Post Syndicated from Swami Sivasubramanian original https://aws.amazon.com/blogs/big-data/realizing-near-real-time-analytics-with-a-zero-etl-future/
Data is at the center of every application, process, and business decision. When data is used to improve customer experiences and drive innovation, it can lead to business growth. According to Forrester, advanced insights-driven businesses are 8.5 times more likely than beginners to report at least 20% revenue growth. However, to realize this growth, managing and preparing the data for analysis has to get easier.
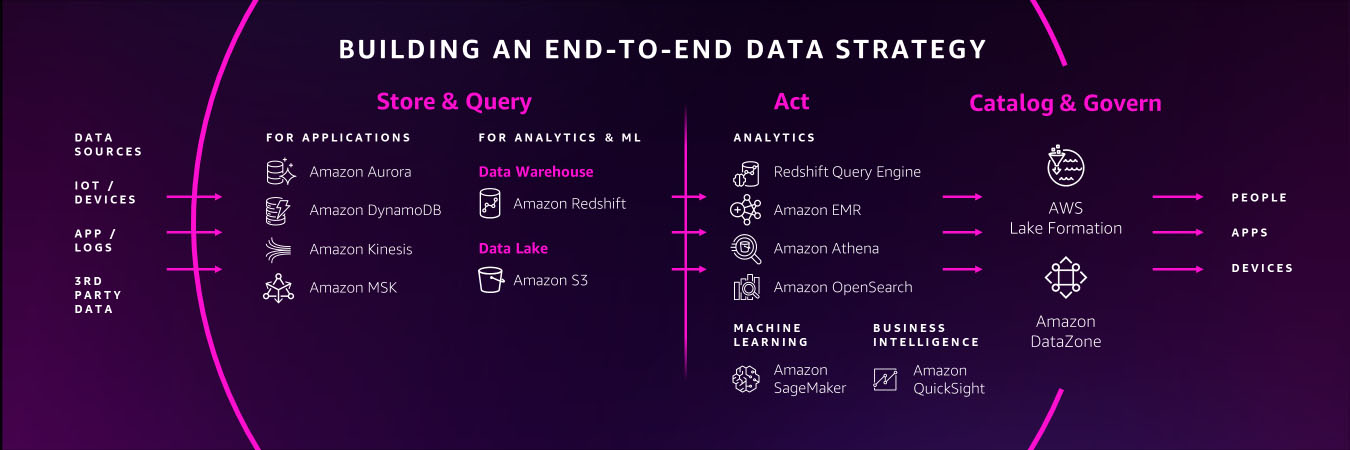
That’s why AWS is investing in a zero-ETL future so that builders can focus more on creating value from data, instead of preparing data for analysis.
Challenges with ETL
What is ETL? Extract, Transform, Load is the process data engineers use to combine data from different sources. ETL can be challenging, time-consuming, and costly. Firstly, it invariably requires data engineers to create custom code. Next, DevOps engineers have to deploy and manage the infrastructure to make sure the pipelines scale with the workload. In case the data sources change, data engineers have to manually make changes in their code and deploy it again. While all of this is happening—a process that can take days—data analysts can’t run interactive analysis or build dashboards, data scientists can’t build machine learning (ML) models or run predictions, and end-users can’t make data-driven decisions.
Furthermore, the time required to build or change pipelines makes the data unfit for near-real-time use cases such as detecting fraudulent transactions, placing online ads, and tracking passenger train schedules. In these scenarios, the opportunity to improve customer experiences, address new business opportunities, or lower business risks can simply be lost.
On the flip side, when organizations can quickly and seamlessly integrate data that is stored and analyzed in different tools and systems, they get a better understanding of their customers and business. As a result, they can make data-driven predictions with more confidence, improve customer experiences, and promote data-driven insights across the business.
AWS is bringing its zero-ETL vision to life
We have been making steady progress towards bringing our zero-ETL vision to life. For example, customers told us that they want to ingest streaming data into their data stores for doing analytics—all without delving into the complexities of ETL.
With Amazon Redshift Streaming Ingestion, organizations can configure Amazon Redshift to directly ingest high-throughput streaming data from Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis Data Streams and make it available for near-real-time analytics in just a few seconds. They can connect to multiple data streams and pull data directly into Amazon Redshift without staging it in Amazon Simple Storage Service (Amazon S3). After running analytics, the insights can be made available broadly across the organization with Amazon QuickSight, a cloud-native, serverless business intelligence service. QuickSight makes it incredibly simple and intuitive to get to answers with Amazon QuickSight Q, which allows users to ask business questions about their data in natural language and receive answers quickly through data visualizations.
Another example of AWS’s investment in zero-ETL is providing the ability to query a variety of data sources without having to worry about data movement. Using federated query in Amazon Redshift and Amazon Athena, organizations can run queries across data stored in their operational databases, data warehouses, and data lakes so that they can create insights from across multiple data sources with no data movement. Data analysts and data engineers can use familiar SQL commands to join data across several data sources for quick analysis, and store the results in Amazon S3 for subsequent use. This provides a flexible way to ingest data while avoiding complex ETL pipelines.
More recently, AWS introduced Amazon Aurora zero-ETL integration with Amazon Redshift at AWS re:Invent 2022. Check out the following video:
We learned from customers that they spend significant time and resources building and managing ETL pipelines between transactional databases and data warehouses. For example, let’s say a global manufacturing company with factories in a dozen countries uses a cluster of Aurora databases to store order and inventory data in each of those countries. When the company executives want to view all of the orders and inventory, the data engineers would have to build individual data pipelines from each of the Aurora clusters to a central data warehouse so that the data analysts can query the combined dataset. To do this, the data integration team has to write code to connect to 12 different clusters and manage and test 12 production pipelines. After the team deploys the code, it has to constantly monitor and scale the pipelines to optimize performance, and when anything changes, they have to make updates across 12 different places. It is quite a lot of repetitive work.
No more need for custom ETL pipelines between Aurora and Amazon Redshift
The Aurora zero-ETL integration with Amazon Redshift brings together the transactional data of Aurora with the analytics capabilities of Amazon Redshift. It minimizes the work of building and managing custom ETL pipelines between Aurora and Amazon Redshift. Unlike the traditional systems where data is siloed in one database and the user has to make a trade-off between unified analysis and performance, data engineers can replicate data from multiple Aurora database clusters into the same or new Amazon Redshift instance to derive holistic insights across many applications or partitions. Updates in Aurora are automatically and continuously propagated to Amazon Redshift so the data engineers have the most recent information in near-real time. The entire system can be serverless and dynamically scales up and down based on data volume, so there’s no infrastructure to manage. Now, organizations get the best of both worlds—fast, scalable transactions in Aurora together with fast, scalable analytics in Amazon Redshift—all in one seamless system. With near-real-time access to transactional data, organizations can leverage Amazon Redshift’s analytics and capabilities such as built-in ML, materialized views, data sharing, and federated access to multiple data stores and data lakes to derive insights from transactional and other data.
Improving the zero-ETL performance is a continuous goal for AWS. For instance, one of our early zero-ETL preview customers observed that the hundreds of thousands of transactions produced every minute from their Amazon Aurora MySQL databases appeared in less than 10 seconds into their Amazon Redshift warehouse. Previously, they had more than a 2-hour delay moving data from their ETL pipeline into Amazon Redshift. With the zero-ETL integration between Aurora and Redshift, they are now able to achieve near-real time analytics.
This integration is now available in Public Preview. To learn more, refer to Getting started guide for near-real-time analytics using Amazon Aurora zero-ETL integration with Amazon Redshift.
Zero-ETL makes data available to data engineers at the point of use through direct integrations between services and direct querying across a variety of data stores. This frees the data engineers to focus on creating value from the data, instead of spending time and resources building pipelines. AWS will continue investing in its zero-ETL vision so that organizations can accelerate their use of data to drive business growth.
About the Author
 Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.
Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.



 Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.
Herain Oberoi leads Product Marketing for AWS’s Databases, Analytics, BI, and Blockchain services. His team is responsible for helping customers learn about, adopt, and successfully use AWS services. Prior to AWS, he held various product management and marketing leadership roles at Microsoft and a successful startup that was later acquired by BEA Systems. When he’s not working, he enjoys spending time with his family, gardening, and exercising.