Post Syndicated from Nevi Shah original https://blog.cloudflare.com/whats-new-with-d1/


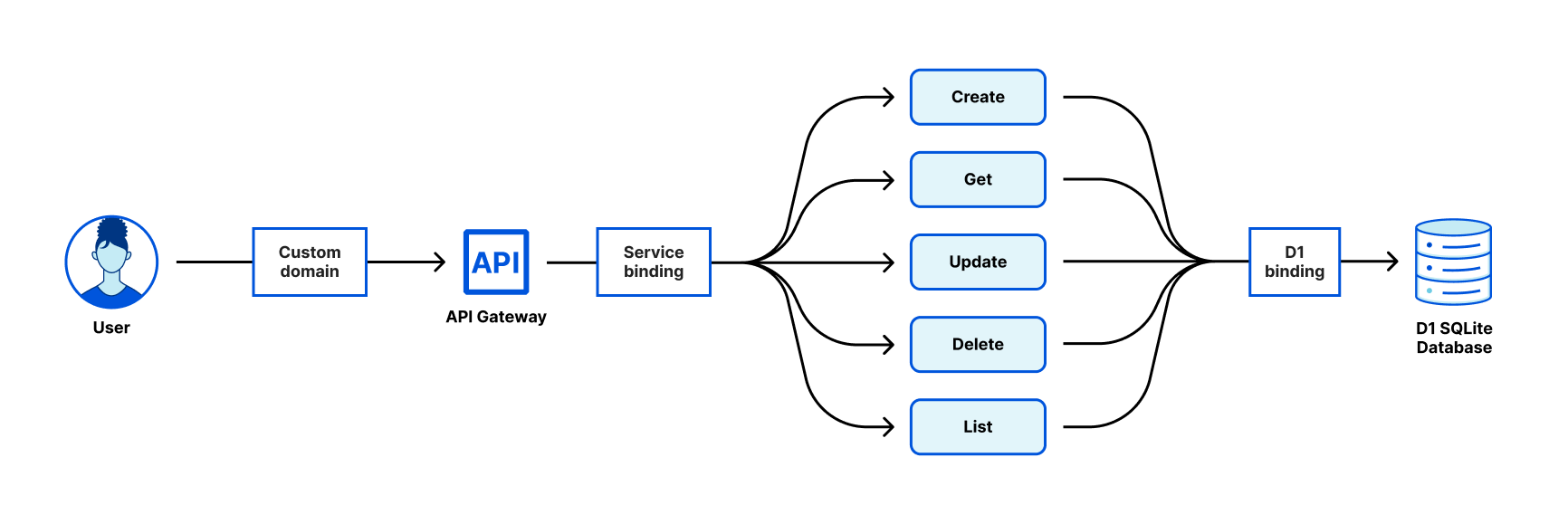
When we announced D1 in May of this year, we knew it would be the start of something new – our first SQL database with Cloudflare Workers. Prior to D1 we’ve announced storage options like KV (key-value store), Durable Objects (single location, strongly consistent data storage) and R2 (blob storage). But the question always remained “How can I store and query relational data without latency concerns and an easy API?”
The long awaited “Cloudflare Database” was the true missing piece to build your application entirely on Cloudflare’s global network, going from a blank canvas in VSCode to a full stack application in seconds. Compatible with the popular SQLite API, D1 empowers developers to build out their databases without getting bogged down by complexity and having to manage every underlying layer.
Since our launch announcement in May and private beta in June, we’ve made great strides in building out our vision of a serverless database. With D1 still in private beta but an open beta on the horizon, we’re excited to show and tell our journey of building D1 and what’s to come.
The D1 Experience
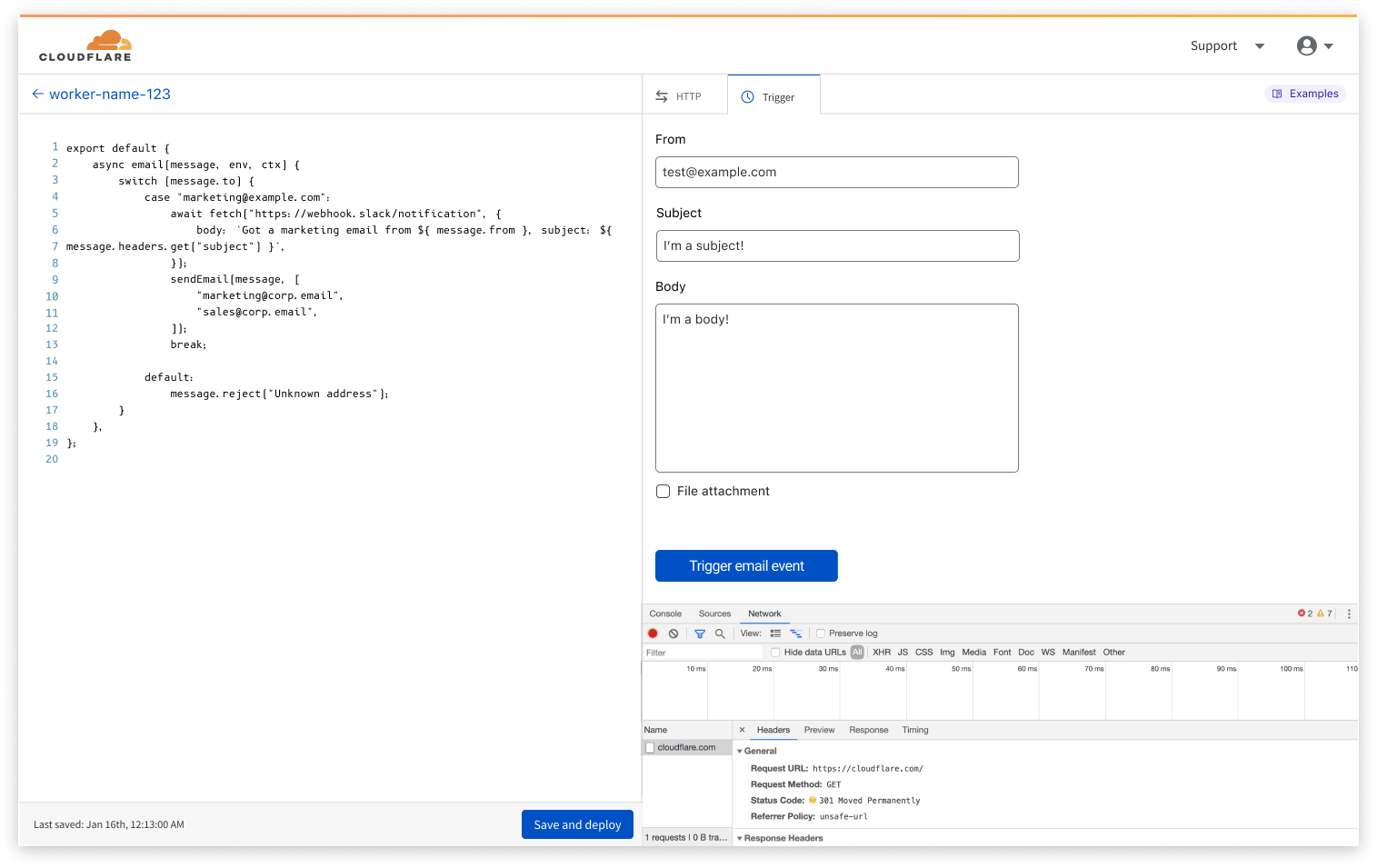
We knew from Cloudflare Workers feedback that using Wrangler as the mechanism to create and deploy applications is loved and preferred by many. That’s why when Wrangler 2.0 was announced this past May alongside D1, we took advantage of the new and improved CLI for every part of the experience from data creation to every update and iteration. Let’s take a quick look on how to get set up in a few easy steps.
Create your database
With the latest version of Wrangler installed, you can create an initialized empty database with a quick
npx wrangler d1 create my_database_name
To get your database up and running! Now it’s time to add your data.
Bootstrap it
It wouldn’t be the “Cloudflare way” if you had to sit through an agonizingly long process to get set up. So we made it easy and painless to bring your existing data from an old database and bootstrap your new D1 database. You can run
wrangler d1 execute my_database-name --file ./filename.sql
and pass through an existing SQLite .sql file of your choice. Your database is now ready for action.
Develop & Test Locally
With all the improvements we’ve made to Wrangler since version 2 launched a few months ago, we’re pleased to report that D1 has full remote & local wrangler dev support:
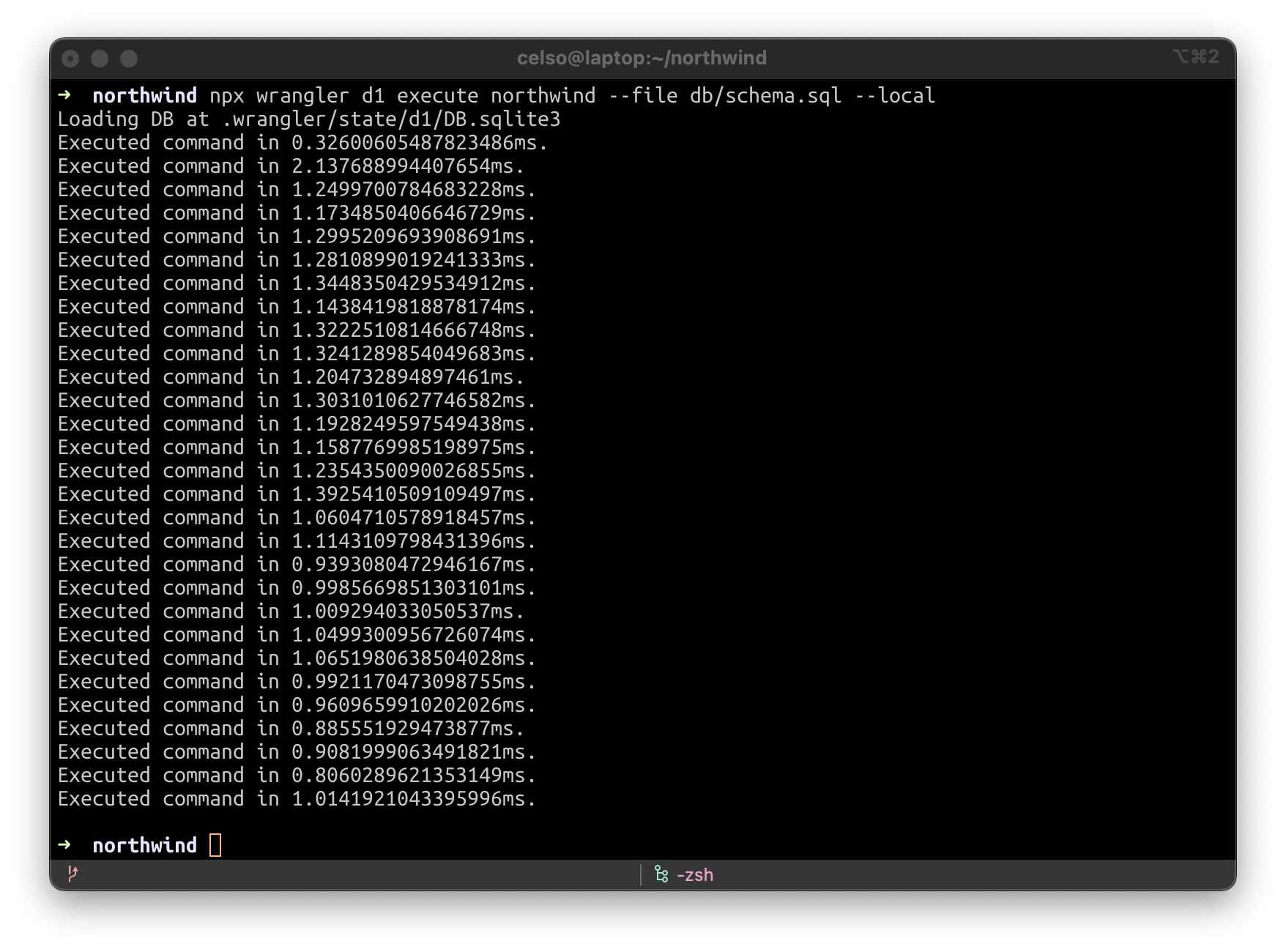
When running wrangler dev -–local -–persist, an SQLite file will be created inside .wrangler/state. You can then use a local GUI program for managing it, like SQLiteFlow (https://www.sqliteflow.com/) or Beekeeper (https://www.beekeeperstudio.io/).
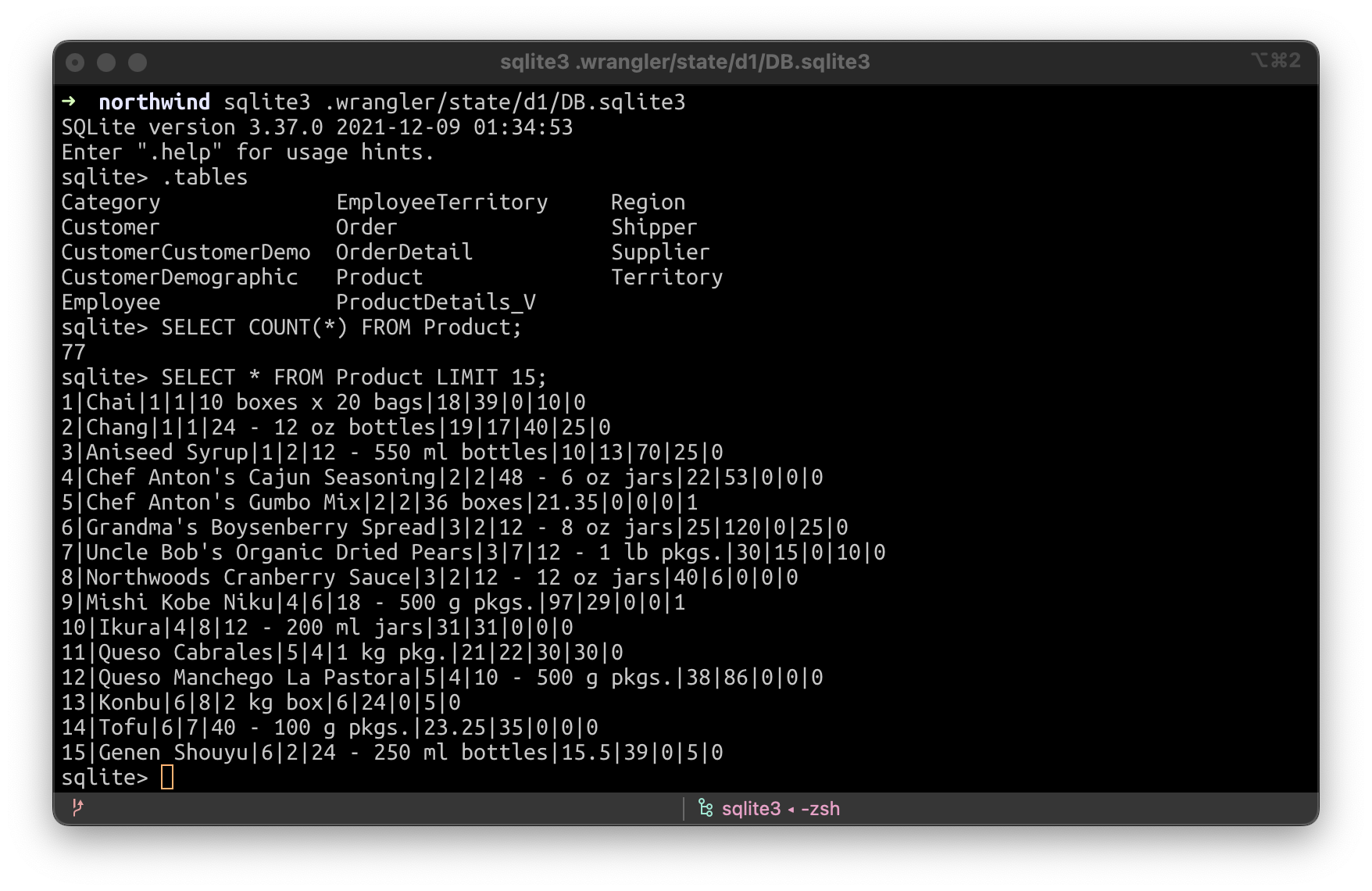
Or you can simply use SQLite directly with the SQLite command line by running sqlite3 .wrangler/state/d1/DB.sqlite3:
Automatic backups & one-click restore
No matter how much you test your changes, sometimes things don’t always go according to plan. But with Wrangler you can create a backup of your data, view your list of backups or restore your database from an existing backup. In fact, during the beta, we’re taking backups of your data every hour automatically and storing them in R2, so you will have the option to rollback if needed.
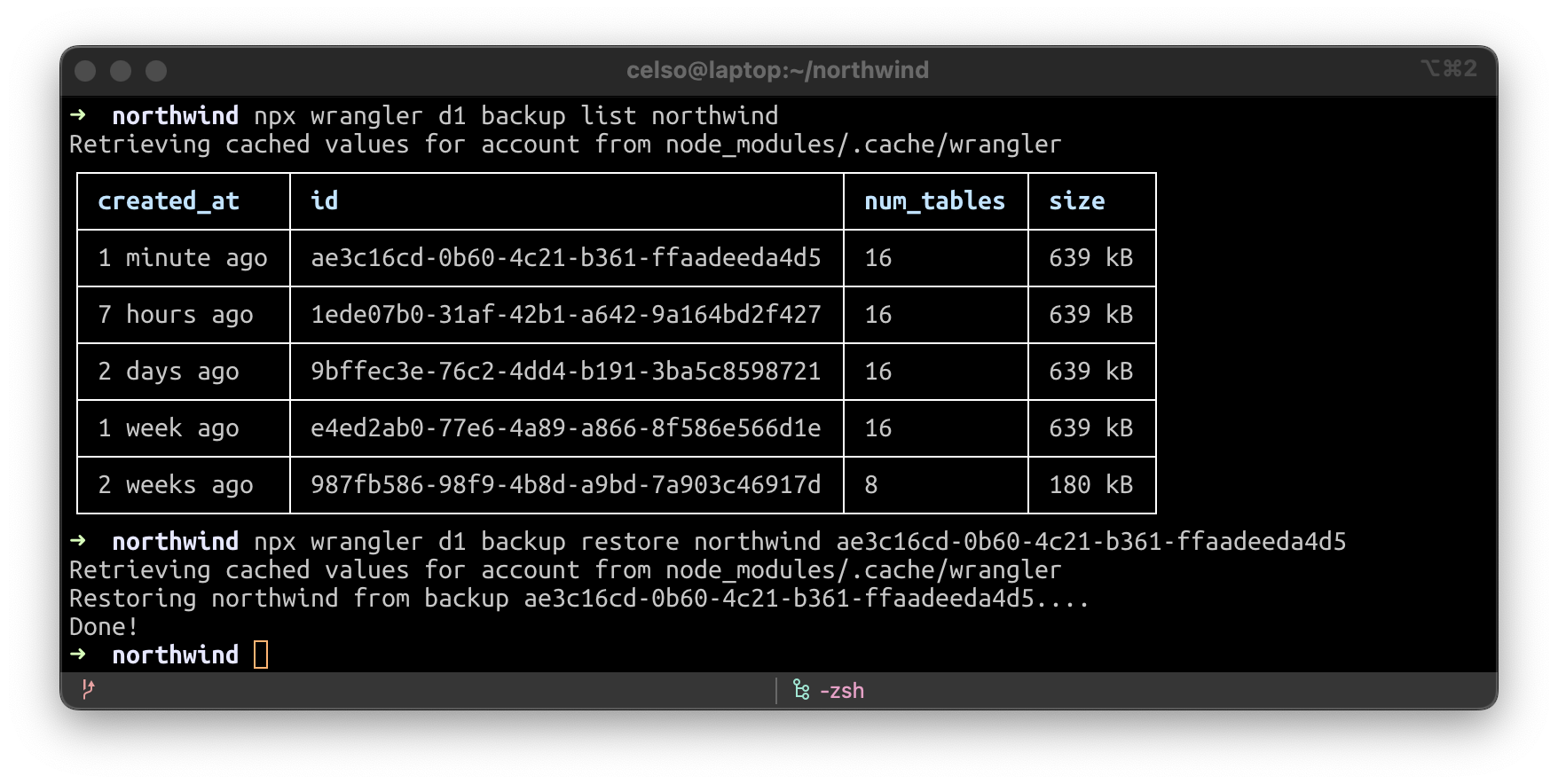
And the best part – if you want to use a production snapshot for local development or to reproduce a bug, simply copy it into the .wrangler/state directory and wrangler dev –-local –-persist will pick it up!
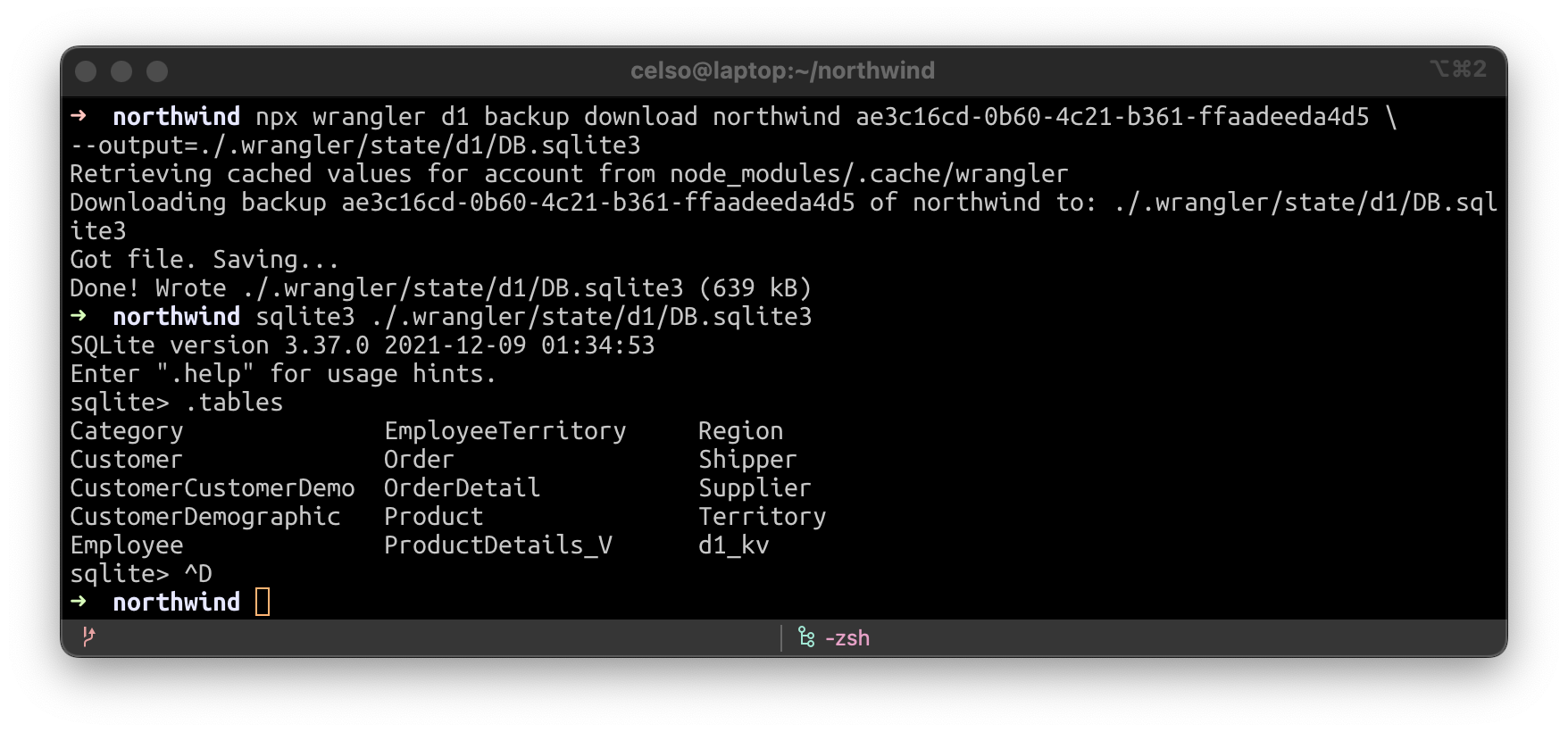
Let’s download a D1 backup to our local disk. It’s SQLite compatible.
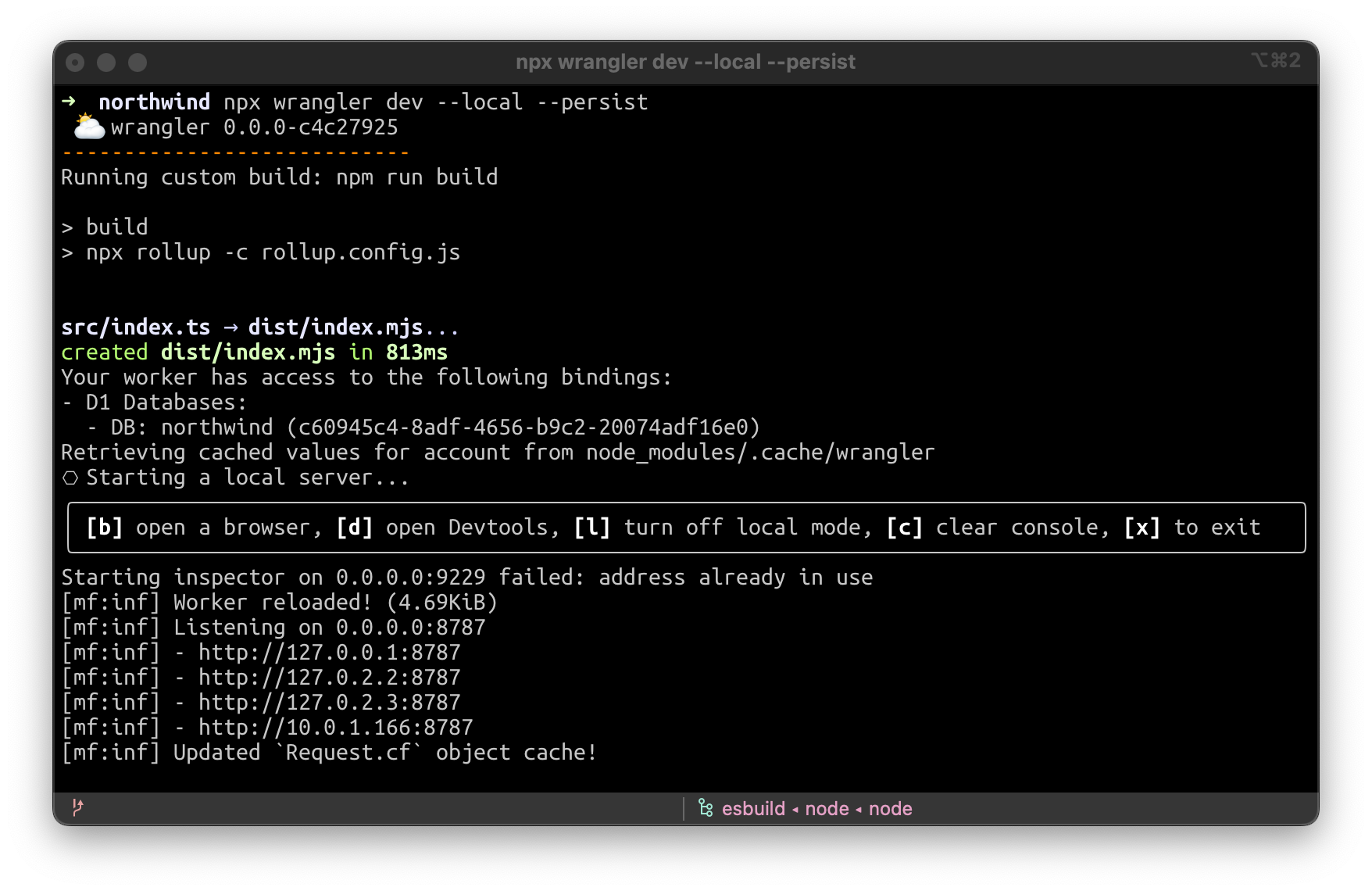
Now let’s run our D1 worker locally, from the backup.
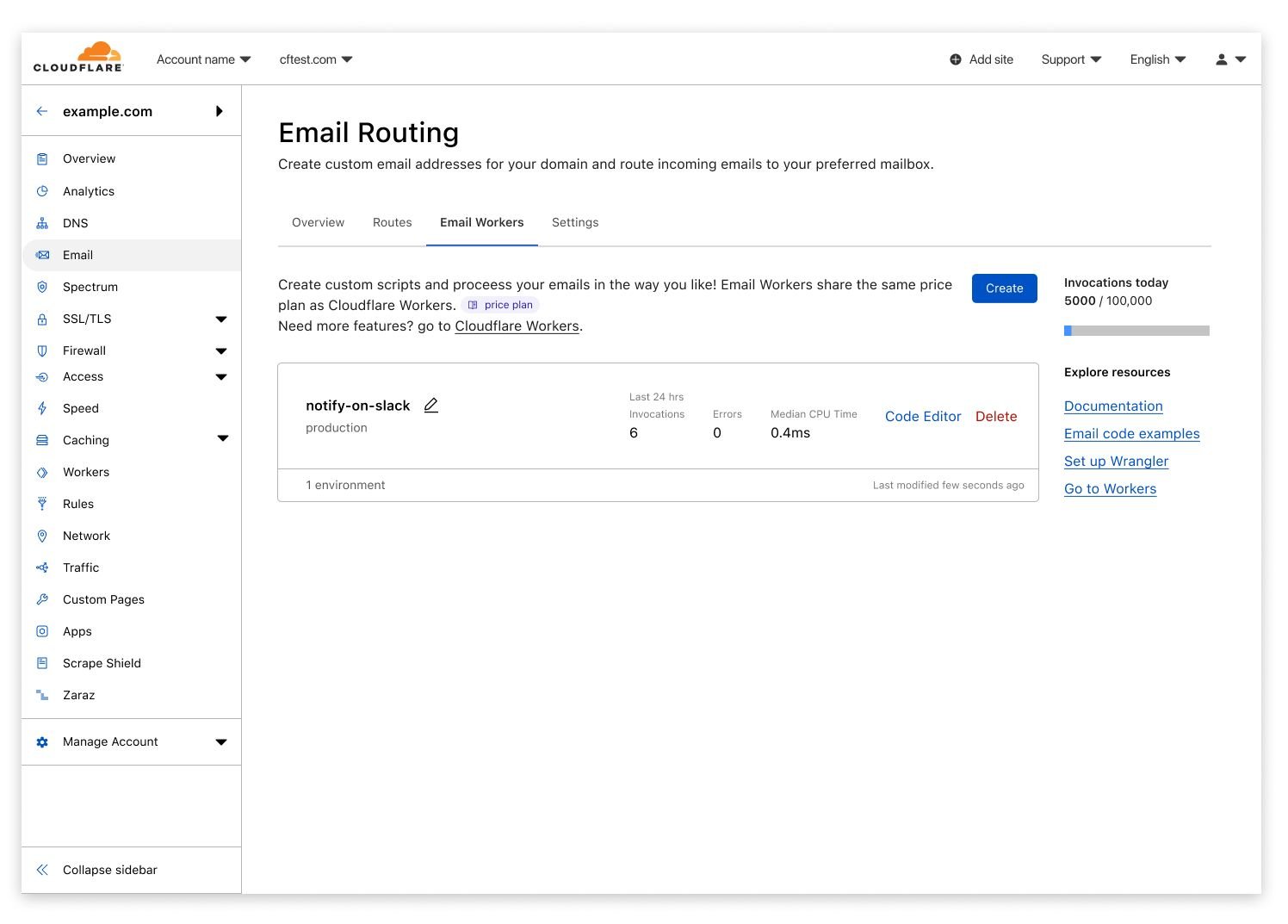
Create and Manage from the dashboard
However, we realize that CLIs are not everyone’s jam. In fact, we believe databases should be accessible to every kind of developer – even those without much database experience! D1 is available right from the Cloudflare dashboard giving you near total command parity with Wrangler in just a few clicks. Bootstrapping your database, creating tables, updating your database, viewing tables and triggering backups are all accessible right at your fingertips.
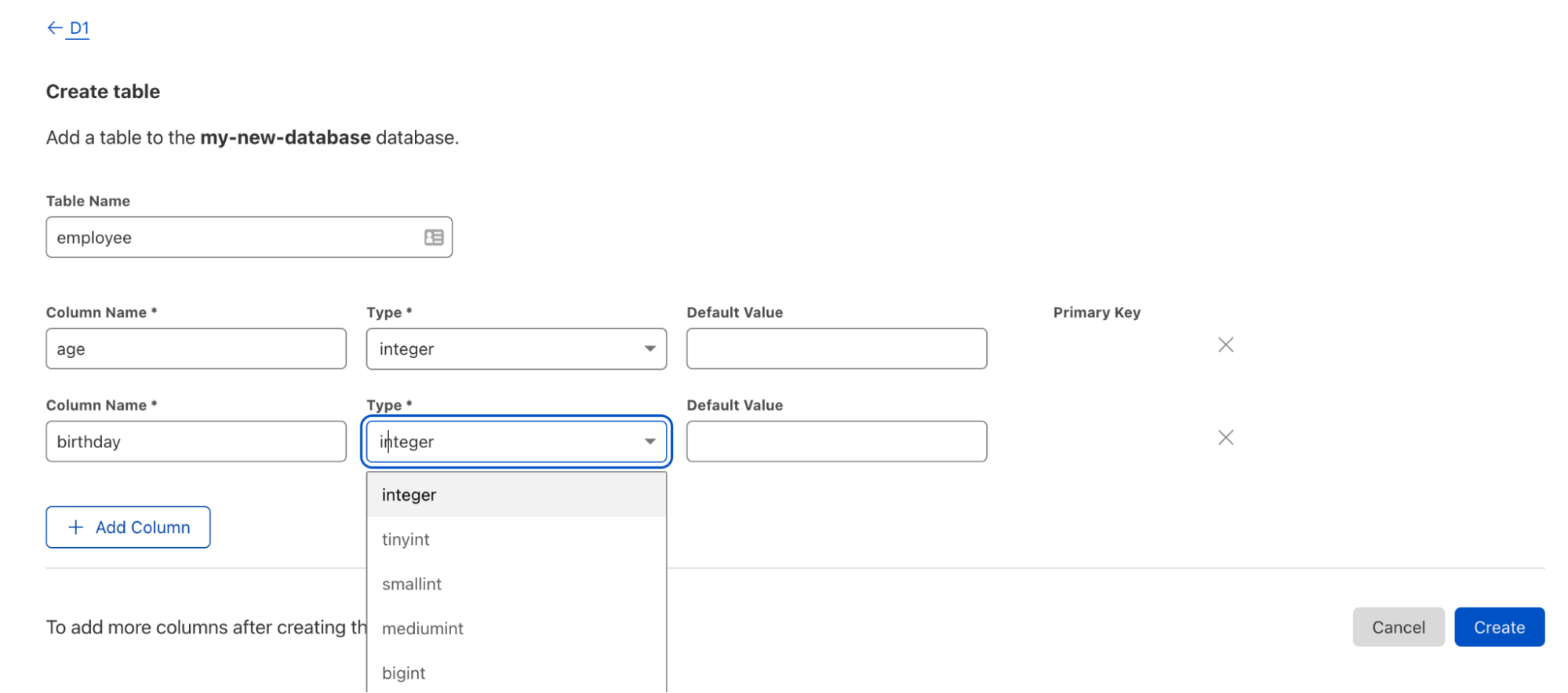
Changes made in the UI are instantly available to your Worker — no deploy required!
We’ve told you about some of the improvements we’ve landed since we first announced D1, but as always, we also wanted to give you a small taste (with some technical details) of what’s ahead. One really important functionality of a database is transactions — something D1 wouldn’t be complete without.
Sneak peek: how we’re bringing JavaScript transactions to D1
With D1, we strive to present a dramatically simplified interface to creating and querying relational data, which for the most part is a good thing. But simplification occasionally introduces drawbacks, where a use-case is no longer easily supported without introducing some new concepts. D1 transactions are one example.
Transactions are a unique challenge
You don’t need to specify where a Cloudflare Worker or a D1 database run—they simply run everywhere they need to. For Workers, that is as close as possible to the users that are hitting your site right this second. For D1 today, we don’t try to run a copy in every location worldwide, but dynamically manage the number and location of read-only replicas based on how many queries your database is getting, and from where. However, for queries that make changes to a database (which we generally call “writes” for short), they all have to travel back to the single Primary D1 instance to do their work, to ensure consistency.
But what if you need to do a series of updates at once? While you can send multiple SQL queries with .batch() (which does in fact use database transactions under the hood), it’s likely that, at some point, you’ll want to interleave database queries & JS code in a single unit of work.
This is exactly what database transactions were invented for, but if you try running BEGIN TRANSACTION in D1 you’ll get an error. Let’s talk about why that is.
Why native transactions don’t work
The problem arises from SQL statements and JavaScript code running in dramatically different places—your SQL executes inside your D1 database (primary for writes, nearest replica for reads), but your Worker is running near the user, which might be on the other side of the world. And because D1 is built on SQLite, only one write transaction can be open at once. Meaning that, if we permitted BEGIN TRANSACTION, any one Worker request, anywhere in the world, could effectively block your whole database! This is a quite dangerous thing to allow:
- A Worker could start a transaction then crash due to a software bug, without calling
ROLLBACK. The primary would be blocked, waiting for more commands from a Worker that would never come (until, probably, some timeout). - Even without bugs or crashes, transactions that require multiple round-trips between JavaScript and SQL could end up blocking your whole system for multiple seconds, dramatically limiting how high an application built with Workers & D1 could scale.
But allowing a developer to define transactions that mix both SQL and JavaScript makes building applications with Workers & D1 so much more flexible and powerful. We need a new solution (or, in our case, a new version of an old solution).
A way forward: stored procedures
Stored procedures are snippets of code that are uploaded to the database, to be executed directly next to the data. Which, at first blush, sounds exactly like what we want.
However, in practice, stored procedures in traditional databases are notoriously frustrating to work with, as anyone who’s developed a system making heavy use of them will tell you:
- They’re often written in a different language to the rest of your application. They’re usually written in (a specific dialect of) SQL or an embedded language like Tcl/Perl/Python. And while it’s technically possible to write them in JavaScript (using an embedded V8 engine), they run in such a different environment to your application code it still requires significant context-switching to maintain them.
- Having both application code and in-database code affects every part of the development lifecycle, from authoring, testing, deployment, rollbacks and debugging. But because stored procedures are usually introduced to solve a specific problem, not as a general purpose application layer, they’re often managed completely manually. You can end up with them being written once, added to the database, then never changed for fear of breaking something.
With D1, we can do better.
The point of a stored procedure was to execute directly next to the data—uploading the code and executing it inside the database was simply a means to that end. But we’re using Workers, a global JavaScript execution platform, can we use them to solve this problem?
It turns out, absolutely! But here we have a few options of exactly how to make it work, and we’re working with our private beta users to find the right API. In this section, I’d like to share with you our current leading proposal, and invite you all to give us your feedback.
When you connect a Worker project to a D1 database, you add the section like the following to your wrangler.toml:
[[ d1_databases ]]
# What binding name to use (e.g. env.DB):
binding = "DB"
# The name of the DB (used for wrangler d1 commands):
database_name = "my-d1-database"
# The D1's ID for deployment:
database_id = "48a4224e-...3b09"
# Which D1 to use for `wrangler dev`:
# (can be the same as the previous line)
preview_database_id = "48a4224e-...3b09"
# NEW: adding "procedures", pointing to a new JS file:
procedures = "./src/db/procedures.js"
That D1 Procedures file would contain the following (note the new db.transaction() API, that is only available within a file like this):
export default class Procedures {
constructor(db, env, ctx) {
this.db = db
}
// any methods you define here are available on env.DB.Procedures
// inside your Worker
async Checkout(cartId: number) {
// Inside a Procedure, we have a new db.transaction() API
const result = await this.db.transaction(async (txn) => {
// Transaction has begun: we know the user can't add anything to
// their cart while these actions are in progress.
const [cart, user] = Helpers.loadCartAndUser(cartId)
// We can update the DB first, knowing that if any of the later steps
// fail, all these changes will be undone.
await this.db
.prepare(`UPDATE cart SET status = ?1 WHERE cart_id = ?2`)
.bind('purchased', cartId)
.run()
const newBalance = user.balance - cart.total_cost
await this.db
.prepare(`UPDATE user SET balance = ?1 WHERE user_id = ?2`)
// Note: the DB may have a CHECK to guarantee 'user.balance' can not
// be negative. In that case, this statement may fail, an exception
// will be thrown, and the transaction will be rolled back.
.bind(newBalance, cart.user_id)
.run()
// Once all the DB changes have been applied, attempt the payment:
const { ok, details } = await PaymentAPI.processPayment(
user.payment_method_id,
cart.total_cost
)
if (!ok) {
// If we throw an Exception, the transaction will be rolled back
// and result.error will be populated:
// throw new PaymentFailedError(details)
// Alternatively, we can do both of those steps explicitly
await txn.rollback()
// The transaction is rolled back, our DB is now as it was when we
// started. We can either move on and try something new, or just exit.
return { error: new PaymentFailedError(details) }
}
// This is implicitly called when the .transaction() block finishes,
// but you can explicitly call it too (potentially committing multiple
// times in a single db.transaction() block).
await txn.commit()
// Anything we return here will be returned by the
// db.transaction() block
return {
amount_charged: cart.total_cost,
remaining_balance: newBalance,
}
})
if (result.error) {
// Our db.transaction block returned an error or threw an exception.
}
// We're still in the Procedure, but the Transaction is complete and
// the DB is available for other writes. We can either do more work
// here (start another transaction?) or return a response to our Worker.
return result
}
}
And in your Worker, your DB binding now has a “Procedures” property with your function names available:
const { error, amount_charged, remaining_balance } =
await env.DB.Procedures.Checkout(params.cartId)
if (error) {
// Something went wrong, `error` has details
} else {
// Display `amount_charged` and `remaining_balance` to the user.
}
Multiple Procedures can be triggered at one time, but only one db.transaction() function can be active at once: any other write queries or other transaction blocks will be queued, but all read queries will continue to hit local replicas and run as normal. This API gives you the ability to ensure consistency when it’s essential but with the minimal impact on total overall performance worldwide.
Request for feedback
As with all our products, feedback from our users drives the roadmap and development. While the D1 API is in beta testing today, we’re still seeking feedback on the specifics. However, we’re pleased that it solves both the problems with transactions that are specific to D1 and the problems with stored procedures described earlier:
- Code is executing as close as possible to the database, removing network latency while a transaction is open.
- Any exceptions or cancellations of a transaction cause an instant rollback—there is no way to accidentally leave one open and block the whole D1 instance.
- The code is in the same language as the rest of your Worker code, in the exact same dialect (e.g. same TypeScript config as it’s part of the same build).
- It’s deployed seamlessly as part of your Worker. If two Workers bind to the same D1 instance but define different procedures, they’ll only see their own code. If you want to share code between projects or databases, extract a library as you would with any other shared code.
- In local development and test, the procedure works just like it does in production, but without the network call, allowing seamless testing and debugging as if it was a local function.
- Because procedures and the Worker that define them are treated as a single unit, rolling back to an earlier version never causes a skew between the code in the database and the code in the Worker.
The D1 ecosystem: contributions from the community
We’ve told you about what we’ve been up to and what’s ahead, but one of the unique things about this project is all the contributions from our users. One of our favorite parts of private betas is not only getting feedback and feature requests, but also seeing what ideas and projects come to fruition. While sometimes this means personal projects, with D1, we’re seeing some incredible contributions to the D1 ecosystem. Needless to say, the work on D1 hasn’t just been coming from within the D1 team, but also from the wider community and other developers at Cloudflare. Users have been showing off their D1 additions within our Discord private beta channel and giving others the opportunity to use them as well. We wanted to take a moment to highlight them.
workers-qb
Dealing with raw SQL syntax is powerful (and using the D1 .bind() API, safe against SQL injections) but it can be a little clumsy. On the other hand, most existing query builders assume direct access to the underlying DB, and so aren’t suitable to use with D1. So Cloudflare developer Gabriel Massadas designed a small, zero-dependency query builder called workers-qb:
import { D1QB } from 'workers-qb'
const qb = new D1QB(env.DB)
const fetched = await qb.fetchOne({
tableName: "employees",
fields: "count(*) as count",
where: {
conditions: "active = ?1",
params: [true]
},
})
Check out the project homepage for more information: https://workers-qb.massadas.com/.
D1 console
While you can interact with D1 through both Wrangler and the dashboard, Cloudflare Community champion, Isaac McFadyen created the very first D1 console where you can quickly execute a series of queries right through your terminal. With the D1 console, you don’t need to spend time writing the various Wrangler commands we’ve created – just execute your queries.
This includes all bells and whistles you would expect from a modern database console including multiline input, command history, validation for things D1 may not yet support, and ability to save your Cloudflare credentials for later use.
Check out the full project on GitHub or NPM for more information.
Miniflare test Integration
The Miniflare project, which powers Wrangler’s local development experience, also provides fully-fledged test environments for popular JavaScript test runners, Jest and Vitest. With this comes the concept of Isolated Storage, allowing each test to run independently, so that changes made in one don’t affect the others. Brendan Coll, creator of Miniflare, guided the D1 test implementation to give the same benefits:
import Worker from ‘../src/index.ts’
const { DB } = getMiniflareBindings();
beforeAll(async () => {
// Your D1 starts completely empty, so first you must create tables
// or restore from a schema.sql file.
await DB.exec(`CREATE TABLE entries (id INTEGER PRIMARY KEY, value TEXT)`);
});
// Each describe block & each test gets its own view of the data.
describe(‘with an empty DB’, () => {
it(‘should report 0 entries’, async () => {
await Worker.fetch(...)
})
it(‘should allow new entries’, async () => {
await Worker.fetch(...)
})
])
// Use beforeAll & beforeEach inside describe blocks to set up particular DB states for a set of tests
describe(‘with two entries in the DB’, () => {
beforeEach(async () => {
await DB.prepare(`INSERT INTO entries (value) VALUES (?), (?)`)
.bind(‘aaa’, ‘bbb’)
.run()
})
// Now, all tests will run with a DB with those two values
it(‘should report 2 entries’, async () => {
await Worker.fetch(...)
})
it(‘should not allow duplicate entries’, async () => {
await Worker.fetch(...)
})
])
All the databases for tests are run in-memory, so these are lightning fast. And fast, reliable testing is a big part of building maintainable real-world apps, so we’re thrilled to extend that to D1.
Want access to the private beta?
Feeling inspired?
We love to see what our beta users build or want to build especially when our products are at an early stage. As we march toward an open beta, we’ll be looking specifically for your feedback. We are slowly letting more folks into the beta, but if you haven’t received your “golden ticket” yet with access, sign up here! Once you’ve been invited in, you’ll receive an official welcome email.
As always, happy building!