Post Syndicated from Zaid Farooqui original https://blog.cloudflare.com/stream-live/


We’re excited to introduce the open beta of Stream Live, an end-to-end scalable live-streaming platform that allows you to focus on growing your live video apps, not your codebase.
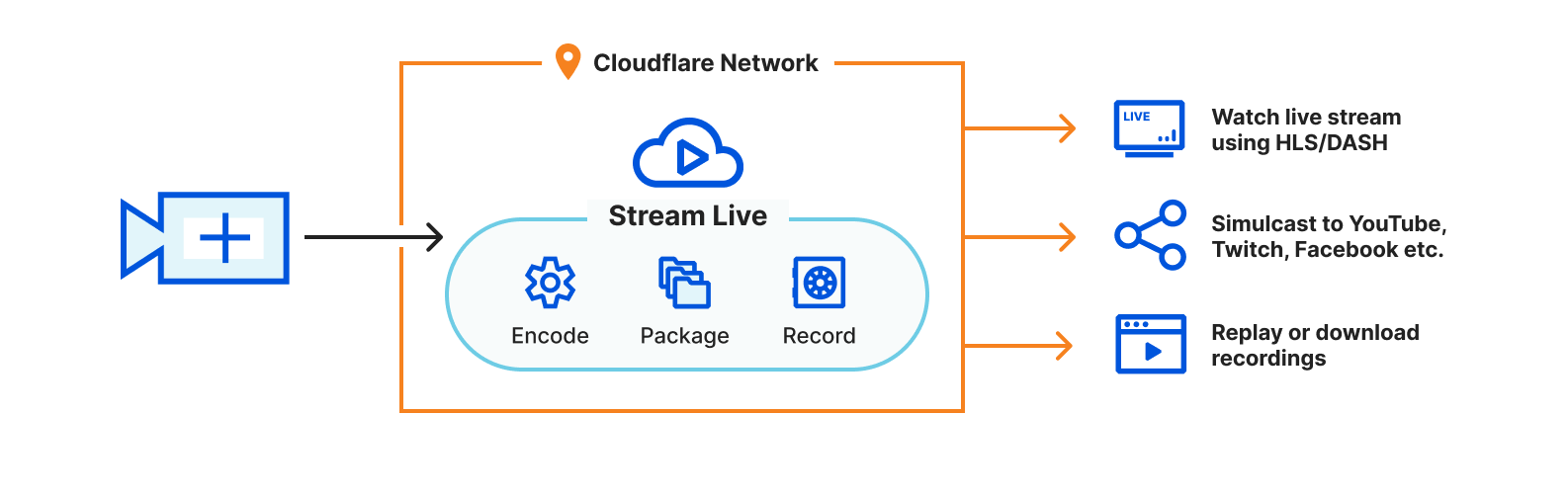
With Stream Live, you can painlessly grow your streaming app to scale to millions of concurrent broadcasters and millions of concurrent users. Start sending live video from mobile or desktop using the industry standard RTMPS protocol to millions of viewers instantly. Stream Live works with the most popular live video broadcasting software you already use, including ffmpeg, OBS or Zoom. Your broadcasts are automatically recorded, optimized and delivered using the Stream player.
When you are building your live infrastructure from scratch, you have to answer a few critical questions:
- “Which codec(s) are we going to use to encode the videos?”
- “Which protocols are we going to use to ingest and deliver videos?”
- “How are the different components going to impact latency?”
We built Stream Live, so you don’t have to think about these questions and spend considerable engineering effort answering them. Stream Live abstracts these pesky yet important implementation details by automatically choosing the most compatible codec and streaming protocol for the client device. There is no limit to the number of live broadcasts you can start and viewers you can have on Stream Live. Whether you want to make the next viral video sharing app or securely broadcast all-hands meetings to your company, Stream will scale with you without having to spend months building and maintaining video infrastructure.
Built-in Player and Access Control
Every live video gets an embed code that can be placed inside your app, enabling your users to watch the live stream. You can also use your own player with included support for the two major HTTP streaming formats — HLS and DASH — for a granular control over the user experience.
You can limit who can view your live videos with self-expiring tokenized links for each viewer. When generating the tokenized links, you can define constraints including time-based expiration, geo-fencing and IP restrictions. When building an online learning site or a video sharing app, you can put videos behind authentication, so only logged-in users can view your videos. Or if you are building a live concert platform, you may have agreements to only allow viewers from specific countries or regions. Stream’s signed tokens help you comply with complex and custom rulesets.
Instant Recordings
With Stream Live, you don’t have to wait for a recording to be available after the live broadcast ends. Live videos automatically get converted to recordings in less than a second. Viewers get access to the recording instantly, allowing them to catch up on what they missed.
Instant Scale
Whether your platform has one active broadcaster or ten thousand, Stream Live scales with your use case. You don’t have to worry about adding new compute instances, setting up availability zones or negotiating additional software licenses.
Legacy live video pipelines built in-house typically ingest and encode the live stream continents away in a single location. Video that is ingested far away makes video streaming unreliable, especially for global audiences. All Cloudflare locations run the necessary software to ingest live video in and deliver video out. Once your video broadcast is in the Cloudflare network, Stream Live uses the Cloudflare backbone and Argo to transmit your live video with increased reliability.
Broadcast with 15 second latency
Depending on your video encoder settings, the time between you broadcasting and the video displaying on your viewer’s screens can be as low as fifteen seconds with Stream Live. Low latency allows you to build interactive features such as chat and Q&A into your application. This latency is good for broadcasting meetings, sports, concerts, and worship, but we know it doesn’t cover all uses for live video.
We’re on a mission to reduce the latency Stream Live adds to near-zero. The Cloudflare network is now within 50ms for 95% of the world’s population. We believe we can significantly reduce the delay from the broadcaster to the viewer in the coming months. Finally, in the world of live-streaming, latency is only meaningful once you can assume reliability. By using the Cloudflare network spanning over 250 locations, you get unparalleled reliability that is critical for live events.
Simple and predictable pricing
Stream Live is available as a pay-as-you-go service based on the duration of videos recorded and duration of video viewed.
- It costs $5 per 1,000 minutes of video storage capacity per month. Live-streamed videos are automatically recorded. There is no additional cost for ingesting the live stream.
- It costs $1 per 1,000 minutes of video viewed.
- There are no surprises. You never have to pay hidden costs for video ingest, compute (encoding), egress or storage found in legacy video pipelines.
- You can control how much you spend with Stream using billing alerts and restrict viewing by creating signed tokens that only work for authorized viewers.
Cloudflare Stream encodes the live stream in multiple quality levels at no additional cost. This ensures smooth playback for your viewers with varying Internet speed. As your viewers move from Wi-Fi to mobile networks, videos continue playing without interruption. Other platforms that offer live-streaming infrastructure tend to add extra fees for adding quality levels that caters to a global audience.
If your use case consists of thousands of concurrent broadcasters or millions of concurrent viewers, reach out to us for volume pricing.
Go live with Stream
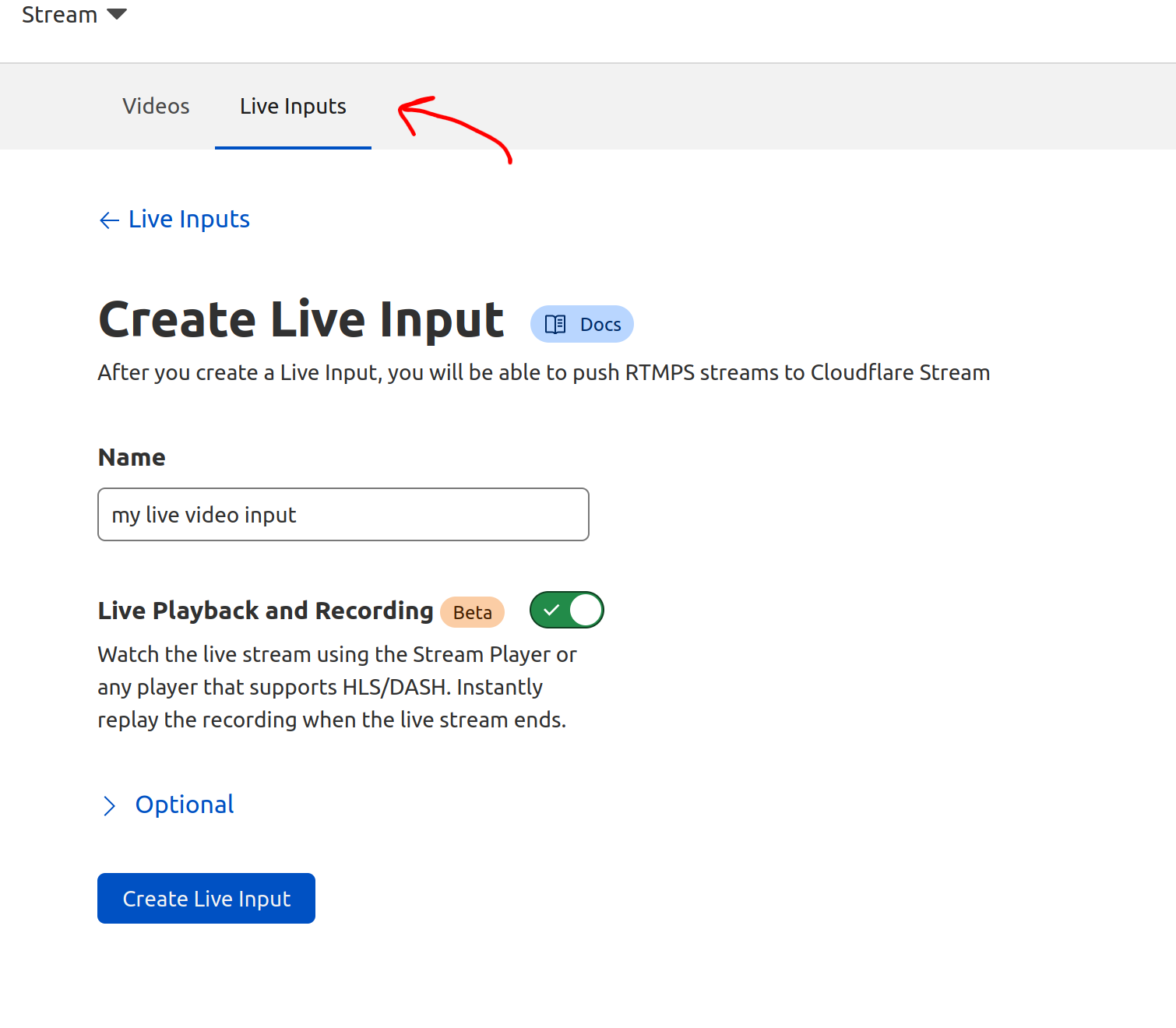
Stream works independent of any domain on Cloudflare. If you already have a Cloudflare account with a Stream subscription, you can begin using Stream Live by clicking on the “Live Input” tab on the Stream Dashboard and creating a new input:
If you are new to Cloudflare, sign up for Cloudflare Stream.