Post Syndicated from Hyeonho Kim original https://aws.amazon.com/blogs/architecture/how-karrot-built-a-feature-platform-on-aws-part-1-motivation-and-feature-serving/
This post is co-written with Hyeonho Kim, Jinhyeong Seo and Minjae Kwon from Karrot.
Karrot is Korea’s leading local community and a service centered on all possible connections in the neighborhood. Beyond simple flea markets, it strengthens connections between neighbors, local stores, and public institutions, and creates a warm and active neighborhood as its core value.
Karrot uses a recommendation system to provide users with connections that match their interests and neighborhoods, and to provide personalized experiences. In particular, you can check customized content on the home screen of the Karrot application. Personalized content is continuously updated by analyzing the user’s activity patterns without having to set a special interest category. The core of the feed is to provide new and interesting content, and Karrot is constantly working to improve user satisfaction for this purpose. Karrot actively uses a recommendation system to provide personalized and recommended content. In this system, the feature platform plays a key role along with the machine learning (ML) recommendation model. The feature platform acts as a data store that stores and serves data necessary for the ML recommendation model, such as the user’s behavior history and article information.
This two-part series starts by presenting our motivation, our requirements, and the solution architecture, focusing on feature serving. Part 2 covers the process of collecting features in real-time and batch ingestion into an online store, and the technical approaches for stable operation.
Background of the feature platform at Karrot
Karrot recognized the need for a feature platform in early 2021, about 2 years after implementing a recommendation system in their application. At that time, Karrot was achieving significant growth in various metrics through active usage of the recommendation system. By showing personalized feeds to each user beyond chronological feeds, they observed a more than 30% increase in click-through rates and higher user satisfaction. As the recommendation system’s impact continued to grow, the ML team naturally faced the challenge of advancing the system.
In ML-based systems, various high-quality input data (clicks, conversion actions, and so on) is considered a crucial element. These input data are typically called features. At Karrot, data including user behavior logs, action logs, and status values are collectively referred to as user features, and logs related to articles are called article features.
To improve the accuracy of personalized recommendations, various types of features are needed. A system that can efficiently manage these features and quickly deliver them to ML recommendation models is essential. Here, serving means the process of providing real-time data needed when the recommendation system suggests personalized content to users. However, the feature management approach in the existing recommendation system had some limitations, with the following key issues:
- Dependency on flea market server – Because the initial recommendation system existed as an internal library on the flea market server, the source code of the web application had to be changed whenever the recommendation logic was modified or a feature was added. This reduced the flexibility of deployment and made it difficult to optimize resources.
- Limited scalability of recommendation logic and features – The initial recommendation system directly depended on the flea market database and only considered flea market articles. This made it impossible to expand to new article types like local community, local jobs, and advertisements, which are managed by different data sources. Additionally, feature-related code was hardcoded, making it difficult to explore, add, or modify features.
- Lack of feature data source reliability – Although features were retrieved from various repositories such as Amazon Simple Storage Service (Amazon S3), Amazon ElastiCache, and Amazon Aurora, the reliability of data quality was low due to the lack of a consistent schema and collection pipeline. This was a major limitation in securing the latest features and consistency.
The following diagram illustrates the initial recommendation system backend structure.
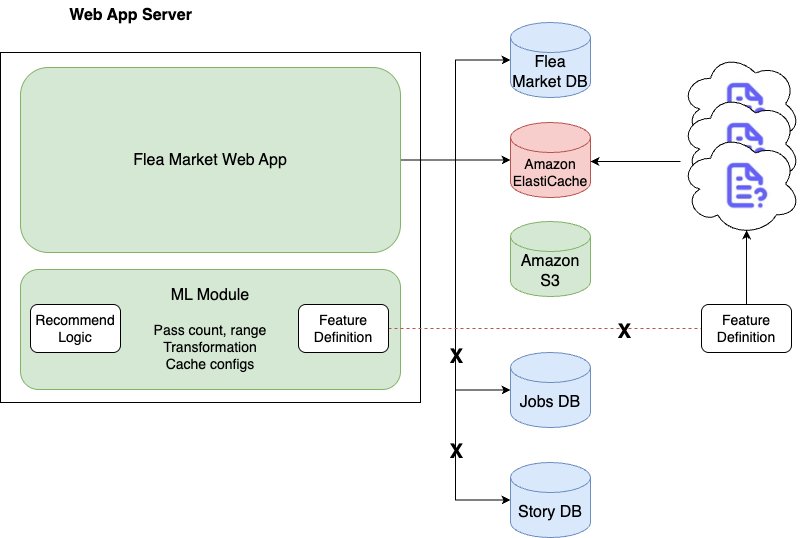
To solve these problems, we needed a new central system that could efficiently support feature management, real-time ingestion, and serving, and so we started the feature platform project.
Requirements of the feature platform
The following functional requirements were organized by separating the feature platform into an independent service:
- Record and rapidly serve the top N most recent actions performed by users. Allow parameterization of both the top N value and the lookup period.
- Support user-specific features such as notification keywords in addition to action features.
- Process features from various article types beyond just flea market articles.
- Handle arbitrary data types for all features, including primitive types, lists, sets, and maps.
- Provide real-time updates for both action features and user characteristic features.
- Provide flexibility in feature lists, counts, and lookup periods for each request.
To implement these functional requirements, a new platform was necessary. This platform needed three core capabilities: real-time ingestion of various feature types, storage with consistent schema, and quick response to diverse query requests. Although these requirements initially seemed ambiguous, designing a generalized structure enabled efficient configuration of data ingestion pipelines, storage methods, and serving schemas, leading to clearer development objectives.
In addition to functional requirements, the technical requirements included:
- Serving traffic: 1,500 or more requests per second (RPS)
- Ingestion traffic: 400 or more writes per second (WPS)
- Top N values: 30–50
- Single feature size: Up to 8 KB
- Total number of features: Over 3 billion or more
At the time, the variety and number of features in use were limited, and the recommendation models were simple, resulting in modest technical requirements. However, considering the rapid growth rate, a significant increase in system requirements was anticipated. Based on this prediction, higher targets were set beyond the initial requirements. As of February 2025, the serving and ingestion traffic has increased by about 90 times compared to the initial requirements, and the total number of features has increased by hundreds of times. The ability to handle this rapid growth was made possible by the highly scalable architecture of the feature platform, which we discuss in the following sections.
Solution overview
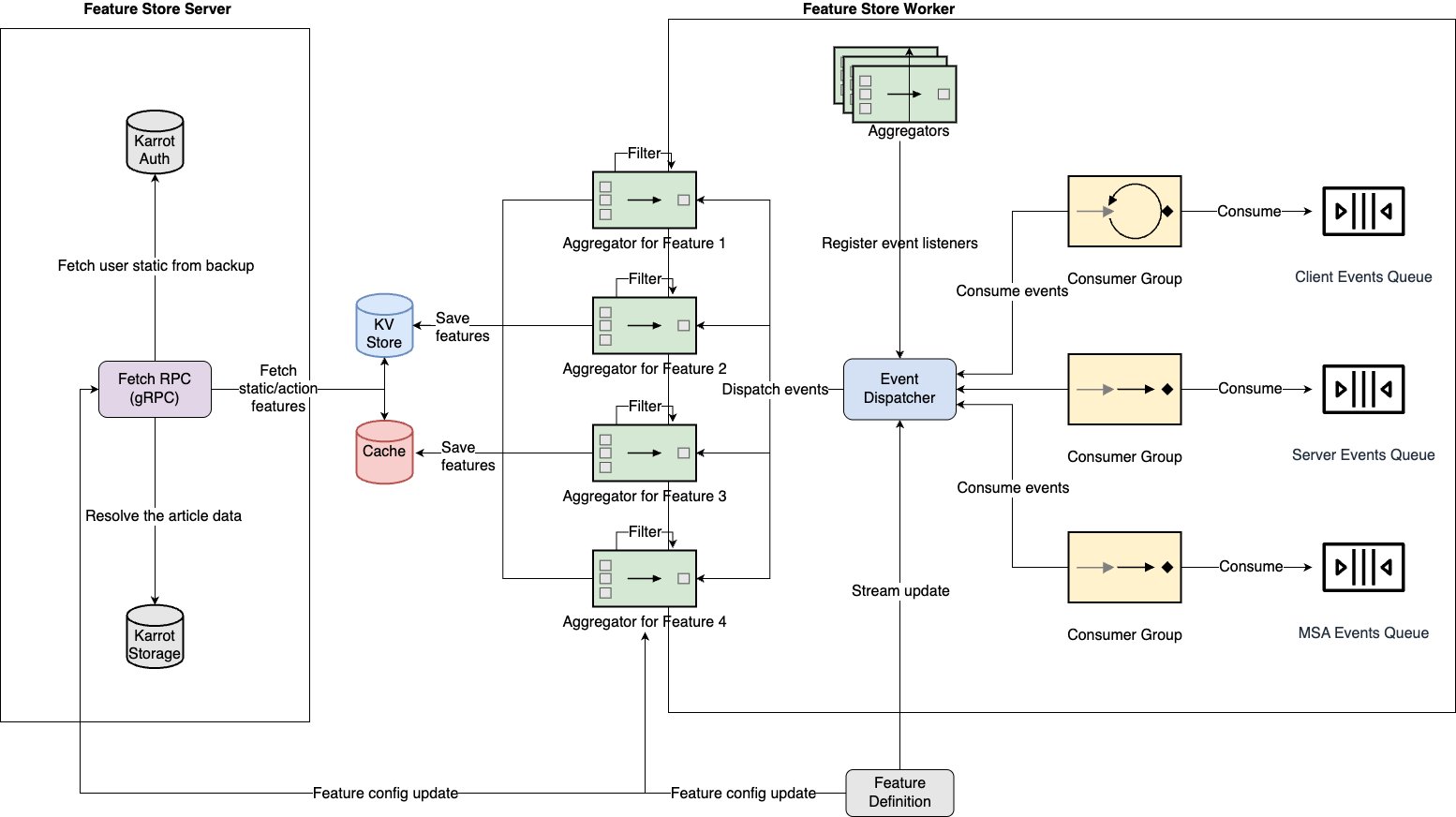
The following diagram illustrates the architecture of the feature platform.
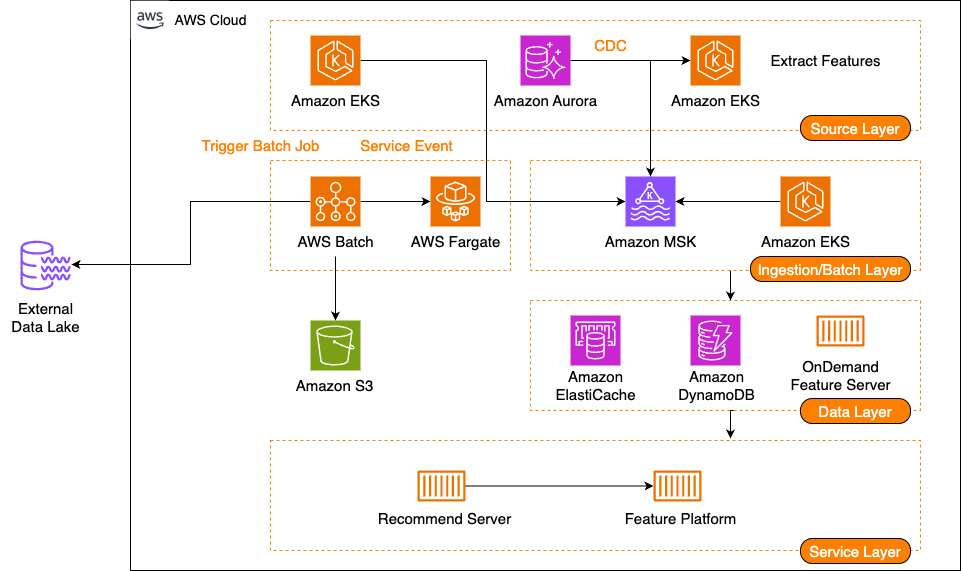
The feature platform consists of three main components: feature serving, a stream ingestion pipeline, and a batch ingestion pipeline.
Part 1 of this series will cover feature serving. Feature serving is the core function of receiving client requests and providing the required features. Karrot designed this system with four major components:
- Server – A server that receives and processes feature serving requests, and is a pod located on Amazon Elastic Kubernetes Service (Amazon EKS)
- Remote cache – A remote cache layer shared by servers, and uses ElastiCache
- Database – A persistence layer that stores features, and uses Amazon DynamoDB
- On-demand feature server – A server that serves features that can’t be stored in the remote cache and database due to compliance issues, or that require real-time calculations every time
From a data store perspective, feature serving should serve high-cardinality features with low latency at scale. Karrot introduced multi-level cache and subdivided serving strategies according to the characteristics of the features:
- Local cache (tier 1 cache) – An in-memory store located within the server, suitable for cases where the data size is small and is frequently accessed or requires fast response times
- Remote cache (tier 2 cache) – Suitable for cases where the data size is medium and is frequently accessed
- Database (tier 3 cache) – Suitable for cases where the data size is large and is not frequently accessed or is less sensitive to response times
Schema design
The feature platform stores multiple features together using the concept of feature groups, such as column families. All feature groups are defined through the feature group schema, called feature group specifications, and each feature group specification defines the name of the feature group, required features, and so on.
Based on this concept, the key design is defined as follows:
- Partition key:
<feature_group_name>#<feature_group_id> - Sort key:
<feature_group_timestamp>or a string representing null
To illustrate how this works in practice, let’s explore an example of a feature group representing recently clicked flea market articles by user 1234. Consider the following scenario:
- Feature group name:
recent_user_clicked_fleaMarketArticles - User ID:
1234 - Click timestamp:
987654321 - Features in the feature group:
- Clicked article ID:
a - User session ID:
1111
- Clicked article ID:
In this example, the keys and feature group are created as follows:
- Partition key:
recent_user_clicked_fleaMarketArticles#1234 - Sort Key:
987654321 - Value:
{"0": "a", "1": "1111"}
Features defined in the feature group specification maintain a fixed order, using this ordering like an enum when saving the feature group.
Feature serving read/write flow
The feature platform uses a multi-level cache and database for feature serving, as shown in the following diagram.
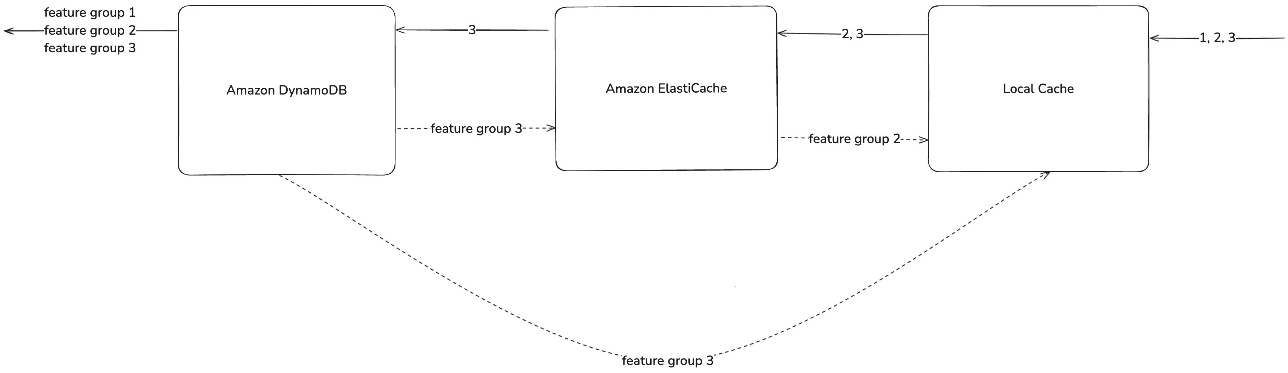
To illustrate this process, let’s examine how the system retrieves feature groups 1, 2, and 3 from flea market articles. The read flow (solid lines in the preceding diagram) demonstrates data access optimization using a multi-level cache strategy:
- When a query request comes in, first check the local cache.
- Data not in the local cache is searched in ElastiCache.
- Data not in ElastiCache is searched in DynamoDB.
- The feature groups found at each stage are collected and returned as the final response.
The write flow (dotted lines in the preceding diagram) consists of the following steps:
- Feature groups that have cache misses are stored in each cache level.
- Data not found in the local cache but found in the remote cache or database is stored in the upper-level cache.
- Data found in ElastiCache is stored in the local cache.
- Data found in DynamoDB is stored in both ElastiCache and the local cache.
- Cache write operations are performed asynchronously in the background.
This approach presents a strategy to maintain data consistency and improve future access time in the multi-level cache structure. In an ideal situation, serving works well without any problems with just the preceding flow. However, the reality was not like that. The problems experienced included cache misses, consistency, and penetration problems:
- Cache miss problem – Frequent cache misses slow down the response time and put a burden on the next level cache or database. Karrot uses the Probabilistic Early Expirations (PEE) technique to proactively refresh data that is likely to be retrieved again in the future, thereby maintaining low latency and mitigating cache stampede.
- Cache consistency problem – If the Time-To-Live (TTL) of a cache is set incorrectly, it can affect recommendation quality or reduce system efficiency. Karrot sets soft and hard TTL separately, and sometimes uses a write-through caching strategy together to synchronize cache and database to alleviate consistency problems. In addition, jitter is added to spread out the TTL deletion time to alleviate the cache stampede of feature groups written at similar times.
- Cache penetration problem – Continuous queries for non-existent feature groups can lead to DynamoDB queries, resulting in increased costs and response times. The platform resolves this through negative caching, storing information about non-existent feature groups to reduce unnecessary database queries. Additionally, the system monitors the ratio of missing feature groups in DynamoDB, negative cache hit rates, and potential consistency problems.
Future improvements for feature serving
Karrot is considering the following future improvements to their feature serving solution:
- Large data caching – Recently, the demand for storing large data features has been increasing. This is because as Karrot grows, the number of features also increases. Also, as the demand for embeddings increases along with the rapid growth of large language models (LLMs), the size of data to be stored has increased. Accordingly, we are reviewing more efficient serving by using an embedded database.
- Efficient use of cache memory – Even if an efficient TTL value is set initially, the efficiency tends to decrease as the user’s usage pattern changes and the model is changed. Also, as more feature groups are defined, monitoring becomes more difficult. It should be straightforward to find the optimal TTL value for the cache based on data. We are considering a method to efficiently use memory while maintaining a high recommendation quality through cache hit rate and feature group loss prevention. Should we cache a feature group that is only retrieved once? What about a feature group that is retrieved twice? The current feature platform attempts caching even if a cache miss occurs only one time. We believe that all feature groups that have cache misses are worth caching. This naturally increases the inefficiency of caching. An advanced policy is needed to determine and cache feature groups that are worth caching based on various data. This will increase the efficiency of cache usage.
- Multi-level cache optimization – Currently, the feature platform has a multi-level cache structure, and the complexity will increase if an embedded database is added in the future. Therefore, it is necessary to find and set the optimal settings by considering different cache levels. In the future, we will try to maximize efficiency by considering different levels of cache settings.
Conclusion
In this post, we examined how Karrot built their feature platform, focusing on feature serving capabilities. As of February 2025, the platform reliably handles over 100,000 RPS with P99 latency under 30 milliseconds, providing stable recommendation services through a scalable architecture that efficiently manages traffic increases.
Part 2 will explore how features are generated using consistent feature schemas and ingestion pipelines through the feature platform.