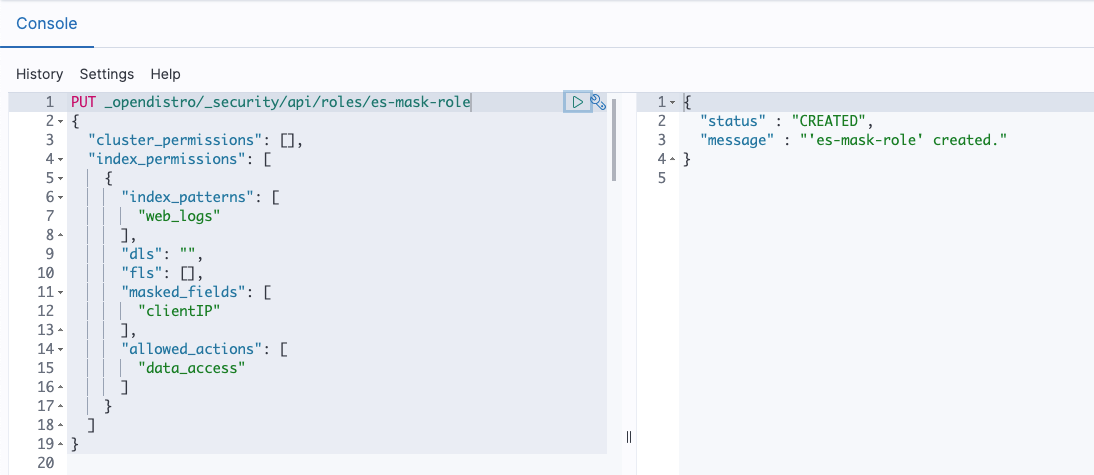
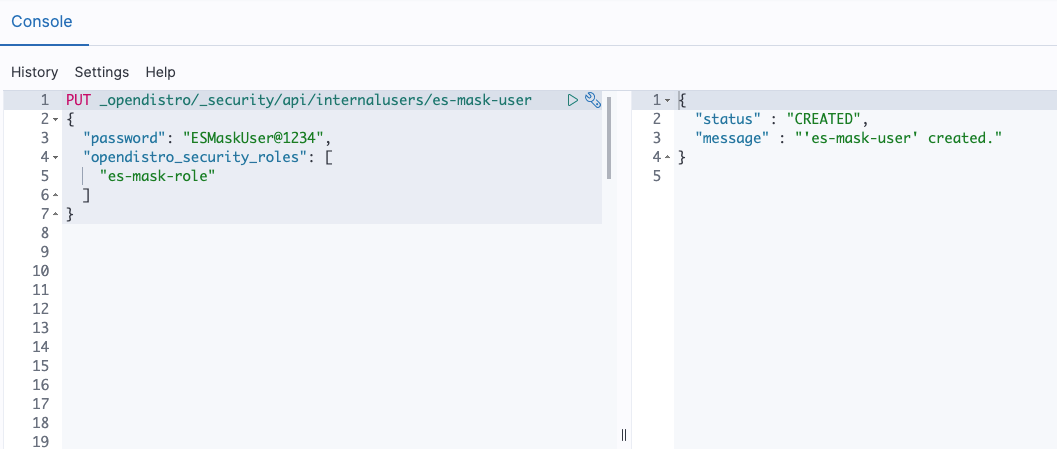
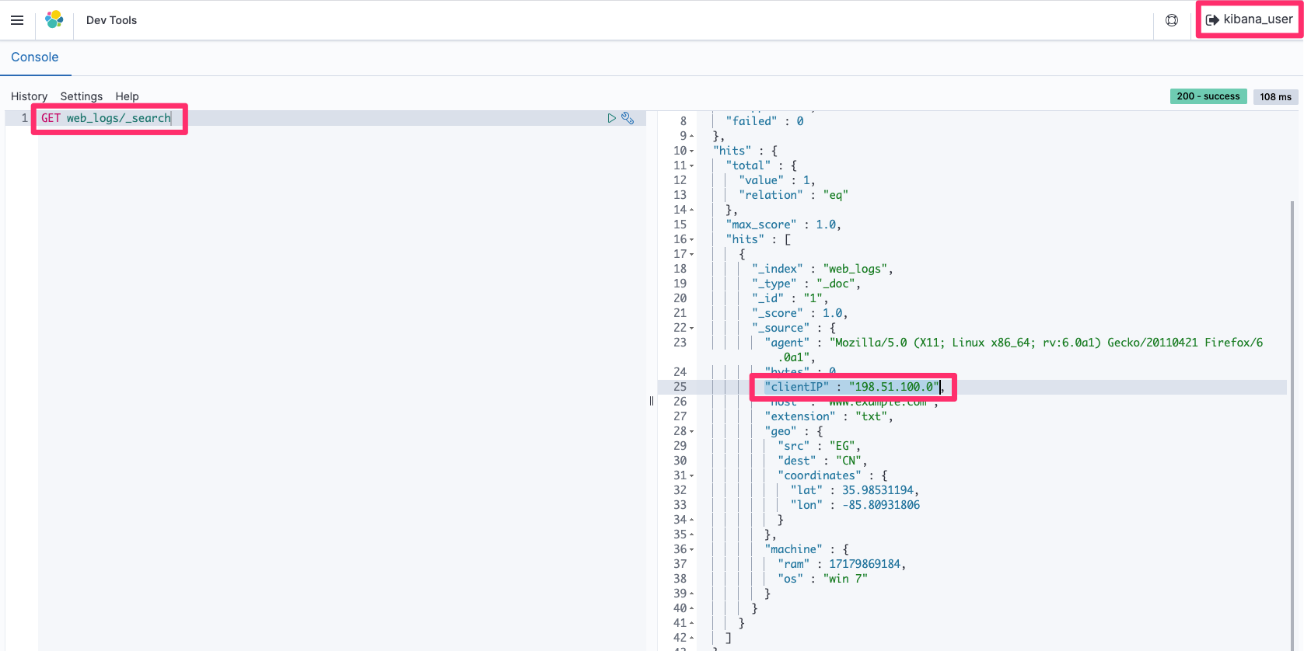
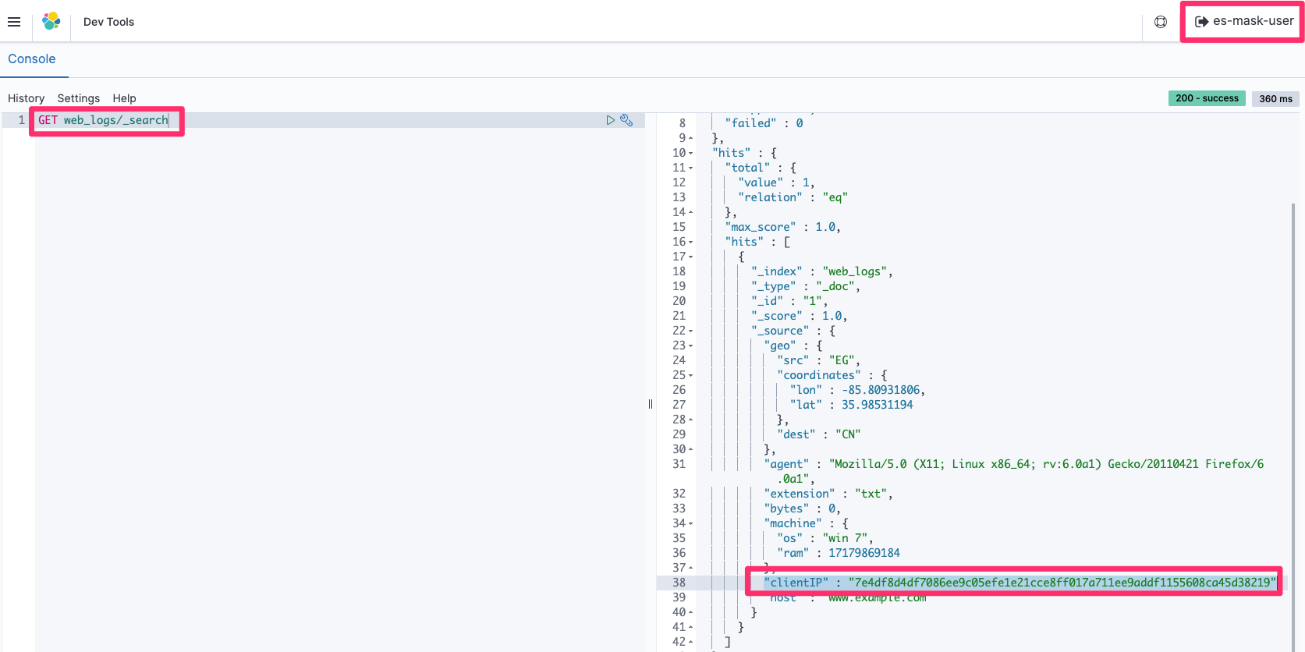
Post Syndicated from Prashant Agrawal original https://aws.amazon.com/blogs/big-data/search-going-beyond-keywords-with-amazon-opensearch-service/
Search technology, specifically web search technology, has been around for more than 30 years. You entered a few words in a text box, clicked “Search,” and received a series of links. However, the results were often a mix of related, non-related, and general links. If the results didn’t contain the information you needed, you reformulated your query and submitted it to the search engine again. Some of the breakdowns occurred around language—the text you matched was missing some context that disambiguated your search terms. Other breakdowns were conceptual in nature—you made inferences yourself that led you to new, successful search terms. In all cases, you were the agent that adjusted your search until you received the right information in response. Search engines fail to understand context, so you had to act as translators between your information needs and the rigid keyword system.
With the advent of natural language models like large language models (LLMs) and foundation models (FMs), AI-powered search systems are able to incorporate more of the searcher’s intelligence into the application, relieving you of some of the burden of iterating over search results. On the search side, application designers can choose to employ semantic, hybrid, multimodal, and sparse search. These methods use LLMs and other models to generate a vector representation of a piece of text and a query to provide nearest-neighbor matching. On the application side, application designers are employing AI agents embedded in workflows that can make multiple passes over the search system, rewrite user queries, and rescore results. With these advances, searchers expect intelligent, context-aware results.
As user interactions become more nuanced, many organizations are enhancing their existing search capabilities with intent-based understanding. The emergence of language models that create vector embeddings brings opportunities to further enhance search systems by combining traditional relevancy algorithms with semantic understanding. This hybrid approach allows applications to better interpret user intent, handle natural language variations, and deliver more contextually relevant results. By integrating these complementary capabilities, organizations can build upon their robust search infrastructure to create more intuitive and responsive search experiences that understand the keywords and also the reason behind the query.
This post describes how organizations can enhance their existing search capabilities with vector embeddings using Amazon OpenSearch Service. We discuss why traditional keyword search falls short of modern user expectations, how vector search enables more intelligent and contextual results, and the measurable business impact achieved by organizations like Amazon Prime Video, Juicebox, and Amazon Music. We examine the practical steps for modernizing search infrastructure while maintaining the precision of traditional search systems. This post is the first in a series designed to guide you through implementing modernized search applications, using technologies such as vector search, generative AI, and agentic AI to create more powerful and intuitive search experiences.
Going beyond keyword search
Keyword-based search engines remain essential in today’s digital landscape, providing precise results for product matching and structured queries. Although these traditional systems excel at exact matches and metadata filtering, many organizations are enhancing them with semantic capabilities to better understand user intent and natural language variations. This complementary approach allows search systems to maintain their foundational strengths while adapting to more diverse search patterns and user expectations. In practice, this leads to several business-critical challenges:
- Missed opportunities and inefficient discovery – Traditional search approaches tend to oversimplify user intent, grouping diverse search behaviors into broad categories. When Amazon Prime Video users searched for “live soccer,” the search results included documentaries like “This is Football: Season 1”; users were seeing irrelevant results that were keyword matches, but missed the context encoded in “live” as a keyword.
- Inability to adapt to changing search behavior – Search behavior is evolving rapidly. Users now employ conversational language, ask full questions, and expect systems to understand context and nuance. Juicebox encountered this challenge with recruiting search engines that relied on simple Boolean or keyword-based searches, and couldn’t capture the nuance and intent behind complex recruiting queries, leading to large volumes of irrelevant results.
- Limited personalization and contextual understanding – Search engines can be enhanced with personalization capabilities through additional investment in technology and infrastructure. For example, Amazon Music improved its recommendation system by augmenting traditional search capabilities with personalization features, allowing the service to consider user preferences, listening history, and behavioral patterns when delivering results. This demonstrates how organizations can build upon fundamental search functionality to create more tailored experiences when specific use cases warrant the investment.
- Hidden business impact of poor search – Inefficient search also has measurable business impacts. For instance, Juicebox recruiters were spending unnecessary time filtering through irrelevant results, making the process time-consuming and inefficient. Amazon Prime Video discovered that their original search experience, designed for movies and TV shows, wasn’t meeting the needs of sports fans, creating a disconnect between search queries and relevant results.
Importance of building modern search applications
Organizations are at a pivotal moment in enterprise search evolution. User interactions with information are fundamentally changing and analysts predict that the shift from traditional search interactions to AI-powered interfaces will continue to accelerate through 2026, as users increasingly expect more conversational and context-aware experiences. This transformation reflects evolving user expectations for more intuitive, intent-driven search experiences that understand not just what users type, but what they mean.
Real-world implementations demonstrate the tangible value of enhancing existing search. Examples like Amazon Prime Video and Juicebox demonstrate how semantic understanding and augmenting traditional search with vector capabilities can improve performance and increase end-customer satisfaction. The ability to deliver personalized, context-aware search experiences is becoming a key differentiator in today’s digital landscape.
Although organizations recognize these opportunities, many seek guidance on practical implementation. Successful organizations are taking a complementary approach by enhancing their proven search infrastructure with vector capabilities rather than replacing existing systems. Organizations can deliver more sophisticated search experiences that meet both current and future user needs, combining traditional search precision with semantic understand. The path forward isn’t about replacing existing search systems but enhancing them to create more powerful, intuitive search experiences that drive measurable business value.
Transforming business value and user experiences with vector search
Building upon the strong foundation of traditional search systems, businesses are expanding their search functionality to support more conversational interactions and diverse content types. Vector search complements existing search capabilities, helping organizations extend their search experiences into new domains while maintaining the precision and reliability that traditional search provides. This combination of proven search technology with emerging capabilities creates opportunities for more dynamic and interactive user experiences.
If you’re using OpenSearch Service to power your keyword search, you’re already using a scalable, reliable solution. Juicebox’s migration to vector search reduced query latency from 700 milliseconds to 250 milliseconds while surfacing 35% more relevant candidates for complex queries. Despite handling a massive database of 800 million profiles, the system maintained high recall accuracy and delivered aggregation queries across 100 million profiles. Amazon Music’s success story further reinforces the scalability of vector search solutions. Their recommendation system now efficiently manages 1.05 billion vectors, handling peak loads of 7,100 vector queries per second across multiple geographies to power real-time music recommendations for their vast catalog of 100 million songs.
How vector embeddings transform user experience
Consumers increasingly rely on digital platforms and apps to quickly discover healthy and delicious meal options, especially as busy schedules leave little time for meal planning and preparation. For organizations building these applications, the traditional keyword-based search approach often falls short in delivering the most relevant results to their users. This is where vector search, powered by embeddings and semantic understanding, can make a significant difference.
Imagine you’re a developer at an ecommerce company building a food delivery app for your customers. When a user enters a search query like “Quick, healthy dinner with tofu, no dairy,” a traditional keyword-based search would only return recipes that explicitly contain those exact words in the metadata. This approach has several shortcomings:
- Missed synonyms – Recipes labeled as “30-minute meals” instead of “quick” would be missed, even though they match the user’s intent.
- Lack of semantic understanding – Dishes that are healthy and nutrient-dense, but don’t use the word “healthy” in the metadata, would not be surfaced. The search engine lacks the ability to understand the semantic relationship between “healthy” and nutritional value.
- Inability to detect absence of ingredients – Recipes that don’t contain dairy but don’t explicitly state “dairy-free” would also be missed. The search engine can’t infer the absence of an ingredient.
This limitation means organizations miss valuable opportunities to delight their users and keep them engaged. Imagine if your app’s search function could truly understand the user’s intent, by correlating that “quick” refers to meals under 30 minutes, “healthy” relates to nutrient density, and “no dairy” means excluding ingredients like milk, butter, or cheese. This is precisely where vector search powered by embeddings and semantic understanding can transform the user experience.
Conclusion
This post covered key concepts and business benefits of incorporating vector search into your existing applications and infrastructure. We discussed the limitations of traditional keyword-based search and how vector search can significantly improve user experience. Vector search, powered by generative AI, can detect relevant attributes, better infer the presence or absence of specific criteria, and surface results that better align with user intent, whether your users are searching for products, recipes, research, or knowledge.
Modernizing your search capabilities with vector embeddings is a strategic move that can drive engagement, improve satisfaction, and deliver measurable business outcomes. By taking incremental steps to integrate vector search, your organization can future-proof its applications and stay ahead in an ever-evolving digital landscape.
Our next post will dive into Automatic Semantic Enrichment. We discuss how to generate semantic embeddings using Amazon Bedrock, set up vector-based indexes in OpenSearch Service, and combine vector and keyword search for even more relevant results. We provide step-by-step guidance and sample code to help you enhance your OpenSearch Service infrastructure with vector search, so your users can discover and engage with your data in more meaningful ways.
To learn more, refer to Amazon OpenSearch Service as a Vector Database, and visit our Migration Hub if you’re looking for migration and system modernization guidance and resources. For more blog posts about vector databases, refer to the AWS Big Data Blog. The following posts can help you learn more about vector database best practices and OpenSearch Service capabilities:
- Save big on OpenSearch: Unleashing Intel AVX-512 for binary vector performance
- Optimize multimodal search using the TwelveLabs Embed API and Amazon OpenSearch Service
- Amazon OpenSearch Service vector database capabilities revisited
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.

 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat. Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch
Hendy Wijaya is a Senior OpenSearch Specialist Solutions Architect at Amazon Web Services. Hendy enables customers to leverage AWS services to achieve their business objectives and gain competitive advantages. He is passionate in collaborating with customers in getting the best out of OpenSearch and Amazon OpenSearch Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.
Utkarsh Agarwal is a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He specializes in Amazon OpenSearch Service. He provides guidance and technical assistance to customers thus enabling them to build scalable, highly available and secure solutions in AWS Cloud. In his free time, he enjoys watching movies, TV series and of course cricket! Lately, he his also attempting to master the art of cooking in his free time – The taste buds are excited, but the kitchen might disagree.





 Satish Nandi is a Senior Technical Product Manager for Amazon OpenSearch Service.
Satish Nandi is a Senior Technical Product Manager for Amazon OpenSearch Service.











 Jon Handler (@_searchgeek) is a Sr. Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with the CloudSearch and Elasticsearch teams, providing help and guidance to a broad range of customers who have search workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine.
Jon Handler (@_searchgeek) is a Sr. Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with the CloudSearch and Elasticsearch teams, providing help and guidance to a broad range of customers who have search workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale, eCommerce search engine.






 Prashant Agrawal is a Specialist Solutions Architect at Amazon Web Services based in Seattle, WA.. Prashant works closely with Amazon OpenSearch team, helping customers migrate their workloads to the AWS Cloud. Before joining AWS, Prashant helped various customers use Elasticsearch for their search and analytics use cases.
Prashant Agrawal is a Specialist Solutions Architect at Amazon Web Services based in Seattle, WA.. Prashant works closely with Amazon OpenSearch team, helping customers migrate their workloads to the AWS Cloud. Before joining AWS, Prashant helped various customers use Elasticsearch for their search and analytics use cases.