I’m delighted to be joining Cloudflare as Vice President of Sales in the US, Canada, and Latin America.
I’ve had the privilege of leading sales for some of the world’s most iconic tech companies, including IBM and Cisco. During my career I’ve led international teams numbering in the thousands and driving revenue in the billions of dollars while serving some of the world’s largest enterprise customers. I’ve seen first-hand the evolution of technology and what it can achieve for businesses, from robotics, automation, and data analytics, to cloud computing, cybersecurity, and AI.
I firmly believe Cloudflare is well on its way to being one of the next iconic tech companies.
Why Cloudflare
Cloudflare has a unique opportunity to help businesses navigate an enduring wave of technological change. There are few companies in the world that operate in the three most exciting fields of innovation that will continue to shape our world in the coming years: cloud computing, AI, and cybersecurity. Cloudflare is one of those companies. When I was approached for this role, I spoke to a wide range of connections across the financial sector, private companies, and government. The feedback was unanimous that Cloudflare is poised on the edge of exhilarating growth.
Driving predictable, profitable revenue
I was fortunate to join Cisco two years after its annual revenue passed the $1 billion mark and had the privilege of helping scale the business to more than $49 billion in revenue the year I left. Cloudflare passed the $1 billion milestone just last year, and I see the same potential for growth here as I saw at Cisco.
Cloudflare’s global sales organization is growing. I’m excited to help accelerate that process in a way that delivers recurring revenue for the business while ensuring we retain a very high bar in terms of the talent we bring onto the team. My experience leading complex, cross-functional sales organizations within large global companies has taught me a great deal about the common traits among highly effective sales functions.
The groups of individuals that come together to make true teams are the ones that successfully focus on a unifying goal and develop skills like communication, attitude, process, organization, consistency, collaboration, partnership, and accountability. These teams embrace diversity and bring out of each other the best expertise, creativity, and skills, making the team stronger and keeping the goal in focus.
Making our customers our north star
We will achieve the opportunity ahead of us only as long as we have our customers as our north star. Today, the Americas represent more than half of Cloudflare’s revenue worldwide and are home to some of our largest and most strategic customers – both in the private and public sectors – including 30% of the Fortune 1000. Brands from Zendesk to Shopify and from Colgate-Palmolive to Mars rely on Cloudflare to operate their businesses in a fast, secure, and reliable way.
Whatever the technology, there are three common fundamentals I’ve found essential to creating value for customers: being the expert on their challenges, understanding how to pick the right combination of products, services, and solutions from those available, and knowing your competition.
Cloudflare already has an incredible and growing range of products and services that are helping millions of individuals and organizations maximize the opportunities presented by cloud computing and generative AI, all while staying safe from the threat of cyberattacks.
What helping to build a better Internet means to me
If it were needed, one additional deciding factor behind my excitement in joining Cloudflare is its ambitious mission to help build a better Internet. As a father, I want the Internet to be a safe and valuable resource for my family and friends and for generations to come. I don’t want my daughter to have to worry about her personal data and privacy as she’s buying Billie Eilish concert tickets online (and, yes, I’m going too).
Today Cloudflare’s connectivity cloud protects nearly 20% of all websites online and stops 209 billion cyber attacks daily. In addition to its growing customer base, Cloudflare is living up to its mission by offering its services for free to millions more individuals and small businesses, including the most vulnerable voices online through its Project Galileo initiative.
The combination of a strong mission, genuine values, a great team, and incredible technology isn’t a given in every company, but is evident at Cloudflare. I’m excited to play a part as Cloudflare continues to scale its business and help build a better Internet for everyone.
If you’re interested in learning more about what Cloudflare can do for your organization, please get in touch here. If you’re an ambitious, talented sales professional looking for your next challenging and rewarding career move, check out our open positions here.
2023 was the first year that non-participating countries could vote for their favorites during the Eurovision Song Contest, adding millions of additional viewers and voters to an already impressive 162 million tuning in from the participating countries. It became a truly global event with a potential for disruption from multiple sources. To prepare for anything, Cloudflare helped scale and protect the voting application, used by millions of dedicated fans around the world to choose the winner.
In this blog we will cover how once.net built their platform based.io to monitor, manage and scale the Eurovision voting application to handle all traffic using many Cloudflare services. The speed with which DNS changes made through the Cloudflare API propagate globally allowed them to scale their backend within seconds. At the same time, Cloudflare Pages was ready to serve any amount of traffic to the voting landing page so fans didn’t miss a beat. And to cap it off, by combining Cloudflare CDN, DDoS protection, WAF, and Turnstile, they made sure that attackers didn’t steal any of the limelight.
The unsung heroes
Based.iois a resilient live data platform built by the once.net team, with the capability to scale up to 400 million concurrent connected users. It’s built from the ground up for speed and performance, consisting of an observable real time graph database, networking layer, cloud functions, analytics and infrastructure orchestration. Since all system information, traffic analysis and disruptions are monitored in real time, it makes the platform instantly responsive to variable demand, which enables real time scaling of your infrastructure during spikes, outages and attacks.
Although the based.io platform on its own is currently in closed beta, it is already serving a few flagship customers in production assisted by the software and services of the once.net team. One such customer is Tally, a platform used by multiple broadcasters in Europe to add live interaction to traditional television. Over 100 live shows have been performed using the platform. Another is Airhub, a startup that handles and logs automatic drone flights. And of course the star of this blog post, the Eurovision Song Contest.
Setting the stage
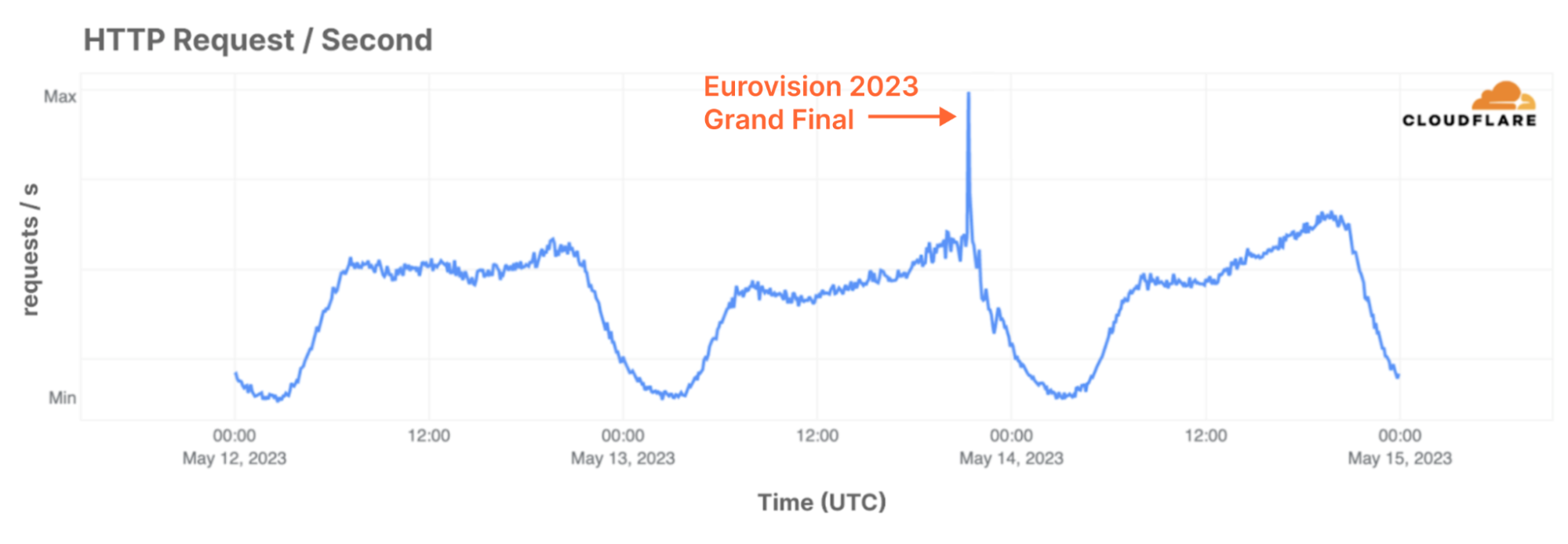
The Eurovision Song Contest is one of the world’s most popular broadcasted contests, and this year it reached 162 million people across 38 broadcasting countries. In addition, on TikTok the three live shows were viewed 4.8 million times, while 7.6 million people watched the Grand Final live on YouTube. With such an audience, it is no surprise that Cloudflare sees the impact of it on the Internet. Last year, we wrote a blog post where we showed lower than average traffic during, and higher than average traffic after the grand final. This year, the traffic from participating countries showed an even more remarkable surge:
HTTP Requests per Second from Norway, with a similar pattern visible in countries such as the UK, Sweden and France. Internet traffic spiked at 21:20 UTC, when voting started.
Such large amounts of traffic are nothing new to the Eurovision Song Contest. Eurovision has relied on Cloudflare’s services for over a decade now and Cloudflare has helped to protect Eurovision.tv and improve its performance through noticeable faster load time to visitors from all corners of the world. Year after year, the team of Eurovision continued to use our services more, discovering additional features to improve performance and reliability further, with increasingly fine-grained control over their traffic flows. Eurovision.tv uses Page Rules to cache additional content on Cloudflare’s edge, speeding up delivery without sacrificing up-to-the-minute updates during the global event. Finally, to protect their backend and content management system, the team has placed their admin portals behind Cloudflare Zero Trust to delegate responsibilities down to individual levels.
Since then the contest itself has also evolved – sometimes by choice, sometimes by force. During the COVID-19 pandemic in-person cheering became impossible for many people due to a reduced live audience, resulting in the Eurovision Song Contest asking once.net to build a new iOS and Android application in which fans could cheer virtually. The feature was an instant hit, and it was clear that it would become part of this year’s contest as well.
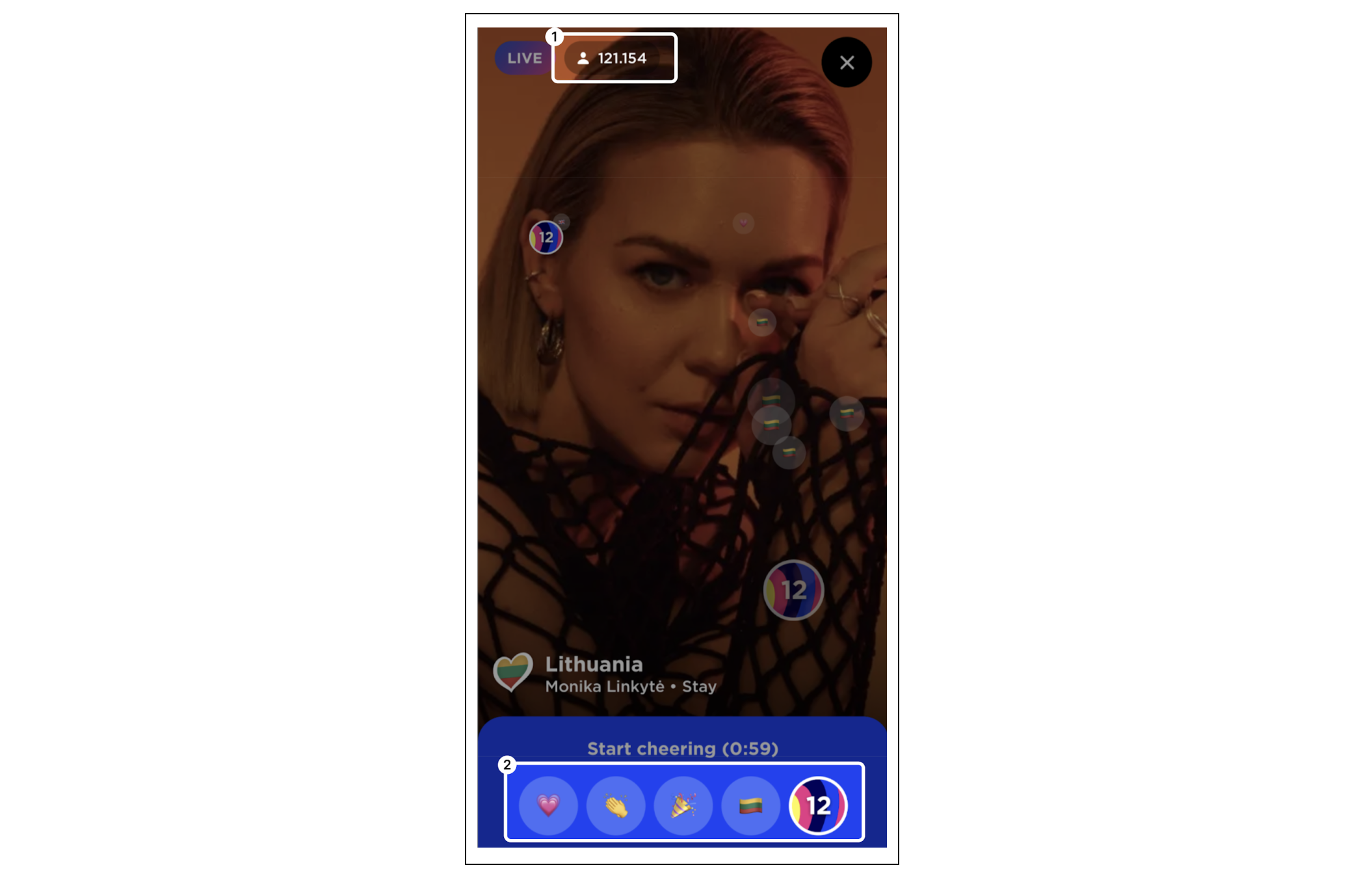
A screenshot of the official Eurovision Song Contest application showing the real-time number of connected fans (1) and allowing them to cheer (2) for their favorites.
In 2023, once.net was also asked to handle the paid voting from the regions where phone and SMS voting was not possible. It was the first time that Eurovision allowed voting online. The challenge that had to be overcome was the extreme peak demand on the platform when the show was live, and especially when the voting window started.
Complicating it further, was the fact that during last year’s show, there had been a large number of targeted and coordinated attacks.
To prepare for these spikes in demand and determined adversaries, once.net needed a platform that isn’t only resilient and highly scalable, but could also act as a mitigation layer in front of it. once.net selected Cloudflare for this functionality and integrated Cloudflare deeply with its real-time monitoring and management platform. To understand how and why, it’s essential to understand based.io underlying architecture.
The based.io platform
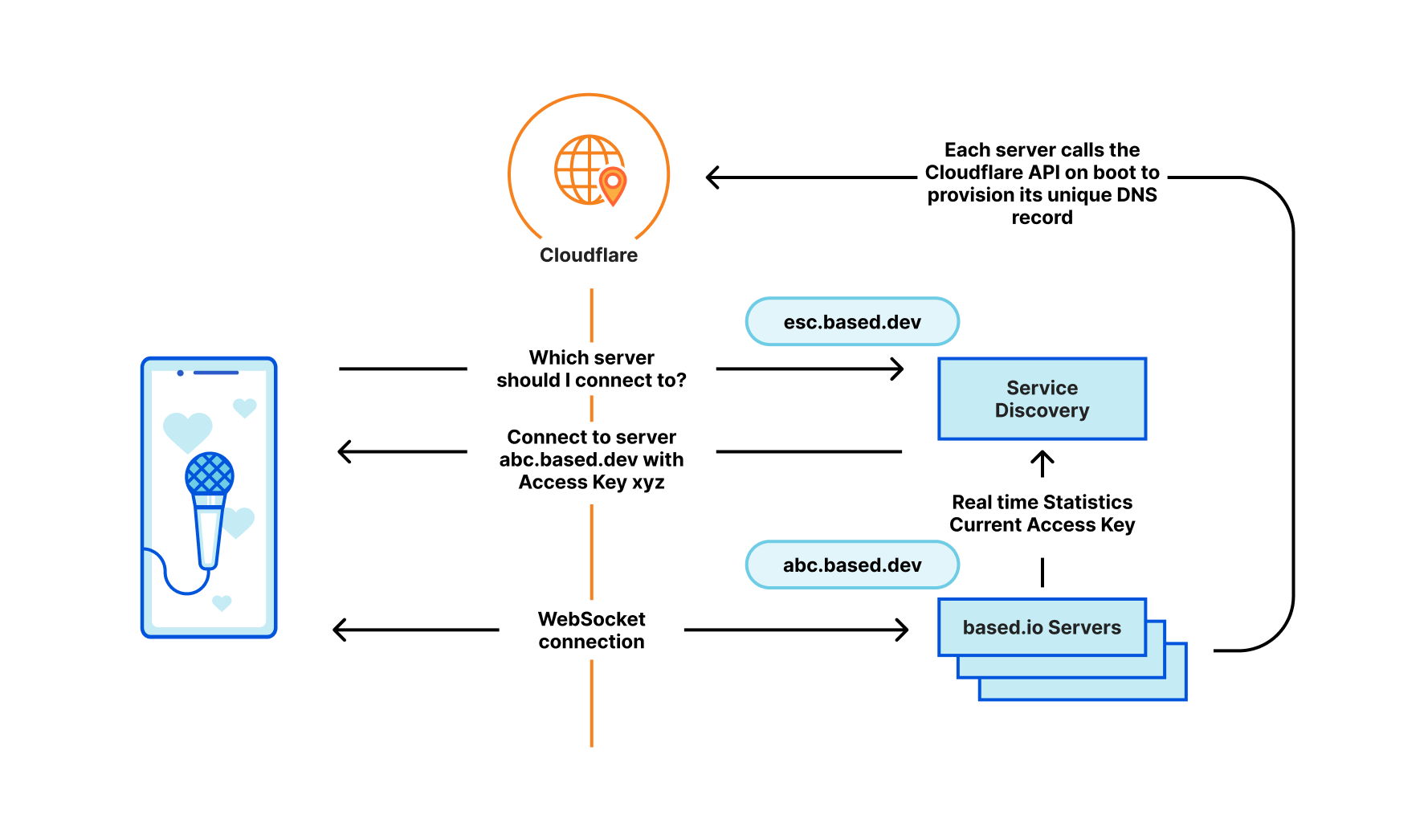
Instead of relying on network or HTTP load balancers, based.io uses a client-side service discovery pattern, selecting the most suitable server to connect to and leveraging Cloudflare's fast cache propagation infrastructure to handle spikes in traffic (both malicious and benign).
First, each server continuously registers a unique access key that has an expiration of 15 seconds, which must be used when a client connects to the server. In addition, the backend servers register their health (such as active connections, CPU, memory usage, requests per second, etc.) to the service registry every 300 milliseconds. Clients then request the optimal server URL and associated access key from a central discovery registry and proceed to establish a long lived connection with that server. When a server gets overloaded it will disconnect a certain amount of clients and those clients will go through the discovery process again.
The central discovery registry would normally be a huge bottleneck and attack target. based.io resolves this by putting the registry behind Cloudflare's global network with a cache time of three seconds. Since the system relies on real-time stats to distribute load and uses short lived access keys, it is crucial that the cache updates fast and reliably. This is where Cloudflare’s infrastructure proved its worth, both due to the fast updating cache and reducing load with Tiered Caching.
Not using load balancers means the based.io system allows clients to connect to the backend servers through Cloudflare, resulting in better performance and a more resilient infrastructure by eliminating the load balancers as potential attack surface. It also results in a better distribution of connections, using the real-time information of server health, amount of active connections, active subscriptions.
Scaling up the platform happens automatically under load by deploying additional machines that can each handle 40,000 connected users. These are spun up in batches of a couple of hundred and as each machine spins up, it reaches out directly to the Cloudflare API to configure its own DNS record and proxy status. Thanks to Cloudflare’s high speed DNS system, these changes are then propagated globally within seconds, resulting in a total machine turn-up time of around three seconds. This means faster discovery of new servers and faster dynamic rebalancing from the clients. And since the voting window of the Eurovision Song Contest is only 45 minutes, with the main peak within minutes after the window opens, every second counts!
High level architecture of the based.io platform used for the 2023 Eurovision Song Contest
To vote, users of the mobile app and viewers globally were pointed to the voting landing page, esc.vote. Building a frontend web application able to handle this kind of an audience is a challenge in itself. Although hosting it yourself and putting a CDN in front seems straightforward, this still requires you to own, configure and manage your origin infrastructure. once.net decided to leverage Cloudflare’s infrastructure directly by hosting the voting landing page on Cloudflare Pages. Deploying was as quick as a commit to their Git repository, and they never had to worry about reachability or scaling of the webpage.
once.net also used Cloudflare Turnstile to protect their payment API endpoints that were used to validate online votes. They used the invisible Turnstile widget to make sure the request was not coming from emulated browsers (e.g. Selenium). And best of all, using the invisible Turnstile widget the user did not have to go through extra steps, which allowed for a better user experience and better conversion.
Cloudflare Pages stealing the show!
After the two semi-finals went according to plan with approximately 200,000 concurrent users during each,May 13 brought the Grand Final. The once.net team made sure that there were enough machines ready to take the initial load, jumped on a call with Cloudflare to monitor and started looking at the number of concurrent users slowly increasing. During the event, there were a few attempts to DDoS the site, which were automatically and instantaneously mitigated without any noticeable impact to any visitors.
The based.io discovery registry server also got some attention. Since the cache TTL was set quite low at five seconds, a high rate of distributed traffic to it could still result in a significant load. Luckily, on its own, the highly optimized based.io server can already handle around 300,000 requests per second. Still, it was great to see that during the event the cache hit ratio for normal traffic was 20%, and during one significant attack the cache hit ratio peaked towards 80%. This showed how easy it is to leverage a combination of Cloudflare CDN and DDoS protection to mitigate such attacks, while still being able to serve dynamic and real time content.
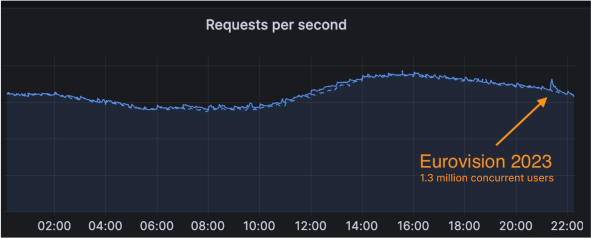
When the curtains finally closed, 1.3 million concurrent users connected to the based.io platform at peak. The based.io platform handled a total of 350 million events and served seven million unique users in three hours. The voting landing page hosted by Cloudflare Pages served 2.3 million requests per second at peak, and made sure that the voting payments were by real human fans using Turnstile. Although the Cloudflare platform didn’t blink for such a flood of traffic, it is no surprise that it shows up as a short crescendo in our traffic statistics:
Get in touch with us
If you’re also working on or with an application that would benefit from Cloudflare’s speed and security, but don’t know where to start, reach out and we’ll work together.
I started at Cloudflare in April 2018. I was excited to join an innovative company that operates with integrity and takes customer needs into account when planning product roadmaps. After 2.5 years at Cloudflare, this excitement has only grown, as it has become even clearer that our customers’ feedback is essential to our business. At an all-hands meeting this November, Michelle Zatlyn, our co-founder and COO, said that “every time we see things and approach problems from the lens of a customer, we make better decisions.” One of the ways we make these decisions is through Customer Success Managers funneling our customers’ feedback to our product and engineering teams.
As a Strategic Customer Success Manager, I meet regularly with my customers to better understand their experience with Cloudflare and work cross-functionally with our internal teams to continually improve it. One thing my customers often mention to me, regardless of industry or size, is their appreciation that their feedback is not only heard but understood and actioned. We are an engineering-driven company that remains agile enough to incorporate customer feedback into our product roadmap and development cycle when that feedback aligns with our business priorities. In fact, for us, this customer feedback loop is a priority in and of itself.
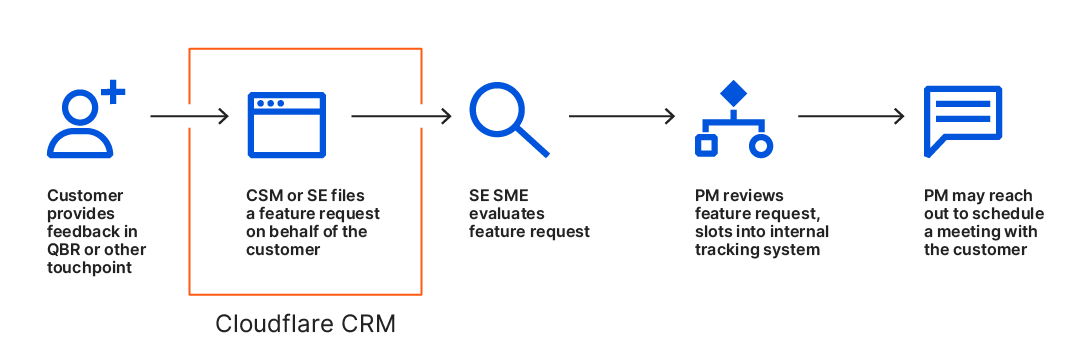
Customer Success Managers, along with Solutions Engineers and Account Executives, convert customer feedback raised in Quarterly Business Reviews or other touchpoints into feature requests routed directly to Cloudflare’s Product and Engineering teams. Here’s how it works:
A feature request is submitted in our internal CRM on behalf of Cloudflare customers. It includes a description of the request, details on the desired solution, any current or potential workarounds, and level of urgency.
All feature requests are then evaluated by our Solutions Engineering Subject Matter Experts to ensure they have the necessary data and are properly classified.
Product Managers then review the feature requests and connect them with our internal tracking systems.
Often, our Product and Engineering teams already have many of these features planned as part of our roadmap, but customer requests can influence when we take action on these items and/or how we build these products. Factors that can impact these decisions include:
How critical the requests are,
The volume of customer requests per product or feature,
Partnerships with customers and promises we’ve made to these customers, and
Strategic direction from Cloudflare leadership
After these feature requests are filed on behalf of our customers, our Product team may reach out to Customer Success Managers to schedule meetings with our customers to ensure they understand their specific use cases and incorporate these requirements into product development.
Let’s illustrate this process with a real-life example. One of my customers, a large financial institution (Customer A), uses Cloudflare for Secondary DNS. Secondary DNS allows an organization to use multiple providers to host and relay its DNS information. It is traditionally used as a synchronized backup for an organization’s primary DNS infrastructure. Secondary DNS offers redundancy across many different nameservers, all of which are synchronized and thus respond to queries with the same answers. Using a Secondary DNS configuration allows for resiliency, availability, and a better overall end-user experience.
This particular customer was evaluating a multi-vendor approach to DNS and HTTP services including DDoS mitigation, WAF, and CDN, potentially utilizing Cloudflare at all levels for certain web applications. Cloudflare and many other HTTP proxy services can be provisioned and enabled over DNS, responding to DNS queries with our own IP space, attracting customer traffic, and performing the required functions. Only then is this HTTP traffic sent upstream to a customer’s infrastructure. Because an organization’s Secondary DNS nameservers should all respond with the same synchronized answers, it means any given customer using “standard” Secondary DNS cannot also use their Secondary DNS providers for HTTP proxy services (Layer 7 DDoS mitigation, WAF, CDN, etc). Customer A wanted to leverage our proxy services while simultaneously relying on Cloudflare’s global scale and redundancy as a (Secondary) DNS provider.
Another customer interested in this feature (Customer B) was an organization whose on-premise DNS servers had logic that automatically updated their records. They wanted a single Secondary DNS provider that could receive their automated DNS record transfers and respond to queries at scale, while also allowing them to choose which records to proxy. This would let them benefit from Cloudflare’s DNS and proxy services without having to re-architect or migrate their entire DNS infrastructure.
I filed feature requests, and our DNS team reached out to schedule time with these customers to better understand their use cases and ensure the feature we were building would support their desired configuration.
Enter Secondary DNS Override: rather than responding to every DNS query with the answer pre-defined by a customer’s DNS master, the customer instructs Cloudflare, as Secondary DNS vendor, to, in some cases, respond to queries with Cloudflare’s own IP space, which is what enables our HTTP proxy services.
We created Secondary DNS Override to proxy traffic for Customer A’s web apps utilizing multi-CDN, allowing them to benefit from Cloudflare’s security and performance features, despite having Secondary DNS already in use. Once Secondary DNS override was implemented, any of their end-users receiving DNS responses from Cloudflare (remember, only one DNS provider of many) now experienced the benefit of Cloudflare’s HTTP proxy services. Customer B simply enabled the automatic transfer of zone files to Cloudflare and set up their on-premise infrastructure as “hidden primary”; they could now utilize Cloudflare proxy services as they had requested.
While building the feature, our DNS team and designated account teams remained in close contact with both of these customers and more to keep them updated every step of the way.
We shipped our Secondary DNS Override feature in November 2019, API-only at first, and UI feature parity followed the next quarter. Customers were able to take advantage of Secondary DNS Override via API as soon as it was available, while simultaneously giving feedback on what they hoped to see in Cloudflare’s UI. They were delighted with the consultative approach we took while building out their desired features, as we demonstrated commitment to a strong partnership.
This feature is one example of the countless requests that have resulted in products and features shipped by Cloudflare’s Product and Engineering teams. Most feature requests originate as customer feedback provided in Quarterly Business Reviews, led by Customer Success Managers as part of our Premium Success offerings, and at the annual health check as part of our Standard Success offering.
Maintaining a close relationship with our customers and ensuring they are deriving the most value from our products is of the utmost importance to Cloudflare CSMs. Tell your CSM today how Cloudflare can help you mitigate risk, increase ROI, and achieve your business objectives. To learn more about Secondary DNS Override specifically or Cloudflare in general, please visit this link and a member of our team will reach out to you!
Customer Success Managers offer continual strategic and technical guidance by way of interactive workshops, account reviews, tuning sessions and regular product updates.
Our product development and design teams constantly work on new features and product updates based on your input.
It’s a team effort. As part of our Premium Success offering, we can introduce you to Product Managers for in-depth conversations about our solutions and how they can apply to your business goals.
Cloudflare is always rapidly evolving and expanding our solutions! As technology advances, so does the sophistication of attacks. Through machine learning and behavioural analysis, we are able to ship new products to ensure you remain secure without impacting performance.
Reach out to your Customer Success Manager to gain more information on how they can accelerate your business.
The Success Story
Hi there. My name is Jake Jones and I’m a Customer Success Manager at Cloudflare covering the Middle East and Africa. When I look at what success means to me, it’s becoming a trusted advisor for my customers by taking a genuine interest in their priorities and helping them reach desired goals. I’ve learnt that successful partnerships are a byproduct of successful relationship building. Every customer is unique with their own specific IT set-up, ranging from legacy, cloud and hybrid infrastructures. Here is a short tale of how a collaboration with a Cloudflare customer resulted in multiple wins…
Let’s call the customer Dynamic, which is a befitting name as we constantly work together to review their infrastructure and optimise the Cloudflare platform further. We’ve all heard the phrase “people buy from people”, but true buy-in comes from forming genuine relationships.
In late 2019, when Dynamic came to Cloudflare, we understood and welcomed their emphasis on vendor collaboration. To achieve this we met regularly and had interactive workshops together, to prioritise which of Cloudflare’s solutions would be the most valuable to them. We sought to understand how they operate, their infrastructure, and most importantly, how we could help. In the first few months of the relationship, we mapped out future initiatives, projects and mitigation strategies (should an attack arise).
In the spring of 2020 attacks did arise and were diverse in nature, aiming to overload their website and IP subnets – we could not let this happen! Fortunately, through proactive communication, we understood each other’s workflow and had pre-established how Cloudflare could quickly protect against vulnerabilities. The attack was quickly mitigated through our automatic DDoS protection, with Magic Transit ensuring Dynamics on-premise infrastructure remained safeguarded. In turn, their reputation was upheld and any financial loss was minimized.
Fortunately, it’s not all doom and gloom. We’re there for the good times too! For example, we love to get feedback and grant exclusive access to our beta (early release) launches as part of our Premium Success offering.
Having access to Cloudflare’s beta programme is an excellent opportunity to knowledge share and improve the user experience. With this information, we feedback to our product and design team with recommendations on new functionalities the customer would like to see. However, it’s not only our solutions that are enhanced. We are continually evolving our infrastructure and adding more capacity on our servers, to accommodate the growing market landscape.
The moral of the story is that collaboration and relationship building leads to secure platform consolidation and trust in those who manage it.
Get in contact
To all Enterprise Customers, contact your CSM. We are here to make you more successful! For all others that would like to know more, follow this link and one of our team will contact you to start you on your path to success.
Anyone with public-facing web properties is likely to have bot traffic on their website.
One type of bot that commonly targets eCommerce and online portals is a ‘scraper bot’.
Some scraper bots are good (such as those used by search engines to assess your website’s content to inform search results, or price comparison sites to help inform consumer decisions), however many are malicious, and will work to scrape not only images but also pricing data from your site for use by a competitor.
Many Bot Management providers will need to divert your traffic to a dedicated data centre to analyse your traffic and ‘scrub’ it clean from malicious bot traffic before sending it on to your site. While effective this will almost certainly add latency to the traffic’s ‘journey’ resulting in degraded user experience. Look for a technology partner with an expansive network who can scan your traffic in real time as it passes through any data centre on their network.
Good and bad scraper bots behave in largely the same way, making it difficult for bot protection systems to differentiate between the two. A common challenge with Bot Management solutions is that they can return a high number of false positives (legitimate bot or customer traffic blocked as though it were malicious). This can result in legitimate customers being challenged to various and repeated authentication challenges, or in extreme cases, blocked altogether. Look for a technology partner who can consistently return low rates of false positives on your traffic.
The Success Story
I often joke that the key to understanding what that role of Customer Success is all about is to say: repeat the sentence again slowly… it’s there, in the name. Customer Success is, at its core, about making customers successful. And this is what makes our day, and makes us happy. Allow me to share a short story on how Cloudflare made a successful customer even more so with our Bot Management solution.
Once upon a time, an online property portal, let’s call them Property Portal, came to Cloudflare for our DDoS and WAF solution. We worked well together. The customer liked our ease of use and we delivered on our promise to provide performance and security to them. As Property Portal’s brand and digital footprint grew, so did the instances of malicious bot traffic, in particular ‘scraper bots’.
They say that imitation is the sincerest form of flattery. But when that imitation turns into someone else profiting off your IP, the shine starts to wear off, and that ‘imitation’ starts to become something more akin to outright theft. This is a challenge common to market leaders in the eCommerce and online portal space, where market leading organizations who pride themselves on presenting a solid portfolio of quality product offerings often find that competing sites seem to be not only replicating their content but matching or undercutting their prices in near real time.
Cloudflare wasn’t working with Property Portal when they first started facing these challenges, and as such, Property Portal engaged another party – at that time, one of the market leaders in the space – to provide a Bot Management solution for them.
At first pass, this seemed to solve the problem, however it wasn’t long before additional challenges became apparent:
performance was impacted slightly as this solution required traffic to be re-routed to a scrubbing centre to be ‘scrubbed’ of requests from bad bots before coming to their site;
a small percentage of malicious bots were still getting through and scraping valuable content of their website, and most damagingly;
Property Portal discovered that they were seeing a significant number of ‘false positives’, resulting in rising frustration for legitimate visitors (buyers, sellers and renters) repeatedly being asked to complete challenges in order to validate that they were human and not bots as they tried to navigate through the site.
During this time, Cloudflare released and matured our own Bot Management offering. Being aware that Property Portal weren’t seeing success from their existing solution, the account team began discussing the value of consolidating their bot solution with their DDoS and WAF offering from Cloudflare. We were given very clear success criteria which in technical terms, translated to the following:
Don’t mess anything up, deprecate our user experience, or make us change our domains if we switch to you;
Stop more of the bad traffic.;
And most importantly, let more of the good users in, and stop challenging them as much as our current provider does (reduce the number of false positives).
We passed with flying colours. In addition, Property Portal was happy that they were able to consolidate additional services under one vendor.
For our side, Cloudflare now has the privilege of knowing that we are helping to improve the experience for many of Property Portal’s end customers, while at the same time working to protect their IP and hard work by keeping the ‘imitators’ and their scraper bots at a safe distance.
Does any of the above feel familiar to you? Do your competitors have the uncanny ability to present near identical inventory, images or pricing to yours just as soon as you publish changes to your site? Or, are you keen to learn more in order to stay ahead of the bot armies?
Well, you’ve come to the right place, friend:
If you’re the self-serve type then take a look at our learning centre here and here, or our product pages. (And yes, we have a (good) chat bot there waiting to help you).
If ‘tuning in and geeking out’ is your preferred method of learning, then tune into the next episode of ‘Customers + Success’ on Cloudflare TV where I’ll be interviewing some of the people involved in this case, and hearing more about the challenges that this customer faced first-hand. The segment will air at 4PM PST October 21st / 7AM SGT October 22nd / 10AM AEST October 22nd, and will be appearing on the CFTV schedule in the next week.
Alternatively, if you consume your knowledge in old-fashioned human style feel free to contact us here. Someone from our team will be in touch to get you the answers you are looking for.
In March, governments all over the world issued stay-at-home orders, causing a mass migration to teleworking. Alongside many of our partners, Cloudflare launched free products and services supported by onboarding sessions to help our clients secure and accelerate their remote work environments. Over the past few months, a dedicated team of specialists met with hundreds of organizations – from tiny startups, to massive corporations – to help them extend better security and performance to a suddenly-remote workforce.
Most companies we heard from had a VPN in place, but it wasn’t set up to accommodate a full-on remote work environment. When employees began working from home, they found that the VPN was getting overloaded with requests, causing performance lags.
While many organizations had bought more VPN licenses to allow employees to connect to their tools, they found that just having licenses wasn’t enough: they needed to reduce the amount of traffic flowing through their VPN by taking select applications off of the private network.
We Were Built For This
My name is Dina and I am a Customer Success Manager (CSM) in our San Francisco office. I am responsible for ensuring the success of Cloudflare’s Enterprise customers and managing all of their post-sales experience. As CSMs, we bring strong product knowledge, best practices and a high degree of empathy to ensure our customers’ satisfaction with Cloudflare’s services. This is driven through delivering the value of our products and services to our customer’s business via regular check-ins and quarterly reviews.
One customer I work with, a service that connects physicians to patients over the Internet, was forced to respond to a requirement for the entire company to work-from-home within 48 hours. This company could not move their entire workforce to a VPN without overwhelming their appliances and IT Help Desk. Any interruption to business continuity could threaten the provider’s ability to deliver services to customers during a time of peak demand, and especially during a time when doctors’ office environments felt unsafe.
Cloudflare Access had been a product of interest for my customer for a while now, and the adoption of the product couldn’t have come at a better time. As an enterprise customer, they enlisted the help of our subject matter experts to troubleshoot the sudden WFH situation. With the help of the Cloudflare CSM, solution engineers, and product managers, the organization was able to migrate internally-hosted applications to Cloudflare Access in less than 15 minutes.
Hundreds of team members began using Cloudflare Access within the next 24 hours. We were able to operationalize a critical call center app without a VPN at the click of a button. In the words of the customer, “…we should have done this a long time ago. It’s beautiful, this is perfect.” Virtually overnight, over 700 users were immediately signed on, and more are being added daily as the company grows and working from home remains a necessity. It could even become a permanent way of working for many organizations around the world.
It’s More Than A Solution
At Cloudflare, our customers are our top priority. Our constant innovation and transparency maintain our customers’ trust and support. This particular telemedicine company has been a Cloudflare customer for 5 years, not only because of the technology, but because of those exact priorities we uphold.
The customer’s journey follows a pattern I see often in my role: this customer initially used Cloudflare for Infrastructure products to protect external sites – their website and customer-facing applications. Because they leverage our solutions in this way, the domain of their call center app was already IP whitelisted on Cloudflare via Zone lockdown, one of our Enterprise features. With their deep knowledge and experience with Cloudflare, they could easily apply the same benefits they were getting from WAF and CDN to their internal employees.
Throughout their tenure with Cloudflare, this customer has constantly interacted with us through events (when they were in-person 😔), webinars, email communication, feature request reviews, and frequent catch-ups over the phone. These conversations provided regular opportunities for the customer to expand their knowledge of Cloudflare, build trust, and grow their usage of Cloudflare’s services. The customer first learned about our Access technology at Cloudflare Connect in NYClast year.
The event proved to be the perfect forum for them to interact with the Cloudflare community, discover new technology, and discuss and brainstorm with onsite technical experts. The customer had been using Cloudflare for our core security and performance services for a long time. They had been receiving value from our other services, and when COVID-19 hit, Cloudflare was there as a trusted advisor and partner to easily tackle this inevitable situation. Everything they’ve learned through their constant interaction with the Cloudflare team, and at Cloudflare events, finally came to fruition.
I tell this customer’s story to raise awareness and encourage our customers – and really anyone interested – to stay up to date with the constant innovation here at Cloudflare. We continue to host and facilitate events and webinars. This allows you, as our customer, to learn and derive value from our technology, so your business is further protected and optimized. After a webinar and one meeting with us, you can transition your whole work environment to virtual.
Listen in on webinars, attend events, and read up on our blog, developer docs, and support pages, so you can easily call us, and with a click of a button turn on the next feature that will enhance your site and work experience.
Interested in Learning More?
Join Cloudflare’s Product Managers each month to hear the latest highlights, including this month’s feature on Cloudflare for Teams and Cloudflare Workers.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.