One of the things that makes Cloudflare unique is our Innovation Weeks. Rather than having one large conference annually, we have multiple Innovation Weeks throughout the year to highlight new product announcements, beta products opening up to general availability, and share how our customers are using Cloudflare to help build a better Internet.
Internally, these weeks generate a lot of energy and excitement as well, as they provide an opportunity for teams from across Cloudflare to work together on product delivery and celebrate company-wide successes. In 2021, we had seven Cloudflare Innovation Weeks. As we start planning our 2022 Innovation Weeks, we are reflecting back on the highlights from each of these weeks.
Security Week kicked off Cloudflare’s 2021 Innovation Weeks with a series of foundational security announcements. The Internet wasn’t built with security in mind, but the products and partnerships announced this week continued Cloudflare’s core mission of helping build a better Internet—one that companies of all sizes can plug into and be protected by default from the types of attacks that have historically resulted in loss of data, computing resources, and customer confidence.
During our first Impact Week, we reflected on how we are achieving Cloudflare’s mission–helping build a better Internet– and why we continue to prioritize projects that give back to the Internet. Impact Week highlighted some of the things we are doing as a company around environmental, social and governance initiatives. We launched Project Pangea, a free program to provide secure, reliable access to the Internet for community networks that support under-served communities. We also shared how we are committed to helping build a green Internet through efficiency, renewable energy, and providing developers a choice to run their workloads in the most energy efficient data centers. In addition, we published our first human rights policy in order to better serve our mission and core values.
We launched two amazing performance features with Signed Exchanges reducing load times and increasing SEO rankings with one click as well as Early Hints which can reduce loading times by 30%.
As part of Speed week, we also announced Cloudflare Images which stores, resizes, optimizes and serves images so that all of our customers can build a scalable, affordable image pipeline.
This is the week in which we celebrate Cloudflare’s birthday. We launched the company 11 years ago: September 27, 2010. It has been our tradition, since our first birthday, to use this week to launch innovative products that we think of as our gift back to the Internet. In 2021, we announced Cloudflare R2, our object-based storage with no egress fees, tackled solutions to Email Spoofing and Phishing, shared how we are expanding our network into office buildings as well as many more product announcements and Cloudflare TV executive fireside chats and product discussions.
During Full Stack Week, we brought the vision of the Network is the Computer to life — allowing developers to build their entire application on our network, soup to nuts. Over the course of the week, we made a series of announcements, each providing another critical piece of the puzzle, necessary to build a full stack application.
As part of Cloudflare’s recent Privacy Week we hosted a series of fireside chats on security, privacy, and compliance. Many of these conversations touched on the intricate legal debate being held in Europe around data sovereignty. Here are some of the highlights.
To learn more about the solutions Cloudflare launched to help businesses navigate their compliance needs — including the new data localization suite — see our recent blog post here.
Prof. Dr. Wilfried Bernhardt Honorary professor — University of Leipzig, Attorney, CEO Bernhardt IT Management Consulting GmbH
We have to agree to go down a common road, a common path. And this common path can really only consist of saying: let’s sit down together again. I’m talking about the European Commission and, above all, the new administration in the United States. We are all waiting for them expectantly.
And then we look at what our common fundamental values are and see if we don’t simply come together better than we have in the past. After all, our fundamental values are the same: human rights, democracy, the rule of law. You have to concede that there are some differences in understanding when it comes to interpreting what privacy means — well, in the US freedom of expression is sometimes considered more important than privacy. In Europe, it’s perhaps the other way around.
But if we look at it without ideological blinders, we can certainly come together. After all, when it comes to fighting terrorism and crime, it is common insights that play an important role. So it would be a great pity if we didn’t come together. But it is not permissible that, for example, American authorities simply say: we will allow ourselves access to European data of European Union citizens, we don’t have to ask anyone, and we don’t grant legal protection either. To be honest, that’s not how it works.
Iverna McGowan Director of the Europe Office, Center for Democracy & Technology (CDT)
My hope would be that we have a more global approach to international privacy standards. And I think for 2021 in Europe, it will be all about the Digital Services Act. And of course on the individual users’ rights as well, on free expression.
I think that human rights advocates will all have a lot of work to do to make sure that we guard our own rights to express ourselves online, but also protect people from harassment and hate. Getting that balance right in law and practice, I think, is going to be really important to maintain the Internet as a free and open space where we can organize and fight to protect human rights and democracy.
We at the Center for Democracy & Technology are strong advocates and practitioners of multistakeholder approaches. So these kinds of dialogues between the private sector and civil society to get into the details of, what are the technical solutions, what does that mean in different places? I think that’s going to be really important to get some of these policy challenges right.
Marshall Erwin Chief Security Officer, Mozilla Corporation
In the US we see a lack of a strong privacy regime, which is a problem — but also you don’t really see mandatory data retention and you don’t really see mandatory blocking in the US. Parts of Europe do have various sort of retention regimes or mandatory blocking regimes, or at least there is a desire within the policy space within Europe, to consider especially the DNS as a tool to facilitate content blocking.
Now, we think that’s a very bad idea for a number of reasons, partly because it’s bad on principle. It will result in risk to free expression. And also because it’s not a very effective way to address a lot of these serious content problems that bubble up today. And that’s the argument that I tend to make. We are actively thinking about the right set of solutions for malicious content on the Web. But blocking at this level, the stack through the DNS system — it’s a bad idea. It’s not going to work, and it will have serious free expression challenges.
Dr. Katrin Suder Chairperson of the Advisory Council on Digitalization for the German Federal Government, Member of Cloudflare’s Board of Directors
I think a lot of realism has come in, realism about what is actually feasible and what is possible, and at the same time the recognition that we don’t want to lose the innovation that American companies in particular are bringing.
How will this continue? Of course, that’s always difficult to predict in a process like this. I think what is actually needed, and we have talked about this in various forums, is first of all a clean assessment process for the current situation. Where do we actually stand with sovereignty? We have to be honest about this. So, where are we actually dependent and how can we deal with this dependency?
Because there are dependencies where you can perhaps say, yes, so be it, maybe it’s not so bad. And then there are perhaps dependencies that are very critical. That’s where you have to invest, but not to replicate, rather to push the next generation, so to speak. And I think this process should be driven by the European Commission.
Thomas Boué Director General, Policy — EMEA, BSA | The Software Alliance
One of the things that we spend time thinking about — and it’s going to be a long-term project, because it will not happen overnight — but it’s about: how can like-minded democracies find a way to create a standard? What will be the standard for acceptable government access to data and national security practices? What would be the ways that they would conduct these investigations? What would be the safeguards that exist? What would be the means of redress or of challenging those?
These are the things that need to happen between countries that are like-minded, that value privacy, but that also value the security of their citizens. And how can it go forward by creating this standard that would then bring a lot more clarity, a lot more certainty and a lot more appeased views in this entire debate. And that is the thing that we think is essential. We know that work is being done on this in certain fora — such as the OECD — and we very much encourage countries to think about this more, and to find a way forward.
Privacy matters. Privacy and Compliance are at the heart of Cloudflare’s products and solutions. We are committed to providing built-in data protection and privacy throughout our global network and for every product in our portfolio. This is why we have dedicated a whole week to highlight important aspects of how we are working to make sure privacy will stay at the core of all we do as a business.
In case you missed any of the blog posts this week addressing the topics of Privacy and Compliance, you’ll find a summary below.
Welcome to Privacy & Compliance Week: Reflecting Values at Cloudflare’s Core
We started the week with this introduction by Matthew Prince. The blog post summarizes the early decisions that the founding team made to make sure customer data is kept private, that we do not sell or rent this data to third parties, and why trust is the foundation of our business. > Read the full blog post.
Introducing the Cloudflare Data Localization Suite
Cloudflare’s network is private and compliant by design. Preserving end-user privacy is core to our mission of helping to build a better Internet; we’ve never sold personal data about customers or end-users of our network. We comply with laws like GDPR and maintain certifications such as ISO-27001. In a blog post by John Graham-Cumming, we announced the Data Localization Suite, which helps businesses get the performance and security benefits of Cloudflare’s global network while making it easy to set rules and controls at the edge about where their data is stored and protected. The Data Localization Suite is available now as an add-on for Enterprise customers. > Read the full blog post.
Privacy needs to be built into the Internet
John also reflected upon three phases of the evolution of the Internet: from its invention to the mid-1990s the race was on for expansion and connectivity. Then, as more devices and networks became interconnected, the focus shifted with the introduction of SSL in 1994 to a second phase where security became paramount. We’re now in the full swing of phase 3, where privacy is becoming more and more important than ever. > Read the full blog post.
Helping build the next generation of privacy-preserving protocols
The Internet is growing in terms of its capacity and the number of people using it and evolving in terms of its design and functionality. As a player in the Internet ecosystem, Cloudflare has a responsibility to help the Internet grow in a way that respects and provides value for its users. In this blog post, Nick Sullivan summarizes several announcements on improving Internet protocols with respect to something important to our customers and Internet users worldwide: privacy. These initiatives are focussed around: fixing one of the last information leaks in HTTPS through Encrypted Client Hello (ECH), which supersedes Encrypted SNI; making DNS even more private by supporting Oblivious DNS-over-HTTPS (ODoH); developing a superior protocol for password authentication, OPAQUE, that makes password breaches less likely to occur. > Read the full blog post.
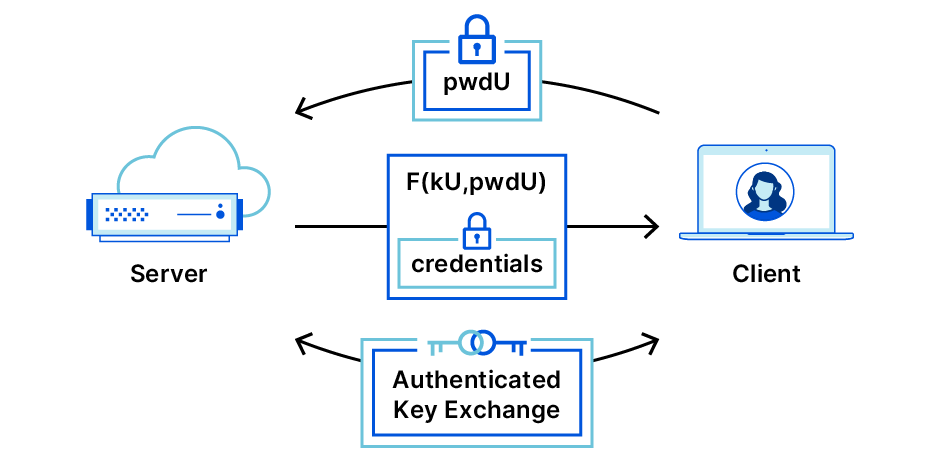
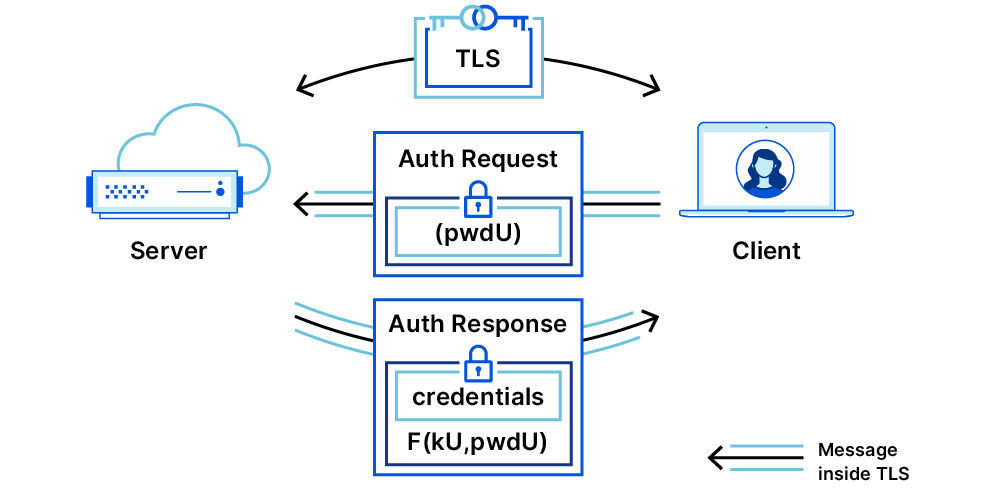
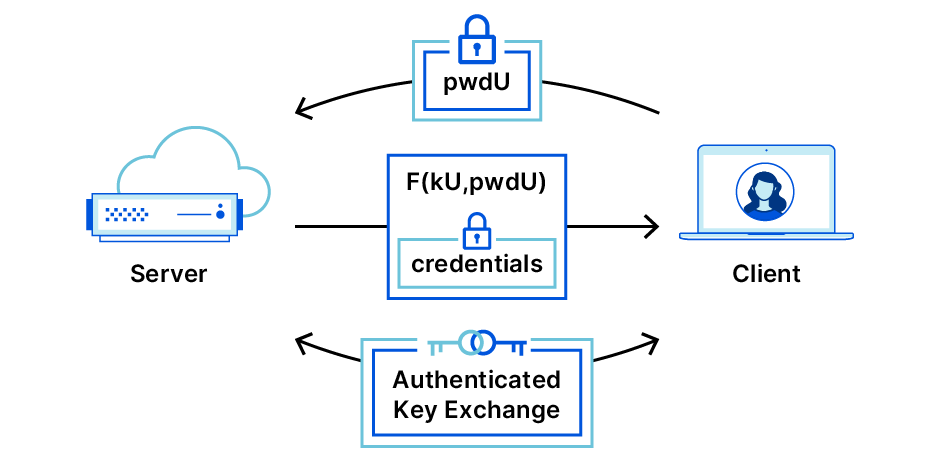
OPAQUE: The Best Passwords Never Leave your Device
Passwords are a problem. They are a problem for reasons that are familiar to most readers. For us at Cloudflare, the problem lies much deeper and broader. Most readers will immediately acknowledge that passwords are hard to remember and manage, especially as password requirements grow increasingly complex. Luckily there are great software packages and browser add-ons to help manage passwords. Unfortunately, the greater underlying problem is beyond the reaches of software to solve. Today’s deep-dive blog post by Tatiana Bradley, into OPAQUE, is one possible answer. OPAQUE is one among many examples of systems that enable a password to be useful without it ever leaving your possession. No one likes passwords, but as long they’re in use, at least we can ensure they are never given away. > Read the full blog post.
Good-bye ESNI, hello ECH!
In this post Christopher Patton dives into Encrypted Client Hello (ECH), a new extension for TLS that promises to significantly enhance the privacy of this critical Internet protocol. Today, a number of privacy-sensitive parameters of the TLS connection are negotiated in the clear. This leaves a trove of metadata available to network observers, including the endpoints’ identities, how they use the connection, and so on. > Read the full blog post.
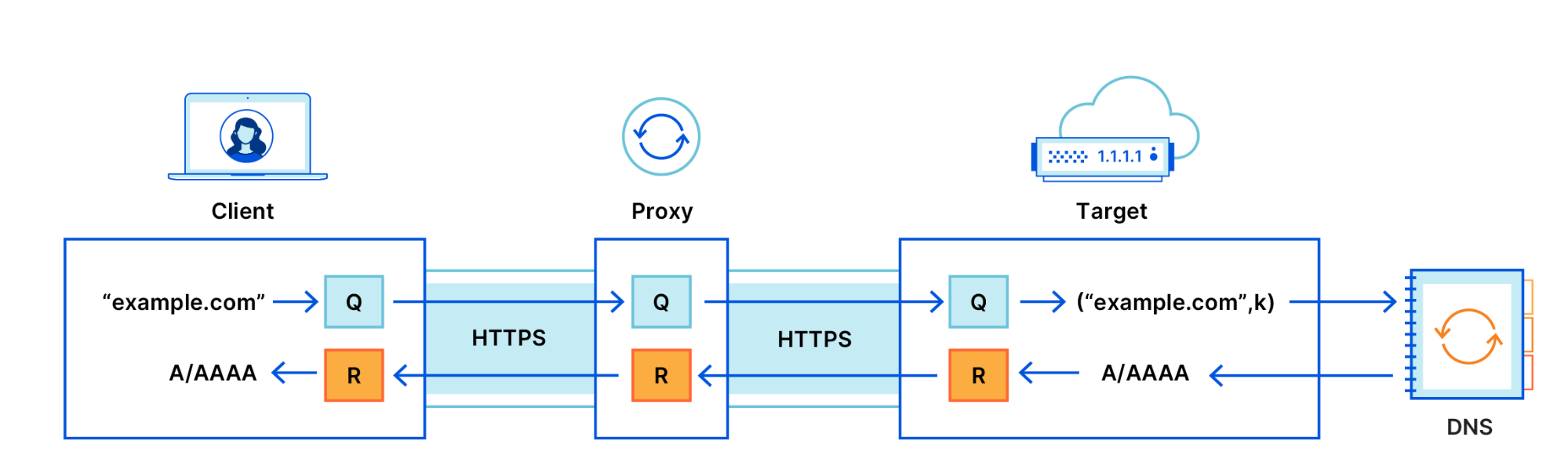
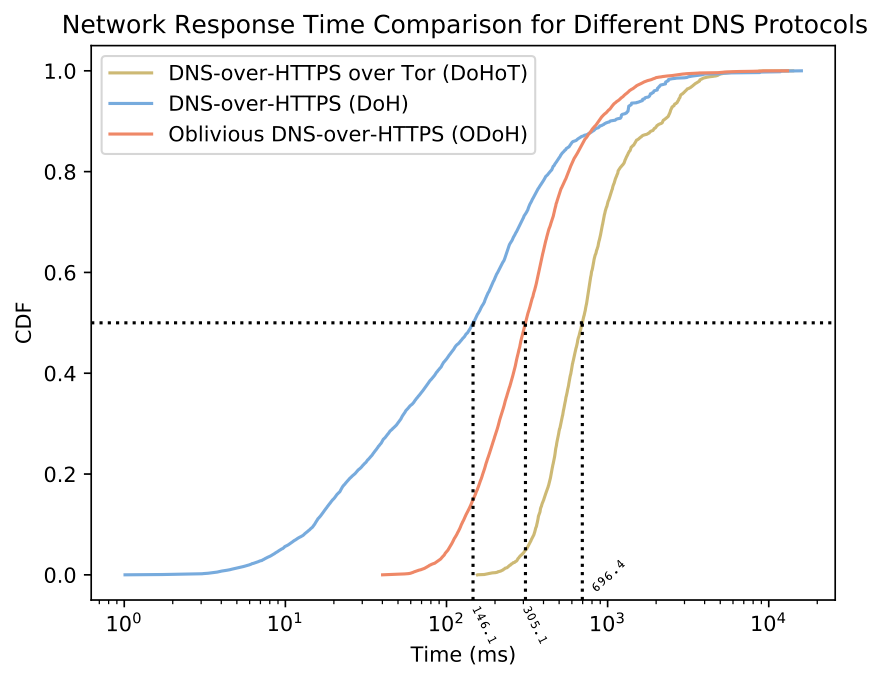
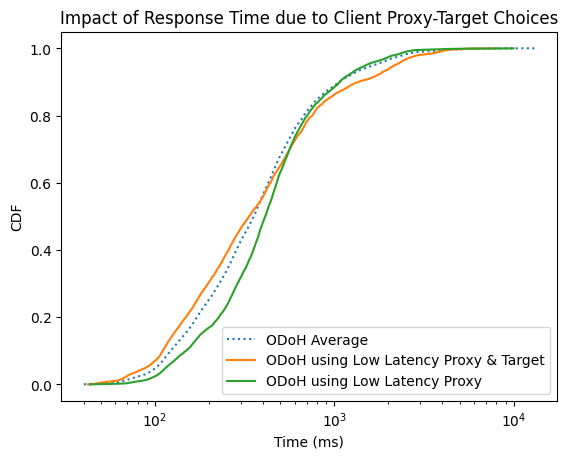
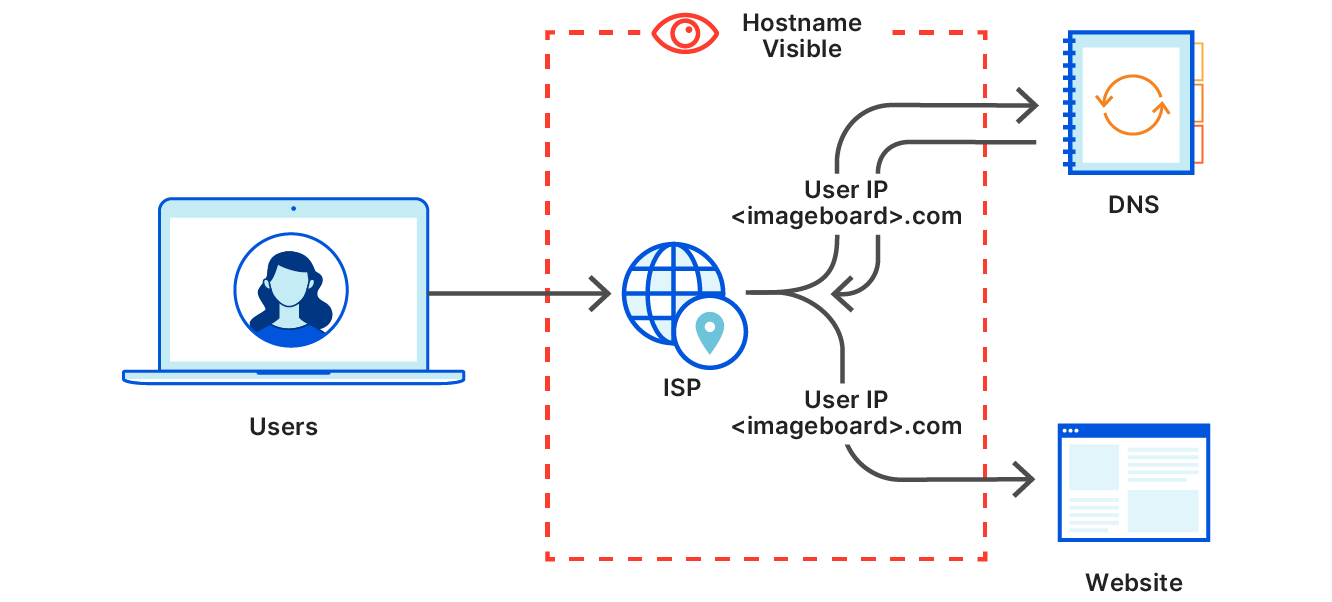
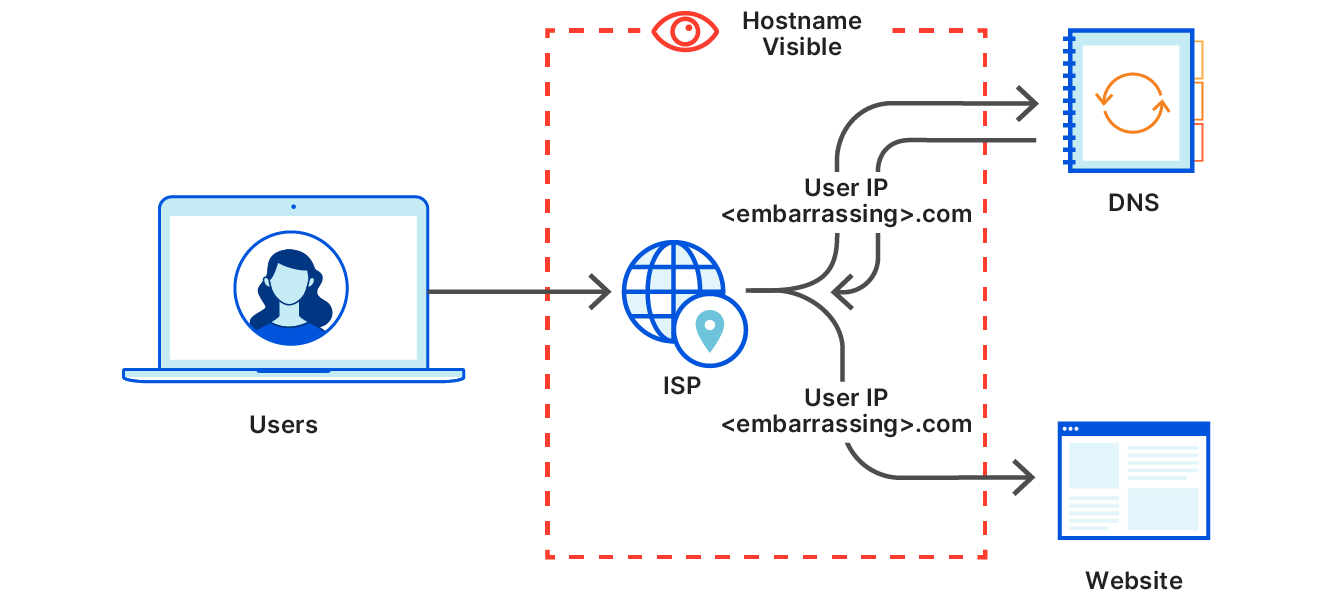
Improving DNS Privacy with Oblivious DoH in 1.1.1.1
Tanya Verma and Sudheesh Singanamalla wrote this blog post for our announcement of support for a new proposed DNS standard — co-authored by engineers from Cloudflare, Apple, and Fastly — that separates IP addresses from queries, so that no single entity can see both at the same time. Even better, we’ve made source code available, so anyone can try out ODoH, or run their own ODoH service! > Read the full blog post.
Deprecating the __cfduid cookie
Cloudflare never tracks end-users across sites or sells their personal data. However, we didn’t want there to be any questions about our cookie use, and we don’t want any customer to think they need a cookie banner because of what we do. Therefore we’ve announced that Cloudflare is deprecating the __cfduid cookie. Starting on 10 May 2021, we will stop adding a “Set-Cookie” header on all HTTP responses. The last __cfduid cookies will expire 30 days after that. So why did we use the __cfduid cookie before, and why can we remove it now? Read the full blog post by Sergi Isasi to find out.
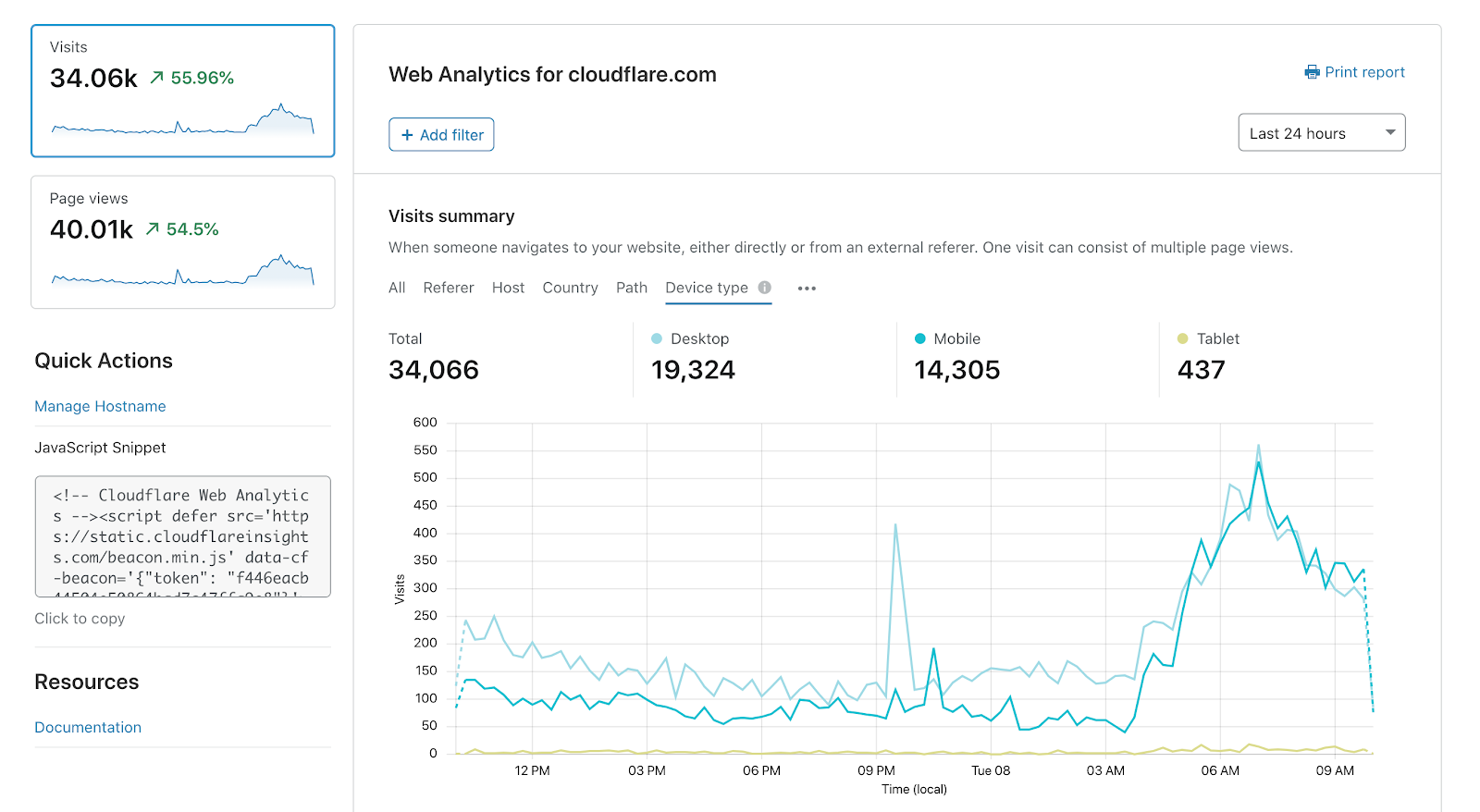
Cloudflare’s privacy-first Web Analytics is now available for everyone
In September, we announced that we’re building a new, free Web Analytics product for the whole web. In this blog post by Jon Levine, we’re announcing that anyone can now sign up to use our new Web Analytics — even without changing your DNS settings. In other words, Cloudflare Web Analytics can now be deployed by adding an HTML snippet (in the same way many other popular web analytics tools are) making it easier than ever to use privacy-first tools to understand visitor behavior.
Announcing Workplace Records for Cloudflare for Teams
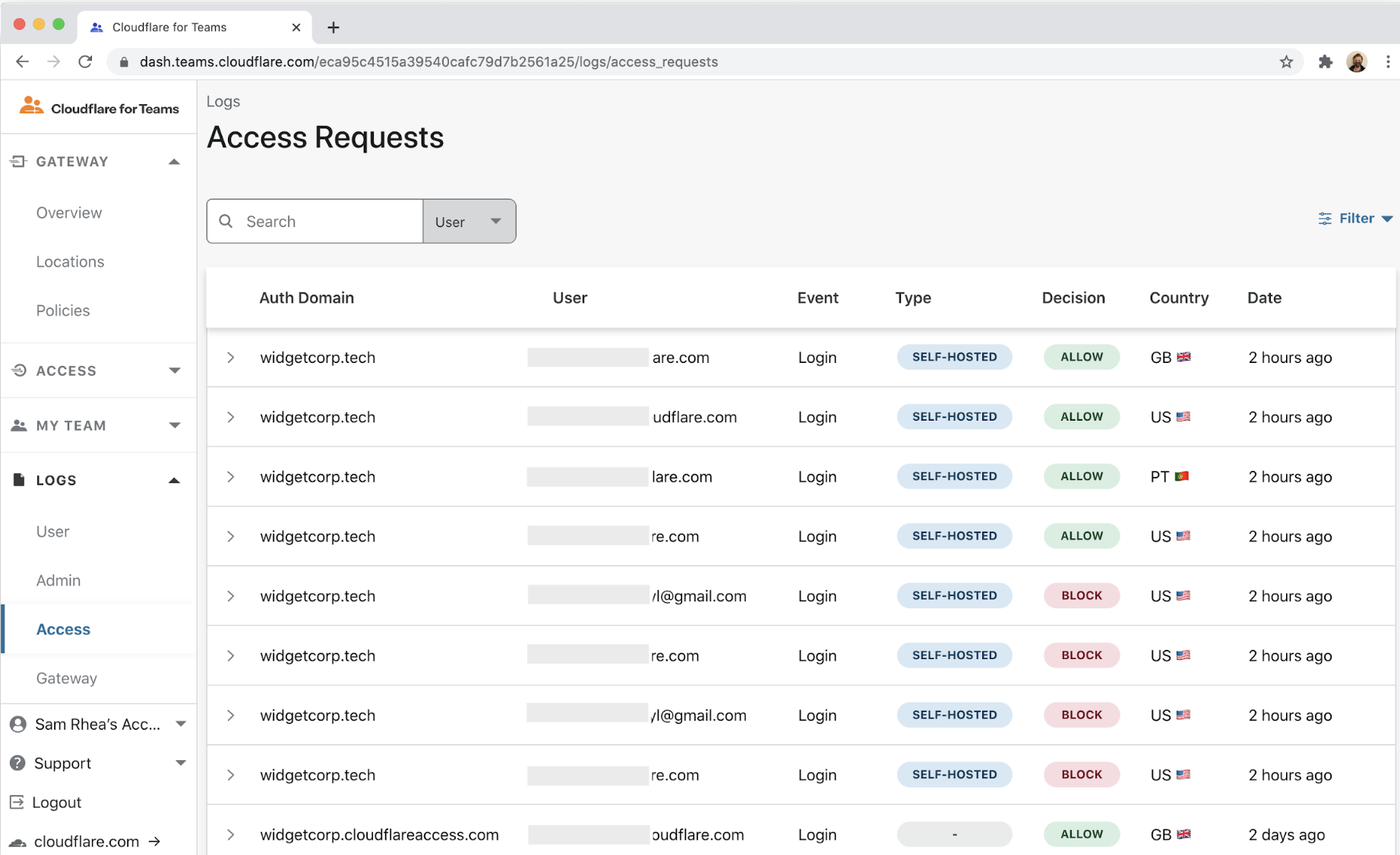
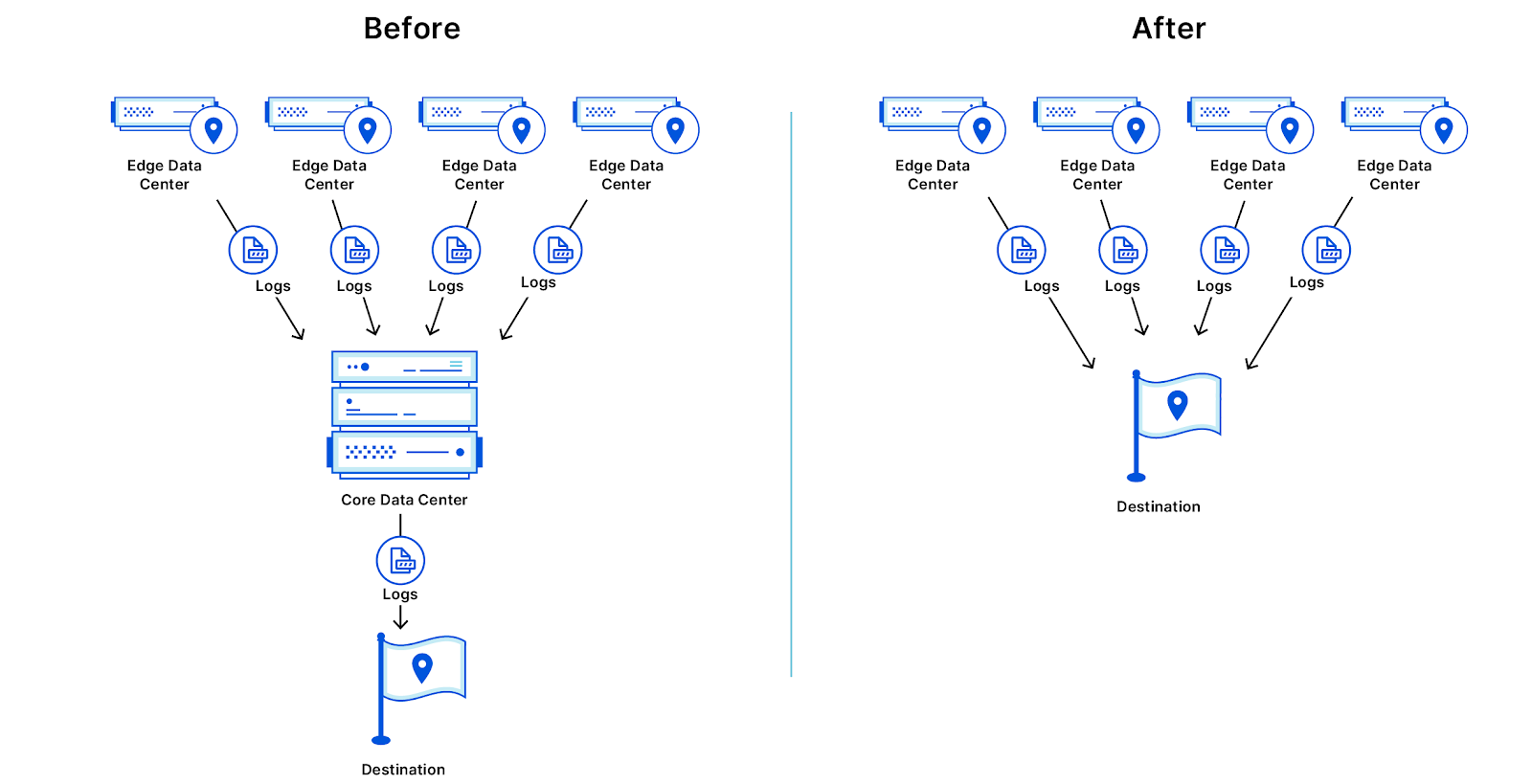
As businesses worldwide have shifted to remote work, many employees have been working from “home” — wherever that may be. Some employees have taken this opportunity to venture further from where they usually are, sometimes crossing state and national borders. Businesses worldwide pay employment taxes based on where their employees do work. For most businesses and in normal times, where employees do work has been relatively easy to determine: it’s where they come into the office. But 2020 has made everything more complicated, even taxes. In this blog post by Matthew Prince and Sam Rhea, we’re announcing the beta of a new feature for Cloudflare for Teams to help solve this problem: Workplace Records. Cloudflare for Teams uses Access and Gateway logs to provide the state and country from which employees are working. Workplace Records can be used to help finance, legal, and HR departments determine where payroll taxes are due and provide a record to defend those decisions.
Securing the post-quantum world
Quantum computing will change the face of Internet security forever — particularly in the realm of cryptography, which is the way communications and information are secured across channels like the Internet. Cryptography is critical to almost every aspect of modern life, from banking to cellular communications to connected refrigerators and systems that keep subways running on time. This ultra-powerful, highly sophisticated new generation of computing has the potential to unravel decades of work that have been put into developing the cryptographic algorithms and standards we use today. When will a quantum computer be built that is powerful enough to break all modern cryptography? By some estimates, it may take 10 to 15 years. This makes deploying post-quantum cryptography as soon as possible a pressing privacy concern. Cloudflare is taking steps to accelerate this transition. Read the full blog post by Nick Sullivan to find out more.
How to Build a Global Network that Complies with Local Law
Governments around the world have long had an interest in getting access to online records. Sometimes law enforcement is looking for evidence relevant to criminal investigations. Sometimes intelligence agencies are looking to learn more about what foreign governments or actors are doing. And online service providers of all kinds often serve as an access point for those electronic records.
For service providers like Cloudflare, though, those requests can be fraught. The work that law enforcement and other government authorities do is important. At the same time, the data that law enforcement and other government authorities are seeking does not belong to us. By using our services, our customers have put us in a position of trust over that data. Maintaining that trust is fundamental to our business and our values. Alissa Stark details in her blog post how Cloudflare works to ensure compliance with laws like GDPR, particularly in the face of legal orders that might put us in the difficult position of being required to violate it and that requires involving the courts.
Encrypting your WAF Payloads with Hybrid Public Key Encryption (HPKE)
The Cloudflare Web Application Firewall (WAF) blocks more than 72B malicious requests per day from reaching our customers’ applications. Typically, our users can easily confirm these requests were not legitimate by checking the URL, the query parameters, or other metadata that Cloudflare provides as part of the security event log in the dashboard. Request headers may contain cookies and POST payloads may contain username and password pairs submitted during a login attempt among other sensitive data.
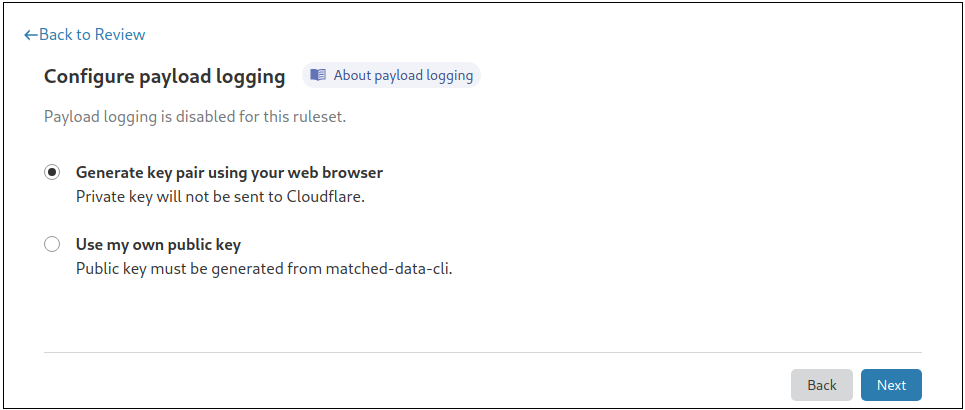
We recognize that providing clear visibility in any security event is a core feature of a firewall, as this allows users to better fine-tune their rules. To accomplish this, while ensuring end-user privacy, we built encrypted WAF matched payload logging. This feature will log only the specific component of the request the WAF has deemed malicious — and it is encrypted using a customer-provided key to ensure that no Cloudflare employee can examine the data. Michael Tremante goes over this in full detail, explaining how only application owners who also have access to the Cloudflare dashboard as Super Administrators will be able to configure encrypted matched payload logging.
Supporting Jurisdictional Restrictions for Durable Objects
Durable Objects, currently in limited beta, already make it easy for customers to manage state on Cloudflare Workers without worrying about provisioning infrastructure. Greg McKeon announces in this blog post the upcoming launch of Jurisdictional Restrictions for Durable Objects, which ensure that a Durable Object only stores and processes data in a given geographical region. Jurisdictional Restrictions make it easy for developers to build serverless, stateful applications that not only comply with today’s regulations but can handle new and updated policies as new regulations are added. Head over to the blog post to read more and also request an invite to the beta.
I want my Cloudflare TV
We have also had a full week of CloudflareTV segments focussed on privacy and compliance and you can get the full list and more details on our dedicated Privacy Week page.
As always, we welcome your feedback and comments and we stay committed to putting the privacy and safety of your data at the core of everything we do.
The Cloudflare Web Application Firewall (WAF) blocks more than 72B malicious requests per day from reaching our customers’ applications. Typically, our users can easily confirm these requests were not legitimate by checking the URL, the query parameters, or other metadata that Cloudflare provides as part of the security event log in the dashboard.
Sometimes investigating a WAF event requires a bit more research and a trial and error approach, as the WAF may have matched against a field that is not logged by default.
Not logging all parts of a request is intentional: HTTP headers and payloads often contain sensitive data, including personally identifiable information, which we consider a toxic asset. Request headers may contain cookies and POST payloads may contain username and password pairs submitted during a login attempt among other sensitive data.
We recognize that providing clear visibility in any security event is a core feature of a firewall, as this allows users to better fine tune their rules. To accomplish this, while ensuring end-user privacy, we built encrypted WAF matched payload logging. This feature will log only the specific component of the request the WAF has deemed malicious — and it is encrypted using a customer-provided key to ensure that no Cloudflare employee can examine the data*. Additionally, the crypto uses an exciting new standard — developed in part by Cloudflare — called Hybrid Public Key Encryption (HPKE).
*All Cloudflare logs are encrypted at rest. This feature implements a second layer of encryption for the specific matched fields so that only the customer can decrypt it.
Encrypting Matched Payloads
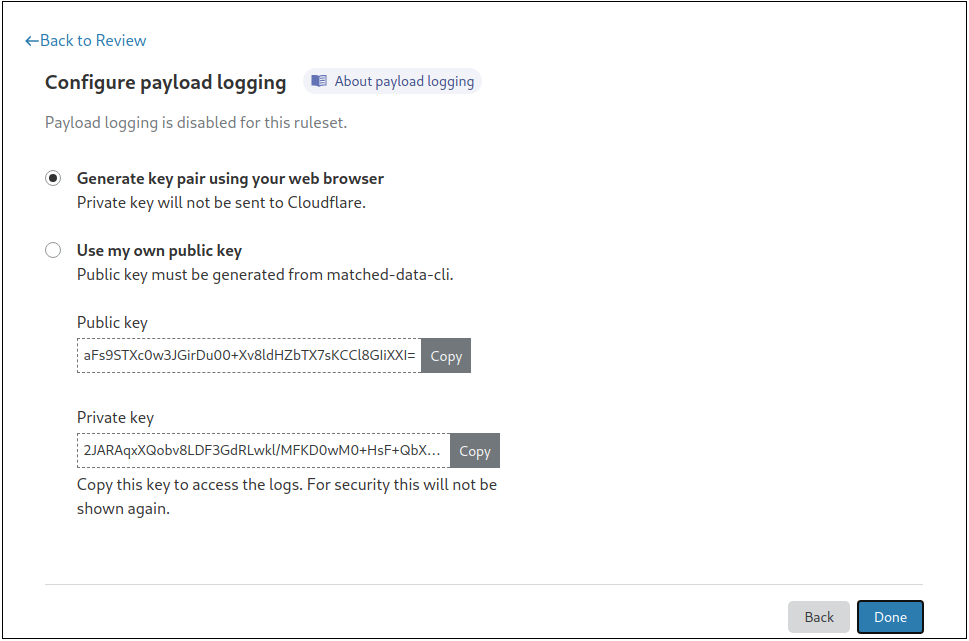
To turn on this feature, you need to provide a public key, or generate a private-public key pair directly from the dashboard. Your data will then be encrypted using Hybrid Public Key Encryption (HPKE), which offers a great combination of both performance and security.
To simplify this process, we have built an easy-to-use command line utility to generate the key pair:
Cloudflare does not store the private key and it is our customers’ responsibility to ensure it is stored safely. Lost keys, and the data encrypted with them, cannot be recovered but customers can rotate keys to be used with future payloads.
Once encrypted, payloads will be available in the logs as encrypted base64 blobs within the metadata field:
Decrypting payloads can be done via the dashboard from the Security Events log, or by using the command line utility, as shown below. If done via the dashboard, the browser will decrypt the payload locally (i.e., client side) and will not send the private key to Cloudflare.
In the example above, the WAF matched against the REQUEST_HEADERS:REFERER field. Any other fields the WAF matched on would be similarly logged.
Better Logging with User Privacy in Mind
In the coming months, this feature will be available on our dashboard to our Enterprise customers. Enterprise customers who would like this feature enabled sooner should reach out to their account team. Only application owners who also have access to the Cloudflare dashboard as Super Administrators will be able to configure encrypted matched payload logging. Those who do not have access to the private key, including Cloudflare staff, are not able to decrypt the logs.
We are also excited for this feature to be one of our first to use Hybrid Public Key Encryption, and for Cloudflare to use this emerging standard developed by the Crypto Forum Research Group (CFRG), the research body that supports the development of Internet standards at the IETF. And stay tuned, we will publish a deep dive post with the technical details soon!
We’ve spent a lot of time over the course of this week talking about Cloudflare engineers building technical solutions to improve privacy, increase control over data, and thereby, help our customers address regulatory challenges. But not all challenges can be solved with engineering. We sometimes have to build policies and procedures that anticipate our customers’ concerns. That has been an approach we’ve used to address government and other legal requests for data throughout the years.
Governments around the world have long had an interest in getting access to online records. Sometimes law enforcement is looking for evidence relevant to criminal investigations. Sometimes intelligence agencies are looking to learn more about what foreign governments or actors are doing. And online service providers of all kinds often serve as an access point for those electronic records.
For service providers like Cloudflare, though, those requests can be fraught. The work that law enforcement and other government authorities do is important. At the same time, the data that law enforcement and other government authorities are seeking does not belong to us. By using our services, our customers have put us in a position of trust over that data. Maintaining that trust is fundamental to our business and our values.
These tensions are compounded by the fact that different governments have different standards for the protection of personal data. The United States, for example, prohibits companies from disclosing the content of communications — including to non-U.S. governments — in all but certain legally defined circumstances. The European Union, which has long considered the privacy of communications and the protection of personal data to be fundamental human rights, protects all EU personal data through the General Data Protection Regulation (GDPR). Although these protections overlap in certain respects, they differ both in their scope and whom they protect.
The differences between legal frameworks matter, particularly when it comes to whether legal requests for information from foreign governments are determined to be consistent with privacy requirements. In recent years, for example, the Court of Justice of the European Union (CJEU) has concluded on multiple occasions that U.S. legal restrictions on gathering data, along with certain voluntary commitments like the Privacy Shield, or its predecessor, the U.S.-EU Safe Harbor, are not adequate to comply with EU privacy requirements, largely because of U.S. laws that allow legal authorities to collect information on non-U.S. citizens for foreign intelligence purposes. Indeed, the European Data Protection Board (EDPB) has taken the position that a U.S. criminal law request for data — outside of a legal process in which countries in the EU maintain some control over the information being produced — is not a legitimate basis for the transfer of personal data subject to GDPR.
At heart, these are fights over when it is appropriate for one government to use legal orders or other legal processes to access data about another country’s citizens. And these are not just fights happening in Europe. Although their policy responses are not consistent, an increasing number of countries now see access to their citizens’ data as a national security concern. From our perspective, these battles between nation-states are battles between giants. But they were also foreseeable.
Preparing Policies for Battles Between Giants
Cloudflare has long had policies to address concerns about access to personal data, both because we believe it’s the right thing to do and because the conflicts of law we are seeing today seemed inevitable. As a global company, with customers, equipment, and employees in many countries, we understand that different countries have different legal standards. But when there is a conflict between two different legal standards, we default to the one that is most privacy-protective. And we always require legal process. Because once you have opened the gate to data, it can be difficult to close.
Beginning with our very first transparency report detailing law enforcement requests for data in 2013, we’ve made public commitments about how we approach requests for data and public statements about things we have never done. We call the public statements about things we have never done warrant ‘canaries’, with the idea that they serve a signaling function to the outside world. They are a public statement that we would not take these actions willingly, and a mechanism to convey information — by removal of the statement from the site — that we might otherwise be restricted from disclosing. . We’ve also committed to challenge any legal order seeking to have us break these commitments, in court if necessary. Our goal was to be very clear — not only to our customers but to governments around the world — about where we were drawing our lines.
Regulatory entities have started to recognize the value of privacy commitments, particularly when they can be enforced by contract. Indeed, the commitments we have included in our transparency reports for years are exactly the types of commitments the European Commission has recommended be included in its draft Standard Contractual Clauses for compliance with the GDPR.
Cloudflare’s warrant canaries
As a security company, we know that maintaining control over access to our networks is an absolute imperative. That is why our security team has focused on access controls, logging, and monitoring, and goes through multiple third-party assessments per year. We want to ensure that our customers understand that there is no exemption in those controls for law enforcement or government actors. That’s why we state both that Cloudflare has never installed law enforcement software or equipment anywhere on our network, and that we have never provided any government organization a feed of our customers’ content transiting our network.
Cloudflare believes that strong encryption — both for content and metadata — is necessary for privacy online. If a country is seeking to prevent a foreign intelligence service from accessing its citizens’ personal information, the first step should be encryption of that personal information. But customers and regulators also need to be confident that the encryption itself is trustworthy. So we have commitments that we have never turned over our encryption or authentication keys, or our customers’ encryption or authentication keys, to anyone, and that we have never weakened, compromised, or subverted our encryption at the request of law enforcement or any other third party.
Cloudflare’s other commitments go to the integrity of the Internet itself. We do not believe that our systems should be exploited to lead people to sites that they did not intend to visit or to alter the content they get online. Therefore, we’ve publicly stated that we have never modified customer content or modified the intended destination of DNS responses at the request of law enforcement or another third party.
Providing Our Customers with Notice of Government Requests
Cloudflare has long believed that our customers deserve notice when anyone — including a law enforcement agency or other government actor — uses legal process to request their data so that they can challenge the request. Indeed, we have had a policy of providing notice to our customers since our earliest days as a company. In 2014, we worked with the Electronic Frontier Foundation to bring a legal challenge to a National Security Letter that restricted our ability to disclose the receipt of the letter to anyone. The court finally ruled that we were allowed to publicly disclose the NSL after three long years of litigation.
Although we recognize that there might be some circumstances in which it might be appropriate for law enforcement to temporarily restrict disclosure to preserve the viability of an investigation, we believe that the government should be required to justify any non-disclosure provision, and that any non-disclosure provision should be explicitly time-limited to the minimum time necessary for the purpose at hand. Because U.S. courts have suggested that indefinite non-disclosure orders raise constitutional problems, the U.S. Department of Justice issued guidance in 2017 instructing federal prosecutors to limit non-disclosure orders to no longer than a year, except in exceptional circumstances.
That has not, however, stopped all U.S. law enforcement from seeking indefinite non-disclosure orders. Indeed, we have received at least 28 non-disclosure orders since 2017 that did not include an end date. Working with the American Civil Liberties Union (ACLU), Cloudflare has threatened litigation when we have received such indefinite non-disclosure orders. In each case, the government has subsequently inserted time limits on the non-disclosure requirements in those orders, allowing us to provide our customers notice of the requests.
Addressing Conflicts of Law
Maintaining compliance with laws like GDPR, particularly in the face of legal orders that might put us in the difficult position of being required to violate it, requires involving the courts. A service provider like Cloudflare can ask a court to quash legal requests because of a conflict of law, and we have committed, both in our public statements, and contractually in our Data Processing Addendum, that we would take that step if necessary to avoid such a conflict. Our view is that the conflict should be pushed back where it belongs — between the two governments that are fighting over who should be entitled to access information.
Conclusion
Ultimately, addressing the challenges associated with running a global network that complies with different privacy laws around the world requires coming back to the values that we have championed since our earliest days as a company. Be principled and transparent, respect privacy, require due process, and provide customers with notice so that they can make their own decisions about their data.
We wanted to close out Privacy & Compliance Week by talking about something universal and certain: taxes. Businesses worldwide pay employment taxes based on where their employees do work. For most businesses and in normal times, where employees do work has been relatively easy to determine: it’s where they come into the office. But 2020 has made everything more complicated, even taxes.
As businesses worldwide have shifted to remote work, employees have been working from “home” — wherever that may be. Some employees have taken this opportunity to venture further from where they usually are, sometimes crossing state and national borders.
In a lot of ways, it’s gone better than expected. We’re proud of helping provide technology solutions like Cloudflare for Teams that allow employees to work from anywhere and ensure they still have a fast, secure connection to their corporate resources. But increasingly we’ve been hearing from the heads of the finance, legal, and HR departments of our customers with a concern: “If I don’t know where my employees are, I have no idea where I need to pay taxes.”
Today we’re announcing the beta of a new feature for Cloudflare for Teams to help solve this problem: Workplace Records. Cloudflare for Teams uses Access and Gateway logs to provide the state and country from which employees are working. Workplace Records can be used to help finance, legal, and HR departments determine where payroll taxes are due and provide a record to defend those decisions.
Every location became a potential workplace
Before 2020, employees who frequently traveled could manage tax jurisdiction reporting by gathering plane tickets or keeping manual logs of where they spent time. It was tedious, for employees and our payroll team, but manageable.
The COVID pandemic transformed that chore into a significant challenge for our finance, legal, and HR teams. Our entire organization was suddenly forced to work remotely. If we couldn’t get comfortable that we knew where people were working, we worried we may be forced to impose somewhat draconian rules requiring employees to check-in. That didn’t seem very Cloudflare-y.
The challenge impacts individual team members as well. Reporting mistakes can lead to tax penalties for employees or amendments during filing season. Our legal team started to field questions from employees stuck in new regions because of travel restrictions. Our payroll team prepared for a backlog of amendments.
Logging jurisdiction without manual reporting
When team members open their corporate laptops and start a workday, they log in to Cloudflare Access — our Zero Trust tool that protects applications and data. Cloudflare Access checks their identity and other signals like multi-factor methods to determine if they can proceed. Importantly, the process also logs their region so we can enforce country-specific rules.
Our finance, legal, and HR teams worked with our engineering teams to use that model to create Workplace Records. We now have the confidence to know we can meet our payroll tax obligations without imposing onerous limitations on team members. We’re able to prepare and adjust, in real-time, while confidentially supporting our employees as they work remotely for wherever is most comfortable and productive for them.
Respecting team member privacy
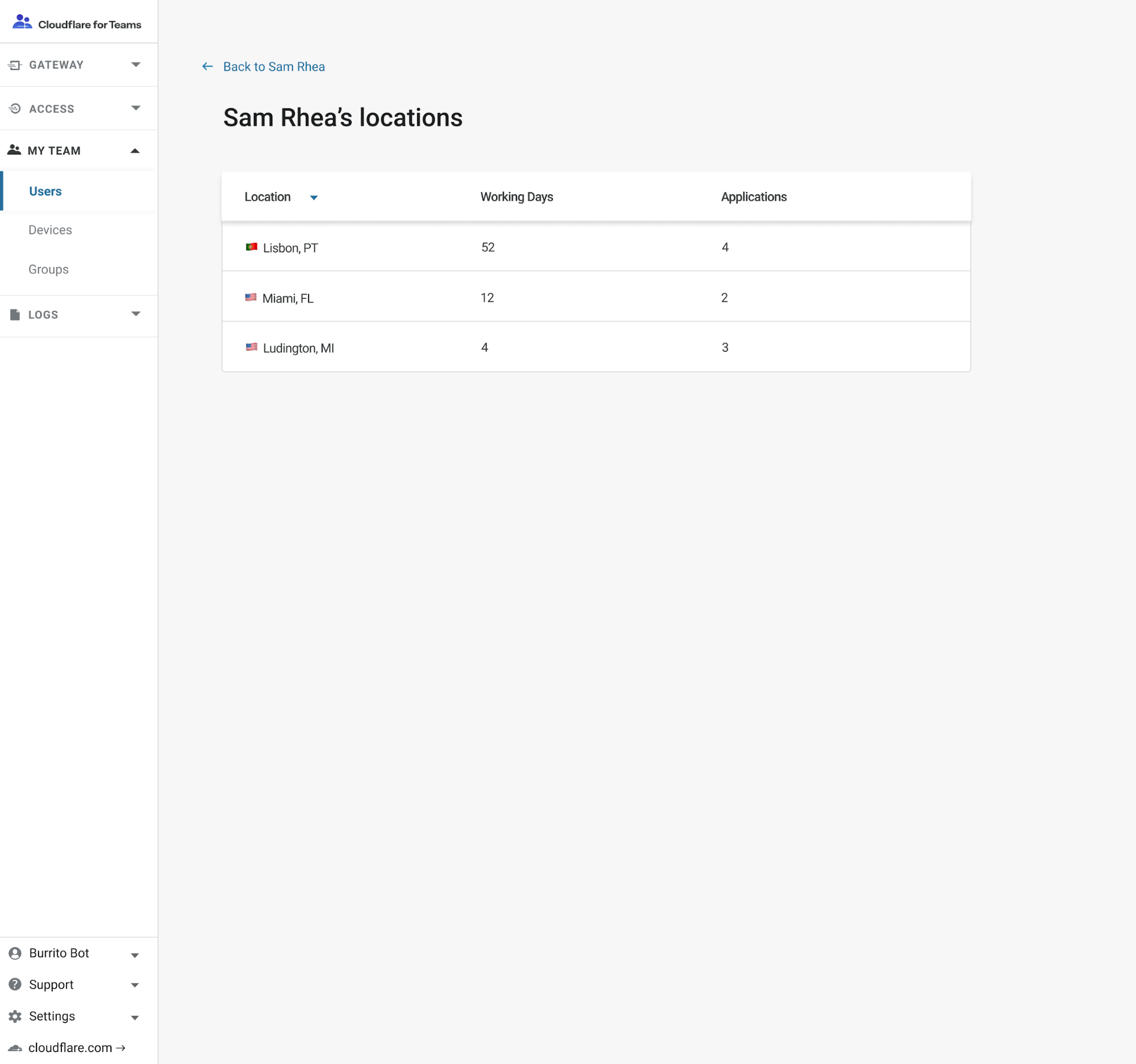
Workplace Records only provides resolution within a taxable jurisdiction, not a specific address. The goal is to give only the information that finance, legal, and HR departments need to ensure they can meet their compliance obligations.
The system also generates these reports by capturing team member logins to work applications on corporate devices. We use the location of that login to determine “this was a workday from Texas”. If a corporate laptop is closed or stored away for the weekend, we aren’t capturing location logs. We’d rather team members enjoy time off without connecting.
Two clicks to enforce regional compliance
Workplace Records can also help ensure company policy compliance for a company’s teams. For instance, companies may have policies about engineering teams only creating intellectual property in countries in which transfer agreements are in place. Workplace Records can help ensure that engineering work isn’t being done in countries that may put the intellectual property at risk.
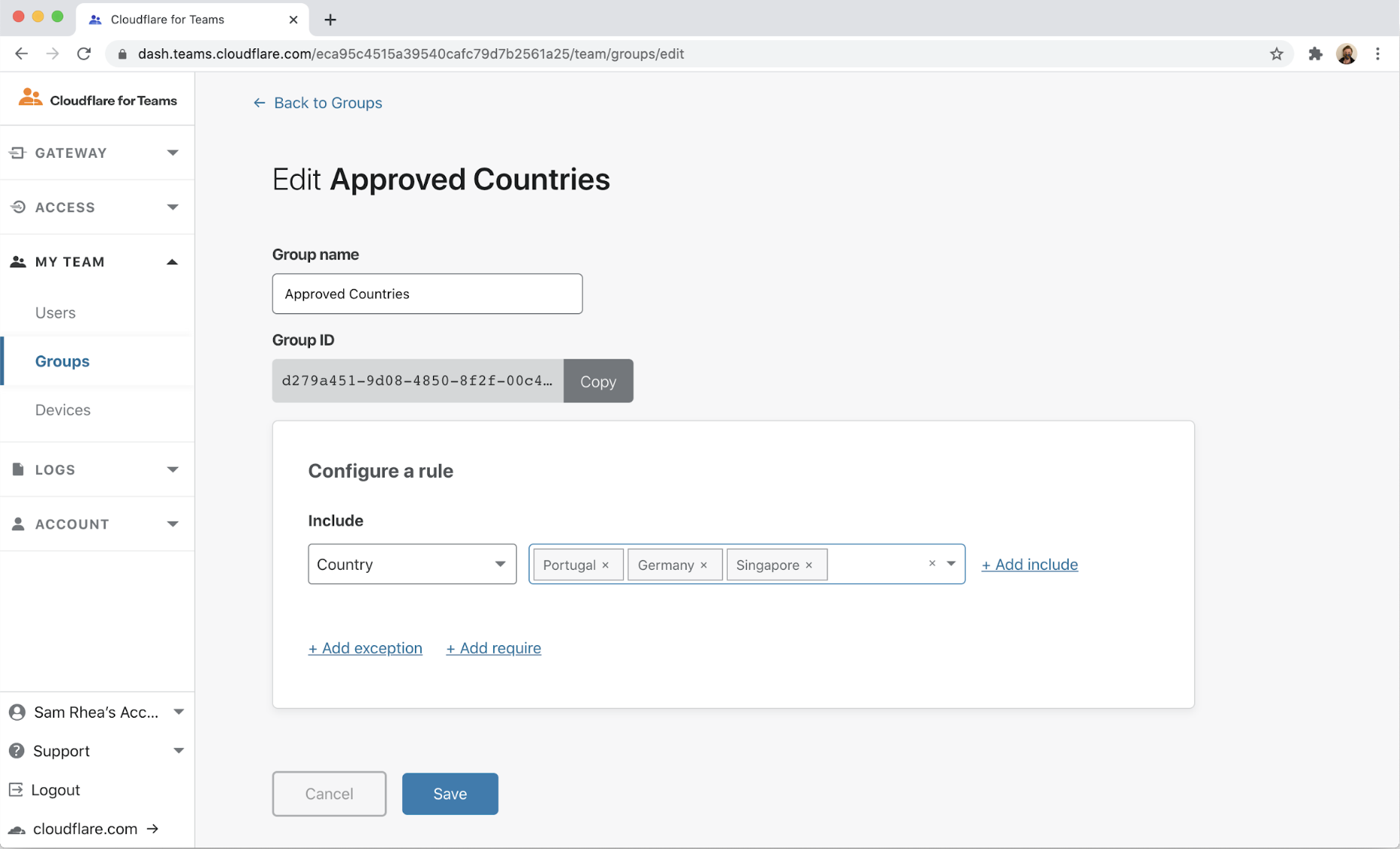
Administrators can build rules in Cloudflare Access to require that team members connect to internal or SaaS applications only from countries where they operate. Cloudflare’s network will check every request both for identity and the region from which they’re connecting.
We also heard from our own accounting teams that some regions enforce strict tax penalties when employees work without an incorporated office or entity. In the same way that you can require users to work only from certain countries, you can also block users from connecting to your applications from specific regions.
No deciphering required
When we started planning Workplace Records, our payroll team asked us to please not send raw data that added more work on them to triage and sort.
Available today, you can view the country of each login to internal systems on a per-user basis. You can export this data to an external SIEM and you can build rules that control access to systems by country.
Launching today in beta is a new UI that summarizes the working days spent in specific regions for each user. Workplace Records will add a company-wide report early in Q1. The service is available as a report for free to all Cloudflare for Teams customers.
Going forward, we plan to work with Human Capital Management (HCM), Human Resource Information Systems (HRIS), Human Resource Management Systems (HRMS), and Payroll providers to automatically integrate Workplace Records.
What’s next?
At Cloudflare, we know even after the pandemic we are going to be more tolerant of remote work than before. The more that we can allow our team to work remotely and ensure we are meeting our regulatory, compliance, and tax obligations, the more flexibility we will be able to provide.
Cloudflare for Teams with Workplace Records is helping solve a challenge for our finance, legal, and HR teams. Now with the launch of the beta, we hope we can help enable a more flexible and compliant work environment for all our Cloudflare for Teams customers. This feature will be available to all Cloudflare for Teams subscribers early next week. You can start using Cloudflare for Teams today at no cost for up to 50 users, including the Workplace Records feature.
At Cloudflare, we prioritize initiatives that improve the security and privacy of our products and services. The security organization believes trust and transparency are foundational principles that are ingrained in what we build, the policies we set, and the data we protect. Many of our enterprise customers have stringent regulatory compliance obligations and require their cloud service providers like ourselves to provide assurance that we meet and exceed industry security standards. In the last couple of years, we’ve decided to invest in ways to make the evaluation of our security posture easier. We did so not only by obtaining recognized security certifications and reports in an aggressive timeline, but we also built a team that partners with our customers to provide transparency into our security and privacy practices.
Security Certifications & Reports
We understand the importance of providing transparency into our security processes, controls, and how our customers can continuously rely on them to operate effectively. Cloudflare complies with and supports the following standards:
SOC-2 Type II / SOC 3 (Service Organizations Controls) – Cloudflare maintains SOC reports that include the security, confidentiality, and availability trust principles. The SOC-2 report provides assurance that our products and underlying infrastructure are secure and highly available while protecting the confidentiality of our customer’s data. We engage with our third-party assessors on an annual basis, and the report provided to our customers covers a period of one full year.
ISO 27001:2013 (International Standards Organization) – Cloudflare’s ISO certification covers our entire platform including our edge network and core data centers. Customers can be assured that Cloudflare has a formal information security management program that adheres to a globally recognized standard.
PCI Data Security Standard (DSS) – Cloudflare engages with a QSA (qualified security assessor) on an annual basis to evaluate us as a Level 1 Merchant and a Service Provider. This way, we can assure our customers that we meet the requirements to transmit their payment data securely. As a service provider, our customers can trust Cloudflare’s products to meet requirements of the DSS and transmit cardholder data securely through our services.
HIPAA/HITECH Act (Health Insurance Portability and Accountability Act/Health Information Technology for Economic and Clinical Health – Covered healthcare entities that are leveraging our enterprise version of our security products to protect their application layer can be assured that Cloudflare can sign Business Associates Agreements (BAA).
1.1.1.1 Public DNS Resolver Privacy Examination – Cloudflare conducted a first-of-its-kind privacy examination by a leading accounting firm to determine whether the 1.1.1.1 resolver was effectively configured to meet Cloudflare’s privacy commitments. A public summary of the assessment can be found here.
Security Engagement Team
We understood that having security compliance certifications and reports would provide ease of mind when using our products, but we knew it may not be enough for those who are sending their most sensitive information through our services. We decided that it was paramount to build out a Security Engagement Team within our Security Organization. Our Security Engagement Team can work with our customer’s security and compliance functions to understand their regulatory and compliance landscape. They are here to understand our customer’s use cases, address concerns, and communicate asks and requests to our Validations, Risk, and Security Engineering Teams so we know what’s top of mind from our customers.
We strive to put trust first. The certifications and reports we obtain, the security features we build, the white papers, faqs, and documents that we create — we build all of these resources based on the needs of our customers. In the future, we will continue to listen closely to our customers, with the goal of continuously improving the security and privacy of our products and services.
For more information about our certifications and reports please visit our compliance page – cloudflare.com/compliance. You can also reach us at [email protected] for any questions.
In September, we announced that we’re building a new, free Web Analytics product for the whole web. Today, I’m excited to announce that anyone can now sign up to use our new Web Analytics — even without changing your DNS settings. In other words, Cloudflare Web Analytics can now be deployed by adding an HTML snippet (in the same way many other popular web analytics tools are) making it easier than ever to use privacy-first tools to understand visitor behavior.
Why does the web need another analytics service?
Popular analytics vendors have business models driven by ad revenue. Using them implies a bargain: they track visitor behavior and create buyer profiles to retarget your visitors with ads; in exchange, you get free analytics.
At Cloudflare, our mission is to help build a better Internet, and part of that is to deliver essential web analytics to everyone with a website, without compromising user privacy. For free. We’ve never been interested in tracking users or selling advertising. We don’t want to know what you do on the Internet — it’s not our business.
Our customers have long relied on Cloudflare’s Analytics because we’re accurate, fast, and privacy-first. In September we released a big upgrade to analytics for our existing customers that made them even more flexible.
However, we know that there are many folks who can’t use our analytics, simply because they’re not able to onboard to use the rest of Cloudflare for Infrastructure — specifically, they’re not able to change their DNS servers. Today, we’re bringing the power of our analytics to the whole web. By adding a simple HTML snippet to your website, you can start measuring your web traffic — similar to other popular analytics vendors.
What can I do with Cloudflare Web Analytics?
We’ve worked hard to make our analytics as powerful and flexible as possible — while still being fast and easy to use.
When measuring analytics about your website, the most common questions are “how much traffic did I get?” and “how many people visited?” We answer this by measuring page views (the total number of times a page view was loaded) and visits (the number of times someone landed on a page view from another website).
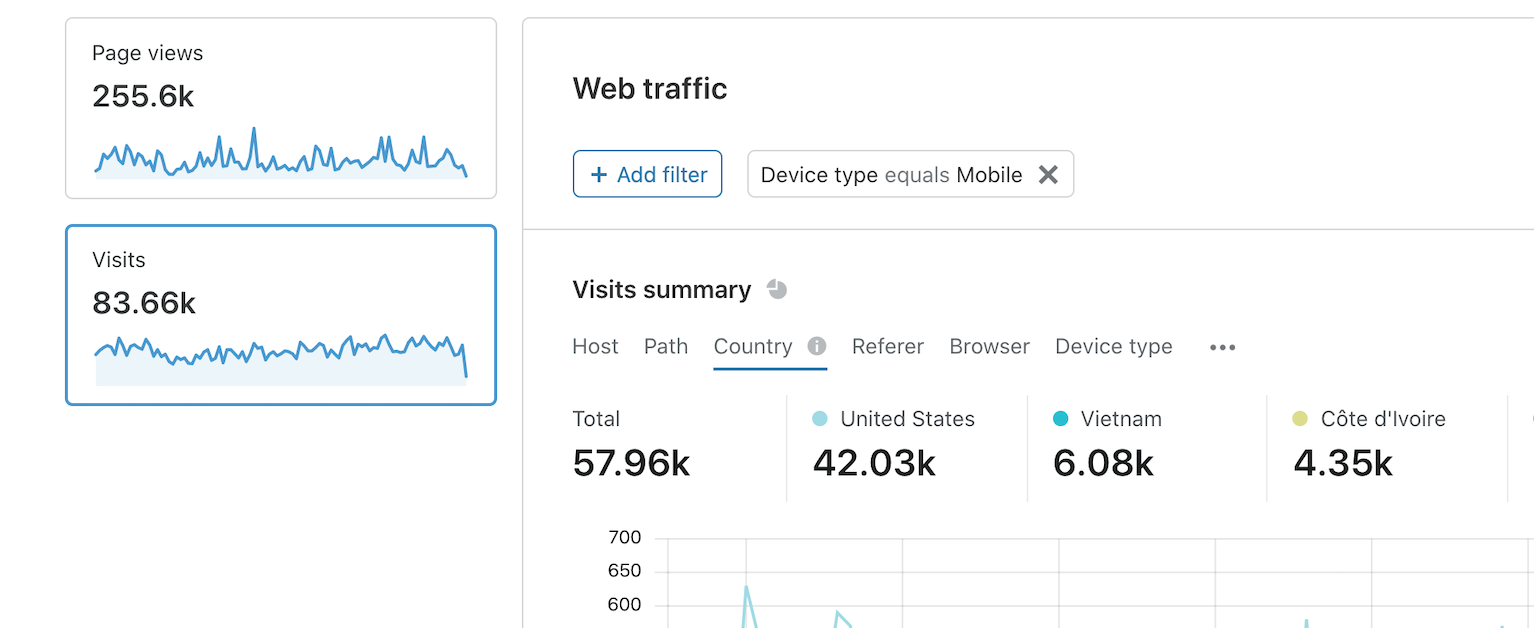
With Cloudflare Web Analytics, it’s easy to switch between measuring page views or visits. Within each view, you can see top pages, countries, device types and referrers.
My favorite thing is the ability to add global filters, and to quickly drill into the most important data with actions like “zoom” and “group by”. Say you publish a new blog post, and you want to see the top sites that send you traffic right after you email your subscribers about it. It’s easy to zoom into the time period when you hit the email, and group by to see the top pages. Then you can add a filter to just that page — and then finally view top referrers for that page. It’s magic!
Best of all, our analytics is free. We don’t have limits based on the amount of traffic you can send it. Thanks to our ABR technology, we can serve accurate analytics for websites that get anywhere from one to one billion requests per day.
How does the new Web Analytics work?
Traditionally, Cloudflare Analytics works by measuring traffic at our edge. This has some great benefits; namely, it catches all traffic, even from clients that block JavaScript or don’t load HTML. At the edge, we can also block bots, add protection from our WAF, and measure the performance of your origin server.
The new Web Analytics works like most other measurement tools: by tracking visitors on the client. We’ve long had client-side measuring tools with Browser Insights, but these were only available to orange-cloud users (i.e. Cloudflare customers).
Today, for the first time, anyone can get access to our client-side analytics — even if you don’t use the rest of Cloudflare. Just add our JavaScript snippet to any website, and we can start collecting metrics.
How do I sign up?
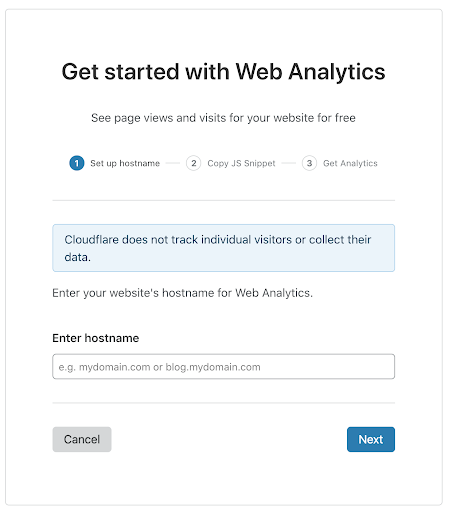
We’ve worked hard making our onboarding as simple as possible.
First, enter the name of your website. It’s important to use the domain name that your analytics will be served on — we use this to filter out any unwanted “spam” analytics reports.
(At this time, you can only add analytics from one website to each Cloudflare account. In the coming weeks we’ll add support for multiple analytics properties per account.)
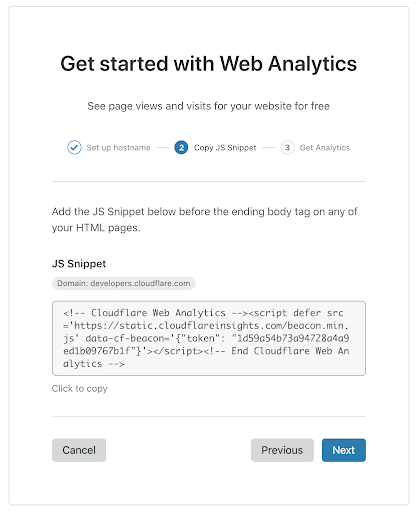
Next, you’ll see a script tag that you can copy onto your website. We recommend adding this just before the closing </body> tag on the pages you want to measure.
And that’s it! After you release your website and start getting visits, you’ll be able to see them in analytics.
What does privacy-first mean?
Being privacy-first means we don’t track individual users for the purposes of serving analytics. We don’t use any client-side state (like cookies or localStorage) for analytics purposes. Cloudflare also doesn’t track users over time via their IP address, User Agent string, or any other immutable attributes for the purposes of displaying analytics — we consider “fingerprinting” even more intrusive than cookies, because users have no way to opt out.
The concept of a “visit” is key to this approach. Rather than count unique IP addresses, which would require storing state about what each visitor does, we can simply count the number of page views that come from a different site. This provides a perfectly usable metric that doesn’t compromise on privacy.
What’s next
This is just the start for our privacy-first Analytics. We’re excited to integrate more closely with the rest of Cloudflare, and give customers even more detailed stats about performance and security (not just traffic.) We’re also hoping to make our analytics even more powerful as a standalone product by building support for alerts, real-time time updates, and more.
Please let us know if you have any questions or feedback, and happy measuring!
Cloudflare is deprecating the __cfduid cookie. Starting on 10 May 2021, we will stop adding a “Set-Cookie” header on all HTTP responses. The last __cfduid cookies will expire 30 days after that.
We never used the __cfduid cookie for any purpose other than providing critical performance and security services on behalf of our customers. Although, we must admit, calling it something with “uid” in it really made it sound like it was some sort of user ID. It wasn’t. Cloudflare never tracks end users across sites or sells their personal data. However, we didn’t want there to be any questions about our cookie use, and we don’t want any customer to think they need a cookie banner because of what we do.
So why did we use the __cfduid cookie before, and why can we remove it now?
The primary use of the cookie is for detectingbots on the web. Malicious bots may disrupt a service that has been explicitly requested by an end user (through DDoS attacks) or compromise the security of a user’s account (e.g. through brute force password cracking or credential stuffing, among others). We use many signals to build machine learning models that can detect automated bot traffic. The presence and age of the cfduid cookie was just one signal in our models. So for our customers who benefit from our bot management products, the cfduid cookie is a tool that allows them to provide a service explicitly requested by the end user.
The value of the cfduid cookie is derived from a one-way MD5 hash of the cookie’s IP address, date/time, user agent, hostname, and referring website — which means we can’t tie a cookie to a specific person. Still, as a privacy-first company, we thought: Can we find a better way to detect bots that doesn’t rely on collecting end user IP addresses?
For the past few weeks, we’ve been experimenting to see if it’s possible to run our bot detection algorithms without using this cookie. We’ve learned that it will be possible for us to transition away from using this cookie to detect bots. We’re giving notice of deprecation now to give our customers time to transition, while our bot management team works to ensure there’s no decline in quality of our bot detection algorithms after removing this cookie. (Note that some Bot Management customers will still require the use of a different cookie after April 1.)
While this is a small change, we’re excited about any opportunity to make the web simpler, faster, and more private.
Most communication on the modern Internet is encrypted to ensure that its content is intelligible only to the endpoints, i.e., client and server. Encryption, however, requires a key and so the endpoints must agree on an encryption key without revealing the key to would-be attackers. The most widely used cryptographic protocol for this task, called key exchange, is the Transport Layer Security (TLS) handshake.
In this post we’ll dive into Encrypted Client Hello (ECH), a new extension for TLS that promises to significantly enhance the privacy of this critical Internet protocol. Today, a number of privacy-sensitive parameters of the TLS connection are negotiated in the clear. This leaves a trove of metadata available to network observers, including the endpoints’ identities, how they use the connection, and so on.
ECH encrypts the full handshake so that this metadata is kept secret. Crucially, this closes a long-standing privacy leak by protecting the Server Name Indication (SNI) from eavesdroppers on the network. Encrypting the SNI secret is important because it is the clearest signal of which server a given client is communicating with. However, and perhaps more significantly, ECH also lays the groundwork for adding future security features and performance enhancements to TLS while minimizing their impact on the privacy of end users.
ECH is the product of close collaboration, facilitated by the IETF, between academics and the tech industry leaders, including Cloudflare, our friends at Fastly and Mozilla (both of whom are the affiliations of co-authors of the standard), and many others. This feature represents a significant upgrade to the TLS protocol, one that builds on bleeding edge technologies, like DNS-over-HTTPS, that are only now coming into their own. As such, the protocol is not yet ready for Internet-scale deployment. This article is intended as a sign post on the road to full handshake encryption.
Background
The story of TLS is the story of the Internet. As our reliance on the Internet has grown, so the protocol has evolved to address ever-changing operational requirements, use cases, and threat models. The client and server don’t just exchange a key: they negotiate a wide variety of features and parameters: the exact method of key exchange; the encryption algorithm; who is authenticated and how; which application layer protocol to use after the handshake; and much, much more. All of these parameters impact the security properties of the communication channel in one way or another.
SNI is a prime example of a parameter that impacts the channel’s security. The SNI extension is used by the client to indicate to the server the website it wants to reach. This is essential for the modern Internet, as it’s common nowadays for many origin servers to sit behind a single TLS operator. In this setting, the operator uses the SNI to determine who will authenticate the connection: without it, there would be no way of knowing which TLS certificate to present to the client. The problem is that SNI leaks to the network the identity of the origin server the client wants to connect to, potentially allowing eavesdroppers to infer a lot of information about their communication. (Of course, there are other ways for a network observer to identify the origin — the origin’s IP address, for example. But co-locating with other origins on the same IP address makes it much harder to use this metric to determine the origin than it is to simply inspect the SNI.)
Although protecting SNI is the impetus for ECH, it is by no means the only privacy-sensitive handshake parameter that the client and server negotiate. Another is the ALPN extension, which is used to decide which application-layer protocol to use once the TLS connection is established. The client sends the list of applications it supports — whether it’s HTTPS, email, instant messaging, or the myriad other applications that use TLS for transport security — and the server selects one from this list, and sends its selection to the client. By doing so, the client and server leak to the network a clear signal of their capabilities and what the connection might be used for.
Some features are so privacy-sensitive that their inclusion in the handshake is a non-starter. One idea that has been floated is to replace the key exchange at the heart of TLS with password-authenticated key-exchange (PAKE). This would allow password-based authentication to be used alongside (or in lieu of) certificate-based authentication, making TLS more robust and suitable for a wider range of applications. The privacy issue here is analogous to SNI: servers typically associate a unique identifier to each client (e.g., a username or email address) that is used to retrieve the client’s credentials; and the client must, somehow, convey this identity to the server during the course of the handshake. If sent in the clear, then this personally identifiable information would be easily accessible to any network observer.
A necessary ingredient for addressing all of these privacy leaks is handshake encryption, i.e., the encryption of handshake messages in addition to application data. Sounds simple enough, but this solution presents another problem: how do the client and server pick an encryption key if, after all, the handshake is itself a means of exchanging a key? Some parameters must be sent in the clear, of course, so the goal of ECH is to encrypt all handshake parameters except those that are essential to completing the key exchange.
In order to understand ECH and the design decisions underpinning it, it helps to understand a little bit about the history of handshake encryption in TLS.
Handshake encryption in TLS
TLS had no handshake encryption at all prior to the latest version, TLS 1.3. In the wake of the Snowden revelations in 2013, the IETF community began to consider ways of countering the threat that mass surveillance posed to the open Internet. When the process of standardizing TLS 1.3 began in 2014, one of its design goals was to encrypt as much of the handshake as possible. Unfortunately, the final standard falls short of full handshake encryption, and several parameters, including SNI, are still sent in the clear. Let’s take a closer look to see why.
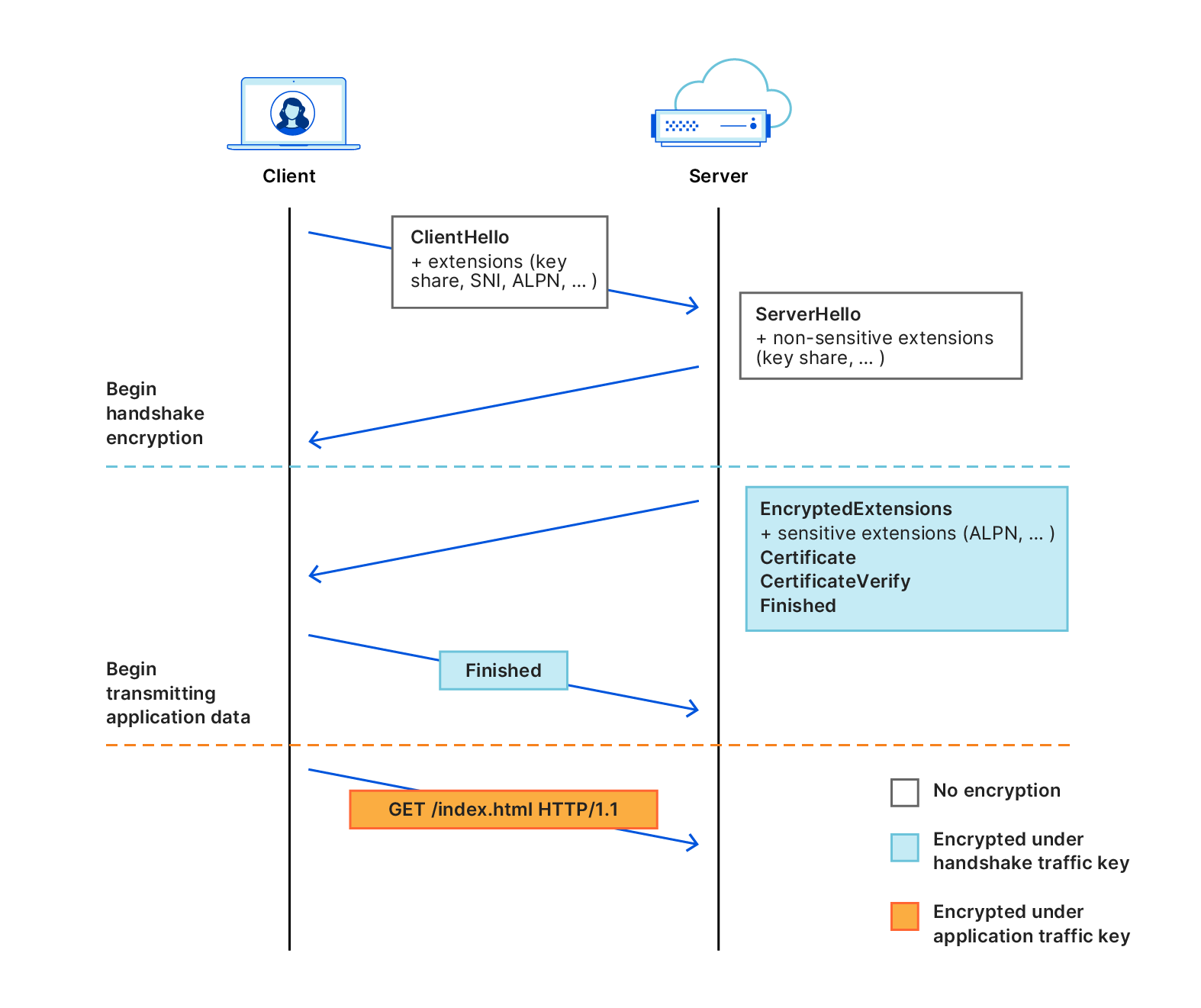
The TLS 1.3 protocol flow is illustrated in Figure 1. Handshake encryption begins as soon as the client and server compute a fresh shared secret. To do this, the client sends a key share in its ClientHello message, and the server responds in its ServerHello with its own key share. Having exchanged these shares, the client and server can derive a shared secret. Each subsequent handshake message is encrypted using the handshake traffic key derived from the shared secret. Application data is encrypted using a different key, called the application traffic key, which is also derived from the shared secret. These derived keys have different security properties: to emphasize this, they are illustrated with different colors.
The first handshake message that is encrypted is the server’s EncryptedExtensions. The purpose of this message is to protect the server’s sensitive handshake parameters, including the server’s ALPN extension, which contains the application selected from the client’s ALPN list. Key-exchange parameters are sent unencrypted in the ClientHello and ServerHello.
Figure 1: The TLS 1.3 handshake.
All of the client’s handshake parameters, sensitive or not, are sent in the ClientHello. Looking at Figure 1, you might be able to think of ways of reworking the handshake so that some of them can be encrypted, perhaps at the cost of additional latency (i.e., more round trips over the network). However, extensions like SNI create a kind of “chicken-and-egg” problem.
The client doesn’t encrypt anything until it has verified the server’s identity (this is the job of the Certificate and CertificateVerify messages) and the server has confirmed that it knows the shared secret (the job of the Finished message). These measures ensure the key exchange is authenticated, thereby preventing monster-in-the-middle (MITM) attacks in which the adversary impersonates the server to the client in a way that allows it to decrypt messages sent by the client. Because SNI is needed by the server to select the certificate, it needs to be transmitted before the key exchange is authenticated.
In general, ensuring confidentiality of handshake parameters used for authentication is only possible if the client and server already share an encryption key. But where might this key come from?
Full handshake encryption in the early days of TLS 1.3. Interestingly, full handshake encryption was once proposed as a core feature of TLS 1.3. In early versions of the protocol (draft-10, circa 2015), the server would offer the client a long-lived public key during the handshake, which the client would use for encryption in subsequent handshakes. (This design came from a protocol called OPTLS, which in turn was borrowed from the original QUIC proposal.) Called “0-RTT”, the primary purpose of this mode was to allow the client to begin sending application data prior to completing a handshake. In addition, it would have allowed the client to encrypt its first flight of handshake messages following the ClientHello, including its own EncryptedExtensions, which might have been used to protect the client’s sensitive handshake parameters.
Ultimately this feature was not included in the final standard (RFC 8446, published in 2018), mainly because its usefulness was outweighed by its added complexity. In particular, it does nothing to protect the initial handshake in which the client learns the server’s public key. Parameters that are required for server authentication of the initial handshake, like SNI, would still be transmitted in the clear.
Nevertheless, this scheme is notable as the forerunner of other handshake encryption mechanisms, like ECH, that use public key encryption to protect sensitive ClientHello parameters. The main problem these mechanisms must solve is key distribution.
Before ECH there was (and is!) ESNI
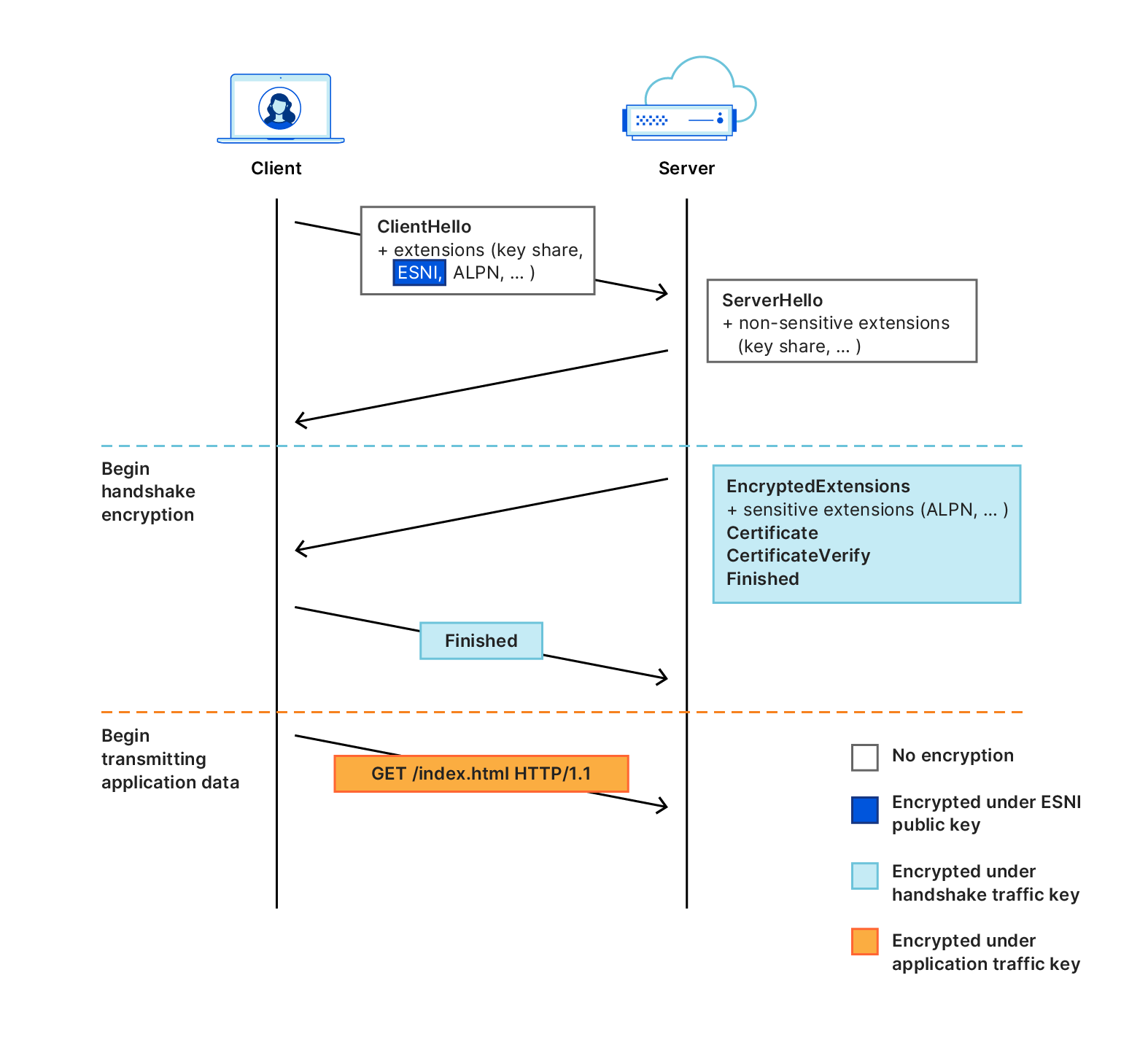
The immediate predecessor of ECH was the Encrypted SNI (ESNI) extension. As its name implies, the goal of ESNI was to provide confidentiality of the SNI. To do so, the client would encrypt its SNI extension under the server’s public key and send the ciphertext to the server. The server would attempt to decrypt the ciphertext using the secret key corresponding to its public key. If decryption were to succeed, then the server would proceed with the connection using the decrypted SNI. Otherwise, it would simply abort the handshake. The high-level flow of this simple protocol is illustrated in Figure 2.
Figure 2: The TLS 1.3 handshake with the ESNI extension. It is identical to the TLS 1.3 handshake, except the SNI extension has been replaced with ESNI.
For key distribution, ESNI relied on another critical protocol: Domain Name Service (DNS). In order to use ESNI to connect to a website, the client would piggy-back on its standard A/AAAA queries a request for a TXT record with the ESNI public key. For example, to get the key for crypto.dance, the client would request the TXT record of _esni.crypto.dance:
The base64-encoded blob contains an ESNI public key and related parameters such as the encryption algorithm.
But what’s the point of encrypting SNI if we’re just going to leak the server name to network observers via a plaintext DNS query? Deploying ESNI this way became feasible with the introduction of DNS-over-HTTPS (DoH), which enables encryption of DNS queries to resolvers that provide the DoH service (1.1.1.1 is an example of such a service.). Another crucial feature of DoH is that it provides an authenticated channel for transmitting the ESNI public key from the DoH server to the client. This prevents cache-poisoning attacks that originate from the client’s local network: in the absence of DoH, a local attacker could prevent the client from offering the ESNI extension by returning an empty TXT record, or coerce the client into using ESNI with a key it controls.
While ESNI took a significant step forward, it falls short of our goal of achieving full handshake encryption. Apart from being incomplete — it only protects SNI — it is vulnerable to a handful of sophisticated attacks, which, while hard to pull off, point to theoretical weaknesses in the protocol’s design that need to be addressed.
ESNI was deployed by Cloudflare and enabled by Firefox, on an opt-in basis, in 2018, an experience that laid bare some of the challenges with relying on DNS for key distribution. Cloudflare rotates its ESNI key every hour in order to minimize the collateral damage in case a key ever gets compromised. DNS artifacts are sometimes cached for much longer, the result of which is that there is a decent chance of a client having a stale public key. While Cloudflare’s ESNI service tolerates this to a degree, every key must eventually expire. The question that the ESNI protocol left open is how the client should proceed if decryption fails and it can’t access the current public key, via DNS or otherwise.
Another problem with relying on DNS for key distribution is that several endpoints might be authoritative for the same origin server, but have different capabilities. For example, a request for the A record of “example.com” might return one of two different IP addresses, each operated by a different CDN. The TXT record for “_esni.example.com” would contain the public key for one of these CDNs, but certainly not both. The DNS protocol does not provide a way of atomically tying together resource records that correspond to the same endpoint. In particular, it’s possible for a client to inadvertently offer the ESNI extension to an endpoint that doesn’t support it, causing the handshake to fail. Fixing this problem requires changes to the DNS protocol. (More on this below.)
The future of ESNI. In the next section, we’ll describe the ECH specification and how it addresses the shortcomings of ESNI. Despite its limitations, however, the practical privacy benefit that ESNI provides is significant. Cloudflare intends to continue its support for ESNI until ECH is production-ready.
The ins and outs of ECH
The goal of ECH is to encrypt the entire ClientHello, thereby closing the gap left in TLS 1.3 and ESNI by protecting all privacy-sensitive handshake-parameters. Similar to ESNI, the protocol uses a public key, distributed via DNS and obtained using DoH, for encryption during the client’s first flight. But ECH has improvements to key distribution that make the protocol more robust to DNS cache inconsistencies. Whereas the ESNI server aborts the connection if decryption fails, the ECH server attempts to complete the handshake and supply the client with a public key it can use to retry the connection.
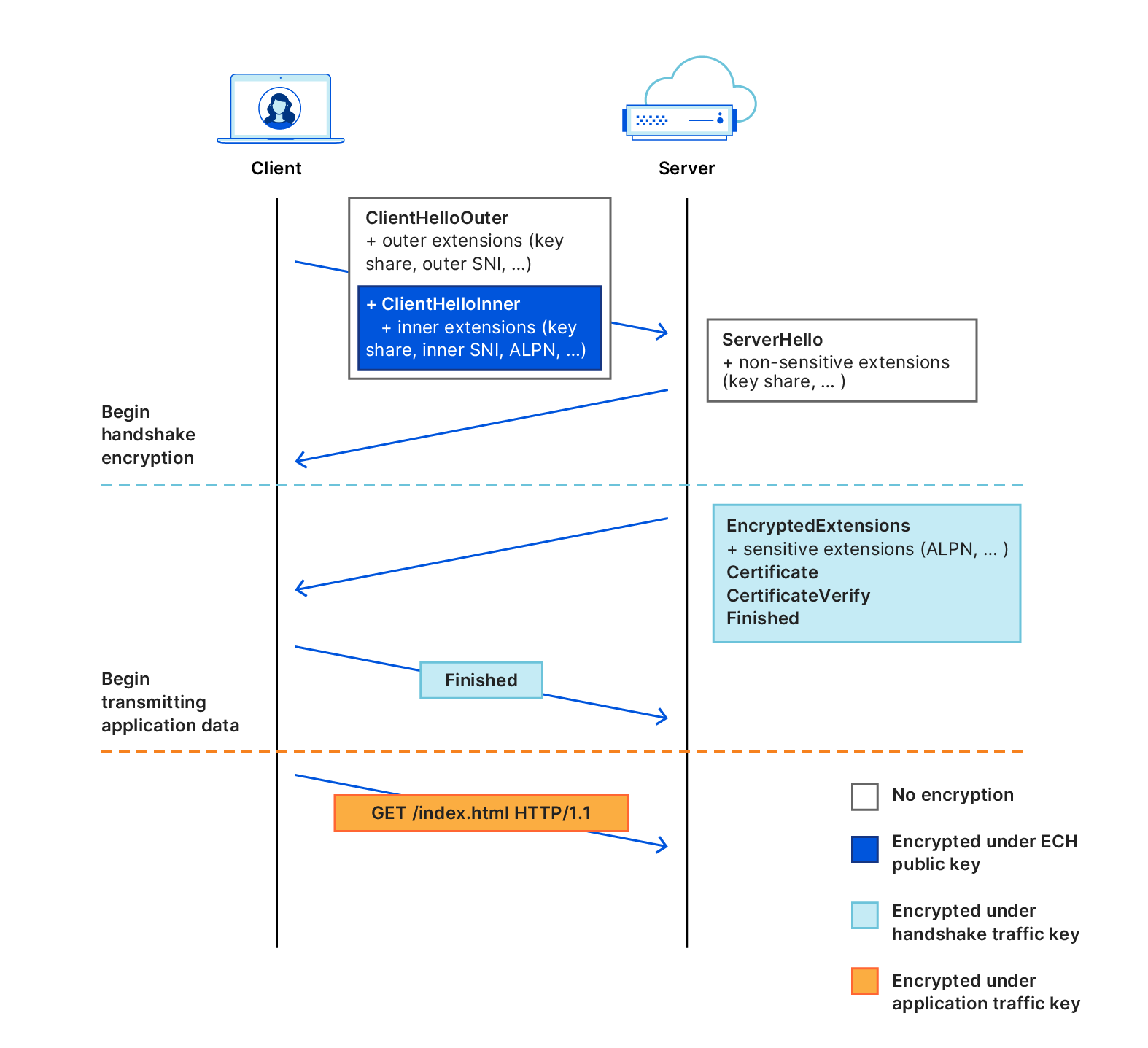
But how can the server complete the handshake if it’s unable to decrypt the ClientHello? As illustrated in Figure 3, the ECH protocol actually involves two ClientHello messages: the ClientHelloOuter, which is sent in the clear, as usual; and the ClientHelloInner, which is encrypted and sent as an extension of the ClientHelloOuter. The server completes the handshake with just one of these ClientHellos: if decryption succeeds, then it proceeds with the ClientHelloInner; otherwise, it proceeds with the ClientHelloOuter.
Figure 3: The TLS 1.3 handshake with the ECH extension.
The ClientHelloInner is composed of the handshake parameters the client wants to use for the connection. This includes sensitive values, like the SNI of the origin server it wants to reach (called the backend server in ECH parlance), the ALPN list, and so on. The ClientHelloOuter, while also a fully-fledged ClientHello message, is not used for the intended connection. Instead, the handshake is completed by the ECH service provider itself (called the client-facing server), signaling to the client that its intended destination couldn’t be reached due to decryption failure. In this case, the service provider also sends along the correct ECH public key with which the client can retry handshake, thereby “correcting” the client’s configuration. (This mechanism is similar to how the server distributed its public key for 0-RTT mode in the early days of TLS 1.3.)
At a minimum, both ClientHellos must contain the handshake parameters that are required for a server-authenticated key-exchange. In particular, while the ClientHelloInner contains the real SNI, the ClientHelloOuter also contains an SNI value, which the client expects to verify in case of ECH decryption failure (i.e., the client-facing server). If the connection is established using the ClientHelloOuter, then the client is expected to immediately abort the connection and retry the handshake with the public key provided by the server. It’s not necessary that the client specify an ALPN list in the ClientHelloOuter, nor any other extension used to guide post-handshake behavior. All of these parameters are encapsulated by the encrypted ClientHelloInner.
This design resolves — quite elegantly, I think — most of the challenges for securely deploying handshake encryption encountered by earlier mechanisms. Importantly, the design of ECH was not conceived in a vacuum. The protocol reflects the diverse perspectives of the IETF community, and its development dovetails with other IETF standards that are crucial to the success of ECH.
The first is an important new DNS feature known as the HTTPS resource record type. At a high level, this record type is intended to allow multiple HTTPS endpoints that are authoritative for the same domain name to advertise different capabilities for TLS. This makes it possible to rely on DNS for key distribution, resolving one of the deployment challenges uncovered by the initial ESNI deployment. For a deep dive into this new record type and what it means for the Internet more broadly, check out Alessandro Ghedini’s recent blog post on the subject.
The second is the CFRG’s Hybrid Public Key Encryption (HPKE) standard, which specifies an extensible framework for building public key encryption schemes suitable for a wide variety of applications. In particular, ECH delegates all of the details of its handshake encryption mechanism to HPKE, resulting in a much simpler and easier-to-analyze specification. (Incidentally, HPKE is also one of the main ingredients of Oblivious DNS-over-HTTPS.
The road ahead
The current ECH specification is the culmination of a multi-year collaboration. At this point, the overall design of the protocol is fairly stable. In fact, the next draft of the specification will be the first to be targeted for interop testing among implementations. Still, there remain a number of details that need to be sorted out. Let’s end this post with a brief overview of the road ahead.
Resistance to traffic analysis
Ultimately, the goal of ECH is to ensure that TLS connections made to different origin servers behind the same ECH service provider are indistinguishable from one another. In other words, when you connect to an origin behind, say, Cloudflare, no one on the network between you and Cloudflare should be able to discern which origin you reached, or which privacy-sensitive handshake-parameters you and the origin negotiated. Apart from an immediate privacy boost, this property, if achieved, paves the way for the deployment of new features for TLS without compromising privacy.
Encrypting the ClientHello is an important step towards achieving this goal, but we need to do a bit more. An important attack vector we haven’t discussed yet is traffic analysis. This refers to the collection and analysis of properties of the communication channel that betray part of the ciphertext’s contents, but without cracking the underlying encryption scheme. For example, the length of the encrypted ClientHello might leak enough information about the SNI for the adversary to make an educated guess as to its value (this risk is especially high for domain names that are either particularly short or particularly long). It is therefore crucial that the length of each ciphertext is independent of the values of privacy-sensitive parameters. The current ECH specification provides some mitigations, but their coverage is incomplete. Thus, improving ECH’s resistance to traffic analysis is an important direction for future work.
The spectre of ossification
An important open question for ECH is the impact it will have on network operations.
One of the lessons learned from the deployment of TLS 1.3 is that upgrading a core Internet protocol can trigger unexpected network behavior. Cloudflare was one of the first major TLS operators to deploy TLS 1.3 at scale; when browsers like Firefox and Chrome began to enable it on an experimental basis, they observed a significantly higher rate of connection failures compared to TLS 1.2. The root cause of these failures was network ossification, i.e., the tendency of middleboxes — network appliances between clients and servers that monitor and sometimes intercept traffic — to write software that expects traffic to look and behave a certain way. Changing the protocol before middleboxes had the chance to update their software led to middleboxes trying to parse packets they didn’t recognize, triggering software bugs that, in some instances, caused connections to be dropped completely.
This problem was so widespread that, instead of waiting for network operators to update their software, the design of TLS 1.3 was altered in order to mitigate the impact of network ossification. The ingenious solution was to make TLS 1.3 “look like” another protocol that middleboxes are known to tolerate. Specifically, the wire format and even the contents of handshake messages were made to resemble TLS 1.2. These two protocols aren’t identical, of course — a curious network observer can still distinguish between them — but they look and behave similar enough to ensure that the majority of existing middleboxes don’t treat them differently. Empirically, it was found that this strategy significantly reduced the connection failure rate enough to make deployment of TLS 1.3 viable.
Once again, ECH represents a significant upgrade for TLS for which the spectre of network ossification looms large. The ClientHello contains parameters, like SNI, that have existed in the handshake for a long time, and we don’t yet know what the impact will be of encrypting them. In anticipation of the deployment issues ossification might cause, the ECH protocol has been designed to look as much like a standard TLS 1.3 handshake as possible. The most notable difference is the ECH extension itself: if middleboxes ignore it — as they should, if they are compliant with the TLS 1.3 standard — then the rest of the handshake will look and behave very much as usual.
It remains to be seen whether this strategy will be enough to ensure the wide-scale deployment of ECH. If so, it is notable that this new feature will help to mitigate the impact of future TLS upgrades on network operations. Encrypting the full handshake reduces the risk of ossification since it means that there are less visible protocol features for software to ossify on. We believe this will be good for the health of the Internet overall.
Conclusion
The old TLS handshake is (unintentionally) leaky. Operational requirements of both the client and server have led to privacy-sensitive parameters, like SNI, being negotiated completely in the clear and available to network observers. The ECH extension aims to close this gap by enabling encryption of the full handshake. This represents a significant upgrade to TLS, one that will help preserve end-user privacy as the protocol continues to evolve.
The ECH standard is a work-in-progress. As this work continues, Cloudflare is committed to doing its part to ensure this important upgrade for TLS reaches Internet-scale deployment.
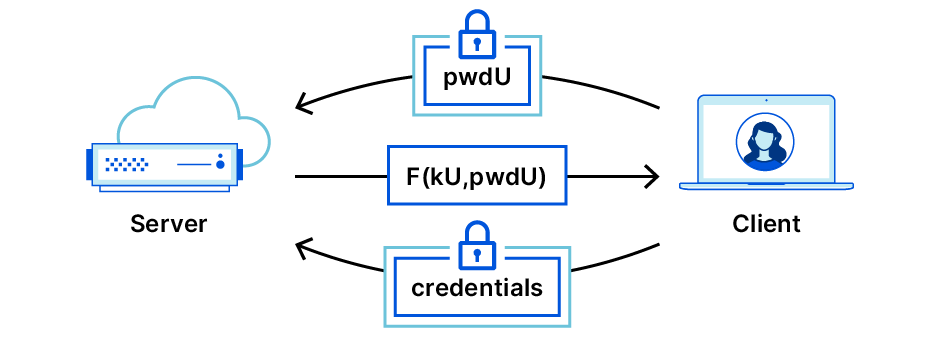
Passwords are a problem. They are a problem for reasons that are familiar to most readers. For us at Cloudflare, the problem lies much deeper and broader. Most readers will immediately acknowledge that passwords are hard to remember and manage, especially as password requirements grow increasingly complex. Luckily there are great software packages and browser add-ons to help manage passwords. Unfortunately, the greater underlying problem is beyond the reaches of software to solve.
The fundamental password problem is simple to explain, but hard to solve: A password that leaves your possession is guaranteed to sacrifice security, no matter its complexity or how hard it may be to guess. Passwords are insecure by their very existence.
You might say, “but passwords are always stored in encrypted format!” That would be great. More accurately, they are likely stored as a salted hash, as explained below. Even worse is that there is no way to verify the way that passwords are stored, and so we can assume that on some servers passwords are stored in cleartext. The truth is that even responsibly stored passwords can be leaked and broken, albeit (and thankfully) with enormous effort. An increasingly pressing problem stems from the nature of passwords themselves: any direct use of a password, today, means that the password must be handled in the clear.
You say, “but my password is transmitted securely over HTTPS!” This is true.
You say, “but I know the server stores my password in hashed form, secure so no one can access it!” Well, this puts a lot of faith in the server. Even so, let’s just say that yes, this may be true, too.
There remains, however, an important caveat — a gap in the end-to-end use of passwords. Consider that once a server receives a password, between being securely transmitted and securely stored, the password has to be read and processed. Yes, as cleartext!
And it gets worse — because so many are used to thinking in software, it’s easy to forget about the vulnerability of hardware. This means that even if the software is somehow trusted, the password must at some point reside in memory. The password must at some point be transmitted over a shared bus to the CPU. These provide vectors of attack to on-lookers in many forms. Of course, these attack vectors are far less likely than those presented by transmission and permanent storage, but they are no less severe (recent CPU vulnerabilities such as Spectre and Meltdown should serve as a stark reminder.)
The only way to fix this problem is to get rid of passwords altogether. There is hope! Research and private sector communities are working hard to do just that. New standards are emerging and growing mature. Unfortunately, passwords are so ubiquitous that it will take a long time to agree on and supplant passwords with new standards and technology.
At Cloudflare, we’ve been asking if there is something that can be done now, imminently. Today’s deep-dive into OPAQUE is one possible answer. OPAQUE is one among many examples of systems that enable a password to be useful without it ever leaving your possession. No one likes passwords, but as long they’re in use, at least we can ensure they are never given away.
I’ll be the first to admit that password-based authentication is annoying. Passwords are hard to remember, tedious to type, and notoriously insecure. Initiatives to reduce or replace passwords are promising. For example, WebAuthn is a standard for web authentication based primarily on public key cryptography using hardware (or software) tokens. Even so, passwords are frustratingly persistent as an authentication mechanism. Whether their persistence is due to their ease of implementation, familiarity to users, or simple ubiquity on the web and elsewhere, we’d like to make password-based authentication as secure as possible while they persist.
My internship at Cloudflare focused on OPAQUE, a cryptographic protocol that solves one of the most glaring security issues with password-based authentication on the web: though passwords are typically protected in transit by HTTPS, servershandle them in plaintext to check their correctness. Handling plaintext passwords is dangerous, as accidentally logging or caching them could lead to a catastrophic breach. The goal of the project, rather than to advocate for adoption of any particular protocol, is to show that OPAQUE is a viable option among many for authentication. Because the web case is most familiar to me, and likely many readers, I will use the web as my main example.
Web Authentication 101: Password-over-TLS
When you type in a password on the web, what happens? The website must check that the password you typed is the same as the one you originally registered with the site. But how does this check work?
Usually, your username and password are sent to a server. The server then checks if the registered password associated with your username matches the password you provided. Of course, to prevent an attacker eavesdropping on your Internet traffic from stealing your password, your connection to the server should be encrypted via HTTPS (HTTP-over-TLS).
Despite use of HTTPS, there still remains a glaring problem in this flow: the server must store a representation of your password somewhere. Servers are hard to secure, and breaches are all too common. Leaking this representation can cause catastrophic security problems. (For records of the latest breaches, check out https://haveibeenpwned.com/).
To make these leaks less devastating, servers often apply a hash function to user passwords. A hash function maps each password to a unique, random-looking value. It’s easy to apply the hash to a password, but almost impossible to reverse the function and retrieve the password. (That said, anyone can guess a password, apply the hash function, and check if the result is the same.)
With password hashing, plaintext passwords are no longer stored on servers. An attacker who steals a password database no longer has direct access to passwords. Instead, the attacker must apply the hash to many possible passwords and compare the results with the leaked hashes.
Unfortunately, if a server hashes only the passwords, attackers can download precomputed rainbow tables containing hashes of trillions of possible passwords and almost instantly retrieve the plaintext passwords. (See https://project-rainbowcrack.com/table.htm for a list of some rainbow tables).
With this in mind, a good defense-in-depth strategy is to use salted hashing, where the server hashes your password appended to a random, per-user value called a salt. The server also saves the salt alongside the username, so the user never sees or needs to submit it. When the user submits a password, the server re-computes this hash function using the salt. An attacker who steals password data, i.e., the password representations and salt values, must then guess common passwords one by one and apply the (salted) hash function to each guessed password. Existing rainbow tables won’t help because they don’t take the salts into account, so the attacker needs to make a new rainbow table for each user!
This (hopefully) slows down the attack enough for the service to inform users of a breach, so they can change their passwords. In addition, the salted hashes should be hardened by applying a hash many times to further slow attacks. (See https://blog.cloudflare.com/keeping-passwords-safe-by-staying-up-to-date/ for a more detailed discussion).
These two mitigation strategies — encrypting the password in transit and storing salted, hardened hashes — are the current best practices.
A large security hole remains open. Password-over-TLS (as we will call it) requires users to send plaintext passwords to servers during login, because servers must see these passwords to match against registered passwords on file. Even a well-meaning server could accidentally cache or log your password attempt(s), or become corrupted in the course of checking passwords. (For example, Facebook detected in 2019 that it had accidentally been storing hundreds of millions of plaintext user passwords). Ideally, servers should never see a plaintext password at all.
But that’s quite a conundrum: how can you check a password if you never see the password? Enter OPAQUE: a Password-Authenticated Key Exchange (PAKE) protocol that simultaneously proves knowledge of a password and derives a secret key. Before describing OPAQUE in detail, we’ll first summarize PAKE functionalities in general.
Password Proofs with Password-Authenticated Key Exchange
Password-Authenticated Key Exchange (PAKE) was proposed by Bellovin and Merrit in 1992, with an initial motivation of allowing password-authentication without the possibility of dictionary attacks based on data transmitted over an insecure channel.
Essentially, a plain, or symmetric, PAKE is a cryptographic protocol that allows two parties who share only a password to establish a strong shared secret key. The goals of PAKE are:
1) The secret keys will match if the passwords match, and appear random otherwise.
2) Participants do not need to trust third parties (in particular, no Public Key Infrastructure),
3) The resulting secret key is not learned by anyone not participating in the protocol – including those who know the password.
4) The protocol does not reveal either parties’ password to each other (unless the passwords match), or to eavesdroppers.
In sum, the only way to successfully attack the protocol is to guess the password correctly while participating in the protocol. (Luckily, such attacks can be mostly thwarted by rate-limiting, i.e, blocking a user from logging in after a certain number of incorrect password attempts).
Given these requirements, password-over-TLS is clearly not a PAKE, because:
Password-over-TLS provides the user no assurance that the server knows their password or a derivative of it — a server could accept any input from the user with no checks whatsoever.
That said, plain PAKE is still worse than Password-over-TLS, simply because it requires the server to store plaintext passwords. We need a PAKE that lets the server store salted hashes if we want to beat the current practice.
An improvement over plain PAKE is what’s called an asymmetric PAKE (aPAKE), because only the client knows the password, and the server knows a hashed password. An aPAKE has the four properties of PAKE, plus one more:
5) An attacker who steals password data stored on the server must perform a dictionary attack to retrieve the password.
The issue with most existing aPAKE protocols, however, is that they do not allow for a salted hash (or if they do, they require that salt to be transmitted to the user, which means the attacker has access to the salt beforehand and can begin computing a rainbow table for the user before stealing any data). We’d like, therefore, to upgrade the security property as follows:
5*) An attacker who steals password data stored on the server must perform a per-user dictionary attack to retrieve the password after the data is compromised.
OPAQUE is the first aPAKE protocol with a formal security proof that has this property: it allows for a completely secret salt.
OPAQUE – Servers safeguard secrets without knowing them!
OPAQUE is what’s referred to as a strong aPAKE, which simply means that it resists these pre-computation attacks by using a secretly salted hash on the server. OPAQUE was proposed and formally analyzed by Stanislaw Jarecki, Hugo Krawcyzk and Jiayu Xu in 2018 (full disclosure: Stanislaw Jarecki is my academic advisor). The name OPAQUE is a combination of the names of two cryptographic protocols: OPRF and PAKE. We already know PAKE, but what is an OPRF? OPRF stands for Oblivious Pseudo-Random Function, which is a protocol by which two parties compute a function F(key, x) that is deterministic but outputs random-looking values. One party inputs the value x, and another party inputs the key – the party who inputs x learns the result F(key, x) but not the key, and the party providing the key learns nothing. (You can dive into the math of OPRFs here: https://blog.cloudflare.com/privacy-pass-the-math/).
The core of OPAQUE is a method to store user secrets for safekeeping on a server, without giving the server access to those secrets. Instead of storing a traditional salted password hash, the server stores a secret envelope for you that is “locked” by two pieces of information: your password known only by you, and a random secret key (like a salt) known only by the server. To log in, the client initiates a cryptographic exchange that reveals the envelope key to the client, but, importantly, not to the server.
The server then sends the envelope to the user, who now can retrieve the encrypted keys. (The keys included in the envelope are a private-public key pair for the user, and a public key for the server.) These keys, once unlocked, will be the inputs to an Authenticated Key Exchange (AKE) protocol, which allows the user and server to establish a secret key which can be used to encrypt their future communication.
OPAQUE consists of two phases, being credential registration and login via key exchange.
OPAQUE: Registration Phase
Before registration, the user first signs up for a service and picks a username and password. Registration begins with the OPRF flow we just described: Alice (the user) and Bob (the server) do an OPRF exchange. The result is that Alice has a random key rwd,derived from the OPRF output F(key, pwd), where key is a server-owned OPRF key specific to Alice and pwd is Alice’s password.
Within his OPRF message, Bob sends the public key for his OPAQUE identity. Alice then generates a new private/public key pair, which will be her persistent OPAQUE identity for Bob’s service, and encrypts her private key along with Bob’s public key with the rwd (we will call the result an encrypted envelope). She sends this encrypted envelope along with her public key (unencrypted) to Bob, who stores the data she provided, along with Alice’s specific OPRF keysecret, in a database indexed by her username.
OPAQUE: Login Phase
The login phase is very similar. It starts the same way as registration — with an OPRF flow. However, on the server side, instead of generating a new OPRF key, Bob instead looks up the one he created during Alice’s registration. He does this by looking up Alice’s username (which she provides in the first message), and retrieving his record of her. This record contains her public key, her encrypted envelope, and Bob’s OPRF key for Alice.
He also sends over the encrypted envelope which Alice can decrypt with the output of the OPRF flow. (If decryption fails, she aborts the protocol — this likely indicates that she typed her password incorrectly, or Bob isn’t who he says he is). If decryption succeeds, she now has her own secret key and Bob’s public key. She inputs these into an AKE protocol with Bob, who, in turn, inputs his private key and her public key, which gives them both a fresh shared secret key.
Integrating OPAQUE with an AKE
An important question to ask here is: what AKE is suitable for OPAQUE? The emerging CFRG specification outlines several options, including 3DH and SIGMA-I. However, on the web, we already have an AKE at our disposal: TLS!
Recall that TLS is an AKE because it provides unilateral (and mutual) authentication with shared secret derivation. The core of TLS is a Diffie-Hellman key exchange, which by itself is unauthenticated, meaning that the parties running it have no way to verify who they are running it with. (This is a problem because when you log into your bank, or any other website that stores your private data, you want to be sure that they are who they say they are). Authentication primarily uses certificates, which are issued by trusted entities through a system called Public Key Infrastructure (PKI). Each certificate is associated with a secret key. To prove its identity, the server presents its certificate to the client, and signs the TLS handshake with its secret key.
Modifying this ubiquitous certificate-based authentication on the web is perhaps not the best place to start. Instead, an improvement would be to authenticate the TLS shared secret, using OPAQUE, after the TLS handshake completes. In other words, once a server is authenticated with its typical WebPKI certificate, clients could subsequently authenticate to the server. This authentication could take place “post handshake” in the TLS connection using OPAQUE.
Exported Authenticators are one mechanism for “post-handshake” authentication in TLS. They allow a server or client to provide proof of an identity without setting up a new TLS connection. Recall that in the standard web case, the server establishes their identity with a certificate (proving, for example, that they are “cloudflare.com”). But if the same server also holds alternate identities, they must run TLS again to prove who they are.
The basic Exported Authenticator flow works resembles a classical challenge-response protocol, and works as follows. (We’ll consider the server authentication case only, as the client case is symmetric).
At any point after a TLS connection is established, Alice (the client) sends an authenticator request to indicate that she would like Bob (the server) to prove an additional identity. This request includes a context (an unpredictable string — think of this as a challenge), and extensions which include information about what identity the client wants to be provided. For example, the client could include the SNI extension to ask the server for a certificate associated with a certain domain name other than the one initially used in the TLS connection.
On receipt of the client message, if the server has a valid certificate corresponding to the request, it sends back an exported authenticator which proves that it has the secret key for the certificate. (This message has the same format as an Auth message from the client in TLS 1.3 handshake – it contains a Certificate, a CertificateVerify and a Finished message). If the server cannot or does not wish to authenticate with the requested certificate, it replies with an empty authenticator which contains only a well formed Finished message.
The client then checks that the Exported Authenticator it receives is well-formed, and then verifies that the certificate presented is valid, and if so, accepts the new identity.
In sum, Exported Authenticators provide authentication in a higher layer (such as the application layer) safely by leveraging the well-vetted cryptography and message formats of TLS. Furthermore, it is tied to the TLS session so that authentication messages can’t be copied and pasted from one TLS connection into another. In other words, Exported Authenticators provide exactly the right hooks needed to add OPAQUE-based authentication into TLS.
OPAQUE with Exported Authenticators (OPAQUE-EA)
OPAQUE-EA allows OPAQUE to run at any point after a TLS connection has already been set up. Recall that Bob (the server) will store his OPAQUE identity, in this case a signing key and verification key, and Alice will store her identity — encrypted — on Bob’s server. (The registration flow where Alice stores her encrypted keys is the same as in regular OPAQUE, except she stores a signing key, so we will skip straight to the login flow). Alice and Bob run two request-authenticate EA flows, one for each party, and OPAQUE protocol messages ride along in the extensions section of the EAs. Let’s look in detail how this works.
First, Alice generates her OPRF message based on her password. She creates an Authenticator Request asking for Bob’s OPAQUE identity, and includes (in the extensions field) her username and her OPRF message, and sends this to Bob over their established TLS connection.
Bob receives the message and looks up Alice’s username in his database. He retrieves her OPAQUE record containing her verification key and encrypted envelope, and his OPRF key. He uses the OPRF key on the OPRF message, and creates an Exported Authenticator proving ownership of his OPAQUE signing key, with an extension containing his OPRF message and the encrypted envelope. Additionally, he sends a new Authenticator Request asking Alice to prove ownership of her OPAQUE signing key.
Alice parses the message and completes the OPRF evaluation using Bob’s message to get output rwd, and uses rwd to decrypt the envelope. This reveals her signing key and Bob’s public key. She uses Bob’s public key to validate his Authenticator Response proof, and, if it checks out, she creates and sends an Exported Authenticator proving that she holds the newly decrypted signing key. Bob checks the validity of her Exported Authenticator, and if it checks out, he accepts her login.
My project: OPAQUE-EA over HTTPS
Everything described above is supported by lots and lots of theory that has yet to find its way into practice. My project was to turn the theory into reality. I started with written descriptions of Exported Authenticators, OPAQUE, and a preliminary draft of OPAQUE-in-TLS. My goal was to get from those to a working prototype.
My demo shows the feasibility of implementing OPAQUE-EA on the web, completely removing plaintext passwords from the wire, even encrypted. This provides a possible alternative to the current password-over-TLS flow with better security properties, but no visible change to the user.
A few of the implementation details are worth knowing. In computer science, abstraction is a powerful tool. It means that we can often rely on existing tools and APIs to avoid duplication of effort. In my project I relied heavily on mint, an open-source implementation of TLS 1.3 in Go that is great for prototyping. I also used CIRCL’s OPRF API. I built libraries for Exported Authenticators, the core of OPAQUE, and OPAQUE-EA (which ties together the two).
I made the web demo by wrapping the OPAQUE-EA functionality in a simple HTTP server and client that pass messages to each other over HTTPS. Since a browser can’t run Go, I compiled from Go to WebAssembly (WASM) to get the Go functionality in the browser, and wrote a simple script in JavaScript to call the WASM functions needed.
Since current browsers do not give access to the underlying TLS connection on the client side, I had to implement a work-around to allow the client to access the exporter keys, namely, that the server simply computes the keys and sends them to the client over HTTPS. This workaround reduces the security of the resulting demo — it means that trust is placed in the server to provide the right keys. Even so, the user’s password is still safe, even if a malicious server provided bad keys— they just don’t have assurance that they actually previously registered with that server. However, in the future, browsers could include a mechanism to support exported keys and allow OPAQUE-EA to run with its full security properties.
You can explore my implementation on Github, and even follow the instructions to spin up your own OPAQUE-EA test server and client. I’d like to stress, however, that the implementation is meant as a proof-of-concept only, and must not be used for production systems without significant further review.
OPAQUE-EA Limitations
Despite its great properties, there will definitely be some hurdles in bringing OPAQUE-EA from a proof-of-concept to a fully fledged authentication mechanism.
Browser support for TLS exporter keys. As mentioned briefly before, to run OPAQUE-EA in a browser, you need to access secrets from the TLS connection called exporter keys. There is no way to do this in the current most popular browsers, so support for this functionality will need to be added.
Overhauling password databases. To adopt OPAQUE-EA, servers need not only to update their password-checking logic, but also completely overhaul their password databases. Because OPAQUE relies on special password representations that can only be generated interactively, existing salted hashed passwords cannot be automatically updated to OPAQUE records. Servers will likely need to run a special OPAQUE registration flow on a user-by-user basis. Because OPAQUE relies on buy-in from both the client and the server, servers may need to support the old method for a while before all clients catch up.
Reliance on emerging standards. OPAQUE-EA relies on OPRFs, which is in the process of standardization, and Exported Authenticators, a proposed standard. This means that support for these dependencies is not yet available in most existing cryptographic libraries, so early adopters may need to implement these tools themselves.
Summary
As long as people still use passwords, we’d like to make the process as secure as possible. Current methods rely on the risky practice of handling plaintext passwords on the server side while checking their correctness. PAKEs, and (specifically aPAKEs) allow secure password login without ever letting the server see the passwords.
OPAQUE is also being explored within other companies. According to Kevin Lewi, a research scientist from the Novi Research team at Facebook, they are “excited by the strong cryptographic guarantees provided by OPAQUE and are actively exploring OPAQUE as a method for further safeguarding credential-protected fields that are stored server-side.”
OPAQUE is one of the best aPAKEs out there, and can be fully integrated into TLS. You can check out the core OPAQUE implementation here and the demo TLS integration here. A running version of the demo is also available here. A Typescript client implementation of OPAQUE is coming soon. If you’re interested in implementing the protocol, or encounter any bugs with the current implementation, please drop us a line at [email protected]! Consider also subscribing to the IRTF CFRG mailing list to track discussion about the OPAQUE specification and its standardization.
Today we are announcing support for a new proposed DNS standard — co-authored by engineers from Cloudflare, Apple, and Fastly — that separates IP addresses from queries, so that no single entity can see both at the same time. Even better, we’ve made source code available, so anyone can try out ODoH, or run their own ODoH service!
But first, a bit of context. The Domain Name System (DNS) is the foundation of a human-usable Internet. It maps usable domain names, such as cloudflare.com, to IP addresses and other information needed to connect to that domain. A quick primer about the importance and issues with DNS can be read in a previous blog post. For this post, it’s enough to know that, in the initial design and still dominant usage of DNS, queries are sent in cleartext. This means anyone on the network path between your device and the DNS resolver can see both the query that contains the hostname (or website) you want, as well as the IP address that identifies your device.
To safeguard DNS from onlookers and third parties, the IETF standardized DNS encryption with DNS over HTTPS (DoH) and DNS over TLS (DoT). Both protocols prevent queries from being intercepted, redirected, or modified between the client and resolver. Client support for DoT and DoH is growing, having been implemented in recent versions of Firefox, iOS, and more. Even so, until there is wider deployment among Internet service providers, Cloudflare is one of only a few providers to offer a public DoH/DoT service. This has raised two main concerns. One concern is that the centralization of DNS introduces single points of failure (although, with data centers in more than 100 countries, Cloudflare is designed to always be reachable). The other concern is that the resolver can still link all queries to client IP addresses.
Cloudflare is committed to end-user privacy. Users of our public DNS resolver service are protected by a strong, audited privacy policy. However, for some, trusting Cloudflare with sensitive query information is a barrier to adoption, even with such a strong privacy policy. Instead of relying on privacy policies and audits, what if we could give users an option to remove that bar with technical guarantees?
Today, Cloudflare and partners are launching support for a protocol that does exactly that: Oblivious DNS over HTTPS, or ODoH for short.
ODoH Partners:
We’re excited to launch ODoH with several leading launch partners who are equally committed to privacy.
A key component of ODoH is a proxy that is disjoint from the target resolver. Today, we’re launching ODoH with several leading proxy partners, including: PCCW, SURF, and Equinix.
“ODoH is a revolutionary new concept designed to keep users’ privacy at the center of everything. Our ODoH partnership with Cloudflare positions us well in the privacy and “Infrastructure of the Internet” space. As well as the enhanced security and performance of the underlying PCCW Global network, which can be accessed on-demand via Console Connect, the performance of the proxies on our network are now improved by Cloudflare’s 1.1.1.1 resolvers. This model for the first time completely decouples client proxy from the resolvers. This partnership strengthens our existing focus on privacy as the world moves to a more remote model and privacy becomes an even more critical feature.” — Michael Glynn, Vice President, Digital Automated Innovation, PCCW Global
“We are partnering with Cloudflare to implement better user privacy via ODoH. The move to ODoH is a true paradigm shift, where the users’ privacy or the IP address is not exposed to any provider, resulting in true privacy. With the launch of ODoH-pilot, we’re joining the power of Cloudflare’s network to meet the challenges of any users around the globe. The move to ODoH is not only a paradigm shift but it emphasizes how privacy is important to any users than ever, especially during 2020. It resonates with our core focus and belief around Privacy.” — Joost van Dijk, Technical Product Manager, SURF
How does Oblivious DNS over HTTPS (ODoH) work?
ODoH works by adding a layer of public key encryption, as well as a network proxy between clients and DoH servers such as 1.1.1.1. The combination of these two added elements guarantees that only the user has access to both the DNS messages and their own IP address at the same time.
There are three players in the ODoH path. Looking at the figure above, let’s begin with the target. The target decrypts queries encrypted by the client, via a proxy. Similarly, the target encrypts responses and returns them to the proxy. The standard says that the target may or may not be the resolver (we’ll touch on this later). The proxy does as a proxy is supposed to do, in that it forwards messages between client and target. The client behaves as it does in DNS and DoH, but differs by encrypting queries for the target, and decrypting the target’s responses. Any client that chooses to do so can specify a proxy and target of choice.
Together, the added encryption and proxying provide the following guarantees:
The target sees only the query and the proxy’s IP address.
The proxy has no visibility into the DNS messages, with no ability to identify, read, or modify either the query being sent by the client or the answer being returned by the target.
Only the intended target can read the content of the query and produce a response.
These three guarantees improve client privacy while maintaining the security and integrity of DNS queries. However, each of these guarantees relies on one fundamental property — that the proxy and the target servers do not collude. So long as there is no collusion, an attacker succeeds only if both the proxy and target are compromised.
One aspect of this system worth highlighting is that the target is separate from the upstream recursive resolver that performs DNS resolution. In practice, for performance, we expect the target to be the same. In fact, 1.1.1.1 is now both a recursive resolver and a target! There is no reason that a target needs to exist separately from any resolver. If they are separated then the target is free to choose resolvers, and just act as a go-between. The only real requirement, remember, is that the proxy and target never collude.
Also, importantly, clients are in complete control of proxy and target selection. Without any need for TRR-like programs, clients can have privacy for their queries, in addition to security. Since the target only knows about the proxy, the target and any upstream resolver are oblivious to the existence of any client IP addresses. Importantly, this puts clients in greater control over their queries and the ways they might be used. For example, clients could select and alter their proxies and targets any time, for any reason!
ODoH Message Flow
In ODoH, the ‘O’ stands for oblivious, and this property comes from the level of encryption of the DNS messages themselves. This added encryption is `end-to-end` between client and target, and independent from the connection-level encryption provided by TLS/HTTPS. One might ask why this additional encryption is required at all in the presence of a proxy. This is because two separate TLS connections are required to support proxy functionality. Specifically, the proxy terminates a TLS connection from the client, and initiates another TLS connection to the target. Between those two connections, the DNS message contexts would otherwise appear in plaintext! For this reason, ODoH additionally encrypts messages between client and target so the proxy has no access to the message contents.
The whole process begins with clients that encrypt their query for the target using HPKE. Clients obtain the target’s public key via DNS, where it is bundled into a HTTPS resource record and protected by DNSSEC. When the TTL for this key expires, clients request a new copy of the key as needed (just as they would for an A/AAAA record when that record’s TTL expires). The usage of a target’s DNSSEC-validated public key guarantees that only the intended target can decrypt the query and encrypt a response (answer).
Clients transmit these encrypted queries to a proxy over an HTTPS connection. Upon receipt, the proxy forwards the query to the designated target. The target then decrypts the query, produces a response by sending the query to a recursive resolver such as 1.1.1.1, and then encrypts the response to the client. The encrypted query from the client contains encapsulated keying material from which targets derive the response encryption symmetric key.
This response is then sent back to the proxy, and then subsequently forwarded to the client. All communication is authenticated and confidential since these DNS messages are end-to-end encrypted, despite being transmitted over two separate HTTPS connections (client-proxy and proxy-target). The message that otherwise appears to the proxy as plaintext is actually an encrypted garble.
What about Performance? Do I have to trade performance to get privacy?
We’ve been doing lots of measurements to find out, and will be doing more as ODoH deploys more widely. Our initial set of measurement configurations spanned cities in the USA, Canada, and Brazil. Importantly, our measurements include not just 1.1.1.1, but also 8.8.8.8 and 9.9.9.9. The full set of measurements, so far, is documented for open access.
In those measurements, it was important to isolate the cost of proxying and additional encryption from the cost of TCP and TLS connection setup. This is because the TLS and TCP costs are incurred by DoH, anyway. So, in our setup, we ‘primed’ measurements by establishing connections once and reusing that connection for all measurements. We did this for both DoH and for ODoH, since the same strategy could be used in either case.
The first thing that we can say with confidence is that the additional encryption is marginal. We know this because we randomly selected 10,000 domains from the Tranco million dataset and measured both encryption of the A record with a different public key, as well as its decryption. The additional cost between a proxied DoH query/response and its ODoH counterpart is consistently less than 1ms at the 99th percentile.
The ODoH request-response pipeline, however, is much more than just encryption. A very useful way of looking at measurements is by looking at the cumulative distribution chart — if you’re familiar with these kinds of charts, skip to the next paragraph. In contrast to most charts where we start along the x-axis, with cumulative distributions we often start with the y-axis.
The chart below shows the cumulative distributions for query/response times in DoH, ODoH, and DoH when transmitted over the Tor Network. The dashed horizontal line that starts on the left from 0.5 is the 50% mark. Along this horizontal line, for any plotted curve, the part of the curve below the dashed line is 50% of the data points. Now look at the x-axis, which is a measure of time. The lines that appear to the left are faster than lines to the right. One last important detail is that the x-axis is plotted on a logarithmic scale. What does this mean? Notice that the distance between the labeled markers (10x) is equal in cumulative distributions but the ‘x’ is an exponent, and represents orders of magnitude. So, while the time difference between the first two markers is 9ms, the difference between the 3rd and 4th markers is 900ms.
In this chart, the middle curve represents ODoH measurements. We also measured the performance of privacy-preserving alternatives, for example, DoH queries transmitted over the Tor network as represented by the right curve in the chart. (Additional privacy-preserving alternatives are captured in the open access technical report.) Compared to other privacy-oriented DNS variants, ODoH cuts query time in half, or better. This point is important since privacy and performance rarely play nicely together, so seeing this kind of improvement is encouraging!
The chart above also tells us that 50% of the time ODoH queries are resolved in fewer than 228ms. Now compare the middle line to the left line that represents ‘straight-line’ (or normal) DoH without any modification. That left plotline says that 50% of the time, DoH queries are resolved in fewer than 146ms. Looking below the 50% mark, the curves also tell us that ½ the time that difference is never greater than 100ms. On the other side, looking at the curves above the 50% mark tells us that ½ ODoH queries are competitive with DoH.
Those curves also hide a lot of information, so it is important to delve further into the measurements. The chart below has three different cumulative distribution curves that describe ODoH performance if we select proxies and targets by their latency. This is also an example of the insights that measurements can reveal, some of which are counterintuitive. For example, looking above 0.5, these curves say that ½ of ODoH query/response times are virtually indistinguishable, no matter the choice of proxy and target. Now shift attention below 0.5 and compare the two solid curves against the dashed curve that represents overall average. This region suggests that selecting the lowest-latency proxy and target offers minimal improvement over the average but, most importantly, it shows that selecting the lowest-latency proxy leads to worse performance!
Open questions remain, of course. This first set of measurements were executed largely in North America. Does performance change at a global level? How does this affect client performance, in practice? We’re working on finding out, and this release will help us to do that.
Interesting! Can I experiment with ODoH? Is there an open ODoH service?
Yes, and yes! We have open sourced our interoperable ODoH implementations in Rust, odoh-rs and Go, odoh-go, as well as integrated the target into the Cloudflare DNS Resolver. That’s right, 1.1.1.1 is ready to receive queries via ODoH.
We have also open sourced test clients in Rust, odoh-client-rs, and Go, odoh-client-go, to demo ODoH queries. You can also check out the HPKE configuration used by ODoH for message encryption to 1.1.1.1 by querying the service directly:
We are working to add ODoH to existing stub resolvers such as cloudflared. If you’re interested in adding support to a client, or if you encounter bugs with the implementations, please drop us a line at [email protected]! Announcements about the ODoH specification and server will be sent to the IETF DPRIVEmailing list. You can subscribe and follow announcements and discussion about the specification here.
We are committed to moving it forward in the IETF and are already seeing interest from client vendors. Eric Rescorla, CTO of Firefox, says, “Oblivious DoH is a great addition to the secure DNS ecosystem. We’re excited to see it starting to take off and are looking forward to experimenting with it in Firefox.” We hope that more operators join us along the way and provide support for the protocol, by running either proxies or targets, and we hope client support will increase as the available infrastructure increases, too.
The ODoH protocol is a practical approach for improving privacy of users, and aims to improve the overall adoption of encrypted DNS protocols without compromising performance and user experience on the Internet.
Acknowledgements
Marek Vavruša and Anbang Wen were instrumental in getting the 1.1.1.1 resolver to support ODoH. Chris Wood and Peter Wu helped get the ODoH libraries ready and tested.
Over the last ten years, Cloudflare has become an important part of Internet infrastructure, powering websites, APIs, and web services to help make them more secure and efficient. The Internet is growing in terms of its capacity and the number of people using it and evolving in terms of its design and functionality. As a player in the Internet ecosystem, Cloudflare has a responsibility to help the Internet grow in a way that respects and provides value for its users. Today, we’re making several announcements around improving Internet protocols with respect to something important to our customers and Internet users worldwide: privacy.
Developing a superior protocol forpasswordauthentication, OPAQUE, that makes password breaches less likely to occur
Each of these projects impacts an aspect of the Internet that influences our online lives and digital footprints. Whether we know it or not, there is a lot of private information about us and our lives floating around online. This is something we can help fix.
For over a year, we have been working through standards bodies like the IETF and partnering with the biggest names in Internet technology (including Mozilla, Google, Equinix, and more) to design, deploy, and test these new privacy-preserving protocols at Internet scale. Each of these three protocols touches on a critical aspect of our online lives, and we expect them to help make real improvements to privacy online as they gain adoption.
A continuing tradition at Cloudflare
One of Cloudflare’s core missions is to support and develop technology that helps build a better Internet. As an industry, we’ve made exceptional progress in making the Internet more secure and robust. Cloudflare is proud to have played a part in this progress through multiple initiatives over the years.
Here are a few highlights:
Universal SSL™. We’ve been one of the driving forces for encrypting the web. We launched Universal SSL in 2014 to give website encryption to our customers for free and have actively been working along with certificate authorities like Let’s Encrypt, web browsers, and website operators to help remove mixed content. Before Universal SSL launched to give all Cloudflare customers HTTPS for free, only 30% of connections to websites were encrypted. Through the industry’s efforts, that number is now 80% — and a much more significant proportion of overall Internet traffic. Along with doing our part to encrypt the web, we have supported the Certificate Transparency project via Nimbus and Merkle Town, which has improved accountability for the certificate ecosystem HTTPS relies on for trust.
TLS 1.3 and QUIC. We’ve also been a proponent of upgrading existing security protocols. Take Transport Layer Security (TLS), the underlying protocol that secures HTTPS. Cloudflare engineers helped contribute to the design of TLS 1.3, the latest version of the standard, and in 2016 we launched support for an early version of the protocol. This early deployment helped lead to improvements to the final version of the protocol. TLS 1.3 is now the most widely used encryption protocol on the web and a vital component of the emerging QUIC standard, of which we were also early adopters.
Securing Routing, Naming, and Time. We’ve made major efforts to help secure other critical components of the Internet. Our efforts to help secure Internet routing through our RPKI toolkit, measurement studies, and “Is BGP Safe Yet” tool have significantly improved the Internet’s resilience against disruptive route leaks. Our time service (time.cloudflare.com) has helped keep people’s clocks in sync with more secure protocols like NTS and Roughtime. We’ve also made DNS more secure by supporting DNS-over-HTTPS and DNS-over-TLS in 1.1.1.1 at launch, along with one-click DNSSEC in our authoritative DNS service and registrar.
Continuing to improve the security of the systems of trust online is critical to the Internet’s growth. However, there is a more fundamental principle at play: respect. The infrastructure underlying the Internet should be designed to respect its users.
Building an Internet that respects users
When you sign in to a specific website or service with a privacy policy, you know what that site is expected to do with your data. It’s explicit. There is no such visibility to the users when it comes to the operators of the Internet itself. You may have an agreement with your Internet Service Provider (ISP) and the site you’re visiting, but it’s doubtful that you even know which networks your data is traversing. Most people don’t have a concept of the Internet beyond what they see on their screen, so it’s hard to imagine that people would accept or even understand what a privacy policy from a transit wholesaler or an inspection middlebox would even mean.
Without encryption, Internet browsing information is implicitly shared with countless third parties online as information passes between networks. Without secure routing, users’ traffic can be hijacked and disrupted. Without privacy-preserving protocols, users’ online life is not as private as they would think or expect. The infrastructure of the Internet wasn’t built in a way that reflects their expectations.
Normal network flowNetwork flow with malicious route leak
The good news is that the Internet is continuously evolving. One of the groups that help guide that evolution is the Internet Architecture Board (IAB). The IAB provides architectural oversight to the Internet Engineering Task Force (IETF), the Internet’s main standard-setting body. The IAB recently published RFC 8890, which states that individual end-users should be prioritized when designing Internet protocols. It says that if there’s a conflict between the interests of end-users and the interest of service providers, corporations, or governments, IETF decisions should favor end users. One of the prime interests of end-users is the right to privacy, and the IAB published RFC 6973 to indicate how Internet protocols should take privacy into account.
Today’s technical blog posts are about improvements to the Internet designed to respect user privacy. Privacy is a complex topic that spans multiple disciplines, so it’s essential to clarify what we mean by “improving privacy.” We are specifically talking about changing the protocols that handle privacy-sensitive information exposed “on-the-wire” and modifying them so that this data is exposed to fewer parties. This data continues to exist. It’s just no longer available or visible to third parties without building a mechanism to collect it at a higher layer of the Internet stack, the application layer. These changes go beyond website encryption; they go deep into the design of the systems that are foundational to making the Internet what it is.
The toolbox: cryptography and secure proxies
Two tools for making sure data can be used without being seen are cryptography and secureproxies.
Cryptography allows information to be transformed into a format that a very limited number of people (those with the key) can understand. Some describe cryptography as a tool that transforms data security problems into key management problems. This is a humorous but fair description. Cryptography makes it easier to reason about privacy because only key holders can view data.
Another tool for protecting access to data is isolation/segmentation. By physically limiting which parties have access to information, you effectively build privacy walls. A popular architecture is to rely on policy-aware proxies to pass data from one place to another. Such proxies can be configured to strip sensitive data or block data transfers between parties according to what the privacy policy says.
Both these tools are useful individually, but they can be even more effective if combined. Onion routing (the cryptographic technique underlying Tor) is one example of how proxies and encryption can be used in tandem to enforce strong privacy. Broadly, if party A wants to send data to party B, they can encrypt the data with party B’s key and encrypt the metadata with a proxy’s key and send it to the proxy.
Platforms and services built on top of the Internet can build in consent systems, like privacy policies presented through user interfaces. The infrastructure of the Internet relies on layers of underlying protocols. Because these layers of the Internet are so far below where the user interacts with them, it’s almost impossible to build a concept of user consent. In order to respect users and protect them from privacy issues, the protocols that glue the Internet together should be designed with privacy enabled by default.
Data vs. metadata
The transition from a mostly unencrypted web to an encrypted web has done a lot for end-user privacy. For example, the “coffeeshop stalker” is no longer an issue for most sites. When accessing the majority of sites online, users are no longer broadcasting every aspect of their web browsing experience (search queries, browser versions, authentication cookies, etc.) over the Internet for any participant on the path to see. Suppose a site is configured correctly to use HTTPS. In that case, users can be confident their data is secure from onlookers and reaches only the intended party because their connections are both encrypted and authenticated.
However, HTTPS only protects the content of web requests. Even if you only browse sites over HTTPS, that doesn’t mean that your browsingpatterns are private. This is because HTTPS fails to encrypt a critical aspect of the exchange: the metadata. When you make a phone call, the metadata is the phone number, not the call’s contents. Metadata is the data about the data.
To illustrate the difference and why it matters, here’s a diagram of what happens when you visit a website like an imageboard. Say you’re going to a specific page on that board (https://<imageboard>.com/room101/) that has specific embedded images hosted on <embarassing>.com.
Page load for an imageboard, returning an HTML page with an image from an embarassing siteSubresource fetch for the image from an embarassing site
The space inside the dotted line here represents the part of the Internet that your data needs to transit. They include your local area network or coffee shop, your ISP, an Internet transit provider, and it could be the network portion of the cloud provider that hosts the server. Users often don’t have a relationship with these entities or a contract to prevent these parties from doing anything with the user’s data. And even if those entities don’t look at the data, a well-placed observer intercepting Internet traffic could see anything sent unencrypted. It would be best if they just didn’t see it at all. In this example, the fact that the user visited <imageboard>.com can be seen by an observer, which is expected. However, though page content is encrypted, it’s possible to learn which specific page you’ve visited can be seen since <embarassing>.com is also visible.
It’s a general rule that if data is available to on-path parties on the Internet, some of these on-path parties will use this data. It’s also true that these on-path parties need some metadata in order to facilitate the transport of this data. This balance is explored in RFC 8558, which explains how protocols should be designed thoughtfully with respect to the balance between too much metadata (bad for privacy) and too little metadata (bad for operations).
In an ideal world, Internet protocols would be designed with the principle of least privilege. They would provide the minimum amount of information needed for the on-path parties (the pipes) to do the job of transporting the data to the right place and keep everything else confidential by default. Current protocols, including TLS 1.3 and QUIC, are important steps towards this ideal but fall short with respect to metadata privacy.
Knowing both who you are and what you do online can lead to profiling
Today’s announcements reflect two metadata protection levels: the first involves limiting the amount of metadata available to third-party observers (like ISPs). The second involves restricting the amount of metadata that users share with service providers themselves.
Hostnames are an example of metadata that needs to be protected from third-party observers, which DoH and ECH intend to do. However, it doesn’t make sense to hide the hostname from the site you’re visiting. It also doesn’t make sense to hide it from a directory service like DNS. A DNS server needs to know which hostname you’re resolving to resolve it for you!
A privacy issue arises when a service provider knows about both what sites you’re visiting and who you are. Individual websites do not have this dangerous combination of information (except in the case of third party cookies, which are going away soon in browsers), but DNS providers do. Thankfully, it’s not actually necessary for a DNS resolver to know *both* the hostname of the service you’re going to and which IP you’re coming from. Disentangling the two, which is the goal of ODoH, is good for privacy.
The Internet is part of ‘our’ Infrastructure
Roads should be well-paved, well lit, have accurate signage, and be optimally connected. They aren’t designed to stop a car based on who’s inside it. Nor should they be! Like transportation infrastructure, Internet infrastructure is responsible for getting data where it needs to go, not looking inside packets, and making judgments. But the Internet is made of computers and software, and software tends to be written to make decisions based on the data it has available to it.
Privacy-preserving protocols attempt to eliminate the temptation for infrastructure providers and others to peek inside and make decisions based on personal data. A non-privacy preserving protocol like HTTP keeps data and metadata, like passwords, IP addresses, and hostnames, as explicit parts of the data sent over the wire. The fact that they are explicit means that they are available to any observer to collect and act on. A protocol like HTTPS improves upon this by making some of the data (such as passwords and site content) invisible on the wire using encryption.
The three protocols we are exploring today extend this concept.
ECH takes most of the unencrypted metadata in TLS (including the hostname) and encrypts it with a key that was fetched ahead of time.
ODoH (a new variant of DoH co-designed by Apple, Cloudflare, and Fastly engineers) uses proxies and onion-like encryption to make the source of a DNS query invisible to the DNS resolver. This protects the user’s IP address when resolving hostnames.
OPAQUE uses a new cryptographic technique to keep passwords hidden even from the server. Utilizing a construction called an Oblivious Pseudo-Random Function (as seen in Privacy Pass), the server does not learn the password; it only learns whether or not the user knows the password.
By making sure Internet infrastructure acts more like physical infrastructure, user privacy is more easily protected. The Internet is more private if private data can only be collected where the user has a chance to consent to its collection.
Doing it together
As much as we’re excited about working on new ways to make the Internet more private, innovation at a global scale doesn’t happen in a vacuum. Each of these projects is the output of a collaborative group of individuals working out in the open in organizations like the IETF and the IRTF. Protocols must come about through a consensus process that involves all the parties that make up the interconnected set of systems that power the Internet. From browser builders to cryptographers, from DNS operators to website administrators, this is truly a global team effort.
We also recognize that sweeping technical changes to the Internet will inevitably also impact the technical community. Adopting these new protocols may have legal and policy implications. We are actively working with governments and civil society groups to help educate them about the impact of these potential changes.
We’re looking forward to sharing our work today and hope that more interested parties join in developing these protocols. The projects we are announcing today were designed by experts from academia, industry, and hobbyists together and were built by engineers from Cloudflare Research (including the work of interns, which we will highlight) with everyone’s support Cloudflare.
If you’re interested in this type of work, we’re hiring!
The first phase of the Internet lasted until the early 1990s. During that time it was created and debugged, and grew globally. Its growth was not hampered by concerns about data security or privacy. Until the 1990s the race was for connectivity.
Connectivity meant that people could get online and use the Internet wherever they were. Because the “inter” in Internet implied interoperability the network was able to grow rapidly using a variety of technologies. Think dialup modems using ordinary phones lines, cable modems sending the Internet over coax originally designed for television, Ethernet, and, later, fibre optic connections and WiFi.
By the 1990s, the Internet was being used widely and for uses far beyond its academic origins. Early web pioneers, like Netscape, realized that the potential for e-commerce was gigantic but would be held back if people couldn’t have confidence in the security of online transactions.
Thus, with the introduction of SSL in 1994, the Internet moved to a second phase where security became paramount. Securing the web, and the Internet more generally, helped create the dotcom rush and the secure, online world we live in today. But this security was misunderstood by some as providing guarantees about privacy which it did not.
People feel safe going online to shop, read the news, look up ailments and search for a life partner because cryptography prevents an eavesdropper from seeing what they are doing, and provides a guarantee that a website is who it claims to be. But it does not provide any privacy guarantee. The website you are visiting knows, at the very least, the IP address of your Internet connection.
And even with encryption a well placed eavesdropper can learn at least the names of websites you are visiting because of that information leaks from protocols that weren’t designed to preserve privacy.
People who aim to remain anonymous on the Internet therefore turn to technologies like Tor or VPNs. But remaining anonymous from a website you shop from or an airline’s online booking site doesn’t make any sense. In those instances, the company you are dealing with will know who you are because you tell them your home address, name, passport number etc. You want them to know.
That makes privacy a nuanced thing: you want to remain anonymous to an eavesdropper but make sure a retailer knows where you live.
The connectivity phase of the Internet made it possible for you to connect to a computer anywhere in the world just as easily as one in your own city. The security phase of the Internet solved the problem of giving you confidence to hand over information to an airline or a retailer. Combining these two phases resulted in an Internet you can trust to transmit your data, but little control over where that data ultimately ended up.
Phase 3
A French citizen could just as easily buy goods from a Spanish website as from a North American one. In both cases, the retailer would know the French name and address where the purchases were to be delivered. This creates a conundrum for a privacy-conscious citizen. The Internet created an amazing global platform for commerce, news and information (how easy it is for the French citizen to stay in contact with family in Cote d’Ivoire and even read the local news there from afar).
And while shopping an eavesdropper (such as an ISP, a coffee shop owner or an intelligence agency) could tell which website the French citizen was visiting.
And the Internet also meant that your and my information is dispersed across the world. And different countries have different rules about how that data is to be stored and shared. And countries and regions have data sharing agreements to allow cross-border transfer of private information about citizens.
Concerns about eavesdropping and where data ends up have created the world we are living in today where privacy concerns are coming to the forefront, especially in Europe but in many other countries as well.
In addition, the economics and flexibility of SaaS and cloud applications meant that it made sense to actually transfer data to a limited number of large data centers (which are sometimes confusingly called regions) where data from people all over the world can be processed. And, by and large, that was the world of the Internet, universal connectivity, widespread security, and data sharing through cross-border agreements.
This apparent utopia got snowed on by the leaking of secret documents describing the relationship between the US NSA (and its Five Eyes partners) and large Internet companies, and that intelligence agencies were scooping up data from choke points on the Internet. Those revelations brought to the public’s attention the fact that their data could, in some cases, be accessed by foreign intelligence agencies
Quite quickly those large data centers in far flung countries looked like a bad idea, and governments and citizens started to demand control of data. This is the third phase of the Internet. Privacy joins universal connectivity and security as core.
But what is control over data or privacy? Different governments have different ideas and different requirements, which can differ for different data sets. Some countries are convinced that the only way to control data is to keep it inside their countries, where they believe they can control who gets access to it. Other countries believe that they can address the risks by putting restrictions to prevent certain governments or companies from getting access to data. And the regulatory challenges are only getting more complicated.
This will be an enormous challenge for companies that have built a business on aggregating citizens’ information in order to target advertising, but it is also a challenge for anyone offering an Internet service. Just as companies have had to face the scourge of DDoS attacks and hacking, and have had to stay up to date with the latest in encryption technology, they will fundamentally have to store and process their customers’ data in different countries in different ways.
The European Union, in particular, has pushed a comprehensive approach to data privacy. Although the EU has had data protection principles in place since 1995, the implementation of the EU’s General Data Protection Regulation (GDPR) in 2018 has generated a new era of privacy online. GDPR imposes limitations on how the personal data of EU residents can be collected, stored, deleted, modified and otherwise processed.
Among the GDPR’s requirements are provisions on how EU personal data should be protected if that personal data leaves the EU. Although the US and the EU worked together to develop a set of voluntary commitments to make it easier for companies to transfer data between the two countries, that framework — the Privacy Shield — was invalidated this past summer. As a result, companies are grappling with how they can transfer data outside the EU, consistent with GDPR requirements. Recommendations recently issued by the European Data Protection Board (EDPB), which require data exporters to assess the law in third countries, determine whether that law adequately protects privacy, and if necessary, obtain guarantees of additional safeguards from data importers, have only added to companies’ concerns.
This anxiety over whether there are controls over data adequate to address the concerns of European regulators has prompted many of our customers to explore whether it is possible to prevent data subject to the GDPR from leaving the EU at all.
Gone are the days when all the world’s data could be processed in a massive data center regardless of its provenance.
One reaction to this change could be a retreat into every country building its own online email services, HR systems, e-commerce providers, and more. This would be a massive wasted effort. There are economies of scale if the same service can be used by Germans, Peruvians, Indonesians, Australians…
The answer to this privacy challenge is the same as the answer to the connectivity and security phases of the Internet: build it! We need to build a privacy-respecting Internet and give companies the tools to easily build privacy-respecting applications.
This week we’ll be talking about new tools from Cloudflare that make building privacy-respecting applications easy by allowing companies to situate their users’ data in the countries and regions of their choosing. And we’ll be talking about new protocols that build privacy into the very structure of the Internet. We’ll update on the latest quantum-resistant algorithms that help keep private data private today and into the far future.
We’ll show how it’s possible to run a massive DNS resolver service like 1.1.1.1 and preserve users’ privacy through a clever new protocol. We’ll look at how to make passwords that can’t be leaked. And we’ll give everyone the power to get web analytics without tracking people.
Welcome to Phase 3 of the Internet: always on, always secure, always private.
Today we’re excited to announce the Cloudflare Data Localization Suite, which helps businesses get the performance and security benefits of Cloudflare’s global network, while making it easy to set rules and controls at the edge about where their data is stored and protected.
The Data Localization Suite is available now as an add-on for Enterprise customers.
Cloudflare’s network is private and compliant by design. Preserving end-user privacy is core to our mission of helping to build a better Internet; we’ve never sold personal data about customers or end users of our network. We comply with laws like GDPR and maintain certifications such as ISO-27001.
Today, we’re announcing tools that make it simple for our customers to build the same rigor into their own applications. In this post, I’ll explain the different types of data that we process and how the Data Localization Suite keeps this data local.
We’ll also talk about how Cloudflare makes it possible to build applications that comply with data locality laws, while remaining fast, secure and scalable.
Why keep data local?
Cloudflare’s customers have increasing desire or face legal requirements for data locality: they want to control the geographic location where their data is handled. Many categories of data that our customers process (including healthcare, legal, or financial data) may be subject to obligations that specify the data be stored or processed in a specific location. The preference or requirement for data localization is growing across jurisdictions such as the EU, India, and Brazil; over time, we expect more customers in more places will be expected to keep data local.
Although “data locality” sounds like a simple concept, our conversations with Cloudflare customers make clear that there are a number of unique challenges they face in the attempt to move toward this goal. The availability of information on their Internet properties will remain global–they don’t want to limit access to their websites to local jurisdictions–but they want to make sure data stays local. Variously, they are trying to figure out:
How do I build local requirements into my global online operations?
How do I make sure unencrypted traffic is only available locally?
How do I make sure personal data is handled according to localization obligations?
How do I make sure my applications only store data in certain locations?
The Cloudflare Data Localization Suite attempts to respond to these questions.
Until now, customers who wanted to localize their data had to choose to restrict their application to one data center, or to one cloud provider’s region. This is a fragile approach, fraught with performance, reliability, and security challenges. Cloudflare is creating a new paradigm: customers should be able to get the performance and security benefits of our global network, while effortlessly keeping their data local.
Encryption is the backbone of privacy
Before we go into data locality, we should discuss encryption. Privacy isn’t possible without strong encryption; otherwise, anyone could snoop your customers’ data, regardless of where it’s stored.
Data is often described as being “in transit” and “at rest”. It’s critically important that both are encrypted. Data “in transit” refers to just that—data while it’s moving about on the wire, whether a local network or the public Internet. “At rest” generally means stored on a disk somewhere, whether a spinning HDD or a modern SSD.
In transit, Cloudflare can enforce that all traffic to end-users uses modern TLS and gets the highest level of encryption possible. We can also enforce that all traffic back to customers’ origin servers is always encrypted. Communication between all our edge and core data centers is always encrypted.
Cloudflare encrypts all of the data we handle at rest, usually with disk-level encryption. From cached files on our edge network, to configuration state in databases in our core data centers—every byte is encrypted at rest.
Control where TLS private keys can be accessed
Given the importance of encryption, one of the most sensitive pieces of data that our customers trust us to protect are their cryptographic keys, which enable data to be decrypted. Cloudflare offers two ways for customers to ensure that their private keys are only accessible in locations they specify.
Keyless SSL allows a customer to store and manage their own SSL private keys for use with Cloudflare on any external infrastructure of their choosing. Customers can use a variety of systems for their keystore, including hardware security modules (“HSMs”), virtual servers, and hardware running Unix/Linux and Windows that is housed in environments customers control. Cloudflare never has access to the private key with Keyless SSL.
Geo Key Manager gives customers granular control over which locations should store their keys. For example, a customer can choose for the private keys required for inspection of traffic to only be accessible inside data centers located in the European Union.
Manage where HTTPS requests and responses are inspected
In order to deploy our WAF, or detect malicious bot traffic, Cloudflare must terminate TLS in our edge data centers and inspect HTTPS request and response payloads.
Regional Services gives organizations control over where their traffic is inspected. With Regional Services enabled, traffic is ingested on Cloudflare’s global Anycast network at the location closest to the client, where we can provide L3 and L4 DDoS protection. Instead of being inspected at the HTTP level at that data center, this traffic is securely transmitted to Cloudflare data centers inside the region selected by the customer and handled there.
Control the logs and analytics generated by your traffic
In addition to making our customers’ infrastructure and teams faster, more secure, and more reliable, we also provide insights into what our services do, and how customers can make better use of them. We gather metadata about the traffic that goes through our edge data centers, and use this to improve the operation of our own network: for example, by crafting WAF rules to block the latest attacks, or by developing machine learning models to detect malicious bots. We also make this data available to our customers in the form of logs and analytics.
This only requires a subset of the metadata to be processed in our core data centers in the US/EU. This data contains information about how many requests were served, how much data was sent, how long requests took, and other information that is essential for the operation of our network.
With Edge Log Delivery, customers can send logs directly from the edge to their partner of choice—for example, an Azure storage bucket in their preferred region, or an instance of Splunk that runs in an on-premise data center. With this option, customers can still get their complete logs in their preferred region, without these logs first flowing through either of our US or EU core data centers.
Edge Log Delivery is in early beta for Enterprise customers today—please visit our product page for more information.
Ultimately, we are working towards providing customers full control over where their metadata is stored, and for how long. In the coming year, we plan to allow customers to be able to choose exactly which fields are stored, and for how long, and in which location.
Building location-aware applications from the ground up
So far, we’ve discussed how Cloudflare’s products can offer global performance and security solutions for our customers, while keeping their existing keys, application data, and metadata local.
But we know that customers are also struggling to use existing, traditional cloud systems to manage their data locality needs. Existing platforms may allow code or data to be deployed to a specific region, but having copies of applications in each region, and managing state across each of them, can be challenging at best (or impossible at worst).
The ultimate promise of serverless has been to allow any developer to say “I don’t care where my code runs, just make it scale.” Increasingly, another promise will need to be “I do care where my code runs, and I need more control to satisfy my compliance department.” Cloudflare Workers allows you the best of both worlds, with instant scaling, locations that span more than 100 countries around the world, and the granularity to choose exactly what you need.
We are announcing a major improvement that lets customers control where their applications store data: Workers Durable Objects will support Jurisdiction Restrictions. Durable Objects provide globally consistent state and coordination to serverless applications running on the Cloudflare Workers platform. Jurisdiction Restrictions will make it possible for users to ensure that their Durable Objects do not store data or run outside of a given jurisdiction—making it trivially simple to build applications that combine global performance with local compliance. With automatic migration of Durable Objects, adapting to new rules will be as simple as adding a tag to a set of Durable Objects.
Building for the long haul
The data localization landscape is constantly evolving. Since we began working on the Data Localization Suite, the European Data Protection Board has released new guidance about how data may be transferred between the EU and the US. And we know this is just the beginning — over time, more regions and more industries will have data localization requirements.
At Cloudflare, we stay on top of the latest developments around data protection so our customers don’t have to. The Data Localization Suite gives our customers the tools to set rules and controls at the edge about where their data is stored and protected, while taking advantage of our global network.
Tomorrow kicks off Cloudflare’s Privacy & Compliance Week. Over the course of the week, we’ll be announcing ways that our customers can use our service to ensure they are in compliance with an increasingly complicated set of rules and laws around the world.
Early in Cloudflare’s history, when Michelle, Lee, and I were talking about the business we wanted to build, we kept coming back to the word trust. We realized early on that if we were not trustworthy then no one would ever choose to route their Internet traffic through us. Above all else, we are in the trust business.
Every employee at Cloudflare goes through orientation. I teach one of the sessions titled “What Is Cloudflare?” I fill several white boards with notes and diagrams talking about where we fit in to the market. But I leave one for the end so I can write the word TRUST, in capital letters, and underline it three times. Trust is the foundation of our business.
Standing Up For Our Customers from Our Early Days
That’s why we’ve made decisions that other companies may not have. In January 2013 the FBI showed up at our door with a National Security Letter requesting information on a customer. It was incredibly scary.
We had fewer than 30 employees at the time. The agents, while professional, were incredibly intimidating. And the letter ordered us to turn over information and forbid us from discussing it with anyone other than our attorneys.
There’s a proper role for law enforcement, but National Security Letters, which at the time had almost no oversight, could be written and enforced by a single branch of the US government, and gagged recipients from talking about them indefinitely, ran counter to the foundational principles of due process. So we decided to sue the United States government.
I am thankful for Cloudflare’s Board for encouraging us to always fight for our principles. I am also thankful for the Electronic Frontier Foundation, who served as our attorneys in the case. It took several years, and we were gagged from talking about it until 2017, but ultimately the FBI withdrew the letter and Congress has taken steps to reform the law and ensure better oversight. There is a proper role for law enforcement, but when it crosses a line and infringes on basic principles of due process, then we believe it’s important to challenge it.
It’s all about trust.
Recognizing It’s Not Our Data
The same is true for the commercial side of our business. As soon as Cloudflare took off, the ad tech companies came knocking: “Do you have any idea how much you could make if you just let us cookie and retarget individuals passing through your network?” I took a lot of those meetings in our early days, but always came away feeling uneasy. Talking through it with Michelle she concisely expressed why we would never be in the advertising business: “It’s not our data.”
And that’s right. For our customers who do run ads on their sites, if we sold the data then we’d effectively be undercutting them. And, more fundamentally, if we were some invisible service that tracked you online without your knowledge then that would fail the creepiness test. While we believe there can be good ad-supported businesses, Cloudflare will never be one.
As a result, we’ve always seen any personally identifiable information that passes through our network as a toxic asset and purged it as quickly as possible. That can be a tension because we are a security company and part of security requires us to be able to know, for instance, if a particular IP address is sending DDoS traffic. But we’ve invested in implementing or inventing technologies — like Universal SSL, Privacy Pass, Encrypted DNS, and ESNI — that keep your private data private, including from us.
Again, it’s all about trust.
Privacy In Our DNA
While Cloudflare started in California, we have had a global perspective from our earliest days. Today, nearly half of our C-level executives are Europeans, including our CTO, CIO, and CFO. Michelle, my co-founder and Cloudflare’s COO, is Canadian, a country that shares many of Europe’s values around privacy. We have offices around the world and far more engineers working outside of Silicon Valley than inside of it.
I wrote the first version of our Privacy Policy back in 2010. It included from the first draft this clear statement: “Cloudflare will not sell, rent, or give away any of your personal information without your consent. It is our overriding privacy principle that any personal information you provide to us is just that: private.” That is still true today. While other tech companies have made their policies more flexible over time, we’ve made ours stricter, including committing to a list of things we have never done and will fight like hell to never do:
Cloudflare has never turned over our encryption or authentication keys or our customers’ encryption or authentication keys to anyone.
Cloudflare has never installed any law enforcement software or equipment anywhere on our network.
Cloudflare has never provided any law enforcement organization a feed of our customers’ content transiting our network.
Cloudflare has never modified customer content at the request of law enforcement or another third party.
Cloudflare has never modified the intended destination of DNS responses at the request of law enforcement or another third party.
Cloudflare has never weakened, compromised, or subverted any of its encryption at the request of law enforcement or another third party.
While many tech companies struggled to comply with privacy regulations such as GDPR, at Cloudflare it was relatively easy because the principles it imposed were at our core from our very outset. We don’t have a business if we don’t have trust, and being transparent, principled, and respecting the sanctity of personal data is critical to us continuously earning that trust.
Improving the Privacy of Our Service
But we’re not done; we can do more. There are things that have irked me about our service for a long time. For instance, from our earliest days we’ve used the _cfduid cookie to help with some of our security functions. That has meant that if you used Cloudflare you couldn’t be completely cookieless. John Graham-Cumming and I challenged the team earlier this year to see if we could kill it. Our team rose to the challenge and this week we’re announcing its deprecation. To my mind, that announcement alone is worth an entire week of celebrations.
We have multiple data centers around the world that aggregate and process data in order to display logs and provide features. While having geographic redundancy helps with availability, some customers want to make sure their data never leaves a particular region. This week we’ll be giving users a lot more control over what data is processed where.
And, like we have during Privacy and Encryption weeks in years past, we will continue to invest in technologies to enable better encryption and more private use of core Internet services like DNS. Wouldn’t it be cool if, for example, we could ensure that no DNS provider could ever see both who is using their service and also where on the Internet those users are going? Stay tuned!
Helping Customers With Increasingly Complex Compliance Challenges
While we continue to invest in ensuring Cloudflare leads the way on privacy, more and more of our customers are also looking for solutions to be more private themselves. This month we expect that the EU’s new Digital Services Act will be proposed. We expect that it will continue to raise the bar on how companies doing business in Europe have to handle customers’ data. While the Internet giants will have the resources to comply with these heightened requirements, for everyone else they will create new challenges.
To that end, this week we’re announcing the Cloudflare Data Localization Suite. It provides our customers with a powerful set of tools to ensure they have control over how and where their data is processed in order to help comply with increasingly complex local data processing requirements. This includes enhancements to Workers, our edge computing and storage platform, to help modern applications get built such that users’ data never leaves their own country or region.
It’s clear to us that the model of sending all your customer data back to a data center in Ashburn, VA, regardless of where those customers are located in the world, will look as antiquated in an increasingly privacy-conscious world as carrying a stack of punch cards to a central mainframe would today. In the not too distant future, regulations are inevitably going to force data storage and processing to be local. And, with a network that today already spans more than 100 countries, Cloudflare stands ready to help our customers enable that more private future.
Stay Tuned
Stay tuned this week to our blog for a series of announcements. Since these are topics that are so important in Europe right now, we’ll be simultaneously publishing most of them in French, Italian, Spanish, Portuguese, and German as well as English. Also check out Cloudflare TV where we’ll be interviewing a series of people whose views on privacy and compliance we respect and have learned from.
Cloudflare’s mission is to help build a better Internet. And there is no doubt that a better Internet is a more private Internet. With that in mind, welcome to Privacy & Compliance Week.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.