Post Syndicated from Pratik Patel original https://aws.amazon.com/blogs/big-data/amazon-kinesis-data-streams-launches-on-demand-advantage-for-instant-throughput-increases-and-streaming-at-scale/
Today, AWS announced the new Amazon Kinesis Data Streams On-demand Advantage mode, which includes warm throughput capability and an updated pricing structure. With this feature you can enable instant scaling for traffic surges while optimizing costs for consistent streaming workloads. On-demand Advantage mode is a cost-effective way to stream with Kinesis Data Streams for use cases that ingest at least 10 MiB/s in aggregate or have hundreds of data streams in an AWS Region.
In this post, we explore this new feature, including key use cases, configuration options, pricing considerations, and best practices for optimal performance.
Real-world use cases
As streaming data volumes grow and use cases evolve, you can face two common challenges with your streaming workloads:
Challenge 1: Preparing for traffic spikes
Many businesses experience predictable but significant traffic surges during events like product launches, content releases, or holiday sales. Using an on-demand capacity mode, you have to complete several steps when preparing for traffic spikes:
- Transition to provisioned mode
- Manually estimate and increase shards based on anticipated peak demand
- Wait for scaling operations to finish
- Subsequently return to on-demand mode
This mode-switching process was time consuming, required careful planning, and introduced operational complexity, forcing customers to either accept this operational burden, overprovision capacity well in advance, or risk throttling during critical business periods when data ingestion reliability matters most.
Challenge 2: Cost optimization for consistent workloads
Organizations with large, consistent streaming workloads want to optimize costs without sacrificing the simplicity and scalability available with on-demand streams. On-demand capacity mode serves well for fluctuating data traffic, yet customers desired a more economical approach to handle high-volume streaming workloads.
On-demand Advantage directly address both challenges by providing the capability to warm on-demand streams and a new pricing structure. With the new On-demand Advantage mode, there is no longer a fixed, per-stream charge, and the throughput usage is priced at a lower rate. The only requirement is that the account commits to streaming with at least 25 MiB/s of data ingest and 25 MiB/s of data retrieval usage.
This launch improves data streaming across multiple industries:
- Online gaming companies can now prepare their streams for game launches without the cumbersome process of switching between modes and manually calculating shard requirements
- Media and entertainment providers can support smooth data ingestion during major content releases and live events
- E-commerce services can handle holiday sales traffic while optimizing costs for their baseline workloads.
By combining instant scaling with cost efficiency, you can confidently manage both predictable traffic surges and consistent streaming volumes without compromising on performance or budget.
How it works
The key features of On-demand Advantage mode are warm throughput and committed-usage pricing.
Warm throughput
With the warm throughput feature, available once you’ve enabled On-demand Advantage mode, you can configure your Kinesis Data Streams on-demand streams to have instantly available throughput capacity up to 10 GiB/s. This means you can proactively prepare on-demand streams for expected peak traffic events without the cumbersome process of switching between provisioned modes and manually calculating shard requirements. Key benefits include:
- The ability to prepare for peak events so you can handle traffic surges smoothly
- Alleviation of the need to build custom scaling solutions
- The capability to continue scaling automatically beyond warm throughput if needed, up to 10 GiB/s or 10 million events per second
- No additional fee for maintaining warm capacity
Committed-usage pricing
When you’ve enabled On-demand Advantage mode, the billing for the on-demand streams switches to a new structure that removes the stream hour charge and offers a discount of at least 60% for the throughput usage. Based on US East (N. Virginia) pricing, data ingested is priced 60% lower, data retrieval is priced 60% lower, Enhanced fan-out data retrieval is 68% lower, and extended retention is priced 77% lower. In return, you commit to stream 25 MiB/s for at least 24 hours. Even when actual usage is lower, if you enable this setting, you’re charged for the minimum 25 MiB/s throughput at the discounted price. Overall, the signficant discounts offered means that On-demand Advantage is more cost-effective for use cases that ingest at least 10 MiB/s in aggregate, fan out to more than two consumer applications, or have hundreds of data streams in an AWS Region.
Getting started
Follow these steps to start using On-demand Advantage mode.
Enabling On-demand Advantage mode
To start using the On-demand Advantage mode:
In the AWS Management Console
- Navigate to the Kinesis Data Streams console
- Navigate to the Account Settings tab
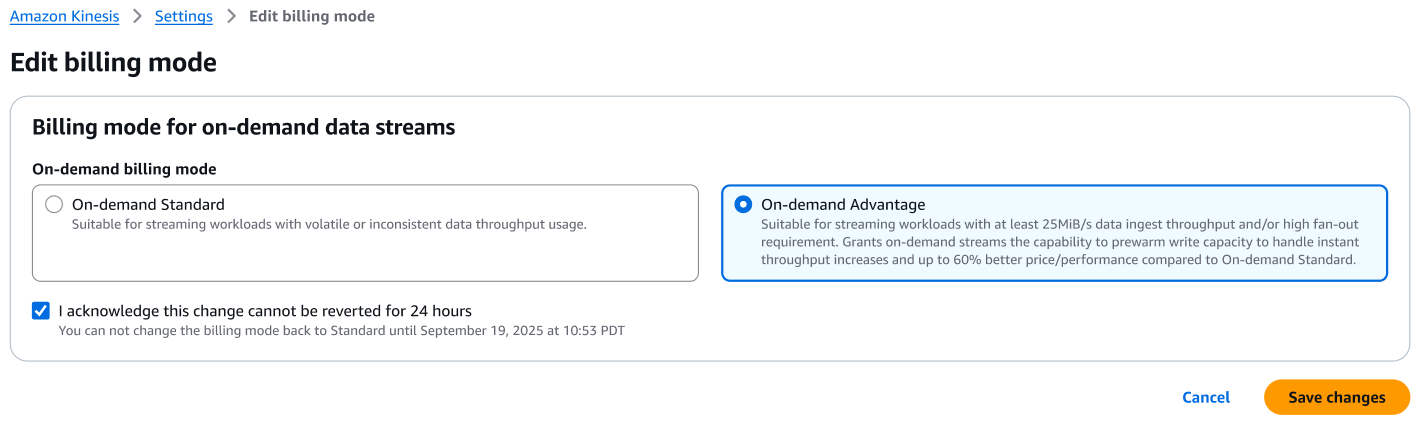
- Choose Edit billing mode
- Select the On-demand Advantage option
- Select the checkbox, I acknowledge this change cannot be reverted for 24 hours
- Choose Save changes
Using the AWS CLI
You can run the following CLI command to enable the minimum throughput billing commitment:
Using the AWS SDK
You can use the SDK to enable the minimum throughput billing commitment. The following Python example shows how to do it:
Once enabled, you commit your stream to this pricing mode for a minimum period of 24 hours, after which you can opt out as needed.
Configuring warm throughput
To start using warm throughput for Kinesis Data Streams On-demand:
Using the AWS Management Console
- Navigate to the Kinesis Data Streams console
- Select your stream and go to the Configuration tab
- Choose Edit next to Warm Throughput
- Set your desired warm throughput (up to 10 GiB/s)
- Save your changes
Using the AWS CLI
You can run the following CLI command to enable the warm throughput:
Using the AWS SDK:
You can use the SDK to enable warm throughput. The following Python example shows how to do it:
You can also create a new on-demand stream with warm throughput using the existing CreateStream API, or set warm throughput when converting a data stream from provisioned to On-demand Advantage mode.
Throttling and best practices for optimal performance
When working with warm throughput, it’s important to understand how capacity is managed. Each stream can instantly handle traffic up to the configured warm throughput level and will automatically scale beyond that as needed.
For optimal performance with warm throughput:
- Use a uniformly distributed partition key strategy to evenly distribute records across shards and avoid hotspots and consider your partition key strategy carefully as you can ingest a maximum of 1 MiB/s of data per partition key, regardless of the warm throughput configured.
- Monitor throughput metrics to adjust warm throughput settings based on actual usage patterns.
- Implement backoff and retry logic in producer applications to handle potential throttling.
For cost optimization with committed usage pricing:
- Analyze your daily throughput to verify it is at least 10 MiB/s.
- Consider consolidating streams across your organization to maximize the benefit of the discount for on-demand streams.
- Use cost effective data retrievals with – Use Enhanced Fan-Out – Use Enhanced Fan-Out consumers for applications that need dedicated throughput with 68% lower data retrievals cost in advantage mode.
Warm throughput in action
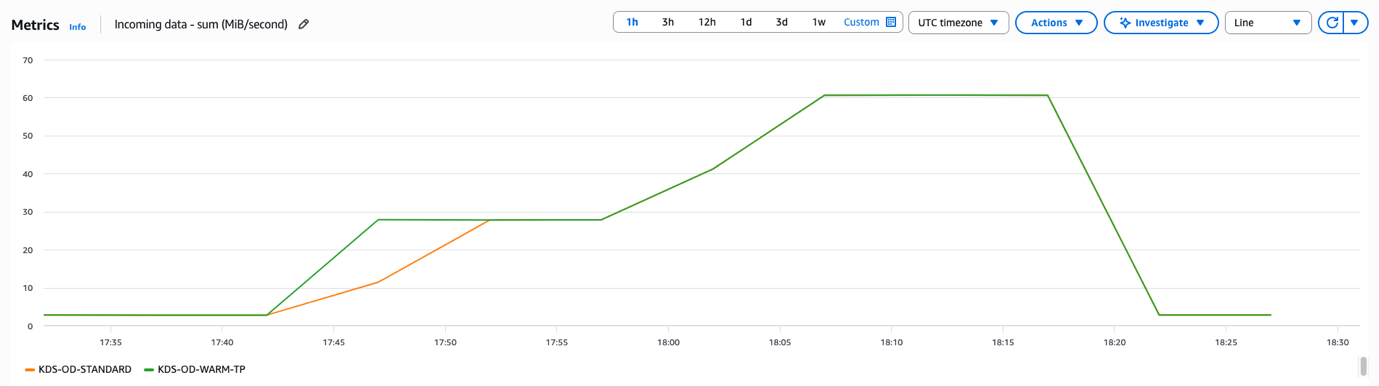
To demonstrate how warm throughput behaves, we enabled committed pricing in an AWS account and created two on-demand streams: “KDS-OD-STANDARD” and “KDS-OD-WARM-TP”. The “KDS-OD-WARM-TP” stream was configured with 100 MiB/second warm throughput, while “KDS-OD-STANDARD” remained as a regular on-demand stream without warm throughput, as demonstrated in the following screenshot.

In our experiment, we initially simulated approximately 2 MiB/second traffic ingest for both “KDS-OD-STANDARD” and “KDS-OD-WARM-TP” streams. We used a UUID as a partition key so that traffic was evenly distributed across the shards of the Kinesis data streams, helping prevent potential hotspots that might skew our results. After establishing this baseline, we increased the ingest traffic to around 28 MiB/second within 10 minutes. We then further escalated the traffic to exceed 60 MiB/second within 15 minutes of the initial increase, as illustrated in the following screenshot.
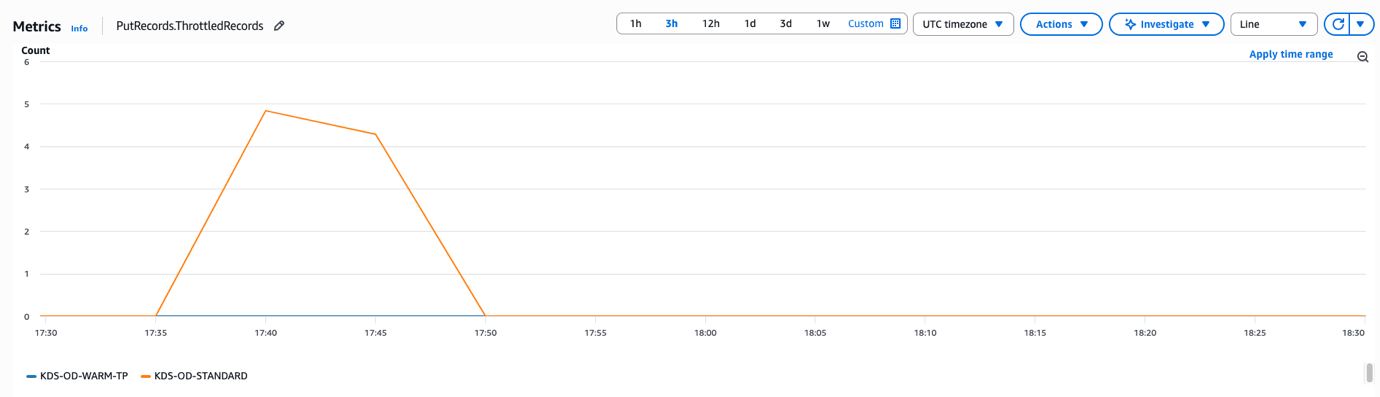
The following graph shows the ThrottledRecords CloudWatch metric for both “KDS-OD-STANDARD” and “KDS-OD-WARM-TP” that the warm throughput-enabled stream (“KDS-OD-WARM-TP”) did not encounter throttles during both traffic spikes, as it had 100 MiB/second warm throughput configured. In contrast, the standard on-demand stream (“KDS-OD-STANDARD”) experienced throttling when we increased traffic by 14x initially and by 2x later, before eventually scaling to bring throttles back to zero. This experiment demonstrates that you can use warm throughput to instantly prepare for peak usage times and avoid throttling during sudden traffic increases.
Conclusion
As we outlined in this post, the new Amazon Kinesis Data Streams On-demand Advantage mode provides significant benefits for organizations of different sizes:
- Instant scaling for predictable traffic surges without overprovisioning.
- Cost optimization for consistent streaming workloads with at least 60% discount.
- Simplified operations with no need to switch between different capacity modes.
- Enhanced flexibility to handle both expected and unexpected traffic patterns.
With these enhancements you can build and operate real-time streaming applications at many scales. Kinesis Data Streams now provides the ideal combination of scalability, performance, and cost-efficiency.
To learn more about these new features, visit the Amazon Kinesis Data Streams documentation.



















 Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy.
Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy. Amar is a seasoned Data Analytics specialist at AWS UK, who helps AWS customers to deliver large-scale data solutions. With deep expertise in AWS analytics and machine learning services, he enables organizations to drive data-driven transformation and innovation. He is passionate about building high-impact solutions and actively engages with the tech community to share knowledge and best practices in data analytics.
Amar is a seasoned Data Analytics specialist at AWS UK, who helps AWS customers to deliver large-scale data solutions. With deep expertise in AWS analytics and machine learning services, he enables organizations to drive data-driven transformation and innovation. He is passionate about building high-impact solutions and actively engages with the tech community to share knowledge and best practices in data analytics. Priyanka Chaudhary is a Senior Solutions Architect and data analytics specialist. She works with AWS customers as their trusted advisor, providing technical guidance and support in building Well-Architected, innovative industry solutions.
Priyanka Chaudhary is a Senior Solutions Architect and data analytics specialist. She works with AWS customers as their trusted advisor, providing technical guidance and support in building Well-Architected, innovative industry solutions.





 Pratik Patel is a Sr Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively helps in keeping customer’s AWS environments operationally healthy.
Pratik Patel is a Sr Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively helps in keeping customer’s AWS environments operationally healthy.