Post Syndicated from Zaid Zaid original https://blog.cloudflare.com/celebrating-one-year-of-project-cybersafe-schools

August 8, 2024, is the first anniversary of Project Cybersafe Schools, Cloudflare’s initiative to provide free security tools to small school districts in the United States.
Cloudflare announced Project Cybersafe Schools at the White House on August 8, 2023 as part of the Back to School Safely: K-12 Cybersecurity Summit hosted by First Lady Dr. Jill Biden. The White House highlighted Cloudflare’s commitment to provide free resources to small school districts in the United States. Project Cybersafe Schools supports eligible K-12 public school districts with a package of Zero Trust cybersecurity solutions – for free, and with no time limit. These tools help eligible school districts minimize their exposure to common cyber threats.
Cloudflare’s mission is to help build a better Internet. One way we do that is by supporting organizations that are particularly vulnerable to cyber threats and lack the resources to protect themselves through projects like Project Galileo, the Athenian Project, the Critical Infrastructure Defense Project, Project Safekeeping, and most recently, Project Secure Health.
Schools are vulnerable to cyber attacks
In Q2 2024, education ranked 4th on the list of most attacked industries. Between 2016 and 2022, there were 1,619 K-12 cyber incidents. Since we launched Project Cybersafe Schools in August 2023, there have been a number of cyber attacks targeting hundreds of thousands of students. In August 2023, Prince George’s County Public Schools in Maryland fell victim to a ransomware attack that affected the personal data of more than 100,000 people. Then, in December 2023, a Cincinnati area school district suffered a cyber attack that resulted in the loss of $1.7M. In 2024, there have been numerous incidents affecting K-12 schools across the U.S., including in Massachusetts, New Jersey, and Washington state. The smallest school districts are often the most vulnerable because of a lack of resources or capacity. Sometimes, the person responsible for cybersecurity does so in addition to another primary role, whether as a teacher, coach or administrator.
We are proud of our impact, but we can do more
There are about 14,000 school districts in the United States, and about 9,800 of them have fewer than 2,500 students. All 9,800 of those small public school districts are eligible for Project Cybersafe Schools (for free, and with no time limit – see below for all the details), and we want to help as many as possible. We are proud of the number of school districts that we have onboarded since August 2023, but it is not enough. We want to do more, and we can onboard more school districts by getting the word out about Project Cybersafe Schools. When we published an update in December 2023 encouraging school districts to sign up before the holiday break, we saw a noticeable bump in the number of inquiries from eligible school districts. If you work at a small school district in the United States, we encourage you to see if you qualify for this program.
Nearly 30 states have school districts now enrolled in Project Cybersafe Schools, representing every region of the country. Since we launched the program, we have onboarded nearly 120 qualifying school districts. As a result, more than 160,000 students, teachers, and staff are protected by Cloudflare’s cloud email security to protect against a broad spectrum of threats including Business Email Compromise, multichannel phishing, credential harvesting, and other targeted attacks. These school districts are also receiving protection against Internet threats with DNS filtering by preventing users from reaching unwanted or harmful online content like ransomware or phishing sites.
Attacks prevented by Project Cybersafe Schools in 2024
When the White House launched its National Cybersecurity Strategy in March 2023, Acting National Cyber Director Kemba Walden noted in her remarks that “we expect school districts to go toe-to-toe with transnational criminal organizations largely by themselves. This isn’t just unfair; it’s ineffective.” Cloudflare agrees, and this is one of the reasons we launched Project Cybersafe Schools after conversations with officials from the Cybersecurity & Infrastructure Security Agency (CISA), the Department of Education, and the White House about how we could help to protect small school districts in the United States from cyber threats.
Year to date, Cloudflare’s cloud email security solution has identified and blocked more than 2 million malicious emails targeting the school districts enrolled in Project Cybersafe Schools. This represents roughly 3.5% of their total email traffic, though certain school districts are attacked at a far higher rate. In one district, malicious emails blocked by Cloudflare represented more than 15% of all email traffic.
Another challenge facing these schools is the large volume of spam emails sent their way. While some of this spam is promotional and not overtly malicious, it can often be used in a variety of attacks. Project Cybersafe Schools has prevented more than 2.2 million spam emails from clogging the inboxes of the school districts who have enrolled.
According to CISA, more than 90% of all cyber attacks begin with a phishing email. So helping these school districts secure their email inboxes is a critical factor in reducing their cyber risk. With email providing a relatively high success rate for gaining initial access, it’s no surprise that attackers continue to exploit email users with increasingly sophisticated and evasive techniques that bypass native security controls. And the consequences of these attacks can be severe: Recovery time can extend from two all the way up to nine months – that’s almost an entire school year.
Here’s what a few Project Cybersafe Schools participants have to say about the impact of the program on their school district:
“What Cloudflare’s Project Cybersafe Schools has allowed us to do as a rural district is add a missing layer of protection to our devices, providing a previously missing and unique layer of security even off our secure network. Where other options would cost us somewhere in the thousands, we are now able to secure devices for free using one of the simplest and scalable platforms, featuring one of the easiest learning curves I’ve worked with. Cloudflare’s feature set as a whole for districts are unparalleled and integration is a must for schools looking to add an additional layer of protection to their network architecture, which by my estimation should be everyone.” – Wyatt Determan, Technology Specialist (HLWW Public School District, Minnesota)
“Since implementing the Cybersafe Schools program as our secure email gateway, we’ve saved over $5,000 per year compared to similar solutions. The program has effectively filtered out numerous malicious emails, greatly enhancing our security posture. Its seamless integration and user-friendly interface make it easy for our IT team to manage. Cybersafe Schools has become a critical part of our IT infrastructure, ensuring a safe and secure educational environment.” – Paul Strout, Network Manager (Regional School Unit RSU71, Belfast, Maine)
What Zero Trust services are available?
Eligible K-12 public school districts in the United States have access to a package of enterprise-level Zero Trust cybersecurity services for free and with no time limit – there is no catch and no underlying obligations. Eligible organizations will benefit from:
- Email Protection: Safeguards inboxes with cloud email security by protecting against a broad spectrum of threats including malware-less Business Email Compromise, multichannel phishing, credential harvesting, and other targeted attacks.
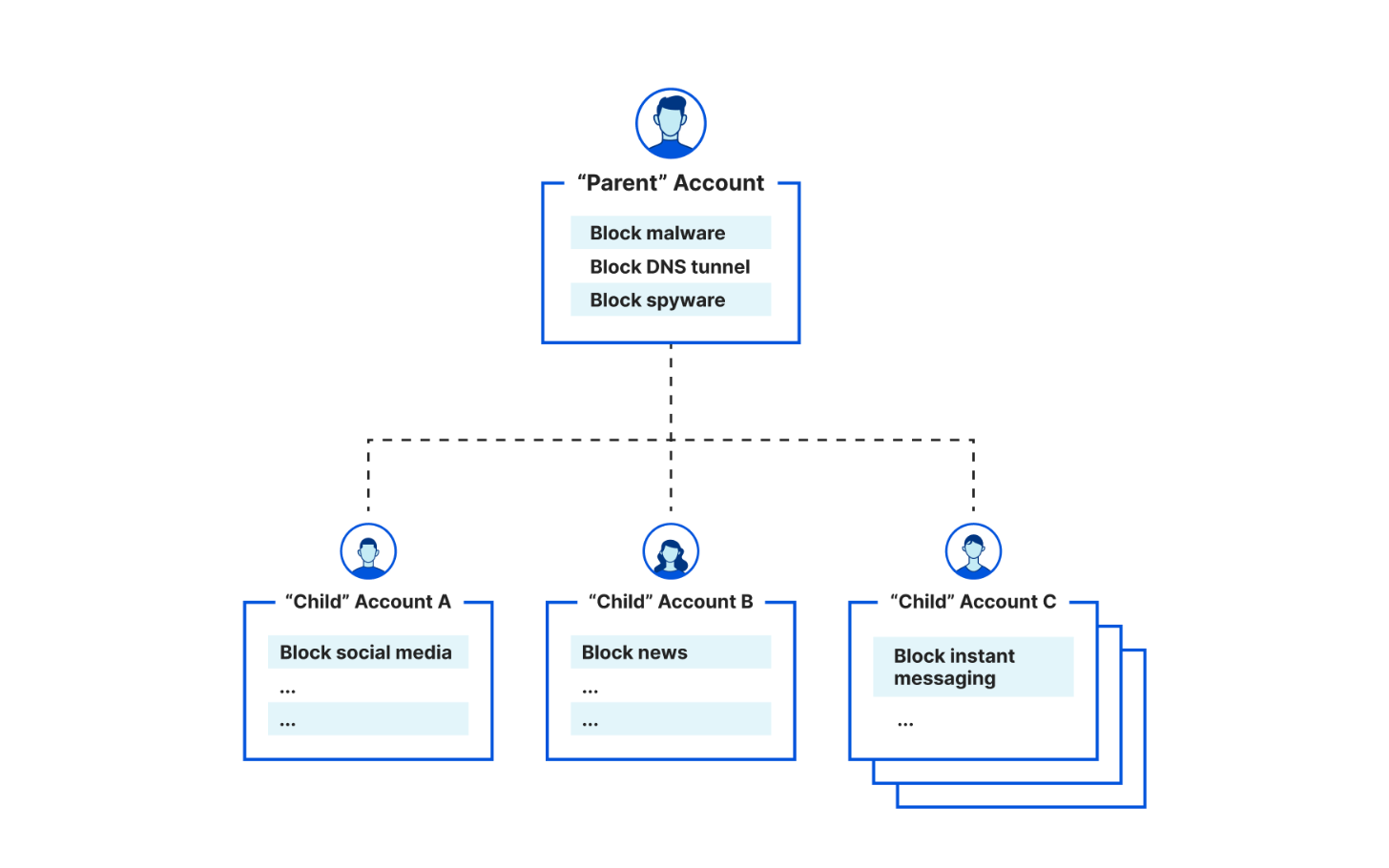
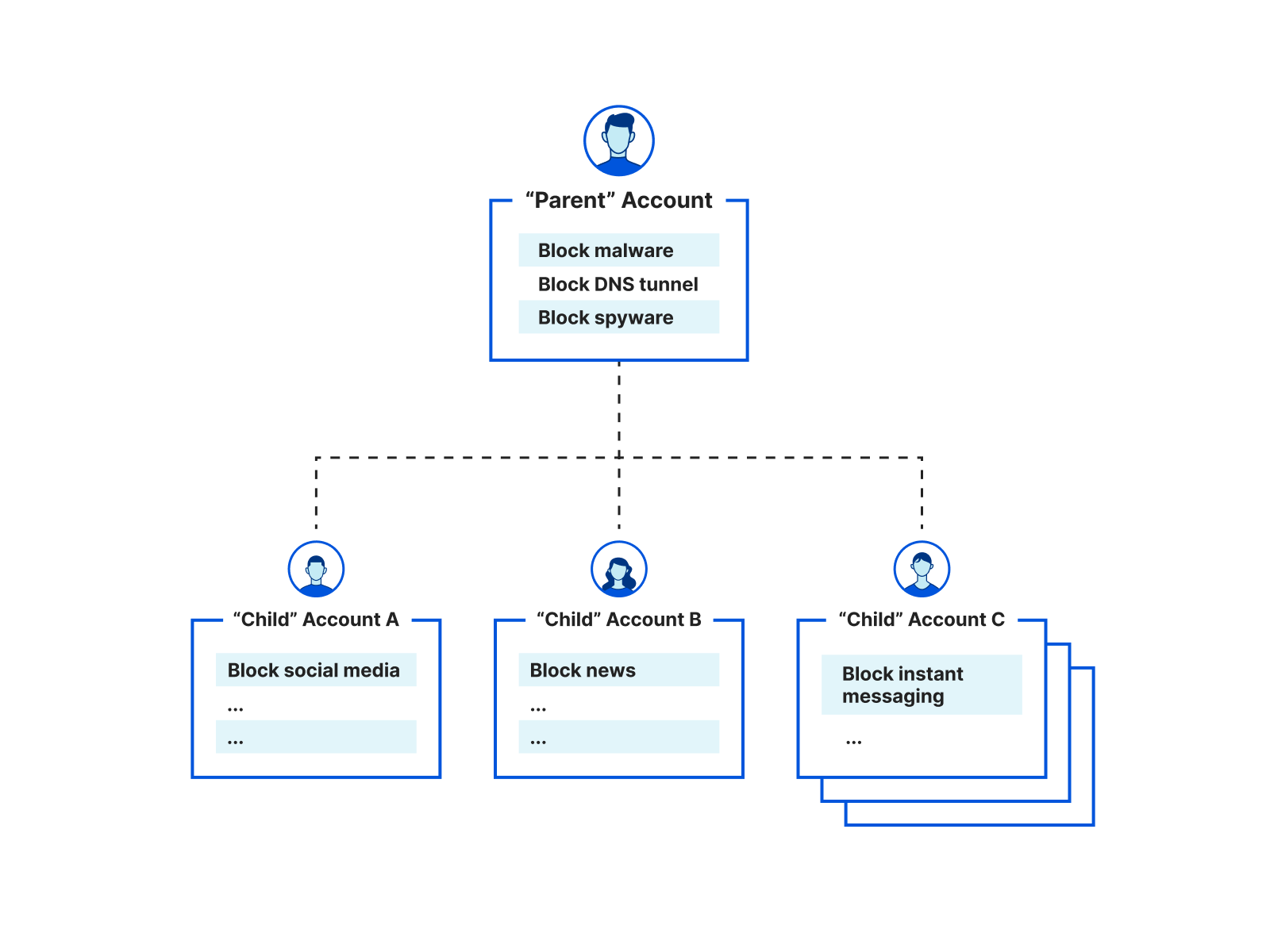
- DNS Filtering: Protects against Internet threats with DNS filtering by preventing users from reaching unwanted or harmful online content like ransomware or phishing sites and can be deployed to comply with the Children’s Internet Protection Act (CIPA).
Who can apply?
To be eligible, Project Cybersafe Schools participants must be:
- K-12 public school districts located in the United States
- Up to 2,500 students in the district
If you think your school district may be eligible, we welcome you to contact us to learn more. Please fill out the form today.
For schools or school districts that do not qualify for Project Cybersafe Schools, Cloudflare has other packages available with educational pricing. If you do not qualify for Project Cybersafe Schools, but are interested in our educational services, please contact us at [email protected].