For the last five years, once a month, we have hosted an online seminar sharing computing education research. Seminars are organised as usually year-long series with changing themes. In 2025, for example, our theme was ‘Teaching about AI and data science’. In 2024, it was ‘Teaching programming (with or without AI)’.
It is not surprising that for the last few years our focus has been on AI technology, and for 2026 we will continue this. But we will shift from showcasing how computing education research is changing teaching and learning in computing lessons, to showcasing how computing education research in other disciplines, such as art or geography, is starting to include teaching about AI. For example, art lessons may change so that learners find out how professional artists are using AI tools to create arts. Or geography lessons may change so that learners discover how professional geographers are using AI to make predictions about physical or human aspects of geography, such as volcanic activity and global warming.
Our series for 2026 is called ‘Applied AI’. This title recognises that AI technology is applied across contexts, across careers, across disciplines, and this means what we teach across school subjects will change.
Encouraging a pull from disciplines, rather than a push from computer science
The majority of resources and professional development material related to teaching about AI have been developed by the computer science community. For example, we have developed the popular Experience AI resources in collaboration with Google DeepMind. In these resources, the contexts were carefully selected to represent real-world examples across disciplines, and to to enable the teaching of particular technical or social and ethical concepts. This could be described as “a push” of content from computing towards other disciplines. For example, to enable teaching about the ethical issues around plagiarism, an art context is used in the Experience AI resources; to enable teaching about the potential benefits of using AI tools, an ecological geography context is used.
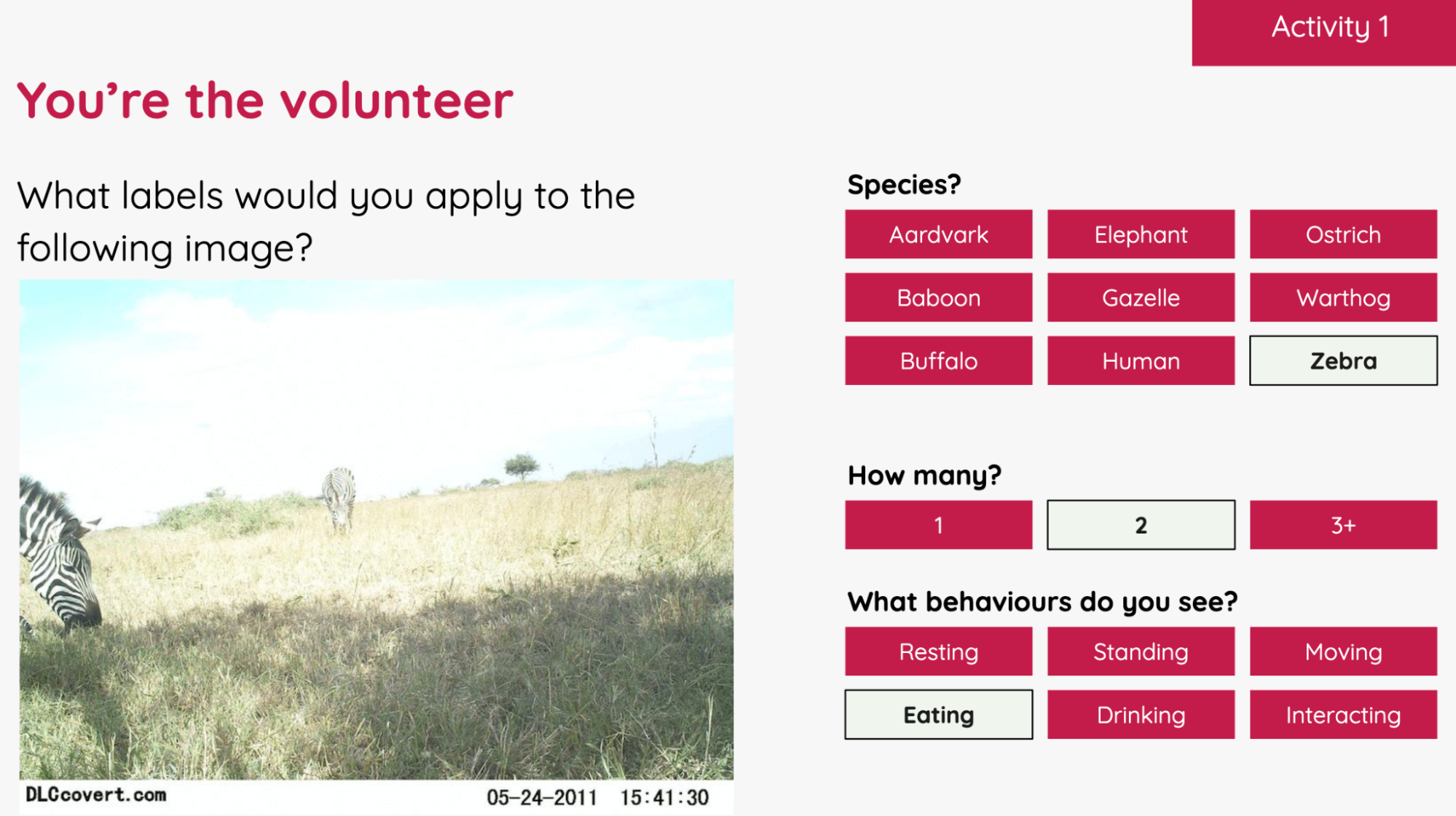
Example activity from the Experience AI resources, focused on ecology
AI applications are always situated within a particular topic. Most current AI applications are data-driven: vast amounts of data are collected and processed to produce models that can then either be used to generate outputs or make predictions. For example, data about artworks can be collected and used to train a model for generating outputs similar to the artworks; this is an application of AI in the art discipline. Or data on wild fires can be collected and used to train a model for making predictions about current or prospective fires; this is an application of AI in the geography discipline.
Example activity from the Experience AI resources, focused on meteorology
In reality, the best people to recognise how AI technology is being applied in a discipline and what students in that discipline should be taught about these applications are the people working in the discipline, for example the art and geography teachers. Computer science educators can work to build the technical understanding and the general social and ethical understanding that is common across applications. But the detail of how AI technology is changing a discipline can only truly be understood by the respective community, by the artists and art educators, by the geographers and the geography educators.
An emerging focus
At present, though, most educators are grappling with how they can use AI tools for productivity, such as creating lesson plans, or answering emails. Or they are looking at how they can use AI for general teaching and learning, for example for personalisation, say for students with additional needs. The idea that their underpinning discipline is changing is, perhaps, not yet on teachers’ radar. But at universities, such as in undergraduate courses, and in the world of work, education and training are changing. Data science courses are now being offered across faculties, including science, geography, language, and art faculties. These changes will start to filter down to school-based education via curriculum change. While some resources and professional development materials addressing this shift are already becoming available, change is still fragile and patchy.
Raising awareness, building community and a common language
The aims of our Applied AI research seminar series in 2026 are to start to:
Raise awareness of the forthcoming changes that applying AI will bring to disciplines
Build a cross-discipline community
Think about a common language that could be used across disciplines
If we can start to agree on what common concepts could be taught in the arts, sciences and humanities, it gives us a better chance to:
Understand how to use AI as it is applied in different disciplines
Help students to build useful mental models and develop the agency and critical thinking skills they need to evaluate these applications and decide when and how to use them and how far to trust them
We need your help
To make our 2026 series a success, we need to spread the word about our seminars to groups of educators, researchers, industry and policy makers across the arts, sciences, and humanities.
Please tell those you know in these groups about the seminar series, and share it through your social media and other networks. If you have ideas for subject associations we could connect with or publications where we can write about our series, please let us know.
Join our ‘Applied AI’ seminar series
We have already arranged the following seminars across 2026 and will add more speakers for the remaining monthly slots soon. Seminars always take place online on Tuesdays at 17:00 to 18:30 UK time.
10 February: Social studies, public policy, economics and AI — Thema Monroe-White (George Mason University, USA)
17 March: Arts and AI — Rebecca Fiebrink (University of the Arts London, UK)
14 April: Healthcare and AI — Kathryn Jessen Eller (Data Science, AI & You (DSAIY) in Healthcare, USA)
14 July: Literacy and AI — Dan Verständig (Goethe University Frankfurt, Germany)
8 September: History and AI — Jie Chao (The Concord Consortium)
6 October: Robotics and AI — Eleni Petraki & Damith Herath (University of Canberra, Australia)
10 November: Geography and AI — Doreen Boyd (University of Nottingham, UK)
To sign up and take part, click the button below. We’ll then send you information about joining. We hope to see you there.
At a time when many young people are using AI for personal and learning purposes, schools are trying to figure out what to teach about AI and how (find out more in this summer 2025 data about young people’s usage of AI in the UK). One aspect of this is how technical we should get in explaining how AI works, particularly if we want to debunk naive views of the capabilities of the technology, such as that AI tools ‘think’. In this month’s research seminar, we found out how AI contexts can be added to current classroom maths to make maths more interesting and relevant while teaching the core concepts of AI.
At our computing education research seminar in July, a group of researchers from the CAMMP (Computational and Mathematical Modeling Program) research project shared their work:
Prof. Dr. Martin Frank, Founder of CAMMP (Karlsruhe Institute of Technology (KIT), Germany).
Assistant Prof. Dr. Sarah Schönbrodt (University of Salzburg, Austria)
Research Associate Stephan Kindler (Karlsruhe Institute of Technology (KIT), Germany)
They talked about how maths already taught in secondary schools can be used to demystify AI. At first glance, this seems difficult to do, as it is often assumed that school-aged learners will not be able to understand how these systems work. This is especially the case for artificial neural networks, which are usually seen as a black box technology — they may be relatively easy to use, but it’s not as easy to understand how they work. Despite this, the Austrian and German team have developed a clear way to explain some of the fundamental elements of AI using school-based maths.
Sarah Schönbrodt started by challenging us to consider that learning maths is an essential part in developing AI skills, as:
AI systems using machine learning are data-driven and are based on mathematics, especially statistics and data
Authentic machine learning techniques can be used to bring to life existing classroom maths concepts
Real and relevant problems and associated data are available for teachers to use
A set of workshops for secondary maths classrooms
Sarah explained how the CAMMP team have developed a range of teaching and learning materials on AI (and beyond) with an overall goal to “allow students to solve authentic, real and relevant problems using mathematical modeling and computers”.
She reflected that much of school maths is set in contexts that are abstract, and may not be very interesting or relevant to students. Therefore, introducing AI-based contexts, which are having a huge impact on society and students’ lives, is both an opportunity to make maths more engaging and also a way to demystify AI.
Old-fashioned contexts are often used to teach classroom maths concepts. Those same concepts could be taught using real-world AI contexts. (Slide from the researchers’ presentation.)
Workshops designed and researched by the team include contexts such as privacy in social networks to learn about decision trees, personalised Netflix recommendations to learn about k-nearest neighbour, word predictions to learn about N-Grams, and predicting life expectancy to learn about regression and neural networks.
Learning about classification models: traffic lights and the support vector machine
For the seminar, Sarah walked through the steps to learn about support vector machines. This is an upper secondary workshop for students aged 17 to 18 years old. The context of the lesson is an image problem — specifically, classifying the data representing the colours of a simplified traffic light system (two lights to start with) to work out if a traffic light is red or green.
She walked through each of the steps of the maths workshop:
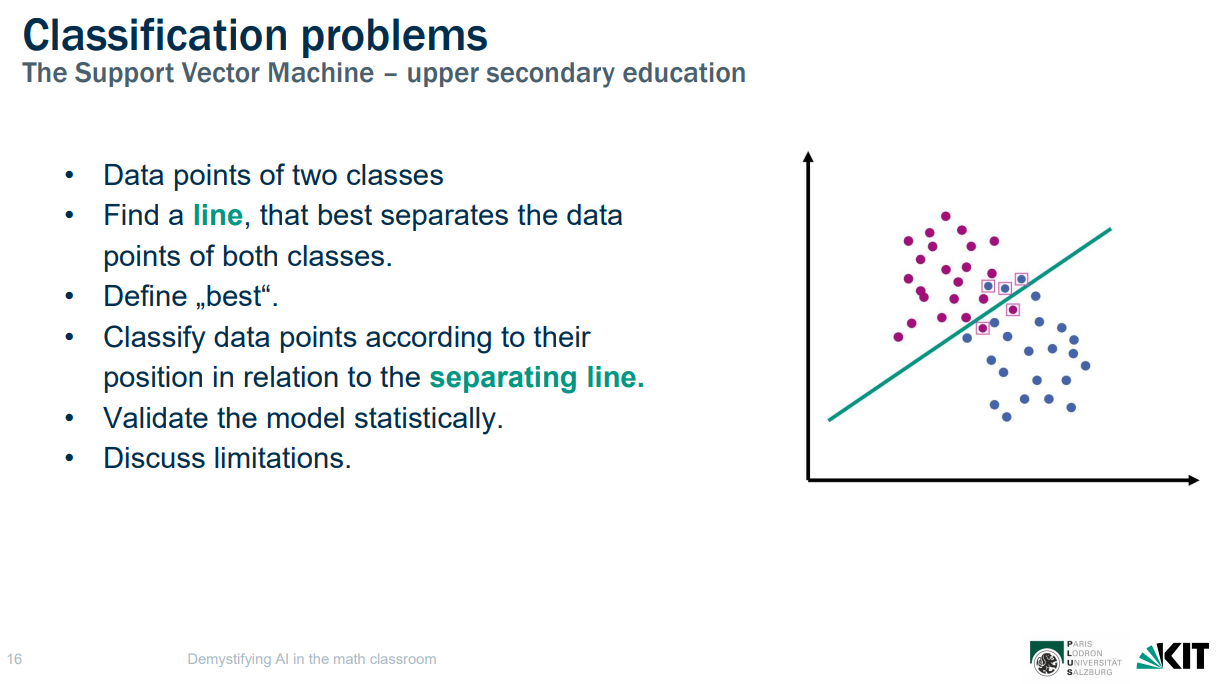
Plotting data points of two classes, the representation of green and red traffic lights
Finding a line that best separates the data points of both classes
Figuring out what best is
Classifying the data points in relation to the chosen (separating) line
Validating the model statistically to see if it is useful in classifying new data points, including using test data and creating a contingency table (also called a confusion matrix)
Discussing limitations, including social and ethical issues
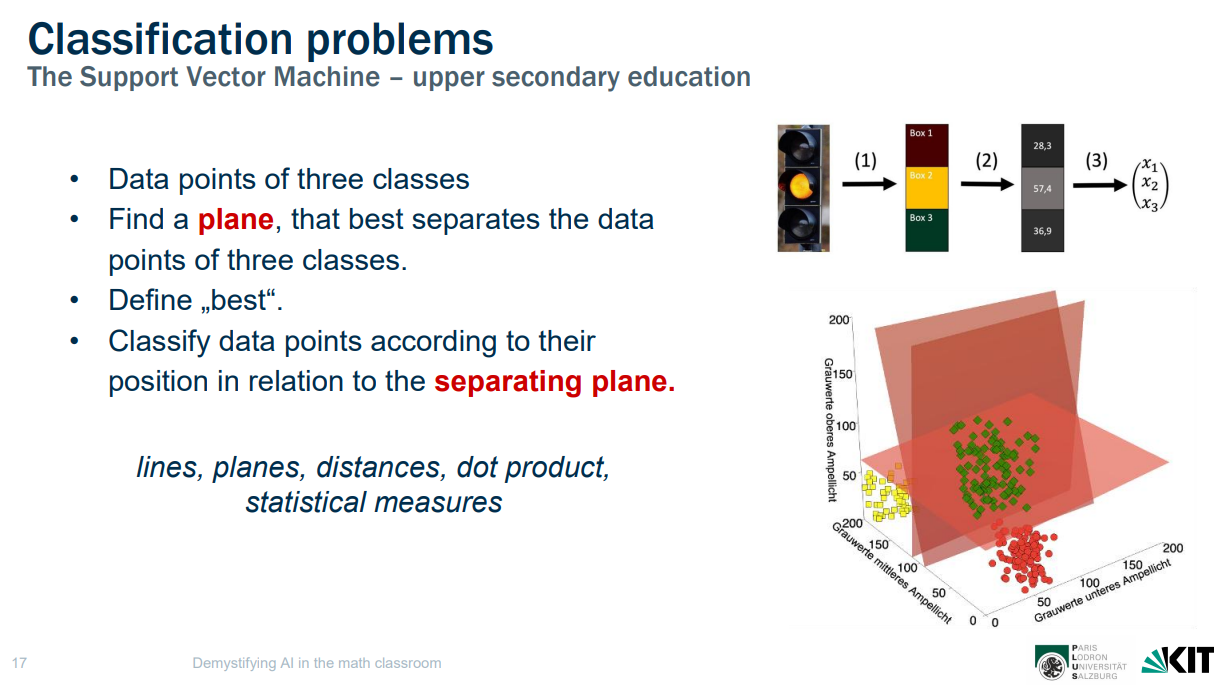
Explaining how three traffic lights can be expressed as three-dimensional data by using planes
By classifying green and red traffic light data, students are learning about lines, classifying data, and considering limitations. (Slide from the researchers’ presentation.)
Throughout the presentation, Sarah pointed out where the maths taught was linked to the Austrian and German mathematics curriculum.
Learning about planes, separating planes, and starting to see how data can be represented in vectors. (Slide from the researchers’ presentation.)
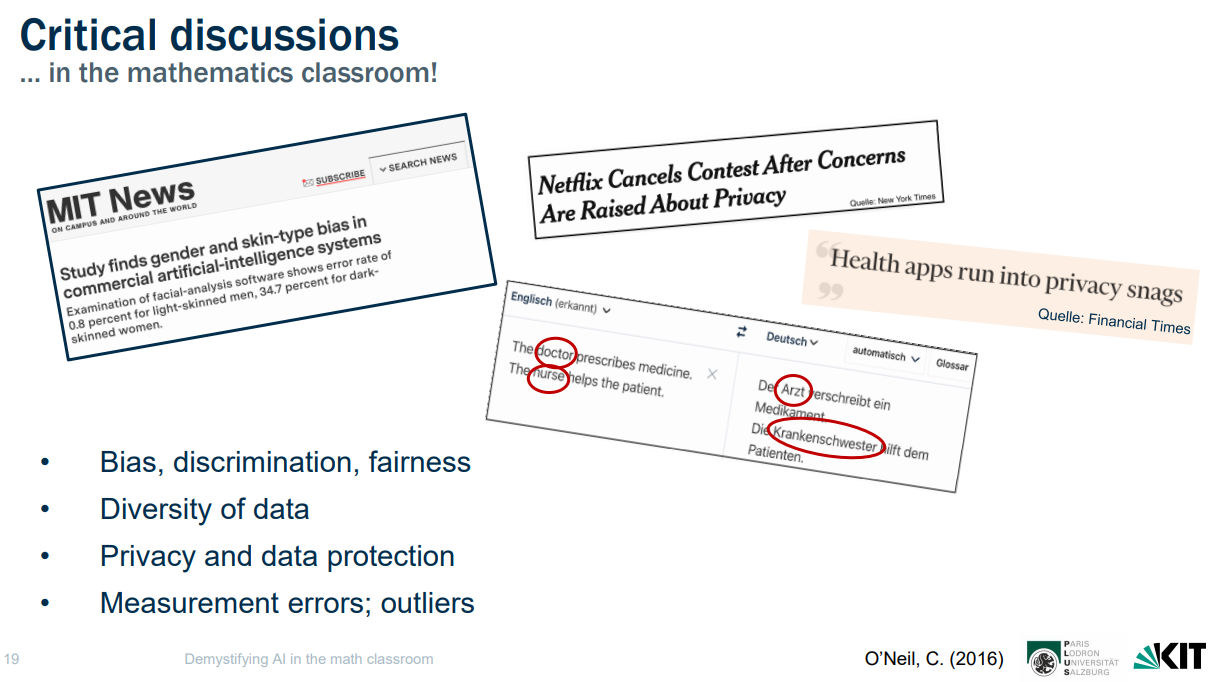
Learning about social and ethical issues
Learning about the social and ethical issues in data-driven systems. (Slide from the researchers’ presentation.)
As well as learning about lines, planes, distances, dot product and statistical measures, learners are also engaged in discussing the social and ethical issues of the approach taken. They are encouraged to think about bias, data diversity, privacy, and the impact of errors on people. For example, if the model wrongly predicts a light as green when it is red, then an autonomous car would run through a red traffic light. This would likely be a bigger consequence than stopping at a green traffic light that was mis-predicted as red. So should the best line reduce this kind of error?
To teach the workshops, Sarah explained they have developed interactive Jupyter notebooks, where no programming skills are needed. Students fill in the gaps of example code, explore simulations, and write their ideas for discussion for the whole class. No software needs to be installed, feedback is direct, and there are in-depth tasks and staggered hints.
Learning about regression models: Weather forecasting and the toy artificial neural network
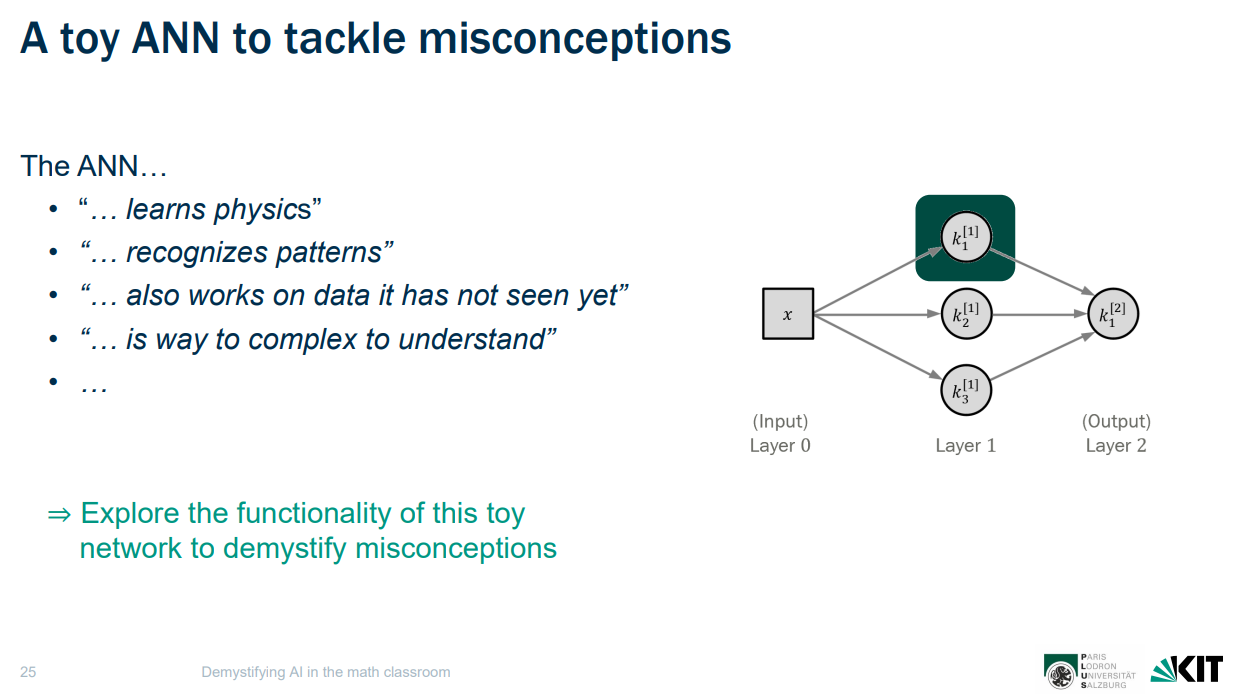
Stephan went on to introduce artificial neural networks (ANNs), which are the basis of generative AI applications like chatbots and image generation systems. He focused on regression models, such as those used in weather forecasting.
ANNs are very complex. Therefore, to start to understand the fundamentals of this technology, he introduced a ‘toy ANN’ with one input, three nodes, and one output. A function is performed on the input data at each node. With the toy network, the team wants to tackle a major and common misconception: that students think that ANN systems learn, recognise, see, and understand, when really it’s all just maths.
Tackling misconceptions about ANNs by exploring how they work in a toy version. (Slide from the researchers’ presentation.)
The learning activity starts by looking at one node with one input and one output, and can be described as a mathematical function, with a concatenation of two functions (in this case a linear and activation function). Stephan shared an online simulator that visualises how the toy neural network can be explored as students change two parameters (in this case, weight and bias of the functions). Students then look at the overall network, and the way that the output from the three nodes is combined. Again, they can explore this in the simulator. Students compare simple data about weather prediction to the model, and discover they need more functions — more nodes to better fit the data. The activity helps students learn that ANN systems are just highly adjustable mathematical functions that, by adding nodes, can approximate relationships in a given data set. But the approximation only works in the bounds (intervals) in which data points are given, showing that ANNs do not ‘understand’ or ’know’ — it’s just maths.
Stephen finished by explaining the mutual benefits of AI education and maths education. He suggested maths will enable a deeper understanding of AI, and give students a way to realistically assess the opportunities and risks of AI tools and show them the role that humans have in designing AI systems. He also explained that classroom maths education can benefit from incorporating AI contexts. This approach highlights how maths underpins the design and understanding of everyday systems, supports more effective teaching, and promotes an interdisciplinary way of learning across subjects.
Some personal reflections — which may not be quite right!
I have been researching the teaching of AI and machine learning for around five years now, since before ChatGPT and other similar tools burst on the scene. Since then, I have seen an increasing number of resources to teach about the social and ethical issues of the topic, and there are a bewildering number of learning activities and tools for students to train simple models. There are frameworks for the data lifecycle, and an emerging set of activities to follow to prepare data, compare model types, and deploy simple applications. However, I felt the need to understand and to teach about, at a very simple level, the basic building blocks of data-driven technologies. When I heard the CAMMP team present their work at the AIDEA conference in February 2025, I was entirely amazed and I asked them to present here at our research seminar series. This was a piece of the puzzle that I had been searching for — a way to explain the ‘bottom of the technical stack of fundamental concepts’. The team is taking very complex ideas and reducing them to such an extent that we can use secondary classroom maths to show that AI is not magic and AI systems do not think. It’s just maths. The maths is still hard, and teachers will still need the skills to carefully guide students step by step so they can build a useful mental model.
I think we can simplify these ideas further, and create unplugged activities, simulations, and ways for students to explore these basic building blocks of data representation, as well as classification and representing approximations of complex patterns and prediction. I can sense the beginnings of new ideas in computational thinking, though they’re still taking shape. We’re researching these further and will keep you updated.
Finding out more
If you would like to find out more about the CAMMP resources, you can watch the seminar recording, look at the CAMMP website or try out their online materials. For example, the team shared a link to the jupyter notebooks they use to teach the workshops they demonstrated (and others). You can use these with a username of ‘cammp_YOURPSEUDONYM’, where you can set ‘YOURPSEUDONYM’ to any letters, and you can choose any password. They also shared their toy ANN simulation. The CAMMP team are not the only researchers who are investigating how to teach about AI in maths lessons. You can find a set of other research papers here.
Join our next seminar
In our current seminar series, we’re exploring teaching about AI and data science. Join us at our last seminar of the series on Tuesday, 27 January 2026 from 17:00 to 18:30 GMT to hear Salomey Afua Addo talk about using unplugged approaches to teach about neural networks.
To sign up and take part, click the button below. We’ll then send you information about joining. We hope to see you there.
AI has become a pervasive term that is heard with trepidation, excitement, and often a furrowed brow in school staffrooms. For educators, there is pressure to use AI applications for productivity — to save time, to help create lesson plans, to write reports, to answer emails, etc. There is also a lot of interest in using AI tools in the classroom, for example, to personalise or augment teaching and learning. However, without understanding AI technology, neither productivity nor personalisation are likely to be successful as teachers and students alike must be critical consumers of these new ways of working to be able to use them productively.
Fifty teachers and researchers share knowledge about teaching about AI.
In both England and globally, there are few new AI-based curricula being introduced and the drive for teachers and students to learn about AI in schools is lagging, with limited initiatives supporting teachers in what to teach and how to teach it. At the Raspberry Pi Foundation and Raspberry Pi Computing Education Research Centre, we decided it was time to investigate this missing link of teaching about AI, and specifically to discover what the teachers who are leading the way in this topic are doing in their classrooms.
A day of sharing and activities in Cambridge
We organised a day-long, face-to-face symposium with educators who have already started to think deeply about teaching about AI, have started to create teaching resources, and are starting to teach about AI in their classrooms. The event was held in Cambridge, England, on 1 February 2025, at the head office of the Raspberry Pi Foundation.
Teachers collaborated and shared their knowledge about teaching about AI.
Over 150 educators and researchers applied to take part in the symposium. With only 50 places available, we followed a detailed protocol, whereby those who had the most experience teaching about AI in schools were selected. We also made sure that educators and researchers from different teaching contexts were selected so that there was a good mix of primary to further education phases represented. Educators and researchers from England, Scotland, and the Republic of Ireland were invited and gathered to share about their experiences. One of our main aims was to build a community of early adopters who have started along the road of classroom-based AI curriculum design and delivery.
Inspiration, examples, and expertise
To inspire the attendees with an international perspective of the topics being discussed, Professor Matti Tedre, a visiting academic from Finland, gave a brief overview of the approach to teaching about AI and resources that his research team have developed. In Finland, there is no compulsory distinct computing topic taught, so AI is taught about in other subjects, such as history. Matti showcased tools and approaches developed from the Generation AI research programme in Finland. You can read about the Finnish research programme and Matti’s two month visit to the Raspberry Pi Computing Education Research Centre in our blog.
A Finnish perspective to teaching about AI.
Attendees were asked to talk about, share, and analyse their teaching materials. To model how to analyse resources, Ben Garside from the Raspberry Pi Foundation modelled how to complete the activities using the Experience AI resources as an example. The Experience AI materials have been co-created with Google DeepMind and are a suite of free classroom resources, teacher professional development, and hands-on activities designed to help teachers confidently deliver AI lessons. Aimed at learners aged 11 to 14, the materials are informed by the AI education framework developed at the Raspberry Pi Computing Education Research Centre and are grounded in real-world contexts. We’ve recently released new lessons on AI safety, and we’ve localised the resources for use in many countries including Africa, Asia, Europe, and North America.
In the morning session, Ben exemplified how to talk about and share learning objectives, concepts, and research underpinning materials using the Experience AI resources and in the afternoon he discussed how he had mapped the Experience AI materials to the UNESCO AI competency framework for students.
UNESCO provide important expertise.
Kelly Shiohira, from UNESCO, kindly attended our session, and gave an invaluable insight into the UNESCO AI competency framework for students. Kelly is one of the framework’s authors and her presentation helped teachers understand how the materials had been developed. The attendees then used the framework to analyse their resources, to identify gaps and to explore what progression might look like in the teaching of AI.
Teachers shared their knowledge about teaching about AI.
Throughout the day, the teachers worked together to share their experience of teaching about AI. They considered the concepts and learning objectives taught, what progression might look like, what the challenges and opportunities were of teaching about AI, what research informed the resources and what research needs to be done to help improve the teaching and learning of AI.
What next?
We are now analysing the vast amount of data that we gathered from the day and we will share this with the symposium participants before we share it with a wider audience. What is clear from our symposium is that teachers have crucial insights into what should be taught to students about AI, and how, and we are greatly looking forward to continuing this journey with them.
As well as the symposium, we are also conducting academic research in this area, you can read more about this in our Annual Report and on our research webpages. We will also be consulting with teachers and AI experts. If you’d like to ensure you are sent links to these blog posts, then sign up to our newsletter. If you’d like to take part in our research and potentially be interviewed about your perspectives on curriculum in AI, then contact us at: [email protected]
We also are sharing the research being done by ourselves and other researchers in the field at our research seminars. This year, our seminar series is on teaching about AI and data science in schools. Please do sign up and come along, or watch some of the presentations that have already been delivered by the amazing research teams who are endeavouring to discover what we should be teaching about AI and how in schools
AI, machine learning (ML), and data science infuse our daily lives, from the recommendation functionality on music apps to technologies that influence our healthcare, transport, education, defence, and more.
What jobs will be affected by AL, ML, and data science remains to be seen, but it is increasingly clear that students will need to learn something about these topics. There will be new concepts to be taught, new instructional approaches and assessment techniques to be used, new learning activities to be delivered, and we must not neglect the professional development required to help educators master all of this.
As AI and data science are incorporated into school curricula and teaching and learning materials worldwide, we ask: What’s the research basis for these curricula, pedagogy, and resource choices?
In 2024, we showcased researchers who are investigating how AI can be leveraged to support the teaching and learning of programming. But in 2025, we look at what should be taught about AI, ML, and data science in schools and how we should teach this.
Our 2025 seminar speakers — so far!
We are very excited that we have already secured several key researchers in the field.
On 21 January, Shuchi Grover will kick off the seminar series by giving an important overview of AI in the K–12 landscape, including developing both AI literacy and AI ethics. Shuchi will provide concrete examples and recently developed frameworks to give educators practical insights on the topic.
Our second session will focus on a teacher professional development (PD) programme to support the introduction of AI in Upper Bavarian schools. Franz Jetzinger from the Technical University of Munich will summarise the PD programme and share how teachers implemented the topic in their classroom, including the difficulties they encountered.
Again from Germany, Lukas Höper from Paderborn University, with Carsten Schulte will describe important research on data awareness and introduce a framework that is likely to be key for learning about data-driven technology. The pair will talk about the Data Awareness Framework and how it has been used to help learners explore, evaluate, and be empowered in looking at the role of data in everyday applications.
Our April seminar will see David Weintrop from the University of Maryland introduce, with his colleagues, a data science curriculum called API Can Code, aimed at high-school students. The group will highlight the strategies needed for integrating data science learning within students’ lived experiences and fostering authentic engagement.
Later in the year, Jesús Moreno-Leon from the University of Seville will help us consider the thorny but essential question of how we measure AI literacy. Jesús will present an assessment instrument that has been successfully implemented in several research studies involving thousands of primary and secondary education students across Spain, discussing both its strengths and limitations.
What to expect from the seminars
Our seminars are designed to be accessible to anyone interested in the latest research about AI education — whether you’re a teacher, educator, researcher, or simply curious. Each session begins with a presentation from our guest speaker about their latest research findings. We then move into small groups for a short discussion and exchange of ideas before coming back together for a Q&A session with the presenter.
Attendees of our 2024 series told us that they valued that the talks “explore a relevant topic in an informative way“, the “enthusiasm and inspiration”, and particularly the small-group discussions because they “are always filled with interesting and varied ideas and help to spark my own thoughts”.
The seminars usually take place on Zoom on the first Tuesday of each month at 17:00–18:30 GMT / 12:00–13:30 ET / 9:00–10:30 PT / 18:00–19:30 CET.
You can find out more about each seminar and the speakers on our upcoming seminar page. And if you are unable to attend one of our talks, you can watch them from our previous seminar page, where you will also find an archive of all of our previous seminars dating back to 2020.
How to sign up
To attend the seminars, please register here. You will receive an email with the link to join our next Zoom call. Once signed up, you will automatically be notified of upcoming seminars. You can unsubscribe from our seminar notifications at any time.
Worldwide, the use of generative AI systems and related technologies is transforming our lives. From marketing and social media to education and industry, these technologies are being used everywhere, even if it isn’t obvious. Yet, despite the growing availability and use of generative AI tools, governments are still working out how and when to regulate such technologies to ensure they don’t cause unforeseen negative consequences.
The researchers at the Raspberry Pi Foundation have been looking at research that will help inform curriculum design and resource development to teach about AI in school. As part of this work, a number of research themes have been established, which we would like to explore with educators at a face-to-face symposium.
These research themes include the SEAME model, a simple way to analyse learning experiences about AI technology, as well as anthropomorphisation and how this might influence the formation of mental models about AI products. These research themes have become the cornerstone of the Experience AI resources we’ve co-developed with Google DeepMind. We will be using these materials to exemplify how the research themes can be used in practice as we review the recently published UNESCO AI competencies.
Most importantly, we will also review how we can help teachers and learners move from a rule-based view of problem solving to a data-driven view, from computational thinking 1.0 to computational thinking 2.0.
A call for teacher input on the AI curriculum
Over ten years ago, teachers in England experienced a large-scale change in what they needed to teach in computing lessons when programming was more formally added to the curriculum. As we enter a similar period of change — this time to introduce teaching about AI technologies — we want to hear from teachers as we collectively start to rethink our subject and curricula.
We think it is imperative that educators’ voices are heard as we reimagine computer science and add data-driven technologies into an already densely packed learning context.
Join our Research and Educator Community Symposium
In this symposium, we will bring together UK educators and researchers to review research themes, competency frameworks, and early international AI curricula and to reflect on how to advance approaches to teaching about AI. This will be a practical day of collaboration to produce suggested key concepts and pedagogical approaches and highlight research needs.
This symposium focuses on teaching about AI technologies, so we will not be looking at which AI tools might be used in general teaching and learning or how they may change teacher productivity.
It is vitally important for young people to learn how to use AI technologies in their daily lives so they can become discerning consumers of AI applications. But how should we teach them? Please help us start to consider the best approach by signing up for our Research and Educator Community Symposium by 9 December 2024.
Information at a glance
When: Saturday, 1 February 2025 (10am to 5pm)
Where: Raspberry Pi Foundation Offices, Cambridge
Who: If you have started teaching about AI, are creating related resources, are providing professional development about AI technologies, or if you are planning to do so, please apply to attend our symposium. Travel funding is available for teachers in England.
Please note we expect to be oversubscribed, so book early and tell us about why you are interested in taking part. We will notify all applicants of the outcome of their application by 11 December.
People have many different reasons to think that children and teenagers need to learn about artificial intelligence (AI) technologies. Whether it’s that AI impacts young people’s lives today, or that understanding these technologies may open up careers in their future — there is broad agreement that school-level education about AI is important.
But how do you actually design lessons about AI, a technical area that is entirely new to young people? That was the question we needed to answer as we started Experience AI, our exciting collaboration with DeepMind, a leading AI company.
Our approach to developing AI education resources
As part of Experience AI, we are creating a free set of lesson resources to help teachers introduce AI and machine learning (ML) to KS3 students (ages 11 to 14). In England this area is not currently part of the national curriculum, but it’s starting to appear in all sorts of learning materials for young people.
We reviewed over 500 existing resources that are used to teach AI and ML.
As part of this research, we reviewed over 500 existing resources that are used to teach AI and ML. We found that the vast majority of them were one-off activities, and many claimed to be appropriate for learners of any age. There were very few sets of lessons, or units of work, that were tailored to a specific age group. Activities often had vague learning objectives, or none at all. We rarely found associated assessment activities. These were all shortcomings we wanted to avoid in our set of lessons.
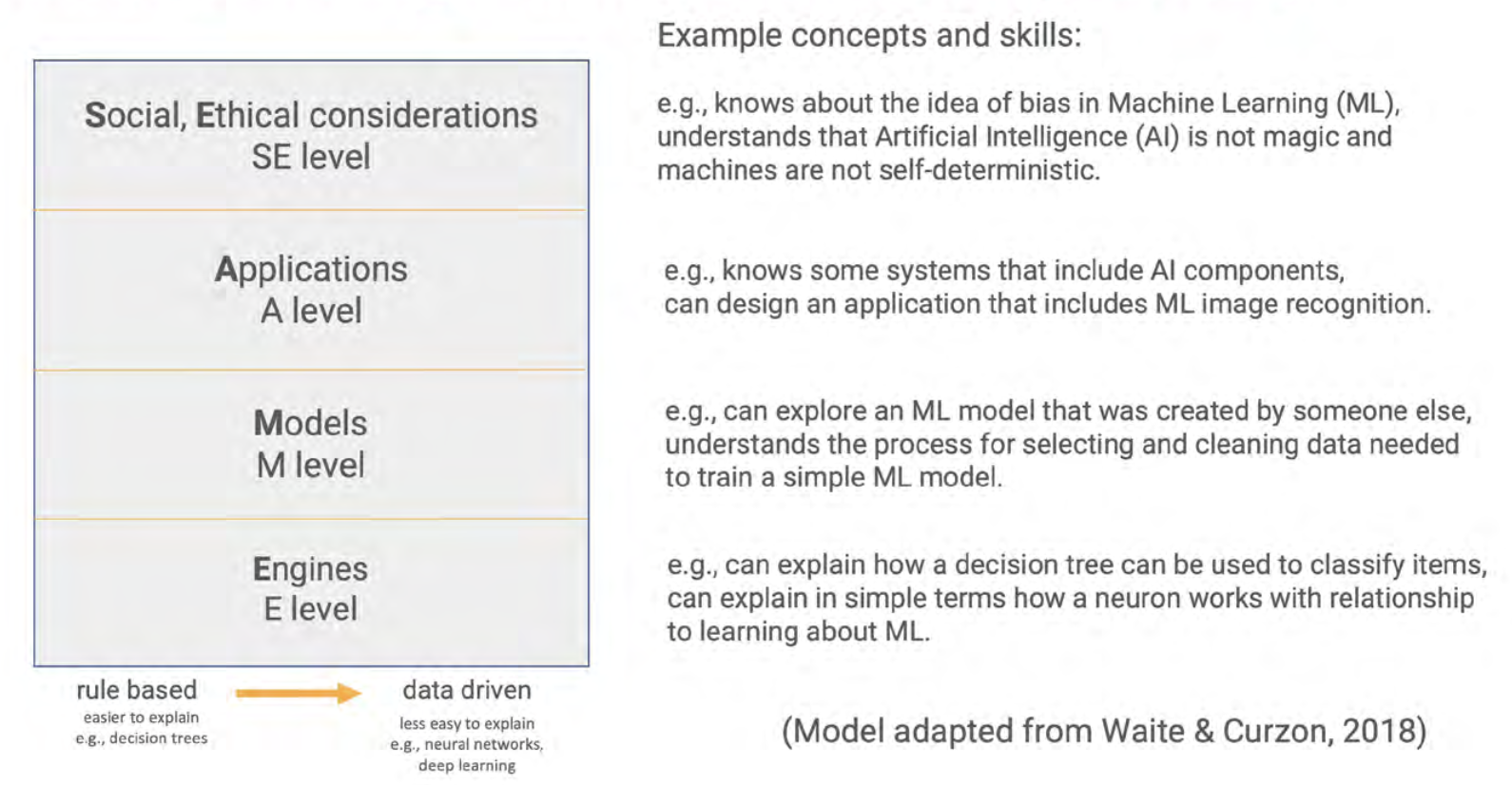
The SEAME framework gives you a simple way to group learning objectives and resources related to teaching AI and ML, based on whether they focus on social and ethical aspects (SE), applications (A), models (M), or engines (E, i.e. how AI works). We hope that it will be a useful tool for anyone who is interested in looking at resources to teach AI.
What do AI education resources focus on?
The four levels of the SEAME framework do not indicate a hierarchy or sequence. Instead, they offer a way for teachers, resource developers, and researchers to talk about the focus of AI learning activities.
Social and ethical aspects (SE)
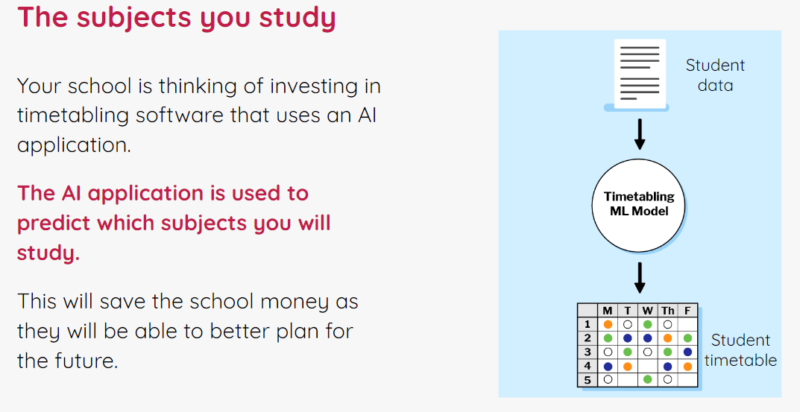
The SE level covers activities that relate to the impact of AI on everyday life, and to its implications for society. Learning objectives and their related resources categorised at this level introduce students to issues such as privacy or bias concerns, the impact of AI on employment, misinformation, and the potential benefits of AI applications.
An example activity in the Experience AI lessons where learners think about the social and ethical issues of an AI application that predicts what subjects they might want to study. This activity is mostly focused on the social and ethical level of the SEAME framework, but also links to the applications and models levels.
Applications (A)
The A level refers to activities related to applications and systems that use AI or ML models. At this level, learners do not learn how to train models themselves, or how such models work. Learning objectives at this level include knowing a range of AI applications and starting to understand the difference between rule-based and data-driven approaches to developing applications.
Models (M)
The M level concerns the models underlying AI and ML applications. Learning objectives at this level include learners understanding the processes used to train and test models. For example, through resources focused on the M level, students could learn about the different learning paradigms of ML (i.e., supervised, unsupervised, or reinforcement learning).
An example activity in the Experience AI lessons where students learn about classification. This activity is mostly focused on the models level of the SEAME framework, but also links to the social and ethical and the applications levels.
Engines (E)
The E level is related to the engines that make AI models work. This is the most hidden and complex level, and for school-aged learners may need to be taught using unplugged activities and visualisations. Learning objectives could include understanding the basic workings of systems such as data-driven decision trees and artificial neural networks.
Covering the four levels
Some learning activities may focus on a single level, but activities can also span more than one level. For example, an activity may start with learners trying out an existing ‘rock-paper-scissors’ application that uses an ML model to recognise hand shapes. This would cover the applications level. If learners then move on to train the model to improve its accuracy by adding more image data, they work at the models level.
Other activities cover several SEAME levels to address a specific concept. For example, an activity focussed on bias might start with an example of the societal impact of bias (SE level). Learners could then discuss the AI applications they use and reflect on how bias impacts them personally (A level). The activity could finish with learners exploring related data in a simple ML model and thinking about how representative the data is of all potential application users (M level).
The set of lessons on AI we are developing in collaboration with DeepMind covers all four levels of SEAME.
The set of Experience AI lessons we are developing in collaboration with DeepMind covers all four levels of SEAME. The lessons are based on carefully designed learning objectives and specifically targeted to KS3 students. Lesson materials include presentations, videos, student activities, and assessment questions.
We’re releasing the Experience AI lessons very soon — if you want to be the first to hear news about them, please sign up here.
The SEAME framework as a tool for research on AI education
For researchers, we think the SEAME framework will, for example, be useful to analyse school curriculum material to see whether some age groups have more learning activities available at one level than another, and whether this changes over time. We may find that primary school learners work mostly at the SE and A levels, and secondary school learners move between the levels with increasing clarity as they develop their knowledge. It may also be the case that some learners or teachers prefer activities focused on one level rather than another. However, we can’t be sure: research is needed to investigate the teaching and learning of AI and ML across all year groups.
That’s why we’re excited to welcome Salomey Afua Addo to the Raspberry Pi Computing Education Research Centre. Salomey joined the Centre as a PhD student in January, and her research will focus on approaches to the teaching and learning of AI. We’re looking forward to seeing the results of her work.
When we teach children and young people about computing, do we consider how the subject has developed over time, how it relates to our students’ lives, and importantly, what our values are? Professor Pratim Sengupta shared some of the research he and his colleagues have been working on related to these questions in our June 2022 research seminar.
Prof. Pratim Sengupta
Pratim revealed a complex landscape where we as educators can be easily trapped by what may seem like good intentions, thereby limiting learning and excluding some students. His presentation, entitled Computational heterogeneity in STEM education, introduced me to the concept of technocentrism and profoundly impacted my thinking about the essence of programming and how I research it. In this blog post, particularly for those unable to attend this stimulating seminar, I give my simplified view of the rich philosophy shared by Pratim, and my fledgling steps to admit to my technocentrism and overcome it.
Our seminars on teaching cross-disciplinary computing
Between May 2022 and November 2022, we are hosting a new series of free research seminars about teaching computing in different ways and in different contexts. This second seminar of the series was well attended with participants from the USA, Asia, Africa, and Europe, including teachers, researchers, and industry professionals, who contributed to a lively and thought-provoking discussion.
Pratim is a learning scientist based in Canada with a long and distinguished career. He has studied how to teach computational modelling in K-12 STEM classrooms and investigates the complexity of learning. Grounded in working with teachers and students, he brings together computing, science, education, and social justice. Based on his work at Northwestern University, Vanderbilt University, and now with the Mind, Matter and Media lab at the University of Calgary, Pratim has published hundreds of academic papers over some 20 years. Pratim and his team challenge how we focus on making technological artefacts — code for code’s sake — in computing education, and refocuses us on the human experience of coding and learning to code.
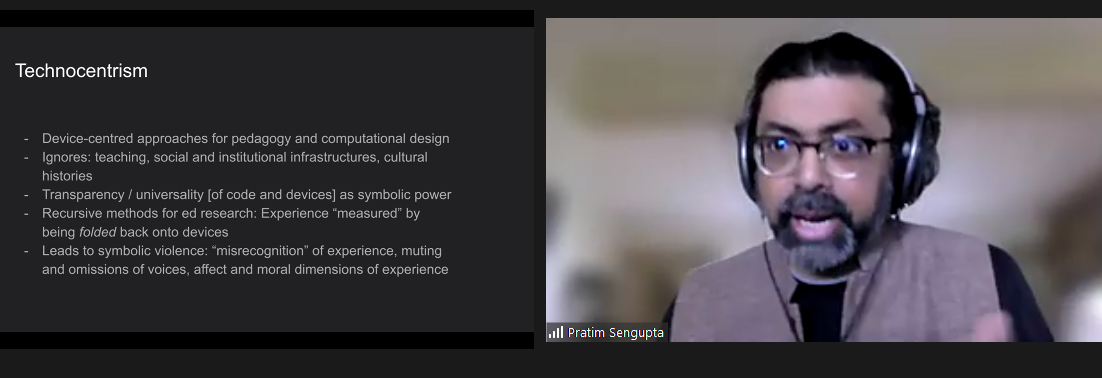
What is technocentrism?
Pratim started the seminar by giving us an overview of some of the key ideas that underpin the way that computing is usually taught in schools, including technocentrism (Figure 1).
Figure 1: The features of technocentrism, a way of thinking about how we teach computing, particularly programming (Sengupta, 2022). Click to enlarge.
I have come to a simplified understanding of technocentrism. To me, it appears to be a way of looking at how we learn about computer science, where one might:
Focus on the finished product (e.g. a computer program), rather than thinking about the people who create, learn about, or use a program
Ignore the context and the environment, rather than paying attention to the history, the political situation, and the social context of the task at hand
View computing tasks as being implemented (enacted) by writing code, rather than seeing computing activities as rich and complex jumbles of meaning-making and communication that involve people using chatter, images, and lots of gestures
Anchor learning in concepts and skills, rather than placing the values and viewpoints of learners at the heart of teaching
Examples of technocentrism and how to overcome it
Pratim recounted several research activities that he and his team have engaged with. These examples highlight instances of potential technocentrism and investigate how we might overcome it.
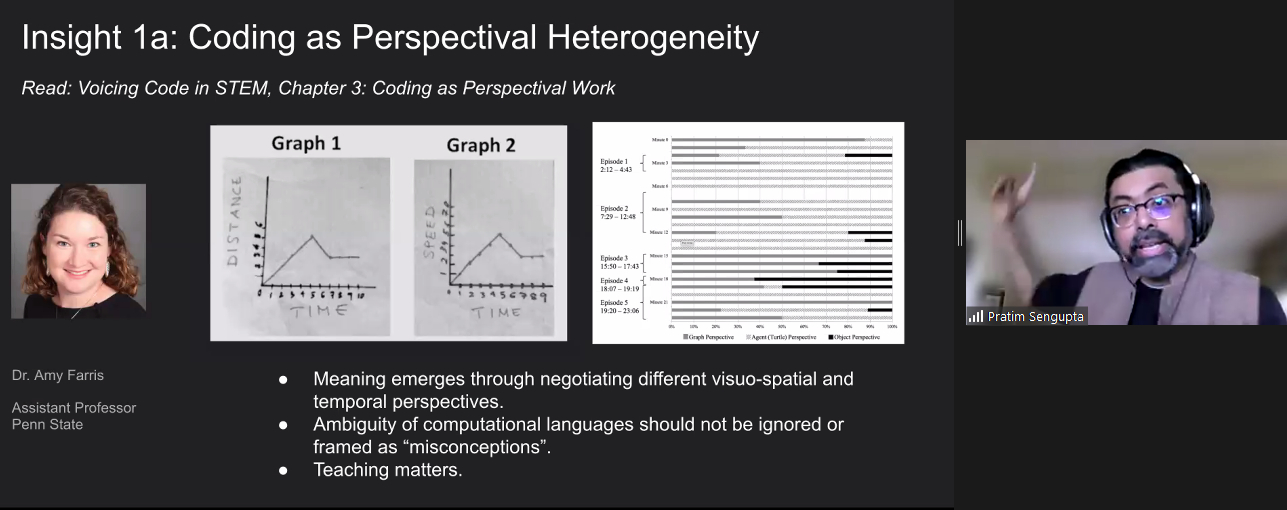
In the first example research activity, Pratim explained how in maths and physics lessons, middle school students were asked to develop models to solve time and distance problems. Rather than immediately coding a potential solution, the researcher and teacher supported the learners to spend much time developing a shared perspective to understand and express the problems first. Students grappled with different ways of representing the context, including graphs and diagrams (see Figure 2). Gradually and carefully, teachers shifted students to recognise what was important and what was not, to move them toward a meaningful language to describe and solve the problems.
Figure 2: Two graphs from students showing different representations of a context, and a researcher’s bar chart representing how students’ shared understanding emerged over time (Sengupta, 2022). Click to enlarge.
In a second example research activity, students were asked to build a machine that draws shapes using sensors, motors, and code. Rather than jumping straight to a solution, the students spent time with authentic users of their machines. Throughout the process, students worked with others, expressing the context through physical movement, clarifying their thoughts by drawing diagrams, and finding the sweet spot between coding, engineering design, and maths (see Figure 3).
Figure 3: Students used physical movements and user guides to be with others and publicly share and experience the task with authentic users (Sengupta, 2022). Click to enlarge.
In a third example research activity, racial segregation of US communities was discussed with pre-service teachers. The predominately white teachers found talking about the topic very difficult at the beginning of the activity. To overcome this hesitancy, teachers were first asked to work with a simulation that modelled the process of segregation through abstracted dots (or computational agents), a transitional other. Following this hypothetical representation, the context was then recontextualised through a map of real data points of the ethnicity of residents in an area of the US. This kind of map is called a Racial Dot Map based on US census data. When the teachers were able to interpret the link between the abstracted dot simulation and the real-world data they were able to talk about racism and segregation in a way they could not do before. The initial simulation and the recontextualisation were a pedagogical tool to reveal racism and provide a space where students felt comfortable discussing their values and beliefs that would otherwise have remained implicit.
Figure 4: To facilitate discussion of racial segregation, a simulation was used that bridges abstracted dots and real people, giving pre-service teachers a space to reflect on discrimination (Sengupta, 2022). Click to enlarge.
My takeaways
Pratim shared four implications of this research for computing pedagogy (see Figure 5).
Figure 5: Pratim’s four implications for pedagogy. Click to enlarge
As a researcher of pedagogy, these points provide takeaways that I can relate to my own research practice:
Code is a voice within an experience rather than symbols at a point in time. For example, when I listen to students predicting what a snippet of code will do, I think of the active nature of each carefully chosen command and how for each student, the code corresponds with them differently.
Code lives as a translation bridging many dimensions, such as data representation, algorithms, syntax, and user views. This statement resonates deeply with my liking of Carsten Schultes’s block model [1] but extends to include the people involved.
We should listen carefully and attentively to teachers, rather than making assumptions about what happens in classrooms. Teachers create new ideas. This takeaway is very important and reminds me about the trust and relationships built between teachers and researchers and how important it is to listen.
Uncertainty and ambiguity exist in learning, and this can take time to recognise. This final point makes me smile. As a developer, teacher, and researcher, I have found dealing with ambiguity hard at various points in my career. Still, over time, I think I am getting better at seeing it and celebrating it.
Listening to Pratim share his research on the teaching and learning of computing and the pitfalls of technocentrism has made me think deeply about how I view computer science as a subject and do research about it. I have shared some of my reflections in this blog, and I plan to incorporate the underlying theory and ideas in my ongoing research projects.
If you would like to find out more about Pratim’s work, please look over his slides, watch his presentation, read the upcoming chapter in our seminar proceedings, or respond to this blog by leaving a comment so we can discuss!
Computer programming is now part of the school curriculum in England and many other countries. Although not necessarily the primary focus of the computing curriculum, programming can be the area teachers find most challenging to teach. There is much evidence emerging from research on how to teach programming, particularly from projects with undergraduate learners. That’s why I recently wrote a report summarising over 170 programming pedagogy papers: Teaching programming in schools: A review of approaches and strategies.
I hope this blog post about how I approached writing the report whets your appetite to read it, and encourages you to read more research summaries in general.
My approach to summarising research papers
Summarising findings from more than 170 research papers into 34 pages was not a task for the faint-hearted. I could not have embarked on this task without previous experience of writing similar, smaller reviews; working on a host of research projects; and writing reports about research for many different audiences.
I love reading about computer science education. It evokes very strong emotions, making me by turns happy, curious, impressed, alarmed, and even cross. When I summarise the papers of other researchers, I am very careful when deciding what to include and what to leave out, in order to do the researchers’ work justice while not overselling it or misleading readers. Sometimes research papers can be hard to fathom, with lots of jargon and statistics. In other papers, the conclusions drawn have many limitations: the project the paper describes hasn’t produced robust enough evidence to give a clear, generalisable message. Academic integrity and not misrepresenting the work of others is paramount. And naturally, there are many more than 170 papers about teaching programming, but I had to stop somewhere. All this makes summarising research a tricky task that one has to undertake with great care.
Another important aspect of summarising research is how to group papers. A long list saying “this paper said this”, “this paper said that” would not be easy to access and would not draw out overall themes. Often research studies span many topics. What might be a helpful grouping for one reader might not be interesting for another.
For this report, I grouped papers into three sections:
Classroom strategies: Here I included well-researched classroom strategies that teachers can use to teach programming in schools
Contexts and environments for learning programming: Here I outlined research related to opportunities for teaching programming, including different programming languages and the classroom context
Supporting learners: Here I summarised research that helps teachers support learners, particularly learners who have difficulties with programming
Why you as a teacher should read research summaries
Teachers, as very busy professionals, have little time to replan lessons, and programming lessons are challenging to start with. However, the potential long-term benefit may outweigh the short-term cost when it comes to reading research summaries: new insights from firmly grounded research can improve your teaching and enable more of your learners to be successful.
The process of translating research into practice is an area that I and the research team here are particularly interested in investigating. We are looking forward to working with teachers to explore this.
The Raspberry Pi Foundation regularly shares research summaries in the form of:
In this blog post we explore good practices around creating online computing questions, specifically multiple choice questions (MCQs). Multiple choice questions are a popular way to help teachers and learners work out the next steps in learning, and to assess learning in examinations. As a case study, we look at some data related to learner responses to computing questions on the Oak National Academy platform.
The case study illustrates the many things MCQ authors have to think about while designing questions, and that there is much more research needed to understand how to get an MCQ “just right”.
Uses of multiple choice questions
Online auto-marked MCQs are now being integrated into classroom activities, set as homework, and used in self-led learning at home. Software products involving MCQs, such as Kahoot and Socratic, are easy to use for many, and have become popular in some learning contexts. MCQ may have become more prevalent due to increased online teaching and the availability of whole curricula through platforms such as the Oak National Academy.
Think about the thinking processes the learner will use when answering the question, and make sure the processes are productive for their learning
Don’t make the question super easy or too difficult, but make it challenging — the difficulty needs to be “just right”
Keep the phrasing of the question simple
Ensure that all answers are plausible; providing three or four answers is usually a good idea
Be aware that if learners pick the wrong answer, this can reinforce the wrong thinking
Provide corrective feedback to learners who pick the wrong answer
What I find particularly interesting about Andrew’s advice is the need to make the difficulty of the MCQ “just right” for learners. But what does “just right” look like in practice? More research is needed to work this out.
The anatomy of a multiple choice question
When talking about MCQs, there are technical terms to describe question features, e.g.:
Incorrect answers are called distractors (or lures)
A distractor is defined as plausible if it’s an answer a layperson would see as a reasonable answer
Plausible distractors are called working distractors
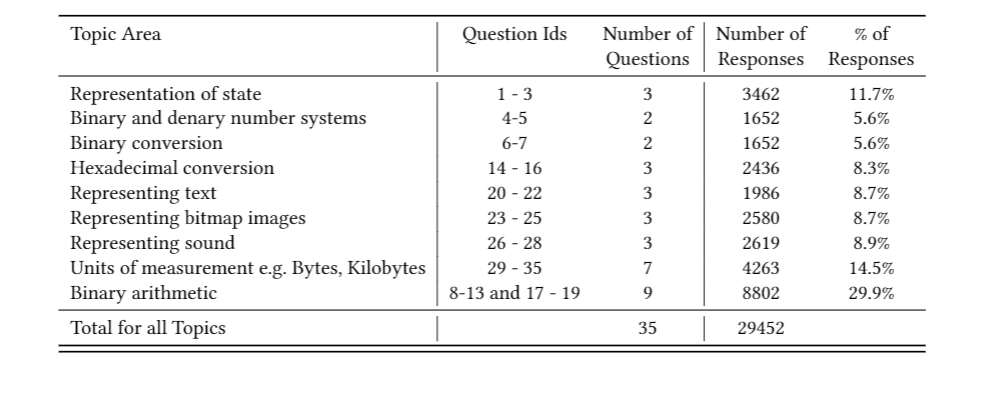
Over this period of four months, learners on the platform made more than 29,000 question attempts on the thirty-five questions across the nine lessons that make up this data representation unit. Here is a breakdown of the questions by topic area:
Responses to MCQs in the GCSE Computer Science data representation unit on Oak National Academy, data from February 2021 to end of May 2021 (click to enlarge)
As shown in the table, more questions relate to binary arithmetic than to any other topic area. This was a specific design decision, as it is well-known that learners need lots of practice of the processes involved in answering binary arithmetic questions.
Let’s look at an example question from the binary arithmetic topic area, with one correct answer and two distractors. The learning objective being addressed with this question is ‘Perform addition in binary on two binary numbers’.
One of the MCQs in the GCSE Computer Science data representation unit on the Oak National Academy, as displayed on the online platform
As shown in the table below, in four months, 1170 attempts were made to answer the example question. 65% of the attempts were correct responses, and 35% were not, with 21% of responses being distractor b, and 14% distractor c. These distractors appear to be working distractors, as they were chosen by more than 5% of learners, which has been suggested as a rule-of-thumb threshold that distractors have to clear to be classed as working.
Example MCQ in the GCSE Computer Science data representation unit on the Oak National Academy, plus response data from February 2021 to end of May 2021 (click to enlarge)
However, because of the lack of research into MCQs, we cannot say for certain that this question is “just right” — it may be too hard. We need to do further research to find this out.
Creating multiple choice questions is not easy
The process of creating good MCQs is not an easy task, because question authors need to think about many things, including:
What learning objectives are to be addressed
What plausible distractors can be used
What level of difficulty is right for learners
What type of thinking the questions are encouraging, and how this is useful for learners
In order for MCQs to be useful for learners and teachers, much more research is needed in this area to show how to reliably produce MCQs that are “just right” and encourage productive thinking processes. We are very much looking forward to looking at this topic in our research work.
To find out more about the computing education research we are doing, you can browse our website, take part in our monthly seminars, and read our publications.
How does teaching children and young people about machine learning (ML) differ from teaching them about other aspects of computing? Professor Matti Tedre and Dr Henriikka Vartiainen from the University of Eastern Finland shared some answers at our latest research seminar.
We need to determine how to teach young people about machine learning, and what teachers need to know to help their learners form correct mental models.
Their presentation, titled ‘ML education for K-12: emerging trajectories’, had a profound impact on my thinking about how we teach computational thinking and programming. For this blog post, I have simplified some of the complexity associated with machine learning for the benefit of readers who are new to the topic.
Machine learning is not magic — what needs to change in computing education to make sure learners don’t see ML systems as magic boxes?
Our seminars on teaching AI, ML, and data science
We’re currently partnering with The Alan Turing Institute to host a series of free research seminars about how to teach artificial intelligence (AI) and data science to young people.
The seminar with Matti and Henriikka, the third one of the series, was very well attended. Over 100 participants from San Francisco to Rajasthan, including teachers, researchers, and industry professionals, contributed to a lively and thought-provoking discussion.
Matti Tedre
Henriikka Vartiainen
Representing a large interdisciplinary team of researchers, Matti and Henriikka have been working on how to teach AI and machine learning for more than three years, which in this new area of study is a long time. So far, the Finnish team has written over a dozen academic papers based on their pilot studies with kindergarten-, primary-, and secondary-aged learners.
Current teaching in schools: classical rule-driven programming
Matti and Henriikka started by giving an overview of classical programming and how it is currently taught in schools. Classical programming can be described as rule-driven. Example features of classical computer programs and programming languages are:
A classical language has a strict syntax, and a limited set of commands that can only be used in a predetermined way
A classical language is deterministic, meaning we can guarantee what will happen when each line of code is run
A classical program is executed in a strict, step-wise order following a known set of rules
When we teach this type of programming, we show learners how to use a deductive problem solving approach or workflow: defining the task, designing a possible solution, and implementing the solution by writing a stepwise program that is then run on a computer. We encourage learners to avoid using trial and error to write programs. Instead, as they develop and test a program, we ask them to trace it line by line in order to predict what will happen when each line is run (glass-box testing).
The features of classical (rule-driven) programming approaches as taught in computer science education (CSE) (Tedre & Vartiainen, 2021).
Classical programming underpins the current view of computational thinking (CT). Our speakers called this version of CT ‘CT 1.0’. So what’s the alternative Matti and Henriikka presented, and how does it affect what computational thinking is or may become?
Machine learning (data-driven) models and new computational thinking (CT 2.0)
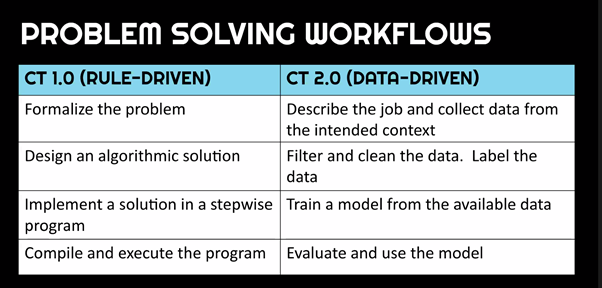
Rule-based programming languages are not being eradicated. Instead, software systems are being augmented through the addition of machine learning (data-driven) elements. Many of today’s successful software products, such as search engines, image classifiers, and speech recognition programs, combine rule-driven software and data-driven models. However, the workflows for these two approaches to solving problems through computing are very different.
Problem solving is very different depending on whether a rule-driven computational thinking (CT 1.0) approach or a data-driven computational thinking (CT 2.0) approach is used (Tedre & Vartiainen,2021).
Significantly, while in rule-based programming (and CT 1.0), the focus is on solving problems by creating algorithms, in data-driven approaches, the problem solving workflow is all about the data. To highlight the profound impact this shift in focus has on teaching and learning computing, Matti introduced us to a new version of computational thinking for machine learning, CT 2.0, which is detailed in a forthcoming research paper.
Because of the focus on data rather than algorithms, developing a machine learning model is not at all like developing a classical rule-driven program. In classical programming, programs can be traced, and we can predict what will happen when they run. But in data-driven development, there is no flow of rules, and no absolutely right or wrong answer.
There are major differences between rule-driven computational thinking (CT 1.0) and data-driven computational thinking (CT 2.0), which impact what computing education needs to take into account (Tedre & Vartiainen,2021).
Machine learning models are created iteratively using training data and must be cross-validated with test data. A tiny change in the data provided can make a model useless. We rarely know exactly why the output of an ML model is as it is, and we cannot explain each individual decision that the model might have made. When evaluating a machine learning system, we can only say how well it works based on statistical confidence and efficiency.
Machine learning education must cover ethical and societal implications
The ethical and societal implications of computer science have always been important for students to understand. But machine learning models open up a whole new set of topics for teachers and students to consider, because of these models’ reliance on large datasets, the difficulty of explaining their decisions, and their usefulness for automating very complex processes. This includes privacy, surveillance, diversity, bias, job losses, misinformation, accountability, democracy, and veracity, to name but a few.
I see the shift in problem solving approach as a chance to strengthen the teaching of computing in general, because it opens up opportunities to teach about systems, uncertainty, data, and society.
Jane Waite
Teaching machine learning: the challenges of magic boxes and new mental models
For teaching classical rule-driven programming, much time and effort has been put into researching learners’ understanding of what a program will do when it is run. This kind of understanding is called a learner’s mental model or notional machine. An approach teachers often use to help students develop a useful mental model of a program is to hide the detail of how the program works and only gradually reveal its complexity. This approach is described with the metaphor of hiding the detail of elements of the program in a box.
Data-driven models in machine learning systems are highly complex and make little sense to humans. Therefore, they may appear like magic boxes to students. This view needs to be banished. Machine learning is not magic. We have just not figured out yet how to explain the detail of data-driven models in a way that allows learners to form useful mental models.
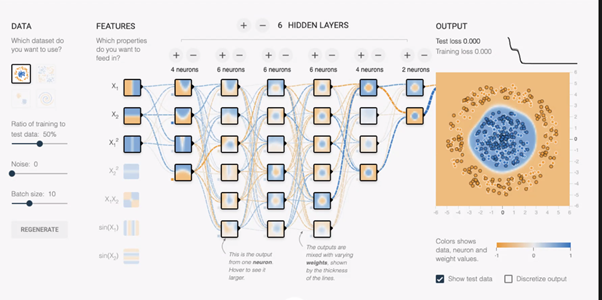
An example of a representation of a machine learning model in TensorFlow, an online machine learning tool (Tedre & Vartiainen,2021).
Some existing ML tools aim to help learners form mental models of ML, for example through visual representations of how a neural network works (see Figure 2). But these explanations are still very complex. Clearly, we need to find new ways to help learners of all ages form useful mental models of machine learning, so that teachers can explain to them how machine learning systems work and banish the view that machine learning is magic.
Some tools and teaching approaches for ML education
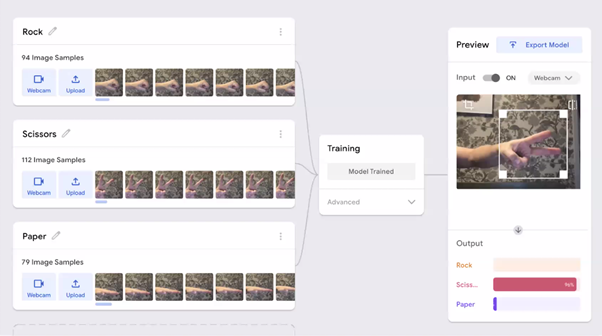
Matti and Henriikka’s team piloted different tools and pedagogical approaches with different age groups of learners. In terms of tools, since large amounts of data are needed for machine learning projects, our presenters suggested that tools that enable lots of data to be easily collected are ideal for teaching activities. Media-rich education tools provide an opportunity to capture still images, movements, sounds, or sense other inputs and then use these as data in machine learning teaching activities. For example, to create a machine learning–based rock-paper-scissors game, students can take photographs of their hands to train a machine learning model using Google Teachable Machine.
Photos of hands are used to train a Teachable Machine machine learning model as part of a project to create a rock-paper-scissors game (Tedre & Vartiainen, 2021).
Similar to tools that teach classic programming to novice students (e.g. Scratch), some of the new classroom tools for teaching machine learning have a drag-and-drop interface (e.g. Cognimates). Using such tools means that in lessons, there can be less focus on one of the more complex aspects of learning to program, learning programming language syntax. However, not all machine learning education products include drag-and-drop interaction, some instead have their own complex languages (e.g. Wolfram Programming Lab), which are less attractive to teachers and learners. In their pilot studies, the Finnish team found that drag-and-drop machine learning tools appeared to work well with students of all ages.
The different pedagogical approaches the Finnish research team used in their pilot studies included an exploratory approach with preschool children, who investigated machine learning recognition of happy or sad faces; and a project-based approach with older students, who co-created machine learning apps with web-based tools such as Teachable Machine and Learn Machine Learning (built by the research team), supported by machine learning experts.
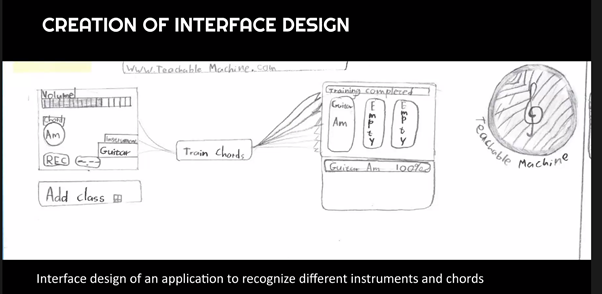
Example of a middle school (age 8 to 11) student’s design for a machine learning app that recognises different instruments and chords (Tedre & Vartiainen, 2021).
What impact these pedagogies have on students’ long-term mental models about machine learning has yet to be researched. If you want to find out more about the classroom pilot studies, the academic paper is a very accessible read.
My take-aways: new opportunities, new research questions
We all learned a tremendous amount from Matti and Henriikka and their perspectives on this important topic. Our seminar participants asked them many questions about the pedagogies and practicalities of teaching machine learning in class, and raised concerns about squeezing more into an already packed computing curriculum.
For me, the most significant take-away from the seminar was the need to shift focus from algorithms to data and from CT 1.0 to CT 2.0. Learning how to best teach classical rule-driven programming has been a long journey that we have not yet completed. We are forming an understanding of what concepts learners need to be taught, the progression of learning, key mental models, pedagogical options, and assessment approaches. For teaching data-driven development, we need to do the same.
The question of how we make sure teachers have the necessary understanding is key.
Jane Waite
I see the shift in problem solving approach as a chance to strengthen the teaching of computing in general, because it opens up opportunities to teach about systems, uncertainty, data, and society. I think it will help us raise awareness about design, context, creativity, and student agency. But I worry about how we will introduce this shift. In my view, there is a considerable risk that we will be sucked into open-ended, project-based learning, with busy and fun but shallow learning experiences that result in restricted conceptual development for students.
I also worry about how we can best help teachers build up the knowledge and experience to support their students. In the Q&A after the seminar, I asked Matti and Henriikka about the role of their team’s machine learning experts in their pilot studies. It seemed to me that without them, the pilot lessons would not have worked, as the participating teachers and students would not have had the vocabulary to talk about the process and would not have known what was doable given the available time, tools, and student knowledge.
The question of how we make sure teachers have the necessary understanding is key. Many existing professional development resources for teachers wanting to learn about ML seem to imply that teachers will all need a PhD in statistics and neural network optimisation to engage with machine learning education. This is misleading. But teachers do need to understand the machine learning concepts that their students need to learn about, and I think we don’t yet know exactly what these concepts are.
In summary, clearly more research is needed. There are fundamental questions still to be answered about what, when, and how we teach data-driven approaches to software systems development and how this impacts what we teach about classical, rule-based programming. But to me, that is exciting, and I am very much looking forward to the journey ahead.
We have another four seminars in our monthly series on AI, machine learning, and data science education. Find out more about them on this page, and catch up on past seminar blogs and recordings here.
At our next seminar on Tuesday 7 December at 17:00–18:30 GMT, we will welcome Professor Rose Luckin from University College London. She will be presenting on what it is about AI that makes it useful for teachers and learners.
PS You can build your understanding of machine learning by joining our latest free online course, where you’ll learn foundational concepts and train your own ML model!
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.