at here at Cloudflare. It’s what we’ve had practice at for over a decade of running our platform. It’s all just one giant scheduler.
Our vision for our AI platform is to help solve the exact challenges in deploying AI workloads that we’ve been helping developers solve for, well, any other type of workload. Whether you’re deploying directly on us with Workers AI, or another provider, we’ll help provide the tools you need to access the models you need, without overpaying for idle compute.
Don’t worry, it’s all going to be fine.
So what can you expect this week?
No one in my family can keep a secret — my sister cannot get me a birthday present without spoiling it the week before. For me, the anticipation and the look of surprise is part of the fun! My coworkers seem to have clued into this.
While I won’t give away too much, we’ve already teased out a few things last week (you can find some hints here, here and here), as well as in this blog post if you read closely (because as it turns out, I too, can’t help myself).
See you tomorrow!
Our series of announcements starts on Monday, April 1st. We look forward to sharing them with you here on our blog, and discussing them with you on Discord and X.
Today we are announcing new pricing for Cloudflare Workers and Pages Functions, where you are billed based on CPU time, and never for the idle time that your Worker spends waiting on network requests and other I/O. Unlike other platforms, when you build applications on Workers, you only pay for the compute resources you actually use.
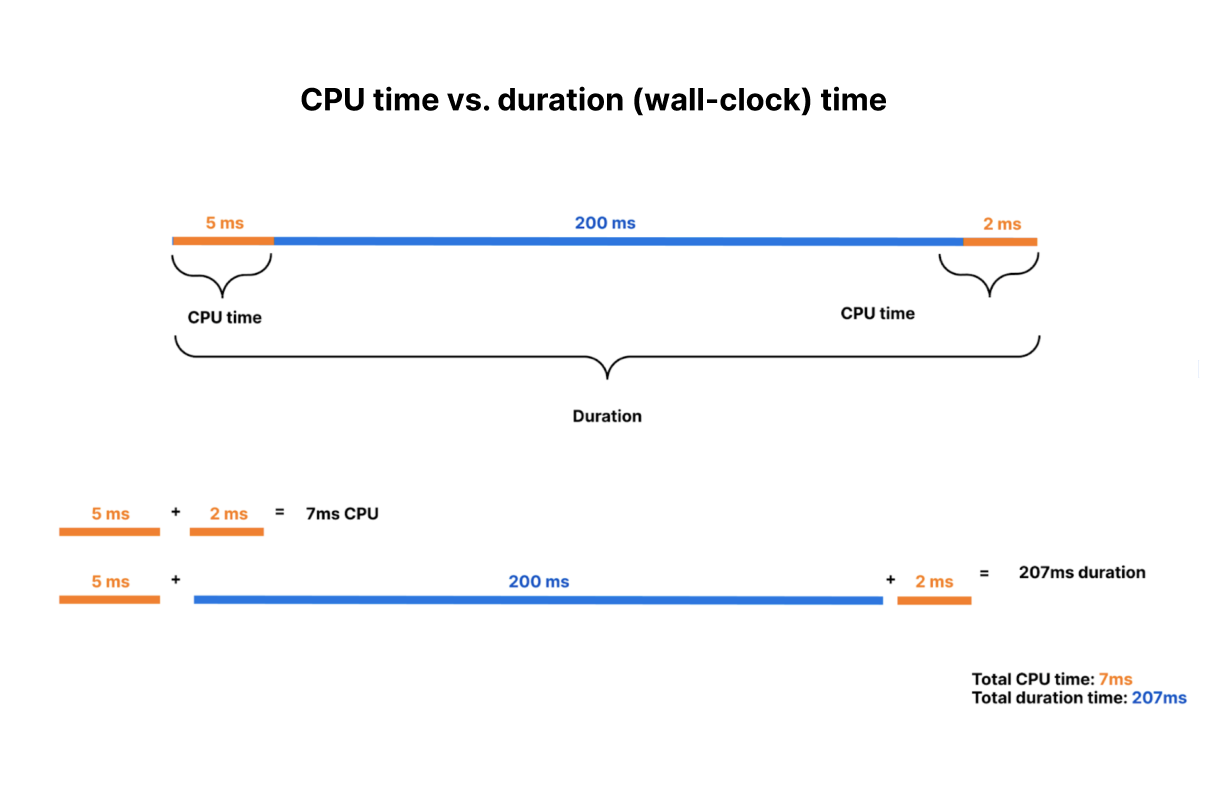
Why is this exciting? To date, all large serverless compute platforms have billed based on how long your function runs — its duration or “wall time”. This is a reflection of a new paradigm built on a leaky abstraction — your code may be neatly packaged up into a “function”, but under the hood there’s a virtual machine (VM). A VM can’t be paused and resumed quickly enough to execute another piece of code while it waits on I/O. So while a typical function might take 100ms to run, it might typically spend only 10ms doing CPU work, like crunching numbers or parsing JSON, with the rest of time spent waiting on I/O.
This status quo has meant that you are billed for this idle time, while nothing is happening.
With this announcement, Cloudflare is the first and only global serverless platform to offer standard pricing based on CPU time, rather than duration. We think you should only pay for the compute time you actually use, and that’s how we’re going to bill you going forward.
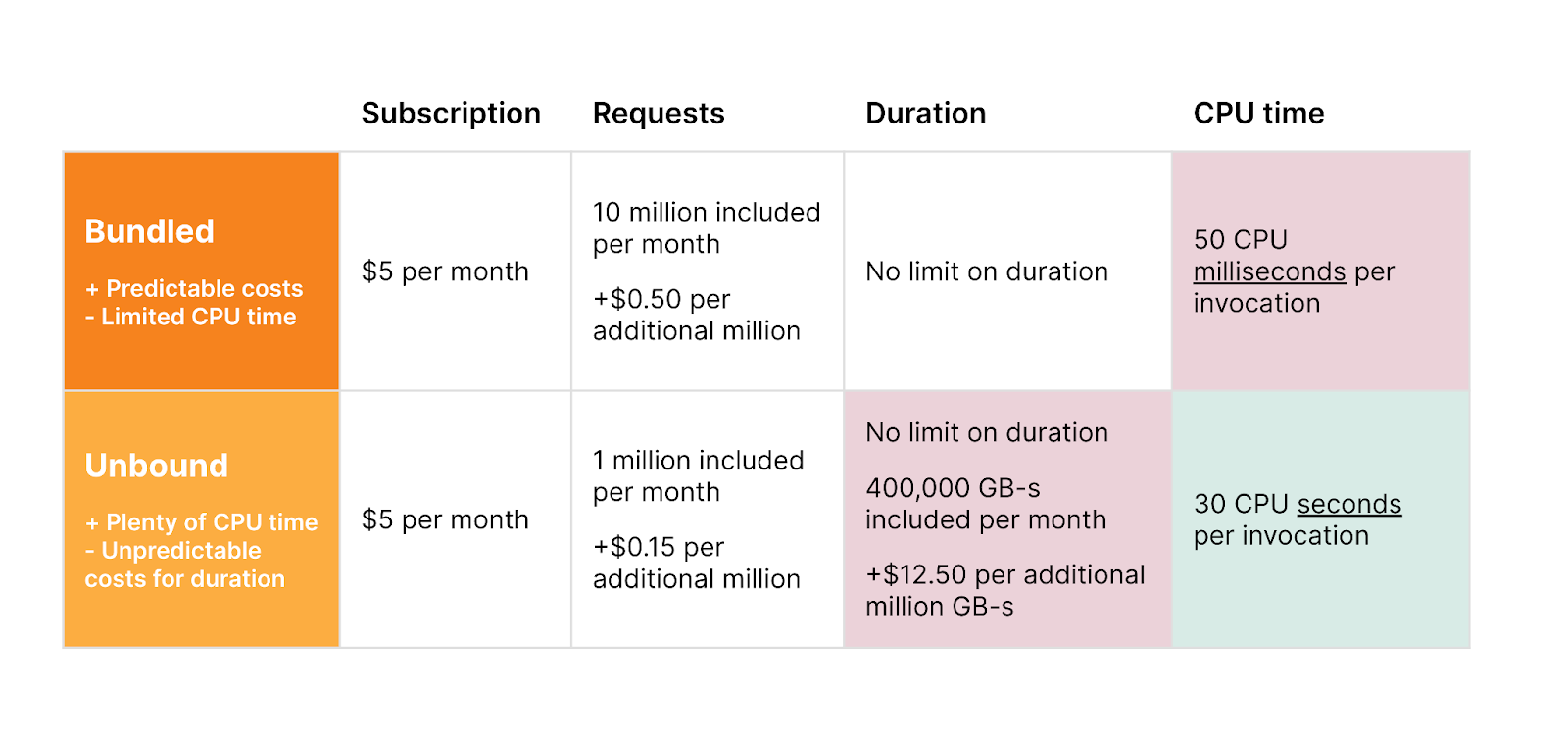
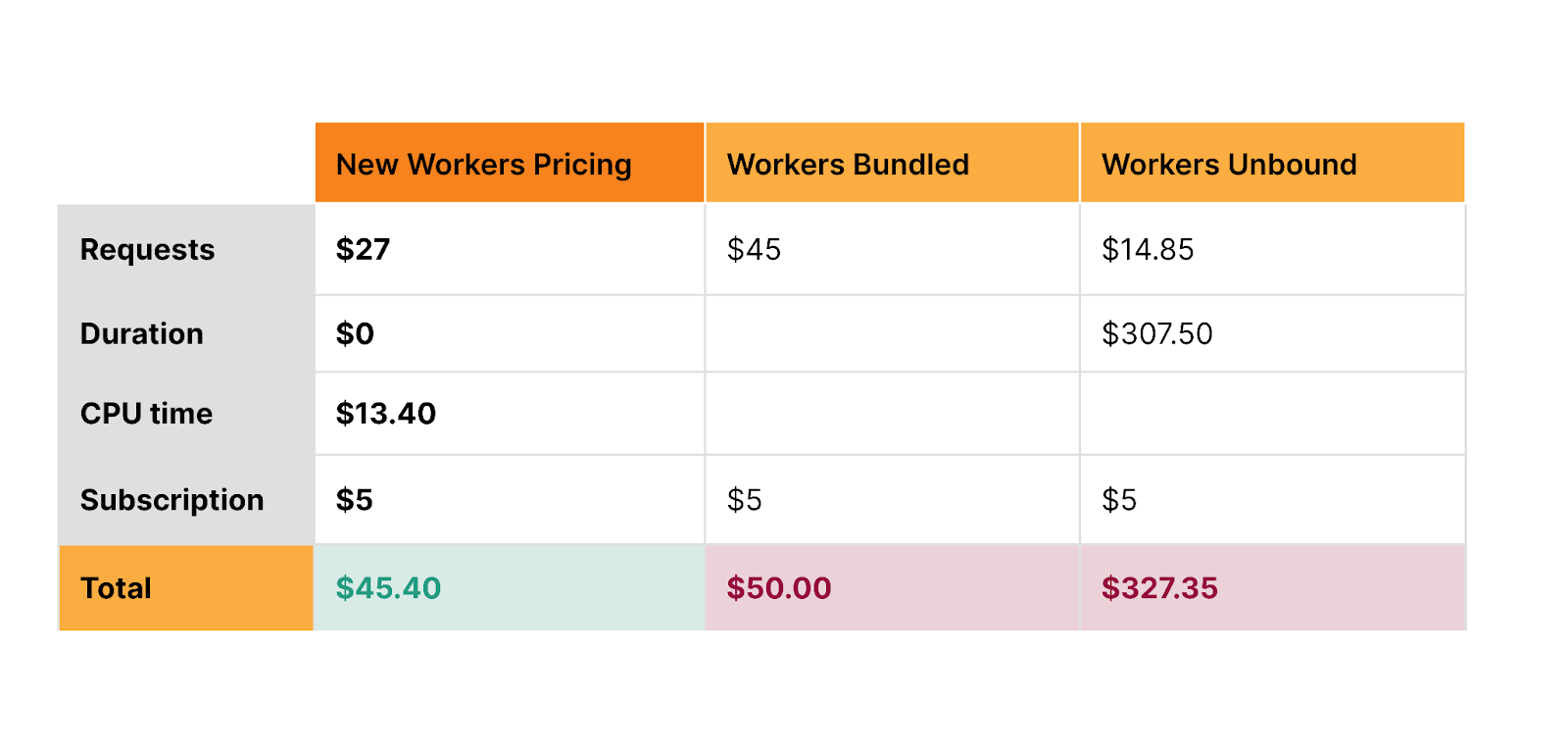
Old pricing — two pricing models, each with tradeoffs
New pricing — one simple and predictable pricing model
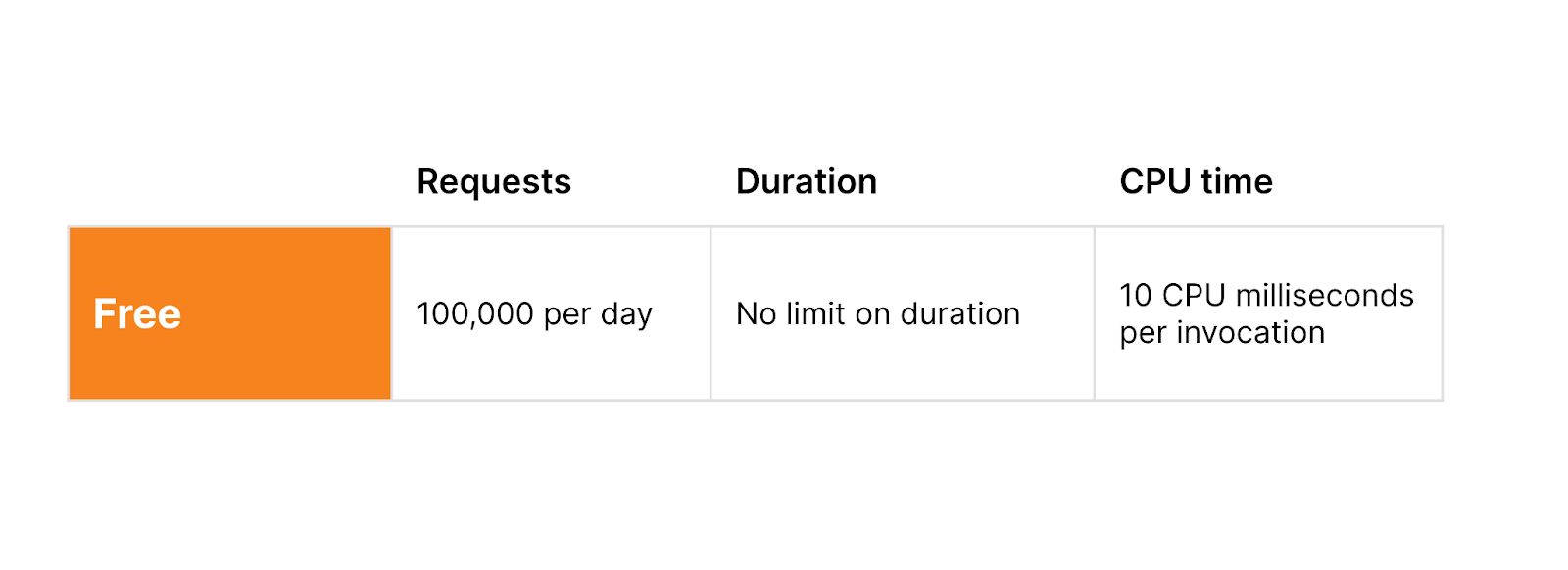
With the same generous Free plan
Unlike wall time (duration, or GB-s), CPU time is more predictable and under your control. When you make a request to a third party API, you can’t control how long that API takes to return a response. This time can be quite long, and vary dramatically — particularly when building AI applications that make inference requests to LLMs. If a request takes twice as long to complete, duration-based billing means you pay double. By contrast, CPU time is consistent and unaffected by time spent waiting on I/O — purely a function of the logic and processing of inputs on outputs to your Worker. It is entirely under your control.
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You’ll be able to estimate how much new pricing will cost in the Cloudflare dashboard. For the majority of current applications, new pricing is the same or less expensive than the previous Bundled and Unbound pricing plans.
If you’re on our Workers Paid plan, you will have until March 1, 2024 to switch to the new pricing on your own, after which all of your projects will be automatically migrated to new pricing. If you’re an Enterprise customer, any contract renewals after March 1, 2024, will use the new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect. And since CPU time is fully in your control, the more you optimize your Worker’s compute time, the less you’ll pay. Your incentives are aligned with ours, to make efficient use of compute resources on Region: Earth.
The challenge of truly scaling to zero
The beauty of serverless is that it allows teams to focus on what matters most — delivering value to their customers, rather than managing infrastructure. It saves you money by effortlessly scaling up and down all over the world based on your traffic, whether you’re an early stage startup or Shopify during Black Friday.
One of the promises of serverless is the idea of scaling to zero — once those big days subside, you no longer have to pay for virtual machines to sit idle before your autoscaling kicks in, or be charged by the hour for instances that you barely ended up using. No compute = no bills for usage. Or so, at least, is the promise of serverless.
Yet, there’s one hidden cost, where even in the serverless world you will find yourself paying for idle resources — what happens when your function is sitting around waiting on I/O? With pricing based on the duration that a function runs, you’re still billed for time that your service is doing zero work, and just waiting on network requests.
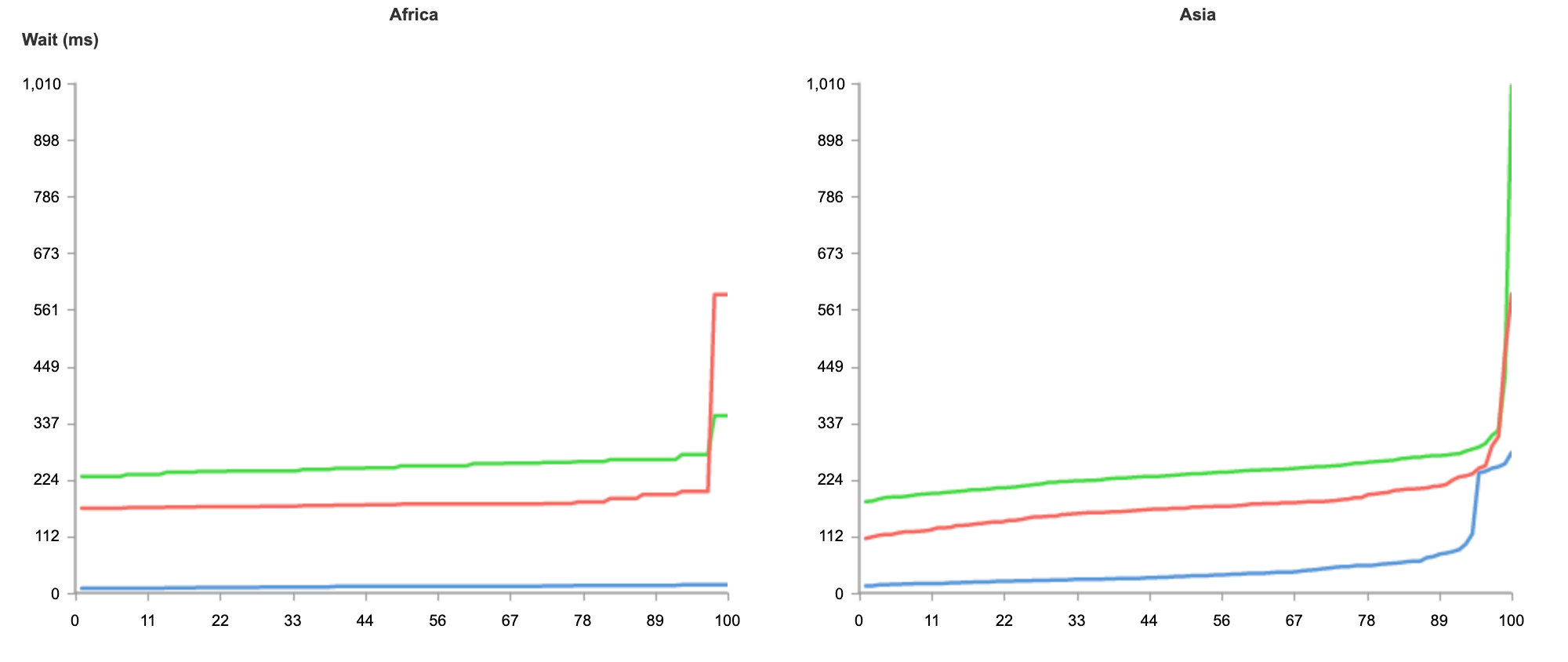
Most applications spend far more time waiting on this I/O than they do using the CPU, often ten times more.
Imagine a similar scenario in your own life — you grab a cab to go to the airport. On the way, the driver decides to stop to refuel and grab a snack, but leaves the meter running. This is not time spent bringing you closer to your destination, but it’s time that you’re paying for. Now imagine for the time the driver was refueling the car, the meter was paused. That’s the difference between CPU time and duration, or wall clock time.
But rather than waiting on the driver to refuel or grab a Snickers bar, what is it that you’re actually paying for when it comes to serverless compute?
Time spent waiting on services you don’t control
Most applications depend on one or many external service providers. Providers of hosted large language models (LLMs) like GPT-4 or Stable Diffusion. Databases as a service. Payment processors. Or simply an API request to a system outside your control. This is where software development is headed — rather than reinventing the wheel and slowly building everything themselves, both fast-moving startups and the Fortune 500 increasingly build using other services to avoid undifferentiated heavy lifting.
Every time an application interacts with one of these external services, it has to send data over the network and wait until it receives a response. And while some services are lightning fast, others can take considerable time, like waiting for a payment processor or for a large media file to be uploaded or converted. Your own application sits idle for most of the request, waiting on services outside your control.
Until today, you’ve had to pay while your application waits. You’ve had to pay more when a service you depend on has an operational issue and slows down, or times out in responding to your request. This has been a disincentive to incrementally move parts of your application to serverless.
Cloudflare’s new pricing: the first serverless platform to truly scale down to zero
The idea of “scale to zero” is that you never have to keep instances of your application sitting idle, waiting for something to happen. Serverless is more than just not having to manage servers or virtual machines — you shouldn’t have to provision and manage the number of compute resources that are available or warm.
Our new pricing takes the “scale to zero” concept even further, and extends it to whether your application is actually performing work. If you’re still paying while nothing is happening, we don’t think that’s truly scale to zero. Your application is idle. The CPU can be used for other tasks. Whether your application is “running” is an old concept lifted from an era before multi-tenant cloud platforms. What matters is if you are actually using compute resources.
Pay less, deploy everywhere, without hidden costs
Let’s compare what you’d pay on new Workers pricing to AWS Lambda, for the following Worker:
One billion requests per month
Seven CPU milliseconds per request
200ms duration per request
The above table is for informational purposes only. Prices are limited to the public fees as of September 20, 2023, and do not include taxes and any other fees. AWS Lambda and Lambda @ Edge prices are based on publicly available pricing in US-East (Ohio) region as published on https://aws.amazon.com/lambda/pricing/
New Workers pricing makes building AI applications dramatically cheaper
Yesterday we announced a new suite of products to let you build AI applications on Cloudflare — Workers AI, AI Gateway, and our new vector database, Vectorize.
Nearly everyone is building new products and features using AI models right now. Large language models and generative AI models are incredibly powerful. But they aren’t always fast — asking a model to create an image, transcribe a segment of audio, or write a story often takes multiple seconds — far longer than a typical API response or database query that we expect to return in tens of milliseconds. There is significant compute work going on behind the scenes, and that means longer duration per request to a Worker.
New Workers pricing makes this much less expensive than it was previously on the Unbound usage model.
Let’s take the same example as above, but instead assume the duration of the request is two seconds (2000ms), because the Worker makes an inference request to a large AI model. With new Workers pricing, you pay the exact same amount, no matter how long this request takes.
No surprise bills — set a maximum limit on CPU time for each Worker
Surprise bills from cloud providers are an unfortunately common horror story. In the old way of provisioning compute resources, forgetting to shut down an instance of a database or virtual machine can cost hundreds of dollars. And accidentally autoscaling up too high can be even worse.
We’re building new safeguards to prevent these kinds of scenarios on Workers. As part of new pricing, you will be able to cap CPU usage on a per-Worker basis.
For example, if you have a Worker with a p99 CPU time of 15ms, you might use this to set a max CPU limit of 40ms — enough headroom to ensure that your worker will run successfully, while ensuring that even if you ship a bug that causes a CPU time to ratchet up dramatically, or have an edge case that causes infinite recursion, you can’t suddenly rack up a giant unexpected bill, or be vulnerable to a denial of wallet attack. This can be particularly helpful if your worker handles variable or user-generated input, to guard against edge cases that you haven’t accounted for.
Alternatively, if you’re running a production service, but want to make sure you stay on top of your costs, we will also be adding the option to configure notifications that can automatically email you, page you, or send a webhook if your worker exceeds a particular amount of CPU time per request. You will be able to choose at what threshold you want to be notified, and how.
New ways to “hibernate” Durable Objects while keeping connections alive
While Workers are stateless functions, Durable Objects are stateful and long-lived, commonly used to coordinate and persist real-time state in chat, multiplayer games, or collaborative apps. And unlike Workers, duration-based pricing fits Durable Objects well. As long as one or more clients are connected to a Durable Object, it keeps state available in memory. Durable Objects pricing will remain duration-based, and is not changing as part of this announcement.
What about when a client is connected to a Durable Object, but no work has happened for a long time? Consider a collaborative whiteboard app built using Durable Objects. A user of the app opens the app in a browser tab, but then forgets about it, and leaves it running for days, with an open WebSocket connection. Just like with Workers, we don’t think you should have to pay for this idle time. But until recently, there hasn’t been an API to signal to us that a Durable Object can be safely “hibernated”.
The recently introduced Hibernation API, currently in beta, allows you to set an automatic response to be used while hibernated and serialize state such that it survives hibernation. This gives Cloudflare the inputs we need in order to maintain open WebSocket connections from clients, while “hibernating” the Durable Object such that it is not actively running, and you are not billed for idle time. The result is that your state is always available in-memory when actually need it, but isn’t unnecessarily kept around when it’s not. As long as your Durable Object is hibernating, even if there are active clients still connected over a WebSocket, you won’t be billed for duration.
Snippets make Cloudflare’s CDN programmable — for free
What if you just want to modify a header, do a country code redirect, or cache a custom query? Developers have relied on Workers to program Cloudflare’s CDN like this for many years. With the announcement of Cloudflare Snippets last year, now in alpha, we’re making it free.
If you use Workers today for these smaller use cases, to customize any of Cloudflare’s application services, Snippets will be the optimal, zero cost option.
A serverless platform without limits
Developers are building ever larger and more complex full-stack applications on Workers each month. Our promise to you is to help you scale in any direction, without worrying about paying for idle time or having to manage and provision compute resources across regions.
This also means not having to worry about limits. Workers already serves many millions of requests per second, and scales and performs so well that we are rebuilding our own CDN on top of Workers. Individual Workers can now be up to 10MB, with a max startup time of 400ms, and can be easily composed together using Service Bindings. Entire platforms are built on top of Workers, with a growing number of companies allowing their own customers to write and deploy custom code and applications via Workers for Platforms. Some of the biggest platforms in the world rely on Cloudflare and the Workers platform during the most critical moments.
New pricing removes limits on the types of applications that could be built cost effectively with duration-based pricing. It removes the ceiling on CPU time from our original request-based pricing. We’re excited to see what you build, and are committed to being the development platform where you’re not constrained by limits on scale, regions, instances, concurrency or whatever else you need to handle to grow and operate globally.
When will new pricing be available?
Starting October 31, 2023, you will have the option to opt in individual Workers and Pages Functions projects on your account to new pricing, and newly created projects will default to new pricing. You will have until March 1, 2024, or the end of your Enterprise contract, whichever comes later, to switch to new pricing on your own, after which all of your projects will be automatically migrated to new pricing. You’ll receive plenty of advance notice via email and dashboard notifications before any changes go into effect.
Between now and then, we want to hear from you. We’ve based new pricing off feedback we’ve heard from developers building serverless applications, and companies estimating and projecting their costs. Tell us what you think of new pricing by sharing your feedback in this survey. We read every response.
Today, we’re excited to announce that we are partnering with Hugging Face to make AI models more accessible and affordable than ever before to developers.
There are three things we look forward to making available to developers over the coming months:
We’re excited to bring serverless GPU models to Hugging Face — no more wrangling infrastructure or paying for unused capacity. Just pick your model, and go;
Bringing popular Hugging Face optimized models to Cloudflare’s model catalog;
Introduce Cloudflare integrations as a part of Hugging Face’s Inference solutions.
Hosting over 500,000 models and serving over one million model downloads a day, Hugging Face is the go-to place for developers to add AI to their applications.
Meanwhile, over the past six years at Cloudflare, our goal has been to make it as easy as possible for developers to bring their ideas and applications to life on our developer platform.
As AI has become a critical part of every application, this partnership has felt like a natural match to put tools in the hands of developers to make deploying AI easy and affordable.
“Hugging Face and Cloudflare both share a deep focus on making the latest AI innovations as accessible and affordable as possible for developers. We’re excited to offer serverless GPU services in partnership with Cloudflare to help developers scale their AI apps from zero to global, with no need to wrangle infrastructure or predict the future needs of your application — just pick your model and deploy.” — Clem Delangue, CEO of Hugging Face.
We’re excited to share what’s to come, so we wanted to give you a sneak peek into what’s ahead.
Hugging Face models at your fingertips
As a developer, when you have an idea, you want to be able to act on it as quickly as possible. Through our partnership, we’re excited to provide you with familiar models, regardless of where you’re getting started.
If you’re using Cloudflare’s developer platform to build applications, we’re excited to bring Hugging Face models into the flow as a native part of the experience. You will soon be able to deploy Hugging Face models, optimized for performance and speed, right from Cloudflare’s dashboard.
Alternatively, if you’re used to perusing and finding your models on Hugging Face, you will soon be able to deploy them directly from the Hugging Face UI directly to Workers AI.
Both of our teams are committed to building the best developer experiences possible, so we look forward to continuing to file away any friction that gets in developers’ ways of building the next big AI idea.
Bringing serverless GPU inference to Hugging Face users
Hugging Face offers multiple inference solutions to serve predictions from the 500,000 models hosted on the platform without managing infrastructure, from the free and rate-limited Inference API, to dedicated infrastructure deployments with Inference Endpoints, and even in-browser edge inference with Transformers.js.
We look forward to working closely with the teams at Hugging Face to enable new experiences powered by Cloudflare: from new serverless GPU inference solutions, to new edge use cases – stay tuned!
See you soon!
We couldn’t wait to share the news with our developers about our partnership, and can’t wait to put these experiences in the hands of developers over the coming months.
Today, Cloudflare’s Workers platform is the place over a million developers come to build sophisticated full-stack applications that previously wouldn’t have been possible.
Of course, Workers didn’t start out that way. It started, on a day like today, as a Birthday Week announcement. It may not have had all the bells and whistles that exist today, but if you got to try Workers when it launched, it conjured this feeling: “this is different, and it’s going to change things”. All of a sudden, going from nothing to a fully scalable, global application took seconds, not hours, days, weeks or even months. It was the beginning of a different way to build applications.
If you’ve played with generative AI over the past few months, you may have had a similar feeling. Surveying a few friends and colleagues, our “aha” moments were all a bit different, but the overarching sentiment across the industry at this moment is unanimous — this is different, and it’s going to change things.
Today, we’re excited to make a series of announcements that we believe will make a similar impact as Workers did in the future of computing. Without burying the lede any further, here they are:
Workers AI (formerly known as Constellation), running on NVIDIA GPUs on Cloudflare’s global network, bringing the serverless model to AI — pay only for what you use, spend less time on infrastructure, and more on your application.
Vectorize, our vector Database, making it easy, fast and affordable to index and store vectors to support use cases that require access not just to running models, but customized data too.
AI Gateway, giving organizations the tools to cache, rate limit and observe their AI deployments regardless of where they’re running.
But that’s not all.
Doing big things is a team sport, and we don’t want to do it alone. Like in so much of what we do, we stand on the shoulders of giants. We’re thrilled to partner with some of the biggest players in the space: NVIDIA, Microsoft, Hugging Face, Databricks, and Meta.
Our announcements today mark just the beginning of Cloudflare’s journey into the AI space, like Workers did six years ago. While we encourage you to dive into each of our announcements (you won’t be disappointed!), we also wanted to take the chance to step back and provide you with a bit of our broader vision for AI, and how these announcements fit into it.
Inference: The future of AI workloads
There are two main processes involved in AI: training and inference.
Training a generative AI model is a long-running (sometimes months-long) compute intensive process, which results in a model. Training workloads are therefore best suited for running in traditional centralized cloud locations. Given the recent challenges in being able to obtain long-running access to GPUs, resulting in companies going multi-cloud, we’ve talked about the ways in which R2 can provide an essential service that eliminates egress fees for the training data to be accessed from any compute cloud. But that’s not what we’re here to talk about today.
While training requires many resources upfront, the much more ubiquitous AI-related compute task is inference. If you’ve recently asked ChatGPT a question, generated an image, translated some text, then you’ve performed an inference task. Since inference is required upon every single invocation (rather than just once), we expect that inference will become the dominant AI-related workload.
If training is best suited for a centralized cloud, then what is the best place for inference?
The network — “just right” for inference
The defining characteristic of inference is that there’s usually a user waiting on the other end of it. That is, it’s a latency sensitive task.
The best place, you might think, for a latency sensitive task is on the device. And it might be in some cases, but there are a few problems. First, hardware on devices is not nearly as powerful. Battery life.
On the other hand, you have centralized cloud compute. Unlike devices, the hardware running in centralized cloud locations has nothing if not horsepower. The problem, of course, is that it’s hundreds of milliseconds away from the user. And sometimes, they’re even across borders, which presents its own set of challenges.
So devices are not yet powerful enough, and centralized cloud is too far away. This makes the network the goldilocks of inference. Not too far, with sufficient compute power — just right.
The first inference cloud, running on Region Earth
One lesson we learned building our developer platform is that running applications at network scale not only helps optimize performance and scale (though obviously that’s a nice benefit!), but even more importantly, creates the right level of abstraction for developers to move fast.
Workers AI for serverless inference
Kicking things off with our announcement of Workers AI, we’re bringing the first truly serverless GPU cloud, to its perfect match — Region Earth. No machine learning expertise, no rummaging for GPUs. Just pick one of our provided models, and go.
We’ve put a lot of thought into designing Workers AI to make the experience of deploying a model as smooth as possible.
And if you’re deploying any models in the year 2023, chances are, one of them is an LLM.
Vectorize for… storing vectors!
To build an end-to-end AI-operated chat bot, you also need a way to present the user with a UI, parse the corpus of information you want to pass it (for example your product catalog), use the model to convert it into embeddings — and store them somewhere. Up until today, we offered the products you needed for the first two, but the latter — storing embeddings — requires a unique solution: a vector database.
Just as when we announced Workers, we soon after announced Workers KV — there’s little you can do with compute, without access to state. The same is true of AI — to build meaningful AI use cases, you need to give AI access to state. This is where a vector database comes into play, and why today we’re also excited to announce Vectorize, our own vector database.
AI Gateway for caching, rate limiting and visibility into your AI deployments
At Cloudflare, when we set out to improve something, the first step is always to measure it — if you can’t measure it, how can you improve it? When we heard about customers struggling to reign in AI deployment costs, we thought about how we would approach it — measure it, then improve it.
Our AI Gateway helps you do both!
Real-time observation capabilities empower proactive management, making it easier to monitor, debug, and fine-tune AI deployments. Leveraging it to cache, rate limit, and monitor AI deployments is essential for optimizing performance and managing costs effectively. By caching frequently used AI responses, it reduces latency and bolsters system reliability, while rate limiting ensures efficient resource allocation, mitigating the challenges of spiraling AI costs.
Collaborating with Meta to bring Llama 2 to our global network
Until recently, the only way to have access to an LLM was through calls to proprietary models. Training LLMs is a serious investment — in time, computing, and financial resources, and thus not something that’s accessible to most developers. Meta’s release of Llama 2, an open-source LLM, has presented an exciting shift, allowing developers to run and deploy their own LLMs. Except of course, one small detail — you still have to have access to a GPU to do so.
By making Llama 2 available as a part of the Workers AI catalog, we look forward to giving every developer access to an LLM — no configuration required.
Having a running model is, of course, just one component of an AI application.
Leveraging the ONNX runtime to make moving between cloud to edge to device seamless for developers
While the edge may be the optimal location for solving many of these problems, we do expect that applications will continue to be deployed at other locations along the spectrum of device, edge and centralized cloud.
Take for example, self-driving cars — when you’re making decisions where every millisecond matters, you need to make these decisions on the device. Inversely, if you’re looking to run hundred-billion parameter versions of models, the centralized cloud is going to be better suited for your workload.
The question then becomes: how do you navigate between these locations smoothly?
Since our initial release of Constellation (now called Workers AI), one technology we were particularly excited by was the ONNX runtime. The ONNX runtime creates a standardized environment for running models, which makes it possible to run various models across different locations.
We already talked about the edge as a great place for running inference itself, but it’s also great as a routing layer to help guide workloads smoothly across all three locations, based on the use case, and what you’re looking to optimize for — be it latency, accuracy, cost, compliance, or privacy.
Partnering with Hugging Face to provide optimized models at your fingertips
There’s nothing of course that can help developers go faster than meeting them where they are, so we are partnering with Hugging Face to bring serverless inference to available models, right where developers explore them.
Partnering with Databricks to make AI models
Together with Databricks, we will be bringing the power of MLflow to data scientists and engineers. MLflow is an open-source platform for managing the end-to-end machine learning lifecycle, and this partnership will make it easier for users to deploy and manage ML models at scale. With this partnership, developers building on Cloudflare Workers AI will be able to leverage MLFlow compatible models for easy deployment into Cloudflare’s global network. Developers can use MLflow to efficiently package, implement, deploy and track a model directly into Cloudflare’s serverless developer platform.
AI that doesn’t keep your CIO or CFO or General Counsel up at night
Things are moving quickly in AI, and it’s important to give developers the tools they need to get moving, but it’s hard to move fast when there are important considerations to worry about. What about compliance, costs, privacy?
Compliance-friendly AI
Much as most of us would prefer not to think about it, AI and data residency are becoming increasingly regulated by governments. With governments requiring that data be processed locally or that their residents’ data be stored in-country, businesses have to think about that in the context of where inference workloads run as well. While with regard to latency, the network edge provides the ability to go as wide as possible. When it comes to compliance, the power of a network that spans 300 cities, and an offering like our Data Localization Suite, we enable the granularity required to keep AI deployments local.
Budget-friendly AI
Talking to many of our friends and colleagues experimenting with AI, one sentiment seems to resonate — AI is expensive. It’s easy to let costs get away before even getting anything into production or realizing value from it. Our intent with our AI platform is to make costs affordable, but perhaps more importantly, only charge you for what you use. Whether you’re using Workers AI directly, or our AI gateway, we want to provide the visibility and tools necessary to prevent AI spend from running away from you.
Privacy-friendly AI
If you’re putting AI front and center of your customer experiences and business operations, you want to be reassured that any data that runs through it is in safe hands. As has always been the case with Cloudflare, we’re taking a privacy-first approach. We can assure our customers that we will not use any customer data passing through Cloudflare for inference to train large language models.
No, but really — we’re just getting started
We're just getting started with AI, folks, and boy, are we in for a wild ride! As we continue to unlock the benefits of this technology, we can't help but feel a sense of awe and wonder at the endless possibilities that lie ahead. From revolutionizing healthcare to transforming the way we work, AI is poised to change the game in ways we never thought possible. So buckle up, folks, because the future of AI is looking brighter than ever – and we can't wait to see what's next!
This wrap up message may have been generated by AI, but the sentiment is genuine — this is just the beginning, and we can’t wait to see what you build.
During Cloudflare's 2023 Developer Week, we announced Constellation, a set of APIs that allow everyone to run fast, low-latency inference tasks using pre-trained machine learning/AI models, directly on Cloudflare’s network.
Constellation update
We now have a few thousand accounts onboarded in the Constellation private beta and have been listening to our customer's feedback to evolve and improve the platform. Today, one month after the announcement, we are upgrading Constellation with three new features:
Bigger models We are increasing the size limit of your models from 10 MB to 50 MB. While still somewhat conservative during the private beta, this new limit opens doors to more pre-trained and optimized models you can use with Constellation.
Tensor caching When you run a Constellation inference task, you pass multiple tensor objects as inputs, sometimes creating big data payloads. These inputs travel through the wire protocol back and forth when you repeat the same task, even when the input changes from multiple runs are minimal, creating unnecessary network and data parsing overhead.
The client API now supports caching input tensors resulting in even better network latency and faster inference times.
XGBoost runtime Constellation started with the ONNX runtime, but our vision is to support multiple runtimes under a common API. Today we're adding the XGBoost runtime to the list.
XGBoost is an optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable, and it's known for its performance in structured and tabular data tasks.
You can start uploading and using XGBoost models today.
You can find the updated documentation with these new features and an example on how to use the XGBoost runtime with Constellation in our Developers Documentation.
An era of globally distributed AI
Since Cloudflare’s network is globally distributed, Constellation is our first public release of globally distributed machine learning.
But what does this mean? You may not think of a global network as the place to deploy your machine learning tasks, but machine learning has been a core part of what’s enabled much of Cloudflare’s core functionality for many years. And we run it across our global network in 300 cities.
Is this large spike in traffic an attack or a Black Friday sale? What’s going to be the best way to route this request based on current traffic patterns? Is this request coming from a human or a bot? Is this HTTP traffic a zero-day? Being able to answer these questions using automated machine learning and AI, rather than human intervention, is one of the things that’s enabled Cloudflare to scale.
But this is just a small sample of what globally distributed machine learning enables. The reason this was so helpful for us was because we were able to run this machine learning as an integrated part of our stack, which is why we’re now in the process of opening it up to more and more developers with Constellation.
As Michelle Zatlyn, our co-founder likes to say, we’re just getting started (in this space) — every day we’re adding hundreds of new users to our Constellation beta, testing out and globally deploying new models, and beyond that, deploying new hardware to support the new types of workloads that AI will bring to the our global network.
With that, we wanted to share a few announcements and some use cases that help illustrate why we’re so excited about globally distributed AI. And since it’s Speed Week, it should be no surprise that, well, speed is at the crux of it all.
Custom tailored web experiences, powered by AI
We’ve long known about the importance of performance when it comes to web experiences — in e-commerce, every second of page load time can have as much as a 7% drop off effect on conversion. But being fast is not enough. It’s necessary, but not sufficient. You also have to be accurate.
That is, rather than serving one-size-fits-all experiences, users have come to expect that you know what they want before they do.
So you have to serve personalized experiences, and you have to do it fast. That’s where Constellation can come into play. With Constellation, as a part of your e-commerce application that may already be served from Cloudflare’s network through Workers or Pages, or even store data in D1, you can now perform tasks such as categorization (what demographic is this customer most likely in?) and personalization (if you bought this, you may also like that).
Making devices smarter wherever they are
Another use case where performance is critical is in interacting with the real world. Imagine a face recognition system that detects whether you’re human or not every time you go into your house. Every second of latency makes a difference (especially if you’re holding heavy groceries).
Running inference on Cloudflare’s network, means that within 95% of the world’s population, compute, and thus a decision, is never going to be more than 50ms away. This is in huge contrast to centralized compute, where if you live in Europe, but bought a doorbell system from a US-based company, may be up to hundreds of milliseconds round trip away.
You may be thinking, why not just run the compute on the device then?
For starters, running inference on the device doesn’t guarantee fast performance. Most devices with built in intelligence are run on microcontrollers, often with limited computational abilities (not a high-end GPU or server-grade CPU). Milliseconds become seconds; depending on the volume of workloads you need to process, the local inference might not be suitable. The compute that can be fit on devices is simply not powerful enough for high-volume complex operations, certainly not for operating at low-latency.
But even user experience aside (some devices don’t interface with a user directly), there are other downsides to running compute directly on devices.
The first is battery life — the longer the compute, the shorter the battery life. There's always a power consumption hit, even if you have a custom ASIC chip or a Tensor Processing Unit (TPU), meaning shorter battery life if that's one of your constraints. For consumer products, this means having to switch out your doorbell battery (lest you get locked out). For operating fleets of devices at scale (imagine watering devices in a field) this means costs of keeping up with, and swapping out batteries.
Lastly, device hardware, and even software, is harder to update. As new technologies or more efficient chips become available, upgrading fleets of hundreds or thousands of devices is challenging. And while software updates may be easier to manage, they’ll never be as easy as updating on-cloud software, where you can effortlessly ship updates multiple times a day!
Speaking of shipping software…
AI applications, easier than ever with Constellation
Speed Week is not just about making your applications or devices faster, but also your team!
For the past six years, our developer platform has been making it easy for developers to ship new code with Cloudflare Workers. With Constellation, it’s now just as easy to add Machine Learning to your existing application, with just a few commands.
And if you don’t believe us, don’t just take our word for it. We’re now in the process of opening up the beta to more and more customers. To request access, head on over to the Cloudflare Dashboard where you’ll see a new tab for Constellation. We encourage you to check out our tutorial for getting started with Constellation — this AI thing may be even easier than you expected it to be!
We’re just getting started
This is just the beginning of our journey for helping developers build AI driven applications, and we’re already thinking about what’s next.
We look forward to seeing what you build, and hearing your feedback.
We announced Cloudflare Workers in 2017, giving developers access to compute on our network. We were excited about the possibilities this unlocked, but we quickly realized — most real world applications are stateful. Since then, we’ve delivered KV, Durable Objects, and R2, giving developers access to various types of storage.
Today, we’re excited to announce D1, our first SQL database.
While the wait on beta access shouldn’t be long — we’ll start letting folks in as early as June (sign up here), we’re excited to share some details of what’s to come.
Meet D1, the database designed for Cloudflare Workers
D1 is built on SQLite. Not only is SQLite the most ubiquitous database in the world, used by billions of devices a day, it’s also the first ever serverless database. Surprised? SQLite was so ahead of its time, it dubbed itself “serverless” before the term gained connotation with cloud services, and originally meant literally “not involving a server”.
Since Workers itself runs between the server and the client, and was inspired by technology built for the client, SQLite seemed like the perfect fit for our first entry into databases.
So what can you build with D1? The true answer is “almost anything!”, that might not be very helpful in triggering the imagination, so how about a live demo?
D1 Demo: Northwind Traders
You can check out an example of D1 in action by trying out our demo running here: northwind.d1sql.com.
If you’re wondering “Who are Northwind Traders?”, Northwind Traders is the “Hello, World!” of databases, if you will. A sample database that Microsoft would provide alongside Microsoft Access to use as their own tutorial. It first appeared 25 years ago in 1997, and you’ll find many examples of its use on the Internet.
It’s a typical business application, with a realistic schema, with many foreign keys, across many different tables — a truly timeless representation of data.
When was the recent order of Queso Cabrales shipped, and what ship was it on? You can quickly find out. Someone calling in about ordering some Chai? Good thing Exotic Liquids still has 39 units in stock, for just \$18 each.
We welcome you to play and poke around, and answer any questions you have about Northwind Trading’s business.
The Northwind Traders demo also features a dashboard where you can find details and metrics about the D1 SQL queries happening behind the scenes.
What can you build with D1?
Going back to our original question before the demo, however, what can you build with D1?
While you may not be running Northwind Traders yourself, you’re likely running a very similar piece of software somewhere. Even at the very core of Cloudflare’s service is a database. A SQL database filled with tables, materialized views and a plethora of stored procedures. Every time a customer interacts with our dashboard they end up changing state in that database.
The reality is that databases are everywhere. They are inside the web browser you’re reading this on, inside every app on your phone, and the storage for your bank transaction, travel reservations, business applications, and on and on. Our goal with D1 is to help you build anything from APIs to rich and powerful applications, including eCommerce sites, accounting software, SaaS solutions, and CRMs.
You can even combine D1 with Cloudflare Access and create internal dashboards and admin tools that are securely locked to only the people in your organization. The world, truly, is your oyster.
The D1 developer experience
We’ll talk about the capabilities, and upcoming features further down in the post, but at the core of it, the strength of D1 is the developer experience: allowing you to go from nothing to a full stack application in an instant. Think back to a tool you’ve used that made development feel magical — that’s exactly what we want developing with Workers and D1 to feel like.
To give you a sense of it, here’s what getting started with D1 will look like.
Creating your first D1 database
With D1, you will be able to create a database, in just a few clicks — define the tables, insert or upload some data, no need to memorize any commands unless you need to.
Of course, if the command-line is your jam, earlier this week, we announced the new and improved Wrangler 2, the best tool for wrangling and deploying your Workers, and soon also your tool for deploying D1. Wrangler will also come with native D1 support, so you can create & manage databases with a few simple commands:
Accessing D1 from your Worker
Attaching D1 to your Worker is as easy as creating a new binding. Each D1 database that you attach to your Worker gets attached with its own binding on the env parameter:
export default {
async fetch(request, env, ctx) {
const { pathname } = new URL(request.url)
if (pathname === '/num-products') {
const { result } = await env.DB.get(`SELECT count(*) AS num_products FROM Product;`)
return new Response(`There are ${result.num_products} products in the D1 database!`)
}
}
}
Or, for a slightly more complex example, you can safely pass parameters from the URL to the database using a Router and parameterised queries:
import { Router } from 'itty-router';
const router = Router();
router.get('/product/:id', async ({ params }, env) => {
const { result } = await env.DB.get(
`SELECT * FROM Product WHERE ID = $id;`,
{ $id: params.id }
)
return new Response(JSON.stringify(result), {
headers: {
'content-type': 'application/json'
}
})
})
export default {
fetch: router.handle,
}
So what can you expect from D1?
First and foremost, we want you to be able to develop with D1, without having to worry about cost.
At Cloudflare, we don’t believe in keeping your data hostage, so D1, like R2, will be free of egress charges. Our plan is to price D1 like we price our storage products by charging for the base storage plus database operations performed.
But, again, we don’t want our customers worrying about the cost or what happens if their business takes off, and they need more storage or have more activity. We want you to be able to build applications as simple or complex as you can dream up. We will ensure that D1 costs less and performs better than comparable centralized solutions. The promise of serverless and a global network like Cloudflare’s is performance and lower cost driven by our architecture.
Here’s a small preview of the features in D1.
Read replication
With D1, we want to make it easy to store your whole application’s state in the one place, so you can perform arbitrary queries across the full data set. That’s what makes relational databases so powerful.
However, we don’t think powerful should be synonymous with cumbersome. Most relational databases are huge, monolithic things and configuring replication isn’t trivial, so in general, most systems are designed so that all reads and writes flow back to a single instance. D1 takes a different approach.
With D1, we want to take configuration off your hands, and take advantage of Cloudflare’s global network. D1 will create read-only clones of your data, close to where your users are, and constantly keep them up-to-date with changes.
Batching
Many operations in an application don’t just generate a single query. If your logic is running in a Worker near your user, but each of these queries needs to execute on the database, then sending them across the wire one-by-one is extremely inefficient.
D1’s API includes batching: anywhere you can send a single SQL statement you can also provide an array of them, meaning you only need a single HTTP round-trip to perform multiple operations. This is perfect for transactions that need to execute and commit atomically:
async function recordPurchase(userId, productId, amount) {
const result = await env.DB.exec([
[
`UPDATE users SET balance = balance - $amount WHERE user_id = $user_id`,
{ $amount: amount, $user_id: userId },
],
[
'UPDATE product SET total_sales = total_sales + $amount WHERE product_id = $product_id',
{ $amount: amount, $product_id: productId },
],
])
return result
}
Embedded compute
But we’re going further. With D1, it will be possible to define a chunk of your Worker code that runs directly next to the database, giving you total control and maximum performance—each request first hits your Worker near your users, but depending on the operation, can hand off to another Worker deployed alongside a replica or your primary D1 instance to complete its work.
Backups and redundancy
There are few things as critical as the data stored in your main application’s database, so D1 will automatically save snapshots of your database to Cloudflare’s cloud storage service, R2, at regular intervals, with a one-click restoration process. And, since we’re building on the redundant storage of Durable Objects, your database can physically move locations as needed, resulting in self-healing from even the most catastrophic problems in seconds.
Importing and exporting data
While D1 already supports the SQLite API, making it easy for you to write your queries, you might also need data to run them on. If you’re not creating a brand-new application, you may want to import an existing dataset from another source or database, which is why we’ll be working on allowing you to bring your own data to D1.
Likewise, one of SQLite’s advantages is its portability. If your application has a dedicated staging environment, say, you’ll be able to clone a snapshot of that data down to your local machine to develop against. And we’ll be adding more flexibility, such as the ability to create a new database with a set of test data for each new pull request on your Pages project.
What’s next?
This wouldn’t be a Cloudflare announcement if we didn’t conclude on “we’re just getting started!” — and it’s true! We are really excited about all the powerful possibilities our database on our global network opens up.
Are you already thinking about what you’re going to build with D1 and Workers? Same. Give us your details, and we’ll give you access as soon as we can — look out for a beta invite from us starting as early as June 2022!
As a business, whether a startup or Fortune 500 company, your number one priority is to make your customers happy and successful with your product. To your customers, however, success and happiness sometimes seems to be just one feature away.
“If only you could customize X, we’ll be able to use your product” – the largest prospect in your pipeline. “If you just let us do Y, we’ll expand our usage of your product by 10x” – your most strategic existing customer.
You want your product to be everything to everybody, but engineering can only keep up so quickly, so, what gives?
Today, we’re announcing Workers for Platforms, our tool suite to help make any product programmable, and help our customers deliver value to their customers and developers instantaneously.
A more programmable interface
One way to give your customers the ability to programmatically interact with your product is by providing them with APIs. That is a big part of why APIs are so prolific today — enabling code (whether your own, or that of a 3rd party) to engage with your applications is nothing short of revolutionary.
But there’s still a problem. While APIs can give developers the ability to interact with your application programmatically, developers are ultimately always limited by the abstractions exposed to them by the API. You, an application owner, have to have predicted how the customer would use your product, and then built out the API to support the use case. If there’s one thing I have learned as a product manager, it’s almost impossible to predict how customers will use a product. And if there’s a second thing I’ve learned, it’s that even with plentiful engineering resources, it’s also almost impossible to build all the functionality required to keep said customers happy.
There is another way, however.
Functions, in contrast to APIs, provide the lowest level primitives (rather than abstractions on top of them). This lets the developer define the right behavior from there — and they can even define their own APIs on top.
In this sense, functions and APIs are actually complementary to each other — you may even choose to call another API directly from your function. For example, if you’re handling an event in a messaging system, you could implement your own feature to send an email by calling an email API, or create a ticket in your ticketing system, etc.
This gets at why we’re so excited about Workers for Platforms: it enables you to expose a direct way for your customers’ developers to bring their own logic to any application. We think it’s going to unlock a wave of customer-led innovation on top of companies that adopt it, and has the potential to be as impactful to building applications on the web as the API has been.
A better experience for developers
While Workers for Platforms expose a more powerful paradigm for making product programmable, they also result in a better experience for you as a developer.
Today, as a developer, before you can even get started using APIs or webhooks, there’s a list of tedious tasks you have to deal with first. First, you have to set up somewhere to host your code, whether a server (or serverless function), and expose it via an external endpoint to be able. You have to deal with ops, custom tokens, figuring out the new authentication schema, all before you get started. Then you have to maintain that service, and make sure that it stays up to ensure that events are always processed properly.
With functions embedded directly into the products you’re using, you can just start writing the code.
Why hasn’t this model been embraced until now?
Allowing developers to program how events work seems obvious, but just because it’s obvious doesn’t mean it’s easy.
At Cloudflare, we encountered this very problem five years ago — we were onboarding larger and larger customers onto our network, each needing to dictate the fate of a request in their own way. While Page Rules offered a way to modify behavior by URL, customers wanted to control behavior based on cookie, header, geolocation, and more!
We realized our engineering team couldn’t keep up with every request, so we decided to allow customers to bend our product to their own needs.
As we looked for an approach to this problem, we looked for a solution that would meet the two following requirements:
Performance requirement: it’s unacceptable for a CDN, which should make your site faster to introduce latency. How do we make this so fast you don’t even notice it’s there?
Security requirement: how do we run untrusted code securely?
While these requirements are especially critical when you offer performance and security products, solving these challenges is critical when giving your customers the ability to program your product. If the function needs to run on the critical path to your user, introducing latency is equally unacceptable. And of course, no one wants to get breached just to have their users be able to program.
Creating a really fast and secure multi-tenant environment is no easy feat.
When we evaluated our options for solving this problem, we first turned to technologies that existed for solving this problem on the server — serverless functions already existed at time, but were powered by containers, which would introduce cold-start, which was, well, a non-starter. So we turned to the browser, or specifically Chrome, which was powered by V8, and decided to take the same approach, and run it on our servers.
And while the approach sounds simple (and perhaps in retrospect obvious, as these things tend to seem), running a large multi-tenant development platform at scale is no small effort. If a part of the purpose of allowing customers to program your offering is to free up engineering efforts to focus on building new features, the effort it takes to maintain and scale such a development platform may defeat the purpose.
What we realized recently was that we weren’t alone in trying to solve this problem.
Companies like Shopify, building their next generation programmable storefront, Oxygen, were trying to solve the same thing. They wanted to enable their customers to run custom storefronts, and be able to offer the best performance possible, while maintaining a secure, multi-tenant environment.
“Shopify is the Internet’s commerce infrastructure, with millions of merchants using the platform,” said Zach Koch, product director, custom storefronts, at Shopify. “Partnering with Cloudflare, we’re able to give developers the tools they need to build unique and performant storefronts. We are excited to work with Cloudflare to alleviate some complexities of building commerce experiences – like scalability and global availability – so that developers can instead focus on what makes their brand distinct.”
How can you build your next platform on Workers for Platforms?
Working with platforms like Shopify to help them address their developers’ needs, helped us realize another thing — developer experience is not one-size-fits-all. That is, while we’re building our platform for a broad set of developers, eCommerce developers might have a much more specialized set of needs, best solved by a tailored developer experience. And, while the underlying technology is the same, making platforms their experiences using the same high level concepts as our direct customers need doesn’t make sense.
Since no one knows your customers better than you, we want you, the platform provider, to design the best experience for your users. Workers for Platforms exposes a new set of tools and APIs to integrate directly into the deployment flow you want to design (see what we did there?).
Tags API to manage your functions at scale
Using our APIs, whenever a developer wants to deploy a script on your platform, you can call our APIs to deploy a new Worker in the background. Unlike our traditional Workers offering, Workers for Platforms is designed to be used at scale, to manage hundreds of thousands to millions of Cloudflare Workers.
Depending on how you manage your deployment services, or users, we now also provide the option to use tags to manage groupings of scripts. For example, if a user deletes their account, and you would like to make sure all their Workers are cleaned up. With tags, you can now add any arbitrary tags (such as user ID) per script, to enable bulk actions.
Trace Workers
Where there’s smoke, there’s fire, and where there’s code, well, bugs are also bound to be. When giving developers the tools to write and deploy code, you must also give them the means to debug it.
Trace Workers allow you to collect any information about a request that was handled by a Worker, including any logs or exceptions, and pass them onto your customer. A Trace Worker is a Worker that will receive information about the execution of other Workers, and can forward it to a destination of your choosing, enabling use cases such as live logging or long term storage.
Here is a simple trace Worker that sends its trace data to an HTTP endpoint:
Chaining multiple Workers together using Dynamic Dispatch
From working with a few of our early customers, another need we were hearing about often was the ability to run your own code, before running your customer’s code. Perhaps you want to run a layer of authentication, sanitize input or output, or even provide useful information downstream (like user or account IDs).
For this you may want to maintain your own Worker. However, when it’s done executing, you want to be able to call the next Worker, with your customer’s code.
Example:
let user_worker = dispatcher.get('customer-worker-123');
let response = await user_worker.fetch(request);
Custom domains, and more!
The features above are only the new Workers features we enabled for our customers as of this week, but our goal is to provide all the tools you need to build your platform. For example, you can use Workers for Platforms with Cloudflare for SaaS to create custom domains. (And stay tuned for the “and more!”).
How do I get access?
As is the case with any new product we release, we have no doubt we have so much to learn from our customers and their use cases. Since we want to support you, and make sure you’re set up for success, if you’re interested, we’d love to get to know you and your use case, and get you set up with all the tools you need. To get started, we ask that you fill out our form, and we’ll get in touch with you.
In the meantime, you’re welcome to get started checking out our developer docs, or saying hi in our Discord.
Just getting started
We faced this problem ourselves five years ago — we needed to give our customers the ability to augment our offering in a way that worked for them, so we did just that when we launched Cloudflare Workers. Allowing our customers to program our global network to meet their needs has enabled us to support more customers on our development platform, while enabling our engineering team to focus on turning the most requested customizations into features.
We look forward to seeing both what your developers build on your platform (and we believe you, yourself will be surprised with the use cases developers come up with that you could never dream up yourself), and what your engineering team is able to tackle in parallel!
450,000 developers have used Cloudflare Workers since we launched.
When we announced Cloudflare Workers nearly five years ago, we had no idea if we’d ever be in this position. But a lot of care, hard work — not to mention dogfooding — later, we’ve been absolutely blown away by the use cases and applications built on our developer platform, not to mention the community that’s grown around the product.
My job isn’t just speaking to developers who are already using Cloudflare Workers, however. I spend a lot of time talking to developers who aren’t yet using Workers, too. Despite how cool the tech is — the performance, the ability to just code without worrying about anything else like containers, and the total cost advantages — there are two things that cause developers to hesitate in engaging with us on Workers.
The first: they worry about being locked in. No matter how bullish on the technology you are, if you’re betting the future of a company on a development platform, you don’t want the possibility of being held to ransom. And second: as a developer, you want a local development environment to quickly iterate and test your changes. These concerns might seem unrelated, but they always come up in the form of the same question: can Cloudflare please open source the runtime?
We’re excited to put these concerns to bed. As the first announcement of Platform Week, today Cloudflare is announcing the open sourcing of the Workers runtime under the Apache-2.0 license!
While the code itself will be the best answer to most of the questions you have (we still have some work to do before we’re ready to share it), the questions we did want to answer today were: why are we doing this, and why now?
Development on the web has always been done in the open. If you’re like me, maybe your very first experience writing and looking at code was clicking on “View Source” on a website, and inspecting the HTML to see what pieces you could borrow. So many of the foundational pieces you build on today are open source, from the site, to the browser, to the many frameworks and libraries that are now available to developers. The same is true for us, so much of what we’re able to build is standing on the shoulders of giants like V8.
It was never our intention to introduce opaqueness into the stack, but in reality, when we first announced Workers five years ago, we took a really huge bet.
We wanted to give developers the ability to program on our network, but couldn’t do it at the expense of performance or security. While building on a battle tested technology like V8 seemed promising from a security standpoint, existing runtimes built on V8, couldn’t give us the security guarantees we needed to run a large multi-tenant environment, without the added security layer of a container, which would introduce latency (read: cold starts). Not only were cold starts not acceptable, but in reality, our data centers are much smaller than the centralized monoliths of traditional cloud. Even if we could run existing applications on the edge without cold starts, the code footprint would be far too large to enable every single one of our customers to have access to compute on every node of our global network.
So, we had to get inventive, and the first place we looked was web standards, or the Service Workers API. While Service Workers were designed to run in the browser, the model of Requests and Responses fit our use case really well. And, we liked the idea of the code you write being portable to other environments (and hoped that new players that came up would support the same model).
And that’s exactly what happened.
This all might seem obvious in retrospect, but at the time, it was a huge bet. We didn’t know at the time whether this was going to work. Whether this approach would take off, whether this would all work at scale, whether developers would adopt this model, despite it diverging from what JavaScript looked like on the server-side at the time…
What we did know was that we had a lot to prove, that we didn’t want to lock anyone in, and that open sourcing something properly is not an effort we wanted to take lightly. We wanted to support our community the same way we felt supported by all the open source projects we ourselves were building upon.
Now, it feels like we’re finally there, and we believe the next step in our runtime’s evolution is to give it to the world, and let developers build with it wherever they want, however they want.
Of course, since we’re talking about open source, we already know what you’re going to ask next: what license are we going to use? We plan to use the Apache-2.0 license — we want developers to be able to build on our platform freely.
What’s next?
Open sourcing the runtime alone is not enough to allow developers to write code, free of lock in concerns, which is why we have another announcement coming up today.
And after that, well, if you’ve been following Cloudflare for a while, you know that there’s a certain time in the year, when we like to give back to the Internet. That might be a pretty good bet for the timing of what’s next! 🙂
Principled. It’s one of Cloudflare’s three core values (alongside curiosity and transparency).
It’s a word that we came back to quite a bit in thinking through a question that has been foundational in driving us for this year’s Platform Week: what makes a truly great developer platform?
Of course, when it comes to evaluating developer platforms, the temptation is to focus on the “feeds and speeds” part of the equation. Who is the fastest? Who has the coolest tech? Who lets you do stuff that previously you could not?
Undoubtedly, these are all important questions. But we realized that the fun and shiny things which are often answers to these questions can easily become distractions from the true promise of developing on the Internet — and even traps that the less principled developer platforms can use to lure you into their arms.
The promise being, of course: that you can pull together solutions from a variety of different providers, to build something greater than what you’d be able to do with any one of them alone. That you can build something based on whatever is best when you sit down to create your application. And of course, if something better subsequently comes along, then you can switch to it and take advantage of that, too. When you think about it, it makes sense: all the Internet really is a network based on a common set of standards that allows us all to talk to each other.
And yet, when it comes to the cloud platforms, it feels like we’re further away from that promise than ever before.
How did that happen?
When you start to think about why: well, many of the winners of the cloud have become too big for their (and our) own good. The same players that were underdogs have become incumbents — not just bending the world to their will, but sticking to their assumptions of what the world looked like a decade ago. We went from a highly competitive environment, with an even distribution of power, to something entirely unbalanced. Somewhere along the way, Hotel California became the theme song of the cloud: a friendly face welcomes you in… and then you can’t leave.
This manifests in many ways.
Sometimes it takes the form of egregious egress fees, where you are stuck with using in-ecosystem tooling instead of the best tool for the job. We don’t believe in that. We want an Internet that allows for specialization, where developers can use the best across several offerings, bringing together those services to build something incredible. But that requires giving developers freedom of choice: without hidden pricing considerations pushing you to stay with large, incumbent vendors. In fact, in many respects, freedom of choice is the promise of the Internet for developers.
We want to get back to that.
But it’s not just pricing. Other times, lock-in happens through the code or APIs needed to build with a service. Developers tie their applications to the services that power them, and eventually, without you even realizing it, it becomes incredibly cumbersome to switch off. We’ve watched the Internet become more proprietary, where vendors offer products as a service without the ability to run them anywhere else. Of course, that’s where standards come in, defining the same language and behavior across vendors.
Developers win when we open up the APIs we support and languages we speak, and rally several competing options around a common set. Continuously winning a developer’s business shouldn’t be because you’ve made someone dependent on you, and they can’t get out — it should be because what you’re offering is better than the alternatives.
When that happens, developers win.
This Platform Week, we don’t want to deliver on just new and shiny things (though there will be a few of those, too!). We want to deliver on principles. On letting the best solution win. On breaking developers out of lock in: whether because of code, or because of economics.
To get this right, we must start at the very beginning — the foundation. Everything we do is built on the foundation of the open web and open standards. That’s not something we take lightly, and certainly not something we take for granted. We decided the right way to kick this week off would be by giving back, and helping do what we can to help push the web, and those open standards forward.
So, that’s the foundation. But now you need the right blocks to build on it.
There’s one building block we know you’re excited about, it’s data. And we are too, which is why we’ll be giving you an update on a certain something we’ve had in beta the last little while. And that’s not all, either: there may even be a sequel.
Data is one thing, but applications need to share that data with services to extract value. This week we’ll make it easier and cheaper to connect the pieces of your stack together, enabling the sending of information where you need it, when you need it.
As we all know, the reason we all work so hard as developers is to enable that most critical of functionality: sharing pictures and videos of cats and babies. There are always better ways of doing it though, and we’re going to dedicate a whole day to new ways to upload, stream and share these gems.
And finally, we want to help the Internet become more programmable. Platforms offer real customizability to the developers they serve: enabling them to do things that the platform creator itself never envisioned. When you work with the application services component of Cloudflare, you can customize bot scores, load balancing rules, routing — all by programming our network. And we’re not just talking about relying on APIs to do things that we, the original developer, initially envisioned. We’re talking about true programmability. Whether you want to build a customized bot within an existing chat application, or a bespoke experience on an eCommerce website builder, we’re excited to move development beyond the era of the API into true programmability, beyond our walls, right across the web.
But back to it: principled.
Yes, we’re going to be delivering this week on all the innovation that you’ve come to expect from us. And you know what we can’t wait to see? All the amazing things you’re able to build — but it won’t just be on us. In fact, it might not be on us at all, and that’s completely ok. What we’re excited about is you building things on all the incredible providers out there, the ones that are equally dedicated to helping build a better Internet for all developers.
As you read this you are using the Internet. Stop and think about that for a minute. We speak about finding something “on the Internet”; we speak about “using the Internet” to perform a task. We essentially never say something like “I’m going to look for this on a server using the Internet as an intermediary between my computer and the server”.
We speak about and think about the Internet as a single, whole entity that we use and rely on. That’s behind the vision of “The Network is the Computer”. What matters is not the component parts that go into “the Internet” but what they come together to create.
We don’t want anyone to think about “caching content on a server in a Cloudflare data center” or “writing code that runs on (something called) the edge”. We want you to simply think of it as a single, global network that provides a CDN, a WAF, DDoS protection, Zero Trust and the ability to write infinitely scalable code and have it just work.
Scaling software is hard, and almost no programmer wants to spend their time worrying what will happen if there’s high demand for the thing they’ve built. That’s our job. You write the code, we’ll make it scale everywhere on the planet. Just deploy to our network.
To do that we’ve followed the trail that started with people writing assembly language for a machine they’d constructed themselves, via machines they bought and installed operating systems on and on to virtual machines running those OSes. At the end of the trail is serverless: don’t worry about the underlying hardware or operating system. Just write code and deploy it.
Because Cloudflare’s network is everywhere on the planet and close to every end user, any code you deploy is also close to your users. Physically close and network close. That means you get high performance and low latency. We’ll see more on that this coming week, where someone built a game that uses a phone as a controller with the game running on a computer, yet the communication between controller and game computer goes through our network. Mind. Blown.
So you have code that can be deployed globally, held securely by Cloudflare and accessed with very low latency from anywhere. What are you going to write on the Cloudflare network? Come join over 350,000 developers using Cloudflare Workers to build the next new thing.
It’s been joked before that Cloudflare has a blog, and maintains a network as a side hustle to have content for the blog. This is of course ridiculous, we don’t maintain a network to have content for the blog, we maintain a network to power a blog 🙂
Jokes aside, while many of our efforts do go towards the network, there are many other critical pieces of software that are core to Cloudflare’s business: our marketing site, our dashboard, our APIs and user configuration, developer docs and all the infrastructure that makes Cloudflare Cloudflare.
We’re avid believers in dogfooding, and have talked on this very blog about the ways in which we build Cloudflare on Cloudflare. Since the release of Workers in 2017, many of our teams have been able to accelerate their velocity by building on Workers. But, compute alone is not enough.
This week, as we do in our Innovation Weeks, we’ll make a series of announcements to help paint a vision for how we see the future of compute, and giving our developers the tools they need to build their next application on our network.
We’ll start with the perhaps most fundamental building block — data. Earlier this year during Birthday Week, we announced R2 Object Storage, enabling developers to store, well, whatever they want, providing another crucial building block. But there are many other types of data stores developers may need access to, ourselves included!
Going from the backend to the frontend, last year, we announced Cloudflare Pages, the best way to build static sites. But then we thought, why stop there? We’re excited about some announcements to bring the backend closer to the frontend than ever.
What did we miss? Video, images, payments? Don’t worry, we’ve got you covered.
Oh, and of course, the most important part of creating an application is you — the developer! We want to ensure you can not only build the fastest, most secure application, but have fun doing it. From the very first line of code you write, to the first push you make to production, we want you to have the best experience possible wrangling your code.
The best part about building a developer platform is seeing what you build with it — we’re excited to shine a spotlight on our community members, and the spectacular applications they’ve built with us (2.5 million and counting!). We’ll be featuring them on our blog, as well as Cloudflare TV. Hope you join us for the week ahead!
Forrester’s New Wave for Edge Development Platforms has just been announced. We’re thrilled that they have named Cloudflare a leader (you can download a complimentary copy of the report here).
Since the very beginning, Cloudflare has sought to help developers building on the web, and since the introduction of Workers in 2017, Cloudflare has enabled developers to deploy their applications to the edge itself.
According to the report by Forrester Vice President, Principal Analyst, Jeffrey Hammond, Cloudflare “offers strong compute, data services and web development capabilities. Alongside Workers, Workers KV adds edge data storage. Pages, Stream and Images provide higher level platform services for modern web workloads. Cloudflare has an intuitive developer experience, fast, global deployment of updated code, and minimal cold start times.”
Reimagining development for the modern web
Building on the web has come a long way. The idea that one might have to buy a physical machine in order to build a website seems incomprehensible now. The cloud has played a major role in making it easier for developers to get started. However, since the advent of the cloud, things have stalled — and innovation has become more incremental. That means that while developers don’t have to think about buying a server, they’re still tasked with thinking about where in the world it is, how to add concurrency to handle increasing traffic, and how to make them secure.
We wanted to abstract that all away. Our aim: to reimagine what things might look like if developers could truly just think about the application they wanted to build. Leaving the scaling, speed, and even compliance, to us.
Of course, reimagining things is always scary. There’s no guarantee that taking a new approach is going to work — it usually requires a leap of faith.
It’s been gratifying to see developers flock to our platform — and the applications they’ve been able to build, free of scalability and latency constraints, have been phenomenal.
It’s also gratifying to be named a Leader in Edge Development Platforms by Forrester — one of the preeminent analyst firms in the industry. We feel it really does provide industry recognition to the approach we bet on four years ago.
Cloudflare is the most differentiated among all the vendors evaluated
We received a differentiated rating in the following criteria:
Developer experience
Programming model
Platform execution model
“Day 2+” experience
Integrations
Roadmap
Vision
Market approach
While being able to build our platform atop Cloudflare’s network gave us an advantage in eliminating latency from the start, we knew that wasn’t enough to compel developers to think in a new way. Since the release of Workers, we have relentlessly focused on making the experience of building a new application as easy as possible at every step of the way: from onboarding, through day 2, and beyond.
This approach extends beyond tooling, and to how we think about additional services developers need in order to complete their applications. For example, in thinking about providing data solutions on the edge, we again wanted to make the distributed nature of the system just work, rather than making developers think about it, which is what led us to develop Durable Objects. With Durable Objects, Cloudflare can make intelligent decisions about where to store the data based on access patterns (or compliance — whichever is most important to the developer), rather than forcing the developer to think about regions.
As we expand our offering, it’s important to us that it continues to be intuitive and easy for developers to solve problems.
We’re just getting started
But, we’re not stopping here. As our cofounder Michelle likes to say, we’re just getting started. We recognize this is just the beginning of the journey to bring the full stack to the edge. We have some exciting announcements coming in the next couple of weeks — stay tuned!
Just about four years ago, we announced Cloudflare Workers, a serverless platform that runs directly on the edge.
Throughout this week, we will talk about the many ways Cloudflare is helping make applications that already exist on the web faster. But if today is the day you decide to make your idea come to life, building your project on the Cloudflare edge, and deploying it directly to the tubes of the Internet is the best way to guarantee your application will always be fast, for every user, regardless of their location.
It’s been a few years since we talked about how Cloudflare Workers compares to other serverless platforms when it comes to performance, so we decided it was time for an update. While most of our work on the Workers platform over the past few years has gone into making the platform more powerful: introducing new features, APIs, storage, debugging and observability tools, performance has not been neglected.
Today, Workers is 30% faster than it was three years ago at P90. And it is 210% faster than Lambda@Edge, and 298% faster than Lambda.
How do you measure the performance of serverless platforms?
I’ve run hundreds of performance benchmarks between CDNs in the past — the formula is simple: we use a tool called Catchpoint, which makes requests from nodes all over the world to the same asset, and reports back on the time it took for each location to return a response.
Measuring serverless performance is a bit different — since the thing you’re comparing is the performance of compute, rather than a static asset, we wanted to make sure all functions performed the same operation.
In our 2018 blog on speed testing, we had each function simply return the current time. For the purposes of this test, “serverless” products that were not able to meet the minimum criteria of being able to perform this task were disqualified. Serverless products used in this round of testing executed the same function, of identical computational complexity, to ensure accurate and fair results.
It’s also important to note what it is that we’re measuring. The reason performance matters, is because it impacts the experience of actual end customers. It doesn’t matter what the source of latency is: DNS, network congestion, cold starts… the customer doesn’t care what the source is, they care about wasting time waiting for their application to load.
It is therefore important to measure performance in terms of the end user experience — end to end, which is why we use global benchmarks to measure performance.
The result below shows tests run from 50 nodes all over the world, across North America, South America, Europe, Asia and Oceania.
As you can see from the results, no matter where users are in the world, when it comes to speed, Workers can guarantee the best experience for customers.
In the case of Workers, getting the best performance globally requires no additional effort on the developers’ part. Developers do not need to do any additional load balancing, or configuration of regions. Every deployment is instantly live on Cloudflare’s extensive edge network.
Even if you’re not seeking to address a global audience, and your customer base is conveniently located on the East coast of the United States, Workers is able to guarantee the fastest response on all requests.
Above, we have the results just from Washington, DC, as close as we could get to us-east-1. And again, without any optimization, Workers is 34% faster.
Why is that?
What defines the performance of a serverless platform?
Other than the performance of the code itself, from the perspective of the end user, serverless application performance is fundamentally a function of two variables: distance an application executes from the user, and the time it takes the runtime itself to spin up. The realization that distance from the user is becoming a greater and greater bottleneck on application performance is causing many serverless vendors to push deeper and deeper into the edge. Running applications on the edge — closer to the end user — increases performance. As 5G comes online, this trend will only continue to accelerate.
However, many cloud vendors in the serverless space run into a critical problem when addressing the issue when competing for faster performance. And that is: the legacy architecture they’re using to build out their offerings doesn’t work well with the inherent limitations of the edge.
Since the goal behind the serverless model is to intentionally abstract away the underlying architecture, not everyone is clear on how legacy cloud providers like AWS have created serverless offerings like Lambda. Legacy cloud providers deliver serverless offerings by spinning up a containerized process for your code. The provider auto-scales all the different processes in the background. Every time a container is spun up, the entire language runtime is spun up with it, not just your code.
To help address the first graph, measuring global performance, vendors are attempting to move away from their large, centralized architecture (a few, big data centers) to a distributed, edge-based world (a greater number of smaller data centers all over the world) to close the distance between applications and end users. But there’s a problem with their approach: smaller data centers mean fewer machines, and less memory. Each time vendors pursue a small but many data centers strategy to operate closer to the edge, the likelihood of a cold start occurring on any individual process goes up.
This effectively creates a performance ceiling for serverless applications on container-based architectures. If legacy vendors with small data centers move your application closer to the edge (and the users), there will be fewer servers, less memory, and more likely that an application will need a cold start. To reduce the likelihood of that, they’re back to a more centralized model; but that means running your applications from one of a few big centralized data centers. These larger centralized data centers, by definition, are almost always going to be further away from your users.
You can see this at play in the graph above by looking at the results of the tests when running in Lambda@Edge — despite the reduced proximity to the end user, p90 performance is slower than that of Lambda’s, as containers have to spin up more frequently.
Serverless architectures built on containers can move up and down the frontier, but ultimately, there’s not much they can do to shift that frontier curve.
What makes Workers so fast?
Workers was designed from the ground up for an edge-first serverless model. Since Cloudflare started with a distributed edge network, rather than trying to push compute from large centralized data centers out into the edge, working under those constraints forced us to innovate.
In one of our previous blog posts, we’ve discussed how this innovation translated to a new paradigm shift with Workers’ architecture being built on lightweight V8 isolates that can spin up quickly, without introducing a cold start on every request.
Not only has running isolates given us advantage out of the box, but as V8 gets better, so does our platform. For example, when V8 announced Liftoff, a compiler for WASM, all WASM Workers instantly got faster.
Similarly, whenever improvements are made to Cloudflare’s network (for example, when we add new data centers) or stack (e.g., supporting new, faster protocols like HTTP/3), Workers instantly benefits from it.
Additionally, we’re always seeking to make improvements to Workers itself to make the platform even faster. For example, last year, we released an improvement that helped eliminate cold starts for our customers.
One key advantage that helps Workers identify and address performance gaps is the scale at which it operates. Today, Workers services hundreds of thousands of developers, ranging from hobbyists to enterprises all over the world, serving millions of requests per second. Whenever we make improvements for a single customer, the entire platform gets faster.
Performance that matters
The ultimate goal of the serverless model is to enable developers to focus on what they do best — build experiences for their users. Choosing a serverless platform that can offer the best performance out of the box means one less thing developers have to worry about. If you’re spending your time optimizing for cold starts, you’re not spending your time building the best feature for your customers.
Just like developers want to create the best experience for their users by improving the performance of their application, we’re constantly striving to improve the experience for developers building on Workers as well.
In the same way customers don’t want to wait for slow responses, developers don’t want to wait on slow deployment cycles.
This is where the Workers platform excels yet again.
Any deployment on Cloudflare Workers takes less than a second to propagate globally, so you don’t want to spend time waiting on your code deploy, and users can see changes as quickly as possible.
Of course, it’s not just the deployment time itself that’s important, but the efficiency of the full development cycle, which is why we’re always seeking to improve it at every step: from sign up to debugging.
Don’t just take our word for it!
Needless to say, much as we try to remain neutral, we’re always going to be just a little biased. Luckily, you don’t have to take our word for it.
We invite you to sign up and deploy your first Worker today — it’ll just take a few minutes!
Across multiple cultures around the world, this time of year is a time of celebration and sharing of gifts with the people we care the most about. In that spirit, we thought we’d take this time to give back to the developer community that has been so supportive of Cloudflare for the last 10 years.
Today, the path from an idea to a website is paved with good intentions
Websites are the way we express ourselves on the web. It doesn’t matter if you’re a hobbyist with a blog, or the largest of corporations with millions of customers — if you want to reach people outside the confines of 140 280 characters, the web is the place to be.
As a frontend developer, it’s your responsibility to bring this expression to life. And make no mistake — with so many frontend frameworks, tooling, and static site generators at your disposal — it’s a great time to be in your line of work.
That is, of course, right up until the point when you’re ready to show your work off to the world. That’s when things can start to get a little hairy.
At this point, continuing to keep things local rather than committing to source starts to become… irresponsible. But then: how do you quickly iterate and maintain momentum? As you change things, you need to make sure those changes don’t get lost — saving them to source control — while keeping in sync with what’s currently deployed to production.
There are no great solutions.
If you’re in a larger organization, you might have a DevOps organization devoted to exactly that: automating deployments using Continuous Integration (CI) tooling.
Most CI tooling, however, is quite cumbersome, and for good reason — to allow organizations to customize their automation, regardless of their stack and setup. But for the purpose of developing a website, it can still feel like an unnecessary and frustrating diversion on the road to delivering your web project. Configuring a .yaml file, adding and removing commands, waiting minutes for each build to run, and praying to the CI gods at each one that these are the right commands. Hopelessly rerunning the same build over and over, and expecting a different result.
Often, hours are lost. The process stands in the way of you and doing your best work.
Cloudflare Pages: letting frontend devs do what they do best
We think there’s a better way.
With Cloudflare Pages, we set out to simplify every step along the journey by tying deployment to your existing development workflow.
Seamless Git integration, with builds built-in
With Cloudflare Pages, all you have to do is select your repo, and tell us which framework you’re using. We’ll take care of chanting CI incantations on your behalf, while you keep doing what you were already doing: git commit and git push your changes — we’ll build and deploy them for you.
As the project grows, so do the stakes, and the number of collaborators.
For a site in production, changes need to be reviewed thoroughly. As the reviewer, looking at the code, and skimming for red flags only gets you so far. To thoroughly review, you have to commit or git stash your changes, pull down locally, get it running to make sure it actually works — looking at code alone won’t catch everything!
The other developers on the team are not the only stakeholders. There are designers, marketers, PMs who want to provide feedback before the changes go out.
Unique preview URLs
With Cloudflare Pages, each commit gets its own unique URL. Preview URLs make it easier to get meaningful code reviews without the overhead of pulling down the branch. They also make it easier to get feedback from PMs, designers and marketers on the latest iteration, bridging the gap between mocks and code.
Infinite staging
“Does anyone mind if I take over staging?” might also sound like a familiar question. With Cloudflare Pages, each feature branch will have its own dedicated consistent alias, allowing you to have a consistent URL for the latest changes.
With Preview and Production environments, all feature branches and preview links will be built with preview variables, so you can experiment without impacting production data.
When you’re ready to deploy to production, we’ll redeploy to production for you with the updated production environment variables.
Collaboration for all
Collaboration is the key to building amazing websites and products — the more the merrier! As a security company, we definitely don’t want you sharing password and credentials. Which is why we provide multi user access for free for unlimited users — invite all your friends, on us!
Modern sites with modern standards
We all know premature optimization is a cardinal sin, but once your project is in front of customers you want to have the best performance possible. If it’s successful, you also want it to be available!
Today, this is time you have to spend optimizing performance (chasing those 100 lighthouse scores), and scaling, from a few to millions of users.
Luckily, we happen to know a thing or two about running a global network of 200 data centers though, so we’ve got you covered.
With Pages, your site is deployed directly to our edge, milliseconds away from customers, and at global scale.
The latest web standards are fun to read about on Hacker News but not fun to implement yourself. With Cloudflare Pages, we’ll do the heavy lifting to keep you ahead of the curve: IPv6, HTTP/3, TLS 1.3, all the latest image formats.
Oh, and one more thing
We’re really excited for developers and their teams to use Cloudflare Pages to collaborate on the best static sites together. There’s just one thing that didn’t sit quite right with us: why stop at static sites?
What if we could make building full-blown, dynamic applications just as easy?
Although APIs are a core part of the JAMstack, today that refers primarily to the robust API economy developers have access to. And while that’s great, it’s not always enough. If you want to build your own APIs, and store user or application data, you need more than third party APIs. What to do, though?
Well, this is the point at which it’s mighty helpful we’ve already built a global serverless platform: Cloudflare Workers. Workers allows frontend developers to easily write scalable backends to their applications in the same language as the frontend, JavaScript.
Over the coming months, we’ll be working on integrating Workers and Pages into a seamless experience. It’ll work the exact same way Pages does: just write your code, git push, and we’ll deploy it for you. The only difference is, it won’t just be your frontend, it’ll be your backend, too. And just to be clear: this is not just for stateless functions. With Workers KV and Durable Objects, we see a huge opportunity to really enable any web application to be built on this platform.
We’re super excited about the future of Pages, and how with the power of Cloudflare Workers behind it, it represents a bold vision for how new applications are going to be built on the web.
But you know the thing about gifts? They’re no good without someone to receive them. We’d love for you to sign up for our beta and try out Cloudflare Pages!
PS: we’re hiring!
Want to help us shape the future of development on the web? Join our team.
Cloudflare Workers — our serverless platform — allows developers around the world to run their applications from our network of 200 datacenters, as close as possible to their users.
A few weeks ago we announced a release candidate for wrangler dev — today, we’re excited to take wrangler dev, the world’s first edge-based development environment, to GA with the release of wrangler 1.11.
Think locally, develop globally
It was once assumed that to successfully run an application on the web, one had to go and acquire a server, set it up (in a data center that hopefully you had access to), and then maintain it on an ongoing basis. Luckily for most of us, that assumption was challenged with the emergence of the cloud. The cloud was always assumed to be centralized — large data centers in a single region (“us-east-1”), reserved for compute. The edge? That was for caching static content.
Again, assumptions are being challenged.
Cloudflare Workers is about moving compute from a centralized location to the edge. And it makes sense: if users are distributed all over the globe, why should all of them be routed to us-east-1, on the opposite side of the world, causing latency and degrading user experience?
But challenging one assumption caused others to come into view. One of the most obvious ones was: would a local development environment actually provide the best experience for someone looking to test their Worker code? Trying to fit the entire Cloudflare edge, with all its dependencies onto a developer’s machine didn’t seem to be the best approach. Especially given that the place the developer was going to run that code in production was mere milliseconds away from the computer they were running on.
When I was in college, getting started with programming, one of the biggest barriers to entry was installing all the dependencies required to run a single library. I would go as far as to say that the third, and often forgotten hardest problem in computer science is dependency management.
We’ve not the first to try and unify development environments across machines — tools such as Docker aim to solve this exact problem by providing a prepackaged development environment.
Yet, packaging up the Workers runtime is not quite so simple.
Beyond the Workers runtime, there are many components that make up Cloudflare’s edge, including DNS resolution, the Cloudflare cache — all of those parts are what makes Cloudflare Workers so powerful. That means that without those components, a standalone runtime is insufficient to represent the behavior of Worker request handling. The reason to develop locally first is to have the opportunity to experiment without affecting production. Thus, having a local development environment that truly reflects production is a requirement.
wrangler dev
wrangler dev provides all the convenience of a local development environment, without the headache of trying to reproduce the reality of production locally — and then having to keep the two environments in sync.
By running at the edge, it provides a high fidelity, consistent experience for all developers, without sacrificing the speedy feedback loop of a local development environment.
Live reloading
As you update your code, wrangler dev will detect changes, and push the new version of your code to the edge.
console.log() at your fingertips
Previously to extract your console logs from the Workers runtime, you had to have the Workers Preview open in a browser window at all times. With wrangler dev, you can receive your own logs, directly to your terminal of choice.
Cache API, KV, and more!
Since wrangler dev runs on the edge, you can now easily test the state of a cache.put(), without having to deploy your Worker to production.
wrangler dev will spin up a new KV namespace for development, so you don’t have to worry about affecting your production data.
And if you’re looking to test out some of the features provided on request.cf that provide rich information about the request such as geo-location — they will all be provided from the Cloudflare data center.
Get started
wrangler dev is now available in the latest version of Wrangler, the official Cloudflare Workers CLI.
To get started, follow our installation instructions here.
What’s next?
wrangler dev is just our first foray into giving our developers more visibility and agility with their development process.
We recognize that we have a lot more work to do to meet our developers needs, including providing an easy testing framework for Workers, and allowing our customers to observe their Workers’ behavior in production.
Just as wrangler dev provides a quick feedback loop between our developers and their code, we love to have a tight feedback loop between our developers and our product. We love to hear what you’re building, how you’re building it, and how we can help you build it better.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.