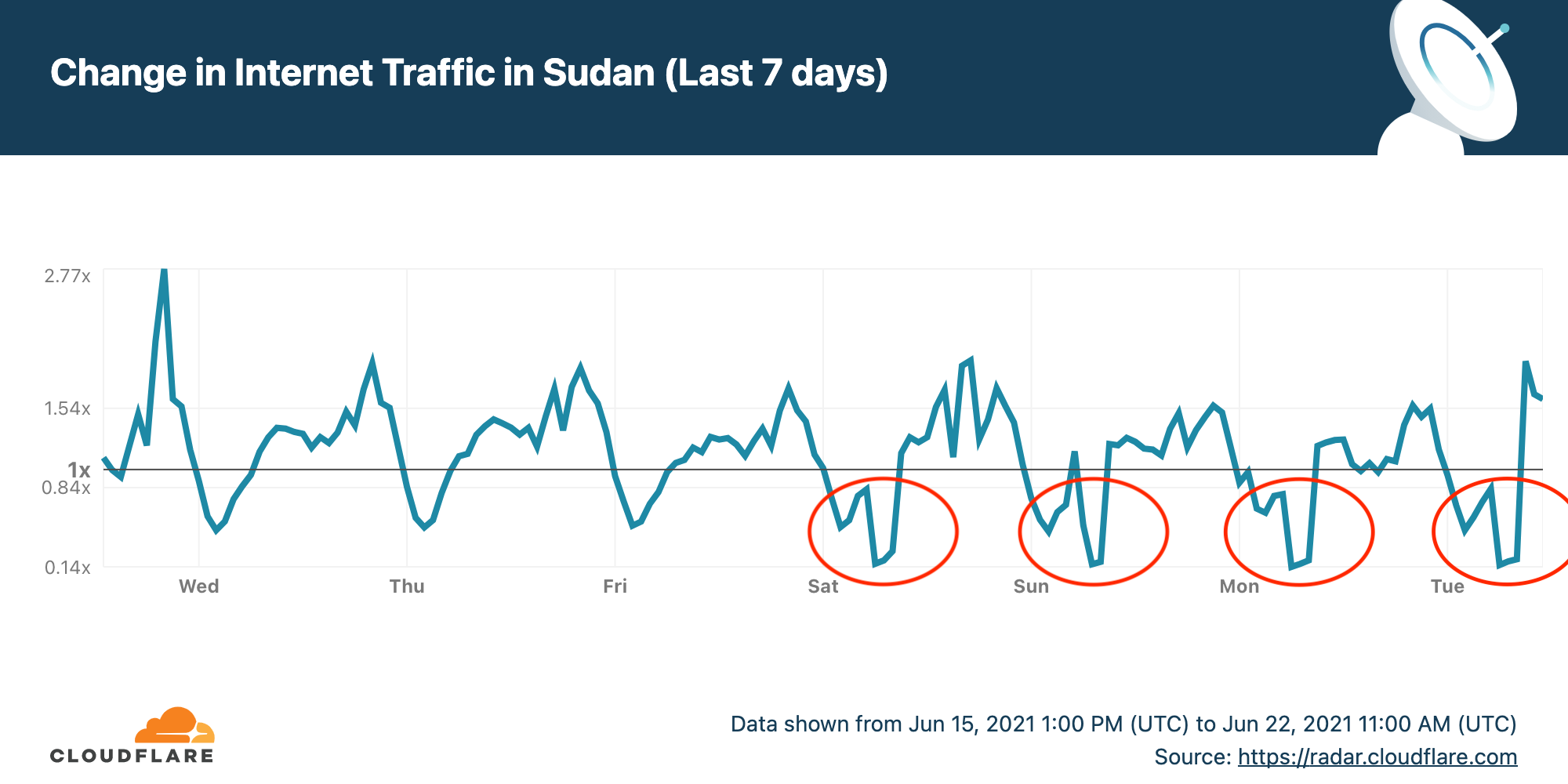
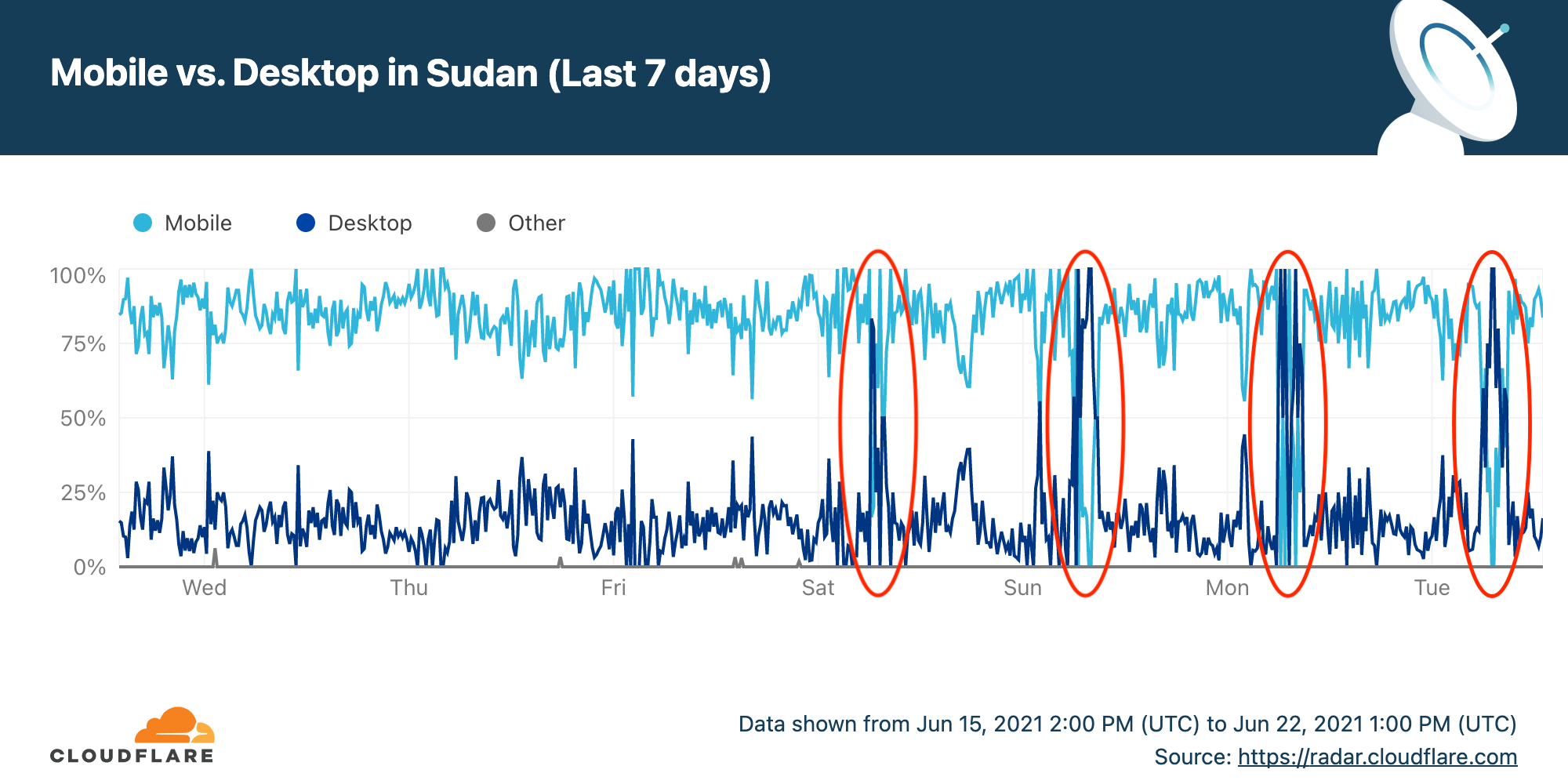
Post Syndicated from John Graham-Cumming original https://blog.cloudflare.com/understanding-where-the-internet-isnt-good-enough-yet/


Since March 2020, the Internet has been the trusty sidekick that’s helped us through the pandemic. Or so it seems to those of us lucky enough to have fast, reliable (and often cheap) Internet access.
With a good connection you could keep working (if you were fortunate enough to have a job that could be done online), go to school or university, enjoy online entertainment like streaming movies and TV, games, keep up with the latest news, find out vital healthcare information, schedule a vaccination and stay in contact with loved ones and friends with whom you’d normally be spending time in person.
Without a good connection though, all those things were hard or impossible.
Sadly, access to the Internet is not uniformly distributed. Some have cheap, fast, low latency, reliable connections, others have some combination of expensive, slow, high latency and unreliable connections, still others have no connection at all. Close to 60% of the world have Internet access leaving a huge 40% without it at all.
This inequality of access to the Internet has real-world consequences. Without good access it is so much harder to communicate, to get vital information, to work and to study. Inequality of access isn’t a technical problem, it’s a societal problem.
This week, Cloudflare is announcing Project Pangea with the goal of helping reduce this inequality. We’re helping community networks get onto the Internet cheaply, securely and with good bandwidth and latency. We can’t solve all the challenges of bringing fast, cheap broadband access to everyone (yet) but we can give fast, reliable transit to ISPs in underserved communities to help move in that direction. Please refer to our Pangea announcement for more details.
The Tyranny of Averages
To understand why Project Pangea is important, you need to understand how different the experience of accessing the Internet is around the world. From a distance, the world looks blue and green. But we all know that our planet varies wildly from place to place: deserts and rainforests, urban jungles and placid rural landscapes, mountains, valleys and canyons, volcanos, salt flats, tundra, and verdant, rolling hills.
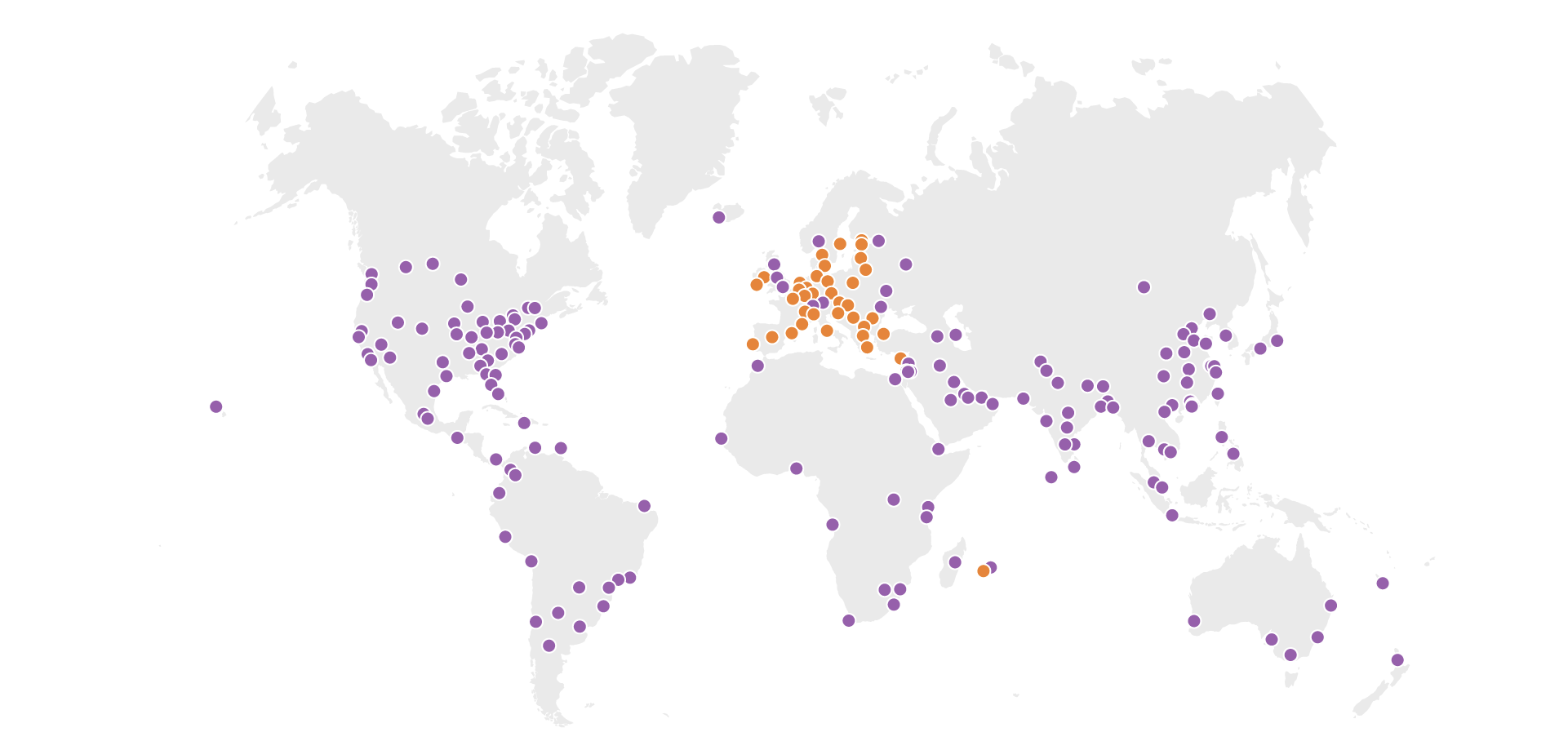
Cloudflare is in a unique position to measure the performance and reach of the Internet over this vast landscape. We have servers in more than 200 cities in over 100 countries, we process 10s of trillions of Internet requests every month. Our network and customers and their users span the globe, every country in every network.
Zoom out to the level of a city, county, state, or country, and average Internet performance can look good — or, at least, acceptable. Zoom in, however, and the inequalities start to show. Perhaps part of a county has great performance, and another limps along at barely dial-up speeds — or worse. Or perhaps a city has some neighborhoods with fantastic fiber service, and others that are underserved and struggling with spotty access.
Inequality of Internet access isn’t a distant problem, it’s not limited to developing countries, it exists in the richest countries in the world as well as the poorest. There are still many parts of the world where a Zoom call is hard or impossible to make. And if you’re reading this on a good Internet connection, you may be surprised to learn that places with poor or no Internet are not far from you at all.
Bandwidth and Latency in Eight Countries
For Impact Week, we’ve analyzed Internet data in the United States, Brazil, United Kingdom, Germany, France, South Africa, Japan, and Australia to build a picture of Internet performance.
Below, you’ll find detailed maps of where the Internet is fast and slow (focusing on available bandwidth) and far away from the end user (at least in terms of the latency between the client and server). We’d have loved to have used a single metric, however, it’s hard for a single number to capture the distribution of good, bad, and non-existent Internet traffic in a region. It’s for that reason that we’ve used two metrics to represent performance: latency and bandwidth (otherwise known as throughput). The maps below are colored to show the differences in bandwidth and latency and answer part of the question: “How good is the Internet in different places around the world?”
As we like to say, we’re just getting started with this — we intend to make more of this data and analysis available in the near future. In the meantime, if you’re a local official who wants to better understand their community’s relative performance, please reach out — we’d love to connect with you. Or, if you’re interested in your own Internet performance, you can visit speed.cloudflare.com to run a personalized test on your connection.
A Quick Refresher on Latency and Bandwidth
Before we begin, a quick reminder: latency (usually measured in milliseconds or ms) is the time it takes for communications to go to an Internet destination from your device and back, whereas bandwidth is the amount of data that can be transferred in a second (it’s usually measured in megabits per second or Mbps).
Both latency and bandwidth affect the performance of an Internet connection. High latency particularly affects things like online gaming where quick responses from servers are needed, but also shows up by slowing down the loading of complex web pages, and even interrupting some streaming video. Low bandwidth makes downloading anything slow: be it images on a webpage, the new app you want to try out on your phone, or the latest movie.
Blinking your eyes takes about 100ms; but you’ll begin to notice performance changes around 60ms of latency and below 30ms is gold class performance, seeing little to no delay in video streaming or gaming.
United States
United States median throughput: 50.27Mbps
US median latency: 46.69ms
The US government has long recognized the importance of improving the Internet for underserved communities, but the Federal Communications Commission (FCC), the US agency responsible for determining where investment is most needed, has struggled to accurately map Internet access across the country. Although the FCC has embarked on a new data collection effort to improve the accuracy of existing maps, the US government still lacks a comprehensive understanding of the areas that would most benefit from broadband investment.
Cloudflare’s data confirms the overall concerns with inconsistent access to the Internet and helps fill in some of the current gaps. A glance at the two maps of the US below will show that, even zoomed out to county level, there is inequality across the country. High latency and low bandwidth stand out as red areas.
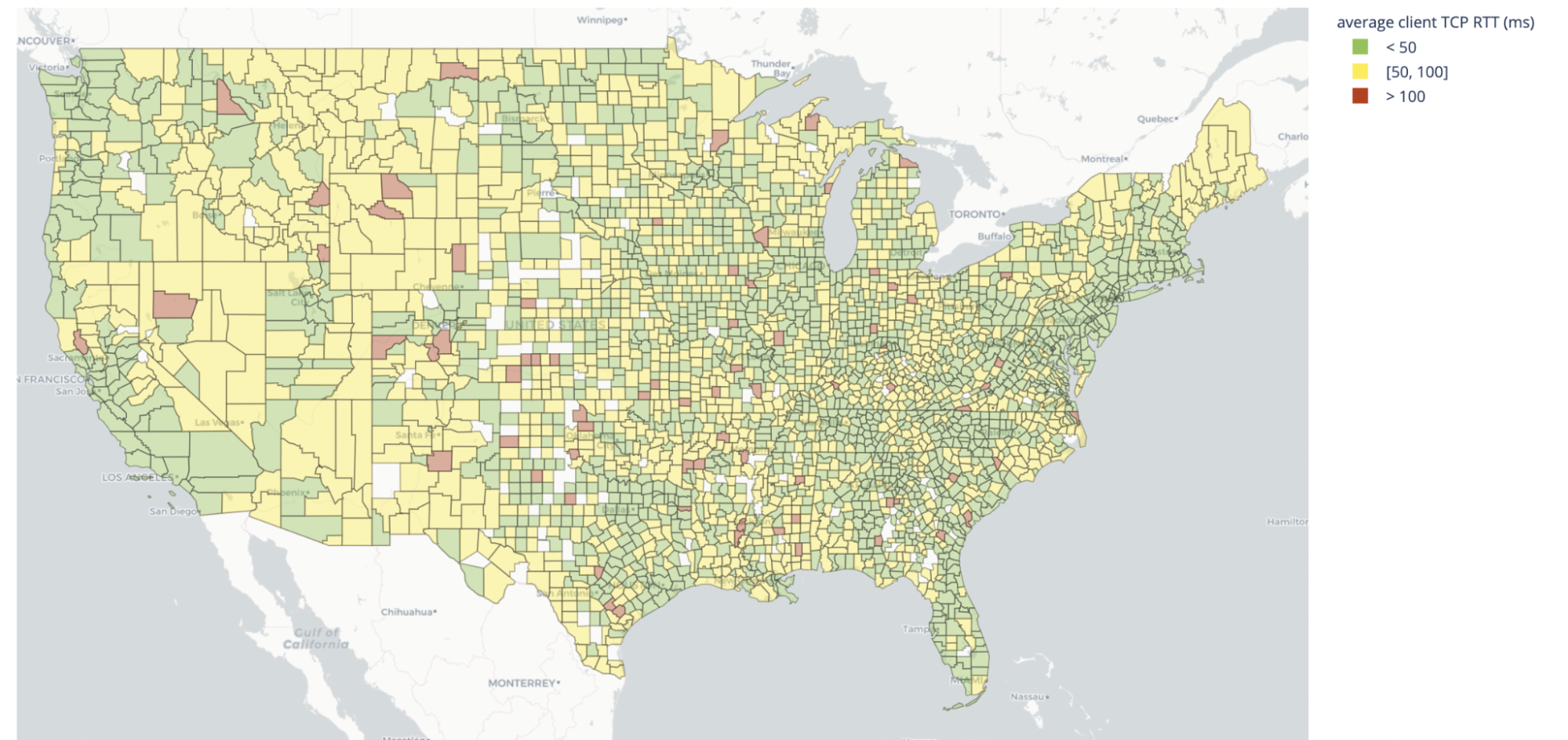
US locations with the lowest latency (best) and highest latency (worst) are as follows.
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| La Habra, California | Parrottsville, Tennessee |
| Midlothian, Texas | Loganville, Wisconsin |
| Los Alamitos, California | Mackinaw City, Michigan |
| St Louis, Missouri | Reno, Nevada |
| Fort Worth, Texas | Eva, Tennessee |
| Sugar Grove, North Carolina | Milwaukee, Wisconsin |
| Rockwall, Texas | Grove City, Minnesota |
| Justin, Texas | Sacred Heart, Minnesota |
| Denton, Texas | Scottsboro, Alabama |
| Hampton, Georgia | Vesta, Minnesota |
When thinking about bandwidth, 5 to 10Mbps are generally good enough for video conferencing, but ultra-HD TV watching might consume up to 20Mbps easily. For context, the Federal Communications Commission (FCC) defines the minimum bandwidth for “Advanced Service” at 25 Mbps.
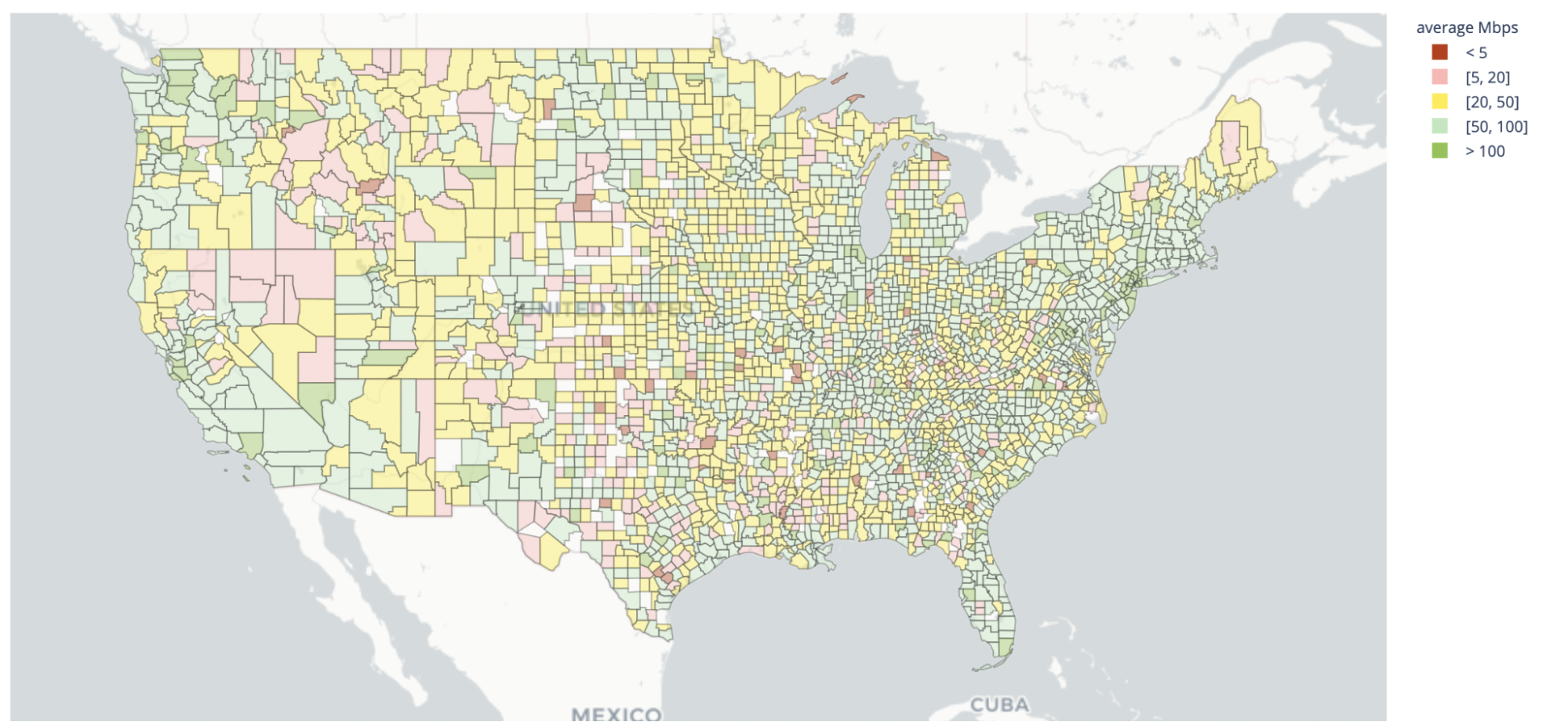
The best performing (i.e., the highest bandwidth) in the US tells an interesting story. New York City comes out on top, but if you were to zoom in on the city you’d find pockets of inequality. You can read more about our partnership with NYC Mesh in the Project Pangea post and how they are helping bring better Internet to underserved parts of the Big Apple. Notice how the tyranny of averages can disguise a problem.
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| New York, New York | Ozark, Missouri |
| Hartford, Connecticut | Stanly, North Carolina |
| Avery, North Carolina | Ellis, Kansas |
| Red Willow, Nebraska | Marion, West Virginia |
| McLean, Kentucky | Sedgwick, Kansas |
| Franklin, Alabama | Calhoun, West Virginia |
| Montgomery, Pennsylvania | Jasper, Georgia |
| Cook, Illinois | Buchanan, Missouri |
| Montgomery, Maryland | Wetzel, West Virginia |
| Monroe, Pennsylvania | North Slope, Alaska |
Contrary to popular discourse about access to the Internet as a product of the rural-urban divide, we found that poor performance was not unique to rural areas. Los Angeles, Milwaukee, Florida’s Orange County, Fairfax, San Bernardino, Knox County, and even San Francisco have pockets of uniformly poor performance, often while adjoining ZIP codes have stronger performance.
Even in areas with excellent Internet connectivity, the same connectivity to the same resources can cost wildly different amounts. Internet prices for end-users correlates with the number of ISPs in an area, i.e. the greater the consumer choice, the better the price. President Biden’s recent competition Executive Order, called out the lack of choice for broadband, noting “More than 200 million U.S. residents live in an area with only one or two reliable high-speed internet providers, leading to prices as much as five times higher in these markets than in markets with more options.”
The following cities have the greatest choice of Internet providers:
| Geography |
|---|
| New York, New York |
| Los Angeles, California |
| Chicago, Illinois |
| Dallas, Texas |
| Washington, District of Columbia |
| Jersey City, New Jersey |
| Newark, New Jersey |
| Secaucus, New Jersey |
| Columbus, Ohio |
One might expect less populated areas to have uniformly slower performance. There are, however, pockets of poor performance even in densely populated areas such as Los Angeles (California), Milwaukee (Wisconsin), Orange County (Florida), Fairfax (Virginia), San Bernardino (California), Knox County (Tennessee), and even San Francisco (California).
In as many as 9% of ZIP codes, average latency exceeds 150ms, the acceptable threshold of performance to run a videoconferencing service such as Zoom.
Australia
Australia median throughput: 33.34Mbps
Australia median latency: 42.04ms
In general, Australia seems to suffer very poor broadband speeds, with speeds that are not capable of sustaining households watching video streaming, and possibly struggling with multiple video calls. The problem isn’t just a rural one either, while the inner cities showed good broadband speed, often with fiber-to-the-building Internet access, suburban areas suffered. Larger suburban areas like the Illawarra had similar speeds to more rural centers like Wagga Wagga, showing this is more than just an urban divide.
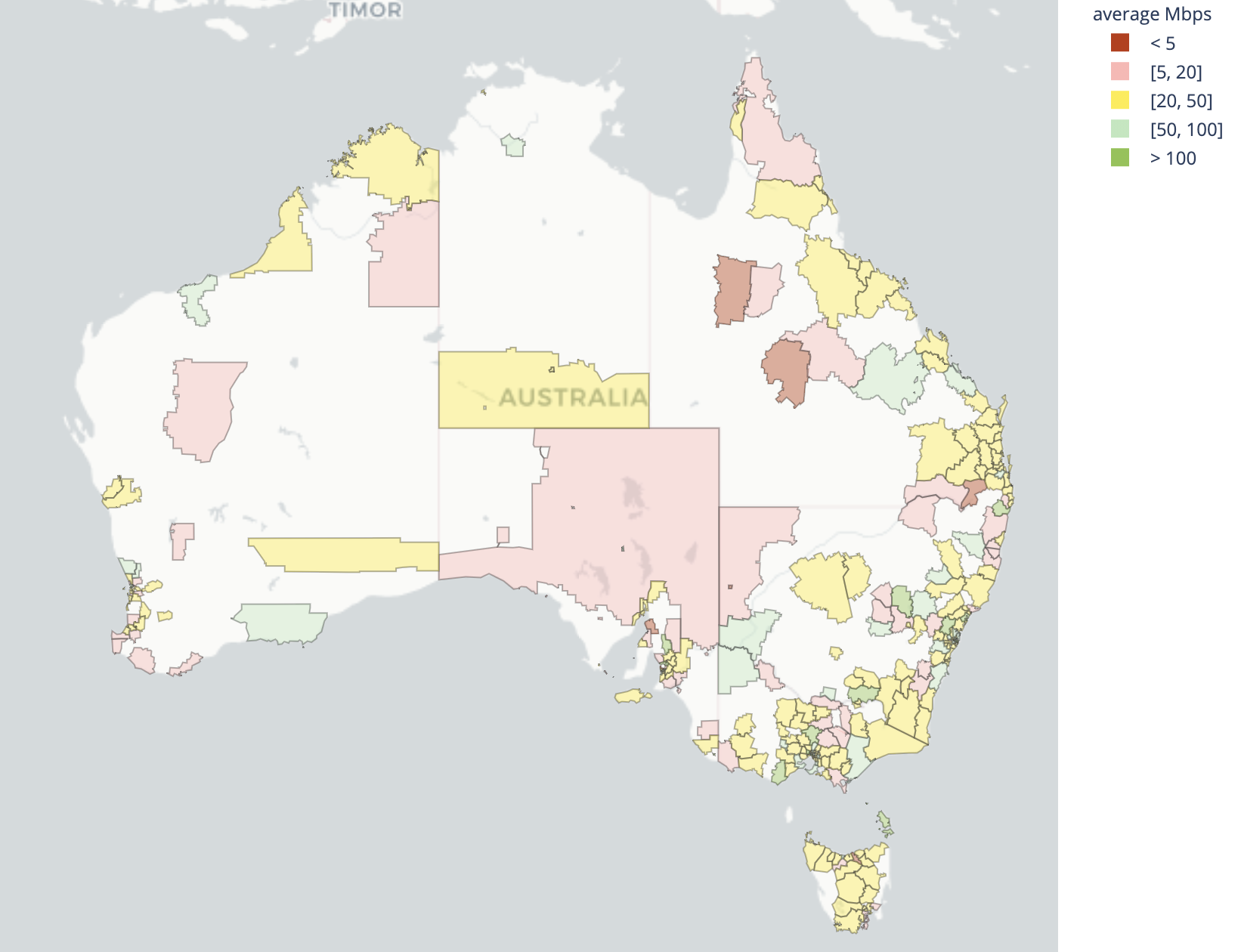
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Inner West Sydney, New South Wales | West Tamar, Tasmania |
| Port Phillip, Victoria | Bassendean, Western Australia |
| Woollahra, New South Wales | Alexandrina, South Australia |
| Brimbank, Victoria | Bayswater, Western Australia |
| Lake Macquarie, New South Wales | Augusta-Margaret River, Western Australia |
| Hawkesbury, New South Wales | Goulburn Mulwaree, New South Wales |
| Sydney, New South Wales | Goyder, South Australia |
| Wentworth, New South Wales | Kingborough, Tasmania |
| Hunters Hill, New South Wales | Cottesloe, Western Australia |
| Blacktown, New South Wales | Lithgow, New South Wales |
The irony is that, from a latency perspective, Australia actually performs quite well.
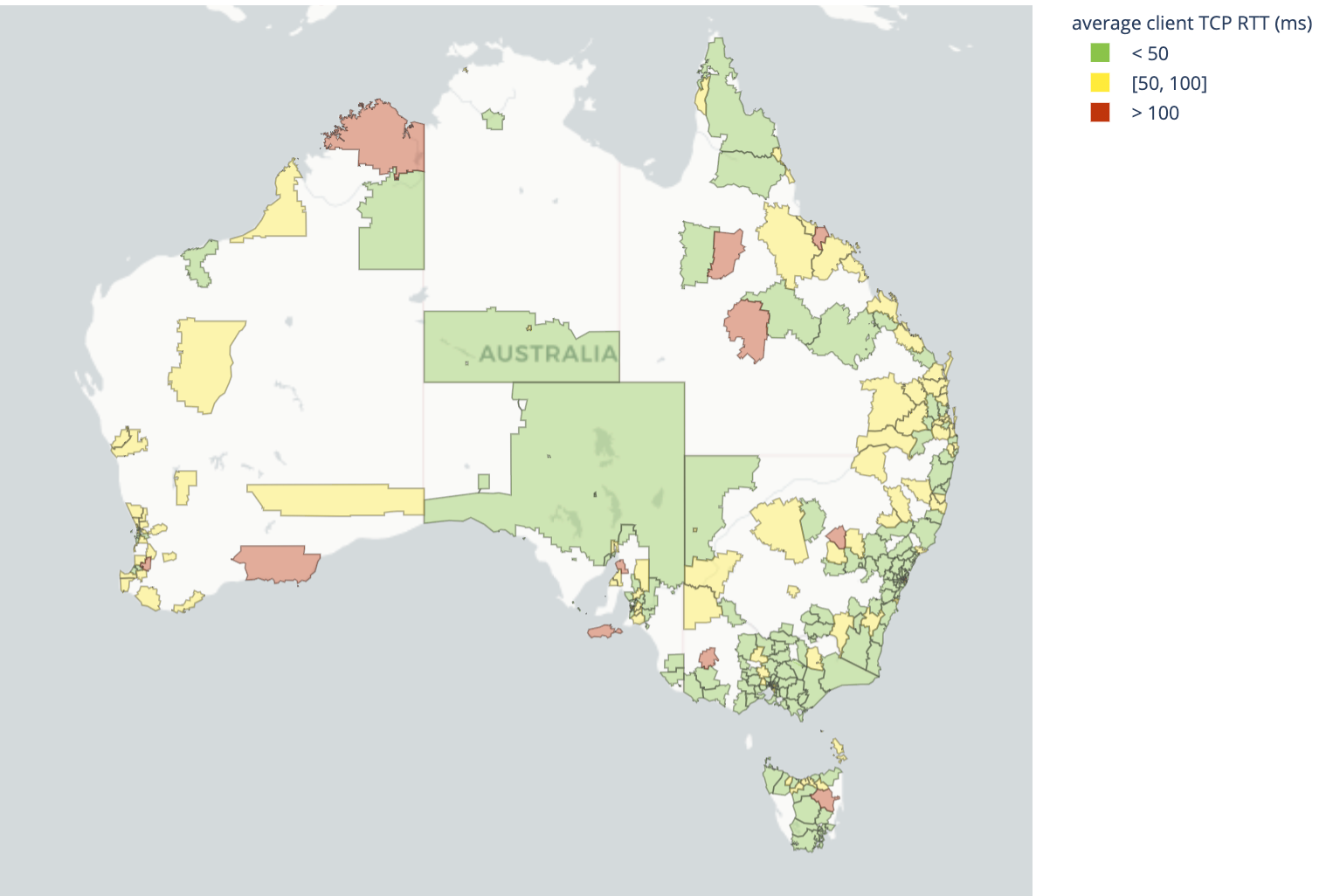
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Port Phillip, Victoria | Narromine, New South Wales |
| Mornington Peninsula, Victoria | North Sydney, New South Wales |
| Whittlesea, Victoria | Northern Midlands, Tasmania |
| Penrith, New South Wales | Swan, Western Australia |
| Mid-Coast, New South Wales | Wanneroo, Western Australia |
| Campbelltown, New South Wales | Snowy Valleys, New South Wales |
| Northern Beaches, New South Wales | Parkes, New South Wales |
| Strathfield, New South Wales | Broome, Western Australia |
| Latrobe, Victoria | Griffith, New South Wales |
| Surf Coast, Victoria | Busselton, Western Australia |
Japan
Japan median throughput: 61.4Mbps
Japan median latency: 31.89ms
Japan’s Internet has consistently low latency, including in distant areas such as Okinawa prefecture, 1,000 miles away from Tokyo.
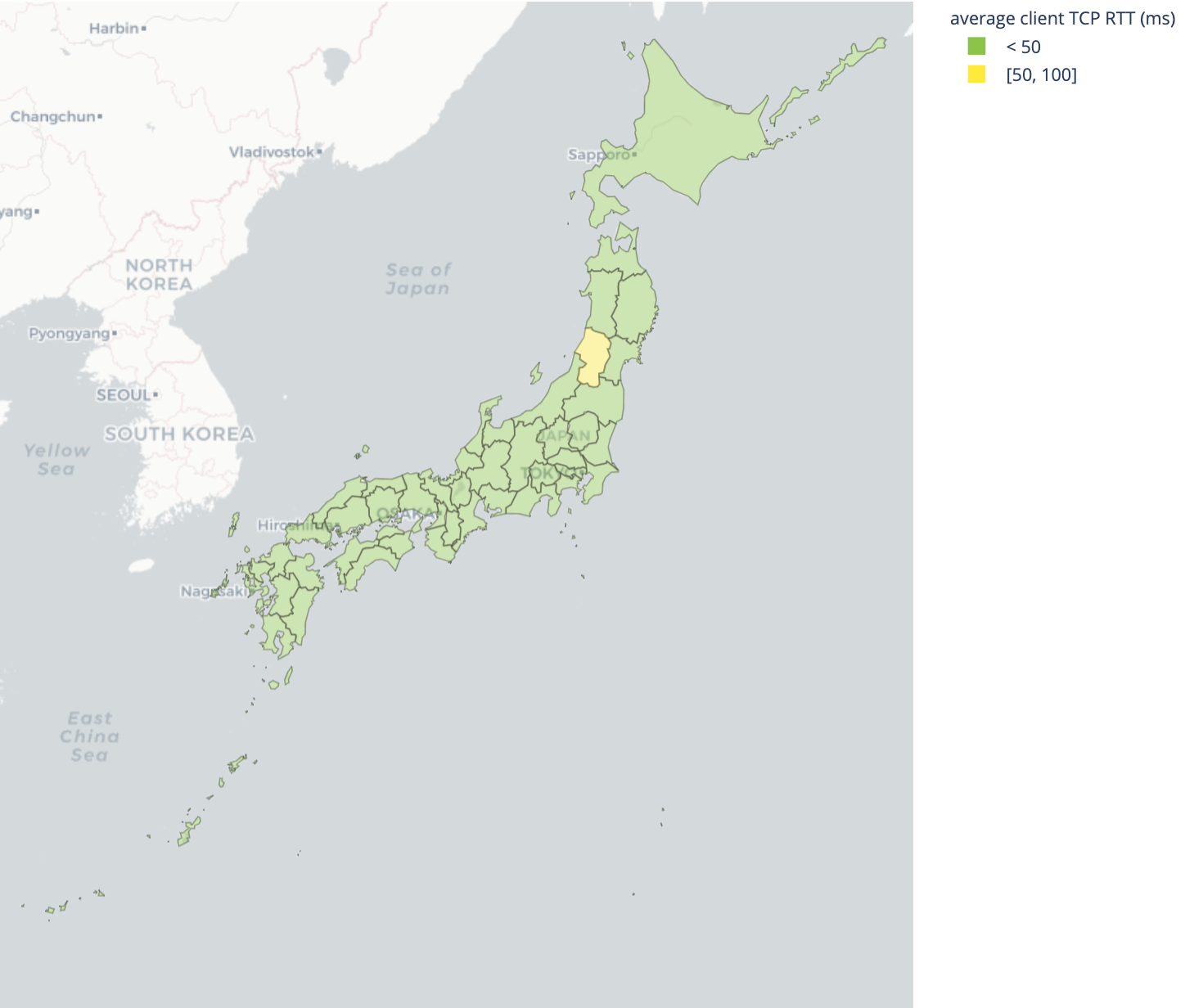
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Nara | Yamagata |
| Osaka | Okinawa |
| Shiga | Miyazaki |
| Kōchi | Nagasaki |
| Kyoto | Ōita |
| Tochigi | Kagoshima |
| Tokushima | Yamaguchi |
| Wakayama | Tottori |
| Kanagawa | Saga |
| Aichi | Ehime |
However, it’s a different story when it comes to bandwidth. Several prefectures in Kyushu Island, Okinawa Prefecture, and Western Honshu have performance falling behind the rest of the country. Unsurprisingly, the best Internet performance is seen in Tokyo, with the highest concentration of people and data centers.
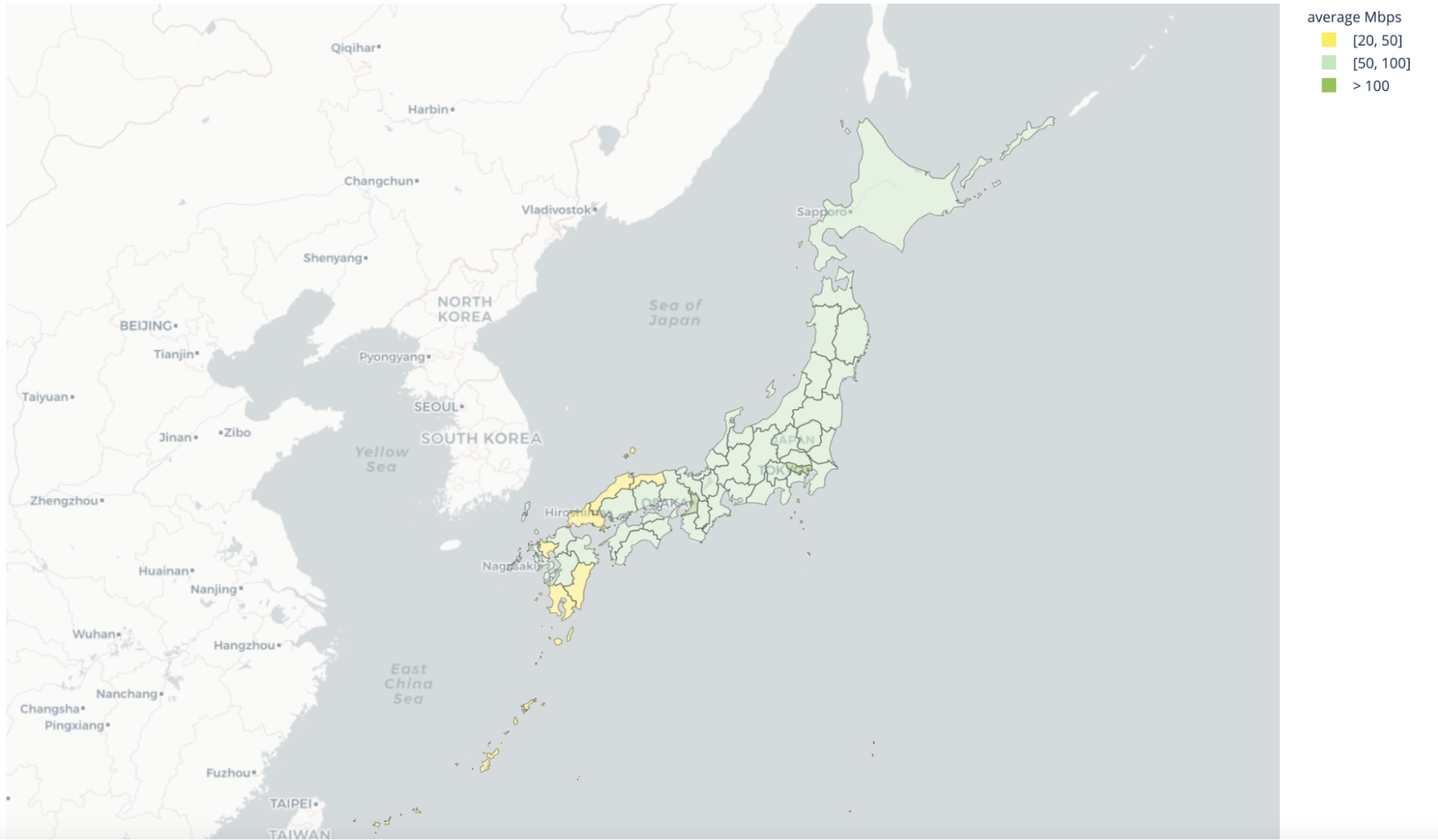
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Osaka | Tottori |
| Tokyo | Shimane |
| Kanagawa | Yamaguchi |
| Nara | Okinawa |
| Chiba | Saga |
| Aomori | Miyazaki |
| Hyōgo | Kagoshima |
| Kyoto | Yamagata |
| Tokushima | Nagasaki |
| Kōchi | Fukui |
United Kingdom
United Kingdom median throughput: 53.8Mbps
United Kingdom median latency: 34.12ms
The United Kingdom has good latency throughout most of the country, however bandwidth is a different story. The best performance is seen in inner London as well as some other larger cities like Manchester. London and Manchester are also the homes of the UK’s largest Internet exchange points. More effort to localize data into other cities, like Edinburgh, would be an important step to improving performance for those regions.
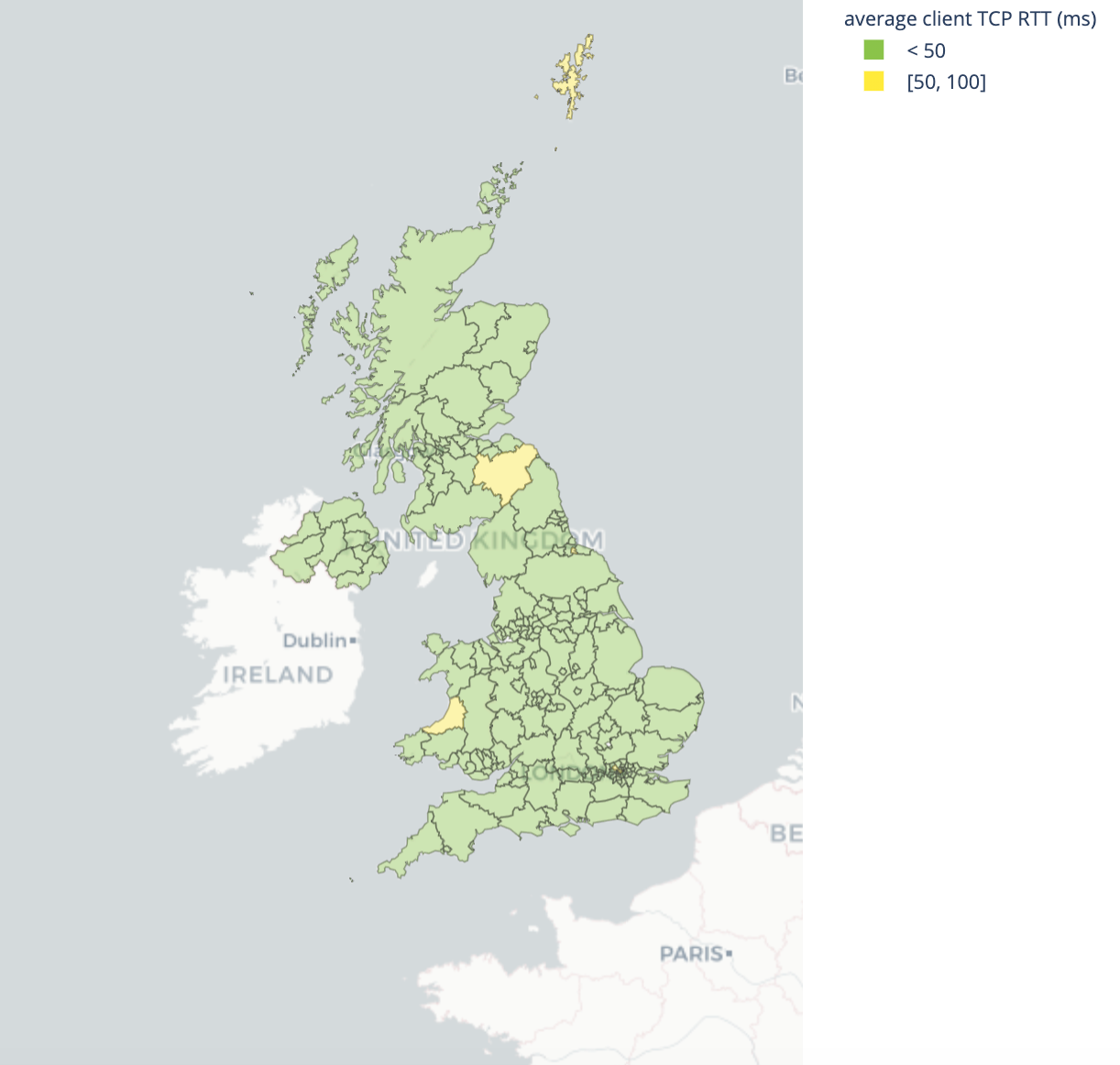
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Sutton | Brent |
| Milton Keynes | Ceredigion |
| Lambeth | Westminster |
| Cardiff | Scottish Borders |
| Harrow | Shetland Islands |
| Hackney | Middlesbrough |
| Islington | Fermanagh and Omagh |
| Kensington and Chelsea | Slough |
| Thurrock | Highland |
| Kingston upon Thames | Denbighshire |
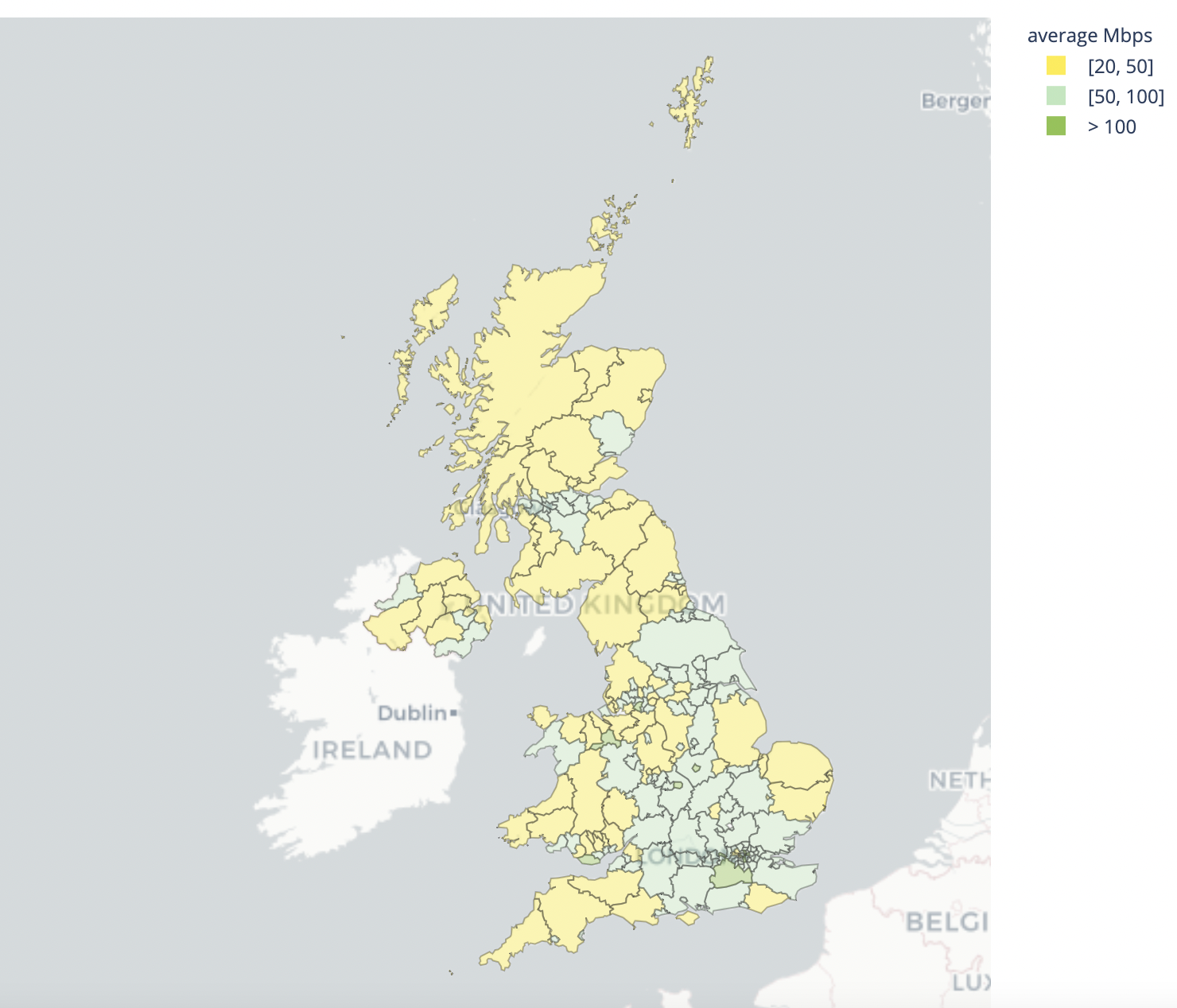
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| City of London | Orkney Islands |
| Slough | Shetland Islands |
| Lambeth | Blaenau Gwent |
| Surrey | Ceredigion |
| Tower Hamlets | Isle of Anglesey |
| Coventry | Fermanagh and Omagh |
| Wrexham | Scottish Borders |
| Islington | Denbighshire |
| Vale of Glamorgan | Midlothian |
| Leicester | Rutland |
Germany
Germany median throughput: 48.79Mbps
Germany median latency: 42.1ms
Germany has some of the best performance centered on Frankfurt am Main, which is one of the major Internet hubs of the world, however what was formerly East Germany, has higher latency, and slower speeds, leaning to a poorer Internet performance.
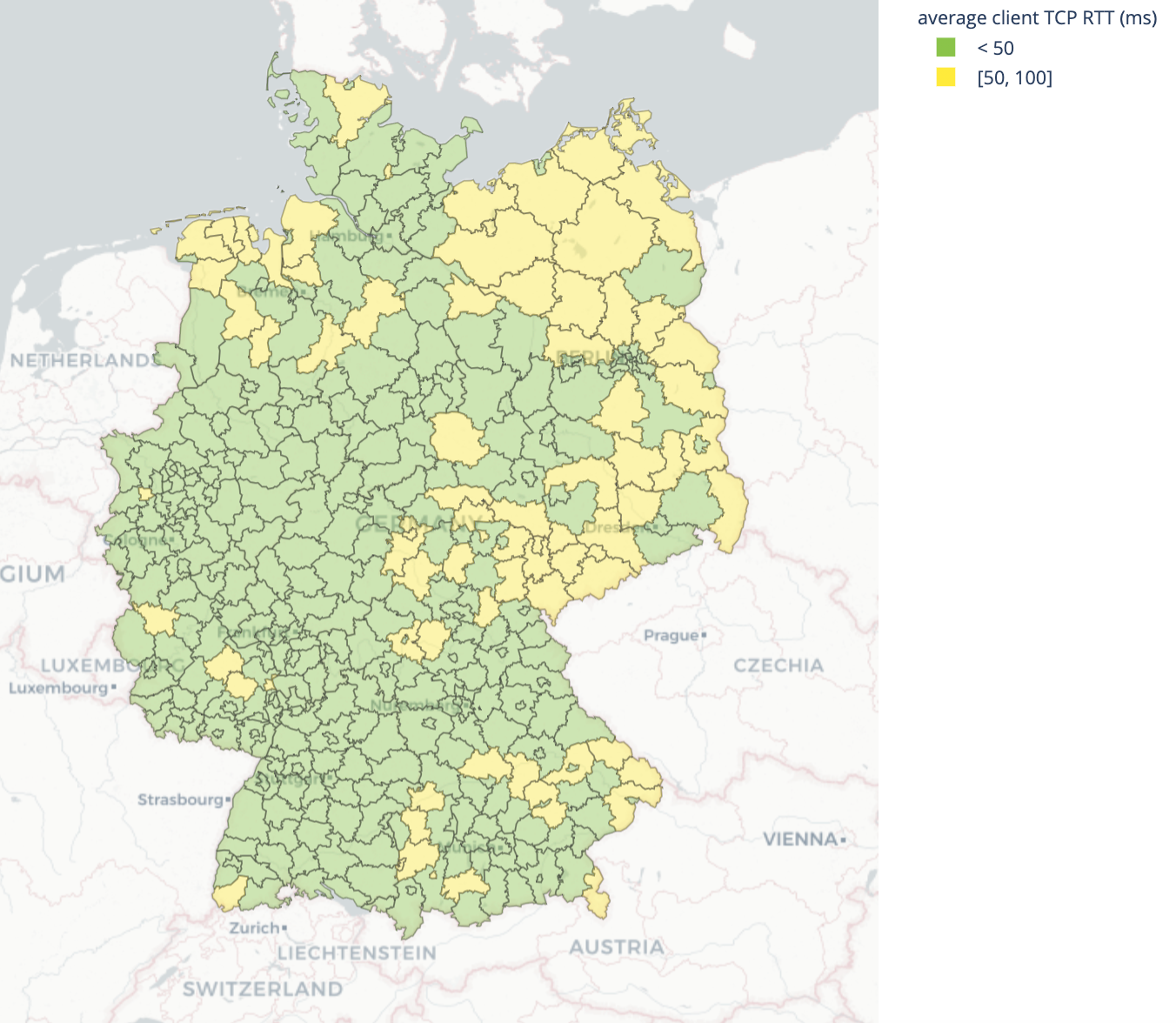
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Erlangen | Harz |
| Coesfeld | Nordwestmecklenburg |
| Weißenburg-Gunzenhausen | Saale-Holzland-Kreis |
| Heinsberg | Elbe-Elster |
| Main-Taunus-Kreis | Vorpommern-Greifswald |
| Main-Kinzig-Kreis | Vorpommern-Rügen |
| Darmstadt | Kyffhäuserkreis |
| Peine | Barnim |
| Herzogtum Lauenburg | Rostock |
| Segeberg | Meißen |
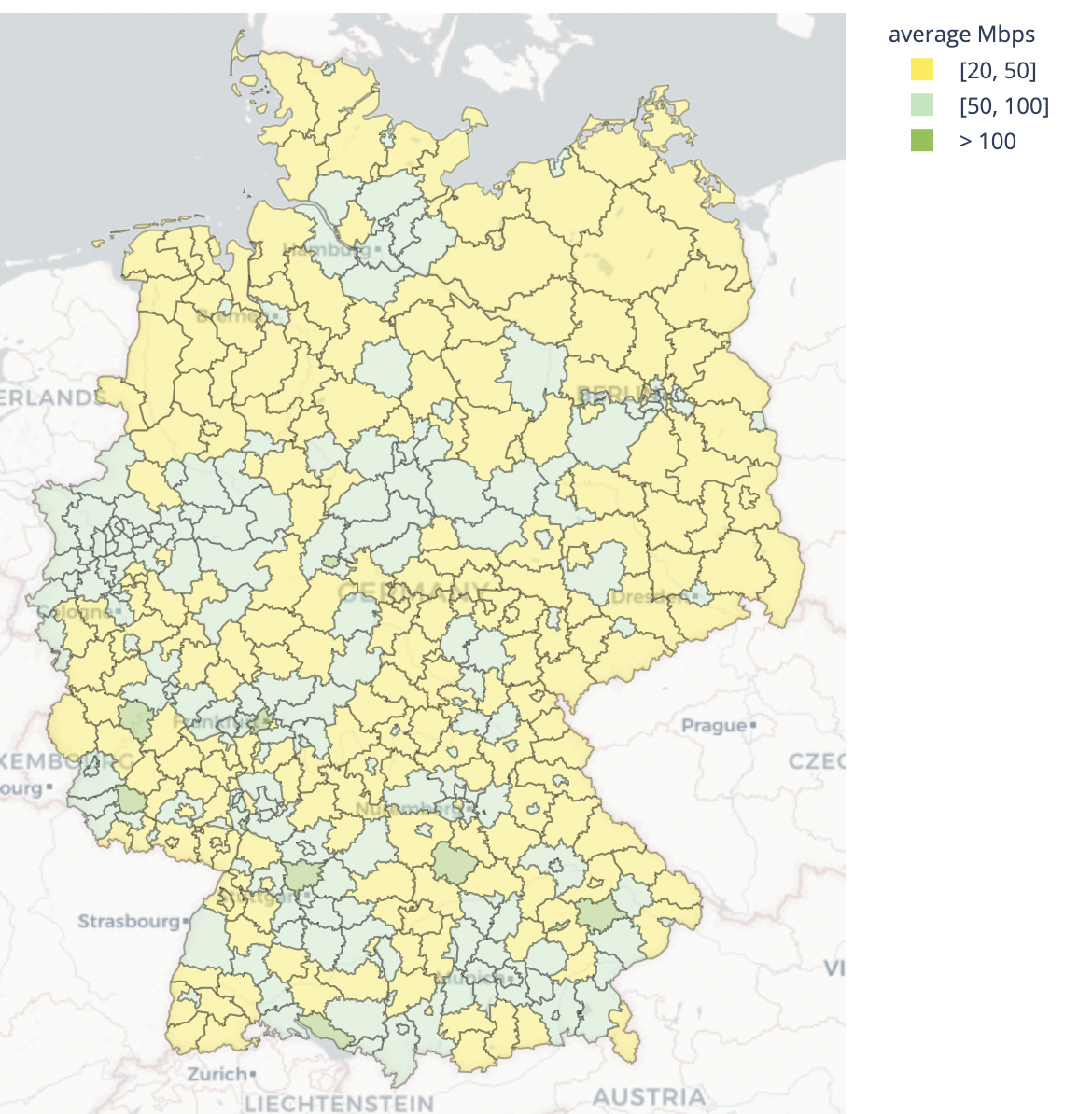
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Weißenburg-Gunzenhausen | Saale-Holzland-Kreis |
| Frankfurt am Main | Weimarer Land |
| Kassel | Vulkaneifel |
| Cochem-Zell | Kusel |
| Dingolfing-Landau | Spree-Neiße |
| Bodenseekreis | Eisenach |
| Sankt Wendel | Unstrut-Hainich-Kreis |
| Landshut | Saale-Orla-Kreis |
| Ludwigsburg | Weimar |
| Speyer | Südliche Weinstraße |
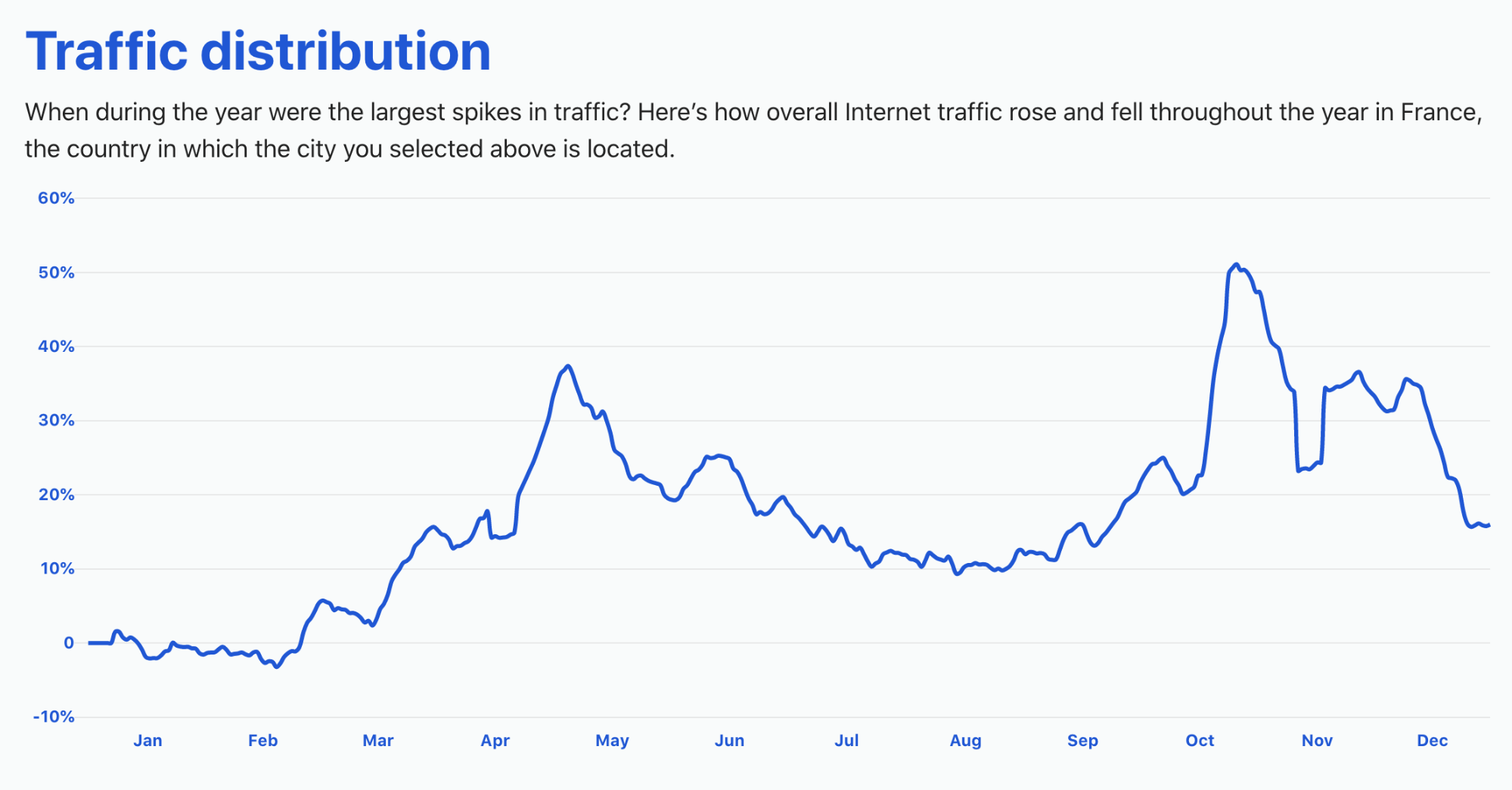
France
France median throughput: 48.51Mbps
France median latency: 54.2ms
Paris has long been the Internet hub in France. Marseille has started to grow as a hub, especially with the large number of submarine cables landing. Other interconnection hubs in Lyon and Bordeaux are where we’ll start to see growth as Internet hubs. These four cities are where we also see the best performance, with the highest speeds and lowest latencies, giving the best Internet performance.

| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Antony | Clamecy |
| Boulogne-Billancourt | Beaune |
| Lyon | Ambert |
| Lille | Commercy |
| Versailles | Vitry-le-François |
| Nogent-sur-Marne | Villefranche-de-Rouergue |
| Bobigny | Lure |
| Marseille | Avranches |
| Saint-Germain-en-Laye | Oloron-Sainte-Marie |
| Créteil | Privas |
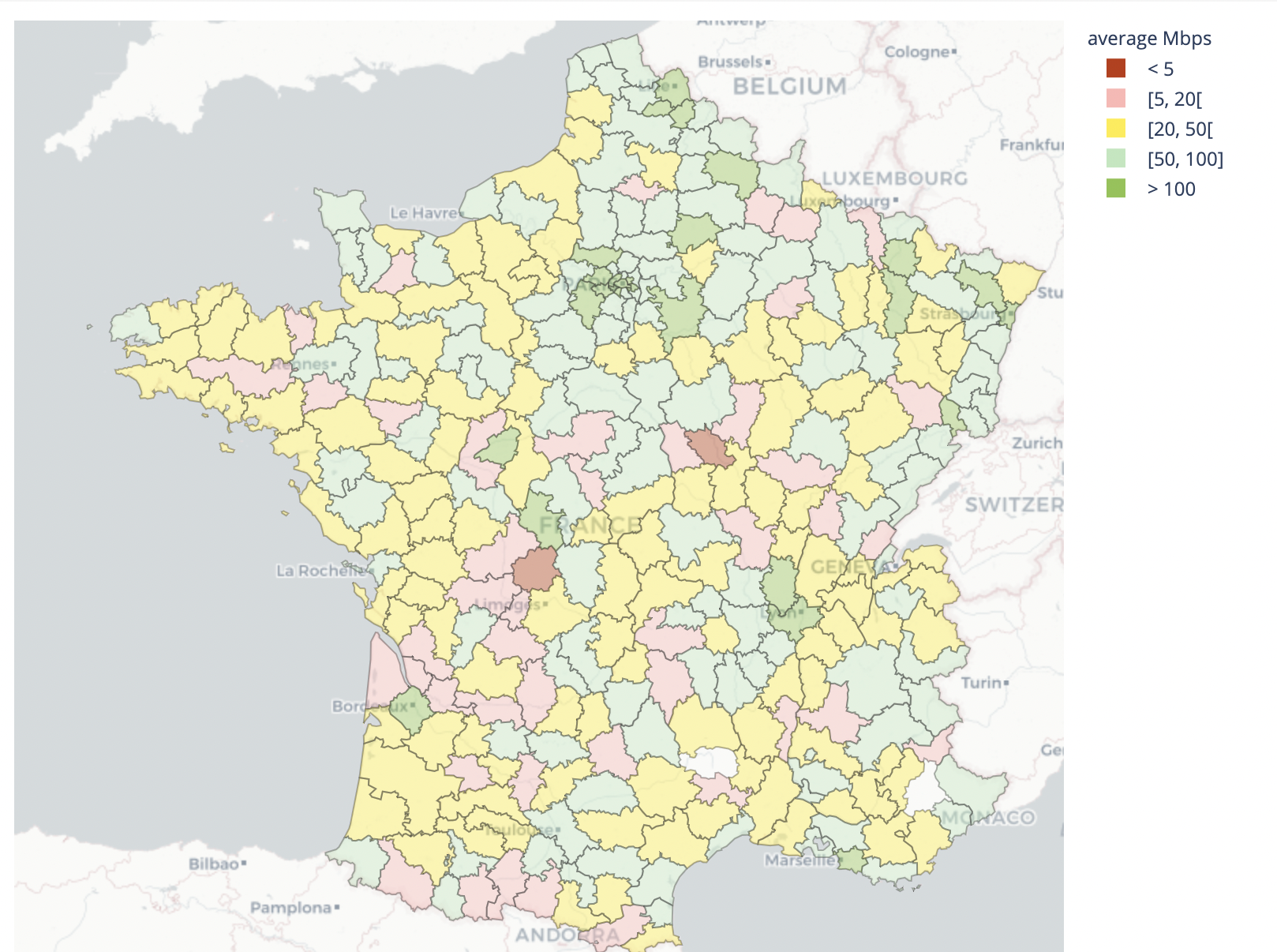
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Boulogne-Billancourt | Clamecy |
| Antony | Bellac |
| Marseille | Issoudun |
| Lille | Vitry-le-François |
| Nanterre | Sarlat-la-Canéda |
| Paris | Segré |
| Lyon | Rethel |
| Bobigny | Avallon |
| Versailles | Privas |
| Saverne | Sartène |
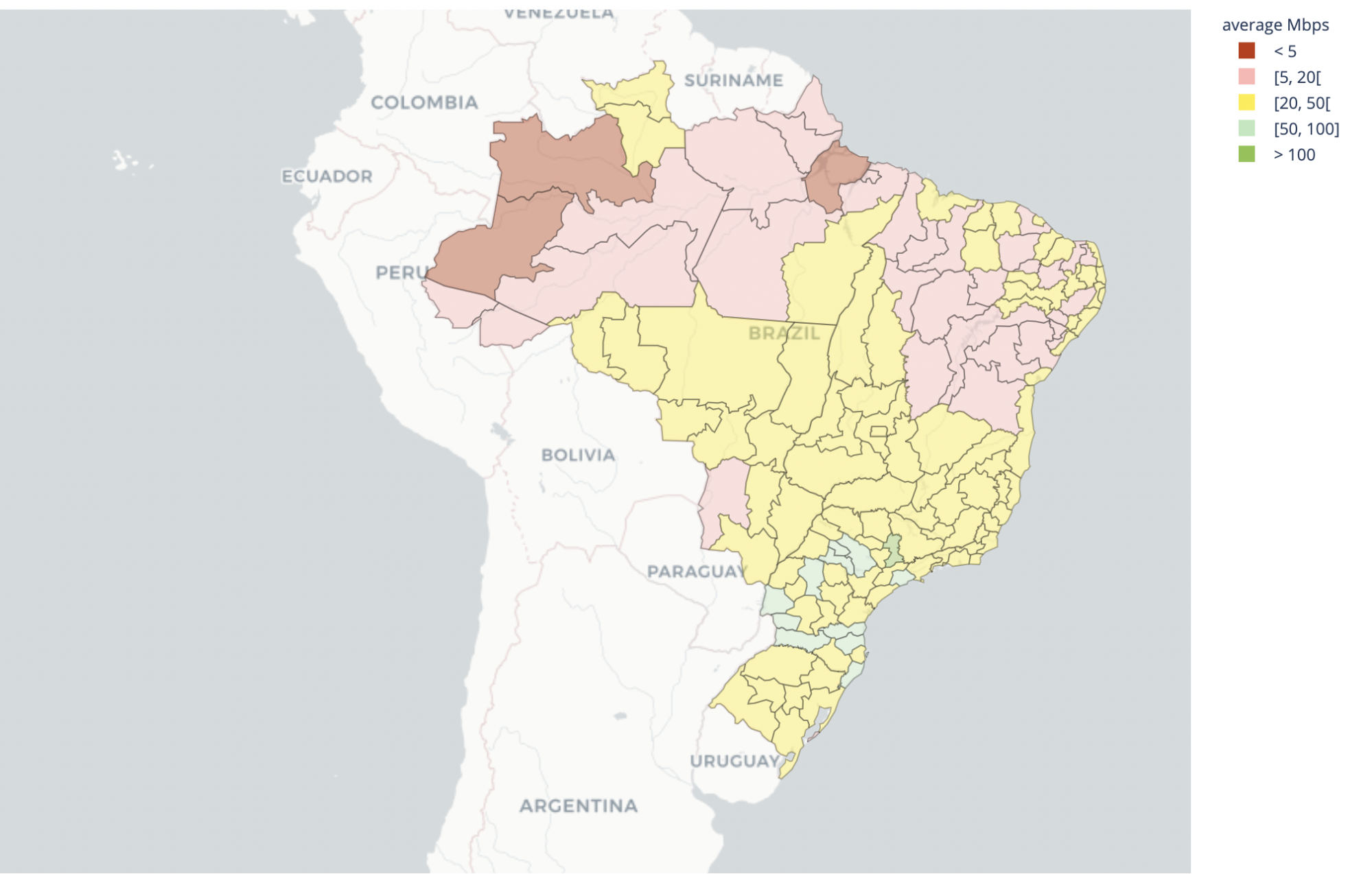
Brazil
Brazil median throughput: 26.28Mbps
Brazil median latency: 49.25ms
Much of Brazil has good, low latency Internet performance, given geographic proximity to the major Internet hubs in São Paulo and Rio de Janeiro. Much of the Amazon has low speeds and high latency, for those parts that are actually connected to the Internet.
Campinas is one stand out, with some of the best performing Internet across Brazil, and is also the site of a recent Cloudflare data center launch.
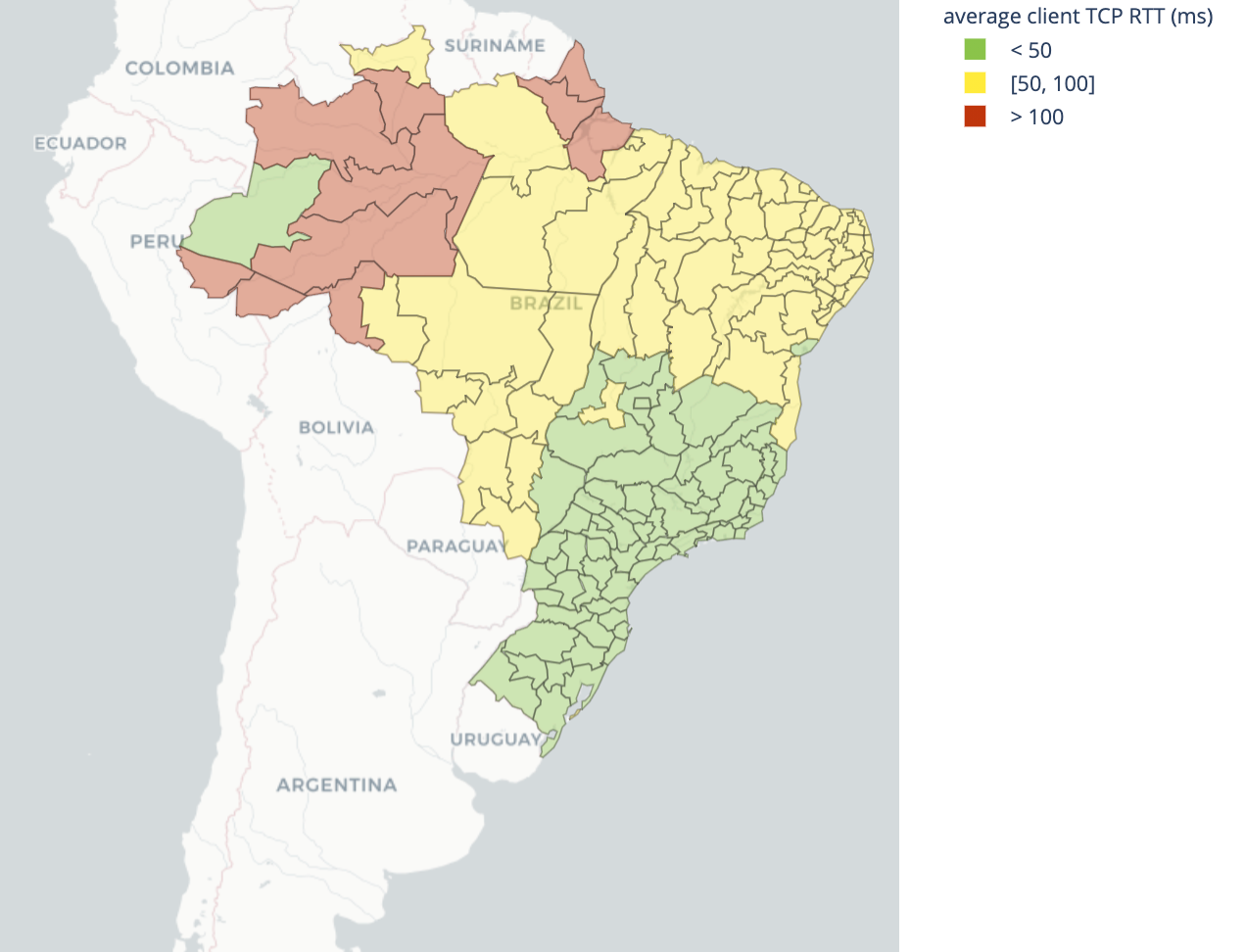
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Vale do Paraiba Paulista | Vale do Acre |
| Assis | Sul Amazonense |
| Sudoeste Amazonense | Marajo |
| Litoral Sul Paulista | Vale do Jurua |
| Baixadas | Sul de Roraima |
| Centro Fluminense | Centro Amazonense |
| Sul Catarinense | Madeira-Guapore |
| Vale do Paraiba Paulista | Sul do Amapa |
| Noroeste Fluminense | Metropolitana de Belem |
| Bauru | Baixo Amazonas |
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Metropolitana do Rio de Janeiro | Sudoeste Amazonense |
| Campinas | Marajo |
| Metropolitana de São Paulo | Norte Amazonense |
| Oeste Catarinense | Baixo Amazonas |
| Marilia | Sudeste Rio-Grandense |
| Vale do Itajaí | Sul Amazonense |
| Sul Catarinense | Centro-Sul Cearense |
| Sudoeste Paranaense | Sudoeste Paraense |
| Grande Florianópolis | Sertão Sergipano |
| Norte Catarinense | Sertoes Cearenses |
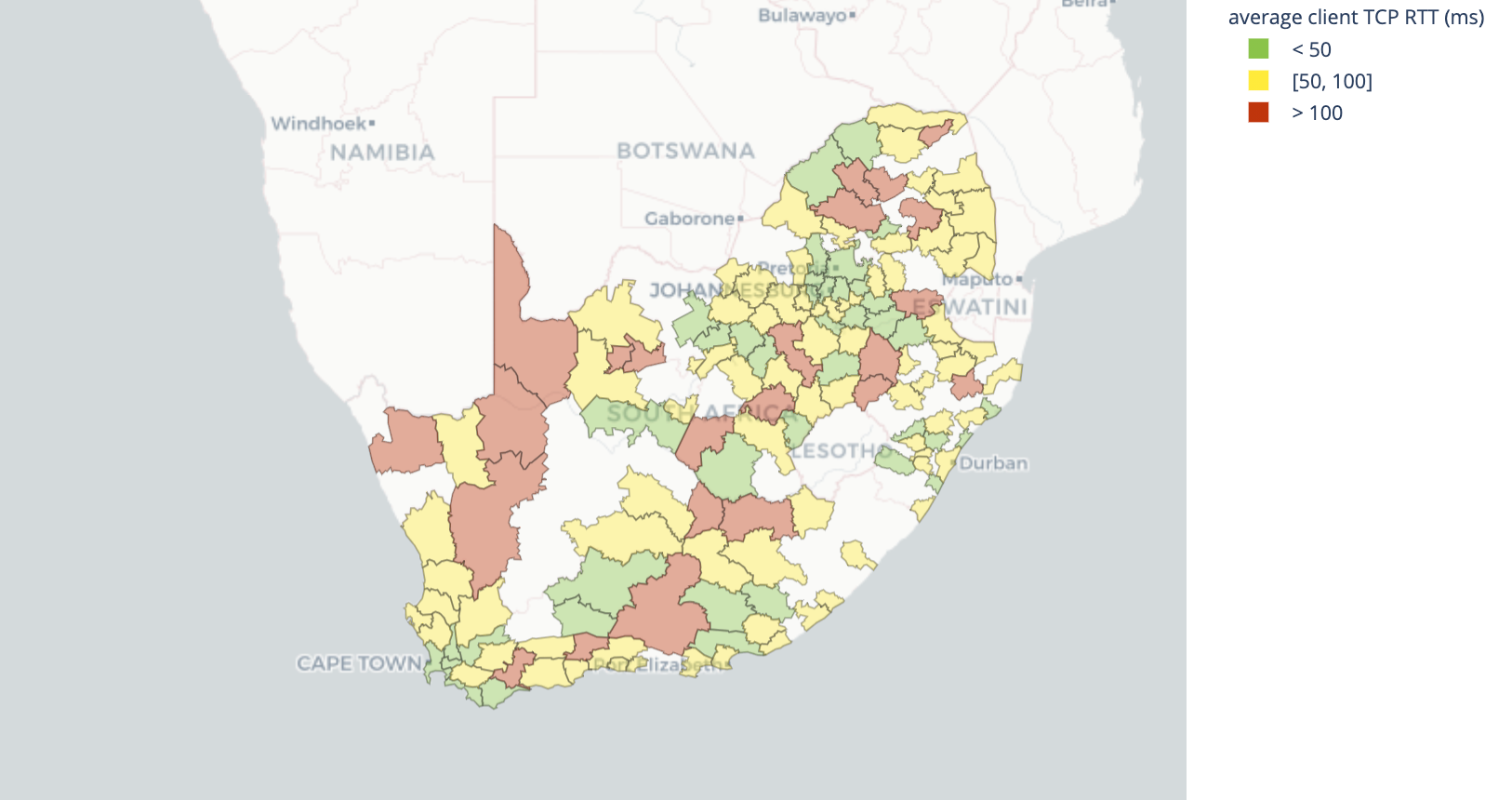
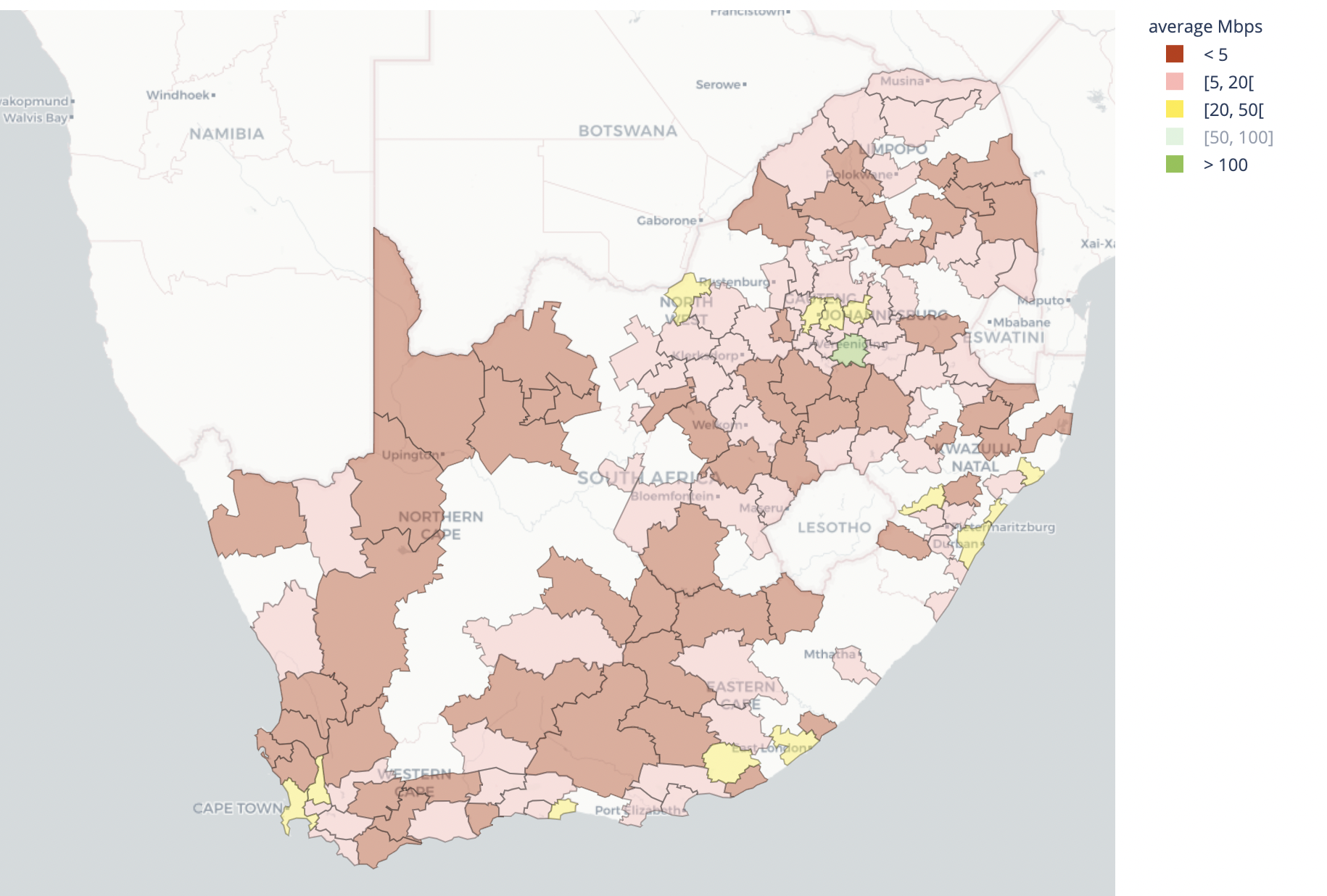
South Africa
South Africa median throughput: 6.4Mbps
South Africa median latency: 59.78ms
Johannesburg has been the historical hub for South Africa’s Internet. This is where many Internet giants have built data centers, and it shows in latency as distance from Johannesburg. South Africa has grown to have two more Internet hubs in Cape Town and Durban. Internet performance also follows these three cities. However, much of South Africa’s Internet performance lacks the ability for video streaming and video conferencing in high definition.
| Best performing geographies by latency | Worst performing geographies by latency |
|---|---|
| Siyancuma | Dr Beyers Naude |
| uMshwathi | Mogalakwena |
| City of Tshwane | Ulundi |
| Breede Valley | Modimolle/Mookgophong |
| City of Cape Town | Maluti a Phofung |
| Overstrand | Moqhaka |
| Local Municipality of Madibeng | Thulamela |
| Metsimaholo | Walter Sisulu |
| Stellenbosch | Dawid Kruiper |
| Ekurhuleni | Ga-Segonyana |
| Best performing geographies by throughput | Worst performing geographies by throughput |
|---|---|
| Siyancuma | Dr Beyers Naude |
| City of Cape Town | Walter Sisulu |
| City of Johannesburg | Lekwa-Teemane |
| Ekurhuleni | Dr Nkosazana Dlamini Zuma |
| Drakenstein | Emthanjeni |
| eThekwini | Dawid Kruiper |
| Buffalo City | Swellendam |
| uMhlathuze | Merafong City |
| City of Tshwane | Blue Crane Route |
| City of Matlosana | Modimolle/Mookgophong |
Case Study on ISP Concentration’s Impact on Performance: Alabama, USA
One question we had as we went through a lot of this data: does ISP concentration impact Internet performance?
On one hand, there’s a case to be made that more ISP competition results in no one vendor being able to invest sufficient resources to build out a fast network. On the other hand, well, classical economics would suggest that monopolies are bad, right?
To investigate the question further, we did a deep dive into Alabama in the United States, the 24th most populous state in the US. We tracked two key metrics across 65 counties: Internet performance as defined by average download speed, and ISP concentration, as measured by the largest ISP’s traffic share.
Here is the raw data:
| County | Avg. Download Speed | Largest ISP’s Traffic Share | County | Avg. Download Speed | Largest ISP’s Traffic Share |
|---|---|---|---|---|---|
| Marion | 53.77 | 41% | Franklin | 32.01 | 83% |
| Escambia | 29.14 | 43% | Coosa | 82.15 | 83% |
| Etowah | 56.07 | 49% | Crenshaw | 44.49 | 84% |
| Jackson | 37.77 | 52% | Randolph | 21.4 | 86% |
| Winston | 59.25 | 56% | Lamar | 33.94 | 86% |
| Montgomery | 79.5 | 58% | Autuaga | 65.55 | 86% |
| Baldwin | 49.06 | 58% | Choctaw | 23.97 | 87% |
| Houston | 73.73 | 61% | Butler | 29.86 | 90% |
| Dallas | 86.92 | 62% | Pike | 50.54 | 92% |
| Marshall | 59.93 | 62% | Sumter | 38.52 | 91% |
| Chambers | 72.05 | 63% | Pickens | 43.76 | 92% |
| Jefferson | 99.84 | 64% | Marengo | 42.89 | 92% |
| Elmore | 71.05 | 66% | Macon | 12.69 | 92% |
| Fayette | 41.7 | 68% | Lawrence | 62.87 | 92% |
| Lauderdale | 62.87 | 69% | Bullock | 23.89 | 92% |
| Colbert | 47.91 | 70% | Chilton | 17.13 | 95% |
| DeKalb | 58.55 | 70% | Wilcox | 62.12 | 93% |
| Morgan | 61.78 | 71% | Monroe | 20.74 | 96% |
| Washington | 5.14 | 72% | Dale | 55.46 | 97% |
| Geneva | 32.01 | 73% | Coffee | 58.18 | 97% |
| Lee | 78.1 | 73% | Conecuh | 34.94 | 97% |
| Tuscaloosa | 58.85 | 76% | Cleburne | 38.25 | 97% |
| Cullman | 61.03 | 77% | Clarke | 38.14 | 97% |
| Covington | 35.48 | 78% | Calhoun | 64.19 | 97% |
| Shelby | 69.66 | 79% | Lowndes | 9.91 | 98% |
| St. Clair | 33.05 | 79% | Russell | 49.48 | 98% |
| Blount | 40.58 | 80% | Henry | 4.69 | 98% |
| Mobile | 68.77 | 80% | Limestone | 71.6 | 98% |
| Walker | 39.36 | 81% | Bibb | 70.14 | 98% |
| Barbour | 51.48 | 82% | Cherokee | 17.13 | 99% |
| Tallapoosa | 60 | 82% | Greene | 4.76 | 99% |
| Madison | 99 | 83% | Clay | 3.42 | 100% |
Across most of Alabama, we see very high ISP concentration. For the majority of counties, the largest ISP has 80% (or higher) share of traffic, while all the other ISPs combined operate at considerably smaller scale. In only three counties (Marion, Escambia and Etowah) does each ISP carry less than 50% of user traffic. Interestingly, Etowah is one of the best performing in the state, while Henry, a county where 98% of Internet traffic is concentrated behind a single ISP is the worst performing.
Where it gets interesting is when you plot the data, tracking the non-dominant ISP by traffic share (which is simply 100% less the traffic share of the dominant ISP) against the performance (as measured by download speed) and then use a linear line of best fit to find the relationship. Here’s what you get:

As you can see, there is a strong positive relationship between the non-dominant ISP’s traffic share and the average download speed. As the non-dominant ISP increases its traffic share, Internet speeds tend to improve. The conclusion is clear: if you want to improve Internet performance in a region, foster more competition between multiple Internet service providers.
The Other Performance Challenge: Limited ISP Exchanges, and Tromboning
There is more to the story, however, than just concentration. Alabama, like a lot of other regions that aren’t served well by ISPs, faces another performance challenge: poor routing, also sometimes known as “tromboning”.
Consider Tuskegee in Alabama, home to a local university.
In Tuskegee, choice is limited. Consumers only have a single choice for high-speed broadband. But even once an off-campus student has local access to the Internet, it isn’t truly local: Tuskegee students on a different ISP than their university will likely see their traffic detour all the way through Atlanta (two hours northeast by car!) before making its way back to school.
This doesn’t happen in isolation: today, the largest ISPs only exchange traffic with other networks in a handful of cities, notably Seattle, San Jose, Los Angeles, Dallas, Chicago, Atlanta, Miami, Ashburn, and New York City.
If you’re in one of these big cities, you’re unlikely to suffer from tromboning. But if you’re not? Your Internet traffic can often have to travel further away before looping back, similar to the shape of a trombone, reducing your Internet performance. Tromboning contributes to inefficiency and drives up the cost of Internet access. An increasing amount of traffic is wastefully carried to cities far away, instead of keeping the data local.
You can visualize how your Internet traffic is flowing, by using tools like traceroute.
As an example, we ran tests using RIPE Atlas probes to Facebook from Alabama, and unfortunately found extremes where traffic can sometimes take a highly circuitous route — traffic going to Atlanta, then Ashburn, Paris, Amsterdam, before making its way back to Alabama. The path begins on AT&T’s network and goes to Atlanta where it enters the network for Telia (an IP transit provider), crosses the Atlantic, meets Facebook, and then comes back.
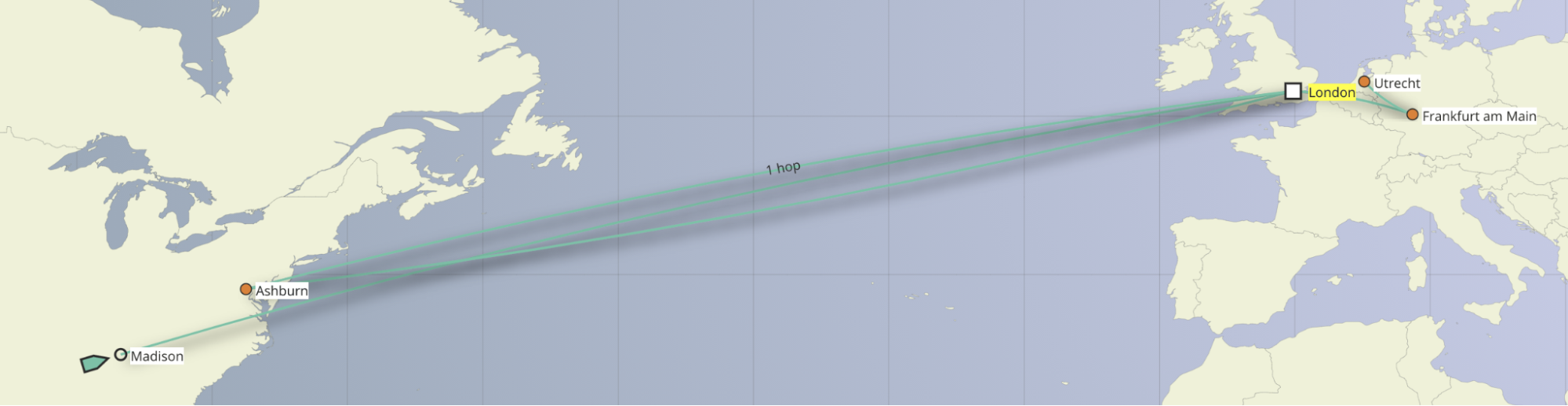
Traceroute to 157.240.201.35 (157.240.201.35), 48 byte packets
1- 192.168.6.1 1.435ms 0.912ms 0.636ms
2- 99.22.36.1 99-22-36-1.lightspeed.dctral.sbcglobal.net AS7018 1.26ms 1.134ms 1.107ms
3- 99.173.216.214 AS7018 3.185ms 3.173ms 3.099ms
4- 12.122.140.70 cr84.attga.ip.att.net AS7018 11.572ms 13.552ms 15.038ms
5 - * * *
6- 192.205.33.42 AS7018 8.695ms 9.185ms 8.703ms
7- 62.115.125.129 ash-bb2-link.ip.twelve99.net AS1299 23.53ms 22.738ms 23.012ms
8- 62.115.112.243 prs-bb1-link.ip.twelve99.net AS1299 115.516ms 115.52ms 115.211ms
9- 62.115.134.96 adm-bb3-link.ip.twelve99.net AS1299 113.487ms 113.405ms 113.25ms
10- 62.115.136.195 adm-b1-link.ip.twelve99.net AS1299 115.443ms 115.703ms 115.45ms
11- 62.115.148.231 facebook-ic331939-adm-b1.ip.twelve99-cust.net AS1299 134.149ms 113.885ms 114.246ms
12- 129.134.51.84 po151.asw02.ams2.tfbnw.net AS32934 113.27ms 113.078ms 113.149ms
13- 129.134.48.101 po226.psw04.ams4.tfbnw.net AS32934 114.529ms 114.439ms 117.257ms
14- 157.240.38.227 AS32934 113.281ms 113.365ms 113.448ms
15- 157.240.201.35 edge-star-mini-shv-01-ams4.facebook.com AS32934 115.013ms 115.223ms 115.112ms
The intent here isn’t to shame AT&T, Telia, or Facebook — nor is this challenge unique to them. Facebook’s content is undoubtedly cached in Atlanta and the request from Alabama should go no further than that. While many possible conditions within and between these three networks could have caused this tromboning, in the end, the consumer suffers.
The solution? Have more major ISPs exchange in more cities and with more networks. Of course, there’d be an upfront cost involved in doing so, even if it would reduce cost more over the long run.
Conclusion
As William Gibson famously observed: the future is here, but it’s just not evenly distributed.
One of the clearest takeaways from the data and analysis presented here is that Internet access varies tremendously across geographies. But it’s not just a case of the developed world vs the developing, or even rural vs urban. There are underserved urban communities and regions of the developed world that do not score as highly as you might expect.
Furthermore, our case study of Alabama shows that the structure of the ISP market is incredibly important to promoting performance. We found a strong positive correlation between more competition and faster performance. Similarly, there’s a lot of opportunity for more networks to interconnect in more places, to avoid bad routing.
Finally, if we want to get the other 40% of the world online, we are going to need more initiatives that drive up access and drive down cost. There’s plenty of scope to help — and we’re excited to be launching Project Pangea to help.