With Zabbix Summit Online 2021 just around the corner, it’s time to have a quick overview of the 6.0 LTS features that we can expect to see featured during the event. The Zabbix 6.0 LTS release aims to deliver some of the long-awaited enterprise-level features while also improving the general user experience, performance, scalability, and many other aspects of Zabbix.
Native Zabbix server cluster
Many of you will be extremely happy to hear that Zabbix 6.0 LTS release comes with out-of-the-box High availability for Zabbix Server. This means that HA will now be supported natively, without having to use external tools to create Zabbix Server clusters.
The native Zabbix Server cluster will have a speech dedicated to it during the Zabbix Summit Online 2021. You can expect to learn both the inner workings of the HA solution, the configuration and of course the main benefits of using the native HA solution. You can also take a look at the in-development version of the native Zabbix server cluster in the latest Zabbix 6.0 LTS alpha release.
Business service monitoring and root cause analysis
Service monitoring is also about to go through a significant redesign, focusing on delivering additional value by providing robust Business service monitoring (BSM)features. This is achieved by delivering significant additions to the existing service status calculation logic. With features such as service weights, service status analysis based on child problem severities, ability to calculate service status based on the number or percentage of children in a problem state, users will be able to implement BSM on a whole new level. BSM will also support root cause analysis – users will be informed about the root cause problem of the service status change.
All of this and more, together with examples and use cases will be covered during a separate speech dedicated to BSM. In addition, some of the BSM features are available in the latest Zabbix 6.0 LTS alpha release – with more to come as we continue working on the Zabbix 6.0 release.
Audit log redesign
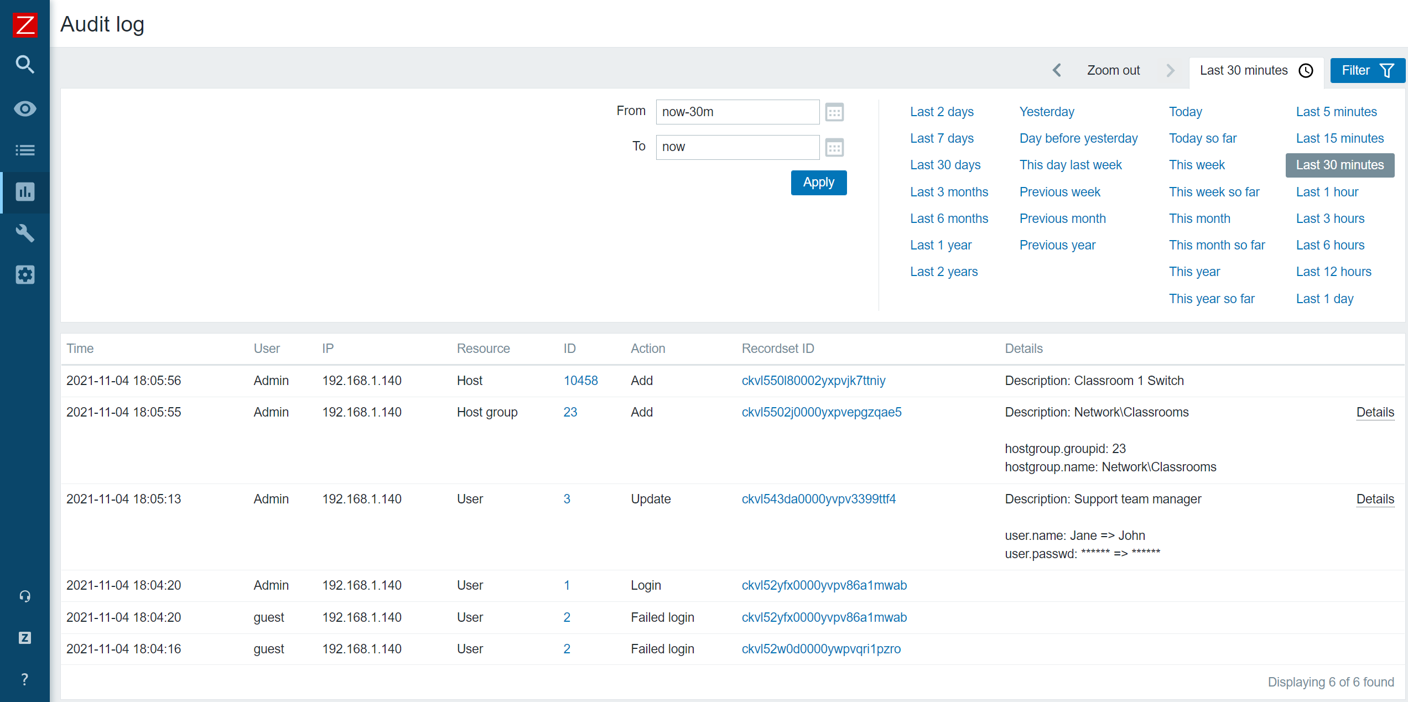
The Audit log is another existing feature that has received a complete redesign. With the ability to log each and every change performed both by the Zabbix Server and Zabbix Frontend, the Audit log will become an invaluable source of audit information. Of course, the redesign also takes performance into consideration – the redesign was developed with the least possible performance impact in mind.
The audit log is constantly in development and the current Zabbix 6.0 LTS alpha release offers you an early look at the feature. We will also be covering the technical details of the new audit log implementation during the Summit and will explain how we are able to achieve minimal performance impact with major improvements to Zabbix audit logging.
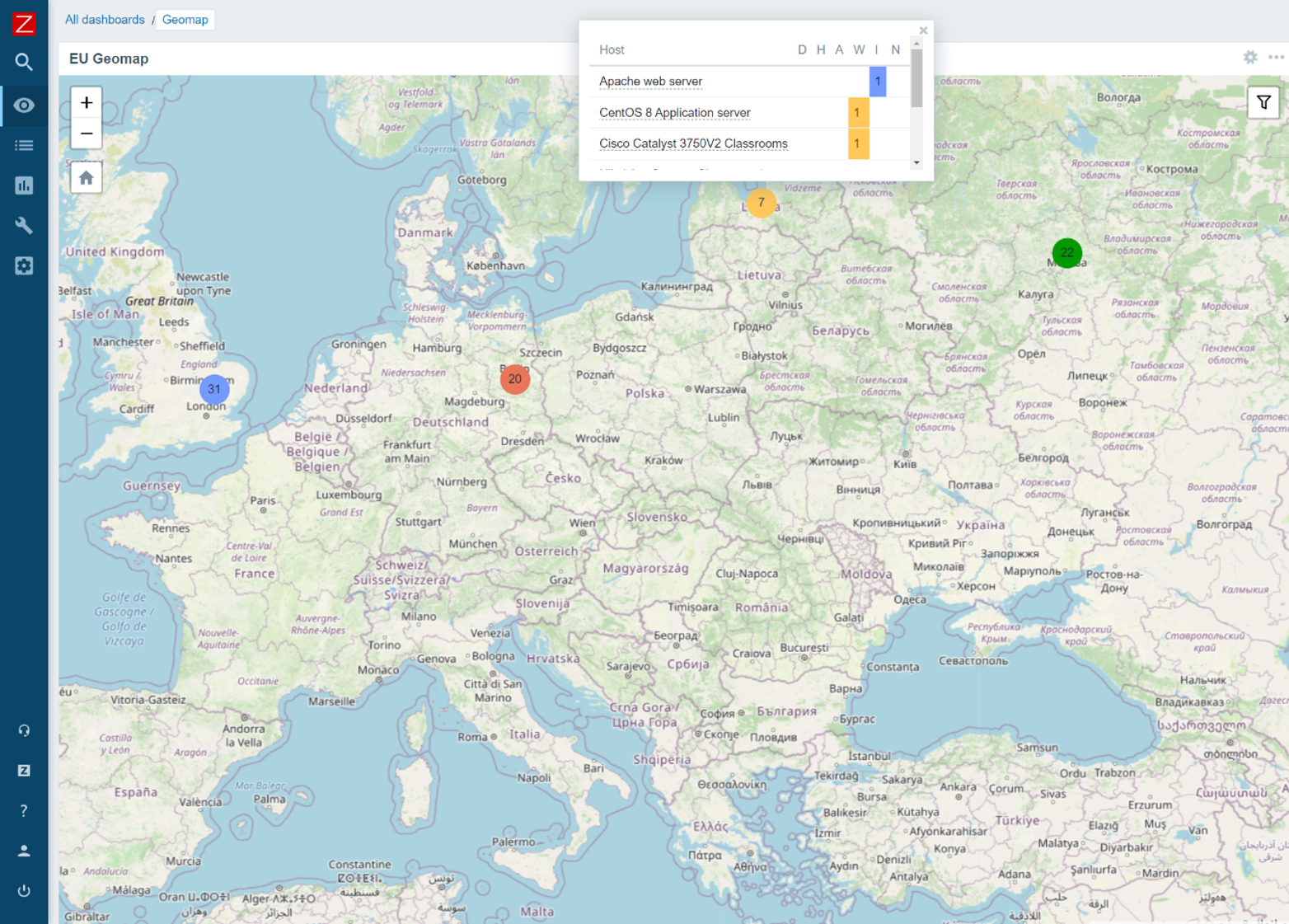
Geographical maps
With Geographical maps, our users can finally display their entities on a geographical map based on the coordinates of the entity. Geographical maps can be used with multiple geographical map providers and display your hosts with their most severe problems. In addition, geographical maps will react dynamically to Zoom levels and support filtering.
The latest Zabbix 6.0 Alpha release includes the Geomap widget – feel free to deploy it in your QA environment, check out the different map providers, filter options and other great features that come with this widget.
Machine learning
When it comes to problem detection, Zabbix 6.0 LTS will deliver multiple trend new functions. A specific set of functions provides machine learning functionality for Anomaly detection and Baseline monitoring.
The topic will be covered in-depth during the Zabbix Summit Online 2021. We will look at the configuration of the new functions and also take a deeper dive at the logic and algorithms used under the hood.
During the Zabbix Summit Online 2021, we will also cover many other new features, such as:
New Dashboard widgets
New items for Zabbix Agent
New templates and integrations
Zabbix login password complexity settings
Performance improvements for Zabbix Server, Zabbix Proxy, and Zabbix Frontend
UI and UX improvements
Zabbix login password complexity requirements
New history and trend functions
And more!
Not only will you get the chance to have an early look at many new features not yet available in the latest alpha release, but also you will have a great chance to learn the inner workings of the new features, the upgrade and migration process to Zabbix 6.0 LTS and much more!
We are extremely excited to share all of the new features with our community, so don’t miss out – take a look at the full Zabbix Summit online 2021 agenda and register for the event by visiting our Zabbix Summit page, and we will see you at the Zabbix Summit Online 2021 on November 25!
Data is the lifeblood of Grab and the insights we gain from it drive all the most critical business decisions made by Grabbers and our leaders every day.
Grab’s Data Engineering (DE) team is responsible for maintaining the data platform, which consists of data pipelines, job schedulers, and the query/computation engines that are the key components for generating insights from data. SQL is the core language for analytics at Grab and as of early 2020, our Presto platform serves about 200 user groups that add up to 500 users who run 350,000 queries every day. These queries span across 10,000 tables that process up to 1PB of data daily.
In 2016, we started the DataGateway project to enable us to manage data access for the hundreds of Grabbers who needed access to Presto for their work. Since then, DataGateway has grown to become much more than just an access control mechanism for Presto. In this blog, we want to share what we’ve achieved since the initial launch of the project.
The problems we wanted to solve
As we were reviewing the key challenges around data access in Grab and assessing possible solutions, we came up with this prioritized list of user requirements we wanted to work on:
Use a single endpoint to serve everyone.
Manage user access to clusters, schemas, tables, and fields.
Provide seamless user experience when presto clusters are scaled up/down, in/out, or provisioned/decommissioned.
Capture audit trail of user activities.
To provide Grabbers with the critical need of interactive querying, as well as performing extract, transform, load (ETL) jobs, we evaluated several technologies. Presto was among the ones we evaluated, and was what we eventually chose although it didn’t meet all of our requirements out of the box. In order to address these gaps, we came up with the idea of a security gateway for the Presto compute engine that could also act as a load balancer/proxy, this is how we ended up creating the DataGateway.
DataGateway is a service that sits between clients and Presto clusters. It is essentially a smart HTTP proxy server that is an abstraction layer on top of the Presto clusters that handles the following actions:
Parse incoming SQL statements to get requested schemas, tables, and fields.
Manage user Access Control List (ACL) to limit users’ data access by checking against the SQL parsing results.
Manage users’ cluster access.
Redirect users’ traffic to the authorized clusters.
Show meaningful error messages to users whenever the query is rejected or exceptions from clusters are encountered.
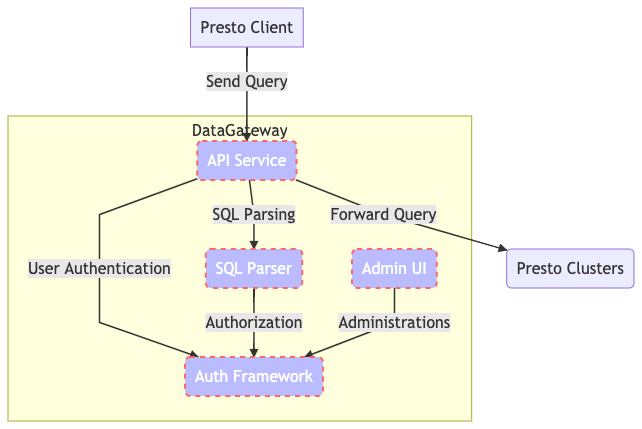
Anatomy of DataGateway
The DataGateway’s key components are as follows:
API Service
SQL Parser
Auth framework
Administration UI
We leveraged Kubernetes to run all these components as microservices.
Figure 1. DataGateway Key Components
API Service
This is the component that manages all users and cluster-facing processes. We integrated this service with the Presto API, which means it appears to be the same as a Presto cluster to a client. It accepts query requests from clients, gets the parsing result and runs authorization from the SQL Parser and the Auth Framework.
If everything is good to go, the API Service forwards queries to the assigned clusters and continues the entire query process.
Auth Framework
This handles both authentication and authorization requests. It stores the ACL of users and communicates with the API Service and the SQL Parser to run the entire authentication process. But why is it a microservice instead of a module in API Service, you ask? It’s because we keep evolving the security checks at Grab to ensure that everything is compliant with our security requirements, especially when dealing with data.
We wanted to make it flexible to fulfill ad-hoc requests from the security team without affecting the API Service. Furthermore, there are different authentication methods out there that we might need to deal with (OAuth2, SSO, you name it). The API Service supports multiple authentication frameworks that enable different authentication methods for different users.
SQL Parser
This is a SQL parsing engine to get schema, tables, and fields by reading SQL statements. Since Presto SQL parsing works differently in each version, we would compile multiple SQL Parsers that are identical to the Presto clusters we run. The SQL Parser becomes the single source of truth.
Admin UI
This is a UI for Presto administrators to manage clusters and user access, as well as to select an authentication framework, making it easier for the administrators to deal with the entire ecosystem.
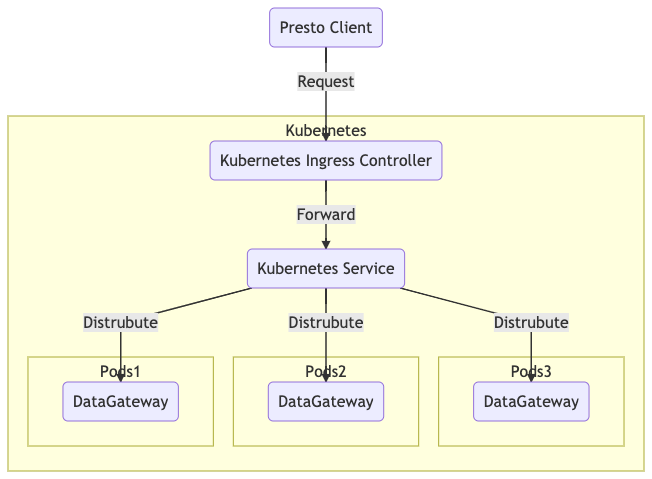
How we deployed DataGateway using Kubernetes
In the past couple of years, we’ve had significant growth in workloads from analysts and data scientists. As we were very enthusiastic about Kubernetes, DataGateway was chosen as one of the earliest services for deployment in Kubernetes. DataGateway in Kubernetes is known to be highly available and fully scalable to handle traffic from users and systems.
We also tested the HPA feature of Kubernetes, which is a dynamic scaling feature to scale in or out the number of pods based on actual traffic and resource consumption.
Figure 2. DataGateway deployment using Kubernetes
Functionality of DataGateway
This section highlights some of the ways we use DataGateway to manage our Presto ecosystem efficiently.
Restrict users based on Schema/Table level access
In a setup where a Presto cluster is deployed on AWS Amazon Elastic MapReduce (EMR) or Elastic Kubernetes Service (EKS), we configure an IAM role and attach it to the EMR or EKS nodes. The IAM role is set to limit the access to S3 storage. However, the IAM only provides bucket-level and file-level control; it doesn’t meet our requirements to have schema, table, and column-level ACLs. That’s how DataGateway is found useful in such scenarios.
One of the DataGateway services is an SQL Parser. As previously covered, this is a service that parses and digs out schemas and tables involved in a query. The API service receives the parsing result and checks against the ACL of users, and decides whether to allow or reject the query. This is a remarkable improvement in our security control since we now have another layer to restrict access, on top of the S3 storage. We’ve implemented an SQL-based access control down to table level.
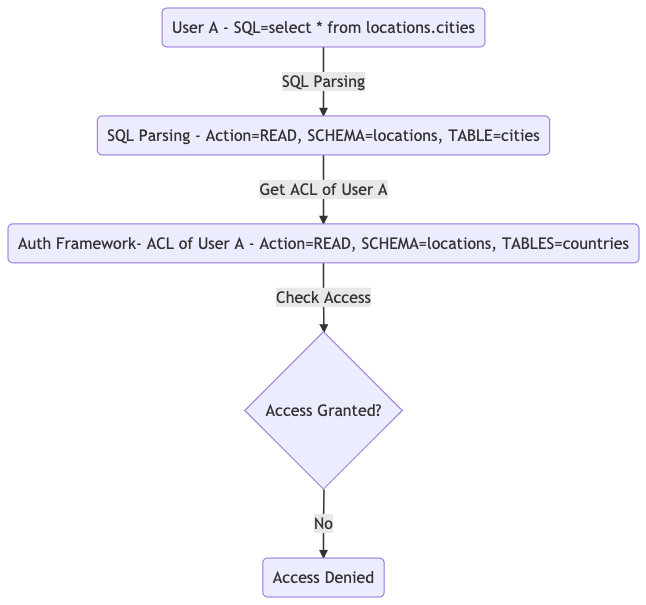
As shown in the Figure 3, user A is trying run a SQL statement select * from locations.cities. The SQL Parser reads the statement and tells the API service that user A is trying to read data from the table cities in the schema locations. Then, the API service checks against the ACL of user A. The service finds that user A has only read access to table countries in schema locations. Eventually, the API service denies this attempt because user A doesn’t have read access to table cities in the schema locations.
Figure 3. An example of how to check user access to run SQL statements
The above flow shows an access denied result because the user doesn’t have the appropriate permissions.
Seamless User Experience during the EMR migration
We use AWS EMR to deploy Presto as an SQL query engine since deployment is really easy. However, without DataGateway, any EMR operations such as terminations, new cluster deployment, config changes, and version upgrades, would require quite a bit of user involvement. We would sometimes need users to make changes on their side. For example, request users to change the endpoints to connect to suitable clusters.
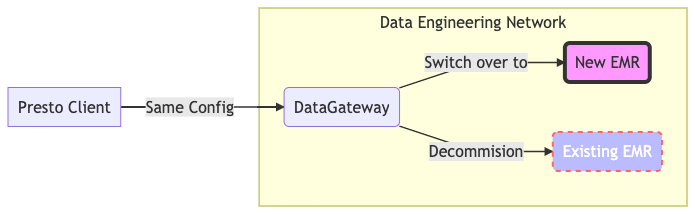
With DataGateway, ACLs exist for each of the user accounts. The ACL includes the list of EMR clusters that users are allowed to access. As a Presto access management platform, here the DataGateway redirects user traffics to an appropriate cluster based on the ACL, like a proxy. Users always connect to the same endpoint we offer, which is the DataGateway. To switch over from one cluster to another, we just need to edit the cluster ACL and everything is handled seamlessly.
Figure 4. Cluster switching using DataGateway
Figure 4 highlights the case when we’re switching EMR from one cluster to another. No changes are required from users.
We executed the migration of our entire Presto platform from an AWS EMR instance to another AWS EMR instance using the same methodology. The migrations were executed with little to no disruption for our users. We were able to move 40 clusters with hundreds of users. They were able to issue millions of queries daily in a few phases over a couple of months.
In most cases, users didn’t have to make any changes on their end, they just continued using Presto as usual while we made the changes in the background.
Multi-Cloud Data Lake/Presto Cluster maintenance
Recently, we started to build and maintain data lakes not just in one cloud, but two – in AWS and Azure. Since most end-users are AWS-based, and each team has their own AWS sub-account to run their services and workloads, it would be a nightmare to bridge all the connections and access routes between these two clouds from end-to-end, sub-account by sub-account.
Here, the DataGateway plays the role of the multi-cloud gateway. Since all end-users’ AWS sub-accounts have peered to DataGateway’s network, everything becomes much easier to handle.
For end-users, they retain the same Presto connection profile. The DE team then handles the connection setup from DataGateway to Azure, and also the deployment of Presto clusters in Azure.
When all is set, end-users use the same endpoint to DataGateway. We offer a feature called Cluster Switch that allows users to switch between AWS Presto cluster and Azure Presto Cluster on the fly by filling in parameters on the connection string. This feature allows users to switch to their target Presto cluster without any endpoint changes. The switch works instantly whenever they do the change. That means users can run different queries in different clusters based on their requirements.
This feature has helped the DE team to maintain Presto Cluster easily. We can spin up different Presto clusters for different teams, so that each team has their own query engine to run their queries with dedicated resources.
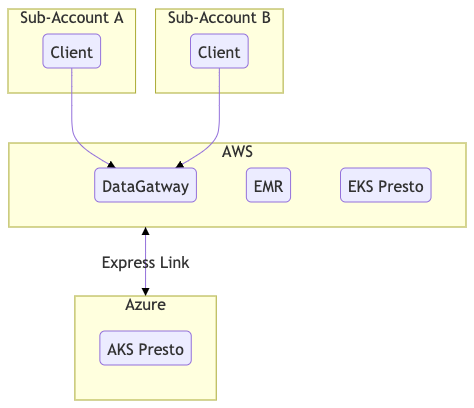
Figure 5. Sub-account connections and Queries
Figure 5 shows an example of how sub-accounts connect to DataGateway and run queries on resources in different clouds and clusters.
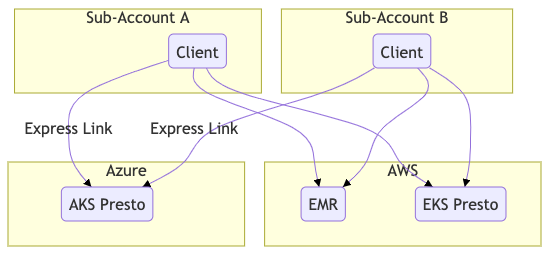
Figure 6. Sample scenario without DataGateway
Figure 6 shows a scenario of what would happen if DataGatway doesn’t exist. Each of the accounts would have to maintain its own connections, Virtual Private Cloud (VPC) peering, and express link to connect to our Presto resources.
Summary
DataGateway is playing a key role in Grab’s entire Presto ecosystem. It helps us manage user access and cluster selections on a single endpoint, ensuring that everyone is running their Presto queries on the same place. It also helps distribute workload to different types and versions of Presto clusters.
When we started to deploy the DataGateway on Kubernetes, our vision for the Presto ecosystem underwent an epic change as it further motivated us to continuously improve. Since then, we’ve had new ideas on deployment method/pipeline, microservice implementations, scaling strategy, resource control, we even made use of Kubernetes and designed an on-demand, container-based Presto cluster provisioning engine. We’ll share this in another engineering blog, so do stay tuned!.
We also made crucial enhancements on data access control as we extended Presto’s access controls down to the schema/table-level.
In day-to-day operations, especially when we started to implement data lake in multiple clouds, DataGateway solved a lot of implementation issues. DataGateway made it simpler to switch a user’s Presto cluster from one cloud to another or allow a user to use a different Presto cluster using parameters. DataGateway allowed us to provide a seamless experience to our users.
Looking forward, we’ve more and more ideas for our Presto ecosystem, such Spark DataGateway or AWS Athena integrations, to keep our data safe at any time and to provide our users with a smoother experience when dealing with data used for analysis or research.
Authored by Vinnson Lee on behalf of the Presto Development Team at Grab – Edwin Law, Qui Hieu Nguyen, Rahul Penti, Wenli Wan, Wang Hui and the Data Engineering Team.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.