Post Syndicated from Rajesh original https://aws.amazon.com/blogs/devops/improving-customer-experience-and-reducing-cost-with-codeguru-profiler/
Amazon CodeGuru is a set of developer tools powered by machine learning that provides intelligent recommendations for improving code quality and identifying an application’s most expensive lines of code. Amazon CodeGuru Profiler allows you to profile your applications in a low impact, always on manner. It helps you improve your application’s performance, reduce cost and diagnose application issues through rich data visualization and proactive recommendations. CodeGuru Profiler has been a very successful and widely used service within Amazon, before it was offered as a public service. This post discusses a few ways in which internal Amazon teams have used and benefited from continuous profiling of their production applications. These uses cases can provide you with better insights on how to reap similar benefits for your applications using CodeGuru Profiler.
Inside Amazon, over 100,000 applications currently use CodeGuru Profiler across various environments globally. Over the last few years, CodeGuru Profiler has served as an indispensable tool for resolving issues in the following three categories:
- Performance bottlenecks, high latency and CPU utilization
- Cost and Infrastructure utilization
- Diagnosis of an application impacting event
API latency improvement for CodeGuru Profiler
What could be a better example than CodeGuru Profiler using itself to improve its own performance?
CodeGuru Profiler offers an API called BatchGetFrameMetricData, which allows you to fetch time series data for a set of frames or methods. We noticed that the 99th percentile latency (i.e. the slowest 1 percent of requests over a 5 minute period) metric for this API was approximately 5 seconds, higher than what we wanted for our customers.
Solution
CodeGuru Profiler is built on a micro service architecture, with the BatchGetFrameMetricData API implemented as set of AWS Lambda functions. It also leverages other AWS services such as Amazon DynamoDB to store data and Amazon CloudWatch to record performance metrics.
When investigating the latency issue, the team found that the 5-second latency spikes were happening during certain time intervals rather than continuously, which made it difficult to easily reproduce and determine the root cause of the issue in pre-production environment. The new Lambda profiling feature in CodeGuru came in handy, and so the team decided to enable profiling for all its Lambda functions. The low impact, continuous profiling capability of CodeGuru Profiler allowed the team to capture comprehensive profiles over a period of time, including when the latency spikes occurred, enabling the team to better understand the issue.
After capturing the profiles, the team went through the flame graphs of one of the Lambda functions (TimeSeriesMetricsGeneratorLambda) and learned that all of its CPU time was spent by the thread responsible to publish metrics to CloudWatch. The following screenshot shows a flame graph during one of these spikes.

As seen, there is a single call stack visible in the above flame graph, indicating all the CPU time was taken by the thread invoking above code. This helped the team immediately understand what was happening. Above code was related to the thread responsible for publishing the CloudWatch metrics. This thread was publishing these metrics in a synchronized block and as this thread took most of the CPU, it caused all other threads to wait and the latency to spike. To fix the issue, the team simply changed the TimeSeriesMetricsGeneratorLambda Lambda code, to publish CloudWatch metrics at the end of the function, which eliminated contention of this thread with all other threads.
Improvement
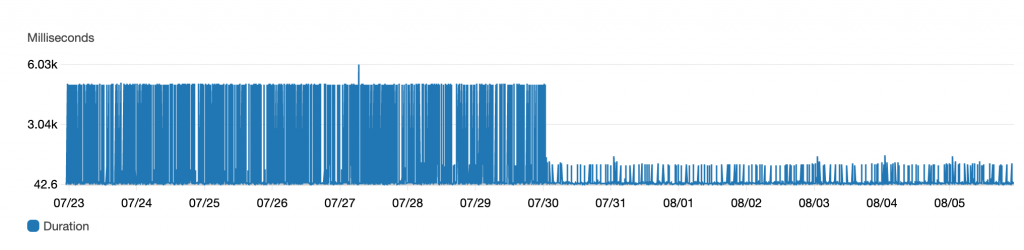
After the fix was deployed, the 5 second latency spikes were gone, as seen in the following graph.
Cost, infrastructure and other improvements for CAGE
CAGE is an internal Amazon retail service that does royalty aggregation for digital products, such as Kindle eBooks, MP3 songs and albums and more. Like many other Amazon services, CAGE is also customer of CodeGuru Profiler.
CAGE was experiencing latency delays and growing infrastructure cost, and wanted to reduce them. Thanks to CodeGuru Profiler’s always-on profiling capabilities, rich visualization and recommendations, the team was able to successfully diagnose the issues, determine the root cause and fix them.
Solution
With the help of CodeGuru Profiler, the CAGE team identified several reasons for their degraded service performance and increased hardware utilization:
- Excessive garbage collection activity – The team reviewed the service flame graphs (see the following screenshot) and identified that a lot of CPU time was spent getting garbage collection activities, 65.07% of the total service CPU.

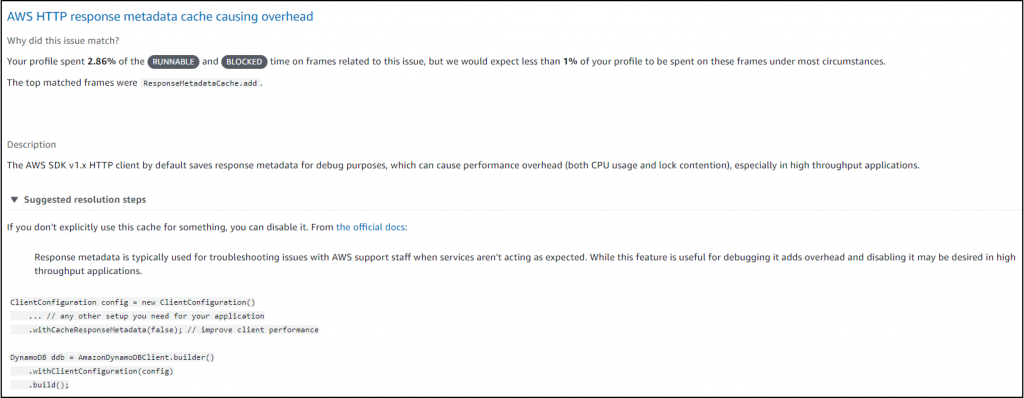
- Metadata overhead – The team followed CodeGuru Profiler recommendation to identify that the service’s DynamoDB responses were consuming higher CPU, 2.86% of total CPU time. This was due to the response metadata caching in the AWS SDK v1.x HTTP client that was turned on by default. This was causing higher CPU overhead for high throughput applications such as CAGE. The following screenshot shows the relevant recommendation.
- Excessive logging – The team also identified excessive logging of its internal Amazon ION structures. The team initially added this logging for debugging purposes, but was unaware of its impact on the CPU cost, taking 2.28% of the overall service CPU. The following screenshot is part of the flame graph that helped identify the logging impact.

The team used these flame graphs and CodeGuru Profiler provided recommendations to determine the root cause of the issues and systematically resolve them by doing the following:
- Switching to a more efficient garbage collector
- Removing excessive logging
- Disabling metadata caching for Dynamo DB response
Improvements
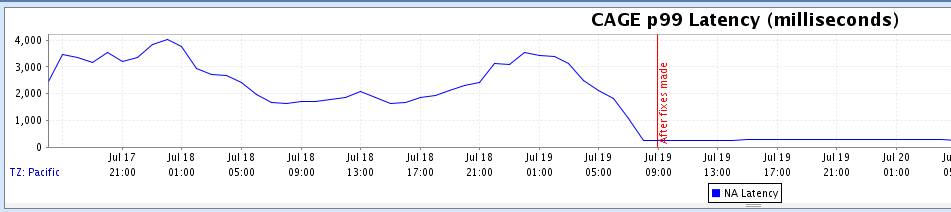
After making these changes, the team was able to reduce their infrastructure cost by 25%, saving close to $2600 per month. Service latency also improved, with a reduction in service’s 99th percentile latency from approximately 2,500 milliseconds to 250 milliseconds in their North America (NA) region as shown below.
The team also realized a side benefit of having reduced log verbosity and saw a reduction in log size by 55%.
Event Analysis of increased checkout latency for Amazon.com
During one of the high traffic times, Amazon retail customers experienced higher than normal latency on their checkout page. The issue was due to one of the downstream service’s API experiencing high latency and CPU utilization. While the team quickly mitigated the issue by increasing the service’s servers, the always-on CodeGuru Profiler came to the rescue to help diagnose and fix the issue permanently.
Solution
The team analyzed the flame graphs from CodeGuru Profiler at the time of the event and noticed excessive CPU consumption (69.47%) when logging exceptions using Log4j2. See the following screenshot taken from an earlier version of CodeGuru Profiler user interface.

With CodeGuru Profiler flame graph and other metrics, the team quickly confirmed that the issue was due to excessive exception logging using Log4j2. This downstream service had recently upgraded to Log4j2 version 2.8, in which exception logging could be expensive, due to the way Log4j2 handles class-loading of certain stack frames. Log4j 2.x versions enabled class loading by default, which was disabled in 1.x versions, causing the increased latency and CPU utilization. The team was not able to detect this issue in pre-production environment, as the impact was observable only in high traffic situations.
Improvement
After they understood the issue, the team successfully rolled out the fix, removing the unnecessary exception trace logging to fix the issue. Such performance issues and many others are proactively offered as CodeGuru Profiler recommendations, to ensure you can proactively learn about such issues with your applications and quickly resolve them.
Conclusion
I hope this post provided a glimpse into various ways CodeGuru Profiler can benefit your business and applications. To get started using CodeGuru Profiler, see Setting up CodeGuru Profiler.
For more information about CodeGuru Profiler, see the following:
Investigating performance issues with Amazon CodeGuru Profiler
Optimizing application performance with Amazon CodeGuru Profiler
Find Your Application’s Most Expensive Lines of Code and Improve Code Quality with Amazon CodeGuru