Post Syndicated from Sai Parthasaradhi original https://aws.amazon.com/blogs/architecture/disaster-recovery-approaches-for-db2-databases-on-aws/
As you migrate your critical enterprise workloads from an IBM Db2 on-premises database to the AWS Cloud, it’s critical to have a reliable and effective disaster recovery (DR) strategy. This helps the database applications operate with little or no disruption from unexpected events like a natural disaster.
Recovery point objective (RPO), recovery time objective (RTO), and cost, are three key metrics to consider when developing your DR strategy, (see Figure 1.) Based on these metrics, you can define your DR strategy for Db2 databases on AWS. It can be either an on-demand backup restore approach or nearly continuous replication method.

Figure 1. Disaster recovery strategies
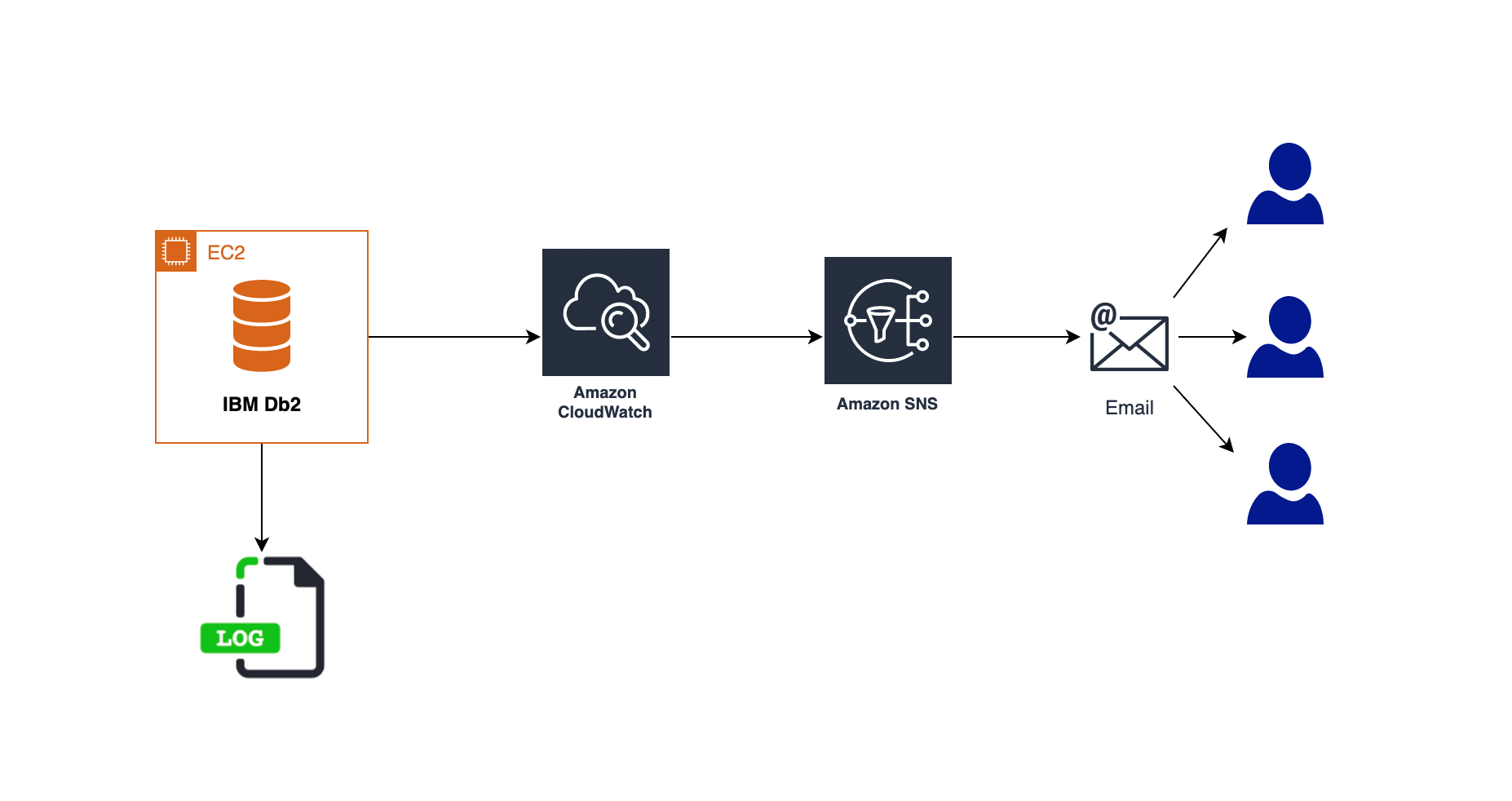
In this post, we show an overview of active/passive cross-Region disaster recovery options for the Db2 database on Amazon Elastic Compute Cloud (Amazon EC2). This solution uses native Db2 features and AWS services such as Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), and Amazon VPC Peering connection.
Approach 1: Db2 log shipping
In this approach, the transactional log files produced by the primary database are made available to the standby database via a log archive location. The transaction logs from the archive location can be replayed on the standby database by manually applying the Rollforward command, or by setting up user exit programs.
We can use Amazon S3 or Amazon EFS as the log archive location to share the logs with the standby database hosted in a secondary AWS Region.
Using Amazon S3:
Starting Db2 11.5.7, we can specify DB2REMOTE Amazon S3 storage for LOGARCHMETH1 and LOGARCHMETH2 database log archive method configuration parameters. This enables us to archive/retrieve transaction logs to/from Amazon S3.
In Figure 2, we enable Amazon S3 Cross-Region Replication (CRR) between the S3 buckets in the primary and the DR AWS Regions. This permits the transaction logs to be replicated into the S3 bucket in the DR Region.
We set up an AWS Lambda function to tell AWS Systems Manager (SSM) to run a command document. This document runs a bash script containing Rollforward command on the standby database instance. The Lambda function can be invoked based on the S3 bucket events in the DR Region.

Figure 2. Db2 log shipping using S3 Cross-Region Replication
This approach works as follows:
- The transactions are committed and the active transaction log files gets closed on the primary database. It then marks the log file as ready for archive into the destination (the S3 bucket.)
- The database asynchronously archives the log files into the S3 bucket archive location in the primary Region. This gets replicated to the S3 bucket in the DR Region.
- This S3 event in the DR Region will initiate an AWS Lambda function to apply the Rollforward database operation on the standby database.
- Db2 pulls the logs from the S3 bucket in the DR Region and applies them to the standby database.
- When the primary Region is unavailable, initiate failover manually or by using scripts on the standby database. Use the Rollforward command so that the database can replay up to the end of logs and stop and be ready to accept client connections.
Using Amazon EFS:
In this approach, we configure the database parameter LOGARCHMETH1 with Amazon EFS as an archive location for transaction logs using the DISK option. It will push the transaction logs to a directory on Amazon EFS.
As shown in Figure 3, we configure a Replication for Amazon EFS to automatically replicate the database archive logs to the EFS in the DR Region. This can be mounted on the standby database.

Figure 3. Db2 log shipping using Amazon EFS replication
This approach replicates transaction logs to EFS. We can schedule a script for every few minutes that runs the Rollforward command to replay the logs on the standby database.
Alternatively, we can use the user exit programs provided along with the Db2 installation. This automatically applies the logs with the log archive method LOGARCHMETH1 with the parameter value set to USEREXIT.
This approach has the following advantages:
- Straightforward setup, with minimal database configurations.
- This can be a DR option for multi-partitioned database environments or environments where federation is set up with two-phase commit for federated transactions.
- Bulk load operations on the primary database can be replayed on standby by sharing the load image using EFS.
- Rollforward operation progress can be checked on standby using monitoring commands.
Limitations of this approach are as follows:
- We cannot connect to the standby database to offload read-only workloads as the database will be in Rollforward recovery mode.
- We must write custom scripts like Lambda, user exit programs, or bash scripts to replay the logs on the standby database.
- Non-logged operations, such as database configuration parameters or nonrecoverable bulk data loads, are not replayed on standby database.
- Automated failover to standby is not possible.
Approach 2: Db2 highly available and disaster recovery (HADR) auxiliary standby
In this approach, we set up Db2 Highly Available and Disaster Recovery (HADR) to deploy an auxiliary Db2 standby database in a secondary or DR AWS Region.
The architecture for this approach is shown in Figure 4, and works as follows:
- We establish TCP/IP connectivity between the primary and auxiliary Db2 standby database using Amazon VPC Peering connection.
- Any transaction written on the primary Db2 database is committed without waiting for replication onto the auxiliary standby database.
- Replicated transactions are replayed on the auxiliary standby database, which connects with the primary database in a remote catchup state.
- When the primary AWS Region is unavailable, promote standby database to primary using the takeover commands manually.

Figure 4. Db2 HADR with auxiliary standby database
This approach has the following advantages:
- The replication is handled by the database automatically without the need for custom scripts.
- We can enable reads on standby to offload read-only workload, such as reporting from the primary database to stand by. This will reduce the load on the primary database.
- Key metrics such as replication lag, connection status, and errors can be monitored from the primary database.
Limitations of this approach are as follows:
- Non-logged operations, such as database configuration parameters or nonrecoverable bulk data loads are not replayed on the standby database.
- This approach is not supported in a multi-partitioned database environment or two phase commit federated transactions.
- Automated failover to standby is not possible.
- There are various other restrictions, which must be evaluated.
Conclusion
In this post, we discussed how to set up a disaster recovery Db2 database using database native features and AWS services. We discussed the advantages and restrictions for each. You can use this post as a reference for setting up the right disaster recovery approach for your database to minimize data loss and maintain business continuity. Let us know your comments, we always love your feedback!
For further reading: