Post Syndicated from Janne Pikkarainen original https://blog.zabbix.com/whats-up-home-welcome-to-my-zabbixverse/21353/
By day, I am a monitoring technical lead in a global cyber security company. By night, I monitor my home with Zabbix and Grafana in very creative ways. But what has Zabbix to do with Blender 3D software or virtual reality? Read on.
Full-stack monitoring is an old concept — in the IT world, it means your service is monitored all the way from physical level (data center environmental status like temperature or smoke detection, power, network connectivity, hardware status…) to operating system status, to your application status, enriched with all kinds of data such as application logs or end-to-end testing performance. Zabbix has very mature support for that, but how about… full house monitoring in 3D and, possibly, in virtual reality?
Slow down, what are you talking about?
The catacombs of my heart do have a place for 3D modeling. I am not a talented 3D artist, not by a long shot, but I have flirted with 3D apps since Amiga 500 and it’s Real 3D 1.4, then later with Amiga 1200 a legally purchased Tornado 3D, and not so legally downloaded Lightwave. With Linux, so after 1999 for me, I have used POV-Ray about 20 years ago, and as Blender went open source a long time ago, I have tried it out every now and then.
So, in theory, I can do 3D. In practice, it’s the “Hmm, I wonder what happens if I press this button” approach I use.
Not so slow, get to the point, please
Okay. There are several reasons why I am doing this whole home monitoring thing.
- I have been doing IT monitoring for 20+ years, so really, there is not much new for me. Don’t get that wrong — boring is GOOD when it comes to business monitoring. Your business does count on it, and it’s perfect that whatever you need to monitor, you can do it reliably and easily. But for me, it does not challenge my brain or get my creative juices flowing. Monitoring the 3D world sure does.
- With my home Zabbix & Grafana, I can get as wild and childish as I ever want. Of course, not so much at work. (Though I admit that at work I did set up an easter egg Grafana dashboard called OnlyFans — it is literally showing how the cooling fans of our servers and other devices are doing).
- I want to give y’all new ideas and motivation to take your monitoring to the next level.
- I want to help raise Zabbix as a product to a whole new level from traditional IT monitoring to monitoring the environment we all live in — anyway, the future of monitoring will more and more be in the real world, too
2D or not 2D, that is the question
For traditional IT monitoring, 2D interface and 2D alerts are OK, maybe apart from physical rack location visualization, where it definitely helps if a sysadmin can locate a malfunctioning server easily from a picture.
For the Real World monitoring, it is a different story. I’m sure an electrician would appreciate if the alert would contain pictures or animations visualizing the exact location of whatever was broken. The same for plumbers, guards, whoever needs to get to fix something in huge buildings, fast.
Let’s get to it
Now that you know my motivation, let’s finally get started!
In my case, leaping Zabbix from 2D to 3D meant just a bunch of easy steps:
- Model my home in Sweet Home 3D; it’s very easy to use and definitely easier for my back than my wife requesting “could we try out how the sofa would look like over there…?”
- Import the Sweet Home 3D object to Blender
- In Blender, relabel the interesting objects to match with the names in Zabbix
- Hook Zabbix and Blender together with Python and Blender Python API, so Zabbix can change the alerting object somehow for its properties — change material, change color, add a glow effect, make it fire/smoke/explode, whatever
- Ask Blender Python API to export the rendered results as PNG images and as X3D files
Home sweet home
Sweet Home 3D is a relatively easy-to-use home modeling application. It’s free, and already contains a generous bunch of furniture, and with a small sum, you’ll get access to many, many more items.
After a few moments, I had my home modeled in Sweet Home 3D.

Next, I exported the file to .obj format, recognized by Blender.
Will it blend?
In Blender, I created a new scene, removed the meme-worthy default cube, and imported the Sweet Home 3D model to Blender.

Oh wow, it worked! Next, I needed to label the interesting items, such as our living room TV to match the names in Zabbix.

You modeled your home. Great! But does this Zabbix —> Blender integration work?
Yes, it does. Here is my first “let’s throw in some random objects into a Blender scene and try to manipulate it from Zabbix” attempt before any Sweet Home 3D business.

Fancy? No. Meaningful? Yes. There’s a lot going on in here.
- Through Python, Zabbix was able to modify a Blender scene and change some colors to red.
- Blender rendered the scene in its headless server mode (without GUI), and saved the resulting PNG still frame.
- The script ran by Zabbix did copy the image to be available for Zabbix UI (in my case, I created /assets/3d/ directory which contains everything relevant to this experiment).
- Zabbix URL widget is showing the image.
My Zabbix is now consulting Blender for every severity >=Average trigger, and I can also run the rendering manually any time I want.
First, here’s the manual refresh.


Next, here is the trigger:

Static image result
Here is a static PNG image rendering result by Blender Eevee rendering engine. Like gaming engines, Eevee cuts some corners when it comes to accuracy, but with a powerful GPU it can do wonders in real-time or at least in near-real-time.
The “I am not a 3D artist” part will hit you now hard. Cover your eyes, this will hurt. Here’s the Eevee rendering result.

That green color? No, our home is not like that. I just tried to make this thing look more futuristic, perhaps Matrix-like… but now it looks like… well… like I would have used a 3D program. The red Rudolph the Rednose Reindeer nose-like thing? I imagined it would be a neatly glowing red sphere along with the TV glowing, indicating an alert with our TV. Fail for the visual part, but at least the alert logic works! And don’t ask why the TV looks so strange.
But you get the point. Imagine if a warehouse/factory/whatever monitoring center would see something like this in their alerts. No more cryptic “Power socket S1F1A255DU not working” alerts, instead, the alert would pinpoint the alert in a visual way.
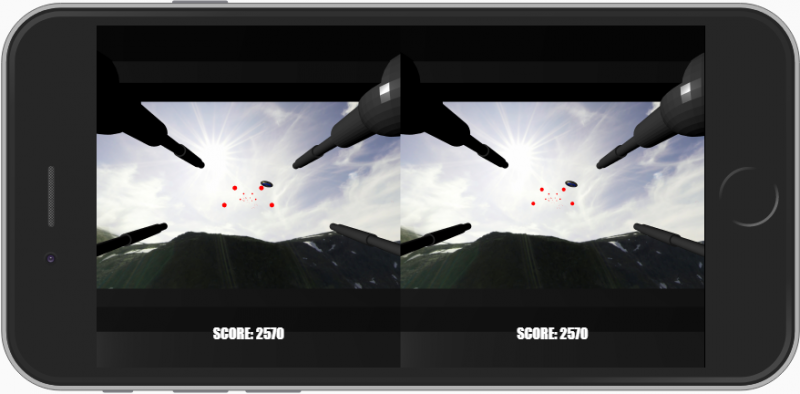
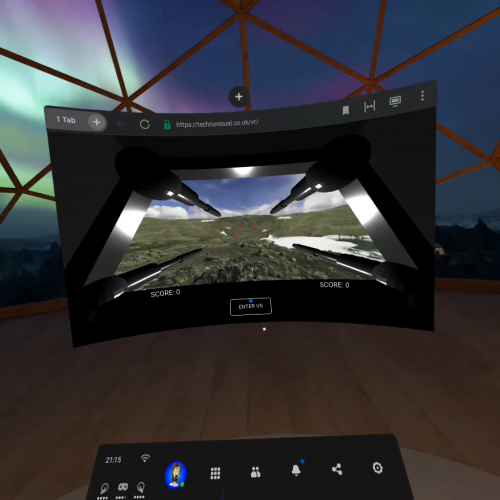
There was supposed to be an earth-shattering VR! Where’s the VR?
Mark Zuckerberg, be very afraid with your Metaverse, as Zabbixverse will rule the world. Among many other formats, Blender can export its scenes to X3D format. It’s one of the virtual world formats our web browsers do support, and dead simple to embed inside Zabbix/Grafana. Blender would support WebGL, too, but getting X3D to run only needed the use of <x3d> tag, so for my experiment, it was super easy.
The video looks crappy because I have not done any texture/light work yet, but the concept works! In the video, it is me controlling the movement.
In my understanding, X3D/WebGL supports VR headsets, too, so in theory you could be observing the status of whatever physical facility you monitor through your VR headset.
Of course, this works in Grafana, too.
How much does this cost to implement?
It’s free! I mean, Zabbix is free, Python is free and Blender is free, and open source. If you have some 3D blueprints of your facility in a format Blender can support — it supports plenty — you’re all set! Have an engineer or two or ten for doing the 3D scene labeling work, and pretty soon you will see you are doing your monitoring in 3D world.
What are the limitations?
The new/resolved alerts are not updated to the scene in real-time. For PNG files that does not matter much, as those are static and Zabbix can update those as often as needed, but for the interactive X3D files it’s a shame that for now the scene will only be updated whenever you refresh the page, or Zabbix does it for you. I need to learn if I can update X3D properties in real-time instead of a forced page load.
Coming up next week: monitoring Philips OneBlade
Next week I will show you how I monitor a Philips OneBlade shaver for its estimated runtime left. The device does not have any IoT functionality, so how do I monitor it? Tune in to this blog next week at the same Zabbix time.
I have been working at Forcepoint since 2014 and never get bored of inventing new ways to visualize data.
The post What’s Up, Home? Welcome to my Zabbixverse appeared first on Zabbix Blog.