Post Syndicated from Raks Khare original https://aws.amazon.com/blogs/big-data/amazon-redshift-python-user-defined-functions-will-reach-end-of-support-after-june-30-2026/
The Amazon Redshift integration with AWS Lambda provides the capability to create Amazon Redshift Lambda user-defined functions (UDFs). This capability delivers flexibility, enhanced integrations, and security for functions defined in Lambda that can be run through SQL queries. Amazon Redshift Lambda UDFs offer many advantages:
- Enhanced integration – You can connect to external services or APIs from within your UDF logic, enabling richer data enrichment and operational workflows.
- Multiple Python runtimes – Lambda UDFs benefit from Lambda function support for multiple Python runtimes depending on specific use cases. In addition, the new versions and security patches are available within a month of their official release.
- Independent scaling – Lambda UDFs use Lambda compute resources, so heavy compute or memory-intensive tasks don’t impact query performance or resource concurrency within Amazon Redshift.
- Isolation and security – You can isolate custom code execution in a separate service boundary. This simplifies maintenance, monitoring, budgeting, and permission management.
Because Lambda UDFs provide these significant advantages in integration, flexibility, scalability, and security, we will be ending support for Python UDFs in Amazon Redshift. We recommend that you migrate your existing Python UDFs to Lambda UDFs by June 30, 2026.
- October 30, 2025 – Creation of new Python UDFs will no longer be supported (existing functions can still be invoked)
- June 30, 2026 – Execution of existing Python UDFs will be suspended
In this post, we walk you through how to migrate your existing Python UDFs to Lambda UDFs, set up monitoring and cost evaluations, and review key considerations for a smooth transition.
Solution overview
You can create UDFs for tasks such as tokenization, encryption and decryption, or data science functionality like the Levenshtein distance calculation. For this post, we provide examples for customers who have Python UDFs in place, demonstrating how to replace them with Lambda UDFs.
The Levenshtein function, also known as the Levenshtein distance or edit distance, is a string metric used to measure the difference between two sequences of characters. Although this functionality was previously implemented using Python UDFs using the Python library in Amazon Redshift, Lambda provides a more efficient and scalable solution. This post demonstrates how to migrate from Python UDFs to Lambda UDFs for calculating Levenshtein distances.
Prerequisites
You must have the following:
- An AWS account.
- One of the following resources, depending on your use case:
- A Redshift cluster if you are using Amazon Redshift Provisioned. For instructions, refer to Create a sample Amazon Redshift cluster.
- A Redshift workgroup if you are using Amazon Redshift Serverless. For instructions, refer to Create a workgroup with a namespace.
- An AWS Identity and Access Management (IAM) role that is able to ingest data from Amazon Simple Storage Service (Amazon S3) to Amazon Redshift. Set the IAM role as the default for Amazon Redshift.
- Permissions to create Lambda functions and access Amazon CloudWatch.
Prepare the data
To set up our use case, complete the following steps:
- On the Amazon Redshift console, choose Query editor v2 under Explorer in the navigation pane.
- Connect to your Redshift data warehouse.
- Create a table and load data. The following query loads 30,000,000 rows in the
customertable:
Identify existing Python UDFs
Run the following script to list existing Python UDFs:
The following is our existing Python UDF definition for Levenshtein distance:
Convert the Python UDF function to a Lambda UDF
You can simplify converting your Python UDF to a Lambda UDF using Amazon Q Developer, a generative AI-powered assistant. It handles code transformation, packaging, and integration logic, accelerating migration and improving scalability. Integrated with popular developer tools like VS Code, JetBrains, and others, Amazon Q streamlines workflows so teams can modernize analytics using serverless architectures with minimal effort.
Amazon Q Developer code suggestions are based on large language models (LLMs) trained on billions of lines of code, including open source and Amazon code. Always review a code suggestion before accepting it, and you might need to edit it to make sure that it does exactly what you intended.
Create a Lambda function
Complete the following steps to create a Lambda function:
- On the Lambda console, choose Functions in the navigation pane.
- Choose Create function.
- Choose Author from scratch.
- For Function name, enter a custom name (for example,
levenshtein_distance_func). - For Runtime, choose your code environment. (The examples in this post are compatible with Python 3.12.)
- For Architecture, select your system architecture. (The examples in this post are compatible with x86_64.)

- For Execution role, select Create a new role with basic Lambda permissions.

- Choose Create function.
- Choose Code and add the following code:
- Choose configuration and update Timeout to 1 minute.
You can modify memory to optimize performance. To learn more, see Optimizing Levenshtein User-Defined Function in Amazon Redshift.

Create an Amazon Redshift IAM role
To allow your Amazon Redshift cluster to invoke the Lambda function, you must set up proper IAM permissions. Complete the following steps:
- Identify the IAM role associated with your Amazon Redshift cluster. If you don’t have one, create a new IAM role for Amazon Redshift.
- Add the following IAM policy to this role, providing your AWS Region and AWS account number:
Create a Lambda UDF
Run following script to create your Lambda UDF:
Test the solution
To test the solution, run the following script using the Python UDF:
The following table shows our output.

Run the same script using the Lambda UDF:

The results of both UDFs match.
Replace the Python UDF with the Lambda UDF
You can use the following steps in preproduction for testing:
- Revoke access for the Python UDF:
- Grant access to the Lambda UDF:
- After full testing of the Lambda UDF has been performed, you can drop the Python UDF.
- Rename the Lambda UDF
fn_lambda_levenshtein_distancetofn_levenshtein_distanceso the end-user and application code doesn’t need to change:
- Validate with the following query:
Cost evaluation
To evaluate the cost of the Lambda UDF, complete the following steps:
- Run the following script to create a table using a SELECT query, which uses the Lambda UDF:
You can inspect the query logs using CloudWatch Log Insights.
- On the CloudWatch console, choose Logs in the navigation pane, then choose Log Insights.
- Filter by the Lambda UDF and use the following query to identify the number of Lambda invocations.

- Use following query to find the cost of the Lambda UDF for the specific duration you selected:
For this example, we used the us-east-1 Region using ARM-based instances. For more details on Lambda pricing by Region and the Free Tier limit, see AWS Lambda pricing.
- Choose Summarize results.
The cost of this Lambda UDF invocation was $0.02329 for 30 million rows.

Monitor Lambda UDFs
Monitoring Lambda UDFs involves tracking both the Lambda function’s performance and the impact on the Redshift query execution. Because UDFs execute externally, a dual approach is necessary.
CloudWatch metrics and logs for Lambda functions
CloudWatch provides comprehensive monitoring for Lambda functions, such as the following key metrics:
- Invocations – Tracks the number of times the Lambda function is called, indicating UDF usage frequency
- Duration – Measures execution time, helping identify performance bottlenecks
- Errors – Counts failed invocations, which is critical for detecting issues in UDF logic
- Throttles – Indicates when Lambda limits invocations due to concurrency caps, which can delay query results
- Logs – CloudWatch Logs capture detailed execution output, including errors and custom log messages, aiding in debugging
- Alarms – Configures alarms for high error rates (for example, Errors > 0) or excessive duration (for example, Duration > 1 second) to receive proactive notifications
Redshift query performance
Within Amazon Redshift, system views provide comprehensive insights into Lambda UDF performance and errors:
- SYS_QUERY_HISTORY – Identifies queries that have called your Lambda UDFs by filtering with the UDF name in the
query_textcolumn. This helps track usage patterns and execution frequency. - SYS_QUERY_DETAIL – Provides granular execution metrics for queries involving Lambda UDFs, helping identify performance bottlenecks at the step level.
- Performance aggregation – Generates summary reports of Lambda UDF performance metrics, including execution count, average duration, and maximum duration to track performance trends over time.
The following table summarizes the monitoring tools available.
| Monitoring Tool | Purpose | Key Metrics/Views |
| CloudWatch Metrics | Track Lambda function performance | Invocations, Duration, Errors, Throttles |
| CloudWatch Logs | Debug Lambda execution issues | Error messages, custom logs |
| SYS_QUERY_HISTORY | Track Lambda UDF usage patterns | Query execution times, status, user information, query text |
| SYS_QUERY_DETAIL | Analyze Lambda UDF performance | Step-level execution details, resource utilization, query plan information |
| Performance Summary Reports | Track UDF performance trends | Execution count, average/maximum duration, total elapsed time |
Monitoring approach for Lambda UDFs in Amazon Redshift
For analyzing individual queries, you can use the following code to track how your Lambda UDFs are being used across your organization:
This helps you do the following:
- Identify frequent users
- Monitor execution patterns
- Track usage trends
- Detect unauthorized access
You can also create comprehensive monitoring by using query history to monitor performance metrics at the user level:
Additionally, you can generate weekly performance reports using the following aggregation query:
Considerations
To maximize the benefits of Lambda UDFs, consider the following aspects to optimize performance, provide reliability, secure data, and manage costs. If you have Python UDFs that don’t use Python libraries, consider whether they are candidates to convert to SQL UDFs.
The following are key performance considerations:
- Batching – Amazon Redshift batches multiple rows into a single Lambda invocation to reduce call frequency, improving efficiency. Make sure the Lambda function handles batched inputs efficiently. For more details, see Accessing external components using Amazon Redshift Lambda UDFs.
- Parallel invocations – Redshift cluster slices invoke Lambda functions in parallel, enhancing performance for large datasets. Design functions to support concurrent executions.
- Cold starts – Lambda functions might experience cold start delays, particularly if infrequently used. Languages like Python or Node.js typically have faster startup times than Java, reducing latency.
- Function optimization – Optimize Lambda code for quick execution, minimizing resource usage and latency. For example, avoid unnecessary computations or external API calls.
Consider the following error handling methods:
- Robust lambda logic – Implement comprehensive error handling in the Lambda function to manage exceptions gracefully. Return clear error messages in the JSON response, as specified in the Amazon Redshift-Lambda interface. For more details, see Scalar Lambda UDFs.
- Error propagation – Lambda errors can cause Redshift query failures. Monitor
SYS_QUERY_HISTORYfor query-level issues and CloudWatch Logs for detailed Lambda errors. - JSON interface – The Lambda function must return a JSON object with
success,error_msg,num_records, andresultsfields. Use proper formatting to avoid query disruptions.
Clean up
Complete the following steps to clean up your resources:
- Delete the Redshift provisioned or serverless endpoint.
- Delete the Lambda function.
- Delete the IAM roles you created.
Conclusion
Lambda UDFs unlock a new level of flexibility, performance, and maintainability for extending Amazon Redshift. By decoupling custom logic from the warehouse engine, teams can scale independently, adopt modern runtimes, and integrate external systems.
If you’re currently using Python UDFs in Amazon Redshift, it’s time to explore the benefits of migrating to Lambda UDFs. With the generative AI capabilities of Amazon Q Developer, you can automate much of this transformation and accelerate your modernization journey. To learn more, refer to the Lambda UDF examples GitHub repo and Data Tokenization with Amazon Redshift and Protegrity.
About the authors
 Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family.
Raks Khare is a Senior Analytics Specialist Solutions Architect at AWS based out of Pennsylvania. He helps customers across varying industries and regions architect data analytics solutions at scale on the AWS platform. Outside of work, he likes exploring new travel and food destinations and spending quality time with his family.
 Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
 Yanzhu Ji is a Product Manager in the Amazon Redshift team. She has experience in product vision and strategy in industry-leading data products and platforms. She has outstanding skill in building substantial software products using web development, system design, database, and distributed programming techniques. In her personal life, Yanzhu likes painting, photography, and playing tennis.
Yanzhu Ji is a Product Manager in the Amazon Redshift team. She has experience in product vision and strategy in industry-leading data products and platforms. She has outstanding skill in building substantial software products using web development, system design, database, and distributed programming techniques. In her personal life, Yanzhu likes painting, photography, and playing tennis.
 Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.
Harshida Patel is a Analytics Specialist Principal Solutions Architect, with AWS.








 Jyoti Aggarwal is a Product Management Lead for AWS zero-ETL. She leads the product and business strategy, including driving initiatives around performance, customer experience, and security. She brings along an expertise in cloud compute, data pipelines, analytics, artificial intelligence (AI), and data services including databases, data warehouses and data lakes.
Jyoti Aggarwal is a Product Management Lead for AWS zero-ETL. She leads the product and business strategy, including driving initiatives around performance, customer experience, and security. She brings along an expertise in cloud compute, data pipelines, analytics, artificial intelligence (AI), and data services including databases, data warehouses and data lakes. Gopal Paliwal is a Principal Engineer for Amazon Redshift, leading the software development of ZeroETL initiatives for Amazon Redshift.
Gopal Paliwal is a Principal Engineer for Amazon Redshift, leading the software development of ZeroETL initiatives for Amazon Redshift. Harman Nagra is a Principal Solutions Architect at AWS, based in San Francisco. He works with global financial services organizations to design, develop, and optimize their workloads on AWS.
Harman Nagra is a Principal Solutions Architect at AWS, based in San Francisco. He works with global financial services organizations to design, develop, and optimize their workloads on AWS. Sumanth Punyamurthula is a Senior Data and Analytics Architect at Amazon Web Services with more than 20 years of experience in leading large analytical initiatives, including analytics, data warehouse, data lakes, data governance, security, and cloud infrastructure across travel, hospitality, financial, and healthcare industries.
Sumanth Punyamurthula is a Senior Data and Analytics Architect at Amazon Web Services with more than 20 years of experience in leading large analytical initiatives, including analytics, data warehouse, data lakes, data governance, security, and cloud infrastructure across travel, hospitality, financial, and healthcare industries.

 Poulomi Dasgupta is a Senior Analytics Solutions Architect with AWS. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems. Outside of work, she likes travelling and spending time with her family.
Poulomi Dasgupta is a Senior Analytics Solutions Architect with AWS. She is passionate about helping customers build cloud-based analytics solutions to solve their business problems. Outside of work, she likes travelling and spending time with her family. Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.
Saurav Das is part of the Amazon Redshift Product Management team. He has more than 16 years of experience in working with relational databases technologies and data protection. He has a deep interest in solving customer challenges centered around high availability and disaster recovery.

























 Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking. Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture. Enrico Siragusa is a Senior Software Development Engineer at Amazon Redshift. He contributed to query processing and materialized views. Enrico holds a M.Sc. in Computer Science from the University of Paris-Est and a Ph.D. in Bioinformatics from the International Max Planck Research School in Computational Biology and Scientific Computing in Berlin.
Enrico Siragusa is a Senior Software Development Engineer at Amazon Redshift. He contributed to query processing and materialized views. Enrico holds a M.Sc. in Computer Science from the University of Paris-Est and a Ph.D. in Bioinformatics from the International Max Planck Research School in Computational Biology and Scientific Computing in Berlin.






















 Blessing Bamiduro is part of the Amazon Redshift Product Management team. She works with customers to help explore the use of Amazon Redshift ML in their data warehouse. In her spare time, Blessing loves travels and adventures.
Blessing Bamiduro is part of the Amazon Redshift Product Management team. She works with customers to help explore the use of Amazon Redshift ML in their data warehouse. In her spare time, Blessing loves travels and adventures.









































 Juan Luis Polo Garzon is an Associate Specialist Solutions Architect at AWS, specialized in analytics workloads. He has experience helping customers design, build and modernize their cloud-based analytics solutions. Outside of work, he enjoys travelling, outdoors and hiking, and attending to live music events.
Juan Luis Polo Garzon is an Associate Specialist Solutions Architect at AWS, specialized in analytics workloads. He has experience helping customers design, build and modernize their cloud-based analytics solutions. Outside of work, he enjoys travelling, outdoors and hiking, and attending to live music events. Sushmita Barthakur is a Senior Solutions Architect at Amazon Web Services, supporting Enterprise customers architect their workloads on AWS. With a strong background in Data Analytics and Data Management, she has extensive experience helping customers architect and build Business Intelligence and Analytics Solutions, both on-premises and the cloud. Sushmita is based out of Tampa, FL and enjoys traveling, reading and playing tennis.
Sushmita Barthakur is a Senior Solutions Architect at Amazon Web Services, supporting Enterprise customers architect their workloads on AWS. With a strong background in Data Analytics and Data Management, she has extensive experience helping customers architect and build Business Intelligence and Analytics Solutions, both on-premises and the cloud. Sushmita is based out of Tampa, FL and enjoys traveling, reading and playing tennis.












 Erol Murtezaoglu, a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems, in order to deliver solutions that exceed expectations.
Erol Murtezaoglu, a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems, in order to deliver solutions that exceed expectations. Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She has over 18 years of experience in data and analytics. She is passionate about telling stories with data and enjoys creating engaging visuals to unearth actionable insights.
Sapna Maheshwari is a Sr. Solutions Architect at Amazon Web Services. She has over 18 years of experience in data and analytics. She is passionate about telling stories with data and enjoys creating engaging visuals to unearth actionable insights. Karthik Ramanathan is a Software Engineer with Amazon Redshift and is based in San Francisco. He brings close to two decades of development experience across the networking, data storage and IoT verticals. When not at work he is also a writer and loves to be in the water.
Karthik Ramanathan is a Software Engineer with Amazon Redshift and is based in San Francisco. He brings close to two decades of development experience across the networking, data storage and IoT verticals. When not at work he is also a writer and loves to be in the water. Albert Harkema is a Software Development Engineer at AWS. He is known for his curiosity and deep-seated desire to understand the inner workings of complex systems. His inquisitive nature drives him to develop software solutions that make life easier for others. Albert’s approach to problem-solving emphasizes efficiency, reliability, and long-term stability, ensuring that his work has a tangible impact. Through his professional experiences, he has discovered the potential of technology to improve everyday life.
Albert Harkema is a Software Development Engineer at AWS. He is known for his curiosity and deep-seated desire to understand the inner workings of complex systems. His inquisitive nature drives him to develop software solutions that make life easier for others. Albert’s approach to problem-solving emphasizes efficiency, reliability, and long-term stability, ensuring that his work has a tangible impact. Through his professional experiences, he has discovered the potential of technology to improve everyday life.




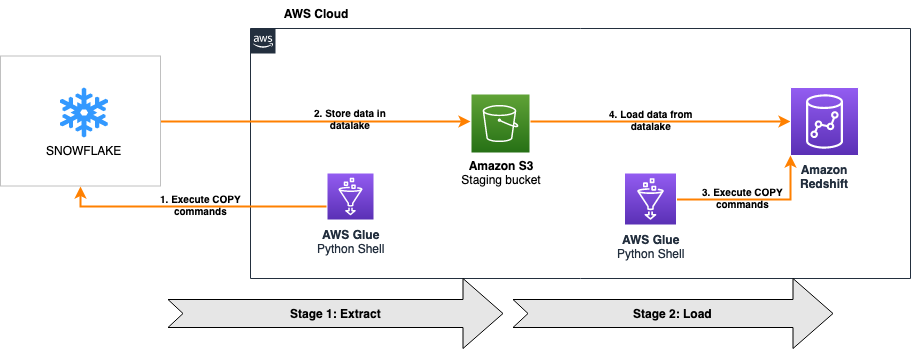
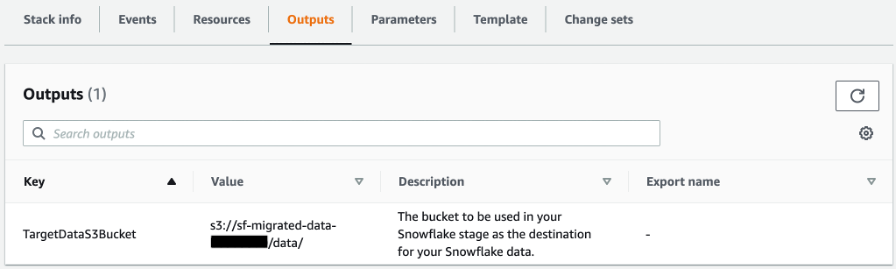
 You can also automate the preceding COPY commands using tasks, which can be scheduled to run at a set frequency for automatic copy of CDC data from Snowflake to Amazon S3.
You can also automate the preceding COPY commands using tasks, which can be scheduled to run at a set frequency for automatic copy of CDC data from Snowflake to Amazon S3. Now the tasks will run every 5 minutes and look for new data in the stream tables to offload to Amazon S3.As soon as data is migrated from Snowflake to Amazon S3, Redshift Auto Loader automatically infers the schema and instantly creates corresponding tables in Amazon Redshift. Then, by default, it starts loading data from Amazon S3 to Amazon Redshift every 5 minutes. You can also
Now the tasks will run every 5 minutes and look for new data in the stream tables to offload to Amazon S3.As soon as data is migrated from Snowflake to Amazon S3, Redshift Auto Loader automatically infers the schema and instantly creates corresponding tables in Amazon Redshift. Then, by default, it starts loading data from Amazon S3 to Amazon Redshift every 5 minutes. You can also