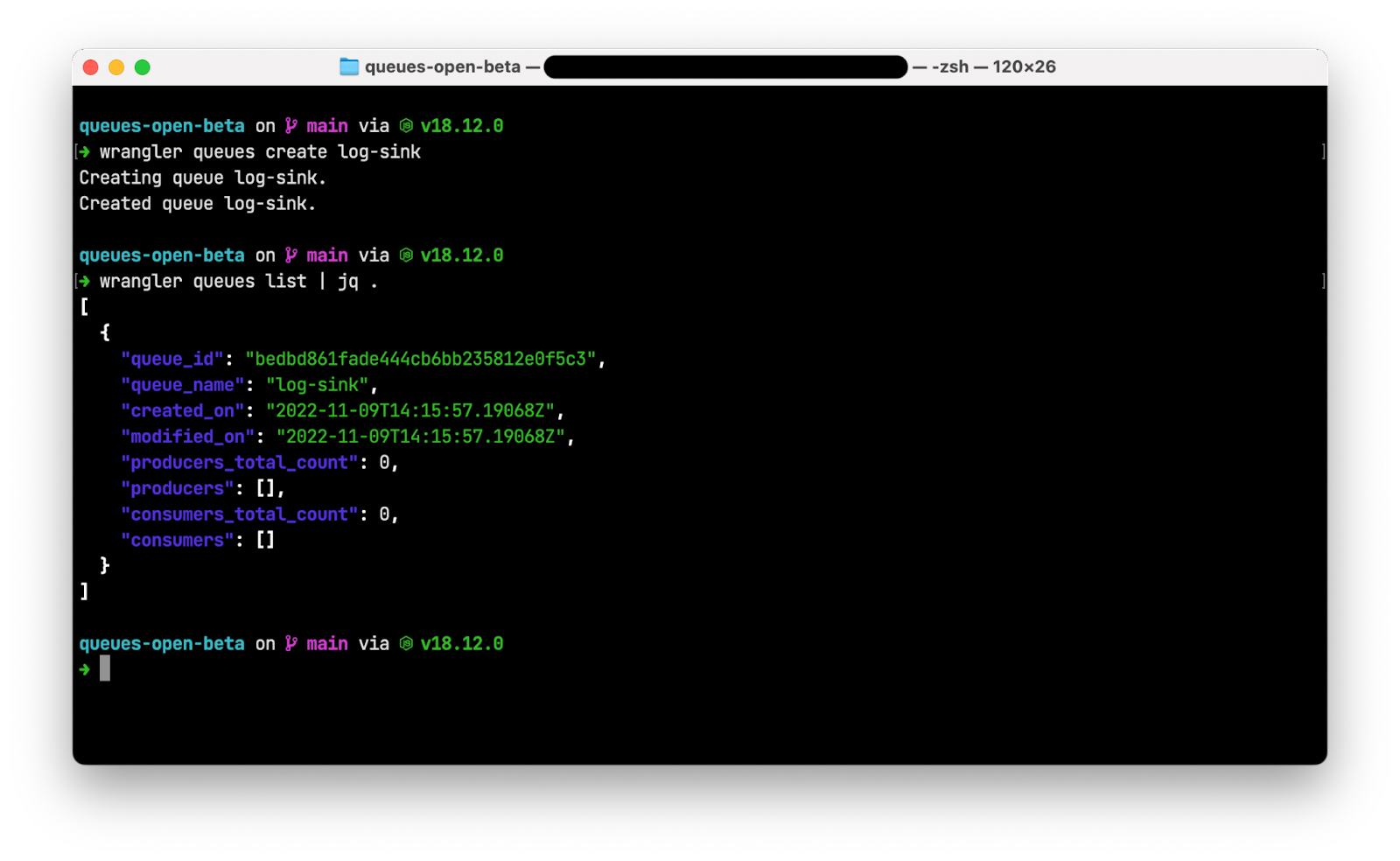
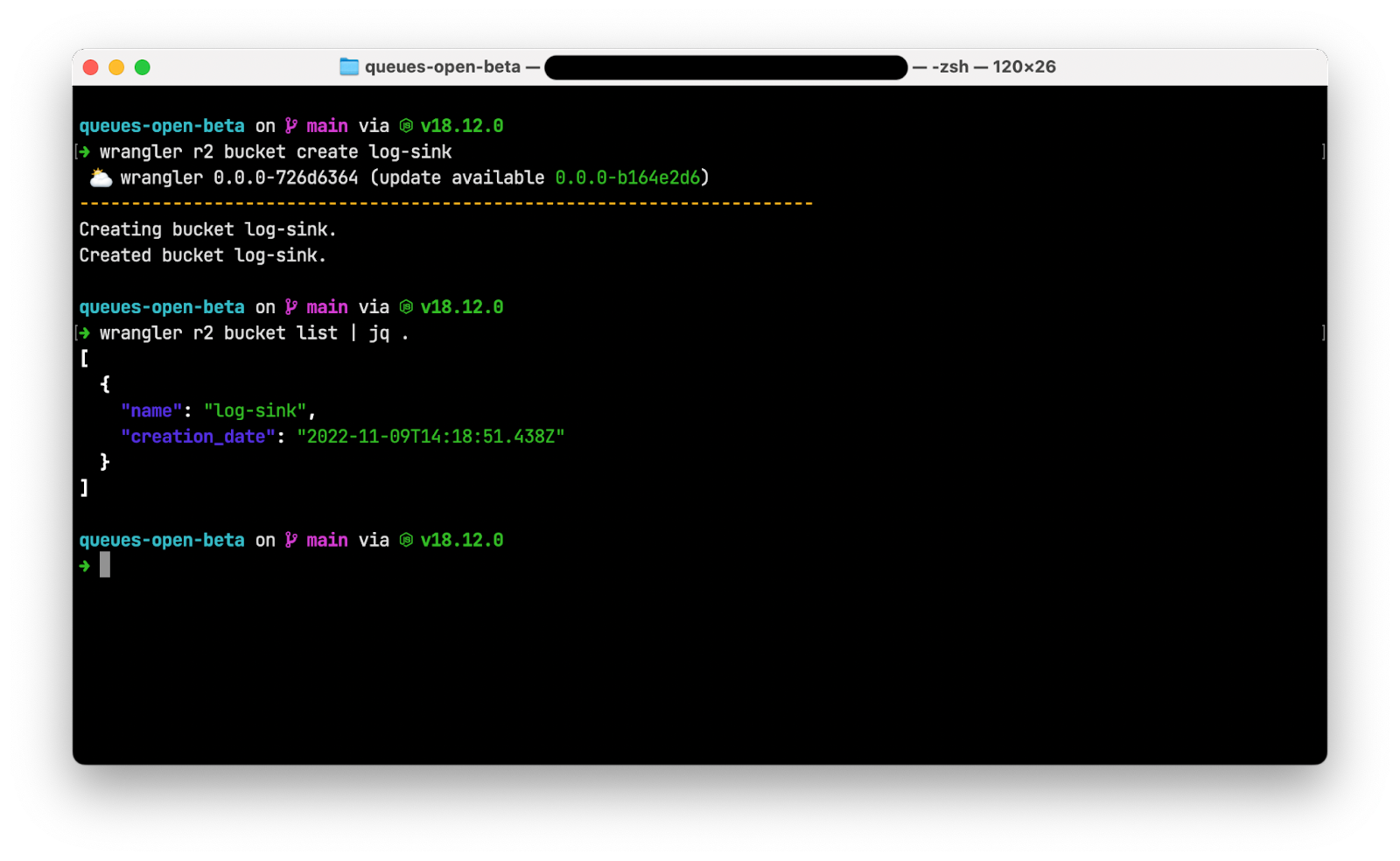
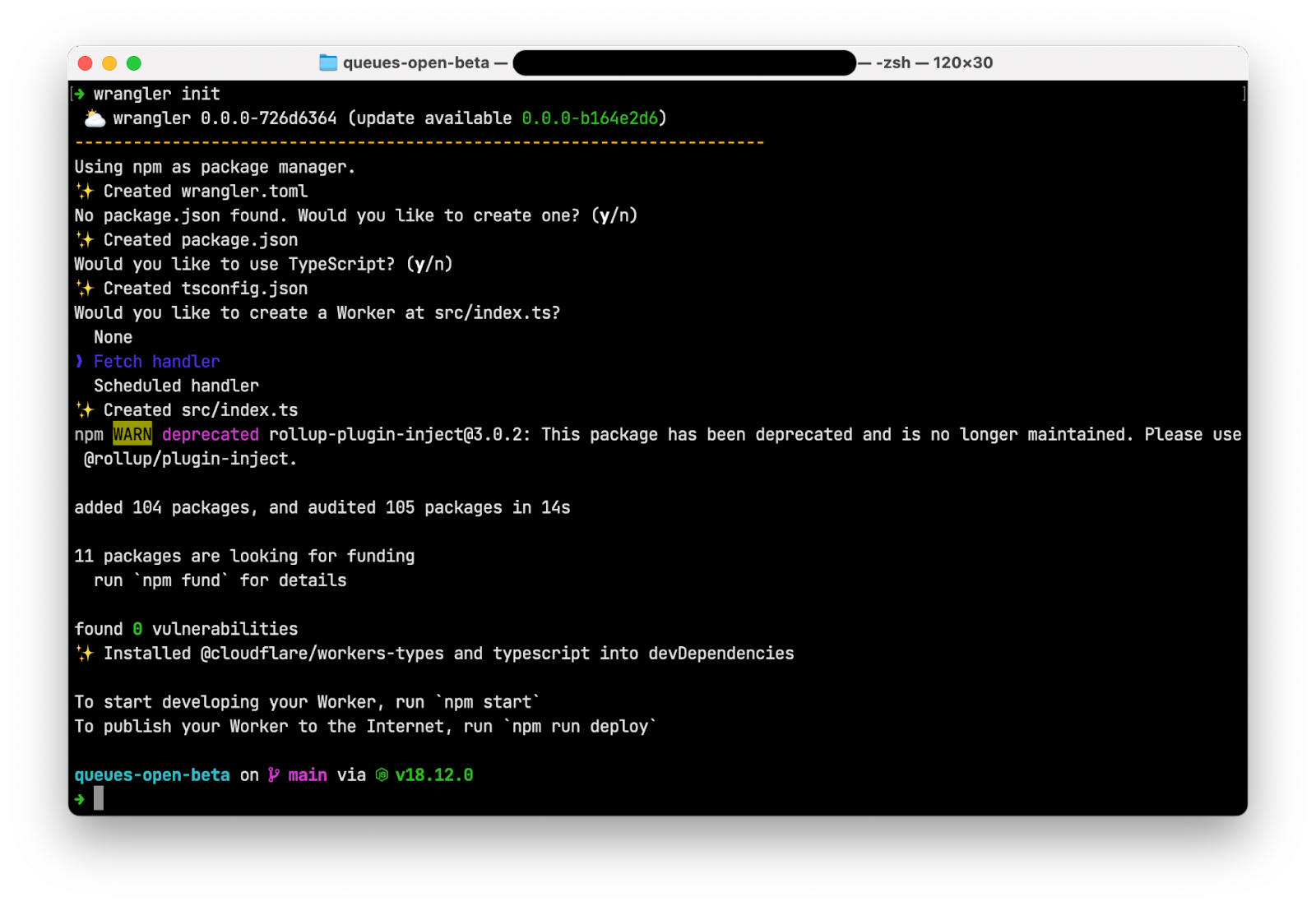
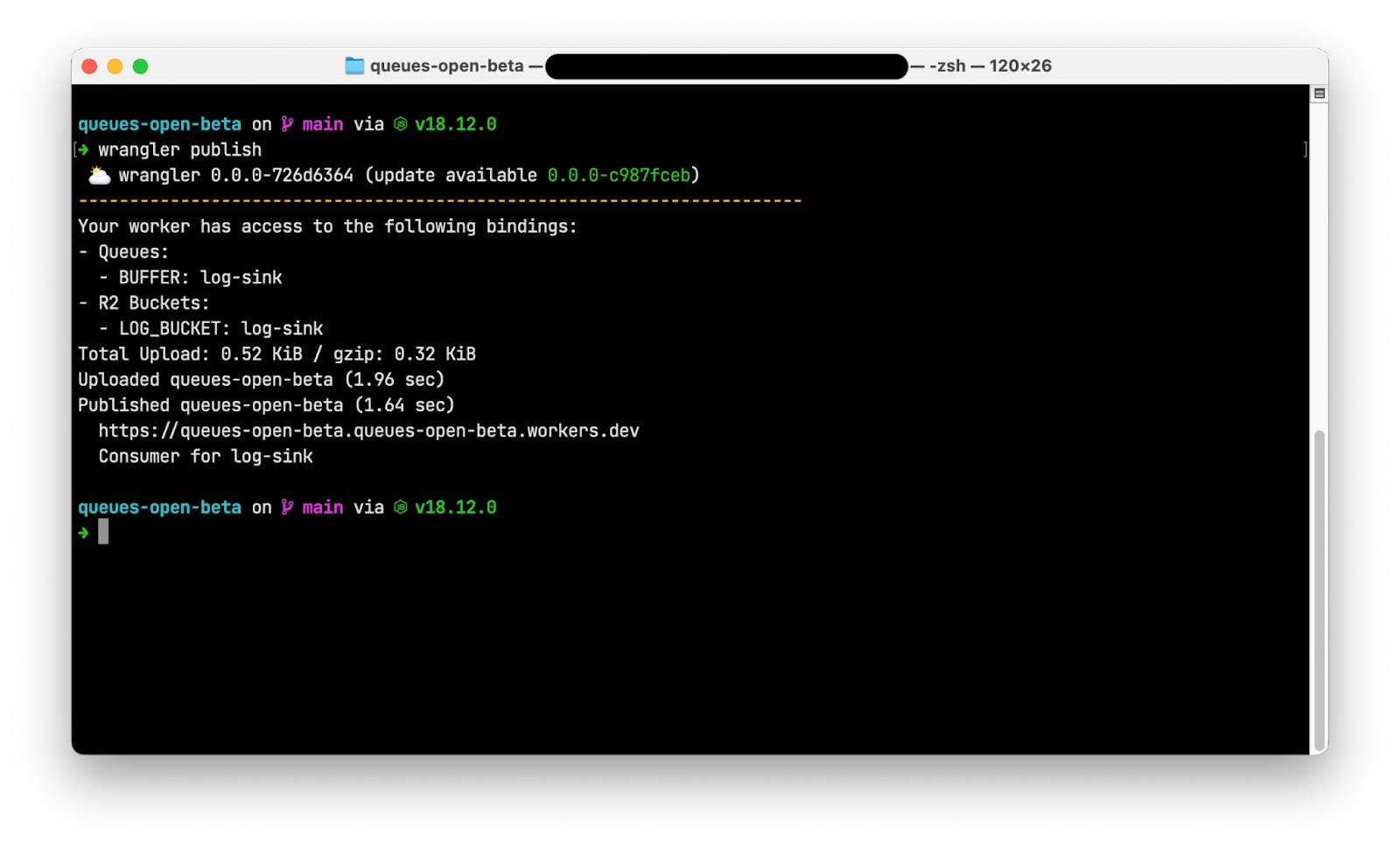
Post Syndicated from Peter Bacon Darwin original https://blog.cloudflare.com/fragment-piercing/
Bring micro-frontend benefits to legacy Web applications

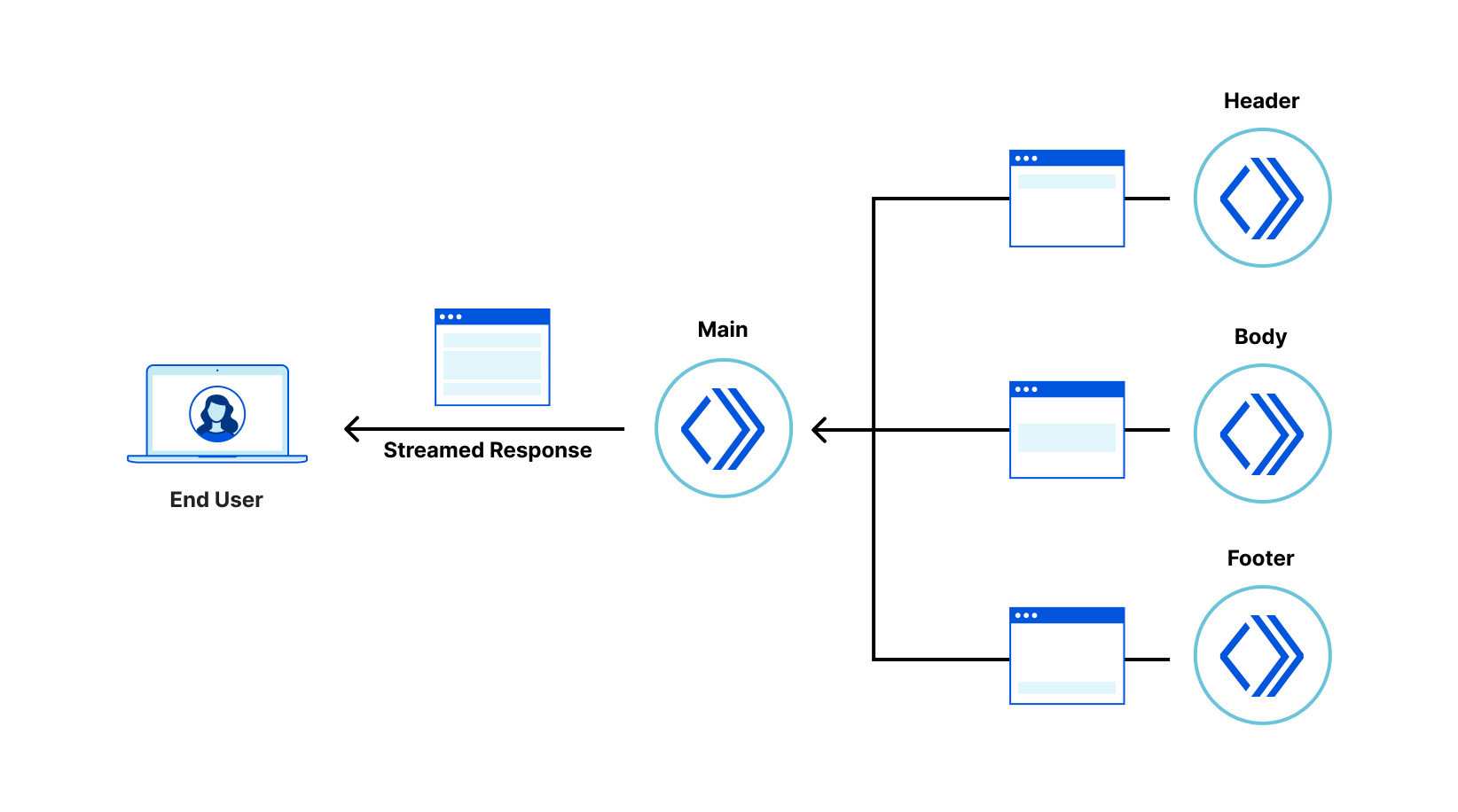
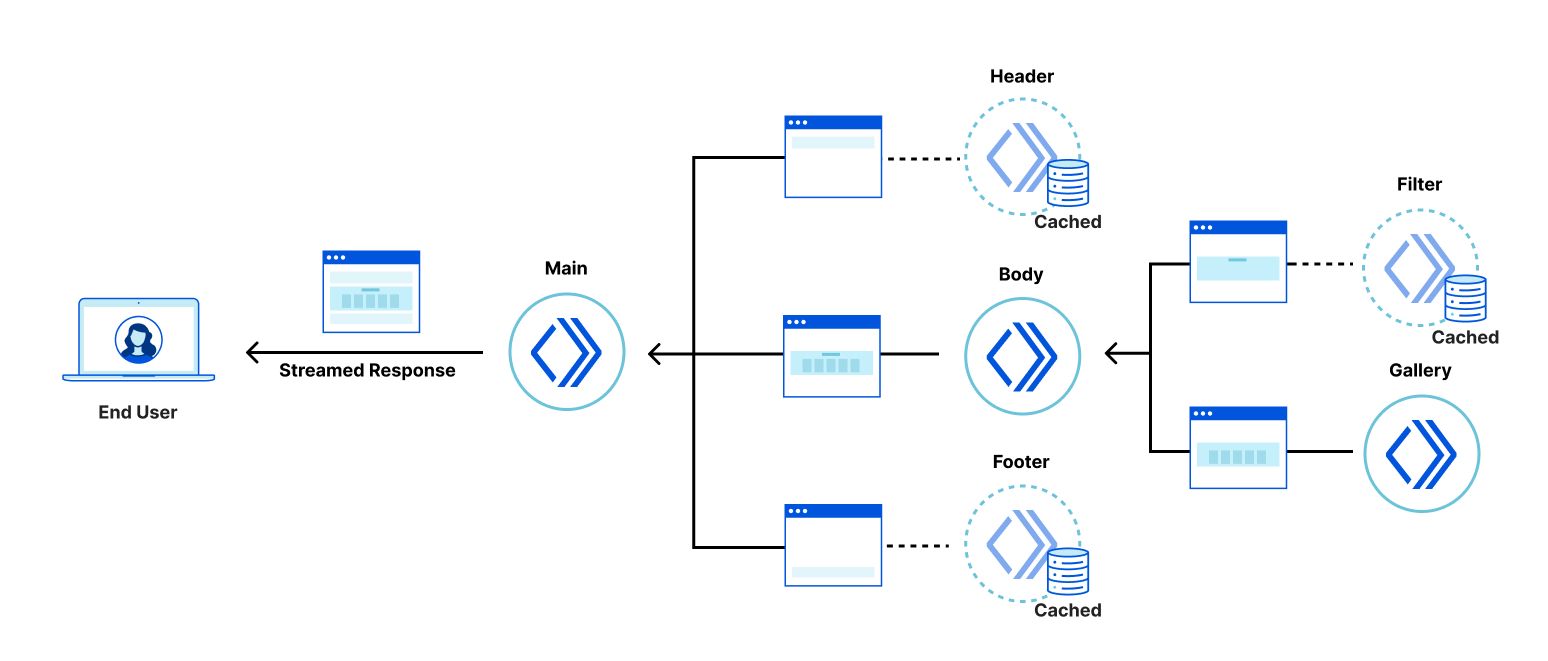
Recently, we wrote about a new fragment architecture for building Web applications that is fast, cost-effective, and scales to the largest projects, while enabling a fast iteration cycle. The approach uses multiple collaborating Cloudflare Workers to render and stream micro-frontends into an application that is interactive faster than traditional client-side approaches, leading to better user experience and SEO scores.
This approach is great if you are starting a new project or have the capacity to rewrite your current application from scratch. But in reality most projects are too large to be rebuilt from scratch and can adopt architectural changes only in an incremental way.
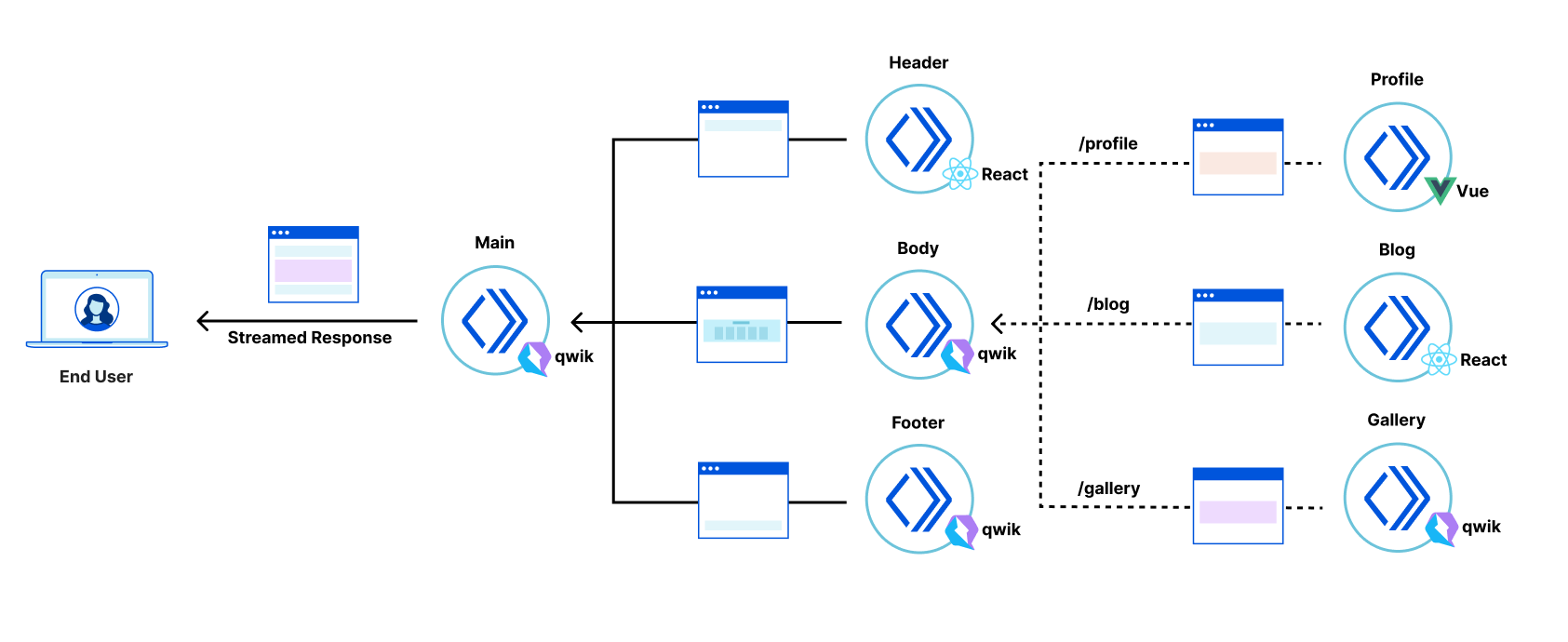
In this post we propose a way to replace only selected parts of a legacy client-side rendered application with server-side rendered fragments. The result is an application where the most important views are interactive sooner, can be developed independently, and receive all the benefits of the micro-frontend approach, while avoiding large rewrites of the legacy codebase. This approach is framework-agnostic; in this post we demonstrate fragments built with React, Qwik, and SolidJS.
The pain of large frontend applications
Many large frontend applications developed today fail to deliver good user experience. This is often caused by architectures that require large amounts of JavaScript to be downloaded, parsed and executed before users can interact with the application. Despite efforts to defer non-critical JavaScript code via lazy loading, and the use of server-side rendering, these large applications still take too long to become interactive and respond to the user’s inputs.
Furthermore, large monolithic applications can be complex to build and deploy. Multiple teams may be collaborating on a single codebase and the effort to coordinate testing and deployment of the project makes it hard to develop, deploy and iterate on individual features.
As outlined in our previous post, micro-frontends powered by Cloudflare Workers can solve these problems but converting an application monolith to a micro-frontend architecture can be difficult and expensive. It can take months, or even years, of engineering time before any benefits are perceived by users or developers.
What we need is an approach where a project can incrementally adopt micro-frontends into the most impactful parts of the application incrementally, without needing to rewrite the whole application in one go.
Fragments to the rescue
The goal of a fragment based architecture is to significantly decrease loading and interaction latency for large web applications (as measured via Core Web Vitals) by breaking the application into micro-frontends that can be quickly rendered (and cached) in Cloudflare Workers. The challenge is how to integrate a micro-frontend fragment into a legacy client-side rendered application with minimal cost to the original project.
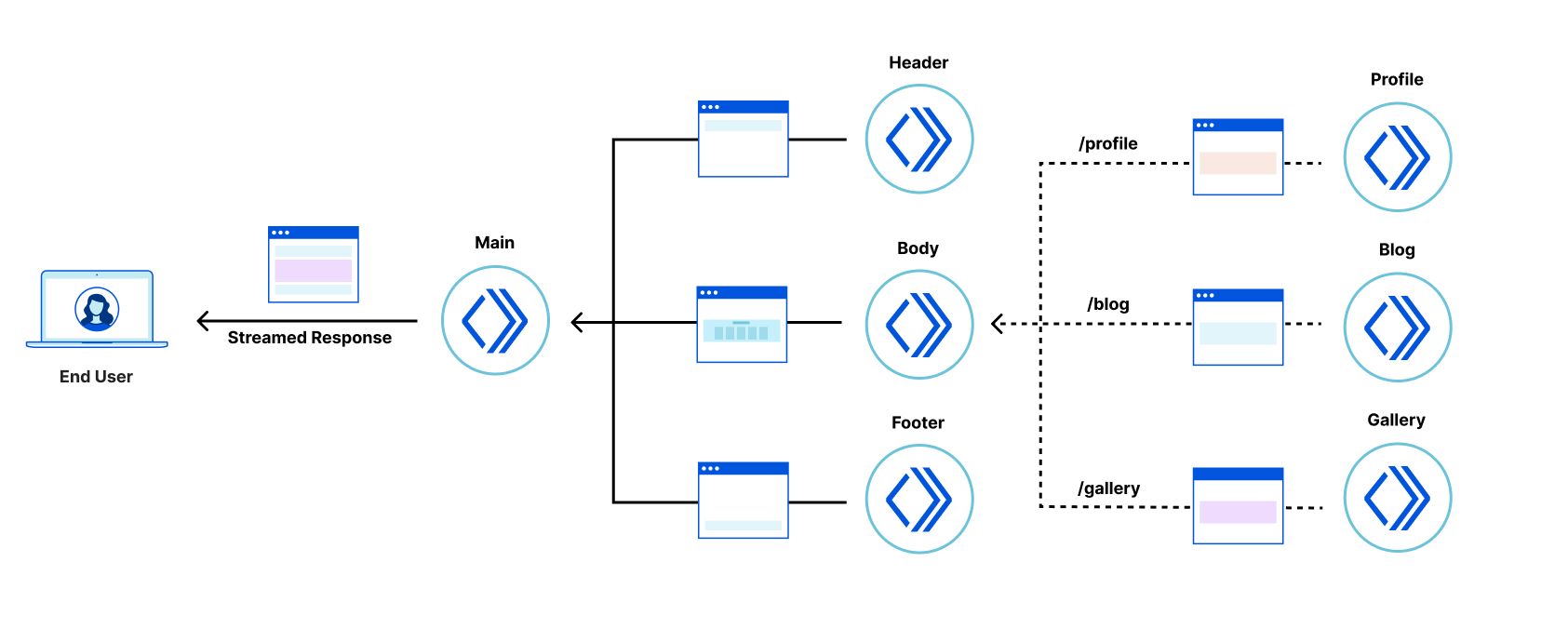
The technique we propose allows us to convert the most valuable parts of a legacy application’s UI, in isolation from the rest of the application.
It turns out that, in many applications, the most valuable parts of the UI are often nested within an application “shell” that provides header, footer, and navigational elements. Examples of these include a login form, product details panel in an e-commerce application, the inbox in an email client, etc.
Let’s take a login form as an example. If it takes our application several seconds to display the login form, the users will dread logging in, and we might lose them. We can however convert the login form into a server-side rendered fragment, which is displayed and interactive immediately, while the rest of the legacy application boots up in the background. Since the fragment is interactive early, the user can even submit their credentials before the legacy application has started and rendered the rest of the page.
This approach enables engineering teams to deliver valuable improvements to users in just a fraction of the time and engineering cost compared to traditional approaches, which either sacrifice user experience improvements, or require a lengthy and high-risk rewrite of the entire application. It allows teams with monolithic single-page applications to adopt a micro-frontend architecture incrementally, target the improvements to the most valuable parts of the application, and therefore front-load the return on investment.
An interesting challenge in extracting parts of the UI into server-side rendered fragments is that, once displayed in the browser, we want the legacy application and the fragments to feel like a single application. The fragments should be neatly embedded within the legacy application shell, keeping the application accessible by correctly forming the DOM hierarchy, but we also want the server-side rendered fragments to be displayed and become interactive as quickly as possible — even before the legacy client-side rendered application shell comes into existence. How can we embed UI fragments into an application shell that doesn’t exist yet? We resolved this problem via a technique we devised, which we call “fragment piercing”.
Fragment piercing
Fragment piercing combines HTML/DOM produced by server-side rendered micro-frontend fragments with HTML/DOM produced by a legacy client-side rendered application.
The micro-frontend fragments are rendered directly into the top level of the HTML response, and are designed to become immediately interactive. In the background, the legacy application is client-side rendered as a sibling of these fragments. When it is ready, the fragments are “pierced” into the legacy application – the DOM of each fragment is moved to its appropriate place within the DOM of the legacy application – without causing any visual side effects, or loss of client-side state, such as focus, form data, or text selection. Once “pierced”, a fragment can begin to communicate with the legacy application, effectively becoming an integrated part of it.
Here, you can see a “login” fragment and the empty legacy application “root” element at the top level of the DOM, before piercing.
<body>
<div id="root"></div>
<piercing-fragment-host fragment-id="login">
<login q:container...>...</login>
</piercing-fragment-host>
</body>
And here you can see that the fragment has been pierced into the “login-page” div in the rendered legacy application.
<body>
<div id="root">
<header>...</header>
<main>
<div class="login-page">
<piercing-fragment-outlet fragment-id="login">
<piercing-fragment-host fragment-id="login">
<login q:container...>...</login>
</piercing-fragment-host>
</piercing-fragment-outlet>
</div>
</main>
<footer>...</footer>
</div>
</body>
To keep the fragment from moving and causing a visible layout shift during this transition, we apply CSS styles that position the fragment in the same way before and after piercing.
At any time an application can be displaying any number of pierced fragments, or none at all. This technique is not limited only to the initial load of the legacy application. Fragments can also be added to and removed from an application, at any time. This allows fragments to be rendered in response to user interactions and client-side routing.
With fragment piercing, you can start to incrementally adopt micro-frontends, one fragment at a time. You decide on the granularity of fragments, and which parts of the application to turn into fragments. The fragments don’t all have to use the same Web framework, which can be useful when switching stacks, or during a post-acquisition integration of multiple applications.
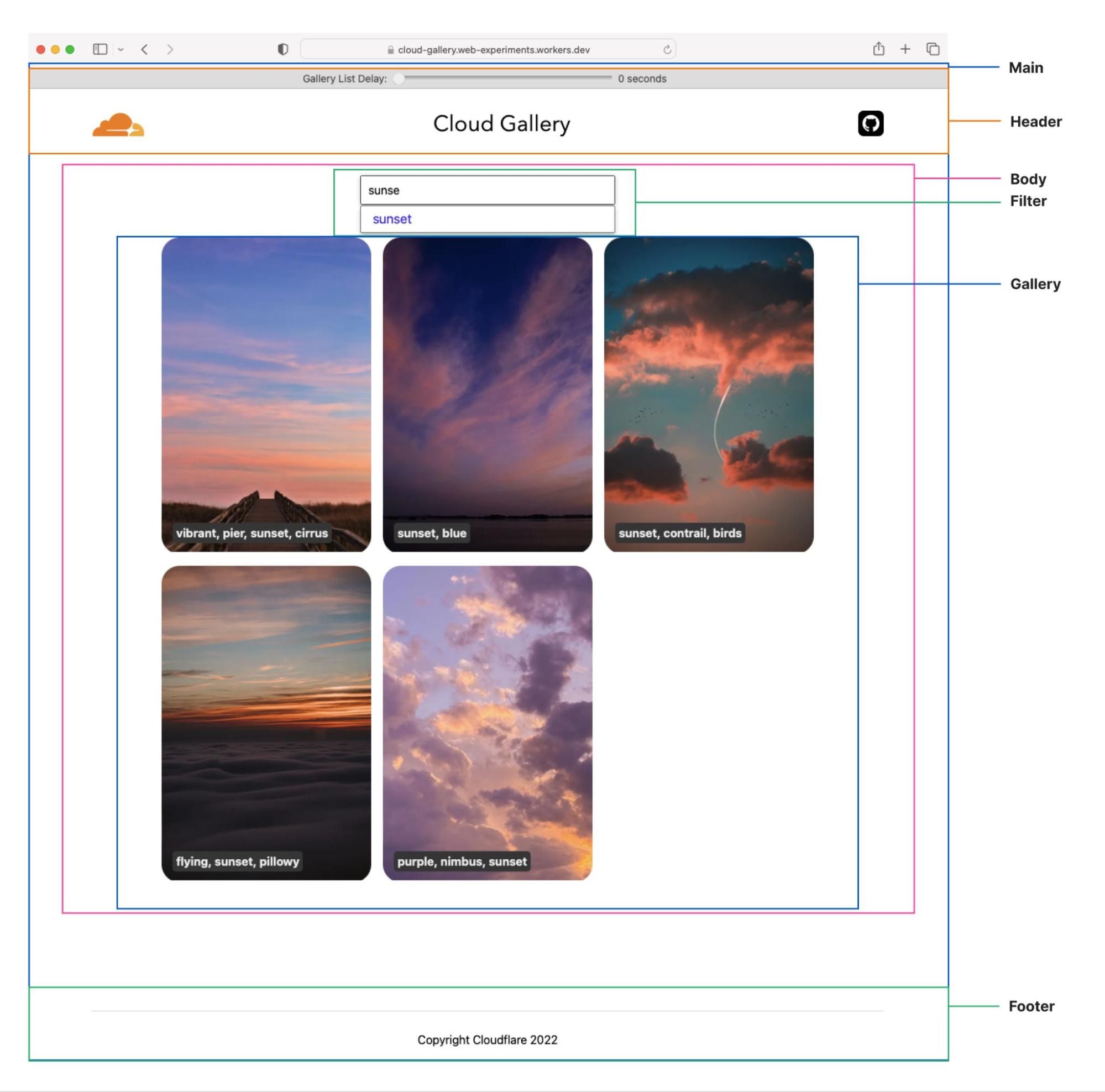
The “Productivity Suite” demo
As a demonstration of fragment piercing and incremental adoption we have developed a “productivity suite” demo application that allows users to manage to-do lists, read hacker news, etc. We implemented the shell of this application as a client-side rendered React application — a common tech choice in corporate applications. This is our “legacy application”. There are three routes in the application that have been updated to use micro-frontend fragments:
/login– a simple dummy login form with client-side validation, displayed when users are not authenticated (implemented in Qwik)./todos– manages one or more todo lists, implemented as two collaborating fragments:/news– a clone of the HackerNews demo (implemented in SolidJS).
This demo showcases that different independent technologies can be used for both the legacy application and for each of the fragments.
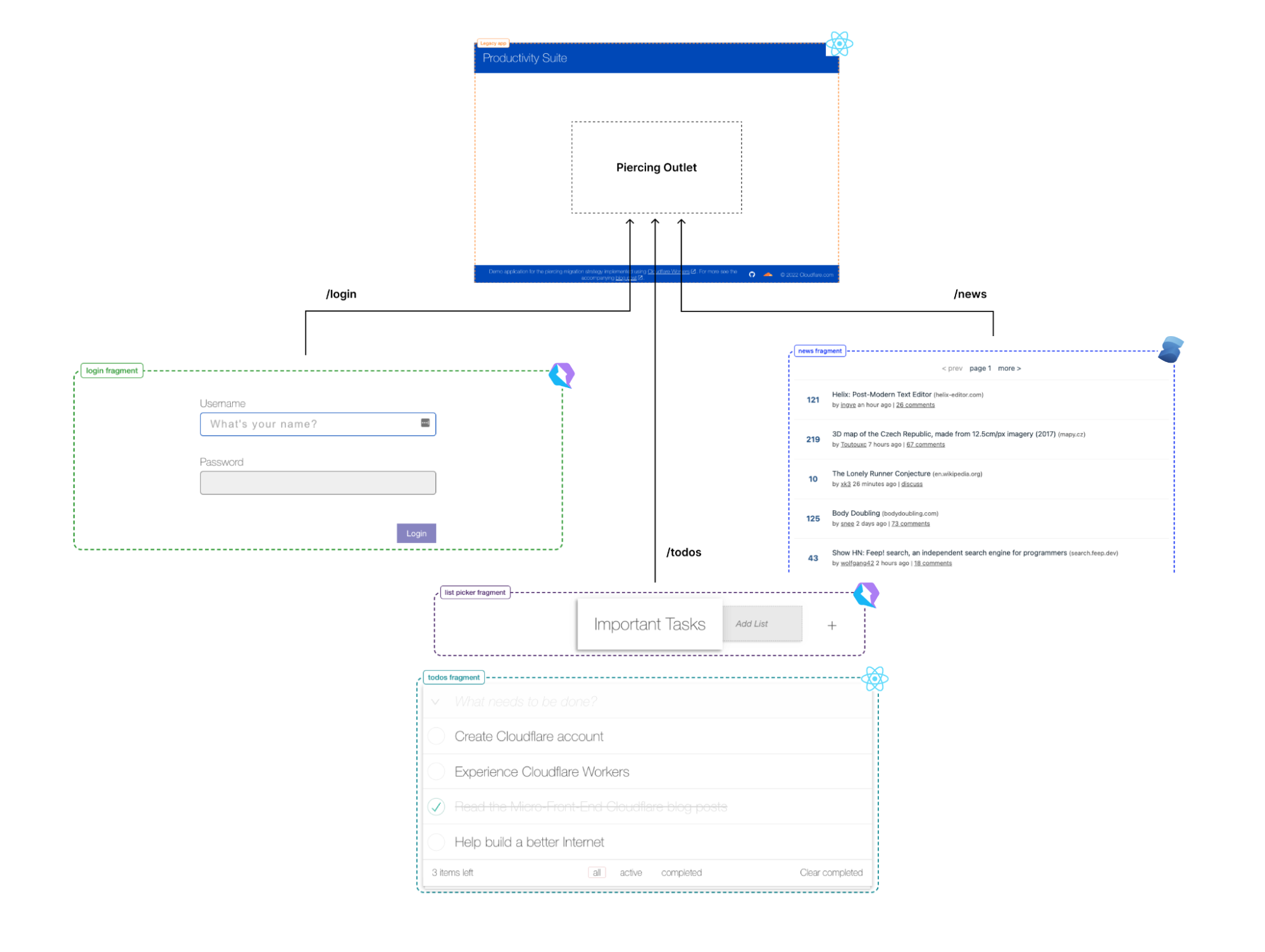
The application is deployed at https://productivity-suite.web-experiments.workers.dev/.
To try it out, you first need to log in – simply use any username you like (no password needed). The user’s data is saved in a cookie, so you can log out and back in using the same username. After you’ve logged in, navigate through the various pages using the navigation bar at the top of the application. In particular, take a look at the “Todo Lists” and “News” pages to see the piercing in action.
At any point, try reloading the page to see that fragments are rendered instantly while the legacy application loads slowly in the background. Try interacting with the fragments even before the legacy application has appeared!
At the very top of the page there are controls to let you see the impact of fragment piercing in action.

- Use the “Legacy app bootstrap delay” slider to set the simulated delay before the legacy application starts.
- Toggle “Piercing Enabled” to see what the user experience would be if the app did not use fragments.
- Toggle “Show Seams” to see where each fragment is on the current page.
How it works
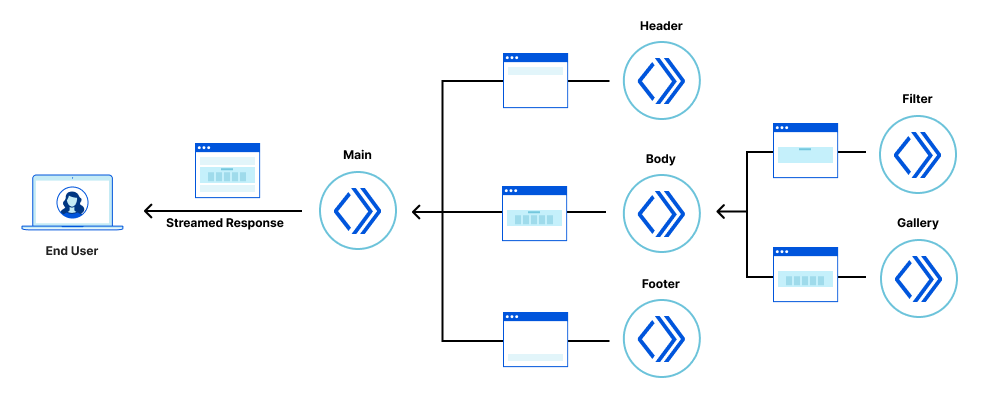
The application is composed of a number of building blocks.
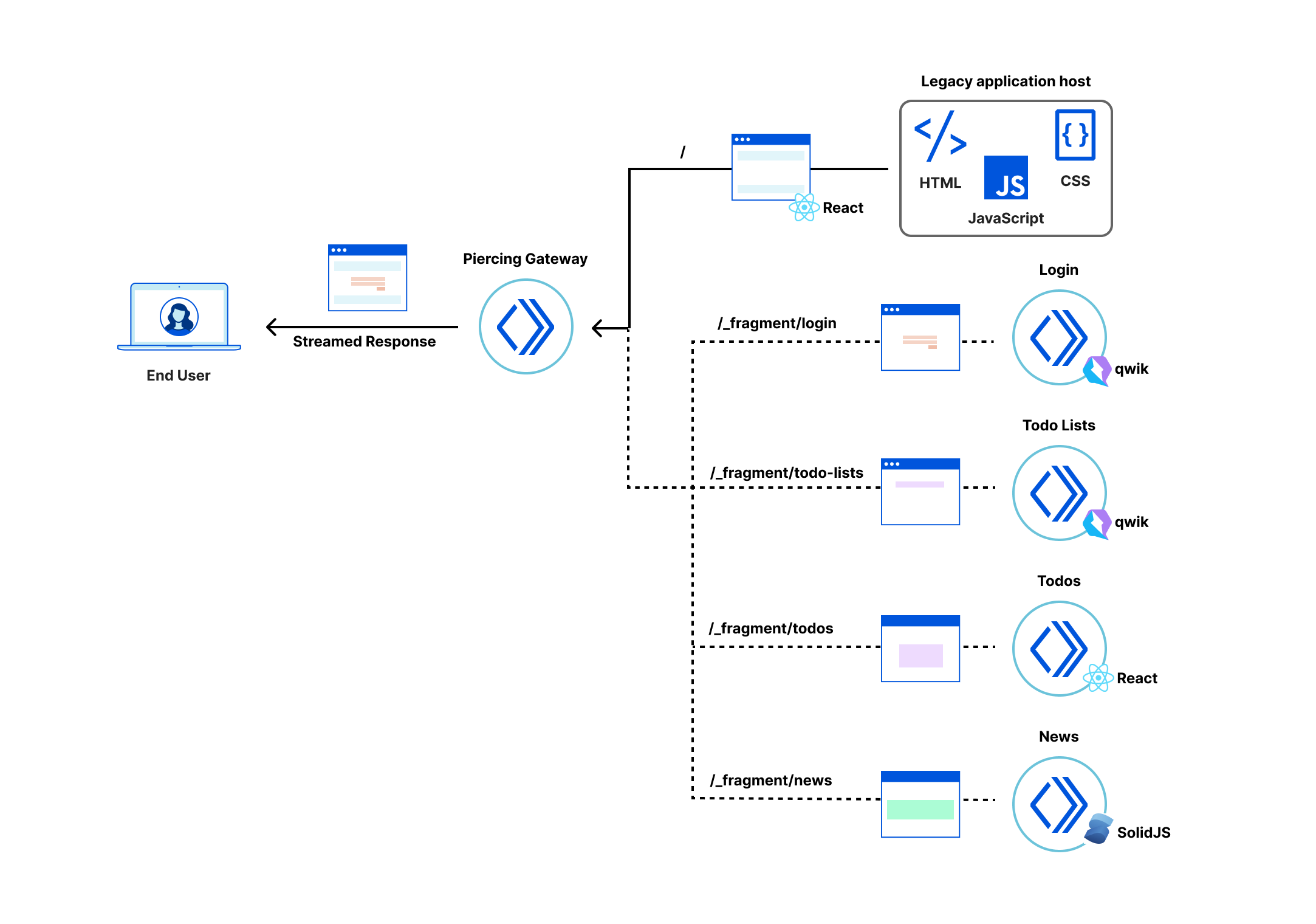
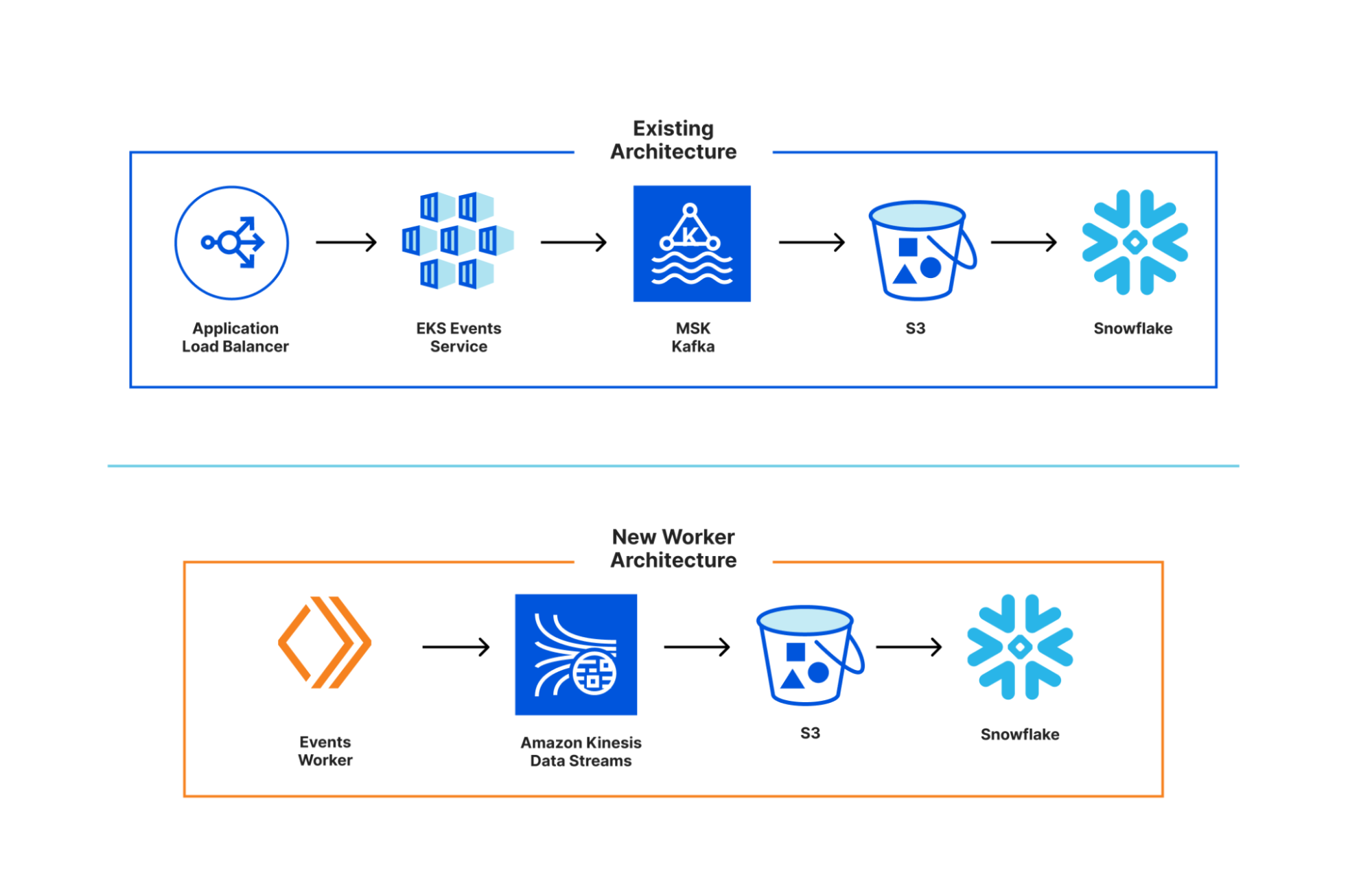
The Legacy application host in our demo serves the files that define the client-side React application (HTML, JavaScript and stylesheets). Applications built with other tech stacks would work just as well. The Fragment Workers host the micro-frontend fragments, as described in our previous fragment architecture post. And the Gateway Worker handles requests from the browser, selecting, fetching and combining response streams from the legacy application and micro-frontend fragments.
Once these pieces are all deployed, they work together to handle each request from the browser. Let’s look at what happens when you go to the `/login` route.
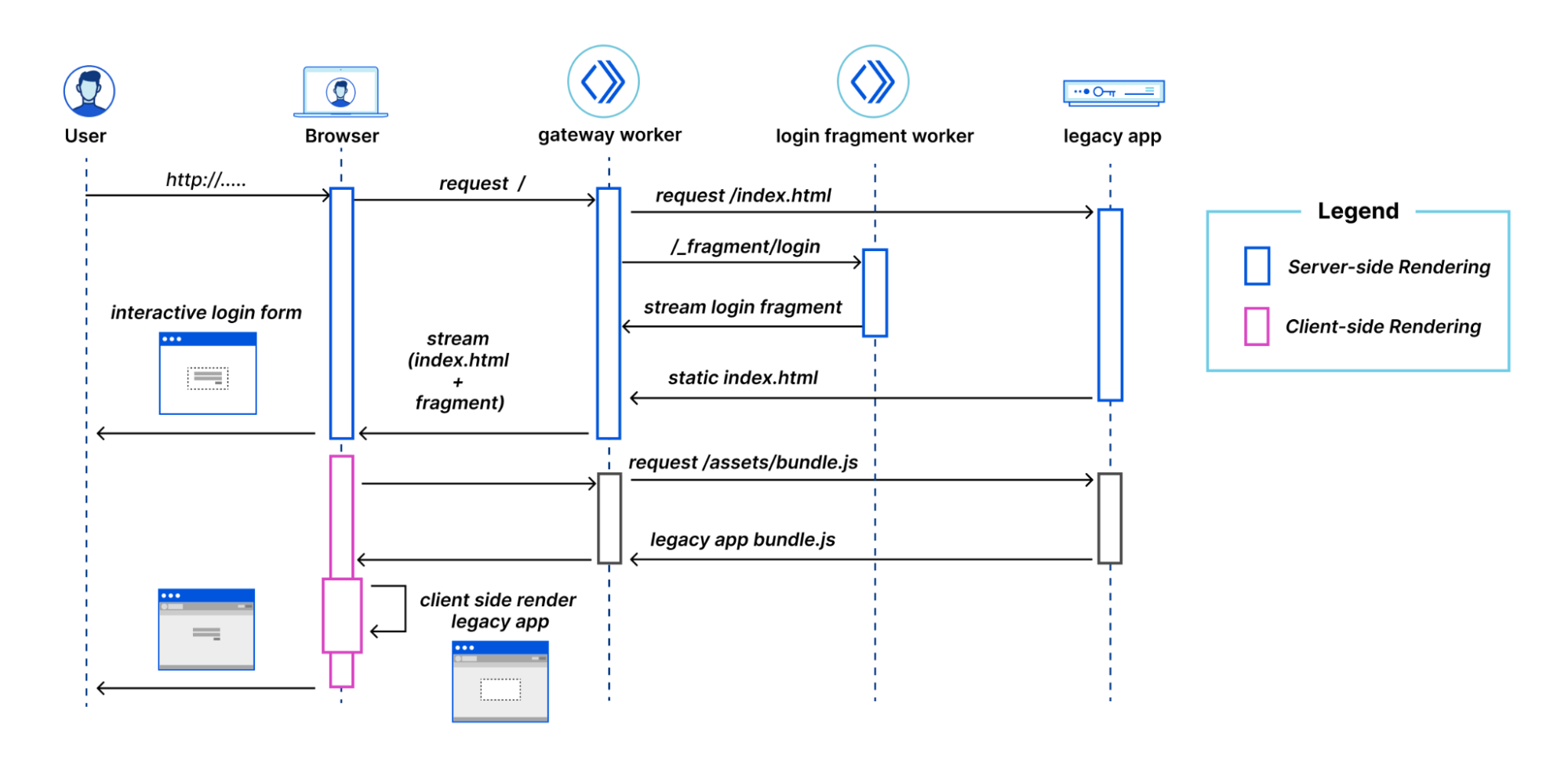
The user navigates to the application and the browser makes a request to the Gateway Worker to get the initial HTML. The Gateway Worker identifies that the browser is requesting the login page. It then makes two parallel sub-requests – one to fetch the index.html of the legacy application, and another to request the server-side rendered login fragment. It then combines these two responses into a single response stream containing the HTML that is delivered to the browser.
The browser displays the HTML response containing the empty root element for the legacy application, and the server-side rendered login fragment, which is immediately interactive for the user.
The browser then requests the legacy application’s JavaScript. This request is proxied by the Gateway Worker to the Legacy application host. Similarly, any other assets for the legacy application or fragments get routed through the Gateway Worker to the legacy application host or appropriate Fragment Worker.
Once the legacy application’s JavaScript has been downloaded and executed, rendering the shell of the application in the process, the fragment piercing kicks in, moving the fragment into the appropriate place in the legacy application, while preserving all of its UI state.
While focussed on the login fragment to explain fragment piercing, the same ideas apply to the other fragments implemented in the /todos and /news routes.
The piercing library
Despite being implemented using different Web frameworks, all the fragments are integrated into the legacy application in the same way using helpers from a “Piercing Library”. This library is a collection of server-side and client-side utilities that we developed, for the demo, to handle integrating the legacy application with micro-frontend fragments. The main features of the library are the PiercingGateway class, fragment host and fragment outlet custom elements, and the MessageBus class.
PiercingGateway
The PiercingGateway class can be used to instantiate a Gateway Worker that handles all requests for our application’s HTML, JavaScript and other assets. The `PiercingGateway` routes requests through to the appropriate Fragment Workers or to the host of the Legacy Application. It also combines the HTML response streams from these fragments with the response from the legacy application into a single HTML stream that is returned to the browser.
Implementing a Gateway Worker is straightforward using the Piercing Library. Create a new gateway instance of PiercingGateway, passing it the URL to the legacy application host and a function to determine whether piercing is enabled for the given request. Export the gateway as the default export from the Worker script so that the Workers runtime can wire up its fetch() handler.
const gateway = new PiercingGateway<Env>({
// Configure the origin URL for the legacy application.
getLegacyAppBaseUrl: (env) => env.APP_BASE_URL,
shouldPiercingBeEnabled: (request) => ...,
});
...
export default gateway;
Fragments can be registered by calling the registerFragment() method so that the gateway can automatically route requests for a fragment’s HTML and assets to its Fragment Worker. For example, registering the login fragment would look like:
gateway.registerFragment({
fragmentId: "login",
prePiercingStyles: "...",
shouldBeIncluded: async (request) => !(await isUserAuthenticated(request)),
});
Fragment host and outlet
Routing requests and combining HTML responses in the Gateway Worker is only half of what makes piercing possible. The other half needs to happen in the browser where the fragments need to be pierced into the legacy application using the technique we described earlier.
The fragment piercing in the browser is facilitated by a pair of custom elements, the fragment host (<piercing-fragment-host>) and the fragment outlet (<piercing-fragment-outlet>).
The Gateway Worker wraps the HTML for each fragment in a fragment host. In the browser, the fragment host manages the life-time of the fragment and is used when moving the fragment’s DOM into position in the legacy application.
<piercing-fragment-host fragment-id="login">
<login q:container...>...</login>
</piercing-fragment-host>
In the legacy application, the developer marks where a fragment should appear when it is pierced by adding a fragment outlet. Our demo application’s Login route looks as follows:
export function Login() {
…
return (
<div className="login-page" ref={ref}>
<piercing-fragment-outlet fragment-id="login" />
</div>
);
}
When a fragment outlet is added to the DOM, it searches the current document for its associated fragment host. If found, the fragment host and its contents are moved inside the outlet. If the fragment host is not found, the outlet will make a request to the gateway worker to fetch the fragment HTML, which is then streamed directly into the fragment outlet, using the writable-dom library (a small but powerful library developed by the MarkoJS team).
This fallback mechanism enables client-side navigation to routes that contain new fragments. This way fragments can be rendered in the browser via both initial (hard) navigation and client-side (soft) navigation.
Message bus
Unless the fragments in our application are completely presentational or self-contained, they also need to communicate with the legacy application and other fragments. The MessageBus is a simple asynchronous, isomorphic, and framework-agnostic communication bus that the legacy application and each of the fragments can access.
In our demo application the login fragment needs to inform the legacy application when the user has authenticated. This message dispatch is implemented in the Qwik LoginForm component as follows:
const dispatchLoginEvent = $(() => {
getBus(ref.value).dispatch("login", {
username: state.username,
password: state.password,
});
state.loading = true;
});
The legacy application can then listen for these messages like this:
useEffect(() => {
return getBus().listen<LoginMessage>("login", async (user) => {
setUser(user);
await addUserDataIfMissing(user.username);
await saveCurrentUser(user.username);
getBus().dispatch("authentication", user);
navigate("/", { replace: true, });
});
}, []);
We settled on this message bus implementation because we needed a solution that was framework-agnostic, and worked well on both the server as well as client.
Give it a go!
With fragments, fragment piercing, and Cloudflare Workers, you can improve performance as well as the development cycle of legacy client-side rendered applications. These changes can be adopted incrementally, and you can even do so while implementing fragments with a Web framework for your choice.
The “Productivity Suite” application demonstrating these capabilities can be found at https://productivity-suite.web-experiments.workers.dev/.
All the code we have shown is open-source and published to Github: https://github.com/cloudflare/workers-web-experiments/tree/main/productivity-suite.
Feel free to clone the repository. It is easy to run locally and even deploy your own version (for free) to Cloudflare. We tried to make the code as reusable as possible. Most of the core logic is in the piercing library that you could try in your own projects. We’d be thrilled to receive feedback, suggestions, or hear about applications you’d like to use it for. Join our GitHub discussion or also reach us on our discord channel.
We believe that combining Cloudflare Workers with the latest ideas from frameworks will drive the next big steps forward in improved experiences for both users and developers in Web applications. Expect to see more demos, blog posts and collaborations as we continue to push the boundaries of what the Web can offer. And if you’d also like to be directly part of this journey, we are also happy to share that we are hiring!