Post Syndicated from Amber Runnels original https://aws.amazon.com/blogs/big-data/how-twilio-built-a-multi-engine-query-platform-using-amazon-athena-and-open-source-presto/
Twilio is a customer engagement platform that powers real-time, personalized customer experiences for leading brands through APIs that democratize communications channels like voice, text, chat, and video.
At Twilio, we manage a 20 petabyte-scale Amazon Simple Storage Service (Amazon S3) data lake that serves the analytics needs of over 1,500 users, processing 2.5 million queries monthly, and scanning an average of 85 PB of data. To meet our growing demands for scalability, emerging technology support, and data mesh architecture adoption, we built Odin, a multi-engine query platform that provides an abstraction layer built on top of Presto Gateway.
In this post, we discuss how we designed and built Odin, combining Amazon Athena with open-source Presto to create a flexible, scalable data querying solution.
A growing need for a multi-engine platform
Our data platform has been built on Presto since its inception, but over the years as we expanded to support multiple business lines and diverse use cases, we began to encounter challenges related to scalability, operational overhead, and cost management. Maintaining the platform through frequent version upgrades also became difficult. These upgrades required significant time to evaluate backwards compatibility, integrate with our existing data ecosystem, and determine optimal configurations across releases.
The administrative burden of upgrades and our commitment to minimizing user disruption caused our Presto version to fall behind. This prevented us from accessing the latest features and optimizations available in later releases. The adoption of Apache Hudi for our transaction-dependent critical workloads created a new requirement which our existing Presto deployment version couldn’t support. We needed an up-to-date Presto or Trino compatible service to accommodate these use cases while still reducing the operational overhead of maintaining our own query infrastructure.
Building a comprehensive data platform required us to balance multiple competing requirements and business constraints. We needed a solution that could support diverse workload types, from interactive analytics to ETL batch processing, while providing the flexibility to optimize compute resources based on specific use cases. We also wanted to improve upon cost management and attribution in our shared multi-tenanted query platform. Additionally, we needed to ensure that adopting any new technology did not cause any disruption to our users and maintained backward compatibility with existing systems during the transition period.
Selecting Amazon Athena as our modern analytics engine
Our users relied on SQL for interactive analysis, and we wanted to preserve this experience and make use of our existing jobs and application code. This meant we needed a Presto-compatible analytics service to modernize our data platform.
Amazon Athena is a serverless interactive query service built on Presto and Trino that allows you to run queries using a familiar ANSI SQL interface. Athena appealed to us due to its compatibility with open-source Trino and its seamless upgrade experience. Athena helps to ease the burden of managing a large-scale query infrastructure, and with provisioned capacity, offers predictable and scalable pricing for our largest query workloads. Athena’s workgroups provided the query and cost management capabilities we needed to efficiently support diverse teams and workload patterns with minimal overhead.
The ability to blend on-demand and dedicated serverless capacity models allows us to optimize workload distribution for our requirements, achieving the flexibility and scalability needed in a managed query environment. To address latency-sensitive and predictive query workloads, we adopted provisioned capacity for its serverless capacity guarantee and workload concurrency control features. For queries that may be ad-hoc and more flexible in scheduling, we opted to use the cost-efficient multi-tenant on-demand model, which optimizes resource utilization through shared infrastructure. In parallel to migrating workloads to Athena, we also needed a way to support legacy workloads that use custom implementations of Presto features. This requirement drove us to abstract the underlying implementation, allowing us to present users with a unified interface. This would give us the flexibility key to future proof our infrastructure and use the most appropriate compute for the workload and use case.
The birth of Odin
The following diagram shows Twilio’s multi-engine query platform that incorporates both Amazon Athena and open-source Presto.
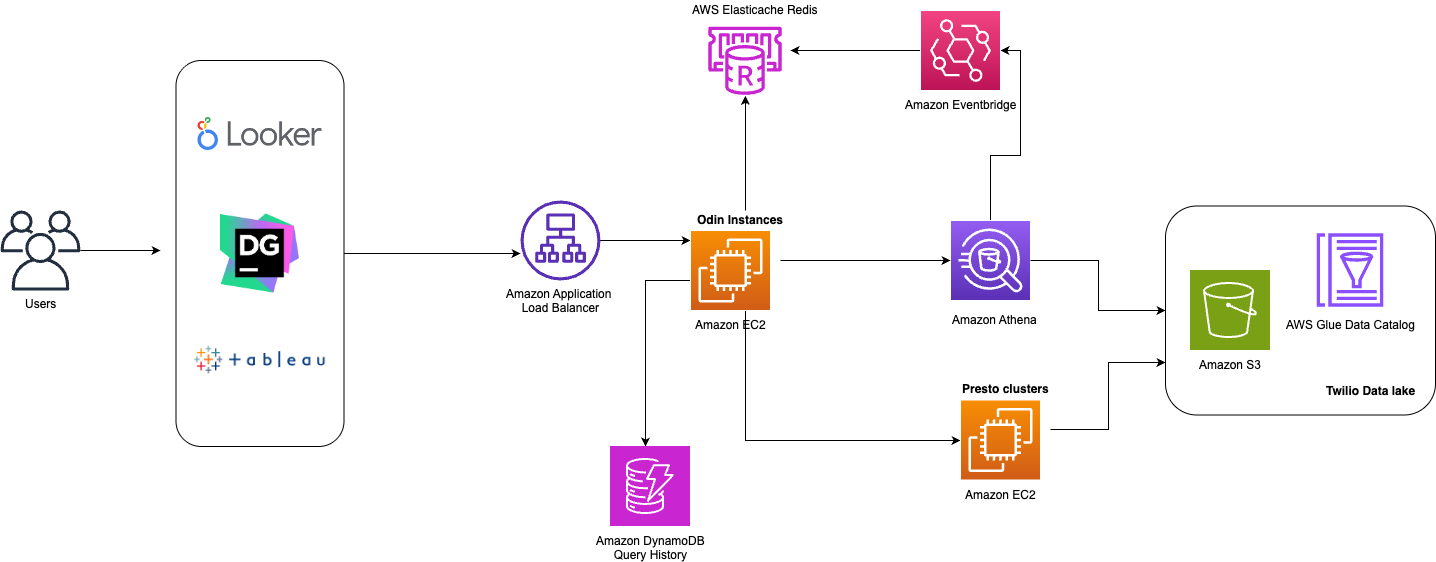
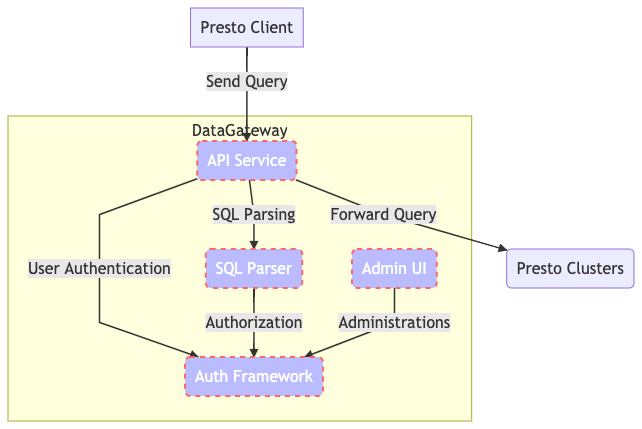
High Level Architecture of Odin’s Query Engines
Odin is a Presto-based gateway built on Zuul, an open-source L7 application gateway developed by Netflix. Zuul had already demonstrated its scalability at Twilio, having been successfully adopted by other internal teams. Since end users primarily connect to the platform via a JDBC connector using the Presto Driver (which operates through HTTP calls), Zuul’s specialization in HTTP call management made it an ideal technical choice for our needs.
Odin functions as a central hub for query processing, employing a pluggable design that accommodates various query frameworks for maximum extensibility and flexibility. To interact with the Odin platform users are initially directed to an Amazon Application Load Balancer that sits in front of the Odin instances running on Amazon EC2. The Odin instances handle the authentication, routing, and entire query workflow throughout the query’s lifetime. Amazon ElastiCache for Redis handles the query tracking for Athena and Amazon DynamoDB is responsible for the maintaining the query history. Both query engines, Amazon Athena and the Presto clusters running on Amazon EC2,are supported by the AWS Glue Data Catalog as the metastore repository and query data from our Amazon S3-based data lake.
Routing queries to multiple engines
We had a variety of use cases that were being served by this query platform and therefore we opted to use Amazon Athena as our primary query engine while continuing to route certain legacy workloads to our Presto clusters. Prior to our architectural redesign, we encountered operational challenges due to our end users being tightly bound to specific Presto clusters which led to inevitable disruptions during maintenance windows. Additionally, users frequently overloaded individual clusters with diverse workloads ranging from lightweight ad-hoc analytics to complex data warehousing queries and resource-intensive ETL processes. This prompted us to implement a more sophisticated routing solution, one that was use case focused and not tightly bound to the specific underlying compute.
To enable routing across multiple query engines within the same platform, we developed a query hint mechanism that allows users to specify their intended use case. Users append this hint to the JDBC string via the X-Presto-Extra-Credential header, which Odin’s logical routing layer then evaluates alongside multiple factors including user identity, query origin, and fallback planning. The system also assesses whether the target resource has sufficient capacity, if not, it reroutes the query to an alternative resource with available capacity. While users provide initial context through their hints, Odin makes the final routing decisions intelligently on the server side. This approach balances user input with centralized orchestration, ensuring consistent performance and resource availability.
For example, say a user might specify the following connection string when connecting to the Odin platform from a Tableau client:
The connection string uses the extraCredentials header to signal execution on Athena, where Odin validates query submission details, including the submitting user and tool, before determining the appropriate Athena workgroup for initial routing. Since this Tableau data source and user qualify as “critical queries,” the system routes them to a workgroup backed by capacity reservations. However, if that workgroup has too many pending queries in the execution queue, Odin’s routing logic automatically redirects to alternative workgroups with greater available resources. When necessary, queries may ultimately route to workgroups running on on-demand capacity. Through this fallback logic, Odin provides built-in load balancing at the routing layer, ensuring optimal utilization across the underlying compute infrastructure.
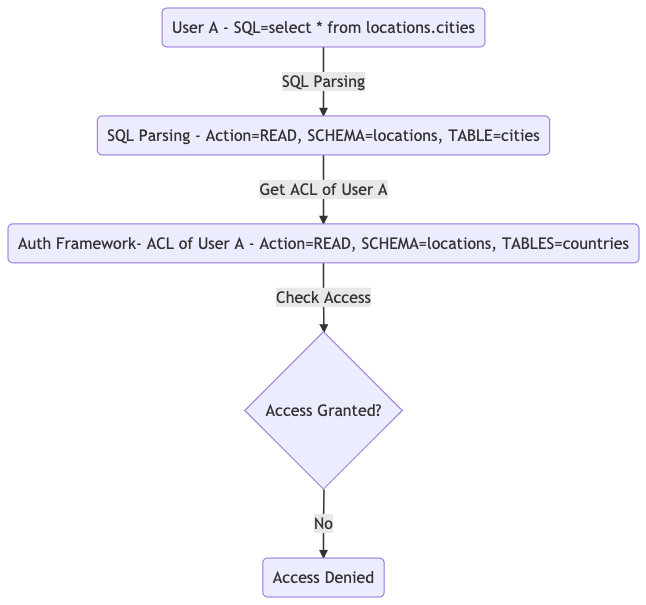
Here is an example workflow of how our queries are routed to Athena workgroups:
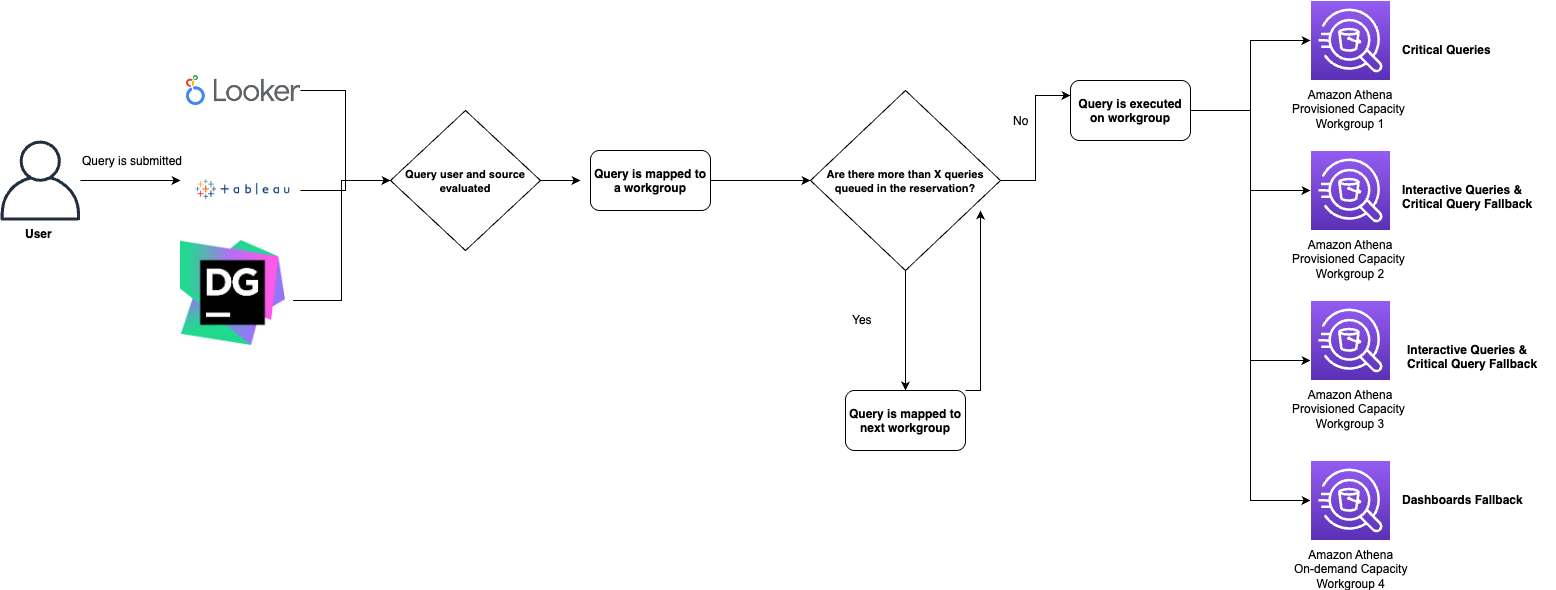
Once a query has been submitted to a workgroup for execution, Odin will also log the routing decision in our tracking system based on Amazon ElastiCache for Redis so that Odin’s routing logic can maintain real-time awareness of queue depths across all Athena workgroups. Additionally, Odin uses Amazon EventBridge to integrate with Amazon Athena to keep track of a query state change and create event-based workflows. Our Redis-based query tracking system effectively handles edge cases, such as when a JDBC client terminates mid-query. Even during such unexpected interruptions, the platform consistently maintains and updates the accurate state of the query.
Query history
Following successful query routing to either an Athena workgroup or one of our open-source Presto clusters, Odin persists the query identifier and destination endpoint in a query history table in DynamoDB. This design utilizes a RESTful architecture where initial query submissions operate as POST requests, while subsequent status checks function as GET requests that utilize DynamoDB as the authoritative lookup mechanism to locate and poll the appropriate execution engine. By centralizing query execution records in DynamoDB rather than maintaining state on individual servers, we’ve created a truly stateless system where incoming requests can be handled by any Amazon EC2 instance hosting our Odin web service.
Lessons learned
The transition from open-source Presto to Athena required some adaptation time, due to subtle differences in how these query engines operate. Since our Odin framework was built on the Presto driver, we needed to modify our processing approach to ensure compatibility between both systems.
As we began to adopt Athena for more use cases, we noticed a difference in the record counts between Athena and the original Presto queries. We discovered this was due to open-source Presto returning results with every page containing a header column, whereas Athena results only contain the header column on the first page and subsequent pages containing records only. This difference meant that for a 60-page result set, Athena would return 59 fewer rows than open-source Presto. Once we identified this pagination behavior, we optimized Odin’s result handling logic to properly interpret and process Athena’s format, so that queries would return accurate results.
Due to the nature of using the Odin platform, most of our interactions with the Athena service are API driven so we make use of the ResultSet object with the GetQueryResults API to retrieve query execution data. Using this mechanism, the API returns the data as all VARCHAR data type, even for complex types such as row, map, or array. This created a challenge because Odin uses the Presto driver for query parsing, resulting in a type mismatch between the expected formats and actual returned data. To address this, we implemented a translation layer within the Odin framework that converts all data types to VARCHAR and handles any downstream implications of this conversion internally.
These technical adjustments, while initially challenging, highlighted the importance of carefully managing the subtle differences between different query execution engines when building a unified data platform.
Scale of Odin and looking ahead
The Odin platform serves over 1,500 users who execute approximately 80,000 queries daily, totaling 2.5 million queries per month. Odin also powers more than 5,000 Business Intelligence (BI) reports and dashboards for Tableau and Looker. The queries are executed across our multi-engine landscape of more than 30 workgroups in Athena based on both provisioned capacity and on-demand workgroups and 4 Presto clusters on running on EC2 instances with Auto Scaling enabled that run on average 180 instances each. As Twilio continues to experience rapid growth, our Odin platform has enabled us to mature our technology stacks by both upgrading existing compute resources and integrating new technologies. We can do all this without disrupting the experience for our end users. While Odin serves as our foundation, we’re excited to continue to expand this pluggable infrastructure. Our roadmap includes migrating our self-managed open-source Presto implementation to EMR Trino, introducing Apache Spark as a compute engine via Amazon EMR Serverless or AWS Glue jobs, and integrating generative AI capabilities to intelligently route queries across Odin’s various compute options.
Conclusion
In this post, we’ve shared how we built Odin, our unified multi-engine query platform. By combining AWS services like Amazon Athena, Amazon ElastiCache for Redis, and Amazon DynamoDB with our open-source technology stack, we created a transparent abstraction layer for users. This integration has resulted in a highly available and resilient platform environment that serves our query processing needs.
By embracing this multi-engine approach, not only did we solve our query infrastructure challenges but we also established a flexible foundation that will continue to evolve with our data needs, ensuring we can deliver powerful insights at scale regardless of how technology trends shift in the future.
To learn more and get started using Amazon Athena, please see the Athena User Guide.