Post Syndicated from Jane Waite original https://www.raspberrypi.org/blog/machine-learning-education-school-computational-thinking-2-0-research-seminar/
How does teaching children and young people about machine learning (ML) differ from teaching them about other aspects of computing? Professor Matti Tedre and Dr Henriikka Vartiainen from the University of Eastern Finland shared some answers at our latest research seminar.

Their presentation, titled ‘ML education for K-12: emerging trajectories’, had a profound impact on my thinking about how we teach computational thinking and programming. For this blog post, I have simplified some of the complexity associated with machine learning for the benefit of readers who are new to the topic.

Our seminars on teaching AI, ML, and data science
We’re currently partnering with The Alan Turing Institute to host a series of free research seminars about how to teach artificial intelligence (AI) and data science to young people.
The seminar with Matti and Henriikka, the third one of the series, was very well attended. Over 100 participants from San Francisco to Rajasthan, including teachers, researchers, and industry professionals, contributed to a lively and thought-provoking discussion.
-

Matti Tedre -
Henriikka Vartiainen


Representing a large interdisciplinary team of researchers, Matti and Henriikka have been working on how to teach AI and machine learning for more than three years, which in this new area of study is a long time. So far, the Finnish team has written over a dozen academic papers based on their pilot studies with kindergarten-, primary-, and secondary-aged learners.
Current teaching in schools: classical rule-driven programming
Matti and Henriikka started by giving an overview of classical programming and how it is currently taught in schools. Classical programming can be described as rule-driven. Example features of classical computer programs and programming languages are:
- A classical language has a strict syntax, and a limited set of commands that can only be used in a predetermined way
- A classical language is deterministic, meaning we can guarantee what will happen when each line of code is run
- A classical program is executed in a strict, step-wise order following a known set of rules
When we teach this type of programming, we show learners how to use a deductive problem solving approach or workflow: defining the task, designing a possible solution, and implementing the solution by writing a stepwise program that is then run on a computer. We encourage learners to avoid using trial and error to write programs. Instead, as they develop and test a program, we ask them to trace it line by line in order to predict what will happen when each line is run (glass-box testing).

Classical programming underpins the current view of computational thinking (CT). Our speakers called this version of CT ‘CT 1.0’. So what’s the alternative Matti and Henriikka presented, and how does it affect what computational thinking is or may become?
Machine learning (data-driven) models and new computational thinking (CT 2.0)
Rule-based programming languages are not being eradicated. Instead, software systems are being augmented through the addition of machine learning (data-driven) elements. Many of today’s successful software products, such as search engines, image classifiers, and speech recognition programs, combine rule-driven software and data-driven models. However, the workflows for these two approaches to solving problems through computing are very different.
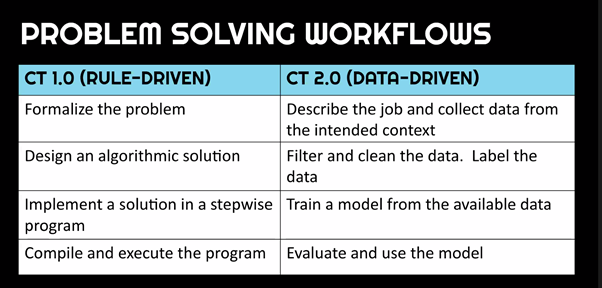
Significantly, while in rule-based programming (and CT 1.0), the focus is on solving problems by creating algorithms, in data-driven approaches, the problem solving workflow is all about the data. To highlight the profound impact this shift in focus has on teaching and learning computing, Matti introduced us to a new version of computational thinking for machine learning, CT 2.0, which is detailed in a forthcoming research paper.
Because of the focus on data rather than algorithms, developing a machine learning model is not at all like developing a classical rule-driven program. In classical programming, programs can be traced, and we can predict what will happen when they run. But in data-driven development, there is no flow of rules, and no absolutely right or wrong answer.

Machine learning models are created iteratively using training data and must be cross-validated with test data. A tiny change in the data provided can make a model useless. We rarely know exactly why the output of an ML model is as it is, and we cannot explain each individual decision that the model might have made. When evaluating a machine learning system, we can only say how well it works based on statistical confidence and efficiency.
Machine learning education must cover ethical and societal implications
The ethical and societal implications of computer science have always been important for students to understand. But machine learning models open up a whole new set of topics for teachers and students to consider, because of these models’ reliance on large datasets, the difficulty of explaining their decisions, and their usefulness for automating very complex processes. This includes privacy, surveillance, diversity, bias, job losses, misinformation, accountability, democracy, and veracity, to name but a few.
I see the shift in problem solving approach as a chance to strengthen the teaching of computing in general, because it opens up opportunities to teach about systems, uncertainty, data, and society.
Jane Waite
Teaching machine learning: the challenges of magic boxes and new mental models
For teaching classical rule-driven programming, much time and effort has been put into researching learners’ understanding of what a program will do when it is run. This kind of understanding is called a learner’s mental model or notional machine. An approach teachers often use to help students develop a useful mental model of a program is to hide the detail of how the program works and only gradually reveal its complexity. This approach is described with the metaphor of hiding the detail of elements of the program in a box.
Data-driven models in machine learning systems are highly complex and make little sense to humans. Therefore, they may appear like magic boxes to students. This view needs to be banished. Machine learning is not magic. We have just not figured out yet how to explain the detail of data-driven models in a way that allows learners to form useful mental models.
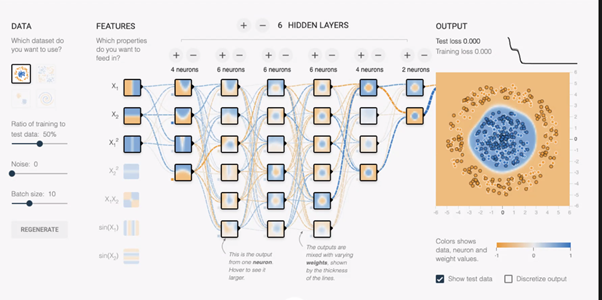
Some existing ML tools aim to help learners form mental models of ML, for example through visual representations of how a neural network works (see Figure 2). But these explanations are still very complex. Clearly, we need to find new ways to help learners of all ages form useful mental models of machine learning, so that teachers can explain to them how machine learning systems work and banish the view that machine learning is magic.
Some tools and teaching approaches for ML education
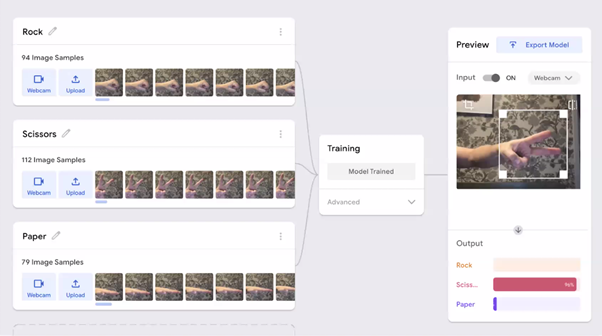
Matti and Henriikka’s team piloted different tools and pedagogical approaches with different age groups of learners. In terms of tools, since large amounts of data are needed for machine learning projects, our presenters suggested that tools that enable lots of data to be easily collected are ideal for teaching activities. Media-rich education tools provide an opportunity to capture still images, movements, sounds, or sense other inputs and then use these as data in machine learning teaching activities. For example, to create a machine learning–based rock-paper-scissors game, students can take photographs of their hands to train a machine learning model using Google Teachable Machine.
Similar to tools that teach classic programming to novice students (e.g. Scratch), some of the new classroom tools for teaching machine learning have a drag-and-drop interface (e.g. Cognimates). Using such tools means that in lessons, there can be less focus on one of the more complex aspects of learning to program, learning programming language syntax. However, not all machine learning education products include drag-and-drop interaction, some instead have their own complex languages (e.g. Wolfram Programming Lab), which are less attractive to teachers and learners. In their pilot studies, the Finnish team found that drag-and-drop machine learning tools appeared to work well with students of all ages.
The different pedagogical approaches the Finnish research team used in their pilot studies included an exploratory approach with preschool children, who investigated machine learning recognition of happy or sad faces; and a project-based approach with older students, who co-created machine learning apps with web-based tools such as Teachable Machine and Learn Machine Learning (built by the research team), supported by machine learning experts.
What impact these pedagogies have on students’ long-term mental models about machine learning has yet to be researched. If you want to find out more about the classroom pilot studies, the academic paper is a very accessible read.
My take-aways: new opportunities, new research questions
We all learned a tremendous amount from Matti and Henriikka and their perspectives on this important topic. Our seminar participants asked them many questions about the pedagogies and practicalities of teaching machine learning in class, and raised concerns about squeezing more into an already packed computing curriculum.
For me, the most significant take-away from the seminar was the need to shift focus from algorithms to data and from CT 1.0 to CT 2.0. Learning how to best teach classical rule-driven programming has been a long journey that we have not yet completed. We are forming an understanding of what concepts learners need to be taught, the progression of learning, key mental models, pedagogical options, and assessment approaches. For teaching data-driven development, we need to do the same.
The question of how we make sure teachers have the necessary understanding is key.
Jane Waite
I see the shift in problem solving approach as a chance to strengthen the teaching of computing in general, because it opens up opportunities to teach about systems, uncertainty, data, and society. I think it will help us raise awareness about design, context, creativity, and student agency. But I worry about how we will introduce this shift. In my view, there is a considerable risk that we will be sucked into open-ended, project-based learning, with busy and fun but shallow learning experiences that result in restricted conceptual development for students.
I also worry about how we can best help teachers build up the knowledge and experience to support their students. In the Q&A after the seminar, I asked Matti and Henriikka about the role of their team’s machine learning experts in their pilot studies. It seemed to me that without them, the pilot lessons would not have worked, as the participating teachers and students would not have had the vocabulary to talk about the process and would not have known what was doable given the available time, tools, and student knowledge.

The question of how we make sure teachers have the necessary understanding is key. Many existing professional development resources for teachers wanting to learn about ML seem to imply that teachers will all need a PhD in statistics and neural network optimisation to engage with machine learning education. This is misleading. But teachers do need to understand the machine learning concepts that their students need to learn about, and I think we don’t yet know exactly what these concepts are.
In summary, clearly more research is needed. There are fundamental questions still to be answered about what, when, and how we teach data-driven approaches to software systems development and how this impacts what we teach about classical, rule-based programming. But to me, that is exciting, and I am very much looking forward to the journey ahead.
Join our next free seminar
To find out what others recommend about teaching AI and ML, catch up on last month’s seminar with Professor Carsten Schulte and colleagues on centring data instead of code in the teaching of AI.
We have another four seminars in our monthly series on AI, machine learning, and data science education. Find out more about them on this page, and catch up on past seminar blogs and recordings here.
At our next seminar on Tuesday 7 December at 17:00–18:30 GMT, we will welcome Professor Rose Luckin from University College London. She will be presenting on what it is about AI that makes it useful for teachers and learners.
We look forward to meeting you there!
PS You can build your understanding of machine learning by joining our latest free online course, where you’ll learn foundational concepts and train your own ML model!
The post The machine learning effect: Magic boxes and computational thinking 2.0 appeared first on Raspberry Pi.