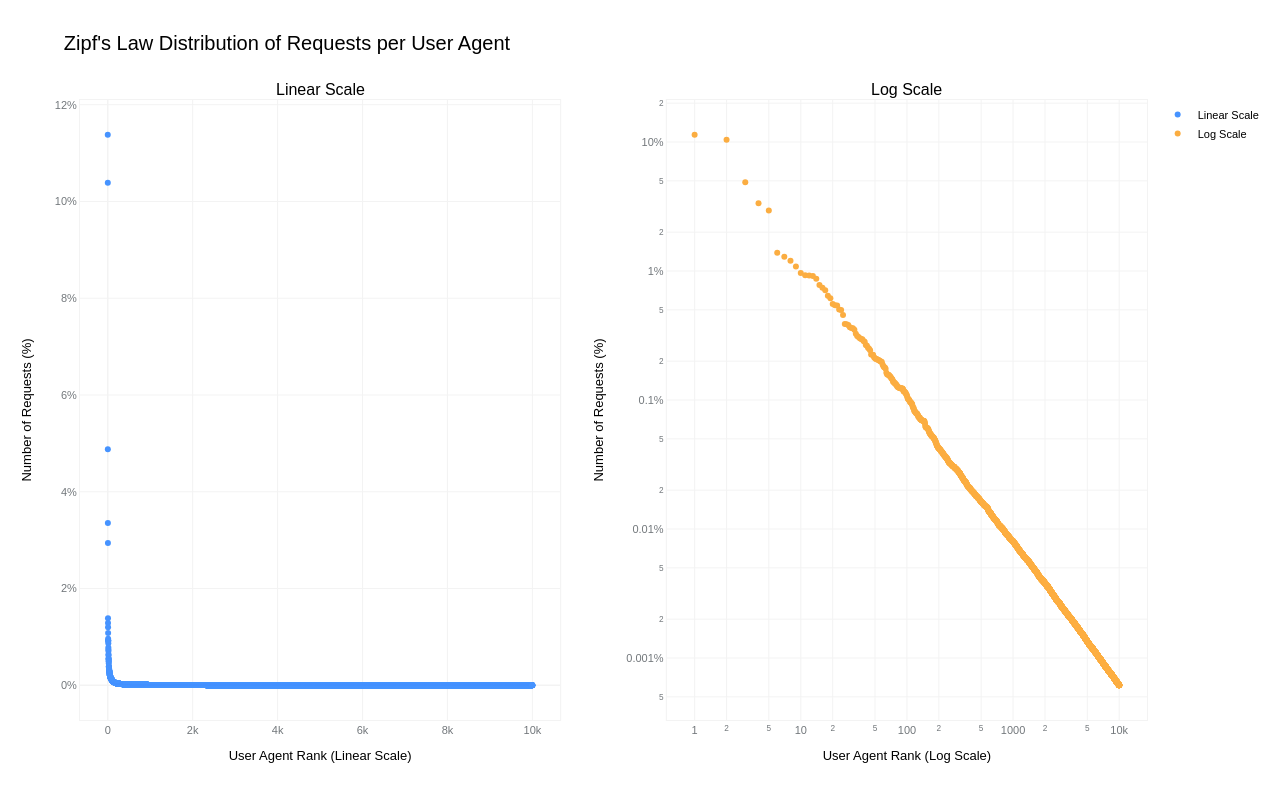
Post Syndicated from Alex Bocharov original https://blog.cloudflare.com/ja4-signals
For many years, Cloudflare has used advanced fingerprinting techniques to help block online threats, in products like our DDoS engine, our WAF, and Bot Management. For the purposes of Bot Management, fingerprinting characteristic elements of client software help us quickly identify what kind of software is making an HTTP request. It’s an efficient and accurate way to differentiate a browser from a Python script, while preserving user privacy. These fingerprints are used on their own for simple rules, and they underpin complex machine learning models as well.
Making sure our fingerprints keep pace with the pace of change on the Internet is a constant and critical task. Bots will always adapt to try and look more browser-like. Less frequently, browsers will introduce major changes to their behavior and affect the entire Internet landscape. Last year, Google did exactly that, making older TLS fingerprints almost useless for identifying the latest version of Chrome.
JA3 Fingerprint
JA3 fingerprint introduced by Salesforce researchers in 2017 and later adopted by Cloudflare, involves creating a hash of the TLS ClientHello message. This hash includes the ordered list of TLS cipher suites, extensions, and other parameters, providing a unique identifier for each client. Cloudflare customers can use JA3 to build detection rules and gain insight into their network traffic.
In early 2023, Google implemented a change in Chromium-based browsers to shuffle the order of TLS extensions – a strategy aimed at disrupting the detection capabilities of JA3 and enhancing the robustness of the TLS ecosystem. This modification was prompted by concerns that fixed fingerprint patterns could lead to rigid server implementations, potentially causing complications each time Chrome updates were rolled out. Over time, JA3 became less useful due to the following reasons:
-
Randomization of TLS extensions: Browsers began randomizing the order of TLS extensions in their ClientHello messages. This change meant that the JA3 fingerprints, which relied on the sequential order of these extensions, would vary with each connection, making it unreliable for identifying unique clients. (Further information can be found at Stamus Networks.)
-
Inconsistencies across tools: Different tools and databases that implemented JA3 fingerprinting often produced varying results due to discrepancies in how they handled TLS extensions and other protocol elements. This inconsistency hindered the effectiveness of JA3 fingerprints for reliable cross-organization sharing and threat intelligence. (Further information can be found at Fingerprint.)
-
Limited scope and lack of adaptability: JA3 focused solely on elements within the TLS ClientHello packet, covering only a narrow portion of the OSI model’s layers. This limited scope often missed crucial context about a client’s environment. Additionally, as newer transport layer protocols like QUIC became popular, JA3’s methodology – originally designed for older client implementations of TLS and not including modern protocols – proved ineffective.
Enter JA4 fingerprint
In response to these challenges, FoxIO developed JA4, a successor to JA3 that offers a more robust, adaptable, and reliable method for fingerprinting TLS clients across various protocols, including emerging standards like QUIC. Officially launched in September 2023, JA4 is part of the broader JA4+ suite that includes fingerprints for multiple protocols such as TLS, HTTP, and SSH. This suite is designed to be interpretable by both humans and machines, thereby enhancing threat detection and security analysis capabilities.
JA4 fingerprint is resistant to the randomization of TLS extensions and incorporates additional useful dimensions, such as Application Layer Protocol Negotiation (ALPN), which were not part of JA3. The introduction of JA4 has been met with positive reception in the cybersecurity community, with several open-source tools and commercial products beginning to incorporate it into their systems, including Cloudflare. The JA4 fingerprint is available under the BSD 3-Clause license, promoting seamless upgrades from JA3. Other fingerprints within the suite, such as JA4S (TLS Server Response) and JA4H (HTTP Client Fingerprinting), are licensed under the proprietary FoxIO License, which is designed for broader use but requires specific arrangements for commercial monetization.
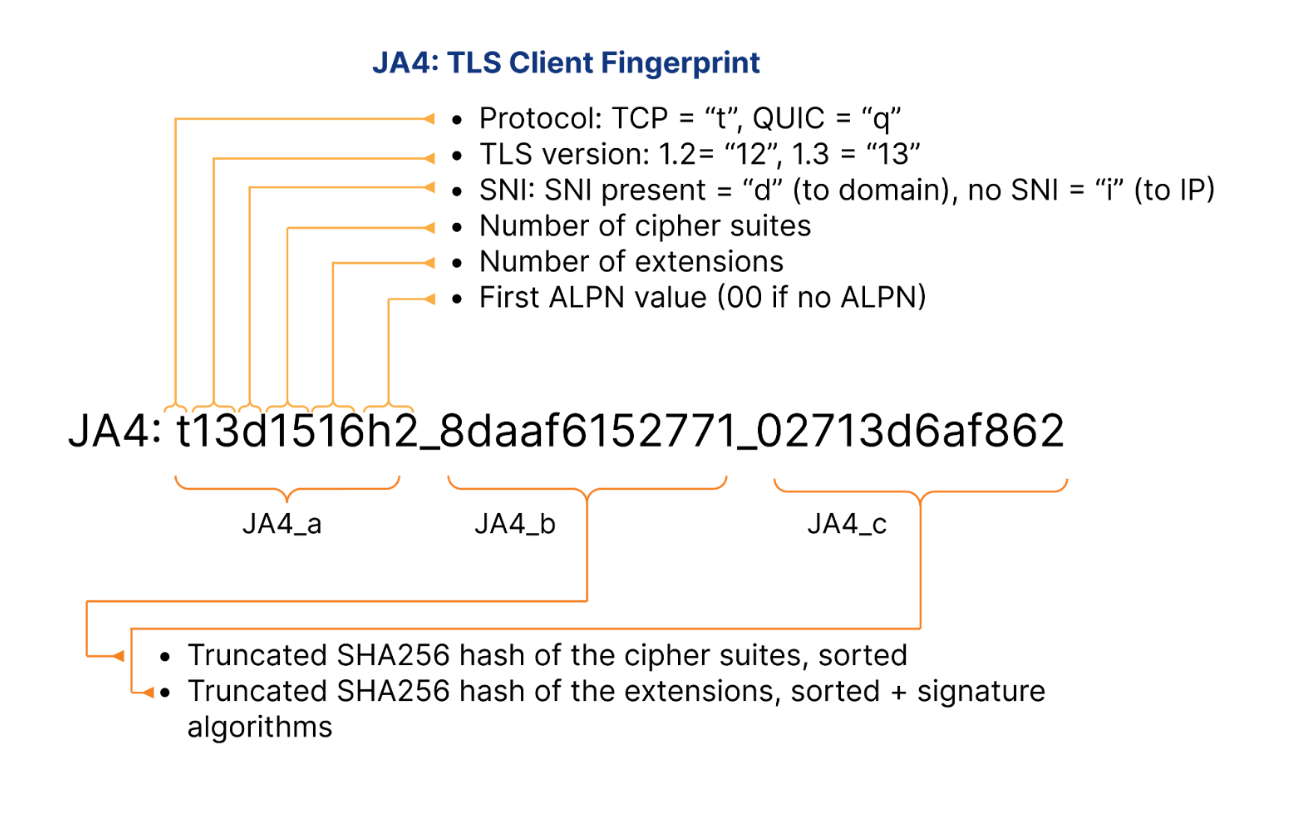
Let’s take a look at specific JA4 fingerprint example, representing the latest version of Google Chrome on Linux:
-
Protocol Identifier (t): Indicates the use of TLS over TCP. This identifier is crucial for determining the underlying protocol, distinguishing it from q for QUIC or d for DTLS.
-
TLS Version (13): Represents TLS version 1.3, confirming that the client is using one of the latest secure protocols. The version number is derived from analyzing the highest version supported in the ClientHello, excluding any GREASE values.
-
SNI Presence (d): The presence of a domain name in the Server Name Indication. This indicates that the client specifies a domain (d), rather than an IP address (i would indicate the absence of SNI).
-
Cipher Suites Count (15): Reflects the total number of cipher suites included in the ClientHello, excluding any GREASE values. It provides insight into the cryptographic options the client is willing to use.
-
Extensions Count (16): Indicates the count of distinct extensions presented by the client in the ClientHello. This measure helps identify the range of functionalities or customizations the client supports.
-
ALPN Values (h2): Represents the Application-Layer Protocol Negotiation protocol, in this case, HTTP/2, which indicates the protocol preferences of the client for optimized web performance.
-
Cipher Hash (8daaf6152771): A truncated SHA256 hash of the list of cipher suites, sorted in hexadecimal order. This unique hash serves as a compact identifier for the client’s cipher suite preferences.
-
Extension Hash (02713d6af862): A truncated SHA256 hash of the sorted list of extensions combined with the list of signature algorithms. This hash provides a unique identifier that helps differentiate clients based on the extensions and signature algorithms they support.
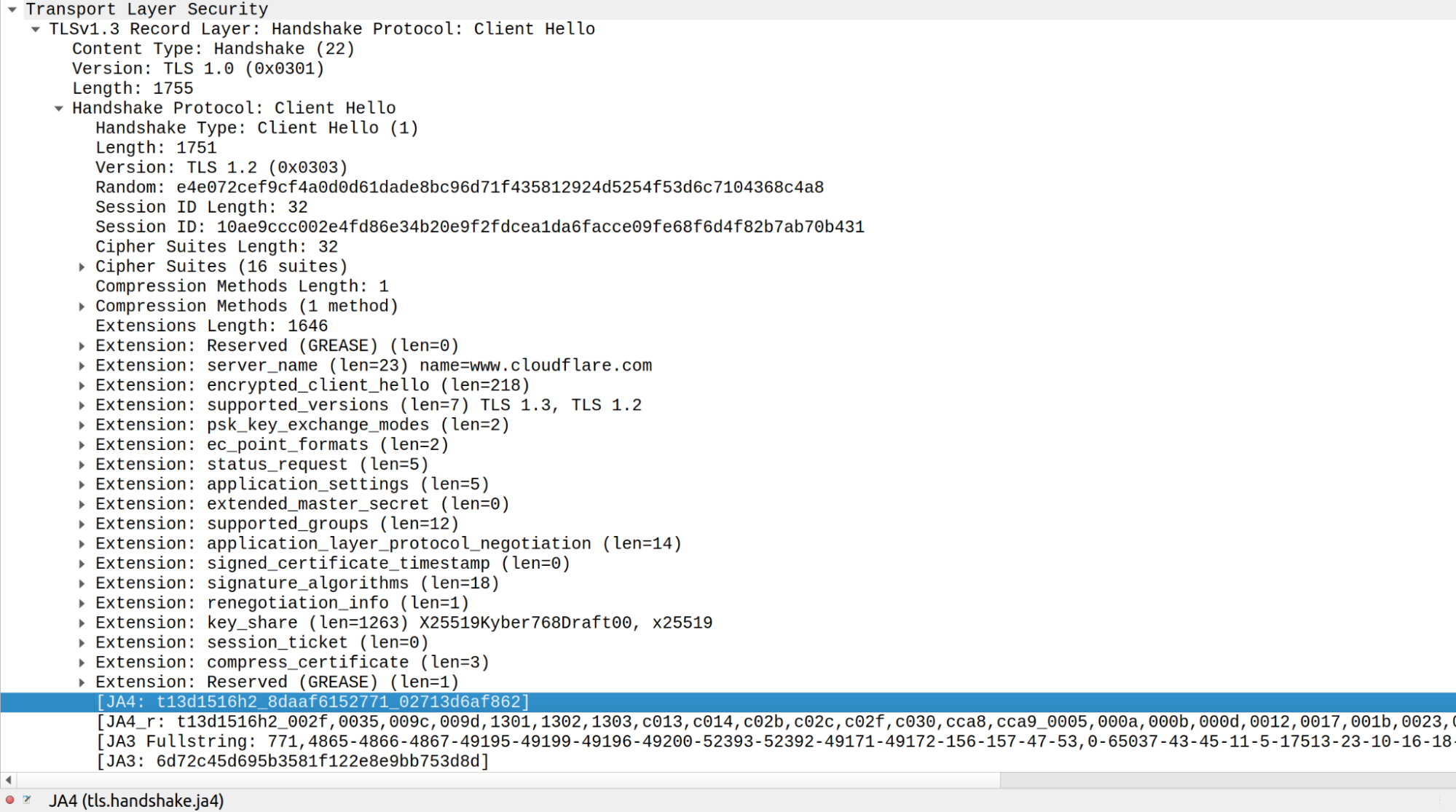
Here is a Wireshark example of TLS ClientHello from the latest Chrome on Linux querying https://www.cloudflare.com:
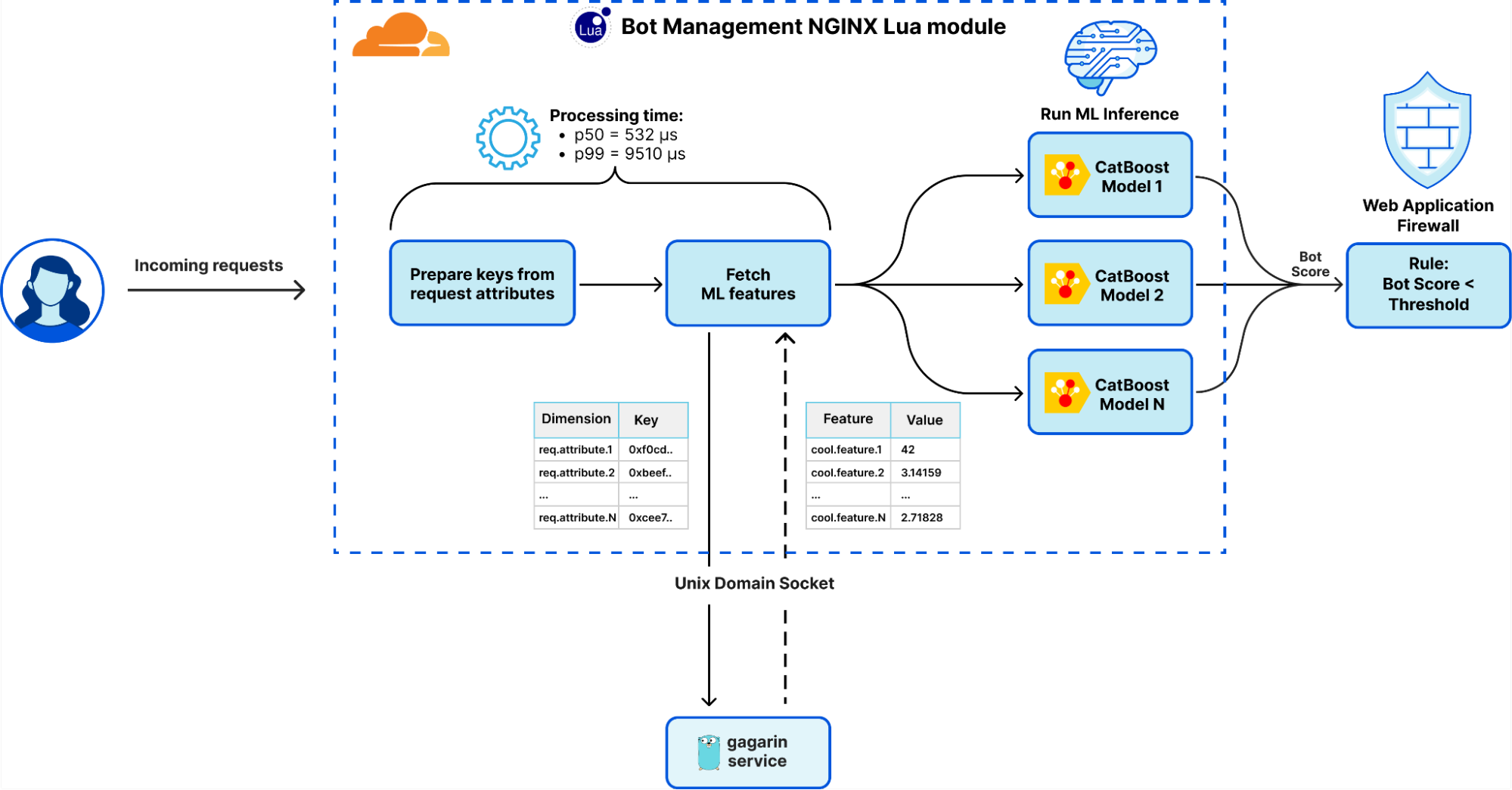
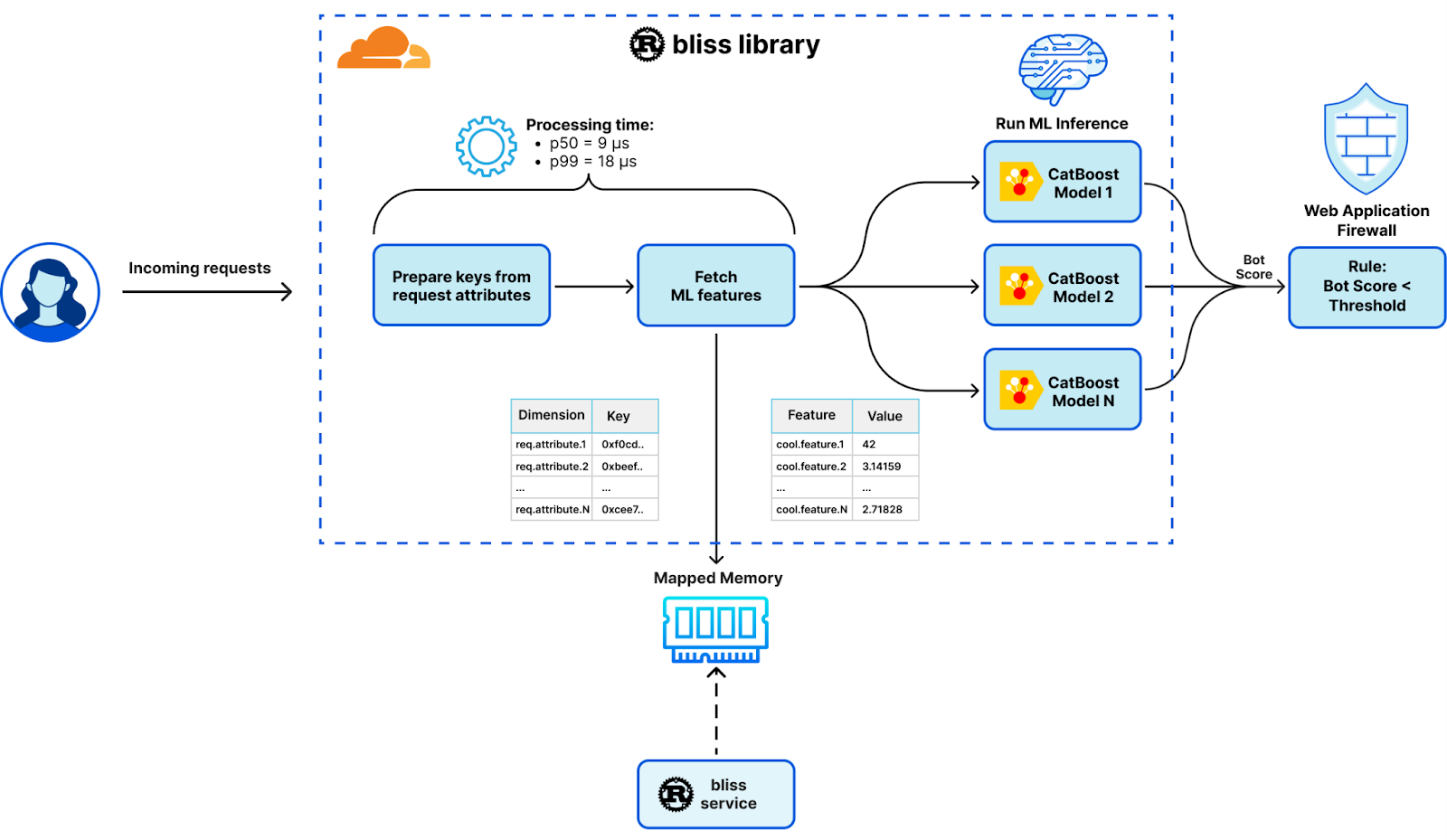
Integrating JA4 support into Cloudflare required rethinking our approach to parsing TLS ClientHello messages, which were previously handled in separate implementations across C, Lua, and Go. Recognizing the need to boost performance and ensure memory safety, we developed a new Rust-based crate, client-hello-parser. This unified parser not only simplifies modifications by centralizing all related logic but also prepares us for future transitions, such as replacing nginx with an upcoming Rust-based service. Additionally, this streamlined parser facilitates the exposure of JA4 fingerprints across our platform, improving the integration with Cloudflare’s firewall rules, Workers, and analytics systems.
Parsing ClientHello
client-hello-parser is an internal Rust crate designed for parsing TLS ClientHello messages. It aims to simplify the process of analyzing TLS traffic by providing a straightforward way to decode and inspect the initial handshake messages sent by clients when establishing TLS connections. This crate efficiently populates a ClientHelloParsed struct with relevant parsed fields, including version 1 and version 2 fingerprints, and JA3 and JA4 hashes, which are essential for network traffic analysis and fingerprinting.
Key benefits of the client-hello-parser library include:
-
Optimized memory usage: The library achieves amortized zero heap allocations, verified through extensive testing with the dhat crate to track memory allocations. Utilizing the tiny_vec crate, it begins with stack allocations for small vectors backed by fixed-size arrays, resorting to heap allocations only when these vectors exceed their initial size. This method ensures efficient reuse of all vectors, maintaining amortized zero heap allocations.
-
Memory safety: Reinforced by Rust’s robust borrow checker and complemented by extensive fuzzing, which has helped identify and resolve potential security vulnerabilities previously undetected in C implementations.
-
Ultra-low latency: The parser benefits from using faster_hex for efficient hex encoding/decoding, which utilizes SIMD instructions to speed up processing. The use of Rust iterators also helps in optimizing performance, often allowing the compiler to generate SIMD-optimized assembly code. This efficiency is further enhanced through the use of BigEndianIterator, which allows for efficient streaming-like processing of TLS ClientHello bytes in a single pass.
Parser benchmark results:
client_hello_benchmark/parse/parse-short-502
time: [497.15 ns 497.23 ns 497.33 ns]
thrpt: [2.0107 Melem/s 2.0111 Melem/s 2.0115 Melem/s]
client_hello_benchmark/parse/parse-long-1434
time: [992.82 ns 993.55 ns 994.99 ns]
thrpt: [1.0050 Melem/s 1.0065 Melem/s 1.0072 Melem/s]The benchmark results demonstrate that the parser efficiently handles different sizes of ClientHello messages, with shorter messages being processed at a rate of approximately 2 million elements per second, and longer messages at around 1 million elements per second, showcasing the effectiveness of SIMD optimizations and Rust’s iterator performance in real-world applications.
Robust testing suite: Includes dozens of real-life TLS ClientHello message examples, with parsed components verified against Wireshark with JA3 and JA4 plugins. Additionally, Cargo fuzzer with memory sanitizer ensures no memory leaks or edge cases leading to core dumps. Backward compatibility tests with the legacy C parser, imported as a dependency and called via FFI, confirm that both parsers yield equivalent results.
Seamless integration with nginx: The crate, compiled as a dynamic library, is linked to the nginx binary, ensuring a smooth transition from the legacy parser to the new Rust-based parser through backwards compatibility tests.
The transition to a new Rust-based parser has enabled the retirement of multiple implementations across different languages (C, Lua, and Go), significantly enhancing performance and parser robustness against edge cases. This shift also facilitates the easier integration of new features and business logic for parsing TLS ClientHello messages, streamlining future expansions and security updates.
With Cloudflare JA4 fingerprints implemented on our network, we were left with another problem to solve. When JA3 was released, we saw some scenarios where customers were surprised by traffic from a new JA3 fingerprint and blocked it, only to find the fingerprint was a new browser release, or an OS update had caused a change in the fingerprint used by their mobile device. By giving customers just a hash, customers still lack context. We wanted to give our customers the necessary context to help them make informed decisions about the safety of a fingerprint, so they can act quickly and confidently on it. As more of our customers embrace AI, we’ve heard more demand from our customers to break out the signals that power our bot detection. These customers want to run complex models on proprietary data that has to stay in their control, but they want to have Cloudflare’s unique perspective on Internet traffic when they do it. To us, both use cases sounded like the same problem.
Enter JA4 Signals
In the ever-evolving landscape of web security, traditional fingerprinting techniques like JA3 and JA4 have proven invaluable for identifying and managing web traffic. However, these methods alone are not sufficient to address the sophisticated tactics employed by malicious agents. Fingerprints can be easily spoofed, they change frequently, and traffic patterns and behaviors are constantly evolving. This is where JA4 Signals come into play, providing a robust and comprehensive approach to traffic analysis.
JA4 Signals are inter-request features computed based on the last hour of all traffic that Cloudflare sees globally. On a daily basis, we analyze over 15 million unique JA4 fingerprints generated from more than 500 million user agents and billions of IP addresses. This breadth of data enables JA4 Signals to provide aggregated statistics that offer deeper insights into global traffic patterns – far beyond what single-request or connection fingerprinting can achieve. These signals are crucial for enhancing security measures, whether through simple firewall rules, Workers scripts, or advanced machine learning models.
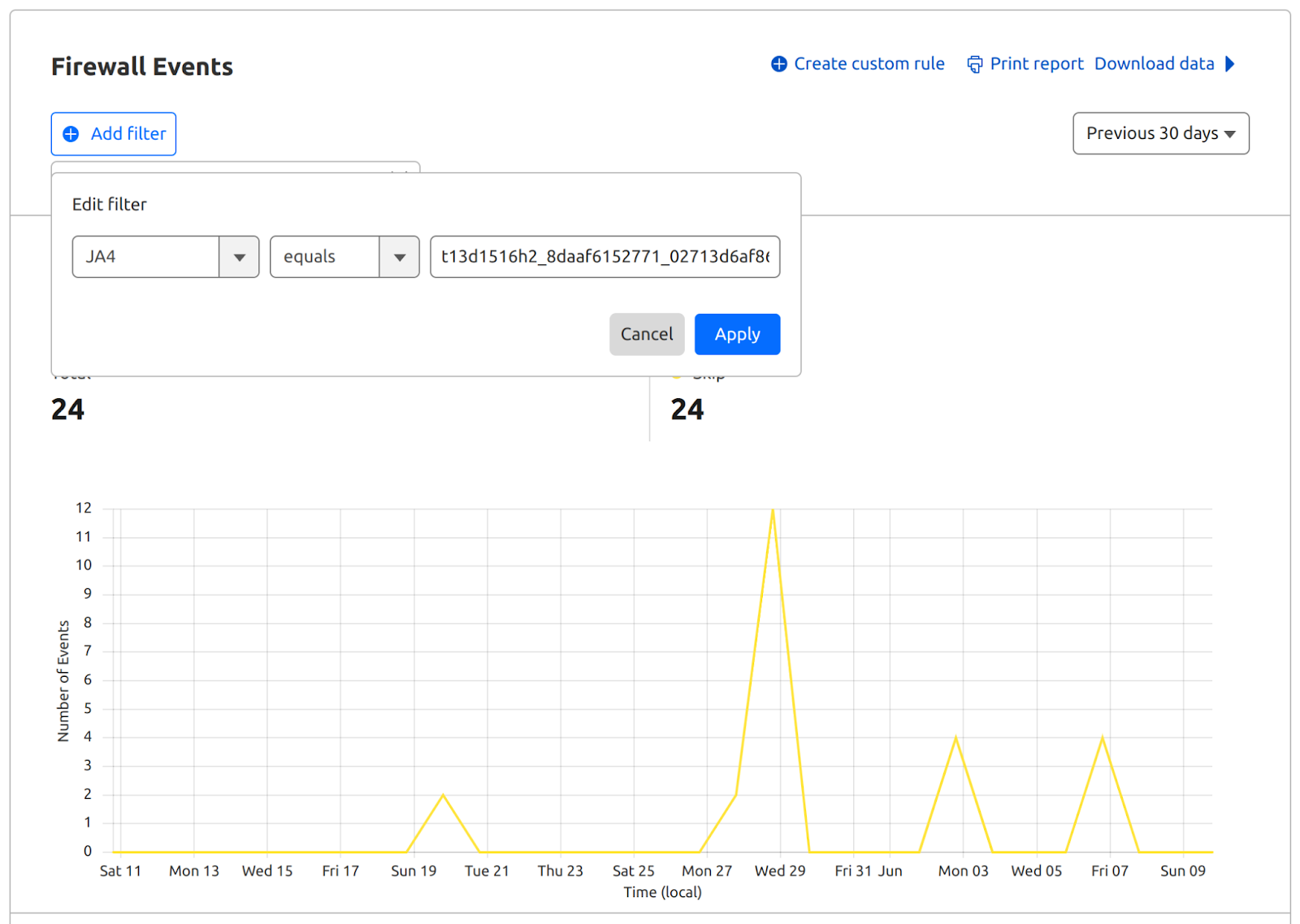
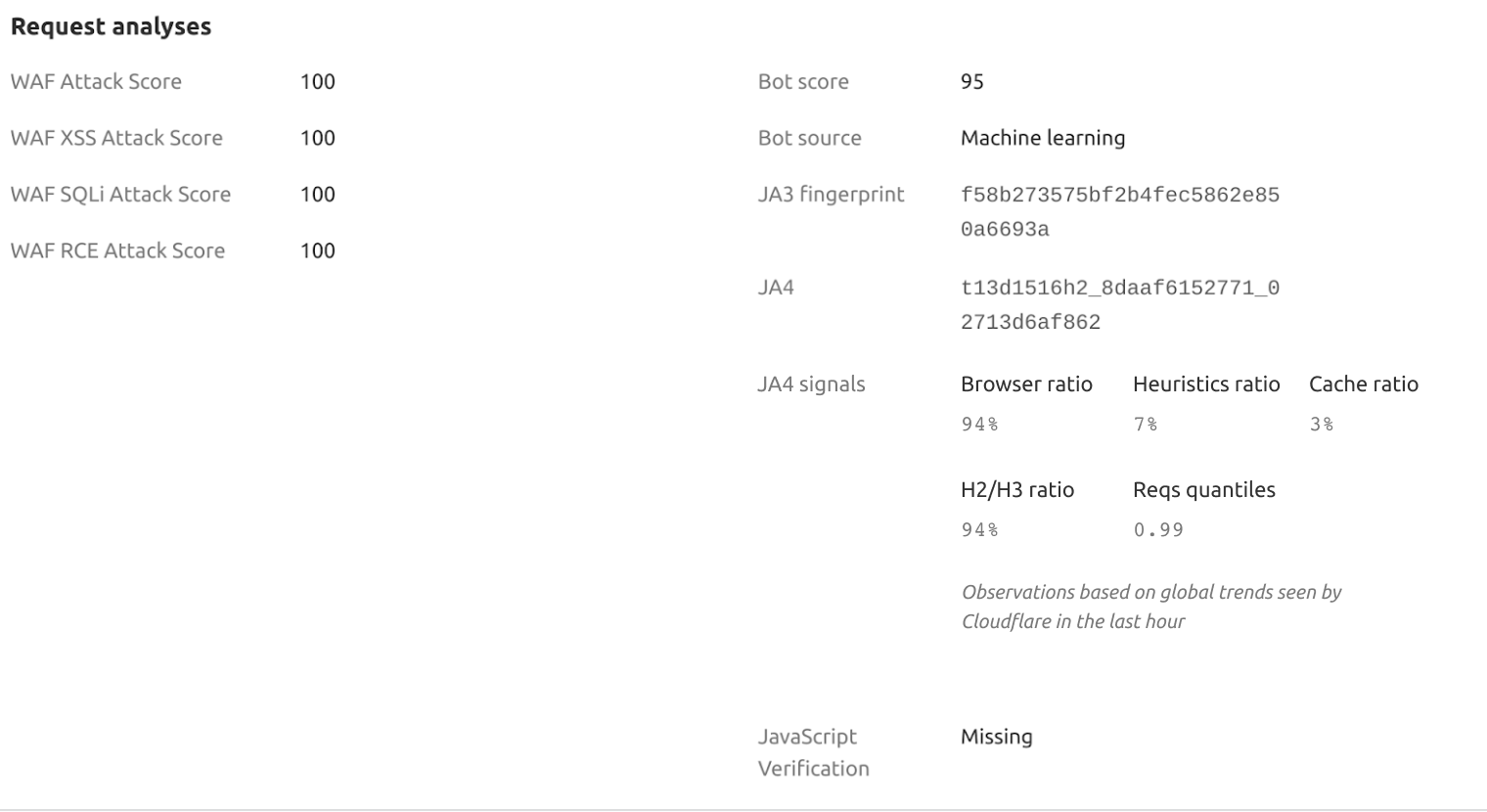
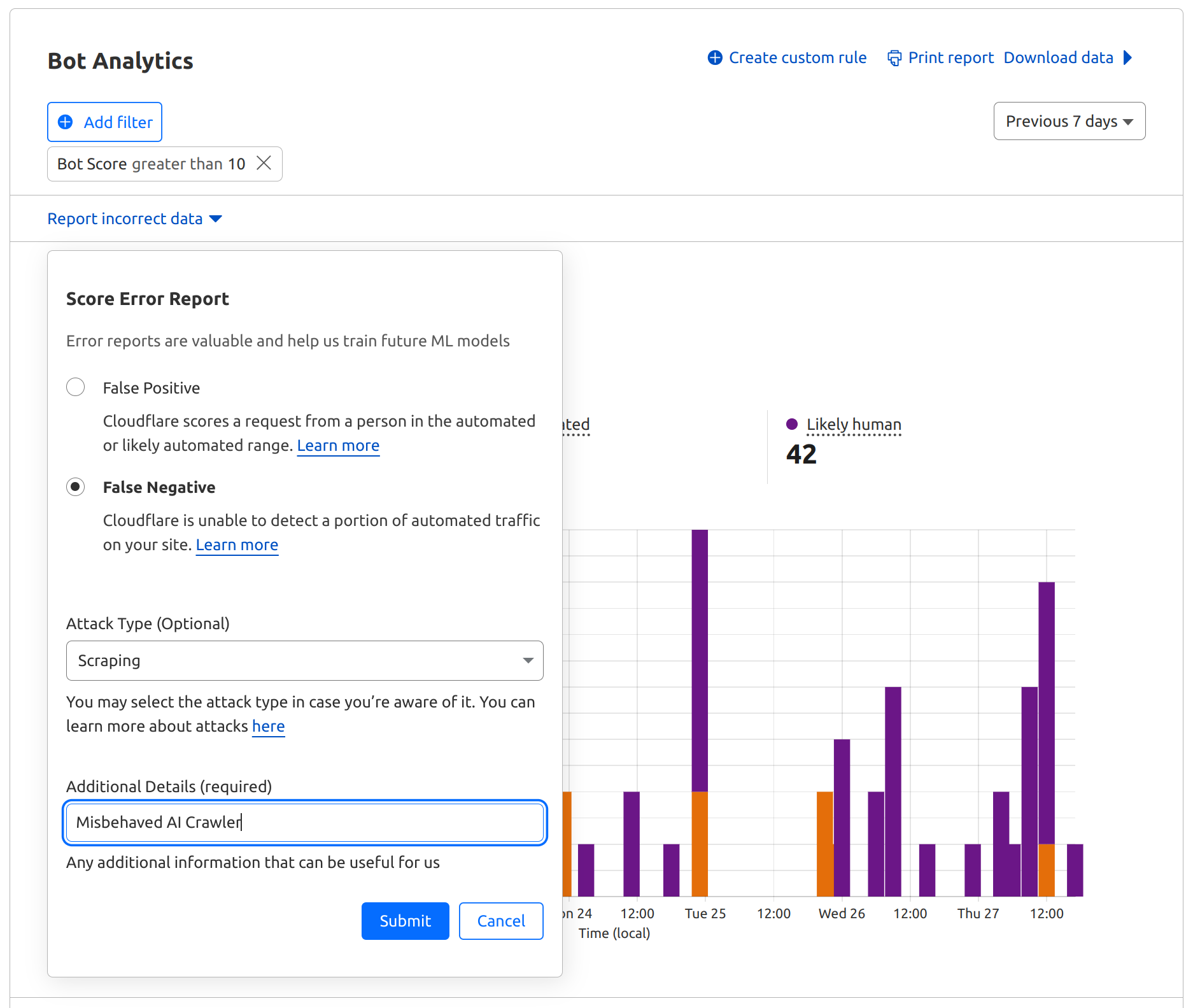
Let’s consider a specific example of JA4 Signals from a Firewall events activity log, which involves the latest version of Chrome:
This example highlights that a particular HTTP request received a Bot Score of 95, suggesting it likely originated from a human user operating a browser rather than an automated program or a bot. Analyzing JA4 Signals in this context provides deeper insight into the behavior of this client (latest Linux Chrome) in comparison to other network clients and their respective JA4 fingerprints. Here are a few examples of the signals our customers can see on any request:
|
JA4 Signal |
Description |
Value example |
Interpretation |
|
browser_ratio_1h |
The ratio of requests originating from browser-based user agents for the JA4 fingerprint in the last hour. Higher values suggest a higher proportion of browser-based requests. |
0.942 |
Indicates a 94.2% browser-based request rate for this JA4. |
|
cache_ratio_1h |
The ratio of cacheable responses for the JA4 fingerprint in the last hour. Higher values suggest a higher proportion of responses that can be cached. |
0.534 |
Shows a 53.4% cacheable response rate for this JA4. |
|
h2h3_ratio_1h |
The ratio of HTTP/2 and HTTP/3 requests combined with the total number of requests for the JA4 fingerprint in the last hour. Higher values indicate a higher proportion of HTTP/2 and HTTP/3 requests compared to other protocol versions. |
0.987 |
Reflects a 98.7% rate of HTTP/2 and HTTP/3 requests. |
|
reqs_quantile_1h |
The quantile position of the JA4 fingerprint based on the number of requests across all fingerprints in the last hour. Higher values indicate a relatively higher number of requests compared to other fingerprints. |
1 |
High volume of requests compared to other JA4s. |
The JA4 fingerprint and JA4 Signals are now available in the Firewall Rules UI, Bot Analytics and Workers. Customers can now use these fields to write custom rules, rate-limiting rules, transform rules, or Workers logic using JA4 fingerprint and JA4 Signals.
Let’s demonstrate how to use JA4 Signals with the following Worker example. This script processes incoming requests by parsing and categorizing JA4 Signals, providing a clear structure for further analysis or rule application within Cloudflare Workers:
/**
* Event listener for 'fetch' events. This triggers on every request to the worker.
*/
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
/**
* Main handler for incoming requests.
* @param {Request} request - The incoming request object from the fetch event.
* @returns {Response} A response object with JA4 Signals in JSON format.
*/
async function handleRequest(request) {
// Safely access the ja4Signals object using optional chaining, which prevents errors if properties are undefined.
const ja4Signals = request.cf?.botManagement?.ja4Signals || {};
// Construct the response content, including both the original ja4Signals and the parsed signals.
const responseContent = {
ja4Signals: ja4Signals,
jaSignalsParsed: parseJA4Signals(ja4Signals)
};
// Return a JSON response with appropriate headers.
return new Response(JSON.stringify(responseContent), {
status: 200,
headers: {
"content-type": "application/json;charset=UTF-8"
}
})
}
/**
* Parses the JA4 Signals into categorized groups based on their names.
* @param {Object} ja4Signals - The JA4 Signals object that may contain various metrics.
* @returns {Object} An object with categorized JA4 Signals: ratios, ranks, and quantiles.
*/
function parseJA4Signals(ja4Signals) {
// Define the keys for each category of signals.
const ratios = ['h2h3_ratio_1h', 'heuristic_ratio_1h', 'browser_ratio_1h', 'cache_ratio_1h'];
const ranks = ['uas_rank_1h', 'paths_rank_1h', 'reqs_rank_1h', 'ips_rank_1h'];
const quantiles = ['reqs_quantile_1h', 'ips_quantile_1h'];
// Return an object with each category containing only the signals that are present.
return {
ratios: filterKeys(ja4Signals, ratios),
ranks: filterKeys(ja4Signals, ranks),
quantiles: filterKeys(ja4Signals, quantiles)
};
}
/**
* Filters the keys in the ja4Signals object that match the list of specified keys and are not undefined.
* @param {Object} ja4Signals - The JA4 Signals object.
* @param {Array} keys - An array of keys to filter from the ja4Signals object.
* @returns {Object} A filtered object containing only the specified keys that are present in ja4Signals.
*/
function filterKeys(ja4Signals, keys) {
const filtered = {};
// Iterate over the specified keys and add them to the filtered object if they exist in ja4Signals.
keys.forEach(key => {
// Check if the key exists and is not undefined to handle optional presence of each signal.
if (ja4Signals && ja4Signals[key] !== undefined) {
filtered[key] = ja4Signals[key];
}
});
return filtered;
}Benefits of JA4 Signals
-
Comprehensive traffic analysis: JA4 Signals aggregate data over an hour to provide a holistic view of traffic patterns. This method enhances the ability to identify emerging threats and abnormal behaviors by analyzing changes over time rather than in isolation.
-
Precision in anomaly detection: Leveraging detailed inter-request features, JA4 Signals enable the precise detection of anomalies that may be overlooked by single-request fingerprinting. This leads to more accurate identification of sophisticated cyber threats.
-
Globally scalable insights: By synthesizing data at a global scale, JA4 Signals harness the strength of Cloudflare’s network intelligence. This extensive analysis makes the system less susceptible to manipulation and provides a resilient foundation for security protocols.
-
Dynamic security enforcement: JA4 Signals can dynamically inform security rules, from simple firewall configurations to complex machine learning algorithms. This adaptability ensures that security measures evolve in tandem with changing traffic patterns and emerging threats.
-
Reduction in false positives and negatives: With the detailed insights provided by JA4 Signals, security systems can distinguish between legitimate and malicious traffic more effectively, reducing the occurrence of false positives and negatives and improving overall system reliability.
Conclusion
The introduction of JA4 fingerprint and JA4 Signals marks a significant milestone in advancing Cloudflare’s security offerings, including Bot Management and DDoS protection. These tools not only enhance the robustness of our traffic analysis but also showcase the continuous evolution of our network fingerprinting techniques. The efficiency of computing JA4 fingerprints enables real-time detection and response to emerging threats. Similarly, by leveraging aggregated statistics and inter-request features, JA4 Signals provide deep insights into traffic patterns at speeds measured in microseconds, ensuring that no detail is too small to be captured and analyzed.
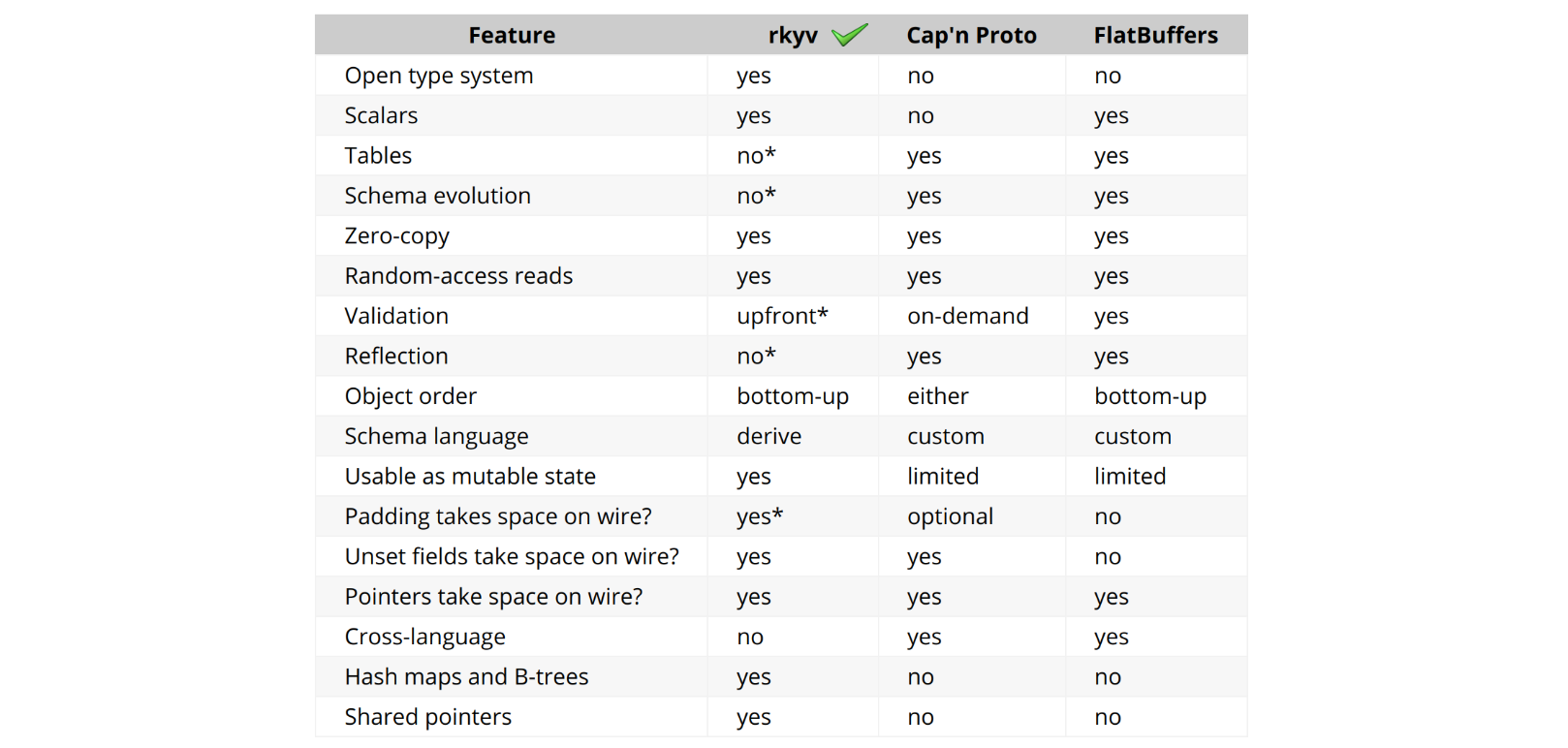
These security features are underpinned by the scalable techniques and open-sourced libraries outlined in “Every request, every microsecond: scalable machine learning at Cloudflare”. This discussion highlights how Cloudflare’s innovations not only analyze vast amounts of data but also transform this analysis into actionable, reliable, and dynamically adaptable security measures.
Any Enterprise business with a bot problem will benefit from Cloudflare’s unique JA4 implementation and our perspective on bot traffic, but customers who run their own internal threat models will also benefit from access to data insights from a network that processes over 50 million requests per second. Please get in touch with us to learn more about our Bot Management offering.