Post Syndicated from Diana Kirby original https://www.raspberrypi.org/blog/how-ai-shapes-your-feed-an-explainable-social-media-simulator-for-the-classroom/
Social media can have a powerful impact on the way we see and experience the world. What we see in our feeds is not random: it is determined by AI-driven systems that collect vast amounts of data, build user profiles, analyse engagement, and generate recommendations. But while young people are prolific users of social media, studies show that many have little understanding of what is happening ‘under the hood’

In our September research seminar, we welcomed back Henriikka Vartiainen and Matti Tedre from the University of Eastern Finland. They introduced Somekone, a social media simulator that is designed to help learners understand some of the fundamental processes behind social media platforms. Their team has been developing AI education materials and tools since 2019, including GenAI Teachable Machine, which they presented at our May research seminar.
Collaboration and co-design
Henriikka explained that the development of the Somekone tool emerged from the team’s long-term collaboration with teachers and schools in Finland. They co-developed the tool with the aim of making concepts like data collection, engagement, profiling, recommendations, filter bubbles, and polarisation visible and explainable for students aged 11 to 13 years old.

A four-phase learning model
Henriikka described the pedagogical model that the team follows in all of their AI education interventions. Their goal is not only to support students to develop their understanding of AI concepts, but also to foster ethical awareness and a sense of agency.
- Phase 1: Contextualisation and familiarisation
Students begin by discussing their experiences with social media and their initial ideas about how platforms such as TikTok, YouTube, and Instagram work. This activates students’ prior knowledge and helps connect the learning to their own interests. It also enables teachers to uncover any misconceptions the students may have. - Phase 2: Exploration
Students explore their initial ideas by experimenting with the Somekone tool. They discover how different types of data are collected and combined for profiling in a way that connects these new concepts to their own everyday lives. - Phase 3: Design and inquiry
Students explore the Somekone tool more deeply. Teachers guide them through activities where the students analyse, interpret, and discuss the data they can see in the tool. Importantly, the data they are using has all been gathered from their activity on the platform. Students can see how the likes, follows, and comments they and their classmates make change the images they are shown, and this is all real time. - Phase 4: Ethical and societal reflection
Students reflect on what they have learnt and consider the broader impacts of social media. Teachers encourage them to think critically, question the way social media platforms currently work, and imagine alternatives. At the end of the project, students write letters to decision-makers with their suggestions for how social media could better serve children’s interests.
Inside the simulator
Matti then gave a live demonstration of Somekone. Nothing compares to seeing the tool in action, so do check out the video of his demo here!
Students log on to the tool and are presented with an Instagram-style feed of images. They scroll through the feed and like, share, or comment on images that catch their attention or match their interests. For many students this is a very familiar type of environment, and they really enjoy playing with the app!

However, the unique value of Somekone is that it provides students with a real-time view of the way data is collected from every single user interaction, and demonstrates what is done with that data. It also allows students to experiment with a social media tool in the classroom without any data protection issues, as all of the data is stored locally.
Learners explore:
- Data collection in real time. Working in pairs, one student browses the image feed, while the other watches a live view of the data that the simulator is collecting every time their partner interacts with or simply pauses on a post.
- Profile building. Somekone shows how all this data accumulates to build a profile. Students watch their profiles developing based on the way they and their classmates are interacting with their feeds.
- Clustering and connections. Students then see how the tool groups profiles to create clusters of users with similar interests. Often friendship groups in the classroom are evident on screen because students sitting next to each other have all chosen to engage with the same things!
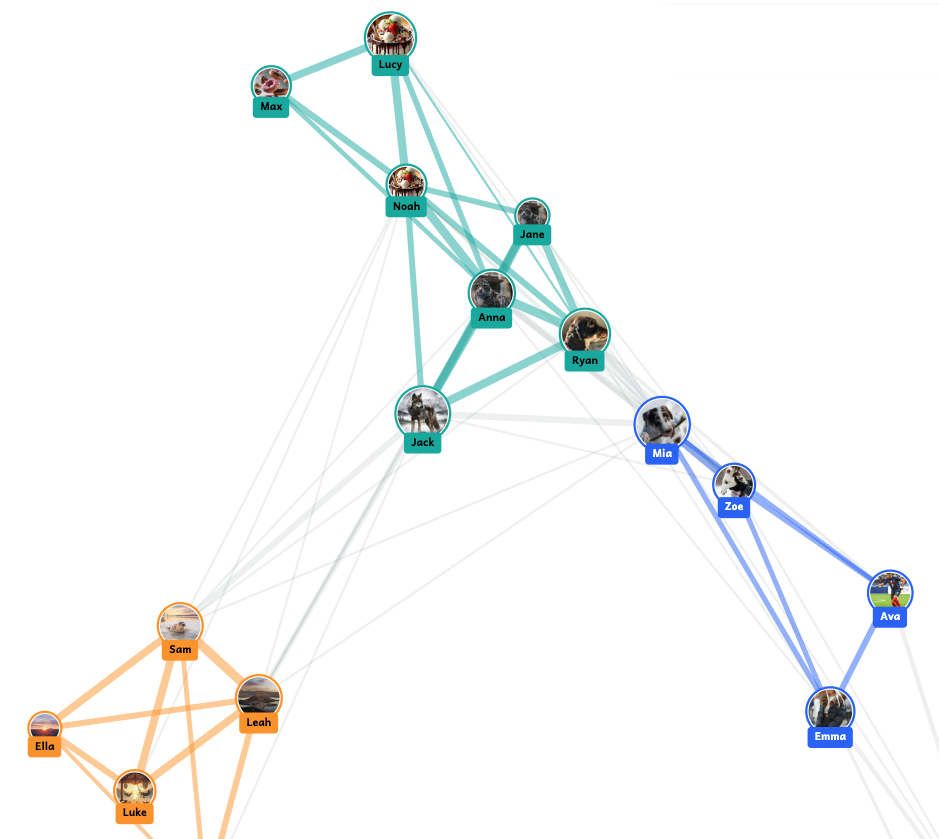
The simulator creates clusters of users with similar interests, which update in real time as students interact with posts on their feeds
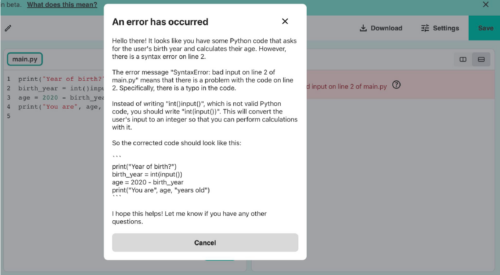
- Explainable recommendations. A key feature of Somekone is that it provides explanations for why it recommends posts to users. Students learn that recommendations can be based on various things, such as the image’s tag matching the tag on other posts they liked, or the image being popular among other users with similar profiles to theirs. These are the mechanisms that underpin real recommendation systems, but Somekone makes them explicit.
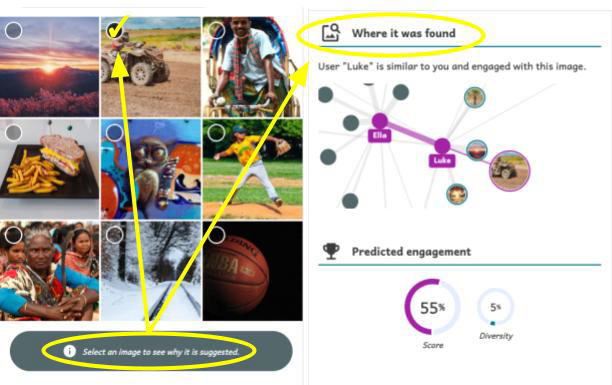
The tool provides an explanation for why each post is recommended
- Filter bubbles and polarisation. A filter bubble forms when a user only sees social media posts that match their existing interests or beliefs, due to highly personalised recommendation systems. Somekone presents this concept in a visually compelling way through a heatmap showing all the content in the system, with a colour scale indicating which posts are most likely to be shown to a particular user, and which they will never encounter. By comparing different users’ filter bubbles side by side, students start to understand how polarisation can arise. As Matti said: “If our feeds are so different from each other that I never see the pictures that you see and you never see the pictures I see, then […] we don’t even share the same reality”.

Two users’ heatmaps presented side by side, showing their respective filter bubbles
- Algorithm settings. A key learning opportunity is that students can adjust the algorithm’s parameters and observe how this changes their feed and their filter bubble. They can choose between personalised or non-personalised recommendations, select how posts are ranked, and decide whether to allow any diversity in the popularity of posts recommended to them. This is key to ‘opening up the box’.
For teachers, the tool has a simple guided interface to make it easy to use in class. There is also a button that teachers can use to pause the app, stopping students from scrolling (much to their dismay!) in order to focus their attention on the teacher when they are explaining concepts.
Evidence of impact
The research team used pre- and post-tests to evaluate what impact the intervention had on students’ understanding of social media mechanisms and on their sense of agency in relation to data. They conducted the post-test a week after the intervention, and then also did a delayed post-test six months later to see whether any changes were sustained. They found:
- Improved understanding of key concepts. Learners showed statistically significant improvements in identifying different types of data traces and in understanding how data profiling works. They also showed some improvement in grasping recommendation mechanisms.
- Retention over time. These improvements were generally still evident six months later, particularly in the case of understanding data traces.
- Stronger sense of agency. The team found that students’ sense of data agency improved after taking part in the intervention. This is really important as students are more likely to want to study a topic further if they have feelings of agency and self-efficacy.
Accessing the tool
The Somekone tool is freely available online — in Finnish, English, German, and French — at somekone.gen-ai.fi. The developer Nick Pope has also made the source code available on GitHub at github.com/knicos/genai-somekone.
However, the supporting materials and teacher resources are currently only available in Finnish and the underpinning pedagogies relate to the Finnish context.
Join our next seminar
Join us at our next seminar on Tuesday, 11 November from 17:00 to 18:30 GMT to hear Karl-Emil Bilstrup (Copenhagen University) speak about using the micro:bit to explore machine learning practices. We hope to see you there!
To sign up and take part in our research seminars, click below:
You can also view the schedule of our upcoming seminars, and catch up on past seminars on our previous seminars page.
The post How AI shapes your feed: An explainable social media simulator for the classroom appeared first on Raspberry Pi Foundation.