It’s been about nine months since Cloudflare announced support for Signed Exchanges (SXG), a web platform specification to deterministically verify the cached version of a website and enable third parties such as search engines and news aggregators to serve it much faster than the origin ever could.
faster websites= better SEO and lower bounce rates
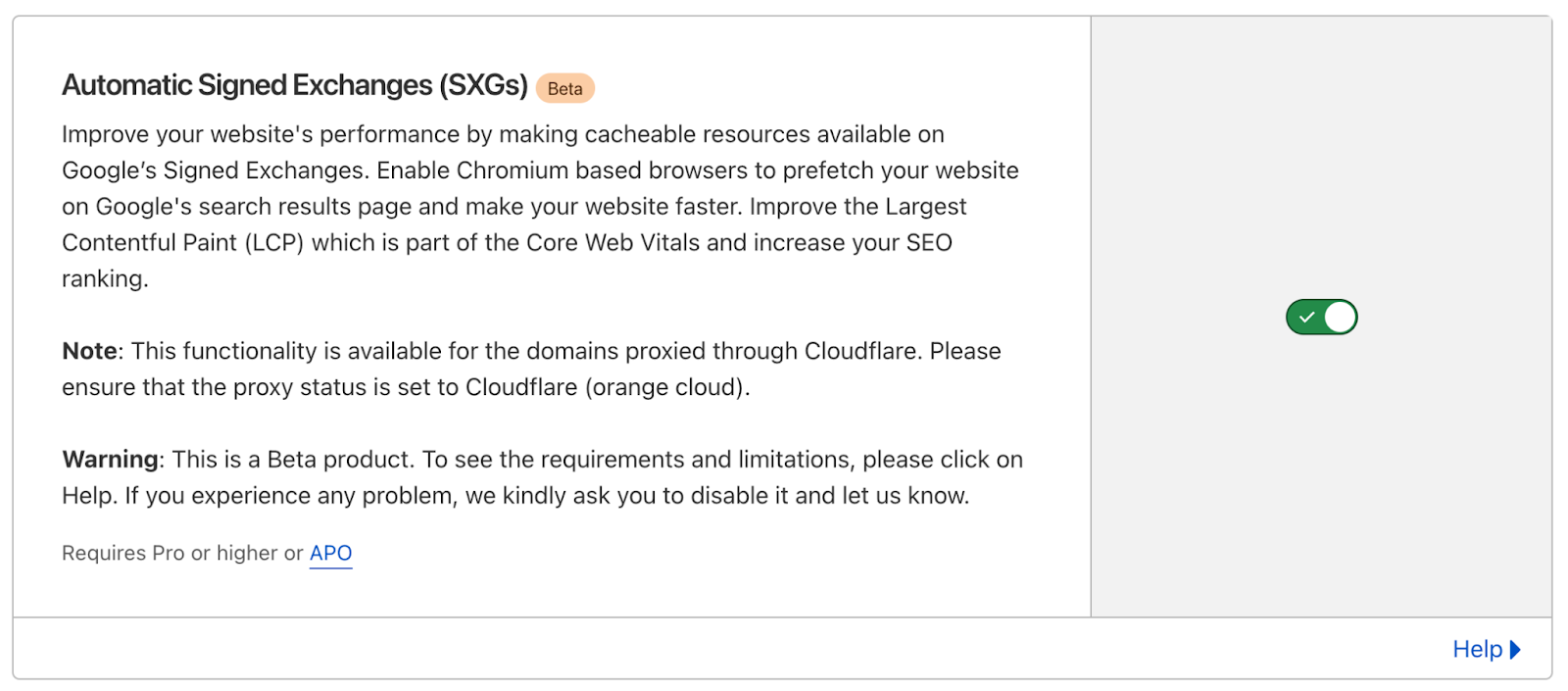
And if setting up and maintaining SXGs through the open source toolkit is a complex yet very valuable endeavor, with Cloudflare’s Automatic Signed Exchanges it becomes a no-brainer. Just enable it with one click and see for yourself.
Our own measurements
Now that Signed Exchanges have been available on Chromium for Android for several months we dove into the change in performance our customers have experienced in the real world.
We picked the 500 most visited sites that have Automatic Signed Exchanges enabled and saw that 425 of them (85%) saw an improvement in LCP, which is widely considered as the Core Web Vital with the most impact on SEO and where SXG should make the biggest difference.
Out of those same 500 Cloudflare sites 389 (78%) saw an improvement in First Contentful Paint (FCP) and a whopping 489 (98%) saw an improvement in Time to First Byte (TTFB). The TTFB improvement measured here is an interesting case since if the exchange has already been prefetched, when the user clicks on the link the resource is already in the client browser cache and the TTFB measurement becomes close to zero.
Overall, the median customer saw an improvement of over 20% across these metrics. Some customers saw improvements of up to 80%.
There were also a few customers that did not see an improvement, or saw a slight degradation of their metrics.
One of the main reasons for this is that SXG wasn’t compatible with server-side personalization (e.g., serving different HTML for logged-in users) until today. To solve that, today Google added ‘Dynamic SXG’, that selectively enables SXG for visits from cookieless users only (more details on the Google blog post here). Dynamic SXG are supported today – all you need to do is add a `Vary: Cookie’ annotation to the HTTP header of pages that contain server-side personalization.
Note: Signed Exchanges are compatible with client-side personalization (lazy-loading).
To see what the Core Web Vitals look like for your own users across the world we recommend a RUM solution such as our free and privacy-first Web Analytics.
Now available for Desktop and Android
Starting today, Signed Exchanges is also supported by Chromium-based desktop browsers, including Chrome, Edge and Opera.
If you enabled Automatic Signed Exchanges on your Cloudflare dashboard, no further action is needed – the supported desktop browsers will automatically start being served the SXG version of your site’s content. Google estimates that this release will, on average, double SXG’s coverage of your site’s visits, enabling improved loading and performance for more users.
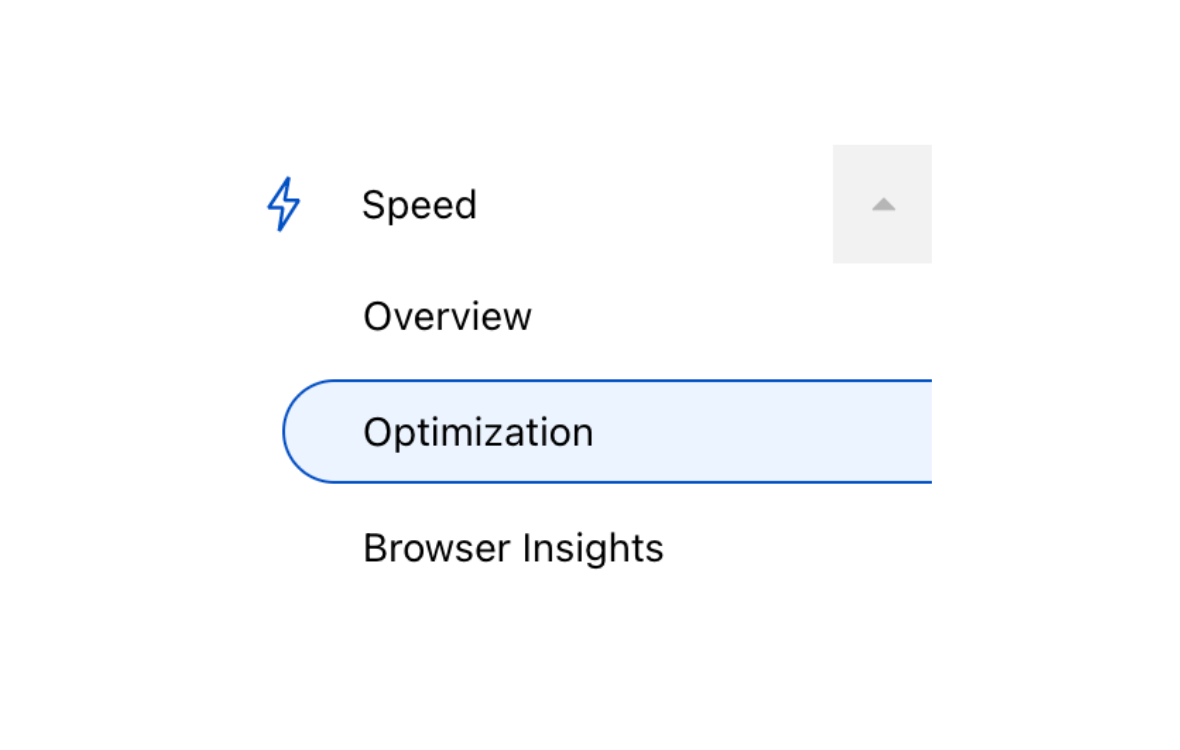
And if you haven’t yet enabled it but are curious about the impact SXG will have on your site, Automatic Signed Exchanges is available through the Speed > Optimization link on your Cloudflare dashboard (more details here).
Until today, Cloudflare Workers has been a great solution to setting headers, but we wanted to create an even smoother developer experience. Today, we’re excited to announce that Pages now natively supports custom headers on your projects! Simply create a _headers file in the build directory of your project and within it, define the rules you want to apply.
/developer-docs/*
X-Hiring: Looking for a job? We're hiring engineers
(https://www.cloudflare.com/careers/jobs)
What can you set with custom headers?
Being able to set custom headers is useful for a variety of reasons — let’s explore some of your most popular use cases.
Search Engine Optimization (SEO)
When you create a Pages project, a pages.dev deployment is created for your project which enables you to get started immediately and easily preview changes as you iterate. However, we realize this poses an issue — publishing multiple copies of your website can harm your rankings in search engine results. One way to solve this is by disabling indexing on all pages.dev subdomains, but we see many using their pages.dev subdomain as their primary domain. With today’s announcement you can attach headers such as X-Robots-Tag to hint to Google and other search engines how you’d like your deployment to be indexed.
For example, to prevent your pages.dev deployment from being indexed, you can add the following to your _headers file:
Customizing headers doesn’t just help with your site’s search result ranking — a number of browser security features can be configured with headers. A few headers that can enhance your site’s security are:
X-Frame-Options: You can prevent click-jacking by informing browsers not to embed your application inside another (e.g. with an <iframe>).
X-Content-Type-Option: nosniff: To prevent browsers from interpreting a response as any other content-type than what is defined with the Content-Type header.
Referrer-Policy: This allows you to customize how much information visitors give about where they’re coming from when they navigate away from your page.
Permissions-Policy: Browser features can be disabled to varying degrees with this header (recently renamed from Feature-Policy).
Content-Security-Policy: And if you need fine-grained control over the content in your application, this header allows you to configure a number of security settings, including similar controls to the X-Frame-Options header.
You can configure these headers to protect an /app/* path, with the following in your _headers file:
Modern browsers implement a security protection called CORS or Cross-Origin Resource Sharing. This prevents one domain from being able to force a user’s action on another. Without CORS, a malicious site owner might be able to do things like make requests to unsuspecting visitors’ banks and initiate a transfer on their behalf. However, with CORS, requests are prevented from one origin to another to stop the malicious activity.
There are, however, some cases where it is safe to allow these cross-origin requests. So-called, “simple requests” (such as linking to an image hosted on a different domain) are permitted by the browser. Fetching these resources dynamically is often where the difficulty arises, and the browser is sometimes overzealous in its protection. Simple static assets on Pages are safe to serve to any domain, since the request takes no action and there is no visitor session. Because of this, a domain owner can attach CORS headers to specify exactly which requests can be allowed in the _headers file for fine-grained and explicit control.
For example, the use of the asterisk will enable any origin to request any asset from your Pages deployment:
/*
Access-Control-Allow-Origin: *
To be more restrictive and limit requests to only be allowed from a ‘staging’ subdomain, we can do the following:
To support all these use cases for custom headers, we had to build a new engine to determine which rules to apply for each incoming request. Backed, of course, by Workers, this engine supports splats and placeholders, and allows you to include those matched values in your headers.
Although we don’t support all of its features, we’ve modeled this matching engine after the URLPattern specification which was recently shipped with Chrome 95. We plan to be able to fully implement this specification for custom headers once URLPattern lands in the Workers runtime, and there should hopefully be no breaking changes to migrate.
Enhanced support for redirects
With this same engine, we’re bringing these features to your _redirects file as well. You can now configure your redirects with splats, placeholders and status codes as shown in the example below:
Custom headers and redirects for Cloudflare Pages can be configured today. Check out our documentation to get started, and let us know how you’re using it in our Discord server. We’d love to hear about what this unlocks for your projects!
Coming up…
And finally, if a _headers file and enhanced support for _redirects just isn’t enough for you, we also have something big coming very soon which will give you the power to build even more powerful projects. Stay tuned!
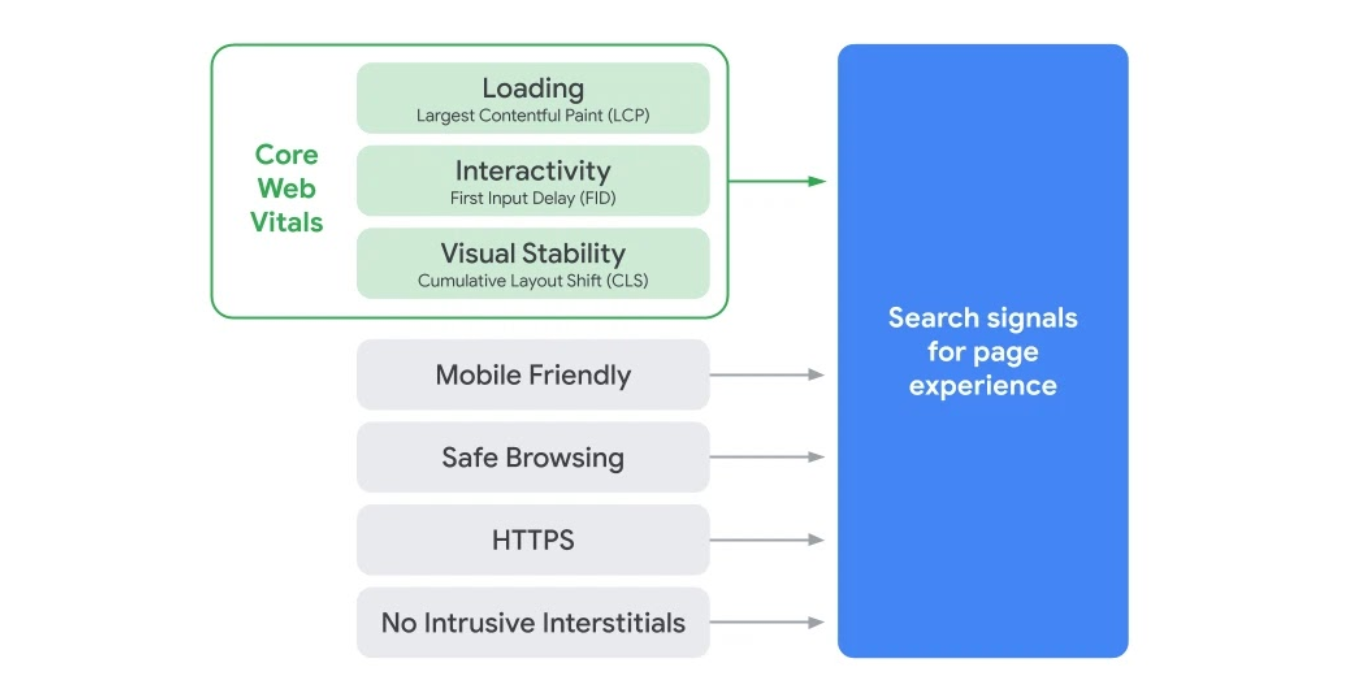
Making things fast is one of the things we do at Cloudflare. More responsive websites, apps, APIs, and networks directly translate into improved conversion and user experience. Today, Google announced that Google Search will directly take web performance and page experience data into account when ranking results on their search engine results pages (SERPs), beginning in May 2021.
Specifically, Google Search will prioritize results based on how pages score on Core Web Vitals, a measurement methodology Cloudflare has worked closely with Google to establish, and we have implemented support for in our analytics tools.
Source: “Search Page Experience Graphic” by Google is licensed under CC BY 4.0
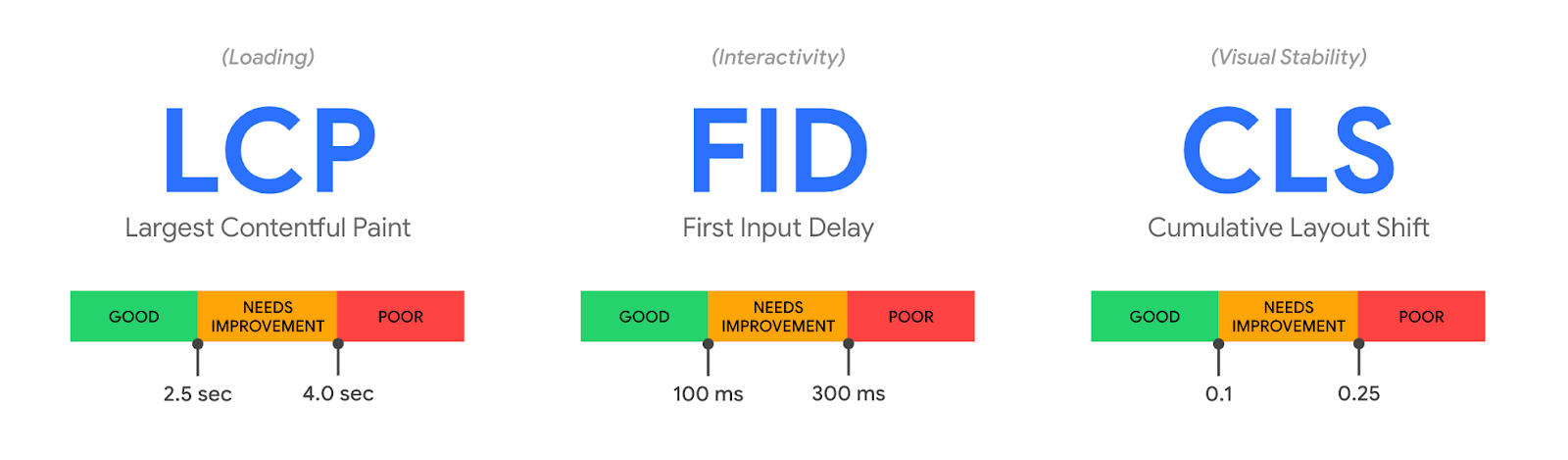
The Core Web Vitals metrics are Largest Contentful Paint (LCP, a loading measurement), First Input Delay (FID, a measure of interactivity), and Cumulative Layout Shift (CLS, a measure of visual stability). Each one is directly associated with user perceptible page experience milestones. All three can be improved using our performance products, and all three can be measured with our Cloudflare Browser Insights product, and soon, with our free privacy-aware Cloudflare Web Analytics.
SEO experts have always suspected faster pages lead to better search ranking. With today’s announcement from Google, we can say with confidence that Cloudflare helps you achieve the web performance trifecta: our product suite makes your site faster, gives you direct visibility into how it is performing (and use that data to iteratively improve), and directly drives improved search ranking and business results.
“Google providing more transparency about how Search ranking works is great for the open Web. The fact they are ranking using real metrics that are easy to measure with tools like Cloudflare’s analytics suite makes today’s announcement all the more exciting. Cloudflare offers a full set of tools to make sites incredibly fast and measure ‘incredibly’ directly.”
– Matt Weinberg, president of Happy Cog, a full-service digital agency.
Cloudflare helps make your site faster
Cloudflare offers a diverse, easy to deploy set of products to improve page experience for your visitors. We offer a rich, configurable set of tools to improve page speed, which this post is too small to contain. Unlike Fermat, who once famously described a math problem and then said “the margin is too small to contain the solution”, and then let folks spend three hundred plus years trying to figure out his enigma, I’m going to tell you how to solve web performance problems with Cloudflare. Here are the highlights:
Caching and Smart Routing
The typical website is composed of a mix of static assets, like images and product descriptions, and dynamic content, like the contents of a shopping cart or a user’s profile page. Cloudflare caches customers’ static content at our edge, avoiding the need for a full roundtrip to origin servers each time content is requested. Because our edge network places content very close (in physical terms) to users, there is less distance to travel and page loads are consequently faster. Thanks, Einstein.
And Argo Smart Routing helps speed page loads that require dynamic content. It analyzes and optimizes routing decisions across the global Internet in real-time. Think Waze, the automobile route optimization app, but for Internet traffic.
Just as Waze can tell you which route to take when driving by monitoring which roads are congested or blocked, Smart Routing can route connections across the Internet efficiently by avoiding packet loss, congestion, and outages.
Using caching and Smart Routing directly improves page speed and experience scores like Web Vitals. With today’s announcement from Google, this also means improved search ranking.
Content optimization
Caching and Smart Routing are designed to reduce and speed up round trips from your users to your origin servers, respectively. Cloudflare also offers features to optimize the content we do serve.
Cloudflare Image Resizing allows on-demand sizing, quality, and format adjustments to images, including the ability to convert images to modern file formats like WebP and AVIF.
Delivering images this way to your end-users helps you save bandwidth costs and improve performance, since Cloudflare allows you to optimize images already cached at the edge.
For WordPress operators, we recently launched Automatic Platform Optimization (APO). With APO, Cloudflare will serve your entire site from our edge network, ensuring that customers see improved performance when visiting your site. By default, Cloudflare only caches static content, but with APO we can also cache dynamic content (like HTML) so the entire site is served from cache. This removes round trips from the origin drastically improving TTFB and other site performance metrics. In addition to caching dynamic content, APO caches third party scripts to further reduce the need to make requests that leave Cloudflare’s edge network.
Workers and Workers Sites
Reducing load on customer origins and making sure we serve the right content to the right clients at the right time are great, but what if customers want to take things a step further and eliminate origin round trips entirely? What if there was no origin? Before we get into Schrödinger’s cat/server territory, we can make this concrete: Cloudflare offers tools to serve entire websites from our edge, without an origin server being involved at all. For more on Workers Sites, check out our introductory blog post and peruse our Built With Workers project gallery.
As big proponents of dogfooding, many of Cloudflare’s own web properties are deployed to Workers Sites, and we use Web Vitals to measure our customers’ experiences.
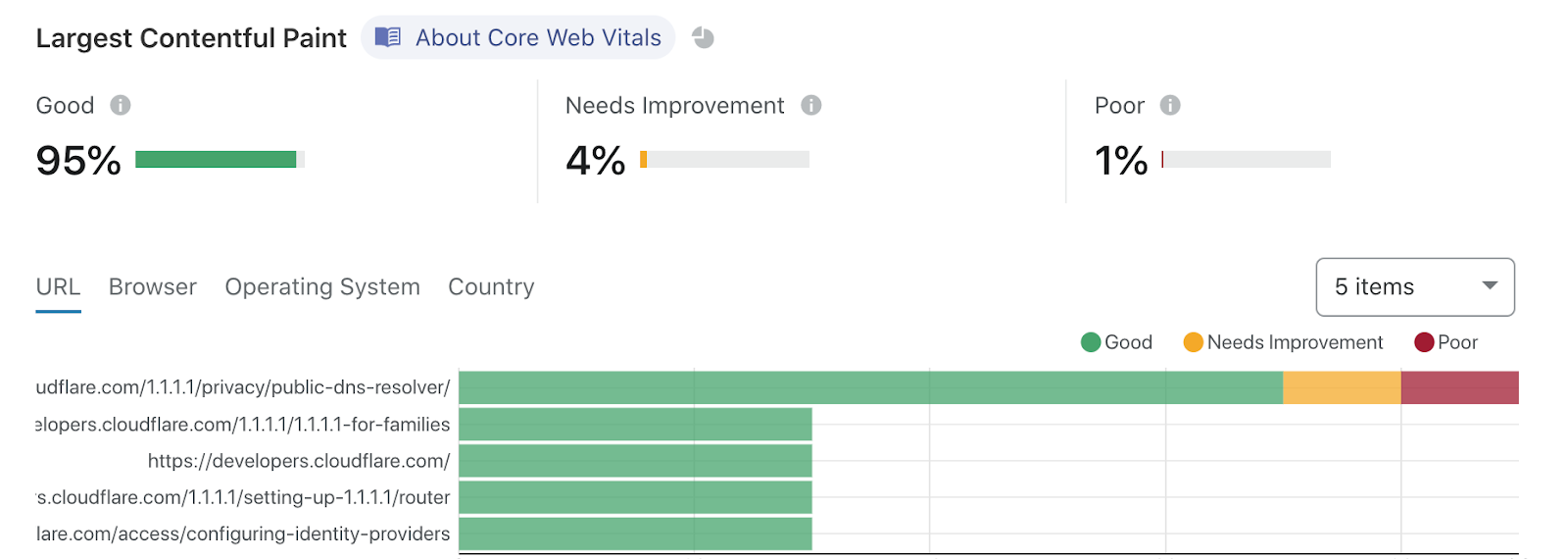
Using Workers Sites, our developers.cloudflare.com site, which gets hundreds of thousands of visits a day and is critical to developers building atop our platform, is able to attain incredible Web Vitals scores:
These scores are superb, showing the performance and ease of use of our edge, our static website delivery system, and our analytics toolchain.
Cloudflare Web Analytics and Browser Insights directly measure the signals Google is prioritizing
As illustrated above, Cloudflare makes it easy to directly measure Web Vitals with Browser Insights. Enabling Browser Insights for websites proxied by Cloudflare takes one click in the Speed tab of the Cloudflare dashboard. And if you’re not proxying sites through Cloudflare, Web Vitals measurements will be supported in our upcoming, free, Cloudflare Web Analytics product that any site, using Cloudflare’s proxy or not, can use.
Web Vitals breaks down user experience into three components:
Loading: How long did it take for content to become available?
Interactivity: How responsive is the website when you interact with it?
Visual stability: How much does the page move around while loading?
It’s challenging to create a single metric that captures these high-level components. Thankfully, the folks at Google Chrome team have thought about this, and earlier this year introduced three “Core” Web Vitals metrics: Largest Contentful Paint, First Input Delay, and Cumulative Layout Shift.
Cloudflare Browser Insights measures all three metrics directly in your users’ browsers, all with one-click enablement from the Cloudflare dashboard.
Once enabled, Browser Insights works by inserting a JavaScript “beacon” into HTML pages. You can control where the beacon loads if you only want to measure specific pages or hostnames. If you’re using CSP version 3, we’ll even automatically detect the nonce (if present) and add it to the script.
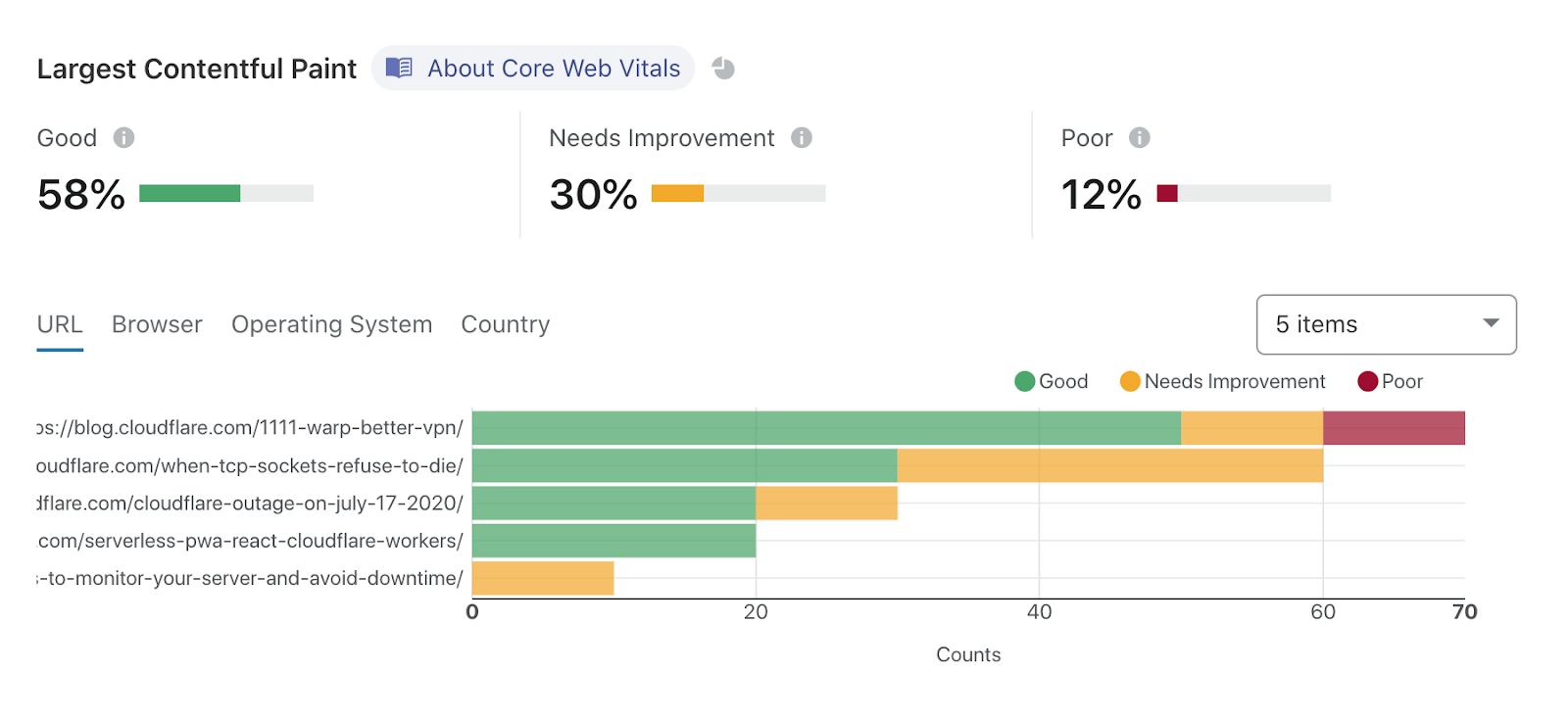
To start using Browser Insights, just head over to the Speed tab in the dashboard.
An example Browser Insights report, showing what pages on blog.cloudflare.com need improvement.
Making pages fast is better for everyone
Google’s announcement today, that Web Vitals measurements will be a key part of search ranking starting in May 2021, places even more emphasis on running fast, accessible websites.
Using Cloudflare’s performance tools, like our best-of-breed caching, Argo Smart Routing, content optimization, and Cloudflare Workers® products, directly improves page experience and Core Web Vitals measurements, and now, very directly, where your pages appear in Google Search results. And you don’t have to take our word for this — our analytics tools directly measure Web Vitals scores, instrumenting your real users’ experiences.
We’re excited to help our customers build fast websites, understand exactly how fast they are, and rank highly on Google search as a result. Render on!
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.