Post Syndicated from Matthew Prince original https://blog.cloudflare.com/automatically-replacing-polyfill-io-links-with-cloudflares-mirror-for-a-safer-internet

polyfill.io, a popular JavaScript library service, can no longer be trusted and should be removed from websites.
Multiple reports, corroborated with data seen by our own client-side security system, Page Shield, have shown that the polyfill service was being used, and could be used again, to inject malicious JavaScript code into users’ browsers. This is a real threat to the Internet at large given the popularity of this library.
We have, over the last 24 hours, released an automatic JavaScript URL rewriting service that will rewrite any link to polyfill.io found in a website proxied by Cloudflare to a link to our mirror under cdnjs. This will avoid breaking site functionality while mitigating the risk of a supply chain attack.
Any website on the free plan has this feature automatically activated now. Websites on any paid plan can turn on this feature with a single click.
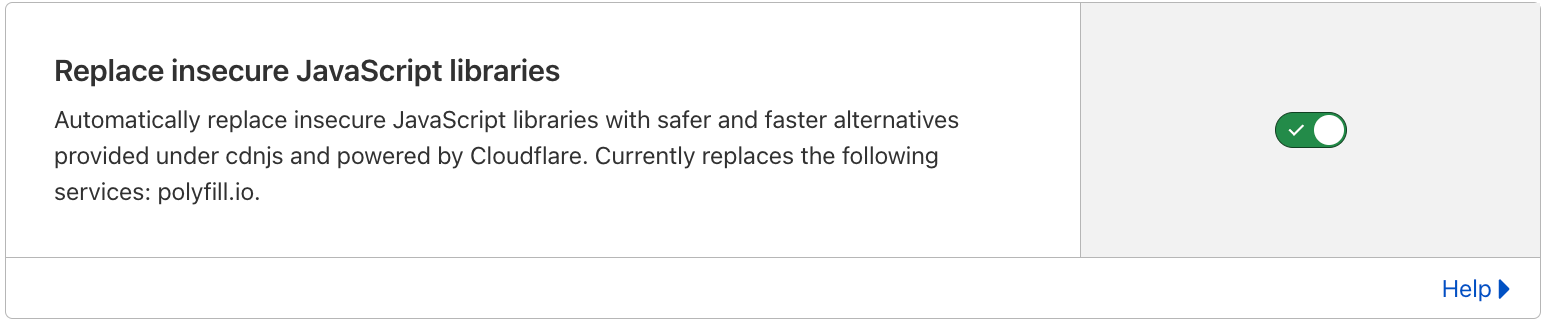
You can find this new feature under Security ⇒ Settings on any zone using Cloudflare.
Contrary to what is stated on the polyfill.io website, Cloudflare has never recommended the polyfill.io service or authorized their use of Cloudflare’s name on their website. We have asked them to remove the false statement and they have, so far, ignored our requests. This is yet another warning sign that they cannot be trusted.
If you are not using Cloudflare today, we still highly recommend that you remove any use of polyfill.io and/or find an alternative solution. And, while the automatic replacement function will handle most cases, the best practice is to remove polyfill.io from your projects and replace it with a secure alternative mirror like Cloudflare’s even if you are a customer.
You can do this by searching your code repositories for instances of polyfill.io and replacing it with cdnjs.cloudflare.com/polyfill/ (Cloudflare’s mirror). This is a non-breaking change as the two URLs will serve the same polyfill content. All website owners, regardless of the website using Cloudflare, should do this now.
How we came to this decision
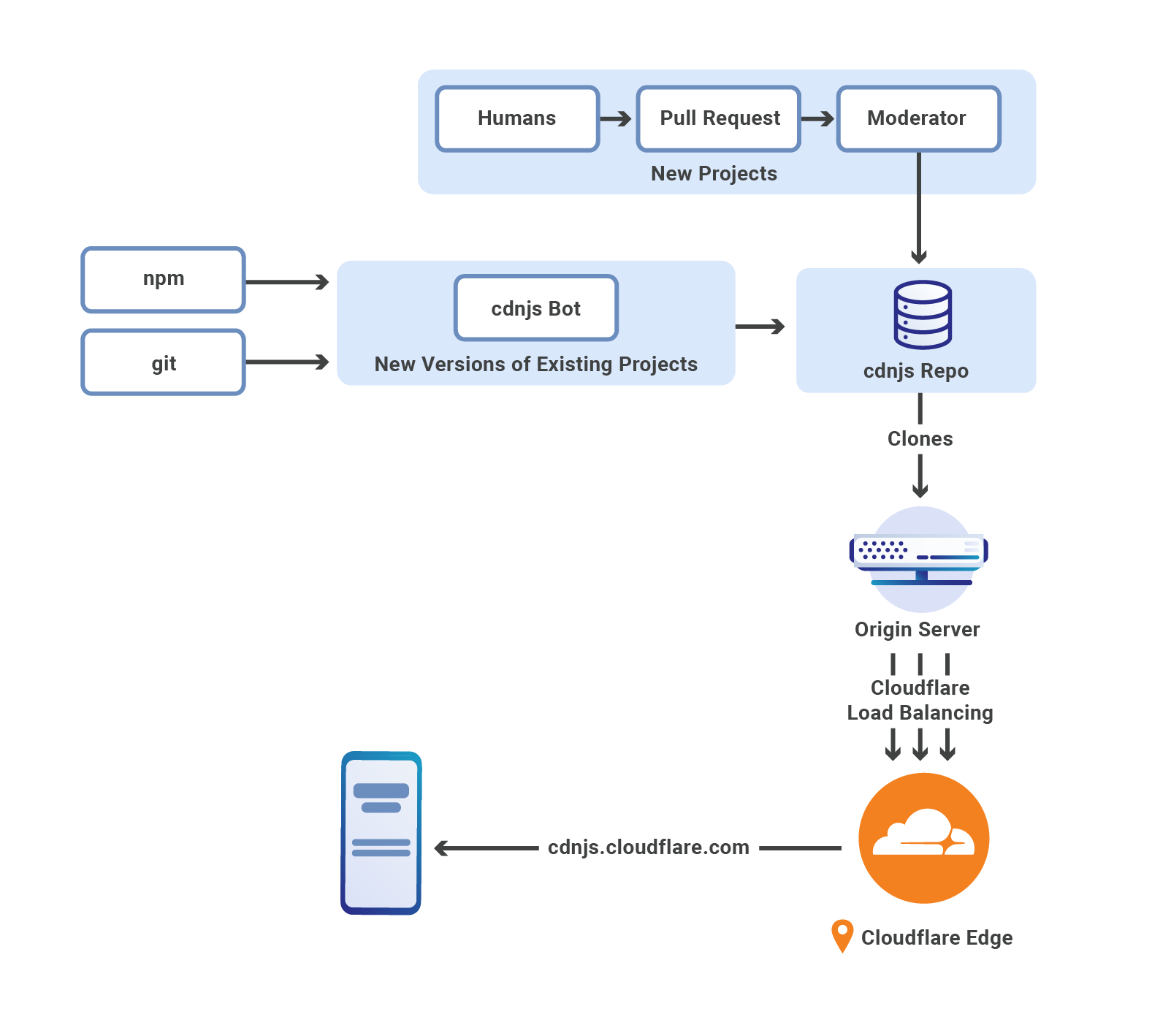
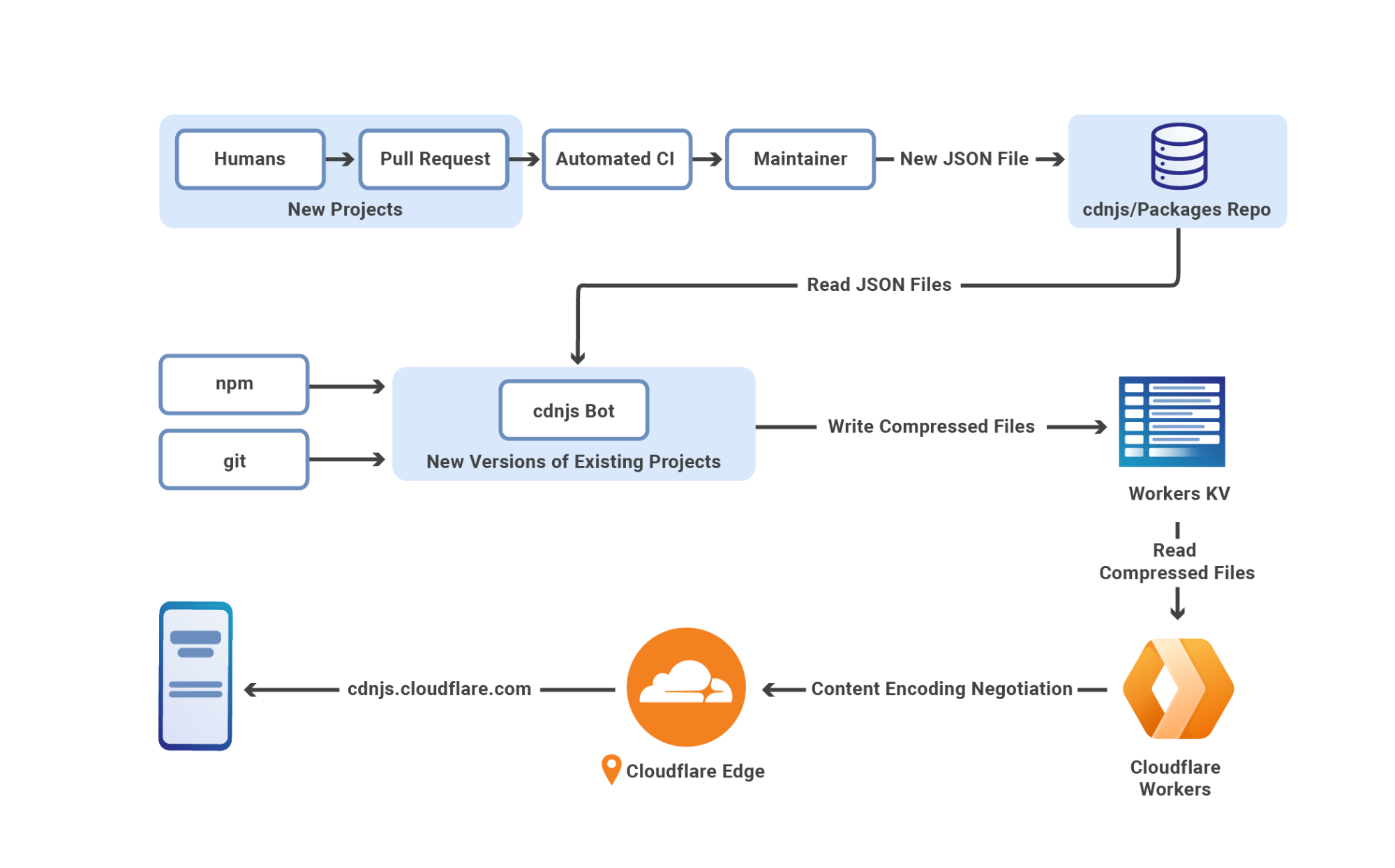
Back in February, the domain polyfill.io, which hosts a popular JavaScript library, was sold to a new owner: Funnull, a relatively unknown company. At the time, we were concerned that this created a supply chain risk. This led us to spin up our own mirror of the polyfill.io code hosted under cdnjs, a JavaScript library repository sponsored by Cloudflare.
The new owner was unknown in the industry and did not have a track record of trust to administer a project such as polyfill.io. The concern, highlighted even by the original author, was that if they were to abuse polyfill.io by injecting additional code to the library, it could cause far reaching security problems on the Internet affecting several hundreds of thousands websites. Or it could be used to perform a targeted supply-chain attack against specific websites.
Unfortunately, that worry came true on June 25, 2024 as the polyfill.io service was being used to inject nefarious code that, under certain circumstances, redirected users to other websites.
We have taken the exceptional step of using our ability to modify HTML on the fly to replace references to the polyfill.io CDN in our customers’ websites with links to our own, safe, mirror created back in February.
In the meantime, additional threat feed providers have also taken the decision to flag the domain as malicious. We have not outright blocked the domain through any of the mechanisms we have because we are concerned it could cause widespread web outages given how broadly polyfill.io is used with some estimates indicating usage on nearly 4% of all websites.
Corroborating data with Page Shield
The original report indicates that malicious code was injected that, under certain circumstances, would redirect users to betting sites. It was doing this by loading additional JavaScript that would perform the redirect, under a set of additional domains which can be considered Indicators of Compromise (IoCs):
https://www.googie-anaiytics.com/analytics.js
https://www.googie-anaiytics.com/html/checkcachehw.js
https://www.googie-anaiytics.com/gtags.js
https://www.googie-anaiytics.com/keywords/vn-keyword.json
https://www.googie-anaiytics.com/webs-1.0.1.js
https://www.googie-anaiytics.com/analytics.js
https://www.googie-anaiytics.com/webs-1.0.2.js
https://www.googie-anaiytics.com/ga.js
https://www.googie-anaiytics.com/web-1.0.1.js
https://www.googie-anaiytics.com/web.js
https://www.googie-anaiytics.com/collect.js
https://kuurza.com/redirect?from=bitget
(note the intentional misspelling of Google Analytics)
Page Shield, our client side security solution, is available on all paid plans. When turned on, it collects information about JavaScript files loaded by end user browsers accessing your website.
By looking at the database of detected JavaScript files, we immediately found matches with the IoCs provided above starting as far back as 2024-06-08 15:23:51 (first seen timestamp on Page Shield detected JavaScript file). This was a clear indication that malicious activity was active and associated with polyfill.io.
Replacing insecure JavaScript links to polyfill.io
To achieve performant HTML rewriting, we need to make blazing-fast HTML alterations as responses stream through Cloudflare’s network. This has been made possible by leveraging ROFL (Response Overseer for FL). ROFL powers various Cloudflare products that need to alter HTML as it streams, such as Cloudflare Fonts, Email Obfuscation and Rocket Loader
ROFL is developed entirely in Rust. The memory-safety features of Rust are indispensable for ensuring protection against memory leaks while processing a staggering volume of requests, measuring in the millions per second. Rust’s compiled nature allows us to finely optimize our code for specific hardware configurations, delivering performance gains compared to interpreted languages.
The performance of ROFL allows us to rewrite HTML on-the-fly and modify the polyfill.io links quickly, safely, and efficiently. This speed helps us reduce any additional latency added by processing the HTML file.
If the feature is turned on, for any HTTP response with an HTML Content-Type, we parse all JavaScript script tag source attributes. If any are found linking to polyfill.io, we rewrite the src attribute to link to our mirror instead. We map to the correct version of the polyfill service while the query string is left untouched.
The logic will not activate if a Content Security Policy (CSP) header is found in the response. This ensures we don’t replace the link while breaking the CSP policy and therefore potentially breaking the website.
Default on for free customers, optional for everyone else
Cloudflare proxies millions of websites, and a large portion of these sites are on our free plan. Free plan customers tend to have simpler applications while not having the resources to update and react quickly to security concerns. We therefore decided to turn on the feature by default for sites on our free plan, as the likelihood of causing issues is reduced while also helping keep safe a very large portion of applications using polyfill.io.
Paid plan customers, on the other hand, have more complex applications and react quicker to security notices. We are confident that most paid customers using polyfill.io and Cloudflare will appreciate the ability to virtually patch the issue with a single click, while controlling when to do so.
All customers can turn off the feature at any time.
This isn’t the first time we’ve decided a security problem was so widespread and serious that we’d enable protection for all customers regardless of whether they were a paying customer or not. Back in 2014, we enabled Shellshock protection for everyone. In 2021, when the log4j vulnerability was disclosed we rolled out protection for all customers.
Do not use polyfill.io
If you are using Cloudflare, you can remove polyfill.io with a single click on the Cloudflare dashboard by heading over to your zone ⇒ Security ⇒ Settings. If you are a free customer, the rewrite is automatically active. This feature, we hope, will help you quickly patch the issue.
Nonetheless, you should ultimately search your code repositories for instances of polyfill.io and replace them with an alternative provider, such as Cloudflare’s secure mirror under cdnjs (https://cdnjs.cloudflare.com/polyfill/). Website owners who are not using Cloudflare should also perform these steps.
The underlying bundle links you should use are:
For minified: https://cdnjs.cloudflare.com/polyfill/v3/polyfill.min.js
For unminified: https://cdnjs.cloudflare.com/polyfill/v3/polyfill.js
Doing this ensures your website is no longer relying on polyfill.io.