Post Syndicated from Monika Singh original https://blog.cloudflare.com/alerts-observability

Many people have probably come across the ‘this is fine’ meme or the original comic. This is what a typical day for a lot of on-call personnel looks like. On-calls get a lot of alerts, and dealing with too many alerts can result in alert fatigue – a feeling of exhaustion caused by responding to alerts that lack priority or clear actions. Ensuring the alerts are actionable and accurate, not false positives, is crucial because repeated false alarms can desensitize on-call personnel. To this end, within Cloudflare, numerous teams conduct periodic alert analysis, with each team developing its own dashboards for reporting. As members of the Observability team, we’ve encountered situations where teams reported inaccuracies in alerts or instances where alerts failed to trigger, as well as provided assistance in dealing with noisy/flapping alerts.
Observability aims to enhance insight into the technology stack by gathering and analyzing a broader spectrum of data. In this blog post, we delve into alert observability, discussing its importance and Cloudflare’s approach to achieving it. We’ll also explore how we overcome shortcomings in alert reporting within our architecture to simplify troubleshooting using open-source tools and best practices. Join us to understand how we use alerts effectively and use simple tools and practices to enhance our alerts observability, resilience, and on-call personnel health.

Being on-call can disrupt sleep patterns, impact social life, and hinder leisure activities, potentially leading to burnout. While burnout can be caused by several factors, one contributing factor can be excessively noisy alerts or receiving alerts that are neither important nor actionable. Analyzing alerts can help mitigate the risk of such burnout by reducing unnecessary interruptions and improving the overall efficiency of the on-call process. It involves periodic review and feedback to the system for improving alert quality. Unfortunately, only some companies or teams do alert analysis, even though it is essential information that every on-call or manager should have access to.
Alert analysis is useful for on-call personnel, enabling them to easily see which alerts have fired during their shift to help draft handover notes and not miss anything important. In addition, managers can generate reports from these stats to see the improvements over time, as well as helping assess on-call vulnerability to burnout. Alert analysis also helps with writing incident reports, to see if alerts were fired, or to determine when an incident started.
Let’s first understand the alerting stack and how we used open-source tools to gain greater visibility into it, which allowed us to analyze and optimize its effectiveness.
Prometheus architecture at Cloudflare
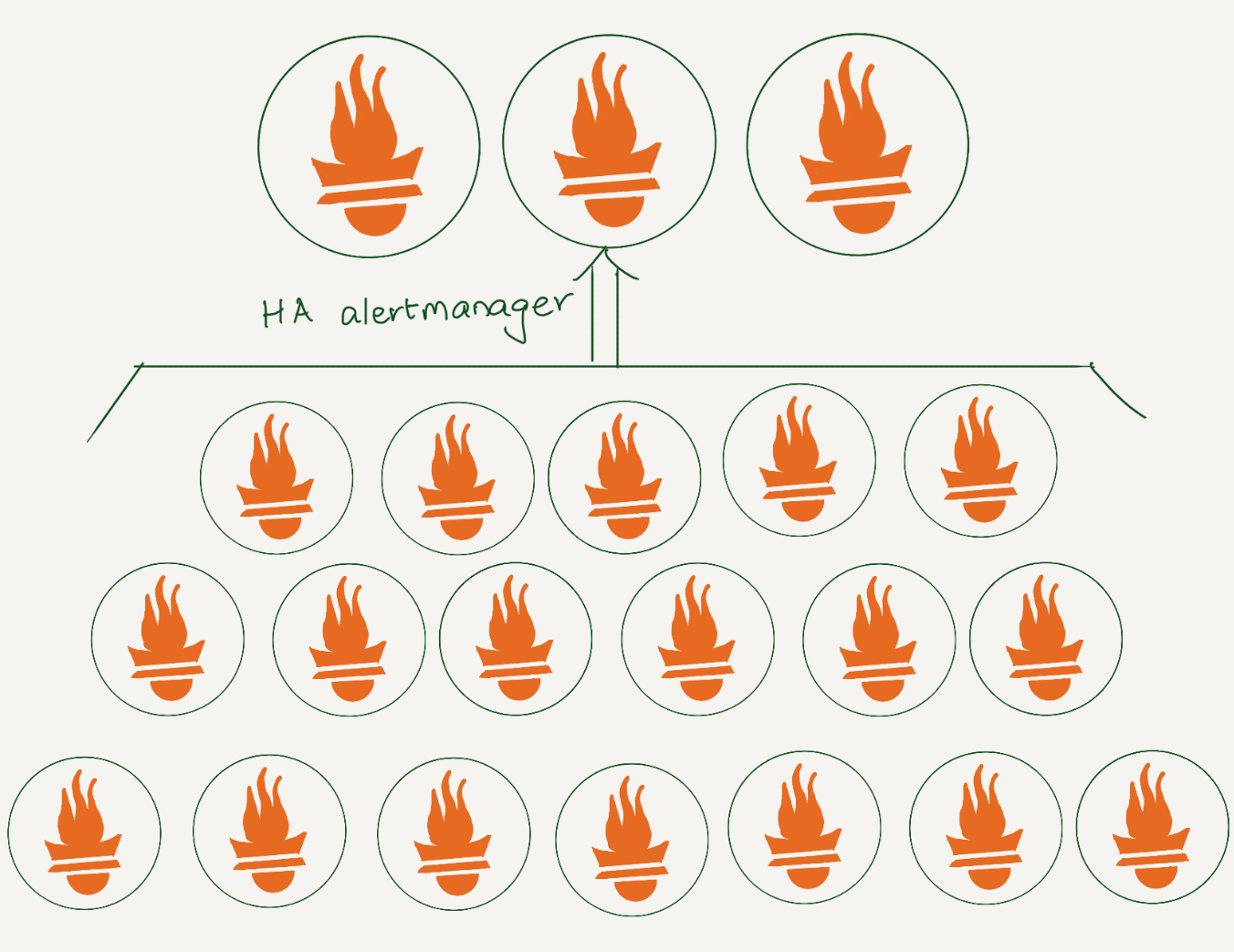
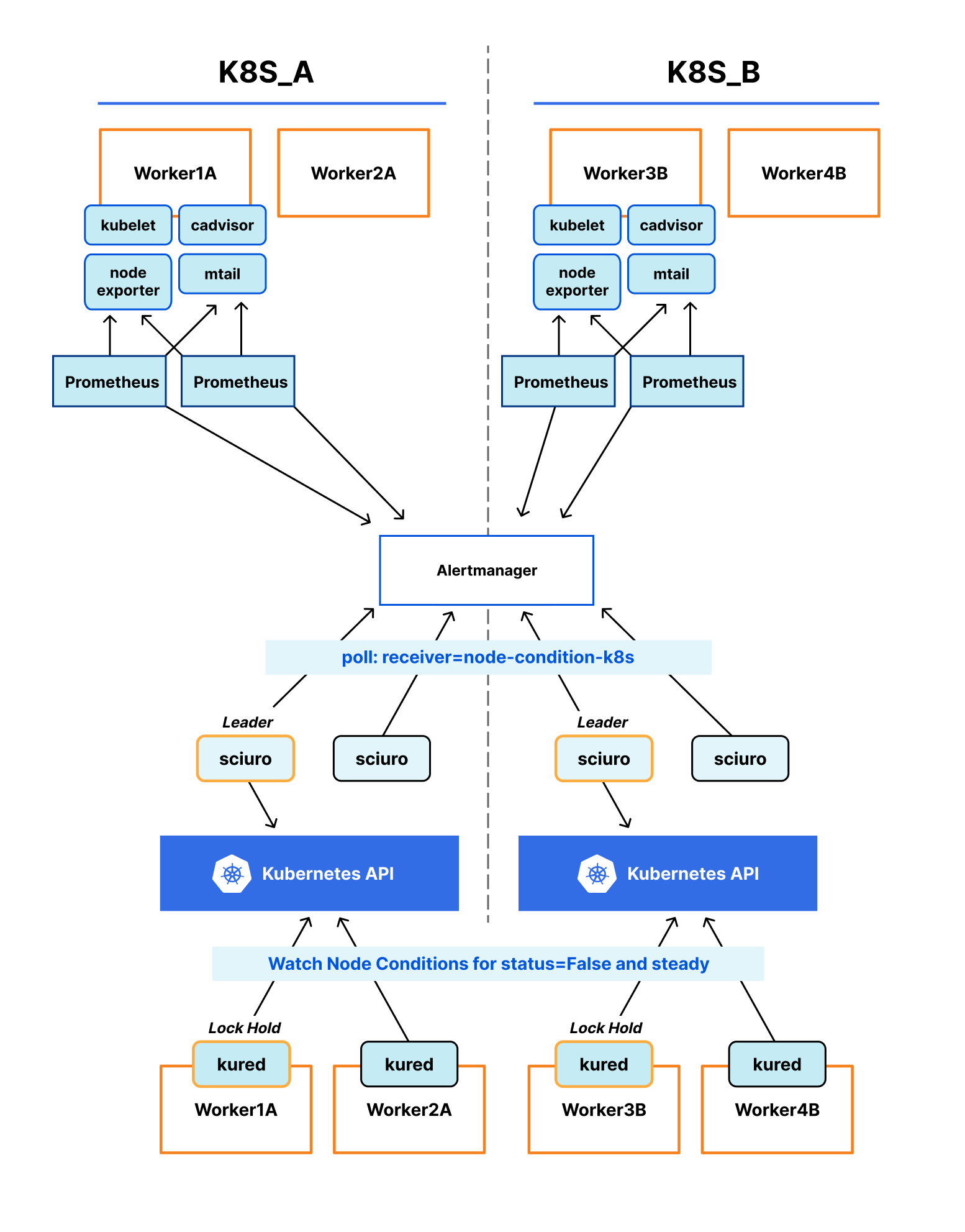
At Cloudflare, we rely heavily on Prometheus for monitoring. We have data centers in more than 310 cities, and each has several Prometheis. In total, we have over 1100 Prometheus servers. All alerts are sent to a central Alertmanager, where we have various integrations to route them. Additionally, using an alertmanager webhook, we store all alerts in a datastore for analysis.
Lifecycle of an alert
Prometheus collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when the alerting conditions are met. Once an alert goes into firing state, it will be sent to the alertmanager.
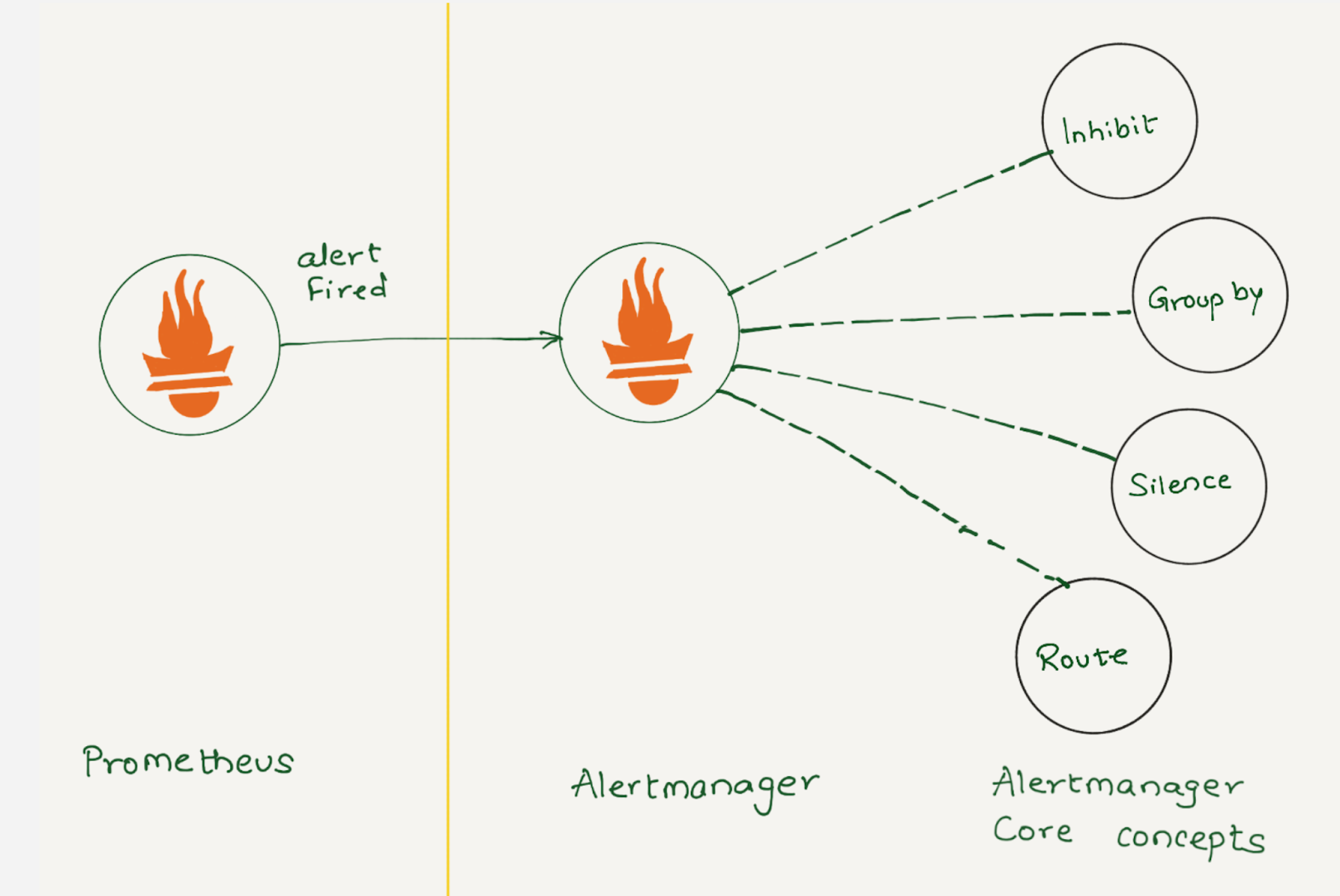
Depending on the configuration, once Alertmanager receives an alert, it can inhibit, group, silence, or route the alerts to the correct receiver integration, such as chat, PagerDuty, or ticketing system. When configured properly, Alertmanager can mitigate a lot of alert noise. Unfortunately, that is not the case all the time, as not all alerts are optimally configured.
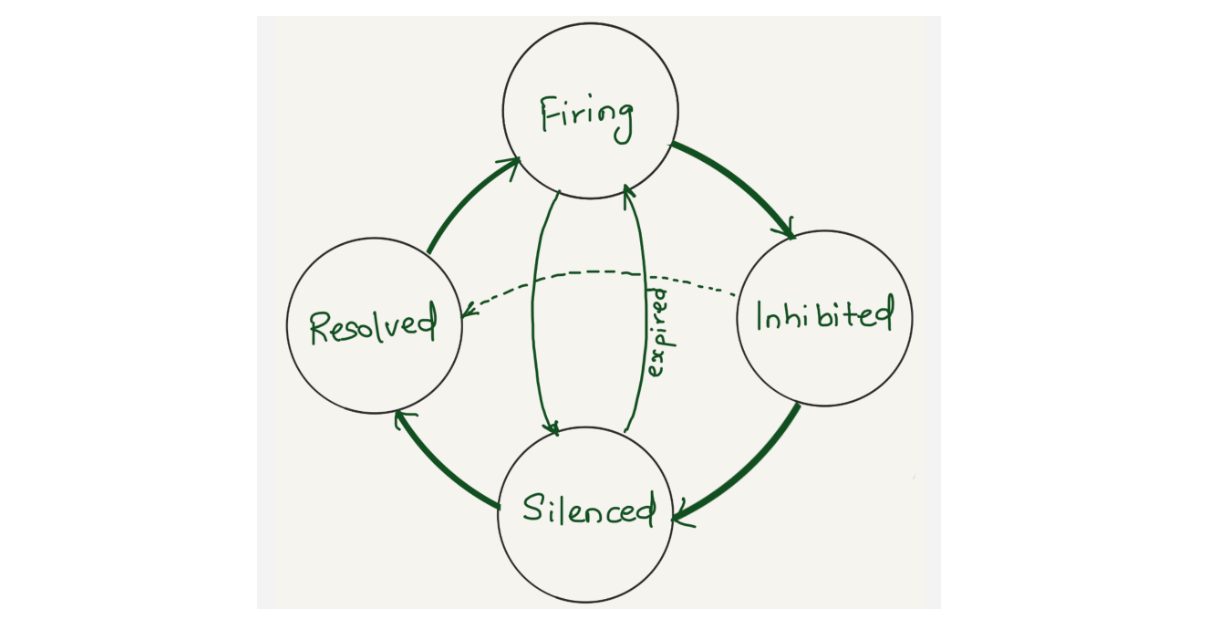
Alertmanager sends notifications for firing and resolved alert events via webhook integration. We were using alertmanager2es, which receives webhook alert notifications from Alertmanager and inserts them into an Elasticsearch index for searching and analysis. Alertmanager2es has been a reliable tool for us over the years, offering ways to monitor alerting volume, noisy alerts and do some kind of alert reporting. However, it had its limitations. The absence of silenced and inhibited alert states made troubleshooting issues challenging. We often found ourselves guessing why an alert didn’t trigger – was it silenced by another alert or perhaps inhibited by one? Without concrete data, we lacked the means to confirm what was truly happening.
Since the Alertmanager doesn’t provide notifications for silenced or inhibited alert events via webhook integration, the alert reporting we were doing was somewhat lacking or incomplete. However, the Alertmanager API provides querying capabilities and by querying the /api/alerts alertmanager endpoint, we can get the silenced and inhibited alert states. Having all four states in a datastore will enhance our ability to improve alert reporting and troubleshoot Alertmanager issues.
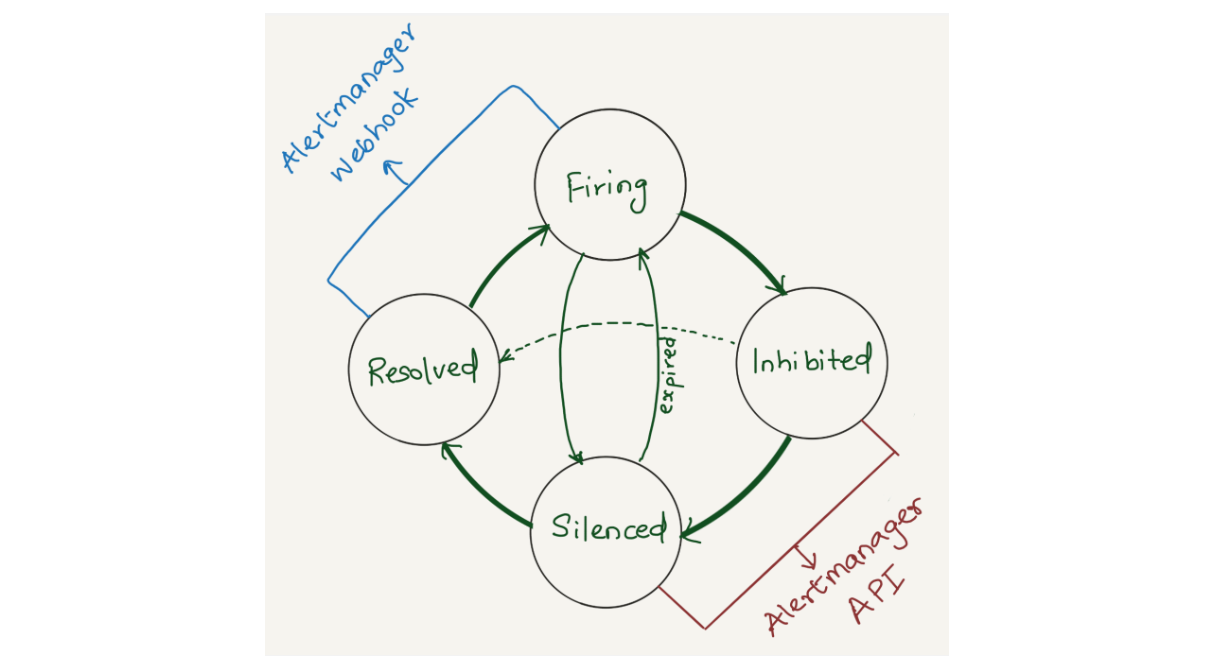
Solution
We opted to aggregate all states of the alerts (firing, silenced, inhibited, and resolved) into a datastore. Given that we’re gathering data from two distinct sources (the webhook and API) each in varying formats and potentially representing different events, we correlate alerts from both sources using the fingerprint field. The fingerprint is a unique hash of the alert’s label set which enables us to match alerts across responses from the Alertmanager webhook and API.

The Alertmanager API offers additional fields compared to the webhook (highlighted in pastel red on the right), such as silencedBy and inhibitedBy IDs, which aid in identifying silenced and inhibited alerts. We store both webhook and API responses in the datastore as separate rows. While querying, we match the alerts using the fingerprint field.
We decided to use a vector.dev instance to transform the data as necessary, and store it in a data store. Vector.dev (acquired by Datadog) is an open-source, high-performance, observability data pipeline that supports a vast range of sources to read data from and supports a lot of sinks for writing data to, as well as a variety of data transformation operations.
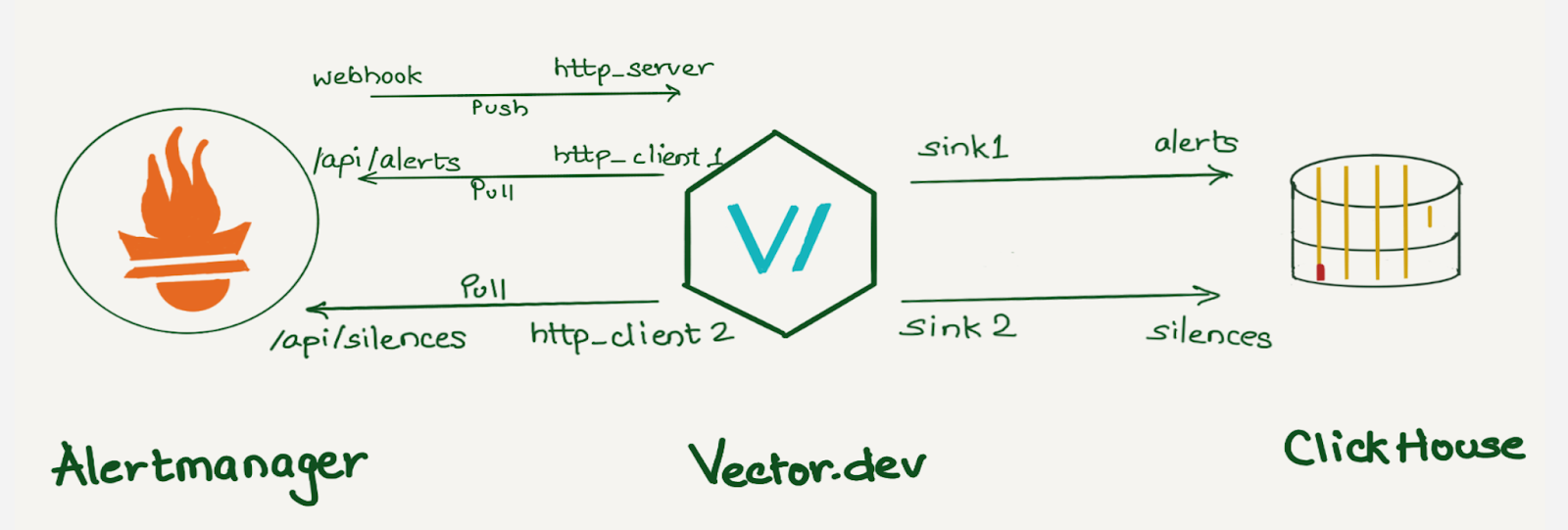
Although we use ClickHouse to store this data, any other database can be used here. ClickHouse was chosen as a data store because it provides various data manipulation options. It allows aggregating data during insertion using Materialized Views, reduces duplicates with the replacingMergeTree table engine, and supports JOIN statements.

If we were to create individual columns for all the alert labels, the number of columns would grow exponentially with the addition of new alerts and unique labels. Instead, we decided to create individual columns for a few common labels like alert priority, instance, dashboard, alert-ref, alertname, etc., which helps us analyze the data in general and keep all other labels in a column of type Map(String, String). This was done because we wanted to keep all the labels in the datastore with minimal resource usage and allow users to query specific labels or filter alerts based on particular labels. For example, we can select all Prometheus alerts using labelsmap[‘service’’] = ‘Prometheus’.
Dashboards
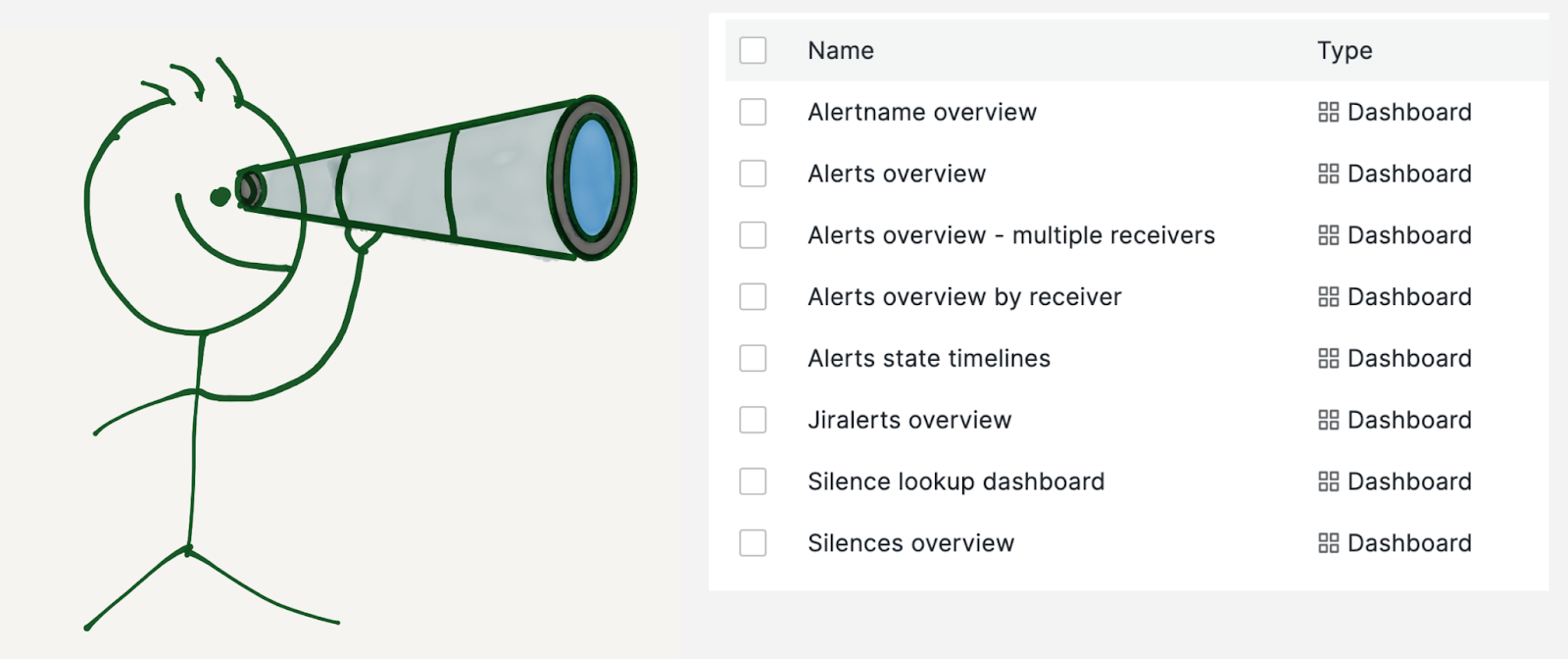
We built multiple dashboards on top of this data:
- Alerts overview: To get insights into all the alerts the Alertmanager receives.
- Alertname overview: To drill down on a specific alert.
- Alerts overview by receiver: This is similar to alerts overview but specific to a team or receiver.
- Alerts state timeline: This dashboard shows a snapshot of alert volume at a glance.
- Jiralerts overview: To get insights into the alerts the ticket system receives.
- Silences overview: To get insights into the Alertmanager silences.
Alerts overview

The image is a screenshot of the collapsed alerts overview dashboard by receiver. This dashboard comprises general stats, components, services, and alertname breakdown. The dashboard also highlights the number of P1 / P2 alerts in the last one day / seven days / thirty days, top alerts for the current quarter, and quarter-to-quarter comparison.
Component breakdown
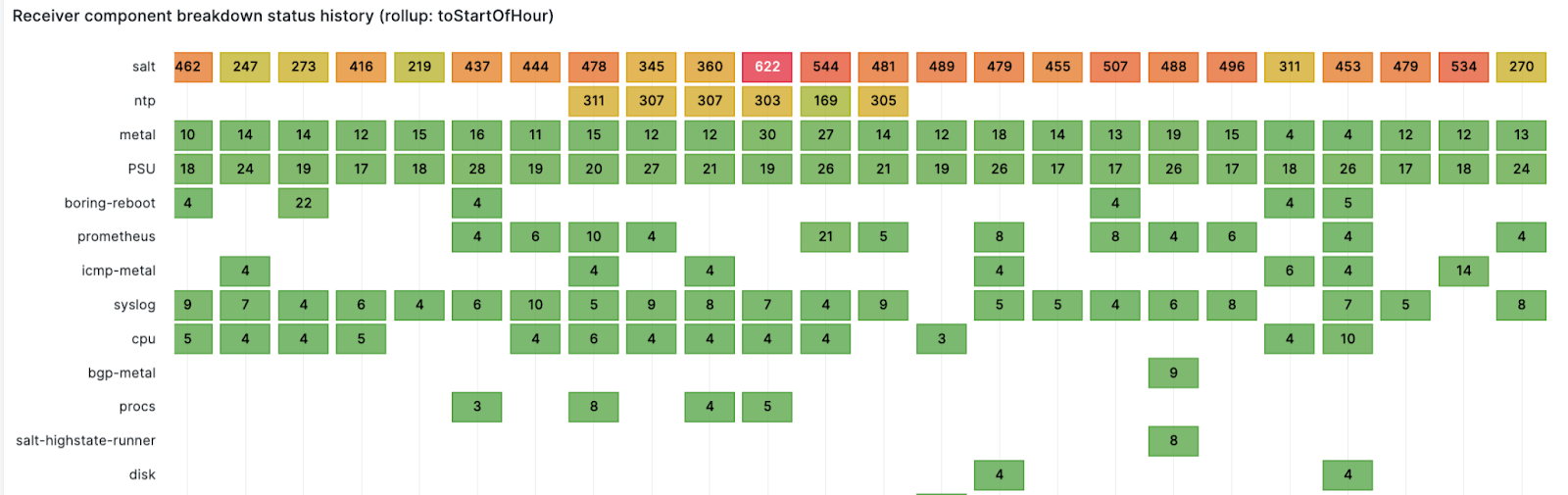
We route alerts to teams and a team can have multiple services or components. This panel shows firing alerts component counts over time for a receiver. For example, the alerts are sent to the observability team, which owns multiple components like logging, metrics, traces, and errors. This panel gives an alerting component count over time, and provides a good idea about which component is noisy and at what time at a glance.
Timeline of alerts
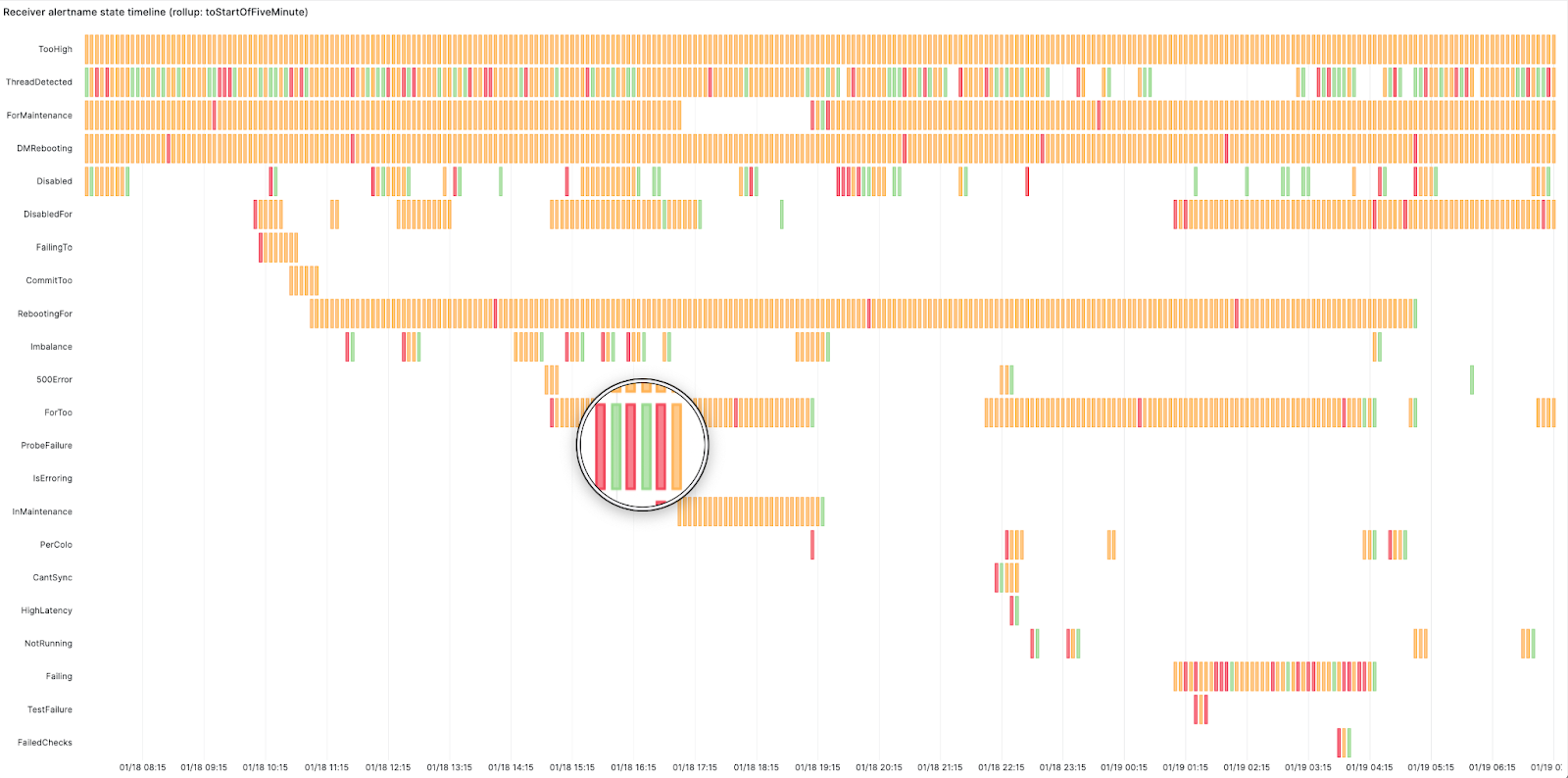
We created this swimlane view using Grafana’s state timeline panel for the receivers. The panel shows how busy the on-call was and at what point. Red here means the alert started firing, orange represents the alert is active and green means it has resolved. It displays the start time, active duration, and resolution of an alert. This highlighted alert is changing state too frequently from firing to resolved – this looks like a flapping alert. Flapping occurs when an alert changes state too frequently. This can happen when alerts are not configured properly and need tweaking, such as adjusting the alert threshold or increasing the for duration period in the alerting rule. The for duration field in the alerting rules adds time tolerance before an alert starts firing. In other words, the alert won’t fire unless the condition is met for ‘X’ minutes.
Findings
There were a few interesting findings within our analysis. We found a few alerts that were firing and did not have a notify label set, which means the alerts were firing but were not being sent or routed to any team, creating unnecessary load on the Alertmanager. We also found a few components generating a lot of alerts, and when we dug in, we found that they were for a cluster that was decommissioned where the alerts were not removed. These dashboards gave us excellent visibility and cleanup opportunities.
Alertmanager inhibitions
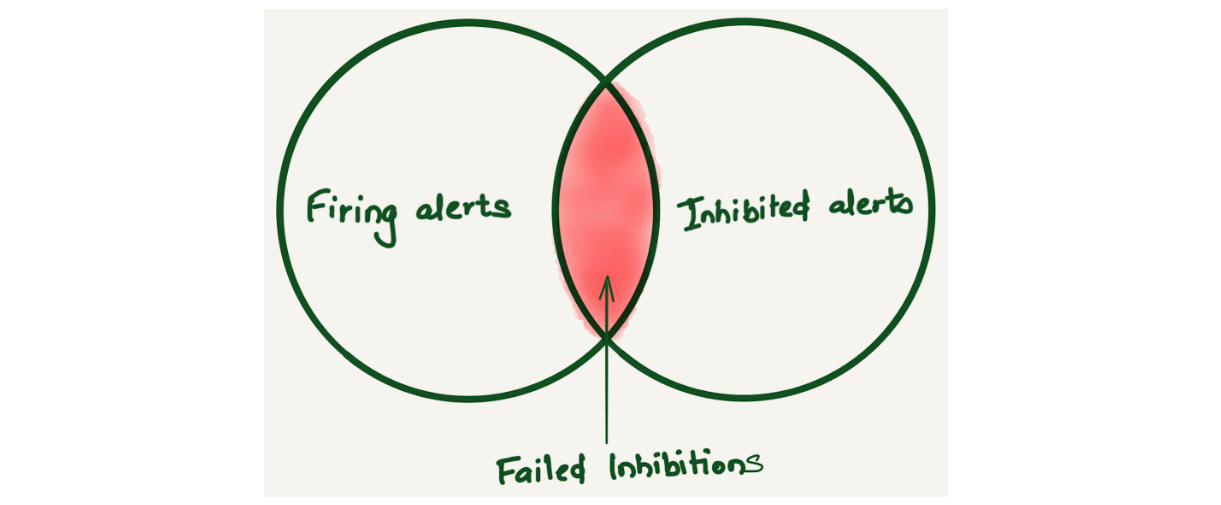
Alertmanager inhibition allows suppressing a set of alerts or notifications based on the presence of another set of alerts. We found that Alertmanager inhibitions were not working sometimes. Since there was no way to know about this, we only learned about it when a user reported getting alerted for inhibited alerts. Imagine a Venn diagram of firing and inhibited alerts to understand failed inhibitions. Ideally, there should be no overlap because the inhibited alerts shouldn’t be firing. But if there is an overlap, that means inhibited alerts are firing, and this overlap is considered a failed inhibition alert.
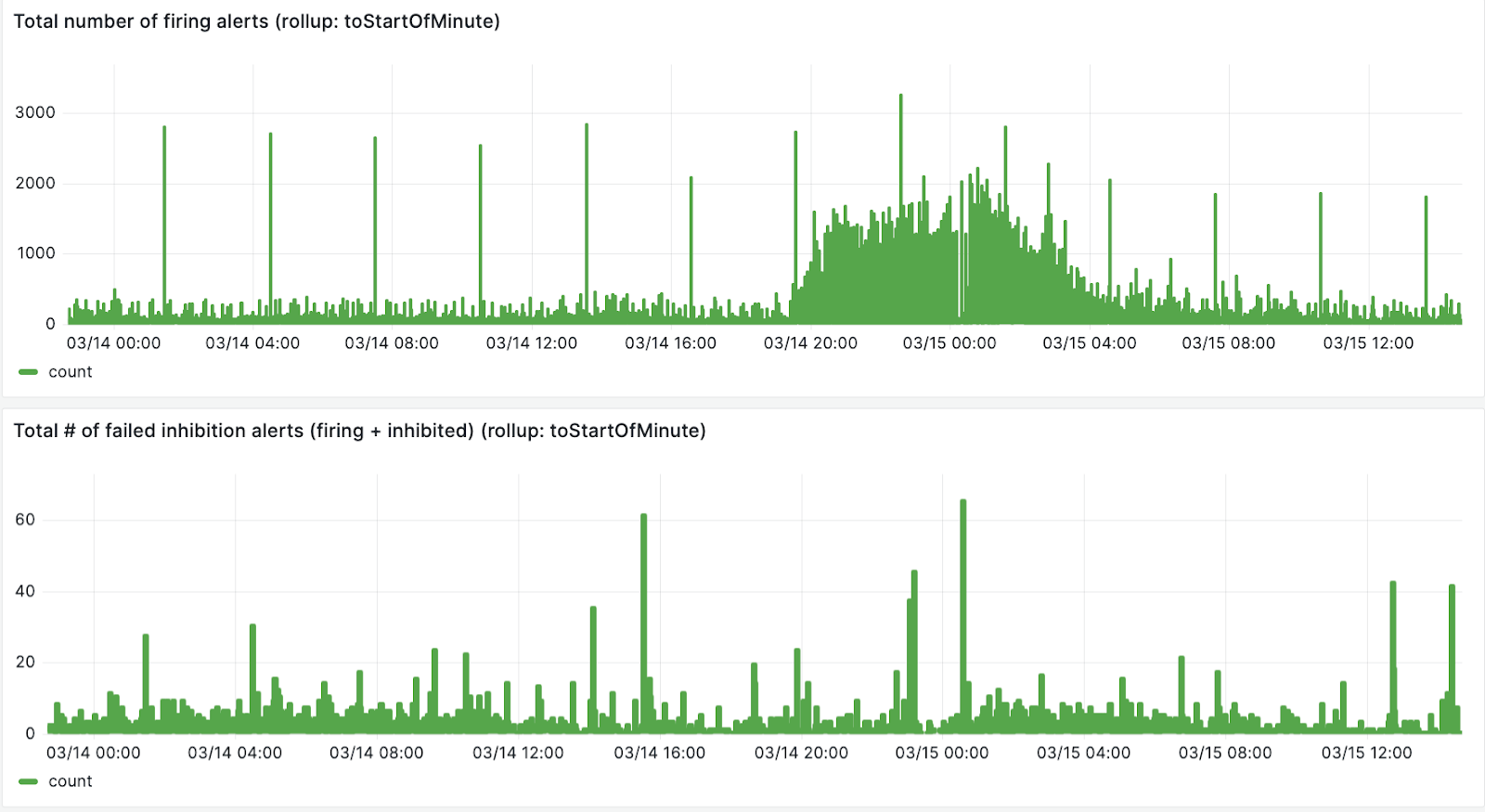
After storing alert notifications in ClickHouse, we were able to come up with a query to find the fingerprint of the `alertnames` where the inhibitions were failing using the following query:
SELECT $rollup(timestamp) as t, count() as count
FROM
(
SELECT
fingerprint, timestamp
FROM alerts
WHERE
$timeFilter
AND status.state = 'firing'
GROUP BY
fingerprint, timestamp
) AS firing
ANY INNER JOIN
(
SELECT
fingerprint, timestamp
FROM alerts
WHERE
$timeFilter
AND status.state = 'suppressed' AND notEmpty(status.inhibitedBy)
GROUP BY
fingerprint, timestamp
) AS suppressed USING (fingerprint)
GROUP BY t
The first panel in the image below is the total number of firing alerts, the second panel is the number of failed inhibitions.
We can also create breakdown for each failed inhibited alert
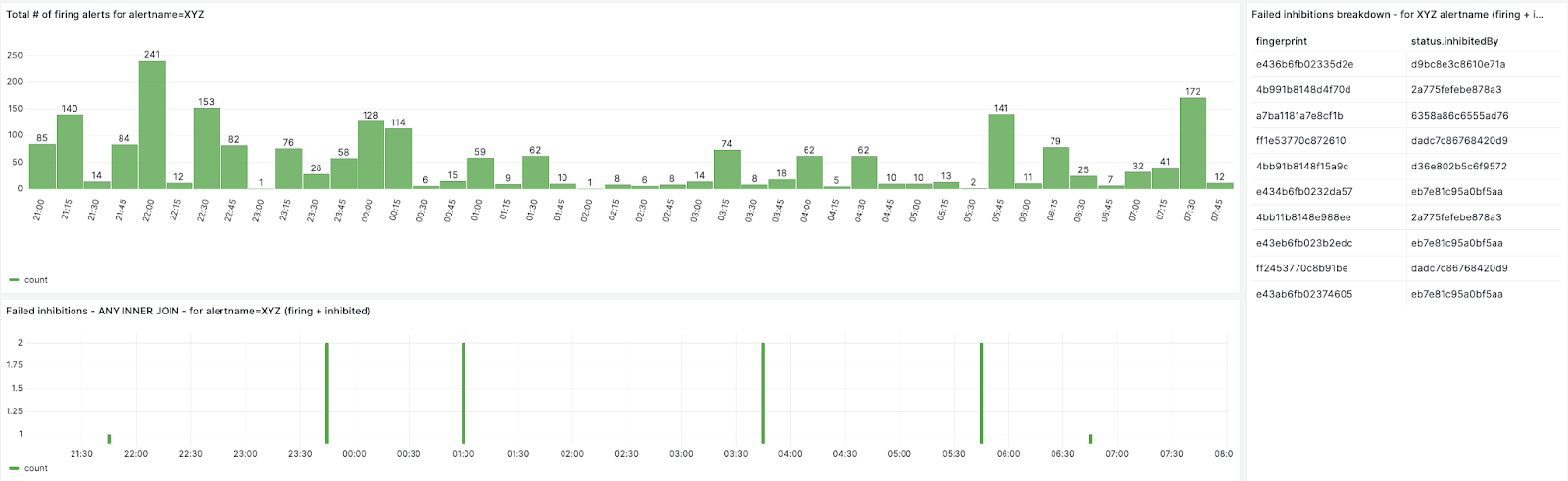
By looking up the fingerprint from the database, we could map the alert inhibitions and found that the failed inhibited alerts have an inhibition loop. For example, alert Service_XYZ_down is inhibited by alert server_OOR, alert server_OOR is inhibited by alert server_down, and server_down is inhibited by alert server_OOR.
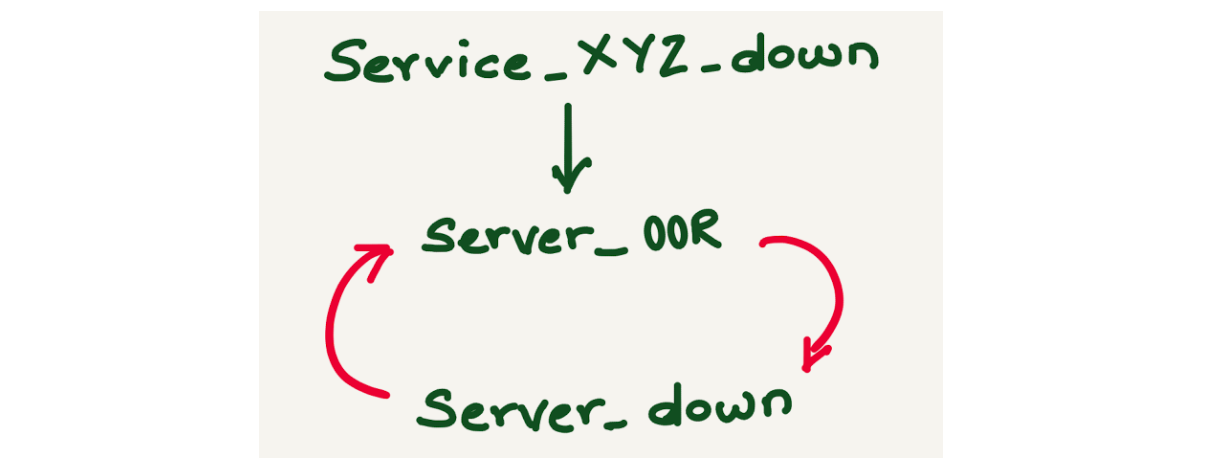
Failed inhibitions can be avoided if alert inhibitions are configured carefully.
Silences

Alertmanager provides a mechanism to silence an alert while it is being worked on or during maintenance. Silence can mute the alerts for a given time and it can be configured based on matchers, which can be an exact match, a regex, an alert name, or any other label. The silence matcher doesn’t necessarily translate to the alertname. By doing alert analysis, we could map the alerts and the silence ID by doing a JOIN query on the alerts and silences tables. We also discovered a lot of stale silences, where silence was created for a long duration and is not relevant anymore.
DIY Alert analysis
The directory contains a basic demo for implementing alerts observability. Running `docker-compose up` spawns several containers, including Prometheus, Alertmanager, Vector, ClickHouse, and Grafana. The vector.dev container queries the Alertmanager alerts API and writes the data into ClickHouse after transforming it. The Grafana dashboard showcases a demo of Alerts and Silences overview.
Make sure you have docker installed and run docker compose up to get started.
Visit http://localhost:3000/dashboards to explore the prebuilt demo dashboards.
Conclusion
As part of the observability team, we manage the Alertmanager, which is a multi-tenant system. It’s crucial for us to have visibility to detect and address system misuse, ensuring proper alerting. The use of alert analysis tools has significantly enhanced the experience for on-call personnel and our team, offering swift access to the alert system. Alerts observability has facilitated the troubleshooting of events such as why an alert did not fire, why an inhibited alert fired, or which alert silenced / inhibited another alert, providing valuable insights for improving alert management.
Moreover, alerts overview dashboards facilitate rapid review and adjustment, streamlining operations. Teams use these dashboards in the weekly alert reviews to provide tangible evidence of how an on-call shift went, identify which alerts fire most frequently, becoming candidates for cleanup or aggregation thus curbing system misuse and bolstering overall alert management. Additionally, we can pinpoint services that may require particular attention. Alerts observability has also empowered some teams to make informed decisions about on-call configurations, such as transitioning to longer but less frequent shifts or integrating on-call and unplanned work shifts.
In conclusion, alert observability plays a crucial role in averting burnout by minimizing interruptions and enhancing on-call duties’ efficiency. Offering alerts observability as a service benefits all teams by obviating the need for individual dashboard development and fostering a proactive monitoring culture.
If you found this blog post interesting and want to work on observability, please check out our job openings – we’re hiring for Alerting and Logging!